
| 2020 | ||
|---|---|---|
| Months | ||
| Jan | Feb | Mar |
| Apr | May | Jun |
| Jul | Aug | Sep |
| Oct | Nov | Dec |
| 2019 | ||
|---|---|---|
| Months | ||
| Jan | Feb | Mar |
| Apr | May | Jun |
| Jul | Aug | Sep |
| Oct | Nov | Dec |
| 2018 | ||
|---|---|---|
| Months | ||
| Jan | Feb | Mar |
| Apr | May | Jun |
| Jul | Aug | Sep |
| Oct | Nov | Dec |
| 2017 | ||
|---|---|---|
| Months | ||
| Jan | Feb | Mar |
| Apr | May | Jun |
| Jul | Aug | Sep |
| Oct | Nov | Dec |
| 2016 | ||
|---|---|---|
| Months | ||
| Jan | Feb | Mar |
| Apr | May | Jun |
| Jul | Aug | Sep |
| Oct | Nov | Dec |
| 2015 | ||
|---|---|---|
| Months | ||
| Jan | Feb | Mar |
| Apr | May | Jun |
| Jul | Aug | Sep |
| Oct | Nov | Dec |
| 2014 | ||
|---|---|---|
| Months | ||
| Jan | Feb | Mar |
| Apr | May | Jun |
| Jul | Aug | Sep |
| Oct | Nov | Dec |
| 2013 | ||
|---|---|---|
| Months | ||
| Jan | Feb | Mar |
| Apr | May | Jun |
| Jul | Aug | Sep |
| Oct | Nov | Dec |
| 2012 | ||
|---|---|---|
| Months | ||
| Jan | Feb | Mar |
| Apr | May | Jun |
| Jul | Aug | Sep |
| Oct | Nov | Dec |
What has been done
1. Verified basic ptrace(2) functionality:
- debugger cannot attach to PID0 (as root and user)
- debugger cannot attach to PID1 (as user)
- debugger cannot attach to PID1 with sercurelevel >= 1 (as root and user)
- debugger cannot attach to self
- debugger cannot attach to another process unless the process's root directory is at or below the tracing process's root
2. Verified the full matrix of combinations of wait(2) and ptrace(2) in the following test-cases
- tracee can emit PT_TRACE_ME for parent and raise SIGSTOP followed by _exit(2)
- tracee can emit PT_TRACE_ME for parent and raise SIGSTOP followed by _exit(2), with perent sending SIGINT and catching this singal only once with a signal handler and without termination of tracee
- tracee can emit PT_TRACE_ME for parent and raise SIGSTOP, with perent sending SIGINT and terminating the child without signal handler
- tracee can emit PT_TRACE_ME for parent and raise SIGSTOP, with perent sending SIGINT and terminating the child without signal handler
- tracee can emit PT_TRACE_ME for parent and raise SIGCONT, and parent reports it as process stopped
- assert that tracer sees process termination earlier than the parent
- assert that any tracer sees process termination earlier than its parent
- assert that tracer parent can PT_ATTACH to its child
- assert that tracer child can PT_ATTACH to its parent
- assert that tracer sees its parent when attached to tracer (check getppid(2))
- assert that tracer sees its parent when attached to tracer (check sysctl(7) and struct kinfo_proc2)
- assert that tracer sees its parent when attached to tracer (check /proc/curproc/status 3rd column)
- verify that empty EVENT_MASK is preserved
- verify that PTRACE_FORK in EVENT_MASK is preserved
- verify that fork(2) is intercepted by ptrace(2) with EVENT_MASK set to PTRACE_FORK
- verify that fork(2) is not intercepted by ptrace(2) with empty EVENT_MASK
- verify that vfork(2) is intercepted by ptrace(2) with EVENT_MASK set to PTRACE_VFORK [currently EVENT_VFORK not implemented]
- verify that vfork(2) is not intercepted by ptrace(2) with empty EVENT_MASK [currently failing as EVENT_VFORK not implemented]
- verify PT_IO with PIOD_READ_D and len = sizeof(uint8_t)
- verify PT_IO with PIOD_READ_D and len = sizeof(uint16_t)
- verify PT_IO with PIOD_READ_D and len = sizeof(uint32_t)
- verify PT_IO with PIOD_READ_D and len = sizeof(uint64_t)
- verify PT_IO with PIOD_WRITE_D and len = sizeof(uint8_t)
- verify PT_IO with PIOD_WRITE_D and len = sizeof(uint16_t)
- verify PT_IO with PIOD_WRITE_D and len = sizeof(uint32_t)
- verify PT_IO with PIOD_WRITE_D and len = sizeof(uint64_t)
- verify PT_READ_D called once
- verify PT_READ_D called twice
- verify PT_READ_D called three times
- verify PT_READ_D called four times
- verify PT_WRITE_D called once
- verify PT_WRITE_D called twice
- verify PT_WRITE_D called three times
- verify PT_WRITE_D called four times
- verify PT_IO with PIOD_READ_D and PIOD_WRITE_D handshake
- verify PT_IO with PIOD_WRITE_D and PIOD_READ_D handshake
- verify PT_READ_D with PT_WRITE_D handshake
- verify PT_WRITE_D with PT_READ_D handshake
- verify PT_IO with PIOD_READ_I and len = sizeof(uint8_t)
- verify PT_IO with PIOD_READ_I and len = sizeof(uint16_t)
- verify PT_IO with PIOD_READ_I and len = sizeof(uint32_t)
- verify PT_IO with PIOD_READ_I and len = sizeof(uint64_t)
- verify PT_READ_I called once
- verify PT_READ_I called twice
- verify PT_READ_I called three times
- verify PT_READ_I called four times
- verify plain PT_GETREGS call without further steps
- verify plain PT_GETREGS call and retrieve PC
- verify plain PT_GETREGS call and retrieve SP
- verify plain PT_GETREGS call and retrieve INTRV
- verify PT_GETREGS and PT_SETREGS calls without changing regs
- verify plain PT_GETFPREGS call without further steps
- verify PT_GETFPREGS and PT_SETFPREGS calls without changing regs
- verify single PT_STEP call
- verify PT_STEP called twice
- verify PT_STEP called three times
- verify PT_STEP called four times
- verify that PT_CONTINUE with SIGKILL terminates child
- verify that PT_KILL terminates child
- verify basic LWPINFO call for single thread (PT_TRACE_ME)
- verify basic LWPINFO call for single thread (PT_ATTACH from tracer)
3. Documentation of ptrace(2)
- documented PT_SET_EVENT_MASK, PT_GET_EVENT_MASK and PT_GET_PROCESS_STATE
- updated and fixed documentation of PT_DUMPCORE
- documented PT_GETXMMREGS and PT_SETXMMREGS (i386 port specific)
- documented PT_GETVECREGS and PT_SETVECREGS (ppc ports specific)
- other tweaks and cleanups in the documentation
4. exect(3) - execve(2) wrapper with tracing capabilities
Researched its usability and added ATF test, it's close to be marked for removal - it's marked as broken as it is on all ports... this call was inherited from BSD4.2 (VAX) and was never useful since the inception as it is enabling singlestepping before calling execve(2) and tracing libc calls before switching to new process image.
5. pthread_dbg(3) - POSIX threads debugging library documentation
- added documentation for the library in man-page
- upstreamed to the mandoc project to recognize the pthread_dbg(3) library
- document td_close(3) close connection to a threaded process
- document td_map_pth2thr(3) convert a pthread_t to a thread handle
- document td_open(3) make connection to a threaded process
- document td_thr_getname(3) get the user-assigned name of a thread
- document td_thr_info(3) get information on a thread
- document td_thr_iter(3) iterate over the threads in the process
6. pthread_dbg(3) - pthread debug library - t_dummy tests
- assert that dummy lookup functions stops td_open(3)
- assert that td_open(3) for basic proc_{read,write,lookup} works
- asserts that calling td_open(3) twice for the same process fails
7. pthread_dbg(3) - pthread debug library - test of features
- assert that td_thr_iter(3) call without extra logic works
- assert that td_thr_iter(3) call is executed for each thread once
- assert that for each td_thr_iter(3) call td_thr_info(3) is valid
- assert that for each td_thr_iter(3) call td_thr_getname(3) is valid
- assert that td_thr_getname(3) handles shorter buffer parameter and the result is properly truncated
- assert that pthread_t can be translated with td_map_pth2thr(3) to td_thread_t -- and assert earlier that td_thr_iter(3) call is valid
- assert that pthread_t can be translated with td_map_pth2thr(3) to td_thread_t -- and assert later that td_thr_iter() call is valid
- assert that pthread_t can be translated with td_map_pth2thr(3) to td_thread_t -- compare thread's name of pthread_t and td_thread_t
- assert that pthread_t can be translated with td_map_pth2thr(3) to td_thread_t -- assert that thread is in the TD_STATE_RUNNING state
8. pthread_dbg(3) - pthread debug library - code fixes
- fix pt_magic (part of pthread_t) read in td_thr_info(3)
- correct pt_magic reads in td_thr_{getname,suspend,resume}(3)
- fix pt_magic read in td_map_pth2thr(3)
- always set trailing '\0' in td_thr_getname(3) to compose valid ASCIIZ string
- kill SA thread states (TD_STATE_*) in pthread_dbg and add TD_STATE_DEAD
- obsolete thread_type in td_thread_info_st in pthread_dbg.h
This library was designed for Scheduler Activation, and this feature was removed in NetBSD 5.0.
9. wait(2) family tests
- test that wait6(2) handled stopped/continued process loop
- test whether wait(2)-family of functions return error and set ECHILD for lack of children
- test whether wait(2)-family of functions return error and set ECHILD for lack of children, with WNOHANG option verifying that error is still signaled and errno set
10. Debug Registers assisted watchpoints:
- fix rdr6() function on amd64
- add accessors for available x86 Debug Registers (DR0-DR3, DR6, DR7)
- switch x86 CPU Debug Register types from vaddr_t to register_t
- torn down KSTACK_CHECK_DR0, i386-only feature to detect stack overflow
12. i386 port tests
- call PT_GETREGS and iterate over General Purpose registers
13. amd64 port tests
- call PT_GETREGS and iterate over General Purpose registers
- call PT_COUNT_WATCHPOINTS and assert four available watchpoints
- call PT_COUNT_WATCHPOINTS and assert four available watchpoints, verify that we can read these watchpoints
- call PT_COUNT_WATCHPOINTS and assert four available watchpoints, verify that we can read and write unmodified these watchpoints
- call PT_COUNT_WATCHPOINTS and test code trap with watchpoint 0
- call PT_COUNT_WATCHPOINTS and test code trap with watchpoint 1
- call PT_COUNT_WATCHPOINTS and test code trap with watchpoint 2
- call PT_COUNT_WATCHPOINTS and test code trap with watchpoint 3
- call PT_COUNT_WATCHPOINTS and test write trap with watchpoint 0
- call PT_COUNT_WATCHPOINTS and test write trap with watchpoint 1
- call PT_COUNT_WATCHPOINTS and test write trap with watchpoint 2
- call PT_COUNT_WATCHPOINTS and test write trap with watchpoint 3
- call PT_COUNT_WATCHPOINTS and test write trap with watchpoint 0
- call PT_COUNT_WATCHPOINTS and test rw trap with watchpoint 0 on data read
- call PT_COUNT_WATCHPOINTS and test rw trap with watchpoint 1 on data read
- call PT_COUNT_WATCHPOINTS and test rw trap with watchpoint 2 on data read
- call PT_COUNT_WATCHPOINTS and test rw trap with watchpoint 3 on data read
14. Other minor improvements
- document in wtf(7) PCB process control block
- fix cpu_switchto(9) prototype in a comment in RICSV
15. Add support for hardware assisted watchpoints/breakpoints API in ptrace(2)
Add new ptrace(2) calls:- PT_COUNT_WATCHPOINTS - count the number of available hardware watchpoints
- PT_READ_WATCHPOINT - read struct ptrace_watchpoint from the kernel state
- PT_WRITE_WATCHPOINT - write new struct ptrace_watchpoint state, this includes enabling and disabling watchpoints
typedef struct ptrace_watchpoint {
int pw_index; /* HW Watchpoint ID (count from 0) */
lwpid_t pw_lwpid; /* LWP described */
struct mdpw pw_md; /* MD fields */
} ptrace_watchpoint_t;
For example amd64 defines MD as follows:
struct mdpw {
void *md_address;
int md_condition;
int md_length;
};
These calls are protected with the __HAVE_PTRACE_WATCHPOINTS guard.
Tested on amd64, initial support added for i386 and XEN.
16. Reported bugs:
- PR kern/51596 (ptrace(2): raising SIGCONT in a child results with WIFCONTINUED and WIFSTOPPED true in the parent)
- PR kern/51600 (Tracer must detect zombie before child's parent)
- PR standards/51603 WIFCONTINUED()=true always implies WIFSTOPPED()=true
- PR standards/51606 wait(2) with WNOHANG does not return errno ECHILD for lack of children
- PR kern/51621: PT_ATTACH from a parent is unreliable [false positive]
- PR kern/51624: Tracee process cannot see its appropriate parent when debugged by a tracer
- PR kern/51630 ptrace(2) command PT_SET_EVENT_MASK: option PTRACE_VFORK unsupported
- PR lib/51633 tests/lib/libpthread_dbg/t_dummy unreliable [false positive]
- PR lib/51635 td_thr_iter in seems broken [false positive]
- PR lib/51636: It's not possible to run under gdb(1) programs using the pthread_dbg library
- PR kern/51649: PRIxREGISTER and PTRACE_REG_* mismatch
- PR kern/51685 (ptrace(2): Signal does not set PL_EVENT_SIGNAL in (struct ptrace_lwpinfo.)pl_event)
- PR port-amd64/51700 exect(3) misdesigned and hangs
.... and several critical ones not reported and fixed directly by the NetBSD team.
Credit for Christos Zoulas and K. Robert Elz for helping with the mentioned bugs.
17. Added doc/TODO.ptrace entries
- verify ppid of core dump generated with PT_DUMPCORE it must point to the real parent, not tracer
- adapt OpenBSD regress test (regress/sys/ptrace/ptrace.c) for the ATF context
- add new ptrace(2) calls to lock (suspend) and unlock LWP within a process
- add PT_DUMPCORE tests in the ATF framework
- add ATF tests for PT_WRITE_I and PIOD_WRITE_I - test mprotect restrictions
- add ATF tests for PIOD_READ_AUXV
- add tests for the procfs interface covering all functions available on the same level as ptrace(2)
- add support for PT_STEP, PT_GETREGS, PT_SETREGS, PT_GETFPREGS, PT_SETFPREGS in all ports
- integrate all ptrace(2) features in gdb
- add ptrace(2) NetBSD support in LLDB
- add support for detecting equivalent events to PTRACE_O_TRACEEXEC, PTRACE_O_TRACECLONE, PTRACE_O_TRACEEXIT from Linux
- exect(3) rething or remove -- maybe PT_TRACE_ME + PTRACE_O_TRACEEXEC?
- refactor pthread_dbg(3) to only query private pthread_t data, otherwise it duplicates ptrace(2) interface and cannot cover all types of threads
Features in ELF, DWARF, CTF, DTrace are out of scope of the above list.
Plan for the coming weeks
My initial goal is to copy the Linux Process Plugin and add minimal functional support for NetBSD in LLDB. It will be followed with running and passing some tests from the lldb-server test-suite.
This is a shift from the original plan about porting FreeBSD Process Plugin to NetBSD, as the FreeBSD one is lacking remote debugging support and it needs to be redone from scratch.
I'm going to fork wip/lldb-git (as for git snapshot from 16 Dec 2016) for the purpose of this task to wip/lldb-netbsd and work there.
Next steps after finishing this task are to sync up with Pavel from the LLDB team after New Year. The NetBSD Process Plugin will be used as a reference to create new Common Process Plugin shared between Linux and (Net)BSD.
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue to fund projects and services to the open-source community. Please consider visiting the following URL, and chip in what you can:
What has been done
1. Verified basic ptrace(2) functionality:
- debugger cannot attach to PID0 (as root and user)
- debugger cannot attach to PID1 (as user)
- debugger cannot attach to PID1 with sercurelevel >= 1 (as root and user)
- debugger cannot attach to self
- debugger cannot attach to another process unless the process's root directory is at or below the tracing process's root
2. Verified the full matrix of combinations of wait(2) and ptrace(2) in the following test-cases
- tracee can emit PT_TRACE_ME for parent and raise SIGSTOP followed by _exit(2)
- tracee can emit PT_TRACE_ME for parent and raise SIGSTOP followed by _exit(2), with perent sending SIGINT and catching this singal only once with a signal handler and without termination of tracee
- tracee can emit PT_TRACE_ME for parent and raise SIGSTOP, with perent sending SIGINT and terminating the child without signal handler
- tracee can emit PT_TRACE_ME for parent and raise SIGSTOP, with perent sending SIGINT and terminating the child without signal handler
- tracee can emit PT_TRACE_ME for parent and raise SIGCONT, and parent reports it as process stopped
- assert that tracer sees process termination earlier than the parent
- assert that any tracer sees process termination earlier than its parent
- assert that tracer parent can PT_ATTACH to its child
- assert that tracer child can PT_ATTACH to its parent
- assert that tracer sees its parent when attached to tracer (check getppid(2))
- assert that tracer sees its parent when attached to tracer (check sysctl(7) and struct kinfo_proc2)
- assert that tracer sees its parent when attached to tracer (check /proc/curproc/status 3rd column)
- verify that empty EVENT_MASK is preserved
- verify that PTRACE_FORK in EVENT_MASK is preserved
- verify that fork(2) is intercepted by ptrace(2) with EVENT_MASK set to PTRACE_FORK
- verify that fork(2) is not intercepted by ptrace(2) with empty EVENT_MASK
- verify that vfork(2) is intercepted by ptrace(2) with EVENT_MASK set to PTRACE_VFORK [currently EVENT_VFORK not implemented]
- verify that vfork(2) is not intercepted by ptrace(2) with empty EVENT_MASK [currently failing as EVENT_VFORK not implemented]
- verify PT_IO with PIOD_READ_D and len = sizeof(uint8_t)
- verify PT_IO with PIOD_READ_D and len = sizeof(uint16_t)
- verify PT_IO with PIOD_READ_D and len = sizeof(uint32_t)
- verify PT_IO with PIOD_READ_D and len = sizeof(uint64_t)
- verify PT_IO with PIOD_WRITE_D and len = sizeof(uint8_t)
- verify PT_IO with PIOD_WRITE_D and len = sizeof(uint16_t)
- verify PT_IO with PIOD_WRITE_D and len = sizeof(uint32_t)
- verify PT_IO with PIOD_WRITE_D and len = sizeof(uint64_t)
- verify PT_READ_D called once
- verify PT_READ_D called twice
- verify PT_READ_D called three times
- verify PT_READ_D called four times
- verify PT_WRITE_D called once
- verify PT_WRITE_D called twice
- verify PT_WRITE_D called three times
- verify PT_WRITE_D called four times
- verify PT_IO with PIOD_READ_D and PIOD_WRITE_D handshake
- verify PT_IO with PIOD_WRITE_D and PIOD_READ_D handshake
- verify PT_READ_D with PT_WRITE_D handshake
- verify PT_WRITE_D with PT_READ_D handshake
- verify PT_IO with PIOD_READ_I and len = sizeof(uint8_t)
- verify PT_IO with PIOD_READ_I and len = sizeof(uint16_t)
- verify PT_IO with PIOD_READ_I and len = sizeof(uint32_t)
- verify PT_IO with PIOD_READ_I and len = sizeof(uint64_t)
- verify PT_READ_I called once
- verify PT_READ_I called twice
- verify PT_READ_I called three times
- verify PT_READ_I called four times
- verify plain PT_GETREGS call without further steps
- verify plain PT_GETREGS call and retrieve PC
- verify plain PT_GETREGS call and retrieve SP
- verify plain PT_GETREGS call and retrieve INTRV
- verify PT_GETREGS and PT_SETREGS calls without changing regs
- verify plain PT_GETFPREGS call without further steps
- verify PT_GETFPREGS and PT_SETFPREGS calls without changing regs
- verify single PT_STEP call
- verify PT_STEP called twice
- verify PT_STEP called three times
- verify PT_STEP called four times
- verify that PT_CONTINUE with SIGKILL terminates child
- verify that PT_KILL terminates child
- verify basic LWPINFO call for single thread (PT_TRACE_ME)
- verify basic LWPINFO call for single thread (PT_ATTACH from tracer)
3. Documentation of ptrace(2)
- documented PT_SET_EVENT_MASK, PT_GET_EVENT_MASK and PT_GET_PROCESS_STATE
- updated and fixed documentation of PT_DUMPCORE
- documented PT_GETXMMREGS and PT_SETXMMREGS (i386 port specific)
- documented PT_GETVECREGS and PT_SETVECREGS (ppc ports specific)
- other tweaks and cleanups in the documentation
4. exect(3) - execve(2) wrapper with tracing capabilities
Researched its usability and added ATF test, it's close to be marked for removal - it's marked as broken as it is on all ports... this call was inherited from BSD4.2 (VAX) and was never useful since the inception as it is enabling singlestepping before calling execve(2) and tracing libc calls before switching to new process image.
5. pthread_dbg(3) - POSIX threads debugging library documentation
- added documentation for the library in man-page
- upstreamed to the mandoc project to recognize the pthread_dbg(3) library
- document td_close(3) close connection to a threaded process
- document td_map_pth2thr(3) convert a pthread_t to a thread handle
- document td_open(3) make connection to a threaded process
- document td_thr_getname(3) get the user-assigned name of a thread
- document td_thr_info(3) get information on a thread
- document td_thr_iter(3) iterate over the threads in the process
6. pthread_dbg(3) - pthread debug library - t_dummy tests
- assert that dummy lookup functions stops td_open(3)
- assert that td_open(3) for basic proc_{read,write,lookup} works
- asserts that calling td_open(3) twice for the same process fails
7. pthread_dbg(3) - pthread debug library - test of features
- assert that td_thr_iter(3) call without extra logic works
- assert that td_thr_iter(3) call is executed for each thread once
- assert that for each td_thr_iter(3) call td_thr_info(3) is valid
- assert that for each td_thr_iter(3) call td_thr_getname(3) is valid
- assert that td_thr_getname(3) handles shorter buffer parameter and the result is properly truncated
- assert that pthread_t can be translated with td_map_pth2thr(3) to td_thread_t -- and assert earlier that td_thr_iter(3) call is valid
- assert that pthread_t can be translated with td_map_pth2thr(3) to td_thread_t -- and assert later that td_thr_iter() call is valid
- assert that pthread_t can be translated with td_map_pth2thr(3) to td_thread_t -- compare thread's name of pthread_t and td_thread_t
- assert that pthread_t can be translated with td_map_pth2thr(3) to td_thread_t -- assert that thread is in the TD_STATE_RUNNING state
8. pthread_dbg(3) - pthread debug library - code fixes
- fix pt_magic (part of pthread_t) read in td_thr_info(3)
- correct pt_magic reads in td_thr_{getname,suspend,resume}(3)
- fix pt_magic read in td_map_pth2thr(3)
- always set trailing '\0' in td_thr_getname(3) to compose valid ASCIIZ string
- kill SA thread states (TD_STATE_*) in pthread_dbg and add TD_STATE_DEAD
- obsolete thread_type in td_thread_info_st in pthread_dbg.h
This library was designed for Scheduler Activation, and this feature was removed in NetBSD 5.0.
9. wait(2) family tests
- test that wait6(2) handled stopped/continued process loop
- test whether wait(2)-family of functions return error and set ECHILD for lack of children
- test whether wait(2)-family of functions return error and set ECHILD for lack of children, with WNOHANG option verifying that error is still signaled and errno set
10. Debug Registers assisted watchpoints:
- fix rdr6() function on amd64
- add accessors for available x86 Debug Registers (DR0-DR3, DR6, DR7)
- switch x86 CPU Debug Register types from vaddr_t to register_t
- torn down KSTACK_CHECK_DR0, i386-only feature to detect stack overflow
12. i386 port tests
- call PT_GETREGS and iterate over General Purpose registers
13. amd64 port tests
- call PT_GETREGS and iterate over General Purpose registers
- call PT_COUNT_WATCHPOINTS and assert four available watchpoints
- call PT_COUNT_WATCHPOINTS and assert four available watchpoints, verify that we can read these watchpoints
- call PT_COUNT_WATCHPOINTS and assert four available watchpoints, verify that we can read and write unmodified these watchpoints
- call PT_COUNT_WATCHPOINTS and test code trap with watchpoint 0
- call PT_COUNT_WATCHPOINTS and test code trap with watchpoint 1
- call PT_COUNT_WATCHPOINTS and test code trap with watchpoint 2
- call PT_COUNT_WATCHPOINTS and test code trap with watchpoint 3
- call PT_COUNT_WATCHPOINTS and test write trap with watchpoint 0
- call PT_COUNT_WATCHPOINTS and test write trap with watchpoint 1
- call PT_COUNT_WATCHPOINTS and test write trap with watchpoint 2
- call PT_COUNT_WATCHPOINTS and test write trap with watchpoint 3
- call PT_COUNT_WATCHPOINTS and test write trap with watchpoint 0
- call PT_COUNT_WATCHPOINTS and test rw trap with watchpoint 0 on data read
- call PT_COUNT_WATCHPOINTS and test rw trap with watchpoint 1 on data read
- call PT_COUNT_WATCHPOINTS and test rw trap with watchpoint 2 on data read
- call PT_COUNT_WATCHPOINTS and test rw trap with watchpoint 3 on data read
14. Other minor improvements
- document in wtf(7) PCB process control block
- fix cpu_switchto(9) prototype in a comment in RICSV
15. Add support for hardware assisted watchpoints/breakpoints API in ptrace(2)
Add new ptrace(2) calls:- PT_COUNT_WATCHPOINTS - count the number of available hardware watchpoints
- PT_READ_WATCHPOINT - read struct ptrace_watchpoint from the kernel state
- PT_WRITE_WATCHPOINT - write new struct ptrace_watchpoint state, this includes enabling and disabling watchpoints
typedef struct ptrace_watchpoint {
int pw_index; /* HW Watchpoint ID (count from 0) */
lwpid_t pw_lwpid; /* LWP described */
struct mdpw pw_md; /* MD fields */
} ptrace_watchpoint_t;
For example amd64 defines MD as follows:
struct mdpw {
void *md_address;
int md_condition;
int md_length;
};
These calls are protected with the __HAVE_PTRACE_WATCHPOINTS guard.
Tested on amd64, initial support added for i386 and XEN.
16. Reported bugs:
- PR kern/51596 (ptrace(2): raising SIGCONT in a child results with WIFCONTINUED and WIFSTOPPED true in the parent)
- PR kern/51600 (Tracer must detect zombie before child's parent)
- PR standards/51603 WIFCONTINUED()=true always implies WIFSTOPPED()=true
- PR standards/51606 wait(2) with WNOHANG does not return errno ECHILD for lack of children
- PR kern/51621: PT_ATTACH from a parent is unreliable [false positive]
- PR kern/51624: Tracee process cannot see its appropriate parent when debugged by a tracer
- PR kern/51630 ptrace(2) command PT_SET_EVENT_MASK: option PTRACE_VFORK unsupported
- PR lib/51633 tests/lib/libpthread_dbg/t_dummy unreliable [false positive]
- PR lib/51635 td_thr_iter in seems broken [false positive]
- PR lib/51636: It's not possible to run under gdb(1) programs using the pthread_dbg library
- PR kern/51649: PRIxREGISTER and PTRACE_REG_* mismatch
- PR kern/51685 (ptrace(2): Signal does not set PL_EVENT_SIGNAL in (struct ptrace_lwpinfo.)pl_event)
- PR port-amd64/51700 exect(3) misdesigned and hangs
.... and several critical ones not reported and fixed directly by the NetBSD team.
Credit for Christos Zoulas and K. Robert Elz for helping with the mentioned bugs.
17. Added doc/TODO.ptrace entries
- verify ppid of core dump generated with PT_DUMPCORE it must point to the real parent, not tracer
- adapt OpenBSD regress test (regress/sys/ptrace/ptrace.c) for the ATF context
- add new ptrace(2) calls to lock (suspend) and unlock LWP within a process
- add PT_DUMPCORE tests in the ATF framework
- add ATF tests for PT_WRITE_I and PIOD_WRITE_I - test mprotect restrictions
- add ATF tests for PIOD_READ_AUXV
- add tests for the procfs interface covering all functions available on the same level as ptrace(2)
- add support for PT_STEP, PT_GETREGS, PT_SETREGS, PT_GETFPREGS, PT_SETFPREGS in all ports
- integrate all ptrace(2) features in gdb
- add ptrace(2) NetBSD support in LLDB
- add support for detecting equivalent events to PTRACE_O_TRACEEXEC, PTRACE_O_TRACECLONE, PTRACE_O_TRACEEXIT from Linux
- exect(3) rething or remove -- maybe PT_TRACE_ME + PTRACE_O_TRACEEXEC?
- refactor pthread_dbg(3) to only query private pthread_t data, otherwise it duplicates ptrace(2) interface and cannot cover all types of threads
Features in ELF, DWARF, CTF, DTrace are out of scope of the above list.
Plan for the coming weeks
My initial goal is to copy the Linux Process Plugin and add minimal functional support for NetBSD in LLDB. It will be followed with running and passing some tests from the lldb-server test-suite.
This is a shift from the original plan about porting FreeBSD Process Plugin to NetBSD, as the FreeBSD one is lacking remote debugging support and it needs to be redone from scratch.
I'm going to fork wip/lldb-git (as for git snapshot from 16 Dec 2016) for the purpose of this task to wip/lldb-netbsd and work there.
Next steps after finishing this task are to sync up with Pavel from the LLDB team after New Year. The NetBSD Process Plugin will be used as a reference to create new Common Process Plugin shared between Linux and (Net)BSD.
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue to fund projects and services to the open-source community. Please consider visiting the following URL, and chip in what you can:A cyclic trend in operating systems is moving things in and out of the kernel for better performance. Currently, the pendulum is swinging in the direction of userspace being the locus of high performance. The anykernel architecture of NetBSD ensures that the same kernel drivers work in a monolithic kernel, userspace and beyond. One of those driver stacks is networking. In this article we assume that the NetBSD networking stack is run outside of the monolithic kernel in a rump kernel and survey the open source interface layer options.
There are two sub-aspects to networking. The first facet is supporting network protocols and suites such as IPv6, IPSec and MPLS. The second facet is delivering packets to and from the protocol stack, commonly referred to as the interface layer. While the first facet for rump kernels is unchanged from the networking stack running in a monolithic NetBSD kernel, there is support for a number of interfaces not available in kernel mode.
DPDK
The Data Plane Development Kit is meant to be used for high-performance, multiprocessor-aware networking. DPDK offers network access by attaching to hardware and providing a hardware-independent API for sending and receiving packets. The most common runtime environment for DPDK is Linux userspace, where a UIO userspace driver framework kernel module is used to enable access to PCI hardware. The NIC drivers themselves are provided by DPDK and run in application processes.
For high performance, DPDK uses a run-to-completion scheduling model -- the same model is used by rump kernels. This scheduling model means that NIC devices are accessed in polled mode without any interrupts on the fast path. The only interrupts that are used by DPDK are for slow-path operations such as notifications of link status change.
The rump kernel interface driver for DPDK is available here. DPDK itself is described in significant detail in the documents available from the Intel DPDK page.
netmap
Like DPDK, netmap offers user processes access to NIC hardware with a high-performance userspace packet processing intent. Unlike DPDK, netmap reuses NIC drivers from the host kernel and provides memory-mapped buffer rings for accessing the device packet queues. In other words, the device drivers still remain in the host kernel, but low-level and low-overhead access to hardware is made available to userspace processes. In addition to the memory-mapping of buffers, netmap uses other performance optimization methods such as batch processing and buffer reallocation, and can easily saturate a 10GigE with minimum-size frames. Another significant difference to DPDK is that netmap allows also for a blocking mode of operation.
Netmap is coupled with a high-performance software virtual switch called VALE. It can be used to interconnect networks between virtual machines and processes such as rump kernels. The netmap API is used also by VALE, so VALE switching can be used with the rump kernel driver for netmap.
The rump kernel interface driver for netmap is available here. Multiple papers describing netmap and VALE are available from the netmap page.
TAP
A tap device injects packets written into a device node, e.g. /dev/tap, to a tap virtual network interface. Conversely, packets received by the virtual tap network can be read from the device node. The tap network interface can be bridged with other network interfaces to provide further network access. While indirect access to network hardware via the bridge is not maximally efficient, it is not hideously slow either: a rump kernel backed by a tap device can saturate a gigabit Ethernet. The advantage of the tap device is portability, as it is widely available on Unix-type systems. Tap interfaces also virtualize nicely, and most operating systems will allow unprivileged processes to use tap interface as long as the processes have the credentials to access the respective device nodes.
The tap device was the original method for accessing with a rump kernel. In fact, the in-kernel side of the rump kernel network driver was rather short-sightedly named virt back in 2008. The virt driver and the associated hypercalls are available in the NetBSD tree. Fun fact: the tap driver is also the method for packet shovelling when running the NetBSD TCP/IP stack in the Linux kernel; the rationale is provided in a comment here and also by running wc -l.
Xen hypercalls
After a fashion, using Xen hypercalls is a variant of using the TAP device: a virtualized network resource is accessed using high-level hypercalls. However, instead of accessing the network backend from a device node, Xen hypercalls are used. The Xen driver is limited to the Xen environment and is available here.
NetBSD PCI NIC drivers
The previous examples we have discussed use a high-level interface to packet I/O functions. For example, to send a packet, the rump kernel will issue a hypercall which essentially says "transmit these data", and the network backend handles the request. When using NetBSD PCI drivers, the hypercalls work at a low level, and deal with for example reading/writing the PCI configuration space and mapping the device memory space into the rump kernel. As a result, using NetBSD PCI device drivers in a rump kernel work exactly like in a regular kernel: the PCI devices are probed during rump kernel bootstrap, relevant drivers are attached, and packet shovelling works by the drivers fiddling the relevant device registers.
The hypercall interfaces and necessary kernel-side implementations are currently hosted in the repository providing Xen support for rump kernels. Strictly speaking, there is nothing specific to Xen in these bits, and they will most likely be moved out of the Xen repository once PCI device driver support for other planned platforms, such as Linux userspace, is completed. The hypercall implementations, which are Xen specific, are available here.
shmif
For testing networking, it is advantageous to have an interface which can communicate with other networking stacks on the same host without requiring elevated privileges, special kernel features or a priori setup in the form of e.g. a daemon process. These requirements are filled by shmif, which uses file-backed shared memory as a bus for Ethernet frames. Each interface attaches to a pathname, and interfaces attached to the same pathname see the the same traffic.
The shmif driver is available in the NetBSD tree.
We presented a total of six open source network backends for networking with rump kernels. These backends represent four different methodologies:
- DPDK and netmap provide high-performance network hardware access using high-level hypercalls.
- TAP and Xen hypercall drivers provide access to virtualized network resources using high-level hypercalls.
- NetBSD PCI drivers access hardware directly using register-level device access to send and receive packets.
- shmif allows for unprivileged testing of the networking stack without relying on any special kernel drivers or global resources.
Choice is a good thing here, as the optimal backend ultimately depends on the characteristics of the application.
The advantages are better verifyability that the source code matches the binaries, thus addressing one of the many steps one has to check before trusting the software one runs.
We discussed various topics during the conference in small groups:
- technical aspects (how to achieve this, how to cooperate over distributions, ...)
- social aspects (how to argue for it with programmers, managers, lay people) financial aspects (how to get funding for such work)
- lots of other stuff

Making the base system reproducible: a big part of the work for this has already been done, but there a number of open issues, visible e.g. in Debian's regularly scheduled test builds, up to the fact that this is not the default yet.
Making pkgsrc reproducible: This will be a huge task, since pkgsrc targets so many and diverse platforms. On the other hand, we have a very good framework below that that should help.
For giggles, I've compared the binary packages for png built on 7.99.22 and 7.99.23 (in my chrooted pbulk only though) and found that most differences were indeed only timestamps. So there's probably a lot of low-hanging fruit in this area as well.
If you want to help, here are some ideas:
- fix the MKREPRO bugs (like PRs 48355, 48637, 48638, 50119, 50120, 50122)
- check https://reproducible.debian.net/netbsd/netbsd.html for more issues, or do your own tests
- discuss turning on MKREPRO by default
- starting working on reproducibility in pkgsrc:
- remove gzip time stamps from binary packages
- use a fixed time stamp for files inside binary packages (perhaps depending on newest file in sources, or latest change in pkgsrc files for the pkg)
- identify more of the issues, like how to get symbols ordered reproducible in binaries (look at shells/bash)
The list of supported multiprocessor boards currently is:
- Banana Pi (BPI)
- Cubieboard 2 (CUBIEBOARD)
- Cubietruck (CUBIETRUCK)
- Merrii Hummingbird A31 (HUMMINGBIRD_A31)
- CUBOX-I
- NITROGEN6X
Details how to create bootable media and various other information for the Allwinner boards can be found on the NetBSD/evbarm on Allwinner Technology SoCs wiki page.
The release engineering team is discussing how to bring all those changes into the netbsd-7 branch as well, so that we can call NetBSD 7.0 "the ARM SoC release".
While multicore ARM chips are mostly known for being used in cell phones and tablet devices, there are also some nice "tiny PC" variants out there, like the CubieTruck, which originally comes with a small transparent case that allows piggybacking it onto a 2.5" hard disk:

Image from cubieboard.org under creative commons license.
This is nice to put next to your display, but a bit too tiny and fragile for my test lab - so I reused an old (originally mac68k cartridge) SCSI enclosure for mine:

Image by myself under creative commons license.
This machine is used to run regular tests for big endian  arm, the results are gathered here. Running it big-endian is just a way to trigger more bugs.
arm, the results are gathered here. Running it big-endian is just a way to trigger more bugs.
The last test run logged on the page is already done with an SMP kernel. No regressions were found so far, and the other bugs (sligtly more than 30 failures in the test run is way too much) will be addressed one by one.
Now happy multi-ARM-ing everyone, and I am looking forward to a great NetBSD 7.0 release!
The NetBSD Project is pleased to announce NetBSD 5.1.5, the fifth security/bugfix update of the NetBSD 5.1 release branch, and NetBSD 5.2.3, the third security/bugfix update of the NetBSD 5.2 release branch. They represent a selected subset of fixes deemed important for security or stability reasons, and if you are running a prior release of either branch, we strongly suggest that you update to one of these releases.
For more details, please see the NetBSD 5.1.5 release notes or NetBSD 5.2.3 release notes.
Complete source and binaries for NetBSD are available for download at many sites around the world. A list of download sites providing FTP, AnonCVS, SUP, and other services may be found at http://www.NetBSD.org/mirrors/.That is, make it load a kernel, identify / setup the CPU, attach a serial console. This is what it looks like:
U-Boot SPL 2013.10-rc3-g9329ab16a204 (Jun 26 2014 - 09:43:22)
SDRAM H5TQ2G83CFR initialization... done
U-Boot 2013.10-rc3-g9329ab16a204 (Jun 26 2014 - 09:43:22)
Board: ci20 (Ingenic XBurst JZ4780 SoC)
DRAM: 1 GiB
NAND: 8192 MiB
MMC: jz_mmc msc1: 0
In: eserial3
Out: eserial3
Err: eserial3
Net: dm9000
ci20# dhcp
ERROR: resetting DM9000 -> not responding
dm9000 i/o: 0xb6000000, id: 0x90000a46
DM9000: running in 8 bit mode
MAC: d0:31:10:ff:7e:89
operating at 100M full duplex mode
BOOTP broadcast 1
DHCP client bound to address 192.168.0.47
*** Warning: no boot file name; using 'C0A8002F.img'
Using dm9000 device
TFTP from server 192.168.0.44; our IP address is 192.168.0.47
Filename 'C0A8002F.img'.
Load address: 0x88000000
Loading: #################################################################
##############
284.2 KiB/s
done
Bytes transferred = 1146945 (118041 hex)
ci20# bootm
## Booting kernel from Legacy Image at 88000000 ...
Image Name: evbmips 7.99.1 (CI20)
Image Type: MIPS NetBSD Kernel Image (gzip compressed)
Data Size: 1146881 Bytes = 1.1 MiB
Load Address: 80020000
Entry Point: 80020000
Verifying Checksum ... OK
Uncompressing Kernel Image ... OK
subcommand not supported
ci20# g 80020000
## Starting applicatpmap_steal_memory: seg 0: 0x30c 0x30c 0xffff 0xffff
Loaded initial symtab at 0x802502d4, strtab at 0x80270cb4, # entries 8323
Copyright (c) 1996, 1997, 1998, 1999, 2000, 2001, 2002, 2003, 2004, 2005,
2006, 2007, 2008, 2009, 2010, 2011, 2012, 2013, 2014
The NetBSD Foundation, Inc. All rights reserved.
Copyright (c) 1982, 1986, 1989, 1991, 1993
The Regents of the University of California. All rights reserved.
NetBSD 7.99.1 (CI20) #113: Sat Nov 22 09:58:39 EST 2014
ml@blackbush:/home/build/obj_evbmips32/sys/arch/evbmips/compile/CI20
Ingenic XBurst
total memory = 1024 MB
avail memory = 1001 MB
kern.module.path=/stand/evbmips/7.99.1/modules
mainbus0 (root)
cpu0 at mainbus0: 1200.00MHz (hz cycles = 120000, delay divisor = 12)
cpu0: Ingenic XBurst (0x3ee1024f) Rev. 79 with unknown FPC type (0x330000) Rev. 0
cpu0: 32 TLB entries, 16MB max page size
cpu0: 32KB/32B 8-way set-associative L1 instruction cache
cpu0: 32KB/32B 8-way set-associative write-back L1 data cache
com0 at mainbus0: Ingenic UART, working fifo
com0: console
root device:
What works:
- CPU identification and setup
- serial console via UART0
- reset ( by provoking a watchdog timeout )
- basic timers - enough for delay(), since the CPUs don't have MIPS cycle counters
- dropping into ddb and poking around
What doesn't work (yet):
- interrupts
- everything else
Biggest obstacle - believe it or not, the serial port. The on-chip UARTs are mostly 16550 compatible. Mostly. The difference is one bit in the FIFO control register which, if not set, powers down the UART. So throwing data at the UART by hand worked but as soon as the com driver took over the line went dead. It took me a while to find that one.
FOSDEM 2014 will take place on 1–2 February, 2014, in Brussels, Belgium. Just like in the last years, there will be both a BSD booth and a developer's room (on Saturday).
The topics of the devroom include all BSD operating systems. Every talk is welcome, from internal hacker discussion to real-world examples and presentations about new and shiny features. The default duration for talks will be 45 minutes including discussion. Feel free to ask if you want to have a longer or a shorter slot.
If you already submitted a talk last time, please note that the procedure is slightly different.
To submit your proposal, visit
https://penta.fosdem.org/submission/FOSDEM14/
and follow the instructions to create an account and an “event”. Please select “BSD devroom” as the track. (Click on “Show all” in the top right corner to display the full form.)
Please include the following information in your submission:
- The title and subtitle of your talk (please be descriptive, as titles will be listed with ~500 from other projects)
- A short abstract of one paragraph
- A longer description if you wish to do so
- Links to related websites/blogs etc.
The deadline for submissions is December 20, 2013. The talk committee, consisting of Daniel Seuffert, Marius Nünnerich and Benny Siegert, will consider the proposals. If yours has been accepted, you will be informed by e-mail before the end of the year.
The NetBSD Project is pleased to announce NetBSD 7.0, the fifteenth major release of the NetBSD operating system.
This release brings stability improvements, hundreds of bug fixes, and many new features. Some highlights of the NetBSD 7.0 release are:
- DRM/KMS support brings accelerated graphics to x86 systems using modern Intel and Radeon devices.
- Multiprocessor ARM support.
- Support for many new ARM boards:
- Raspberry Pi 2
- ODROID-C1
- BeagleBoard, BeagleBone, BeagleBone Black
- MiraBox
- Allwinner A20, A31: Cubieboard2, Cubietruck, Banana Pi, etc.
- Freescale i.MX50, i.MX51: Kobo Touch, Netwalker
- Xilinx Zynq: Parallella, ZedBoard
- Major NPF improvements:
- BPF with just-in-time (JIT) compilation by default.
- Support for dynamic rules.
- Support for static (stateless) NAT.
- Support for IPv6-to-IPv6 Network Prefix Translation (NPTv6) as per RFC 6296.
- Support for CDB based tables (uses perfect hashing and guarantees lock-free O(1) lookups).
- Multiprocessor support in the USB subsystem.
- blacklistd(8), a new daemon that integrates with packet filters to dynamically protect other network daemons such as ssh, named, and ftpd from network break-in attempts.
- Numerous improvements in the handling of disk wedges (see dkctl(8) for information about wedges).
- GPT support in sysinst via the extended partitioning menu.
- Lua kernel scripting.
- epoc32, a new port which supports Psion EPOC PDAs.
- GCC 4.8.4, which brings support for C++11.
- Optional fully BSD-licensed C/C++ runtime env: compiler_rt, libc++, libcxxrt.
For a more complete list of changes in NetBSD 7.0, see the release notes.
Complete source and binaries for NetBSD 7.0 are available for download at many sites around the world. A list of download sites providing FTP, AnonCVS, and other services may be found at http://www.NetBSD.org/mirrors/.
If NetBSD makes your life better, please consider making a donation to The NetBSD Foundation in order to support the continued development of this fine operating system. As a non-profit organization with no commercial backing, The NetBSD Foundation depends on donations from its users. Your donation helps us fund large development projects, cover operating expenses, and keep the servers alive. For information about donating, visit http://www.NetBSD.org/donations/
In keeping with NetBSD's policy of supporting only the current (7.x) and next most recent (6.x) release majors, the release of NetBSD 7.0 marks the end of life for the 5.x branches. As in the past, a month of overlapping support is being provided in order to ease the migration to newer releases.
On November 9, the following branches will no longer be maintained:
- netbsd-5-2
- netbsd-5-1
- netbsd-5
Furthermore:
- There will be no more pullups to the branches (even for security issues)
- There will be no security advisories made for any of the 5.x releases
- The existing 5.x releases on ftp.NetBSD.org will be moved into /pub/NetBSD-archive/
We hope 7.0 serves you well!
Tutorials
I came to Paris on Wednesday in order to participate in tutorials:
- Thursday - DTrace for Developers: no more printfs - by George Neville-Neil
- Friday - How to untangle your threads from a giant lock in a multiprocessor system - by Taylor R. Campbell
The NetBSD Summit
On Friday there was a NetBSD summit that gathered around 15 developers. I have not participated in it myself because of the tutorial on SMP. There were three presentations:
- News from the version control front - by joerg,
- Scripting DDB with Forth - by uwe,
- NetBSD on Google Compute Engine - by bsiegert.
Talks
During Saturday and Sunday there were several NetBSD and pkgsrc related presentations:
- A Modern Replacement for BSD spell(1) - Abhinav Upadhyay
- Portable Hotplugging: NetBSD's uvm_hotplug(9) API development - Cherry G. Mathew
- Hardening pkgsrc - Pierre Pronchery
- Reproducible builds on NetBSD - Christos Zoulas
- The school of hard knocks - PT1 - Sevan Janiyan
- The LLDB Debugger on NetBSD - Kamil Rytarowski
- What's in store for NetBSD 8.0? - Alistair Crooks
During the closing ceremony there was a speech by Alistair Crooks on behalf of The NetBSD Foundation.
LLDB
At the conference I presented my work on "The LLDB Debugger on NetBSD":
Plan for the next milestone
Resume porting tsan and msan to NetBSD with a plan to switch back to the LLDB porting.
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL, and chip in what you can:
Tutorials
I came to Paris on Wednesday in order to participate in tutorials:
- Thursday - DTrace for Developers: no more printfs - by George Neville-Neil
- Friday - How to untangle your threads from a giant lock in a multiprocessor system - by Taylor R. Campbell
The NetBSD Summit
On Friday there was a NetBSD summit that gathered around 15 developers. I have not participated in it myself because of the tutorial on SMP. There were three presentations:
- News from the version control front - by joerg,
- Scripting DDB with Forth - by uwe,
- NetBSD on Google Compute Engine - by bsiegert.
Talks
During Saturday and Sunday there were several NetBSD and pkgsrc related presentations:
- A Modern Replacement for BSD spell(1) - Abhinav Upadhyay
- Portable Hotplugging: NetBSD's uvm_hotplug(9) API development - Cherry G. Mathew
- Hardening pkgsrc - Pierre Pronchery
- Reproducible builds on NetBSD - Christos Zoulas
- The school of hard knocks - PT1 - Sevan Janiyan
- The LLDB Debugger on NetBSD - Kamil Rytarowski
- What's in store for NetBSD 8.0? - Alistair Crooks
During the closing ceremony there was a speech by Alistair Crooks on behalf of The NetBSD Foundation.
LLDB
At the conference I presented my work on "The LLDB Debugger on NetBSD":
Plan for the next milestone
Resume porting tsan and msan to NetBSD with a plan to switch back to the LLDB porting.
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL, and chip in what you can:
President: William J. Coldwell <billc>
Vice President: Jeremy C. Reed <reed>
Secretary: Christos Zoulas <christos>
Treasurer: Christos Zoulas <christos>
Assistant Secretary: Thomas Klausner <wiz>
Assistant Treasurer: Taylor R. Campbell <riastradh>
President: William J. Coldwell <billc>
Vice President: Jeremy C. Reed <reed>
Secretary: Christos Zoulas <christos>
Treasurer: Christos Zoulas <christos>
Assistant Secretary: Thomas Klausner <wiz>
Assistant Treasurer: Taylor R. Campbell <riastradh>
Let me tell you about my experience at
EuroBSDcon 2017
in Paris, France. We will
see what was presented during the NetBSD developer summit on Friday
and then we will give a look to all of the
NetBSD and
pkgsrc presentations given during
the conference session on Saturday and Sunday. Of course, a lot of
fun also happened on the "hall track", the several breaks
during the conference and the dinners we had together with other
*BSD developers and community! This is difficult to describe and
I will try to just share some part of that with photographs that
we have taken. I can just say that it was a really beautiful
experience, I had a great time with others and, after coming back
home... ...I miss all of that! So, if you have never been in
any BSD conferences I strongly suggest you to go to the next ones,
so please stay tuned via
NetBSD Events.
Being there this is probably the only way to understand these feelings!
Thursday (21/09): NetBSD developers dinner
Arriving in Paris via a night train from Italy I
literally sleep-walked through Paris getting lost again and again.
After getting in touch with other developers we had a dinner together and went
sightseeing for a^Wseveral beers!
Friday (22/09): NetBSD developers summit
On Friday morning we met for the NetBSD developers summit kindly hosted by Arolla.

From left to right: alnsn, sborrill;
abhinav; uwe and leot;
christos, cherry, ast and
bsiegert; martin and khorben.
The devsummit was moderated by Jörg (joerg) and organized by
Jean-Yves (jym).
NetBSD on Google Compute Engine -- Benny Siegert (bsiegert)
After a self-presentation the devsummit presentations session started with the
talk presented by Benny (bsiegert) about NetBSD on Google
Compute Engine.
Benny first introduced Google Compute Engine (GCE) and then started describing how to run NetBSD on it.
At the moment there are no official NetBSD images and so users need to create their own. However, netbsd-gce script completely automatize this process that:
- uses Anita to stage an installation in QEMU
- adjust several tweaks to ensure that networking and storage will work on GCE
- packs the image into a
.tar.gzfile
The .tar.gz image then just need to be uploaded to a Cloud Storage
bucket, create a GCE image from it and then launch VMs based on that image.
He also discussed about GCE instance metadata, several problems founds and how they were fixed (it's better to use NetBSD 8_BETA or -current!) and some future works.
For more information slides (PDF) of the talk are also available.
Scripting DDB with Forth -- Valery Ushakov (uwe)
Valery (uwe) presented a talk about Scripting DDB
with Forth. It was based on a long story and actually the
first discussion about it appeared on
tech-kern@
mailing list in his
Scripting DDB in Forth?
thread (ddb(4)
is the NetBSD in-kernel debugger).
He showed how one can associate forth commands/conditions with ddb breakpoints. He used "pid divisible by 3" as an example of condition for a breakpoint set in getpid(2) system call:
db{0}> forth
ok : field create , does> @ + ;
ok #300 field lwp>l_proc
ok #120 field proc>p_pid
ok : getpid curlwp lwp>l_proc @ proc>p_pid @ ;
ok : checkpid getpid dup ." > PID IS " . cr 3 mod 0= ;
ok bye
-- STACK: <empty>
db{0}> break sys_getpid_with_ppid
db{0}> command . = checkpid
db{0}> c
...and then on a shell:
# (:)
fatal breakpoint trap in supervisor mode
trap type 1 code 0 eip 0xc090df89 cs 0x8 eflags 0x246 cr2 0xad8ef2c0 ilevel 0 esp 0xc0157fbd
curlwp 0xc2b5c2c0 pid 798 lid 1 lowest kstack 0xdabb42c0
> PID IS 798
-- STACK:
0xffffffff -1
Breakpoint in pid 798.1 (ksh) at netbsd:sys_getpid_with_ppid: pushl %ebp
db{0}> c
# (:)
fatal breakpoint trap in supervisor mode
trap type 1 code 0 eip 0xc090df89 cs 0x8 eflags 0x246 cr2 0xad8ef2c0 ilevel 0 esp 0xc0157fbd
curlwp 0xc2b5c2c0 pid 823 lid 1 lowest kstack 0xdabb42c0
> PID IS 823
-- STACK:
0x00000000 0
Command returned 0
#
If you are more interested in this presentation I strongly suggest to also give
a look to uwe's
forth Mercurial repository.
News from the version control front -- Jörg Sonnenberger (joerg)
The third presentation of the devsummit was a presentation about the recent work done by
Jörg (joerg) in the VCS conversions.
Jörg started the presentation discussing about the infrastructure used for the CVS -> Fossil -> Git conversion and CVS -> Fossil -> Mercurial conversion.
It's worth also noticing that the Mercurial conversion is fully integrated and is regularly pushed to Bitbucket and src repository pushed some scalability limits to Bitbucket!
Mercurial performance were also compared to the Git ones in details for several operations.
A check list that compared the current status of the NetBSD VCS migration to the FreeBSD VCS wiki one was described and then Jörg discussed the pending work and answered several questions in the Q&A.
For more information please give a look to the
joerg's presentation slides (HTML).
If you would like to help for the VCS migration please also get in touch with
him!
Afternoon discussions and dinner
After the lunch we had several non-scheduled discussions, some time
for hacking, etc. We then had a nice dinner together (it was in a
restaurant with a very nice waiter who always shouted after
every order or after accidently dropping and crashing dishes!, yeah! That's
probably a bit weird but I liked that attitude!  and then did some
sightseeing and had a beer together.
and then did some
sightseeing and had a beer together.

From left to right: uwe, bad, ast,
leot, martin, abhinav,
sborrill, alnsn, spz.

From left to right: uwe, bad, ast,
christos, leot, martin,
sborrill, alnsn, spz.
Saturday (23/09): First day of conference session and Social Event
A Modern Replacement for BSD spell(1) -- Abhinav Upadhyay (abhinav)
Abhinav (abhinav) presented his work on the new
spell(1)
implementation he's working (that isn't just a spell replacement
but also a library that can be used by other programs!).
He described the current limitations of old spell(1) (to get an
idea please give a look to bin/48684),
described the project goals of the new spell(1), additions to
/usr/share/dict/words, digged a bit in the implementation and
discussed several algorithms used and then provided a performance comparison
with other popular free software spell checkers
(aspell,
hunspell and ispell).
He also showed an interactive demo of the new spell(1) in-action
integrated with a shell for auto-completion and spell check.
If you would like to try it please give a look to
nbspell Git repository
that contains the code and dicts for the new spell(1)!
Video recording (YouTube) of the talk and slides (PDF) are also available!
Portable Hotplugging: NetBSD's uvm_hotplug(9) API development -- Cherry G. Mathew (cherry)
Cherry (cherry) presented recent work done with Santhosh N.
Raju (fox) about
uvm_hotplug(9).
The talk covered most "behind the scenes" work: how TDD (test driven
development) was used, how uvm_hotplug(9) was designed
and implemented (with comparisons to the old implementation),
interesting edge cases during the development and how
atf(7)
was used to do performance testing.
It was very interesting to learn how Cherry and Santhosh worked on that and on the conclusion Cherry pointed out the importance of using existing Software Engineering techniques in Systems Programming.
Video recording (YouTube) and slides (PDF) of the talk are also available!
Hardening pkgsrc -- Pierre Pronchery (khorben)
Pierre (khorben) presented a talk about recent pkgsrc security
features added in the recent months (and most of them also active on the just
released pkgsrc-2017Q3!).
He first introduced how security management and releng is handled
in pkgsrc, how to use
pkg_admin(1)
fetch-pkg-vulnerabilities and audit
commands, etc.
Then package signatures (generation, installation) and recent hardening features in pkgsrc were discussed in details, first introducing them and then how pkgsrc handles them:
- SSP: Stack Smashing Protection (enabled via
PKGSRC_USE_SSPinmk.conf) - Fortify (enabled via
PKGSRC_USE_FORTIFYinmk.conf) - Stack check (enabled via
PKGSRC_USE_STACK_CHECKinmk.conf) - Position-Independent Executables (PIE) (enabled via
PKGSRC_MKPIEinmk.conf) - RELRO and BIND_NOW (enabled via
PKGSRC_USE_RELROinmk.conf)
Challenges for each hardening features and future works were discussed.
For more information video recording (YouTube) and slides (PDF) of the talk are available. A good introduction and reference for all pkgsrc hardening features is the Hardening packages wiki page.
Reproducible builds on NetBSD -- Christos Zoulas (christos)
Christos (christos) presented the work about reproducible builds on
NetBSD.
In his talk he first provided a rationale about reproducible builds (to learn
more please give a look to
reproducible-builds.org!), he
then discussed about the NetBSD (cross) build process, the
current status
and build variations that are done in the tests.reproducible-builds.org
build machines.
Then he provided and described several sources of difference that were present in non-reproducible builds, like file-system timestamps, parallel builds headaches due directory/build order, path normalization, etc. For each of them he also discussed in details how these problems were solved in NetBSD.
In the conclusion the status and possible TODOs were also discussed (please note
that both -current and -8 are all built with
reproducible flags (-P option of build.sh)!)
Video recording (YouTube) of Christos' talk is available. Apart the resources discussed above a nice introduction to reproducible builds in NetBSD is also the NetBSD fully reproducible builds blog post written by Christos last February!
Social event
The social event on Saturday evening took place on a boat that cruised on the Seine river.
It was a very nice and different way to sightsee Paris, eat and enjoy some drinks and socialize and discuss with other developers and community.

Sunday (24/09): Second day of conference session
The school of hard knocks - PT1 -- Sevan Janiyan (sevan)
Sevan (sevan) presented a talk about several notes and lessons learnt
whilst running tutorials to introduce NetBSD at several events
(OSHUG #46 and
OSHUG #57 and
#58) and experiences from past events
(Chiphack 2013).
He described problems a user may experience and how NetBSD was introduced, in particular trying to avoid the steep learning curve involved when experimenting with operating systems as a first step, exploring documentation/source code, cross-building, scripting in high-level programming languages (Lua) and directly prototyping and getting pragmatic via rump.
Video recording (YouTube) of Sevan's talk and slides (HTML) are available.
The LLDB Debugger on NetBSD -- Kamil Rytarowski (kamil)
Kamil (kamil) presented a talk about the recent LLDB debugger and a
lot of other related debuggers (but also
non-strictly-related-to-debugging!) works he's doing in the last
months.
He first introduced debugging concepts in general, provided several examples and then he started discussing LLDB porting to NetBSD.
He then discussed about
ptrace(2)
and other introspection interfaces, the several improvements done and tests
added for ptrace(2) in
atf(7).
He also discussed about tracking LLDB's trunk (if you are more curious please
give a look to wip/llvm-git,
wip/clang-git, wip/lldb-git packages in pkgsrc-wip!) and about LLVM sanitizers
and their current status in NetBSD.
In the conclusion he also discussed various TODOs in these areas.
Video recording (YouTube)
and slides (HTML)
of Kamil's talk are available.
Kamil also regularly write status update blog posts on
blog.NetBSD.org and
tech-toolchain@ mailing
list, so please stay tuned!
What's in store for NetBSD 8.0? -- Alistair Crooks (agc)
Alistair (agc) presented a talk about what we will see in NetBSD
8.0.
He discussed about new hardware supported (really "new", not new "old" hardware!
Of course also support for VAXstation 4000 TURBOchannel USB and GPIO is actually
new hardware as well! :)), LLVM/Clang, virtualization, PGP signing, updated
utilities in NetBSD, new networking features (e.g. bouyer's
sockcan implementation), u-boot,
dtrace(1),
improvements and new ports testing, reproducible builds,
FDT (Flattened Device Tree) and a lot of other news!
The entire presentation was done using the Socratic method (Q&A) and it was very interactive and nice!
Video recording (YouTube) and slides (PDF) of Alistair's talk are available.
Sunday dinner
After the conference we did some sightseeing in Paris, had a dinner together and then enjoyed some beers!

On the left side: abhinav, ast, seb, christos
On the right side: leot, Riastradh, uwe, sevan, agc, sborrill

On the left side: martin, ast, seb, christos
On the right side: leot, Riastradh, uwe, sevan, agc, sborrill
Conclusion
It was a very nice weekend and conference. It is worth to mention that EuroBSDcon 2017 was the biggest BSD conference (more than 300 people attended it!).
I would like to thank the entire EuroBSDcon organising committee (Baptiste Daroussin, Antoine Jacoutot, Jean-Sébastien Pédron and Jean-Yves Migeon), EuroBSDcon programme commitee (Antoine Jacoutot, Lars Engels, Ollivier Robert, Sevan Janiyan, Jörg Sonnenberger, Jasper Lievisse Adriaanse and Janne Johansson) and EuroBSDcon Foundation for organizing such a wonderful conference!
I also would like to thank the speakers for presenting very interesting talks, all developers and community that attended the NetBSD devsummit and conference, in particular Jean-Yves and Jörg, for organizing and moderating the devsummit and Arolla that kindly hosted us for the NetBSD devsummit!
A special thanks also to Abhinav (abhinav) and Martin
(martin) for photographs and locals Jean-Yves (jym)
and Stoned (seb) for helping us in not get lost in Paris'
rues!
Thank you!
Let me tell you about my experience at
EuroBSDcon 2017
in Paris, France. We will
see what was presented during the NetBSD developer summit on Friday
and then we will give a look to all of the
NetBSD and
pkgsrc presentations given during
the conference session on Saturday and Sunday. Of course, a lot of
fun also happened on the "hall track", the several breaks
during the conference and the dinners we had together with other
*BSD developers and community! This is difficult to describe and
I will try to just share some part of that with photographs that
we have taken. I can just say that it was a really beautiful
experience, I had a great time with others and, after coming back
home... ...I miss all of that! So, if you have never been in
any BSD conferences I strongly suggest you to go to the next ones,
so please stay tuned via
NetBSD Events.
Being there this is probably the only way to understand these feelings!
Thursday (21/09): NetBSD developers dinner
Arriving in Paris via a night train from Italy I
literally sleep-walked through Paris getting lost again and again.
After getting in touch with other developers we had a dinner together and went
sightseeing for a^Wseveral beers!
Friday (22/09): NetBSD developers summit
On Friday morning we met for the NetBSD developers summit kindly hosted by Arolla.
From left to right: alnsn, sborrill;
abhinav; uwe and leot;
christos, cherry, ast and
bsiegert; martin and khorben.
The devsummit was moderated by Jörg (joerg) and organized by
Jean-Yves (jym).
NetBSD on Google Compute Engine -- Benny Siegert (bsiegert)
After a self-presentation the devsummit presentations session started with the
talk presented by Benny (bsiegert) about NetBSD on Google
Compute Engine.
Benny first introduced Google Compute Engine (GCE) and then started describing how to run NetBSD on it.
At the moment there are no official NetBSD images and so users need to create their own. However, netbsd-gce script completely automatize this process that:
- uses Anita to stage an installation in QEMU
- adjust several tweaks to ensure that networking and storage will work on GCE
- packs the image into a
.tar.gzfile
The .tar.gz image then just need to be uploaded to a Cloud Storage
bucket, create a GCE image from it and then launch VMs based on that image.
He also discussed about GCE instance metadata, several problems founds and how they were fixed (it's better to use NetBSD 8_BETA or -current!) and some future works.
For more information slides (PDF) of the talk are also available.
Scripting DDB with Forth -- Valery Ushakov (uwe)
Valery (uwe) presented a talk about Scripting DDB
with Forth. It was based on a long story and actually the
first discussion about it appeared on
tech-kern@
mailing list in his
Scripting DDB in Forth?
thread (ddb(4)
is the NetBSD in-kernel debugger).
He showed how one can associate forth commands/conditions with ddb breakpoints. He used "pid divisible by 3" as an example of condition for a breakpoint set in getpid(2) system call:
db{0}> forth
ok : field create , does> @ + ;
ok #300 field lwp>l_proc
ok #120 field proc>p_pid
ok : getpid curlwp lwp>l_proc @ proc>p_pid @ ;
ok : checkpid getpid dup ." > PID IS " . cr 3 mod 0= ;
ok bye
-- STACK: <empty>
db{0}> break sys_getpid_with_ppid
db{0}> command . = checkpid
db{0}> c
...and then on a shell:
# (:)
fatal breakpoint trap in supervisor mode
trap type 1 code 0 eip 0xc090df89 cs 0x8 eflags 0x246 cr2 0xad8ef2c0 ilevel 0 esp 0xc0157fbd
curlwp 0xc2b5c2c0 pid 798 lid 1 lowest kstack 0xdabb42c0
> PID IS 798
-- STACK:
0xffffffff -1
Breakpoint in pid 798.1 (ksh) at netbsd:sys_getpid_with_ppid: pushl %ebp
db{0}> c
# (:)
fatal breakpoint trap in supervisor mode
trap type 1 code 0 eip 0xc090df89 cs 0x8 eflags 0x246 cr2 0xad8ef2c0 ilevel 0 esp 0xc0157fbd
curlwp 0xc2b5c2c0 pid 823 lid 1 lowest kstack 0xdabb42c0
> PID IS 823
-- STACK:
0x00000000 0
Command returned 0
#
If you are more interested in this presentation I strongly suggest to also give
a look to uwe's
forth Mercurial repository.
News from the version control front -- Jörg Sonnenberger (joerg)
The third presentation of the devsummit was a presentation about the recent work done by
Jörg (joerg) in the VCS conversions.
Jörg started the presentation discussing about the infrastructure used for the CVS -> Fossil -> Git conversion and CVS -> Fossil -> Mercurial conversion.
It's worth also noticing that the Mercurial conversion is fully integrated and is regularly pushed to Bitbucket and src repository pushed some scalability limits to Bitbucket!
Mercurial performance were also compared to the Git ones in details for several operations.
A check list that compared the current status of the NetBSD VCS migration to the FreeBSD VCS wiki one was described and then Jörg discussed the pending work and answered several questions in the Q&A.
For more information please give a look to the
joerg's presentation slides (HTML).
If you would like to help for the VCS migration please also get in touch with
him!
Afternoon discussions and dinner
After the lunch we had several non-scheduled discussions, some time
for hacking, etc. We then had a nice dinner together (it was in a
restaurant with a very nice waiter who always shouted after
every order or after accidently dropping and crashing dishes!, yeah! That's
probably a bit weird but I liked that attitude! and then did some
sightseeing and had a beer together.
From left to right: uwe, bad, ast,
leot, martin, abhinav,
sborrill, alnsn, spz.
From left to right: uwe, bad, ast,
christos, leot, martin,
sborrill, alnsn, spz.
Saturday (23/09): First day of conference session and Social Event
A Modern Replacement for BSD spell(1) -- Abhinav Upadhyay (abhinav)
Abhinav (abhinav) presented his work on the new
spell(1)
implementation he's working (that isn't just a spell replacement
but also a library that can be used by other programs!).
He described the current limitations of old spell(1) (to get an
idea please give a look to bin/48684),
described the project goals of the new spell(1), additions to
/usr/share/dict/words, digged a bit in the implementation and
discussed several algorithms used and then provided a performance comparison
with other popular free software spell checkers
(aspell,
hunspell and ispell).
He also showed an interactive demo of the new spell(1) in-action
integrated with a shell for auto-completion and spell check.
If you would like to try it please give a look to
nbspell Git repository
that contains the code and dicts for the new spell(1)!
Video recording (YouTube) of the talk and slides (PDF) are also available!
Portable Hotplugging: NetBSD's uvm_hotplug(9) API development -- Cherry G. Mathew (cherry)
Cherry (cherry) presented recent work done with Santhosh N.
Raju (fox) about
uvm_hotplug(9).
The talk covered most "behind the scenes" work: how TDD (test driven
development) was used, how uvm_hotplug(9) was designed
and implemented (with comparisons to the old implementation),
interesting edge cases during the development and how
atf(7)
was used to do performance testing.
It was very interesting to learn how Cherry and Santhosh worked on that and on the conclusion Cherry pointed out the importance of using existing Software Engineering techniques in Systems Programming.
Video recording (YouTube) and slides (PDF) of the talk are also available!
Hardening pkgsrc -- Pierre Pronchery (khorben)
Pierre (khorben) presented a talk about recent pkgsrc security
features added in the recent months (and most of them also active on the just
released pkgsrc-2017Q3!).
He first introduced how security management and releng is handled
in pkgsrc, how to use
pkg_admin(1)
fetch-pkg-vulnerabilities and audit
commands, etc.
Then package signatures (generation, installation) and recent hardening features in pkgsrc were discussed in details, first introducing them and then how pkgsrc handles them:
- SSP: Stack Smashing Protection (enabled via
PKGSRC_USE_SSPinmk.conf) - Fortify (enabled via
PKGSRC_USE_FORTIFYinmk.conf) - Stack check (enabled via
PKGSRC_USE_STACK_CHECKinmk.conf) - Position-Independent Executables (PIE) (enabled via
PKGSRC_MKPIEinmk.conf) - RELRO and BIND_NOW (enabled via
PKGSRC_USE_RELROinmk.conf)
Challenges for each hardening features and future works were discussed.
For more information video recording (YouTube) and slides (PDF) of the talk are available. A good introduction and reference for all pkgsrc hardening features is the Hardening packages wiki page.
Reproducible builds on NetBSD -- Christos Zoulas (christos)
Christos (christos) presented the work about reproducible builds on
NetBSD.
In his talk he first provided a rationale about reproducible builds (to learn
more please give a look to
reproducible-builds.org!), he
then discussed about the NetBSD (cross) build process, the
current status
and build variations that are done in the tests.reproducible-builds.org
build machines.
Then he provided and described several sources of difference that were present in non-reproducible builds, like file-system timestamps, parallel builds headaches due directory/build order, path normalization, etc. For each of them he also discussed in details how these problems were solved in NetBSD.
In the conclusion the status and possible TODOs were also discussed (please note
that both -current and -8 are all built with
reproducible flags (-P option of build.sh)!)
Video recording (YouTube) of Christos' talk is available. Apart the resources discussed above a nice introduction to reproducible builds in NetBSD is also the NetBSD fully reproducible builds blog post written by Christos last February!
Social event
The social event on Saturday evening took place on a boat that cruised on the Seine river.
It was a very nice and different way to sightsee Paris, eat and enjoy some drinks and socialize and discuss with other developers and community.
Sunday (24/09): Second day of conference session
The school of hard knocks - PT1 -- Sevan Janiyan (sevan)
Sevan (sevan) presented a talk about several notes and lessons learnt
whilst running tutorials to introduce NetBSD at several events
(OSHUG #46 and
OSHUG #57 and
#58) and experiences from past events
(Chiphack 2013).
He described problems a user may experience and how NetBSD was introduced, in particular trying to avoid the steep learning curve involved when experimenting with operating systems as a first step, exploring documentation/source code, cross-building, scripting in high-level programming languages (Lua) and directly prototyping and getting pragmatic via rump.
Video recording (YouTube) of Sevan's talk and slides (HTML) are available.
The LLDB Debugger on NetBSD -- Kamil Rytarowski (kamil)
Kamil (kamil) presented a talk about the recent LLDB debugger and a
lot of other related debuggers (but also
non-strictly-related-to-debugging!) works he's doing in the last
months.
He first introduced debugging concepts in general, provided several examples and then he started discussing LLDB porting to NetBSD.
He then discussed about
ptrace(2)
and other introspection interfaces, the several improvements done and tests
added for ptrace(2) in
atf(7).
He also discussed about tracking LLDB's trunk (if you are more curious please
give a look to wip/llvm-git,
wip/clang-git, wip/lldb-git packages in pkgsrc-wip!) and about LLVM sanitizers
and their current status in NetBSD.
In the conclusion he also discussed various TODOs in these areas.
Video recording (YouTube)
and slides (HTML)
of Kamil's talk are available.
Kamil also regularly write status update blog posts on
blog.NetBSD.org and
tech-toolchain@ mailing
list, so please stay tuned!
What's in store for NetBSD 8.0? -- Alistair Crooks (agc)
Alistair (agc) presented a talk about what we will see in NetBSD
8.0.
He discussed about new hardware supported (really "new", not new "old" hardware!
Of course also support for VAXstation 4000 TURBOchannel USB and GPIO is actually
new hardware as well! :)), LLVM/Clang, virtualization, PGP signing, updated
utilities in NetBSD, new networking features (e.g. bouyer's
sockcan implementation), u-boot,
dtrace(1),
improvements and new ports testing, reproducible builds,
FDT (Flattened Device Tree) and a lot of other news!
The entire presentation was done using the Socratic method (Q&A) and it was very interactive and nice!
Video recording (YouTube) and slides (PDF) of Alistair's talk are available.
Sunday dinner
After the conference we did some sightseeing in Paris, had a dinner together and then enjoyed some beers!
On the left side: abhinav, ast, seb, christos
On the right side: leot, Riastradh, uwe, sevan, agc, sborrill
On the left side: martin, ast, seb, christos
On the right side: leot, Riastradh, uwe, sevan, agc, sborrill
Conclusion
It was a very nice weekend and conference. It is worth to mention that EuroBSDcon 2017 was the biggest BSD conference (more than 300 people attended it!).
I would like to thank the entire EuroBSDcon organising committee (Baptiste Daroussin, Antoine Jacoutot, Jean-Sébastien Pédron and Jean-Yves Migeon), EuroBSDcon programme commitee (Antoine Jacoutot, Lars Engels, Ollivier Robert, Sevan Janiyan, Jörg Sonnenberger, Jasper Lievisse Adriaanse and Janne Johansson) and EuroBSDcon Foundation for organizing such a wonderful conference!
I also would like to thank the speakers for presenting very interesting talks, all developers and community that attended the NetBSD devsummit and conference, in particular Jean-Yves and Jörg, for organizing and moderating the devsummit and Arolla that kindly hosted us for the NetBSD devsummit!
A special thanks also to Abhinav (abhinav) and Martin
(martin) for photographs and locals Jean-Yves (jym)
and Stoned (seb) for helping us in not get lost in Paris'
rues!
Thank you!
Current design
The current design is based on a specialized kernel called the "prekern", which operates between the bootloader and the kernel itself. The kernel is compiled as a raw library with the GENERIC_KASLR configuration file, while the prekern is compiled as a static binary. When the machine boots, the bootloader jumps into the prekern. The prekern relocates the kernel at a random virtual address (VA), and jumps into it. Finally, the kernel performs some cleanup, and executes normally.
Currently, the kernel is randomized as a single block. That is to say, a random VA is chosen, and the kernel text->rodata->data sections are mapped contiguously starting from there. It has several drawbacks, but it's a first shot.
To complete this implementation, work had to be done at three levels: the bootloader, the prekern and the kernel. I committed several of the kernel and bootloader patches discreetly a few months ago, to pave some way for real changes. In the past few weeks, I changed the low-level x86 layer of the kernel and replaced several hard-coded (and sometimes magic) values by variables, in such a way that the kernel can run with a non-static memory layout. Finally, the last step was committing the prekern itself to the source tree.
Future work
- Randomize the kernel sections independently, and intertwine them.
- Modify several kernel entry points not to leak kernel addresses to userland.
- Randomize the kernel heap too (which is still static for now).
- Fix a few other things that need some more work.
How to use
All of the patches are now in NetBSD-current. Instructions on how to install and use this implementation can be found here; they are inlined below, and probably won't change in the future.
Make sure you have a v5.11 bootloader installed. If you don't, build and install a new bootloader:
$ cd /usr/src/sys/arch/i386/stand/boot
$ make
# cp biosboot/boot /
Build and install a KASLR kernel:
$ cd /usr/src
$ ./build.sh -u kernel=GENERIC_KASLR
# cp /usr/obj/sys/arch/amd64/compile/GENERIC_KASLR/netbsd /netbsd_kaslr
Finally, build and install a prekern:
$ cd /usr/src/sys/arch/amd64/stand/prekern
$ make
# cp prekern /prekern
Reboot your machine. In the boot prompt, enter:
> pkboot netbsd_kaslr
The system will boot with no further user interaction. Should you encounter
any regression or unexpected behavior, please report it immediately
to tech-kern.
Note that you can still boot a static kernel, by typing as usual:
> boot netbsd
Availability
This KASLR implementation will be available starting from NetBSD 9. Once it is stabilized, it may be backported to NetBSD 8. Until then, feel free to test it!
Current design
The current design is based on a specialized kernel called the "prekern", which operates between the bootloader and the kernel itself. The kernel is compiled as a raw library with the GENERIC_KASLR configuration file, while the prekern is compiled as a static binary. When the machine boots, the bootloader jumps into the prekern. The prekern relocates the kernel at a random virtual address (VA), and jumps into it. Finally, the kernel performs some cleanup, and executes normally.
Currently, the kernel is randomized as a single block. That is to say, a random VA is chosen, and the kernel text->rodata->data sections are mapped contiguously starting from there. It has several drawbacks, but it's a first shot.
To complete this implementation, work had to be done at three levels: the bootloader, the prekern and the kernel. I committed several of the kernel and bootloader patches discreetly a few months ago, to pave some way for real changes. In the past few weeks, I changed the low-level x86 layer of the kernel and replaced several hard-coded (and sometimes magic) values by variables, in such a way that the kernel can run with a non-static memory layout. Finally, the last step was committing the prekern itself to the source tree.
Future work
- Randomize the kernel sections independently, and intertwine them.
- Modify several kernel entry points not to leak kernel addresses to userland.
- Randomize the kernel heap too (which is still static for now).
- Fix a few other things that need some more work.
How to use
All of the patches are now in NetBSD-current. Instructions on how to install and use this implementation can be found here; they are inlined below, and probably won't change in the future.
Make sure you have a v5.11 bootloader installed. If you don't, build and install a new bootloader:
$ cd /usr/src/sys/arch/i386/stand/boot
$ make
# cp biosboot/boot /
Build and install a KASLR kernel:
$ cd /usr/src
$ ./build.sh -u kernel=GENERIC_KASLR
# cp /usr/obj/sys/arch/amd64/compile/GENERIC_KASLR/netbsd /netbsd_kaslr
Finally, build and install a prekern:
$ cd /usr/src/sys/arch/amd64/stand/prekern
$ make
# cp prekern /prekern
Reboot your machine. In the boot prompt, enter:
> pkboot netbsd_kaslr
The system will boot with no further user interaction. Should you encounter
any regression or unexpected behavior, please report it immediately
to tech-kern.
Note that you can still boot a static kernel, by typing as usual:
> boot netbsd
Availability
This KASLR implementation will be available starting from NetBSD 9. Once it is stabilized, it may be backported to NetBSD 8. Until then, feel free to test it!
Michael van Elst, Taylor R. Campbell, Thomas Klausner
We'd like to sincerely thank the departing board members for their service during their term:
Matthew Sporleder, SAITOH Masanobu, Christos Zoulas
Christos will be remaining as Secretary and Treasurer for the Foundation.
Your 2016-2017 Directors of the Foundation are:
Erik Berls
Taylor R. Campbell
William J. Coldwell
Michael van Elst
Thomas Klausner
Jeremy C. Reed
S. P. Zeidler
The current office holders of the Foundation are:
President: William J. Coldwell
Vice President: Jeremy C. Reed
Secretary: Christos Zoulas
Treasurer: Christos Zoulas
Thank you to all of the developers that nominated and voted, the NomCom, the Voting Administrator and Voting Validator.
Respectfully submitted for the Board of Directors,
William J. Coldwell
Michael van Elst, Taylor R. Campbell, Thomas Klausner
We'd like to sincerely thank the departing board members for their service during their term:
Matthew Sporleder, SAITOH Masanobu, Christos Zoulas
Christos will be remaining as Secretary and Treasurer for the Foundation.
Your 2016-2017 Directors of the Foundation are:
Erik Berls
Taylor R. Campbell
William J. Coldwell
Michael van Elst
Thomas Klausner
Jeremy C. Reed
S. P. Zeidler
The current office holders of the Foundation are:
President: William J. Coldwell
Vice President: Jeremy C. Reed
Secretary: Christos Zoulas
Treasurer: Christos Zoulas
Thank you to all of the developers that nominated and voted, the NomCom, the Voting Administrator and Voting Validator.
Respectfully submitted for the Board of Directors,
William J. Coldwell
Greetings,
The NetBSD Foundation has initiated a contract with Kamil Rytarowski
to complete the following during it:
1. Add missing interfaces in ptrace(2), mostly sync it with
the FreeBSD capabilities, add ATF tests, add documentation.
2. Develop process plugin in LLDB based on the FreeBSD code in
LLDB and make it functional (start passing at least some tests).
3. Revamp the process plugin in LLDB for new remote debugging
capabilities (in order to get it accepted and merged upstream),
pass more tests.
4. LLDB x86 support, pass more of the standard LLDB tests
and import LLDB to the NetBSD base. Add some ATF LLDB basic
functionality tests to the tree. The original tests are
unreliable and generate false positives.
5. Develop missing features needed for .NET (POSIX robust
mutexes), add ATF tests.
6. Develop missing features for VirtualBox as host, including
needing sigevent(2) on par with POSIX and SIGEV_KEVENT, and
other real-time AIO related interfaces as needed.
7. Port Apple's Swift programming language. Enhance .NET port to
validate new interface and correct more issues as needed.
8. Improve VirtualBox host support. Make it build first by disabling
missing features of providing empty facades for them.
9. Implement CDROM, floppy, NIC support for NetBSD in VBox as host.
10. Make VirtualBox runnable at least with a restricted feature set, ship
it in pkgsrc, and submit it upstream.
The NetBSD Foundation will continue to work diligently with the
community to fund projects furthering specific key and quality
improvements to the NetBSD projects. We have a list of projects at
http://wiki.netbsd.org/projects/ as well as welcome other proposals
to move our flag forward to next releases!
Thank you to Kamil for committing to it and we all look forward to it!
The NetBSD Foundation is a non-profit organization and welcomes any
donations to help us continue to fund projects and services to the
open-source community. Please consider visiting the following URL,
and chip in what you can:
http://netbsd.org/donations/#how-to-donate
Submitted for The NetBSD Foundation,
William J. Coldwell (billc@)
President, Chairperson
20161012: edited to fix #10 to be the correct wording.
Greetings,
The NetBSD Foundation has initiated a contract with Kamil Rytarowski
to complete the following during it:
1. Add missing interfaces in ptrace(2), mostly sync it with
the FreeBSD capabilities, add ATF tests, add documentation.
2. Develop process plugin in LLDB based on the FreeBSD code in
LLDB and make it functional (start passing at least some tests).
3. Revamp the process plugin in LLDB for new remote debugging
capabilities (in order to get it accepted and merged upstream),
pass more tests.
4. LLDB x86 support, pass more of the standard LLDB tests
and import LLDB to the NetBSD base. Add some ATF LLDB basic
functionality tests to the tree. The original tests are
unreliable and generate false positives.
5. Develop missing features needed for .NET (POSIX robust
mutexes), add ATF tests.
6. Develop missing features for VirtualBox as host, including
needing sigevent(2) on par with POSIX and SIGEV_KEVENT, and
other real-time AIO related interfaces as needed.
7. Port Apple's Swift programming language. Enhance .NET port to
validate new interface and correct more issues as needed.
8. Improve VirtualBox host support. Make it build first by disabling
missing features of providing empty facades for them.
9. Implement CDROM, floppy, NIC support for NetBSD in VBox as host.
10. Make VirtualBox runnable at least with a restricted feature set, ship
it in pkgsrc, and submit it upstream.
The NetBSD Foundation will continue to work diligently with the
community to fund projects furthering specific key and quality
improvements to the NetBSD projects. We have a list of projects at
http://wiki.netbsd.org/projects/ as well as welcome other proposals
to move our flag forward to next releases!
Thank you to Kamil for committing to it and we all look forward to it!
The NetBSD Foundation is a non-profit organization and welcomes any
donations to help us continue to fund projects and services to the
open-source community. Please consider visiting the following URL,
and chip in what you can:
http://netbsd.org/donations/#how-to-donate
Submitted for The NetBSD Foundation,
William J. Coldwell (billc@)
President, Chairperson
20161012: edited to fix #10 to be the correct wording.
The NetBSD Project is pleased to announce NetBSD 7.0.2, the second security/bugfix update of the NetBSD 7.0 release branch. It represents a selected subset of fixes deemed important for security or stability reasons. If you are running an earlier release of NetBSD, we strongly suggest updating to 7.0.2.
For more details, please see the release notes.
Complete source and binaries for NetBSD are available for download at many sites around the world. A list of download sites providing FTP, AnonCVS, SUP, and other services may be found at http://www.NetBSD.org/mirrors/.
The NetBSD Project is pleased to announce NetBSD 7.0.2, the second security/bugfix update of the NetBSD 7.0 release branch. It represents a selected subset of fixes deemed important for security or stability reasons. If you are running an earlier release of NetBSD, we strongly suggest updating to 7.0.2.
For more details, please see the release notes.
Complete source and binaries for NetBSD are available for download at many sites around the world. A list of download sites providing FTP, AnonCVS, SUP, and other services may be found at http://www.NetBSD.org/mirrors/.
The NetBSD Project is pleased to announce NetBSD 6.1.5, the fifth security/bugfix update of the NetBSD 6.1 release branch, and NetBSD 6.0.6, the sixth security/bugfix update of the NetBSD 6.0 release branch. They represent a selected subset of fixes deemed important for security or stability reasons, and if you are running a prior release of either branch, we strongly suggest that you update to one of these releases.
For more details, please see the NetBSD 6.1.5 release notes or NetBSD 6.0.6 release notes.
Complete source and binaries for NetBSD are available for download at many sites around the world. A list of download sites providing FTP, AnonCVS, SUP, and other services may be found at http://www.NetBSD.org/mirrors/.The following report is by Manuel Wiesinger:
First of all, I like to thank the NetBSD Foundation for enabling me to successfully complete this Google Summer of Code. It has been a very valuable experience for me.
My project is a defragmentation tool for FFS. I want to point out at the beginning that it is not ready for use yet.
What has been done:
Fragment analysis + reordering. When a file is smaller or equal than the file system's fragment size, it is stored as a fragment. One can think of a fragment as a block. It can happen that there are many small files that occupy a fragment. When the file systems changes over time it can happen that there are many blocks containing fewer fragments than they can hold. The optimization my tool does is to pack all these fragments into fewer blocks. This way the system may get a little more free space.
Directory optimization. When a directory gets deleted, the space for that directory and its name are appended to the previous directory. This can be imagined like a linked list. My tool reads that list and writes all entries sequentially.
Non-contiguous files analysis + reordering strategy. This is what most other operating systems call defragmentation - a reordering of blocks, so that blocks belonging to the same file or directory can be read sequentially.
What did not work as expected
Testing: I thought that it is the most productive and stable to work with unit tests. Strictly test driven development. It was not really effective to play around with rump/atf. Although I always started a new implementation step by generating a file system in a state where it can be optimized. So I wrote the scripts, took a look if they did what I intended (of course, they did not always).
I'm a bit disappointed about the amount of code. But as I said before, the hardest part is to figure out how things work. The amount it does is relatively much, I expected more lines of code to be needed to get where I am now.
Before applying for this project, I took a close look at UFS. But it was not close enough. There were many surprises. E.g. I had no idea that there are gaps in files on purpose, to exploit the rotation of hard disks.
Time management, everything took longer than I expected. Mostly because it was really hard to figure out how things work. Lacking documentation is a huge problem too.
Things I learned
A huge lesson learned in software engineering. It is always different than expected, if you do not have a lot of experience.
I feel more confident to read and patch kernel code. All my previous experiences were not so in-depth. (e.g., I worked with pintos). The (mental) barrier of kernel/system programming is gone. For example I see a chance now to take a look on ACPI, and see if I can write a patch to get suspend working on my notebook.
I got more contact with the NetBSD community, and got a nice overview how things work. The BSD community here is very mixed. There are not many NetBSD people.
CVS is better than most of my friends say.
I learned about pkgsrc, UVM, and other smaller things about NetBSD too, but that's not worth mentioning in detail.
How I intend to continue:
After a sanity break, of the whole project, there are several possibilities.
In the next days I will speak to a supervisor at my university, if I can continue the project as a project thesis (I still need to do one). It may even include online defragmentation, based on snapshots. That's my preferred option.
I definitely want to finish this project, since I spent so much time and effort. It would be a shame otherwise.
What there is to do technically
Once the defragmentation works, given enough space to move a file. I want to find a way where you can defragment it even when there is too little space. This can be achieved by simply moving blocks piece by piece, and use the files' space as 'free space'.
Online defragmentation. I already skimmed hot snapshots work. It should be possible.
Improve the tests.
It should be easy to get this compiling on older releases. Currently it compiles only on -current.
Eventually it's worth it to port the tests to atf/rump on the long run.
Conclusion
I will continue to work, and definitely continue to use and play with NetBSD!
It's a stupid thing that a defrag tool is worth little (nothing?) on SSDs. But since NetBSD is designed to run on (almost) any hardware, this does not bug me a lot.
Thank you NetBSD! Although it was a lot of hard work. It was a lot of fun!
Manuel Wiesinger
/proc/#/ctl).
LLVM
The majority of the work has been done in the LLVM projects.
The developed features are not production ready and they will need productization in the future. There are still issues with paths mismatch ("netbsd" vs "netbsd8.99" vs "netbsd8.99.1") when looking for NetBSD specific support for the compiler-rt features. There is also a need for integration with pkgsrc, as not everything behaves sanely (conflicts with wrappers). The tools are also restricted to be built with the Clang compiler, as GCC support is currently broken. I also noted that the sanitizers behave wrongly in the standalone build (out of the LLVM sources).
I expect to sort out the mentioned problems after finishing LLDB.
LLVM JIT
There is ongoing discussion with the LLVM community about new JIT API that will be compatible with NetBSD PaX MPROTECT. There have been developed and introduced cleanups in the code (like better error handling templates) in order to prepare a draft of new API.
ASAN
All local code for ASan has been merged upstream. This includes NetBSD patches in LLVM, Clang and compiler-rt.
All but two (one on i386 version and the other on amd64) tests (check-asan) pass.
UBSAN
Similarly to ASan, UBsan has been fully upstreamed. All tests (check-ubsan) pass.
SafeStack
SafeStack is a software security hardening technique that creates two stacks: one for data that needs to be kept safe, such as return addresses and function pointers; and an unsafe stack for everything else.
With PaX ASLR (Address Space Layout Randomization) and PaX MPROTECT (mprotect(2) restrictions) SafeStack is an excellent candidate for inclusion in pkgsrc.
Core programs could be hardened as well, but the shortcoming of SafeStack for basesystem utilities is pulling in additional dependencies like libpthread on every executable.
Using SafeStack adds marginal overhead.
libFuzzer
Citing the project page, LibFuzzer is an in-process, coverage-guided, evolutionary fuzzing engine.
LibFuzzer is linked with the library under test, and feeds fuzzed inputs to the library via a specific fuzzing entry point (aka 'target function'); the fuzzer then tracks which areas of the code are reached, and generates mutations on the corpus of input data in order to maximize the code coverage. The code coverage information for libFuzzer is provided by LLVM's SanitizerCoverage instrumentation.
This functionality still requires more sanitizers to get aboard and is now of restricted functionality.
TSAN
Part of the TSan code has been upstreamed. However, a functional port isn't finished yet.
The current issues are: proper process memory map handling and NetBSD specific setjmp(3)-like functions support.
LSAN
I was also working on LSan. This sanitizer already builds and appears to be quite completed, however there is work needed for the implementation of StopTheWorld() function to self-introspect the process and threads. I'm researching a new kernel API for this purpose, but it might wait till the end of LLDB porting.
MSAN
So far I have not been working on the MSan specific bits. The majority of the code has been upstreamed for this sanitizer in the common sanitizer framework, the proper handling of the NetBSD specific process map is still to be done.
PROFILE
The profile library is used to collect coverage information. It already passes most of the tests, however it's not turned on, as upstream requested additional time to be spent on the issues and it's not a priority right now.
NetBSD kernel
I've removed the filesystem tracing feature.
This is a legacy interface from 4.4BSD, and it was
introduced to overcome shortcomings of ptrace(2) at that time, which are
no longer relevant (performance). Today /proc/#/ctl offers a narrow
subset of ptrace(2) commands and is not applicable for modern
applications use beyond simplistic tracing scenarios.
This removal simplified kernel internals. Users are still able to
use all the other /proc files.
This change doesn't affect other procfs files and Linux compat
features within mount_procfs(8). /proc/#/ctl isn't available on Linux.
Plan for the next milestone
This month I will not work on a new development and I will focus on relax and taking part in EuroBSDCon in Paris. I will speak about the LLDB porting to NetBSD.
Long-term goals are finishing the basis sanitizers (msan, tsan) and switching back to LLDB porting. The sanitizers will be used to develop and debug the LLVM debugger. There is also integration with sanitizers in LLDB.
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL, and chip in what you can:
/proc/#/ctl).
LLVM
The majority of the work has been done in the LLVM projects.
The developed features are not production ready and they will need productization in the future. There are still issues with paths mismatch ("netbsd" vs "netbsd8.99" vs "netbsd8.99.1") when looking for NetBSD specific support for the compiler-rt features. There is also a need for integration with pkgsrc, as not everything behaves sanely (conflicts with wrappers). The tools are also restricted to be built with the Clang compiler, as GCC support is currently broken. I also noted that the sanitizers behave wrongly in the standalone build (out of the LLVM sources).
I expect to sort out the mentioned problems after finishing LLDB.
LLVM JIT
There is ongoing discussion with the LLVM community about new JIT API that will be compatible with NetBSD PaX MPROTECT. There have been developed and introduced cleanups in the code (like better error handling templates) in order to prepare a draft of new API.
ASAN
All local code for ASan has been merged upstream. This includes NetBSD patches in LLVM, Clang and compiler-rt.
All but two (one on i386 version and the other on amd64) tests (check-asan) pass.
UBSAN
Similarly to ASan, UBsan has been fully upstreamed. All tests (check-ubsan) pass.
SafeStack
SafeStack is a software security hardening technique that creates two stacks: one for data that needs to be kept safe, such as return addresses and function pointers; and an unsafe stack for everything else.
With PaX ASLR (Address Space Layout Randomization) and PaX MPROTECT (mprotect(2) restrictions) SafeStack is an excellent candidate for inclusion in pkgsrc.
Core programs could be hardened as well, but the shortcoming of SafeStack for basesystem utilities is pulling in additional dependencies like libpthread on every executable.
Using SafeStack adds marginal overhead.
libFuzzer
Citing the project page, LibFuzzer is an in-process, coverage-guided, evolutionary fuzzing engine.
LibFuzzer is linked with the library under test, and feeds fuzzed inputs to the library via a specific fuzzing entry point (aka 'target function'); the fuzzer then tracks which areas of the code are reached, and generates mutations on the corpus of input data in order to maximize the code coverage. The code coverage information for libFuzzer is provided by LLVM's SanitizerCoverage instrumentation.
This functionality still requires more sanitizers to get aboard and is now of restricted functionality.
TSAN
Part of the TSan code has been upstreamed. However, a functional port isn't finished yet.
The current issues are: proper process memory map handling and NetBSD specific setjmp(3)-like functions support.
LSAN
I was also working on LSan. This sanitizer already builds and appears to be quite completed, however there is work needed for the implementation of StopTheWorld() function to self-introspect the process and threads. I'm researching a new kernel API for this purpose, but it might wait till the end of LLDB porting.
MSAN
So far I have not been working on the MSan specific bits. The majority of the code has been upstreamed for this sanitizer in the common sanitizer framework, the proper handling of the NetBSD specific process map is still to be done.
PROFILE
The profile library is used to collect coverage information. It already passes most of the tests, however it's not turned on, as upstream requested additional time to be spent on the issues and it's not a priority right now.
NetBSD kernel
I've removed the filesystem tracing feature.
This is a legacy interface from 4.4BSD, and it was
introduced to overcome shortcomings of ptrace(2) at that time, which are
no longer relevant (performance). Today /proc/#/ctl offers a narrow
subset of ptrace(2) commands and is not applicable for modern
applications use beyond simplistic tracing scenarios.
This removal simplified kernel internals. Users are still able to
use all the other /proc files.
This change doesn't affect other procfs files and Linux compat
features within mount_procfs(8). /proc/#/ctl isn't available on Linux.
Plan for the next milestone
This month I will not work on a new development and I will focus on relax and taking part in EuroBSDCon in Paris. I will speak about the LLDB porting to NetBSD.
Long-term goals are finishing the basis sanitizers (msan, tsan) and switching back to LLDB porting. The sanitizers will be used to develop and debug the LLVM debugger. There is also integration with sanitizers in LLDB.
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL, and chip in what you can:
You can find Mercurial versions of src, pkgsrc and xsrc under
and
The same rules as for the fossil and github repositories apply, i.e. there may be occasional glitches and if it becomes too bad, they might be recreated from scratch.
See more information in the posted thread to tech-repository.
You can find Mercurial versions of src, pkgsrc and xsrc under
and
The same rules as for the fossil and github repositories apply, i.e. there may be occasional glitches and if it becomes too bad, they might be recreated from scratch.
See more information in the posted thread to tech-repository.
Traditionally, developers in distributions like NetBSD merge 3rd party sources upstream once in a while with major release bumps, like switching from GCC 4.8.x to GCC 5.x. The time frame between the releases can be several months or a few years. This appears as a one-time effort from time to time, however with each software revision the code starts to rot on undermaintained targets. This results in local compatibility patches, which are rarely ready or applicable for upstream and thus detached from the development progress. Upstream developers tend to assume that minimal activity from such projects is a result of having no users and not verifying new code on them.
A good way to improve the situation and ensure quality of software that would shorten developers' time and cost, to deepen relations between NetBSD developers and upstream 3rd party software is to attach a build cluster node within the testing infrastructure.
The shortcoming of this approach is that it requires hardware, bandwidth and admin maintenance. The advantage is closer and better support for the NetBSD platform directly from the 3rd party software developers and the immediate detection of regressions, further reducing development time.
After the process of restoration the NetBSD support within the GDB and binutils projects, there is a new member in the GDB's cluster farm that verifies correct build status on NetBSD/amd64. This bot is hosted within The NetBSD Foundation's internal infrastructure.
The immediate follow up is to turn on --enable-targets=all, which will build all the available backends. Only a few more patches are needed to achieve this milestone.
Next steps involve extending this bot to verify other projects within the shared binutils-gdb repository. This includes GNU binutils itself, ld, gold (after adding appropriate platform support), gas, sim and gprof.
The ultimate goal is to enable execution of all tests for each new binutils-gdb commit in the upstream repository. This must be preceded by accomplishing the ongoing contracted task sponsored by The NetBSD Foundation - to port the LLDB debugger to NetBSD, as the LLVM debugger opens a door for new software from the same field.
Traditionally, developers in distributions like NetBSD merge 3rd party sources upstream once in a while with major release bumps, like switching from GCC 4.8.x to GCC 5.x. The time frame between the releases can be several months or a few years. This appears as a one-time effort from time to time, however with each software revision the code starts to rot on undermaintained targets. This results in local compatibility patches, which are rarely ready or applicable for upstream and thus detached from the development progress. Upstream developers tend to assume that minimal activity from such projects is a result of having no users and not verifying new code on them.
A good way to improve the situation and ensure quality of software that would shorten developers' time and cost, to deepen relations between NetBSD developers and upstream 3rd party software is to attach a build cluster node within the testing infrastructure.
The shortcoming of this approach is that it requires hardware, bandwidth and admin maintenance. The advantage is closer and better support for the NetBSD platform directly from the 3rd party software developers and the immediate detection of regressions, further reducing development time.
After the process of restoration the NetBSD support within the GDB and binutils projects, there is a new member in the GDB's cluster farm that verifies correct build status on NetBSD/amd64. This bot is hosted within The NetBSD Foundation's internal infrastructure.
The immediate follow up is to turn on --enable-targets=all, which will build all the available backends. Only a few more patches are needed to achieve this milestone.
Next steps involve extending this bot to verify other projects within the shared binutils-gdb repository. This includes GNU binutils itself, ld, gold (after adding appropriate platform support), gas, sim and gprof.
The ultimate goal is to enable execution of all tests for each new binutils-gdb commit in the upstream repository. This must be preceded by accomplishing the ongoing contracted task sponsored by The NetBSD Foundation - to port the LLDB debugger to NetBSD, as the LLVM debugger opens a door for new software from the same field.
We welcome Pierre Pronchery and Makoto Fujiwara to the 2017 Board of Directors. We look forward to working with you!
We appreciate all of the wonderful work that S.P.Zeidler and Erik Berls have done on the board during their time as directors, and are grateful for their excellent service to the foundation.
Thank you to all members participating by nominating candidates and voting on the slate.
Respectfully submitted for The NetBSD Foundation,
William J. Coldwell
President/Chairperson
We welcome Pierre Pronchery and Makoto Fujiwara to the 2017 Board of Directors. We look forward to working with you!
We appreciate all of the wonderful work that S.P.Zeidler and Erik Berls have done on the board during their time as directors, and are grateful for their excellent service to the foundation.
Thank you to all members participating by nominating candidates and voting on the slate.
Respectfully submitted for The NetBSD Foundation,
William J. Coldwell
President/Chairperson
Recently my RKM MK68 machine arrived - a few NetBSD developers have got an engineering sample, kindly provided by Rikomagic, arranged by even more kind cooperation by Christophe Prévotaux from the Bitrig Project.
It is a nice, small 8 core 64 bit arm machine:

Rikomagic provided some documentation, and they have been nice and responsive to our questions for more, so full support for this nice piece of hardware should be a matter of time only.
It will require merging some changes for aarch64 that Matt Thomas already made, which also include a switch of mips to the generic pmap implementation - and unfortunately do not yet work on some mips variants.
I plan to use my machine, once it runs NetBSD, to do regular test runs (of course). But there are a lot of other things to do first, starting with soldering the serial console.
However, I am about to leave for EuroBSDCon 2015, so this will have to wait until next week.
P.S.: I am also still hoping for a 64bit tegra k1 based Chromebook (with free enough boot loader to run NetBSD). I need to replace my aging (huge and heavy) amd64 notebook finally!
There are a number of motivations for running applications directly on top of the Xen hypervisor without resorting to a full general-purpose OS. For example, one might want to maximally isolate applications with minimal overhead. Leaving the OS out of the picture decreases overhead, since for example the inter-application protection offered normally by virtual memory is already handled by the Xen hypervisor. However, at the same time problems arise: applications expect and use many services normally provided by the OS, for example files, sockets, event notification and so forth. We were able to set up a production quality environment for running applications as Xen DomU's in a few weeks by reusing hundreds of thousands of lines of unmodified driver and infrastructure code from NetBSD. While the amount of driver code may sound like a lot for running single applications, keep in mind that it involves for example file systems, the TCP/IP stack, stdio, system calls and so forth -- the innocent-looking open() alone accepts over 20 flags which must be properly handled. The remainder of this post looks at the effort in more detail.
I have been on a path to maximize the reuse potential of the NetBSD kernel with a technology called rump kernels. Things started out with running unmodified drivers in userspace on NetBSD, but the ability to host rump kernels has since spread to the userspace of other operating systems, web browsers (when compiled to javascript), and even the Linux kernel. Running rump kernels directly on the Xen hypervisor has been suggested by a number of people over the years. It provides a different sort of challenge, since as opposed to the environments mentioned previously, the Xen hypervisor is a "bare metal" type of environment: the guest is in charge of everything starting from bootstrap and page table management. The conveniently reusable Xen Mini-OS was employed for interfacing with the bare metal environment, and the necessary rump kernel hypercalls were built upon that. The environment for running unmodified NetBSD kernel drivers (e.g. TCP/IP) and system call handlers (e.g. socket()) directly on top of the Xen hypervisor was available after implementing the necessary rump kernel hypercalls (note: link points to the initial revision).
Shortly after I had published the above, I was contacted by Justin Cormack with whom I had collaborated earlier on his ljsyscall project, which provides system call interfaces to Lua programs. He wanted to run the LuaJIT interpreter and his ljsyscall implementation directly on top of Xen. However, in addition to system calls which were already handled by the rump kernel, the LuaJIT interpreter uses interfaces from libc, so we added the NetBSD libc to the mix. While currently the libc sources are hosted on github, we plan to integrate the changes into the upstream NetBSD sources as soon as things settle (see the repo for instructions on how to produce a diff and verify that the changes really are tiny). The same repository hosts the math library libm, but it is there just for convenience reasons so that these early builds deliver everything from a single checkout. It has been verified that you can alternatively use libm from a standard NetBSD binary distribution, as supposedly you could any other user-level library. The resulting architecture is depicted below.

The API and ABI we provide are the same as of a regular NetBSD installation. Apart from some limitations, such as the absense of fork() -- would it duplicate the DomU? -- objects compiled for a regular NetBSD installation can be linked into the DomU image and booted to run directly as standalone applications on top of Xen. As proofs of concept, I created a demo where a Xen DomU configures TCP/IP networking, mounts a file system image, and runs a httpd daemon to serve the contents, and Justin's demo runs the LuaJIT interpreter and executes the self-test suite for ljsyscall. Though there is solid support for running applications, not all of the work is done. Especially the build framework needs to be more flexible, and everyone who has a use case for this technology is welcome to test out their application and contribute ideas and code for improving the framework.
In conclusion, we have shown that it is straightforward to reuse both kernel and library code from an existing real-world operating system in creating an application environment which can run on top of a bare-metal type cloud platform. By being able to use in the order of 99.9% of the code -- that's 1,000 lines written per 1,000,000 used unmodified -- from an existing, real-world proven source, the task was quick to pull off, the result is robust, and the offered application interfaces are complete. Some might call our work a "yet another $fookernel", but we call it a working result and challenge everyone to evaluate it for themselves.
Yesterday I wrote a serious, user-oriented post about running applications directly on the Xen hypervisor. Today I compensate for the seriousness by writing a why-so-serious, happy-buddha type kernel hacker post. This post is about using NetBSD kernel PCI drivers in rump kernels on Xen, with device access courtesy of Xen PCI passthrough.
I do not like hardware. The best thing about hardware is that it gives software developers the perfect excuse to blame something else for their problems. The second best thing about hardware is that most of the time you can fix problems with physical violence. The third best thing about hardware is that it enables running software. Apart from that, the characteristics of hardware are undesirable: you have to possess the hardware, it does not virtualize nicely, it is a black box subject to the whims of whoever documented it, etc. Since rump kernels are targeting reuse and virtualization of kernel drivers in an environment-agnostic fashion, needless to say, there is a long, non-easy truce between hardware drivers and rump kernels.
Many years ago I did work which enabled USB drivers to run in rump kernels. The approach was to use the ugen device node to access the physical device from userspace. In other words, the layers which transported the USB protocol to and from the device remained in the host kernel, while the interpretation of the contents was moved to userspace; a USB host controller driver was written to act as the middleman between these two. While the approach did allow to run USB drivers such as umass and ucom, and it did give me much-needed exercise in the form of having to plug and unplug USB devices while testing, the whole effort was not entirely successful. The lack of success was due to too much of the driver stack, namely the USB host controller and ugen drivers, residing outside of the rump kernel. The first effect was that due to my in-userspace development exercising in-kernel code (via the ugen device) in creative ways, I experienced way too many development host kernel panics. Some of the panics could be fixed, while others were more in the department "well I have no idea why it decided to crash now or how to repeat the problem". The second effect was being able to use USB drivers in rump kernels only on NetBSD hosts, again foiling environment-agnostism (is that even a word?). The positive side-effect of the effort was adding ioconf and pseudo-root support to config(1), thereby allowing modular driver device tree specifications to be written in the autoconf DSL instead of having to be open-coded into the driver in C.
In the years that followed, the question of rump kernels supporting real device drivers which did not half-hide behind the host's skirt became a veritable FAQ. My answer remained the same: "I don't think it's difficult at all, but there's no way I'm going to do it since I hate hardware". While it was possible to run specially crafted drivers in conjuction with rump kernels, e.g. DPDK drivers for PCI NICs, using any NetBSD driver and supported device was not possible. However, after bolting rump kernels to run on top of Xen, the opportunity to investigate Xen's PCI passthrough capabilities presented itself, and I did end up with support for PCI drivers. Conclusion: I cannot be trusted to not do something.
The path to making PCI devices work consisted of taking n small steps. The trick was staying on the path instead of heading toward the light. If you do the "imagine how it could work and then make it work like that" development like I do, you'll no doubt agree that the steps presented below are rather obvious. (The relevant NetBSD man pages are linked in parenthesis. Also note that the implementations of these interfaces are MD in NetBSD, making for a clean cut into the NetBSD kernel architecture)
- passing PCI config space read and writes to the Xen hypervisor (pci(9))
- mapping the device memory space into the Xen guest and providing access methods (bus_space(9))
- mapping Xen events channels to driver interrupt handlers (pci_intr(9))
- allocating DMA-safe memory and translating memory addresses to and from machine addresses, which are even more physical than physical addresses (bus_dma(9))
On the Xen side of things, the hypercalls for all of these tasks are more or less one-liner calls into the Xen Mini-OS (which, if you read my previous post, is the layer which takes care of the lowest level details of running rump kernels on top of Xen).
And there we have it, NetBSD PCI drivers running on a rump kernel on Xen. The two PCI NIC drivers I tested both even pass the allencompassing ping test (and the can-configure-networking-using-dhcp test too). There's nothing like a dmesg to brighten the day.
Closing thoughts: virtual machine emulators are great, but you lose the ability to kick the hardware.
All open issues (wrong colours on scaled images, failing https, ...) have been resolved.
Here is a new screeenshot:
{kind=link}
The NetBSD Project is pleased to announce NetBSD 5.2.1, the first security/bugfix update of the NetBSD 5.2 release branch, and NetBSD 5.1.3, the third security/bugfix update of the NetBSD 5.1 release branch. They represent a selected subset of fixes deemed important for security or stability reasons, and if you are running a release of NetBSD prior to 5.1.3, you are recommended to update to a supported NetBSD 5.x or NetBSD 6.x version.
For more details, please see the NetBSD 5.2.1 release notes or NetBSD 5.1.3 release notes.
Complete source and binaries for NetBSD 5.2.1 and NetBSD 5.1.3 are available for download at many sites around the world. A list of download sites providing FTP, AnonCVS, SUP, and other services may be found at http://www.NetBSD.org/mirrors/.Updates to NetBSD 6.x will be coming in the next few days.
The NetBSD Project is pleased to announce NetBSD 6.1.2, the second security/bugfix update of the NetBSD 6.1 release branch, and NetBSD 6.0.3, the third security/bugfix update of the NetBSD 6.0 release branch. They represent a selected subset of fixes deemed important for security or stability reasons, and if you are running a prior release of NetBSD 6.x3, you are recommended to update.
For more details, please see the NetBSD 6.1.2 release notes or NetBSD 6.0.3 release notes.
Complete source and binaries for NetBSD 6.1.2 and NetBSD 6.0.3 are available for download at many sites around the world. A list of download sites providing FTP, AnonCVS, SUP, and other services may be found at http://www.NetBSD.org/mirrors/.Google Summer of Code 2016 is now over. We have polished the code and documentation and submitted the final term evaluation on 23rd of August 2016. The mentors evaluated us in the following week.
If you are impatient (and this time impatience is definitely a virtue!) please take a look to all The NetBSD Foundation GSoC 2016 projects' code submissions!
Introduction
In part 1 we have learned what happens under the hood when we split debugging symbols: how debugging information is stored/stripped off, the relevant ELF sections involved, various tools to dump that information, etc..
In particular, we have studied what happens on NetBSD when we set the
MKDEBUG* flags.
With this background we can finally try to implement this functionality in the
pkgsrc infrastructure. In this blog post we
will first give a practical look at PKG_DEBUGDATA and then we
will analyze the code that I have written in the first mid-term of the GSoC to
accomplish that.
PKG_DEBUGDATA in action
Before digging in the implementation of debugdata functionality let's see what it produces!
In part 1
we took as example a very simple program that just prints out the lyrics of
Ten Green Bottles song. After packaging it as
local/green-bottles
let's just build it without any special pkgsrc system variables set:
$ cd pkgsrc/local/green-bottles $ make install [...] $ green-bottles ten green bottles hanging on the wall [...] $ pkg_info -L green-bottles Information for green-bottles-0: Files: /usr/pkg/bin/green-bottles $ gdb `which green-bottles` GNU gdb (GDB) 7.10.1 Copyright (C) 2015 Free Software Foundation, Inc. License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html> [...] Reading symbols from /usr/pkg/bin/green-bottles...(no debugging symbols found)...done. (gdb) quit
That's expected because we did not set any special CFLAGS nor
INSTALL_UNSTRIPPED.
Before setting PKG_DEBUGDATA to "yes" let's inspect its
documentation via the help target:
$ make help topic=PKG_DEBUGDATA ===> mk/bsd.debugdata.mk (keywords: INSTALL_UNSTRIPPED PKG_DEBUGLEVEL PKG_DEBUGDATA debug): # This Makefile fragment is included by bsd.pkg.mk and implements the # logic needed to strip debug symbols off the program/libraries. # # User-settable variables: # # PKG_DEBUGDATA # If "yes", install stripped debug symbols for all programs and shared # libraries. Please notice that if it is defined INSTALL_UNSTRIPPED will # be also defined internally. # # PKG_DEBUGLEVEL # Used to control the granularity of the debug information. Can be # "small", "default", "detailed". # TODO: the name of this variable should be changed because it can be # TODO: easily confused with PKG_DEBUG_LEVEL! # # See also: # INSTALL_UNSTRIPPED #
Now that we have finally an idea of what PKG_DEBUGDATA does, let's
set it and reinstall the green-bottles package:
$ make clean deinstall [...] $ PKG_DEBUGDATA=yes make install [...] ===> Installing for green-bottles-0 [...] => Stripping debug symbols => Installing debug data [...] => Checking for missing debug data in green-bottles-0 [...]
Apart from the various phases we can see three extra messages that are now printed out: stripping of debug symbols, installing of debug data and a check for missing debug data.
If we inspect the files installed we can now also see
green-bottles.debug:
$ pkg_info -L green-bottles Information for green-bottles-0: Files: /usr/pkg/bin/green-bottles.debug /usr/pkg/bin/green-bottles
Indeed if we now try to run it through gdb(1):
$ gdb `which green-bottles`
GNU gdb (GDB) 7.10.1
Copyright (C) 2015 Free Software Foundation, Inc.
[...]
Reading symbols from /usr/pkg/bin/green-bottles...Reading symbols from /usr/pkg/bin/green-bottles.debug...done.
done.
(gdb) b main
Breakpoint 1 at 0xad0: file green-bottles.c, line 29.
(gdb) run
Starting program: /usr/pkg/bin/green-bottles
Breakpoint 1, main () at green-bottles.c:29
29 {
(gdb)
[...]
green-bottles was installed as usual without requiring any changes
from MAINTAINERs, in fact the various .debug files
are generated, installed and added to the PLIST dynamically.
A look at mk/bsd.debugdata.mk and mk/check/check-debugdata.mk implementation
All the functionalities that implement stripping of the debug data from
installed programs and libraries are implemented entirely in
bsd.debugdata.mk.
check/check-debugdata.mk
checks that all programs and libraries have the debug
data correctly stripped into their corresponding *.debug files.
mk/bsd.debugdata.mk
The
first 23 lines of bsd.debugdata.mk contain a comment that is also
accessible via the help
target. In particular it describes all the user-settable variables:
-
PKG_DEBUGDATA: if "yes" it turns on debugdata functionality to generate the*.debugfiles and then install them as part of the package. -
PKG_DEBUGLEVEL: useful to control the granularity of the debug information, i.e. the-glevel flag passed to the compiler. It can be "small", "default" and "detailed".
Then _VARGROUPS and _USER_VARS.<vargroup>
are set accordingly. These are used by the show-all target (if you
are more curious regarding that please just try make show-all and/or
give a look to
mk/misc/show.mk).
After various definitions of some used variables (should be self-explainable)
_FIND_DEBUGGABLEDATA_ERE is defined as an Extended Regular
Expression that is used to match potential files that can be stripped.
_FIND_DEBUGGABLEDATA_ERE is then used to limit the file list
generated via
_FIND_DEBUGGABLEDATA_FILELIST_CMD
Lines 63-86 pass the appropriate debug flags and debug level to the compiler.
Then _PLIST_DEBUGDATA is added to the PLIST_SRC_DFLT
variable. PLIST_SRC_DFLT contains all the default
PLISTs that
usually resides in pkgsrc/category/PLIST* (e.g. PLIST,
PLIST.common, PLIST.NetBSD, etc.). If you are more
interested in how it works, please give a look to
mk/plist/plist.mk.
In this way all the *.debug files listed in
_PLIST_DEBUGDATA are dynamically appended to the package
PLIST.
In lines
90-111 generate-strip-debugdata target is defined. It
basically just does the operations we have explored in
part 1
with little adjustments for pkgsrc:
- Check if the current file is strippable via objdump(1)
-
If the current file is strippable
objcopy --only-keep-debug program|library program.debug|library.debugis invoked in order to populate the.debugfile. -
If the current file is strippable
objcopy --strip-debug -p -R .gnu_debuglink --add-gnu-debuglink=program.debug|library.debug program|libraryis invoked to delete the debug information from the current file (program or library) and to add the.gnu_debuglinkELF section to it so that the debugger knows where to pick the corresponding.debugfile. -
Append the
.debugpath and filename to the_PLIST_DEBUGDATAfile.
To accomplish that RUN is used to run all shell commands without
printing them. Please note that when RUN is used all shell commands
should be terminated with a semicolon. For more information regarding
RUN please take a look at make help topic=RUN.
In lines
113-122 install-strip-debugdata is defined. It just installs all
*.debug files via INSTALL_DATA.
install-strip-debugdata target will then be invoked after the
post-install phase.
mk/check/check-debugdata.mk
First 26 lines of check-debugdata.mk contain a comment for the pkgsrc online documentation. It describes the following user-settable variables:
-
CHECK_DEBUGDATA: if "yes" it enables debugdata checks (by default most checks are usually enabled only if PKG_DEVELOPER is "yes")
...and the following package-settable variables:
-
CHECK_DEBUGDATA_SKIP: list of shell patterns that should be excluded from the check. -
CHECK_DEBUGDATA_SUPPORTED: whether the check should be enabled for the package or not.
Like what it was done for
bsd.debugdata.mk, _VARGROUPS and
_{USER,PKG}_VARS.check-debugdata are defined accordingly.
Similarly to what was done for _FIND_DEBUGGABLEDATA_ERE and
_FIND_DEBUGGABLEDATA_FILELIST_CMD in
bsd.debugdata.mk,
_CHECK_DEBUGDATA_ERE and
_CHECK_DEBUGDATA_FILELIST_CMD
are defined.
In lines
54-103 _check-debugdata target is defined.
_check-debugdata performs the following checks, respectively:
- Check that the program/library is readable.
-
If the program/library is a file format recognizable by
objdump(1)
check if it has a
.gnu_debuglinkELF section. -
Check that the respective
.debugfile of the program/library is readable. -
Print a warning message if the
.debugfile does not contain a.debug_infoELF section.
Other minor changes in mk/*
In order to instruct pkgsrc to pick up bsd.debugdata.mk and
checks/check-debugdata.mk, nothing intrusive though:
-
Add
.include "bsd.debugdata.mk"inbsd.pkg.mk. -
Add
TOOLS_PLATFORM.objcopyandTOOLS_PLATFORM.objdumptomk/tools/tools.NetBSD.mk(otherOPSYSs will also needed to be adjusted similarly) -
Add
CHECK_DEBUGDATA_SUPPORTEDtocheck/bsd.check-vars.mk. -
Add
.include "check-debugdata.mk"incheck/bsd.check.mk.
Conclusion
In this blog post we have learned what PKG_DEBUGDATA does via a
practical example.
Then we have examinated how bsd.debugdata.mk and
checks/check-debugdata.mk are implemented.
PKG_DEBUGDATA is completely agnostic if a package uses
GNU configure, cmake, etc., and it is expected to work without any changes.
I have only tested it with simple packages also containing libraries and the
ones that uses libtool but I have still not tested it in the wild and some minor
adjustements can be probably needed.
Thanks again to Google for organizing Google Summer of Code, The NetBSD Foundation and in particular my mentors David Maxwell, Jöerg Sonnenberger, Taylor R. Campbell, Thomas Klausner and William J. Coldwell.
References
- The pkgsrc guide, Alistair Crooks, Hubert Feyrer, The pkgsrc Developers
-
PMake -- A Tutorial, Adam de Boor
(available under
/usr/share/doc/ref1/make/in PS and text format) - make(1)
- objdump(1)
- objcopy(1)
- gdb(1)
- pkgsrc/mk/misc/show.mk, 1.12
- pkgsrc/mk/plist/plist.mk, 1.49
- pkgsrc/mk/bsd.pkg.mk, 1.2021
- pkgsrc/mk/check/bsd.check-vars.mk 1.8
- pkgsrc/mk/check/bsd.check.mk 1.8
Google Summer of Code 2016 is now over. We have polished the code and documentation and submitted the final term evaluation on 23rd of August 2016. The mentors evaluated us in the following week.
If you are impatient (and this time impatience is definitely a virtue!) please take a look to all The NetBSD Foundation GSoC 2016 projects' code submissions!
Introduction
In part 1 we have learned what happens under the hood when we split debugging symbols: how debugging information is stored/stripped off, the relevant ELF sections involved, various tools to dump that information, etc..
In particular, we have studied what happens on NetBSD when we set the
MKDEBUG* flags.
With this background we can finally try to implement this functionality in the
pkgsrc infrastructure. In this blog post we
will first give a practical look at PKG_DEBUGDATA and then we
will analyze the code that I have written in the first mid-term of the GSoC to
accomplish that.
PKG_DEBUGDATA in action
Before digging in the implementation of debugdata functionality let's see what it produces!
In part 1
we took as example a very simple program that just prints out the lyrics of
Ten Green Bottles song. After packaging it as
local/green-bottles
let's just build it without any special pkgsrc system variables set:
$ cd pkgsrc/local/green-bottles $ make install [...] $ green-bottles ten green bottles hanging on the wall [...] $ pkg_info -L green-bottles Information for green-bottles-0: Files: /usr/pkg/bin/green-bottles $ gdb `which green-bottles` GNU gdb (GDB) 7.10.1 Copyright (C) 2015 Free Software Foundation, Inc. License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html> [...] Reading symbols from /usr/pkg/bin/green-bottles...(no debugging symbols found)...done. (gdb) quit
That's expected because we did not set any special CFLAGS nor
INSTALL_UNSTRIPPED.
Before setting PKG_DEBUGDATA to "yes" let's inspect its
documentation via the help target:
$ make help topic=PKG_DEBUGDATA ===> mk/bsd.debugdata.mk (keywords: INSTALL_UNSTRIPPED PKG_DEBUGLEVEL PKG_DEBUGDATA debug): # This Makefile fragment is included by bsd.pkg.mk and implements the # logic needed to strip debug symbols off the program/libraries. # # User-settable variables: # # PKG_DEBUGDATA # If "yes", install stripped debug symbols for all programs and shared # libraries. Please notice that if it is defined INSTALL_UNSTRIPPED will # be also defined internally. # # PKG_DEBUGLEVEL # Used to control the granularity of the debug information. Can be # "small", "default", "detailed". # TODO: the name of this variable should be changed because it can be # TODO: easily confused with PKG_DEBUG_LEVEL! # # See also: # INSTALL_UNSTRIPPED #
Now that we have finally an idea of what PKG_DEBUGDATA does, let's
set it and reinstall the green-bottles package:
$ make clean deinstall [...] $ PKG_DEBUGDATA=yes make install [...] ===> Installing for green-bottles-0 [...] => Stripping debug symbols => Installing debug data [...] => Checking for missing debug data in green-bottles-0 [...]
Apart from the various phases we can see three extra messages that are now printed out: stripping of debug symbols, installing of debug data and a check for missing debug data.
If we inspect the files installed we can now also see
green-bottles.debug:
$ pkg_info -L green-bottles Information for green-bottles-0: Files: /usr/pkg/bin/green-bottles.debug /usr/pkg/bin/green-bottles
Indeed if we now try to run it through gdb(1):
$ gdb `which green-bottles`
GNU gdb (GDB) 7.10.1
Copyright (C) 2015 Free Software Foundation, Inc.
[...]
Reading symbols from /usr/pkg/bin/green-bottles...Reading symbols from /usr/pkg/bin/green-bottles.debug...done.
done.
(gdb) b main
Breakpoint 1 at 0xad0: file green-bottles.c, line 29.
(gdb) run
Starting program: /usr/pkg/bin/green-bottles
Breakpoint 1, main () at green-bottles.c:29
29 {
(gdb)
[...]
green-bottles was installed as usual without requiring any changes
from MAINTAINERs, in fact the various .debug files
are generated, installed and added to the PLIST dynamically.
A look at mk/bsd.debugdata.mk and mk/check/check-debugdata.mk implementation
All the functionalities that implement stripping of the debug data from
installed programs and libraries are implemented entirely in
bsd.debugdata.mk.
check/check-debugdata.mk
checks that all programs and libraries have the debug
data correctly stripped into their corresponding *.debug files.
mk/bsd.debugdata.mk
The
first 23 lines of bsd.debugdata.mk contain a comment that is also
accessible via the help
target. In particular it describes all the user-settable variables:
-
PKG_DEBUGDATA: if "yes" it turns on debugdata functionality to generate the*.debugfiles and then install them as part of the package. -
PKG_DEBUGLEVEL: useful to control the granularity of the debug information, i.e. the-glevel flag passed to the compiler. It can be "small", "default" and "detailed".
Then _VARGROUPS and _USER_VARS.<vargroup>
are set accordingly. These are used by the show-all target (if you
are more curious regarding that please just try make show-all and/or
give a look to
mk/misc/show.mk).
After various definitions of some used variables (should be self-explainable)
_FIND_DEBUGGABLEDATA_ERE is defined as an Extended Regular
Expression that is used to match potential files that can be stripped.
_FIND_DEBUGGABLEDATA_ERE is then used to limit the file list
generated via
_FIND_DEBUGGABLEDATA_FILELIST_CMD
Lines 63-86 pass the appropriate debug flags and debug level to the compiler.
Then _PLIST_DEBUGDATA is added to the PLIST_SRC_DFLT
variable. PLIST_SRC_DFLT contains all the default
PLISTs that
usually resides in pkgsrc/category/PLIST* (e.g. PLIST,
PLIST.common, PLIST.NetBSD, etc.). If you are more
interested in how it works, please give a look to
mk/plist/plist.mk.
In this way all the *.debug files listed in
_PLIST_DEBUGDATA are dynamically appended to the package
PLIST.
In lines
90-111 generate-strip-debugdata target is defined. It
basically just does the operations we have explored in
part 1
with little adjustments for pkgsrc:
- Check if the current file is strippable via objdump(1)
-
If the current file is strippable
objcopy --only-keep-debug program|library program.debug|library.debugis invoked in order to populate the.debugfile. -
If the current file is strippable
objcopy --strip-debug -p -R .gnu_debuglink --add-gnu-debuglink=program.debug|library.debug program|libraryis invoked to delete the debug information from the current file (program or library) and to add the.gnu_debuglinkELF section to it so that the debugger knows where to pick the corresponding.debugfile. -
Append the
.debugpath and filename to the_PLIST_DEBUGDATAfile.
To accomplish that RUN is used to run all shell commands without
printing them. Please note that when RUN is used all shell commands
should be terminated with a semicolon. For more information regarding
RUN please take a look at make help topic=RUN.
In lines
113-122 install-strip-debugdata is defined. It just installs all
*.debug files via INSTALL_DATA.
install-strip-debugdata target will then be invoked after the
post-install phase.
mk/check/check-debugdata.mk
First 26 lines of check-debugdata.mk contain a comment for the pkgsrc online documentation. It describes the following user-settable variables:
-
CHECK_DEBUGDATA: if "yes" it enables debugdata checks (by default most checks are usually enabled only if PKG_DEVELOPER is "yes")
...and the following package-settable variables:
-
CHECK_DEBUGDATA_SKIP: list of shell patterns that should be excluded from the check. -
CHECK_DEBUGDATA_SUPPORTED: whether the check should be enabled for the package or not.
Like what it was done for
bsd.debugdata.mk, _VARGROUPS and
_{USER,PKG}_VARS.check-debugdata are defined accordingly.
Similarly to what was done for _FIND_DEBUGGABLEDATA_ERE and
_FIND_DEBUGGABLEDATA_FILELIST_CMD in
bsd.debugdata.mk,
_CHECK_DEBUGDATA_ERE and
_CHECK_DEBUGDATA_FILELIST_CMD
are defined.
In lines
54-103 _check-debugdata target is defined.
_check-debugdata performs the following checks, respectively:
- Check that the program/library is readable.
-
If the program/library is a file format recognizable by
objdump(1)
check if it has a
.gnu_debuglinkELF section. -
Check that the respective
.debugfile of the program/library is readable. -
Print a warning message if the
.debugfile does not contain a.debug_infoELF section.
Other minor changes in mk/*
In order to instruct pkgsrc to pick up bsd.debugdata.mk and
checks/check-debugdata.mk, nothing intrusive though:
-
Add
.include "bsd.debugdata.mk"inbsd.pkg.mk. -
Add
TOOLS_PLATFORM.objcopyandTOOLS_PLATFORM.objdumptomk/tools/tools.NetBSD.mk(otherOPSYSs will also needed to be adjusted similarly) -
Add
CHECK_DEBUGDATA_SUPPORTEDtocheck/bsd.check-vars.mk. -
Add
.include "check-debugdata.mk"incheck/bsd.check.mk.
Conclusion
In this blog post we have learned what PKG_DEBUGDATA does via a
practical example.
Then we have examinated how bsd.debugdata.mk and
checks/check-debugdata.mk are implemented.
PKG_DEBUGDATA is completely agnostic if a package uses
GNU configure, cmake, etc., and it is expected to work without any changes.
I have only tested it with simple packages also containing libraries and the
ones that uses libtool but I have still not tested it in the wild and some minor
adjustements can be probably needed.
Thanks again to Google for organizing Google Summer of Code, The NetBSD Foundation and in particular my mentors David Maxwell, Jöerg Sonnenberger, Taylor R. Campbell, Thomas Klausner and William J. Coldwell.
References
- The pkgsrc guide, Alistair Crooks, Hubert Feyrer, The pkgsrc Developers
-
PMake -- A Tutorial, Adam de Boor
(available under
/usr/share/doc/ref1/make/in PS and text format) - make(1)
- objdump(1)
- objcopy(1)
- gdb(1)
- pkgsrc/mk/misc/show.mk, 1.12
- pkgsrc/mk/plist/plist.mk, 1.49
- pkgsrc/mk/bsd.pkg.mk, 1.2021
- pkgsrc/mk/check/bsd.check-vars.mk 1.8
- pkgsrc/mk/check/bsd.check.mk 1.8
There was a nice, friendly and informal summit of NetBSD developers (and interested users) in Sofia on Friday, September 26, 2014.
Bernd Ernesti (veego@) took this photo:
{kind=link}
In the back row from left to right:
Masao Uebayashi (uebayasi), Thomas Klausner (wiz), Yann Sionneau, Marc Balmer (mbalmer), Justin Cormack (justin), Jaap Boender (jaapb), Adrian Steinmann (ast), Martin Husemann (martin), Taylor R Campbell (riastradh), Michael van Elst (mlelstv), Sevan Janiyan, Alexander Nasonov (alnsn).
In the front row, from left to right:
Julian Coleman (jdc), Joerg Sonnenberger (joerg), Valeriy E. Ushakov (uwe), Christoph Badura (bad), S.P.Zeidler (spz), Pierre Pronchery (khorben), Stephen Borrill (sborrill)
Some Developers made it to the conference only after the summit, so Emmanuel Dreyfus (manu), Luke Mewburn (lukem) and Lourival Neto (lneto) are unfortunately missing on that picture.
Marc Balmer presented some slides prepared by Masanobu SAITOH about ongoing work at IIJ.
Marc also proposed some extensions to the in-tree httpd (aka bozohttpd) to allow creation of simple dynamic content via "Lua templates". The question whether it would be possible to serve www.netbsd.org by bozohttpd was discussed, and only administrative reasons seem to prevent it - which was overall considered "good enough".
Pierre Pronchery presented his work on EdgeBSD - and why he does not consider it a fork, but more a playground for experimentation. He also reported on some of his experiences with using git on the NetBSD source tree.
Two more slightly TNF internal issues were discussed, and after that the whole crowd moved to dinner (including a bit of Bulgarian wine).
Having an in-person meeting of a relative huge number of NetBSD developers was considered very useful and we will try to repeat it at other occasions. Next time, if similar attendance is likely, we will plan for more time (like a full day) and also create a schedule of talks/presentations up front, still with the option to add ad-hoc ones.
The NetBSD Project is pleased to announce NetBSD 6.1.1, the first security/bugfix update of the NetBSD 6.1 release branch. It represents a selected subset of fixes deemed important for security or stability reasons.
For more details, please see the 6.1.1 release notes.
Complete source and binaries for NetBSD 6.1.1 are available for download at many sites around the world. A list of download sites providing FTP, AnonCVS, SUP, and other services may be found at http://www.NetBSD.org/mirrors/.
The most time-consuming part of operating system development is obtaining enough drivers to enable the OS to run real applications which interact with the real world. NetBSD's rump kernels allow reducing that time to almost zero, for example for developing special-purpose operating systems for the cloud and embedded IoT devices. This article describes an experiment in creating an OS by using a rump kernel for drivers. It attempts to avoid going into full detail on the principles of rump kernels, which are available for interested readers from rumpkernel.org. We start by defining the terms in the title:
- OS: operating system, i.e. the overhead that enables applications to run
- internet-ready: supports POSIX applications and talks TCP/IP
- a week: 7 days, in this case the period between Wednesday night last week and Wednesday night this week
- from scratch: began by writing the assembly instructions for the kernel entry point
- rump kernel: partial kernel consisting of unmodified NetBSD kernel drivers
- bare metal: what you get from the BIOS/firmware
Why would anyone want to write a new OS? If you look at our definition of "OS", you notice that you want to keep the OS as small as possible. Sometimes you might not care, e.g. in case of a desktop PC, but other times when hardware resources are limited or you have high enough security concerns, you actually might care. For example, NetBSD itself is not able to run on systems without a MMU, but the OS described in this article does not use virtual memory at all, and yet it can run most of the same applications as NetBSD can. Another example: if you want to finetune the OS to suit your application, it's easier to tune a simple OS than a very complicated general purpose OS. The motivation for this work came in fact from someone who was looking to provision applications as services on top of VMWare, but found that no existing solution supported the system interfaces his applications needed without dragging an entire classic OS along for the ride.
Let's move on to discussing what an OS needs to support for it to be able to host for example a web server written for a regular OS such as Linux or the BSDs. The list gets quite long. You need a file system where the web server reads the served pages from, you need a TCP/IP stack to communicate with the clients, and you need a network interface driver to be able to send and receive packets. Furthermore, you need the often overlooked, yet very surprisingly complicated system call handlers. For example, opening a socket is not really very complicated to handle. Neither is reading and writing data. However, when you start piling things like fcntl(O_NONBLOCK) and poll() on top, things get trickier. By a rough estimate, if you run an httpd on NetBSD, approximately 100k lines of code from kernel are used just to service the requests that the httpd makes. If you do the math (and bc did), there are 86400 seconds in a week. The OS we are discussing is able to run an off-the-shelf httpd, but definitely I did not write >1 line of code per second 24/7 during the past week.
Smoke and Mirrors, CGI Edition
The key to happiness is not to write 100k lines of code from scratch, nor to port it from another OS, as both are time-consuming and error-prone techniques, and error-proneness leads to even more consumption of time. Rump kernels come into the picture as the key to happiness and provide the necessary drivers.
As the old saying goes: "rump kernels do not an OS make", and we need the rest of the bits that make up the OS side of the software stack from somewhere. These bits need to make it seem like the drivers in a rump kernel are running inside the NetBSD kernel, hence "smoke and mirrors". What is surprising is how little code needs to exist between the drivers and the hardware, just some hundreds of lines of code. More specifically, in the bare metal scenario we need support for:
- low level machine dependent code
- thread support and a scheduler
- rump kernel hypercall layer
- additionally: bundling the application into a bootable image
The figure below illustrates the rump kernel software stack. The arrows correspond to the above list (in reverse order). We go over the list starting from the top of the list (bottom of the figure).

Low level machine dependent code is what the OS uses to get the CPU and devices to talking terms with the rest of OS. Before we can do anything useful, we need to bootstrap. Bootstrapping x86-32 is less work than one would expect, which incidentally is also why the OS runs only in 32bit mode (adding 64bit support would not likely be many hours of work — and patches are welcome). Thanks to the Multiboot specification, the bootstrap code is more or less just a question of setting the stack pointer and jumping to C code. In C code we need to parse the amount of physical memory available and initialize the console. Since NetBSD device drivers mainly use interrupts, we also need interrupt support for the drivers to function correctly. On x86, interrupt support means setting up the CPU's interrupt descriptor tables and programming the interrupt controller. Since rump kernels do not support interrupts, in addition we need a small interrupt stub that transfers the interrupt request to a thread context which calls the rump kernel. In total, the machine dependent code is only a few hundred lines. The OSDev.org wiki contains a lot of information which was useful when hammering the hardware into shape. The other source of x86 hardware knowledge was x86 support in NetBSD.
Threads and scheduling might sound intimidating, but they are not. First, rump kernels can run on top of any kinds of threads you throw at them, so we can just use the ones which are the simplest to implement: cooperative threads. Note, simple does not mean poorly performing threads, and in fact the predictability of cooperative threads, at least in my opinion, makes them more likely to perform better than preemptive threading in cases where you are honing an OS for a single application. Second, I already had access to an implementation which served as the basis: Justin Cormack's work on userspace fibers, which in turn has its roots in Xen MiniOS we use for running rump kernel on the Xen hypervisor, could be re-purposed as the threads+scheduler implementation, with the context switch code kindly borrowed from MiniOS.
The rump kernel hypercall interface is what rump kernels themselves run on. While the implementation is platform-specific, our baremetal OS shares a large portion of its qualities with the Xen platform that was already supported. Therefore, most of the Xen implementation applied more or less directly. One notable exception to the similarities is that Xen paravirtualized devices are not available on bare metal and therefore we access all I/O devices via the PCI bus.
All we need now is the application, a.k.a. "userspace". Support for application interfaces (POSIX syscalls, libc, etc.) readily exists for rump kernels, so we just use what is already available. The only remaining issue is building the bundle that we bootstrap. For that, we can repurpose Ian Jackson's app-tools which were originally written for the rump kernel Xen platform. Using app-tools, we could build a bootable image containing thttpd simply by running the app-tools wrappers for ./configure and make. The image below illustrates part of the build output, along with booting the image in QEMU and testing that the httpd really works. The use of QEMU, i.e. software-emulated bare metal, is due to convenience reasons.

Conclusions
You probably noticed that whole thing is just bolting a lot of working components together while writing minimal amounts of necessary glue. That is exactly the point: never write or port or hack what you can reuse without modification. Code reusability has always been the strength of NetBSD and rump kernels add another dimension to that quality.
The source code for the OS discussed in this post is available under a 2-clause BSD license from repo.rumpkernel.org/rumpuser-baremetal.
LLVM
In order to achieve the goals of testability concerning the LLVM projects, I had to prepare a new pkgsrc-wip package called llvm-all-in-one that contains 12 active LLVM projects within one tree. The set of these projects is composed of: llvm, clang, compiler-rt, libcxx, libcxxabi, libunwind, test-suite, openmp, llgo, lld, lldb, clang-tools-extra. These were required to build and execute test-suites in the LLVM's projects. Ideally the tests should work in standalone packages - built out-of-LLVM-sources - and with GCC/Clang, however the real life is less bright and this forced me to use Clang as the system compiler an all-in-one package in order to develop the work environment with the ability to build and execute unit tests.
There were four threads within LLVM:
- Broken std::call_once with libstdc++. This is an old and well-known bug, which was usually worked around with a homegrown implementation llvm::call_once. I've discovered that the llvm::call_once workaround isn't sufficient for the whole LLVM functionality, as std::call_once can be called internally inside the libstdc++ libraries - like within the C++11 futures interface. This bug has been solved by Joerg Sonnenberger in the ELF dynamic linker.
- Unportable shell construct hardcoded in tests ">&". This has been fixed upstream.
- LLVM JIT. The LLVM Memory generic allocator (or page mapper) was designed to freely map pages with any combination of the protection bits: R,W,X. This approach breaks on NetBSD with PaX MPROTECT and requires redesign of the interfaces. This is the continuation of the past month AllocateRWX and ReleaseRWX compatibility with NetBSD improvements. I've prepared few variations of local patches addressing these issues and it's still open for discussion with upstream. My personal preference is to remove the current API entirely and introduce a newer one with narrowed down functionality to swap between readable (R--), writable (RW-) and executable (R-X) memory pages. This would effectively enforce W^X.
- Sanitizers support. Right now, I keep the patches locally in order to upstream the common sanitizer code in compiler-rt.
The LLVM JIT API is the last cause of unexpected failures in check-llvm. This breaks MCJIT, ORCJIT and ExecutionEngine libraries and causes around 200 unexpected failures within tests.
Clang
I've upstreamed a patch that enables ubsan and asan on Clang's frontend for NetBSD/amd64. This support isn't complete, and requires sanitizers' support code upstreamed to compiler-rt.
compiler-rt
The current compiler-rt tasks can be divided into:
- upstream sanitizer common code shared with POSIX platforms
- upstream sanitizer common code shared with Linux and FreeBSD
- upstream sanitizer common code shared with FreeBSD
- upstream sanitizer common code specific to NetBSD
- build, execute and pass tests for sanitizer common code in check-santizer
This means that ubsan, asan and the rest of the specific sanitizers wait in queue.
All the mentioned tasks are being worked on simultaneously, with a soft goal to finish them one after another from the first to the last one.
The last point with check-sanitizer unveiled so far two generic bugs on NetBSD:
- Return errno EFAULT instead of EACCES on memory fault with read(2)/write(2)-like syscalls.
- Honor PTHREAD_DESTRUCTOR_ITERATIONS in libpthread.
Plan for the next milestone
I have decided not to open new issues in with the coming month and focus on upstreaming the remaining LLVM code. The roadmap for the next month is to continue working on the goals of the previous months. std::call_once is an example that every delayed bug keeps biting again and again in future.
LLVM 5.0.0 is planned to be released this month (August) and there is a joint motivation with the upstream maintainer to push compatibility fixes for LLVM JIT. There is an option to submit a workaround now and introduce refactoring for the trunk and next version (6.0.0).
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL, and chip in what you can:
LLVM
In order to achieve the goals of testability concerning the LLVM projects, I had to prepare a new pkgsrc-wip package called llvm-all-in-one that contains 12 active LLVM projects within one tree. The set of these projects is composed of: llvm, clang, compiler-rt, libcxx, libcxxabi, libunwind, test-suite, openmp, llgo, lld, lldb, clang-tools-extra. These were required to build and execute test-suites in the LLVM's projects. Ideally the tests should work in standalone packages - built out-of-LLVM-sources - and with GCC/Clang, however the real life is less bright and this forced me to use Clang as the system compiler an all-in-one package in order to develop the work environment with the ability to build and execute unit tests.
There were four threads within LLVM:
- Broken std::call_once with libstdc++. This is an old and well-known bug, which was usually worked around with a homegrown implementation llvm::call_once. I've discovered that the llvm::call_once workaround isn't sufficient for the whole LLVM functionality, as std::call_once can be called internally inside the libstdc++ libraries - like within the C++11 futures interface. This bug has been solved by Joerg Sonnenberger in the ELF dynamic linker.
- Unportable shell construct hardcoded in tests ">&". This has been fixed upstream.
- LLVM JIT. The LLVM Memory generic allocator (or page mapper) was designed to freely map pages with any combination of the protection bits: R,W,X. This approach breaks on NetBSD with PaX MPROTECT and requires redesign of the interfaces. This is the continuation of the past month AllocateRWX and ReleaseRWX compatibility with NetBSD improvements. I've prepared few variations of local patches addressing these issues and it's still open for discussion with upstream. My personal preference is to remove the current API entirely and introduce a newer one with narrowed down functionality to swap between readable (R--), writable (RW-) and executable (R-X) memory pages. This would effectively enforce W^X.
- Sanitizers support. Right now, I keep the patches locally in order to upstream the common sanitizer code in compiler-rt.
The LLVM JIT API is the last cause of unexpected failures in check-llvm. This breaks MCJIT, ORCJIT and ExecutionEngine libraries and causes around 200 unexpected failures within tests.
Clang
I've upstreamed a patch that enables ubsan and asan on Clang's frontend for NetBSD/amd64. This support isn't complete, and requires sanitizers' support code upstreamed to compiler-rt.
compiler-rt
The current compiler-rt tasks can be divided into:
- upstream sanitizer common code shared with POSIX platforms
- upstream sanitizer common code shared with Linux and FreeBSD
- upstream sanitizer common code shared with FreeBSD
- upstream sanitizer common code specific to NetBSD
- build, execute and pass tests for sanitizer common code in check-santizer
This means that ubsan, asan and the rest of the specific sanitizers wait in queue.
All the mentioned tasks are being worked on simultaneously, with a soft goal to finish them one after another from the first to the last one.
The last point with check-sanitizer unveiled so far two generic bugs on NetBSD:
- Return errno EFAULT instead of EACCES on memory fault with read(2)/write(2)-like syscalls.
- Honor PTHREAD_DESTRUCTOR_ITERATIONS in libpthread.
Plan for the next milestone
I have decided not to open new issues in with the coming month and focus on upstreaming the remaining LLVM code. The roadmap for the next month is to continue working on the goals of the previous months. std::call_once is an example that every delayed bug keeps biting again and again in future.
LLVM 5.0.0 is planned to be released this month (August) and there is a joint motivation with the upstream maintainer to push compatibility fixes for LLVM JIT. There is an option to submit a workaround now and introduce refactoring for the trunk and next version (6.0.0).
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL, and chip in what you can:
In this blog post series I will discuss about SUBPACKAGES work
done during
Google Summer of Code 2017.
In this first part I'll briefly introduce what are SUBPACKAGES,
why and when can be useful and finally we'll give a quick look to a trivial
pkgsrc package that uses them. At the end
we'll also dive a bit on parts of the pkgsrc infrastructure that needed to be
adjusted for implementing that.
Introduction
SUBPACKAGES (on some package systems they are known as
multi-packages, but this term for pkgsrc is already used by packages
that can be built against several versions (e.g. Python, PHP, Ruby packages))
consist in generating multiple binary packages from a single pkgsrc package.
For example, from a pkgsrc package - local/frobnitzem - we will
see how to generate three separate binary packages:
frobnitzem-foo, frobnitzem-bar and
frobnitzem-baz.
This can be useful to separate several components of binary
packages (and avoid to run the extract and
configure phase two times!),
for debugpkgs
(so that all *.debug files containing debug symbols are contained
in a separate -debugpkg package that can be installed only when it
is needed), etc..
A simple SUBPACKAGES package: frobnitzem!
To understand how SUBPACKAGES works and can be useful let's start
to see an example of it in practice: frobnitzem.
frobnitzem is a trivial package that just install three scripts in
${PREFIX}/bin, let's see it:
% cd pkgsrc/local/frobnitzem
% tree
.
|-- DESCR
|-- Makefile
|-- PLIST
`-- files
`-- frobnitzem
|-- frobnitzem-bar
|-- frobnitzem-baz
`-- frobnitzem-foo
2 directories, 6 files
% find . -type f | xargs tail -n +1
==> ./Makefile <==
# $NetBSD$
DISTNAME= frobnitzem-0
CATEGORIES= local
MASTER_SITES= # empty
DISTFILES= # empty
MAINTAINER= leot%NetBSD.org@localhost
HOMEPAGE= http://netbsd.org/~leot/gsoc2017-diary/
COMMENT= Simple subpackages example
LICENSE= public-domain
FILESDIR= ${.CURDIR}/../../local/frobnitzem/files
WRKSRC= ${WRKDIR}/frobnitzem
NO_BUILD= yes
do-extract:
${CP} -r ${FILESDIR}/frobnitzem ${WRKDIR}
do-install:
${INSTALL_SCRIPT_DIR} ${DESTDIR}${PREFIX}/bin
${INSTALL_SCRIPT} ${WRKSRC}/frobnitzem-foo ${DESTDIR}${PREFIX}/bin
${INSTALL_SCRIPT} ${WRKSRC}/frobnitzem-bar ${DESTDIR}${PREFIX}/bin
${INSTALL_SCRIPT} ${WRKSRC}/frobnitzem-baz ${DESTDIR}${PREFIX}/bin
.include "../../mk/bsd.pkg.mk"
==> ./files/frobnitzem/frobnitzem-bar <==
#!/bin/sh
echo "bar"
==> ./files/frobnitzem/frobnitzem-baz <==
#!/bin/sh
echo "baz"
==> ./files/frobnitzem/frobnitzem-foo <==
#!/bin/sh
echo "foo"
==> ./PLIST <==
@comment $NetBSD$
bin/frobnitzem-bar
bin/frobnitzem-baz
bin/frobnitzem-foo
==> ./DESCR <==
frobnitzem, collection of foo, bar, baz scripts.
(Or, a bit more seriously this is just a very simple package to
test subpackages support!)
Nothing fancy, just three simple scripts, frobnitzem-{bar,baz,foo}
that will respectively print to the standard output bar,
baz and foo.
Let's build and install the frobnitzem package:
% make install ===> Installing dependencies for frobnitzem-0 ===> Overriding tools for frobnitzem-0 ===> Extracting for frobnitzem-0 [...] ===> Installing for frobnitzem-0 [...] ===> Installing binary package of frobnitzem-0 [...]
And now let's try scripts installed as part of the frobnitzem
package:
% foreach w (bar baz foo) ... frobnitzem-$w ... end bar baz foo
Okay, as we expected. Despite frobnitzem-{foo,bar,baz} don't do
anything particularly useful we can split the frobnitzem-0
package in three separate subpackages: frobnitzem-foo-0,
frobnitzem-bar-0 and
frobnitzem-baz-0 (they provides different functionalities and can
also coexist if they're in separated binary packages).
To do that we need to slighty adjust Makefile, split the
PLIST in PLIST.{foo,bar,baz} (one for each separate
subpackage), split the DESCR in DESCR.{foo,bar,baz}.
So, at the end in local/frobnitzem we'll have:
% tree
.
|-- DESCR.bar
|-- DESCR.baz
|-- DESCR.foo
|-- Makefile
|-- PLIST.bar
|-- PLIST.baz
|-- PLIST.foo
`-- files
`-- frobnitzem
|-- frobnitzem-bar
|-- frobnitzem-baz
`-- frobnitzem-foo
2 directories, 10 files
Splitting DESCR and PLIST
DESCR and PLIST splits are straightforward. We just
provide a separate DESCR.<spkg> for each subpackage,
e.g. for the foo subpackage:
% cat DESCR.foo frobnitzem, collection of foo, bar, baz scripts. (Or, a bit more seriously this is just a very simple package to test subpackages support!) This package provide the foo functionalities.
Similarly, regarding PLISTs, we just provide a separate
PLIST.<spkg> for each subpackage, e.g. for the
foo subpackage:
% cat PLIST.foo @comment $NetBSD$ bin/frobnitzem-foo
Makefile changes
In Makefile we'll need to list all SUBPACKAGES hence we'll add the
following line as first paragraph:
SUBPACKAGES= foo bar baz
We'll then need to define a PKGNAME.<spkg> for each
subpackages:
PKGNAME.foo= frobnitzem-foo-0 PKGNAME.bar= frobnitzem-bar-0 PKGNAME.baz= frobnitzem-baz-0
...and similarly COMMENT variable should be defined for each
subpackage via COMMENT.<spkg>:
COMMENT.foo= Simple subpackages example (foo) COMMENT.bar= Simple subpackages example (bar) COMMENT.baz= Simple subpackages example (baz)
To recap here how we have adjusted Makefile, all the other lines rest unchanged:
% sed '/LICENSE/q' < Makefile # $NetBSD$ SUBPACKAGES= foo bar baz DISTNAME= frobnitzem-0 PKGNAME.foo= frobnitzem-foo-0 PKGNAME.bar= frobnitzem-bar-0 PKGNAME.baz= frobnitzem-baz-0 MASTER_SITES= # empty DISTFILES= # empty CATEGORIES= local MAINTAINER= leot%NetBSD.org@localhost HOMEPAGE= http://netbsd.org/~leot/gsoc2017-diary/ COMMENT.foo= Simple subpackages example (foo) COMMENT.bar= Simple subpackages example (bar) COMMENT.baz= Simple subpackages example (baz) LICENSE= public-domain
Finally we can install it^Wthem! The usual make
install will generate three binary packages
(frobnitzem-foo-0.tgz, frobnitzem-bar-0.tgz,
frobnitzem-baz-0.tgz) and install all of them:
% make install ===> Installing dependencies for frobnitzem-0 [...] ===> Overriding tools for frobnitzem-0 ===> Extracting for frobnitzem-0 [...] ===> Installing for frobnitzem-0 [...] => Creating binary package /home/leot/repos/netbsd-github/pkgsrc/packages/All/frobnitzem-foo-0.tgz => Creating binary package /home/leot/repos/netbsd-github/pkgsrc/packages/All/frobnitzem-bar-0.tgz => Creating binary package /home/leot/repos/netbsd-github/pkgsrc/packages/All/frobnitzem-baz-0.tgz [...] ===> Installing binary package of frobnitzem-foo-0 ===> Installing binary package of frobnitzem-bar-0 ===> Installing binary package of frobnitzem-baz-0 [...]
Now we can try them and use pkg_info(1) to get some information about them:
% frobnitzem-foo foo % pkg_info -Fe /usr/pkg/bin/frobnitzem-foo frobnitzem-foo-0 % pkg_info frobnitzem-baz Information for frobnitzem-baz-0: Comment: Simple subpackages example (baz) Description: frobnitzem, collection of foo, bar, baz scripts. (Or, a bit more seriously this is just a very simple package to test subpackages support!) This package provide the baz functionalities. Homepage: http://netbsd.org/~leot/gsoc2017-diary/ % pkg_info -L frobnitzem-bar Information for frobnitzem-bar-0: Files: /usr/pkg/bin/frobnitzem-bar
So we can see that make install actually installed three different
binary packages.
To deinstall all SUBPACKAGES we can run make deinstall
in the local/frobnitzem directory (that will remove all
subpackages) or we can just manually invoke
pkg_delete(1).
An high-level look at how SUBPACKAGES support is implemented
Most of the changes needed are in mk/pkgformat/pkg/ hierarchy
(previously known as mk/flavour and then renamed and generalized to
other package formats during
Anton Panev's Google Summer of Code 2011).
The code in mk/pkgformat/${PKG_FORMAT}/ handle the interaction of
pkgsrc with the particular ${PKG_FORMAT}, e.g. for pkg
populate meta-data files used by
pkg_create(1),
install/delete packages via
pkg_add(1),
and
pkg_delete(1),
etc.
For more information
mk/pkgformat/README
is a good introduction to pkgformat hierarchy.
Most of the changes done respect the following template:
.if !empty(SUBPACKAGES)
. for _spkg_ in ${SUBPACKAGES}
[... code that handles SUBPACKAGES case ...]
. endfor
.else # !SUBPACKAGES
[... existing (and usually completely unmodified) code ...]
.endif # SUBPACKAGES
In particular, in mk/pkgformat/pkg/ targets were adjusted to
create/install/deinstall/etc. all subpackages.
Apart mk/pkgformat other changes were needed in
mk/install/install.mk in order to adjust the install
phase for SUBPACKAGES.
Regarding PLIST.<spkg> handling mk/plist/plist.mk
needed some adjustments to honor each PLIST per-subpackage.
mk/bsd.pkg.mk needed to be adjusted too in order to honor several
per-subpackage variables (the *.<spkg> ones) and
per-subpackage DESCR.<spkg>.
Conclusion
In this first part of this blog post series we have seen what are
SUBPACKAGES, when and why they can be useful.
We have then seen a practical example of them taking a very trivial package and learned how to "subpackage-ify" it.
Then we have described - from an high-level perspective - the changes needed to
the pkgsrc infrastructure for the SUBPACKAGES features that we have
used. If you are more interested in them please give a look to the
pkgsrc debugpkg
branch that contains all work done described in this blog post.
In the next part we will see how to handle *DEPENDS and
buildlink3 inclusion for subpackages.
I would like to thanks Google for organizing Google Summer of Code, the entire The NetBSD Foundation and in particular my mentors Taylor R. Campbell, William J. Coldwell and Thomas Klausner for providing precious guidance during these three months. A special thank you also to Jörg Sonnenberger who provided very useful suggestions. Thank you!
In this blog post series I will discuss about SUBPACKAGES work
done during
Google Summer of Code 2017.
In this first part I'll briefly introduce what are SUBPACKAGES,
why and when can be useful and finally we'll give a quick look to a trivial
pkgsrc package that uses them. At the end
we'll also dive a bit on parts of the pkgsrc infrastructure that needed to be
adjusted for implementing that.
Introduction
SUBPACKAGES (on some package systems they are known as
multi-packages, but this term for pkgsrc is already used by packages
that can be built against several versions (e.g. Python, PHP, Ruby packages))
consist in generating multiple binary packages from a single pkgsrc package.
For example, from a pkgsrc package - local/frobnitzem - we will
see how to generate three separate binary packages:
frobnitzem-foo, frobnitzem-bar and
frobnitzem-baz.
This can be useful to separate several components of binary
packages (and avoid to run the extract and
configure phase two times!),
for debugpkgs
(so that all *.debug files containing debug symbols are contained
in a separate -debugpkg package that can be installed only when it
is needed), etc..
A simple SUBPACKAGES package: frobnitzem!
To understand how SUBPACKAGES works and can be useful let's start
to see an example of it in practice: frobnitzem.
frobnitzem is a trivial package that just install three scripts in
${PREFIX}/bin, let's see it:
% cd pkgsrc/local/frobnitzem
% tree
.
|-- DESCR
|-- Makefile
|-- PLIST
`-- files
`-- frobnitzem
|-- frobnitzem-bar
|-- frobnitzem-baz
`-- frobnitzem-foo
2 directories, 6 files
% find . -type f | xargs tail -n +1
==> ./Makefile <==
# $NetBSD$
DISTNAME= frobnitzem-0
CATEGORIES= local
MASTER_SITES= # empty
DISTFILES= # empty
MAINTAINER= leot%NetBSD.org@localhost
HOMEPAGE= http://netbsd.org/~leot/gsoc2017-diary/
COMMENT= Simple subpackages example
LICENSE= public-domain
FILESDIR= ${.CURDIR}/../../local/frobnitzem/files
WRKSRC= ${WRKDIR}/frobnitzem
NO_BUILD= yes
do-extract:
${CP} -r ${FILESDIR}/frobnitzem ${WRKDIR}
do-install:
${INSTALL_SCRIPT_DIR} ${DESTDIR}${PREFIX}/bin
${INSTALL_SCRIPT} ${WRKSRC}/frobnitzem-foo ${DESTDIR}${PREFIX}/bin
${INSTALL_SCRIPT} ${WRKSRC}/frobnitzem-bar ${DESTDIR}${PREFIX}/bin
${INSTALL_SCRIPT} ${WRKSRC}/frobnitzem-baz ${DESTDIR}${PREFIX}/bin
.include "../../mk/bsd.pkg.mk"
==> ./files/frobnitzem/frobnitzem-bar <==
#!/bin/sh
echo "bar"
==> ./files/frobnitzem/frobnitzem-baz <==
#!/bin/sh
echo "baz"
==> ./files/frobnitzem/frobnitzem-foo <==
#!/bin/sh
echo "foo"
==> ./PLIST <==
@comment $NetBSD$
bin/frobnitzem-bar
bin/frobnitzem-baz
bin/frobnitzem-foo
==> ./DESCR <==
frobnitzem, collection of foo, bar, baz scripts.
(Or, a bit more seriously this is just a very simple package to
test subpackages support!)
Nothing fancy, just three simple scripts, frobnitzem-{bar,baz,foo}
that will respectively print to the standard output bar,
baz and foo.
Let's build and install the frobnitzem package:
% make install ===> Installing dependencies for frobnitzem-0 ===> Overriding tools for frobnitzem-0 ===> Extracting for frobnitzem-0 [...] ===> Installing for frobnitzem-0 [...] ===> Installing binary package of frobnitzem-0 [...]
And now let's try scripts installed as part of the frobnitzem
package:
% foreach w (bar baz foo) ... frobnitzem-$w ... end bar baz foo
Okay, as we expected. Despite frobnitzem-{foo,bar,baz} don't do
anything particularly useful we can split the frobnitzem-0
package in three separate subpackages: frobnitzem-foo-0,
frobnitzem-bar-0 and
frobnitzem-baz-0 (they provides different functionalities and can
also coexist if they're in separated binary packages).
To do that we need to slighty adjust Makefile, split the
PLIST in PLIST.{foo,bar,baz} (one for each separate
subpackage), split the DESCR in DESCR.{foo,bar,baz}.
So, at the end in local/frobnitzem we'll have:
% tree
.
|-- DESCR.bar
|-- DESCR.baz
|-- DESCR.foo
|-- Makefile
|-- PLIST.bar
|-- PLIST.baz
|-- PLIST.foo
`-- files
`-- frobnitzem
|-- frobnitzem-bar
|-- frobnitzem-baz
`-- frobnitzem-foo
2 directories, 10 files
Splitting DESCR and PLIST
DESCR and PLIST splits are straightforward. We just
provide a separate DESCR.<spkg> for each subpackage,
e.g. for the foo subpackage:
% cat DESCR.foo frobnitzem, collection of foo, bar, baz scripts. (Or, a bit more seriously this is just a very simple package to test subpackages support!) This package provide the foo functionalities.
Similarly, regarding PLISTs, we just provide a separate
PLIST.<spkg> for each subpackage, e.g. for the
foo subpackage:
% cat PLIST.foo @comment $NetBSD$ bin/frobnitzem-foo
Makefile changes
In Makefile we'll need to list all SUBPACKAGES hence we'll add the
following line as first paragraph:
SUBPACKAGES= foo bar baz
We'll then need to define a PKGNAME.<spkg> for each
subpackages:
PKGNAME.foo= frobnitzem-foo-0 PKGNAME.bar= frobnitzem-bar-0 PKGNAME.baz= frobnitzem-baz-0
...and similarly COMMENT variable should be defined for each
subpackage via COMMENT.<spkg>:
COMMENT.foo= Simple subpackages example (foo) COMMENT.bar= Simple subpackages example (bar) COMMENT.baz= Simple subpackages example (baz)
To recap here how we have adjusted Makefile, all the other lines rest unchanged:
% sed '/LICENSE/q' < Makefile # $NetBSD$ SUBPACKAGES= foo bar baz DISTNAME= frobnitzem-0 PKGNAME.foo= frobnitzem-foo-0 PKGNAME.bar= frobnitzem-bar-0 PKGNAME.baz= frobnitzem-baz-0 MASTER_SITES= # empty DISTFILES= # empty CATEGORIES= local MAINTAINER= leot%NetBSD.org@localhost HOMEPAGE= http://netbsd.org/~leot/gsoc2017-diary/ COMMENT.foo= Simple subpackages example (foo) COMMENT.bar= Simple subpackages example (bar) COMMENT.baz= Simple subpackages example (baz) LICENSE= public-domain
Finally we can install it^Wthem! The usual make
install will generate three binary packages
(frobnitzem-foo-0.tgz, frobnitzem-bar-0.tgz,
frobnitzem-baz-0.tgz) and install all of them:
% make install ===> Installing dependencies for frobnitzem-0 [...] ===> Overriding tools for frobnitzem-0 ===> Extracting for frobnitzem-0 [...] ===> Installing for frobnitzem-0 [...] => Creating binary package /home/leot/repos/netbsd-github/pkgsrc/packages/All/frobnitzem-foo-0.tgz => Creating binary package /home/leot/repos/netbsd-github/pkgsrc/packages/All/frobnitzem-bar-0.tgz => Creating binary package /home/leot/repos/netbsd-github/pkgsrc/packages/All/frobnitzem-baz-0.tgz [...] ===> Installing binary package of frobnitzem-foo-0 ===> Installing binary package of frobnitzem-bar-0 ===> Installing binary package of frobnitzem-baz-0 [...]
Now we can try them and use pkg_info(1) to get some information about them:
% frobnitzem-foo foo % pkg_info -Fe /usr/pkg/bin/frobnitzem-foo frobnitzem-foo-0 % pkg_info frobnitzem-baz Information for frobnitzem-baz-0: Comment: Simple subpackages example (baz) Description: frobnitzem, collection of foo, bar, baz scripts. (Or, a bit more seriously this is just a very simple package to test subpackages support!) This package provide the baz functionalities. Homepage: http://netbsd.org/~leot/gsoc2017-diary/ % pkg_info -L frobnitzem-bar Information for frobnitzem-bar-0: Files: /usr/pkg/bin/frobnitzem-bar
So we can see that make install actually installed three different
binary packages.
To deinstall all SUBPACKAGES we can run make deinstall
in the local/frobnitzem directory (that will remove all
subpackages) or we can just manually invoke
pkg_delete(1).
An high-level look at how SUBPACKAGES support is implemented
Most of the changes needed are in mk/pkgformat/pkg/ hierarchy
(previously known as mk/flavour and then renamed and generalized to
other package formats during
Anton Panev's Google Summer of Code 2011).
The code in mk/pkgformat/${PKG_FORMAT}/ handle the interaction of
pkgsrc with the particular ${PKG_FORMAT}, e.g. for pkg
populate meta-data files used by
pkg_create(1),
install/delete packages via
pkg_add(1),
and
pkg_delete(1),
etc.
For more information
mk/pkgformat/README
is a good introduction to pkgformat hierarchy.
Most of the changes done respect the following template:
.if !empty(SUBPACKAGES)
. for _spkg_ in ${SUBPACKAGES}
[... code that handles SUBPACKAGES case ...]
. endfor
.else # !SUBPACKAGES
[... existing (and usually completely unmodified) code ...]
.endif # SUBPACKAGES
In particular, in mk/pkgformat/pkg/ targets were adjusted to
create/install/deinstall/etc. all subpackages.
Apart mk/pkgformat other changes were needed in
mk/install/install.mk in order to adjust the install
phase for SUBPACKAGES.
Regarding PLIST.<spkg> handling mk/plist/plist.mk
needed some adjustments to honor each PLIST per-subpackage.
mk/bsd.pkg.mk needed to be adjusted too in order to honor several
per-subpackage variables (the *.<spkg> ones) and
per-subpackage DESCR.<spkg>.
Conclusion
In this first part of this blog post series we have seen what are
SUBPACKAGES, when and why they can be useful.
We have then seen a practical example of them taking a very trivial package and learned how to "subpackage-ify" it.
Then we have described - from an high-level perspective - the changes needed to
the pkgsrc infrastructure for the SUBPACKAGES features that we have
used. If you are more interested in them please give a look to the
pkgsrc debugpkg
branch that contains all work done described in this blog post.
In the next part we will see how to handle *DEPENDS and
buildlink3 inclusion for subpackages.
I would like to thanks Google for organizing Google Summer of Code, the entire The NetBSD Foundation and in particular my mentors Taylor R. Campbell, William J. Coldwell and Thomas Klausner for providing precious guidance during these three months. A special thank you also to Jörg Sonnenberger who provided very useful suggestions. Thank you!
On behalf of the NetBSD release engineering team, it is my distinct pleasure to announce that the third release candidate of NetBSD 7.0 is now available for download. As the old Schoolhouse Rock song tells us, three is a magic number. We're hoping that RC3 will be the magic/last release candidate of 7.0.
Some of the changes since 7.0_RC2 are:
- Add a resize_root boot operation (disabled by default). If resize_root=YES in rc.conf then the system attempts to resize the root file system to fill its partition prior to mounting read-write.
- Enable SMP on Raspberry Pi 2.
- evbarm: Rename beagleboard.img to armv7.img. The new image includes the same kernels as beagleboard.img plus support for Raspberry Pi 2, ODROID-C1, Cubieboard2, Cubietruck, Hummingbird A31, and Banana Pi.
- evbarm: For armv7.img and rpi.img, enable support for auto-growing the SD card root filesystem.
- Various DRMKMS stability improvements.
- Avoid kernel panic on starting X on Intel 855GM machines. PR kern/49875.
- Fix an uninitalized lock panic when trying to start a Xen kernel with LOCKDEBUG and more than one vcpu.
- Fix an issue where x86 microcode updates could fail if memory was not 16 byte aligned.
- Fix an IPFilter panic.
- macppc: Fix ofwboot failure on PowerPC 603 machines.
- OpenSSH: Apply fix for CVE-2015-5600.
- Fix an issue where fsck_ffs didn't properly handle replaying a WAPBL journal on disks with non-DEV_BSIZE sectors.
- Fix error in the setlist scripts that resulted in /bin/[ being missing from the base set. PR bin/50109.
- Make libperfuse handle resource limits properly.
- Make uplcom(4) suspend/resume.
- Fix case where coretemp(4) didn't attach on some newer CPUs.
- Avoid hanging on some machines after attaching ehci(4).
- Fix crash on oboe(4) attach. PR port-i386/50076.
- mountd(8): Write the correct pid is written to pidfile. PR bin/50125.
- patch(1): Guard against malicious filenames and substitution commands.
- patch(1): Drop SCCS support.
- ypserv(8): When transferring a secure map to a slave server, don't lose the secure flag. PR bin/50057.
- resize_ffs(8):
- Make get_dev_size work on regular files too.
- Add -c to check to see if grow/shrink is required.
- Divide by DEV_BSIZE when returning size of file.
- Handle case in grow() where last cylinder group is too small for ufs2.
- Add a -p flag, which displays a progress bar.
- disklabel(8): Fix a bug that resulted in sun2 liveimages being non-bootable.
- Update libXi to 1.7.4.
- Update BIND to 9.10.2-P3.
The full list of changes can be found near the bottom of http://ftp.NetBSD.org/pub/NetBSD/NetBSD-7.0_RC3/CHANGES-7.0
Binaries of NetBSD 7.0_RC3 are available for download at:
http://ftp.NetBSD.org/pub/NetBSD/NetBSD-7.0_RC3/
Those who prefer to build from source can either use the netbsd-7-0-RC3 tag or follow the netbsd-7 branch.
As always, please let us know how 7.0_RC3 works for you! Any feedback, whether good or bad, is welcome. Problems should be reported through the usual channels (submit a PR or write to the appropriate list). More general feedback is welcome at releng@NetBSD.org.
In July we cleaned up the repository so it can be converted easily; since then we've been working on the infrastructure and details of the conversion. The main tasks are now finished. We have set up a server for it which hosts a preliminary git conversion (on wip.pkgsrc.org) of the CVS repository, created a mailing list for the commit messages, pkgsrc-wip-changes, and prepared a list of authors for the conversion.
We've also provided a conversion of pkgsrc-wip based on data from July so that it can be tested on (nearly) live data. If you are interested in beta-testing the setup, send a suggestion for a username and an SSH public key to me. Details on how to test are on the NetBSD wiki but will probably change some more over time.
We still need help for the conversion: if you are or were a wip contributor, please let me know by September 15 what name and email to use for the conversion from CVS to git. This conversion will not be done again, so after that date, the commit data will be final.
The NVIDIA Jetson TK1 is a quad-core ARMv7 development board that features an NVIDIA Tegra K1 (32-bit) SoC (quad-core Cortex-A15 @ 2.3GHz), 2GB RAM, gigabit ethernet, SATA, HDMI, mini-PCIE, and more.
Since my last status update on the port, HDMI video and audio support have been added along with a handful of stability fixes.
NetBSD -current includes support for this board with the JETSONTK1 kernel. The following hardware is supported:
- Cortex-A15 (multiprocessor)
- CPU frequency scaling
- ARM generic timer
- Clock and reset controller
- GPIO controller
- MPIO / pinmux controller
- Memory controller
- Power management controller
- I2C controller
- UART serial console
- Watchdog timer
- SDMMC controller
- USB 2.0 controller
- AHCI SATA controller
- HD audio controller (HDMI audio)
- HDMI framebuffer console
- PCI express controller, including mini-PCIE slot
- On-board Realtek 8111G gigabit ethernet
- Serial EEPROM
- Temperature sensor
- RF kill switch
- Power button
Of course, Xorg works too:
See the NetBSD/evbarm on NVIDIA Tegra wiki page for more details.
Copyright (c) 1996, 1997, 1998, 1999, 2000, 2001, 2002, 2003, 2004, 2005,
2006, 2007, 2008, 2009, 2010, 2011, 2012, 2013, 2014, 2015
The NetBSD Foundation, Inc. All rights reserved.
Copyright (c) 1982, 1986, 1989, 1991, 1993
The Regents of the University of California. All rights reserved.
NetBSD 7.99.20 (JETSONTK1) #189: Sat Jul 25 12:47:31 ADT 2015
jmcneill@megatron.local:/Users/jmcneill/netbsd/src/sys/arch/evbarm/compile/obj/JETSONTK1
total memory = 2047 MB
avail memory = 2021 MB
sysctl_createv: sysctl_create(machine_arch) returned 17
timecounter: Timecounters tick every 10.000 msec
mainbus0 (root)
cpu0 at mainbus0 core 0: 2292 MHz Cortex-A15 r3p3 (Cortex V7A core)
cpu0: DC enabled IC enabled WB disabled EABT branch prediction enabled
cpu0: sctlr: 0xc51c7d
cpu0: actlr: 0x80000041
cpu0: revidr: 0
cpu0: mpidr: 0x80000000
cpu0: isar: [0]=0x2101110 [1]=0x13112111 [2]=0x21232041 [3]=0x11112131, [4]=0x10011142, [5]=0
cpu0: mmfr: [0]=0x10201105 [1]=0x40000000 [2]=0x1240000 [3]=0x2102211
cpu0: pfr: [0]=0x1131 [1]=0x11011
cpu0: 32KB/64B 2-way L1 PIPT Instruction cache
cpu0: 32KB/64B 2-way write-back-locking-C L1 PIPT Data cache
cpu0: 2048KB/64B 16-way write-through L2 PIPT Unified cache
vfp0 at cpu0: NEON MPE (VFP 3.0+), rounding, NaN propagation, denormals
vfp0: mvfr: [0]=0x10110222 [1]=0x11111111
cpu1 at mainbus0 core 1
cpu2 at mainbus0 core 2
cpu3 at mainbus0 core 3
armperiph0 at mainbus0
armgic0 at armperiph0: Generic Interrupt Controller, 192 sources (183 valid)
armgic0: 32 Priorities, 160 SPIs, 7 PPIs, 16 SGIs
armgtmr0 at armperiph0: ARMv7 Generic 64-bit Timer (12000 kHz)
armgtmr0: interrupting on irq 27
timecounter: Timecounter "armgtmr0" frequency 12000000 Hz quality 500
tegraio0 at mainbus0: Tegra K1 (T124)
tegracar0 at tegraio0: CAR
tegracar0: PLLX = 2292000000 Hz
tegracar0: PLLC = 88000000 Hz
tegracar0: PLLE = 292968 Hz
tegracar0: PLLU = 480000000 Hz
tegracar0: PLLP0 = 408000000 Hz
tegracar0: PLLD2 = 594000000 Hz
tegragpio0 at tegraio0: GPIO
gpio0 at tegragpio0 (A): 8 pins
gpio1 at tegragpio0 (B): 8 pins
gpio2 at tegragpio0 (C): 8 pins
gpio3 at tegragpio0 (D): 8 pins
gpio4 at tegragpio0 (E): 8 pins
gpio5 at tegragpio0 (F): 8 pins
gpio6 at tegragpio0 (G): 8 pins
gpio7 at tegragpio0 (H): 8 pins
gpio8 at tegragpio0 (I): 8 pins
gpio9 at tegragpio0 (J): 8 pins
gpio10 at tegragpio0 (K): 8 pins
gpio11 at tegragpio0 (L): 8 pins
gpio12 at tegragpio0 (M): 8 pins
gpio13 at tegragpio0 (N): 8 pins
gpio14 at tegragpio0 (O): 8 pins
gpio15 at tegragpio0 (P): 8 pins
gpio16 at tegragpio0 (Q): 8 pins
gpiobutton0 at gpio16 pins 0: Power button
gpio17 at tegragpio0 (R): 8 pins
gpio18 at tegragpio0 (S): 8 pins
gpio19 at tegragpio0 (T): 8 pins
gpio20 at tegragpio0 (U): 8 pins
gpio21 at tegragpio0 (V): 8 pins
gpio22 at tegragpio0 (W): 8 pins
gpio23 at tegragpio0 (X): 8 pins
gpiorfkill0 at gpio23 pins 7
gpio24 at tegragpio0 (Y): 8 pins
gpio25 at tegragpio0 (Z): 8 pins
gpio26 at tegragpio0 (AA): 8 pins
gpio27 at tegragpio0 (BB): 8 pins
gpio28 at tegragpio0 (CC): 8 pins
gpio29 at tegragpio0 (DD): 8 pins
gpio30 at tegragpio0 (EE): 8 pins
tegratimer0 at tegraio0: Timers
tegratimer0: default watchdog period is 10 seconds
tegramc0 at tegraio0: MC
tegrapmc0 at tegraio0: PMC
tegraxusbpad0 at tegraio0: XUSB PADCTL
tegrampio0 at tegraio0: MPIO
tegrai2c0 at tegraio0 port 0: I2C1
tegrai2c0: interrupting on irq 70
iic0 at tegrai2c0: I2C bus
seeprom0 at iic0 addr 0x56: AT24Cxx or compatible EEPROM: size 256
titemp0 at iic0 addr 0x4c: TMP451
tegrai2c1 at tegraio0 port 1: I2C2
tegrai2c1: interrupting on irq 116
iic1 at tegrai2c1: I2C bus
tegrai2c2 at tegraio0 port 2: I2C3
tegrai2c2: interrupting on irq 124
iic2 at tegrai2c2: I2C bus
tegrai2c3 at tegraio0 port 3: I2C4
tegrai2c3: interrupting on irq 152
iic3 at tegrai2c3: I2C bus
ddc0 at iic3 addr 0x50: DDC
tegrai2c4 at tegraio0 port 4: I2C5
tegrai2c4: interrupting on irq 85
iic4 at tegrai2c4: I2C bus
com3 at tegraio0 port 3: ns16550a, working fifo
com3: console
tegrartc0 at tegraio0: RTC
sdhc2 at tegraio0 port 2: SDMMC3
sdhc2: interrupting on irq 51
sdhc2: SDHC 4.0, rev 3, DMA, 48000 kHz, 3.0V 3.3V, 4096 byte blocks
sdmmc2 at sdhc2 slot 0
ahcisata0 at tegraio0: SATA
ahcisata0: interrupting on irq 55
ahcisata0: AHCI revision 1.31, 2 ports, 32 slots, CAP 0xe620ff01<PSC,SSC,PMD,ISS=0x2=Gen2,SAL,SALP,SSNTF,SNCQ,S64A>
atabus0 at ahcisata0 channel 0
hdaudio0 at tegraio0: HDA
hdaudio0: interrupting on irq 113
hdafg0 at hdaudio0: NVIDIA Tegra124 HDMI
hdafg0: HDMI00 8ch: Digital Out [Jack]
hdafg0: 8ch/0ch 48000Hz PCM16*
audio0 at hdafg0: full duplex, playback, capture, mmap, independent
ehci0 at tegraio0 port 0: USB1
ehci0: interrupting on irq 52
ehci0: EHCI version 1.10
ehci0: switching to host mode
usb0 at ehci0: USB revision 2.0
ehci1 at tegraio0 port 1: USB2
ehci1: interrupting on irq 53
ehci1: EHCI version 1.10
ehci1: switching to host mode
usb1 at ehci1: USB revision 2.0
ehci2 at tegraio0 port 2: USB3
ehci2: interrupting on irq 129
ehci2: EHCI version 1.10
ehci2: switching to host mode
usb2 at ehci2: USB revision 2.0
tegrahost1x0 at tegraio0: HOST1X
tegradc0 at tegraio0 port 0: DISPLAYA
tegradc1 at tegraio0 port 1: DISPLAYB
tegrahdmi0 at tegraio0: HDMI
tegrahdmi0: display connected
no data for est. mode 640x480x67
tegrahdmi0: connected to HDMI display
genfb0 at tegradc1 output tegrahdmi0
genfb0: framebuffer at 0x9ab00000, size 1920x1080, depth 32, stride 7680
wsdisplay0 at genfb0 kbdmux 1
wsmux1: connecting to wsdisplay0
wsdisplay0: screen 0-3 added (default, vt100 emulation)
tegrapcie0 at tegraio0: PCIE
tegrapcie0: interrupting on irq 130
pci0 at tegrapcie0 bus 0
pci0: memory space enabled, rd/line, rd/mult, wr/inv ok
ppb0 at pci0 dev 0 function 0: vendor 10de product 0e12 (rev. 0xa1)
ppb0: PCI Express capability version 2 <Root Port of PCI-E Root Complex> x2 @ 5.0GT/s
ppb0: link is x1 @ 2.5GT/s
pci1 at ppb0 bus 1
pci1: memory space enabled, rd/line, wr/inv ok
athn0 at pci1 dev 0 function 0athn0: Atheros AR9285
athn0: rev 2 (1T1R), ROM rev 13, address 00:17:c4:d7:d0:58
athn0: interrupting at irq 130
athn0: 11b rates: 1Mbps 2Mbps 5.5Mbps 11Mbps
athn0: 11g rates: 1Mbps 2Mbps 5.5Mbps 11Mbps 6Mbps 9Mbps 12Mbps 18Mbps 24Mbps 36Mbps 48Mbps 54Mbps
ppb1 at pci0 dev 1 function 0: vendor 10de product 0e13 (rev. 0xa1)
ppb1: PCI Express capability version 2 <Root Port of PCI-E Root Complex> x1 @ 5.0GT/s
ppb1: link is x1 @ 2.5GT/s
pci2 at ppb1 bus 2
pci2: memory space enabled, rd/line, wr/inv ok
re0 at pci2 dev 0 function 0: RealTek 8168/8111 PCIe Gigabit Ethernet (rev. 0x0c)
re0: interrupting at irq 130
re0: Ethernet address 00:04:4b:2f:51:a2
re0: using 512 tx descriptors
rgephy0 at re0 phy 7: RTL8251 1000BASE-T media interface, rev. 0
rgephy0: 10baseT, 10baseT-FDX, 100baseTX, 100baseTX-FDX, 1000baseT-FDX, auto
timecounter: Timecounter "clockinterrupt" frequency 100 Hz quality 0
cpu2: 2292 MHz Cortex-A15 r3p3 (Cortex V7A core)
cpu2: DC enabled IC enabled WB disabled EABT branch prediction enabled
cpu2: sctlr: 0xc51c7d
cpu2: actlr: 0x80000040
cpu2: revidr: 0
cpu2: mpidr: 0x80000002
cpu2: isar: [0]=0x2101110 [1]=0x13112111 [2]=0x21232041 [3]=0x11112131, [4]=0x10011142, [5]=0
cpu2: mmfr: [0]=0x10201105 [1]=0x40000000 [2]=0x1240000 [3]=0x2102211
cpu2: pfr: [0]=0x1131 [1]=0x11011
cpu2: 32KB/64B 2-way L1 PIPT Instruction cache
cpu2: 32KB/64B 2-way write-back-locking-C L1 PIPT Data cache
cpu2: 2048KB/64B 16-way write-through L2 PIPT Unified cache
vfp2 at cpu2: NEON MPE (VFP 3.0+), rounding, NaN propagation, denormals
vfp2: mvfr: [0]=0x10110222 [1]=0x11111111
cpu1: 2292 MHz Cortex-A15 r3p3 (Cortex V7A core)
cpu1: DC enabled IC enabled WB disabled EABT branch prediction enabled
cpu1: sctlr: 0xc51c7d
cpu1: actlr: 0x80000040
cpu1: revidr: 0
cpu1: mpidr: 0x80000001
cpu1: isar: [0]=0x2101110 [1]=0x13112111 [2]=0x21232041 [3]=0x11112131, [4]=0x10011142, [5]=0
cpu1: mmfr: [0]=0x10201105 [1]=0x40000000 [2]=0x1240000 [3]=0x2102211
cpu1: pfr: [0]=0x1131 [1]=0x11011
cpu1: 32KB/64B 2-way L1 PIPT Instruction cache
cpu1: 32KB/64B 2-way write-back-locking-C L1 PIPT Data cache
cpu1: 2048KB/64B 16-way write-through L2 PIPT Unified cache
vfp1 at cpu1: NEON MPE (VFP 3.0+), rounding, NaN propagation, denormals
vfp1: mvfr: [0]=0x10110222 [1]=0x11111111
cpu3: 2292 MHz Cortex-A15 r3p3 (Cortex V7A core)
cpu3: DC enabled IC enabled WB disabled EABT branch prediction enabled
cpu3: sctlr: 0xc51c7d
cpu3: actlr: 0x80000040
cpu3: revidr: 0
cpu3: mpidr: 0x80000003
cpu3: isar: [0]=0x2101110 [1]=0x13112111 [2]=0x21232041 [3]=0x11112131, [4]=0x10011142, [5]=0
cpu3: mmfr: [0]=0x10201105 [1]=0x40000000 [2]=0x1240000 [3]=0x2102211
cpu3: pfr: [0]=0x1131 [1]=0x11011
cpu3: 32KB/64B 2-way L1 PIPT Instruction cache
cpu3: 32KB/64B 2-way write-back-locking-C L1 PIPT Data cache
cpu3: 2048KB/64B 16-way write-through L2 PIPT Unified cache
vfp3 at cpu3: NEON MPE (VFP 3.0+), rounding, NaN propagation, denormals
vfp3: mvfr: [0]=0x10110222 [1]=0x11111111
uhub0 at usb0: Tegra EHCI root hub, class 9/0, rev 2.00/1.00, addr 1
uhub0: 1 port with 1 removable, self powered
uhub1 at usb2: Tegra EHCI root hub, class 9/0, rev 2.00/1.00, addr 1
uhub1: 1 port with 1 removable, self powered
uhub2 at usb1: Tegra EHCI root hub, class 9/0, rev 2.00/1.00, addr 1
uhub2: 1 port with 1 removable, self powered
ahcisata0 port 0: device present, speed: 3.0Gb/s
ld1 at sdmmc2: <0x27:0x5048:SD64G:0x30:0x01ce4def:0x0dc>
ld1: 59504 MB, 7585 cyl, 255 head, 63 sec, 512 bytes/sect x 121864192 sectors
ld1: 4-bit width, bus clock 48.000 MHz
wd0 at atabus0 drive 0
wd0: <OCZ-AGILITY3>
wd0: drive supports 16-sector PIO transfers, LBA48 addressing
wd0: 111 GB, 232581 cyl, 16 head, 63 sec, 512 bytes/sect x 234441648 sectors
wd0: drive supports PIO mode 4, DMA mode 2, Ultra-DMA mode 6 (Ultra/133)
wd0(ahcisata0:0:0): using PIO mode 4, DMA mode 2, Ultra-DMA mode 6 (Ultra/133) (using DMA)
uhidev0 at uhub0 port 1 configuration 1 interface 0
uhidev0: Logitech USB Receiver, rev 2.00/29.00, addr 2, iclass 3/1
ukbd0 at uhidev0: 8 modifier keys, 6 key codes
wskbd0 at ukbd0 mux 1
wskbd0: connecting to wsdisplay0
uhidev1 at uhub0 port 1 configuration 1 interface 1
uhidev1: Logitech USB Receiver, rev 2.00/29.00, addr 2, iclass 3/1
uhidev1: 17 report ids
ums0 at uhidev1 reportid 2: 16 buttons, W and Z dirs
wsmouse0 at ums0 mux 0
uhid0 at uhidev1 reportid 3: input=4, output=0, feature=0
uhid1 at uhidev1 reportid 4: input=1, output=0, feature=0
uhid2 at uhidev1 reportid 16: input=6, output=6, feature=0
uhid3 at uhidev1 reportid 17: input=19, output=19, feature=0
boot device: ld1
root on ld1a dumps on ld1b
mountroot: trying smbfs...
mountroot: trying ntfs...
mountroot: trying nfs...
mountroot: trying msdos...
mountroot: trying ext2fs...
mountroot: trying ffs...
root file system type: ffs
kern.module.path=/stand/evbarm/7.99.20/modules
WARNING: preposterous TOD clock time
WARNING: using filesystem time
WARNING: CHECK AND RESET THE DATE!
init: copying out path `/sbin/init' 11
WARNING: module error: vfs load failed for `compat', error 2
WARNING: module error: vfs load failed for `compat', error 2
WARNING: module error: vfs load failed for `compat', error 2
WARNING: module error: vfs load failed for `compat', error 2
WARNING: module error: vfs load failed for `compat', error 2
WARNING: module error: vfs load failed for `compat', error 2
re0: link state UP (was UNKNOWN)
athn0: link state UP (was UNKNOWN)
On behalf of the NetBSD project, it is my pleasure to announce the second release candidate of NetBSD 7.0.
Some of the changes since 7.0_RC1 are:
- OpenSSL updated to 1.0.1p
- BIND updated to 9.10.2-P2
- IPSEC support is now included by default in Xen kernels
- Fix several security issues in calendar(1)
- installboot(8) now supports wedge names
- Fix a quota panic when using WAPBL (PR 49948)
- Fix a memory leak in the drm2 code
- Avoid an X crash on i915 DRMKMS
- Add a postinstall(8) check to ensure that /etc/man.conf reflects the modern mandoc world (PR 50020)
- Add a postinstall(8) check to ensure that /etc/fonts/fonts.conf is up to date
- tset(1): Fix handling of the erase character
- gdb(1): Fix attaching to a running process again after previously detaching
- NPF: handle unregistered interfaces correctly
- npfctl(8): Fix a NULL dereference
- zgrep(1): suppress the prefixing of filename on output when only one file is specified, to match grep(1)'s output
- Fix lrint(x) and llrint(x) when x is larger than 2**51 (PR 49690)
- Bump MAXTSIZ and MAXDSIZ on amiga, fixing gcc 4.8 execution
- Fix MKCTF=yes on drm2 kernels
- Make clock_t unsigned int everywhere, so it's the same on LP64 and IPL32 architectures
- arm: if halt is requested and there is no console, keep looping instead of rebooting
- sparc64: Fix booting of kernels with more than 4 MB combined .data and .bss segments
- powerpc: Fix occasional FPU register corruption (PR 50037)
- m68k: Fix atomic_cas_{8,16} and __sync_bool_compare_and_swap_{1,2,4} (PR 49995)
The full list of changes can be found near the bottom of http://ftp.NetBSD.org/pub/NetBSD/NetBSD-7.0_RC2/CHANGES-7.0
Binaries of NetBSD 7.0_RC2 are available for download at:
http://ftp.NetBSD.org/pub/NetBSD/NetBSD-7.0_RC2/
Those who prefer to build from source can either use the netbsd-7-0-RC2 tag or follow the netbsd-7 branch.
As always, please let us know how 7.0_RC2 works for you! Any feedback, whether good or bad, is welcome. Problems should be reported through the usual channels (submit a PR or write to the appropriate list). More general feedback is welcome at releng@NetBSD.org.
The last year's pkgsrcCon 2016 event took place in Kraków, Poland.
Slides are available on the event site.
Video recordings are stored at https://archive.org/details/pkgsrcCon-2016.
We would like to thank the organizers, sponsors and promotion from the Jagiellonian University, The NetBSD Foundation, Programista Magazyn, OS World, and Subcarpathian BSD User Group.
The last year's pkgsrcCon 2016 event took place in Kraków, Poland.
Slides are available on the event site.
Video recordings are stored at https://archive.org/details/pkgsrcCon-2016.
We would like to thank the organizers, sponsors and promotion from the Jagiellonian University, The NetBSD Foundation, Programista Magazyn, OS World, and Subcarpathian BSD User Group.
dogfood
When I have realized that in order to work on the LLVM sanitizers I need to use Clang as the compiler. A part of the compiler-rt (lowlevel LLVM compiler runtime library) has code specifically incompatible with GCC. It was mainly related to intrinsic instructions for atomic functions. I tried to research how much work is needed to port it to GCC. It happened to be non-trivial and I filed a bug on the LLVM bugzilla.
These circumstances made me to switch to Clang as the pkgsrc toolchain. I was using it to test the compilation of small bulks of packages and record build and compiler problems. To save time, I used ccache as my cache for builds.
My options in mk.conf(5):
PKGSRC_COMPILER= ccache clang CCACHE_BASE= /usr/local CCACHE_DIR= /public/ccache_tmp CCACHE_LOGFILE= /tmp/ccache.txt PKG_CC= clang PKG_CXX= clang++ CLANGBASE= /usr/local HAVE_LLVM= yes
It's worth noting that ccache with pkgsrc won't check $HOME/.ccache for configuration, it must be placed in $CCACHE_DIR/ccache.conf.
The documented problems can be summarized as:
- Broken ccache in pkgsrc for C++11 packages.
The pkgsrc framework started supporting C++ languages in the USE_LANGUAGES definition. Packages with newly added USE_LANGUAGES values (such as c++11) were not compiled with ccache because ccache.mk was not yet aware of such values. This broke support of these packages to set these values to be built with ccache. I've corrected it and introduced a new option CCACHE_LOGFILE to more easily track execution of ccache and detect errors. - Broken ccache in pkgsrc for a custom toolchain.
ccache tries finding a real-compiler looking for it in $PATH. When I have built clang within pkgsrc to work on it (installed into/usr/pkg), and I had my main toolchain in/usr/localit was picking the one from/usr/pkgfor new builds and it resulted in cache-misses for new builds. I have installed a fix for it to pass ccache specific PATH to always find the appropriate compiler. - Header <execinfo.h> cannot be included on Clang 5.0.0svn.
For some reason compilers tend to install their own headers that overshadow the system headers. This resulted in build failures in programs including plain <execinfo.h> header (for the backtrace(3) function). This system header used to include <stddef.h> that included our <sys/cdefs.h>... with shadowed <stddef.h> by Clang 5.0.0svn (from $PREFIX/lib/clang/5.0.0/include/stddef.h). Christos Zoulas fixed it by making <execinfo.h> standalone and independent from standard libc headers. - __float128 and GNU libstdc++.
Our basesystem GNU libstdc++ enables __float128 on i386, amd64 and i64 ports. As of now the LLVM equivalent library contains partial support for this type. This results in a problem that affects 3rd party programs in the setup of Clang + libstdc++ detect __float128 support and break because the compiler does not define appropriate global define __FLOAT128__. This issue is still open for discussion on how to solve it for NetBSD. - gforth optimization problems.
Upstream gforth developers ported this FORTH compiler to Clang, and triggered an optimization issue with attempting to needlessly solve a complex internal problem. This results with compilation times of several minutes on a modern CPUs instead of getting the results immediately. The problem has been already reported on the LLVM bugzilla and I have filed a report that it is still valid. - bochs can be built with clang.
A while ago, bochs was buildable only by the GCC compilers and the Clang toolchain was blacklisted. I have verified that this is no longer the case and unmasked the package for compilers other than GCC.
LLVM and Clang testsuites
I have prepared Clang and LLVM testsuites to execute on NetBSD. Correctness of both projects is crucial for LLDB and the LLVM sanitizers to work because their issues resound problems inside programs that depend on them. Originally I have corrected the tests with local patches to build with GCC, and switched later to Clang. I have restructured the packages in pkgsrc-wip in order to execute the test-suite. I have fixed 20 test failures in LLVM implementing AllocateRWX and ReleaseRWX for the NetBSD flavor of PaX MPROTECT. There are still over 200 failures to solve!
It's worth noting that the googletest library (used in a modified version in LLVM and in a regular one in Clang) finally accepted the NetBSD patches.
LLVM asan and ubsan
I expect to get four LLVM sanitizers working in order to move on to LLDB: asan (address sanitizer), ubsan (undefined behavior sanitizer), tsan (thread sanitizer), msan (memory sanitizer). The other ones like dfsan (data-flow sanitizer) or lsan (leak sanitizer) are currently to be skipped. In general, sanitizers are part of the LLDB functionality that I want to get aboard on NetBSD, as there are plugins to integrate them within the debugger. In the current state I require them to debug bugs inside LLDB/NetBSD.
The original work on sanitizers in GCC (with libsanitizer) has been done by Christos Zoulas. GCC libsanitizer is a close sibling of compiler-rt/lib from the LLVM project. I picked up his work and integrated it into compiler-rt and developed the rest (code differences, fixing bugs, Clang/LLVM specific parts in llvm/ and clang/) and I managed to get asan and ubsan to work.
Users should pickup pkgsrc-wip in revision 3e7c52b97b4d6cb8ea69a081409ac818c812c34a and install wip/{llvm,clang,compiler-rt}-netbsd. Clang will be ready for usage:
/usr/pkg/bin/clang -fsanitize=undefined test.cand
/usr/pkg/bin/clang -fsanitize=address test.c
Additional compiler commands that may improve the experience:
-g -O0 -fno-omit-frame-pointer -pie -fPIE
These sanitizers are not production ready and are active under development.
Plan for the next milestone
Roadmap for the next month:
- Finish and send upstream LLVM asan and ubsan support.
- Correct more problems triggered by LLVM and Clang test-suites.
- Resume msan and tsan porting.
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL, and chip in what you can:
dogfood
When I have realized that in order to work on the LLVM sanitizers I need to use Clang as the compiler. A part of the compiler-rt (lowlevel LLVM compiler runtime library) has code specifically incompatible with GCC. It was mainly related to intrinsic instructions for atomic functions. I tried to research how much work is needed to port it to GCC. It happened to be non-trivial and I filed a bug on the LLVM bugzilla.
These circumstances made me to switch to Clang as the pkgsrc toolchain. I was using it to test the compilation of small bulks of packages and record build and compiler problems. To save time, I used ccache as my cache for builds.
My options in mk.conf(5):
PKGSRC_COMPILER= ccache clang CCACHE_BASE= /usr/local CCACHE_DIR= /public/ccache_tmp CCACHE_LOGFILE= /tmp/ccache.txt PKG_CC= clang PKG_CXX= clang++ CLANGBASE= /usr/local HAVE_LLVM= yes
It's worth noting that ccache with pkgsrc won't check $HOME/.ccache for configuration, it must be placed in $CCACHE_DIR/ccache.conf.
The documented problems can be summarized as:
- Broken ccache in pkgsrc for C++11 packages.
The pkgsrc framework started supporting C++ languages in the USE_LANGUAGES definition. Packages with newly added USE_LANGUAGES values (such as c++11) were not compiled with ccache because ccache.mk was not yet aware of such values. This broke support of these packages to set these values to be built with ccache. I've corrected it and introduced a new option CCACHE_LOGFILE to more easily track execution of ccache and detect errors. - Broken ccache in pkgsrc for a custom toolchain.
ccache tries finding a real-compiler looking for it in $PATH. When I have built clang within pkgsrc to work on it (installed into/usr/pkg), and I had my main toolchain in/usr/localit was picking the one from/usr/pkgfor new builds and it resulted in cache-misses for new builds. I have installed a fix for it to pass ccache specific PATH to always find the appropriate compiler. - Header <execinfo.h> cannot be included on Clang 5.0.0svn.
For some reason compilers tend to install their own headers that overshadow the system headers. This resulted in build failures in programs including plain <execinfo.h> header (for the backtrace(3) function). This system header used to include <stddef.h> that included our <sys/cdefs.h>... with shadowed <stddef.h> by Clang 5.0.0svn (from $PREFIX/lib/clang/5.0.0/include/stddef.h). Christos Zoulas fixed it by making <execinfo.h> standalone and independent from standard libc headers. - __float128 and GNU libstdc++.
Our basesystem GNU libstdc++ enables __float128 on i386, amd64 and i64 ports. As of now the LLVM equivalent library contains partial support for this type. This results in a problem that affects 3rd party programs in the setup of Clang + libstdc++ detect __float128 support and break because the compiler does not define appropriate global define __FLOAT128__. This issue is still open for discussion on how to solve it for NetBSD. - gforth optimization problems.
Upstream gforth developers ported this FORTH compiler to Clang, and triggered an optimization issue with attempting to needlessly solve a complex internal problem. This results with compilation times of several minutes on a modern CPUs instead of getting the results immediately. The problem has been already reported on the LLVM bugzilla and I have filed a report that it is still valid. - bochs can be built with clang.
A while ago, bochs was buildable only by the GCC compilers and the Clang toolchain was blacklisted. I have verified that this is no longer the case and unmasked the package for compilers other than GCC.
LLVM and Clang testsuites
I have prepared Clang and LLVM testsuites to execute on NetBSD. Correctness of both projects is crucial for LLDB and the LLVM sanitizers to work because their issues resound problems inside programs that depend on them. Originally I have corrected the tests with local patches to build with GCC, and switched later to Clang. I have restructured the packages in pkgsrc-wip in order to execute the test-suite. I have fixed 20 test failures in LLVM implementing AllocateRWX and ReleaseRWX for the NetBSD flavor of PaX MPROTECT. There are still over 200 failures to solve!
It's worth noting that the googletest library (used in a modified version in LLVM and in a regular one in Clang) finally accepted the NetBSD patches.
LLVM asan and ubsan
I expect to get four LLVM sanitizers working in order to move on to LLDB: asan (address sanitizer), ubsan (undefined behavior sanitizer), tsan (thread sanitizer), msan (memory sanitizer). The other ones like dfsan (data-flow sanitizer) or lsan (leak sanitizer) are currently to be skipped. In general, sanitizers are part of the LLDB functionality that I want to get aboard on NetBSD, as there are plugins to integrate them within the debugger. In the current state I require them to debug bugs inside LLDB/NetBSD.
The original work on sanitizers in GCC (with libsanitizer) has been done by Christos Zoulas. GCC libsanitizer is a close sibling of compiler-rt/lib from the LLVM project. I picked up his work and integrated it into compiler-rt and developed the rest (code differences, fixing bugs, Clang/LLVM specific parts in llvm/ and clang/) and I managed to get asan and ubsan to work.
Users should pickup pkgsrc-wip in revision 3e7c52b97b4d6cb8ea69a081409ac818c812c34a and install wip/{llvm,clang,compiler-rt}-netbsd. Clang will be ready for usage:
/usr/pkg/bin/clang -fsanitize=undefined test.cand
/usr/pkg/bin/clang -fsanitize=address test.c
Additional compiler commands that may improve the experience:
-g -O0 -fno-omit-frame-pointer -pie -fPIE
These sanitizers are not production ready and are active under development.
Plan for the next milestone
Roadmap for the next month:
- Finish and send upstream LLVM asan and ubsan support.
- Correct more problems triggered by LLVM and Clang test-suites.
- Resume msan and tsan porting.
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL, and chip in what you can:
This years pkgsrcCon returned to London once again. It was last held in London back in 2014. The 2014 con was the first pkgsrcCon I attended, I had been working on Darwin/PowerPC fixes for some months and presented on the progress I'd made with a 12" G4 PowerBook. I took away a G4 Mac Mini that day to help spare the PowerBook for use and dedicate a machine for build and testing. The offer of PowerPC hardware donations was repeated at this years con, thanks to jperkin@ who showed up with a backpack full of Mac Minis (more on that later).
Since 2014 we have held cons in Berlin (2015) & Krakow (2016). In Krakow we had talks about a wide range of projects over 2 days, from Haiku Ports to Common Lisp to midipix (building native PE binaries for Windows) and back to the BSDs. I was very pleased to continue the theme of a diverse program this year.
Aside from pkgsrc and NetBSD, we had talks about FreeBSD, OpenBSD, Slackware Linux, and Plan 9.
Things began with a pub gathering on the Friday for the pre-con social, we hung out and chatted till almost midnight on a wide range of topics, such as supporting a system using NFS on MS-DOS, the origins of pdksh, corporate IT, culture and many other topics.
On parting I was asked about the starting time on Saturday as there was some conflicting information. I learnt that the registration email had stated a later start than I had scheduled for & advertised on the website, by 30 minutes.
Lesson learnt: register for your own event!
Not a problem, I still needed to setup a webpage for the live video stream, I could do both when I got back. With some trimming here and there I had a new schedule, I posted that to the pkgsrcCon website and moved to trying to setup a basic web page which contained a snippet of javascript to play a live video stream from Scale Engine.
2+ hours later, it was pointed out that the XSS protection headers on pkgsrc.org breaks the functionality. Thanks to jmcneill@ for debugging and providing a working page.
Saturday started off with Giovanni Bechis speaking about pledge in OpenBSD and adding support to various packages in their ports tree, alnsn@ then spoke about installing packages from a repo hosted on the Tor network.
After a quick coffee break we were back to hear Charles Forsyth speak about how Plan 9 and Inferno dealt with portability, building software and the problem which are avoided by the environment there. This was followed by a very energetic rant by David Spencer from the Slackbuilds project on packaging 3rd party software. Slackbuilds is a packaging system for Slackware Linux, which was inspired by FreeBSD ports.
For the first slot after lunch, agc@ gave a talk on the early history of pkgsrc followed by Thomas Merkel on using vagrant to test pkgsrc changes with ease, locally, using vagrant. khorben@ covered his work on adding security to pkgsrc and bsiegert@ covered the benefits of performing our bulk builds in the cloud and the challenges we currently face.
My talk was about some topics and ideas which had inspired me or caught my attention, and how it could maybe apply to my work.The title of the talk was taken from the name of Andrew Weatherall's Saint Etienne remix, possibly referring to two different styles of track (dub & vocal) merged into one or something else. I meant it in terms of applicability of thoughts and ideas. After me, agc@ gave a second talk on the evolution of the Netflix Open Connect appliance which runs FreeBSD and Vsevolod Stakhov wrapped up the day with a talk about the technical implementation details of the successor to pkg_tools in FreeBSD, called pkg, and how it could be of benefit for pkgsrc.
Netflix confirms it: BSD is not dying #pkgsrcCon
— Benny Siegert (@bentsukun) July 1, 2017
For day 2 we gathered for a hack day at the London Hack Space.
I had burn't some some CD of the most recent macppc builds of NetBSD 8.0_BETA and -current to install and upgrade Mac Minis. I setup the donated G4 minis for everyone in a dual-boot configuration and moved on to taking apart my MacBook Air to inspect the wifi adapter as I wanted to replace it with something which works on FreeBSD. It was not clear from the ifixit teardown photos of cards size, it seemed like a normal mini-PCIe card but it turned out to be far smaller. Thomas had also had the same card in his and we are not alone. Thomas has started putting together a driver for the Broadcom card, the project is still in its early days and lacks support for encrypted networks but hopefully it will appear on review.freebsd.org in the future.
weidi@ worked on fixing SunOS bugs in various packages and later in the night we setup a NetBSD/macppc bulk build environment together on his Mac Mini.
Thomas setup an OpenGrock instance to index the source code of all the software available for packaging in pkgsrc. This helps make the evaluation of changes easier and the scope of impact a little quicker without having to run through a potentially lengthy bulk build with a change in mind to realise the impact.
bsiegert@ cleared his ticket and email backlog for pkgsrc and alnsn@ got NetBSD/evbmips64-eb booting on his EdgeRouter Lite.
#pkgsrcCon hackathon work by @docscream: https://t.co/3GY3TRtdNV code search over everything (still indexing)
— Wiedi (@wied0r) July 2, 2017
On Monday we reconvened at the Hack Space again and worked some more. I started putting together the talks page with the details from Saturday and the the slides which I had received, in preperation for the videos which would come later in the week. By 3pm pkgsrcCon was over. I was pretty exhausted but really pleased to have had a few days of techie fun.
Many thanks to The NetBSD Foundation for purchasing a camera to use for streaming the event and a speedy response all round by the board. The Open Source Specialist Group at BCS, The Chartered Institute for IT and the London Hack Space for hosting us. Scale Engine for providing streaming facility. weidi@ for hosting the recorded videos.
Allan Jude for pointers, Jared McNeill for debugging, NYCBUG and Patrick McEvoy for tips on streaming, the attendees and speakers. This year we had speakers from USA, Italy, Germany and London E2.
Looking forward to pkgsrcCon 2018!
The videos and slides are available here and the Internet Archive.
This years pkgsrcCon returned to London once again. It was last held in London back in 2014. The 2014 con was the first pkgsrcCon I attended, I had been working on Darwin/PowerPC fixes for some months and presented on the progress I'd made with a 12" G4 PowerBook. I took away a G4 Mac Mini that day to help spare the PowerBook for use and dedicate a machine for build and testing. The offer of PowerPC hardware donations was repeated at this years con, thanks to jperkin@ who showed up with a backpack full of Mac Minis (more on that later).
Since 2014 we have held cons in Berlin (2015) & Krakow (2016). In Krakow we had talks about a wide range of projects over 2 days, from Haiku Ports to Common Lisp to midipix (building native PE binaries for Windows) and back to the BSDs. I was very pleased to continue the theme of a diverse program this year.
Aside from pkgsrc and NetBSD, we had talks about FreeBSD, OpenBSD, Slackware Linux, and Plan 9.
Things began with a pub gathering on the Friday for the pre-con social, we hung out and chatted till almost midnight on a wide range of topics, such as supporting a system using NFS on MS-DOS, the origins of pdksh, corporate IT, culture and many other topics.
On parting I was asked about the starting time on Saturday as there was some conflicting information. I learnt that the registration email had stated a later start than I had scheduled for & advertised on the website, by 30 minutes.
Lesson learnt: register for your own event!
Not a problem, I still needed to setup a webpage for the live video stream, I could do both when I got back. With some trimming here and there I had a new schedule, I posted that to the pkgsrcCon website and moved to trying to setup a basic web page which contained a snippet of javascript to play a live video stream from Scale Engine.
2+ hours later, it was pointed out that the XSS protection headers on pkgsrc.org breaks the functionality. Thanks to jmcneill@ for debugging and providing a working page.
Saturday started off with Giovanni Bechis speaking about pledge in OpenBSD and adding support to various packages in their ports tree, alnsn@ then spoke about installing packages from a repo hosted on the Tor network.
After a quick coffee break we were back to hear Charles Forsyth speak about how Plan 9 and Inferno dealt with portability, building software and the problem which are avoided by the environment there. This was followed by a very energetic rant by David Spencer from the Slackbuilds project on packaging 3rd party software. Slackbuilds is a packaging system for Slackware Linux, which was inspired by FreeBSD ports.
For the first slot after lunch, agc@ gave a talk on the early history of pkgsrc followed by Thomas Merkel on using vagrant to test pkgsrc changes with ease, locally, using vagrant. khorben@ covered his work on adding security to pkgsrc and bsiegert@ covered the benefits of performing our bulk builds in the cloud and the challenges we currently face.
My talk was about some topics and ideas which had inspired me or caught my attention, and how it could maybe apply to my work.The title of the talk was taken from the name of Andrew Weatherall's Saint Etienne remix, possibly referring to two different styles of track (dub & vocal) merged into one or something else. I meant it in terms of applicability of thoughts and ideas. After me, agc@ gave a second talk on the evolution of the Netflix Open Connect appliance which runs FreeBSD and Vsevolod Stakhov wrapped up the day with a talk about the technical implementation details of the successor to pkg_tools in FreeBSD, called pkg, and how it could be of benefit for pkgsrc.
Netflix confirms it: BSD is not dying #pkgsrcCon
— Benny Siegert (@bentsukun) July 1, 2017
For day 2 we gathered for a hack day at the London Hack Space.
I had burn't some some CD of the most recent macppc builds of NetBSD 8.0_BETA and -current to install and upgrade Mac Minis. I setup the donated G4 minis for everyone in a dual-boot configuration and moved on to taking apart my MacBook Air to inspect the wifi adapter as I wanted to replace it with something which works on FreeBSD. It was not clear from the ifixit teardown photos of cards size, it seemed like a normal mini-PCIe card but it turned out to be far smaller. Thomas had also had the same card in his and we are not alone. Thomas has started putting together a driver for the Broadcom card, the project is still in its early days and lacks support for encrypted networks but hopefully it will appear on review.freebsd.org in the future.
weidi@ worked on fixing SunOS bugs in various packages and later in the night we setup a NetBSD/macppc bulk build environment together on his Mac Mini.
Thomas setup an OpenGrock instance to index the source code of all the software available for packaging in pkgsrc. This helps make the evaluation of changes easier and the scope of impact a little quicker without having to run through a potentially lengthy bulk build with a change in mind to realise the impact.
bsiegert@ cleared his ticket and email backlog for pkgsrc and alnsn@ got NetBSD/evbmips64-eb booting on his EdgeRouter Lite.
#pkgsrcCon hackathon work by @docscream: https://t.co/3GY3TRtdNV code search over everything (still indexing)
— Wiedi (@wied0r) July 2, 2017
On Monday we reconvened at the Hack Space again and worked some more. I started putting together the talks page with the details from Saturday and the the slides which I had received, in preperation for the videos which would come later in the week. By 3pm pkgsrcCon was over. I was pretty exhausted but really pleased to have had a few days of techie fun.
Many thanks to The NetBSD Foundation for purchasing a camera to use for streaming the event and a speedy response all round by the board. The Open Source Specialist Group at BCS, The Chartered Institute for IT and the London Hack Space for hosting us. Scale Engine for providing streaming facility. weidi@ for hosting the recorded videos.
Allan Jude for pointers, Jared McNeill for debugging, NYCBUG and Patrick McEvoy for tips on streaming, the attendees and speakers. This year we had speakers from USA, Italy, Germany and London E2.
Looking forward to pkgsrcCon 2018!
The videos and slides are available here and the Internet Archive.
 A new SUNXI evbarm kernel has appeared recently in NetBSD -current with support for boards based on the Allwinner H3 system on a chip (SoC). The H3 SoC is a quad-core Cortex-A7 SoC designed primarily for set-top boxes, but has managed to find its way into many single-board computers (SBC). This is one of the first evbarm ports built from the ground up with device tree support, which helps us to use a single kernel config to support many different boards.
A new SUNXI evbarm kernel has appeared recently in NetBSD -current with support for boards based on the Allwinner H3 system on a chip (SoC). The H3 SoC is a quad-core Cortex-A7 SoC designed primarily for set-top boxes, but has managed to find its way into many single-board computers (SBC). This is one of the first evbarm ports built from the ground up with device tree support, which helps us to use a single kernel config to support many different boards.
To get these boards up and running, first we need to deal with low-level startup code. For the SUNXI kernel this currently lives in sys/arch/evbarm/sunxi/. The purpose of this code is fairly simple; initialize the boot CPU and initialize the MMU so we can jump to the kernel. The initial MMU configuration needs to cover a few things -- early on we need to be able to access the kernel, UART debug console, and the device tree blob (DTB) passed in from U-Boot. We wrap the kernel in a U-Boot header that claims to be a Linux kernel; this is no accident! This tells U-Boot to use the Linux boot protocol when loading the kernel, which ensures that the DTB (loaded by U-Boot) is processed and passed to us in r2.
Once the CPU and MMU are ready, we jump to the generic ARM FDT implementation of initarm in sys/arch/evbarm/fdt/fdt_machdep.c. The first thing this code does is validate and relocate the DTB data. After it has been relocated, we compare the compatible property of the root node in the device tree with the list of ARM platforms compiled into the kernel. The Allwinner sunxi platform code lives in sys/arch/arm/sunxi/sunxi_platform.c. The sunxi platform code provides SoC-specific versions of code needed early at boot. We need to know how to initialize the debug console, spin up application CPUs, reset the board, etc.
Instead of writing H3-specific code for spinning up application CPUs, I took advantage of U-Boot's Power State Coordination Interface implementation. A psci(4) driver was added and the allwinner,sun8i-h3 platform code was modified to use this code to start up all processors.
With a bit of luck, we're now booting and enumerating devices. Apart from a few devices, almost nothing works yet as we are missing a driver for the CCU. The CCU in the Allwinner H3 SoC controls PLLs and most of the clock generation, division, muxing, and gating. Since there are many similarities between Allwinner SoCs, I opted to write generic CCU code and then SoC-specific frontends. The resulting code lives in sys/arch/arm/sunxi/; generic code as sunxi_ccu.c and H3-specific code in sun8i_h3_ccu.c.
Now we have a CCU driver, we can attach a com(4) and have a valid console device.
After this, it's a matter of writing drivers and/or adapting existing code to attach to fdtbus based on the bindings used in the DTB. For cases where we had a compatible driver in the old Allwinner port, I opted to make a copy of the code and FDT-ize it. A few reasons for this -- 1) the old drivers have CCU-specific code with per-SoC ifdefs scattered throughout, 2) I didn't want to break existing kernels, and 3) long term goal is to move the SoCs supported by the old code over to the new code (this process has already started with the Allwinner A31 port).
So what do we get out of this? This is a step towards being able to ship a GENERIC evbarm kernel. I developed the H3 port on two boards, the NanoPi NEO and Orange Pi Plus 2E, but since then users on port-arm@ have been reporting success on many other H3 boards, all from a single kernel config. In addition, I've added support for other Allwinner SoCs (sun8i-a83t, sun6i-a31) to the kernel and have tested booting the same kernel across all 3 SoCs.
Orange Pi Plus 2E boot log is below.
U-Boot SPL 2017.05 (Jul 01 2017 - 17:11:09)
DRAM: 2048 MiB
Trying to boot from MMC1
U-Boot 2017.05 (Jul 01 2017 - 17:11:09 -0300) Allwinner Technology
CPU: Allwinner H3 (SUN8I 1680)
Model: Xunlong Orange Pi Plus 2E
I2C: ready
DRAM: 2 GiB
MMC: SUNXI SD/MMC: 0, SUNXI SD/MMC: 1
In: serial
Out: serial
Err: serial
Net: phy interface7
eth0: ethernet@1c30000
starting USB...
USB0: USB EHCI 1.00
USB1: USB OHCI 1.0
USB2: USB EHCI 1.00
USB3: USB OHCI 1.0
USB4: USB EHCI 1.00
USB5: USB OHCI 1.0
scanning bus 0 for devices... 2 USB Device(s) found
scanning bus 2 for devices... 1 USB Device(s) found
scanning bus 4 for devices... 1 USB Device(s) found
scanning usb for storage devices... 0 Storage Device(s) found
Hit any key to stop autoboot: 0
reading netbsd.ub
6600212 bytes read in 334 ms (18.8 MiB/s)
reading sun8i-h3-orangepi-plus2e.dtb
16775 bytes read in 49 ms (334 KiB/s)
## Booting kernel from Legacy Image at 42000000 ...
Image Name: NetBSD/sunxi 8.99.1
Image Type: ARM Linux Kernel Image (uncompressed)
Data Size: 6600148 Bytes = 6.3 MiB
Load Address: 40008000
Entry Point: 40008000
Verifying Checksum ... OK
## Flattened Device Tree blob at 43000000
Booting using the fdt blob at 0x43000000
Loading Kernel Image ... OK
Loading Device Tree to 49ff8000, end 49fff186 ... OK
Starting kernel ...
[ Kernel symbol table missing! ]
Copyright (c) 1996, 1997, 1998, 1999, 2000, 2001, 2002, 2003, 2004, 2005,
2006, 2007, 2008, 2009, 2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017
The NetBSD Foundation, Inc. All rights reserved.
Copyright (c) 1982, 1986, 1989, 1991, 1993
The Regents of the University of California. All rights reserved.
NetBSD 8.99.1 (SUNXI) #304: Sat Jul 8 11:01:22 ADT 2017
jmcneill@undine.invisible.ca:/usr/home/jmcneill/netbsd/cvs-src/sys/arch/evbarm/compile/obj/SUNXI
total memory = 2048 MB
avail memory = 2020 MB
sysctl_createv: sysctl_create(machine_arch) returned 17
armfdt0 (root)
fdt0 at armfdt0: Xunlong Orange Pi Plus 2E
fdt1 at fdt0
fdt2 at fdt0
cpus0 at fdt0
cpu0 at cpus0: Cortex-A7 r0p5 (Cortex V7A core)
cpu0: DC enabled IC enabled WB disabled EABT branch prediction enabled
cpu0: 32KB/32B 2-way L1 VIPT Instruction cache
cpu0: 32KB/64B 4-way write-back-locking-C L1 PIPT Data cache
cpu0: 512KB/64B 8-way write-through L2 PIPT Unified cache
vfp0 at cpu0: NEON MPE (VFP 3.0+), rounding, NaN propagation, denormals
cpu1 at cpus0
cpu2 at cpus0
cpu3 at cpus0
gic0 at fdt1: GIC
armgic0 at gic0: Generic Interrupt Controller, 160 sources (150 valid)
armgic0: 16 Priorities, 128 SPIs, 7 PPIs, 15 SGIs
fclock0 at fdt2: 24000000 Hz fixed clock
ffclock0 at fdt2: x1 /1 fixed-factor clock
fclock1 at fdt2: 32768 Hz fixed clock
sunxigates0 at fdt2
sunxiresets0 at fdt1
gtmr0 at fdt0: Generic Timer
armgtmr0 at gtmr0: ARMv7 Generic 64-bit Timer (24000 kHz)
armgtmr0: interrupting on irq 27
sunxigpio0 at fdt1: PIO
gpio0 at sunxigpio0: 94 pins
sunxigpio1 at fdt1: PIO
gpio1 at sunxigpio1: 12 pins
sun8ih3ccu0 at fdt1: H3 CCU
fregulator0 at fdt0: vcc3v3
fregulator1 at fdt0: gmac-3v3
fregulator2 at fdt0: vcc3v0
fregulator3 at fdt0: vcc5v0
sunxiusbphy0 at fdt1: USB PHY
/soc/dma-controller@01c02000 at fdt1 not configured
/soc/codec-analog@01f015c0 at fdt1 not configured
/clocks/ir_clk@01f01454 at fdt2 not configured
sunxiemac0 at fdt1: EMAC
sunxiemac0: interrupting on GIC irq 114
rgephy0 at sunxiemac0 phy 0: RTL8169S/8110S/8211 1000BASE-T media interface, rev. 5
rgephy0: 10baseT, 10baseT-FDX, 100baseTX, 100baseTX-FDX, 1000baseT, 1000baseT-FDX, auto
rgephy1 at sunxiemac0 phy 1: RTL8169S/8110S/8211 1000BASE-T media interface, rev. 5
rgephy1: 10baseT, 10baseT-FDX, 100baseTX, 100baseTX-FDX, 1000baseT, 1000baseT-FDX, auto
psci0 at fdt0: PSCI 0.1
gpioleds0 at fdt0: orangepi:green:pwr orangepi:red:status
gpiokeys0 at fdt0: sw4
sunximmc0 at fdt1: SD/MMC controller
sunximmc0: interrupting on GIC irq 92
sunximmc1 at fdt1: SD/MMC controller
sunximmc1: interrupting on GIC irq 93
sunximmc2 at fdt1: SD/MMC controller
sunximmc2: interrupting on GIC irq 94
ehci0 at fdt1: EHCI
ehci0: interrupting on GIC irq 106
ehci0: 1 companion controller, 1 port
usb0 at ehci0: USB revision 2.0
ohci0 at fdt1: OHCI
ohci0: interrupting on GIC irq 107
ohci0: OHCI version 1.0
usb1 at ohci0: USB revision 1.0
ehci1 at fdt1: EHCI
ehci1: interrupting on GIC irq 108
ehci1: 1 companion controller, 1 port
usb2 at ehci1: USB revision 2.0
ohci1 at fdt1: OHCI
ohci1: interrupting on GIC irq 109
ohci1: OHCI version 1.0
usb3 at ohci1: USB revision 1.0
ehci2 at fdt1: EHCI
ehci2: interrupting on GIC irq 110
ehci2: 1 companion controller, 1 port
usb4 at ehci2: USB revision 2.0
ohci2 at fdt1: OHCI
ohci2: interrupting on GIC irq 111
ohci2: OHCI version 1.0
usb5 at ohci2: USB revision 1.0
/soc/timer@01c20c00 at fdt1 not configured
/soc/watchdog@01c20ca0 at fdt1 not configured
/soc/codec@01c22c00 at fdt1 not configured
com0 at fdt1: ns16550a, working fifo
com0: console
com0: interrupting on GIC irq 32
sunxirtc0 at fdt1: RTC
/soc/ir@01f02000 at fdt1 not configured
cpu3: Cortex-A7 r0p5 (Cortex V7A core)
cpu3: DC enabled IC enabled WB disabled EABT branch prediction enabled
cpu3: 32KB/32B 2-way L1 VIPT Instruction cache
cpu3: 32KB/64B 4-way write-back-locking-C L1 PIPT Data cache
cpu3: 512KB/64B 8-way write-through L2 PIPT Unified cache
vfp3 at cpu3: NEON MPE (VFP 3.0+), rounding, NaN propagation, denormals
cpu1: Cortex-A7 r0p5 (Cortex V7A core)
cpu1: DC enabled IC enabled WB disabled EABT branch prediction enabled
cpu1: 32KB/32B 2-way L1 VIPT Instruction cache
cpu1: 32KB/64B 4-way write-back-locking-C L1 PIPT Data cache
cpu1: 512KB/64B 8-way write-through L2 PIPT Unified cache
vfp1 at cpu1: NEON MPE (VFP 3.0+), rounding, NaN propagation, denormals
cpu2: Cortex-A7 r0p5 (Cortex V7A core)
cpu2: DC enabled IC enabled WB disabled EABT branch prediction enabled
cpu2: 32KB/32B 2-way L1 VIPT Instruction cache
cpu2: 32KB/64B 4-way write-back-locking-C L1 PIPT Data cache
cpu2: 512KB/64B 8-way write-through L2 PIPT Unified cache
vfp2 at cpu2: NEON MPE (VFP 3.0+), rounding, NaN propagation, denormals
sdmmc0 at sunximmc0
sdmmc1 at sunximmc1
sdmmc2 at sunximmc2
uhub0 at usb0: Generic (0000) EHCI root hub (0000), class 9/0, rev 2.00/1.00, addr 1
uhub1 at usb2: Generic (0000) EHCI root hub (0000), class 9/0, rev 2.00/1.00, addr 1
uhub2 at usb3: Generic (0000) OHCI root hub (0000), class 9/0, rev 1.00/1.00, addr 1
uhub3 at usb1: Generic (0000) OHCI root hub (0000), class 9/0, rev 1.00/1.00, addr 1
uhub4 at usb4: Generic (0000) EHCI root hub (0000), class 9/0, rev 2.00/1.00, addr 1
uhub5 at usb5: Generic (0000) OHCI root hub (0000), class 9/0, rev 1.00/1.00, addr 1
ld2 at sdmmc2: <0x15:0x0100:AWPD3R:0x00:0xec19649f:0x000>
sdmmc0: SD card status: 4-bit, C10, U1, V10
ld0 at sdmmc0: <0x27:0x5048:2&DRP:0x07:0x01c828bc:0x109>
ld2: 14910 MB, 7573 cyl, 64 head, 63 sec, 512 bytes/sect x 30535680 sectors
ld0: 15288 MB, 7765 cyl, 64 head, 63 sec, 512 bytes/sect x 31309824 sectors
(manufacturer 0x24c, product 0xf179, standard function interface code 0x7)at sdmmc1 function 1 not configured
ld2: mbr partition exceeds disk size
ld0: 4-bit width, High-Speed/SDR25, 50.000 MHz
ld2: 8-bit width, 52.000 MHz
urtwn0 at uhub0 port 1
urtwn0: Realtek (0xbda) 802.11n NIC (0x8179), rev 2.00/0.00, addr 2
urtwn0: MAC/BB RTL8188EU, RF 6052 1T1R, address e8:de:27:16:0c:81
urtwn0: 1 rx pipe, 2 tx pipes
urtwn0: 11b rates: 1Mbps 2Mbps 5.5Mbps 11Mbps
urtwn0: 11g rates: 1Mbps 2Mbps 5.5Mbps 11Mbps 6Mbps 9Mbps 12Mbps 18Mbps 24Mbps 36Mbps 48Mbps 54Mbps
boot device: ld0
root on ld0a dumps on ld0b
root file system type: ffs
kern.module.path=/stand/evbarm/8.99.1/modules
WARNING: clock lost 6398 days
WARNING: using filesystem time
WARNING: CHECK AND RESET THE DATE!
Sat Jul 8 11:05:42 ADT 2017
Starting root file system check:
/dev/rld0a: file system is clean; not checking
Not resizing /: already correct size
swapctl: adding /dev/ld0b as swap device at priority 0
Starting file system checks:
/dev/rld0e: 22 files, 32340 free (8085 clusters)
random_seed: /var/db/entropy-file: Not present
Setting tty flags.
Setting sysctl variables:
ddb.onpanic: 1 -> 1
Starting network.
Hostname: sunxi
IPv6 mode: host
Configuring network interfaces:.
Adding interface aliases:.
Waiting for DAD to complete for statically configured addresses...
Starting dhcpcd.
Starting mdnsd.
Building databases: dev, utmp, utmpx.
Starting syslogd.
Mounting all file systems...
Clearing temporary files.
Updating fontconfig cache: done.
Creating a.out runtime link editor directory cache.
Checking quotas: done.
Setting securelevel: kern.securelevel: 0 -> 1
Starting virecover.
Checking for core dump...
savecore: no core dump
Starting devpubd.
Starting local daemons:.
Updating motd.
Starting ntpd.
Jul 8 11:05:58 sunxi ntpd[595]: ntp_rlimit: Cannot set RLIMIT_STACK: Invalid argument
Starting sshd.
Starting inetd.
Starting cron.
Sat Jul 8 11:06:02 ADT 2017
NetBSD/evbarm (sunxi) (console)
login:
A new SUNXI evbarm kernel has appeared recently in NetBSD -current with support for boards based on the Allwinner H3 system on a chip (SoC). The H3 SoC is a quad-core Cortex-A7 SoC designed primarily for set-top boxes, but has managed to find its way into many single-board computers (SBC). This is one of the first evbarm ports built from the ground up with device tree support, which helps us to use a single kernel config to support many different boards.
To get these boards up and running, first we need to deal with low-level startup code. For the SUNXI kernel this currently lives in sys/arch/evbarm/sunxi/. The purpose of this code is fairly simple; initialize the boot CPU and initialize the MMU so we can jump to the kernel. The initial MMU configuration needs to cover a few things -- early on we need to be able to access the kernel, UART debug console, and the device tree blob (DTB) passed in from U-Boot. We wrap the kernel in a U-Boot header that claims to be a Linux kernel; this is no accident! This tells U-Boot to use the Linux boot protocol when loading the kernel, which ensures that the DTB (loaded by U-Boot) is processed and passed to us in r2.
Once the CPU and MMU are ready, we jump to the generic ARM FDT implementation of initarm in sys/arch/evbarm/fdt/fdt_machdep.c. The first thing this code does is validate and relocate the DTB data. After it has been relocated, we compare the compatible property of the root node in the device tree with the list of ARM platforms compiled into the kernel. The Allwinner sunxi platform code lives in sys/arch/arm/sunxi/sunxi_platform.c. The sunxi platform code provides SoC-specific versions of code needed early at boot. We need to know how to initialize the debug console, spin up application CPUs, reset the board, etc.
Instead of writing H3-specific code for spinning up application CPUs, I took advantage of U-Boot's Power State Coordination Interface implementation. A psci(4) driver was added and the allwinner,sun8i-h3 platform code was modified to use this code to start up all processors.
With a bit of luck, we're now booting and enumerating devices. Apart from a few devices, almost nothing works yet as we are missing a driver for the CCU. The CCU in the Allwinner H3 SoC controls PLLs and most of the clock generation, division, muxing, and gating. Since there are many similarities between Allwinner SoCs, I opted to write generic CCU code and then SoC-specific frontends. The resulting code lives in sys/arch/arm/sunxi/; generic code as sunxi_ccu.c and H3-specific code in sun8i_h3_ccu.c.
Now we have a CCU driver, we can attach a com(4) and have a valid console device.
After this, it's a matter of writing drivers and/or adapting existing code to attach to fdtbus based on the bindings used in the DTB. For cases where we had a compatible driver in the old Allwinner port, I opted to make a copy of the code and FDT-ize it. A few reasons for this -- 1) the old drivers have CCU-specific code with per-SoC ifdefs scattered throughout, 2) I didn't want to break existing kernels, and 3) long term goal is to move the SoCs supported by the old code over to the new code (this process has already started with the Allwinner A31 port).
So what do we get out of this? This is a step towards being able to ship a GENERIC evbarm kernel. I developed the H3 port on two boards, the NanoPi NEO and Orange Pi Plus 2E, but since then users on port-arm@ have been reporting success on many other H3 boards, all from a single kernel config. In addition, I've added support for other Allwinner SoCs (sun8i-a83t, sun6i-a31) to the kernel and have tested booting the same kernel across all 3 SoCs.
Orange Pi Plus 2E boot log is below.
U-Boot SPL 2017.05 (Jul 01 2017 - 17:11:09)
DRAM: 2048 MiB
Trying to boot from MMC1
U-Boot 2017.05 (Jul 01 2017 - 17:11:09 -0300) Allwinner Technology
CPU: Allwinner H3 (SUN8I 1680)
Model: Xunlong Orange Pi Plus 2E
I2C: ready
DRAM: 2 GiB
MMC: SUNXI SD/MMC: 0, SUNXI SD/MMC: 1
In: serial
Out: serial
Err: serial
Net: phy interface7
eth0: ethernet@1c30000
starting USB...
USB0: USB EHCI 1.00
USB1: USB OHCI 1.0
USB2: USB EHCI 1.00
USB3: USB OHCI 1.0
USB4: USB EHCI 1.00
USB5: USB OHCI 1.0
scanning bus 0 for devices... 2 USB Device(s) found
scanning bus 2 for devices... 1 USB Device(s) found
scanning bus 4 for devices... 1 USB Device(s) found
scanning usb for storage devices... 0 Storage Device(s) found
Hit any key to stop autoboot: 0
reading netbsd.ub
6600212 bytes read in 334 ms (18.8 MiB/s)
reading sun8i-h3-orangepi-plus2e.dtb
16775 bytes read in 49 ms (334 KiB/s)
## Booting kernel from Legacy Image at 42000000 ...
Image Name: NetBSD/sunxi 8.99.1
Image Type: ARM Linux Kernel Image (uncompressed)
Data Size: 6600148 Bytes = 6.3 MiB
Load Address: 40008000
Entry Point: 40008000
Verifying Checksum ... OK
## Flattened Device Tree blob at 43000000
Booting using the fdt blob at 0x43000000
Loading Kernel Image ... OK
Loading Device Tree to 49ff8000, end 49fff186 ... OK
Starting kernel ...
[ Kernel symbol table missing! ]
Copyright (c) 1996, 1997, 1998, 1999, 2000, 2001, 2002, 2003, 2004, 2005,
2006, 2007, 2008, 2009, 2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017
The NetBSD Foundation, Inc. All rights reserved.
Copyright (c) 1982, 1986, 1989, 1991, 1993
The Regents of the University of California. All rights reserved.
NetBSD 8.99.1 (SUNXI) #304: Sat Jul 8 11:01:22 ADT 2017
jmcneill@undine.invisible.ca:/usr/home/jmcneill/netbsd/cvs-src/sys/arch/evbarm/compile/obj/SUNXI
total memory = 2048 MB
avail memory = 2020 MB
sysctl_createv: sysctl_create(machine_arch) returned 17
armfdt0 (root)
fdt0 at armfdt0: Xunlong Orange Pi Plus 2E
fdt1 at fdt0
fdt2 at fdt0
cpus0 at fdt0
cpu0 at cpus0: Cortex-A7 r0p5 (Cortex V7A core)
cpu0: DC enabled IC enabled WB disabled EABT branch prediction enabled
cpu0: 32KB/32B 2-way L1 VIPT Instruction cache
cpu0: 32KB/64B 4-way write-back-locking-C L1 PIPT Data cache
cpu0: 512KB/64B 8-way write-through L2 PIPT Unified cache
vfp0 at cpu0: NEON MPE (VFP 3.0+), rounding, NaN propagation, denormals
cpu1 at cpus0
cpu2 at cpus0
cpu3 at cpus0
gic0 at fdt1: GIC
armgic0 at gic0: Generic Interrupt Controller, 160 sources (150 valid)
armgic0: 16 Priorities, 128 SPIs, 7 PPIs, 15 SGIs
fclock0 at fdt2: 24000000 Hz fixed clock
ffclock0 at fdt2: x1 /1 fixed-factor clock
fclock1 at fdt2: 32768 Hz fixed clock
sunxigates0 at fdt2
sunxiresets0 at fdt1
gtmr0 at fdt0: Generic Timer
armgtmr0 at gtmr0: ARMv7 Generic 64-bit Timer (24000 kHz)
armgtmr0: interrupting on irq 27
sunxigpio0 at fdt1: PIO
gpio0 at sunxigpio0: 94 pins
sunxigpio1 at fdt1: PIO
gpio1 at sunxigpio1: 12 pins
sun8ih3ccu0 at fdt1: H3 CCU
fregulator0 at fdt0: vcc3v3
fregulator1 at fdt0: gmac-3v3
fregulator2 at fdt0: vcc3v0
fregulator3 at fdt0: vcc5v0
sunxiusbphy0 at fdt1: USB PHY
/soc/dma-controller@01c02000 at fdt1 not configured
/soc/codec-analog@01f015c0 at fdt1 not configured
/clocks/ir_clk@01f01454 at fdt2 not configured
sunxiemac0 at fdt1: EMAC
sunxiemac0: interrupting on GIC irq 114
rgephy0 at sunxiemac0 phy 0: RTL8169S/8110S/8211 1000BASE-T media interface, rev. 5
rgephy0: 10baseT, 10baseT-FDX, 100baseTX, 100baseTX-FDX, 1000baseT, 1000baseT-FDX, auto
rgephy1 at sunxiemac0 phy 1: RTL8169S/8110S/8211 1000BASE-T media interface, rev. 5
rgephy1: 10baseT, 10baseT-FDX, 100baseTX, 100baseTX-FDX, 1000baseT, 1000baseT-FDX, auto
psci0 at fdt0: PSCI 0.1
gpioleds0 at fdt0: orangepi:green:pwr orangepi:red:status
gpiokeys0 at fdt0: sw4
sunximmc0 at fdt1: SD/MMC controller
sunximmc0: interrupting on GIC irq 92
sunximmc1 at fdt1: SD/MMC controller
sunximmc1: interrupting on GIC irq 93
sunximmc2 at fdt1: SD/MMC controller
sunximmc2: interrupting on GIC irq 94
ehci0 at fdt1: EHCI
ehci0: interrupting on GIC irq 106
ehci0: 1 companion controller, 1 port
usb0 at ehci0: USB revision 2.0
ohci0 at fdt1: OHCI
ohci0: interrupting on GIC irq 107
ohci0: OHCI version 1.0
usb1 at ohci0: USB revision 1.0
ehci1 at fdt1: EHCI
ehci1: interrupting on GIC irq 108
ehci1: 1 companion controller, 1 port
usb2 at ehci1: USB revision 2.0
ohci1 at fdt1: OHCI
ohci1: interrupting on GIC irq 109
ohci1: OHCI version 1.0
usb3 at ohci1: USB revision 1.0
ehci2 at fdt1: EHCI
ehci2: interrupting on GIC irq 110
ehci2: 1 companion controller, 1 port
usb4 at ehci2: USB revision 2.0
ohci2 at fdt1: OHCI
ohci2: interrupting on GIC irq 111
ohci2: OHCI version 1.0
usb5 at ohci2: USB revision 1.0
/soc/timer@01c20c00 at fdt1 not configured
/soc/watchdog@01c20ca0 at fdt1 not configured
/soc/codec@01c22c00 at fdt1 not configured
com0 at fdt1: ns16550a, working fifo
com0: console
com0: interrupting on GIC irq 32
sunxirtc0 at fdt1: RTC
/soc/ir@01f02000 at fdt1 not configured
cpu3: Cortex-A7 r0p5 (Cortex V7A core)
cpu3: DC enabled IC enabled WB disabled EABT branch prediction enabled
cpu3: 32KB/32B 2-way L1 VIPT Instruction cache
cpu3: 32KB/64B 4-way write-back-locking-C L1 PIPT Data cache
cpu3: 512KB/64B 8-way write-through L2 PIPT Unified cache
vfp3 at cpu3: NEON MPE (VFP 3.0+), rounding, NaN propagation, denormals
cpu1: Cortex-A7 r0p5 (Cortex V7A core)
cpu1: DC enabled IC enabled WB disabled EABT branch prediction enabled
cpu1: 32KB/32B 2-way L1 VIPT Instruction cache
cpu1: 32KB/64B 4-way write-back-locking-C L1 PIPT Data cache
cpu1: 512KB/64B 8-way write-through L2 PIPT Unified cache
vfp1 at cpu1: NEON MPE (VFP 3.0+), rounding, NaN propagation, denormals
cpu2: Cortex-A7 r0p5 (Cortex V7A core)
cpu2: DC enabled IC enabled WB disabled EABT branch prediction enabled
cpu2: 32KB/32B 2-way L1 VIPT Instruction cache
cpu2: 32KB/64B 4-way write-back-locking-C L1 PIPT Data cache
cpu2: 512KB/64B 8-way write-through L2 PIPT Unified cache
vfp2 at cpu2: NEON MPE (VFP 3.0+), rounding, NaN propagation, denormals
sdmmc0 at sunximmc0
sdmmc1 at sunximmc1
sdmmc2 at sunximmc2
uhub0 at usb0: Generic (0000) EHCI root hub (0000), class 9/0, rev 2.00/1.00, addr 1
uhub1 at usb2: Generic (0000) EHCI root hub (0000), class 9/0, rev 2.00/1.00, addr 1
uhub2 at usb3: Generic (0000) OHCI root hub (0000), class 9/0, rev 1.00/1.00, addr 1
uhub3 at usb1: Generic (0000) OHCI root hub (0000), class 9/0, rev 1.00/1.00, addr 1
uhub4 at usb4: Generic (0000) EHCI root hub (0000), class 9/0, rev 2.00/1.00, addr 1
uhub5 at usb5: Generic (0000) OHCI root hub (0000), class 9/0, rev 1.00/1.00, addr 1
ld2 at sdmmc2: <0x15:0x0100:AWPD3R:0x00:0xec19649f:0x000>
sdmmc0: SD card status: 4-bit, C10, U1, V10
ld0 at sdmmc0: <0x27:0x5048:2&DRP:0x07:0x01c828bc:0x109>
ld2: 14910 MB, 7573 cyl, 64 head, 63 sec, 512 bytes/sect x 30535680 sectors
ld0: 15288 MB, 7765 cyl, 64 head, 63 sec, 512 bytes/sect x 31309824 sectors
(manufacturer 0x24c, product 0xf179, standard function interface code 0x7)at sdmmc1 function 1 not configured
ld2: mbr partition exceeds disk size
ld0: 4-bit width, High-Speed/SDR25, 50.000 MHz
ld2: 8-bit width, 52.000 MHz
urtwn0 at uhub0 port 1
urtwn0: Realtek (0xbda) 802.11n NIC (0x8179), rev 2.00/0.00, addr 2
urtwn0: MAC/BB RTL8188EU, RF 6052 1T1R, address e8:de:27:16:0c:81
urtwn0: 1 rx pipe, 2 tx pipes
urtwn0: 11b rates: 1Mbps 2Mbps 5.5Mbps 11Mbps
urtwn0: 11g rates: 1Mbps 2Mbps 5.5Mbps 11Mbps 6Mbps 9Mbps 12Mbps 18Mbps 24Mbps 36Mbps 48Mbps 54Mbps
boot device: ld0
root on ld0a dumps on ld0b
root file system type: ffs
kern.module.path=/stand/evbarm/8.99.1/modules
WARNING: clock lost 6398 days
WARNING: using filesystem time
WARNING: CHECK AND RESET THE DATE!
Sat Jul 8 11:05:42 ADT 2017
Starting root file system check:
/dev/rld0a: file system is clean; not checking
Not resizing /: already correct size
swapctl: adding /dev/ld0b as swap device at priority 0
Starting file system checks:
/dev/rld0e: 22 files, 32340 free (8085 clusters)
random_seed: /var/db/entropy-file: Not present
Setting tty flags.
Setting sysctl variables:
ddb.onpanic: 1 -> 1
Starting network.
Hostname: sunxi
IPv6 mode: host
Configuring network interfaces:.
Adding interface aliases:.
Waiting for DAD to complete for statically configured addresses...
Starting dhcpcd.
Starting mdnsd.
Building databases: dev, utmp, utmpx.
Starting syslogd.
Mounting all file systems...
Clearing temporary files.
Updating fontconfig cache: done.
Creating a.out runtime link editor directory cache.
Checking quotas: done.
Setting securelevel: kern.securelevel: 0 -> 1
Starting virecover.
Checking for core dump...
savecore: no core dump
Starting devpubd.
Starting local daemons:.
Updating motd.
Starting ntpd.
Jul 8 11:05:58 sunxi ntpd[595]: ntp_rlimit: Cannot set RLIMIT_STACK: Invalid argument
Starting sshd.
Starting inetd.
Starting cron.
Sat Jul 8 11:06:02 ADT 2017
NetBSD/evbarm (sunxi) (console)
login:
NetBSD is happy to announce a generous setup provided by Fastly to give us CDN services. We are live with cdn.NetBSD.org for downloading iso files, binary packages, and anything else that you would find on ftp.NetBSD.org.
nycdn is using nyftp.NetBSD.org as an origin so you can use it to download build snapshots and other useful stuff you would otherwise find on nyftp. (NetBSD-daily for example)
We have already changed some default download links (downloads and pkgsrc) and some pkgsrc files, so you might already be using the cdn without knowing it.
You can also change your PKG_PATH from ftp://ftp.netbsd.org to http://cdn.netbsd.org
HTTPS also works, but not IPv6
If you are not familiar, a CDN is a globally distributed set of caching proxy servers which makes downloading files faster when they are hot in the cache.
NetBSD is happy to announce a generous setup provided by Fastly to give us CDN services. We are live with cdn.NetBSD.org for downloading iso files, binary packages, and anything else that you would find on ftp.NetBSD.org.
nycdn is using nyftp.NetBSD.org as an origin so you can use it to download build snapshots and other useful stuff you would otherwise find on nyftp. (NetBSD-daily for example)
We have already changed some default download links (downloads and pkgsrc) and some pkgsrc files, so you might already be using the cdn without knowing it.
You can also change your PKG_PATH from ftp://ftp.netbsd.org to http://cdn.netbsd.org
HTTPS also works, but not IPv6
If you are not familiar, a CDN is a globally distributed set of caching proxy servers which makes downloading files faster when they are hot in the cache.
When I got my Sun T1000 machine, it came with a ~80 GB hard disk - good enough for a NetBSD installation, but a bit challenged when you want to use logical domains. Time to expand disk space, or maybe make it faster? But these 1U server machines do not offer a lot of room for extensions, and it is sometimes tricky to get hold of the official extension options nowadays.
So I had fun with disks and modern replacements again... (after the scsi2sd adventures).
The T1000 were offered in single 3.5" disk configurations (this is what I got) or with two 2.5" disks. The mainboard has two sata (sas?) connectors. But the disk tray in my machine is not usable for mounting two 2.5" HDs.
But: the machine has a spare PCIe slot:

and we support NVMe, so why not put a M.2 module in an adapter card in there? I tried and failed. I learned that the T1000's PCIe x4 slot is PCIe version 1, but modern NVMe modules do not fancy working in anything older than PCIe version 3.
Too bad, but whatever. I switched things around, my amd64 desktop machine got a faster "SSD" (i.e. the NVMe), another machine got the SSD freed from there and I ended up with a spare 128 GB sata SSD.
Now the T1000 had a sata connector free, but no way to place the disk and no power connector for it. The mainboard had a legacy 5/12V jack and the single disk used a strange power/sata connector:

but of course that could be replaced easily. I cut a Y-sata power split and one legacy 5/12V power connector from an old (broken) PSU and soldered a dual sata power connector cable that connected to the jack on the mainboard.
I found a small cavity in the at the front of the machine in the sheet separating PSU and disk from the fans and mainboard. Big enough to push a sata power connector and a sata connector through! So I just glued the SSD at the bottom of the chasis in front of the fans (it should be low enough to not harm airflow significantly):

It was a bit tricky to fit the custom power cabling and the standard sata cable alongside the disk, and I hope the disk will not get too hot to unsolder the connectors 

Hardware service technicians would hate this, as usually the T1000 offers really easy and fast hard disk replacement, but I suppose no one but me will ever deal with hardware failure on this particular machine.
Now thats it, fast base system on SSD and plenty of space for other LDOMs data on the second disk:
mpt0 at pci3 dev 2 function 0: Symbios Logic SAS1064 (rev. 0x02) mpt0: interrupting at ivec 7c0 mpt0: Phy 0: Link Status Unknown mpt0: Phy 0: Link Status Unknown scsibus0 at mpt0: 63 targets, 8 luns per target scsibus0: waiting 2 seconds for devices to settle... sd0 at scsibus0 target 0 lun 0: disk fixed sd0: 111 GB, 114474 cyl, 16 head, 127 sec, 512 bytes/sect x 234441648 sectors sd0: tagged queueing sd1 at scsibus0 target 1 lun 0: disk fixed sd1: 1863 GB, 1907730 cyl, 16 head, 127 sec, 512 bytes/sect x 3907029168 sectors sd1: tagged queueing
Unfortunately the machine is louder than hell, and even though the rack is in our basement, the sound level is still irritating elsewhere in the house (massive stone walls, old style german construction). My wife officially hates the T1000.
Now that the hardware is ready, it is time to get it fully supported and import the LDOM management/utilities. I need to find time and help Palle!
When I got my Sun T1000 machine, it came with a ~80 GB hard disk - good enough for a NetBSD installation, but a bit challenged when you want to use logical domains. Time to expand disk space, or maybe make it faster? But these 1U server machines do not offer a lot of room for extensions, and it is sometimes tricky to get hold of the official extension options nowadays.
So I had fun with disks and modern replacements again... (after the scsi2sd adventures).
The T1000 were offered in single 3.5" disk configurations (this is what I got) or with two 2.5" disks. The mainboard has two sata (sas?) connectors. But the disk tray in my machine is not usable for mounting two 2.5" HDs.
But: the machine has a spare PCIe slot:
and we support NVMe, so why not put a M.2 module in an adapter card in there? I tried and failed. I learned that the T1000's PCIe x4 slot is PCIe version 1, but modern NVMe modules do not fancy working in anything older than PCIe version 3.
Too bad, but whatever. I switched things around, my amd64 desktop machine got a faster "SSD" (i.e. the NVMe), another machine got the SSD freed from there and I ended up with a spare 128 GB sata SSD.
Now the T1000 had a sata connector free, but no way to place the disk and no power connector for it. The mainboard had a legacy 5/12V jack and the single disk used a strange power/sata connector:
but of course that could be replaced easily. I cut a Y-sata power split and one legacy 5/12V power connector from an old (broken) PSU and soldered a dual sata power connector cable that connected to the jack on the mainboard.
I found a small cavity in the at the front of the machine in the sheet separating PSU and disk from the fans and mainboard. Big enough to push a sata power connector and a sata connector through! So I just glued the SSD at the bottom of the chasis in front of the fans (it should be low enough to not harm airflow significantly):
It was a bit tricky to fit the custom power cabling and the standard sata cable alongside the disk, and I hope the disk will not get too hot to unsolder the connectors
Hardware service technicians would hate this, as usually the T1000 offers really easy and fast hard disk replacement, but I suppose no one but me will ever deal with hardware failure on this particular machine.
Now thats it, fast base system on SSD and plenty of space for other LDOMs data on the second disk:
mpt0 at pci3 dev 2 function 0: Symbios Logic SAS1064 (rev. 0x02) mpt0: interrupting at ivec 7c0 mpt0: Phy 0: Link Status Unknown mpt0: Phy 0: Link Status Unknown scsibus0 at mpt0: 63 targets, 8 luns per target scsibus0: waiting 2 seconds for devices to settle... sd0 at scsibus0 target 0 lun 0: disk fixed sd0: 111 GB, 114474 cyl, 16 head, 127 sec, 512 bytes/sect x 234441648 sectors sd0: tagged queueing sd1 at scsibus0 target 1 lun 0: disk fixed sd1: 1863 GB, 1907730 cyl, 16 head, 127 sec, 512 bytes/sect x 3907029168 sectors sd1: tagged queueing
Unfortunately the machine is louder than hell, and even though the rack is in our basement, the sound level is still irritating elsewhere in the house (massive stone walls, old style german construction). My wife officially hates the T1000.
Now that the hardware is ready, it is time to get it fully supported and import the LDOM management/utilities. I need to find time and help Palle!
Google Code-In (GCi) is a project like Google Summer Of Code (GSoC), but for younger students. While GSoC is aimed at university students, i.e. for people usually of age 19 or older, GCi wants to recruit pupils for Open Source projects.
When applying for participation, every project had to create a large number of potentially small tasks for students. A task was meant to be two hours of work of an experienced developer, and feasible to be done by a person 13 to 18 years old. Google selected ten participating organisations (this time, NetBSD was the only BSD participating) to insert their tasks into Google Melange (the platform which is used for managing GCi and GSoC).
Then, the students registered at Google Melange, chose a project they wanted to work on, and claimed tasks to do. There were many chats in the NetBSD code channel for students coming in and asking questions about their tasks.
After GCi was over, every organisation had to choose their two favourite students who did the best work. For NetBSD, the choice was difficult, as there were more than two students doing great work, but in the end we chose Mingzhe Wang and Matthew Bauer. These two "grand price winners" were given a trip to Mountain View to visit the Google headquarters and meet with other GCi price winners.
You can see the results on the corresponding wiki page
There were 89 finished tasks, ranging from research tasks (document how other projects manage their documentation), creating howtos, trying out software on NetBSD, writing code (ATF tests and Markdown converters and more), writing manpages and documentation, fixing bugs and converting documentation from the website to the wiki.
Overall, it was a nice experience for NetBSD. On the one hand, some real work was done (for many of them, integration is still pending). On the other hand, it was a stressful time for the NetBSD mentors supervising the students and helping them on their tasks. Especially, we had to learn many lessons (you will find them on the wiki page for GCi 2012), but next time, we will do much better. We will try to apply again next year, but we will need a large bunch of new possible tasks to be chosen again.
So if you think you have a task which doesn't require great prior knowledge, and is solvable within two hours by an experienced developer, but also by a 13-18 year old within finite time, feel free to contact us with an outline, or write it directly to the wiki page for Code-In in the NetBSD wiki.
SX is more or less a vector processor built into a memory controller. The 'or less' part comes from the fact that it can't actually read instructions from memory - the CPU has to feed them one by one. This isn't quite as bad as it sounds - SX has plenty of registers ( 128 - eight of them have special functions, the rest is free for all ) and every instruction takes a count to operate on several subsequent registers or memory locations ( ALU ops can use up to 16, memory accesses up to 32 ). SX supports some parallelism too - the ALUs can do up to two 16bit multiplications and two other arithmetic or logical ops per clock cycle ( 32bit multiplications use both ALUs ). The thing runs at 50MHz - not a whole lot by today's standards but it can be a significant help to any CPUs you can put into these machines.
The kernel part hs been committed a while ago ( see cgfourteen at obio ), always runs in 8bit colour with everything ( scrolling, character drawing etc. ) done by SX. Substantially faster than software only operation.
The Xorg driver ( xf86-video-suncg14 that is, it needs a recent cgfourteen kernel driver to map SX registers ) uses EXA, by default it enables basic acceleration ( Solid and Copy, hardware cursor support has been added years ago ), Xrender acceleration is incomplete and can be enabled by adding Options "Xrender" "true" to the cg14's device section in xorg.conf. For now it implements what's needed for anti-aliased font drawing, assembling alpha maps in video memory and operations KDE3 uses for drawing icons, buttons and so on. As it is now KDE3 looks mostly right - there are a few rendering errors ( for example the corners of the white frame in Konqueror's startup page, also some text is drawn with red and blue channels switched ) but nothing that would interfere with functionality.
Speed isn't great ( well, the hardware is 20 years old ) but the improvement over unaccelerated X is more than noticeable. Some benchmark numbers, all taken on an SS20 with a single 125MHz HyperSPARC:
- x11perf -comppixwin went from 26.3 to 93.7
- x11perf -compwinwin went from 8.8 to 93.5
- x11perf -aaftext went from about 4000 ( 5000 with shadow fb but that's technically cheating since not everything is drawn into video memory ) to 16000
There is still room for improvement - for now all Xrender operations work on one pixel at a time, SX has enough registers to do at least four in most cases. Also, functionality is added as needed whenever I run into it, so other things are likely broken ( I know gtk2 is, but that's easy to fix ) which is why Xrender acceleration is disabled by default.
If you've been reading source-changes@, you likely noticed the recent creation of the netbsd-8 branch. If you haven't been reading source-changes@, here's some news: the netbsd-8 branch has been created, signaling the beginning of the release process for NetBSD 8.0.
We don't have a strict timeline for the 8.0 release, but things are looking pretty good at the moment, and we expect this release to happen in a shorter amount of time than the last couple major releases did.
At this point, we would love for folks to test out netbsd-8 and let us know how it goes. A couple of major improvements since 7.0 are the addition of USB 3 support and an overhaul of the audio subsystem, including an in-kernel mixer. Feedback about these areas is particularly desired.
To download the latest binaries built from the netbsd-8 branch, head to http://daily-builds.NetBSD.org/pub/NetBSD-daily/netbsd-8/
Thanks in advance for helping make NetBSD 8.0 a stellar release!
If you've been reading source-changes@, you likely noticed the recent creation of the netbsd-8 branch. If you haven't been reading source-changes@, here's some news: the netbsd-8 branch has been created, signaling the beginning of the release process for NetBSD 8.0.
We don't have a strict timeline for the 8.0 release, but things are looking pretty good at the moment, and we expect this release to happen in a shorter amount of time than the last couple major releases did.
At this point, we would love for folks to test out netbsd-8 and let us know how it goes. A couple of major improvements since 7.0 are the addition of USB 3 support and an overhaul of the audio subsystem, including an in-kernel mixer. Feedback about these areas is particularly desired.
To download the latest binaries built from the netbsd-8 branch, head to http://daily-builds.NetBSD.org/pub/NetBSD-daily/netbsd-8/
Thanks in advance for helping make NetBSD 8.0 a stellar release!
It turned out that more bugs were unveiled and this is not the final report on LLDB.
The good
Besides the greater enhancements this month I performed a cleanup in the ATF ptrace(2) tests again. Additionally I have managed to unbreak the LLDB Debug build and to eliminate compiler warnings in the NetBSD Native Process Plugin.
It is worth noting that LLVM can run tests on NetBSD again, the patch in gtest/LLVM has been installed by Joerg Sonnenberg and a more generic one has been submitted to the upstream googletest repository. There was also an improvement in ftruncate(2) on the LLVM side (authored by Joerg).
Since LLD (the LLVM linker) is advancing rapidly, it improved support for NetBSD and it can link a functional executable on NetBSD. I submitted a patch to stop crashing it on startup anymore. It was nearly used for linking LLDB/NetBSD and it spotted a real linking error... however there are further issues that need to be addressed in the future. Currently LLD is not part of the mainline LLDB tasks - it's part of improving the work environment. This linker should reduce the linking time - compared to GNU linkers - of LLDB by a factor of 3x-10x and save precious developer time. As of now LLDB linking can take minutes on a modern amd64 machine designed for performance.
Kernel correctness
I have researched (in pkgsrc-wip) initial support for multiple threads in the NetBSD Native Process Plugin. This code revealed - when running the LLDB regression test-suite - new kernel bugs. This unfortunately affects the usability of a debugger in a multithread environment in general and explains why GDB was never doing its job properly in such circumstances.
One of the first errors was asserting kernel panic with PT_*STEP, when a debuggee has more than a single thread. I have narrowed it down to lock primitives misuse in the do_ptrace() kernel code. The fix has been committed.
LLDB and userland correctness
LLDB introduced support for kevent(2) and it contains the following function:
Status MainLoop::RunImpl::Poll() {
in_events.resize(loop.m_read_fds.size());
unsigned i = 0;
for (auto &fd : loop.m_read_fds)
EV_SET(&in_events[i++], fd.first, EVFILT_READ, EV_ADD, 0, 0, 0);
num_events = kevent(loop.m_kqueue, in_events.data(), in_events.size(),
out_events, llvm::array_lengthof(out_events), nullptr);
if (num_events < 0)
return Status("kevent() failed with error %d\n", num_events);
return Status();
}
It works on FreeBSD and MacOSX, however it broke on NetBSD.
Culprit line:
EV_SET(&in_events[i++], fd.first, EVFILT_READ, EV_ADD, 0, 0, 0);
FreeBSD defined EV_SET() as a macro this way:
#define EV_SET(kevp_, a, b, c, d, e, f) do { \
struct kevent *kevp = (kevp_); \
(kevp)->ident = (a); \
(kevp)->filter = (b); \
(kevp)->flags = (c); \
(kevp)->fflags = (d); \
(kevp)->data = (e); \
(kevp)->udata = (f); \
} while(0)
NetBSD version was different:
#define EV_SET(kevp, a, b, c, d, e, f) \
do { \
(kevp)->ident = (a); \
(kevp)->filter = (b); \
(kevp)->flags = (c); \
(kevp)->fflags = (d); \
(kevp)->data = (e); \
(kevp)->udata = (f); \
} while (/* CONSTCOND */ 0)
This resulted in heap damage, as keyp was incremented every time a value was
assigned to (keyp)->.
Without GCC asan and ubsan tools, finding this bug would be much more time consuming, as the random memory corruption was affecting unrelated lambda function in a different part of the code.
To use the GCC sanitizers with packages from pkgsrc, on NetBSD-current, one has to use one or both of these lines:
_WRAP_EXTRA_ARGS.CXX+= -fno-omit-frame-pointer -O0 -g -ggdb -U_FORTIFY_SOURCE -fsanitize=address -fsanitize=undefined -lasan -lubsan CWRAPPERS_APPEND.cxx+= -fno-omit-frame-pointer -O0 -g -ggdb -U_FORTIFY_SOURCE -fsanitize=address -fsanitize=undefined -lasan -lubsan
While there, I have fixed another - generic - bug in the LLVM headers. The class Triple constructor hadn't initialized the SubArch field, which upsetting the GCC address sanitizer. It was triggered in LLDB in the following code:
void ArchSpec::Clear() {
m_triple = llvm::Triple();
m_core = kCore_invalid;
m_byte_order = eByteOrderInvalid;
m_distribution_id.Clear();
m_flags = 0;
}
I have filed a patch for review to address this.
The bad
Unfortunately this is not the full story and there is further mandatory work.
LLDB acceleration
The EV_SET() bug broke upstream LLDB over a month ago, and during this period the debugger was significantly accelerated and parallelized. It is difficult to declare it definitely, but it might be the reason why the tracer's runtime broke due to threading desynchronization. LLDB behaves differently when run standalone, under ktruss(1) and under gdb(1) - the shared bug is that it always fails in one way or another, which isn't trivial to debug.
The ugly
There are also unpleasant issues at the core of the Operating System.
Kernel troubles
Another bug with single-step functions that affects another aspect of correctness - this time with reliable execution of a program - is that processes die in non-deterministic ways when single-stepped. My current impression is that there is no appropriate translation between process and thread (LWP) states under a debugger.
These issues are sibling problems to unreliable PT_RESUME and PT_SUSPEND.
In order to be able to appropriately address this, I have diligently studied this month the Solaris Internals book to get a better image of the design of the NetBSD kernel multiprocessing, which was modeled after this commercial UNIX.
Plan for the next milestone
The current troubles can be summarized as data races in the kernel and at the same time in LLDB. I have decided to port the LLVM sanitizers, as I require the Thread Sanitizer (tsan). Temporarily I have removed the code for tracing processes with multiple threads to hide the known kernel bugs and focus on the LLDB races.
Unfortunately LLDB is not easily bisectable (build time of the LLVM+Clang+LLDB stack, number of revisions), therefore the debugging has to be performed on the most recent code from upstream trunk.
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL, and chip in what you can:
It turned out that more bugs were unveiled and this is not the final report on LLDB.
The good
Besides the greater enhancements this month I performed a cleanup in the ATF ptrace(2) tests again. Additionally I have managed to unbreak the LLDB Debug build and to eliminate compiler warnings in the NetBSD Native Process Plugin.
It is worth noting that LLVM can run tests on NetBSD again, the patch in gtest/LLVM has been installed by Joerg Sonnenberg and a more generic one has been submitted to the upstream googletest repository. There was also an improvement in ftruncate(2) on the LLVM side (authored by Joerg).
Since LLD (the LLVM linker) is advancing rapidly, it improved support for NetBSD and it can link a functional executable on NetBSD. I submitted a patch to stop crashing it on startup anymore. It was nearly used for linking LLDB/NetBSD and it spotted a real linking error... however there are further issues that need to be addressed in the future. Currently LLD is not part of the mainline LLDB tasks - it's part of improving the work environment. This linker should reduce the linking time - compared to GNU linkers - of LLDB by a factor of 3x-10x and save precious developer time. As of now LLDB linking can take minutes on a modern amd64 machine designed for performance.
Kernel correctness
I have researched (in pkgsrc-wip) initial support for multiple threads in the NetBSD Native Process Plugin. This code revealed - when running the LLDB regression test-suite - new kernel bugs. This unfortunately affects the usability of a debugger in a multithread environment in general and explains why GDB was never doing its job properly in such circumstances.
One of the first errors was asserting kernel panic with PT_*STEP, when a debuggee has more than a single thread. I have narrowed it down to lock primitives misuse in the do_ptrace() kernel code. The fix has been committed.
LLDB and userland correctness
LLDB introduced support for kevent(2) and it contains the following function:
Status MainLoop::RunImpl::Poll() {
in_events.resize(loop.m_read_fds.size());
unsigned i = 0;
for (auto &fd : loop.m_read_fds)
EV_SET(&in_events[i++], fd.first, EVFILT_READ, EV_ADD, 0, 0, 0);
num_events = kevent(loop.m_kqueue, in_events.data(), in_events.size(),
out_events, llvm::array_lengthof(out_events), nullptr);
if (num_events < 0)
return Status("kevent() failed with error %d\n", num_events);
return Status();
}
It works on FreeBSD and MacOSX, however it broke on NetBSD.
Culprit line:
EV_SET(&in_events[i++], fd.first, EVFILT_READ, EV_ADD, 0, 0, 0);
FreeBSD defined EV_SET() as a macro this way:
#define EV_SET(kevp_, a, b, c, d, e, f) do { \
struct kevent *kevp = (kevp_); \
(kevp)->ident = (a); \
(kevp)->filter = (b); \
(kevp)->flags = (c); \
(kevp)->fflags = (d); \
(kevp)->data = (e); \
(kevp)->udata = (f); \
} while(0)
NetBSD version was different:
#define EV_SET(kevp, a, b, c, d, e, f) \
do { \
(kevp)->ident = (a); \
(kevp)->filter = (b); \
(kevp)->flags = (c); \
(kevp)->fflags = (d); \
(kevp)->data = (e); \
(kevp)->udata = (f); \
} while (/* CONSTCOND */ 0)
This resulted in heap damage, as keyp was incremented every time a value was
assigned to (keyp)->.
Without GCC asan and ubsan tools, finding this bug would be much more time consuming, as the random memory corruption was affecting unrelated lambda function in a different part of the code.
To use the GCC sanitizers with packages from pkgsrc, on NetBSD-current, one has to use one or both of these lines:
_WRAP_EXTRA_ARGS.CXX+= -fno-omit-frame-pointer -O0 -g -ggdb -U_FORTIFY_SOURCE -fsanitize=address -fsanitize=undefined -lasan -lubsan CWRAPPERS_APPEND.cxx+= -fno-omit-frame-pointer -O0 -g -ggdb -U_FORTIFY_SOURCE -fsanitize=address -fsanitize=undefined -lasan -lubsan
While there, I have fixed another - generic - bug in the LLVM headers. The class Triple constructor hadn't initialized the SubArch field, which upsetting the GCC address sanitizer. It was triggered in LLDB in the following code:
void ArchSpec::Clear() {
m_triple = llvm::Triple();
m_core = kCore_invalid;
m_byte_order = eByteOrderInvalid;
m_distribution_id.Clear();
m_flags = 0;
}
I have filed a patch for review to address this.
The bad
Unfortunately this is not the full story and there is further mandatory work.
LLDB acceleration
The EV_SET() bug broke upstream LLDB over a month ago, and during this period the debugger was significantly accelerated and parallelized. It is difficult to declare it definitely, but it might be the reason why the tracer's runtime broke due to threading desynchronization. LLDB behaves differently when run standalone, under ktruss(1) and under gdb(1) - the shared bug is that it always fails in one way or another, which isn't trivial to debug.
The ugly
There are also unpleasant issues at the core of the Operating System.
Kernel troubles
Another bug with single-step functions that affects another aspect of correctness - this time with reliable execution of a program - is that processes die in non-deterministic ways when single-stepped. My current impression is that there is no appropriate translation between process and thread (LWP) states under a debugger.
These issues are sibling problems to unreliable PT_RESUME and PT_SUSPEND.
In order to be able to appropriately address this, I have diligently studied this month the Solaris Internals book to get a better image of the design of the NetBSD kernel multiprocessing, which was modeled after this commercial UNIX.
Plan for the next milestone
The current troubles can be summarized as data races in the kernel and at the same time in LLDB. I have decided to port the LLVM sanitizers, as I require the Thread Sanitizer (tsan). Temporarily I have removed the code for tracing processes with multiple threads to hide the known kernel bugs and focus on the LLDB races.
Unfortunately LLDB is not easily bisectable (build time of the LLVM+Clang+LLDB stack, number of revisions), therefore the debugging has to be performed on the most recent code from upstream trunk.
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL, and chip in what you can:
the repository conversion setup for NetBSD CVS -> Fossil -> Git has found a new home. Ironically, on former cvs.NetBSD.org hardware. This provides a somewhat faster conversion cycle as well as removing anoncvs.NetBSD.org from the process. This should avoid occasional problems with incomplete syncs. Two other changes have been applied at the same time:
- The Fossil repositories have moved to using the SHA512 checksums internally. To avoid accidents, a new project code is used. This requires Fossil 2.x.
- The Git repositories map user names to @NetBSD.org addresses (src, xsrc) or @pkgsrc.org addresses (pkgsrc). This allows consolidation on github with user accounts, assuming you have the corresponding addresses as primary or secondary address.
The new locations for the repositories are:
The old conversions will be provided for the near future, but likely stop toward the end of the month.
A special thanks goes to Petra and Christos from the admin team for the assistance with the machine setup and low-level CVS clean-ups.
Joerg
-- source https://mail-index.netbsd.org/tech-repository/2017/06/10/msg000637.html
the repository conversion setup for NetBSD CVS -> Fossil -> Git has found a new home. Ironically, on former cvs.NetBSD.org hardware. This provides a somewhat faster conversion cycle as well as removing anoncvs.NetBSD.org from the process. This should avoid occasional problems with incomplete syncs. Two other changes have been applied at the same time:
- The Fossil repositories have moved to using the SHA512 checksums internally. To avoid accidents, a new project code is used. This requires Fossil 2.x.
- The Git repositories map user names to @NetBSD.org addresses (src, xsrc) or @pkgsrc.org addresses (pkgsrc). This allows consolidation on github with user accounts, assuming you have the corresponding addresses as primary or secondary address.
The new locations for the repositories are:
The old conversions will be provided for the near future, but likely stop toward the end of the month.
A special thanks goes to Petra and Christos from the admin team for the assistance with the machine setup and low-level CVS clean-ups.
Joerg
-- source https://mail-index.netbsd.org/tech-repository/2017/06/10/msg000637.html
Born in 1969, he developed a passion for computer science in his youth but chose to study biology. He then attended a bioinformatics training at the Pasteur Institute in 1997 at the end of which he got hired in the scientific IT department. He has continuously worked there since. Not only was he skilled in biology but also in system administration, databases, and programming.
He was introduced to NetBSD in 1999 and quickly became a dedicated user and hacker. He became a NetBSD developer in 2007 for working on Linux/i386 (32 bits) emulation on NetBSD/amd64 (64 bits).
Nicolas leaves a wife and three children.
Memorial note submitted by Marc Baudoin.
Born in 1969, he developed a passion for computer science in his youth but chose to study biology. He then attended a bioinformatics training at the Pasteur Institute in 1997 at the end of which he got hired in the scientific IT department. He has continuously worked there since. Not only was he skilled in biology but also in system administration, databases, and programming.
He was introduced to NetBSD in 1999 and quickly became a dedicated user and hacker. He became a NetBSD developer in 2007 for working on Linux/i386 (32 bits) emulation on NetBSD/amd64 (64 bits).
Nicolas leaves a wife and three children.
Memorial note submitted by Marc Baudoin.
- drivers for on-chip ehci and ohci have been added. Ohci works fine, ehci for some reason detects all high speed devices as full speed and hands them over to ohci. No idea why.
- I2C ports work now, including the onboard RTC. You have to hook up your own battery though.
- we're no longer limited to 256MB, all RAM is usable now.
- onboard ethernet is supported by the dme driver.
The RTC is a bit funny - according to the manual there's a Pericom RTC on iic4 addr 0x68 - not on my preproduction board. I've got something that looks like a PCF8563 at addr 0x51, and so do the production boards that I know of. Some pins on one of the expansion connectors seem to be for a battery but I haven't been able to confirm that yet. Either way, since the main connector is supposed to be Raspberry Pi compatible any RTC module for the RPi should Just Work(tm), with the appropriate line added to the kernel config.
Some more work has been done under the hood, like some preparations for SMP support.
Here's the obligatory boot transcript, complete with incomplete drivers and debug spam:
U-Boot SPL 2013.10-rc3-g9329ab16a204 (Jun 26 2014 - 09:43:22)
SDRAM H5TQ2G83CFR initialization... done
U-Boot 2013.10-rc3-g9329ab16a204 (Jun 26 2014 - 09:43:22)
Board: ci20 (Ingenic XBurst JZ4780 SoC)
DRAM: 1 GiB
NAND: 8192 MiB
MMC: jz_mmc msc1: 0
In: eserial3
Out: eserial3
Err: eserial3
Net: dm9000
ci20# dhcp
ERROR: resetting DM9000 -> not responding
dm9000 i/o: 0xb6000000, id: 0x90000a46
DM9000: running in 8 bit mode
MAC: d0:31:10:ff:7e:89
operating at 100M full duplex mode
BOOTP broadcast 1
DHCP client bound to address 192.168.0.47
*** Warning: no boot file name; using 'C0A8002F.img'
Using dm9000 device
TFTP from server 192.168.0.44; our IP address is 192.168.0.47
Filename 'C0A8002F.img'.
Load address: 0x88000000
Loading: #################################################################
##############################################
369.1 KiB/s
done
Bytes transferred = 1621771 (18bf0b hex)
ci20# bootm
## Booting kernel from Legacy Image at 88000000 ...
Image Name: evbmips 7.99.18 (CI20)
Image Type: MIPS NetBSD Kernel Image (gzip compressed)
Data Size: 1621707 Bytes = 1.5 MiB
Load Address: 80020000
Entry Point: 80020000
Verifying Checksum ... OK
Uncompressing Kernel Image ... OK
subcommand not supported
ci20# g 80020000
## Starting application at 0x80020000 ...
pmap_steal_memory: seg 0: 0x6bf 0x6bf 0xffff 0xffff
Copyright (c) 1996, 1997, 1998, 1999, 2000, 2001, 2002, 2003, 2004, 2005,
2006, 2007, 2008, 2009, 2010, 2011, 2012, 2013, 2014, 2015
The NetBSD Foundation, Inc. All rights reserved.
Copyright (c) 1982, 1986, 1989, 1991, 1993
The Regents of the University of California. All rights reserved.
NetBSD 7.99.18 (CI20) #20: Thu Jun 11 13:06:41 EDT 2015
ml@blackbush:/home/build/obj_evbmips32/sys/arch/evbmips/compile/CI20
Ingenic XBurst
total memory = 1024 MB
avail memory = 997 MB
mainbus0 (root)
cpu0 at mainbus0: 1200.00MHz (hz cycles = 120000, delay divisor = 12)
cpu0: Ingenic XBurst (0x3ee1024f) Rev. 79 with unknown FPC type (0x330000) Rev. 0
cpu0: 32 TLB entries, 16MB max page size
cpu0: 32KB/32B 8-way set-associative L1 instruction cache
cpu0: 32KB/32B 8-way set-associative write-back L1 data cache
com0 at mainbus0: Ingenic UART, working fifo
com0: console
apbus0 at mainbus0
JZ_CLKGR0 3f587fe0
JZ_CLKGR1 000073e0
JZ_SPCR0 00000000
JZ_SPCR1 00000000
JZ_SRBC 00000002
JZ_OPCR 000015e6
JZ_UHCCDR c0000000
dwctwo0 at apbus0 addr 0x13500000 irq 21: USB OTG controller
ohci0 at apbus0 addr 0x134a0000 irq 5: OHCI USB controller
ohci0: OHCI version 1.0
usb0 at ohci0: USB revision 1.0
ehci0 at apbus0 addr 0x13490000 irq 20: EHCI USB controller
48352 46418
UHCCDR: c0000000
UHCCDR: 60000017
caplength 10
ehci0: companion controller, 1 port each: ohci0
usb1 at ehci0: USB revision 2.0
dme0 at apbus0 addr 0x16000000: DM9000 Ethernet controller
jzgpio at apbus0 addr 0x10010000 not configured
jzgpio at apbus0 addr 0x10010100 not configured
jzgpio at apbus0 addr 0x10010200 not configured
jzgpio at apbus0 addr 0x10010300 not configured
jzgpio at apbus0 addr 0x10010400 not configured
jzgpio at apbus0 addr 0x10010500 not configured
jziic0 at apbus0 addr 0x10050000 irq 60: SMBus controller
iic0 at jziic0: I2C bus
jziic1 at apbus0 addr 0x10051000 irq 59: SMBus controller
iic1 at jziic1: I2C bus
jziic2 at apbus0 addr 0x10052000 irq 58: SMBus controller
iic2 at jziic2: I2C bus
jziic3 at apbus0 addr 0x10053000 irq 57: SMBus controller
iic3 at jziic3: I2C bus
jziic4 at apbus0 addr 0x10054000 irq 56: SMBus controller
iic4 at jziic4: I2C bus
pcf8563rtc0 at iic4 addr 0x51: NXP PCF8563 Real-time Clock
jzmmc0 at apbus0 addr 0x13450000 irq 37: SD/MMC controller
25227 24176
jzmmc0: going to use 25227 kHz
MSC*CDR: 80000000
sdmmc0 at jzmmc0
jzmmc1 at apbus0 addr 0x13460000 irq 36: SD/MMC controller
25227 24176
jzmmc1: going to use 25227 kHz
MSC*CDR: 20000018
sdmmc1 at jzmmc1
jzmmc2 at apbus0 addr 0x13470000 irq 35: SD/MMC controller
25227 24176
jzmmc2: going to use 25227 kHz
MSC*CDR: 00000000
sdmmc2 at jzmmc2
jzfb at apbus0 addr 0x13050000 not configured
JZ_CLKGR0 2c586780
JZ_CLKGR1 000060e0
usb2 at dwctwo0: USB revision 2.0
starting timer interrupt...
jzmmc_bus_clock: 400
sh: 6 freq: 394
sdmmc0: couldn't identify card
sdmmc0: no functions
jzmmc_bus_clock: 0
sh: 7 freq: 197
jzmmc_bus_clock: 400
sh: 6 freq: 394
sdmmc1: couldn't identify card
sdmmc1: no functions
jzmmc_bus_clock: 0
sh: 7 freq: 197
jzmmc_bus_clock: 400
sh: 6 freq: 394
sdmmc2: couldn't identify card
sdmmc2: no functions
jzmmc_bus_clock: 0
sh: 7 freq: 197
uhub0 at usb0: Ingenic OHCI root hub, class 9/0, rev 1.00/1.00, addr 1
uhub1 at usb1: Ingenic EHCI root hub, class 9/0, rev 2.00/1.00, addr 1
uhub2 at usb2: Ingenic DWC2 root hub, class 9/0, rev 2.00/1.00, addr 1
PS_LS(1): 00001801
port1: 00001801
port2: 00000000
ehci0: handing over full speed device on port 1 to ohci0
umass0 at uhub2 port 1 configuration 1 interface 0
umass0: Generic Mass Storage Device, rev 2.00/1.05, addr 2
scsibus0 at umass0: 2 targets, 1 lun per target
sd0 at scsibus0 target 0 lun 0: disk removable
sd0: fabricating a geometry
sd0: 15193 MB, 15193 cyl, 64 head, 32 sec, 512 bytes/sect x 31116288 sectors
root on sd0a dumps on sd0b
sd0: fabricating a geometry
/: replaying log to memory
kern.module.path=/stand/evbmips/7.99.18/modules
pid 1(init): ABI set to O32 (e_flags=0x70001007)
Thu Jun 11 07:15:08 GMT 2015
uhub3 at uhub0 port 1: Terminus Technology USB 2.0 Hub [MTT], class 9/0, rev 2.00/1.00, addr 2
Starting root file system check:
/dev/rsd0a: file system is journaled; not checking
/: replaying log to disk
umass1 at uhub3 port 5 configuration 1 interface 0
umass1: LaCie P'9220 Mobile Drive, rev 2.10/0.06, addr 3
scsibus1 at umass1: 2 targets, 1 lun per target
sd1 at scsibus1 target 0 lun 0: disk fixed
sd1: 465 GB, 16383 cyl, 16 head, 63 sec, 512 bytes/sect x 976773168 sectors
swapctl: adding /dev/sd1b as swap device at priority 0
Starting file system checks:
/dev/rsd0e: file system is journaled; not checking
/dev/rsd0g: file system is journaled; not checking
/dev/rsd0f: 1 files, 249856 free (31232 clusters)
/dev/rsd1e: file system is journaled; not checking
random_seed: /var/db/entropy-file: Not present
Setting tty flags.
Setting sysctl variables:
ddb.onpanic: 1 -> 0
Starting network.
Hostname: ci20
IPv6 mode: autoconfigured host
Configuring network interfaces: dme0.
Adding interface aliases:.
add net default: gateway 192.168.0.1
Waiting for DAD to complete for statically configured addresses...
/usr: replaying log to disk
Building databases: dev, dev, utmp, utmpx.
Starting syslogd.
Starting rpcbind.
Mounting all file systems...
/stuff: replaying log to disk
/home: replaying log to disk
Clearing temporary files.
Updating fontconfig cache: done.
Checking quotas: done.
/etc/rc: WARNING: /etc/exports is not readable.
/etc/rc.d/mountd exited with code 1
Setting securelevel: kern.securelevel: 0 -> 1
Starting virecover.
Checking for core dump...
savecore: no core dump
Starting local daemons:.
Updating motd.
Starting ntpd.
Starting sshd.
Starting mdnsd.
Jun 11 03:23:01 ci20 mdnsd: mDNSResponder (Engineering Build) starting
Starting inetd.
Starting cron.
The following components reported failures:
/etc/rc.d/mountd
See /var/run/rc.log for more information.
Thu Jun 11 03:23:02 EDT 2015
NetBSD/evbmips (ci20) (console)
login:
On behalf of the NetBSD project, it is my pleasure to announce the first release candidate of NetBSD 7.0.
Many changes have been made since 6.0. Here are a few highlights:
- Greatly improved support for modern Intel and Radeon graphics hardware through a port of the Linux DRM/KMS code. Most X.Org components have been updated as well.
- ARM multiprocessor support
- Support for new ARM boards, some of which are listed below:
- Raspberry Pi 2
- ODROID-C1
- BeagleBoard-xM
- BeagleBone
- BeagleBone Black
- Banana Pi
- Cubieboard 2
- Cubietruck
- Merii Hummingbird
- Marvell ARMADA XP
- GlobalScale MiraBox
- Kobo
- Sharp Netwalker PC-Z1
- GPT support in sysinst
- Lua kernel scripting
- Multiprocessor USB stack
- Many improvements to NPF, the NetBSD packet filter
- GCC 4.8.4 (and optionally, LLVM/Clang 3.6.1)
Binaries of NetBSD 7.0_RC1 are available for download at:
http://ftp.netbsd.org/pub/NetBSD/NetBSD-7.0_RC1/
Those who prefer to build from source can either use the netbsd-7-0-RC1 tag or follow the netbsd-7 branch.
Please help us out by testing 7.0_RC1. We love any and all feedback. Report problems through the usual channels (submit a PR or write to the appropriate list). More general feedback is welcome at releng@NetBSD.org. Your input will help us put the finishing touches on what promises to be a great release!
Sitting in one of the nice pubs in Edinburgh during KohaCon, I had the idea to add MARC records as a proper datatype to the PostgreSQL database server. After a discussion with Marc Véron and Dobrica Pavlinusic about what that could mean, I decided to just try it and I have now a basic implementation (or, more a proof of concept). So here is some information on this:
The pkgsrc team has prepared the 50th release of their package management system, with the 2016Q1 version. It's infrequent event, as the 100th release will be held after 50 quarters.
The NetBSD team has prepared series of interviews with the authors. The 2nd one is with Sevan Janiyan, a developer well known for his bulk builds for several platforms.
Hi Sevan, please introduce yourself.
Hello,
I'm Sevan Janiyan. A sysadmin from England and a NetBSD developer, working on the pkgsrc packaging system. My areas of focus are pkgsrc security and Darwin (PowerPC) but as I enjoy running many operating systems I manage builds on a variety of them across different CPU architectures. I was a user of pkgsrc for many years but only started working on pkgsrc itself early 2014 when I obtained a PowerBook from a friend and started fixing issues on OS X Tiger/PowerPC. I was invited to become a member of TNF in 2015.
First of all, congratulations on the 50th release of pkgsrc! How do you feel about this anniversary?
It's fantastic to see a tool that has evolved over time, it's extremely flexible and has grown support for numerous operating systems during this period. Not only can it serve as the native packaging system for most OS' but thanks to its multi platform support, it can be used to save a lot of effort in implementing a packaging system on a project when a set of packages need to be built and deployed in a consistent manner across multiple operating systems.
What are the main benefits of the pkgsrc system?
The ability the provide a single API for dealing with multiple environments & toolchains, for example translating a setting to the relevant flags to compliment the compiler in use.
Unprivileged mode allows a user to build the tools they require in a
location which executables are permitted and the user has write access
e.g your home directory when the partition it resides on is not mounted
noexec
The buildlink framework - it provides the ability to detect components available on the host operating system & allows a user the choice whether to build against such a component or to opt for a version provided by pkgsrc itself.
Where and how do you use pkgsrc?
pkgsrc is an essential part of my sysadmin tool belt, on one hand I rely on it to obtain a set of packages on a system without touching the systems packaging system. This is for example on a customer system where I either have not been given root access or I do not wish to install a package on a system with a big dependency list for my personal use.
The packages in pkgsrc generally see very little in terms of local changes, besides tweaks to ensure package integrates into the system. This encourages interaction from developers with projects to upstream changes. This can be a benefit when debugging software issues where it is not certain if the issue exists in the version of software package from OS vendor or there is a bug in the software project upstream.
The ability to bootstrap multiple instances of the packaging system under different prefixes permits a user to install multiple and conflicting versions of software in isolated locations on a system.
As a use case, I worked on a project troubleshooting a clients varnish instance. The issues they were experiencing was specific to the version packaged for their OS by vendor. This was varnish 3.x and 4.1.0 had just been released, we decided to evaluate varnish 4.1.0 but as there were changes to the configuration language some development would need to by carried out, to adapt things to the new syntax. To reduce downtime the instance of varnish installed using the native package manager was left untouched and continued running, pkgsrc was bootstrapped in a separate location and varnish was installed from there. The development work to bring the config up to date happened with the new version of varnish from pkgsrc listening on a different port, but running alongside the original 3.x instance. Switching between the two instances was just a matter of changing ports to forward traffic to on the front-end web servers. Unfortunately 4.1.0 release had some bugs, so we considered trying 4.0.x. Another instance of pkgsrc was bootstrapped & v4.0.x was installed, again running on another port. This instance was brought up alongside the other two instance and started receiving traffic, at this point it was trivial to evaluate behaviour across 3 different versions of a piece of software running on a single host.
What are the pkgsrc projects you are currently working on?
I've worked very little in the tree recently. I continue to run the bulk builds of pkgsrc-current on a variety of systems and have recently begun making the packages generated from some of these builds for people to be able evaluate pkgsrc. At present there are packages for OS X Tiger (PowerPC), Debian Linux (amd64 & armv7), FreeBSD (amd64) and OmniOS published on https://files.venture37.com/pkgsrc/packages
Debian/armv7
http://mail-index.netbsd.org/pkgsrc-users/2016/03/22/msg023192.html
Debian/amd64
http://mail-index.netbsd.org/pkgsrc-users/2016/03/26/msg023209.html
FreeBSD/amd64
http://mail-index.netbsd.org/pkgsrc-users/2016/03/29/msg023222.html
If you analyze the current state of pkgsrc, which improvements and changes do you wish for the future?
A better mechanism for running the bulkbuilds or to grok how to setup the parallel builds.
Do you have any practical tips to share with the pkgsrc users?
As I mentioned with the varnish example, you can save a considerable amount of effort when required to run multiple instances of conflicting components by using pkgsrc. As everything isolated to a given prefix, specified during bootstrap, it's trivial to run multiple versions of Ruby for example without any conflict.
You can leverage this to experiment with changes which could be deemed volatile using other means.
What's the best way to start contributing to pkgsrc and what needs to be done?
Pick an OS from list, try to bootstrap pkgsrc on it, try to install some packages. If the process failed at any stage, file a bug report even better if the report includes a patch.
Rinse, repeat
If you have resources to attempt larger builds, follow the steps to setup a bulk build environment and run a build. The results ideally should be published on a public webserver & the report posted to the pkgsrc-bulk list, developers and maintainers use these reports to see problems and it could serve as a starting point for a potential contributor as a list of things that need to be fixed.
Bulktracker also makes use of these reports to build a picture of the status of packages and their impact across multiple platforms.
Do you plan to participate in the upcoming pkgsrcCon 2016 in Kraków (1-3 July)?
Yes, see you there
Sevan
The pkgsrc team has prepared the 50th release of their package management system, with the 2016Q1 version. It's infrequent event, as the 100th release will be held after 50 quarters.
The NetBSD team has prepared series of interviews with the authors. The 2nd one is with Sevan Janiyan, a developer well known for his bulk builds for several platforms.
Hi Sevan, please introduce yourself.
Hello,
I'm Sevan Janiyan. A sysadmin from England and a NetBSD developer, working on the pkgsrc packaging system. My areas of focus are pkgsrc security and Darwin (PowerPC) but as I enjoy running many operating systems I manage builds on a variety of them across different CPU architectures. I was a user of pkgsrc for many years but only started working on pkgsrc itself early 2014 when I obtained a PowerBook from a friend and started fixing issues on OS X Tiger/PowerPC. I was invited to become a member of TNF in 2015.
First of all, congratulations on the 50th release of pkgsrc! How do you feel about this anniversary?
It's fantastic to see a tool that has evolved over time, it's extremely flexible and has grown support for numerous operating systems during this period. Not only can it serve as the native packaging system for most OS' but thanks to its multi platform support, it can be used to save a lot of effort in implementing a packaging system on a project when a set of packages need to be built and deployed in a consistent manner across multiple operating systems.
What are the main benefits of the pkgsrc system?
The ability the provide a single API for dealing with multiple environments & toolchains, for example translating a setting to the relevant flags to compliment the compiler in use.
Unprivileged mode allows a user to build the tools they require in a
location which executables are permitted and the user has write access
e.g your home directory when the partition it resides on is not mounted
noexec
The buildlink framework - it provides the ability to detect components available on the host operating system & allows a user the choice whether to build against such a component or to opt for a version provided by pkgsrc itself.
Where and how do you use pkgsrc?
pkgsrc is an essential part of my sysadmin tool belt, on one hand I rely on it to obtain a set of packages on a system without touching the systems packaging system. This is for example on a customer system where I either have not been given root access or I do not wish to install a package on a system with a big dependency list for my personal use.
The packages in pkgsrc generally see very little in terms of local changes, besides tweaks to ensure package integrates into the system. This encourages interaction from developers with projects to upstream changes. This can be a benefit when debugging software issues where it is not certain if the issue exists in the version of software package from OS vendor or there is a bug in the software project upstream.
The ability to bootstrap multiple instances of the packaging system under different prefixes permits a user to install multiple and conflicting versions of software in isolated locations on a system.
As a use case, I worked on a project troubleshooting a clients varnish instance. The issues they were experiencing was specific to the version packaged for their OS by vendor. This was varnish 3.x and 4.1.0 had just been released, we decided to evaluate varnish 4.1.0 but as there were changes to the configuration language some development would need to by carried out, to adapt things to the new syntax. To reduce downtime the instance of varnish installed using the native package manager was left untouched and continued running, pkgsrc was bootstrapped in a separate location and varnish was installed from there. The development work to bring the config up to date happened with the new version of varnish from pkgsrc listening on a different port, but running alongside the original 3.x instance. Switching between the two instances was just a matter of changing ports to forward traffic to on the front-end web servers. Unfortunately 4.1.0 release had some bugs, so we considered trying 4.0.x. Another instance of pkgsrc was bootstrapped & v4.0.x was installed, again running on another port. This instance was brought up alongside the other two instance and started receiving traffic, at this point it was trivial to evaluate behaviour across 3 different versions of a piece of software running on a single host.
What are the pkgsrc projects you are currently working on?
I've worked very little in the tree recently. I continue to run the bulk builds of pkgsrc-current on a variety of systems and have recently begun making the packages generated from some of these builds for people to be able evaluate pkgsrc. At present there are packages for OS X Tiger (PowerPC), Debian Linux (amd64 & armv7), FreeBSD (amd64) and OmniOS published on https://files.venture37.com/pkgsrc/packages
Debian/armv7
http://mail-index.netbsd.org/pkgsrc-users/2016/03/22/msg023192.html
Debian/amd64
http://mail-index.netbsd.org/pkgsrc-users/2016/03/26/msg023209.html
FreeBSD/amd64
http://mail-index.netbsd.org/pkgsrc-users/2016/03/29/msg023222.html
If you analyze the current state of pkgsrc, which improvements and changes do you wish for the future?
A better mechanism for running the bulkbuilds or to grok how to setup the parallel builds.
Do you have any practical tips to share with the pkgsrc users?
As I mentioned with the varnish example, you can save a considerable amount of effort when required to run multiple instances of conflicting components by using pkgsrc. As everything isolated to a given prefix, specified during bootstrap, it's trivial to run multiple versions of Ruby for example without any conflict.
You can leverage this to experiment with changes which could be deemed volatile using other means.
What's the best way to start contributing to pkgsrc and what needs to be done?
Pick an OS from list, try to bootstrap pkgsrc on it, try to install some packages. If the process failed at any stage, file a bug report even better if the report includes a patch.
Rinse, repeat
If you have resources to attempt larger builds, follow the steps to setup a bulk build environment and run a build. The results ideally should be published on a public webserver & the report posted to the pkgsrc-bulk list, developers and maintainers use these reports to see problems and it could serve as a starting point for a potential contributor as a list of things that need to be fixed.
Bulktracker also makes use of these reports to build a picture of the status of packages and their impact across multiple platforms.
Do you plan to participate in the upcoming pkgsrcCon 2016 in Kraków (1-3 July)?
Yes, see you there
Sevan
The pkgsrc team has prepared the 50th release of their package management system, with the 2016Q1 version. It's infrequent event, as the 100th release will be held after 50 quarters.
The NetBSD team has prepared series of interviews with the authors. The 3rd one is with Thomas Klausner, a developer well known for his maintainership of the pkgsrc-wip project.
First of all, congratulations on the 50th release of pkgsrc! How do you feel about this anniversary?
I'm very glad that pkgsrc that so many people find pkgsrc useful and like working on it, both on pkgsrc itself and pkgsrc-wip.
What are the main benefits of the pkgsrc system?
Get packages installed on your system, and keep them up-to-date, and don't worry about the underlying operating system.
Where and how do you use pkgsrc?
I use pkgsrc on my desktop machine at home and on various servers.
What are the pkgsrc projects you are currently working on?
Currently I have no single big project. I regularly try to keep a couple of hundred packages up-to-date, and to feed back patches upstream, so more software builds out-of-the-box. This also has the advantages of making updates easier, and spreading awareness of pkgsrc and NetBSD. Recently I've been more focusing on pushing upstream the pkgsrc patches for firefox.
If you analyze the current state of pkgsrc, which improvements and changes do you wish for the future?
A recent issue is that we need to add a framework for PaX security features; luckily, this is already implemented and just needs merging. Longer term I think our binary package tools could use some love and fresh code.
Do you have any practical tips to share with the pkgsrc users?
If you build your packages yourself, then use pkgtools/mksandbox to create sandboxes and run bulk builds inside them using pkgtools/pbulk. It makes life in general and updates in particular so much easier!
What's the best way to start contributing to pkgsrc and what needs to be done?
The easiest way is to start using pkgsrc on your own machines. Once you feel comfortable with that you'll probably notice that you want to update a package, or add a new one. If you reach that point, visit http://pkgsrc.org/wip/ to get commit access to the pkgsrc wip repository.
If you need help, contact the pkgsrc-users mailing list or visit us in #pkgsrc on freenode!
Do you plan to participate in the upcoming pkgsrcCon 2016 in Kraków (1-3 July)?
Definitely! I'm looking forward to meeting other pkgsrc developers again or for the first time, and to many interesting talks.
Cheers,
Thomas
The pkgsrc team has prepared the 50th release of their package management system, with the 2016Q1 version. It's infrequent event, as the 100th release will be held after 50 quarters.
The NetBSD team has prepared series of interviews with the authors. The 3rd one is with Thomas Klausner, a developer well known for his maintainership of the pkgsrc-wip project.
First of all, congratulations on the 50th release of pkgsrc! How do you feel about this anniversary?
I'm very glad that pkgsrc that so many people find pkgsrc useful and like working on it, both on pkgsrc itself and pkgsrc-wip.
What are the main benefits of the pkgsrc system?
Get packages installed on your system, and keep them up-to-date, and don't worry about the underlying operating system.
Where and how do you use pkgsrc?
I use pkgsrc on my desktop machine at home and on various servers.
What are the pkgsrc projects you are currently working on?
Currently I have no single big project. I regularly try to keep a couple of hundred packages up-to-date, and to feed back patches upstream, so more software builds out-of-the-box. This also has the advantages of making updates easier, and spreading awareness of pkgsrc and NetBSD. Recently I've been more focusing on pushing upstream the pkgsrc patches for firefox.
If you analyze the current state of pkgsrc, which improvements and changes do you wish for the future?
A recent issue is that we need to add a framework for PaX security features; luckily, this is already implemented and just needs merging. Longer term I think our binary package tools could use some love and fresh code.
Do you have any practical tips to share with the pkgsrc users?
If you build your packages yourself, then use pkgtools/mksandbox to create sandboxes and run bulk builds inside them using pkgtools/pbulk. It makes life in general and updates in particular so much easier!
What's the best way to start contributing to pkgsrc and what needs to be done?
The easiest way is to start using pkgsrc on your own machines. Once you feel comfortable with that you'll probably notice that you want to update a package, or add a new one. If you reach that point, visit http://pkgsrc.org/wip/ to get commit access to the pkgsrc wip repository.
If you need help, contact the pkgsrc-users mailing list or visit us in #pkgsrc on freenode!
Do you plan to participate in the upcoming pkgsrcCon 2016 in Kraków (1-3 July)?
Definitely! I'm looking forward to meeting other pkgsrc developers again or for the first time, and to many interesting talks.
Cheers,
Thomas
The pkgsrc team has prepared the 50th release of their package management system, with the 2016Q1 version. It's infrequent event, as the 100th release will be held after 50 quarters.
The NetBSD team has prepared series of interviews with the authors. The next one is with Benny Siegert, a developer active in the release engineering team.
Hi Benny, please introduce yourself.
I came to pkgsrc to my work on MirBSD. MirBSD only had a handful of developers, so there was not enough manpower to maintain our own ports tree -- not that we didn't try! In the end, we decided to support pkgsrc, and I joined the NetBSD project as a developer, in an amazingly quick and painless process.
My dayjob is as an SRE at Google; luckily, Google allows me to use my 20% time to work on pkgsrc. Working in this job has changed my perspective on computing. I try to apply some of the SRE principles (automate repetitive work, discipline in bug tracking, etc.) to my work in pkgsrc.
First of all, congratulations on the 50th release of pkgsrc! How do you feel about this anniversary?
Wow, 50 releases already! I find it remarkable how pkgsrc has continued on a stable growth trajectory all these years. And together, we have built one of the best and most advanced package collections.
What are the main benefits of the pkgsrc system?
pkgsrc runs on almost any platform that you are likely to use, from NetBSD, other BSDs, commercial Unixes, Linux and Mac OS. Whatever the platform, you have the same huge choice of up-to-date packages. You can install them with a single command. That's pretty compelling.
Where and how do you use pkgsrc?
These days, I mostly use pkgsrc on NetBSD and Mac OS X. On the Mac, pkgsrc may not be the most popular package collection but it still works amazingly well. (By the way, I applaud the team behind saveosx.org for making an effort to make pkgsrc more widely known among Mac users.)
What are the pkgsrc projects you are currently working on?
By accident, I ended up being the maintainer of the pkgsrc stable
branch I am the one who handles most of the security updates to the
stable release.
As a fan of the Go programming language (and a contributor to the project), I work on making software written in Go easy to use in pkgsrc. There is infrastructure (go-package.mk) for packaging Go software easily.
If you analyze the current state of pkgsrc, which improvements and changes do you wish for the future?
I would love to have more modern tooling. Gnats for bugs and CVS for the repository are both outdated. But this is an ongoing discussion.
I would also like to have a more rigorous handling of security fixes. The vulnerability DB is great and kept very well; on the other hand actually fixing the vulnerabilities is sometimes neglected, particularly for packages that not many people use.
Do you have any practical tips to share with the pkgsrc users?
- If you are on a machine where you do not have root access (such as a shared Linux machine), you can bootstrap pkgsrc in unprivileged mode. This way, everything builds and installs without needing to use root rights.
- Read up on "pkg_admin audit" and use it regularly, to find when you have packages with security problems installed.
What's the best way to start contributing to pkgsrc and what needs to be done?
pkgsrc-wip has a really low barrier to entry. Try to make your own package for something simple and put it in wip.
Look in pkgsrc/doc/TODO, it contains some suggestions for things you may want to work on. There is also a long list of suggested package updates in there, you can send a PR with patch for these.
Finally, if you run "pkg_admin audit", as I suggested above, and
discover that pkgsrc does not contain a fix for a given vulnerability,
you can try to find a patch and submit it via PR. I would be more than
happy to apply it
Do you plan to participate in the upcoming pkgsrcCon 2016 in Kraków (1-3 July)?
pkgsrcCon is a fantastic conference. I am not 100% sure yet if I can make it but I will try to.
The pkgsrc team has prepared the 50th release of their package management system, with the 2016Q1 version. It's infrequent event, as the 100th release will be held after 50 quarters.
The NetBSD team has prepared series of interviews with the authors. The next one is with Benny Siegert, a developer active in the release engineering team.
Hi Benny, please introduce yourself.
I came to pkgsrc to my work on MirBSD. MirBSD only had a handful of developers, so there was not enough manpower to maintain our own ports tree -- not that we didn't try! In the end, we decided to support pkgsrc, and I joined the NetBSD project as a developer, in an amazingly quick and painless process.
My dayjob is as an SRE at Google; luckily, Google allows me to use my 20% time to work on pkgsrc. Working in this job has changed my perspective on computing. I try to apply some of the SRE principles (automate repetitive work, discipline in bug tracking, etc.) to my work in pkgsrc.
First of all, congratulations on the 50th release of pkgsrc! How do you feel about this anniversary?
Wow, 50 releases already! I find it remarkable how pkgsrc has continued on a stable growth trajectory all these years. And together, we have built one of the best and most advanced package collections.
What are the main benefits of the pkgsrc system?
pkgsrc runs on almost any platform that you are likely to use, from NetBSD, other BSDs, commercial Unixes, Linux and Mac OS. Whatever the platform, you have the same huge choice of up-to-date packages. You can install them with a single command. That's pretty compelling.
Where and how do you use pkgsrc?
These days, I mostly use pkgsrc on NetBSD and Mac OS X. On the Mac, pkgsrc may not be the most popular package collection but it still works amazingly well. (By the way, I applaud the team behind saveosx.org for making an effort to make pkgsrc more widely known among Mac users.)
What are the pkgsrc projects you are currently working on?
By accident, I ended up being the maintainer of the pkgsrc stable
branch I am the one who handles most of the security updates to the
stable release.
As a fan of the Go programming language (and a contributor to the project), I work on making software written in Go easy to use in pkgsrc. There is infrastructure (go-package.mk) for packaging Go software easily.
If you analyze the current state of pkgsrc, which improvements and changes do you wish for the future?
I would love to have more modern tooling. Gnats for bugs and CVS for the repository are both outdated. But this is an ongoing discussion.
I would also like to have a more rigorous handling of security fixes. The vulnerability DB is great and kept very well; on the other hand actually fixing the vulnerabilities is sometimes neglected, particularly for packages that not many people use.
Do you have any practical tips to share with the pkgsrc users?
- If you are on a machine where you do not have root access (such as a shared Linux machine), you can bootstrap pkgsrc in unprivileged mode. This way, everything builds and installs without needing to use root rights.
- Read up on "pkg_admin audit" and use it regularly, to find when you have packages with security problems installed.
What's the best way to start contributing to pkgsrc and what needs to be done?
pkgsrc-wip has a really low barrier to entry. Try to make your own package for something simple and put it in wip.
Look in pkgsrc/doc/TODO, it contains some suggestions for things you may want to work on. There is also a long list of suggested package updates in there, you can send a PR with patch for these.
Finally, if you run "pkg_admin audit", as I suggested above, and
discover that pkgsrc does not contain a fix for a given vulnerability,
you can try to find a patch and submit it via PR. I would be more than
happy to apply it
Do you plan to participate in the upcoming pkgsrcCon 2016 in Kraków (1-3 July)?
pkgsrcCon is a fantastic conference. I am not 100% sure yet if I can make it but I will try to.
The pkgsrc team has prepared the 50th release of their package management system, with the 2016Q1 version. It's infrequent event, as the 100th release will be held after 50 quarters.
The NetBSD team has prepared series of interviews with the authors. The next one is with Jonathan Perkin, a developer in the Joyent team.
Hi Jonathan, please introduce yourself.
Hello! Thirty-something, married with 4 kids. Obviously this means life is usually pretty busy! I work as a Software Engineer for Joyent, where we provide SmartOS zones (also known as "containers" these days) running pkgsrc. This means I am in the privileged position of getting paid to work full-time on what for many years has been my hobby.
First of all, congratulations on the 50th release of pkgsrc! How do you feel about this anniversary?
I've been involved in pkgsrc since 2001, which was a few years before we started the quarterly releases. Back then and during the early 2000s there was a significant amount of work going into the pkgsrc infrastructure to give it all the amazing features that we have today, but that often meant the development branch had some rough edges while those features were still being integrated across the tree.
The quarterly releases gave users confidence in building from a stable release without unexpected breakages, and also helped developers to schedule any large changes at the appropriate time.
At Joyent we make heavy use of the quarterly releases, producing new SmartOS images for each branch, so for example our 16.1.x images are based on pkgsrc-2016Q1, and so on.
Reaching the 50th release makes me feel old! It also makes me feel proud that we've come a long way, yet still have people who want to be involved and continue to develop both the infrastructure and packages.
I'd also like to highlight the fantastic work of the pkgsrc releng team, who work to ensure the releases are kept up-to-date until the next one is released. They do a great job and we benefit a lot from their work.
What are the main benefits of the pkgsrc system?
For me the big one is portability. This is what sets it apart from all other package managers (and, increasingly, software in general), not just because it runs on so many platforms but because it is such a core part of the infrastructure and has been constantly developed and refined over the years. We are now up to 23 distinct platforms, not counting different distributions, and adding support for new ones is relatively easy thanks to the huge amount of work which has gone into the infrastructure.
The other main benefit for me is the buildlink infrastructure and various quality checks we have. As someone who distributes binary packages to end users, it is imperative that those packages work as expected on the target environment and don't have any embarrassing bugs. The buildlink system ensures (amongst other things) that dependencies are correct and avoids many issues around build host pollution. We then have a number of QA scripts which analyse the generated package and ensure that the contents are accurate, RPATHs are correct, etc. It's not perfect and there are more tests we could write, but these catch a lot of mistakes that would otherwise go undetected until a user submits a bug report.
Others for me are unprivileged support, signed packages, multi-version support, pbulk, and probably a lot of other things I've forgotten and take for granted!
Where and how do you use pkgsrc?
As mentioned above I work on pkgsrc for SmartOS. We are probably one of the biggest users of pkgsrc in the world, shipping over a million package downloads per year and rising to our users, not including those distributed as part of our images or delivered from mirrors. This is where I spend the majority of my time working on pkgsrc, and it is all performed remotely on a number of zones running in the Joyent Public Cloud. The packages we build are designed to run not just on SmartOS but across all illumos distributions, and so I also have an OmniOS virtual machine locally where I test new releases before announcing them.
As an OS X user, I also use pkgsrc on my MacBook. This is generally where I perform any final tests before committing changes to pkgsrc so that I'm reasonably confident they are correct, but I also install a bunch of different packages from pkgsrc (mutt, ffmpeg, nodejs, jekyll, pstree etc) for my day-to-day work. I also have a number of Mac build servers in my loft and at the Joyent offices in San Francisco where I produce the binary OS X packages we offer which are starting to become popular among users looking for an alternative to Homebrew or MacPorts.
Finally, I have a few Linux machines also running in the Joyent Public Cloud which I have configured for continuous bulk builds of pkgsrc trunk. These help me to test any infrastructure changes I'm working on to ensure that they are portable and correct.
On all of these machines I have written infrastructure to perform builds inside chroots, ensuring a consistent environment and allowing me to work on multiple things simultaneously. They all have various tools installed (git, pkgvi, pkglint, etc) to aid my personal development workflow. We then make heavy use of GitHub and Jenkins to manage automatic builds when pushing to various branches.
What are the pkgsrc projects you are currently working on?
One of my priorities over the past year has been on performance. We build a lot of packages (over 40,000 per branch, and we support up to 4 branches simultaneously), and when the latest OpenSSL vulnerability hits it's critical to get a fix out to users as quickly as possible. We're now at the stage where, with a couple of patches, we can complete a full bulk build in under 3 hours. There is still a lot of room for improvement though, so recently I've been looking at slibtool (a libtool replacement written in C) and supporting dash (a minimal POSIX shell which is faster than bash).
There are also a few features we've developed at Joyent that I continue to maintain, such as our multiarch work (which combines 32-bit and 64-bit builds into a single package), additional multi-version support for MySQL and Percona, SMF support, and a bunch of other patches which aren't yet ready to be integrated.
I'm also very keen on getting new users into pkgsrc and turning them into developers, so a lot of my time has been spent on making pkgsrc more accessible, whether that's via our pkgbuild image (which gives users a ready-made pkgsrc development environment) or the developer guides I've written, or maintaining our https://pkgsrc.joyent.com/ website. There's lots more to do in this area though to ensure users of all abilities can contribute meaningfully.
Most of my day-to-day work though is general bug fixing and updating packages, performing the quarterly release builds, and maintaining our build infrastructure.
If you analyze the current state of pkgsrc, which improvements and changes do you wish for the future?
More users and developers! I am one of only a small handful of people who are paid to work on pkgsrc, the vast majority of the work is done by our amazing volunteer community. By its very nature pkgsrc requires constant effort updating existing packages and adding new ones. This is something that will never change and if anything the demand is accelerating, so we need to ensure that we continue to train up and add new developers if we are to keep up.
We need more documentation, more HOWTO guides, simpler infrastructure, easier patch submission, faster and less onerous on-boarding of developers, more bulk builds, more development machines. Plenty to be getting on with!
Some technical changes I'd like to see are better upgrade support, launchd support, integration of a working alternative pkg backend e.g. IPS, bmake IPC (so we don't need to recompute the same variables over and over), and many more!
Do you have any practical tips to share with the pkgsrc users?
Separate your build and install environments, so e.g. build in chroots or in a VM then deploy the built packages to your target. Trying to update a live install is the source of many problems, and there are few things more frustrating than having your development environment be messed up by an upgrade which fails part-way through.
For brand new users, document your experience and tell us what works and what sucks. Many of us have been using pkgsrc for many many years, and have lost your unique ability to identify problems, inconsistencies, and bad documentation.
If you run into problems, connect to Freenode IRC #pkgsrc, and we'll try to help you out. Hang out there even if you aren't having problems!
Finally, if you like pkgsrc, tell your friends, write blog posts, post to Hacker News etc. It's amazing to me how unknown pkgsrc is despite being around for so long, and how many people love it when they discover it.
More users leads to more developers, which leads to improved pkgsrc, which leads to more users, which...
What's the best way to start contributing to pkgsrc and what needs to be done?
Pick something that interests you and just start working on it. The great thing about pkgsrc is that there are open tasks for any ability, from documentation fixes all the way through adding packages to rewriting large parts of the infrastructure.
When you have something to contribute, don't worry about whether it's perfect or how you are to deliver it. Just make it available and let us know via PR, pull request, or just mail, and we can take it from there.
Do you plan to participate in the upcoming pkgsrcCon 2016 in Kraków (1-3 July)?
I am hoping to. If so I usually give a talk on what we've been working on at Joyent over the past year, and will probably do the same.
The pkgsrc team has prepared the 50th release of their package management system, with the 2016Q1 version. It's infrequent event, as the 100th release will be held after 50 quarters.
The NetBSD team has prepared series of interviews with the authors. The next one is with Jonathan Perkin, a developer in the Joyent team.
Hi Jonathan, please introduce yourself.
Hello! Thirty-something, married with 4 kids. Obviously this means life is usually pretty busy! I work as a Software Engineer for Joyent, where we provide SmartOS zones (also known as "containers" these days) running pkgsrc. This means I am in the privileged position of getting paid to work full-time on what for many years has been my hobby.
First of all, congratulations on the 50th release of pkgsrc! How do you feel about this anniversary?
I've been involved in pkgsrc since 2001, which was a few years before we started the quarterly releases. Back then and during the early 2000s there was a significant amount of work going into the pkgsrc infrastructure to give it all the amazing features that we have today, but that often meant the development branch had some rough edges while those features were still being integrated across the tree.
The quarterly releases gave users confidence in building from a stable release without unexpected breakages, and also helped developers to schedule any large changes at the appropriate time.
At Joyent we make heavy use of the quarterly releases, producing new SmartOS images for each branch, so for example our 16.1.x images are based on pkgsrc-2016Q1, and so on.
Reaching the 50th release makes me feel old! It also makes me feel proud that we've come a long way, yet still have people who want to be involved and continue to develop both the infrastructure and packages.
I'd also like to highlight the fantastic work of the pkgsrc releng team, who work to ensure the releases are kept up-to-date until the next one is released. They do a great job and we benefit a lot from their work.
What are the main benefits of the pkgsrc system?
For me the big one is portability. This is what sets it apart from all other package managers (and, increasingly, software in general), not just because it runs on so many platforms but because it is such a core part of the infrastructure and has been constantly developed and refined over the years. We are now up to 23 distinct platforms, not counting different distributions, and adding support for new ones is relatively easy thanks to the huge amount of work which has gone into the infrastructure.
The other main benefit for me is the buildlink infrastructure and various quality checks we have. As someone who distributes binary packages to end users, it is imperative that those packages work as expected on the target environment and don't have any embarrassing bugs. The buildlink system ensures (amongst other things) that dependencies are correct and avoids many issues around build host pollution. We then have a number of QA scripts which analyse the generated package and ensure that the contents are accurate, RPATHs are correct, etc. It's not perfect and there are more tests we could write, but these catch a lot of mistakes that would otherwise go undetected until a user submits a bug report.
Others for me are unprivileged support, signed packages, multi-version support, pbulk, and probably a lot of other things I've forgotten and take for granted!
Where and how do you use pkgsrc?
As mentioned above I work on pkgsrc for SmartOS. We are probably one of the biggest users of pkgsrc in the world, shipping over a million package downloads per year and rising to our users, not including those distributed as part of our images or delivered from mirrors. This is where I spend the majority of my time working on pkgsrc, and it is all performed remotely on a number of zones running in the Joyent Public Cloud. The packages we build are designed to run not just on SmartOS but across all illumos distributions, and so I also have an OmniOS virtual machine locally where I test new releases before announcing them.
As an OS X user, I also use pkgsrc on my MacBook. This is generally where I perform any final tests before committing changes to pkgsrc so that I'm reasonably confident they are correct, but I also install a bunch of different packages from pkgsrc (mutt, ffmpeg, nodejs, jekyll, pstree etc) for my day-to-day work. I also have a number of Mac build servers in my loft and at the Joyent offices in San Francisco where I produce the binary OS X packages we offer which are starting to become popular among users looking for an alternative to Homebrew or MacPorts.
Finally, I have a few Linux machines also running in the Joyent Public Cloud which I have configured for continuous bulk builds of pkgsrc trunk. These help me to test any infrastructure changes I'm working on to ensure that they are portable and correct.
On all of these machines I have written infrastructure to perform builds inside chroots, ensuring a consistent environment and allowing me to work on multiple things simultaneously. They all have various tools installed (git, pkgvi, pkglint, etc) to aid my personal development workflow. We then make heavy use of GitHub and Jenkins to manage automatic builds when pushing to various branches.
What are the pkgsrc projects you are currently working on?
One of my priorities over the past year has been on performance. We build a lot of packages (over 40,000 per branch, and we support up to 4 branches simultaneously), and when the latest OpenSSL vulnerability hits it's critical to get a fix out to users as quickly as possible. We're now at the stage where, with a couple of patches, we can complete a full bulk build in under 3 hours. There is still a lot of room for improvement though, so recently I've been looking at slibtool (a libtool replacement written in C) and supporting dash (a minimal POSIX shell which is faster than bash).
There are also a few features we've developed at Joyent that I continue to maintain, such as our multiarch work (which combines 32-bit and 64-bit builds into a single package), additional multi-version support for MySQL and Percona, SMF support, and a bunch of other patches which aren't yet ready to be integrated.
I'm also very keen on getting new users into pkgsrc and turning them into developers, so a lot of my time has been spent on making pkgsrc more accessible, whether that's via our pkgbuild image (which gives users a ready-made pkgsrc development environment) or the developer guides I've written, or maintaining our https://pkgsrc.joyent.com/ website. There's lots more to do in this area though to ensure users of all abilities can contribute meaningfully.
Most of my day-to-day work though is general bug fixing and updating packages, performing the quarterly release builds, and maintaining our build infrastructure.
If you analyze the current state of pkgsrc, which improvements and changes do you wish for the future?
More users and developers! I am one of only a small handful of people who are paid to work on pkgsrc, the vast majority of the work is done by our amazing volunteer community. By its very nature pkgsrc requires constant effort updating existing packages and adding new ones. This is something that will never change and if anything the demand is accelerating, so we need to ensure that we continue to train up and add new developers if we are to keep up.
We need more documentation, more HOWTO guides, simpler infrastructure, easier patch submission, faster and less onerous on-boarding of developers, more bulk builds, more development machines. Plenty to be getting on with!
Some technical changes I'd like to see are better upgrade support, launchd support, integration of a working alternative pkg backend e.g. IPS, bmake IPC (so we don't need to recompute the same variables over and over), and many more!
Do you have any practical tips to share with the pkgsrc users?
Separate your build and install environments, so e.g. build in chroots or in a VM then deploy the built packages to your target. Trying to update a live install is the source of many problems, and there are few things more frustrating than having your development environment be messed up by an upgrade which fails part-way through.
For brand new users, document your experience and tell us what works and what sucks. Many of us have been using pkgsrc for many many years, and have lost your unique ability to identify problems, inconsistencies, and bad documentation.
If you run into problems, connect to Freenode IRC #pkgsrc, and we'll try to help you out. Hang out there even if you aren't having problems!
Finally, if you like pkgsrc, tell your friends, write blog posts, post to Hacker News etc. It's amazing to me how unknown pkgsrc is despite being around for so long, and how many people love it when they discover it.
More users leads to more developers, which leads to improved pkgsrc, which leads to more users, which...
What's the best way to start contributing to pkgsrc and what needs to be done?
Pick something that interests you and just start working on it. The great thing about pkgsrc is that there are open tasks for any ability, from documentation fixes all the way through adding packages to rewriting large parts of the infrastructure.
When you have something to contribute, don't worry about whether it's perfect or how you are to deliver it. Just make it available and let us know via PR, pull request, or just mail, and we can take it from there.
Do you plan to participate in the upcoming pkgsrcCon 2016 in Kraków (1-3 July)?
I am hoping to. If so I usually give a talk on what we've been working on at Joyent over the past year, and will probably do the same.
The pkgsrc team has prepared the 50th release of their package management system, with the 2016Q1 version. It's infrequent event, as the 100th release will be held after 50 quarters.
The NetBSD team has prepared series of interviews with the authors. The next one is with Ryo ONODERA, a Japanese developer maintaining large C++ packages.
Hi Ryo, please introduce yourself.
Hi,
I am hobbyist.
I maintain some large C++ packages, however my knowledge about recent C++ is poor.
My current home work is to learn modern C++.
First of all, congratulations on the 50th release of pkgsrc! How do you feel about this anniversary?
I am very glad to commit some changes for this remarkable 50th release.
I feel 50 releases is very long history.
The pkgsrc should be improved for next 100th anniversary.
What are the main benefits of the pkgsrc system?
The pkgsrc helps building from source.
Building from source is interesting and I have learned many things from it. It is worth for experiencing.
I like up-to-date software.
And I believe many people like latest software.
Recently security concerns us.
Sharing the recipe for latest software is getting worth, I believe.
Where and how do you use pkgsrc?
My laptop and home NAS run NetBSD/amd64.
And of course I uses pkgsrc.
And some day-job FreeBSD/amd64 servers also use pkgsrc.
What are the pkgsrc projects you are currently working on?
I am user of Mozilla Firefox (pkgsrc/www/firefox) and LibreOffice (pkgsrc/misc/libreoffice).
I need latest ones. And I will keep them up-to-date.
If you analyze the current state of pkgsrc, which improvements and changes do you wish for the future?
I feel Fortran support is not so powerful. This should be improved.
And Chromium browser should be ported to NetBSD.
If I setup great machine, I will try to do it.
Do you have any practical tips to share with the pkgsrc users?
Good /etc/mk.conf or /usr/pkg/etc/mk.conf improve your pkgsrc experience.
At least,
WRKOBJDIR=/usr/tmp/pkgsrc
and
MASTER_SITE_OVERRIDE=http://ftp.XX.netbsd.org/pub/pkgsrc/distfiles/
should improve your pkgsrc experience.
What's the best way to start contributing to pkgsrc and what needs to be done?
Updating simple package is good start point. For example, Font package or simple C software.
I recommend to get commit bit for pkgsrc-wip.
Committing your idea to the repository is invaluable experience.
Do you plan to participate in the upcoming pkgsrcCon 2016 in Kraków (1-3 July)?
Sadly, I cannot do long distance travel...
If video streaming is provided, I will watch it carefully!
Thank you.
Please use and contribute the pkgsrc!
The pkgsrc team has prepared the 50th release of their package management system, with the 2016Q1 version. It's infrequent event, as the 100th release will be held after 50 quarters.
The NetBSD team has prepared series of interviews with the authors. The next one is with Ryo ONODERA, a Japanese developer maintaining large C++ packages.
Hi Ryo, please introduce yourself.
Hi,
I am hobbyist.
I maintain some large C++ packages, however my knowledge about recent C++ is poor.
My current home work is to learn modern C++.
First of all, congratulations on the 50th release of pkgsrc! How do you feel about this anniversary?
I am very glad to commit some changes for this remarkable 50th release.
I feel 50 releases is very long history.
The pkgsrc should be improved for next 100th anniversary.
What are the main benefits of the pkgsrc system?
The pkgsrc helps building from source.
Building from source is interesting and I have learned many things from it. It is worth for experiencing.
I like up-to-date software.
And I believe many people like latest software.
Recently security concerns us.
Sharing the recipe for latest software is getting worth, I believe.
Where and how do you use pkgsrc?
My laptop and home NAS run NetBSD/amd64.
And of course I uses pkgsrc.
And some day-job FreeBSD/amd64 servers also use pkgsrc.
What are the pkgsrc projects you are currently working on?
I am user of Mozilla Firefox (pkgsrc/www/firefox) and LibreOffice (pkgsrc/misc/libreoffice).
I need latest ones. And I will keep them up-to-date.
If you analyze the current state of pkgsrc, which improvements and changes do you wish for the future?
I feel Fortran support is not so powerful. This should be improved.
And Chromium browser should be ported to NetBSD.
If I setup great machine, I will try to do it.
Do you have any practical tips to share with the pkgsrc users?
Good /etc/mk.conf or /usr/pkg/etc/mk.conf improve your pkgsrc experience.
At least,
WRKOBJDIR=/usr/tmp/pkgsrc
and
MASTER_SITE_OVERRIDE=http://ftp.XX.netbsd.org/pub/pkgsrc/distfiles/
should improve your pkgsrc experience.
What's the best way to start contributing to pkgsrc and what needs to be done?
Updating simple package is good start point. For example, Font package or simple C software.
I recommend to get commit bit for pkgsrc-wip.
Committing your idea to the repository is invaluable experience.
Do you plan to participate in the upcoming pkgsrcCon 2016 in Kraków (1-3 July)?
Sadly, I cannot do long distance travel...
If video streaming is provided, I will watch it carefully!
Thank you.
Please use and contribute the pkgsrc!
For the 10th time The NetBSD Foundation was selected for the GSoC 2016!
Now that we're near the first mid-term evaluation and have written the code during these weeks it's also the right time to start writing some reports regarding our projects in this series of blog posts.
About Split debug symbols for pkgsrc builds GSoC project
As part of Split debug symbols for pkgsrc builds GSoC project I'm
working to provide support for pkgsrc packages for splitted packages that just
contain debug symbols for their correspondent package (e.g. for the
foo-0.1.2.tgz package there will be a corresponding
foo-0.1.2-debugpkg.tgz package that just contains stripped debug
symbols of all the former binaries and libraries installed by
foo-0.1.2).
If you're more curious and you would like to know more information about it please take a look to the proposal.
Introduction
In this blog post we will learn how debug information are stored and stripped
off from the programs and/or libraries. We will first write a simple program and
a Makefile to analyze what MKDEBUG* flags in NetBSD do. Then we will take a look more in
depth to how everything is implemented in the various src/share/*.mk
files and at the end we will give a look to related works already implemented in
RPM and dpkg.
A pretty long list of references is also provided for the most curiouses readers!
A quick introduction to ELF and how debug information are stored/stripped off
In order to become familiar with ELF format a good starting point are Object file and Executable and Linkable Format pages from Wikipedia, the free encyclopedia.
Trying to describe ELF format is not easy in short terms so, it is strongly suggested to read the nice article series written by Eric Youngdale for Linux Journal: The ELF Object File Format: Introduction and The ELF Object File Format by Dissection. Please note that these two resources should be enough to completely understand this blog post!
After reading the above resources we have just learned that every programs and libraries in NetBSD (and several other Unix-like operating systems) uses the ELF format. There are four types of ELF object files:
- executable
- relocatable
- shared
- core
For more information regarding them please give a look to elf(5).
We are interested to understand what happens when we compile the
programs/libraries with debugging options (basically the -g option).
NetBSD already supports everything out of the box and so we can quickly start
looking at it just writing a simple Makefile and a program that will print the
lyrics of the famous Ten Green Bottles song! To avoid all the hassle of
providing (multiple times!) the right flags to the compiler and manually
invoke the right tool we can just write a very simple Makefile that will do
everything for us:
$ cat green-bottles/Makefile # $NetBSD$ NOMAN= # defined PROG= green-bottles .include <bsd.prog.mk>
Now that we have the Makefile we can start writing the green-bottles PROGram
(please note that all the green bottles accidentally fall were properly
recycled during the writing of this article):
$ cat green-bottles/green-bottles.c
#include <stdio.h>
void
sing_green_bottles(int n)
{
const char *numbers[] = { "no more", "one", "two", "three", "four", "five",
"six", "seven", "eight", "nine", "ten" };
if ((1 <= n) && (n <= 10)) {
printf("%s green bottle%s hanging on the wall\n",
numbers[n], n > 1 ? "s" : "");
printf("%s green bottle%s hanging on the wall\n",
numbers[n], n > 1 ? "s" : "");
printf("and if %s green bottle should accidentally fall,\n",
n > 2 ? "one" : "that");
printf("there'll be %s green bottles hanging on the wall.\n",
numbers[n - 1]);
}
return;
}
/*
* Sing the famous `Ten Green Bottles' song.
*/
int
main(void)
{
int i;
for (i = 10; i > 0; i--) {
sing_green_bottles(i);
}
return 0;
}
OK! Now everything is ready and if we just invoke make(1) we'll build the program. However, we would like to inspect what's happening behind the scenes, so we'll look at each steps. Please note that right now it is not important that you'll understand everything because we'll look at what make(1) magic do in more details later.
First, we compile the C program to generate the relocatable object file, i.e.
green-bottles.o:
$ cd green-bottles/ $ make green-bottles.o # compile green-bottles/green-bottles.o gcc -O2 -fPIE -std=gnu99 -Werror -c green-bottles.c ctfconvert -g -L VERSION green-bottles.o
Let's see what file(1) says regarding it:
$ file green-bottles.o green-bottles.o: ELF 64-bit LSB relocatable, x86-64, version 1 (SYSV), not stripped
In order to get more information we can use readelf(1) tool provided by the
binutils (GNU binary utilities),
e.g. via readelf -h (the -h option is used
to just print the file headers, if you would like to get more information you
can use the -a option instead):
$ readelf -h green-bottles.o ELF Header: Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00 Class: ELF64 Data: 2's complement, little endian Version: 1 (current) OS/ABI: UNIX - System V ABI Version: 0 Type: REL (Relocatable file) Machine: Advanced Micro Devices X86-64 Version: 0x1 Entry point address: 0x0 Start of program headers: 0 (bytes into file) Start of section headers: 2816 (bytes into file) Flags: 0x0 Size of this header: 64 (bytes) Size of program headers: 0 (bytes) Number of program headers: 0 Size of section headers: 64 (bytes) Number of section headers: 17 Section header string table index: 13
We can see the 17 sections always via readelf (-S option).
Now let's recompile it but via the debugging options turned on:
$ make green-bottles.o MKDEBUG=yes # compile green-bottles/green-bottles.o gcc -O2 -fPIE -g -std=gnu99 -Werror -c green-bottles.c ctfconvert -g -L VERSION -g green-bottles.o
If we are careful we can see that unlike the previous make incantation now the
-g option is passed to the compiler... Let's see if we can inspect that via
readelf:
$ readelf -h green-bottles.o ELF Header: Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00 Class: ELF64 Data: 2's complement, little endian Version: 1 (current) OS/ABI: UNIX - System V ABI Version: 0 Type: REL (Relocatable file) Machine: Advanced Micro Devices X86-64 Version: 0x1 Entry point address: 0x0 Start of program headers: 0 (bytes into file) Start of section headers: 6424 (bytes into file) Flags: 0x0 Size of this header: 64 (bytes) Size of program headers: 0 (bytes) Number of program headers: 0 Size of section headers: 64 (bytes) Number of section headers: 29 Section header string table index: 25
We can note several differences compared to the previous relocatable file
compiled without MKDEBUG:
- Start of section headers (previously 2816, now 6424)
- Number of section headers (previously 17, now 29)
- Section header string table index (previously 13, now 25)
If we compare the sections between the two relocatable files (tips: using:
readelf -WS green-bottles.o | sed -nEe 's/^ \[ *([0-9]+)\] ([^ ]*) .*/\2/p'
is a possible way to do it) we can observe the following new ELF sections:
-
.debug_info: contains main DWARF DIEs (Debugging Information Entry) -
.debug_abbrev: contains abbreviations used in.debug_infosection -
.debug_loc: contains location expressions -
.debug_aranges: contains a table for lookup by addresses of program entities (i.e. data objects, types, functions) -
.debug_ranges: contains address ranges referenced by DIEs -
.debug_line: contains line number program -
.debug_str: contains all strings referenced by.debug_info -
other
.rela.debug_*
It's time to finally build the program:
$ make green-bottles rm -f .gdbinit touch .gdbinit # link green-bottles/green-bottles gcc -pie -shared-libgcc -o green-bottles green-bottles.o -Wl,-rpath-link,/lib -L=/lib ctfmerge -t -g -L VERSION -o green-bottles green-bottles.o
We can observe:
$ readelf -h green-bottles ELF Header: Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00 Class: ELF64 Data: 2's complement, little endian Version: 1 (current) OS/ABI: UNIX - System V ABI Version: 0 Type: DYN (Shared object file) Machine: Advanced Micro Devices X86-64 Version: 0x1 Entry point address: 0x730 Start of program headers: 64 (bytes into file) Start of section headers: 6448 (bytes into file) Flags: 0x0 Size of this header: 64 (bytes) Size of program headers: 56 (bytes) Number of program headers: 7 Size of section headers: 64 (bytes) Number of section headers: 31 Section header string table index: 27
...and for its counterpart compiled via MKDEBUG=yes:
$ readelf -h green-bottles ELF Header: Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00 Class: ELF64 Data: 2's complement, little endian Version: 1 (current) OS/ABI: UNIX - System V ABI Version: 0 Type: DYN (Shared object file) Machine: Advanced Micro Devices X86-64 Version: 0x1 Entry point address: 0x730 Start of program headers: 64 (bytes into file) Start of section headers: 8304 (bytes into file) Flags: 0x0 Size of this header: 64 (bytes) Size of program headers: 56 (bytes) Number of program headers: 7 Size of section headers: 64 (bytes) Number of section headers: 38 Section header string table index: 34
Not so surprisingly the number of the 7 extra sections are exactly the
.debug_* ones!
Now that it's clear the difference between the program compiled with/without
-g option let's see what happen when the debug symbols are stripped off the
program:
$ make green-bottles.debug MKDEBUG=yes # create green-bottles/green-bottles.debug ( objcopy --only-keep-debug green-bottles green-bottles.debug && objcopy --strip-debug -p -R .gnu_debuglink --add-gnu-debuglink=green-bottles.debug green-bottles ) || (rm -f green-bottles.debug; false)
We can try to describe what happened with an image:
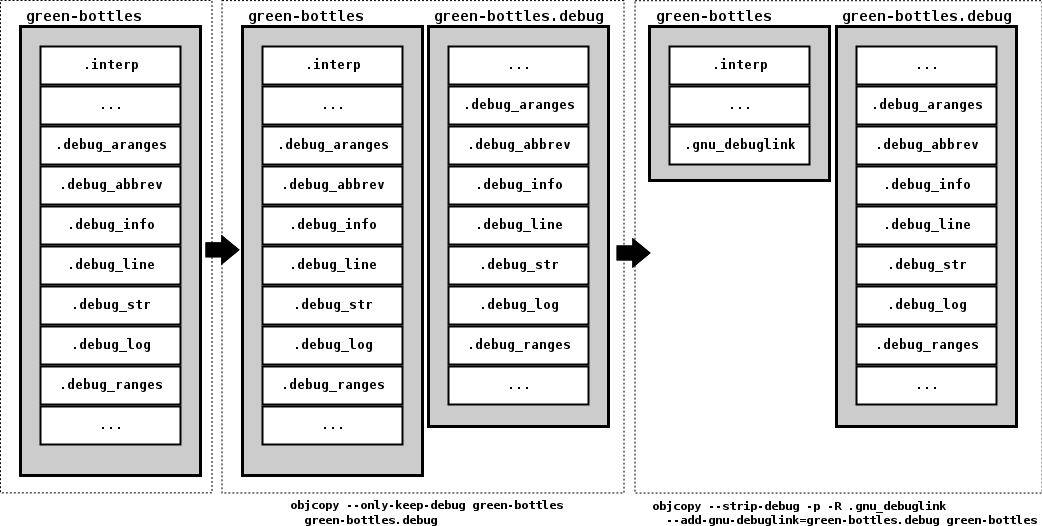
The first objcopy(1)
incantation generate the green-bottles.debug
file.
The second objcopy(1)
incantation strip the debug symbols off
green-bottles (now that they're stored in
green-bottles.debug they are no more needed) and add the
.gnu_debuglink ELF section to it.
Let's quickly look them via file(1):
$ file green-bottles green-bottles.debug green-bottles: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, interpreter /usr/libexec/ld.elf_so, for NetBSD 7.99.29, not stripped green-bottles.debug: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, interpreter *empty*, for NetBSD 7.99.29, not stripped
Using readelf we can note that now green-bottles has 32 sections and
green-bottles.debug has 38 sections. green-bottles has one extra section that
was added by the objcopy(1) incantation, let's see it:
$ readelf -x '.gnu_debuglink' green-bottles Hex dump of section '.gnu_debuglink': 0x00000000 67726565 6e2d626f 74746c65 732e6465 green-bottles.de 0x00000010 62756700 90b06f1c bug...o.
The .gnu_debuglink section contain the basename(3) of the .debug file and
its CRC32. The .gnu_debuglink section is used to properly pick the correct
.debug file from the DEBUGDIR directory (we'll see how it will work later when
we will invoke the GNU debugger).
Regarding the sections in the .debug file all of them are preserved but several
have no data, we can check that by invoking:
$ readelf `seq -f '-x %g' 0 37` green-bottles.debug $ readelf `seq -f '-x %g' 0 31` green-bottles
...and comparing their respective output.
Now that everything should be clearer we can just try to invoke it through gdb(1) and see what happens:
$ gdb ./green-bottles
GNU gdb (GDB) 7.10.1
Copyright (C) 2015 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "x86_64--netbsd".
Type "show configuration" for configuration details.
For bug reporting instructions, please see:
<http://www.gnu.org/software/gdb/bugs/>.
Find the GDB manual and other documentation resources online at:
<http://www.gnu.org/software/gdb/documentation/>.
For help, type "help".
Type "apropos word" to search for commands related to "word"...
Reading symbols from ./green-bottles...Reading symbols from /tmp/green-bottles/green-bottles.debug...done.
done.
(gdb) b main
Breakpoint 1 at 0xac0: file green-bottles.c, line 29.
(gdb) b sing_green_bottles
Breakpoint 2 at 0x940: file green-bottles.c, line 5.
(gdb) run
Starting program: /tmp/green-bottles/green-bottles
Breakpoint 1, main () at green-bottles.c:29
29 {
(gdb) n
32 for (i = 10; i > 0; i--) {
(gdb) n
33 sing_green_bottles(i);
(gdb) print i
$1 = 10
(gdb) cont
Continuing.
Breakpoint 2, sing_green_bottles (n=10) at green-bottles.c:5
5 {
(gdb) bt
#0 sing_green_bottles (n=10) at green-bottles.c:5
#1 0x00000000b7802ad7 in main () at green-bottles.c:33
[... we can now looks and debug it as we wish! ...]
So we can see that the green-bottles.debug file is loaded from the same
directory where green-bottles program was present (in our case
/tmp/green-bottles/ but if a corresponding file .debug is not
found gdb look for it in the DEBUGDIR, i.e. /usr/libdata/debug/;
e.g. for /usr/bin/yes it will look for debug symbols in
/usr/libdata/debug//usr/bin/yes.debug).
This is the same for all other programs and libraries.
A look to what MKDEBUG and MKDEBUGLIB do
NetBSD already provides MKDEBUG and MKDEBUGLIB mk.conf(5) variables to achieve the
separation of the debug symbols. They respectively split symbols from programs
and libraries.
The implementation to do that is in src/share/mk/bsd.prog.mk (for programs) and src/share/mk/bsd.lib.mk (for libraries). Several global variables used are defined in src/share/mk/bsd.own.mk.
bsd.prog.mk
In bsd.prog.mk:58
if MKDEBUG is defined and not "no" [sic] the -g flag is
added to CFLAGS.
In bsd.prog.mk:310
the internal __progdebuginstall make target is defined to
install the .debug file for the respective program. It is then called from
bsd.prog.mk:589
and bsd.prog.mk:604
(respectively for MKUPDATE == "no" and MKUPDATE != "no", please note
the dependency operators ! vs : for the two cases).
In bsd.prog.mk:437
_PROGDEBUG.${_P} is defined as ${PROGNAME.${_P}}.debug,
inside a for loop. ${_P} is just an element of the ${PROGS} and ${PROGS_CXX}
lists.
E.g.: for src/bin/echo
echo is the PROG value. bsd.prog.mk
turns single-program PROG and PROG_CXX variable into the multi-word PROGS and
PROGS_CXX variables.
In bsd.prog.mk:545
there is the most important part. After checking if
_PROGDEBUG.${_P} is defined a ${_PROGDEBUG.${_P}} target is defined and
${OBJCOPY} is invoked two times. In the first incantation the
${_PROGDEBUG.${_P}} file (containing the strip debug symbols) is generated for
${_P}. The second incantation is needed to get rid of (now no more needed) debug
symbols from ${_P} and --add-gnu-debuglink add a .gnu_debuglink section to
${_P} containing the filename of the ${_PROGDEBUG.${_P}}; e.g. for echo it
will be echo.debug (plus the CRC32 of echo.debug - padded as needed).
Regarding other options used by ${OBJCOPY} we should note the -p option needed
to preserve dates and -R is added in order to be sure to update the
.gnu_debuglink section.
For a gentler introduction and to understand why these steps are needed please
read (gdb.info)Separate Debug Files
(you can just use info(1), i.e. info
'(gdb.info)Separate Debug Files').
bsd.lib.mk
The logic and objcopy(1)
incantation are similar to the ones used in
bsd.prog.mk.
The most interesting part is in bsd.lib.mk:622.
Apart the *.debug
files if MKDEBUGLIB is defined and not "no" [sic] also *_g.a archives are
created for the respective libraries archives (although they are stored
directly in the several lib/ directories not in /usr/libdata/debug/).
bsd.own.mk
In bsd.own.mk
various DEBUG* variables are defined:
-
DEBUGDIR: where*.debugfiles are stored. Please notice that this is also the place where debugging symbols are looked (for more information please give a look to objcopy(1)) -
DEBUGGRP: the-goption passed to install(1) for installing debug symbols -
DEBUGOWN: the-ooption passed to install(1) for installing debug symbols -
DEBUGMODE: the-moption passed to install(1) for installing debug symbols
Related works
dpkg
The Debian Developer's Reference
written by the Developer's Reference Team
has a
Best practices for debug packages (section 6.7.9).
The logic used is more or less the same of the one used by src/share/mk in
NetBSD and described above.
After a quick inspection of
dh_strip
(part of debhelper package) some interesting ideas to look further are:
-
the file(1) logic used in
testfile()subroutine -
handling of non-C/C++ programming languages: OCaml native code shared
libraries (
*.cmxs) and nodejs binaries (*.node)
RPM
The Fedora Project Wiki contains some interesting tips, in particular regarding most common issues that happens in stripping debugging symbols in the Packaging:Debuginfo page. Some of the logic is handled in find-debuginfo.sh.
Another interesting resource is the
Releases/FeatureBuildId page.
The page discusses what Red Hat have done regarding using the .note.gnu.build-id
section and why have done them.
(Yet another) interesting idea adopted by Fedora developers is the
Features/MiniDebugInfo.
More information regarding MiniDebugInfo are also present in
(gdb.info)MiniDebugInfo.
Please note that this is not completely related to
stripping debugging symbols (indeed the MiniDebugInfo is directly stored in
program/library!) but can be considered in order to provide better .core (both
in the pkgsrc and NetBSD cases).
Mark J. Wielaard presented in FOSDEM 2016 a talk that summarizes many of the thematics discussed in this diary. Abstract, video recording and more resources are available in the FOSDEM website correspective event page: Where are your symbols, debuginfo and sources?. Apart his talk a very interesting reading is his blog post regarding the talk. In the blog post there are a lot of interesting information, all worth to be taken in consideration also for the pkgsrc case.
Conclusion
In this blog post we have learned what's happening when we use
MKDEBUG*
mk.conf(5) variables
and how everything works.
We have also gave a quick look to other related works, in particular
RPM and dpkg package managers.
If you are curious on what I'm doing right now and you would like to also look at the code you can give a look to the git pkgsrc repository repository fork in the debugpkg branch.
Apart the several references discussed above if you would like to learn more
about several aspects that wasn't discussed there...
Introduction to the DWARF Debugging Format
written by Michael Eager
is a good starting point for DWARF (debugging data format); you can also use
objdump -g to show these information in the *.debug
files.
Regarding GDB a
gentle introduction to it is
Using GNU's GDB Debugger
by Peter Jay Salzman.
I would like to thanks Google for organizing Google Summer of Code and The NetBSD Foundation, without them I would not be able to work on this project!
A particular and big thank you goes to my mentors David Maxwell, Jöerg Sonnenberger, Taylor R. Campbell, Thomas Klausner and William J. Coldwell for the invaluable help, guidance and feedbacks they're providing!
References
- The ELF Object File Format: Introduction, Eric Youngdale
- The ELF Object File Format by Dissection, Eric Youngdale
- Tool Interface Standard (TIS) Executable and Linking Format (ELF) Specification Version 1.2, TIS Committee
- DWARF Debugging Information Format Version 4, DWARF Debugging Information Format Committee
- Introduction to the DWARF Debugging Format, Michael Eager
- Debugging with GDB Tenth Edition for GDB Version 7.10.1, Free Software Foundation, Inc.
- Using GNU's GDB Debugger, Peter Jay Salzman
- Debian Developer's Reference, Developer's Reference Team
- Where are your Symbols, Debuginfo and Sources?, Mark J. Wielaard
- make(1)
- elf(5)
- file(1)
- gcc(1)
- readelf(1)
- objdump(1)
- objcompy(1)
- gdb(1)
- src/share/bsd.README, 1.353
- src/share/bsd.prog.mk, 1.299
- src/share/bsd.lib.mk, 1.367
- src/share/bsd.own.mk, 1.927
For the 10th time The NetBSD Foundation was selected for the GSoC 2016!
Now that we're near the first mid-term evaluation and have written the code during these weeks it's also the right time to start writing some reports regarding our projects in this series of blog posts.
About Split debug symbols for pkgsrc builds GSoC project
As part of Split debug symbols for pkgsrc builds GSoC project I'm
working to provide support for pkgsrc packages for splitted packages that just
contain debug symbols for their correspondent package (e.g. for the
foo-0.1.2.tgz package there will be a corresponding
foo-0.1.2-debugpkg.tgz package that just contains stripped debug
symbols of all the former binaries and libraries installed by
foo-0.1.2).
If you're more curious and you would like to know more information about it please take a look to the proposal.
Introduction
In this blog post we will learn how debug information are stored and stripped
off from the programs and/or libraries. We will first write a simple program and
a Makefile to analyze what MKDEBUG* flags in NetBSD do. Then we will take a look more in
depth to how everything is implemented in the various src/share/*.mk
files and at the end we will give a look to related works already implemented in
RPM and dpkg.
A pretty long list of references is also provided for the most curiouses readers!
A quick introduction to ELF and how debug information are stored/stripped off
In order to become familiar with ELF format a good starting point are Object file and Executable and Linkable Format pages from Wikipedia, the free encyclopedia.
Trying to describe ELF format is not easy in short terms so, it is strongly suggested to read the nice article series written by Eric Youngdale for Linux Journal: The ELF Object File Format: Introduction and The ELF Object File Format by Dissection. Please note that these two resources should be enough to completely understand this blog post!
After reading the above resources we have just learned that every programs and libraries in NetBSD (and several other Unix-like operating systems) uses the ELF format. There are four types of ELF object files:
- executable
- relocatable
- shared
- core
For more information regarding them please give a look to elf(5).
We are interested to understand what happens when we compile the
programs/libraries with debugging options (basically the -g option).
NetBSD already supports everything out of the box and so we can quickly start
looking at it just writing a simple Makefile and a program that will print the
lyrics of the famous Ten Green Bottles song! To avoid all the hassle of
providing (multiple times!) the right flags to the compiler and manually
invoke the right tool we can just write a very simple Makefile that will do
everything for us:
$ cat green-bottles/Makefile # $NetBSD$ NOMAN= # defined PROG= green-bottles .include <bsd.prog.mk>
Now that we have the Makefile we can start writing the green-bottles PROGram
(please note that all the green bottles accidentally fall were properly
recycled during the writing of this article):
$ cat green-bottles/green-bottles.c
#include <stdio.h>
void
sing_green_bottles(int n)
{
const char *numbers[] = { "no more", "one", "two", "three", "four", "five",
"six", "seven", "eight", "nine", "ten" };
if ((1 <= n) && (n <= 10)) {
printf("%s green bottle%s hanging on the wall\n",
numbers[n], n > 1 ? "s" : "");
printf("%s green bottle%s hanging on the wall\n",
numbers[n], n > 1 ? "s" : "");
printf("and if %s green bottle should accidentally fall,\n",
n > 2 ? "one" : "that");
printf("there'll be %s green bottles hanging on the wall.\n",
numbers[n - 1]);
}
return;
}
/*
* Sing the famous `Ten Green Bottles' song.
*/
int
main(void)
{
int i;
for (i = 10; i > 0; i--) {
sing_green_bottles(i);
}
return 0;
}
OK! Now everything is ready and if we just invoke make(1) we'll build the program. However, we would like to inspect what's happening behind the scenes, so we'll look at each steps. Please note that right now it is not important that you'll understand everything because we'll look at what make(1) magic do in more details later.
First, we compile the C program to generate the relocatable object file, i.e.
green-bottles.o:
$ cd green-bottles/ $ make green-bottles.o # compile green-bottles/green-bottles.o gcc -O2 -fPIE -std=gnu99 -Werror -c green-bottles.c ctfconvert -g -L VERSION green-bottles.o
Let's see what file(1) says regarding it:
$ file green-bottles.o green-bottles.o: ELF 64-bit LSB relocatable, x86-64, version 1 (SYSV), not stripped
In order to get more information we can use readelf(1) tool provided by the
binutils (GNU binary utilities),
e.g. via readelf -h (the -h option is used
to just print the file headers, if you would like to get more information you
can use the -a option instead):
$ readelf -h green-bottles.o ELF Header: Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00 Class: ELF64 Data: 2's complement, little endian Version: 1 (current) OS/ABI: UNIX - System V ABI Version: 0 Type: REL (Relocatable file) Machine: Advanced Micro Devices X86-64 Version: 0x1 Entry point address: 0x0 Start of program headers: 0 (bytes into file) Start of section headers: 2816 (bytes into file) Flags: 0x0 Size of this header: 64 (bytes) Size of program headers: 0 (bytes) Number of program headers: 0 Size of section headers: 64 (bytes) Number of section headers: 17 Section header string table index: 13
We can see the 17 sections always via readelf (-S option).
Now let's recompile it but via the debugging options turned on:
$ make green-bottles.o MKDEBUG=yes # compile green-bottles/green-bottles.o gcc -O2 -fPIE -g -std=gnu99 -Werror -c green-bottles.c ctfconvert -g -L VERSION -g green-bottles.o
If we are careful we can see that unlike the previous make incantation now the
-g option is passed to the compiler... Let's see if we can inspect that via
readelf:
$ readelf -h green-bottles.o ELF Header: Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00 Class: ELF64 Data: 2's complement, little endian Version: 1 (current) OS/ABI: UNIX - System V ABI Version: 0 Type: REL (Relocatable file) Machine: Advanced Micro Devices X86-64 Version: 0x1 Entry point address: 0x0 Start of program headers: 0 (bytes into file) Start of section headers: 6424 (bytes into file) Flags: 0x0 Size of this header: 64 (bytes) Size of program headers: 0 (bytes) Number of program headers: 0 Size of section headers: 64 (bytes) Number of section headers: 29 Section header string table index: 25
We can note several differences compared to the previous relocatable file
compiled without MKDEBUG:
- Start of section headers (previously 2816, now 6424)
- Number of section headers (previously 17, now 29)
- Section header string table index (previously 13, now 25)
If we compare the sections between the two relocatable files (tips: using:
readelf -WS green-bottles.o | sed -nEe 's/^ \[ *([0-9]+)\] ([^ ]*) .*/\2/p'
is a possible way to do it) we can observe the following new ELF sections:
-
.debug_info: contains main DWARF DIEs (Debugging Information Entry) -
.debug_abbrev: contains abbreviations used in.debug_infosection -
.debug_loc: contains location expressions -
.debug_aranges: contains a table for lookup by addresses of program entities (i.e. data objects, types, functions) -
.debug_ranges: contains address ranges referenced by DIEs -
.debug_line: contains line number program -
.debug_str: contains all strings referenced by.debug_info -
other
.rela.debug_*
It's time to finally build the program:
$ make green-bottles rm -f .gdbinit touch .gdbinit # link green-bottles/green-bottles gcc -pie -shared-libgcc -o green-bottles green-bottles.o -Wl,-rpath-link,/lib -L=/lib ctfmerge -t -g -L VERSION -o green-bottles green-bottles.o
We can observe:
$ readelf -h green-bottles ELF Header: Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00 Class: ELF64 Data: 2's complement, little endian Version: 1 (current) OS/ABI: UNIX - System V ABI Version: 0 Type: DYN (Shared object file) Machine: Advanced Micro Devices X86-64 Version: 0x1 Entry point address: 0x730 Start of program headers: 64 (bytes into file) Start of section headers: 6448 (bytes into file) Flags: 0x0 Size of this header: 64 (bytes) Size of program headers: 56 (bytes) Number of program headers: 7 Size of section headers: 64 (bytes) Number of section headers: 31 Section header string table index: 27
...and for its counterpart compiled via MKDEBUG=yes:
$ readelf -h green-bottles ELF Header: Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00 Class: ELF64 Data: 2's complement, little endian Version: 1 (current) OS/ABI: UNIX - System V ABI Version: 0 Type: DYN (Shared object file) Machine: Advanced Micro Devices X86-64 Version: 0x1 Entry point address: 0x730 Start of program headers: 64 (bytes into file) Start of section headers: 8304 (bytes into file) Flags: 0x0 Size of this header: 64 (bytes) Size of program headers: 56 (bytes) Number of program headers: 7 Size of section headers: 64 (bytes) Number of section headers: 38 Section header string table index: 34
Not so surprisingly the number of the 7 extra sections are exactly the
.debug_* ones!
Now that it's clear the difference between the program compiled with/without
-g option let's see what happen when the debug symbols are stripped off the
program:
$ make green-bottles.debug MKDEBUG=yes # create green-bottles/green-bottles.debug ( objcopy --only-keep-debug green-bottles green-bottles.debug && objcopy --strip-debug -p -R .gnu_debuglink --add-gnu-debuglink=green-bottles.debug green-bottles ) || (rm -f green-bottles.debug; false)
We can try to describe what happened with an image:
The first objcopy(1)
incantation generate the green-bottles.debug
file.
The second objcopy(1)
incantation strip the debug symbols off
green-bottles (now that they're stored in
green-bottles.debug they are no more needed) and add the
.gnu_debuglink ELF section to it.
Let's quickly look them via file(1):
$ file green-bottles green-bottles.debug green-bottles: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, interpreter /usr/libexec/ld.elf_so, for NetBSD 7.99.29, not stripped green-bottles.debug: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, interpreter *empty*, for NetBSD 7.99.29, not stripped
Using readelf we can note that now green-bottles has 32 sections and
green-bottles.debug has 38 sections. green-bottles has one extra section that
was added by the objcopy(1) incantation, let's see it:
$ readelf -x '.gnu_debuglink' green-bottles Hex dump of section '.gnu_debuglink': 0x00000000 67726565 6e2d626f 74746c65 732e6465 green-bottles.de 0x00000010 62756700 90b06f1c bug...o.
The .gnu_debuglink section contain the basename(3) of the .debug file and
its CRC32. The .gnu_debuglink section is used to properly pick the correct
.debug file from the DEBUGDIR directory (we'll see how it will work later when
we will invoke the GNU debugger).
Regarding the sections in the .debug file all of them are preserved but several
have no data, we can check that by invoking:
$ readelf `seq -f '-x %g' 0 37` green-bottles.debug $ readelf `seq -f '-x %g' 0 31` green-bottles
...and comparing their respective output.
Now that everything should be clearer we can just try to invoke it through gdb(1) and see what happens:
$ gdb ./green-bottles
GNU gdb (GDB) 7.10.1
Copyright (C) 2015 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "x86_64--netbsd".
Type "show configuration" for configuration details.
For bug reporting instructions, please see:
<http://www.gnu.org/software/gdb/bugs/>.
Find the GDB manual and other documentation resources online at:
<http://www.gnu.org/software/gdb/documentation/>.
For help, type "help".
Type "apropos word" to search for commands related to "word"...
Reading symbols from ./green-bottles...Reading symbols from /tmp/green-bottles/green-bottles.debug...done.
done.
(gdb) b main
Breakpoint 1 at 0xac0: file green-bottles.c, line 29.
(gdb) b sing_green_bottles
Breakpoint 2 at 0x940: file green-bottles.c, line 5.
(gdb) run
Starting program: /tmp/green-bottles/green-bottles
Breakpoint 1, main () at green-bottles.c:29
29 {
(gdb) n
32 for (i = 10; i > 0; i--) {
(gdb) n
33 sing_green_bottles(i);
(gdb) print i
$1 = 10
(gdb) cont
Continuing.
Breakpoint 2, sing_green_bottles (n=10) at green-bottles.c:5
5 {
(gdb) bt
#0 sing_green_bottles (n=10) at green-bottles.c:5
#1 0x00000000b7802ad7 in main () at green-bottles.c:33
[... we can now looks and debug it as we wish! ...]
So we can see that the green-bottles.debug file is loaded from the same
directory where green-bottles program was present (in our case
/tmp/green-bottles/ but if a corresponding file .debug is not
found gdb look for it in the DEBUGDIR, i.e. /usr/libdata/debug/;
e.g. for /usr/bin/yes it will look for debug symbols in
/usr/libdata/debug//usr/bin/yes.debug).
This is the same for all other programs and libraries.
A look to what MKDEBUG and MKDEBUGLIB do
NetBSD already provides MKDEBUG and MKDEBUGLIB mk.conf(5) variables to achieve the
separation of the debug symbols. They respectively split symbols from programs
and libraries.
The implementation to do that is in src/share/mk/bsd.prog.mk (for programs) and src/share/mk/bsd.lib.mk (for libraries). Several global variables used are defined in src/share/mk/bsd.own.mk.
bsd.prog.mk
In bsd.prog.mk:58
if MKDEBUG is defined and not "no" [sic] the -g flag is
added to CFLAGS.
In bsd.prog.mk:310
the internal __progdebuginstall make target is defined to
install the .debug file for the respective program. It is then called from
bsd.prog.mk:589
and bsd.prog.mk:604
(respectively for MKUPDATE == "no" and MKUPDATE != "no", please note
the dependency operators ! vs : for the two cases).
In bsd.prog.mk:437
_PROGDEBUG.${_P} is defined as ${PROGNAME.${_P}}.debug,
inside a for loop. ${_P} is just an element of the ${PROGS} and ${PROGS_CXX}
lists.
E.g.: for src/bin/echo
echo is the PROG value. bsd.prog.mk
turns single-program PROG and PROG_CXX variable into the multi-word PROGS and
PROGS_CXX variables.
In bsd.prog.mk:545
there is the most important part. After checking if
_PROGDEBUG.${_P} is defined a ${_PROGDEBUG.${_P}} target is defined and
${OBJCOPY} is invoked two times. In the first incantation the
${_PROGDEBUG.${_P}} file (containing the strip debug symbols) is generated for
${_P}. The second incantation is needed to get rid of (now no more needed) debug
symbols from ${_P} and --add-gnu-debuglink add a .gnu_debuglink section to
${_P} containing the filename of the ${_PROGDEBUG.${_P}}; e.g. for echo it
will be echo.debug (plus the CRC32 of echo.debug - padded as needed).
Regarding other options used by ${OBJCOPY} we should note the -p option needed
to preserve dates and -R is added in order to be sure to update the
.gnu_debuglink section.
For a gentler introduction and to understand why these steps are needed please
read (gdb.info)Separate Debug Files
(you can just use info(1), i.e. info
'(gdb.info)Separate Debug Files').
bsd.lib.mk
The logic and objcopy(1)
incantation are similar to the ones used in
bsd.prog.mk.
The most interesting part is in bsd.lib.mk:622.
Apart the *.debug
files if MKDEBUGLIB is defined and not "no" [sic] also *_g.a archives are
created for the respective libraries archives (although they are stored
directly in the several lib/ directories not in /usr/libdata/debug/).
bsd.own.mk
In bsd.own.mk
various DEBUG* variables are defined:
-
DEBUGDIR: where*.debugfiles are stored. Please notice that this is also the place where debugging symbols are looked (for more information please give a look to objcopy(1)) -
DEBUGGRP: the-goption passed to install(1) for installing debug symbols -
DEBUGOWN: the-ooption passed to install(1) for installing debug symbols -
DEBUGMODE: the-moption passed to install(1) for installing debug symbols
Related works
dpkg
The Debian Developer's Reference
written by the Developer's Reference Team
has a
Best practices for debug packages (section 6.7.9).
The logic used is more or less the same of the one used by src/share/mk in
NetBSD and described above.
After a quick inspection of
dh_strip
(part of debhelper package) some interesting ideas to look further are:
-
the file(1) logic used in
testfile()subroutine -
handling of non-C/C++ programming languages: OCaml native code shared
libraries (
*.cmxs) and nodejs binaries (*.node)
RPM
The Fedora Project Wiki contains some interesting tips, in particular regarding most common issues that happens in stripping debugging symbols in the Packaging:Debuginfo page. Some of the logic is handled in find-debuginfo.sh.
Another interesting resource is the
Releases/FeatureBuildId page.
The page discusses what Red Hat have done regarding using the .note.gnu.build-id
section and why have done them.
(Yet another) interesting idea adopted by Fedora developers is the
Features/MiniDebugInfo.
More information regarding MiniDebugInfo are also present in
(gdb.info)MiniDebugInfo.
Please note that this is not completely related to
stripping debugging symbols (indeed the MiniDebugInfo is directly stored in
program/library!) but can be considered in order to provide better .core (both
in the pkgsrc and NetBSD cases).
Mark J. Wielaard presented in FOSDEM 2016 a talk that summarizes many of the thematics discussed in this diary. Abstract, video recording and more resources are available in the FOSDEM website correspective event page: Where are your symbols, debuginfo and sources?. Apart his talk a very interesting reading is his blog post regarding the talk. In the blog post there are a lot of interesting information, all worth to be taken in consideration also for the pkgsrc case.
Conclusion
In this blog post we have learned what's happening when we use
MKDEBUG*
mk.conf(5) variables
and how everything works.
We have also gave a quick look to other related works, in particular
RPM and dpkg package managers.
If you are curious on what I'm doing right now and you would like to also look at the code you can give a look to the git pkgsrc repository repository fork in the debugpkg branch.
Apart the several references discussed above if you would like to learn more
about several aspects that wasn't discussed there...
Introduction to the DWARF Debugging Format
written by Michael Eager
is a good starting point for DWARF (debugging data format); you can also use
objdump -g to show these information in the *.debug
files.
Regarding GDB a
gentle introduction to it is
Using GNU's GDB Debugger
by Peter Jay Salzman.
I would like to thanks Google for organizing Google Summer of Code and The NetBSD Foundation, without them I would not be able to work on this project!
A particular and big thank you goes to my mentors David Maxwell, Jöerg Sonnenberger, Taylor R. Campbell, Thomas Klausner and William J. Coldwell for the invaluable help, guidance and feedbacks they're providing!
References
- The ELF Object File Format: Introduction, Eric Youngdale
- The ELF Object File Format by Dissection, Eric Youngdale
- Tool Interface Standard (TIS) Executable and Linking Format (ELF) Specification Version 1.2, TIS Committee
- DWARF Debugging Information Format Version 4, DWARF Debugging Information Format Committee
- Introduction to the DWARF Debugging Format, Michael Eager
- Debugging with GDB Tenth Edition for GDB Version 7.10.1, Free Software Foundation, Inc.
- Using GNU's GDB Debugger, Peter Jay Salzman
- Debian Developer's Reference, Developer's Reference Team
- Where are your Symbols, Debuginfo and Sources?, Mark J. Wielaard
- make(1)
- elf(5)
- file(1)
- gcc(1)
- readelf(1)
- objdump(1)
- objcompy(1)
- gdb(1)
- src/share/bsd.README, 1.353
- src/share/bsd.prog.mk, 1.299
- src/share/bsd.lib.mk, 1.367
- src/share/bsd.own.mk, 1.927
So, can we do better? Looking at the size of a GENERIC kernel:
text data bss dec hex filename 2997389 67748 173044 3238181 316925 netbsdit seems we can not easily go below 4 MB (and for other reasons we would need to compile the bootloader differently for that anyway). But 16MB is still quite a difference, so it should work.
Now at the time I started this quest, I only had one VAX machine in real hardware - a VaxStation 4000 M96a, one of the fastest machines, and with 128 MB RAM well equipped. This is nice if you try to natively compile modern gcc, but I did not feel like fiddling with my hardware to create a better test environment for small RAM installations.
Like a year (or so) ago, when I fixed the VAX primary boot blocks (with lots of help from various vaxperts on the port-vax mailing list), SIMH, found in pkgsrc as emulators/simh, proved helpful. Testing various configurations I found an emulated VAX 11/780 with 8 MB to be the smallest I could get working.
The first step of the tuning was obvious: the CD image used a ramdisk based kernel, with the ramdisk containing all of the install system. At the same time, most of the CD was unused. We already use different schemes on i386, amd64 and sparc64 - so I cloned the sparc64 one and adjusted it to VAX. Now we use the GENERIC kernel on CD and mount the ISO9660 filesystem on the CD itself as root file system. The VAX boot loader already could deal with this, only a minor fix was needed for the kernel to recognize some variants of CD drives as boot device.
The resulting CD did boot, but did not go far in userland. The CD did only contain a (mostly) empty /dev directory (without /dev/console), which causes init(8) to mount a tmpfs on /dev and run the MAKEDEV script there. But to my surprise, on the 11/780 mfs was used instead of tmpfs - and we will see why soon. Next step in preparation of the userland for the installer is creating additional tmpfs instances to deal with the read-only nature of the CD used as root. This did not work at all, the mount attempts simply failed - and the installer was very unhappy, as it could not create files in /tmp for example.
I checked, but tmpfs was part of the VAX GENERIC kernel. I tried the install CD on a simulated MicroVAX 3900 with 64 MB of RAM - and to my surprise all of /dev and the three additional tmpfs instances created later worked (as well as the installation procedure). I checked the source (stupid me) and then found the documentation: tmpfs reserved a hard coded 4 MB of RAM for the system. With the GENERIC kernel booted on a 8 MB machine, we had slightly less than 4 MB RAM free, so tmpfs never worked.
One step back - this explained why /dev ended up as a mfs instead of tmpfs. The MAKEDEV code is written to deal with kernels that do include tmpfs, but also with those that do not: it tried tmpfs, and falls back to mfs if that does not work. This made me think, I could do the same (but without even trying tmpfs): I changed the install CD scripts to use mfs instead of tmpfs. The main difference is: mfs uses a userland process to manage the swappable memory. However, we do not have any swap space yet. Checking when sysinst enables swapping for the first time, I found: it never did on VAX. Duh! I added the missing calls to machine dependent code in sysinst, but of course the installer can only enable swap after partitioning is done (and a swap partition got created).
Testing showed: we did not get far enough with four mfs instances. So let us try with fewer. One we do not need is the /dev one: I changed the CD content creation code to pre-populate /dev on the CD. This is not possible with all filesystems, including the original ISO9660 one, but with the so-called Rockridge Extensions it works. We know that it is a modern NetBSD kernel mounting the CD - so support for those extensions is always present. I made some errors and hit some bugs (that got fixed) on the way there, but soon the CD booted without creating a mfs (nor tmpfs) for /dev.
Still, three mfs instances did not survive until sysinst enabled swapping. The userland part was killed once the kernel ran out of memory. I needed tmpfs working with less than 4 MB memory free. After a slight detour and some discussion on the tech-kern mailing list, I changed tmpfs to deal (and only reserve a dynamically scaled amount of memory calculated bv the UVM memory management). With this change, a current install CD just works, and installation completes successful.
The following is just the start of the installation process, the sysinst part afterwards is standard stuff and left out for brevity.
Copyright (c) 1996, 1997, 1998, 1999, 2000, 2001, 2002, 2003, 2004, 2005,
2006, 2007, 2008, 2009, 2010, 2011, 2012, 2013, 2014
The NetBSD Foundation, Inc. All rights reserved.
Copyright (c) 1982, 1986, 1989, 1991, 1993
The Regents of the University of California. All rights reserved.
NetBSD 6.99.43 (GENERIC) #1: Thu Jun 5 22:01:14 CEST 2014
martin@night-owl.duskware.de:/usr/obj/vax/usr/src/sys/arch/vax/compile/GENERIC
VAX 11/780
total memory = 8188 KB
avail memory = 3884 KB
mainbus0 (root)
cpu0 at mainbus0: KA80, S/N 1234(0), hardware ECO level 7(112)
cpu0: 4KB L1 cachen, no FPA
sbi0 at mainbus0
mem0 at sbi0 tr1: standard
mem1 at sbi0 tr2: standard
uba1 at sbi0 tr3: DW780
dz1 at uba1 csr 160100 vec 304 ipl 15
mtc0 at uba1 csr 174500 vec 774 ipl 15
mscpbus0 at mtc0: version 5 model 5
mscpbus0: DMA burst size set to 4
uda0 at uba1 csr 172150 vec 770 ipl 15
mscpbus1 at uda0: version 3 model 6
mscpbus1: DMA burst size set to 4
de0 at uba1 csr 174510 vec 120 ipl 15: delua, hardware address 08:00:2b:cc:dd:ee
mt0 at mscpbus0 drive 0: TU81
mt1 at mscpbus0 drive 1: TU81
mt2 at mscpbus0 drive 2: TU81
mt3 at mscpbus0 drive 3: TU81
ra0 at mscpbus1 drive 0: RA92
ra1 at mscpbus1 drive 1: RA92
racd0 at mscpbus1 drive 3: RRD40
ra0: size 2940951 sectors
ra1: no disk label: size 2940951 sectors
racd0: size 1331200 sectors
boot device: racd0
root on racd0a dumps on racd0b
root file system type: cd9660
init: kernel secur
You are using a serial console, we do not know your terminal emulation.
Please select one, typical values are:
vt100
ansi
xterm
Terminal type (just hit ENTER for 'vt220'): xterm
NetBSD/vax 6.99.43
This menu-driven tool is designed to help you install NetBSD to a hard disk,
or upgrade an existing NetBSD system, with a minimum of work.
In the following menus type the reference letter (a, b, c, ...) to select an
item, or type CTRL+N/CTRL+P to select the next/previous item.
The arrow keys and Page-up/Page-down may also work.
Activate the current selection from the menu by typing the enter key.
+---------------------------------------------+
|>a: Installation messages in English |
| b: Installation auf Deutsch |
| c: Mensajes de instalacion en castellano |
| d: Messages d'installation en français |
| e: Komunikaty instalacyjne w jezyku polskim |
+---------------------------------------------+
Overall this improved NetBSD to better deal with small memory systems. The VAX specific install changes can be brought over to other ports as well, but sometimes changes to the bootloader will be needed.
As one of five, I've been chosen for participating in Google Summer Of Code (GSoC) this year for NetBSD. My project is to write a binary upgrade tool for NetBSD, optionally with a “live update” functionality.read moreWhy an upgrade tool? – Yes, updating currently is easy. You download the set tarballs from a mirror, unpack the kernel, reboot, unpack the rest, reboot, and done. But this is an exhausting procedure, and you have to know that there are actually updates, and what they affect.
Some time ago, Ingenics donated a CI20 board to me and I am in the process of getting that testable. Michael Lorenz did most of the needed work already, but there are issues with the network driver, which make automatic test runs hard.
When a few days ago cavium/octeon support was added to NetBSD-current, I just had to buy an ERLite-3 device:
This is probably the cheapest MIPS64 hardware currently available. It is in-store at many customer electronics shops all over the world.
The ERLite-3 uses a big-endian dual-core octeon chipset, has external serial console (via a cisco console cable) and three gigE ethernet ports. It also features an internal (built in) USB hard disk. It can be configured to boot the NetBSD kernel from that usb disk, or load it via tftp from another server. But booting from internal "disk" plus multiple gigE ports makes it an ideal device for a NetBSD based home or small office firewall, DNS cache, DHCP server setup.
From the NetBSD point of view this device is as plug&play as you can get. Connect the serial console cable, reboot it, press Ctrl-C during early boot and get to the u-boot prompt. Prepare a user land and kernel, like:
build.sh -m evbmips64-eb sets build.sh -m evbmips64-eb kernel=ERLITEThe kernel build will produce a "netbsd" and "netbsd.elf32" file. Extract the created sets in the NFS root directory, cd to the dev directory there and run "sh MAKEDEV all". Put "netbsd" into the NFS root directory. Copy "netbsd.elf32" to the tftp server directory (I renamed mine to "erlite.elf32") and then go back to the edge router console.
dhcp tftp $loadaddr erlite.elf32 bootoctlinuxand your kernel should boot. (Never mind the funny name of the boot command).
The obligatory dmesg:
Copyright (c) 1996, 1997, 1998, 1999, 2000, 2001, 2002, 2003, 2004, 2005,
2006, 2007, 2008, 2009, 2010, 2011, 2012, 2013, 2014, 2015
The NetBSD Foundation, Inc. All rights reserved.
Copyright (c) 1982, 1986, 1989, 1991, 1993
The Regents of the University of California. All rights reserved.
NetBSD 7.99.15 (ERLITE) #1: Wed May 6 21:40:41 CEST 2015
martin@night-owl.duskware.de:/usr/src/sys/arch/evbmips/compile/ERLITE
total memory = 512 MB
avail memory = 490 MB
timecounter: Timecounters tick every 10.000 msec
mainbus0 (root)
cpu0 at mainbus0: 500.00MHz (hz cycles = 5000000, delay divisor = 500)
cpu0: Cavium CN50xx (0xd0601) Rev. 1 with software emulated floating point
cpu0: 64 TLB entries, 512TB (49-bit) VAs, 512TB (49-bit) PAs, 256MB max page size
cpu0: 32KB/128B 4-way set-associative L1 instruction cache
cpu0: 16KB/128B 64-way set-associative write-back coherent L1 data cache
iobus0 at mainbus0
iobus0: initializing POW
iobus0: initializing FPA
com0 at iobus0: address=0x0001180000000800: ns16650, no ERS, working fifo
com0: console
com at iobus0: address=0x0001180000000c00 not configured
octeon_rnm0 at iobus0: address=0x0001180040000000
octeon_rnm0: random number generator enabled: 1hz
octeon_twsi at iobus0: address=0x0001180000001000 not configured
octeon_mpi at iobus0: address=0x0001070000001000 not configured
octeon_gmx0 at iobus0: address=0x0001180008000000
cnmac0 at octeon_gmx0: address=0x0001180008000000: RGMII
cnmac0: Ethernet address 04:18:d6:f0:4b:e4
atphy0 at cnmac0 phy 7: Atheros AR8035 10/100/1000 PHY, rev. 2
atphy0: 10baseT, 10baseT-FDX, 100baseTX, 100baseTX-FDX, 1000baseSX-FDX, 1000baseT-FDX, auto
cnmac1 at octeon_gmx0: address=0x0001180008000000: RGMII
cnmac1: Ethernet address 04:18:d6:f0:4b:e5
atphy1 at cnmac1 phy 6: Atheros AR8035 10/100/1000 PHY, rev. 2
atphy1: 10baseT, 10baseT-FDX, 100baseTX, 100baseTX-FDX, 1000baseSX-FDX, 1000baseT-FDX, auto
cnmac2 at octeon_gmx0: address=0x0001180008000000: RGMII
cnmac2: Ethernet address 04:18:d6:f0:4b:e6
atphy2 at cnmac2 phy 5: Atheros AR8035 10/100/1000 PHY, rev. 2
atphy2: 10baseT, 10baseT-FDX, 100baseTX, 100baseTX-FDX, 1000baseSX-FDX, 1000baseT-FDX, auto
dwctwo0 at iobus0: address=0x0001180068000000
usb0 at dwctwo0: USB revision 2.0
bootbus0 at mainbus0
timecounter: Timecounter "clockinterrupt" frequency 100 Hz quality 0
timecounter: Timecounter "mips3_cp0_counter" frequency 500000000 Hz quality 100
uhub0 at usb0: vendor 0000 DWC2 root hub, class 9/0, rev 2.00/1.00, addr 1
uhub0: 1 port with 1 removable, self powered
umass0 at uhub0 port 1 configuration 1 interface 0
umass0: vendor 13fe USB DISK 2.0, rev 2.00/1.00, addr 2
umass0: using SCSI over Bulk-Only
scsibus0 at umass0: 2 targets, 1 lun per target
sd0 at scsibus0 target 0 lun 0: <, USB DISK 2.0, PMAP> disk removable
sd0: 3824 MB, 959 cyl, 255 head, 32 sec, 512 bytes/sect x 7831552 sectors
boot device:
root device: cnmac0
dump device:
file system (default generic):
root on cnmac0
mountroot: trying nfs...
nfs_boot: trying DHCP/BOOTP
cnmac0: link state UP (was UNKNOWN)
cnmac0: link state DOWN (was UP)
cnmac0: link state UP (was DOWN)
nfs_boot: DHCP next-server: 192.168.150.188
nfs_boot: my_domain=duskware.de
nfs_boot: my_addr=192.168.150.192
nfs_boot: my_mask=255.255.254.0
nfs_boot: gateway=192.168.151.1
root on 192.168.150.188:/hosts/erlite
root time: 0x554ad8bc
root file system type: nfs
kern.module.path=/stand/evbmips/7.99.15/modules
WARNING: no TOD clock present
WARNING: using filesystem time
WARNING: CHECK AND RESET THE DATE!
init path (default /sbin/init):
init: copying out path `/sbin/init' 11
pid 1(init): ABI set to N32 (e_flags=0x20000027)
The port to octeon (thanks IIJ!) is new, but already quite complete. The second cpu core is not yet started, but I hope this will be fixed very soon. No MIPS has been part of the automatic test runs recently, so there is some fallout, as expected. On first try I got several core files, among others from pkg_info, pkg_admin and gdb. The latter makes analyzing the crashes a bit more challenging, but give me a few days ;-}
The 10th pkgsrcCon is happening on the weekend of July 4th and 5th 2015 in Berlin. Developers, contributors, and users are all welcome to attend.
More details can be found on the pkgsrcCon 2015 website.
Call for presentations
Everyone is welcome to make a presentation. So please do! If you already have title or topic please send an email to wiedi@frubar.net.
I look forward to seeing you there!
What has been done in NetBSD
I've managed to achieve the following accomplishments:
Introduction of PT_SETSTEP and PT_CLEARSTEP
This allows to:
- singlestep particular threads,
- combine PT_STEP with PT_SYSCALL,
- combine PT_STEP and emission of a signal.
There are equivalent operations in FreeBSD with the same names.
Introduction of helper macro PTRACE_BREAKPOINT_ASM
This code was prepared by Nick Hudson and it was used in ATF tests to verify behavior of software breakpoints.
Addition of new sysctl(2) functions
Add new defines in sysctl(2) on amd64 and i386 ports. These values are defined in <x86/cpu.h>:
- CPU_FPU_SAVE (15)
int: FPU Instructions layout * to use this, CPU_OSFXSR must be true * 0: FSAVE * 1: FXSAVE * 2: XSAVE * 3: XSAVEOPT
- CPU_FPU_SAVE_SIZE (16)
int: FPU Instruction layout size
- CPU_XSAVE_FEATURES (17)
quad: FPU XSAVE features
- Bump CPU_MAXID from 15 to 18.
These values are useful to get FPU (floating point unit) properties in e.g. a debugger. This information is required to properly implement FPR (floating point register) tracer operations on x86 processors.
Corrections in ptrace(2) man-page
Few mistakes were corrected to make the documentation more correct.
ATF tests cleanup in ptrace(2)
There were added new tests for new ptrace(2) operations (PT_SETSTEP and PT_CLEARSTEP).
Also several tests were updated to reflect the current state of "successfully passed" and "expected failure". This is important to mark issues that are already known and quickly catch new regressions in future changes.
F_GETPATH in fcntl(2)
It was decided that NetBSD will not introduce new fcntl(2) function for compatibility with certain other systems. This means that once LLDB will require this feature, we will need to introduce a workaround in the project.
What has been done in LLDB
The NetBSD Process Plugin in LLDB acquired new capabilities. Additionally enhancements in LLDB were developed such as handling threads in core(5) files.
Floating point support
The x86_64 architecture supports in default properties FXSAVE processor instructions. The FXSAVE feature allows to operate over floating point registers. A thread state (context) is composed of (and not restricted to) general and floating point registers.
The NetBSD Process Plugin acquired the functionality to read these registers and optionally set new values for them.
Watchpoint support
A programmer can use hardware assisted watchpoints to stop execution of a tracee whenever a certain variable or instruction was read/written/executed. The support for this feature has been implemented on NetBSD with ptrace(2) operations PT_SETDBREGS and PT_GETDBREGS. These operations are now available in the LLDB Process plugin.
Threads support in core(5) files
I've included support for LWPs in core(5) files. This means that larger programs with threads, like Firefox that emitted coredump for some reason (usually during crash) can be investigated postmortem.
Demo
I've prepared a recording with the script(1) utility from the NetBSD base system. To replay it:
script -p ./firefox-core.typescript
This recording shows a debugging session of a Firefox core(5) file.
(I was kind to prepare a Linux version of the NetBSD script(1) here).
Plan for the next milestone
The plan for the next milestone is continuing development of threads in the NetBSD Process Plugin. I will need to work more on correctness of ptrace(2) calls as new issues were detected in setups with threads that resulted in crashes.
There is also ongoing work on a new build node running NetBSD-current (prerelease of 8) and building LLVM+Clang+LLDB. I'm working on enabling unit tests to catch functional regressions quickly. The original LLDB node cluster was privately funded by myself in the last two years and has been switched to a machine hosted by The NetBSD Foundation.
To keep this machine up and running (8 CPU, 24 GB RAM) community support through donations is required. This is crucial to actively maintain the LLVM toolchain (Clang, LLDB and others) on NetBSD.
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL, and chip in what you can:
What has been done in NetBSD
I've managed to achieve the following accomplishments:
Introduction of PT_SETSTEP and PT_CLEARSTEP
This allows to:
- singlestep particular threads,
- combine PT_STEP with PT_SYSCALL,
- combine PT_STEP and emission of a signal.
There are equivalent operations in FreeBSD with the same names.
Introduction of helper macro PTRACE_BREAKPOINT_ASM
This code was prepared by Nick Hudson and it was used in ATF tests to verify behavior of software breakpoints.
Addition of new sysctl(2) functions
Add new defines in sysctl(2) on amd64 and i386 ports. These values are defined in <x86/cpu.h>:
- CPU_FPU_SAVE (15)
int: FPU Instructions layout * to use this, CPU_OSFXSR must be true * 0: FSAVE * 1: FXSAVE * 2: XSAVE * 3: XSAVEOPT
- CPU_FPU_SAVE_SIZE (16)
int: FPU Instruction layout size
- CPU_XSAVE_FEATURES (17)
quad: FPU XSAVE features
- Bump CPU_MAXID from 15 to 18.
These values are useful to get FPU (floating point unit) properties in e.g. a debugger. This information is required to properly implement FPR (floating point register) tracer operations on x86 processors.
Corrections in ptrace(2) man-page
Few mistakes were corrected to make the documentation more correct.
ATF tests cleanup in ptrace(2)
There were added new tests for new ptrace(2) operations (PT_SETSTEP and PT_CLEARSTEP).
Also several tests were updated to reflect the current state of "successfully passed" and "expected failure". This is important to mark issues that are already known and quickly catch new regressions in future changes.
F_GETPATH in fcntl(2)
It was decided that NetBSD will not introduce new fcntl(2) function for compatibility with certain other systems. This means that once LLDB will require this feature, we will need to introduce a workaround in the project.
What has been done in LLDB
The NetBSD Process Plugin in LLDB acquired new capabilities. Additionally enhancements in LLDB were developed such as handling threads in core(5) files.
Floating point support
The x86_64 architecture supports in default properties FXSAVE processor instructions. The FXSAVE feature allows to operate over floating point registers. A thread state (context) is composed of (and not restricted to) general and floating point registers.
The NetBSD Process Plugin acquired the functionality to read these registers and optionally set new values for them.
Watchpoint support
A programmer can use hardware assisted watchpoints to stop execution of a tracee whenever a certain variable or instruction was read/written/executed. The support for this feature has been implemented on NetBSD with ptrace(2) operations PT_SETDBREGS and PT_GETDBREGS. These operations are now available in the LLDB Process plugin.
Threads support in core(5) files
I've included support for LWPs in core(5) files. This means that larger programs with threads, like Firefox that emitted coredump for some reason (usually during crash) can be investigated postmortem.
Demo
I've prepared a recording with the script(1) utility from the NetBSD base system. To replay it:
script -p ./firefox-core.typescript
This recording shows a debugging session of a Firefox core(5) file.
(I was kind to prepare a Linux version of the NetBSD script(1) here).
Plan for the next milestone
The plan for the next milestone is continuing development of threads in the NetBSD Process Plugin. I will need to work more on correctness of ptrace(2) calls as new issues were detected in setups with threads that resulted in crashes.
There is also ongoing work on a new build node running NetBSD-current (prerelease of 8) and building LLVM+Clang+LLDB. I'm working on enabling unit tests to catch functional regressions quickly. The original LLDB node cluster was privately funded by myself in the last two years and has been switched to a machine hosted by The NetBSD Foundation.
To keep this machine up and running (8 CPU, 24 GB RAM) community support through donations is required. This is crucial to actively maintain the LLVM toolchain (Clang, LLDB and others) on NetBSD.
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL, and chip in what you can:
Coming soon we have a new set of kernel synchronization routines - localcount(9) - which provide a medium-weight reference-counting mechanism. From the manual page, "During normal operations, localcounts do not need the interprocessor synchronization associated with atomic_ops(3) atomic memory operations, and (unlike psref(9)) localcount references can be held across sleeps and can migrate between CPUs. Draining a localcount requires more expensive interprocessor synchronization than atomic_ops(3) (similar to psref(9)). And localcount references require eight bytes of memory per object per-CPU, significantly more than atomic_ops(3) and almost always more than psref(9)."
We'll be adding localcount(9) reference counting to the device driver cdevsw and bdevsw structures, to ensure that a (modular) device driver cannot be removed while it is active. Modular drivers with initializers for these structures need to be modified to initialize their localcount members, using the DEVSW_MODULE_INIT macro (this change is mandatory for all loadable drivers). To take advantage of the reference counting, the drivers also need to replace all calls to bdevsw_lookup() and cdevsw_lookup() with bdevsw_lookup_acquire() and cdevsw_lookup_acquire() respectively, and then release the reference using bdevsw_release() and cdevsw_release().
We'll also be using localcount(9) to provide reference-counting of individual device units, to prevent a unit from being destroyed while it is active. To implement device unit reference-counting, all calls to device_lookup(), device_find_by_driver_unit(), and device_lookup_private() need to be replaced by their corresponding *_acquire() variant; when the caller is finished using the device, it must release the reference using device_release().
More details and examples can be seen by examining the prg-localcount2 branch in cvs including the new localcount(9) manual page!
Coming soon we have a new set of kernel synchronization routines - localcount(9) - which provide a medium-weight reference-counting mechanism. From the manual page, "During normal operations, localcounts do not need the interprocessor synchronization associated with atomic_ops(3) atomic memory operations, and (unlike psref(9)) localcount references can be held across sleeps and can migrate between CPUs. Draining a localcount requires more expensive interprocessor synchronization than atomic_ops(3) (similar to psref(9)). And localcount references require eight bytes of memory per object per-CPU, significantly more than atomic_ops(3) and almost always more than psref(9)."
We'll be adding localcount(9) reference counting to the device driver cdevsw and bdevsw structures, to ensure that a (modular) device driver cannot be removed while it is active. Modular drivers with initializers for these structures need to be modified to initialize their localcount members, using the DEVSW_MODULE_INIT macro (this change is mandatory for all loadable drivers). To take advantage of the reference counting, the drivers also need to replace all calls to bdevsw_lookup() and cdevsw_lookup() with bdevsw_lookup_acquire() and cdevsw_lookup_acquire() respectively, and then release the reference using bdevsw_release() and cdevsw_release().
We'll also be using localcount(9) to provide reference-counting of individual device units, to prevent a unit from being destroyed while it is active. To implement device unit reference-counting, all calls to device_lookup(), device_find_by_driver_unit(), and device_lookup_private() need to be replaced by their corresponding *_acquire() variant; when the caller is finished using the device, it must release the reference using device_release().
More details and examples can be seen by examining the prg-localcount2 branch in cvs including the new localcount(9) manual page!
- Leonardo Taccari will work add multi-packages support to pkgsrc.
- Maya Rashish will work on the LFS cleanup.
- Utkarsh Anand will make Anita support multiple virtual machine systems and more architectures within them to improve testing coverage.
") ) until August 21st, evaluations, code submission and an announcement of the results on September 6th 2017.
) until August 21st, evaluations, code submission and an announcement of the results on September 6th 2017.
Good luck to all our students and their mentors - we look forward to your work results, and welcome you to The NetBSD Project!
- Leonardo Taccari will work add multi-packages support to pkgsrc.
- Maya Rashish will work on the LFS cleanup.
- Utkarsh Anand will make Anita support multiple virtual machine systems and more architectures within them to improve testing coverage.
") ) until August 21st, evaluations, code submission and an announcement of the results on September 6th 2017.
) until August 21st, evaluations, code submission and an announcement of the results on September 6th 2017.
Good luck to all our students and their mentors - we look forward to your work results, and welcome you to The NetBSD Project!
This software has been developed for multiplatform environments with support for NetBSD since virtually forever. It's the primary tool used by the NetBSD developers and release engineering team. It is run with continuous integration tests for daily commits and execute regression tests through the Automatic Test Framework (ATF).
Since the projects keep researching and developing support for various modern trends in computing, the gap between the QEMU featureset in NetBSD and Linux diverged due to lack of active NetBSD maintenance resulted in breaking the default build.
The QEMU developers warned the Open Source community - with version 2.9 of the emulator - that they will eventually drop support for suboptimally supported hosts if nobody will step in and take the maintainership to refresh the support. This warning was directed to major BSDs, Solaris, AIX and Haiku.
Thankfully the NetBSD position has been filled - making NetBSD to restore official maintenance.
The current roadmap in QEMU/NetBSD is as follows:
- address all build failures [all patches sent to review, part of them already merged upstream],
- address all build warnings,
- restore the QEMU setup to run regression tests on NetBSD.
This effort is spare time activity - as of now without commercial support - and possible thanks to unloading the developer (myself) from more urgently pending tasks in NetBSD thanks to the contract for enhancing debuggers in business hours.
This software has been developed for multiplatform environments with support for NetBSD since virtually forever. It's the primary tool used by the NetBSD developers and release engineering team. It is run with continuous integration tests for daily commits and execute regression tests through the Automatic Test Framework (ATF).
Since the projects keep researching and developing support for various modern trends in computing, the gap between the QEMU featureset in NetBSD and Linux diverged due to lack of active NetBSD maintenance resulted in breaking the default build.
The QEMU developers warned the Open Source community - with version 2.9 of the emulator - that they will eventually drop support for suboptimally supported hosts if nobody will step in and take the maintainership to refresh the support. This warning was directed to major BSDs, Solaris, AIX and Haiku.
Thankfully the NetBSD position has been filled - making NetBSD to restore official maintenance.
The current roadmap in QEMU/NetBSD is as follows:
- address all build failures [all patches sent to review, part of them already merged upstream],
- address all build warnings,
- restore the QEMU setup to run regression tests on NetBSD.
This effort is spare time activity - as of now without commercial support - and possible thanks to unloading the developer (myself) from more urgently pending tasks in NetBSD thanks to the contract for enhancing debuggers in business hours.
The fourth release candidate of NetBSD 6.1 is now available for download at: http://ftp.NetBSD.org/pub/NetBSD/NetBSD-6.1_RC4/. It is expected that this will be the final release candidate, with the official release following very soon.
(Please note that while the third release candidate (RC3) was tagged and built, it was never officially released)
NetBSD 6.1 will be the first feature update for the NetBSD 6 branch. There are many new drivers, some new features, and many bug fixes! Fixes since RC2 include:
- Updated the fix for SA-2013-003 (RNG bug may result in weak cryptographic keys)
- Fixes to npfctl(8) parsing and error handling
- Fix sendto(2) issue with IPv6 UDP datagrams. PR#47408.
- Raspberry Pi: fix handling of large packets in USB host controller
- Fixed an RPC memory corruption issue. PR#13082
- Fixed ACPI issues affecting some AMD systems. PR#47016, PR#47648.
- Change vax MAXPARTITION from 16 to 12, addressing boot issues on some systems
- Bump libpthread minor version to libpthread.so.1.1 for the addition of pthread_cond_setclock() earlier in the 6.1 release cycle; note that this is *NOT* the same as libpthread.so.1.1 in NetBSD-current. (libpthread.so in NetBSD-current is already at version 1.2)
- Provide libc stubs to libpthread, allowing libpthread to be dlopen()ed.
- Fix a userland-triggered panic on x68k systems.
A complete list of changes can be found at:
http://ftp.NetBSD.org/pub/NetBSD/NetBSD-6.1_RC4/CHANGES-6.1
Please help us test this and any upcoming release candidates as much as possible. Remember, any feedback is good feedback. We'd love to hear from you, whether you've got a complaint or a compliment.
The NetBSD Project is pleased to announce NetBSD 6.1, the first feature update of the NetBSD 6 release branch. It represents a selected subset of fixes deemed important for security or stability reasons, as well as new features and enhancements.
Simultaneously, the NetBSD Project is pleased to announce NetBSD 6.0.2, the second security/bugfix update of the NetBSD 6.0 release branch. It represents a selected subset of fixes deemed important for security or stability reasons, without new features.
For more details, please see the 6.1 release notes and the 6.0.2 release notes
Complete source and binaries for NetBSD 6.1 and 6.0.2 are available for download at many sites around the world. A list of download sites providing FTP, AnonCVS, SUP, and other services may be found at http://www.NetBSD.org/mirrors/.One of the itching points used to be Firefox. Late in the Firefox 4.0 release cycle some changes landed in the mozilla main tree that broke it for sparc64 - and for a while no one knew how to fix it.
When lately I had the need to test a web app with all "strange" clients available (I even booted my macppc into MacOS and tried the ancient safari version) I noticed that my sparc64 firefox (3.6.28) was not usable for testing - firefox did not have websocket support back then, which the app I was testing needed.
I checked out the mozilla mercurial tree for the firefox alpha version, applied all pkgsrc patches (we lyhave plenty!) and modified the configuration to generate a debuggable version, and after surprisingly little effort I had it building.
Of course it did not run.
So I started to debugging it (which is not for the light hearted, as you can imagine). Thanks to some bank holiday plus additional bridge day off I used a long weekend and managed to get it running:
Then I tried to run my websocket app again, but it crashed imediately. So I fired up gdb one more time, and this time everything was fixed quickly. My app now runs fine (sorry, no pictures here, it is not yet public).
I filed all necessary changes as bugzilla tickets upstream and am working with the responsible maintainers to get them included.
This will be available in pkgsrc as soon as the official firefox 22 release is imported into pkgsrc.
- Port Linux's drm/kms/gem/i915
- Student: Myron Aub
- System upgrade
- Student: gnrp
- Implement file system flags to scrub data blocks before deletion
- Student: Przemyslaw Sierocinski
- Make NetBSD a supported guest OS under VirtualBox
- Student: Haomai Wang
- Defragmentation for FFS in NetBSD
- Student: Manuel Wiesinger
We hope these students will have an interesting, successful, and also fun summer working with us, heap glory upon their names and do their mentors proud.
We thank all students who discussed and submitted proposals; as in every year, slots are limited and we have to let go worthy proposals.
NetBSD now includes support for Marvell Armada XP SoCs. The port was done by Semihalf and sponsored by Marvell, who have generously agreed to release the source code.
This work was integrated into the NetBSD/evbarm port. The kernel for Armada XP is built from the "ARMADAXP" configuration.
Currently supported hardware include Marvell DB-MV784MP-GP development boards. Adding support for more Armada XP-based boards should be relatively easy.
The port includes support for the PJ4B CPU core and most of the SoC's peripherals:
- UART
- SATA
- PCI Express
- I2C
- SPI
- USB
SMP and on-chip Ethernet are not supported yet (however it is possible to use a PCI Express based Ethernet card).
I was asked to prepare some stats on pkgsrc's growth, as part of the celebrations of pkgsrc-2016Q1, pkgsrc's fiftieth quarterly release.
This mail from 2004 says:
By my calculations, at the end of December 2003, there were 4310 packages in the NetBSD Packages Collection, up from 4170 the previous month, a rise of only 140. We also tagged a new branch for pkgsrc, which is being actively maintained - the branch is called "pkgsrc-2003Q4". As the name implies, we will be branching pkgsrc on a regular basis from now on, and maintaining the branch.
We had previously cut pkgsrc releases to coincide with NetBSD releases, and for some other events, but pkgsrc-2003Q4 can be seen as the first branch where pkgsrc was really its own entity. It can be checked out with the "pkgsrc-2003Q4" tag, and browsed at:
We keep a complete log of changes we have made to pkgsrc since its inception. At the lowest level, pkgsrc-2003Q4 had 3059 pkgsrc entries, whilst 2016Q1 had 14311 pkgsrc entries. Due to different versions of some languages, like python, perl, ruby and php, the number of packages is a much higher number. For instance, 2003Q4 had 4310 packages, and 2016Q1 had 17154. We have also provided a histogram of pkgsrc activity from its inception until now.
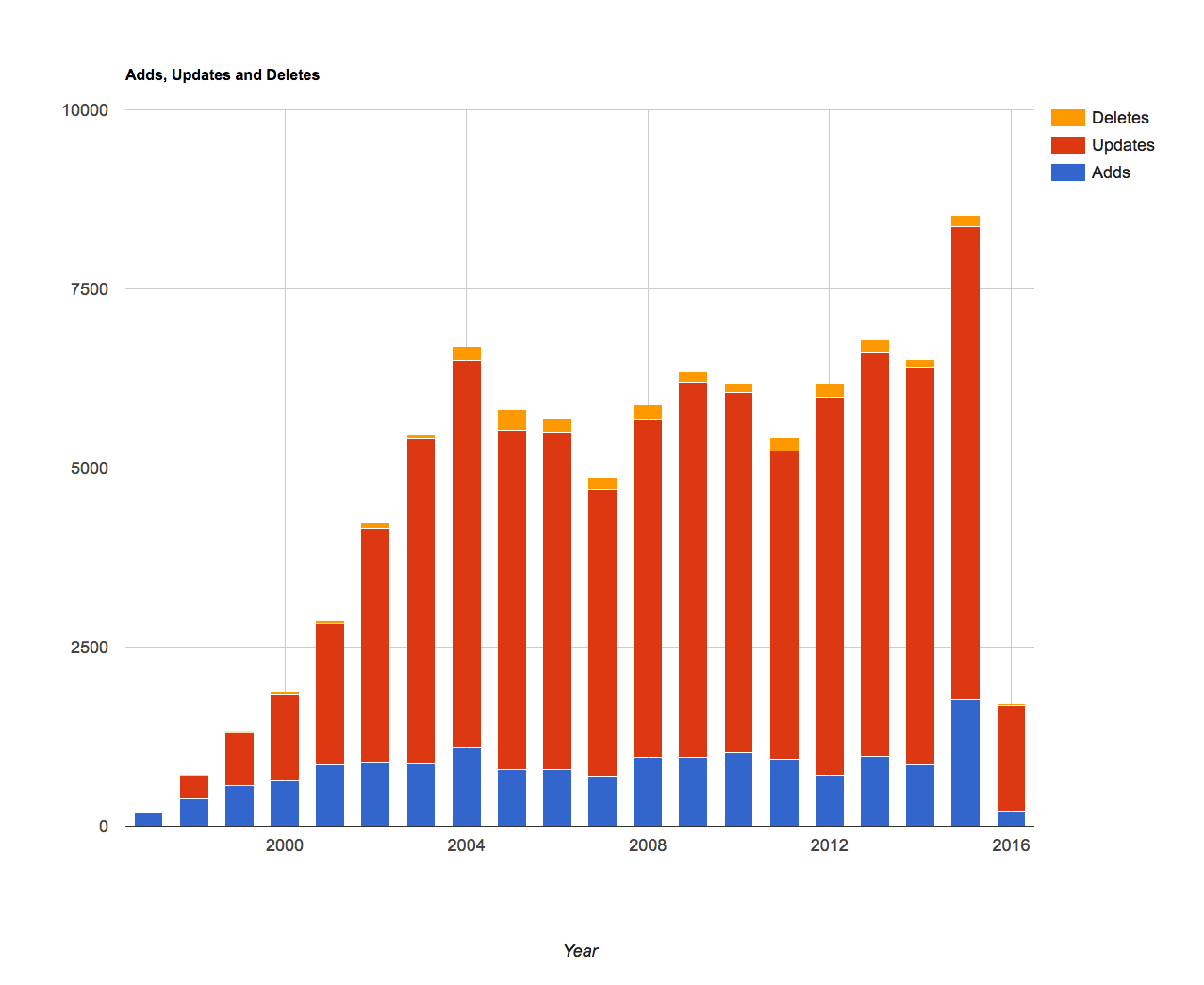
To see how pkgsrc has spread across platforms, 2003Q4 supported 7 platforms, 2016Q1 supports 23 platforms.
In addition, pkgsrc has now grown its own conference. The first pkgsrccon was in Vienna in 2004 -- see the original 2004 pkgsrccon information and this year's pkgsrccon is in Krakow -- see the 2016 pkgsrccon information We also produced a map of pkgsrccon venues for those interested in the history and geography of pkgsrccon.
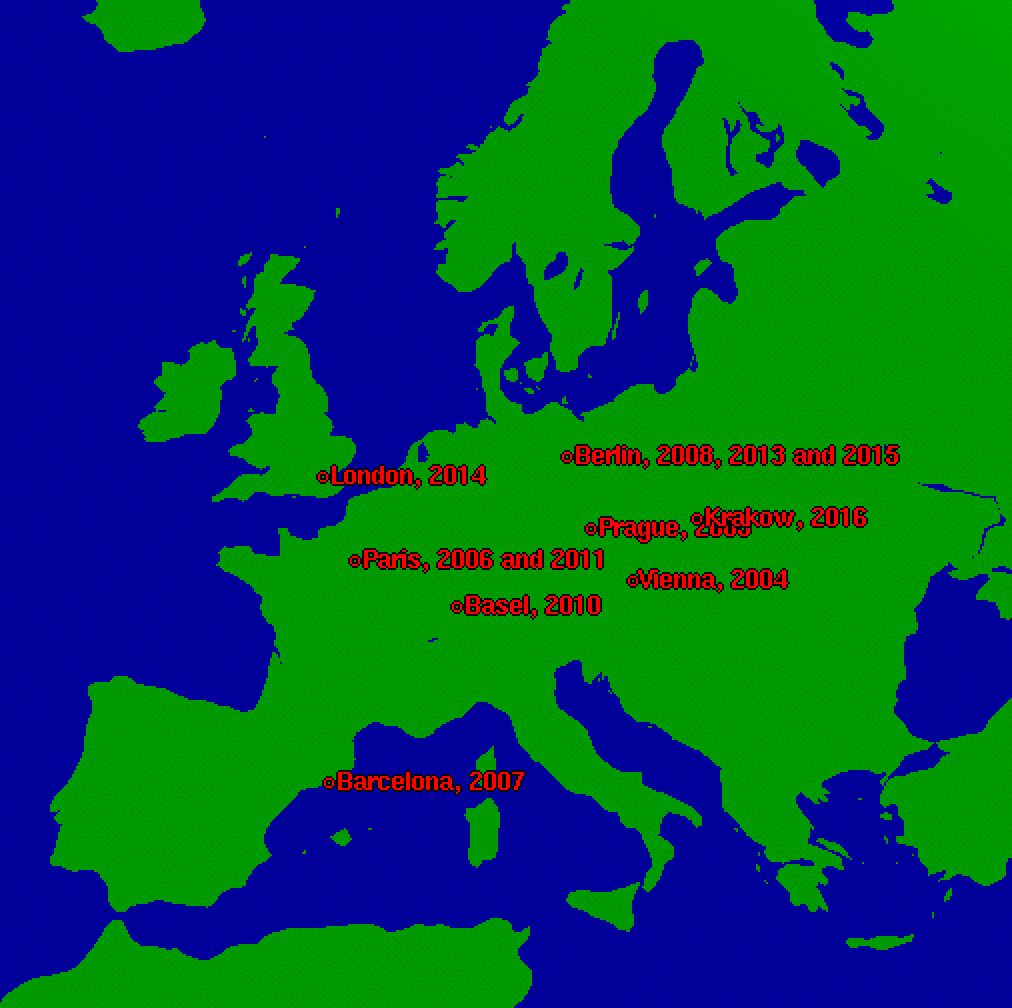
Alistair Crooks
for the pkgsrc team
Sun May 8 11:26:15 PDT 2016
I was asked to prepare some stats on pkgsrc's growth, as part of the celebrations of pkgsrc-2016Q1, pkgsrc's fiftieth quarterly release.
This mail from 2004 says:
By my calculations, at the end of December 2003, there were 4310 packages in the NetBSD Packages Collection, up from 4170 the previous month, a rise of only 140. We also tagged a new branch for pkgsrc, which is being actively maintained - the branch is called "pkgsrc-2003Q4". As the name implies, we will be branching pkgsrc on a regular basis from now on, and maintaining the branch.
We had previously cut pkgsrc releases to coincide with NetBSD releases, and for some other events, but pkgsrc-2003Q4 can be seen as the first branch where pkgsrc was really its own entity. It can be checked out with the "pkgsrc-2003Q4" tag, and browsed at:
We keep a complete log of changes we have made to pkgsrc since its inception. At the lowest level, pkgsrc-2003Q4 had 3059 pkgsrc entries, whilst 2016Q1 had 14311 pkgsrc entries. Due to different versions of some languages, like python, perl, ruby and php, the number of packages is a much higher number. For instance, 2003Q4 had 4310 packages, and 2016Q1 had 17154. We have also provided a histogram of pkgsrc activity from its inception until now.
To see how pkgsrc has spread across platforms, 2003Q4 supported 7 platforms, 2016Q1 supports 23 platforms.
In addition, pkgsrc has now grown its own conference. The first pkgsrccon was in Vienna in 2004 -- see the original 2004 pkgsrccon information and this year's pkgsrccon is in Krakow -- see the 2016 pkgsrccon information We also produced a map of pkgsrccon venues for those interested in the history and geography of pkgsrccon.
Alistair Crooks
for the pkgsrc team
Sun May 8 11:26:15 PDT 2016
Recently on a few mailing lists a discussion about creating a simple turbo-channel USB adapter came up. I have an old Alpha machine with turbo channel and no on-board USB, so considered ordering one - but wanted to know upfront whether that alpha machine still worked.
I started with updating the installation on the alpha to -current, and ran out of disk space!
No big deal, it still had the original ~1GB disk (RZ26) in it, and a full NetBSD install nowadays needs slightly more. I have plenty of unused SCSI disks lying around, but when looking for 50pin ones, I found I have none left.
Another machine I was looking at for a different root disk solution was an old mac68k (Quadra 640 AV). I had replaced the disk it came with by an 8GB one, but it draws too much power for the internal PSU, so I had to move it to an external SCSI enclosure, which is inconvenient.
Additionally both disks made quite some noise and probably would not last a lot longer. So I started looking for "cheap", silent and low-power alternatives.
I found the SCSI2SD project, which looked promising and had a firmware update earlier this year. I ordered a few boards from idead studio and started testing.
The solution is mostly plug & play, a configuration utility allows updating the firmware and configuring the devices.
I did several bonnie++ runs to get an idea of the speed achievable. All machines are not fast, and disk access has always been slow. To get an overall idea, I also tested on a faster alpha (still with slow scsi disks). Then I moved both test machines over to "root on sd card" and tested again. The results look like this:
| Test | Sequential Output | Sequential Input | Random Seeks | Sequential Create | Random Create | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Per Chr | Block | Rewrite | Per Chr | Block | K/s | CPU | Create | Read | Delete | Create | Read | Delete | ||||||||||||
| K/s | CPU | K/s | CPU | K/s | CPU | K/s | CPU | K/s | CPU | /s | CPU | /s | CPU | /s | CPU | /s | CPU | /s | CPU | /s | CPU | |||
| Ref: DS20 | 3436 | 35 | 3460 | 6 | 2935 | 5 | 9565 | 94 | 19494 | 285.7 | 16 | 3 | 878 | 81 | 31793 | 99 | 2939 | 54 | 940 | 84 | 1351 | 96 | 203 | 10 |
| Alpha HD | 906 | 92 | 2146 | 41 | 980 | 24 | 947 | 93 | 2178 | 23 | 78.5 | 14 | 36 | 95 | 926 | 72 | 290 | 90 | 37 | 96 | 39 | 97 | 25 | 34 |
| Alpha SD | 548 | 77 | 897 | 19 | 450 | 9 | 490 | 97 | 1140 | 9 | 24.9 | 4 | 85 | 89 | 1245 | 75 | 437 | 84 | 90 | 93 | 119 | 96 | 29 | 16 |
| Mac HD | 98 | 95 | 737 | 89 | 373 | 91 | 94 | 96 | 647 | 89 | 14.1 | 47 | 22 | 93 | 502 | 75 | 122 | 81 | 23 | 94 | 31 | 97 | 14 | 43 |
| Mac SD | 95 | 95 | 646 | 89 | 339 | 92 | 93 | 96 | 636 | 79 | 14.5 | 75 | 22 | 90 | 473 | 75 | 124 | 85 | 23 | 92 | 32 | 97 | 13 | 46 |
So even for machines with very slow hard disk access, there is a (relatively small?) performance hit with the SCSI2SD solution. Whether it is too bad for your application, depends on various factors - all of the affected machines are very slow overall anyway.
Just a few days ago a new hardware revision of the SCSI2SD cards has been announced which is supposed to improve performance in the future (when the firmware has caught up), so it may be worth to wait (or get the newer hardware) if performance is important.
I have a VAX machine that could go with this solution as well, but results are expected to be similar (or worse) than for the slow alpha, as my vax is pretty fast (for a vax) and has a decent SCSI subsystem.
For reference, below are the full dmesg from the fast reference and both test machines after switching to SD root, and the sniplet for the original hard disk
AlphaServer DS20
"Fast" reference machine
file system: FFSv2, log
Copyright (c) 1996, 1997, 1998, 1999, 2000, 2001, 2002, 2003, 2004, 2005,
2006, 2007, 2008, 2009, 2010, 2011, 2012, 2013, 2014, 2015, 2016
The NetBSD Foundation, Inc. All rights reserved.
Copyright (c) 1982, 1986, 1989, 1991, 1993
The Regents of the University of California. All rights reserved.
NetBSD 7.99.29 (GENERIC-$Revision: 1.368 $) #7: Mon May 23 20:44:04 CEST 2016
martin@martins.aprisoft.de:/ssd/src/sys/arch/alpha/compile/GENERIC
AlphaServer DS20 500 MHz, s/n AY94910150
8192 byte page size, 1 processor.
total memory = 1024 MB
(2712 KB reserved for PROM, 1021 MB used by NetBSD)
avail memory = 994 MB
timecounter: Timecounters tick every 0.976 msec
Kernelized RAIDframe activated
mainbus0 (root)
cpu0 at mainbus0: ID 0 (primary), 21264-4
cpu0: Architecture extensions: 0x303
tsc0 at mainbus0: 21272 Core Logic Chipset, Cchip rev 0
tsc0: 8 Dchips, 2 memory buses of 32 bytes
tsc0: arrays present: 512MB, 512MB, 0MB, 0MB, Dchip 0 rev 1
tsp0 at tsc0
pci0 at tsp0 bus 0
pci0: i/o space, memory space enabled, rd/line, rd/mult, wr/inv ok
sio0 at pci0 dev 5 function 0: vendor 1080 product c693 (rev. 0x00)
cypide0 at pci0 dev 5 function 1: Cypress 82C693 IDE Controller (rev. 0x00)
cypide0: bus-master DMA support present, but unused (registers at unsafe address 0x10000)
cypide0: primary channel wired to compatibility mode
cypide0: primary channel interrupting at isa irq 14
atabus0 at cypide0 channel 0
cypide1 at pci0 dev 5 function 2: Cypress 82C693 IDE Controller (rev. 0x00)
cypide1: hardware does not support DMA
cypide1: primary channel wired to compatibility mode
cypide1: secondary channel interrupting at isa irq 15
atabus1 at cypide1 channel 0
ohci0 at pci0 dev 5 function 3: vendor 1080 product c693 (rev. 0x00)
ohci0: interrupting at isa irq 10
ohci0: OHCI version 1.0, legacy support
usb0 at ohci0: USB revision 1.0
isa0 at sio0
lpt0 at isa0 port 0x3bc-0x3bf irq 7
com0 at isa0 port 0x3f8-0x3ff irq 4: ns16550a, working fifo
com0: console
com1 at isa0 port 0x2f8-0x2ff irq 3: ns16550a, working fifo
pckbc0 at isa0 port 0x60-0x64
attimer0 at isa0 port 0x40-0x43
pcppi0 at isa0 port 0x61
midi0 at pcppi0: PC speaker
spkr0 at pcppi0
isabeep0 at pcppi0
fdc0 at isa0 port 0x3f0-0x3f7 irq 6 drq 2
mcclock0 at isa0 port 0x70-0x71: mc146818 compatible time-of-day clock
attimer0: attached to pcppi0
tsp1 at tsc0
pci1 at tsp1 bus 0
pci1: i/o space, memory space enabled, rd/line, rd/mult, wr/inv ok
tlp0 at pci1 dev 7 function 0: Macronix MX98713 Ethernet, pass 0.0
tlp0: interrupting at dec 6600 irq 47
tlp0: Ethernet address 00:40:05:50:ee:9b
tlp0: 10baseT, 10baseT-FDX, 100baseTX, 100baseTX-FDX
isp0 at pci1 dev 8 function 0: QLogic 1020 Fast Wide SCSI HBA
isp0: interrupting at dec 6600 irq 43
isp1 at pci1 dev 9 function 0: QLogic 1020 Fast Wide SCSI HBA
isp1: interrupting at dec 6600 irq 39
tsciic0 at tsc0
iic0 at tsciic0: I2C bus
timecounter: Timecounter "clockinterrupt" frequency 1024 Hz quality 0
timecounter: Timecounter "PCC" frequency 499882560 Hz quality 1000
scsibus0 at isp0: 16 targets, 8 luns per target
scsibus1 at isp1: 16 targets, 8 luns per target
scsibus0: waiting 2 seconds for devices to settle...
scsibus1: waiting 2 seconds for devices to settle...
uhub0 at usb0: vendor 1080 OHCI root hub, class 9/0, rev 1.00/1.00, addr 1
uhub0: 2 ports with 2 removable, self powered
sd0 at scsibus0 target 0 lun 0: <COMPAQ, BB00911CA0, 3B05> disk fixed
sd0: 8678 MB, 5273 cyl, 20 head, 168 sec, 512 bytes/sect x 17773524 sectors
sd0: sync (50.00ns offset 8), 16-bit (40.000MB/s) transfers, tagged queueing
sd1 at scsibus0 target 1 lun 0: <COMPAQ, BB00912301, B016> disk fixed
sd1: 8678 MB, 5273 cyl, 20 head, 168 sec, 512 bytes/sect x 17773524 sectors
sd1: sync (50.00ns offset 8), 16-bit (40.000MB/s) transfers, tagged queueing
sd2 at scsibus0 target 2 lun 0: <COMPAQ, BB00911CA0, 3B05> disk fixed
sd2: 8678 MB, 5273 cyl, 20 head, 168 sec, 512 bytes/sect x 17773524 sectors
sd2: sync (50.00ns offset 8), 16-bit (40.000MB/s) transfers, tagged queueing
fd0 at fdc0 drive 0: 1.44MB, 80 cyl, 2 head, 18 sec
sd3 at scsibus0 target 3 lun 0: <COMPAQ, BB00912301, B016> disk fixed
sd3: 8678 MB, 5273 cyl, 20 head, 168 sec, 512 bytes/sect x 17773524 sectors
sd3: sync (50.00ns offset 8), 16-bit (40.000MB/s) transfers, tagged queueing
cd0 at scsibus1 target 5 lun 0: <DEC, RRD47 (C) DEC, 1206> cdrom removable
raid0: RAID Level 1
raid0: Components: /dev/sd0a /dev/sd1a
raid0: Total Sectors: 17773440 (8678 MB)
raid1: RAID Level 1
raid1: Components: /dev/sd2a /dev/sd3a
raid1: Total Sectors: 17773440 (8678 MB)
root on raid0a dumps on raid0b
root file system type: ffs
kern.module.path=/stand/alpha/7.99.29/modules
Alpha DEC 3000
with SCSI2SD
Copyright (c) 1996, 1997, 1998, 1999, 2000, 2001, 2002, 2003, 2004, 2005,
2006, 2007, 2008, 2009, 2010, 2011, 2012, 2013, 2014, 2015, 2016
The NetBSD Foundation, Inc. All rights reserved.
Copyright (c) 1982, 1986, 1989, 1991, 1993
The Regents of the University of California. All rights reserved.
NetBSD 7.99.29 (GENERIC-$Revision: 1.368 $) #3: Thu May 5 09:17:11 CEST 2016
martin@martins.aprisoft.de:/ssd/src/sys/arch/alpha/compile/GENERIC
DEC 3000 - M300, 150MHz, s/n
8192 byte page size, 1 processor.
total memory = 98304 KB
(2048 KB reserved for PROM, 96256 KB used by NetBSD)
avail memory = 82352 KB
timecounter: Timecounters tick every 0.976 msec
Kernelized RAIDframe activated
mainbus0 (root)
cpu0 at mainbus0: ID 0 (primary), 21064-1
tcasic0 at mainbus0
tc0 at tcasic0: 12.5 MHz clock
sfb0 at tc0 slot 6 offset 0x2000000: 1280x1024, 8bpp
wsdisplay1 at sfb0 kbdmux 1
wsmux1: connecting to wsdisplay1
ioasic0 at tc0 slot 5 offset 0x0: slow mode
le0 at ioasic0 offset 0xc0000: address 08:00:2b:3c:93:27
le0: 32 receive buffers, 8 transmit buffers
zsc0 at ioasic0 offset 0x100000
vsms0 at zsc0 channel 0
wsmouse0 at vsms0 mux 0
zstty0 at zsc0 channel 1 (console i/o)
zsc1 at ioasic0 offset 0x180000
lkkbd0 at zsc1 channel 0
wskbd0 at lkkbd0 mux 1
wskbd0: connecting to wsdisplay1
zsc1: channel 1 not configured
mcclock0 at ioasic0 offset 0x200000: mc146818 compatible time-of-day clock
bba0 at ioasic0 offset 0x240000
audio0 at bba0: full duplex, playback, capture, mmap
tcds0 at tc0 slot 4 offset 0x0: TurboChannel Dual SCSI (baseboard)
asc0 at tcds0 chip 0: NCR53C94, 25MHz, SCSI ID 0
scsibus0 at asc0: 8 targets, 8 luns per target
timecounter: Timecounter "clockinterrupt" frequency 1024 Hz quality 0
timecounter: Timecounter "PCC" frequency 150006528 Hz quality 1000
lkkbd0: no keyboard
scsibus0: waiting 2 seconds for devices to settle...
sd0 at scsibus0 target 1 lun 0: <codesrc, SCSI2SD, 1.0> disk fixed
sd0: 3712 MB, 473 cyl, 255 head, 63 sec, 512 bytes/sect x 7603200 sectors
sd0: async, 8-bit transfers
root on sd0a dumps on sd0b
root file system type: ffs
kern.module.path=/stand/alpha/7.99.29/modules
with original RZ26
sd0 at scsibus0 target 3 lun 0: disk fixed
sd0: 1001 MB, 2570 cyl, 14 head, 57 sec, 512 bytes/sect x 2050860 sectors
sd0: sync (200.00ns offset 15), 8-bit (5.000MB/s) transfers, tagged queueing
Mac Quadra 640AV
File system: FFSv1, log
with SCSI2SD
Copyright (c) 1996, 1997, 1998, 1999, 2000, 2001, 2002, 2003, 2004, 2005,
2006, 2007, 2008, 2009, 2010, 2011, 2012, 2013, 2014, 2015, 2016
The NetBSD Foundation, Inc. All rights reserved.
Copyright (c) 1982, 1986, 1989, 1991, 1993
The Regents of the University of California. All rights reserved.
NetBSD 7.99.29 (MAC-BETH) #18: Tue May 10 05:40:16 CEST 2016
martin@night-owl.duskware.de:/usr/src/sys/arch/mac68k/compile/MAC-BETH
Apple Macintosh Centris 660AV (68040)
cpu: delay factor 800
fpu: mc68040
total memory = 45056 KB
avail memory = 40248 KB
timecounter: Timecounters tick every 16.666 msec
mrg: 'Quadra AV ROMs' ROM glue, tracing off, debug off, silent traps
mainbus0 (root)
obio0 at mainbus0
esp0 at obio0 addr 0: address 0x2da000: NCR53C96, 25MHz, SCSI ID 7
scsibus0 at esp0: 8 targets, 8 luns per target
adb0 at obio0
intvid0 at obio0 @ 50100600: CIVIC video subsystem
intvid0: 640 x 480, 65536 color
macfb0 at intvid0
wsdisplay0 at macfb0 (kbdmux ignored)
mc0 at obio0: address 08:00:07:46:74:0a
zsc0 at obio0 chip type 0
zsc0 channel 0: d_speed 9600 DCD clk 0 CTS clk 0
zstty0 at zsc0 channel 0 (console i/o)
zsc0 channel 1: d_speed 9600 DCD clk 0 CTS clk 0
zstty1 at zsc0 channel 1
nubus0 at mainbus0
timecounter: Timecounter "clockinterrupt" frequency 60 Hz quality 0
timecounter: Timecounter "VIA1 T2" frequency 783360 Hz quality 100
scsibus0: waiting 2 seconds for devices to settle...
adb0 (direct, Cuda): 2 targets
aed0 at adb0 addr 0: ADB Event device
akbd0 at adb0 addr 2: keyboard II (ISO layout)
wskbd0 at akbd0 (mux ignored)
ams0 at adb0 addr 3: 1-button, 100 dpi mouse
wsmouse0 at ams0 (mux ignored)
sd0 at scsibus0 target 0 lun 0: <codesrc, SCSI2SD, 4.6> disk fixed
sd0: 15104 MB, 1925 cyl, 255 head, 63 sec, 512 bytes/sect x 30934016 sectors
sd0: async, 8-bit transfers
cd0 at scsibus0 target 3 lun 0: <SONY, CD-ROM CDU-8003A, 1.9a> cdrom removable
cd0: async, 8-bit transfers
boot device: sd0
root on sd0a dumps on sd0b
root file system type: ffs
kern.module.path=/stand/mac68k/7.99.29/modules
with hard disk
sd0 at scsibus0 target 0 lun 0: disk fixed
sd0: 8761 MB, 14384 cyl, 3 head, 415 sec, 512 bytes/sect x 17942584 sectors
sd0: async, 8-bit transfers, tagged queueing
Recently on a few mailing lists a discussion about creating a simple turbo-channel USB adapter came up. I have an old Alpha machine with turbo channel and no on-board USB, so considered ordering one - but wanted to know upfront whether that alpha machine still worked.
I started with updating the installation on the alpha to -current, and ran out of disk space!
No big deal, it still had the original ~1GB disk (RZ26) in it, and a full NetBSD install nowadays needs slightly more. I have plenty of unused SCSI disks lying around, but when looking for 50pin ones, I found I have none left.
Another machine I was looking at for a different root disk solution was an old mac68k (Quadra 640 AV). I had replaced the disk it came with by an 8GB one, but it draws too much power for the internal PSU, so I had to move it to an external SCSI enclosure, which is inconvenient.
Additionally both disks made quite some noise and probably would not last a lot longer. So I started looking for "cheap", silent and low-power alternatives.
I found the SCSI2SD project, which looked promising and had a firmware update earlier this year. I ordered a few boards from idead studio and started testing.
The solution is mostly plug & play, a configuration utility allows updating the firmware and configuring the devices.
I did several bonnie++ runs to get an idea of the speed achievable. All machines are not fast, and disk access has always been slow. To get an overall idea, I also tested on a faster alpha (still with slow scsi disks). Then I moved both test machines over to "root on sd card" and tested again. The results look like this:
| Test | Sequential Output | Sequential Input | Random Seeks | Sequential Create | Random Create | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Per Chr | Block | Rewrite | Per Chr | Block | K/s | CPU | Create | Read | Delete | Create | Read | Delete | ||||||||||||
| K/s | CPU | K/s | CPU | K/s | CPU | K/s | CPU | K/s | CPU | /s | CPU | /s | CPU | /s | CPU | /s | CPU | /s | CPU | /s | CPU | |||
| Ref: DS20 | 3436 | 35 | 3460 | 6 | 2935 | 5 | 9565 | 94 | 19494 | 285.7 | 16 | 3 | 878 | 81 | 31793 | 99 | 2939 | 54 | 940 | 84 | 1351 | 96 | 203 | 10 |
| Alpha HD | 906 | 92 | 2146 | 41 | 980 | 24 | 947 | 93 | 2178 | 23 | 78.5 | 14 | 36 | 95 | 926 | 72 | 290 | 90 | 37 | 96 | 39 | 97 | 25 | 34 |
| Alpha SD | 548 | 77 | 897 | 19 | 450 | 9 | 490 | 97 | 1140 | 9 | 24.9 | 4 | 85 | 89 | 1245 | 75 | 437 | 84 | 90 | 93 | 119 | 96 | 29 | 16 |
| Mac HD | 98 | 95 | 737 | 89 | 373 | 91 | 94 | 96 | 647 | 89 | 14.1 | 47 | 22 | 93 | 502 | 75 | 122 | 81 | 23 | 94 | 31 | 97 | 14 | 43 |
| Mac SD | 95 | 95 | 646 | 89 | 339 | 92 | 93 | 96 | 636 | 79 | 14.5 | 75 | 22 | 90 | 473 | 75 | 124 | 85 | 23 | 92 | 32 | 97 | 13 | 46 |
So even for machines with very slow hard disk access, there is a (relatively small?) performance hit with the SCSI2SD solution. Whether it is too bad for your application, depends on various factors - all of the affected machines are very slow overall anyway.
Just a few days ago a new hardware revision of the SCSI2SD cards has been announced which is supposed to improve performance in the future (when the firmware has caught up), so it may be worth to wait (or get the newer hardware) if performance is important.
I have a VAX machine that could go with this solution as well, but results are expected to be similar (or worse) than for the slow alpha, as my vax is pretty fast (for a vax) and has a decent SCSI subsystem.
For reference, below are the full dmesg from the fast reference and both test machines after switching to SD root, and the sniplet for the original hard disk
AlphaServer DS20
"Fast" reference machine
file system: FFSv2, log
Copyright (c) 1996, 1997, 1998, 1999, 2000, 2001, 2002, 2003, 2004, 2005,
2006, 2007, 2008, 2009, 2010, 2011, 2012, 2013, 2014, 2015, 2016
The NetBSD Foundation, Inc. All rights reserved.
Copyright (c) 1982, 1986, 1989, 1991, 1993
The Regents of the University of California. All rights reserved.
NetBSD 7.99.29 (GENERIC-$Revision: 1.368 $) #7: Mon May 23 20:44:04 CEST 2016
martin@martins.aprisoft.de:/ssd/src/sys/arch/alpha/compile/GENERIC
AlphaServer DS20 500 MHz, s/n AY94910150
8192 byte page size, 1 processor.
total memory = 1024 MB
(2712 KB reserved for PROM, 1021 MB used by NetBSD)
avail memory = 994 MB
timecounter: Timecounters tick every 0.976 msec
Kernelized RAIDframe activated
mainbus0 (root)
cpu0 at mainbus0: ID 0 (primary), 21264-4
cpu0: Architecture extensions: 0x303
tsc0 at mainbus0: 21272 Core Logic Chipset, Cchip rev 0
tsc0: 8 Dchips, 2 memory buses of 32 bytes
tsc0: arrays present: 512MB, 512MB, 0MB, 0MB, Dchip 0 rev 1
tsp0 at tsc0
pci0 at tsp0 bus 0
pci0: i/o space, memory space enabled, rd/line, rd/mult, wr/inv ok
sio0 at pci0 dev 5 function 0: vendor 1080 product c693 (rev. 0x00)
cypide0 at pci0 dev 5 function 1: Cypress 82C693 IDE Controller (rev. 0x00)
cypide0: bus-master DMA support present, but unused (registers at unsafe address 0x10000)
cypide0: primary channel wired to compatibility mode
cypide0: primary channel interrupting at isa irq 14
atabus0 at cypide0 channel 0
cypide1 at pci0 dev 5 function 2: Cypress 82C693 IDE Controller (rev. 0x00)
cypide1: hardware does not support DMA
cypide1: primary channel wired to compatibility mode
cypide1: secondary channel interrupting at isa irq 15
atabus1 at cypide1 channel 0
ohci0 at pci0 dev 5 function 3: vendor 1080 product c693 (rev. 0x00)
ohci0: interrupting at isa irq 10
ohci0: OHCI version 1.0, legacy support
usb0 at ohci0: USB revision 1.0
isa0 at sio0
lpt0 at isa0 port 0x3bc-0x3bf irq 7
com0 at isa0 port 0x3f8-0x3ff irq 4: ns16550a, working fifo
com0: console
com1 at isa0 port 0x2f8-0x2ff irq 3: ns16550a, working fifo
pckbc0 at isa0 port 0x60-0x64
attimer0 at isa0 port 0x40-0x43
pcppi0 at isa0 port 0x61
midi0 at pcppi0: PC speaker
spkr0 at pcppi0
isabeep0 at pcppi0
fdc0 at isa0 port 0x3f0-0x3f7 irq 6 drq 2
mcclock0 at isa0 port 0x70-0x71: mc146818 compatible time-of-day clock
attimer0: attached to pcppi0
tsp1 at tsc0
pci1 at tsp1 bus 0
pci1: i/o space, memory space enabled, rd/line, rd/mult, wr/inv ok
tlp0 at pci1 dev 7 function 0: Macronix MX98713 Ethernet, pass 0.0
tlp0: interrupting at dec 6600 irq 47
tlp0: Ethernet address 00:40:05:50:ee:9b
tlp0: 10baseT, 10baseT-FDX, 100baseTX, 100baseTX-FDX
isp0 at pci1 dev 8 function 0: QLogic 1020 Fast Wide SCSI HBA
isp0: interrupting at dec 6600 irq 43
isp1 at pci1 dev 9 function 0: QLogic 1020 Fast Wide SCSI HBA
isp1: interrupting at dec 6600 irq 39
tsciic0 at tsc0
iic0 at tsciic0: I2C bus
timecounter: Timecounter "clockinterrupt" frequency 1024 Hz quality 0
timecounter: Timecounter "PCC" frequency 499882560 Hz quality 1000
scsibus0 at isp0: 16 targets, 8 luns per target
scsibus1 at isp1: 16 targets, 8 luns per target
scsibus0: waiting 2 seconds for devices to settle...
scsibus1: waiting 2 seconds for devices to settle...
uhub0 at usb0: vendor 1080 OHCI root hub, class 9/0, rev 1.00/1.00, addr 1
uhub0: 2 ports with 2 removable, self powered
sd0 at scsibus0 target 0 lun 0: <COMPAQ, BB00911CA0, 3B05> disk fixed
sd0: 8678 MB, 5273 cyl, 20 head, 168 sec, 512 bytes/sect x 17773524 sectors
sd0: sync (50.00ns offset 8), 16-bit (40.000MB/s) transfers, tagged queueing
sd1 at scsibus0 target 1 lun 0: <COMPAQ, BB00912301, B016> disk fixed
sd1: 8678 MB, 5273 cyl, 20 head, 168 sec, 512 bytes/sect x 17773524 sectors
sd1: sync (50.00ns offset 8), 16-bit (40.000MB/s) transfers, tagged queueing
sd2 at scsibus0 target 2 lun 0: <COMPAQ, BB00911CA0, 3B05> disk fixed
sd2: 8678 MB, 5273 cyl, 20 head, 168 sec, 512 bytes/sect x 17773524 sectors
sd2: sync (50.00ns offset 8), 16-bit (40.000MB/s) transfers, tagged queueing
fd0 at fdc0 drive 0: 1.44MB, 80 cyl, 2 head, 18 sec
sd3 at scsibus0 target 3 lun 0: <COMPAQ, BB00912301, B016> disk fixed
sd3: 8678 MB, 5273 cyl, 20 head, 168 sec, 512 bytes/sect x 17773524 sectors
sd3: sync (50.00ns offset 8), 16-bit (40.000MB/s) transfers, tagged queueing
cd0 at scsibus1 target 5 lun 0: <DEC, RRD47 (C) DEC, 1206> cdrom removable
raid0: RAID Level 1
raid0: Components: /dev/sd0a /dev/sd1a
raid0: Total Sectors: 17773440 (8678 MB)
raid1: RAID Level 1
raid1: Components: /dev/sd2a /dev/sd3a
raid1: Total Sectors: 17773440 (8678 MB)
root on raid0a dumps on raid0b
root file system type: ffs
kern.module.path=/stand/alpha/7.99.29/modules
Alpha DEC 3000
with SCSI2SD
Copyright (c) 1996, 1997, 1998, 1999, 2000, 2001, 2002, 2003, 2004, 2005,
2006, 2007, 2008, 2009, 2010, 2011, 2012, 2013, 2014, 2015, 2016
The NetBSD Foundation, Inc. All rights reserved.
Copyright (c) 1982, 1986, 1989, 1991, 1993
The Regents of the University of California. All rights reserved.
NetBSD 7.99.29 (GENERIC-$Revision: 1.368 $) #3: Thu May 5 09:17:11 CEST 2016
martin@martins.aprisoft.de:/ssd/src/sys/arch/alpha/compile/GENERIC
DEC 3000 - M300, 150MHz, s/n
8192 byte page size, 1 processor.
total memory = 98304 KB
(2048 KB reserved for PROM, 96256 KB used by NetBSD)
avail memory = 82352 KB
timecounter: Timecounters tick every 0.976 msec
Kernelized RAIDframe activated
mainbus0 (root)
cpu0 at mainbus0: ID 0 (primary), 21064-1
tcasic0 at mainbus0
tc0 at tcasic0: 12.5 MHz clock
sfb0 at tc0 slot 6 offset 0x2000000: 1280x1024, 8bpp
wsdisplay1 at sfb0 kbdmux 1
wsmux1: connecting to wsdisplay1
ioasic0 at tc0 slot 5 offset 0x0: slow mode
le0 at ioasic0 offset 0xc0000: address 08:00:2b:3c:93:27
le0: 32 receive buffers, 8 transmit buffers
zsc0 at ioasic0 offset 0x100000
vsms0 at zsc0 channel 0
wsmouse0 at vsms0 mux 0
zstty0 at zsc0 channel 1 (console i/o)
zsc1 at ioasic0 offset 0x180000
lkkbd0 at zsc1 channel 0
wskbd0 at lkkbd0 mux 1
wskbd0: connecting to wsdisplay1
zsc1: channel 1 not configured
mcclock0 at ioasic0 offset 0x200000: mc146818 compatible time-of-day clock
bba0 at ioasic0 offset 0x240000
audio0 at bba0: full duplex, playback, capture, mmap
tcds0 at tc0 slot 4 offset 0x0: TurboChannel Dual SCSI (baseboard)
asc0 at tcds0 chip 0: NCR53C94, 25MHz, SCSI ID 0
scsibus0 at asc0: 8 targets, 8 luns per target
timecounter: Timecounter "clockinterrupt" frequency 1024 Hz quality 0
timecounter: Timecounter "PCC" frequency 150006528 Hz quality 1000
lkkbd0: no keyboard
scsibus0: waiting 2 seconds for devices to settle...
sd0 at scsibus0 target 1 lun 0: <codesrc, SCSI2SD, 1.0> disk fixed
sd0: 3712 MB, 473 cyl, 255 head, 63 sec, 512 bytes/sect x 7603200 sectors
sd0: async, 8-bit transfers
root on sd0a dumps on sd0b
root file system type: ffs
kern.module.path=/stand/alpha/7.99.29/modules
with original RZ26
sd0 at scsibus0 target 3 lun 0: disk fixed
sd0: 1001 MB, 2570 cyl, 14 head, 57 sec, 512 bytes/sect x 2050860 sectors
sd0: sync (200.00ns offset 15), 8-bit (5.000MB/s) transfers, tagged queueing
Mac Quadra 640AV
File system: FFSv1, log
with SCSI2SD
Copyright (c) 1996, 1997, 1998, 1999, 2000, 2001, 2002, 2003, 2004, 2005,
2006, 2007, 2008, 2009, 2010, 2011, 2012, 2013, 2014, 2015, 2016
The NetBSD Foundation, Inc. All rights reserved.
Copyright (c) 1982, 1986, 1989, 1991, 1993
The Regents of the University of California. All rights reserved.
NetBSD 7.99.29 (MAC-BETH) #18: Tue May 10 05:40:16 CEST 2016
martin@night-owl.duskware.de:/usr/src/sys/arch/mac68k/compile/MAC-BETH
Apple Macintosh Centris 660AV (68040)
cpu: delay factor 800
fpu: mc68040
total memory = 45056 KB
avail memory = 40248 KB
timecounter: Timecounters tick every 16.666 msec
mrg: 'Quadra AV ROMs' ROM glue, tracing off, debug off, silent traps
mainbus0 (root)
obio0 at mainbus0
esp0 at obio0 addr 0: address 0x2da000: NCR53C96, 25MHz, SCSI ID 7
scsibus0 at esp0: 8 targets, 8 luns per target
adb0 at obio0
intvid0 at obio0 @ 50100600: CIVIC video subsystem
intvid0: 640 x 480, 65536 color
macfb0 at intvid0
wsdisplay0 at macfb0 (kbdmux ignored)
mc0 at obio0: address 08:00:07:46:74:0a
zsc0 at obio0 chip type 0
zsc0 channel 0: d_speed 9600 DCD clk 0 CTS clk 0
zstty0 at zsc0 channel 0 (console i/o)
zsc0 channel 1: d_speed 9600 DCD clk 0 CTS clk 0
zstty1 at zsc0 channel 1
nubus0 at mainbus0
timecounter: Timecounter "clockinterrupt" frequency 60 Hz quality 0
timecounter: Timecounter "VIA1 T2" frequency 783360 Hz quality 100
scsibus0: waiting 2 seconds for devices to settle...
adb0 (direct, Cuda): 2 targets
aed0 at adb0 addr 0: ADB Event device
akbd0 at adb0 addr 2: keyboard II (ISO layout)
wskbd0 at akbd0 (mux ignored)
ams0 at adb0 addr 3: 1-button, 100 dpi mouse
wsmouse0 at ams0 (mux ignored)
sd0 at scsibus0 target 0 lun 0: <codesrc, SCSI2SD, 4.6> disk fixed
sd0: 15104 MB, 1925 cyl, 255 head, 63 sec, 512 bytes/sect x 30934016 sectors
sd0: async, 8-bit transfers
cd0 at scsibus0 target 3 lun 0: <SONY, CD-ROM CDU-8003A, 1.9a> cdrom removable
cd0: async, 8-bit transfers
boot device: sd0
root on sd0a dumps on sd0b
root file system type: ffs
kern.module.path=/stand/mac68k/7.99.29/modules
with hard disk
sd0 at scsibus0 target 0 lun 0: disk fixed
sd0: 8761 MB, 14384 cyl, 3 head, 415 sec, 512 bytes/sect x 17942584 sectors
sd0: async, 8-bit transfers, tagged queueing
The NetBSD Project is pleased to announce NetBSD 7.0.1, the first security/bugfix update of the NetBSD 7.0 release branch. It represents a selected subset of fixes deemed important for security or stability reasons. If you are running an earlier release of NetBSD, we strongly suggest updating to 7.0.1.
For more details, please see the release notes.
Complete source and binaries for NetBSD are available for download at many sites around the world. A list of download sites providing FTP, AnonCVS, SUP, and other services may be found at http://www.NetBSD.org/mirrors/.
The NetBSD Project is pleased to announce NetBSD 7.0.1, the first security/bugfix update of the NetBSD 7.0 release branch. It represents a selected subset of fixes deemed important for security or stability reasons. If you are running an earlier release of NetBSD, we strongly suggest updating to 7.0.1.
For more details, please see the release notes.
Complete source and binaries for NetBSD are available for download at many sites around the world. A list of download sites providing FTP, AnonCVS, SUP, and other services may be found at http://www.NetBSD.org/mirrors/.
The pkgsrc team has prepared the 50th release of their package management system, with the 2016Q1 version. It's infrequent event, as the 100th release will be held after 50 quarters.
The NetBSD team has prepared series of interviews with the authors. We started with Joerg Sonnenberger, a developer well known for his LLVM on NetBSD contribution.
Hi Joerg, please introduce yourself.
Hello Kamil,
I'm a software developer with a background in mathematics. Since I am doing Open Source development primarily for fun, my interests are changing over time and cover many different topics.
First of all, congratulations on the 50th release of pkgsrc! How do you feel about this anniversary?
The pkgsrc quarterly branches were one of the reasons for me to start looking at pkgsrc -- a bit more than a decade ago. As such, my 40th branch has passed recently as well, so it is a bit personal as well. I'm looking back proudly to what we have achieved, but also a bit sad to some of the faces and names that disappeared from the community over that time.
What are the main benefits of the pkgsrc system?
For me, the biggest advantage of pkgsrc is to provide me with the freedom to have a consistent environment across different platforms. Having to deal with BSD, Solaris and Linux flavours, it is very important to be able to sit down and get a consistent set of tools, consistent patches for programs to depend on etc.
Where and how do you use pkgsrc?
I'm using it on my own NetBSD and SmartOS systems as well as for providing software images for my customers at work.
What are the pkgsrc projects you are currently working on?
After that time focusing on bug hunting for the clang builds, I've recently returned to working on pbulk again. There are a number of areas where the distributed build can be improved. My main goal at the moment is to reduce the required coupling of master and slave. Sharing the distfiles is more challenging than it seems on first sight. NFS or null mounts are one option, but often, different packages sharing the same tarball are built in parallel. On an update, they will try to fetch the same file concurrently and often fail badly. The receipt I ended up using for the NetBSD 7.0 bulk builds is a low-memory virtual machine with nginx distribution the distfiles to all build slaves via HTTP(S). If a new file is obtained from elsewhere, it will be uploaded back to my local mirror via PUT. This has been quite reliable so far, but I still have to document the various steps involved for others. The new part will be better handling of the binary packages themselve. Using something like PUT again makes it easier to provide signatures without exposing the key material to all builds.
If you analyze the current state of pkgsrc, which improvements and changes do you wish for the future?
The biggest new term wish is that Leonardo's Summer of Code project will be successful and we finally get a proper infrastructure for building multiple packages in one step. The removal of non-DESTDIR support was kind of a show stopper for doing this sanely and that one is finally done. It didn't even take 10 years to reach that point From an infrastructural point of view, I want to tackle the shell fragment library topic again soon and also work on improving the build performance. The cwrapper support has been pending for a while, someone (else) has to sit down and fix the USE_CROSSBASE handling. I think that's the only real fallout we have left in the tree for making it the default, with all the performance boosts it can provide. More resources for builds is a general wish, but that also often requires porting to new hardware and the like.
Do you have any practical tips to share with the pkgsrc users?
The only practical tip is to aggressively use virtual machines or chroots for building whenever you can't just use binary packages. I.e. if you can't use pre-made binary packages, make your own.
What's the best way to start contributing to pkgsrc and what needs to be done?
Adopt a package, keep it updated and care for it and its environment. Everything tends to start from that. While pkglint is a handy tool for improving your own contributions, especially in pkgsrc-wip, it often helps even more to chat with a regular contributor whenever more challenging problems happen. Unlike many Linux packaging system, we try very hard to make simple things easy and compact. Many problems have different solutions and I sometimes look back to my own changes from years ago and find better solutions now. It is hard to put this kind of experience into documentation. None had the resources for training Watson yet.
Do you plan to participate in the upcoming pkgsrcCon 2016 in Kraków (1-3 July)?
I plan to come, I just don't know if I have time to prepare a presentation for it
Joerg
The pkgsrc team has prepared the 50th release of their package management system, with the 2016Q1 version. It's infrequent event, as the 100th release will be held after 50 quarters.
The NetBSD team has prepared series of interviews with the authors. We started with Joerg Sonnenberger, a developer well known for his LLVM on NetBSD contribution.
Hi Joerg, please introduce yourself.
Hello Kamil,
I'm a software developer with a background in mathematics. Since I am doing Open Source development primarily for fun, my interests are changing over time and cover many different topics.
First of all, congratulations on the 50th release of pkgsrc! How do you feel about this anniversary?
The pkgsrc quarterly branches were one of the reasons for me to start looking at pkgsrc -- a bit more than a decade ago. As such, my 40th branch has passed recently as well, so it is a bit personal as well. I'm looking back proudly to what we have achieved, but also a bit sad to some of the faces and names that disappeared from the community over that time.
What are the main benefits of the pkgsrc system?
For me, the biggest advantage of pkgsrc is to provide me with the freedom to have a consistent environment across different platforms. Having to deal with BSD, Solaris and Linux flavours, it is very important to be able to sit down and get a consistent set of tools, consistent patches for programs to depend on etc.
Where and how do you use pkgsrc?
I'm using it on my own NetBSD and SmartOS systems as well as for providing software images for my customers at work.
What are the pkgsrc projects you are currently working on?
After that time focusing on bug hunting for the clang builds, I've recently returned to working on pbulk again. There are a number of areas where the distributed build can be improved. My main goal at the moment is to reduce the required coupling of master and slave. Sharing the distfiles is more challenging than it seems on first sight. NFS or null mounts are one option, but often, different packages sharing the same tarball are built in parallel. On an update, they will try to fetch the same file concurrently and often fail badly. The receipt I ended up using for the NetBSD 7.0 bulk builds is a low-memory virtual machine with nginx distribution the distfiles to all build slaves via HTTP(S). If a new file is obtained from elsewhere, it will be uploaded back to my local mirror via PUT. This has been quite reliable so far, but I still have to document the various steps involved for others. The new part will be better handling of the binary packages themselve. Using something like PUT again makes it easier to provide signatures without exposing the key material to all builds.
If you analyze the current state of pkgsrc, which improvements and changes do you wish for the future?
The biggest new term wish is that Leonardo's Summer of Code project will be successful and we finally get a proper infrastructure for building multiple packages in one step. The removal of non-DESTDIR support was kind of a show stopper for doing this sanely and that one is finally done. It didn't even take 10 years to reach that point From an infrastructural point of view, I want to tackle the shell fragment library topic again soon and also work on improving the build performance. The cwrapper support has been pending for a while, someone (else) has to sit down and fix the USE_CROSSBASE handling. I think that's the only real fallout we have left in the tree for making it the default, with all the performance boosts it can provide. More resources for builds is a general wish, but that also often requires porting to new hardware and the like.
Do you have any practical tips to share with the pkgsrc users?
The only practical tip is to aggressively use virtual machines or chroots for building whenever you can't just use binary packages. I.e. if you can't use pre-made binary packages, make your own.
What's the best way to start contributing to pkgsrc and what needs to be done?
Adopt a package, keep it updated and care for it and its environment. Everything tends to start from that. While pkglint is a handy tool for improving your own contributions, especially in pkgsrc-wip, it often helps even more to chat with a regular contributor whenever more challenging problems happen. Unlike many Linux packaging system, we try very hard to make simple things easy and compact. Many problems have different solutions and I sometimes look back to my own changes from years ago and find better solutions now. It is hard to put this kind of experience into documentation. None had the resources for training Watson yet.
Do you plan to participate in the upcoming pkgsrcCon 2016 in Kraków (1-3 July)?
I plan to come, I just don't know if I have time to prepare a presentation for it
Joerg
Ever since I realized that the anykernel was the best way to construct a modern general purpose operating system kernel, I have been performing experiments by running unmodified NetBSD kernel drivers in rump kernels in various environments (nb. here driver does not mean a hardware device driver, but any driver like a file system driver or TCP driver). These experiments have included userspaces of various platforms, binary kernel modules on Linux and others, and compiling kernel drivers to javascript and running them natively in a web browser. I have also claimed that the anykernel allows harnessing drivers from a general purpose OS onto more specialized embedded computing devices which are becoming the new norm. This is an attractive possibility because while writing drivers is easy, making them handle all the abnormal conditions of the real world is a time-consuming process. Since the above-mentioned experiments were done on POSIX platforms (yes, even the javascript one), the experiments did not fully support the claim. The most interesting, decidedly non-POSIX platform I could think of for experimentation was the Linux kernel. Even though it had been several years since I last worked in the Linux kernel, my hypothesis was that it would be easy and fast to get unmodified NetBSD kernel drivers running in the Linux kernel as rump kernels.
A rump kernel runs on top of the rump kernel hypervisor. The hypervisor provides high level interfaces to host features, such as memory allocation and thread creation. In this case, the Linux kernel is the host. In principle, there are three steps in getting a rump kernel to run in a given environment. In reality, I prefer a more iterative approach, but the development can be divided into three steps all the same.
- implement generic rump kernel hypercalls, such as memory allocation, thread creation and synchronization
- figure out how to compile and run the rump kernel plus hypervisor in the target environment
- implement I/O related hypercalls for whatever I/O you plan to do
Getting basic functionality up and running was a relatively straightforward process. The only issue that required some thinking was an application binary interface (ABI) mismatch. I was testing on x86 where Linux kernel ABI uses -mregparm=3, which means that function arguments are passed in registers where possible. NetBSD always passes arguments on the stack. When two ABIs collide, the code may run, but since function arguments passed between the two ABIs result in garbage, eventually an error will be hit perhaps in the form of accessing invalid memory. The C code was easy enough to "fix" by applying the appropriate compiler flags. In addition to C code, a rump kernel uses a handful of assembly routines from NetBSD, mostly pertaining to optimizations (e.g. ffs()), but also to access the atomic memory operations of the platform. After assembly routines had been handled, it was possible to load a Linux kernel module which bootstraps a rump kernel in the Linux kernel and does some file system operations on the fictional kernfs file system. A screenshot of the resulting dmesg output is shown below.

It is one thing to execute a computation and an entirely different thing to perform I/O. To test I/O capabilities, I ran a rump kernel providing a TCP/IP driver inside the Linux kernel. For a networking stack to be able to do anything sensible, the interface layer needs to be able to shuffle packets. The quickest way to implement the hypercalls for packet shuffling was to use the same method as a userspace virtual TCP/IP stack might use: read/write packets using the tap device. Some might say that doing this from inside the kernel is cheating, but given that the alternative was to copypaste the tuntap driver and edit it slightly, I call my approach constructive laziness.
The demo itself opens a TCP socket to port 80 on vger.kernel.org (IP address 0x43b484d1 if you want to be really precise), does a HTTP get for "/" and displays the last 500 bytes of the result. TCP/IP is handled by the rump kernel, not by the Linux kernel. Think of it as the Linux kernel having two alternative TCP/IP stacks. Again, a screenshot of the resulting dmesg is shown below. Note that unlike in the first screenshot, there is no printout for the root file system because the configuration used here does not include any file system support. Yes, you can ping 10.0.2.17.

As hypothesized, a rump kernel hypervisor for the Linux kernel was easy and straightforward to implement. Furthermore, it could be done without making any changes to the existing hypercall interface thereby reinforcing the belief that unmodified NetBSD kernel drivers can run on top of most any embedded firmwares just by implementing a light hypervisor layer.
There were no challenges in the experiment, only annoyances. As Linux does not support rump kernels, I had to revert back to the archaic full OS approach to kernel development. The drawbacks of the full OS approach include for example suffering multi-second reboot cycles during iterative development. The other tangential issue that I spent a disproportionately large amount of time with was thinking about how releasing this code would affect existing NetBSD code due to GPL involvement. My conclusion was that this does not matter since all code used by the current demo is open source anyway, and if someone wants to use my code in a product, it is their problem, not mine.
For people interested in examining the implementation, I put the source code for the hypervisor along with the test code in a git repo here. The repository also contains the demos linked from this article. The NetBSD kernel drivers I used are available from ftp.netbsd.org or by getting buildrump.sh and running ./buildrump.sh checkout.
blacklistd by Christos Zoulas
The NetBSD Project is pleased to announce NetBSD 6.1.4, the fourth security/bugfix update of the NetBSD 6.1 release branch, and NetBSD 6.0.5, the fifth security/bugfix update of the NetBSD 6.0 release branch. They represent a selected subset of fixes deemed important for security or stability reasons, and if you are running a prior release of either branch, we strongly suggest that you update to one of these releases.
For more details, please see the NetBSD 6.1.4 release notes or NetBSD 6.0.5 release notes.
Complete source and binaries for NetBSD 6.1.4 and NetBSD 6.0.5 are available for download at many sites around the world. A list of download sites providing FTP, AnonCVS, SUP, and other services may be found at http://www.NetBSD.org/mirrors/.During this month I've finished the needed Native Process Plugin with breakpoints fully supported. In order to achieve this I had to address bugs, add missing features and diligently debug the debugger sniffing on the GDB Remote Protocol line. Since NetBSD-8 is approaching, I have performed the also needed housekeeping on the base system distribution side.
What has been done in NetBSD
I've managed to achieve the following goals:
Clean up in ptrace(2) ATF tests
We have created some maintanance burden for the current ptrace(2) regression tests. The main issues with them is code duplication and the splitting between generic (Machine Independent) and port-specific (Machine Dependent) test files. I've eliminated some of the ballast and merged tests into the appropriate directory tests/lib/libc/sys/. The old location (tests/kernel) was a violation of the tests/README recommendation:
When adding new tests, please try to follow the following conventions.
1. For library routines, including system calls, the directory structure of
the tests should follow the directory structure of the real source tree.
For instance, interfaces available via the C library should follow:
src/lib/libc/gen -> src/tests/lib/libc/gen
src/lib/libc/sys -> src/tests/lib/libc/sys
...
The ptrace(2) interface inhabits src/lib/libc/sys so there is no reason not to move it to its proper home.
PTRACE_FORK on !x86 ports
Along with the motivation from Martin Husemann we have investigated the issue with PTRACE_FORK ATF regression tests. It was discovered that these tests aren't functional on evbarm, alpha, shark, sparc and sparc64 and likely on other non-x86 ports. We have discovered that there is a missing SIGTRAP emitted from the child, during the fork(2) handshake. The proper order of operations is as follows:
- parent emits SIGTRAP with si_code=TRAP_CHLD and pe_set_event=pid of forkee
- child emits SIGTRAP with si_code=TRAP_CHLD and pe_set_event=pid of forker
Only the x86 ports were emitting the second SIGTRAP signal.
The culprit reason has been investigated and narrowed down to the child_return() function in src/sys/arch/x86/x86/syscall.c:
void
child_return(void *arg)
{
struct lwp *l = arg;
struct trapframe *tf = l->l_md.md_regs;
struct proc *p = l->l_proc;
if (p->p_slflag & PSL_TRACED) {
ksiginfo_t ksi;
mutex_enter(proc_lock);
KSI_INIT_EMPTY(&ksi);
ksi.ksi_signo = SIGTRAP;
ksi.ksi_lid = l->l_lid;
kpsignal(p, &ksi, NULL);
mutex_exit(proc_lock);
}
X86_TF_RAX(tf) = 0;
X86_TF_RFLAGS(tf) &= ~PSL_C;
userret(l);
ktrsysret(SYS_fork, 0, 0);
}
This child_return() function was the only one among all the existing ones for other platforms to contain the needed code for SIGTRAP. The appropriate solution was installed by Martin, as we taught our featured signal routing subsystem to handle early signals from the fork(2) calls.
PT_SYSCALL and PT_SYSCALLEMU
Christos Zoulas addressed the misbehavior with tracing syscall entry and syscall exit code. We can again get an event inside a debugger that a debuggee attempts to trigger a syscall and later return from it. This means that a debugger can access the register layout before executing the appropriate kernel code and read it again after executing the syscall. This allows to monitor exact sysentry arguments and return the values afterwards. Another option is to fake the trap frame with new values, it's sometimes useful for debugging.
With the addition of PT_SYSCALLEMU we can implement a virtual kernel syscall monitor. It means that we can fake syscalls within a debugger. In order to achieve this feature, we need to use the PT_SYSCALL operation, catch SIGTRAP with si_code=TRAP_SCE (syscall entry), call PT_SYSCALLEMU and perform an emulated userspace syscall that would have been done by the kernel, followed by calling another PT_SYSCALL with si_code=TRAP_SCX.
This interface makes it possible to introduce the following into NetBSD: truss(1) from FreeBSD and strace(1) from Linux. There used to be a port of at least strace(1) in the past, but it's time to refresh this code. Another immediate consumer is of course in DTrace/libproc... as there are facilities within this library to trace the system call entry and exit in order to catch fork(2) events. Why to catch fork(2)? It can be useful to detach software breakpoints in order to detach them before cloning address space of forker for forkee; and after the operation reapply them again.
What has been done in LLDB
A lot of work has been done with the goal to get breakpoints functional. This target penetrated bugs in the existing local patches and unveiled missing features required to be added. My initial test was tracing a dummy hello-world application in C. I have sniffed the GDB Remote Protocol packets and compared them between Linux and NetBSD. This helped to streamline both versions and bring the NetBSD support to the required Linux level.
As a bonus the initial code for OpenBSD support was also added into the LLDB tree. At the moment OpenBSD only supports opening core(5) files with a single-thread. The same capability was also added for NetBSD.
By the end of March all local patches for LLDB were merged upstream! This resulted in NetBSD being among the first operating systems to use a Native Process Plugin framework with the debugserver capability, alongside Linux & Android. The current FreeBSD support in LLDB is dated and lagging behind and limited to local debugging. A majority of the work to bring FreeBSD on par could well be a case of s/NetBSD/FreeBSD/.
Among the features in the upstreamed NetBSD Process Plugin:
- handling software breakpoints,
- correctly attaching to a tracee,
- supporting NetBSD specific ptrace(2),
- monitoring process termination,
- monitoring SIGTRAP events,
- monitoring SIGSTOP events,
- monitoring other signals events,
- resuming the whole process,
- getting memory region info perms,
- reading memory from tracee,
- writing memory to tracee,
- reading ELF AUXV,
- x86_64 GPR reading and writing,
- detecting debuginfo of the basesystem programs located in /usr/libdata/debug
- adding single step support,
- adding execve(2) trap support,
- placeholder for Floating Point Registers code,
- initial code for the NetBSD specific core(5) files,
- enabling ELF Aux Vector reading on the lldb client side,
- enabling QPassSignals feature for NetBSD on the lldb client side,
- enabling ProcessPOSIXLog on NetBSD,
- minor tweaking.
Demo
It's getting rather difficult to present all the features of the NetBSD Process Plugin without making the example overly long. This is why I will restrict it to a very basic debugging session hosted on NetBSD.
$ cat crashme.c
#include
int
main(int argc, char **argv)
{
int i = argv;
while (i-- != 0)
printf("argv[%d]=%s\n", i, argv[i]);
return 0;
}
$ gcc -w -g -o crashme crashme.c # -w disable all warnings
$ ./crashme
Memory fault (core dumped)
chieftec$ lldb ./crashme
(lldb) target create "./crashme"
Current executable set to './crashme' (x86_64).
(lldb) r
Process 612 launched: './crashme' (x86_64)
Process 612 stopped
* thread #1, stop reason = signal SIGSEGV: address access protected (fault address: 0x7f7ffec88518)
frame #0: 0x000000000040089c crashme`main(argc=1, argv=0x00007f7fffdd6420) at crashme.c:9
6 int i = argv;
7
8 while (i-- != 0)
-> 9 printf("argv[%d]=%s\n", i, argv[i]);
10
11 return 0;
12 }
(lldb) frame var
(int) argc = 1
(char **) argv = 0x00007f7fffdd6420
(int) i = -2268129
(lldb) # i looks wrong, checking argv...
(lldb) p *argv
(char *) $0 = 0x00007f7fffdd6940 "./crashme"
(lldb) # set a brakpoint and restart
(lldb) b main
Breakpoint 1: where = crashme`main + 15 at crashme.c:6, address = 0x000000000040087f
(lldb) r
There is a running process, kill it and restart?: [Y/n] y
Process 612 exited with status = 6 (0x00000006) got unexpected response to k packet: Sff
Process 80 launched: './crashme' (x86_64)
Process 80 stopped
* thread #1, stop reason = breakpoint 1.1
frame #0: 0x000000000040087f crashme`main(argc=1, argv=0x00007f7fff3d17c8) at crashme.c:6
3 int
4 main(int argc, char **argv)
5 {
-> 6 int i = argv;
7
8 while (i-- != 0)
9 printf("argv[%d]=%s\n", i, argv[i]);
(lldb) frame var
(int) argc = 1
(char **) argv = 0x00007f7fff3d17c8
(int) i = 0
(lldb) n
Process 80 stopped
* thread #1, stop reason = step over
frame #0: 0x0000000000400886 crashme`main(argc=1, argv=0x00007f7fff3d17c8) at crashme.c:8
5 {
6 int i = argv;
7
-> 8 while (i-- != 0)
9 printf("argv[%d]=%s\n", i, argv[i]);
10
11 return 0;
(lldb) p i
(int) $1 = -12773432
(lldb) # gotcha i = argv, instead of argc!
(lldb) bt
* thread #1, stop reason = step over
* frame #0: 0x0000000000400886 crashme`main(argc=1, argv=0x00007f7fff3d17c8) at crashme.c:8
frame #1: 0x000000000040078b crashme`___start + 229
(lldb) disassemble --frame --mixed
4 main(int argc, char **argv)
** 5 {
crashme`main:
0x400870 <+0>: pushq %rbp
0x400871 <+1>: movq %rsp, %rbp
0x400874 <+4>: subq $0x20, %rsp
0x400878 <+8>: movl %edi, -0x14(%rbp)
0x40087b <+11>: movq %rsi, -0x20(%rbp)
** 6 int i = argv;
7
0x40087f <+15>: movq -0x20(%rbp), %rax
0x400883 <+19>: movl %eax, -0x4(%rbp)
-> 8 while (i-- != 0)
-> 0x400886 <+22>: jmp 0x4008b3 ; <+67> at crashme.c:8
** 9 printf("argv[%d]=%s\n", i, argv[i]);
10
0x400888 <+24>: movl -0x4(%rbp), %eax
0x40088b <+27>: cltq
0x40088d <+29>: leaq (,%rax,8), %rdx
0x400895 <+37>: movq -0x20(%rbp), %rax
0x400899 <+41>: addq %rdx, %rax
0x40089c <+44>: movq (%rax), %rdx
0x40089f <+47>: movl -0x4(%rbp), %eax
0x4008a2 <+50>: movl %eax, %esi
0x4008a4 <+52>: movl $0x400968, %edi ; imm = 0x400968
0x4008a9 <+57>: movl $0x0, %eax
0x4008ae <+62>: callq 0x400630 ; symbol stub for: printf
** 8 while (i-- != 0)
0x4008b3 <+67>: movl -0x4(%rbp), %eax
0x4008b6 <+70>: leal -0x1(%rax), %edx
0x4008b9 <+73>: movl %edx, -0x4(%rbp)
0x4008bc <+76>: testl %eax, %eax
0x4008be <+78>: jne 0x400888 ; <+24> at crashme.c:9
** 11 return 0;
0x4008c0 <+80>: movl $0x0, %eax
** 12 }
0x4008c5 <+85>: leave
0x4008c6 <+86>: retq
(lldb) version
lldb version 5.0.0 (http://llvm.org/svn/llvm-project/lldb/trunk revision 299109)
(lldb) platform status
Platform: host
Triple: x86_64-unknown-netbsd7.99
OS Version: 7.99.67 (0799006700)
Kernel: NetBSD 7.99.67 (GENERIC) #1: Mon Apr 3 08:09:29 CEST 2017 root@chieftec:/public/netbsd-root/sys/arch/amd64/compile/GENERIC
Hostname: 127.0.0.1
WorkingDir: /public/lldb_devel
Kernel: NetBSD
Release: 7.99.67
Version: NetBSD 7.99.67 (GENERIC) #1: Mon Apr 3 08:09:29 CEST 2017 root@chieftec:/public/netbsd-root/sys/arch/amd64/compile/GENERIC
(lldb) # thank you!
(lldb) q
Quitting LLDB will kill one or more processes. Do you really want to proceed: [Y/n] y
Plan for the next milestone
I've listed the following goals for the next milestone.
- watchpoints support,
- floating point registers support,
- enhance core(5) and make it work for multiple threads
- introduce PT_SETSTEP and PT_CLEARSTEP in ptrace(2)
- support threads in the NetBSD Process Plugin
- research F_GETPATH in fcntl(2)
Beyond the next milestone is x86 32-bit support.
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL, and chip in what you can:
During this month I've finished the needed Native Process Plugin with breakpoints fully supported. In order to achieve this I had to address bugs, add missing features and diligently debug the debugger sniffing on the GDB Remote Protocol line. Since NetBSD-8 is approaching, I have performed the also needed housekeeping on the base system distribution side.
What has been done in NetBSD
I've managed to achieve the following goals:
Clean up in ptrace(2) ATF tests
We have created some maintanance burden for the current ptrace(2) regression tests. The main issues with them is code duplication and the splitting between generic (Machine Independent) and port-specific (Machine Dependent) test files. I've eliminated some of the ballast and merged tests into the appropriate directory tests/lib/libc/sys/. The old location (tests/kernel) was a violation of the tests/README recommendation:
When adding new tests, please try to follow the following conventions.
1. For library routines, including system calls, the directory structure of
the tests should follow the directory structure of the real source tree.
For instance, interfaces available via the C library should follow:
src/lib/libc/gen -> src/tests/lib/libc/gen
src/lib/libc/sys -> src/tests/lib/libc/sys
...
The ptrace(2) interface inhabits src/lib/libc/sys so there is no reason not to move it to its proper home.
PTRACE_FORK on !x86 ports
Along with the motivation from Martin Husemann we have investigated the issue with PTRACE_FORK ATF regression tests. It was discovered that these tests aren't functional on evbarm, alpha, shark, sparc and sparc64 and likely on other non-x86 ports. We have discovered that there is a missing SIGTRAP emitted from the child, during the fork(2) handshake. The proper order of operations is as follows:
- parent emits SIGTRAP with si_code=TRAP_CHLD and pe_set_event=pid of forkee
- child emits SIGTRAP with si_code=TRAP_CHLD and pe_set_event=pid of forker
Only the x86 ports were emitting the second SIGTRAP signal.
The culprit reason has been investigated and narrowed down to the child_return() function in src/sys/arch/x86/x86/syscall.c:
void
child_return(void *arg)
{
struct lwp *l = arg;
struct trapframe *tf = l->l_md.md_regs;
struct proc *p = l->l_proc;
if (p->p_slflag & PSL_TRACED) {
ksiginfo_t ksi;
mutex_enter(proc_lock);
KSI_INIT_EMPTY(&ksi);
ksi.ksi_signo = SIGTRAP;
ksi.ksi_lid = l->l_lid;
kpsignal(p, &ksi, NULL);
mutex_exit(proc_lock);
}
X86_TF_RAX(tf) = 0;
X86_TF_RFLAGS(tf) &= ~PSL_C;
userret(l);
ktrsysret(SYS_fork, 0, 0);
}
This child_return() function was the only one among all the existing ones for other platforms to contain the needed code for SIGTRAP. The appropriate solution was installed by Martin, as we taught our featured signal routing subsystem to handle early signals from the fork(2) calls.
PT_SYSCALL and PT_SYSCALLEMU
Christos Zoulas addressed the misbehavior with tracing syscall entry and syscall exit code. We can again get an event inside a debugger that a debuggee attempts to trigger a syscall and later return from it. This means that a debugger can access the register layout before executing the appropriate kernel code and read it again after executing the syscall. This allows to monitor exact sysentry arguments and return the values afterwards. Another option is to fake the trap frame with new values, it's sometimes useful for debugging.
With the addition of PT_SYSCALLEMU we can implement a virtual kernel syscall monitor. It means that we can fake syscalls within a debugger. In order to achieve this feature, we need to use the PT_SYSCALL operation, catch SIGTRAP with si_code=TRAP_SCE (syscall entry), call PT_SYSCALLEMU and perform an emulated userspace syscall that would have been done by the kernel, followed by calling another PT_SYSCALL with si_code=TRAP_SCX.
This interface makes it possible to introduce the following into NetBSD: truss(1) from FreeBSD and strace(1) from Linux. There used to be a port of at least strace(1) in the past, but it's time to refresh this code. Another immediate consumer is of course in DTrace/libproc... as there are facilities within this library to trace the system call entry and exit in order to catch fork(2) events. Why to catch fork(2)? It can be useful to detach software breakpoints in order to detach them before cloning address space of forker for forkee; and after the operation reapply them again.
What has been done in LLDB
A lot of work has been done with the goal to get breakpoints functional. This target penetrated bugs in the existing local patches and unveiled missing features required to be added. My initial test was tracing a dummy hello-world application in C. I have sniffed the GDB Remote Protocol packets and compared them between Linux and NetBSD. This helped to streamline both versions and bring the NetBSD support to the required Linux level.
As a bonus the initial code for OpenBSD support was also added into the LLDB tree. At the moment OpenBSD only supports opening core(5) files with a single-thread. The same capability was also added for NetBSD.
By the end of March all local patches for LLDB were merged upstream! This resulted in NetBSD being among the first operating systems to use a Native Process Plugin framework with the debugserver capability, alongside Linux & Android. The current FreeBSD support in LLDB is dated and lagging behind and limited to local debugging. A majority of the work to bring FreeBSD on par could well be a case of s/NetBSD/FreeBSD/.
Among the features in the upstreamed NetBSD Process Plugin:
- handling software breakpoints,
- correctly attaching to a tracee,
- supporting NetBSD specific ptrace(2),
- monitoring process termination,
- monitoring SIGTRAP events,
- monitoring SIGSTOP events,
- monitoring other signals events,
- resuming the whole process,
- getting memory region info perms,
- reading memory from tracee,
- writing memory to tracee,
- reading ELF AUXV,
- x86_64 GPR reading and writing,
- detecting debuginfo of the basesystem programs located in /usr/libdata/debug
- adding single step support,
- adding execve(2) trap support,
- placeholder for Floating Point Registers code,
- initial code for the NetBSD specific core(5) files,
- enabling ELF Aux Vector reading on the lldb client side,
- enabling QPassSignals feature for NetBSD on the lldb client side,
- enabling ProcessPOSIXLog on NetBSD,
- minor tweaking.
Demo
It's getting rather difficult to present all the features of the NetBSD Process Plugin without making the example overly long. This is why I will restrict it to a very basic debugging session hosted on NetBSD.
$ cat crashme.c
#include
int
main(int argc, char **argv)
{
int i = argv;
while (i-- != 0)
printf("argv[%d]=%s\n", i, argv[i]);
return 0;
}
$ gcc -w -g -o crashme crashme.c # -w disable all warnings
$ ./crashme
Memory fault (core dumped)
chieftec$ lldb ./crashme
(lldb) target create "./crashme"
Current executable set to './crashme' (x86_64).
(lldb) r
Process 612 launched: './crashme' (x86_64)
Process 612 stopped
* thread #1, stop reason = signal SIGSEGV: address access protected (fault address: 0x7f7ffec88518)
frame #0: 0x000000000040089c crashme`main(argc=1, argv=0x00007f7fffdd6420) at crashme.c:9
6 int i = argv;
7
8 while (i-- != 0)
-> 9 printf("argv[%d]=%s\n", i, argv[i]);
10
11 return 0;
12 }
(lldb) frame var
(int) argc = 1
(char **) argv = 0x00007f7fffdd6420
(int) i = -2268129
(lldb) # i looks wrong, checking argv...
(lldb) p *argv
(char *) $0 = 0x00007f7fffdd6940 "./crashme"
(lldb) # set a brakpoint and restart
(lldb) b main
Breakpoint 1: where = crashme`main + 15 at crashme.c:6, address = 0x000000000040087f
(lldb) r
There is a running process, kill it and restart?: [Y/n] y
Process 612 exited with status = 6 (0x00000006) got unexpected response to k packet: Sff
Process 80 launched: './crashme' (x86_64)
Process 80 stopped
* thread #1, stop reason = breakpoint 1.1
frame #0: 0x000000000040087f crashme`main(argc=1, argv=0x00007f7fff3d17c8) at crashme.c:6
3 int
4 main(int argc, char **argv)
5 {
-> 6 int i = argv;
7
8 while (i-- != 0)
9 printf("argv[%d]=%s\n", i, argv[i]);
(lldb) frame var
(int) argc = 1
(char **) argv = 0x00007f7fff3d17c8
(int) i = 0
(lldb) n
Process 80 stopped
* thread #1, stop reason = step over
frame #0: 0x0000000000400886 crashme`main(argc=1, argv=0x00007f7fff3d17c8) at crashme.c:8
5 {
6 int i = argv;
7
-> 8 while (i-- != 0)
9 printf("argv[%d]=%s\n", i, argv[i]);
10
11 return 0;
(lldb) p i
(int) $1 = -12773432
(lldb) # gotcha i = argv, instead of argc!
(lldb) bt
* thread #1, stop reason = step over
* frame #0: 0x0000000000400886 crashme`main(argc=1, argv=0x00007f7fff3d17c8) at crashme.c:8
frame #1: 0x000000000040078b crashme`___start + 229
(lldb) disassemble --frame --mixed
4 main(int argc, char **argv)
** 5 {
crashme`main:
0x400870 <+0>: pushq %rbp
0x400871 <+1>: movq %rsp, %rbp
0x400874 <+4>: subq $0x20, %rsp
0x400878 <+8>: movl %edi, -0x14(%rbp)
0x40087b <+11>: movq %rsi, -0x20(%rbp)
** 6 int i = argv;
7
0x40087f <+15>: movq -0x20(%rbp), %rax
0x400883 <+19>: movl %eax, -0x4(%rbp)
-> 8 while (i-- != 0)
-> 0x400886 <+22>: jmp 0x4008b3 ; <+67> at crashme.c:8
** 9 printf("argv[%d]=%s\n", i, argv[i]);
10
0x400888 <+24>: movl -0x4(%rbp), %eax
0x40088b <+27>: cltq
0x40088d <+29>: leaq (,%rax,8), %rdx
0x400895 <+37>: movq -0x20(%rbp), %rax
0x400899 <+41>: addq %rdx, %rax
0x40089c <+44>: movq (%rax), %rdx
0x40089f <+47>: movl -0x4(%rbp), %eax
0x4008a2 <+50>: movl %eax, %esi
0x4008a4 <+52>: movl $0x400968, %edi ; imm = 0x400968
0x4008a9 <+57>: movl $0x0, %eax
0x4008ae <+62>: callq 0x400630 ; symbol stub for: printf
** 8 while (i-- != 0)
0x4008b3 <+67>: movl -0x4(%rbp), %eax
0x4008b6 <+70>: leal -0x1(%rax), %edx
0x4008b9 <+73>: movl %edx, -0x4(%rbp)
0x4008bc <+76>: testl %eax, %eax
0x4008be <+78>: jne 0x400888 ; <+24> at crashme.c:9
** 11 return 0;
0x4008c0 <+80>: movl $0x0, %eax
** 12 }
0x4008c5 <+85>: leave
0x4008c6 <+86>: retq
(lldb) version
lldb version 5.0.0 (http://llvm.org/svn/llvm-project/lldb/trunk revision 299109)
(lldb) platform status
Platform: host
Triple: x86_64-unknown-netbsd7.99
OS Version: 7.99.67 (0799006700)
Kernel: NetBSD 7.99.67 (GENERIC) #1: Mon Apr 3 08:09:29 CEST 2017 root@chieftec:/public/netbsd-root/sys/arch/amd64/compile/GENERIC
Hostname: 127.0.0.1
WorkingDir: /public/lldb_devel
Kernel: NetBSD
Release: 7.99.67
Version: NetBSD 7.99.67 (GENERIC) #1: Mon Apr 3 08:09:29 CEST 2017 root@chieftec:/public/netbsd-root/sys/arch/amd64/compile/GENERIC
(lldb) # thank you!
(lldb) q
Quitting LLDB will kill one or more processes. Do you really want to proceed: [Y/n] y
Plan for the next milestone
I've listed the following goals for the next milestone.
- watchpoints support,
- floating point registers support,
- enhance core(5) and make it work for multiple threads
- introduce PT_SETSTEP and PT_CLEARSTEP in ptrace(2)
- support threads in the NetBSD Process Plugin
- research F_GETPATH in fcntl(2)
Beyond the next milestone is x86 32-bit support.
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL, and chip in what you can:
revision 1.1
date: 1993-03-21 10:45:37 +0100; author: cgd; state: Exp;
branches: 1.1.1;
Initial revision
and we continue this legacy.
Work is ongoing to bring this modern toolchain to all other ports too (most of them already work, but some more testing will be done). If you want to try it, just add -V HAVE_GCC=48 to the build.sh invocation.
Note that in parallel clang is available as an alternative option for a few architectures already (i386, amd64, arm, and sparc64), but needs more testing and debugging at least on some of them (e.g. the sparc64 kernel does not boot).
For a project with diverse hardware support like NetBSD, all toolchain updates are a big pain - so a big THANK YOU! to everyone involved; in no particular order Christos Zoulas, matthew green, Nick Hudson, Tohru Nishimura, Frank Wille (and myself).
Due to a strange series of events the code changes needed to support the (slightly unusual) MIPS CPU used in the playstation2 had never been merged into gcc nor binutils mainline. Only recently this has been fixed. Unfortunately the changes have not been pulled up to the gcc 4.8.3 branch (which is available in NetBSD-current), so an external toolchain from pkgsrc is needed for the playstation2.
To install this toolchain, use a pkgsrc-current checkout and cd to cross/gcc-mips-current, then do "make install" - that is all.
Work is in progress to bring the old code up to -current. Hopefully a bootable NetBSD-current kernel will be available soon.
The second release candidate of NetBSD 6.1 is now available for download at: http://ftp.NetBSD.org/pub/NetBSD/NetBSD-6.1_RC2/
NetBSD 6.1 will be the first feature update for the NetBSD 6 branch. There are many new drivers, some new features, and many bug fixes! Fixes since RC1 include:
- Various terminfo fixes (PR#46793, PR#47090, PR#47490, PR#47532)
- Fixed a segfault in awk(1) (PR#47553)
- Moved boottime50 and its associated sysctl into the compat module. (PR#47579)
- Updated tzdata to 2013b, with the latest timezone info
- Fixed a crash when the security.curtain sysctl is enabled (PR#47598)
- Fixed some IPF locking issues
- Fix a crash on statically-linked programs for NetBSD/alpha
A complete list of changes can be found at:
http://ftp.NetBSD.org/pub/NetBSD/NetBSD-6.1_RC2/CHANGES-6.1
Please help us test this and any upcoming release candidates as much as possible. Remember, any feedback is good feedback. We'd love to hear from you, whether you've got a complaint or a compliment.
We get a lot of comments asking for tips on using the raspberry pi so I thought I would point out some docs:
evbarm/rpi wiki docs
An example of the rpi.img can be found here:
http://nyftp.netbsd.org/pub/NetBSD-daily/HEAD/201303221130Z/evbarm/binary/gzimg/ notice the HEAD (NetBSD -current), datestamp, arch path for future reference
There are also some concerns about building a kernel/img on your own.
building NetBSD
build.sh is one of the best features of NetBSD. You can cross compile from almost any other unix-like system with very little difficulty.
This time I will shortly iterate over the finished tasks as I would like to present slides on ptrace(2) in NetBSD.
As usual hundreds of ATF tests were introduced, few Problem Reports filed and two patches upstreamed to LLDB.
What has been done in NetBSD
I've managed to achieve the following goals:
- Marked exect(3) obsolete in libc
- Removed libpthread_dbg(3) from the base distribution
- Added new ptrace(2) operations PT_SET_SIGMASK and PT_GET_SIGMASK
- Switch ptrace(2) PT_WATCHPOINT API to PT_GETDBRGS and PT_SETDBREGS
- Validation of ptrace(2) PT_SYSCALL
The exect(3) interface is no longer functional and it's the proper time to obsolete it. The libpthread_dbg(3) library is no longer needed, it became unnecessary along with the M:N thread model removal.
I originally added the PT_*ET_SIGMASK interface in order to help the criu port for NetBSD. This software is used to checkpoint programs on Linux. Debuggers can also have checkpointing support, for example GDB/Linux has this ability.
The debug registers are finally in the proper form on NetBSD. The previous API had defects as it was designed to be safe, but keeping it safe on the kernel side was impractical. I've finally decided to adapt it to the existing FreeBSD semantics and reuse PT_*ETDBREGS operations. I've verified this new API on real hardware amd64 (Intel i7) and i386 (Intel Pentium IV) with newly written 390 tests. It's worth noting that this API renders GDB to support hardware watchpoints on NetBSD almost out-of-the-box! However it's not free of bugs, after catching a watchpoint, GDB enters on a trap in a dynamic linker (?).
(gdb) c
Continuing.
Watchpoint 2: traceme
Old value = 0
New value = 16
main (argc=1, argv=0x7f7fff79fe30) at test.c:8
8 printf("traceme=%d\n", traceme);
(gdb) c
Continuing.
Watchpoint 2 deleted because the program has left the block in
which its expression is valid.
0x00007f7e3c000782 in _rtld_bind_start () from /usr/libexec/ld.elf_so
(gdb) c
Continuing.
Program received signal SIGTRAP, Trace/breakpoint trap.
0x00007f7e3c0007b5 in _rtld_bind_start () from /usr/libexec/ld.elf_so
(gdb) c
Continuing.
traceme=16
traceme=17
[Inferior 1 (process 28797) exited normally]
Sadly the PT_SYSCALL needs more work. The current implementation is currently broken and cannot stop the process on syscall entry.
What has been done in LLDB
As usual, I've pushed some ready patches to upstream LLDB. The first one covers Debug Register accessors and the second one adds proper thread identity detection on NetBSD.
Porting ptrace(2) software to NetBSD
I have prepared this presentation to illustrate the new code in the context of Linux and other BSDs.
To browse the slides one must use arrow buttons or the mouse scroll wheel. Press the h key for help.
Porting ptrace(2) software to NetBSD.
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL, and chip in what you can:
This time I will shortly iterate over the finished tasks as I would like to present slides on ptrace(2) in NetBSD.
As usual hundreds of ATF tests were introduced, few Problem Reports filed and two patches upstreamed to LLDB.
What has been done in NetBSD
I've managed to achieve the following goals:
- Marked exect(3) obsolete in libc
- Removed libpthread_dbg(3) from the base distribution
- Added new ptrace(2) operations PT_SET_SIGMASK and PT_GET_SIGMASK
- Switch ptrace(2) PT_WATCHPOINT API to PT_GETDBRGS and PT_SETDBREGS
- Validation of ptrace(2) PT_SYSCALL
The exect(3) interface is no longer functional and it's the proper time to obsolete it. The libpthread_dbg(3) library is no longer needed, it became unnecessary along with the M:N thread model removal.
I originally added the PT_*ET_SIGMASK interface in order to help the criu port for NetBSD. This software is used to checkpoint programs on Linux. Debuggers can also have checkpointing support, for example GDB/Linux has this ability.
The debug registers are finally in the proper form on NetBSD. The previous API had defects as it was designed to be safe, but keeping it safe on the kernel side was impractical. I've finally decided to adapt it to the existing FreeBSD semantics and reuse PT_*ETDBREGS operations. I've verified this new API on real hardware amd64 (Intel i7) and i386 (Intel Pentium IV) with newly written 390 tests. It's worth noting that this API renders GDB to support hardware watchpoints on NetBSD almost out-of-the-box! However it's not free of bugs, after catching a watchpoint, GDB enters on a trap in a dynamic linker (?).
(gdb) c
Continuing.
Watchpoint 2: traceme
Old value = 0
New value = 16
main (argc=1, argv=0x7f7fff79fe30) at test.c:8
8 printf("traceme=%d\n", traceme);
(gdb) c
Continuing.
Watchpoint 2 deleted because the program has left the block in
which its expression is valid.
0x00007f7e3c000782 in _rtld_bind_start () from /usr/libexec/ld.elf_so
(gdb) c
Continuing.
Program received signal SIGTRAP, Trace/breakpoint trap.
0x00007f7e3c0007b5 in _rtld_bind_start () from /usr/libexec/ld.elf_so
(gdb) c
Continuing.
traceme=16
traceme=17
[Inferior 1 (process 28797) exited normally]
Sadly the PT_SYSCALL needs more work. The current implementation is currently broken and cannot stop the process on syscall entry.
What has been done in LLDB
As usual, I've pushed some ready patches to upstream LLDB. The first one covers Debug Register accessors and the second one adds proper thread identity detection on NetBSD.
Porting ptrace(2) software to NetBSD
I have prepared this presentation to illustrate the new code in the context of Linux and other BSDs.
To browse the slides one must use arrow buttons or the mouse scroll wheel. Press the h key for help.
Porting ptrace(2) software to NetBSD.
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL, and chip in what you can:
The NetBSD Project is pleased to announce NetBSD 7.1, the first feature update of the NetBSD 7 release branch. It represents a selected subset of fixes deemed important for security or stability reasons, as well as new features and enhancements.
Some highlights of NetBSD 7.1 are:
- Support for Raspberry Pi Zero.
- Initial DRM/KMS support for NVIDIA graphics cards via nouveau (Disabled by default. Uncomment nouveau and nouveaufb in your kernel config to test).
- The addition of vioscsi, a driver for the Google Compute Engine disk.
- Linux compatibility improvements, allowing, e.g., the use of Adobe Flash Player 24.
- wm(4):
- C2000 KX and 2.5G support.
- Wake On Lan support.
- 82575 and newer SERDES based systems now work.
- ODROID-C1 Ethernet now works.
- Numerous bug fixes and stability improvements.
For more details, please see the release notes.
Complete source and binaries for NetBSD are available for download at many sites around the world. A list of download sites providing FTP, AnonCVS, SUP, and other services may be found at http://www.NetBSD.org/mirrors/.
The NetBSD Project is pleased to announce NetBSD 7.1, the first feature update of the NetBSD 7 release branch. It represents a selected subset of fixes deemed important for security or stability reasons, as well as new features and enhancements.
Some highlights of NetBSD 7.1 are:
- Support for Raspberry Pi Zero.
- Initial DRM/KMS support for NVIDIA graphics cards via nouveau (Disabled by default. Uncomment nouveau and nouveaufb in your kernel config to test).
- The addition of vioscsi, a driver for the Google Compute Engine disk.
- Linux compatibility improvements, allowing, e.g., the use of Adobe Flash Player 24.
- wm(4):
- C2000 KX and 2.5G support.
- Wake On Lan support.
- 82575 and newer SERDES based systems now work.
- ODROID-C1 Ethernet now works.
- Numerous bug fixes and stability improvements.
For more details, please see the release notes.
Complete source and binaries for NetBSD are available for download at many sites around the world. A list of download sites providing FTP, AnonCVS, SUP, and other services may be found at http://www.NetBSD.org/mirrors/.
U-Boot SPL 2013.10-rc3-g9329ab16a204 (Jun 26 2014 - 09:43:22)
SDRAM H5TQ2G83CFR initialization... done
U-Boot 2013.10-rc3-g9329ab16a204 (Jun 26 2014 - 09:43:22)
Board: ci20 (Ingenic XBurst JZ4780 SoC)
DRAM: 1 GiB
NAND: 8192 MiB
MMC: jz_mmc msc1: 0
In: eserial3
Out: eserial3
Err: eserial3
Net: dm9000
ci20# dhcp
ERROR: resetting DM9000 -> not responding
dm9000 i/o: 0xb6000000, id: 0x90000a46
DM9000: running in 8 bit mode
MAC: d0:31:10:ff:7e:89
operating at 100M full duplex mode
BOOTP broadcast 1
DHCP client bound to address 192.168.0.47
*** Warning: no boot file name; using 'C0A8002F.img'
Using dm9000 device
TFTP from server 192.168.0.44; our IP address is 192.168.0.47
Filename 'C0A8002F.img'.
Load address: 0x88000000
Loading: #################################################################
#######################################
347.7 KiB/s
done
Bytes transferred = 1519445 (172f55 hex)
ci20# bootm
## Booting kernel from Legacy Image at 88000000 ...
Image Name: evbmips 7.99.5 (CI20)
Image Type: MIPS NetBSD Kernel Image (gzip compressed)
Data Size: 1519381 Bytes = 1.4 MiB
Load Address: 80020000
Entry Point: 80020000
Verifying Checksum ... OK
Uncompressing Kernel Image ... OK
subcommand not supported
ci20# g 80020000
## Starting applicatipmap_steal_memory: seg 0: 0x3b3 0x3b3 0xffff 0xffff
Loaded initial symtab at 0x80304754, strtab at 0x8032d934, # entries 10499
Copyright (c) 1996, 1997, 1998, 1999, 2000, 2001, 2002, 2003, 2004, 2005,
2006, 2007, 2008, 2009, 2010, 2011, 2012, 2013, 2014, 2015
The NetBSD Foundation, Inc. All rights reserved.
Copyright (c) 1982, 1986, 1989, 1991, 1993
The Regents of the University of California. All rights reserved.
NetBSD 7.99.5 (CI20) #170: Sat Mar 7 10:43:03 EST 2015
ml@blackbush:/home/build/obj_evbmips32/sys/arch/evbmips/compile/CI20
Ingenic XBurst
total memory = 256 MB
avail memory = 247 MB
mainbus0 (root)
cpu0 at mainbus0: 1200.00MHz (hz cycles = 120000, delay divisor = 12)
cpu0: Ingenic XBurst (0x3ee1024f) Rev. 79 with unknown FPC type (0x330000) Rev. 0
cpu0: 32 TLB entries, 16MB max page size
cpu0: 32KB/32B 8-way set-associative L1 instruction cache
cpu0: 32KB/32B 8-way set-associative write-back L1 data cache
com0 at mainbus0: Ingenic UART, working fifo
com0: console
apbus0 at mainbus0
dwctwo0 at apbus0: USB controller
jzgpio at apbus0 not configured
jzfb at apbus0 not configured
usb0 at dwctwo0: USB revision 2.0
starting timer interrupt...
uhub0 at usb0: vendor 0000 DWC2 root hub, class 9/0, rev 2.00/1.00, addr 1
uhub1 at uhub0 port 1: vendor 1a40 USB 2.0 Hub [MTT], class 9/0, rev 2.00/1.00, addr 2
uhub1: multiple transaction translators
umass0 at uhub1 port 1 configuration 1 interface 0
umass0: LaCie P'9220 Mobile Drive, rev 2.10/0.06, addr 3
scsibus0 at umass0: 2 targets, 1 lun per target
sd0 at scsibus0 target 0 lun 0: disk fixed
sd0: 465 GB, 16383 cyl, 16 head, 63 sec, 512 bytes/sect x 976773168 sectors
umass1 at uhub1 port 2 configuration 1 interface 0
umass1: Apple Inc. iPod, rev 2.00/0.01, addr 4
scsibus1 at umass1: 2 targets, 1 lun per target
sd1 at scsibus1 target 0 lun 0: disk removable
uhidev0 at uhub1 port 4 configuration 1 interface 0
uhidev0: vendor 04d9 VISENTA V1, rev 1.10/1.00, addr 5, iclass 3/1
ukbd0 at uhidev0: 8 modifier keys, 6 key codes
wskbd0 at ukbd0 (mux ignored)
uhidev1 at uhub1 port 4 configuration 1 interface 1
uhidev1: vendor 04d9 VISENTA V1, rev 1.10/1.00, addr 5, iclass 3/1
uhidev1: 3 report ids
ums0 at uhidev1 reportid 1: 3 buttons, W and Z dirs
wsmouse0 at ums0 (mux ignored)
uhid0 at uhidev1 reportid 2: input=2, output=0, feature=0
uhid1 at uhidev1 reportid 3: input=1, output=0, feature=0
sd1: fabricating a geometry
sd1: 7601 MB, 950 cyl, 64 head, 32 sec, 4096 bytes/sect x 1946049 sectors
uhub2 at uhub1 port 6: vendor 03eb Standard USB Hub, class 9/0, rev 1.10/3.00, addr 6
axe0 at uhub2 port 1
axe0: D-LINK CORPORAION DUB-E100, rev 2.00/10.01, addr 7
axe0: Ethernet address 00:80:c8:37:00:e1
ukphy0 at axe0 phy 3: OUI 0x0009c3, model 0x0005, rev. 4
ukphy0: 10baseT, 10baseT-FDX, 100baseTX, 100baseTX-FDX, auto
root on sd0a dumps on sd0b
kern.module.path=/stand/evbmips/7.99.5/modules
WARNING: no TOD clock present
WARNING: using filesystem time
WARNING: CHECK AND RESET THE DATE!
init: copying out path `/sbin/init' 11
pid 1(init): ABI set to O32 (e_flags=0x70001007)
Thu Mar 5 18:27:33 UTC 2015
Not checking /: fs_passno = 0 in /etc/fstab
swapctl: adding /dev/sd0b as swap device at priority 0
Starting file system checks:
random_seed: /var/db/entropy-file: Not present
Setting tty flags.
Setting sysctl variables:
ddb.onpanic: 1 -> 0
Starting network.
Hostname: ci20
IPv6 mode: autoconfigured host
Configuring network interfaces: axe0.
Adding interface aliases:.
add net default: gateway 192.168.0.1
Waiting for DAD to complete for statically configured addresses...
axe0: link state UP (was UNKNOWN)
Building databases: dev, utmp, utmpx.
Starting syslogd.
Starting rpcbind.
Mounting all file systems...
Clearing temporary files.
Checking quotas: done.
Setting securelevel: kern.securelevel: 0 -> 1
Starting virecover.
Checking for core dump...
savecore: no core dump
Starting local daemons:.
Updating motd.
Starting sshd.
Starting inetd.
Starting cron.
Thu Mar 5 18:27:55 UTC 2015
NetBSD/evbmips (ci20) (console)
login:
Recent commits just added support for the Raspberry Pi 2 inside NetBSD.
It comes with all the peripherals and GPU acceleration features that are available on the first Raspberry Pi, together with a Cortex A7 processor capable of running at 900MHz.
Head directly to the installation notes available in Raspberry Pi's entry in the NetBSD Wiki for a quick way to get your system up and rolling.
Stay tuned for multiprocessor support!
Copyright (c) 1996, 1997, 1998, 1999, 2000, 2001, 2002, 2003, 2004, 2005,
2006, 2007, 2008, 2009, 2010, 2011, 2012, 2013, 2014, 2015
The NetBSD Foundation, Inc. All rights reserved.
Copyright (c) 1982, 1986, 1989, 1991, 1993
The Regents of the University of California. All rights reserved.
NetBSD 7.99.5 (RPI2) #6: Fri Mar 6 16:33:41 GMT 2015
nick@zoom:/wrk/commit/obj.evbearmv7hf-el/wrk/commit/src/sys/arch/evbarm/compile/RPI2
total memory = 944 MB
avail memory = 928 MB
sysctl_createv: sysctl_create(machine_arch) returned 17
timecounter: Timecounters tick every 10.000 msec
mainbus0 (root)
cpu0 at mainbus0 core 0: 600 MHz Cortex-A7 r0p5 (Cortex V7A core)
cpu0: DC enabled IC enabled WB disabled EABT branch prediction enabled
cpu0: isar: [0]=0x2101110 [1]=0x13112111 [2]=0x21232041 [3]=0x11112131, [4]=0x10011142, [5]=0
cpu0: mmfr: [0]=0x10101105 [1]=0x40000000 [2]=0x1240000 [3]=0x2102211
cpu0: pfr: [0]=0x1131 [1]=0x11011
cpu0: 32KB/32B 2-way L1 VIPT Instruction cache
cpu0: 32KB/64B 4-way write-back-locking-C L1 PIPT Data cache
cpu0: 512KB/64B 8-way write-through L2 PIPT Unified cache
vfp0 at cpu0: NEON MPE (VFP 3.0+), rounding, NaN propagation, denormals
vfp0: mvfr: [0]=0x10110222 [1]=0x11111111
cpu1 at mainbus0 core 1: disabled (unresponsive)
cpu2 at mainbus0 core 2: disabled (unresponsive)
cpu3 at mainbus0 core 3: disabled (unresponsive)
obio0 at mainbus0
bcmicu0 at obio0
armgtmr0 at obio0: ARMv7 Generic 64-bit Timer (19200 kHz)
armgtmr0: interrupting on irq 99
timecounter: Timecounter "armgtmr0" frequency 19200000 Hz quality 500
bcmmbox0 at obio0 intr 65: VC mailbox
vcmbox0 at bcmmbox0
vchiq0 at obio0 intr 66: BCM2835 VCHIQ
bcmpm0 at obio0: Power management, Reset and Watchdog controller
bcmdmac0 at obio0: DMA0 DMA2 DMA4 DMA5 DMA8 DMA9 DMA10
bcmrng0 at obio0: RNG
plcom0 at obio0 intr 57
plcom0: txfifo disabled
plcom0: console
genfb0 at obio0: switching to framebuffer console
genfb0: framebuffer at 0x3d6fa000, size 1280x1024, depth 32, stride 5120
wsdisplay0 at genfb0 kbdmux 1: console (default, vt100 emulation)
wsmux1: connecting to wsdisplay0
wsdisplay0: screen 1-3 added (default, vt100 emulation)
sdhc0 at obio0 intr 62: SDHC controller
sdhc0: interrupting on intr 62
dwctwo0 at obio0 intr 9: USB controller
bcmspi0 at obio0 intr 54: SPI
spi0 at bcmspi0: SPI bus
bsciic0 at obio0 intr 53: BSC0
iic0 at bsciic0: I2C bus
bsciic1 at obio0 intr 53: BSC1
iic1 at bsciic1: I2C bus
bcmgpio0 at obio0: GPIO [0...31]
gpio0 at bcmgpio0: 32 pins
bcmgpio1 at obio0: GPIO [32...53]
gpio1 at bcmgpio1: 22 pins
usb0 at dwctwo0: USB revision 2.0
timecounter: Timecounter "clockinterrupt" frequency 100 Hz quality 0
sdhc0: SD Host Specification 3.0, rev.153
sdhc0: using DMA transfer
sdmmc0 at sdhc0 slot 0
uhub0 at usb0: vendor 0000 DWC2 root hub, class 9/0, rev 2.00/1.00, addr 1
uhub0: 1 port with 1 removable, self powered
ld0 at sdmmc0: <0x03:0x5344:SL08G:0x80:0x0bcb2d39:0x08a>
ld0: 7580 MB, 3850 cyl, 64 head, 63 sec, 512 bytes/sect x 15523840 sectors
ld0: 4-bit width, bus clock 50.000 MHz
uhub1 at uhub0 port 1: vendor 0424 product 9514, class 9/0, rev 2.00/2.00, addr 2
uhub1: multiple transaction translators
uhub1: 5 ports with 4 removable, self powered
usmsc0 at uhub1 port 1
usmsc0: vendor 0424 product ec00, rev 2.00/2.00, addr 3
usmsc0: Ethernet address b8:27:eb:13:82:0f
ukphy0 at usmsc0 phy 1: OUI 0x00800f, model 0x000c, rev. 3
ukphy0: 10baseT, 10baseT-FDX, 100baseTX, 100baseTX-FDX, auto
boot device: ld0
root on ld0a dumps on ld0b
mountroot: trying nfs...
mountroot: trying msdos...
mountroot: trying ext2fs...
mountroot: trying ffs...
root file system type: ffs
kern.module.path=/stand/evbarm/7.99.5/modules
vchiq: local ver 6 (min 3), remote ver 6.
vcaudio0 at vchiq0: auds
vchiq_get_state: g_state.remote->initialised != 1 (0)
vchiq: vchiq_initialise: videocore initialized after 1 retries
WARNING: no TOD clock present
WARNING: using filesystem time
WARNING: CHECK AND RESET THE DATE!
The Hardkernel ODROID-C1 is a quad-core ARMv7 development board that features an Amlogic S805 SoC (quad-core Cortex-A5 @ 1.5GHz), 1GB RAM and gigabit ethernet for $35 USD.
The ODROID-C1 is the first Cortex-A5 board supported by NetBSD. Matt Thomas (matt@) added initial Cortex-A5 support to the tree, and based on his work I added support for the Amlogic S805 SoC.
NetBSD -current (and soon 7.0) includes support for this board with the ODROID-C1 kernel. The following hardware is supported:
- Cortex-A5 (multiprocessor)
- CPU frequency scaling
- L2 cache controller
- Interrupt controller
- Cortex-A5 global timer
- Cortex-A5 watchdog
- UART console
- USB OTG controller
- Gigabit ethernet
- SD card slot
- Hardware random number generator
More information on the NetBSD/evbarm on Hardkernel ODROID-C1 wiki page.
Copyright (c) 1996, 1997, 1998, 1999, 2000, 2001, 2002, 2003, 2004, 2005,
2006, 2007, 2008, 2009, 2010, 2011, 2012, 2013, 2014, 2015
The NetBSD Foundation, Inc. All rights reserved.
Copyright (c) 1982, 1986, 1989, 1991, 1993
The Regents of the University of California. All rights reserved.
NetBSD 7.99.5 (ODROID-C1) #350: Wed Mar 18 19:45:17 ADT 2015
Jared@Jared-PC:/cygdrive/d/netbsd/src/sys/arch/evbarm/compile/obj/ODROID-C1
total memory = 1024 MB
avail memory = 1008 MB
sysctl_createv: sysctl_create(machine_arch) returned 17
mainbus0 (root)
cpu0 at mainbus0 core 0: 1512 MHz Cortex-A5 r0p1 (Cortex V7A core)
cpu0: DC enabled IC enabled WB disabled EABT branch prediction enabled
cpu0: 32KB/32B 2-way L1 VIPT Instruction cache
cpu0: 32KB/32B 4-way write-back-locking-C L1 PIPT Data cache
cpu0: 512KB/32B 8-way write-back L2 PIPT Unified cache
vfp0 at cpu0: NEON MPE (VFP 3.0+), rounding, NaN propagation, denormals
cpu1 at mainbus0 core 1
cpu2 at mainbus0 core 2
cpu3 at mainbus0 core 3
armperiph0 at mainbus0
armgic0 at armperiph0: Generic Interrupt Controller, 256 sources (245 valid)
armgic0: 32 Priorities, 224 SPIs, 5 PPIs, 16 SGIs
a9tmr0 at armperiph0: A5 Global 64-bit Timer (378 MHz)
a9tmr0: interrupting on irq 27
a9wdt0 at armperiph0: A5 Watchdog Timer, default period is 12 seconds
arml2cc0 at armperiph0: ARM PL310 r3p3 L2 Cache Controller (disabled)
arml2cc0: cache enabled
amlogicio0 at mainbus0
amlogiccom0 at amlogicio0 port 0: console
amlogiccom0: interrupting at irq 122
amlogicrng0 at amlogicio0
dwctwo0 at amlogicio0 port 0: USB controller
dwctwo1 at amlogicio0 port 1: USB controller
awge0 at amlogicio0: Gigabit Ethernet Controller
awge0: interrupting on irq 40
awge0: Ethernet address: 00:1e:06:c3:7e:be
rgephy0 at awge0 phy 0: RTL8169S/8110S/8211 1000BASE-T media interface, rev. 6
rgephy0: 10baseT, 10baseT-FDX, 100baseTX, 100baseTX-FDX, 1000baseT-FDX, auto
rgephy1 at awge0 phy 1: RTL8169S/8110S/8211 1000BASE-T media interface, rev. 6
rgephy1: 10baseT, 10baseT-FDX, 100baseTX, 100baseTX-FDX, 1000baseT-FDX, auto
amlogicsdhc0 at amlogicio0 port 1: SDHC controller
amlogicsdhc0: interrupting on irq 110
usb0 at dwctwo0: USB revision 2.0
usb1 at dwctwo1: USB revision 2.0
cpu3: 1512 MHz Cortex-A5 r0p1 (Cortex V7A core)
cpu3: DC enabled IC enabled WB disabled EABT branch prediction enabled
cpu3: 32KB/32B 2-way L1 VIPT Instruction cache
cpu3: 32KB/32B 4-way write-back-locking-C L1 PIPT Data cache
cpu3: 512KB/32B 8-way write-back L2 PIPT Unified cache
vfp3 at cpu3: NEON MPE (VFP 3.0+), rounding, NaN propagation, denormals
cpu2: 1512 MHz Cortex-A5 r0p1 (Cortex V7A core)
cpu2: DC enabled IC enabled WB disabled EABT branch prediction enabled
cpu2: 32KB/32B 2-way L1 VIPT Instruction cache
cpu2: 32KB/32B 4-way write-back-locking-C L1 PIPT Data cache
cpu2: 512KB/32B 8-way write-back L2 PIPT Unified cache
vfp2 at cpu2: NEON MPE (VFP 3.0+), rounding, NaN propagation, denormals
cpu1: 1512 MHz Cortex-A5 r0p1 (Cortex V7A core)
cpu1: DC enabled IC enabled WB disabled EABT branch prediction enabled
cpu1: 32KB/32B 2-way L1 VIPT Instruction cache
cpu1: 32KB/32B 4-way write-back-locking-C L1 PIPT Data cache
cpu1: 512KB/32B 8-way write-back L2 PIPT Unified cache
vfp1 at cpu1: NEON MPE (VFP 3.0+), rounding, NaN propagation, denormals
sdmmc0 at amlogicsdhc0
uhub0 at usb0: vendor 0000 DWC2 root hub, class 9/0, rev 2.00/1.00, addr 1
uhub1 at usb1: vendor 0000 DWC2 root hub, class 9/0, rev 2.00/1.00, addr 1
ld0 at sdmmc0: <0x03:0x5344:SU08G:0x80:0x1cda770b:0x0ca>
ld0: 7580 MB, 3850 cyl, 64 head, 63 sec, 512 bytes/sect x 15523840 sectors
ld0: 4-bit width, bus clock 50.000 MHz
uhub2 at uhub1 port 1: vendor 05e3 USB2.0 Hub, class 9/0, rev 2.00/32.98, addr 2
uhub2: multiple transaction translators
boot device: ld0
root on ld0f dumps on ld0b
root file system type: ffs
kern.module.path=/stand/evbarm/7.99.5/modules
WARNING: no TOD clock present
WARNING: using filesystem time
WARNING: CHECK AND RESET THE DATE!
Wed Mar 18 22:45:46 UTC 2015
Starting root file system check:
/dev/rld0f: file system is clean; not checking
Starting file system checks:
/dev/rld0e: 5 files, 52556 free (13139 clusters)
random_seed: /var/db/entropy-file: Not present
Setting tty flags.
Setting sysctl variables:
ddb.onpanic: 1 -> 0
Starting network.
Hostname: empusa
IPv6 mode: host
Configuring network interfaces:.
Adding interface aliases:.
Waiting for DAD completion for statically configured addresses...
Starting dhcpcd.
Building databases: dev, utmp, utmpx.
Starting syslogd.
Mounting all file systems...
Clearing temporary files.
Updating fontconfig cache: done.
Creating a.out runtime link editor directory cache.
Checking quotas: done.
Setting securelevel: kern.securelevel: 0 -> 1
Starting virecover.
Starting local daemons:.
Updating motd.
Starting ntpd.
Starting sshd.
Starting mdnsd.
Mar 18 22:46:07 empusa mdnsd: mDNSResponder (Engineering Build) starting
Starting inetd.
Starting cron.
Wed Mar 18 22:46:08 UTC 2015
NetBSD/evbarm (empusa) (console)
login:
AsiaBSDCon 2015 was held in Tokyo on 12-15 March. It was my first time attending, and with a big NetBSD community in Japan I was very interested to go. Links to most of the talks and slides mentioned below are on the main NetBSD presentations site.
On Friday we had both a closed NetBSD developer session in the morning and an open NetBSD birds of a feather session in the evening. We had developers from Europe, the US and Canada as well as Japan. The BoF session, with around 25 attendees, had a talk by Kazuya Goda, who is not yet a developer but will apply soon, on Development of vxlan(4) using rumpkernel. Vxlan tunnels ethernet frames over UDP and is often used in datacentre multi-tenant applications and for VPN applications. Using the rump kernel made porting from the FreeBSD code extremely easy, with the code being tested in userspace with a tunnel to a FreeBSD box to test interoperability and no changes needed to make it run in kernel.
Taylor Campbell (riastradh@) talked about the staus of DRM/KMS, the direct rendering framework for graphics that is in NetBSD current and will be in 7.0. He had fixed several bugs in the days before the talk, so now is a good time to try out the code on your hardware before 7.0 is out. Porting to non x86 platforms that have compatible cards (radeon) would also be useful at this point.
Makoto Fujiwara (mef@) and Ryo Onodera (ryoon@) talked about pkgsrc, including how to package up software in github, which is now really easy. With the closure of Google Code an whole lot more projects are moving to Github, so it is useful that packaging is so easy.
Jun Ebihara (jun@) gave an overview of the Japan NetBSD users group, which travels all around Japan to a large number of events with a large collection of mainly very small machines which run NetBSD current. These include new machines like the Raspberry Pi and Cubieboard as well as old favourites such as the Zaurus, Jornada and Dreamcast. These were also on display at the conference, and got rather more attention than the very noisy blade server running FreeBSD opposite.
The conference proper, on Friday and Saturday had many NetBSD related talks. A highlight was Dennis Ferguson's (dennis@) keynote on modernising the BSD network stack, based on his experience building commercial BSD based routers; he was a founding engineer at Juniper. We got some history, as well as some detailed recommendations about structuring the network stack structures to match modern protocol hierarchies.
Still on networking, Ryota Ozaki (ozaki@) talked about the work that IIJ, conference sponsors and home to many of the Japanese developers, were doing on supporting MSI interrupts and multi-queue devices, improving performance on multicore systems. Martin Husemann (martin@) talked about running big endian ARM on new hardware, a platform that is not used much and found some bugs.
On Sunday, Taylor talked about doing cross compilation in pkgsrc properly. FreeBSD has taken the aproach of using qemu userspace emulation, but there are problems with this that have to be fudged around, while almost everything can be cross compiled properly with dedication. Perl and Python are an issue, and need volunteers. I (justin@) gave a talk about the rump kernel, and how to make driver development and debugging easier.
There was also lots of excellent food, interesting talks about the rest of the BSD family, and a lot of conversations about many aspects of NetBSD. I highly recommend coming along next year. The call for papers will be earlier, so start planning now.
Background
I am using a sparc64 Sun Blade 2500 (silver) as a desktop machine - for my pretty light "desktop" needs. Besides the usual developer tools (editors, compilers, subversion, hg, git) and admin stuff (all text based) I need mpg123 and mserv for music queues, Gimp for image manipulation and of course Firefox.Recently I updated all my installed pkgs to pkgsrc-current and as usual the new Firefox version failed to build.
Fortunately the issues were minor, as they all had been handled upstream for Firefox 52 already, all I needed to do was back-porting a few fixes. This made the pkg build, but after a few minutes of test browsing, it crashed. Not surprisingly this was reproducible, any web site trying to play audio triggered it. A bit surprising though: the same happened on an amd64 machine I tried next. After a bit digging the bug was easy to fix, and upstream already took the fix and committed it to the libcubeb repository.
Success!
So I am now happily editing this post using Firefox 51 on the Blade 2500.
I saw one crash in two days of browsing, but unfortunately could not (yet) reproduce it (I have gdb attached now). There will be future pkg updates certainly.
Future Obstacles
You may have read elsewhere that Firefox will start to require a working Rust compiler to build.This is a bit unfortunate, as Rust (while academically interesting) is right now not a very good implementation language if you care about portability. The only available compiler requires a working LLVM back end, which we are still debugging. Our auto-builds produce sparc sets with LLVM, but the result is not fully working (due to what we believe being code gen bugs in LLVM). It seems we need to fix this soon (which would be good anyway, independent of the Rust issue). Besides the back end, only very recently traces of sparc64 support popped up in Rust. However, we still have a few firefox versions time to get it all going. I am optimistic.
Another upcoming change is that Cairo (currently used as 2D graphics back end, at least on sparc64) will be phased out and Skia will be the only supported software rendering target. Unfortunately Skia does (as of now) not support any big endian machine at all. I am looking for help getting Skia to work on big endian hardware in general, and sparc64 in particular.
Alternatives
Just in case, I tested a few other browsers and (so far) they all failed:- NetSurf
Nice, small, has a few "tweaks" and does not yet support JavaScript good enough for many sites - MidoriThey call it "lightweight" but it is based on WebKit, which alone is a few times more heavy than all of Firefox. It crashes immediately at startup on sparc64 (I am investigating, but with low priority - actually I had to replace the hard disk in my machine to make enough room for the debug object files for WebKit - it takes ~20GB)
So, while it is a bit of a struggle to keep a modern browser working on my favorite odd-ball architecture, it seems we will get at least to the Firefox 52 ESR release, and that should give us enough time to get Rust working and hopefully continue with Firefox.
Background
I am using a sparc64 Sun Blade 2500 (silver) as a desktop machine - for my pretty light "desktop" needs. Besides the usual developer tools (editors, compilers, subversion, hg, git) and admin stuff (all text based) I need mpg123 and mserv for music queues, Gimp for image manipulation and of course Firefox.Recently I updated all my installed pkgs to pkgsrc-current and as usual the new Firefox version failed to build.
Fortunately the issues were minor, as they all had been handled upstream for Firefox 52 already, all I needed to do was back-porting a few fixes. This made the pkg build, but after a few minutes of test browsing, it crashed. Not surprisingly this was reproducible, any web site trying to play audio triggered it. A bit surprising though: the same happened on an amd64 machine I tried next. After a bit digging the bug was easy to fix, and upstream already took the fix and committed it to the libcubeb repository.
Success!
So I am now happily editing this post using Firefox 51 on the Blade 2500.
I saw one crash in two days of browsing, but unfortunately could not (yet) reproduce it (I have gdb attached now). There will be future pkg updates certainly.
Future Obstacles
You may have read elsewhere that Firefox will start to require a working Rust compiler to build.This is a bit unfortunate, as Rust (while academically interesting) is right now not a very good implementation language if you care about portability. The only available compiler requires a working LLVM back end, which we are still debugging. Our auto-builds produce sparc sets with LLVM, but the result is not fully working (due to what we believe being code gen bugs in LLVM). It seems we need to fix this soon (which would be good anyway, independent of the Rust issue). Besides the back end, only very recently traces of sparc64 support popped up in Rust. However, we still have a few firefox versions time to get it all going. I am optimistic.
Another upcoming change is that Cairo (currently used as 2D graphics back end, at least on sparc64) will be phased out and Skia will be the only supported software rendering target. Unfortunately Skia does (as of now) not support any big endian machine at all. I am looking for help getting Skia to work on big endian hardware in general, and sparc64 in particular.
Alternatives
Just in case, I tested a few other browsers and (so far) they all failed:- NetSurf
Nice, small, has a few "tweaks" and does not yet support JavaScript good enough for many sites - MidoriThey call it "lightweight" but it is based on WebKit, which alone is a few times more heavy than all of Firefox. It crashes immediately at startup on sparc64 (I am investigating, but with low priority - actually I had to replace the hard disk in my machine to make enough room for the debug object files for WebKit - it takes ~20GB)
So, while it is a bit of a struggle to keep a modern browser working on my favorite odd-ball architecture, it seems we will get at least to the Firefox 52 ESR release, and that should give us enough time to get Rust working and hopefully continue with Firefox.
What has been done in NetBSD
1. Triagged issues of ptrace(2) in the DTrace/NetBSD support
Chuck Silvers works on improving DTrace in NetBSD and he has detected an issue when tracer signals are being ignored in libproc. The libproc library is a compatibility layer for DTrace simulating /proc capabilities on the SunOS family of systems.
I've verified that the current behavior of signal routing is incorrect. The NetBSD kernel correctly masks signals emitted by a tracee, not routing them to its tracer. On the other hand the masking rules in the inferior process blacklists signals generated by the kernel, which is incorrect and turns a debugger into a deaf listener. This is the case for libproc as signals were masked and software breakpoints triggering INT3 on i386/amd64 CPUs and SIGTRAP with TRAP_BRKP si_code wasn't passed to the tracer.
This isn't limited to turning a debugger into a deaf listener, but also a regular execution of software breakpoints requires: rewinding the program counter register by a single instruction, removing trap instruction and restoring the original instruction. When an instruction isn't restored and further code execution is pretty randomly affected, it resulted in execution anomalies and breaking of tracee.
A workaround for this is to disable signal masking in tracee.
Another drawback inspired by the DTrace code is to enhance PT_SYSCALL handling by introducing a way to distinguish syscall entry and syscall exit events. I'm planning to add dedicated si_codes for these scenarios. While there, there are users requesting PT_STEP and PT_SYSCALL tracing at the same time in an efficient way without involving heuristcs.
I've filed the mentioned bug:
- kern/51918: Tracee can prevent tracer to get its signals by masking. This issue is still open.
I've added new ATF tests:
- Verify that masking single unrelated signal does not stop tracer from catching other signals
- Verify that masking SIGTRAP in tracee stops tracer from catching this raised signal
- Verify that masking SIGTRAP in tracee does not stop tracer from catching software breakpoints
- Verify that masking SIGTRAP in tracee does not stop tracer from catching single step trap
- Verify that masking SIGTRAP in tracee does not stop tracer from catching exec() breakpoint
- Verify that masking SIGTRAP in tracee does not stop tracer from catching PTRACE_FORK breakpoint
- Verify that masking SIGTRAP in tracee does not stop tracer from catching PTRACE_VFORK breakpoint
- Verify that masking SIGTRAP in tracee does not stop tracer from catching PTRACE_VFORK_DONE breakpoint
- Verify that masking SIGTRAP in tracee does not stop tracer from catching PTRACE_LWP_CREATE breakpoint
- Verify that masking SIGTRAP in tracee does not stop tracer from catching PTRACE_LWP_EXIT breakpoint
2. ELF Auxiliary Vectors
The ELF file format permits to transfer additional information for a process with a dedicated container of properties, it's named ELF Auxilary Vector. Every system has its dedicated way to read this information in a debugger from a tracee. The NetBSD approach is to transfer this vector with a ptrace(2) API PIOD_READ_AUXV. Our interface shares the API with OpenBSD. I filed a bug that our interface returns vector size of 8496 bytes, while OpenBSD has constant 64 bytes. It was diagnosed and fixed by Christos Zoluas that we were incorrectly counting bits and bytes and this enlarged the data streamlined. The bug was harmless and had no known side-effects besides large chunk of zeroed data.
There is also a prepared local patch extending NetBSD platform support to read information for this vector, it's primarily required for correct handling of PIE binaries. At the moment there is no interface similar to "info auxv" to the one from GDB. Unfortunately at the current stage, this code is still unused by NetBSD. I will return to it once the Native Process Plugin is enhanced.
I've filed the mentioned bug:
- kern/51916: ptrace(2) PT_IO option PIOD_READ_AUXV returns large piod_len on exit. This issue has been closed.
I've added new ATF test:
- Verify PT_READ_AUXV called for tracee.
What has been done in LLDB
1. Resolving executable's name with sysctl(7)
In the past the way to retrieve a specified process' executable path name was using Linux-compatibile feature in procfs (/proc). The canonical solution on Linux is to resolve path of /proc/$PID/exe. Christos Zoulas added in DTrace port enhancements a solution similar to FreeBSD to retrieve this property with sysctl(7).
This new approach removes dependency on /proc mounted and Linux compatibility functionality.
Support for this has been submitted to LLDB and merged upstream:
- https://reviews.llvm.org/D29089 - Switch HostInfoNetBSD::GetProgramFileSpec to sysctl(7) committed r293392
2. Real-Time Signals
The key feature of the POSIX standard with Asynchronous I/O is to support Real-Time Signals. One of their use-cases is in .NET debugging facilities. Support for this set of signals was developed during Google Summer of Code 2016 by Charles Cui and reviewed and committed by Christos Zoulas.
I've extended the LLDB capabilities for NetBSD to recognize these signals in the NetBSDSignals class.
Support for this has been submitted to LLDB and merged upstream:
- https://reviews.llvm.org/D29091 - Recognize Real-Time Signals on NetBSD committed r293391
3. Conflict removal with system-wide six.py
The transition from Python 2.x to 3.x is still ongoing and will take a while. The current deadline support for the 2.x generation has been extended to 2020. One of the ways to keep both generations supported in the same source-code is to use the six.py library (py2 x py3 = 6.py). It abstracts commonly used constructs to support both language families.
The issue for packaging LLDB in NetBSD was to install this tiny library unconditionally to a system-wide location. There were several solutions to this approach:
- drop Python 2.x support,
- install six.py into subdirectory,
- make an installation of six.py conditional.
The first solution would turn discussion into flamewar, the second one happened to be too difficult to be properly implemented as the changes were invasive and Python is used in several places of the code-base (tests, bindings...). The final solution was to introduce a new CMake option LLDB_USE_SYSTEM_SIX - disabled by default to retain the current behavior.
To properly implement LLDB_USE_SYSTEM_SIX, I had to dig into installation scripts combined in CMake and Python files. It wasn't helping that Python scripts were reinventing getopt(3) functionality.. and I had to alter it in order to introduce a new option --useSystemSix.
Support for this has been submitted to LLDB and merged upstream:
- https://reviews.llvm.org/D29405 -
Install six.py copy into subdirectory lldbreworked and renamed to Install six.py conditionally committed r294071
4. Do not pass non-POD type variables through variadic function
There was a long standing local patch in pkgsrc, added by Tobias Nygren and detected with Clang.
According to the C++11 standard 5.2.2/7:
Passing a potentially-evaluated argument of class type having a non-trivial copy constructor, a non-trivial move constructor, or a non-trivial destructor, with no corresponding parameter, is conditionally-supported with implementation-defined semantics.
A short example to trigger similar warning was presented by Joerg Sonnenberg:
#include <string>
#include <cstdarg>
void f(std::string msg, ...) {
va_list ap;
va_start(ap, msg);
}
This code compiled against libc++ gives:
test.cc:6:3: error: cannot pass object of non-POD type 'std::string' (aka 'basic_string<char, char_traits<char>, allocator<char> >') through variadic function; call will abort at runtime [-Wnon-pod-varargs]
Support for this has been submitted to LLDB and merged upstream:
- https://reviews.llvm.org/D29256 - Do not pass non-POD type variables through variadic function committed r293774
5. Add NetBSD support in Host::GetCurrentThreadID
Linux has a very specific thread model, where process is mostly equivalent to native thread and POSIX thread - it's completely different on other mainstream general-purpose systems. That said fallback support to translate pthread_t on NetBSD to retrieve the native integer identifier was incorrect. The proper NetBSD function to retrieve light-weigth process identification is to call _lwp_self(2).
Support for this has been submitted to LLDB and merged upstream:
- https://reviews.llvm.org/D29264 - Add NetBSD support in Host::GetCurrentThreadID committed r293625
6. Synchronize PlatformNetBSD with Linux
The old PlatformNetBSD code was based on the FreeBSD version. While the FreeBSD current one is still similar to the one from a year ago, it's inappropriate to handle a remote process plugin approach. This forced me to base refreshed code on Linux.
After realizing that PlatformPlugin on POSIX platforms suffers from code duplication, Pavel Labath helped out to eliminate common functions shared by other systems. This resulted in a shorter patch synchronizing PlatformNetBSD with Linux, this step opened room for FreeBSD to catch up.
Support for this has been submitted to LLDB and merged upstream:
- https://reviews.llvm.org/D29266 - Synchronize PlatformNetBSD with Linux committed r294145
7. Transform ProcessLauncherLinux to ProcessLauncherPosixFork
It is UNIX specific that signal handlers are global per application. This introduces issues with wait(2)-like functions called in tracers, as these functions tend to conflict with real-life libraries, notably GUI toolkits (where SIGCHLD events are handled).
The current best approach to this limitation is to spawn a forkee and establish a remote connection over the GDB protocol with a debugger frontend. ProcessLauncherLinux was prepared with this design in mind and I have added support for NetBSD. Once FreeBSD will catch up, they might reuse the same code.
Support for this has been submitted to LLDB and merged upstream:
- https://reviews.llvm.org/D29347 -
Add ProcessLauncherNetBSD to spawn a traceerenamed to Transform ProcessLauncherLinux to ProcessLauncherPosixFork committed r293768
8. Document that LaunchProcessPosixSpawn is used on NetBSD
Host::GetPosixspawnFlags was built for most POSIX platforms - however only Apple, Linux, FreeBSD and other-GLIBC ones (I assume Debian/kFreeBSD to be GLIBC-like) were documented. I've included NetBSD to this list..
Support for this has been submitted to LLDB and merged upstream:
- Document that LaunchProcessPosixSpawn is used on NetBSD committed r293770
9. Switch std::call_once to llvm::call_once
There is a long-standing bug in libstdc++ on several platforms that std::call_once is broken for cryptic reasons. This motivated me to follow the approach from LLVM and replace it with homegrown fallback implementation llvm::call_once.
This change wasn't that simple at first sight as the original LLVM version used different semantics that disallowed straight definition of non-static once_flag. Thanks to cooperation with upstream the proper solution was coined and LLDB now works without known regressions on libstdc++ out-of-the-box.
Support for this has been submitted to LLVM, LLDB and merged upstream:
- https://reviews.llvm.org/D29288 - Switch std::call_once to llvm::call_once committed r294202
- https://reviews.llvm.org/D29296 - Make llvm::call_once more convenient to reuse out of LLVM committed r293902
- https://reviews.llvm.org/D29552 -
Make llvm::call_once more convenient to reuse out of LLVMabandoned - https://reviews.llvm.org/D29566 - Revamp llvm::once_flag to be closer to std::once_flag committed r294143
10. Other enhancements
I a had plan to push more code in this milestone besides the mentioned above tasks. Unfortunately not everything was testable at this stage.
Among the rescheduled projects:
- In the NetBSD platform code conflict removal in GetThreadName / SetThreadName between pthread_t and lwpid_t. It looks like another bite from the Linux thread model. Proper solution to this requires pushing forward the Process Plugin for NetBSD.
- Host::LaunchProcessPosixSpawn proper setting ::posix_spawnattr_setsigdefault on NetBSD - currently untestable.
- Fix false positives - premature before adding more functions in NetBSD Native Process Plugin.
On the other hand I've fixed a build issue of one test on NetBSD:
- https://reviews.llvm.org/D29403 - Fix multi-process-driver.cpp build on NetBSD committed r293895
Plan for the next milestone
I've listed the following goals for the next milestone.
- mark exect(3) obsolete in libc
- remove libpthread_dbg(3) from the base distribution
- add new API in ptrace(2) PT_SET_SIGMASK and PT_GET_SIGMASK
- add new API in ptrace(2) to resume and suspend a specific thread
- finish switch of the PT_WATCHPOINT API in ptrace(2) to PT_GETDBREGS & PT_SETDBREGS
- validate i386, amd64 and Xen proper support of new interfaces
- upstream to LLDB accessors for debug registers on NetBSD/amd64
- validate PT_SYSCALL and add a functionality to detect and distinguish syscall-entry syscall-exit events
- validate accessors for general purpose and floating point registers
Post mortem
FreeBSD is catching up after NetBSD changes, e.g. with the following commit:
- https://reviews.llvm.org/D29667 - Synchronize PlatformFreeBSD with Linux committed r294340
This move allows to introduce further reduction of code-duplication. There still is a lot of room for improvement. Another benefit for other software distributions, is that they can now appropriately resolve the six.py conflict without local patches.
These examples clearly show that streamlining NetBSD code results in improved support for other systems and creates a cleaner environment for introducing new platforms.
A pure NetBSD-oriented gain is improvement of system interfaces in terms of quality and functionality, especially since DTrace/NetBSD is a quick adopter of new interfaces.. and indirectly a sandbox to sort out bugs in ptrace(2).
The tasks in the next milestone will turn NetBSD's ptrace(2) to be on par with Linux and FreeBSD, this time with marginal differences.
To render it more clearly NetBSD will have more interfaces in read/write mode than FreeBSD has (and be closer to Linux here), on the other hand not so many properites will be available in a thread specific field under the PT_LWPINFO operation that caused suspension of the process.
Another difference is that FreeBSD allows to trace only one type of syscall events: on entry or on exit. At the moment this is not needed in existing software, although it's on the longterm wishlist in the GDB project for Linux.
It turned out that, I was overly optimistic about the feature set in ptrace(2), while the basic ones from the first milestone were enough to implement basic support in LLDB.. it would require me adding major work in heuristics as modern tracers no longer want to perform guessing what might happened in the code and what was the source of signal interruption.
This was the final motivation to streamline the interfaces for monitoring capabilities and now I'm adding remaining interfaces as they are also needed, if not readily in LLDB, there is DTrace and other software that is waiting for them now. Somehow I suspect that I will need them in LLDB sooner than expected.
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue to fund projects and services to the open-source community. Please consider visiting the following URL, and chip in what you can:
What has been done in NetBSD
1. Triagged issues of ptrace(2) in the DTrace/NetBSD support
Chuck Silvers works on improving DTrace in NetBSD and he has detected an issue when tracer signals are being ignored in libproc. The libproc library is a compatibility layer for DTrace simulating /proc capabilities on the SunOS family of systems.
I've verified that the current behavior of signal routing is incorrect. The NetBSD kernel correctly masks signals emitted by a tracee, not routing them to its tracer. On the other hand the masking rules in the inferior process blacklists signals generated by the kernel, which is incorrect and turns a debugger into a deaf listener. This is the case for libproc as signals were masked and software breakpoints triggering INT3 on i386/amd64 CPUs and SIGTRAP with TRAP_BRKP si_code wasn't passed to the tracer.
This isn't limited to turning a debugger into a deaf listener, but also a regular execution of software breakpoints requires: rewinding the program counter register by a single instruction, removing trap instruction and restoring the original instruction. When an instruction isn't restored and further code execution is pretty randomly affected, it resulted in execution anomalies and breaking of tracee.
A workaround for this is to disable signal masking in tracee.
Another drawback inspired by the DTrace code is to enhance PT_SYSCALL handling by introducing a way to distinguish syscall entry and syscall exit events. I'm planning to add dedicated si_codes for these scenarios. While there, there are users requesting PT_STEP and PT_SYSCALL tracing at the same time in an efficient way without involving heuristcs.
I've filed the mentioned bug:
- kern/51918: Tracee can prevent tracer to get its signals by masking. This issue is still open.
I've added new ATF tests:
- Verify that masking single unrelated signal does not stop tracer from catching other signals
- Verify that masking SIGTRAP in tracee stops tracer from catching this raised signal
- Verify that masking SIGTRAP in tracee does not stop tracer from catching software breakpoints
- Verify that masking SIGTRAP in tracee does not stop tracer from catching single step trap
- Verify that masking SIGTRAP in tracee does not stop tracer from catching exec() breakpoint
- Verify that masking SIGTRAP in tracee does not stop tracer from catching PTRACE_FORK breakpoint
- Verify that masking SIGTRAP in tracee does not stop tracer from catching PTRACE_VFORK breakpoint
- Verify that masking SIGTRAP in tracee does not stop tracer from catching PTRACE_VFORK_DONE breakpoint
- Verify that masking SIGTRAP in tracee does not stop tracer from catching PTRACE_LWP_CREATE breakpoint
- Verify that masking SIGTRAP in tracee does not stop tracer from catching PTRACE_LWP_EXIT breakpoint
2. ELF Auxiliary Vectors
The ELF file format permits to transfer additional information for a process with a dedicated container of properties, it's named ELF Auxilary Vector. Every system has its dedicated way to read this information in a debugger from a tracee. The NetBSD approach is to transfer this vector with a ptrace(2) API PIOD_READ_AUXV. Our interface shares the API with OpenBSD. I filed a bug that our interface returns vector size of 8496 bytes, while OpenBSD has constant 64 bytes. It was diagnosed and fixed by Christos Zoluas that we were incorrectly counting bits and bytes and this enlarged the data streamlined. The bug was harmless and had no known side-effects besides large chunk of zeroed data.
There is also a prepared local patch extending NetBSD platform support to read information for this vector, it's primarily required for correct handling of PIE binaries. At the moment there is no interface similar to "info auxv" to the one from GDB. Unfortunately at the current stage, this code is still unused by NetBSD. I will return to it once the Native Process Plugin is enhanced.
I've filed the mentioned bug:
- kern/51916: ptrace(2) PT_IO option PIOD_READ_AUXV returns large piod_len on exit. This issue has been closed.
I've added new ATF test:
- Verify PT_READ_AUXV called for tracee.
What has been done in LLDB
1. Resolving executable's name with sysctl(7)
In the past the way to retrieve a specified process' executable path name was using Linux-compatibile feature in procfs (/proc). The canonical solution on Linux is to resolve path of /proc/$PID/exe. Christos Zoulas added in DTrace port enhancements a solution similar to FreeBSD to retrieve this property with sysctl(7).
This new approach removes dependency on /proc mounted and Linux compatibility functionality.
Support for this has been submitted to LLDB and merged upstream:
- https://reviews.llvm.org/D29089 - Switch HostInfoNetBSD::GetProgramFileSpec to sysctl(7) committed r293392
2. Real-Time Signals
The key feature of the POSIX standard with Asynchronous I/O is to support Real-Time Signals. One of their use-cases is in .NET debugging facilities. Support for this set of signals was developed during Google Summer of Code 2016 by Charles Cui and reviewed and committed by Christos Zoulas.
I've extended the LLDB capabilities for NetBSD to recognize these signals in the NetBSDSignals class.
Support for this has been submitted to LLDB and merged upstream:
- https://reviews.llvm.org/D29091 - Recognize Real-Time Signals on NetBSD committed r293391
3. Conflict removal with system-wide six.py
The transition from Python 2.x to 3.x is still ongoing and will take a while. The current deadline support for the 2.x generation has been extended to 2020. One of the ways to keep both generations supported in the same source-code is to use the six.py library (py2 x py3 = 6.py). It abstracts commonly used constructs to support both language families.
The issue for packaging LLDB in NetBSD was to install this tiny library unconditionally to a system-wide location. There were several solutions to this approach:
- drop Python 2.x support,
- install six.py into subdirectory,
- make an installation of six.py conditional.
The first solution would turn discussion into flamewar, the second one happened to be too difficult to be properly implemented as the changes were invasive and Python is used in several places of the code-base (tests, bindings...). The final solution was to introduce a new CMake option LLDB_USE_SYSTEM_SIX - disabled by default to retain the current behavior.
To properly implement LLDB_USE_SYSTEM_SIX, I had to dig into installation scripts combined in CMake and Python files. It wasn't helping that Python scripts were reinventing getopt(3) functionality.. and I had to alter it in order to introduce a new option --useSystemSix.
Support for this has been submitted to LLDB and merged upstream:
- https://reviews.llvm.org/D29405 -
Install six.py copy into subdirectory lldbreworked and renamed to Install six.py conditionally committed r294071
4. Do not pass non-POD type variables through variadic function
There was a long standing local patch in pkgsrc, added by Tobias Nygren and detected with Clang.
According to the C++11 standard 5.2.2/7:
Passing a potentially-evaluated argument of class type having a non-trivial copy constructor, a non-trivial move constructor, or a non-trivial destructor, with no corresponding parameter, is conditionally-supported with implementation-defined semantics.
A short example to trigger similar warning was presented by Joerg Sonnenberg:
#include <string>
#include <cstdarg>
void f(std::string msg, ...) {
va_list ap;
va_start(ap, msg);
}
This code compiled against libc++ gives:
test.cc:6:3: error: cannot pass object of non-POD type 'std::string' (aka 'basic_string<char, char_traits<char>, allocator<char> >') through variadic function; call will abort at runtime [-Wnon-pod-varargs]
Support for this has been submitted to LLDB and merged upstream:
- https://reviews.llvm.org/D29256 - Do not pass non-POD type variables through variadic function committed r293774
5. Add NetBSD support in Host::GetCurrentThreadID
Linux has a very specific thread model, where process is mostly equivalent to native thread and POSIX thread - it's completely different on other mainstream general-purpose systems. That said fallback support to translate pthread_t on NetBSD to retrieve the native integer identifier was incorrect. The proper NetBSD function to retrieve light-weigth process identification is to call _lwp_self(2).
Support for this has been submitted to LLDB and merged upstream:
- https://reviews.llvm.org/D29264 - Add NetBSD support in Host::GetCurrentThreadID committed r293625
6. Synchronize PlatformNetBSD with Linux
The old PlatformNetBSD code was based on the FreeBSD version. While the FreeBSD current one is still similar to the one from a year ago, it's inappropriate to handle a remote process plugin approach. This forced me to base refreshed code on Linux.
After realizing that PlatformPlugin on POSIX platforms suffers from code duplication, Pavel Labath helped out to eliminate common functions shared by other systems. This resulted in a shorter patch synchronizing PlatformNetBSD with Linux, this step opened room for FreeBSD to catch up.
Support for this has been submitted to LLDB and merged upstream:
- https://reviews.llvm.org/D29266 - Synchronize PlatformNetBSD with Linux committed r294145
7. Transform ProcessLauncherLinux to ProcessLauncherPosixFork
It is UNIX specific that signal handlers are global per application. This introduces issues with wait(2)-like functions called in tracers, as these functions tend to conflict with real-life libraries, notably GUI toolkits (where SIGCHLD events are handled).
The current best approach to this limitation is to spawn a forkee and establish a remote connection over the GDB protocol with a debugger frontend. ProcessLauncherLinux was prepared with this design in mind and I have added support for NetBSD. Once FreeBSD will catch up, they might reuse the same code.
Support for this has been submitted to LLDB and merged upstream:
- https://reviews.llvm.org/D29347 -
Add ProcessLauncherNetBSD to spawn a traceerenamed to Transform ProcessLauncherLinux to ProcessLauncherPosixFork committed r293768
8. Document that LaunchProcessPosixSpawn is used on NetBSD
Host::GetPosixspawnFlags was built for most POSIX platforms - however only Apple, Linux, FreeBSD and other-GLIBC ones (I assume Debian/kFreeBSD to be GLIBC-like) were documented. I've included NetBSD to this list..
Support for this has been submitted to LLDB and merged upstream:
- Document that LaunchProcessPosixSpawn is used on NetBSD committed r293770
9. Switch std::call_once to llvm::call_once
There is a long-standing bug in libstdc++ on several platforms that std::call_once is broken for cryptic reasons. This motivated me to follow the approach from LLVM and replace it with homegrown fallback implementation llvm::call_once.
This change wasn't that simple at first sight as the original LLVM version used different semantics that disallowed straight definition of non-static once_flag. Thanks to cooperation with upstream the proper solution was coined and LLDB now works without known regressions on libstdc++ out-of-the-box.
Support for this has been submitted to LLVM, LLDB and merged upstream:
- https://reviews.llvm.org/D29288 - Switch std::call_once to llvm::call_once committed r294202
- https://reviews.llvm.org/D29296 - Make llvm::call_once more convenient to reuse out of LLVM committed r293902
- https://reviews.llvm.org/D29552 -
Make llvm::call_once more convenient to reuse out of LLVMabandoned - https://reviews.llvm.org/D29566 - Revamp llvm::once_flag to be closer to std::once_flag committed r294143
10. Other enhancements
I a had plan to push more code in this milestone besides the mentioned above tasks. Unfortunately not everything was testable at this stage.
Among the rescheduled projects:
- In the NetBSD platform code conflict removal in GetThreadName / SetThreadName between pthread_t and lwpid_t. It looks like another bite from the Linux thread model. Proper solution to this requires pushing forward the Process Plugin for NetBSD.
- Host::LaunchProcessPosixSpawn proper setting ::posix_spawnattr_setsigdefault on NetBSD - currently untestable.
- Fix false positives - premature before adding more functions in NetBSD Native Process Plugin.
On the other hand I've fixed a build issue of one test on NetBSD:
- https://reviews.llvm.org/D29403 - Fix multi-process-driver.cpp build on NetBSD committed r293895
Plan for the next milestone
I've listed the following goals for the next milestone.
- mark exect(3) obsolete in libc
- remove libpthread_dbg(3) from the base distribution
- add new API in ptrace(2) PT_SET_SIGMASK and PT_GET_SIGMASK
- add new API in ptrace(2) to resume and suspend a specific thread
- finish switch of the PT_WATCHPOINT API in ptrace(2) to PT_GETDBREGS & PT_SETDBREGS
- validate i386, amd64 and Xen proper support of new interfaces
- upstream to LLDB accessors for debug registers on NetBSD/amd64
- validate PT_SYSCALL and add a functionality to detect and distinguish syscall-entry syscall-exit events
- validate accessors for general purpose and floating point registers
Post mortem
FreeBSD is catching up after NetBSD changes, e.g. with the following commit:
- https://reviews.llvm.org/D29667 - Synchronize PlatformFreeBSD with Linux committed r294340
This move allows to introduce further reduction of code-duplication. There still is a lot of room for improvement. Another benefit for other software distributions, is that they can now appropriately resolve the six.py conflict without local patches.
These examples clearly show that streamlining NetBSD code results in improved support for other systems and creates a cleaner environment for introducing new platforms.
A pure NetBSD-oriented gain is improvement of system interfaces in terms of quality and functionality, especially since DTrace/NetBSD is a quick adopter of new interfaces.. and indirectly a sandbox to sort out bugs in ptrace(2).
The tasks in the next milestone will turn NetBSD's ptrace(2) to be on par with Linux and FreeBSD, this time with marginal differences.
To render it more clearly NetBSD will have more interfaces in read/write mode than FreeBSD has (and be closer to Linux here), on the other hand not so many properites will be available in a thread specific field under the PT_LWPINFO operation that caused suspension of the process.
Another difference is that FreeBSD allows to trace only one type of syscall events: on entry or on exit. At the moment this is not needed in existing software, although it's on the longterm wishlist in the GDB project for Linux.
It turned out that, I was overly optimistic about the feature set in ptrace(2), while the basic ones from the first milestone were enough to implement basic support in LLDB.. it would require me adding major work in heuristics as modern tracers no longer want to perform guessing what might happened in the code and what was the source of signal interruption.
This was the final motivation to streamline the interfaces for monitoring capabilities and now I'm adding remaining interfaces as they are also needed, if not readily in LLDB, there is DTrace and other software that is waiting for them now. Somehow I suspect that I will need them in LLDB sooner than expected.
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue to fund projects and services to the open-source community. Please consider visiting the following URL, and chip in what you can:
Introduction
I have been working on and off for almost a year trying to get reproducible builds (the same source tree always builds an identical cdrom) on NetBSD. I did not think at the time it would take as long or be so difficult, so I did not keep a log of all the changes I needed to make. I was also not the only one working on this. Other NetBSD developers have been making improvements for the past 6 years.
I would like to acknowledge the NetBSD build system (aka build.sh) which is a fully portable cross-build system. This build system has given us a head-start in the reproducible builds work.
I would also like to acknowledge the work done by the Debian folks who have provided a platform to run, test and analyze reproducible builds. Special mention to the diffoscope tool that gives an excellent overview of what's different between binary files, by finding out what they are (and if they are containers what they contain) and then running the appropriate formatter and diff program to show what's different for each file.
Finally other developers who have started, motivated and did a lot of work getting us here like Joerg Sonnenberger and Thomas Klausner for their work on reproducible builds, and Todd Vierling and Luke Mewburn for their work on build.sh.
Sources of difference
Here's is what we found that we needed to fix, how we chose to fix it and why, and where are we now.
There are many reasons why two separate builds from the same sources can be different. Here's an (incomplete) list:
timestamps
Many things like to keep track of timestamps, specially archive formats (tar(1), ar(1)), filesystems etc. The way to handle each is different, but the approach is to make them either produce files with a 0 timestamp (where it does not matter like ar), or with a specific timestamp when using 0 does not make sense (it is not useful to the user).dates/times/authors etc. embedded in source files
Some programs like to report the date/time they were built, the author, the system they were built on etc. This can be done either by programmatically finding and creating source files containing that information during build time, or by using standard macros such as __DATE__, __TIME__ etc. Usually putting a constant time or eliding the information (such as we do with kernels and bootblocks) solves the problem.timezone sensitive code
Certain filesystem formats (iso 9660 etc.) don't store raw timestamps but formatted times; to achieve this they convert from a timestamp to localtime, so they are affected by the timezone.directory order/build order
The build order is not constant especially in the presence of parallel builds; neither is directory scan order. If those are used to create output files, the output files will need to be sorted so they become consistent.non-sanitized data stored into files
Writing data structures into raw files can lead to problems. Running the same program in different operating systems or using ASLR makes those issues more obvious.symbolic links/paths
Having paths embedded into binaries (specially for debugging information) can lead to binary differences. Propagation of the logical path can prove problematic.general tool inconsistencies
gcc(1) profiling uses a PROFILE_HOOK macro on RISC targets that utilizes the "current function" number to produce labels. Processing order of functions is not guaranteed. gpt(8) creation involves uuid generation; these are generally random. block allocation on msdos filesystems had a random component. makefs(8) uses timezones with timestamps (iso9660), randomness for block selection (msdos), stores stray pointers in superblock (ffs).toolchain
Every program that is used to generate other output needs to have consistent results. In NetBSD this is done with build.sh, which builds a set of tools from known sources before it can use those tools to build the rest of the system). There is a large number of tools. There are also internal issues with the tools that make their output non reproducible, such as nondeterministic symbol creation or capturing parts of the environment in debugging information.build information / tunables / environment
There are many environment settings, or build variable settings that can affect the build. This needs to be kept constant across builds so we've changed the list of variables that are reported in Makefile.params:.if ${MKREPRO:Uno} != "yes" RELEASEVARS+= BSDOBJDIR BSDSRCDIR BUILDID BUILDINFO BUILDSEED \ DESTDIR KERNARCHDIR KERNCONFDIR KERNOBJDIR KERNSRCDIR MAKE \ MAKEFLAGS NBUILDJOBS NETBSDSRCDIR OBJMACHINE OBJMACHINE_ARCH \ RELEASEDIR RELEASEMACHINEDIR TOOLDIR USR_OBJMACHINE X11SRCDIR .endifmaking sure that the source tree has no local changes
Variables controlling reproducible builds
Reproducible builds are controlled on NetBSD with two variables: MKREPRO (which can be set to yes or no) and MKREPRO_TIMESTAMP which is used to set the timestamp of the builds artifacts. This is usually set to the number of seconds from the epoch. The build.sh -P flag handles reproducible builds automatically: sets the MKREPRO variable to yes, and then finds the latest source file timestamp in the tree and sets MKREPRO_TIMESTAMP to that.
Handling timestamps
The first thing that we needed to understand was how to deal with timestamps. Some of the timestamps are not very useful (for example inside random ar archives) so we choose to 0 them out. Others though become annoying if they are all 0. What does it mean when you mount install media and all the dates on the files are Jan 1, 1970?
We decided that a better timestamp would be the timestamp of the most recently modified file in the source tree. Unfortunately this was not easy to find on NetBSD, because we are still using CVS as the source control system, and CVS does not have a good way to provide that. For that we wrote a tool called cvslatest, that scans the CVS metadata files (CVS/Entries) and finds the latest commit. This works well for freshly checked out trees (since CVS uses the source timestamp when checking out), but not with updated trees (because CVS uses the current time when updating files, so that make(1) thinks they've been modified). To fix that, we've added a new flag to the cvs(1) "update" command -t, that uses the source checkout time.
The build system needs now to evaluate the tree for the latest file running cvslatest(1) and find the latest timestamp in seconds from the Epoch which is set in the MKREPRO_TIMESTAMP variable. This is the same as SOURCE_DATE_EPOCH. Various Makefiles are using this variable and MKRERPO to determine how to produce consistent build artifacts.
For example many commands (tar(1), makefs(8), gpt(8), ...) have been modified to take a --timestamp or -T command line switch to generate output files that use the given timestamp, instead of the current time.
Other software (am-utils, acpica, bootblocks, kernel) used __DATE__ or __TIME__, or captured the user, machine, etc. from the environment and had to be changed to a constant time, user, machine, etc.
roff(7) documents used the td macro to generate the date of formatting in the document have been changed to conditionally use the macro based on register R, for example as in intro.me and then the Makefile was changed to set that register for MKREPRO.
Handling Order
We don't control the build order of things and we also don't control the directory order which can be filesystem dependent. The collation order also is environment specific, and sorting needs to be stable (we have not encountered that problem yet). Two different programs caused us problems here:
- file(1) with the generation of the compiled magic file using directory order (fixed by changing file(1)).
- install-info(1), texinfo(5) files that have no specific order. For that we developed another tool called sortinfo(1) that sorts those files as a post-process step.
Fortunately the filesystem builders and tar programs usually work with input directories that appear to have a consistent order so far, so we did not have to fix things there.
Permissions
NetBSD already keeps permissions for most things consistent in different ways:
- the build system uses install(8) and specifies ownership and mode.
- the mtree(8) program creates build artifacts using consistent ownership and permissions.
Nevertheless, the various architecture-specific distribution media installers used cp(1)/mkdir(1) and needed to be corrected.
Toolchain
Most of the issues found had to do with capturing the environment in debugging information. The two biggest issues were: DW_AT_Producer and DW_AT_comp_dir:
DW_AT_producer : (indirect string, offset: 0x80): GNU C99 5.4.0 \
-fno-canonical-system-headers -mtune=nocona \
-march=x86-64 -g -O2 -std=gnu99 -fPIE -fstack-protector \
-fdebug-prefix-map=$NETBSDSRCDIR=/usr/src \
-fdebug-prefix-map=$X11SRCDIR=/usr/xsrc \
-fdebug-regex-map=/usr/src/(.*)/obj.*=/usr/obj/\1 \
-fdebug-regex-map=/usr/src/(.*)/obj.*/(.*)=/usr/obj/\1/\2 \
--param ssp-buffer-size=1
Here you see two changes we made for reproducible builds:
- We chose to allow variable names (and have gcc(1) expand them) for the source of the prefix map because the source tree location can vary. Others have chosen to skip -fdebug-prefix-map from the variables to be listed.
- We added -fdebug-regex-map so that we could handle the NetBSD specific objdir build functionality. Object directories can have many flavors in NetBSD so it was difficult to use -fdebug-prefix-map to capture that.
DW_AT_comp_dir presented a different challenge. We got non-reproducibility when building on paths where either the source or the object directories contained symbolic links. Although gcc(1) does the right thing handling logical paths (respects $PWD), we found that there were problems both in the NetBSD sh(1) (fixed here) and in the NetBSD make(1) (fixed here). Unfortunately we can't depend on the shell to obey the logical path so we decided to go with:
${MAKE} -C other/dir
instead of:
cd other/dir && ${MAKE}
This works because make(1) is a tool (part of the toolchain we provide) whereas sh(1) is not.
Another weird issue popped up on sparc64 where a single file in the whole source tree does not build reproducibly. This file is asn1_krb5_asn1.c which is generated in here. The problem is that when profiling on RISC machines gcc uses the PROFILE_HOOK macro which in turn uses the "function number" to generate labels. This number is assigned to each function in a source file as it is being compiled. Unfortunately this number is not deterministic because of optimization (a bug?), but fortunately turning optimization off fixes the problem.
Status and future work
As of 2017-02-20 we have fully reproducible builds on amd64 and sparc64. We are planning to work on the following areas:
- Vary more parameters on the system build (filesystem types, build OS's)
- Verify that cross building is reproducible
- Verify that unprivileged builds work
- Test on all the platforms
Introduction
I have been working on and off for almost a year trying to get reproducible builds (the same source tree always builds an identical cdrom) on NetBSD. I did not think at the time it would take as long or be so difficult, so I did not keep a log of all the changes I needed to make. I was also not the only one working on this. Other NetBSD developers have been making improvements for the past 6 years.
I would like to acknowledge the NetBSD build system (aka build.sh) which is a fully portable cross-build system. This build system has given us a head-start in the reproducible builds work.
I would also like to acknowledge the work done by the Debian folks who have provided a platform to run, test and analyze reproducible builds. Special mention to the diffoscope tool that gives an excellent overview of what's different between binary files, by finding out what they are (and if they are containers what they contain) and then running the appropriate formatter and diff program to show what's different for each file.
Finally other developers who have started, motivated and did a lot of work getting us here like Joerg Sonnenberger and Thomas Klausner for their work on reproducible builds, and Todd Vierling and Luke Mewburn for their work on build.sh.
Sources of difference
Here's is what we found that we needed to fix, how we chose to fix it and why, and where are we now.
There are many reasons why two separate builds from the same sources can be different. Here's an (incomplete) list:
timestamps
Many things like to keep track of timestamps, specially archive formats (tar(1), ar(1)), filesystems etc. The way to handle each is different, but the approach is to make them either produce files with a 0 timestamp (where it does not matter like ar), or with a specific timestamp when using 0 does not make sense (it is not useful to the user).dates/times/authors etc. embedded in source files
Some programs like to report the date/time they were built, the author, the system they were built on etc. This can be done either by programmatically finding and creating source files containing that information during build time, or by using standard macros such as __DATE__, __TIME__ etc. Usually putting a constant time or eliding the information (such as we do with kernels and bootblocks) solves the problem.timezone sensitive code
Certain filesystem formats (iso 9660 etc.) don't store raw timestamps but formatted times; to achieve this they convert from a timestamp to localtime, so they are affected by the timezone.directory order/build order
The build order is not constant especially in the presence of parallel builds; neither is directory scan order. If those are used to create output files, the output files will need to be sorted so they become consistent.non-sanitized data stored into files
Writing data structures into raw files can lead to problems. Running the same program in different operating systems or using ASLR makes those issues more obvious.symbolic links/paths
Having paths embedded into binaries (specially for debugging information) can lead to binary differences. Propagation of the logical path can prove problematic.general tool inconsistencies
gcc(1) profiling uses a PROFILE_HOOK macro on RISC targets that utilizes the "current function" number to produce labels. Processing order of functions is not guaranteed. gpt(8) creation involves uuid generation; these are generally random. block allocation on msdos filesystems had a random component. makefs(8) uses timezones with timestamps (iso9660), randomness for block selection (msdos), stores stray pointers in superblock (ffs).toolchain
Every program that is used to generate other output needs to have consistent results. In NetBSD this is done with build.sh, which builds a set of tools from known sources before it can use those tools to build the rest of the system). There is a large number of tools. There are also internal issues with the tools that make their output non reproducible, such as nondeterministic symbol creation or capturing parts of the environment in debugging information.build information / tunables / environment
There are many environment settings, or build variable settings that can affect the build. This needs to be kept constant across builds so we've changed the list of variables that are reported in Makefile.params:.if ${MKREPRO:Uno} != "yes" RELEASEVARS+= BSDOBJDIR BSDSRCDIR BUILDID BUILDINFO BUILDSEED \ DESTDIR KERNARCHDIR KERNCONFDIR KERNOBJDIR KERNSRCDIR MAKE \ MAKEFLAGS NBUILDJOBS NETBSDSRCDIR OBJMACHINE OBJMACHINE_ARCH \ RELEASEDIR RELEASEMACHINEDIR TOOLDIR USR_OBJMACHINE X11SRCDIR .endifmaking sure that the source tree has no local changes
Variables controlling reproducible builds
Reproducible builds are controlled on NetBSD with two variables: MKREPRO (which can be set to yes or no) and MKREPRO_TIMESTAMP which is used to set the timestamp of the builds artifacts. This is usually set to the number of seconds from the epoch. The build.sh -P flag handles reproducible builds automatically: sets the MKREPRO variable to yes, and then finds the latest source file timestamp in the tree and sets MKREPRO_TIMESTAMP to that.
Handling timestamps
The first thing that we needed to understand was how to deal with timestamps. Some of the timestamps are not very useful (for example inside random ar archives) so we choose to 0 them out. Others though become annoying if they are all 0. What does it mean when you mount install media and all the dates on the files are Jan 1, 1970?
We decided that a better timestamp would be the timestamp of the most recently modified file in the source tree. Unfortunately this was not easy to find on NetBSD, because we are still using CVS as the source control system, and CVS does not have a good way to provide that. For that we wrote a tool called cvslatest, that scans the CVS metadata files (CVS/Entries) and finds the latest commit. This works well for freshly checked out trees (since CVS uses the source timestamp when checking out), but not with updated trees (because CVS uses the current time when updating files, so that make(1) thinks they've been modified). To fix that, we've added a new flag to the cvs(1) "update" command -t, that uses the source checkout time.
The build system needs now to evaluate the tree for the latest file running cvslatest(1) and find the latest timestamp in seconds from the Epoch which is set in the MKREPRO_TIMESTAMP variable. This is the same as SOURCE_DATE_EPOCH. Various Makefiles are using this variable and MKRERPO to determine how to produce consistent build artifacts.
For example many commands (tar(1), makefs(8), gpt(8), ...) have been modified to take a --timestamp or -T command line switch to generate output files that use the given timestamp, instead of the current time.
Other software (am-utils, acpica, bootblocks, kernel) used __DATE__ or __TIME__, or captured the user, machine, etc. from the environment and had to be changed to a constant time, user, machine, etc.
roff(7) documents used the td macro to generate the date of formatting in the document have been changed to conditionally use the macro based on register R, for example as in intro.me and then the Makefile was changed to set that register for MKREPRO.
Handling Order
We don't control the build order of things and we also don't control the directory order which can be filesystem dependent. The collation order also is environment specific, and sorting needs to be stable (we have not encountered that problem yet). Two different programs caused us problems here:
- file(1) with the generation of the compiled magic file using directory order (fixed by changing file(1)).
- install-info(1), texinfo(5) files that have no specific order. For that we developed another tool called sortinfo(1) that sorts those files as a post-process step.
Fortunately the filesystem builders and tar programs usually work with input directories that appear to have a consistent order so far, so we did not have to fix things there.
Permissions
NetBSD already keeps permissions for most things consistent in different ways:
- the build system uses install(8) and specifies ownership and mode.
- the mtree(8) program creates build artifacts using consistent ownership and permissions.
Nevertheless, the various architecture-specific distribution media installers used cp(1)/mkdir(1) and needed to be corrected.
Toolchain
Most of the issues found had to do with capturing the environment in debugging information. The two biggest issues were: DW_AT_Producer and DW_AT_comp_dir:
DW_AT_producer : (indirect string, offset: 0x80): GNU C99 5.4.0 \
-fno-canonical-system-headers -mtune=nocona \
-march=x86-64 -g -O2 -std=gnu99 -fPIE -fstack-protector \
-fdebug-prefix-map=$NETBSDSRCDIR=/usr/src \
-fdebug-prefix-map=$X11SRCDIR=/usr/xsrc \
-fdebug-regex-map=/usr/src/(.*)/obj.*=/usr/obj/\1 \
-fdebug-regex-map=/usr/src/(.*)/obj.*/(.*)=/usr/obj/\1/\2 \
--param ssp-buffer-size=1
Here you see two changes we made for reproducible builds:
- We chose to allow variable names (and have gcc(1) expand them) for the source of the prefix map because the source tree location can vary. Others have chosen to skip -fdebug-prefix-map from the variables to be listed.
- We added -fdebug-regex-map so that we could handle the NetBSD specific objdir build functionality. Object directories can have many flavors in NetBSD so it was difficult to use -fdebug-prefix-map to capture that.
DW_AT_comp_dir presented a different challenge. We got non-reproducibility when building on paths where either the source or the object directories contained symbolic links. Although gcc(1) does the right thing handling logical paths (respects $PWD), we found that there were problems both in the NetBSD sh(1) (fixed here) and in the NetBSD make(1) (fixed here). Unfortunately we can't depend on the shell to obey the logical path so we decided to go with:
${MAKE} -C other/dir
instead of:
cd other/dir && ${MAKE}
This works because make(1) is a tool (part of the toolchain we provide) whereas sh(1) is not.
Another weird issue popped up on sparc64 where a single file in the whole source tree does not build reproducibly. This file is asn1_krb5_asn1.c which is generated in here. The problem is that when profiling on RISC machines gcc uses the PROFILE_HOOK macro which in turn uses the "function number" to generate labels. This number is assigned to each function in a source file as it is being compiled. Unfortunately this number is not deterministic because of optimization (a bug?), but fortunately turning optimization off fixes the problem.
Status and future work
As of 2017-02-20 we have fully reproducible builds on amd64 and sparc64. We are planning to work on the following areas:
- Vary more parameters on the system build (filesystem types, build OS's)
- Verify that cross building is reproducible
- Verify that unprivileged builds work
- Test on all the platforms
The second release candidate of NetBSD 7.1 is now available for download at:
http://cdn.NetBSD.org/pub/NetBSD/NetBSD-7.1_RC2/
Those of you who prefer to build from source can continue to follow the netbsd-7 branch or use the netbsd-7-1-RC2 tag.
Most changes made since 7.1_RC1 have been security fixes. See src/doc/CHANGES-7.1 for the full list.
Please help us out by testing 7.1_RC2. We love any and all feedback. Report problems through the usual channels (submit a PR or write to the appropriate list). More general feedback is welcome at releng@NetBSD.org.
The second release candidate of NetBSD 7.1 is now available for download at:
http://cdn.NetBSD.org/pub/NetBSD/NetBSD-7.1_RC2/
Those of you who prefer to build from source can continue to follow the netbsd-7 branch or use the netbsd-7-1-RC2 tag.
Most changes made since 7.1_RC1 have been security fixes. See src/doc/CHANGES-7.1 for the full list.
Please help us out by testing 7.1_RC2. We love any and all feedback. Report problems through the usual channels (submit a PR or write to the appropriate list). More general feedback is welcome at releng@NetBSD.org.
This is due to many people spending significant amounts of time fixing bugs, submitting problem reports, improving tests, and (not unimportant in the cases at hand) improving the in-tree toolchain.
We collect the results of various regular test runs on the releng test results page, but this gives no good overview of the failures found by the different runs. I proposed a GSoC project to help with this; the idea is to collect all test results in a database and have nice query and statistics pages. If you are a student and interested in this, please check the project description.
For the time being, here is an overview of the top performers (< 10 failures) on this week's tests against -current:
| Architecture | Failures | Tests page |
|---|---|---|
| alpha | 0 | link |
| evbarm | 0 | link |
| evbearmv7hf-eb | 0 | link |
| sparc64 | 0 | link |
| amd64 | 8 | link |
| shark | 8 | link |
And the same table for the netbsd-7 branch:
| Architecture | Failures | Tests page |
|---|---|---|
| evbarm | 0 | link |
| sparc64 | 0 | link |
| i386 | 4 | link |
| sparc | 5 | link |
| amd64 | 6 | link |
I will work on getting shark results down to zero next (it is the strangler in my own runs), and then hppa (hi Nick!) and sparc. The ultimate target is my VAX, but I am fighting with various libm and toolchain issues there, so this will take more effort.
Some new drivers were added ( cgtwelve, mgx ), others got improvements ( SX acceleration, support for 8bit tcx ).
- Sun CG3 - has kernel support and works in X with the wsfb driver, the hardware doesn't support a hardware cursor or any kind of acceleration so we won't bother with a dedicated X driver. The hardware supports 8 bit colour only.
- Sun CG6 family, including GX, TGX, XGX and their plus variants - supported with acceleration in both the kernel and X with the suncg6 driver. Hardware cursor is supported, the hardware supports 8 bit colour only.
- Sun ZX/Leo - has accelerated kernel support but no X yet. The sunleo driver from Xorg should work without changes but doesn't support any kind of acceleration yet. The console runs in 8 bit, X will support 24 bit.
- Sun BW2 - has kernel support, should work with the wsfb driver in X.The board doesn't support a hardware cursor or any kind of acceleration. Hardware is monochrome only.
- Weitek P9100 - found in Tadpole SPARCbook 3 series laptops, supported with acceleration in both the kernel and X with the pnozz driver. Hardware cursor is supported. The console runs in 8 bit, X can run in 8, 16 or 24 bit colour.
- Sun S24/TCX - supported with acceleration in both the kernel and X with the suntcx driver. A hardware cursor is supported ( only on S24, the 8bit TCX's DAC doesn't support it ).The console runs in 8 bit, X in 8 or 24 bit.
- Sun CG14 - supported with acceleration ( using the new sx driver ) and hardware cursor in both the kernel and X. The console runs in 8 bit, X in 24 bit. The X driver supports some xrender acceleration as well.
- Fujitsu AG-10e - supported with acceleration in both the kernel and X, a hardware cursor is supported. The console runs in 8 bit, X in 24 bit.
- IGS 1682 found in JavaStation 10 / Krups - supported, but the chip lacks any acceleration features. It does support a hardware cursor though which the wsfb driver can use. Currently X is limited to 8 bit colour alhough the hardware supports up to 24bit.
- Sun CG12 / Matrox SG3 - supported without acceleration in both the kernel and X. The console runs in monochrome or 8 bit, X in 24 bit.
- Southland Media Systems (now Quantum 3D) MGX - supported with acceleration as console, X is currently limited to wsfb in 8 bit. No hardware cursor support in the driver yet .
All boards with dedicated drivers will work as primary or secondary heads in X, boards which use wsfb will only work in X when they are the system console. For example, you can run an SS20 with a cg14 as console, an AG-10e and two CG6 with four heads.
There is also a generic kernel driver ( genfb at sbus ) which may or may not work with graphics hardware not listed here, depending on the board's firmware. If it provides standard properties for width, height, colour depth, stride and framebuffer address it should work but not all boards do this. For example, the ZX doesn't give a framebuffer address and there is no reason to assume it's the only one. Also, there is no standard way to program palette registers via firmware, so even if genfb works colours are likely off. X should work with the wsfb driver, it will likely look a bit odd though.
Boards like the CG8 have older, pre-wscons kernel support and weren't converted due to lack of hardware. They seem to be pretty rare though, in all the years I've been using NetBSD/sparc I have not seen a single user ask about them.
Finally, 3rd party boards not mentioned here are unsupported for lack of hardware in the right hands.
Graphics hardware supported by NetBSD/sparc64 which isn't listed here should work the same way when running a 32bit userland but this is mostly untested.
With the latest updates to NetBSD 7, the Raspberry Pi port now supports hardware acceleration using the built-in Broadcom VideoCore IV GPU. This enables 3D graphics acceleration and hardware accelerated video playback, a first for NetBSD/arm.
The misc/raspberrypi-userland package in pkgsrc includes the client libraries to get started. Some packages have been created to take advantage of this already, with more on the way:
- OMXPlayer: multimedia/omxplayer for video playback
- GStreamer: multimedia/gst-plugins1-omx for decode, and multimedia/gst-plugins1-egl-opengl for a video sink
- ioquake3: games/ioquake3-raspberrypi
For both omxplayer and ioquake3, make sure that the user running them has permissions to /dev/vchiq. In addition, ioquake3 needs permissions to /dev/wsmouse.
# usermod -G wheel jmcneill # chmod 660 /dev/vchiq /dev/wsmouse
The default GPU memory allocation may not be sufficient for ioquake3. Add gpu_mem=128 or gpu_mem=192 to /boot/config.txt if you run into any issues.
More information can be found on the NetBSD Wiki.
The first release candidate of NetBSD 7.1 is now available for download at:
http://cdn.NetBSD.org/pub/NetBSD/NetBSD-7.1_RC1/
Those of you who prefer to build from source can continue to follow the netbsd-7 branch or use the netbsd-7-1-RC1 tag.
There have been quite a lot of changes since 7.0. See src/doc/CHANGES-7.1 for the full list.
Please help us out by testing 7.1_RC1. We love any and all feedback. Report problems through the usual channels (submit a PR or write to the appropriate list). More general feedback is welcome at releng@NetBSD.org.
The first release candidate of NetBSD 7.1 is now available for download at:
http://cdn.NetBSD.org/pub/NetBSD/NetBSD-7.1_RC1/
Those of you who prefer to build from source can continue to follow the netbsd-7 branch or use the netbsd-7-1-RC1 tag.
There have been quite a lot of changes since 7.0. See src/doc/CHANGES-7.1 for the full list.
Please help us out by testing 7.1_RC1. We love any and all feedback. Report problems through the usual channels (submit a PR or write to the appropriate list). More general feedback is welcome at releng@NetBSD.org.
Hrishikesh Goyal worked on the project "Implement Ext4fs support in ReadOnly mode". He tackled two features of an ext4fs implementation: extents and HTree DIR read/write support. His work was committed into the NetBSD source tree in multiple commits.
charles cui worked on adding tests for better "POSIX Test Suite Compliance". This involved porting the Open Posix benchmark suite to NetBSD. Many of the tests showed missing features, and Charles worked with his mentors to improve the results. See his summary for details.
Leonardo Taccari worked on "Split debug symbols for pkgsrc builds". He already blogged about this in much detail on this blog.
A big thank you to Google for sponsoring the students to work on NetBSD, the students for working on the projects, and the mentors that were helping them along!
Hrishikesh Goyal worked on the project "Implement Ext4fs support in ReadOnly mode". He tackled two features of an ext4fs implementation: extents and HTree DIR read/write support. His work was committed into the NetBSD source tree in multiple commits.
charles cui worked on adding tests for better "POSIX Test Suite Compliance". This involved porting the Open Posix benchmark suite to NetBSD. Many of the tests showed missing features, and Charles worked with his mentors to improve the results. See his summary for details.
Leonardo Taccari worked on "Split debug symbols for pkgsrc builds". He already blogged about this in much detail on this blog.
A big thank you to Google for sponsoring the students to work on NetBSD, the students for working on the projects, and the mentors that were helping them along!
[Update, 2017-01-16 20:48 UTC: All issues have been resolved and NetBSD.org should be functioning normally now.]
As some of you may have noticed, the netbsd.org DNS records are broken right now. Two independent incidents caused this to happen:
- UC Berkeley stopped providing secondary DNS service for netbsd.org at adns1.berkeley.edu and adns2.berkeley.edu on a few hours notice, before we had time to update the NS delegations in the ORG. zone. [Update, 2017-01-16 20:48 UTC: The Berkeley network administrators have graciously restored service until we can update our NS delegations. Thanks, Berkeley—for doing this on a US holiday, no less!]
- The network hosting our primary nameserver ns.netbsd.de went offline at around 14:00 UTC for reasons unknown. [Update, 2017-01-16 20:48 UTC: The network and ns.netbsd.de are back up.]
We have sent a request to our registrar to update the delegations to make ns.netbsd.org primary and ns.netbsd.de secondary. We asked them to expedite the process, but owing to the weekend, when the humans who process these requests are off work, it may take another day for that to take effect, and another day after that for the cached TTLs on the old NS delegations to Berkeley's nameservers to expire.
As a provisional stop gap, if you need access to the netbsd.org zone and you can prime your DNS cache with manually entered records, you can prime it with the following records to restore service at your site:
netbsd.org. 86400 IN NS ns.netbsd.org. netbsd.org. 86400 IN NS ns.netbsd.de. ns.netbsd.org. 86400 IN A 199.233.217.200 ns.netbsd.org. 86400 IN AAAA 2001:470:a085:999::53
(Presumably if you are reading this you have some DNS records in the netbsd.org zone cached, but they will eventually expire and you may need some others.)
[Update, 2017-01-16 20:48 UTC: All issues have been resolved and NetBSD.org should be functioning normally now.]
As some of you may have noticed, the netbsd.org DNS records are broken right now. Two independent incidents caused this to happen:
- UC Berkeley stopped providing secondary DNS service for netbsd.org at adns1.berkeley.edu and adns2.berkeley.edu on a few hours notice, before we had time to update the NS delegations in the ORG. zone. [Update, 2017-01-16 20:48 UTC: The Berkeley network administrators have graciously restored service until we can update our NS delegations. Thanks, Berkeley—for doing this on a US holiday, no less!]
- The network hosting our primary nameserver ns.netbsd.de went offline at around 14:00 UTC for reasons unknown. [Update, 2017-01-16 20:48 UTC: The network and ns.netbsd.de are back up.]
We have sent a request to our registrar to update the delegations to make ns.netbsd.org primary and ns.netbsd.de secondary. We asked them to expedite the process, but owing to the weekend, when the humans who process these requests are off work, it may take another day for that to take effect, and another day after that for the cached TTLs on the old NS delegations to Berkeley's nameservers to expire.
As a provisional stop gap, if you need access to the netbsd.org zone and you can prime your DNS cache with manually entered records, you can prime it with the following records to restore service at your site:
netbsd.org. 86400 IN NS ns.netbsd.org. netbsd.org. 86400 IN NS ns.netbsd.de. ns.netbsd.org. 86400 IN A 199.233.217.200 ns.netbsd.org. 86400 IN AAAA 2001:470:a085:999::53
(Presumably if you are reading this you have some DNS records in the netbsd.org zone cached, but they will eventually expire and you may need some others.)
What has been done in NetBSD
1. Verified the full matrix of combinations of wait(2) and ptrace(2) in the following test-cases
- verify basic PT_GET_SIGINFO call for SIGTRAP from tracee
- verify basic PT_GET_SIGINFO and PT_SET_SIGINFO calls without modification of SIGINT from tracee
- verify basic PT_GET_SIGINFO and PT_SET_SIGINFO calls with setting signal to new value
- detect SIGTRAP TRAP_EXEC from tracee
- verify single PT_STEP call with signal information check
- verify that fork(2) is intercepted by ptrace(2) with EVENT_MASK set to PTRACE_FORK and reports correct signal information
- verify that vfork(2) is intercepted by ptrace(2) with EVENT_MASK set to PTRACE_VFORK_DONE
- verify that vfork(2) is intercepted by ptrace(2) with EVENT_MASK set to PTRACE_FORK | PTRACE_VFORK_DONE
- verify that PTRACE_VFORK in EVENT_MASK is preserved
- verify that PTRACE_VFORK_DONE in EVENT_MASK is preserved
- verify that PTRACE_LWP_CREATE in EVENT_MASK is preserved
- verify that PTRACE_LWP_EXIT in EVENT_MASK is preserved
- verify that thread creation is intercepted by ptrace(2) with EVENT_MASK set to PTRACE_LWP_CREATE
- verify that thread termination is intercepted by ptrace(2) with EVENT_MASK set to PTRACE_LWP_EXIT
2. GNU libstdc++ std::call_once bug investigation
The LLVM toolchain internally uses several std::call_once calls, within LLVM and LLDB codebase. The GNU libstdc++ library implements C++11 std::call_once with wrapping pthread_once(3) and a function pointer passed as a TLS (Thread Local Storage) variable. Currently this setup isn't functional with shared linking on NetBSD and apparently on few other systems and hardware platforms. This issue is still unresolved and its status is traced in PR 51139. As of now, there is a walkaround originally prepared for NetBSD, and adapted for others - namely llvm::call_once.
3. Improving documentation and other minor system parts
- rename the SIGPOLL signal to SIGIO in the documentation of siginfo(2)
- replace SIGPOLL references with SIGIO in comments of <sys/siginfo.h>
- document SI_NOINFO in siginfo(2)
- document SI_LWP in siginfo(2)
- document SI_QUEUE in siginfo(2)
- document SI_MESGQ in siginfo(2)
- document TRAP_EXEC in siginfo(2)
- document TRAP_CHLD in siginfo(2)
- document TRAP_LWP in siginfo(2)
- reference siginfo(2) for a SIGCHLD signal in ptrace(2)
- remove unused macro for ATF_TP_ADD_TC_HAVE_DBREGS in src/tests/kernel/t_ptrace_wait.h
- cleanup commented out code after revert of racy vfork(2) commit from year 2012
- remove stub code to redefine PTRACE_FORK in ATF tests
- ... and several microimprovements in the codebase
4. Documentation of ptrace(2) and explanation how debuggers work
- document addr and data argument usage for PT_GET_PROCESS_STATE
- document PT_SET_SIGINFO and PT_GET_SIGINFO
- explain execve(2) handling and behavior, SIGTRAP & TRAP_EXEC
- reference PaX MPROTECT restrictions for debuggers
- explain software breakpoints handling and behavior, SIGTRAP & TRAP_BKPT
- explain single step behavior, SIGTRAP & TRAP_TRACE
- explain that PT_TRACE_ME does not send a SIGSTOP signal
- list predefined MI symbols for help debuggers in port specific headers
- document the current behavior of TRAP_CHLD
- add more notes on PTRACE_FORK events
- document PTRACE_VFORK and PTRACE_VFORK_DONE
- document PTRACE_LWP_CREATE and PTRACE_LWP_EXIT
- import HISTORY notes from FreeBSD
5. Introduction of new siginfo(2) codes for SIGTRAP
- TRAP_EXEC - catch exec() events transforming the calling process into a new process
- TRAP_CHLD - process child trap (fork, vfork and vfork done events)
- TRAP_LWP - process thread traps (birth, termination)
- TRAP_HWWPT - process hardware assisted watchpoints
6. New ptrace(2) interfaces
There were added new interfaces to the native ptrace(2) NetBSD API.Interface to introspect and fake signal information
The PT_GET_SIGINFO interface is designed to read signal information sent to tracee. A program can also fake a signal to be passed to a debugged process, with included destination thread or the whole process. A debugger requires detailed signal information in order to distinguish the exact trap reason easily and precisely, for example whether a program stopped on a software defined breakpoint or a single step trap.
This interface is modeled after the Linux specific calls: PTRACE_GETSIGINFO and PTRACE_SETSIGINFO, but adapted for the NetBSD use-case. FreeBSD currently has no way to fake signal information.
I have modeled this interface to be most efficient in terms of determination what exact thread received the signal. Thanks to it, a process does not need to examine each thread separately and performs only a single ptrace(2) call. This makes a significant difference in a massively threaded software.
The signal information accessors introduce a new structure ptrace_siginfo:
/*
* Signal Information structure
*/
typedef struct ptrace_siginfo {
siginfo_t psi_siginfo; /* signal information structure */
lwpid_t psi_lwpid; /* destination LWP of the signal
* value 0 means the whole process
* (route signal to all LWPs) */
} ptrace_siginfo_t;
I've included in the <sys/ptrace.h> header required file to define the siginfo_t type - <sys/siginfo.h>.
This makes sure that no existing software will break during build due to a missing type definition.
Interface to monitor vfork(2) operations
Forking a process is one of the fundamental design features of a UNIX operating system. There are two basic types of forks: fork(2) and vfork(2) ones. The fork(2) one is designed to spawn a mostly independent child from parent's memory layout, however this operation is costy. In order to address it and optimize the forking operation there is vfork(2) which shares address space with its parent. From the ptrace(2) point of view, the difference between fork(2) and vfork(2) calls is whether a parent giving birth to its child is suspended waiting on child termination or exec() operation or not.
Currently there is an interface to monitor fork(2) operations - PTRACE_FORK - however NetBSD missed the vfork(2) ones. I've added two new functions: PTRACE_VFORK and PTRACE_VFORK_DONE. The former is supposed to notify why a parent gives a vfork(2)-like birth to its child and later when a child is born with vfork(2) from its parent - perfoming a handshake with two SIGTRAP signals emitted from the kernel. Once the parent is resuming it gets a notification for vfork(2) done.
These events throw SIGTRAP signal with the TRAP_CHLD property. Currently PTRACE_VFORK is a stub and it's planned to be fully implemented later.
Interface to monitor thread operations
A debugger requires an interface to monitor thread birth and termination. This is needed in order to properly track the thread list of a process and ensure that every thread has for example applied watchpoints.
I've added two events:
- PTRACE_LWP_CREATE - to report thread births,
- PTRACE_LWP_EXIT - to report thread termination.
This interface reuses the EVENT_MASK and PROCESS_STATE interface. It means that it shares these calls with PTRACE_FORK, PTRACE_VFORK and PTRACE_VFORK_DONE.
To achieve this goal, I've changed the following structure:
typedef struct ptrace_state {
int pe_report_event;
pid_t pe_other_pid;
} ptrace_state_t;
to
typedef struct ptrace_state {
int pe_report_event;
union {
pid_t _pe_other_pid;
lwpid_t _pe_lwp;
} _option;
} ptrace_state_t;
#define pe_other_pid _option._pe_other_pid
#define pe_lwp _option._pe_lwp
This change keeps the size of ptrace_state_t unchanged as both pid_t and lwpid_t
are defined as an int32_t-like integer.
New struct form should not break existing software and be source and binary compatible with it.
I've introduced a new SIGTAP type for thread events: TRAP_LWP.
Hardware assisted watchpoints
I've introduced a few changes to the current interface. One of them is allowing to mix single-step operation with enabled hardware assisted watchpoints. The other one was added new extension pw_type to the ptrace_watchpoint structure.
6. Updated doc/TODO.ptrace entries
The current state of TODO.ptrace - after several updates - is as follows:- verify ppid of core dump generated with PT_DUMPCORE it must point to the real parent, not tracer
- adapt OpenBSD regress test (regress/sys/ptrace/ptrace.c) for the ATF context
- add new ptrace(2) calls to lock (suspend) and unlock LWP within a process
- add PT_DUMPCORE tests in the ATF framework
- add ATF tests for PT_WRITE_I and PIOD_WRITE_I - test mprotect restrictions
- add ATF tests for PIOD_READ_AUXV
- once the API for hardware watchpoints will stabilize, document it
- add tests for the procfs interface covering all functions available on the same level as ptrace(2)
- add support for PT_STEP, PT_GETREGS, PT_SETREGS, PT_GETFPREGS, PT_SETFPREGS in all ports
- integrate all ptrace(2) features in gdb
- add ptrace(2) NetBSD support in LLDB
- add proper implementation of PTRACE_VFORK for vfork(2)-like events
- remove exect(3) - there is no usecase for it
- refactor pthread_dbg(3) to only query private pthread_t data, otherwise it duplicates ptrace(2) interface and cannot cover all types of threads
- add ATF tests for SIGCHLD
- add ATF tests for PT_SYSCALL and PT_SYSCALLEMU
Features in ELF, DWARF, CTF, DTrace are out of scope for the above list.
7. Future directions
After research and testing the current watchpoint interface, I've realized that it's impossible (impractically complicated) to pretend to have a "safe" watchpoint interface inside the kernel, as the current one isn't safe from undefined behavior even on stock amd64. I've decided to revert this code and introduce PT_GETDBREGS and PT_SETDBREGS restricted to INSECURE secure level mode. The good side of this change is that there is already part of the code needed in the kernel, I have a local draft introducing this interface and it will be easier to integrate with LLDB, as Linux and FreeBSD keep having the same interface.
What has been done in LLDB
I work on the LLDB port inside the pkgsrc-wip repository, in the lldb-netbsd package.
To summarize the changes, there were so far 84 commits in this directory. The overall result is a list of 26 patched or added files. The overall diff's length is 3539 lines.
$ wc -l patches/patch-*
12 patches/patch-cmake_LLDBDependencies.cmake
17 patches/patch-cmake_modules_AddLLDB.cmake
14 patches/patch-include_lldb_Host_netbsd_HostThreadNetBSD.h
30 patches/patch-include_lldb_Host_netbsd_ProcessLauncherNetBSD.h
12 patches/patch-source_CMakeLists.txt
12 patches/patch-source_Host_CMakeLists.txt
60 patches/patch-source_Host_common_Host.cpp
13 patches/patch-source_Host_common_NativeProcessProtocol.cpp
21 patches/patch-source_Host_netbsd_HostThreadNetBSD.cpp
175 patches/patch-source_Host_netbsd_ProcessLauncherNetBSD.cpp
23 patches/patch-source_Host_netbsd_ThisThread.cpp
24 patches/patch-source_Initialization_SystemInitializerCommon.cpp
803 patches/patch-source_Plugins_Platform_NetBSD_PlatformNetBSD.cpp
141 patches/patch-source_Plugins_Platform_NetBSD_PlatformNetBSD.h
12 patches/patch-source_Plugins_Process_CMakeLists.txt
13 patches/patch-source_Plugins_Process_NetBSD_CMakeLists.txt
1392 patches/patch-source_Plugins_Process_NetBSD_NativeProcessNetBSD.cpp
188 patches/patch-source_Plugins_Process_NetBSD_NativeProcessNetBSD.h
393 patches/patch-source_Plugins_Process_NetBSD_NativeThreadNetBSD.cpp
92 patches/patch-source_Plugins_Process_NetBSD_NativeThreadNetBSD.h
13 patches/patch-tools_lldb-mi_MICmnBase.cpp
13 patches/patch-tools_lldb-mi_MICmnBase.h
13 patches/patch-tools_lldb-mi_MIDriver.cpp
13 patches/patch-tools_lldb-mi_MIUtilString.cpp
13 patches/patch-tools_lldb-mi_MIUtilString.h
27 patches/patch-tools_lldb-server_CMakeLists.txt
3539 total
1. Native Process NetBSD Plugin
I've created the initial code for the Native Process NetBSD Plugin.
- process resume support (PT_CONTINUE)
- process step support (PT_STEP) - currently not fully functional
- functional callback monitor
- functional process launch operation
- appropriate ptrace(2) wrapper with logging capabilities
- initial NativeThreadNetBSD code
- setup for EVENT_MASK of a traced process (we monitor thread events)
- preliminary code for other functions, like attach to a process and reading/writing memory of a tracee
2. The MonitorCallback function
The MonitorCallback function supports now the following events:
- process exit and retrieve status code
- software breakpoint (TRAP_BRKPT)
- single step (TRAP_TRACE)
- process image swich trap (TRAP_EXEC)
- child traps (TRAP_CHLD) - currently detectable but disabled
- thread trap (TRAP_LWP)
- hardware assisted watchpoint trap (TRAP_HWWPT)
3. Other LLDB code, out of the NativeProcessNetBSD Plugin
During this work segment I've completed the following tasks:
- created initial Native Process Plugin for NetBSD with remote debugging facilities, with skeleton copied from Linux but almost every function used so far had to be rewritten for NetBSD.
- attached the Native Process Plugin for NetBSD to the build infrastructure.
- disabled existing code for retrieving and updating Thread Name in NatBSD host plugin as currently not compatible with the LLDB codebase.
- added NetBSD Process Launcher.
- support proper native NetBSD Thread ID in Host::GetCurrentThreadID.
- upgraded Platform NetBSD Plugin for new remote debugging plugin.
4. Automated LLDB Test Results Summary
The number of passing tests increased by 45% between devel/lldb 3.9.1 and lldb-netbsd 2017-01-21.

The above graphs renders test results for:
- lldb 3.9.1 - the recent version from pkgsrc without newly developed patches
- lldb-nbsd 2016-12-22 - the first startable version with the NativeProcessNetBSD Plugin
- lldb-nbsd 2016-01-18 - the first version with functional MonitorCallback
- lldb-nbsd 2016-01-21 - the first version with functional PT_CONTINUE and partially functional PT_STEP
Example LLDB sessions
It's demo time!
Breakpoint interrupt
In this example, I'm calling a hello world application that is triggering a software breakpoint. It's implemented by embedding int3 call on amd64. The debugger is capable of catching this and resuming till correct process termination.
$ lldb ./int3
(lldb) target create "./int3"
Current executable set to './int3' (x86_64).
(lldb) r
Hello world!
Process 29578 launched: './int3' (x86_64)
Process 29578 stopped
* thread #1, stop reason = signal SIGTRAP
frame #0:
(lldb) c
Process 29578 resuming
Process 29578 exited with status = 0 (0x00000000)
(lldb)
Thread monitor interrupt
In this example we set trap on thread events - creation and termination. The executed program incepts a thread and terminates afterwards, this is caught by the MonitorCallback with appropriate thread list update. After the end, program terminates correctly and passes proper exit status to the debugger.
$ lldb ./lwp_create
(lldb) target create "./lwp_create"
Current executable set to './lwp_create' (x86_64).
(lldb) r
Process 27331 launched: './lwp_create' (x86_64)
Hello world!
Process 27331 stopped
* thread #1, stop reason = SIGTRAP has been caught with Process LWP Trap type
frame #0:
thread #2, stop reason = SIGTRAP has been caught with Process LWP Trap type
frame #0:
(lldb) thread list
Process 27331 stopped
* thread #1: tid = 0x0001, stop reason = SIGTRAP has been caught with Process LWP Trap type
thread #2: tid = 0x0002, stop reason = SIGTRAP has been caught with Process LWP Trap type
(lldb) c
Process 27331 resuming
Process 27331 stopped
* thread #1, stop reason = SIGTRAP has been caught with Process LWP Trap type
frame #0:
(lldb) thread list
Process 27331 stopped
* thread #1: tid = 0x0001, stop reason = SIGTRAP has been caught with Process LWP Trap type
(lldb) c
Process 27331 resuming
It works
Process 27331 exited with status = 0 (0x00000000)
(lldb)
Plan for the next milestone
I've listed the following goals for the next milestone.
- fix conflict with system-wide py-six
- add support for auxv read operation
- switch resolution of pid -> path to executable from /proc to sysctl(7)
- recognize Real-Time Signals (SIGRTMIN-SIGRTMAX)
- upstream !NetBSDProcessPlugin code
- switch std::call_once to llvm::call_once
- add new ptrace(2) interface to lock and unlock threads from execution
- switch the current PT_WATCHPOINT interface to PT_GETDBREGS and PT_SETDBREGS
This work was sponsored by The NetBSD Foundation.
Previous report "Summary of the ptrace(2) project".
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue to fund projects and services to the open-source community. Please consider visiting the following URL, and chip in what you can:
What has been done in NetBSD
1. Verified the full matrix of combinations of wait(2) and ptrace(2) in the following test-cases
- verify basic PT_GET_SIGINFO call for SIGTRAP from tracee
- verify basic PT_GET_SIGINFO and PT_SET_SIGINFO calls without modification of SIGINT from tracee
- verify basic PT_GET_SIGINFO and PT_SET_SIGINFO calls with setting signal to new value
- detect SIGTRAP TRAP_EXEC from tracee
- verify single PT_STEP call with signal information check
- verify that fork(2) is intercepted by ptrace(2) with EVENT_MASK set to PTRACE_FORK and reports correct signal information
- verify that vfork(2) is intercepted by ptrace(2) with EVENT_MASK set to PTRACE_VFORK_DONE
- verify that vfork(2) is intercepted by ptrace(2) with EVENT_MASK set to PTRACE_FORK | PTRACE_VFORK_DONE
- verify that PTRACE_VFORK in EVENT_MASK is preserved
- verify that PTRACE_VFORK_DONE in EVENT_MASK is preserved
- verify that PTRACE_LWP_CREATE in EVENT_MASK is preserved
- verify that PTRACE_LWP_EXIT in EVENT_MASK is preserved
- verify that thread creation is intercepted by ptrace(2) with EVENT_MASK set to PTRACE_LWP_CREATE
- verify that thread termination is intercepted by ptrace(2) with EVENT_MASK set to PTRACE_LWP_EXIT
2. GNU libstdc++ std::call_once bug investigation
The LLVM toolchain internally uses several std::call_once calls, within LLVM and LLDB codebase. The GNU libstdc++ library implements C++11 std::call_once with wrapping pthread_once(3) and a function pointer passed as a TLS (Thread Local Storage) variable. Currently this setup isn't functional with shared linking on NetBSD and apparently on few other systems and hardware platforms. This issue is still unresolved and its status is traced in PR 51139. As of now, there is a walkaround originally prepared for NetBSD, and adapted for others - namely llvm::call_once.
3. Improving documentation and other minor system parts
- rename the SIGPOLL signal to SIGIO in the documentation of siginfo(2)
- replace SIGPOLL references with SIGIO in comments of <sys/siginfo.h>
- document SI_NOINFO in siginfo(2)
- document SI_LWP in siginfo(2)
- document SI_QUEUE in siginfo(2)
- document SI_MESGQ in siginfo(2)
- document TRAP_EXEC in siginfo(2)
- document TRAP_CHLD in siginfo(2)
- document TRAP_LWP in siginfo(2)
- reference siginfo(2) for a SIGCHLD signal in ptrace(2)
- remove unused macro for ATF_TP_ADD_TC_HAVE_DBREGS in src/tests/kernel/t_ptrace_wait.h
- cleanup commented out code after revert of racy vfork(2) commit from year 2012
- remove stub code to redefine PTRACE_FORK in ATF tests
- ... and several microimprovements in the codebase
4. Documentation of ptrace(2) and explanation how debuggers work
- document addr and data argument usage for PT_GET_PROCESS_STATE
- document PT_SET_SIGINFO and PT_GET_SIGINFO
- explain execve(2) handling and behavior, SIGTRAP & TRAP_EXEC
- reference PaX MPROTECT restrictions for debuggers
- explain software breakpoints handling and behavior, SIGTRAP & TRAP_BKPT
- explain single step behavior, SIGTRAP & TRAP_TRACE
- explain that PT_TRACE_ME does not send a SIGSTOP signal
- list predefined MI symbols for help debuggers in port specific headers
- document the current behavior of TRAP_CHLD
- add more notes on PTRACE_FORK events
- document PTRACE_VFORK and PTRACE_VFORK_DONE
- document PTRACE_LWP_CREATE and PTRACE_LWP_EXIT
- import HISTORY notes from FreeBSD
5. Introduction of new siginfo(2) codes for SIGTRAP
- TRAP_EXEC - catch exec() events transforming the calling process into a new process
- TRAP_CHLD - process child trap (fork, vfork and vfork done events)
- TRAP_LWP - process thread traps (birth, termination)
- TRAP_HWWPT - process hardware assisted watchpoints
6. New ptrace(2) interfaces
There were added new interfaces to the native ptrace(2) NetBSD API.Interface to introspect and fake signal information
The PT_GET_SIGINFO interface is designed to read signal information sent to tracee. A program can also fake a signal to be passed to a debugged process, with included destination thread or the whole process. A debugger requires detailed signal information in order to distinguish the exact trap reason easily and precisely, for example whether a program stopped on a software defined breakpoint or a single step trap.
This interface is modeled after the Linux specific calls: PTRACE_GETSIGINFO and PTRACE_SETSIGINFO, but adapted for the NetBSD use-case. FreeBSD currently has no way to fake signal information.
I have modeled this interface to be most efficient in terms of determination what exact thread received the signal. Thanks to it, a process does not need to examine each thread separately and performs only a single ptrace(2) call. This makes a significant difference in a massively threaded software.
The signal information accessors introduce a new structure ptrace_siginfo:
/*
* Signal Information structure
*/
typedef struct ptrace_siginfo {
siginfo_t psi_siginfo; /* signal information structure */
lwpid_t psi_lwpid; /* destination LWP of the signal
* value 0 means the whole process
* (route signal to all LWPs) */
} ptrace_siginfo_t;
I've included in the <sys/ptrace.h> header required file to define the siginfo_t type - <sys/siginfo.h>.
This makes sure that no existing software will break during build due to a missing type definition.
Interface to monitor vfork(2) operations
Forking a process is one of the fundamental design features of a UNIX operating system. There are two basic types of forks: fork(2) and vfork(2) ones. The fork(2) one is designed to spawn a mostly independent child from parent's memory layout, however this operation is costy. In order to address it and optimize the forking operation there is vfork(2) which shares address space with its parent. From the ptrace(2) point of view, the difference between fork(2) and vfork(2) calls is whether a parent giving birth to its child is suspended waiting on child termination or exec() operation or not.
Currently there is an interface to monitor fork(2) operations - PTRACE_FORK - however NetBSD missed the vfork(2) ones. I've added two new functions: PTRACE_VFORK and PTRACE_VFORK_DONE. The former is supposed to notify why a parent gives a vfork(2)-like birth to its child and later when a child is born with vfork(2) from its parent - perfoming a handshake with two SIGTRAP signals emitted from the kernel. Once the parent is resuming it gets a notification for vfork(2) done.
These events throw SIGTRAP signal with the TRAP_CHLD property. Currently PTRACE_VFORK is a stub and it's planned to be fully implemented later.
Interface to monitor thread operations
A debugger requires an interface to monitor thread birth and termination. This is needed in order to properly track the thread list of a process and ensure that every thread has for example applied watchpoints.
I've added two events:
- PTRACE_LWP_CREATE - to report thread births,
- PTRACE_LWP_EXIT - to report thread termination.
This interface reuses the EVENT_MASK and PROCESS_STATE interface. It means that it shares these calls with PTRACE_FORK, PTRACE_VFORK and PTRACE_VFORK_DONE.
To achieve this goal, I've changed the following structure:
typedef struct ptrace_state {
int pe_report_event;
pid_t pe_other_pid;
} ptrace_state_t;
to
typedef struct ptrace_state {
int pe_report_event;
union {
pid_t _pe_other_pid;
lwpid_t _pe_lwp;
} _option;
} ptrace_state_t;
#define pe_other_pid _option._pe_other_pid
#define pe_lwp _option._pe_lwp
This change keeps the size of ptrace_state_t unchanged as both pid_t and lwpid_t
are defined as an int32_t-like integer.
New struct form should not break existing software and be source and binary compatible with it.
I've introduced a new SIGTAP type for thread events: TRAP_LWP.
Hardware assisted watchpoints
I've introduced a few changes to the current interface. One of them is allowing to mix single-step operation with enabled hardware assisted watchpoints. The other one was added new extension pw_type to the ptrace_watchpoint structure.
6. Updated doc/TODO.ptrace entries
The current state of TODO.ptrace - after several updates - is as follows:- verify ppid of core dump generated with PT_DUMPCORE it must point to the real parent, not tracer
- adapt OpenBSD regress test (regress/sys/ptrace/ptrace.c) for the ATF context
- add new ptrace(2) calls to lock (suspend) and unlock LWP within a process
- add PT_DUMPCORE tests in the ATF framework
- add ATF tests for PT_WRITE_I and PIOD_WRITE_I - test mprotect restrictions
- add ATF tests for PIOD_READ_AUXV
- once the API for hardware watchpoints will stabilize, document it
- add tests for the procfs interface covering all functions available on the same level as ptrace(2)
- add support for PT_STEP, PT_GETREGS, PT_SETREGS, PT_GETFPREGS, PT_SETFPREGS in all ports
- integrate all ptrace(2) features in gdb
- add ptrace(2) NetBSD support in LLDB
- add proper implementation of PTRACE_VFORK for vfork(2)-like events
- remove exect(3) - there is no usecase for it
- refactor pthread_dbg(3) to only query private pthread_t data, otherwise it duplicates ptrace(2) interface and cannot cover all types of threads
- add ATF tests for SIGCHLD
- add ATF tests for PT_SYSCALL and PT_SYSCALLEMU
Features in ELF, DWARF, CTF, DTrace are out of scope for the above list.
7. Future directions
After research and testing the current watchpoint interface, I've realized that it's impossible (impractically complicated) to pretend to have a "safe" watchpoint interface inside the kernel, as the current one isn't safe from undefined behavior even on stock amd64. I've decided to revert this code and introduce PT_GETDBREGS and PT_SETDBREGS restricted to INSECURE secure level mode. The good side of this change is that there is already part of the code needed in the kernel, I have a local draft introducing this interface and it will be easier to integrate with LLDB, as Linux and FreeBSD keep having the same interface.
What has been done in LLDB
I work on the LLDB port inside the pkgsrc-wip repository, in the lldb-netbsd package.
To summarize the changes, there were so far 84 commits in this directory. The overall result is a list of 26 patched or added files. The overall diff's length is 3539 lines.
$ wc -l patches/patch-*
12 patches/patch-cmake_LLDBDependencies.cmake
17 patches/patch-cmake_modules_AddLLDB.cmake
14 patches/patch-include_lldb_Host_netbsd_HostThreadNetBSD.h
30 patches/patch-include_lldb_Host_netbsd_ProcessLauncherNetBSD.h
12 patches/patch-source_CMakeLists.txt
12 patches/patch-source_Host_CMakeLists.txt
60 patches/patch-source_Host_common_Host.cpp
13 patches/patch-source_Host_common_NativeProcessProtocol.cpp
21 patches/patch-source_Host_netbsd_HostThreadNetBSD.cpp
175 patches/patch-source_Host_netbsd_ProcessLauncherNetBSD.cpp
23 patches/patch-source_Host_netbsd_ThisThread.cpp
24 patches/patch-source_Initialization_SystemInitializerCommon.cpp
803 patches/patch-source_Plugins_Platform_NetBSD_PlatformNetBSD.cpp
141 patches/patch-source_Plugins_Platform_NetBSD_PlatformNetBSD.h
12 patches/patch-source_Plugins_Process_CMakeLists.txt
13 patches/patch-source_Plugins_Process_NetBSD_CMakeLists.txt
1392 patches/patch-source_Plugins_Process_NetBSD_NativeProcessNetBSD.cpp
188 patches/patch-source_Plugins_Process_NetBSD_NativeProcessNetBSD.h
393 patches/patch-source_Plugins_Process_NetBSD_NativeThreadNetBSD.cpp
92 patches/patch-source_Plugins_Process_NetBSD_NativeThreadNetBSD.h
13 patches/patch-tools_lldb-mi_MICmnBase.cpp
13 patches/patch-tools_lldb-mi_MICmnBase.h
13 patches/patch-tools_lldb-mi_MIDriver.cpp
13 patches/patch-tools_lldb-mi_MIUtilString.cpp
13 patches/patch-tools_lldb-mi_MIUtilString.h
27 patches/patch-tools_lldb-server_CMakeLists.txt
3539 total
1. Native Process NetBSD Plugin
I've created the initial code for the Native Process NetBSD Plugin.
- process resume support (PT_CONTINUE)
- process step support (PT_STEP) - currently not fully functional
- functional callback monitor
- functional process launch operation
- appropriate ptrace(2) wrapper with logging capabilities
- initial NativeThreadNetBSD code
- setup for EVENT_MASK of a traced process (we monitor thread events)
- preliminary code for other functions, like attach to a process and reading/writing memory of a tracee
2. The MonitorCallback function
The MonitorCallback function supports now the following events:
- process exit and retrieve status code
- software breakpoint (TRAP_BRKPT)
- single step (TRAP_TRACE)
- process image swich trap (TRAP_EXEC)
- child traps (TRAP_CHLD) - currently detectable but disabled
- thread trap (TRAP_LWP)
- hardware assisted watchpoint trap (TRAP_HWWPT)
3. Other LLDB code, out of the NativeProcessNetBSD Plugin
During this work segment I've completed the following tasks:
- created initial Native Process Plugin for NetBSD with remote debugging facilities, with skeleton copied from Linux but almost every function used so far had to be rewritten for NetBSD.
- attached the Native Process Plugin for NetBSD to the build infrastructure.
- disabled existing code for retrieving and updating Thread Name in NatBSD host plugin as currently not compatible with the LLDB codebase.
- added NetBSD Process Launcher.
- support proper native NetBSD Thread ID in Host::GetCurrentThreadID.
- upgraded Platform NetBSD Plugin for new remote debugging plugin.
4. Automated LLDB Test Results Summary
The number of passing tests increased by 45% between devel/lldb 3.9.1 and lldb-netbsd 2017-01-21.
The above graphs renders test results for:
- lldb 3.9.1 - the recent version from pkgsrc without newly developed patches
- lldb-nbsd 2016-12-22 - the first startable version with the NativeProcessNetBSD Plugin
- lldb-nbsd 2016-01-18 - the first version with functional MonitorCallback
- lldb-nbsd 2016-01-21 - the first version with functional PT_CONTINUE and partially functional PT_STEP
Example LLDB sessions
It's demo time!
Breakpoint interrupt
In this example, I'm calling a hello world application that is triggering a software breakpoint. It's implemented by embedding int3 call on amd64. The debugger is capable of catching this and resuming till correct process termination.
$ lldb ./int3
(lldb) target create "./int3"
Current executable set to './int3' (x86_64).
(lldb) r
Hello world!
Process 29578 launched: './int3' (x86_64)
Process 29578 stopped
* thread #1, stop reason = signal SIGTRAP
frame #0:
(lldb) c
Process 29578 resuming
Process 29578 exited with status = 0 (0x00000000)
(lldb)
Thread monitor interrupt
In this example we set trap on thread events - creation and termination. The executed program incepts a thread and terminates afterwards, this is caught by the MonitorCallback with appropriate thread list update. After the end, program terminates correctly and passes proper exit status to the debugger.
$ lldb ./lwp_create
(lldb) target create "./lwp_create"
Current executable set to './lwp_create' (x86_64).
(lldb) r
Process 27331 launched: './lwp_create' (x86_64)
Hello world!
Process 27331 stopped
* thread #1, stop reason = SIGTRAP has been caught with Process LWP Trap type
frame #0:
thread #2, stop reason = SIGTRAP has been caught with Process LWP Trap type
frame #0:
(lldb) thread list
Process 27331 stopped
* thread #1: tid = 0x0001, stop reason = SIGTRAP has been caught with Process LWP Trap type
thread #2: tid = 0x0002, stop reason = SIGTRAP has been caught with Process LWP Trap type
(lldb) c
Process 27331 resuming
Process 27331 stopped
* thread #1, stop reason = SIGTRAP has been caught with Process LWP Trap type
frame #0:
(lldb) thread list
Process 27331 stopped
* thread #1: tid = 0x0001, stop reason = SIGTRAP has been caught with Process LWP Trap type
(lldb) c
Process 27331 resuming
It works
Process 27331 exited with status = 0 (0x00000000)
(lldb)
Plan for the next milestone
I've listed the following goals for the next milestone.
- fix conflict with system-wide py-six
- add support for auxv read operation
- switch resolution of pid -> path to executable from /proc to sysctl(7)
- recognize Real-Time Signals (SIGRTMIN-SIGRTMAX)
- upstream !NetBSDProcessPlugin code
- switch std::call_once to llvm::call_once
- add new ptrace(2) interface to lock and unlock threads from execution
- switch the current PT_WATCHPOINT interface to PT_GETDBREGS and PT_SETDBREGS
This work was sponsored by The NetBSD Foundation.
Previous report "Summary of the ptrace(2) project".
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue to fund projects and services to the open-source community. Please consider visiting the following URL, and chip in what you can:
He was one of the pillars of open-source software development and distribution, contributing much to the community as a whole. As is the nature of open-source software, ideas and processes are shared, intertwined, and constantly evolving as they are passed back and forth between projects.
We respect, and are grateful for what Ian did during his career.
Regards,
The NetBSD Foundation and developers
The NetBSD Project is pleased to announce:
- NetBSD 6.1.3, the third security/bugfix update of the NetBSD 6.1 release branch,
- NetBSD 6.0.4, the fourth security/bugfix update of the NetBSD 6.0 release branch,
- NetBSD 5.2.2, the second security/bugfix update of the NetBSD 5.2 release branch,
- and NetBSD 5.1.4, the fourth security/bugfix update of the NetBSD 5.1 release branch
These releases represent a selected subset of fixes deemed important for security or stability reasons. Updating to one of these versions is recommended for users of all prior releases.
For more details, please see the NetBSD 6.1.3 release notes, the NetBSD 6.0.4 release notes, the NetBSD 5.2.2 release notes, or the NetBSD 5.1.4 release notes.
Complete source and binaries for NetBSD 6.1.3, NetBSD 6.0.4, NetBSD 5.2.2 and NetBSD 5.1.4 are available for download at many sites around the world. A list of download sites providing FTP, AnonCVS, SUP, and other services may be found at http://www.NetBSD.org/mirrors/.
LLVM changes
The majority of work was related to interceptors. There was a need to cleanup the local code and develop dedicated tests for new interceptors whenever applicable (i.e. always unless this is a syscall modifying the kernel state such as inserting kernel modules).
Detailed list of commits merged with the upstream LLVM compiler-rt repository:
- Split getpwent and fgetgrent functions in interceptors
- Try to unbreak the build of sanitizers on !NetBSD
- Disable recursive interception for tzset in MSan
- Follow Windows' approach for NetBSD in AlarmCallback()
- Disable XRay test fork_basic_logging for NetBSD
- Prioritize the constructor call of __local_xray_dyninit() (investigated with help of Michal Gorny)
- Adapt UBSan integer truncation tests to NetBSD
- Split remquol() from INIT_REMQUO
- Split lgammal() from INIT_LGAMMAL
- Correct atexit(3) support in MSan/NetBSD (with help of Michal Gorny investigating the failure on Linux)
- Add new interceptor for getmntinfo(3) from NetBSD
- Add new interceptor for mi_vector_hash(3)
- Cast _Unwind_GetIP() and _Unwind_GetRegionStart() to uintptr_t
- Cast the 2nd argument of _Unwind_SetIP() to _Unwind_Ptr (reverted as it broke "MacPro Late 2013")
- Add interceptor for the setvbuf(3) from NetBSD
- Add a new interceptor for getvfsstat(2) from NetBSD
A single patch landed in the LLVM source tree:
- Swap order of discovering of -ltinfo and -lterminfo (originated by Ryo Onodera in pkgsrc)
Patches submitted upstream and still in review:
- Add interceptors for the sha1(3) from NetBSD
- Add interceptors for the md4(3) from NetBSD
- Add interceptors for the rmd160(3) from NetBSD
- Add interceptors for md5(3) from NetBSD
- Add a new interceptor for nl_langinfo(3) from NetBSD
- Add a new interceptor for fparseln(3) from NetBSD
- Add a new interceptor for modctl(2) from NetBSD
- Add a new interceptors for statvfs1(2) and fstatvfs1(2) from NetBSD
- Add a new interceptors for cdbr(3) and cdbw(3) API from NetBSD
- Add interceptors for the sysctl(3) API family from NetBSD
- Add interceptors for the fts(3) API family from NetBSD
- Implement getpeername(2) interceptor
- Add new interceptors for vis(3) API in NetBSD
- Add new interceptor for regex(3) in NetBSD
- Add new interceptor for strtonum(3)
- Add interceptors for the strtoi(3)/strtou(3) from NetBSD
- Add interceptors for the sha2(3) from NetBSD
Patches still kept locally:
- ASan thread's termination destructor
- MSan thread's termination destructor
- Interceptors for getchar(3) API (might be abandoned as FILE/DIR sanitization isn't done)
- Incomplete interceptor for mount(2) (might be abandoned as unfinished)
This month I've received also a piece of help from Michal Gorny who improved the NetBSD support in LLVM projects with the following changes:
- [unittest] Skip W+X MappedMemoryTests when MPROTECT is enabled
- [cmake] Fix detecting terminfo library
Changes to the NetBSD distribution
I've reduced the number of changes to the src/ distribution to corrections related to interceptors.
- Document SHA1FileChunk(3) in sha1(3)
- Fix link sha1.3 <- SHA1File.3
- Define MD4_DIGEST_STRING_LENGTH in <md4.h>
- Correct the documentation of cdbr_open_mem(3)
Plan for the next milestone
I will keep upstreaming local LLVM patches (less than 2000LOC to go!).
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL, and chip in what you can:
Prepared by Michał Górny (mgorny AT gentoo.org).
I'm recently helping the NetBSD developers to improve the support for this operating system in various LLVM components. My first task in this endeavor was to fix build and test issues in as many LLVM projects as timely possible, and get them all covered by the NetBSD LLVM buildbot.
Including more projects in the continuous integration builds is important as it provides the means to timely catch regressions and new issues in NetBSD support. It is not only beneficial because it lets us find offending commits easily but also because it makes other LLVM developers aware of NetBSD porting issues, and increases the chances that the patch authors will fix their mistakes themselves.
Initial buildbot setup and issues
The buildbot setup used by NetBSD is largely based on the LLDB setup used originally by Android, published in the lldb-utils repository. For the purpose of necessary changes, I have forked it as netbsd-llvm-build and Kamil Rytarowski has updated the buildbot configuration to use our setup.
Initially, the very high memory use in GNU ld combined with high job count caused our builds to swap significantly. As a result, the builds were very slow and frequently were terminated due to no output as buildbot presumed them to hang. The fix for this problem consisted of two changes.
Firstly, I have extended the building script to periodically report that it is still active. This ensured that even during prolonged linking buildbot would receive some output and would not terminate the build prematurely.
Secondly, I have split the build task into two parts. The first part uses full ninja job count to build all static libraries. The second part runs with reduced job count to build everything else. Since most of LLVM source files are part of static libraries, this solution makes it possible to build as much as possible with full job count, while reducing it necessarily for GNU ld invocations later.
While working on this setup, we have been informed that the buildbot setup based on external scripts is a legacy design, and that it would be preferable to update it to define buildbot rules directly. However, we have agreed to defer that until our builds mature, as external scripts are more flexible and can be updated without having to request a restart of the LLVM buildbot.
The NetBSD buildbot is part of LLVM buildbot setup, and can be accessed via http://lab.llvm.org:8011/builders/lldb-amd64-ninja-netbsd8. The same machine is also used to run GDB and binutils build tests.
RPATH setup for LLVM builds
Another problem that needed solving was to fix RPATH in built executables to include /usr/pkg/lib, as necessary to find dependencies installed via pkgsrc. Normally, the LLVM build system sets RPATH itself, using a path based on $ORIGIN. However, I have been informed that NetBSD discourages the use of $ORIGIN, and appropriately I have been looking for a better solution.
Eventually, after some experimentation I have come up with the following CMake parameters:
-DCMAKE_BUILD_RPATH="${PWD}/lib;/usr/pkg/lib"
-DCMAKE_INSTALL_RPATH=/usr/pkg/lib
This explicitly disables the standard logic used by LLVM. Build-time RPATH includes the build directory explicitly as to ensure that freshly built shared libraries will be preferred at build time (e.g. when running tests) over previous pkgsrc install; this directory is afterwards removed from rpath when installing.
Building and testing more LLVM sub-projects
The effort so far was to include the following projects in LLVM buildbot runs:
llvm: core LLVM libraries; also includes the test suite of LLVM's lit testing tool
clang: C/C++ compiler
clang-tools-extra: extra C/C++ code manipulation tools (tidy, rename...)
lld: link editor
polly: loop and data-locality optimizer for LLVM
openmp: OpenMP runtime library
libunwind: unwinder library
libcxxabi: low-level support library for libcxx
libcxx: implementation of C++ standard library
lldb: debugger; built without test suite at the moment
Additionally, the following project was considered but it was ultimately skipped as it was not ready for wider testing yet:
llgo: Go compiler
My project fixes
During my work, I have been trying to upstream all the necessary changes ASAP, as to avoid creating additional local patch maintenance burden. This section provides a short list of all patches that have either been merged upstream, or are in process of waiting for review.
LLVM
fixed tests to work without explicit /usr/pkg/bin/python: r348095
disabled tests failing due to touch -a not working on filesystems mounted with noatime option: r348354, r348355
Waiting for upstream review:
Clang
Waiting for upstream review:
LLD
openmp
libcxx
worked around test failing due to tv_sec=-1 not working: r348967
XFAIL-ed uchar.h test as the header is not present on NetBSD: r348973
Waiting for upstream review:
pkgsrc
z3 version bump (submitted to maintainer, waiting for reply)
NetBSD portability
During my work, I have met with a few interesting divergencies between the assumptions made by LLVM developers and the actual behavior of NetBSD. While some of them might be considered bugs, we determined it was preferable to support the current behavior in LLVM. In this section I shortly describe each of them, and indicate the path I took in making LLVM work.
unwind.h
The problem with unwind.h header is a part of bigger issue — while the unwinder API is somewhat defined as part of system ABI, there is no well-defined single implementation on most of the systems. In practice, there are multiple implementations both of the unwinding library and of its headers:
gcc: it implements unwinder library in libgcc; also, has its own unwind.h on Linux (but not on NetBSD)
clang: it has its own unwind.h (but no library)
'non-GNU' libunwind: stand-alone implementation of library and headers
llvm-libunwind: stand-alone implementation of library and headers
libexecinfo: provides unwinder library and unwind.h on NetBSD
Since gcc does not provide unwind.h on NetBSD, using it to build LLVM normally results in the built-in unwinder library from GCC being combined with unwind.h installed as part of libexecinfo. However, the API defined by the latter header is type-incompatible with most of the other implementations, and caused libc++abi build to fail.
In order to resolve the build issue, we agreed to use LLVM's own unwinder implementation (llvm-libunwind) which we were building anyway, via the following CMake option:
-DLIBCXXABI_USE_LLVM_UNWINDER=ON
I have started a thread about fixing unwind.h to be more compatible.
noatime behavior
noatime is a filesystem mount option that is meant to inhibit atime updates on file accesses. This is usually done in order to avoid spurious inode writes when performing read-level operations. However, unlike the other implementations NetBSD not only disables automatic atime updates but also explicitly blocks explicit updates via utime() family of functions.
Technically, this behavior is permitted by POSIX as it permits implementation-defined behavior on updating atimes. However, a small number of LLVM tests explicitly rely on being able to set atime on a test file, and the NetBSD behavior causes them to fail. Without a way to set atime, we had to mark those tests unsupported.
I have started a thread about noatime behavior on tech-kern.
__func__ value
__func__ is defined by the standard to be an arbitrary form of function identifier. On most of the other systems, it is equal to the value of __FUNCTION__ defined by gcc, that is the undecorated function name. However, NetBSD system headers conditionally override this to __PRETTY_FUNCTION__, that is a full function prototype.
This has caused one of the LLVM tests to fail due to matching debug output. Admittedly, this was definitely a problem with the test (since __func__ can have an arbitrary value) and I have fixed it to permit the pretty function form.
Kamil Rytarowski has noted that the override is probably more accidental than expected since the header was not updated for C++11 compilers providing __func__, and started a thread about disabling it.
tar -t output
Another difference I have noted while investigating test failures was in output of tar -t (listing files inside a tarball). Curious enough, both GNU tar and libarchive use C-style escapes in the file list output. NetBSD pax/tar output the filenames raw.
The test meant to verify whether backslash in filenames is archived properly (i.e. not treated equivalent to forward slash). It failed because it expected the backslash to be escaped. I was able to fix it by permitting both forms, as the exact treatment of backslash was not relevant to the test case at hand.
I have compared different tar implementations including NetBSD pax in the article portability of tar features.
(time_t)-1 meaning
One of the libc++ test cases was verifying the handling of negative timestamps using a value of -1 (i.e. one second before the epoch). However, this value seems to be mishandled in some of the BSD implementations, FreeBSD and NetBSD in particular. Curious enough, other negative values work fine.
The easier side of the issue is that some functions (e.g. mktime()) use -1 as an error value. However, this can be easily fixed by inspecting errno for actual errors.
The harder side is that the kernel uses a value of -1 (called ENOVAL) to internally indicate that the timestamp is not to be changed. As a result, an attempt to update the file timestamp to one second before the epoch is going to be silently ignored.
I have fixed the test via extend the FreeBSD workaround to NetBSD, and using a different timestamp. I have also started a thread about (time_t)-1 handling on tech-kern.
Future plans
The plans for the remainder of December include, as time permits:
finishing upstream of the fore-mentioned patches
fixing flaky tests on NetBSD buildbot
upstreaming (and fixing if necessary) the remaining pkgsrc patches
improving NetBSD support in profiling and xray (of compiler-rt)
porting ESan/DFSan
The long-term goals include:
improving support for __float128
porting LLD to NetBSD (currently it passes all tests but does not produce working executables)
finishing LLDB port to NetBSD
porting remaining sanitizers to NetBSD
Prepared by Michał Górny (mgorny AT gentoo.org).
I'm recently helping the NetBSD developers to improve the support for this operating system in various LLVM components. As you can read in my previous report, I've been focusing on fixing build and test failures for the purpose of improving the buildbot coverage.
Previously, I've resolved test failures in LLVM, Clang, LLD, libunwind, openmp and partially libc++. During the remainder of the month, I've been working on the remaining libc++ test failures, improving the NetBSD clang driver and helping Kamil Rytarowski with compiler-rt.
Locale issues in NetBSD / libc++
The remaining libc++ work focused on resolving locale issues. This consisted of two parts:
Resolving incorrect assumptions in re.traits case-insensitivity translation handling: r349378 (D55746),
Enabling locale support and disabling tests failing because of partial locale support in NetBSD: r349379 (D55767).
The first of the problems was related to testing the routine converting strings to common case for the purpose of case-insensitive regular expression matching. The test attempted to translate \xDA and \xFA characters (stored as char) in UTF-8 locale, and expected both of them to map to \xFA, i.e. according to Unicode Latin-1 Supplement. However, this behavior is only exhibited on OSX. Other systems, including NetBSD, FreeBSD and Linux return the character unmodified (i.e. \xDA and \xFA appropriately).
I've came to the conclusion that the most likely cause of the incompatible behavior is that both \xDA and \xFA alone do not comprise valid UTF-8 sequences. However, since the translation function can take only a single char and is therefore incapable of processing multi-byte sequences, it is unclear how it should handle the range \x80..\xFF that's normally used for multi-byte sequences or not used at all. Apparently, the OSX implementers decided to map it into \u0080..\u00FF range, i.e. treat equivalently to wchar_t, while others decided to ignore it.
After some discussion, upstream agreed on removing the two tests for now, and treating the result of this translation as undefined implementation-specific behavior. At the same time, we've left similar cases for L'\xDA' and L'\xFA' which seem to work reliably on all implementations (assuming wchar_t is using UCS-4, UCS-2 or UTF-16 encoding).
The second issue was adding libc++ target info for NetBSD which has been missing so far. This I've based on the rules for FreeBSD, modified to use libc++abi instead of libcxxrt (the former being upstream default, and the latter being abandoned external project). This also included a list of supported locales which caused a large number of additional tests to be run (if I counted correctly, 43 passing and 30 failing).
Some of the tests started failing due to limited locale support on NetBSD. Apparently, the system supports locales only for the purpose of character encoding (i.e. LC_CTYPE category), while the remaining categories are implemented as stubs (see localeconv(3)). After some thinking, we've agreed to list all locales expected by libc++ as supported since NetBSD has support files for them, and mark relevant tests as expected failures. This has the advantage that when locale support becomes more complete, the expected failures will be reported as unexpected passes, and we will know to update the tests accordingly.
Clang driver updates
On specific request of Kamil, I have looked into the NetBSD Clang driver code afterwards. My driver work focused on three separate issues:
Recently added address significance tables (-faddrsig) causing crashes of binutils (r349647; D55828),
Passing -D_REENTRANT when building sanitized code (with prerequisite: r349649, D55832; r349650, D55654,
Establishing proper support for finding and using locally installed LLVM components, i.e. libc++, compiler-rt, etc.
The first problem was mostly a side effect of Kamil testing my z3 bump. He noticed that binutils crash on executables produced by recent versions of clang (example backtrace <http://netbsd.org/~kamil/llvm/strip.txt>). Given my earlier experiences in Gentoo, I correctly guessed that this is caused by address significance table support that is enabled by default in LLVM 7. While technically they should be ignored by tooling not supporting them, it causes verbose warnings in some versions of binutils, and explicit crashes in the 2.27 version used by NetBSD at the moment.
In order to prevent users from experiencing this, we've agreed to disable address significance table by default on NetBSD (users can still explicitly enable them via -faddrsig). What's interesting, the block for disabling LLVM_ADDRSIG has grown since to include PS4 and Gentoo which indicates that we're not the only ones considering this default a bad idea.
The second problem was that Kamil indicated that we should only support sanitizing reentrant versions of the system API. Accordingly, he requested that the driver automatically includes -D_REENTRANT when compiling code with any of the sanitizers enabled. I've implemented a new internal clang API that checks whether any of the sanitizers were enabled, and used it to implicitly pass this option from driver to the actual compiler instance.
The third problem is much more complex. It boils down to the driver using hardcoded paths from a few years back assuming LLVM being installed to /usr as path of /usr/src integration. However, those paths do not really work when clang is run from the build directory or installed manually to /usr/local; which means e.g. clang install with libc++ does not work out of the box.
Sadly, we haven't been able to come up with a really good and reliable solution to this. Even if we could make clang find other components reasonably reliably using executable-relative paths, this would require building executables with RPATHs potentially pointing to (temporary) build directory of LLVM. Eventually, I've decided to abandon the problem and focus on passing appropriate options explicitly when using just-built clang to build and test other components. For the purpose of buildbot, this required using the following option:
-DOPENMP_TEST_FLAGS="-cxx-isystem${PWD}/include/c++/v1"
compiler-rt work
As Kamil is finalizing his work on sanitizers, he left tasks in TODO lists and I picked them up to work on them.
Build fixes
My first two fixes to compiler-rt were plain build fixes, necessary to proceed further. Those were:
Fixing use of variables (whose values could not be directly determined at compile time) for array length: r349645, D55811.
Detecting missing libLLVMTestingSupport and skipping tests requiring it: r349899, D55891.
The first one was a trivial coding slip that was easily fixed by using a constant value for hash length. The second one was more problematic.
Two tests in XRay test suite required LLVMTestingSupport. However, this library is not installed by LLVM, and so is not present when building stand-alone. Normally, similar issues in LLVM were resolved by building the relevant library locally (that's e.g. what we do with gtest). In this case this wasn't feasible due to the library being more tightly coupled with LLVM itself, and adjusting the build system would be non-trivial. Therefore, since only two tests required this we've agreed on disabling this when the library isn't present.
XRay: alignment and MPROTECT problems
The next step was to research XRay test failures. Firstly, all the tests were failing due to PaX MPROTECT. Secondly, after disabling MPROTECT I've been getting the following test failures from check-xray:
XRay-x86_64-netbsd :: TestCases/Posix/fdr-reinit.cc XRay-x86_64-netbsd :: TestCases/Posix/fdr-single-thread.cc
Both tests segfaulted on initializing thread-local data structure. I've came to the conclusion that somehow initializing aligned thread-local data is causing the issue, and built a simple test case for it:
struct FDRLogWriter {
FDRLogWriter() {}
};
struct alignas(64) ThreadLocalData {
FDRLogWriter Buffer{};
};
void f() { thread_local ThreadLocalData foo{}; }
int main() {
f();
return 0;
}
The really curious part of this was that the code produced by g++ worked fine, while the one produced by clang++ segfaulted. At the same time, the LLVM bytecode generated by clang worked fine on both FreeBSD and Linux. Finally, through comparing and manipulating LLVM bytecode I've found the culprit: the alignment was not respected while allocating storage for thread-local data. However, clang assumed it will be and used MOVAPS instructions that caused a segfault on unaligned data.
I wrote about the problem to tech-toolchain and received a reply that TLS alignment is mostly ignored and there is no short term plan for fixing it. As an interim solution, I wrote a patch that disables alignment tips sufficiently to prevent clang from emitting code relying on it: r350029, D56000.
As suggested by Kamil, I discussed the PaX MPROTECT issues with upstream. The direct problem in solving it the usual way is that the code relies on remapping program memory mapped by ld.so, and altering the program code in place. I've been informed that this design was chosen to keep the mechanism simple, and explicitly declaring that XRay is incompatible with system security features such as PaX MPROTECT. As Kamil suggested, I've written an explicit check for MPROTECT being enabled, and made XRay fail with explanatory error message in that case: r350030, D56049.
Improving stdio.h / FILE* interceptor coverage
My final work has been on improving stdio.h coverage in interceptors. It started as a task on adding NetBSD FILE structure support for interceptors (D56109), and expanded into increasing test and interceptor coverage, both for POSIX and NetBSD-specific stdio.h functions.
I have implemented tests for the following functons:
clearerr, feof, ferrno, fileno, fgetc, getc, ungetc: D56136,
fputc, putc, putchar, getc_unlocked, putc_unlocked, putchar_unlocked: D56152,
popen, pclose: D56153,
funopen, funopen2 (in multiple parameter variants): D56154.
Furthermore, I have implemented missing interceptors for the following functions:
Kamil also pointed out that devname_r interceptor has wrong return type on non-NetBSD systems, and I've fixed that for completeness: D56150.
Summary
At this point, NetBSD LLVM buildbot is building and testing the following projects with no expected test failures:
llvm: core LLVM libraries; also includes the test suite of LLVM's lit testing tool
clang: C/C++ compiler
clang-tools-extra: extra C/C++ code manipulation tools (tidy, rename...)
lld: link editor
polly: loop and data-locality optimizer for LLVM
openmp: OpenMP runtime library
libunwind: unwinder library
libcxxabi: low-level support library for libcxx
libcxx: implementation of C++ standard library
It also builds the lldb debugger but does not run its test suite.
The support for compiler-rt is progressing but it is not ready for buildbot inclusion yet.
Future plans
Next month, I'm planning to work on next items from the TODO. Most notably, this includes:
building compiler-rt on buildbot and running the tests,
porting LLD to actually produce working executables on NetBSD,
porting remaining compiler-rt components: DFSan, ESan, LSan, shadowcallstack.
After nearly 3 whole years of development (work started on NetBSD 10 in late 2019), BETA snapshots have finally been published for interested users to test. More changes will be backported from the development branch over the next few months before we tag a final release, so the BETA images will keep getting updated.
What to expect
While NetBSD 10.0 is expected to be a major milestone on performance, especially on multi-core systems, currently the BETA builds have some extra kernel diagnostics enabled that may reduce performance somewhat.
Among the features you can expect to find in NetBSD 10 are reworked cryptography, including compatibility with WireGuardⓇ, automatic swap encryption, new disk encryption methods, and CPU acceleration in the kernel. In hardware support, there are updated GPU drivers from Linux 5.6, support for more ARM hardware (including Rockchip RK356X, NXP i.MX 8M, Amlogic G12, Apple M1, and Raspberry Pi 4), support for new security features found in the latest ARM CPUs, and support for Realtek 2.5 gigabit and new Intel 10/25/40 gigabit ethernet adapters. compat_linux has been ported to AArch64 and DTrace has been ported to MIPS. For retrocomputing enthusiasts, there's improved multiprocessor support on Alpha, and more iMac G5 support. The Xen hypervisor support has received a major rework. There are various new userspace programs, including blkdiscard(8) to manually TRIM a disk, aiomixer(1) to control audio volume, realpath(1), and fsck_udf(8). And loads more...
There are many little details that might be relevant to admins when upgrading from NetBSD 9, so wait and read the final release announcement before you upgrade any production systems. Please note that networking setups using tap(4) as a bridge endpoint must be modified to use vether(4) instead, and compat_linux is no longer built into the kernel for security reasons (load it as a module instead). DisplayPort and HDMI audio is now enabled in the default x86 kernel, so you might need to change the default audio device with audiocfg(1) if you're not getting any sound output. blacklistd(8) was renamed to blocklistd(8).
Downloads
- Installation / USB stick image for 64-bit x86 (hybrid UEFI/BIOS image). Use gunzip and dd to write an .img.gz file on Unix, or Rawrite32 on Windows.
- Installation / USB stick image for 64-bit x86 (legacy BIOS only)
- Installation / USB stick image for 32-bit x86
- For images for various ARM devices, see armbsd.org. All Arm boards without UFEI or Raspberry Pi firmware also require U-Boot to be written the SD card separately when using a generic image.
- Live image for Raspberry Pi 0 or 1
- Live image for Cavium Octeon (also needs U-Boot)
- CD/DVD image for 64-bit x86 (for actual CD/DVDs and virtual machines only)
- CD/DVD image for 32-bit x86
- CD/DVD image for 64-bit Arm virtual machines
- CD/DVD image for SPARC64
- CD/DVD image for Alpha
- More? (e.g. Apple PowerPC/68K, Amiga, Dreamcast, PA-RISC, SGI MIPS, SPARC32, VAX...)
Packages
Third-party software is available from pkgsrc, as ever. Binary packages are available for amd64, and I hope to publish binaries for i386 shortly.
Reporting bugs
Allen Briggs was one of the earliest members of the NetBSD community, pursuing his interest in macBSD, and moving to become a NetBSD developer when the two projects merged. Allen was known for his quiet and relaxed manner, and always brought a keen wisdom with him; allied with his acute technical expertise, he was one of the most valued members of the NetBSD community.
He was a revered member of the NetBSD core team, and keenly involved in many aspects of its application; from working on ARM chips to helping architect many projects, Allen was renowned for his expertise. He was a distinguished engineer at Apple, and used his NetBSD expertise there to bring products to market.
Allen lived in Blacksburg Virginia with his wife and twin boys and was active with various community volunteer groups. His family touched the families of many other NetBSD developers and those friendships have endured beyond his passing.
We have received the following from Allen's family and decided to share it with the NetBSD community. If you can, we would ask you to consider contributing to his Memorial Scholarship.
https://www.ncssm.edu/donate/distance-education/allen-k-briggs-88-memorial-scholarship
The Allen K. Briggs Memorial Scholarship is an endowment to provide scholarships in perpetuity for summer programs at the North Carolina School of Science & Math, which Allen considered to be a place that fundamentally shaped him as a person. We would love to invite Allen's friends and colleagues from the BSD community to donate to this cause so that we can provide more scholarships to students with financial need each year. We are approximately halfway to our goal of $50K with aspirations to exceed that target and fund additional scholarships.
Two quick notes on donating: Important! When donating, you must
select "Allen K. Briggs Memorial Scholarship" under designation
for the donation to be routed to the scholarship If you have the
option to use employer matching (i.e., donating to NCSSM through
an employer portal to secure a match from your employer), please
email the NCSSM Foundation's Director of Development, April Horton
(april.horton@ncssm.edu), after donating to let her know you want
your gift and employer match to go to the Allen K. Briggs Memorial
Scholarship Thanks in advance for your help. I'd be happy to answer
any questions you or any others have about this.
Allen Briggs was one of the earliest members of the NetBSD community, pursuing his interest in macBSD, and moving to become a NetBSD developer when the two projects merged. Allen was known for his quiet and relaxed manner, and always brought a keen wisdom with him; allied with his acute technical expertise, he was one of the most valued members of the NetBSD community.
He was a revered member of the NetBSD core team, and keenly involved in many aspects of its application; from working on ARM chips to helping architect many projects, Allen was renowned for his expertise. He was a distinguished engineer at Apple, and used his NetBSD expertise there to bring products to market.
Allen lived in Blacksburg Virginia with his wife and twin boys and was active with various community volunteer groups. His family touched the families of many other NetBSD developers and those friendships have endured beyond his passing.
We have received the following from Allen's family and decided to share it with the NetBSD community. If you can, we would ask you to consider contributing to his Memorial Scholarship.
https://www.ncssm.edu/donate/distance-education/allen-k-briggs-88-memorial-scholarship
The Allen K. Briggs Memorial Scholarship is an endowment to provide scholarships in perpetuity for summer programs at the North Carolina School of Science & Math, which Allen considered to be a place that fundamentally shaped him as a person. We would love to invite Allen's friends and colleagues from the BSD community to donate to this cause so that we can provide more scholarships to students with financial need each year. We are approximately halfway to our goal of $50K with aspirations to exceed that target and fund additional scholarships.
Two quick notes on donating: Important! When donating, you must
select "Allen K. Briggs Memorial Scholarship" under designation
for the donation to be routed to the scholarship If you have the
option to use employer matching (i.e., donating to NCSSM through
an employer portal to secure a match from your employer), please
email the NCSSM Foundation's Director of Development, April Horton
(april.horton@ncssm.edu), after donating to let her know you want
your gift and employer match to go to the Allen K. Briggs Memorial
Scholarship Thanks in advance for your help. I'd be happy to answer
any questions you or any others have about this.
Since the start of the release process four months ago a lot of improvements went into the branch - more than 500 pullups were processed!
This includes usbnet (a common framework for usb ethernet drivers), aarch64 stability enhancements and lots of new hardware support, installer/sysinst fixes and changes to the NVMM (hardware virtualization) interface.
We hope this will lead to the best NetBSD release ever (only to be topped by NetBSD 10 next year).
Here are a few highlights of the new release:
- Support for Arm AArch64 (64-bit Armv8-A) machines, including "Arm ServerReady" compliant machines (SBBR+SBSA)
- Enhanced hardware support for Armv7-A
- Updated GPU drivers (e.g. support for Intel Kabylake)
- Enhanced virtualization support
- Support for hardware-accelerated virtualization (NVMM)
- Support for Performance Monitoring Counters
- Support for Kernel ASLR
- Support several kernel sanitizers (KLEAK, KASAN, KUBSAN)
- Support for userland sanitizers
- Audit of the network stack
- Many improvements in NPF
- Updated ZFS
- Reworked error handling and NCQ support in the SATA subsystem
- Support a common framework for USB Ethernet drivers (usbnet)
You can download binaries of NetBSD 9.0_RC1 from our Fastly-provided CDN.
For more details refer to the official release announcement.
Please help us out by testing 9.0_RC1. We love any and all feedback. Report problems through the usual channels (submit a PR or write to the appropriate list). More general feedback is welcome, please mail releng. Your input will help us put the finishing touches on what promises to be a great release!
Enjoy!
Martin
Since the start of the release process four months ago a lot of improvements went into the branch - more than 500 pullups were processed!
This includes usbnet (a common framework for usb ethernet drivers), aarch64 stability enhancements and lots of new hardware support, installer/sysinst fixes and changes to the NVMM (hardware virtualization) interface.
We hope this will lead to the best NetBSD release ever (only to be topped by NetBSD 10 next year).
Here are a few highlights of the new release:
- Support for Arm AArch64 (64-bit Armv8-A) machines, including "Arm ServerReady" compliant machines (SBBR+SBSA)
- Enhanced hardware support for Armv7-A
- Updated GPU drivers (e.g. support for Intel Kabylake)
- Enhanced virtualization support
- Support for hardware-accelerated virtualization (NVMM)
- Support for Performance Monitoring Counters
- Support for Kernel ASLR
- Support several kernel sanitizers (KLEAK, KASAN, KUBSAN)
- Support for userland sanitizers
- Audit of the network stack
- Many improvements in NPF
- Updated ZFS
- Reworked error handling and NCQ support in the SATA subsystem
- Support a common framework for USB Ethernet drivers (usbnet)
You can download binaries of NetBSD 9.0_RC1 from our Fastly-provided CDN.
For more details refer to the official release announcement.
Please help us out by testing 9.0_RC1. We love any and all feedback. Report problems through the usual channels (submit a PR or write to the appropriate list). More general feedback is welcome, please mail releng. Your input will help us put the finishing touches on what promises to be a great release!
Enjoy!
Martin
Upstream describes LLDB as a next generation, high-performance debugger. It is built on top of LLVM/Clang toolchain, and features great integration with it. At the moment, it primarily supports debugging C, C++ and ObjC code, and there is interest in extending it to more languages.
In February, I have started working on LLDB, as contracted by the NetBSD Foundation. So far I've been working on reenabling continuous integration, squashing bugs, improving NetBSD core file support, extending NetBSD's ptrace interface to cover more register types and fix compat32 issues, and fixing watchpoint support. In October 2019, I've finished my work on threading support (pending pushes) and fought issues related to upgrade to NetBSD 9.
November was focused on finally pushing the aforementioned patches and major buildbot changes. Notably, I was working on extending the test runs to compiler-rt which required revisiting past driver issues, as well as resolving new ones. More details on this below.
LLDB changes
Test updates, minor fixes
The previous month has left us with a few regressions caused by the kernel upgrade. I've done my best to figure out those I could reasonably fast; for the remaining ones Kamil suggested that I mark them XFAIL for now and revisit them later while addressing broken tests. This is what I did.
While implementing additional tests in the threading patches, I've discovered that the subset of LLDB tests dedicated to testing lldb-server behavior was disabled on NetBSD. I've reenabled lldb-server tests and marked failing tests appropriately.
After enabling and fixing those tests, I've implemented missing support in the NetBSD plugin for getting thread name.
I've also switched our process plugin to use the newer PT_STOP request
over calling kill(). The main advantage of PT_STOP is that it
reliably notifies about SIGSTOP via wait() even if the process is
stopped already.
I've been able to reenable EOF detection test that was previously disabled due to bugs in the old versions of NetBSD 8 kernel.
Threading support pushed
After satisfying the last upstream requests, I was able to merge the three threading support patches:
This fixed 43 tests. It also triggered some flaky tests and a known regression and I'm planning to address them as the part of final bug cracking.
Build bot redesign
Recap of the problems
The tests of clang runtime components (compiler-rt, openmp) are
performed using freshly built clang. This version of clang attempts
to build and link C++ programs with libc++. However, our clang driver
naturally requires system installation of libc++ — after all, we
normally don't want the driver to include temporary build paths for
regular executables! For this reason, building against fresh libc++
in build tree requires appropriate -cxx-isystem, -L and -Wl,-rpath
flags.
So far, we managed to resolve this via using existing mechanisms to add additional flags to the test compiler calls. However, the existing solutions do not seem to suffice for compiler-rt. While technically I could work on adding more support code for that, I've decided it's better to look for a more general and permanent solution.
Two-stage builds
As part of the solution, I've proposed to switch our build bot to a two-stage build model. That is, firstly we're using the system GCC version to build a minimal functioning clang. Then, we're using this newly-built clang to build the whole LLVM suite, including another copy of clang.
The main advantage of this model is that we're verifying whether clang
is capable of building a working copy of itself. Additionally, it
insulates us against problems with host GCC. For example, we've
experienced issues with GCC 8 and the default -O3. On the negative
side, it increases build time significantly, especially that the second
stage needs to be rebuilt from scratch every time.
A common practice in compiler world is to actually do three stages. In this case, it would mean building minimal clang with host compiler, then second stage with first stage clang, then third stage using second stage's clang. This would have the additional benefit of verifying that clang is capable of building a compiler that's fully capable of building itself. However, this seems to have little actual gain for us while it would increase the build time even more.
Compiler wrappers
Another interesting side effect of using the two-stage build model
is that it proves an opportunity of injecting wrappers over clang
and clang++ built in the first stage. Those wrappers allows us to add
necessary -I, -L and -Wl,-rpath arguments without having to patch
the driver for this special case.
Furthermore, I've used this opportunity to add experimental LLD usage to the first stage, and use it instead of GNU ld for the second stage. The LLVM linker has a significantly smaller memory footprint and therefore allows us to improve build efficiency. Sadly, proper LLD support for NetBSD still depends on patches that are waiting for upstream review.
Compiler-rt status and tests
The builds of compiler-rt have been reenabled for the build bot. I am planning to start enabling individual test groups (e.g. builtins, ASAN, MSAN, etc.) as I get them to work. However, there are still other problems to be resolved before that happens.
Firstly, there are new test regressions. Some of them seem to be specifically related to build layout changes, or to use of LLD as linker. I am currently investigating them.
Secondly, compiler-rt tests aim to test all supported multilib targets by default. We are currently preparing to enable compat32 in the kernel on the host running build bot and therefore achieve proper multilib suppor for running them.
Thirdly, ASAN, MSAN and TSAN are incompatible with ASLR (address space layout randomization) that is enabled by default on NetBSD. Furthermore, XRay is incompatible with W^X restriction.
Making tests work with PaX features
Previously, we've already addressed the ASLR incompatibility by adding an explicit check for it and bailing out if it's enabled. However, while this somehow resolves the problem for regular users, it means that the relevant tests can't be run on hosts having ASLR enabled.
Kamil suggested that we should use paxctl to disable ASLR
per-executable here. This has the obvious advantage that it enables
the tests to work on all hosts. However, it required injecting
the paxctl invocation between the build and run step in relevant
tests.
The ‘obvious’ solution to this problem would be to add a kind of
%paxctl_aslr substitution that evaluates to paxctl call on NetBSD,
and to : (no-op) on other systems. However, this required updating
all the relevant tests and making sure that the invocation keeps being
included in new tests.
Instead, I've noticed that the %run substitution is already using
various kinds of wrappers for other targets, e.g. to run tests
via an emulator. I went for a more agreeable solution of substituting
%run in appropriate test suites
with a tiny wrapper calling paxctl before executing the test.
Clang/LLD dependent libraries feature
Introduction to the feature
Enabling the two stage builds had also another side effect. Since stage 2 build is done via clang+LLD, a newly added feature of dependent libraries got enabled and broke our build.
Dependent libraries
are a feature permitting source files to specify additional libraries
that are afterwards injected into linker's invocation. This is done
via a #pragma originally used by MSVC. Consider the following
example:
#include <stdio.h>
#include <math.h>
#pragma comment(lib, "m")
int main() {
printf("%f\n", pow(2, 4.3));
return 0;
}
When the source file is compiled using Clang on an ELF target, the lib
comments are converted into .deplibs object section:
$ llvm-readobj -a --section-data test.o
[...]
Section {
Index: 6
Name: .deplibs (25)
Type: SHT_LLVM_DEPENDENT_LIBRARIES (0x6FFF4C04)
Flags [ (0x30)
SHF_MERGE (0x10)
SHF_STRINGS (0x20)
]
Address: 0x0
Offset: 0x94
Size: 2
Link: 0
Info: 0
AddressAlignment: 1
EntrySize: 1
SectionData (
0000: 6D00 |m.|
)
}
[...]
When the objects are linked into a final executable using LLD, it
collects all libraries from .deplibs sections and links
to the specified libraries.
The example program pasted above would have to be built on systems
requiring explicit -lm (e.g. Linux) via:
$(CC) ... test.c -lm
However, when using Clang+LLD, it is sufficient to call:
clang -fuse-ld=lld ... test.c
and the library is included automatically. Of course, this normally makes little sense because you have to maintain compatibility with other compilers and linkers, as well as old versions of Clang and LLD.
Use of LLVM to approach static library dependency problem
LLVM started using the deplibs feature internally in D62090 in order to specify linkage between runtimes and their dependent libraries. Apparently, the goal was to provide an in-house solution to the static library dependency problem.
The problem discussed is that static libraries on Unix-derived platforms are primitive archives containing object files. Unlike shared libraries, they do not contain lists of other libraries they depend on. As a result, when linking against a static library, the user needs to explicitly pass all the dependent libraries to the linker invocation.
Over years, a number of workarounds were proposed to relieve the user (or build system) from having to know the exact dependencies of the static libraries used. A few worth noting include:
-
libtool archives (
.la) used by libtool as generic wrappers over shared and static libraries, -
library-specific
*-configprograms and pkg-config files, providing options for build systems to utilize, -
GNU ld scripts that can be used in place of libraries to alter linker's behavior.
The first two solutions work at build system level, and therefore are portable to different compilers and linkers. The third one requires linker support but have been used successfully to some degree due to wide deployment of GNU binutils, as well as support in other linkers (e.g. LLD).
Dependent libraries provide yet another attempt to solve the same problem. Unlike the listed approaches, it is practically transparent to the static library format — at the cost of requiring both compiler and linker support. However, since the runtimes are normally supposed to be used by Clang itself, at least the first of the points can be normally assumed to be satisfied.
Why it broke NetBSD?
After all the lengthy introduction, let's get to the point. As a result of my changes, the second stage is now built using Clang/LLD. However, it seems that the original change making use of deplibs in runtimes was tested only on Linux — and it caused failures for us since it implicitly appended libraries not present on NetBSD.
Over time, users of a few other systems have added various #ifdefs
in order to exclude Linux-specific libraries from their systems.
However, this solution is hardly optimal. It requires us to maintain
two disjoint sets of rules for adding each library — one in CMake
for linking of shared libraries, and another one in the source files
for emitting dependent libraries.
Since dependent libraries pragmas are present only in source files
and not headers, I went for a different approach. Instead of using
a second set of rules to decide which libraries to link, I've exported
the results of CMake checks into -D flags, and made dependent
libraries conditional on CMake check results.
Firstly, I've fixed deplibs in libunwind in order to fix builds on NetBSD. Afterwards, per upstream's request I've extended the deplibs fix to libc++ and libc++abi.
Future plans
I am currently still working on fixing regressions after the switch to two-stage build. As things develop, I am also planning to enable further test suites there.
Furthermore, I am planning to continue with the items from the original LLDB plan. Those are:
-
Add support to backtrace through signal trampoline and extend the support to libexecinfo, unwind implementations (LLVM, nongnu). Examine adding CFI support to interfaces that need it to provide more stable backtraces (both kernel and userland).
-
Add support for i386 and aarch64 targets.
-
Stabilize LLDB and address breaking tests from the test suite.
-
Merge LLDB with the base system (under LLVM-style distribution).
This work is sponsored by The NetBSD Foundation
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL to chip in what you can:
Upstream describes LLDB as a next generation, high-performance debugger. It is built on top of LLVM/Clang toolchain, and features great integration with it. At the moment, it primarily supports debugging C, C++ and ObjC code, and there is interest in extending it to more languages.
In February, I have started working on LLDB, as contracted by the NetBSD Foundation. So far I've been working on reenabling continuous integration, squashing bugs, improving NetBSD core file support, extending NetBSD's ptrace interface to cover more register types and fix compat32 issues, and fixing watchpoint support. In October 2019, I've finished my work on threading support (pending pushes) and fought issues related to upgrade to NetBSD 9.
November was focused on finally pushing the aforementioned patches and major buildbot changes. Notably, I was working on extending the test runs to compiler-rt which required revisiting past driver issues, as well as resolving new ones. More details on this below.
LLDB changes
Test updates, minor fixes
The previous month has left us with a few regressions caused by the kernel upgrade. I've done my best to figure out those I could reasonably fast; for the remaining ones Kamil suggested that I mark them XFAIL for now and revisit them later while addressing broken tests. This is what I did.
While implementing additional tests in the threading patches, I've discovered that the subset of LLDB tests dedicated to testing lldb-server behavior was disabled on NetBSD. I've reenabled lldb-server tests and marked failing tests appropriately.
After enabling and fixing those tests, I've implemented missing support in the NetBSD plugin for getting thread name.
I've also switched our process plugin to use the newer PT_STOP request
over calling kill(). The main advantage of PT_STOP is that it
reliably notifies about SIGSTOP via wait() even if the process is
stopped already.
I've been able to reenable EOF detection test that was previously disabled due to bugs in the old versions of NetBSD 8 kernel.
Threading support pushed
After satisfying the last upstream requests, I was able to merge the three threading support patches:
This fixed 43 tests. It also triggered some flaky tests and a known regression and I'm planning to address them as the part of final bug cracking.
Build bot redesign
Recap of the problems
The tests of clang runtime components (compiler-rt, openmp) are
performed using freshly built clang. This version of clang attempts
to build and link C++ programs with libc++. However, our clang driver
naturally requires system installation of libc++ — after all, we
normally don't want the driver to include temporary build paths for
regular executables! For this reason, building against fresh libc++
in build tree requires appropriate -cxx-isystem, -L and -Wl,-rpath
flags.
So far, we managed to resolve this via using existing mechanisms to add additional flags to the test compiler calls. However, the existing solutions do not seem to suffice for compiler-rt. While technically I could work on adding more support code for that, I've decided it's better to look for a more general and permanent solution.
Two-stage builds
As part of the solution, I've proposed to switch our build bot to a two-stage build model. That is, firstly we're using the system GCC version to build a minimal functioning clang. Then, we're using this newly-built clang to build the whole LLVM suite, including another copy of clang.
The main advantage of this model is that we're verifying whether clang
is capable of building a working copy of itself. Additionally, it
insulates us against problems with host GCC. For example, we've
experienced issues with GCC 8 and the default -O3. On the negative
side, it increases build time significantly, especially that the second
stage needs to be rebuilt from scratch every time.
A common practice in compiler world is to actually do three stages. In this case, it would mean building minimal clang with host compiler, then second stage with first stage clang, then third stage using second stage's clang. This would have the additional benefit of verifying that clang is capable of building a compiler that's fully capable of building itself. However, this seems to have little actual gain for us while it would increase the build time even more.
Compiler wrappers
Another interesting side effect of using the two-stage build model
is that it proves an opportunity of injecting wrappers over clang
and clang++ built in the first stage. Those wrappers allows us to add
necessary -I, -L and -Wl,-rpath arguments without having to patch
the driver for this special case.
Furthermore, I've used this opportunity to add experimental LLD usage to the first stage, and use it instead of GNU ld for the second stage. The LLVM linker has a significantly smaller memory footprint and therefore allows us to improve build efficiency. Sadly, proper LLD support for NetBSD still depends on patches that are waiting for upstream review.
Compiler-rt status and tests
The builds of compiler-rt have been reenabled for the build bot. I am planning to start enabling individual test groups (e.g. builtins, ASAN, MSAN, etc.) as I get them to work. However, there are still other problems to be resolved before that happens.
Firstly, there are new test regressions. Some of them seem to be specifically related to build layout changes, or to use of LLD as linker. I am currently investigating them.
Secondly, compiler-rt tests aim to test all supported multilib targets by default. We are currently preparing to enable compat32 in the kernel on the host running build bot and therefore achieve proper multilib suppor for running them.
Thirdly, ASAN, MSAN and TSAN are incompatible with ASLR (address space layout randomization) that is enabled by default on NetBSD. Furthermore, XRay is incompatible with W^X restriction.
Making tests work with PaX features
Previously, we've already addressed the ASLR incompatibility by adding an explicit check for it and bailing out if it's enabled. However, while this somehow resolves the problem for regular users, it means that the relevant tests can't be run on hosts having ASLR enabled.
Kamil suggested that we should use paxctl to disable ASLR
per-executable here. This has the obvious advantage that it enables
the tests to work on all hosts. However, it required injecting
the paxctl invocation between the build and run step in relevant
tests.
The ‘obvious’ solution to this problem would be to add a kind of
%paxctl_aslr substitution that evaluates to paxctl call on NetBSD,
and to : (no-op) on other systems. However, this required updating
all the relevant tests and making sure that the invocation keeps being
included in new tests.
Instead, I've noticed that the %run substitution is already using
various kinds of wrappers for other targets, e.g. to run tests
via an emulator. I went for a more agreeable solution of substituting
%run in appropriate test suites
with a tiny wrapper calling paxctl before executing the test.
Clang/LLD dependent libraries feature
Introduction to the feature
Enabling the two stage builds had also another side effect. Since stage 2 build is done via clang+LLD, a newly added feature of dependent libraries got enabled and broke our build.
Dependent libraries
are a feature permitting source files to specify additional libraries
that are afterwards injected into linker's invocation. This is done
via a #pragma originally used by MSVC. Consider the following
example:
#include <stdio.h>
#include <math.h>
#pragma comment(lib, "m")
int main() {
printf("%f\n", pow(2, 4.3));
return 0;
}
When the source file is compiled using Clang on an ELF target, the lib
comments are converted into .deplibs object section:
$ llvm-readobj -a --section-data test.o
[...]
Section {
Index: 6
Name: .deplibs (25)
Type: SHT_LLVM_DEPENDENT_LIBRARIES (0x6FFF4C04)
Flags [ (0x30)
SHF_MERGE (0x10)
SHF_STRINGS (0x20)
]
Address: 0x0
Offset: 0x94
Size: 2
Link: 0
Info: 0
AddressAlignment: 1
EntrySize: 1
SectionData (
0000: 6D00 |m.|
)
}
[...]
When the objects are linked into a final executable using LLD, it
collects all libraries from .deplibs sections and links
to the specified libraries.
The example program pasted above would have to be built on systems
requiring explicit -lm (e.g. Linux) via:
$(CC) ... test.c -lm
However, when using Clang+LLD, it is sufficient to call:
clang -fuse-ld=lld ... test.c
and the library is included automatically. Of course, this normally makes little sense because you have to maintain compatibility with other compilers and linkers, as well as old versions of Clang and LLD.
Use of LLVM to approach static library dependency problem
LLVM started using the deplibs feature internally in D62090 in order to specify linkage between runtimes and their dependent libraries. Apparently, the goal was to provide an in-house solution to the static library dependency problem.
The problem discussed is that static libraries on Unix-derived platforms are primitive archives containing object files. Unlike shared libraries, they do not contain lists of other libraries they depend on. As a result, when linking against a static library, the user needs to explicitly pass all the dependent libraries to the linker invocation.
Over years, a number of workarounds were proposed to relieve the user (or build system) from having to know the exact dependencies of the static libraries used. A few worth noting include:
-
libtool archives (
.la) used by libtool as generic wrappers over shared and static libraries, -
library-specific
*-configprograms and pkg-config files, providing options for build systems to utilize, -
GNU ld scripts that can be used in place of libraries to alter linker's behavior.
The first two solutions work at build system level, and therefore are portable to different compilers and linkers. The third one requires linker support but have been used successfully to some degree due to wide deployment of GNU binutils, as well as support in other linkers (e.g. LLD).
Dependent libraries provide yet another attempt to solve the same problem. Unlike the listed approaches, it is practically transparent to the static library format — at the cost of requiring both compiler and linker support. However, since the runtimes are normally supposed to be used by Clang itself, at least the first of the points can be normally assumed to be satisfied.
Why it broke NetBSD?
After all the lengthy introduction, let's get to the point. As a result of my changes, the second stage is now built using Clang/LLD. However, it seems that the original change making use of deplibs in runtimes was tested only on Linux — and it caused failures for us since it implicitly appended libraries not present on NetBSD.
Over time, users of a few other systems have added various #ifdefs
in order to exclude Linux-specific libraries from their systems.
However, this solution is hardly optimal. It requires us to maintain
two disjoint sets of rules for adding each library — one in CMake
for linking of shared libraries, and another one in the source files
for emitting dependent libraries.
Since dependent libraries pragmas are present only in source files
and not headers, I went for a different approach. Instead of using
a second set of rules to decide which libraries to link, I've exported
the results of CMake checks into -D flags, and made dependent
libraries conditional on CMake check results.
Firstly, I've fixed deplibs in libunwind in order to fix builds on NetBSD. Afterwards, per upstream's request I've extended the deplibs fix to libc++ and libc++abi.
Future plans
I am currently still working on fixing regressions after the switch to two-stage build. As things develop, I am also planning to enable further test suites there.
Furthermore, I am planning to continue with the items from the original LLDB plan. Those are:
-
Add support to backtrace through signal trampoline and extend the support to libexecinfo, unwind implementations (LLVM, nongnu). Examine adding CFI support to interfaces that need it to provide more stable backtraces (both kernel and userland).
-
Add support for i386 and aarch64 targets.
-
Stabilize LLDB and address breaking tests from the test suite.
-
Merge LLDB with the base system (under LLVM-style distribution).
This work is sponsored by The NetBSD Foundation
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL to chip in what you can:
The NetBSD Project is pleased to announce NetBSD 7.1.1, the first security/bugfix update of the NetBSD 7.1 release branch. It represents a selected subset of fixes deemed important for security or stability reasons. If you are running an earlier release of NetBSD, we strongly suggest updating to 7.1.1.
For more details, please see the release notes.
Complete source and binaries for NetBSD are available for download at many sites around the world. A list of download sites providing FTP, AnonCVS, and other services may be found at http://www.NetBSD.org/mirrors/.
The NetBSD Project is pleased to announce NetBSD 7.1.1, the first security/bugfix update of the NetBSD 7.1 release branch. It represents a selected subset of fixes deemed important for security or stability reasons. If you are running an earlier release of NetBSD, we strongly suggest updating to 7.1.1.
For more details, please see the release notes.
Complete source and binaries for NetBSD are available for download at many sites around the world. A list of download sites providing FTP, AnonCVS, and other services may be found at http://www.NetBSD.org/mirrors/.
The Bay Area
I took part (together with William Coldwell - cryo@) in the GSOC Mentor Summit as a NetBSD delegate. I've presented during the event a presentation with a quick introduction to NetBSD, track history of GSoC involvement and the LLVM Sanitizers work with a stress of sanitizers.
The MeetBSDCa conference is a continuation of the MeetBSD conferences from Poland. I took part there as a speaker talking about Userland Sanitizers in NetBSD. I've also presented the state of virtualization in NetBSD during a discussion panel. Additionally I've prepared a lightning talk about NetBSD Kernel sanitizers and quick status update from The NetBSD Foundation. Unfortunately the schedule was last minute changed (introduction of BSD history talk in the slot of lightning presentations) and the closing ceremony had different proceeding. Nonetheless, I'm sharing these additional quick presentations.
- Bug detecting software in the NetBSD userland: MKSANITIZER
- NetBSD kernel sanitizers
- MeetBSDCa 2018: The NetBSD Foundation update
During the former conference it was a great opportunity to meet people from other Open Source projects, a lot of them are in interaction with NetBSD developers during the process of upstreaming local support patches. During the latter conference it was an opportunity to meet BSD people and people closer to hardware companies.
Upstreaming process of LLVM Sanitizers
I've upstreamed a number of patches to the LLVM source tree. The changes can be summarized as:
- Further reworking the code and approaching the state of installing of sysctl*() inteceptors.
- Fixing or marking failing or hanging tests in the sanitizer test-suites.
- Adapting definitions of syscalls and ioctl(2) operations for NetBSD 8.99.25.
Detailed list of commits merged with the upstream LLVM compiler-rt repository:
- Update ioctl(2) operations for NetBSD 8.99.25
- Update generate_netbsd_ioctls.awk for NetBSD 8.99.25
- Diable test suppressions-library for NetBSD/i386
- Disable BufferOverflowAfterManyFrees for NetBSD
- Mark breaking asan tests on NetBSD
- Switch getline_nohang from XFAIL to UNSUPPORTED for NetBSD
- Mark vptr-non-unique-typeinfo as a broken test for NetBSD/i386
- Mark breaking sanitizer_common tests on NetBSD
- Handle NetBSD alias for pthread_sigmask
- Cast the return value of _Unwind_GetIP() to uptr
- Mark interception_failure_test with XFAIL for NetBSD
- Disable ASan test asan_and_llvm_coverage_test for NetBSD
- Adapt ASan test heavy_uar_test for NetBSD
- Mark breaking TSan tests on NetBSD with XFAIL
- Cleanup includes in sanitizer_platform_limits_netbsd.cc
- Regenerate syscall hooks for NetBSD 8.99.25
- Update generate_netbsd_syscalls.awk for NetBSD 8.99.25
- Handle pthread_sigmask in DemangleFunctionName()
- Drop now hidden ioctl(2) operations for NetBSD
- Handle NetBSD symbol mangling for tzset
- Handle NetBSD symbol mangling for nanosleep and vfork
- Mark test/tsan/getline_nohang as XFAIL for NetBSD
- Disable the GNU strerror_r TSan test for NetBSD
- Mark test/tsan/ignore_lib5 as unsupported for NetBSD
- Mark intercept-rethrow-exception.cc as XFAIL on NetBSD
- Disable failing tests lib/asan/tests on NetBSD
- Skip unsupported MSan tests on NetBSD
- Mark 4 MSan tests as XFAIL for NetBSD
- Mark MSan fork test as UNSUPPORTED on NetBSD
- Reflect the current reality and disable lsan tests on NetBSD
- Use PTHREAD_STACK_MIN conditionally in a test
- Remove remnant code of using indirect syscall on NetBSD
- Don't harcode -ldl test/sanitizer_common/TestCases
- Disable TestCases/pthread_mutexattr_get on NetBSD
- Fix Posix/devname_r for NetBSD
- Unwind local macro DEFINE_INTERNAL()
- Introduce internal_sysctlbyname in place of sysctlbyname
Frequently asked question
People keep asking me about rationale of some design decisions in sanitizers and whether something could be done better. One of such places is to reuse more of libc internals and to not keep bypassing it whenever possible. The motivation to keep redoing the same work for NetBSD is to keep close to the upstream (mostly Linux & Android) source code with a minimal delta between NetBSD vs others support. Doing some operations in a more convenient way is tempting, but it's a danger that someone will need to keep maintaining a larger diff, especially since upstream developers will focus on their own OSes rather than trying to adapt their patches for potentially alternative approaches.
Plan for the next milestone
I will keep upstreaming local LLVM patches (almost 2500LOC to go!).
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL, and chip in what you can:
This post was written by Piyush Sachdeva:
Abstract
The primary goal of the project was to extend posix_spawn(3) to include chdir(2) for the newly created child process. Two functions were supposed to be implemented, namely posix_spawn_file_actions_addchdir() and posix_spawn_file_actions_addfchdir(), to support both chdir(2) and fchdir(2) respectively. posix_spawn() is a POSIX standard method responsible for creating and executing new child processes.
Implementation
The original code can be found at my github tree.
The implementation plan was discussed and made with the guidance of both my mentors Martin Husemann and Joerg Sonnenberger. The plan was divided into three phases each corresponding to the specific part of The NetBSD code-base which is supposed to be touched:
User-Land
The following actions were performed in the user-land to set things up for the kernel-space.
- Add another member to the posix_spawn_file_actions_t struct i.e a union, which would hold the path to chdir to.
- Implement the two functions posix_spawn_file_actions_addchdir()
and posix_spawn_file_actions_addfchdir(). These functions would:
- allocate memory for another posix_spawn_file_actions_t object in the posix_spawn_file_actions_t array.
- take the path/file descriptor from the user as an argument and make the relative field of the newly allocated file actions object, point to it.
- The final step was to add the prototypes for the two new functions to the `src/include/spawn.h' header file
Once the aforementioned changes were made, the only thing left to do was to make the kernel support these two new functions.
Kernel-Space
The following actions were performed inside the kernel space.
- The three functions in the `src/sys/kern_exec.c' file which correspond to the
posix_spawn_file_actions were edited:
- posix_spawn_fa_alloc() was adjusted to make sure that the path passed to posix_spawn_file_actions_addchdir() gets copied from the user-land to the kernel-space.
- Similarly posix_spawn_fa_free() was adjusted to make sure that the memory allocated in case of FAE_CHDIR gets freed as well.
- Finally, two new cases FAE_CHDIR & FAE_FCHDIR were added in the handle_posix_spawn_file_actions(). In each of the cases, a call to one of the two newly created functions (discussed in the next point) do_sys_chdir() and do_sys_fchdir() was made respectively.
Note: At the time of code integration, a helper function was written by Christos Zoulas. This function aimed to reduce the amount of repeated code in both posix_spawn_fa__free() and posix_spawn_fa_alloc()
- Two new functions, similar to the already present sys_chdir() and sys_fchdir() in
`src/sys/vfs_syscalls.c' were created. Namely do_sys_chdir() and do_sys_chdir
were written with two specific thoughts in mind:
- By default sys_chdir() and sys_fchdir() took syscallargs as a parameter. The purpose of the new functions was to replace this with const char * and an int type parameter respectively.
- The do_sys_chdir() also replaced UIO_USERSPACE with UIO_SYSSPACE. This was done because the chdir path passed to this function already resided in the Kernel-space due to the change made in posix_spawn_fa_alloc().
- Finally, the prototypes for the newly written functions were added to the `src/sys/sys/vfs_syscalls.h' file and this file was also included in the 'sys/kern/kern_exec.c'.
Note: Similar to the above changes of user-land and kernel-space, a few tweaks were also made to `src/sys/compat/netbsd/netbsd32.h' and `netbsd32_execve.c'. This was required to help COMPAT_NETBSD32 deal with the new file actions member. However, these changes were made at the time of integration by Martin Husemann.
With most of addition of new features being done, all that remained was testing and documentation.
Testing & Documentation
- A total of ten new test cases have been added to the `src/tests/lib/libc/gen/posix_spawn/t_spawn.c' file.
- Three utility functions were also used to aid in testing. Out of the three, one new function was written and two existing functions (filesize() and empty_outfile()) from `t_fileactions.c' were used. To make sure that the 2 existing functions were shared between both the files i.e `t_spawn.c' and `t_fileactions.c' a new header and C file was created, namely `fa_spawn_utils.h' and `fa_spawn_utils.c'. Following this, the bodies of both the functions were moved from `t_fileactions.c' to `fa_spawn_utils.c' and their prototypes were added to the corresponding header file.
- The general approach that was taken to all test cases was to make posix_spawn() execute ``/bin/pwd'' and write the output to a file. Then read the file and do string comparison. The third function i.e. check_succes() was written for just this purpose.
- The ten test cases cover the following scenarios:
- Absolute path test - for both chdir and fchdir.
- Relative path test - for both chdir and fchdir.
- Trying to open a file instead of directory - for both chdir and fchdir.
- Invalid path/file descriptor (fd=-1) - for both chdir and fchdir.
- Trying to open a directory without access permissions for chdir.
- Opening a closed file descriptor for fchdir.
- The first 8 test cases had a lot of repetitive code. Therefore, at the time of integration, another function was created i.e spawn_chdir(). This function included a huge chunk of the common code and it did all the heavy lifting for those first 8 test cases.
Documentation:
In this matter, a complete man page is written which explains both posix_spawn_file_actions_addchdir() and posix_spawn_file_actions_addfchdir() in great detail. The content of the manual page is taken from the POSIX documentation provided to us by Robert Elz.
Issues
Since the project was well planned from the beginning, it resulted in few issues.
- The user-land was the most straight forward part of the project and I had no trouble sailing through it.
- Kernel space was where things got a bit complicated, as I had to add functionality to pre-existing functions.
- I was completely new to using atf(7) and groff(1). Therefore, it took me some time to understand the respective man pages and become comfortable with testing and documentation part.
Most of the issues faced were generally logistical. As it was my first time doing a kernel project, I was new to building from source, Virtual Machines and other things like SSH. But luckily, I had great help from my mentors and the entire NetBSD community.
Thanks
I would like to express my heartfelt gratitude to The NetBSD Foundation for giving me this opportunity and sponsoring the Project. This project would not have been possible without the constant support and encouragement of both my mentors Martin Husemann and Joerg Sonnenberger. My gratitude to Christos Zoulas who worked on the crucial part of integrating the code. A special mention to all of the other esteemed NetBSD developers, who have helped me navigate through the thick and thin of this project and have answered even my most trivial questions.
This post was written by Piyush Sachdeva:
Abstract
The primary goal of the project was to extend posix_spawn(3) to include chdir(2) for the newly created child process. Two functions were supposed to be implemented, namely posix_spawn_file_actions_addchdir() and posix_spawn_file_actions_addfchdir(), to support both chdir(2) and fchdir(2) respectively. posix_spawn() is a POSIX standard method responsible for creating and executing new child processes.
Implementation
The original code can be found at my github tree.
The implementation plan was discussed and made with the guidance of both my mentors Martin Husemann and Joerg Sonnenberger. The plan was divided into three phases each corresponding to the specific part of The NetBSD code-base which is supposed to be touched:
User-Land
The following actions were performed in the user-land to set things up for the kernel-space.
- Add another member to the posix_spawn_file_actions_t struct i.e a union, which would hold the path to chdir to.
- Implement the two functions posix_spawn_file_actions_addchdir()
and posix_spawn_file_actions_addfchdir(). These functions would:
- allocate memory for another posix_spawn_file_actions_t object in the posix_spawn_file_actions_t array.
- take the path/file descriptor from the user as an argument and make the relative field of the newly allocated file actions object, point to it.
- The final step was to add the prototypes for the two new functions to the `src/include/spawn.h' header file
Once the aforementioned changes were made, the only thing left to do was to make the kernel support these two new functions.
Kernel-Space
The following actions were performed inside the kernel space.
- The three functions in the `src/sys/kern_exec.c' file which correspond to the
posix_spawn_file_actions were edited:
- posix_spawn_fa_alloc() was adjusted to make sure that the path passed to posix_spawn_file_actions_addchdir() gets copied from the user-land to the kernel-space.
- Similarly posix_spawn_fa_free() was adjusted to make sure that the memory allocated in case of FAE_CHDIR gets freed as well.
- Finally, two new cases FAE_CHDIR & FAE_FCHDIR were added in the handle_posix_spawn_file_actions(). In each of the cases, a call to one of the two newly created functions (discussed in the next point) do_sys_chdir() and do_sys_fchdir() was made respectively.
Note: At the time of code integration, a helper function was written by Christos Zoulas. This function aimed to reduce the amount of repeated code in both posix_spawn_fa__free() and posix_spawn_fa_alloc()
- Two new functions, similar to the already present sys_chdir() and sys_fchdir() in
`src/sys/vfs_syscalls.c' were created. Namely do_sys_chdir() and do_sys_chdir
were written with two specific thoughts in mind:
- By default sys_chdir() and sys_fchdir() took syscallargs as a parameter. The purpose of the new functions was to replace this with const char * and an int type parameter respectively.
- The do_sys_chdir() also replaced UIO_USERSPACE with UIO_SYSSPACE. This was done because the chdir path passed to this function already resided in the Kernel-space due to the change made in posix_spawn_fa_alloc().
- Finally, the prototypes for the newly written functions were added to the `src/sys/sys/vfs_syscalls.h' file and this file was also included in the 'sys/kern/kern_exec.c'.
Note: Similar to the above changes of user-land and kernel-space, a few tweaks were also made to `src/sys/compat/netbsd/netbsd32.h' and `netbsd32_execve.c'. This was required to help COMPAT_NETBSD32 deal with the new file actions member. However, these changes were made at the time of integration by Martin Husemann.
With most of addition of new features being done, all that remained was testing and documentation.
Testing & Documentation
- A total of ten new test cases have been added to the `src/tests/lib/libc/gen/posix_spawn/t_spawn.c' file.
- Three utility functions were also used to aid in testing. Out of the three, one new function was written and two existing functions (filesize() and empty_outfile()) from `t_fileactions.c' were used. To make sure that the 2 existing functions were shared between both the files i.e `t_spawn.c' and `t_fileactions.c' a new header and C file was created, namely `fa_spawn_utils.h' and `fa_spawn_utils.c'. Following this, the bodies of both the functions were moved from `t_fileactions.c' to `fa_spawn_utils.c' and their prototypes were added to the corresponding header file.
- The general approach that was taken to all test cases was to make posix_spawn() execute ``/bin/pwd'' and write the output to a file. Then read the file and do string comparison. The third function i.e. check_succes() was written for just this purpose.
- The ten test cases cover the following scenarios:
- Absolute path test - for both chdir and fchdir.
- Relative path test - for both chdir and fchdir.
- Trying to open a file instead of directory - for both chdir and fchdir.
- Invalid path/file descriptor (fd=-1) - for both chdir and fchdir.
- Trying to open a directory without access permissions for chdir.
- Opening a closed file descriptor for fchdir.
- The first 8 test cases had a lot of repetitive code. Therefore, at the time of integration, another function was created i.e spawn_chdir(). This function included a huge chunk of the common code and it did all the heavy lifting for those first 8 test cases.
Documentation:
In this matter, a complete man page is written which explains both posix_spawn_file_actions_addchdir() and posix_spawn_file_actions_addfchdir() in great detail. The content of the manual page is taken from the POSIX documentation provided to us by Robert Elz.
Issues
Since the project was well planned from the beginning, it resulted in few issues.
- The user-land was the most straight forward part of the project and I had no trouble sailing through it.
- Kernel space was where things got a bit complicated, as I had to add functionality to pre-existing functions.
- I was completely new to using atf(7) and groff(1). Therefore, it took me some time to understand the respective man pages and become comfortable with testing and documentation part.
Most of the issues faced were generally logistical. As it was my first time doing a kernel project, I was new to building from source, Virtual Machines and other things like SSH. But luckily, I had great help from my mentors and the entire NetBSD community.
Thanks
I would like to express my heartfelt gratitude to The NetBSD Foundation for giving me this opportunity and sponsoring the Project. This project would not have been possible without the constant support and encouragement of both my mentors Martin Husemann and Joerg Sonnenberger. My gratitude to Christos Zoulas who worked on the crucial part of integrating the code. A special mention to all of the other esteemed NetBSD developers, who have helped me navigate through the thick and thin of this project and have answered even my most trivial questions.
Threading support
I have simplified the struct proc and removed a p_oppid field that stored the numeric process id of the original parent (forker).
This field is not needed as it duplicates p_opptr (current real parent pointer) that is already safe to
use. So far this has not proven to be unsafe.
I have refactored the signal code making it more verbose to reflect the actual needs of the kernel signal code.
I have fixed a nasty bug in the function that is called when a thread returns from the kernel to userland. There was a tiny time window when in certain scenarios a thread was never stopped on process suspension but was instead resumed causing waitpid(2) polling to never return success as the process can be never stopped with a running thread.
There was a race bug that could cause a nested thread termination call, triggering a panic.
With the above changes I was able to reliably run all ATF tests for LWP events (threading events). I have also bumped the threading tests to atually execute 100 concurrent threads, as the higher number can more easily trigger anomalies. In my observations all tests are now rock solid.
There are now no longer any ptrace(2) tests in ATF marked as flaky or disabled. The two main offenders, vfork(2) events and threading events, are now solid.
Michal Gorny detected another source of instability of threads with a LLDB regression test. It was related to emitting a massive number of concurrent threads. I have helped Michal to address this problem and squash the bug.
All of the above changes are now pulled to NetBSD-9 for future 9.0 release.
There are at the time of writing, 4 failing LLDB threading tests and few more related to debug registers. Both failure types are under investigation. They could be bugs in the NetBSD support in some extent, but maybe there is need to fixup something on the kernel level.
The project is still not 100% accomplished but we are now very close to finishing everything in the domain of threads. I could torture the NetBSD kernel for few hours with a massive number of threads and events without a single crash or failure. On the other hand there are still likely some suspicious corner cases that need proper investigation. There are also some suspicious reports for crashes from syzkaller, the kernel fuzzer. Those still need to be promptly checked.
LLVM projects
I have attempted to change our original plan with LLD and instead of mutating the LLD behavior on target basis, write a dedicated LLD wrapper that tunes LLD for NetBSD. My patch is still in review. As an improvement over the previous ones, it wasn't immediately rejected... https://reviews.llvm.org/D69755.
I have upstreamed chunks of code with the following commits:
- [compiler-rt] [msan] Correct the __libc_thr_keycreate prototype
- [compiler-rt] [msan] Support POSIX iconv(3) on NetBSD 9.99.17+
- [compiler-rt] Harmonize __sanitizer_addrinfo with the NetBSD headers
- [compiler-rt] Sync NetBSD syscall hooks with 9.99.17
NetBSD distribution changes
I have switched the iconv(3) function prototype to POSIX-conformant form. The history of this function is documented in iconv(3) as follows:
STANDARDS
iconv_open(), iconv_close(), and iconv() conform to IEEE Std 1003.1-2001
("POSIX.1").
Historically, the definition of iconv has not been consistent across
operating systems. This is due to an unfortunate historical mistake,
documented in this e-mail:
https://www5.opengroup.org/sophocles2/show_mail.tpl?&source=L&listname=austin-group-l&id=7404.
The standards page for the header file defined the second
argument of iconv() as char **, but the standards page for the iconv()
implementation defined it as const char **. The standards committee
later chose to change the function definition to follow the header file
definition (without const), even though the version with const is
arguably more correct. NetBSD used initially the const form. It was
decided to reject the committee's regression and become (technically)
incompatible.
This decision was changed in NetBSD 10 and the iconv() prototype was
synchronized with the standard.
Meanwhile I fixed what was known to be effected in pkgsrc. Unfortunately Qt4/KDE4 had several build issues and this motivated me to fix its users for the new function through upgrades to the Qt5/KDE5 stack. Many dead packages without upgrade path were dropped from pkgsrc.
As there is a new Clang upgrade coming, I have implemented handlers for new UBSan reports: function_type_mismatch_v1() and implicit_conversion(). The first one is a new ABI for function_type_mismatch() and the second one is completely new.
GSoC Mentor Summit
I took part in the GSoC Mentor Summit in Munich and presented a talk titled "NetBSD version 9. What's new in store?".
Plan for the next milestone
Support Michal Gorny in reaching the milestone of passing all threading and debug register tests in LLDB.
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL to chip in what you can:
Threading support
I have simplified the struct proc and removed a p_oppid field that stored the numeric process id of the original parent (forker).
This field is not needed as it duplicates p_opptr (current real parent pointer) that is already safe to
use. So far this has not proven to be unsafe.
I have refactored the signal code making it more verbose to reflect the actual needs of the kernel signal code.
I have fixed a nasty bug in the function that is called when a thread returns from the kernel to userland. There was a tiny time window when in certain scenarios a thread was never stopped on process suspension but was instead resumed causing waitpid(2) polling to never return success as the process can be never stopped with a running thread.
There was a race bug that could cause a nested thread termination call, triggering a panic.
With the above changes I was able to reliably run all ATF tests for LWP events (threading events). I have also bumped the threading tests to atually execute 100 concurrent threads, as the higher number can more easily trigger anomalies. In my observations all tests are now rock solid.
There are now no longer any ptrace(2) tests in ATF marked as flaky or disabled. The two main offenders, vfork(2) events and threading events, are now solid.
Michal Gorny detected another source of instability of threads with a LLDB regression test. It was related to emitting a massive number of concurrent threads. I have helped Michal to address this problem and squash the bug.
All of the above changes are now pulled to NetBSD-9 for future 9.0 release.
There are at the time of writing, 4 failing LLDB threading tests and few more related to debug registers. Both failure types are under investigation. They could be bugs in the NetBSD support in some extent, but maybe there is need to fixup something on the kernel level.
The project is still not 100% accomplished but we are now very close to finishing everything in the domain of threads. I could torture the NetBSD kernel for few hours with a massive number of threads and events without a single crash or failure. On the other hand there are still likely some suspicious corner cases that need proper investigation. There are also some suspicious reports for crashes from syzkaller, the kernel fuzzer. Those still need to be promptly checked.
LLVM projects
I have attempted to change our original plan with LLD and instead of mutating the LLD behavior on target basis, write a dedicated LLD wrapper that tunes LLD for NetBSD. My patch is still in review. As an improvement over the previous ones, it wasn't immediately rejected... https://reviews.llvm.org/D69755.
I have upstreamed chunks of code with the following commits:
- [compiler-rt] [msan] Correct the __libc_thr_keycreate prototype
- [compiler-rt] [msan] Support POSIX iconv(3) on NetBSD 9.99.17+
- [compiler-rt] Harmonize __sanitizer_addrinfo with the NetBSD headers
- [compiler-rt] Sync NetBSD syscall hooks with 9.99.17
NetBSD distribution changes
I have switched the iconv(3) function prototype to POSIX-conformant form. The history of this function is documented in iconv(3) as follows:
STANDARDS
iconv_open(), iconv_close(), and iconv() conform to IEEE Std 1003.1-2001
("POSIX.1").
Historically, the definition of iconv has not been consistent across
operating systems. This is due to an unfortunate historical mistake,
documented in this e-mail:
https://www5.opengroup.org/sophocles2/show_mail.tpl?&source=L&listname=austin-group-l&id=7404.
The standards page for the header file defined the second
argument of iconv() as char **, but the standards page for the iconv()
implementation defined it as const char **. The standards committee
later chose to change the function definition to follow the header file
definition (without const), even though the version with const is
arguably more correct. NetBSD used initially the const form. It was
decided to reject the committee's regression and become (technically)
incompatible.
This decision was changed in NetBSD 10 and the iconv() prototype was
synchronized with the standard.
Meanwhile I fixed what was known to be effected in pkgsrc. Unfortunately Qt4/KDE4 had several build issues and this motivated me to fix its users for the new function through upgrades to the Qt5/KDE5 stack. Many dead packages without upgrade path were dropped from pkgsrc.
As there is a new Clang upgrade coming, I have implemented handlers for new UBSan reports: function_type_mismatch_v1() and implicit_conversion(). The first one is a new ABI for function_type_mismatch() and the second one is completely new.
GSoC Mentor Summit
I took part in the GSoC Mentor Summit in Munich and presented a talk titled "NetBSD version 9. What's new in store?".
Plan for the next milestone
Support Michal Gorny in reaching the milestone of passing all threading and debug register tests in LLDB.
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL to chip in what you can:
Upstream describes LLDB as a next generation, high-performance debugger. It is built on top of LLVM/Clang toolchain, and features great integration with it. At the moment, it primarily supports debugging C, C++ and ObjC code, and there is interest in extending it to more languages.
In February, I have started working on LLDB, as contracted by the NetBSD Foundation. So far I've been working on reenabling continuous integration, squashing bugs, improving NetBSD core file support, extending NetBSD's ptrace interface to cover more register types and fix compat32 issues and fixing watchpoint support. Then, I've started working on improving thread support which is taking longer than expected. You can read more about that in my September 2019 report.
So far the number of issues uncovered while enabling proper threading support has stopped me from merging the work-in-progress patches. However, I've finally reached the point where I believe that the current work can be merged and the remaining problems can be resolved afterwards. More on that and other LLVM-related events happening during the last month in this report.
LLVM news and buildbot status update
LLVM switched to git
Probably the most important event to note is that the LLVM project has switched from Subversion to git, and moved their repositories to GitHub. While the original plan provided for maintaining the old repositories as read-only mirrors, as of today this still hasn't been implemented. For this reason, we were forced to quickly switch buildbot to the git monorepo.
The buildbot is operational now, and seems to be handling git correctly. However, it is connected to the staging server for the time being. Its URL changed to http://lab.llvm.org:8014/builders/netbsd-amd64 (i.e. the port from 8011 to 8014).
Monthly regression report
Now for the usual list of 'what they broke this time'.
LLDB has been given a new API for handling files, in particular for passing them to Python scripts. The change of API has caused some 'bad file descriptor' errors, e.g.:
ERROR: test_SBDebugger (TestDefaultConstructorForAPIObjects.APIDefaultConstructorTestCase)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/data/motus/netbsd8/netbsd8/llvm/tools/lldb/packages/Python/lldbsuite/test/decorators.py", line 343, in wrapper
return func(self, *args, **kwargs)
File "/data/motus/netbsd8/netbsd8/llvm/tools/lldb/packages/Python/lldbsuite/test/python_api/default-constructor/TestDefaultConstructorForAPIObjects.py", line 133, in test_SBDebugger
sb_debugger.fuzz_obj(obj)
File "/data/motus/netbsd8/netbsd8/llvm/tools/lldb/packages/Python/lldbsuite/test/python_api/default-constructor/sb_debugger.py", line 13, in fuzz_obj
obj.SetInputFileHandle(None, True)
File "/data/motus/netbsd8/netbsd8/build/lib/python2.7/site-packages/lldb/__init__.py", line 3890, in SetInputFileHandle
self.SetInputFile(SBFile.Create(file, borrow=True))
File "/data/motus/netbsd8/netbsd8/build/lib/python2.7/site-packages/lldb/__init__.py", line 5418, in Create
return cls.MakeBorrowed(file)
File "/data/motus/netbsd8/netbsd8/build/lib/python2.7/site-packages/lldb/__init__.py", line 5379, in MakeBorrowed
return _lldb.SBFile_MakeBorrowed(BORROWED)
IOError: [Errno 9] Bad file descriptor
Config=x86_64-/data/motus/netbsd8/netbsd8/build/bin/clang-10
----------------------------------------------------------------------
I've been able to determine that the error was produced by flush() method call
invoked on a file descriptor referring to stdin. Appropriately, I've fixed
the type conversion method not to flush read-only fds.
Afterwards, Lawrence D'Anna was able to find and fix another fflush() issue.
A newly added test revealed that platform process list -v command
on NetBSD missed listing the process name. I've fixed it to provide
Arg0 in process info.
Another new test failed due to our target not implementing
ShellExpandArguments() API. Apparently the only target actually
implementing it is Darwin, so I've just marked TestCustomShell XFAIL
on all BSD
targets.
LLDB upstream was forced to reintroduce readline module override that aims to prevent readline and libedit from being loaded into a single program simultaneously. This module failed to build on NetBSD. I've discovered that the original was meant to be built on Linux only, and since the problem still doesn't affect other platforms, I've made it Linux-only again.
libunwind build has been changed to link using the C compiler rather than C++. This caused some libc++ failures on NetBSD. The author has reverted the change for now, and is looking for a better way of resolving the problem.
Finally, I have disabled another OpenMP test that caused NetBSD to hang. While ideally I'd like to have the underlying kernel problem fixed, this is non-trivial and I prefer to focus on LLDB right now.
New LLD work
I've been asked to rebase my LLD patches for the new code. While doing it, I've finally committed the -z nognustack option patch from January.
In the meantime, Kamil's been working on finally resolving the long-standing impasse on LLD design. He is working on a new NetBSD-specific frontend to LLD that would satisfy our system-wide linker requirements without modifying the standard driver used by other platforms.
Upgrade to NetBSD 9 beta
Our recent work, especially the work on threading support has required a number of fixes in the NetBSD kernel. Those fixes were backported to NetBSD 9 branch but not to 8. The 8 kernel used by the buildbot was therefore suboptimal for testing new features. Furthermore, with the 9.0 release coming soon-ish, it became necessary to start actively testing it for regressions.
The buildbot has been upgraded to NetBSD 9 beta on 2019-11-06.
Initially, the upgrade has caused LLDB to start crashing on startup.
I have not been able to pinpoint the exact issue yet. However, I've
established that it happens with -O3 optimization level only,
and I've worked it around by switching the build to -O2. I am
planning to look into the problem more once the buildbot is restored
fully.
The upgrade to nb9 has caused 4 LLDB tests to start succeeding, and 6 to start failing. Namely:
********************
Unexpected Passing Tests (4):
lldb-api :: commands/watchpoints/watchpoint_commands/condition/TestWatchpointConditionCmd.py
lldb-api :: commands/watchpoints/watchpoint_commands/command/TestWatchpointCommandPython.py
lldb-api :: lang/c/bitfields/TestBitfields.py
lldb-api :: commands/watchpoints/watchpoint_commands/command/TestWatchpointCommandLLDB.py
********************
Failing Tests (6):
lldb-shell :: Reproducer/Functionalities/TestExpressionEvaluation.test
lldb-api :: commands/expression/call-restarts/TestCallThatRestarts.py
lldb-api :: functionalities/signal/handle-segv/TestHandleSegv.py
lldb-unit :: tools/lldb-server/tests/./LLDBServerTests/StandardStartupTest.TestStopReplyContainsThreadPcs
lldb-api :: functionalities/inferior-crashing/TestInferiorCrashingStep.py
lldb-api :: functionalities/signal/TestSendSignal.py
I am going to start investigating the new failures shortly.
Further LLDB threading work
Fixes to register support
Enabling thread support revealed a problem in register API introspection
specific to NetBSD. The API responsible for passing registers in groups
to Python was unable to name some of the groups on NetBSD, and the null
names have caused the TestRegistersIterator to fail. Threading
support made this specifically visible by replacing a regular test
failure with Python code error.
In order to resolve the problem, I had to describe all supported
register sets in NetBSD register context.
The code was roughly based on the Linux equivalent, modified to match
register sets used by our ptrace() API. Interestingly, I had to also
include MPX registers that are currently unimplemented, as otherwise
LLDB implicitly put them in an anonymous group.
While at it, I've also changed the register set numbering to match the more common ordering, in order to avoid issues in the future.
Finished basic thread support patch
I've finally completed and submitted the patch for NetBSD thread support. Besides fixing a few mistakes, I've implemented thread affinity support for all relevant SIGTRAP events (breakpoints, traces, hardware watchpoints) and removed incomplete hardware breakpoint stub that caused LLDB to crash.
In its current form, this patch combines three changes essential to correct support of threaded programs:
-
It enables reporting of new and exited threads, and maintains debugged thread list based on that.
-
It modifies the signal (generic and
SIGTRAP) handling functions to read the thread identifier and associate the event with correct thread(s). Previously, all events were assigned to all threads. -
It updates the process resuming function to support controlling the state (running, single-stepping, stopped) of individual threads, and raising a signal either to the whole process or to a single thread. Previously, the code used only the requested action for the first thread and populated it to all threads in the process.
Proper watchpoint support in multi-threaded programs
I've submitted a separate patch to copy watchpoints to newly-created
threads. This is necessary due to
the design of Debug Register support in NetBSD. Quoting the ptrace(2)
manpage:
- debug registers are only per-LWP, not per-process globally
- debug registers must not be inherited after (v)forking a process
- debug registers must not be inherited after forking a thread
- a debugger is responsible to set global watchpoints/breakpoints with the debug registers, to achieve this PTRACE_LWP_CREATE / PTRACE_LWP_EXIT event monitoring function is designed to be used
LLDB supports per-process watchpoints only at the moment. To fit this into NetBSD model, we need to monitor new threads and copy watchpoints to them. Since LLDB does not keep explicit watchpoint information at the moment (it relies on querying debug registers), the proposed implementation verbosely copies dbregs from the currently selected thread (all existing threads should have the same dbregs).
Fixed support for concurrent watchpoint triggers
The final problem I've been investigating was a server crash with the new code when multiple watchpoints were triggered concurrently. My final patch aims to fix handling concurrent watchpoint events.
When a watchpoint is triggered, the kernel delivers SIGTRAP with
TRAP_DBREG to the debugger. The debugger investigates DR6 register
of the specified thread in order to determine which watchpoint was
triggered, and reports it. When multiple watchpoints are triggered
simultaneously, the kernel reports that as series of successive
SIGTRAPs. Normally, that works just fine.
However, on x86 watchpoint triggers are reported before the instruction is executed. For this reason, LLDB temporarily disables the breakpoint, single-steps and reenables it. The problem with that is that the GDB protocol doesn't control watchpoints per thread, so the operation disables and reenables the watchpoint on all threads. As a side effect of this, DR6 is cleared everywhere.
Now, if multiple watchpoints were triggered concurrently, DR6 is set on all relevant threads. However, after handling SIGTRAP on the first one, the disable/reenable (or more specifically, remove/readd) wipes DR6 on all threads. The handler for next SIGTRAP can't establish the correct watchpoint number, and starts looking for breakpoints. Since hardware breakpoints are not implemented, the relevant method returns an error and lldb-server eventually exits.
There are two problems to be solved there. Firstly, lldb-server should not exit in this circumstances. This is already solved in the first patch as mentioned above. Secondly, we need to be able to handle concurrent watchpoint hits independently of the clear/set packets. This is solved by this patch.
There are multiple different approaches to this problem. I've chosen to remodel clear/set watchpoint method in order to prevent it from resetting DR6 if the same watchpoint is being restored, as the alternatives (such as pre-storing DR6 on the first SIGTRAP) have more corner conditions to be concerned about.
The current design of these two methods assumes that the 'clear' method clears both the triggered state in DR6 and control bits in DR7, while the 'set' method sets the address in DR0..3, and the control bits in DR7.
The new design limits the 'clear' method to disabling the watchpoint by clearing the enable bit in DR7. The remaining bits, as well as trigger status and address are preserved. The 'set' method uses them to determine whether a new watchpoint is being set, or the previous one merely reenabled. In the latter case, it just updates DR7, while preserving the previous trigger. In the former, it updates all registers and clears the trigger from DR6.
This solution effectively prevents the disable/reenable logic of LLDB from clearing concurrent watchpoint hits, and therefore makes it possible for the SIGTRAP handler to report them correctly. If the user manually replaces the watchpoint with another one, DR6 is cleared and LLDB does not associate the concurrent trigger to the watchpoint that no longer exists.
Thread status summary
The current version of the patches fixes approximately 47 test failures, and causes approximately 4 new test failures and 2 hanging tests. There is around 7 new flaky tests, related to signals concurrent with breakpoints or watchpoints.
Future plans
The first immediate goal is to investigate and resolve test suite regressions related to NetBSD 9 upgrade. The second goal is to get the threading patches merged, and simultaneously work on resolving the remaining test failures and hangs.
When that's done, I'd like to finally move on with the remaining TODO items. Those are:
-
Add support to backtrace through signal trampoline and extend the support to libexecinfo, unwind implementations (LLVM, nongnu). Examine adding CFI support to interfaces that need it to provide more stable backtraces (both kernel and userland).
-
Add support for i386 and aarch64 targets.
-
Stabilize LLDB and address breaking tests from the test suite.
-
Merge LLDB with the base system (under LLVM-style distribution).
This work is sponsored by The NetBSD Foundation
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL to chip in what you can:
Upstream describes LLDB as a next generation, high-performance debugger. It is built on top of LLVM/Clang toolchain, and features great integration with it. At the moment, it primarily supports debugging C, C++ and ObjC code, and there is interest in extending it to more languages.
In February, I have started working on LLDB, as contracted by the NetBSD Foundation. So far I've been working on reenabling continuous integration, squashing bugs, improving NetBSD core file support, extending NetBSD's ptrace interface to cover more register types and fix compat32 issues and fixing watchpoint support. Then, I've started working on improving thread support which is taking longer than expected. You can read more about that in my September 2019 report.
So far the number of issues uncovered while enabling proper threading support has stopped me from merging the work-in-progress patches. However, I've finally reached the point where I believe that the current work can be merged and the remaining problems can be resolved afterwards. More on that and other LLVM-related events happening during the last month in this report.
LLVM news and buildbot status update
LLVM switched to git
Probably the most important event to note is that the LLVM project has switched from Subversion to git, and moved their repositories to GitHub. While the original plan provided for maintaining the old repositories as read-only mirrors, as of today this still hasn't been implemented. For this reason, we were forced to quickly switch buildbot to the git monorepo.
The buildbot is operational now, and seems to be handling git correctly. However, it is connected to the staging server for the time being. Its URL changed to http://lab.llvm.org:8014/builders/netbsd-amd64 (i.e. the port from 8011 to 8014).
Monthly regression report
Now for the usual list of 'what they broke this time'.
LLDB has been given a new API for handling files, in particular for passing them to Python scripts. The change of API has caused some 'bad file descriptor' errors, e.g.:
ERROR: test_SBDebugger (TestDefaultConstructorForAPIObjects.APIDefaultConstructorTestCase)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/data/motus/netbsd8/netbsd8/llvm/tools/lldb/packages/Python/lldbsuite/test/decorators.py", line 343, in wrapper
return func(self, *args, **kwargs)
File "/data/motus/netbsd8/netbsd8/llvm/tools/lldb/packages/Python/lldbsuite/test/python_api/default-constructor/TestDefaultConstructorForAPIObjects.py", line 133, in test_SBDebugger
sb_debugger.fuzz_obj(obj)
File "/data/motus/netbsd8/netbsd8/llvm/tools/lldb/packages/Python/lldbsuite/test/python_api/default-constructor/sb_debugger.py", line 13, in fuzz_obj
obj.SetInputFileHandle(None, True)
File "/data/motus/netbsd8/netbsd8/build/lib/python2.7/site-packages/lldb/__init__.py", line 3890, in SetInputFileHandle
self.SetInputFile(SBFile.Create(file, borrow=True))
File "/data/motus/netbsd8/netbsd8/build/lib/python2.7/site-packages/lldb/__init__.py", line 5418, in Create
return cls.MakeBorrowed(file)
File "/data/motus/netbsd8/netbsd8/build/lib/python2.7/site-packages/lldb/__init__.py", line 5379, in MakeBorrowed
return _lldb.SBFile_MakeBorrowed(BORROWED)
IOError: [Errno 9] Bad file descriptor
Config=x86_64-/data/motus/netbsd8/netbsd8/build/bin/clang-10
----------------------------------------------------------------------
I've been able to determine that the error was produced by flush() method call
invoked on a file descriptor referring to stdin. Appropriately, I've fixed
the type conversion method not to flush read-only fds.
Afterwards, Lawrence D'Anna was able to find and fix another fflush() issue.
A newly added test revealed that platform process list -v command
on NetBSD missed listing the process name. I've fixed it to provide
Arg0 in process info.
Another new test failed due to our target not implementing
ShellExpandArguments() API. Apparently the only target actually
implementing it is Darwin, so I've just marked TestCustomShell XFAIL
on all BSD
targets.
LLDB upstream was forced to reintroduce readline module override that aims to prevent readline and libedit from being loaded into a single program simultaneously. This module failed to build on NetBSD. I've discovered that the original was meant to be built on Linux only, and since the problem still doesn't affect other platforms, I've made it Linux-only again.
libunwind build has been changed to link using the C compiler rather than C++. This caused some libc++ failures on NetBSD. The author has reverted the change for now, and is looking for a better way of resolving the problem.
Finally, I have disabled another OpenMP test that caused NetBSD to hang. While ideally I'd like to have the underlying kernel problem fixed, this is non-trivial and I prefer to focus on LLDB right now.
New LLD work
I've been asked to rebase my LLD patches for the new code. While doing it, I've finally committed the -z nognustack option patch from January.
In the meantime, Kamil's been working on finally resolving the long-standing impasse on LLD design. He is working on a new NetBSD-specific frontend to LLD that would satisfy our system-wide linker requirements without modifying the standard driver used by other platforms.
Upgrade to NetBSD 9 beta
Our recent work, especially the work on threading support has required a number of fixes in the NetBSD kernel. Those fixes were backported to NetBSD 9 branch but not to 8. The 8 kernel used by the buildbot was therefore suboptimal for testing new features. Furthermore, with the 9.0 release coming soon-ish, it became necessary to start actively testing it for regressions.
The buildbot has been upgraded to NetBSD 9 beta on 2019-11-06.
Initially, the upgrade has caused LLDB to start crashing on startup.
I have not been able to pinpoint the exact issue yet. However, I've
established that it happens with -O3 optimization level only,
and I've worked it around by switching the build to -O2. I am
planning to look into the problem more once the buildbot is restored
fully.
The upgrade to nb9 has caused 4 LLDB tests to start succeeding, and 6 to start failing. Namely:
********************
Unexpected Passing Tests (4):
lldb-api :: commands/watchpoints/watchpoint_commands/condition/TestWatchpointConditionCmd.py
lldb-api :: commands/watchpoints/watchpoint_commands/command/TestWatchpointCommandPython.py
lldb-api :: lang/c/bitfields/TestBitfields.py
lldb-api :: commands/watchpoints/watchpoint_commands/command/TestWatchpointCommandLLDB.py
********************
Failing Tests (6):
lldb-shell :: Reproducer/Functionalities/TestExpressionEvaluation.test
lldb-api :: commands/expression/call-restarts/TestCallThatRestarts.py
lldb-api :: functionalities/signal/handle-segv/TestHandleSegv.py
lldb-unit :: tools/lldb-server/tests/./LLDBServerTests/StandardStartupTest.TestStopReplyContainsThreadPcs
lldb-api :: functionalities/inferior-crashing/TestInferiorCrashingStep.py
lldb-api :: functionalities/signal/TestSendSignal.py
I am going to start investigating the new failures shortly.
Further LLDB threading work
Fixes to register support
Enabling thread support revealed a problem in register API introspection
specific to NetBSD. The API responsible for passing registers in groups
to Python was unable to name some of the groups on NetBSD, and the null
names have caused the TestRegistersIterator to fail. Threading
support made this specifically visible by replacing a regular test
failure with Python code error.
In order to resolve the problem, I had to describe all supported
register sets in NetBSD register context.
The code was roughly based on the Linux equivalent, modified to match
register sets used by our ptrace() API. Interestingly, I had to also
include MPX registers that are currently unimplemented, as otherwise
LLDB implicitly put them in an anonymous group.
While at it, I've also changed the register set numbering to match the more common ordering, in order to avoid issues in the future.
Finished basic thread support patch
I've finally completed and submitted the patch for NetBSD thread support. Besides fixing a few mistakes, I've implemented thread affinity support for all relevant SIGTRAP events (breakpoints, traces, hardware watchpoints) and removed incomplete hardware breakpoint stub that caused LLDB to crash.
In its current form, this patch combines three changes essential to correct support of threaded programs:
-
It enables reporting of new and exited threads, and maintains debugged thread list based on that.
-
It modifies the signal (generic and
SIGTRAP) handling functions to read the thread identifier and associate the event with correct thread(s). Previously, all events were assigned to all threads. -
It updates the process resuming function to support controlling the state (running, single-stepping, stopped) of individual threads, and raising a signal either to the whole process or to a single thread. Previously, the code used only the requested action for the first thread and populated it to all threads in the process.
Proper watchpoint support in multi-threaded programs
I've submitted a separate patch to copy watchpoints to newly-created
threads. This is necessary due to
the design of Debug Register support in NetBSD. Quoting the ptrace(2)
manpage:
- debug registers are only per-LWP, not per-process globally
- debug registers must not be inherited after (v)forking a process
- debug registers must not be inherited after forking a thread
- a debugger is responsible to set global watchpoints/breakpoints with the debug registers, to achieve this PTRACE_LWP_CREATE / PTRACE_LWP_EXIT event monitoring function is designed to be used
LLDB supports per-process watchpoints only at the moment. To fit this into NetBSD model, we need to monitor new threads and copy watchpoints to them. Since LLDB does not keep explicit watchpoint information at the moment (it relies on querying debug registers), the proposed implementation verbosely copies dbregs from the currently selected thread (all existing threads should have the same dbregs).
Fixed support for concurrent watchpoint triggers
The final problem I've been investigating was a server crash with the new code when multiple watchpoints were triggered concurrently. My final patch aims to fix handling concurrent watchpoint events.
When a watchpoint is triggered, the kernel delivers SIGTRAP with
TRAP_DBREG to the debugger. The debugger investigates DR6 register
of the specified thread in order to determine which watchpoint was
triggered, and reports it. When multiple watchpoints are triggered
simultaneously, the kernel reports that as series of successive
SIGTRAPs. Normally, that works just fine.
However, on x86 watchpoint triggers are reported before the instruction is executed. For this reason, LLDB temporarily disables the breakpoint, single-steps and reenables it. The problem with that is that the GDB protocol doesn't control watchpoints per thread, so the operation disables and reenables the watchpoint on all threads. As a side effect of this, DR6 is cleared everywhere.
Now, if multiple watchpoints were triggered concurrently, DR6 is set on all relevant threads. However, after handling SIGTRAP on the first one, the disable/reenable (or more specifically, remove/readd) wipes DR6 on all threads. The handler for next SIGTRAP can't establish the correct watchpoint number, and starts looking for breakpoints. Since hardware breakpoints are not implemented, the relevant method returns an error and lldb-server eventually exits.
There are two problems to be solved there. Firstly, lldb-server should not exit in this circumstances. This is already solved in the first patch as mentioned above. Secondly, we need to be able to handle concurrent watchpoint hits independently of the clear/set packets. This is solved by this patch.
There are multiple different approaches to this problem. I've chosen to remodel clear/set watchpoint method in order to prevent it from resetting DR6 if the same watchpoint is being restored, as the alternatives (such as pre-storing DR6 on the first SIGTRAP) have more corner conditions to be concerned about.
The current design of these two methods assumes that the 'clear' method clears both the triggered state in DR6 and control bits in DR7, while the 'set' method sets the address in DR0..3, and the control bits in DR7.
The new design limits the 'clear' method to disabling the watchpoint by clearing the enable bit in DR7. The remaining bits, as well as trigger status and address are preserved. The 'set' method uses them to determine whether a new watchpoint is being set, or the previous one merely reenabled. In the latter case, it just updates DR7, while preserving the previous trigger. In the former, it updates all registers and clears the trigger from DR6.
This solution effectively prevents the disable/reenable logic of LLDB from clearing concurrent watchpoint hits, and therefore makes it possible for the SIGTRAP handler to report them correctly. If the user manually replaces the watchpoint with another one, DR6 is cleared and LLDB does not associate the concurrent trigger to the watchpoint that no longer exists.
Thread status summary
The current version of the patches fixes approximately 47 test failures, and causes approximately 4 new test failures and 2 hanging tests. There is around 7 new flaky tests, related to signals concurrent with breakpoints or watchpoints.
Future plans
The first immediate goal is to investigate and resolve test suite regressions related to NetBSD 9 upgrade. The second goal is to get the threading patches merged, and simultaneously work on resolving the remaining test failures and hangs.
When that's done, I'd like to finally move on with the remaining TODO items. Those are:
-
Add support to backtrace through signal trampoline and extend the support to libexecinfo, unwind implementations (LLVM, nongnu). Examine adding CFI support to interfaces that need it to provide more stable backtraces (both kernel and userland).
-
Add support for i386 and aarch64 targets.
-
Stabilize LLDB and address breaking tests from the test suite.
-
Merge LLDB with the base system (under LLVM-style distribution).
This work is sponsored by The NetBSD Foundation
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL to chip in what you can:
Per the membership voting, we have seated the new Board of Directors of the NetBSD Foundation:
- Taylor R. Campbell <riastadh@>
- William J. Coldwell <billc@>
- Michael van Elst <mlelstv@>
- Thomas Klausner <wiz@>
- Cherry G. Mathew <cherry@>
- Pierre Pronchery <khorben@>
- Leonardo Taccari <leot@>
We would like to thank Makoto Fujiwara <mef@> and Jeremy C. Reed <reed@> for their service on the Board of Directors during their term(s).
The new Board of Directors have voted in the executive officers for The NetBSD Foundation:
| President: | William J. Coldwell |
| Vice President: | Pierre Pronchery |
| Secretary: | Christos Zoulas |
| Assistant Secretary: | Thomas Klausner |
| Treasurer: | Christos Zoulas |
| Assistant Treasurer: | Taylor R. Campbell |
Thanks to everyone that voted and we look forward to a great 2020.
Per the membership voting, we have seated the new Board of Directors of the NetBSD Foundation:
- Taylor R. Campbell <riastadh@>
- William J. Coldwell <billc@>
- Michael van Elst <mlelstv@>
- Thomas Klausner <wiz@>
- Cherry G. Mathew <cherry@>
- Pierre Pronchery <khorben@>
- Leonardo Taccari <leot@>
We would like to thank Makoto Fujiwara <mef@> and Jeremy C. Reed <reed@> for their service on the Board of Directors during their term(s).
The new Board of Directors have voted in the executive officers for The NetBSD Foundation:
| President: | William J. Coldwell |
| Vice President: | Pierre Pronchery |
| Secretary: | Christos Zoulas |
| Assistant Secretary: | Thomas Klausner |
| Treasurer: | Christos Zoulas |
| Assistant Treasurer: | Taylor R. Campbell |
Thanks to everyone that voted and we look forward to a great 2020.
This report is a continuation of my previous work on Fuzzing Filesystems via AFL.
You can find previous posts where I described the fuzzing (part1, part2) or my EuroBSDcon presentation.
In this part, we won't talk too much about fuzzing itself but I want to describe the process of finding root causes of File system issues and my recent work trying to improve this process.
This story begins with a mount issue that I found during my very first run of the AFL, and I presented it during my talk on EuroBSDcon in Lillehammer.
Invisible Mount point
afl-fuzz: /dev/vnd0: opendisk: Device busy That was the first error that I saw on my setup after couple of seconds of AFL run.
I was not sure what exactly was the problem and thought that mount wrapper might cause a problem.
Although after a long troubleshooting session I realized that this might be my first found issue.
To give the reader a better understanding of the problem without digging too deeply into fuzzer setup or mount process.
Let's assume that we have some broken file system image exposed as a block device visible as a /dev/wd1a.
The device can be easily mounted on mount point mnt1, however when we try to unmount it we get an error: error: ls: /mnt1: No such file or directory, and if we try to use raw system call unmount(2) it also end up with the similar error.
However, we can see clearly that the mount point exists with the mount command:
# mount
/dev/wd0a on / type ffs(local)
...
tmpfson /var/shmtype tmpfs(local)
/dev/vnd0 on /mnt1 type ffs(local)
Thust any lstat(2) based command is trying to convince us that no such directory exists.
# ls / | grep mnt
mnt
mnt1
# ls -alh /mnt1
ls: /mnt1: No such file or directory
# stat /mnt1
stat: /mnt1: lstat: No such file or directory
To understand what is happening we need to dig a little bit deeper than with standard bash tools.
First of all mnt1 is a folder created on the root partition at a local filesystem so getdents(2) or dirent(3) should show it as a entry inside dentry structure on the disk.
Raw getdents syscall is great tool for checking directory content because it reads the data from the directory structure on disk.
# ./getdents /
|inode_nr|rec_len|file_type|name_len(name)|
#: 2, 16, IFDIR, 1 (.)
#: 2, 16, IFDIR, 2 (..)
#: 5, 24, IFREG, 6 (.cshrc)
#: 6, 24, IFREG, 8 (.profile)
#: 7, 24, IFREG, 8 (boot.cfg)
#: 3574272, 24, IFDIR, 3 (etc)
...
#: 3872128, 24, IFDIR, 3 (mnt)
#: 5315584, 24, IFDIR, 4 (mnt1)
Getdentries confirms that we have mnt1 as a directory inside the root of our system fs.
But, we cannot execute lstat, unmount or any other system-call that require a path to this file.
A quick look on definitions of these system calls show their structure:
unmount(const char *dir, int flags);
stat(const char *path, struct stat *sb);
lstat(const char *path, struct stat *sb);
open(const char *path, int flags, ...);All of these function take as an argument path to the file, which as we know will endup in vfs lookup.
How about something that uses filedescryptor? Can we even obtain it?
As we saw earlier running open(2) on path also returns EACCES.
Looks like without digging inside VFS lookup we will not be able to understand the issue.
Get Filesystem Root
After some debugging and code walk I found the place that caused error.
VFS during the name resolution needs to check and switch FS in case of embedded mount points.
After the new filesystem is found VFS_ROOT is issued on that particular mount point.
VFS_ROOT is translated in case of FFS to the ufs_root which calls vcache with fixed value equal to the inode number of root inode which is 2 for UFS.
#define UFS_ROOTINO ((ino_t)2) Below listning with the code of ufs_root from ufs/ufs/ufs_vfsops.c.
int
ufs_root(struct mount *mp, struct vnode **vpp)
{
...
if ((error = VFS_VGET(mp, (ino_t)UFS_ROOTINO, &nvp)) != 0)
return (error);By using the debugger, I was able to make sure that the entry with number 2 after hashing does not exist in the vcache.
As a next step, I wanted to check the Root inode on the given filesystem image.
Filesystem debuggers are good tools to do such checks. NetBSD comes with FSDB which is general-purpose filesystem debugger.
Nonetheless, by default FSDB links against fsck_ffs which makes it tied to the FFS.
Filesystem Debugger for the help!
Filesystem debugger is a tool designed to browse on-disk structure and values of particular entries.
It helps in understanding the Filesystems issues by giving particular values that the system reads from the disk.
Unfortunately, current fsdb_ffs is a bit limited in the amount of information that it exposes.
Example output of trying to browse damaged root inode on corrupted FS.
# fsdb -dnF -f ./filesystem.out
** ./filesystem.out (NO WRITE)
superblock mismatches
...
BAD SUPER BLOCK: VALUES IN SUPER BLOCK DISAGREE WITH THOSE IN FIRST ALTERNATE
clean = 0
isappleufs = 0, dirblksiz = 512
Editing file system `./filesystem.out'
Last Mounted on /mnt
current inode 2: unallocated inode
fsdb (inum: 2)> print
command `print
'
current inode 2: unallocated inode
FSDB Plugin: Print Formatted
Fortunately, fsdb_ffs leaves all necessary interfaces to allows accessing this data with small effort.
I implemented a simple plugin that allows browsing all values inside: inodes, superblock and cylinder groups on FFS.
There are still a couple of todos that have to be finished, but the current version allows us to review inodes.
fsdb (inum: 2)> pf inode number=2 format=ufs1
command `pf inode number=2 format=ufs1
'
Disk format ufs1inode 2 block: 512
----------------------------
di_mode: 0x0 di_nlink: 0x0
di_size: 0x0 di_atime: 0x0
di_atimensec: 0x0 di_mtime: 0x0
di_mtimensec: 0x0 di_ctime: 0x0
di_ctimensec: 0x0 di_flags: 0x0
di_blocks: 0x0 di_gen: 0x6c3122e2
di_uid: 0x0 di_gid: 0x0
di_modrev: 0x0
--- inode.di_oldids ---
We can see that the Filesystem image got wiped out most of the root inode fields.
For comparison, if we will take a look at root inode from freshly created FS we will see the proper structure.
Based on that we can quickly realize that fields: di_mode, di_nlink, di_size, di_blocks are different and can be the root cause.
Disk format ufs1 inode: 2 block: 512
----------------------------
di_mode: 0x41ed di_nlink: 0x2
di_size: 0x200 di_atime: 0x0
di_atimensec: 0x0 di_mtime: 0x0
di_mtimensec: 0x0 di_ctime: 0x0
di_ctimensec: 0x0 di_flags: 0x0
di_blocks: 0x1 di_gen: 0x68881d2c
di_uid: 0x0 di_gid: 0x0
di_modrev: 0x0
--- inode.di_oldids ---
From FSDB and incore to source code
First we will summarize what we already know:
- unmount fails in namei operation failure due to the corrupted FS
- Filesystem has corrupted root inode
- Corrupted root inode has fields: di_mode, di_nlink, di_size, di_blocks set to zero
Now we can find a place where inodes are loaded from the disk, this function for FFS is ffs_init_vnode(ump, vp, ino);.
This function is called during the loading vnode in vfs layer inside ffs_loadvnode.
Quick walkthrough through ffs_loadvnode expose the usage of the field i_mode:
error = ffs_init_vnode(ump, vp, ino);
if (error)
return error;
ip = VTOI(vp);
if (ip->i_mode == 0) {
ffs_deinit_vnode(ump, vp);
return ENOENT;
}
This seems to be a source of our problem. Whenever we are loading inode from disk to obtain the vnode, we validate if i_mode is non zero.
In our case root inode is wiped out, what results that vnode is dropped and an error returned.
So simply we cannot load any inode with i_mode set to the zero, inode number 2 called root is no different here.
Due to that the VFS_LOADVNODE operation always fails, so lookup does and name resolution will return ENOENT error.
To fix this issue we need a root inode validation on mount step, I created such validation and tested against corrupted filesystem image.
The mount return error, which proved the observation that such validation would help.
Conclusions
The following post is a continuation of the project: "Fuzzing Filesystems with kcov and AFL".
I presented how fuzzed bugs, which do not always show up as system panics, can be analyzed, and what
tools a programmer can use.
Above the investigation described the very first bug that I found by fuzzing mount(2) with Afl+kcov.
During that root cause analysis, I realized the need for better tools for debugging Filesystem related issues.
Because of that reason, I added small functionality pf (print-formatted) into the fsdb(8), to allow walking through the on-disk structures.
The described bug was reported with proposed fix based on validation of the root inode on kern-tech mailing list.
Future work
- Tools: I am still progressing with the fuzzing of mount process, however, I do not only focus on the finding bugs but also on tools that can be used for debugging and also doing regression tests.
I am planning to add better support for browsing blocks on inode into the
fsdb-pf, as well as write functionality that would allow more testing and potential recovery easier. - Fuzzing: In next post, I will show a remote setup of AFL with an example of usage.
- I got a suggestion to take a look at FreeBSD UFS security checks on
mount(2)done by McKusick. I think is worth it to see what else is validated and we can port to NetBSD FFS.
This report is a continuation of my previous work on Fuzzing Filesystems via AFL.
You can find previous posts where I described the fuzzing (part1, part2) or my EuroBSDcon presentation.
In this part, we won't talk too much about fuzzing itself but I want to describe the process of finding root causes of File system issues and my recent work trying to improve this process.
This story begins with a mount issue that I found during my very first run of the AFL, and I presented it during my talk on EuroBSDcon in Lillehammer.
Invisible Mount point
afl-fuzz: /dev/vnd0: opendisk: Device busy That was the first error that I saw on my setup after couple of seconds of AFL run.
I was not sure what exactly was the problem and thought that mount wrapper might cause a problem.
Although after a long troubleshooting session I realized that this might be my first found issue.
To give the reader a better understanding of the problem without digging too deeply into fuzzer setup or mount process.
Let's assume that we have some broken file system image exposed as a block device visible as a /dev/wd1a.
The device can be easily mounted on mount point mnt1, however when we try to unmount it we get an error: error: ls: /mnt1: No such file or directory, and if we try to use raw system call unmount(2) it also end up with the similar error.
However, we can see clearly that the mount point exists with the mount command:
# mount
/dev/wd0a on / type ffs(local)
...
tmpfson /var/shmtype tmpfs(local)
/dev/vnd0 on /mnt1 type ffs(local)
Thust any lstat(2) based command is trying to convince us that no such directory exists.
# ls / | grep mnt
mnt
mnt1
# ls -alh /mnt1
ls: /mnt1: No such file or directory
# stat /mnt1
stat: /mnt1: lstat: No such file or directory
To understand what is happening we need to dig a little bit deeper than with standard bash tools.
First of all mnt1 is a folder created on the root partition at a local filesystem so getdents(2) or dirent(3) should show it as a entry inside dentry structure on the disk.
Raw getdents syscall is great tool for checking directory content because it reads the data from the directory structure on disk.
# ./getdents /
|inode_nr|rec_len|file_type|name_len(name)|
#: 2, 16, IFDIR, 1 (.)
#: 2, 16, IFDIR, 2 (..)
#: 5, 24, IFREG, 6 (.cshrc)
#: 6, 24, IFREG, 8 (.profile)
#: 7, 24, IFREG, 8 (boot.cfg)
#: 3574272, 24, IFDIR, 3 (etc)
...
#: 3872128, 24, IFDIR, 3 (mnt)
#: 5315584, 24, IFDIR, 4 (mnt1)
Getdentries confirms that we have mnt1 as a directory inside the root of our system fs.
But, we cannot execute lstat, unmount or any other system-call that require a path to this file.
A quick look on definitions of these system calls show their structure:
unmount(const char *dir, int flags);
stat(const char *path, struct stat *sb);
lstat(const char *path, struct stat *sb);
open(const char *path, int flags, ...);All of these function take as an argument path to the file, which as we know will endup in vfs lookup.
How about something that uses filedescryptor? Can we even obtain it?
As we saw earlier running open(2) on path also returns EACCES.
Looks like without digging inside VFS lookup we will not be able to understand the issue.
Get Filesystem Root
After some debugging and code walk I found the place that caused error.
VFS during the name resolution needs to check and switch FS in case of embedded mount points.
After the new filesystem is found VFS_ROOT is issued on that particular mount point.
VFS_ROOT is translated in case of FFS to the ufs_root which calls vcache with fixed value equal to the inode number of root inode which is 2 for UFS.
#define UFS_ROOTINO ((ino_t)2) Below listning with the code of ufs_root from ufs/ufs/ufs_vfsops.c.
int
ufs_root(struct mount *mp, struct vnode **vpp)
{
...
if ((error = VFS_VGET(mp, (ino_t)UFS_ROOTINO, &nvp)) != 0)
return (error);By using the debugger, I was able to make sure that the entry with number 2 after hashing does not exist in the vcache.
As a next step, I wanted to check the Root inode on the given filesystem image.
Filesystem debuggers are good tools to do such checks. NetBSD comes with FSDB which is general-purpose filesystem debugger.
Nonetheless, by default FSDB links against fsck_ffs which makes it tied to the FFS.
Filesystem Debugger for the help!
Filesystem debugger is a tool designed to browse on-disk structure and values of particular entries.
It helps in understanding the Filesystems issues by giving particular values that the system reads from the disk.
Unfortunately, current fsdb_ffs is a bit limited in the amount of information that it exposes.
Example output of trying to browse damaged root inode on corrupted FS.
# fsdb -dnF -f ./filesystem.out
** ./filesystem.out (NO WRITE)
superblock mismatches
...
BAD SUPER BLOCK: VALUES IN SUPER BLOCK DISAGREE WITH THOSE IN FIRST ALTERNATE
clean = 0
isappleufs = 0, dirblksiz = 512
Editing file system `./filesystem.out'
Last Mounted on /mnt
current inode 2: unallocated inode
fsdb (inum: 2)> print
command `print
'
current inode 2: unallocated inode
FSDB Plugin: Print Formatted
Fortunately, fsdb_ffs leaves all necessary interfaces to allows accessing this data with small effort.
I implemented a simple plugin that allows browsing all values inside: inodes, superblock and cylinder groups on FFS.
There are still a couple of todos that have to be finished, but the current version allows us to review inodes.
fsdb (inum: 2)> pf inode number=2 format=ufs1
command `pf inode number=2 format=ufs1
'
Disk format ufs1inode 2 block: 512
----------------------------
di_mode: 0x0 di_nlink: 0x0
di_size: 0x0 di_atime: 0x0
di_atimensec: 0x0 di_mtime: 0x0
di_mtimensec: 0x0 di_ctime: 0x0
di_ctimensec: 0x0 di_flags: 0x0
di_blocks: 0x0 di_gen: 0x6c3122e2
di_uid: 0x0 di_gid: 0x0
di_modrev: 0x0
--- inode.di_oldids ---
We can see that the Filesystem image got wiped out most of the root inode fields.
For comparison, if we will take a look at root inode from freshly created FS we will see the proper structure.
Based on that we can quickly realize that fields: di_mode, di_nlink, di_size, di_blocks are different and can be the root cause.
Disk format ufs1 inode: 2 block: 512
----------------------------
di_mode: 0x41ed di_nlink: 0x2
di_size: 0x200 di_atime: 0x0
di_atimensec: 0x0 di_mtime: 0x0
di_mtimensec: 0x0 di_ctime: 0x0
di_ctimensec: 0x0 di_flags: 0x0
di_blocks: 0x1 di_gen: 0x68881d2c
di_uid: 0x0 di_gid: 0x0
di_modrev: 0x0
--- inode.di_oldids ---
From FSDB and incore to source code
First we will summarize what we already know:
- unmount fails in namei operation failure due to the corrupted FS
- Filesystem has corrupted root inode
- Corrupted root inode has fields: di_mode, di_nlink, di_size, di_blocks set to zero
Now we can find a place where inodes are loaded from the disk, this function for FFS is ffs_init_vnode(ump, vp, ino);.
This function is called during the loading vnode in vfs layer inside ffs_loadvnode.
Quick walkthrough through ffs_loadvnode expose the usage of the field i_mode:
error = ffs_init_vnode(ump, vp, ino);
if (error)
return error;
ip = VTOI(vp);
if (ip->i_mode == 0) {
ffs_deinit_vnode(ump, vp);
return ENOENT;
}
This seems to be a source of our problem. Whenever we are loading inode from disk to obtain the vnode, we validate if i_mode is non zero.
In our case root inode is wiped out, what results that vnode is dropped and an error returned.
So simply we cannot load any inode with i_mode set to the zero, inode number 2 called root is no different here.
Due to that the VFS_LOADVNODE operation always fails, so lookup does and name resolution will return ENOENT error.
To fix this issue we need a root inode validation on mount step, I created such validation and tested against corrupted filesystem image.
The mount return error, which proved the observation that such validation would help.
Conclusions
The following post is a continuation of the project: "Fuzzing Filesystems with kcov and AFL".
I presented how fuzzed bugs, which do not always show up as system panics, can be analyzed, and what
tools a programmer can use.
Above the investigation described the very first bug that I found by fuzzing mount(2) with Afl+kcov.
During that root cause analysis, I realized the need for better tools for debugging Filesystem related issues.
Because of that reason, I added small functionality pf (print-formatted) into the fsdb(8), to allow walking through the on-disk structures.
The described bug was reported with proposed fix based on validation of the root inode on kern-tech mailing list.
Future work
- Tools: I am still progressing with the fuzzing of mount process, however, I do not only focus on the finding bugs but also on tools that can be used for debugging and also doing regression tests.
I am planning to add better support for browsing blocks on inode into the
fsdb-pf, as well as write functionality that would allow more testing and potential recovery easier. - Fuzzing: In next post, I will show a remote setup of AFL with an example of usage.
- I got a suggestion to take a look at FreeBSD UFS security checks on
mount(2)done by McKusick. I think is worth it to see what else is validated and we can port to NetBSD FFS.
My plan for the next year is to finish implementing TSan and MSan support, followed by a long run of bug fixes for LLDB, ptrace(2), and other related kernel subsystems
TSan
In the past month, I've developed Thread Sanitizer far enough to have a subset of its tests pass on NetBSD, started with addressing breakage related to the memory layout of processes. The reason for this breakage was narrowed down to the current implementation of ASLR, which was too aggressive and which didn't allow enough space to be mapped for Shadow memory. The fix for this was to either force the disabling of ASLR per-process, or globally on the system. The same will certainly happen for MSan executables. After some other corrections, I got TSan to work for the first time ever on October 14th. This was a big achievement, so I've made a snapshot available. Getting the snapshot of execution under GDB was pure hazard.
$ gdb ./a.out
GNU gdb (GDB) 7.12
Copyright (C) 2016 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "x86_64--netbsd".
Type "show configuration" for configuration details.
For bug reporting instructions, please see:
.
Find the GDB manual and other documentation resources online at:
.
For help, type "help".
Type "apropos word" to search for commands related to "word"...
Reading symbols from ./a.out...done.
(gdb) r
Starting program: /public/llvm-build/a.out
[New LWP 2]
==================
WARNING: ThreadSanitizer: data race (pid=1621)
Write of size 4 at 0x000001475d70 by thread T1:
#0 Thread1 /public/llvm-build/tsan.c:4:10 (a.out+0x46bf71)
Previous write of size 4 at 0x000001475d70 by main thread:
#0 main /public/llvm-build/tsan.c:10:10 (a.out+0x46bfe6)
Location is global 'Global' of size 4 at 0x000001475d70 (a.out+0x000001475d70)
Thread T1 (tid=2, running) created by main thread at:
#0 pthread_create /public/llvm/projects/compiler-rt/lib/tsan/rtl/tsan_interceptors.cc:930:3 (a.out+0x412120)
#1 main /public/llvm-build/tsan.c:9:3 (a.out+0x46bfd1)
SUMMARY: ThreadSanitizer: data race /public/llvm-build/tsan.c:4:10 in Thread1
==================
Thread 2 received signal SIGSEGV, Segmentation fault.
I was able to get the above execution results around 10% of the time (being under a tracer had no positive effect on the frequency of successful executions).
I've managed to hit the following final results for this month, with another set of bugfixes and improvements:
check-tsan: Expected Passes : 248 Expected Failures : 1 Unsupported Tests : 83 Unexpected Failures: 44
At the end of the month, TSan can now reliably executabe the same (already-working) program every time. The majority of failures are in tests verifying sanitization of correct mutex locking usage.
There are still problems with NetBSD-specific libc and libpthread bootstrap code that conflicts with TSan. Certain functions (pthread_create(3), pthread_key_create(3), _cxa_atexit()) cannot be started early by TSan initialization, and must be deferred late enough for the sanitizer to work correctly.
MSan
I've prepared a scratch support for MSan on NetBSD to help in researching how far along it is. I've also cloned and adapted the existing FreeBSD bits; however, the code still needs more work and isn't functional yet. The number of passed tests (5) is negligible and most likely does not work at all.
The conclusion after this research is that TSan shall be finished first, as it touches similar code.
In the future, there will be likely another round of iterating the system structs and types and adding the missing ones for NetBSD. So far, this part has been done before executing the real MSan code. I've added one missing symbol that was missing and was detected when attempting to link a test program with MSan.
Sanitizers
The GCC team has merged the LLVM sanitizer code, which has resulted in almost-complete support for ASan and UBsan on NetBSD. It can be found in the latest GCC8 snapshot, located in pkgsrc-wip/gcc8snapshot. Though, do note that there is an issue with getting backtraces from libasan.so, which can be worked-around by backtracing ASan events in a debugger. UBsan also passes all GCC regression tests and appears to work fine. The code enabling sanitizers on the GCC/NetBSD frontend will be submitted upstream once the backtracing issue is fixed and I'm satisfied that there are no other problems.
I've managed to upstream a large portion of generic+TSan+MSan code to compiler-rt and reduce local patches to only the ones that are in progress. This deals with any rebasing issues, and allows me to just focus on the delta that is being worked on.
I've tried out the LLDB builds which have TSan/NetBSD enabled, and they built and started fine. However, there were some false positives related to the mutex locking/unlocking code.
Plans for the next milestone
The general goals are to finish TSan and MSan and switch back to LLDB debugging. I plan to verify the impact of the TSan bootstrap initialization on the observed crashes and research the remaining failures.
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL, and chip in what you can:
My plan for the next year is to finish implementing TSan and MSan support, followed by a long run of bug fixes for LLDB, ptrace(2), and other related kernel subsystems
TSan
In the past month, I've developed Thread Sanitizer far enough to have a subset of its tests pass on NetBSD, started with addressing breakage related to the memory layout of processes. The reason for this breakage was narrowed down to the current implementation of ASLR, which was too aggressive and which didn't allow enough space to be mapped for Shadow memory. The fix for this was to either force the disabling of ASLR per-process, or globally on the system. The same will certainly happen for MSan executables. After some other corrections, I got TSan to work for the first time ever on October 14th. This was a big achievement, so I've made a snapshot available. Getting the snapshot of execution under GDB was pure hazard.
$ gdb ./a.out
GNU gdb (GDB) 7.12
Copyright (C) 2016 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "x86_64--netbsd".
Type "show configuration" for configuration details.
For bug reporting instructions, please see:
.
Find the GDB manual and other documentation resources online at:
.
For help, type "help".
Type "apropos word" to search for commands related to "word"...
Reading symbols from ./a.out...done.
(gdb) r
Starting program: /public/llvm-build/a.out
[New LWP 2]
==================
WARNING: ThreadSanitizer: data race (pid=1621)
Write of size 4 at 0x000001475d70 by thread T1:
#0 Thread1 /public/llvm-build/tsan.c:4:10 (a.out+0x46bf71)
Previous write of size 4 at 0x000001475d70 by main thread:
#0 main /public/llvm-build/tsan.c:10:10 (a.out+0x46bfe6)
Location is global 'Global' of size 4 at 0x000001475d70 (a.out+0x000001475d70)
Thread T1 (tid=2, running) created by main thread at:
#0 pthread_create /public/llvm/projects/compiler-rt/lib/tsan/rtl/tsan_interceptors.cc:930:3 (a.out+0x412120)
#1 main /public/llvm-build/tsan.c:9:3 (a.out+0x46bfd1)
SUMMARY: ThreadSanitizer: data race /public/llvm-build/tsan.c:4:10 in Thread1
==================
Thread 2 received signal SIGSEGV, Segmentation fault.
I was able to get the above execution results around 10% of the time (being under a tracer had no positive effect on the frequency of successful executions).
I've managed to hit the following final results for this month, with another set of bugfixes and improvements:
check-tsan: Expected Passes : 248 Expected Failures : 1 Unsupported Tests : 83 Unexpected Failures: 44
At the end of the month, TSan can now reliably executabe the same (already-working) program every time. The majority of failures are in tests verifying sanitization of correct mutex locking usage.
There are still problems with NetBSD-specific libc and libpthread bootstrap code that conflicts with TSan. Certain functions (pthread_create(3), pthread_key_create(3), _cxa_atexit()) cannot be started early by TSan initialization, and must be deferred late enough for the sanitizer to work correctly.
MSan
I've prepared a scratch support for MSan on NetBSD to help in researching how far along it is. I've also cloned and adapted the existing FreeBSD bits; however, the code still needs more work and isn't functional yet. The number of passed tests (5) is negligible and most likely does not work at all.
The conclusion after this research is that TSan shall be finished first, as it touches similar code.
In the future, there will be likely another round of iterating the system structs and types and adding the missing ones for NetBSD. So far, this part has been done before executing the real MSan code. I've added one missing symbol that was missing and was detected when attempting to link a test program with MSan.
Sanitizers
The GCC team has merged the LLVM sanitizer code, which has resulted in almost-complete support for ASan and UBsan on NetBSD. It can be found in the latest GCC8 snapshot, located in pkgsrc-wip/gcc8snapshot. Though, do note that there is an issue with getting backtraces from libasan.so, which can be worked-around by backtracing ASan events in a debugger. UBsan also passes all GCC regression tests and appears to work fine. The code enabling sanitizers on the GCC/NetBSD frontend will be submitted upstream once the backtracing issue is fixed and I'm satisfied that there are no other problems.
I've managed to upstream a large portion of generic+TSan+MSan code to compiler-rt and reduce local patches to only the ones that are in progress. This deals with any rebasing issues, and allows me to just focus on the delta that is being worked on.
I've tried out the LLDB builds which have TSan/NetBSD enabled, and they built and started fine. However, there were some false positives related to the mutex locking/unlocking code.
Plans for the next milestone
The general goals are to finish TSan and MSan and switch back to LLDB debugging. I plan to verify the impact of the TSan bootstrap initialization on the observed crashes and research the remaining failures.
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL, and chip in what you can:
 Since the last update, we've made a number of improvements to the NetBSD Allwinner port. The SUNXI kernel has grown support for 8 new SoCs, and we added many new device drivers to the source repository.
Since the last update, we've made a number of improvements to the NetBSD Allwinner port. The SUNXI kernel has grown support for 8 new SoCs, and we added many new device drivers to the source repository.
Supported systems
- As of November 2017, we now support the following Allwinner SoCs with the SUNXI kernel: A10, A13, A20, A31, A64, A80, A83T, GR8, H2+, H3, H5, and R8. An up-to-date list of supported SoCs with example boards is maintained on the NetBSD/allwinner wiki page.
- Here's NetBSD running on a 14" Pinebook from Pine64. Since the keyboard and touchpad are connected internally to a USB controller, the device is fully functional.
- A bit more effort was required to get NetBSD running on a PocketCHIP from NextThing Co. The keyboard is wired to an I2C keypad controller, so a new tcakp(4) keyboard driver was required. The touchscreen is supported by the Allwinner port's sunxits driver and can be calibrated with the tpctl(8) utility.
- Many more devices are supported, including (but not limited to) boards from FriendlyARM (NanoPi), Olimex (OLinuXino), Pine64, Sinovoip (BananaPi), and Xunlong (OrangePi).
{kind=link}
{kind=link}
Device driver support
In addition to the countless machine-independent device drivers already in NetBSD, the following Allwinner-specific devices are supported:
Audio codec
The built-in analog audio codec is supported on the following SoCs with the sunxicodec driver: A10, A13, A20, A31, GR8, H2+, H3, and R8.
Ethernet
Ethernet is supported on all applicable Allwinner SoCs. Three ethernet drivers are available:
- Fast Ethernet MAC (EMAC) as found in A10 and A20 family SoCs
- Gigabit Ethernet MAC (GMAC) as found in A20, A31, and A80 family SoCs
- Gigabit Ethernet MAC (EMAC) as found in A64, A83T, H2+, and H3 family SoCs
Framebuffer
Framebuffer console support is available wherever it is supported by U-Boot using the simplefb(4) driver.
Thermal sensors
Thermal sensors are supported on A10, A13, A20, A31, A64, A83T, H2+, and H3 SoCs.
CPU frequency and voltage scaling
On A10, A20, H2+, and H3 SoCs, dynamic CPU frequency and voltage scaling support is available when configured in the device tree. In addition, on H2+ and H3 SoCs, the kernel will automatically detect when the CPU temperature is too high and throttle the CPU frequency and voltage to prevent overheating.
Touch screen
The touch screen controller found in A10, A13, A20, and A31 SoCs is fully supported. The tpctl(8) utility can be used to calibrate the touch screen and has been updated to support standard wsdisplay APIs.
Other drivers
A standard set of devices are supported across all SoCs (where applicable): DMA, GPIO, I2C, interrupt controllers, RTC, SATA, SD/MMC, timers, UART, USB, watchdog, and more.
U-Boot
A framework for U-Boot packages has been added to pkgsrc, and U-Boot packages for many boards already exist.
What now?
There are a few missing features that would be nice to have:
- Wi-Fi (SDIO). There are a lot of different wireless chips used on these boards, but the majority seem to be either Broadcom or Realtek based. We recently ported OpenBSD's bwfm(4) driver to support the USB version of the Broadcom Wi-Fi controllers, with an expectation that SDIO support will follow at some point in the future.
- NAND controller. Most boards have eMMC and/or microSD slots, but this would be really useful for the CHIP / CHIP Pro / PocketCHIP family of devices.
- 64-bit support for sun50i family SoCs
- Readily available install images. A prototype NetBSD ARM Bootable Images site is available with a limited selection of supported boards.
More information
Since the last update, we've made a number of improvements to the NetBSD Allwinner port. The SUNXI kernel has grown support for 8 new SoCs, and we added many new device drivers to the source repository.
Supported systems
- As of November 2017, we now support the following Allwinner SoCs with the SUNXI kernel: A10, A13, A20, A31, A64, A80, A83T, GR8, H2+, H3, H5, and R8. An up-to-date list of supported SoCs with example boards is maintained on the NetBSD/allwinner wiki page.
- Here's NetBSD running on a 14" Pinebook from Pine64. Since the keyboard and touchpad are connected internally to a USB controller, the device is fully functional.
- A bit more effort was required to get NetBSD running on a PocketCHIP from NextThing Co. The keyboard is wired to an I2C keypad controller, so a new tcakp(4) keyboard driver was required. The touchscreen is supported by the Allwinner port's sunxits driver and can be calibrated with the tpctl(8) utility.
- Many more devices are supported, including (but not limited to) boards from FriendlyARM (NanoPi), Olimex (OLinuXino), Pine64, Sinovoip (BananaPi), and Xunlong (OrangePi).
Device driver support
In addition to the countless machine-independent device drivers already in NetBSD, the following Allwinner-specific devices are supported:
Audio codec
The built-in analog audio codec is supported on the following SoCs with the sunxicodec driver: A10, A13, A20, A31, GR8, H2+, H3, and R8.
Ethernet
Ethernet is supported on all applicable Allwinner SoCs. Three ethernet drivers are available:
- Fast Ethernet MAC (EMAC) as found in A10 and A20 family SoCs
- Gigabit Ethernet MAC (GMAC) as found in A20, A31, and A80 family SoCs
- Gigabit Ethernet MAC (EMAC) as found in A64, A83T, H2+, and H3 family SoCs
Framebuffer
Framebuffer console support is available wherever it is supported by U-Boot using the simplefb(4) driver.
Thermal sensors
Thermal sensors are supported on A10, A13, A20, A31, A64, A83T, H2+, and H3 SoCs.
CPU frequency and voltage scaling
On A10, A20, H2+, and H3 SoCs, dynamic CPU frequency and voltage scaling support is available when configured in the device tree. In addition, on H2+ and H3 SoCs, the kernel will automatically detect when the CPU temperature is too high and throttle the CPU frequency and voltage to prevent overheating.
Touch screen
The touch screen controller found in A10, A13, A20, and A31 SoCs is fully supported. The tpctl(8) utility can be used to calibrate the touch screen and has been updated to support standard wsdisplay APIs.
Other drivers
A standard set of devices are supported across all SoCs (where applicable): DMA, GPIO, I2C, interrupt controllers, RTC, SATA, SD/MMC, timers, UART, USB, watchdog, and more.
U-Boot
A framework for U-Boot packages has been added to pkgsrc, and U-Boot packages for many boards already exist.
What now?
There are a few missing features that would be nice to have:
- Wi-Fi (SDIO). There are a lot of different wireless chips used on these boards, but the majority seem to be either Broadcom or Realtek based. We recently ported OpenBSD's bwfm(4) driver to support the USB version of the Broadcom Wi-Fi controllers, with an expectation that SDIO support will follow at some point in the future.
- NAND controller. Most boards have eMMC and/or microSD slots, but this would be really useful for the CHIP / CHIP Pro / PocketCHIP family of devices.
- 64-bit support for sun50i family SoCs
- Readily available install images. A prototype NetBSD ARM Bootable Images site is available with a limited selection of supported boards.
More information
Initial design
As I said in the previous episode, I added in October a Kernel ASLR implementation in NetBSD for 64bit x86 CPUs. This implementation would randomize the location of the kernel in virtual memory as one block: a random VA would be chosen, and the kernel ELF sections would be mapped contiguously starting from there.
This design had several drawbacks: one leak, or one successful cache attack, could be enough to reconstruct the layout of the entire kernel and defeat KASLR.
NetBSD’s new KASLR design significantly improves this situation.
New design
In the new design, each kernel ELF section is randomized independently. That is to say, the base addresses of .text, .rodata, .data and .bss are not correlated. KASLR is already at this stage more difficult to defeat, since you would need a leak or cache attack on each of the kernel sections in order to reconstruct the in-memory kernel layout.
Then, starting from there, several techniques are used to strengthen the implementation even more.
Sub-blocks
The kernel ELF sections are themselves split in sub-blocks of approximately 1MB. The kernel therefore goes from having:
{ .text .rodata .data .bss }
to having
{ .text .text.0 .text.1 ... .text.i .rodata .rodata.0 ... .rodata.j ... .data ...etc }
As of today, this produces a kernel with ~33 sections, each of which is
mapped at a random address and in a random order.
This implies that there can be dozens of .text segments. Therefore, even if you are able to conduct a cache attack and determine that a given range of memory is mapped as executable, you don’t know which sub-block of .text it is. If you manage to obtain a kernel pointer via a leak, you can at most guess the address of the section it finds itself in, but you don’t know the layout of the remaining 32 sections. In other words, defeating this KASLR implementation is much more complicated than in the initial design.
Higher entropy
Each section is put in a 2MB-sized physical memory chunk. Given that the sections are 1MB in size, this leaves half of the 2MB chunk unused. Once in control, the prekern shifts the section within the chunk using a random offset, aligned to the ELF alignment constraint. This offset has a maximum value of 1MB, so that once shifted the section still resides in its initial 2MB chunk:

Fig. A: Physical memory, a random offset has been added.
The prekern then maps these 2MB physical chunks at random virtual addresses; but addresses aligned to 2MB. For example, the two sections in Fig. A will be mapped at two distinct VAs:
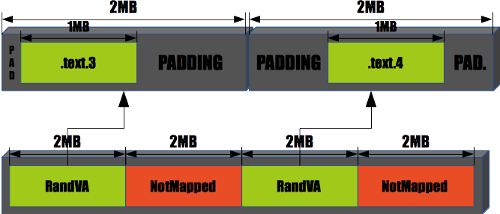
Fig. B: two random, 2MB-aligned ranges of VAs point to the chunks the sections find themselves in.
There is a reason the sections are shifted in memory: it offers higher entropy. If we consider a .text.i section with a 64byte ELF alignment constraint, and give a look at the number of possibilities for the location of the section in memory:
- The prekern shifts the 1MB section in its 2MB chunk, with an offset aligned to 64 bytes. So there are (2MB-1MB)/(64B)=214 possibilities for the offset.
- Then, the prekern uses a 2MB-sized 2MB-aligned range of VA, chosen in a 2GB window. So there are (2GB-2MB)/(2MB)=210-1 possibilities for the VA.
Therefore, there are 214x(210-1)≈224 possible locations for the section. As a comparison with other systems:
| OS | # of possibilities |
|---|---|
| Linux | |
| MacOS | |
| Windows | |
| NetBSD |
Fig. C: comparison of entropies. Note that the other KASLR implementations do not split the kernel sections in sub-blocks.
Of course, we are talking about one .text.i section here; the sections that will be mapped afterwards will have fewer location possibilities because some slots will be already occupied. However, this does not alter the fact that the resulting entropy is still higher than that of the other implementations. Note also that several sections have an alignment constraint smaller than 64 bytes, and that in such cases the entropy is even higher.
Large pages
There is also a reason we chose to use 2MB-aligned 2MB-sized ranges of VAs: when the kernel is in control and initializes itself, it can now use large pages to map the physical 2MB chunks. This greatly improves memory access performance at the CPU level.
Countermeasures against TLB cache attacks
With the memory shift explained above, randomness is therefore enforced at both the physical and virtual levels: the address of the first page of a section does not equal the address of the section itself anymore.
It has, as a side effect, an interesting property: it can mostly mitigate TLB cache attacks. Such attacks operate at the virtual-page level; they will allow you to know that a given large page is mapped as executable, but you don’t know where exactly within that page the section actually begins.
Strong?
This KASLR implementation, which splits the kernel in dozens of sub-blocks, randomizes them independently, while at the same time allowing for higher entropy in a way that offers large page support and some countermeasures against TLB cache attacks, appears to be the most advanced KASLR implementation available publicly as of today.
Feel free to prove me wrong, I would be happy to know!
WIP
Even if it is in a functional state, this implementation is still a work in progress, and some of the issues mentioned in the previous blog post haven't been addressed yet. But feel free to test it and report any issue you encounter. Instructions on how to use this implementation can still be found in the previous blog post, and haven’t changed since.
See you in the next episode!
Initial design
As I said in the previous episode, I added in October a Kernel ASLR implementation in NetBSD for 64bit x86 CPUs. This implementation would randomize the location of the kernel in virtual memory as one block: a random VA would be chosen, and the kernel ELF sections would be mapped contiguously starting from there.
This design had several drawbacks: one leak, or one successful cache attack, could be enough to reconstruct the layout of the entire kernel and defeat KASLR.
NetBSD’s new KASLR design significantly improves this situation.
New design
In the new design, each kernel ELF section is randomized independently. That is to say, the base addresses of .text, .rodata, .data and .bss are not correlated. KASLR is already at this stage more difficult to defeat, since you would need a leak or cache attack on each of the kernel sections in order to reconstruct the in-memory kernel layout.
Then, starting from there, several techniques are used to strengthen the implementation even more.
Sub-blocks
The kernel ELF sections are themselves split in sub-blocks of approximately 1MB. The kernel therefore goes from having:
{ .text .rodata .data .bss }
to having
{ .text .text.0 .text.1 ... .text.i .rodata .rodata.0 ... .rodata.j ... .data ...etc }
As of today, this produces a kernel with ~33 sections, each of which is
mapped at a random address and in a random order.
This implies that there can be dozens of .text segments. Therefore, even if you are able to conduct a cache attack and determine that a given range of memory is mapped as executable, you don’t know which sub-block of .text it is. If you manage to obtain a kernel pointer via a leak, you can at most guess the address of the section it finds itself in, but you don’t know the layout of the remaining 32 sections. In other words, defeating this KASLR implementation is much more complicated than in the initial design.
Higher entropy
Each section is put in a 2MB-sized physical memory chunk. Given that the sections are 1MB in size, this leaves half of the 2MB chunk unused. Once in control, the prekern shifts the section within the chunk using a random offset, aligned to the ELF alignment constraint. This offset has a maximum value of 1MB, so that once shifted the section still resides in its initial 2MB chunk:
Fig. A: Physical memory, a random offset has been added.
The prekern then maps these 2MB physical chunks at random virtual addresses; but addresses aligned to 2MB. For example, the two sections in Fig. A will be mapped at two distinct VAs:
Fig. B: two random, 2MB-aligned ranges of VAs point to the chunks the sections find themselves in.
There is a reason the sections are shifted in memory: it offers higher entropy. If we consider a .text.i section with a 64byte ELF alignment constraint, and give a look at the number of possibilities for the location of the section in memory:
- The prekern shifts the 1MB section in its 2MB chunk, with an offset aligned to 64 bytes. So there are (2MB-1MB)/(64B)=214 possibilities for the offset.
- Then, the prekern uses a 2MB-sized 2MB-aligned range of VA, chosen in a 2GB window. So there are (2GB-2MB)/(2MB)=210-1 possibilities for the VA.
Therefore, there are 214x(210-1)≈224 possible locations for the section. As a comparison with other systems:
| OS | # of possibilities |
|---|---|
| Linux | |
| MacOS | |
| Windows | |
| NetBSD |
Fig. C: comparison of entropies. Note that the other KASLR implementations do not split the kernel sections in sub-blocks.
Of course, we are talking about one .text.i section here; the sections that will be mapped afterwards will have fewer location possibilities because some slots will be already occupied. However, this does not alter the fact that the resulting entropy is still higher than that of the other implementations. Note also that several sections have an alignment constraint smaller than 64 bytes, and that in such cases the entropy is even higher.
Large pages
There is also a reason we chose to use 2MB-aligned 2MB-sized ranges of VAs: when the kernel is in control and initializes itself, it can now use large pages to map the physical 2MB chunks. This greatly improves memory access performance at the CPU level.
Countermeasures against TLB cache attacks
With the memory shift explained above, randomness is therefore enforced at both the physical and virtual levels: the address of the first page of a section does not equal the address of the section itself anymore.
It has, as a side effect, an interesting property: it can mostly mitigate TLB cache attacks. Such attacks operate at the virtual-page level; they will allow you to know that a given large page is mapped as executable, but you don’t know where exactly within that page the section actually begins.
Strong?
This KASLR implementation, which splits the kernel in dozens of sub-blocks, randomizes them independently, while at the same time allowing for higher entropy in a way that offers large page support and some countermeasures against TLB cache attacks, appears to be the most advanced KASLR implementation available publicly as of today.
Feel free to prove me wrong, I would be happy to know!
WIP
Even if it is in a functional state, this implementation is still a work in progress, and some of the issues mentioned in the previous blog post haven't been addressed yet. But feel free to test it and report any issue you encounter. Instructions on how to use this implementation can still be found in the previous blog post, and haven’t changed since.
See you in the next episode!
The process of stabilization and fixing TSan was challenging as there are intermixed types of issues that resulted in one big random breakage bug that is difficult to analyze. Software debuggers need more work with threaded programs, so this was like a chicken-egg problem, to debug debugging utilities.
Corrections
Most of the corrections were in TSan-specific and Common Sanitizer code. There was also one fix in LSan.
TSan: on_exit()/at_exit(3)/__cxa_atexit()
There are different function types for the same purpose: to execute a callback function on thread or process termination. The existing code in TSan wasn't compatible with the NetBSD Operating System:
- on_exit() - This function is Linux-specific, I've disabled it for NetBSD.
- at_exit(3) - It was reimplemented by TSan using __cxa_atexit(), however in an incompatible way for NetBSD. TSan was attempting to register a wrapper callback through __cxa_atexit() with the second argument as a function pointer and the third argument (Dynamic Shared Object pointer) equal with NULL. This approach is not portable and it broke on NetBSD, therefore I had to add a new implementation based on a stack (LIFO container). Every at_exit(3) registering function is intercepted by TSan and the sanitizer pushes it to the local LIFO container, passing its local wrapper function to the system. During the execution of a callback by the OS, we call the wrapper, which pops the originally saved function pointer from the stack and executes it.
- __cxa_atexit() - This callback shared TSan internals with at_exit(3) and is functional on NetBSD.
To assure the changes, I've added a new test named atexit3, which assures the correct order of execution of the at_exit(3) callbacks.
TSan: _lwp_exit()
In order to detect a thread's termination by the TSan interceptors, a mechanism to register a callback function in the pthread(3) destructor was used. The destructor callback was registered with pthread_key_create(3) and this approach was broken on NetBSD for two reasons.
- We cannot register it during early libc and libpthread(3) bootstrap, as the system functions need to initialize.
- The execution of callback functions is not the last event during a POSIX thread entity termination.
I was looking for a mechanism to defer the destructor callback registration to subsequent libc initialization stages, similar to constructor sections. I've understood that this approach was suboptimal because it resulted in further breakage. The NetBSD implementation of a POSIX thread termination notifies a parent thread (waiter for join) and still attempts to acquire mutex. TSan assumed that no longer any thread specific function is called like a mutex acquisition and destroyed part of thread specific data to trace such events. I've switched the POSIX thread termination event detection to the interception of _lwp_exit(2) call, as it's truly the latest interceptable function on NetBSD, detaching the low-level thread entity (LWP) that is the kernel context for POSIX thread.
TSan: Thread Joined vs Thread Exited
Correcting the detection of termination of a thread caused new problems, with a race between two event notifications that happen at the same time:
- Thread A sleeps waiting for joining of thread B.
- Thread B wakes thread A notifying it as joinable.
- Thread B terminates calling _lwp_exit().
Both events are traced by TSan: joining and exiting and they must be intercepted in the order of exiting followed by joining (unless a thread is marked to be detached without joining).
This problem has been analyzed and fixed by the introduction of atomic-function waiters in low-level parts (not exposed to TSan or other sanitizers), that causes busy waiting in ThreadRegistry::JoinThread for notifying the end of execution of ThreadRegistry::FinishThread. This approach happened to be stable and so far no failures are observed. There was a tiny breakage in ppc64-linux, as this change introduced as infinite freeze, but it was caused by an unrelated problem and a faulty test was switched from failing to unsupported.
Sanitizers: GetTls
I've implemented the initial support for determining whether a memory buffer is allocated as Thread-Local-Storage. The current approach uses FreeBSD code, however it's subject to future improvement: in order to make it more generic and aware of dynamic allocation (like after dlopen(3)) TLS vectors.
Sanitizers: Handling NetBSD specific indirection of libpthread functions
I've corrected handling of three libpthread(3) functions on NetBSD:
- pthread_mutex_lock(3),
- pthread_mutex_unlock(3),
- pthread_setcancelstate(3).
Code out of the libpthread(3) context uses the libc symbols:
- __libc_mutex_lock,
- __libc_mutex_unlock,
- __libc_thr_setcancelstate.
The threading library (libpthread(3)) defines strong aliases:
- __strong_alias(__libc_mutex_lock,pthread_mutex_lock)
- __strong_alias(__libc_mutex_unlock,pthread_mutex_unlock)
- __strong_alias(__libc_thr_setcancelstate,pthread_setcancelstate)
This caused that these functions were invisible to sanitizers on NetBSD. I've introduced interception of the libc-specific functions and I have added them as NetBSD-specific aliases for the common pthread(3) functions.
NetBSD needs to intercept both functions, as the regularly named ones are used internally in libpthread(3).
Sanitizers: Adding DemangleFunctionName for backtracing on NetBSD
NetBSD uses indirection for old threading functions for historical reasons. The mangled names are an internal implementation detail and should not be exposed even in backtraces.
- __libc_mutex_init -> pthread_mutex_init
- __libc_mutex_lock -> pthread_mutex_lock
- __libc_mutex_trylock -> pthread_mutex_trylock
- __libc_mutex_unlock -> pthread_mutex_unlock
- __libc_mutex_destroy -> pthread_mutex_destroy
- __libc_mutexattr_init -> pthread_mutexattr_init
- __libc_mutexattr_settype -> pthread_mutexattr_settype
- __libc_mutexattr_destroy -> pthread_mutexattr_destroy
- __libc_cond_init -> pthread_cond_init
- __libc_cond_signal -> pthread_cond_signal
- __libc_cond_broadcast -> pthread_cond_broadcast
- __libc_cond_wait -> pthread_cond_wait
- __libc_cond_timedwait -> pthread_cond_timedwait
- __libc_cond_destroy -> pthread_cond_destroy
- __libc_rwlock_init -> pthread_rwlock_init
- __libc_rwlock_rdlock -> pthread_rwlock_rdlock
- __libc_rwlock_wrlock -> pthread_rwlock_wrlock
- __libc_rwlock_tryrdlock -> pthread_rwlock_tryrdlock
- __libc_rwlock_trywrlock -> pthread_rwlock_trywrlock
- __libc_rwlock_unlock -> pthread_rwlock_unlock
- __libc_rwlock_destroy -> pthread_rwlock_destroy
- __libc_thr_keycreate -> pthread_key_create
- __libc_thr_setspecific -> pthread_setspecific
- __libc_thr_getspecific -> pthread_getspecific
- __libc_thr_keydelete -> pthread_key_delete
- __libc_thr_once -> pthread_once
- __libc_thr_self -> pthread_self
- __libc_thr_exit -> pthread_exit
- __libc_thr_setcancelstate -> pthread_setcancelstate
- __libc_thr_equal -> pthread_equal
- __libc_thr_curcpu -> pthread_curcpu_np
This demangling also fixes several tests that expect the regular pthread(3) function names.
TSan: Handling NetBSD specific indirection of libpthread functions
I've corrected handling of libpthread(3) functions in TSan/NetBSD:
- pthread_cond_init(3),
- pthread_cond_signal(3),
- pthread_cond_broadcast(3),
- pthread_cond_wait(3),
- pthread_cond_destroy(3),
- pthread_mutex_init(3),
- pthread_mutex_destroy(3),
- pthread_mutex_trylock(3),
- pthread_rwlock_init(3),
- pthread_rwlock_destroy(3),
- pthread_rwlock_rdlock(3),
- pthread_rwlock_tryrdlock(3),
- pthread_rwlock_wrlock(3),
- pthread_rwlock_trywrlock(3),
- pthread_rwlock_unlock(3),
- pthread_once(3).
Code out of the libpthread(3) context uses the libc symbols that are prefixed with __libc_, for example: __libc_cond_init.
This has caused that these functions were invisible to sanitizers on NetBSD. Intercepting the libc-specific and adding them as NetBSD-specific aliases for the common pthread(3) functions.
NetBSD needs to intercept both functions, as the regularly named ones are used internally in libpthread(3).
TSan: Correcting NetBSD support in pthread_once(3)
The pthread_once(3)/NetBSD type is built with the following structure:
struct __pthread_once_st {
pthread_mutex_t pto_mutex;
int pto_done;
};
I've set the pto_done position as shifted by __sanitizer::pthread_mutex_t_sz from the beginning of the pthread_once struct.
This corrects deadlocks when the pthread_once(3) function is used.
Sanitizers: Plug dlerror() leak for swift_demangle
InitializeSwiftDemangler() attempts to resolve the swift_demangle symbol. If this is not available, we observe dlerror message leak.
LSan: Detecting thread's termination
I've fixed the same problem as has been analyzed in TSan, and I've switched to the _lwp_exit(2) approach.
Sanitizers: Handling symbol renaming of sigaction on NetBSD
NetBSD uses the __sigaction14 symbol name for historical and compat reasons for the sigaction(2) function name.
I've renamed the interceptors and users of sigaction to sigaction_symname and I've reused it in the code base.
TSan: Correcting mangled_sp on NetBSD/amd64
I've fixed the LongJmp(3) function on NetBSD and pointed the correct place of the RSP (stack pointer) register on NetBSD/amd64.
TSan: Supporting the setjmp(3) family of functions on NetBSD/amd64
I've added support for handling the setjmp(3)/longjmp(3) family of functions on NetBSD/amd64.
There are three types of them on NetBSD:
- setjmp(3) / longjmp(3)
- sigsetjmp(3) / sigsetjmp(3)
- _setjmp(3) / _longjmp(3)
Due to historical and compat reasons the symbol names are mangled:
- setjmp -> __setjmp14
- longjmp -> __longjmp14
- sigsetjmp -> __sigsetjmp14
- siglongjmp -> __siglongjmp14
- _setjmp -> _setjmp
- _longjmp -> _longjmp
This leads to symbol renaming in the existing codebase.
There is no such symbol as __sigsetjmp/__longsetjmp on NetBSD so it has been disabled.
Additonally, I've added a comment that GNU-style executable stack note is not needed on NetBSD. The stack is not executable without it.
TSan: Deferring StartBackgroundThread() and StopBackgroundThread()
NetBSD cannot spawn new POSIX thread entities in early libc and libpthread initialization stage. I've deferred this to the point of intercepting the first pthread_create(3) call.
This is the last change that makes Thread Sanitizer functional on NetBSD/amd64 without downstream patches.
Final TSan results
Results for the check-tsan test-target.
********************
Testing Time: 64.91s
********************
Failing Tests (5):
ThreadSanitizer-x86_64 :: dtls.c
ThreadSanitizer-x86_64 :: ignore_lib5.cc
ThreadSanitizer-x86_64 :: ignored-interceptors-mmap.cc
ThreadSanitizer-x86_64 :: mutex_lock_destroyed.cc
ThreadSanitizer-x86_64 :: vfork.cc
Expected Passes : 290
Expected Failures : 1
Unsupported Tests : 83
Unexpected Failures: 5
The following results present that the all crucial issues are now fixed, and this Sanitizer can be used to trace real software. The remaining problems are minor ones and they are scheduled to be fixed in the future:
- signal_block.cc - there is some race; sometimes it works sometimes it does not work.
- dtls.c - it looks like dynamically allocated TLS vectors are missing on the NetBSD side.
- vfork.cc - testing UB, it looks like NetBSD behaves the same way like Linux does, however the test is failing.
- mutex_lock_destroyed.cc - it is based on UB implemented in style of Linux.
- The other tests fail for similar rare case scenarios like massive mmap(2) calls that seem to overflow the shadow.
LLVM JIT
As noted in the previous reports, there is an ongoing process to improve NetBSD compatiblity with existing Just-In-Time frameworks in LLVM. In the recent month the existing code has been adjusted to the point to pass all existing LLVM tests of JIT code on NetBSD under PaX MPROTECT.
Scudo hardened allocator
I've added initial support for NetBSD in the Scudo hardened allocator. I keep this code locally in pkgsrc-wip/compiler-rt-netbsd.
More work is needed in order to correct the known failures in tests. These are largely caused by the fact that Scudo was a Linux-only feature and the existing tests depend on GLIBC specific internals. They need to be adapted for the default NetBSD allocator (jemalloc(3)).
********************
Testing Time: 5.40s
********************
Failing Tests (32):
Scudo-i386 :: double-free.cpp
Scudo-i386 :: interface.cpp
Scudo-i386 :: memalign.c
Scudo-i386 :: mismatch.cpp
Scudo-i386 :: options.cpp
Scudo-i386 :: overflow.c
Scudo-i386 :: preload.cpp
Scudo-i386 :: quarantine.c
Scudo-i386 :: realloc.cpp
Scudo-i386 :: rss.c
Scudo-i386 :: secondary.c
Scudo-i386 :: sizes.cpp
Scudo-i386 :: valloc.c
Scudo-x86_64 :: alignment.c
Scudo-x86_64 :: double-free.cpp
Scudo-x86_64 :: interface.cpp
Scudo-x86_64 :: malloc.cpp
Scudo-x86_64 :: memalign.c
Scudo-x86_64 :: mismatch.cpp
Scudo-x86_64 :: options.cpp
Scudo-x86_64 :: overflow.c
Scudo-x86_64 :: preload.cpp
Scudo-x86_64 :: quarantine.c
Scudo-x86_64 :: random_shuffle.cpp
Scudo-x86_64 :: realloc.cpp
Scudo-x86_64 :: rss.c
Scudo-x86_64 :: secondary.c
Scudo-x86_64 :: sized-delete.cpp
Scudo-x86_64 :: sizes.cpp
Scudo-x86_64 :: threads.c
Scudo-x86_64 :: valloc.c
Expected Passes : 8
Unexpected Failures: 32
Plans for the next milestone
The next goal is to finish MSan and switch back to LLDB restoration for tracing single threaded programs.
The TSan corrections indirectly increased the number of passing MSan tests. I'm going to solve the detected problems and thanks to the experience with other sanitizers the MSan issues don't seem to be as challenging like as before finishing TSan.
********************
Testing: 0 .. 10.. 20.. 30.. 40.. 50.. 60.. 70.. 80.. 90..
Testing Time: 30.91s
********************
Failing Tests (69):
MemorySanitizer-x86_64 :: allocator_returns_null.cc
MemorySanitizer-x86_64 :: backtrace.cc
MemorySanitizer-x86_64 :: c-strdup.c
MemorySanitizer-x86_64 :: chained_origin.cc
MemorySanitizer-x86_64 :: chained_origin_empty_stack.cc
MemorySanitizer-x86_64 :: chained_origin_limits.cc
MemorySanitizer-x86_64 :: chained_origin_memcpy.cc
MemorySanitizer-x86_64 :: chained_origin_with_signals.cc
MemorySanitizer-x86_64 :: check_mem_is_initialized.cc
MemorySanitizer-x86_64 :: death-callback.cc
MemorySanitizer-x86_64 :: dlopen_executable.cc
MemorySanitizer-x86_64 :: dso-origin.cc
MemorySanitizer-x86_64 :: dtls_test.c
MemorySanitizer-x86_64 :: dtor-base-access.cc
MemorySanitizer-x86_64 :: dtor-bit-fields.cc
MemorySanitizer-x86_64 :: dtor-derived-class.cc
MemorySanitizer-x86_64 :: dtor-multiple-inheritance-nontrivial-class-members.cc
MemorySanitizer-x86_64 :: dtor-multiple-inheritance.cc
MemorySanitizer-x86_64 :: dtor-trivial-class-members.cc
MemorySanitizer-x86_64 :: dtor-vtable-multiple-inheritance.cc
MemorySanitizer-x86_64 :: dtor-vtable.cc
MemorySanitizer-x86_64 :: fork.cc
MemorySanitizer-x86_64 :: ftime.cc
MemorySanitizer-x86_64 :: getaddrinfo-positive.cc
MemorySanitizer-x86_64 :: getaddrinfo.cc
MemorySanitizer-x86_64 :: getc_unlocked.c
MemorySanitizer-x86_64 :: heap-origin.cc
MemorySanitizer-x86_64 :: icmp_slt_allones.cc
MemorySanitizer-x86_64 :: iconv.cc
MemorySanitizer-x86_64 :: ifaddrs.cc
MemorySanitizer-x86_64 :: insertvalue_origin.cc
MemorySanitizer-x86_64 :: mktime.cc
MemorySanitizer-x86_64 :: mmap.cc
MemorySanitizer-x86_64 :: msan_copy_shadow.cc
MemorySanitizer-x86_64 :: msan_dump_shadow.cc
MemorySanitizer-x86_64 :: msan_print_shadow.cc
MemorySanitizer-x86_64 :: msan_print_shadow2.cc
MemorySanitizer-x86_64 :: origin-store-long.cc
MemorySanitizer-x86_64 :: param_tls_limit.cc
MemorySanitizer-x86_64 :: print_stats.cc
MemorySanitizer-x86_64 :: pthread_getattr_np_deadlock.cc
MemorySanitizer-x86_64 :: pvalloc.cc
MemorySanitizer-x86_64 :: readdir64.cc
MemorySanitizer-x86_64 :: realloc-large-origin.cc
MemorySanitizer-x86_64 :: realloc-origin.cc
MemorySanitizer-x86_64 :: report-demangling.cc
MemorySanitizer-x86_64 :: scandir.cc
MemorySanitizer-x86_64 :: scandir_null.cc
MemorySanitizer-x86_64 :: select_float_origin.cc
MemorySanitizer-x86_64 :: select_origin.cc
MemorySanitizer-x86_64 :: sem_getvalue.cc
MemorySanitizer-x86_64 :: signal_stress_test.cc
MemorySanitizer-x86_64 :: sigwait.cc
MemorySanitizer-x86_64 :: stack-origin.cc
MemorySanitizer-x86_64 :: stack-origin2.cc
MemorySanitizer-x86_64 :: strerror_r-non-gnu.c
MemorySanitizer-x86_64 :: strlen_of_shadow.cc
MemorySanitizer-x86_64 :: strndup.cc
MemorySanitizer-x86_64 :: textdomain.cc
MemorySanitizer-x86_64 :: times.cc
MemorySanitizer-x86_64 :: tls_reuse.cc
MemorySanitizer-x86_64 :: tsearch.cc
MemorySanitizer-x86_64 :: tzset.cc
MemorySanitizer-x86_64 :: unaligned_read_origin.cc
MemorySanitizer-x86_64 :: unpoison_string.cc
MemorySanitizer-x86_64 :: use-after-dtor.cc
MemorySanitizer-x86_64 :: use-after-free.cc
MemorySanitizer-x86_64 :: wcsncpy.cc
Expected Passes : 38
Expected Failures : 1
Unsupported Tests : 24
Unexpected Failures: 69
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL, and chip in what you can:
The process of stabilization and fixing TSan was challenging as there are intermixed types of issues that resulted in one big random breakage bug that is difficult to analyze. Software debuggers need more work with threaded programs, so this was like a chicken-egg problem, to debug debugging utilities.
Corrections
Most of the corrections were in TSan-specific and Common Sanitizer code. There was also one fix in LSan.
TSan: on_exit()/at_exit(3)/__cxa_atexit()
There are different function types for the same purpose: to execute a callback function on thread or process termination. The existing code in TSan wasn't compatible with the NetBSD Operating System:
- on_exit() - This function is Linux-specific, I've disabled it for NetBSD.
- at_exit(3) - It was reimplemented by TSan using __cxa_atexit(), however in an incompatible way for NetBSD. TSan was attempting to register a wrapper callback through __cxa_atexit() with the second argument as a function pointer and the third argument (Dynamic Shared Object pointer) equal with NULL. This approach is not portable and it broke on NetBSD, therefore I had to add a new implementation based on a stack (LIFO container). Every at_exit(3) registering function is intercepted by TSan and the sanitizer pushes it to the local LIFO container, passing its local wrapper function to the system. During the execution of a callback by the OS, we call the wrapper, which pops the originally saved function pointer from the stack and executes it.
- __cxa_atexit() - This callback shared TSan internals with at_exit(3) and is functional on NetBSD.
To assure the changes, I've added a new test named atexit3, which assures the correct order of execution of the at_exit(3) callbacks.
TSan: _lwp_exit()
In order to detect a thread's termination by the TSan interceptors, a mechanism to register a callback function in the pthread(3) destructor was used. The destructor callback was registered with pthread_key_create(3) and this approach was broken on NetBSD for two reasons.
- We cannot register it during early libc and libpthread(3) bootstrap, as the system functions need to initialize.
- The execution of callback functions is not the last event during a POSIX thread entity termination.
I was looking for a mechanism to defer the destructor callback registration to subsequent libc initialization stages, similar to constructor sections. I've understood that this approach was suboptimal because it resulted in further breakage. The NetBSD implementation of a POSIX thread termination notifies a parent thread (waiter for join) and still attempts to acquire mutex. TSan assumed that no longer any thread specific function is called like a mutex acquisition and destroyed part of thread specific data to trace such events. I've switched the POSIX thread termination event detection to the interception of _lwp_exit(2) call, as it's truly the latest interceptable function on NetBSD, detaching the low-level thread entity (LWP) that is the kernel context for POSIX thread.
TSan: Thread Joined vs Thread Exited
Correcting the detection of termination of a thread caused new problems, with a race between two event notifications that happen at the same time:
- Thread A sleeps waiting for joining of thread B.
- Thread B wakes thread A notifying it as joinable.
- Thread B terminates calling _lwp_exit().
Both events are traced by TSan: joining and exiting and they must be intercepted in the order of exiting followed by joining (unless a thread is marked to be detached without joining).
This problem has been analyzed and fixed by the introduction of atomic-function waiters in low-level parts (not exposed to TSan or other sanitizers), that causes busy waiting in ThreadRegistry::JoinThread for notifying the end of execution of ThreadRegistry::FinishThread. This approach happened to be stable and so far no failures are observed. There was a tiny breakage in ppc64-linux, as this change introduced as infinite freeze, but it was caused by an unrelated problem and a faulty test was switched from failing to unsupported.
Sanitizers: GetTls
I've implemented the initial support for determining whether a memory buffer is allocated as Thread-Local-Storage. The current approach uses FreeBSD code, however it's subject to future improvement: in order to make it more generic and aware of dynamic allocation (like after dlopen(3)) TLS vectors.
Sanitizers: Handling NetBSD specific indirection of libpthread functions
I've corrected handling of three libpthread(3) functions on NetBSD:
- pthread_mutex_lock(3),
- pthread_mutex_unlock(3),
- pthread_setcancelstate(3).
Code out of the libpthread(3) context uses the libc symbols:
- __libc_mutex_lock,
- __libc_mutex_unlock,
- __libc_thr_setcancelstate.
The threading library (libpthread(3)) defines strong aliases:
- __strong_alias(__libc_mutex_lock,pthread_mutex_lock)
- __strong_alias(__libc_mutex_unlock,pthread_mutex_unlock)
- __strong_alias(__libc_thr_setcancelstate,pthread_setcancelstate)
This caused that these functions were invisible to sanitizers on NetBSD. I've introduced interception of the libc-specific functions and I have added them as NetBSD-specific aliases for the common pthread(3) functions.
NetBSD needs to intercept both functions, as the regularly named ones are used internally in libpthread(3).
Sanitizers: Adding DemangleFunctionName for backtracing on NetBSD
NetBSD uses indirection for old threading functions for historical reasons. The mangled names are an internal implementation detail and should not be exposed even in backtraces.
- __libc_mutex_init -> pthread_mutex_init
- __libc_mutex_lock -> pthread_mutex_lock
- __libc_mutex_trylock -> pthread_mutex_trylock
- __libc_mutex_unlock -> pthread_mutex_unlock
- __libc_mutex_destroy -> pthread_mutex_destroy
- __libc_mutexattr_init -> pthread_mutexattr_init
- __libc_mutexattr_settype -> pthread_mutexattr_settype
- __libc_mutexattr_destroy -> pthread_mutexattr_destroy
- __libc_cond_init -> pthread_cond_init
- __libc_cond_signal -> pthread_cond_signal
- __libc_cond_broadcast -> pthread_cond_broadcast
- __libc_cond_wait -> pthread_cond_wait
- __libc_cond_timedwait -> pthread_cond_timedwait
- __libc_cond_destroy -> pthread_cond_destroy
- __libc_rwlock_init -> pthread_rwlock_init
- __libc_rwlock_rdlock -> pthread_rwlock_rdlock
- __libc_rwlock_wrlock -> pthread_rwlock_wrlock
- __libc_rwlock_tryrdlock -> pthread_rwlock_tryrdlock
- __libc_rwlock_trywrlock -> pthread_rwlock_trywrlock
- __libc_rwlock_unlock -> pthread_rwlock_unlock
- __libc_rwlock_destroy -> pthread_rwlock_destroy
- __libc_thr_keycreate -> pthread_key_create
- __libc_thr_setspecific -> pthread_setspecific
- __libc_thr_getspecific -> pthread_getspecific
- __libc_thr_keydelete -> pthread_key_delete
- __libc_thr_once -> pthread_once
- __libc_thr_self -> pthread_self
- __libc_thr_exit -> pthread_exit
- __libc_thr_setcancelstate -> pthread_setcancelstate
- __libc_thr_equal -> pthread_equal
- __libc_thr_curcpu -> pthread_curcpu_np
This demangling also fixes several tests that expect the regular pthread(3) function names.
TSan: Handling NetBSD specific indirection of libpthread functions
I've corrected handling of libpthread(3) functions in TSan/NetBSD:
- pthread_cond_init(3),
- pthread_cond_signal(3),
- pthread_cond_broadcast(3),
- pthread_cond_wait(3),
- pthread_cond_destroy(3),
- pthread_mutex_init(3),
- pthread_mutex_destroy(3),
- pthread_mutex_trylock(3),
- pthread_rwlock_init(3),
- pthread_rwlock_destroy(3),
- pthread_rwlock_rdlock(3),
- pthread_rwlock_tryrdlock(3),
- pthread_rwlock_wrlock(3),
- pthread_rwlock_trywrlock(3),
- pthread_rwlock_unlock(3),
- pthread_once(3).
Code out of the libpthread(3) context uses the libc symbols that are prefixed with __libc_, for example: __libc_cond_init.
This has caused that these functions were invisible to sanitizers on NetBSD. Intercepting the libc-specific and adding them as NetBSD-specific aliases for the common pthread(3) functions.
NetBSD needs to intercept both functions, as the regularly named ones are used internally in libpthread(3).
TSan: Correcting NetBSD support in pthread_once(3)
The pthread_once(3)/NetBSD type is built with the following structure:
struct __pthread_once_st {
pthread_mutex_t pto_mutex;
int pto_done;
};
I've set the pto_done position as shifted by __sanitizer::pthread_mutex_t_sz from the beginning of the pthread_once struct.
This corrects deadlocks when the pthread_once(3) function is used.
Sanitizers: Plug dlerror() leak for swift_demangle
InitializeSwiftDemangler() attempts to resolve the swift_demangle symbol. If this is not available, we observe dlerror message leak.
LSan: Detecting thread's termination
I've fixed the same problem as has been analyzed in TSan, and I've switched to the _lwp_exit(2) approach.
Sanitizers: Handling symbol renaming of sigaction on NetBSD
NetBSD uses the __sigaction14 symbol name for historical and compat reasons for the sigaction(2) function name.
I've renamed the interceptors and users of sigaction to sigaction_symname and I've reused it in the code base.
TSan: Correcting mangled_sp on NetBSD/amd64
I've fixed the LongJmp(3) function on NetBSD and pointed the correct place of the RSP (stack pointer) register on NetBSD/amd64.
TSan: Supporting the setjmp(3) family of functions on NetBSD/amd64
I've added support for handling the setjmp(3)/longjmp(3) family of functions on NetBSD/amd64.
There are three types of them on NetBSD:
- setjmp(3) / longjmp(3)
- sigsetjmp(3) / sigsetjmp(3)
- _setjmp(3) / _longjmp(3)
Due to historical and compat reasons the symbol names are mangled:
- setjmp -> __setjmp14
- longjmp -> __longjmp14
- sigsetjmp -> __sigsetjmp14
- siglongjmp -> __siglongjmp14
- _setjmp -> _setjmp
- _longjmp -> _longjmp
This leads to symbol renaming in the existing codebase.
There is no such symbol as __sigsetjmp/__longsetjmp on NetBSD so it has been disabled.
Additonally, I've added a comment that GNU-style executable stack note is not needed on NetBSD. The stack is not executable without it.
TSan: Deferring StartBackgroundThread() and StopBackgroundThread()
NetBSD cannot spawn new POSIX thread entities in early libc and libpthread initialization stage. I've deferred this to the point of intercepting the first pthread_create(3) call.
This is the last change that makes Thread Sanitizer functional on NetBSD/amd64 without downstream patches.
Final TSan results
Results for the check-tsan test-target.
********************
Testing Time: 64.91s
********************
Failing Tests (5):
ThreadSanitizer-x86_64 :: dtls.c
ThreadSanitizer-x86_64 :: ignore_lib5.cc
ThreadSanitizer-x86_64 :: ignored-interceptors-mmap.cc
ThreadSanitizer-x86_64 :: mutex_lock_destroyed.cc
ThreadSanitizer-x86_64 :: vfork.cc
Expected Passes : 290
Expected Failures : 1
Unsupported Tests : 83
Unexpected Failures: 5
The following results present that the all crucial issues are now fixed, and this Sanitizer can be used to trace real software. The remaining problems are minor ones and they are scheduled to be fixed in the future:
- signal_block.cc - there is some race; sometimes it works sometimes it does not work.
- dtls.c - it looks like dynamically allocated TLS vectors are missing on the NetBSD side.
- vfork.cc - testing UB, it looks like NetBSD behaves the same way like Linux does, however the test is failing.
- mutex_lock_destroyed.cc - it is based on UB implemented in style of Linux.
- The other tests fail for similar rare case scenarios like massive mmap(2) calls that seem to overflow the shadow.
LLVM JIT
As noted in the previous reports, there is an ongoing process to improve NetBSD compatiblity with existing Just-In-Time frameworks in LLVM. In the recent month the existing code has been adjusted to the point to pass all existing LLVM tests of JIT code on NetBSD under PaX MPROTECT.
Scudo hardened allocator
I've added initial support for NetBSD in the Scudo hardened allocator. I keep this code locally in pkgsrc-wip/compiler-rt-netbsd.
More work is needed in order to correct the known failures in tests. These are largely caused by the fact that Scudo was a Linux-only feature and the existing tests depend on GLIBC specific internals. They need to be adapted for the default NetBSD allocator (jemalloc(3)).
********************
Testing Time: 5.40s
********************
Failing Tests (32):
Scudo-i386 :: double-free.cpp
Scudo-i386 :: interface.cpp
Scudo-i386 :: memalign.c
Scudo-i386 :: mismatch.cpp
Scudo-i386 :: options.cpp
Scudo-i386 :: overflow.c
Scudo-i386 :: preload.cpp
Scudo-i386 :: quarantine.c
Scudo-i386 :: realloc.cpp
Scudo-i386 :: rss.c
Scudo-i386 :: secondary.c
Scudo-i386 :: sizes.cpp
Scudo-i386 :: valloc.c
Scudo-x86_64 :: alignment.c
Scudo-x86_64 :: double-free.cpp
Scudo-x86_64 :: interface.cpp
Scudo-x86_64 :: malloc.cpp
Scudo-x86_64 :: memalign.c
Scudo-x86_64 :: mismatch.cpp
Scudo-x86_64 :: options.cpp
Scudo-x86_64 :: overflow.c
Scudo-x86_64 :: preload.cpp
Scudo-x86_64 :: quarantine.c
Scudo-x86_64 :: random_shuffle.cpp
Scudo-x86_64 :: realloc.cpp
Scudo-x86_64 :: rss.c
Scudo-x86_64 :: secondary.c
Scudo-x86_64 :: sized-delete.cpp
Scudo-x86_64 :: sizes.cpp
Scudo-x86_64 :: threads.c
Scudo-x86_64 :: valloc.c
Expected Passes : 8
Unexpected Failures: 32
Plans for the next milestone
The next goal is to finish MSan and switch back to LLDB restoration for tracing single threaded programs.
The TSan corrections indirectly increased the number of passing MSan tests. I'm going to solve the detected problems and thanks to the experience with other sanitizers the MSan issues don't seem to be as challenging like as before finishing TSan.
********************
Testing: 0 .. 10.. 20.. 30.. 40.. 50.. 60.. 70.. 80.. 90..
Testing Time: 30.91s
********************
Failing Tests (69):
MemorySanitizer-x86_64 :: allocator_returns_null.cc
MemorySanitizer-x86_64 :: backtrace.cc
MemorySanitizer-x86_64 :: c-strdup.c
MemorySanitizer-x86_64 :: chained_origin.cc
MemorySanitizer-x86_64 :: chained_origin_empty_stack.cc
MemorySanitizer-x86_64 :: chained_origin_limits.cc
MemorySanitizer-x86_64 :: chained_origin_memcpy.cc
MemorySanitizer-x86_64 :: chained_origin_with_signals.cc
MemorySanitizer-x86_64 :: check_mem_is_initialized.cc
MemorySanitizer-x86_64 :: death-callback.cc
MemorySanitizer-x86_64 :: dlopen_executable.cc
MemorySanitizer-x86_64 :: dso-origin.cc
MemorySanitizer-x86_64 :: dtls_test.c
MemorySanitizer-x86_64 :: dtor-base-access.cc
MemorySanitizer-x86_64 :: dtor-bit-fields.cc
MemorySanitizer-x86_64 :: dtor-derived-class.cc
MemorySanitizer-x86_64 :: dtor-multiple-inheritance-nontrivial-class-members.cc
MemorySanitizer-x86_64 :: dtor-multiple-inheritance.cc
MemorySanitizer-x86_64 :: dtor-trivial-class-members.cc
MemorySanitizer-x86_64 :: dtor-vtable-multiple-inheritance.cc
MemorySanitizer-x86_64 :: dtor-vtable.cc
MemorySanitizer-x86_64 :: fork.cc
MemorySanitizer-x86_64 :: ftime.cc
MemorySanitizer-x86_64 :: getaddrinfo-positive.cc
MemorySanitizer-x86_64 :: getaddrinfo.cc
MemorySanitizer-x86_64 :: getc_unlocked.c
MemorySanitizer-x86_64 :: heap-origin.cc
MemorySanitizer-x86_64 :: icmp_slt_allones.cc
MemorySanitizer-x86_64 :: iconv.cc
MemorySanitizer-x86_64 :: ifaddrs.cc
MemorySanitizer-x86_64 :: insertvalue_origin.cc
MemorySanitizer-x86_64 :: mktime.cc
MemorySanitizer-x86_64 :: mmap.cc
MemorySanitizer-x86_64 :: msan_copy_shadow.cc
MemorySanitizer-x86_64 :: msan_dump_shadow.cc
MemorySanitizer-x86_64 :: msan_print_shadow.cc
MemorySanitizer-x86_64 :: msan_print_shadow2.cc
MemorySanitizer-x86_64 :: origin-store-long.cc
MemorySanitizer-x86_64 :: param_tls_limit.cc
MemorySanitizer-x86_64 :: print_stats.cc
MemorySanitizer-x86_64 :: pthread_getattr_np_deadlock.cc
MemorySanitizer-x86_64 :: pvalloc.cc
MemorySanitizer-x86_64 :: readdir64.cc
MemorySanitizer-x86_64 :: realloc-large-origin.cc
MemorySanitizer-x86_64 :: realloc-origin.cc
MemorySanitizer-x86_64 :: report-demangling.cc
MemorySanitizer-x86_64 :: scandir.cc
MemorySanitizer-x86_64 :: scandir_null.cc
MemorySanitizer-x86_64 :: select_float_origin.cc
MemorySanitizer-x86_64 :: select_origin.cc
MemorySanitizer-x86_64 :: sem_getvalue.cc
MemorySanitizer-x86_64 :: signal_stress_test.cc
MemorySanitizer-x86_64 :: sigwait.cc
MemorySanitizer-x86_64 :: stack-origin.cc
MemorySanitizer-x86_64 :: stack-origin2.cc
MemorySanitizer-x86_64 :: strerror_r-non-gnu.c
MemorySanitizer-x86_64 :: strlen_of_shadow.cc
MemorySanitizer-x86_64 :: strndup.cc
MemorySanitizer-x86_64 :: textdomain.cc
MemorySanitizer-x86_64 :: times.cc
MemorySanitizer-x86_64 :: tls_reuse.cc
MemorySanitizer-x86_64 :: tsearch.cc
MemorySanitizer-x86_64 :: tzset.cc
MemorySanitizer-x86_64 :: unaligned_read_origin.cc
MemorySanitizer-x86_64 :: unpoison_string.cc
MemorySanitizer-x86_64 :: use-after-dtor.cc
MemorySanitizer-x86_64 :: use-after-free.cc
MemorySanitizer-x86_64 :: wcsncpy.cc
Expected Passes : 38
Expected Failures : 1
Unsupported Tests : 24
Unexpected Failures: 69
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL, and chip in what you can:
Support for running NetBSD on Oracle Cloud Arm-Based Compute Instances has been added to NetBSD -current.
A build of NetBSD/evbarm64 after 2022-10-15 will generate a bootable image (arm64.img.gz) that can be converted to a Custom Image that can run on Oracle Cloud.
To get started, the image needs to be converted to QCOW2 format:
$ gunzip arm64.img.gz $ qemu-img convert -f raw -O qcow2 arm64.img netbsd.qcow2
Next, upload the image to an Oracle Cloud storage bucket.
Once the QCOW2 file has been uploaded, switch to Compute / Custom Images and click Import image. Set an image name, make sure the Operating system field is set to Linux, and select the bucket and object name for your uploaded image. Make sure to select QCOW2 as the Image type. Set the mode to Paravirtualized mode.
After the image is imported, click Edit details and clear all checkboxes except for VM.Standard.A1.Flex. You could also try BM.Standard.A1.160 (bare metal instance) but this is untested. Once the compatible shapes have been updated, click Save changes.
Now click Edit image capabilities, and under the Firmware heading, uncheck BIOS and click Save changes.
Finally, to create an instance, click the Create instance button. Make sure to either provide SSH keys, or download the generated private key in the Add SSH keys section. Click the Create button to start the instance.
The Instance details page will assign you a public IP address. Once the instance has started, you can ssh to it with the SSH key used during image creation as user opc.
$ ssh -i ssh-key-2022-10-15.key opc@x.x.x.x
Last login: Sat Oct 15 18:50:51 2022 from y.y.y.y
NetBSD 9.99.101 (GENERIC64) #9: Sat Oct 15 15:35:49 ADT 2022
Welcome to NetBSD!
This is a development snapshot of NetBSD for testing -- user beware!
Bug reports: https://www.NetBSD.org/support/send-pr.html
Donations to the NetBSD Foundation: https://www.NetBSD.org/donations/
-- UNSAFE KEYS WARNING:
The ssh host keys on this machine have been generated with
not enough entropy configured, so may be predictable.
To fix, follow the "Adding entropy" section in the entropy(7)
man page and after this machine has enough entropy, re-generate
the ssh host keys by running:
sh /etc/rc.d/sshd keyregen
instance-20221015-1520$ sysctl machdep.dmi
machdep.dmi.system-vendor = QEMU
machdep.dmi.system-product = KVM Virtual Machine
machdep.dmi.system-version = virt-4.2
machdep.dmi.chassis-vendor = QEMU
machdep.dmi.chassis-type = QEMU
machdep.dmi.chassis-version = virt-4.2
machdep.dmi.chassis-asset-tag = OracleCloud.com
machdep.dmi.processor-vendor = QEMU
machdep.dmi.processor-version = virt-4.2
machdep.dmi.processor-frequency = 2000 MHz
Upstream describes LLDB as a next generation, high-performance debugger. It is built on top of LLVM/Clang toolchain, and features great integration with it. At the moment, it primarily supports debugging C, C++ and ObjC code, and there is interest in extending it to more languages.
In February, I have started working on LLDB, as contracted by the NetBSD Foundation. So far I've been working on reenabling continuous integration, squashing bugs, improving NetBSD core file support, extending NetBSD's ptrace interface to cover more register types and fix compat32 issues and fixing watchpoint support. Then, I've started working on improving thread support. You can read more about that in my July 2019 report.
I've been on vacation in August, and in September I've resumed the work on LLDB. I've started by fixing new regressions in LLVM suite, then improved my previous patches and continued debugging test failures and timeouts resulting from my patches.
LLVM 8 and 9 in NetBSD
Updates to LLVM 8 src branch
I have been asked to rebase my llvm8 branch of NetBSD src tree. I've done that, and updated it to LLVM 8.0.1 while at it.
LLVM 9 release
The LLVM 9.0.0 final has been tagged in September. I have been doing the pre-release testing for it, and discovered that the following tests were hanging:
LLVM :: ExecutionEngine/MCJIT/eh-lg-pic.ll
LLVM :: ExecutionEngine/MCJIT/eh.ll
LLVM :: ExecutionEngine/MCJIT/multi-module-eh-a.ll
LLVM :: ExecutionEngine/OrcMCJIT/eh-lg-pic.ll
LLVM :: ExecutionEngine/OrcMCJIT/eh.ll
LLVM :: ExecutionEngine/OrcMCJIT/multi-module-eh-a.ll
I couldn't reproduce the problem with LLVM trunk, so I've instead focused on looking for a fix. I've came to the conclusion that the problem was fixed through adding missing linked library. I've requested backport in bug 43196 and it has been merged in r371042.
I didn't put more effort into figuring out why the lack of this linkage caused issues for us. However, as Lang Hames said on the bug, ‘adding the dependency was the right thing to do’.
LLVM 9 for NetBSD src
Afterwards, I have started working on updating my NetBSD src branch for LLVM 9. However, in middle of that I've been informed that Joerg has already finished doing that independently, so I've stopped.
Furthermore, I was informed that LLVM 9.0.0 will not make it to src, since it still lacks some fixes (most notably, adding a pass to lower is.constant and objectsize intrinsics). Joerg plans to import some revision of the trunk instead.
Buildbot regressions
Initial regressions
The first problem that needed solving was LLDB build failure caused by
replacing std::once_flag with llvm::once_flag.
I've came to the conclusion that the build fails because the call site
in LLDB combined std::call_once with llvm::once_flag. The solution
was to replace the former with llvm::call_once.
After fixing the build failure, we had a bunch of test failures on buildbot to address. Kamil helped me and tracked one of them down to a new test for stack exhaustion handling. The test author decided that it ‘is only a best-effort mitigation for the case where things have already gone wrong’, and marked it unsupported on NetBSD.
On the plus side, two of the tests previously failing on NetBSD have been fixed upstream. I've un-XFAIL-ed them appropriately. Five new test failures in LLDB were related to those tests being unconditionally skipped before — I've marked them XFAIL pending further investigation in the future.
Another set of issues was caused by enabling -fvisibility=hidden for libc++ which caused problems when building with GCC. After being pinged, the author decided to enable it only for builds done using clang.
New issues through September
During September, two new issues arose. The first one was my fault,
so I'm going to cover it in appropriate section below. The second one
was new thread_local test failing. Since it was a newly added test
that failed on most of the supported platforms, I've just added NetBSD
to the list of failing platforms.
Current buildbot status
After fixing the immediate issues, the buildbot returned to previous status. The majority of tests pass, with one flaky test repeatedly timing out. Normally, I would skip this specific test in order to have buildbot report only fresh failures. However, since it is threading-related I'm waiting to finish my threading update and reassert afterwards.
Furthermore, I have added --shuffle to lit arguments in order to randomize
the order in which the tests are run. According to upstream, this reduces
the chance of load-intensive tests being run simultaneously and therefore
causing timeouts.
The buildbot host seems to have started crashing recently. OpenMP tests were causing similar issues in the past, and I'm currently trying to figure out whether they are the culprit again.
__has_feature(leak_sanitizer)
Kamil asked me to implement a feature check for leak sanitizer being
used. The __has_feature(leak_sanitizer) preprocessor macro
is complementary to __SANITIZE_LEAK__ used in NetBSD gcc and is used to avoid
reports when leaks are known but the cost of fixing them exceeds the gain.
Progress in threading support
Fixing LLDB bugs
In the course of previous work, I had a patch for threading support in LLDB partially ready. However, the improvements have also resulted in some of the tests starting to hang. The main focus of my late work as investigating those problems.
The first issue that I've discovered was inconsistency in expressing no signal
sent. In some places, LLDB used LLDB_INVALID_SIGNAL (-1) to express that,
in others it used 0. So far this went unnoticed since the end result
in ptrace calls was the same. However, the reworked NetBSD threading support
used explicit PT_SET_SIGINFO which — combined with wrong signal parameter —
wiped previously queued signal.
I've fixed C packet handler,
then fixed c, vCont and s handlers
to use LLDB_INVALID_SIGNAL correctly. However, I've only tested the fixes
with my updated thread support, causing regression in the old code. Therefore,
I've also had to fix LLDB_INVALID_SIGNAL handling in NetBSD plugin for the time being.
Thread suspend/resume kernel problem
Sadly, further investigation of hanging tests led me to the conclusion
that they are caused by kernel bugs. The first bug I've noticed is that
PT_SUSPEND/PT_RESUME do not cause the thread to be resumed correctly.
I have written the following reproducer for it:
#include <assert.h>
#include <lwp.h>
#include <pthread.h>
#include <signal.h>
#include <stdio.h>
#include <unistd.h>
#include <sys/ptrace.h>
#include <sys/wait.h>
void* thread_func(void* foo) {
int i;
printf("in thread_func, lwp = %d\n", _lwp_self());
for (i = 0; i < 100; ++i) {
printf("t2 %d\n", i);
sleep(2);
}
printf("out thread_func\n");
return NULL;
}
int main() {
int ret;
int pid = fork();
assert(pid != -1);
if (pid == 0) {
int i;
pthread_t t2;
ret = ptrace(PT_TRACE_ME, 0, NULL, 0);
assert(ret != -1);
printf("in main, lwp = %d\n", _lwp_self());
ret = pthread_create(&t2, NULL, thread_func, NULL);
assert(ret == 0);
printf("thread started\n");
for (i = 0; i < 100; ++i) {
printf("t1 %d\n", i);
sleep(2);
}
ret = pthread_join(t2, NULL);
assert(ret == 0);
printf("thread joined\n");
}
sleep(1);
ret = kill(pid, SIGSTOP);
assert(ret == 0);
printf("stopped\n");
pid_t waited = waitpid(pid, &ret, 0);
assert(waited == pid);
printf("wait: %d\n", ret);
printf("t2 suspend\n");
ret = ptrace(PT_SUSPEND, pid, NULL, 2);
assert(ret == 0);
ret = ptrace(PT_CONTINUE, pid, (void*)1, 0);
assert(ret == 0);
sleep(3);
ret = kill(pid, SIGSTOP);
assert(ret == 0);
printf("stopped\n");
waited = waitpid(pid, &ret, 0);
assert(waited == pid);
printf("wait: %d\n", ret);
printf("t2 resume\n");
ret = ptrace(PT_RESUME, pid, NULL, 2);
assert(ret == 0);
ret = ptrace(PT_CONTINUE, pid, (void*)1, 0);
assert(ret == 0);
sleep(5);
ret = kill(pid, SIGTERM);
assert(ret == 0);
waited = waitpid(pid, &ret, 0);
assert(waited == pid);
printf("wait: %d\n", ret);
return 0;
}
The program should run a two-threaded subprocess, with both threads outputting successive numbers. The second thread should be suspended shortly, then resumed. However, currently it does not resume.
I believe that this caused by ptrace_startstop()
altering process flags without reimplementing the complete logic as used
by lwp_suspend()
and lwp_continue().
I've been able to move forward by calling the two latter functions
from ptrace_startstop(). However, Kamil has indicated that he'd like
to make those routines use separate bits (to distinguish LWPs stopped
by process from LWPs stopped by debugger), so I haven't pushed my patch
forward.
Multiple thread reporting kernel problem
The second and more important problem is related to how new LWPs are reported to the debugger. Or rather, that they are not reported reliably. When many threads are started by the process in a short time (e.g. in a loop), the debugger receives reports only for some of them.
This can be reproduced using the following program:
#include <assert.h>
#include <lwp.h>
#include <pthread.h>
#include <signal.h>
#include <stdio.h>
#include <unistd.h>
#include <sys/ptrace.h>
#include <sys/wait.h>
void* thread_func(void* foo) {
printf("in thread, lwp = %d\n", _lwp_self());
sleep(10);
return NULL;
}
int main() {
int ret;
int pid = fork();
assert(pid != -1);
if (pid == 0) {
int i;
pthread_t t[10];
ret = ptrace(PT_TRACE_ME, 0, NULL, 0);
assert(ret != -1);
printf("in main, lwp = %d\n", _lwp_self());
raise(SIGSTOP);
printf("main resumed\n");
for (i = 0; i < 10; i++) {
ret = pthread_create(&t[i], NULL, thread_func, NULL);
assert(ret == 0);
printf("thread %d started\n", i);
}
for (i = 0; i < 10; i++) {
ret = pthread_join(t[i], NULL);
assert(ret == 0);
printf("thread %d joined\n", i);
}
return 0;
}
pid_t waited = waitpid(pid, &ret, 0);
assert(waited == pid);
printf("wait: %d\n", ret);
assert(WSTOPSIG(ret) == SIGSTOP);
struct ptrace_event ev;
ev.pe_set_event = PTRACE_LWP_CREATE | PTRACE_LWP_EXIT;
ret = ptrace(PT_SET_EVENT_MASK, pid, &ev, sizeof(ev));
assert(ret == 0);
ret = ptrace(PT_CONTINUE, pid, (void*)1, 0);
assert(ret == 0);
while (1) {
waited = waitpid(pid, &ret, 0);
assert(waited == pid);
printf("wait: %d\n", ret);
if (WIFSTOPPED(ret)) {
assert(WSTOPSIG(ret) == SIGTRAP);
ptrace_siginfo_t info;
ret = ptrace(PT_GET_SIGINFO, pid, &info, sizeof(info));
assert(ret == 0);
struct ptrace_state pst;
ret = ptrace(PT_GET_PROCESS_STATE, pid, &pst, sizeof(pst));
assert(ret == 0);
printf("SIGTRAP: si_code = %d, ev = %d, lwp = %d\n",
info.psi_siginfo.si_code, pst.pe_report_event, pst.pe_lwp);
ret = ptrace(PT_CONTINUE, pid, (void*)1, 0);
assert(ret == 0);
} else
break;
}
return 0;
}
The program starts 10 threads, and the debugger should report 10 SIGTRAP
events for LWPs being started (ev = 8) and the same number for LWPs
exiting (ev = 16). However, initially I've been getting as many
as 4 SIGTRAPs, and the remaining 6 threads went unnoticed.
The issue is that do_lwp_create()
does not raise SIGTRAP directly but defers that to mi_startlwp()
that is called asynchronously as the LWP starts. This means that the former
function can return before SIGTRAP is emitted, and the program can start
another LWP. Since signals are not properly queued, multiple SIGTRAPs
can end up being issued simultaneously and lost.
Kamil has already worked on making simultaneous signal deliver more reliable. However, he reverted his commit as it caused regressions. Nevertheless, applying it made it possible for the test program to get all SIGTRAPs at least most of the time.
The ‘repeated’ SIGTRAPs did not include correct LWP information, though. Kamil has recently fixed that by moving the relevant data from process information to signal information struct. Combined with his earlier patch, this makes my test program pass most of the time (sadly, there seem to be some more race conditions involved).
Summary of threading work
My current work-in-progress patch can be found on Differential as D64647. However, it is currently unsuitable for merging as some tests start failing or hanging as a side effect of the changes. I'd like to try to get as many of them fixed as possible before pushing the changes to trunk, in order to avoid causing harm to the build bot.
The status with the current set of Kamil's work-in-progress patches applied to the kernel includes approximately 4 failing tests and 10 hanging tests.
Other LLVM news
Manikishan Ghantasala has been working on NetBSD-specific clang-format improvements in this year's Google Summer of Code. He is continuing to work on clang-format, and has recently been given commit access to the LLVM project!
Besides NetBSD-specific work, I've been trying to improve a few other areas
of LLVM. I've been working on fixing regressions in stand-alone build support
and regressions in support for BUILD_SHARED_LIBS=ON builds. I have to admit
that while a year ago I was the only person fixing those issues, nowadays I see
more contributions submitting patches for breakages specific to those builds.
I have recently worked on fixing bad assumptions in LLDB's Python support. However, it seems that Haibo Huang has taken it from me and is doing a great job.
My most recent endeavor was fixing LLVM_DISTRIBUTION_COMPONENTS support
in LLVM projects. This is going to make it possible to precisely fine-tune
which components are installed, both in combined tree and stand-alone builds.
Future plans
My first goal right now is to assert what is causing the test host to crash, and restore buildbot stability. Afterwards, I'd like to continue investigating threading problems and provide more reproducers for any kernel issues we may be having. Once this is done, I'd like to finally push my LLDB patch.
Since threading is not the only goal left in the TODO, I may switch between working on it and on the remaining TODO items. Those are:
-
Add support to backtrace through signal trampoline and extend the support to libexecinfo, unwind implementations (LLVM, nongnu). Examine adding CFI support to interfaces that need it to provide more stable backtraces (both kernel and userland).
-
Add support for i386 and aarch64 targets.
-
Stabilize LLDB and address breaking tests from the test suite.
-
Merge LLDB with the base system (under LLVM-style distribution).
This work is sponsored by The NetBSD Foundation
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL to chip in what you can:
Upstream describes LLDB as a next generation, high-performance debugger. It is built on top of LLVM/Clang toolchain, and features great integration with it. At the moment, it primarily supports debugging C, C++ and ObjC code, and there is interest in extending it to more languages.
In February, I have started working on LLDB, as contracted by the NetBSD Foundation. So far I've been working on reenabling continuous integration, squashing bugs, improving NetBSD core file support, extending NetBSD's ptrace interface to cover more register types and fix compat32 issues and fixing watchpoint support. Then, I've started working on improving thread support. You can read more about that in my July 2019 report.
I've been on vacation in August, and in September I've resumed the work on LLDB. I've started by fixing new regressions in LLVM suite, then improved my previous patches and continued debugging test failures and timeouts resulting from my patches.
LLVM 8 and 9 in NetBSD
Updates to LLVM 8 src branch
I have been asked to rebase my llvm8 branch of NetBSD src tree. I've done that, and updated it to LLVM 8.0.1 while at it.
LLVM 9 release
The LLVM 9.0.0 final has been tagged in September. I have been doing the pre-release testing for it, and discovered that the following tests were hanging:
LLVM :: ExecutionEngine/MCJIT/eh-lg-pic.ll
LLVM :: ExecutionEngine/MCJIT/eh.ll
LLVM :: ExecutionEngine/MCJIT/multi-module-eh-a.ll
LLVM :: ExecutionEngine/OrcMCJIT/eh-lg-pic.ll
LLVM :: ExecutionEngine/OrcMCJIT/eh.ll
LLVM :: ExecutionEngine/OrcMCJIT/multi-module-eh-a.ll
I couldn't reproduce the problem with LLVM trunk, so I've instead focused on looking for a fix. I've came to the conclusion that the problem was fixed through adding missing linked library. I've requested backport in bug 43196 and it has been merged in r371042.
I didn't put more effort into figuring out why the lack of this linkage caused issues for us. However, as Lang Hames said on the bug, ‘adding the dependency was the right thing to do’.
LLVM 9 for NetBSD src
Afterwards, I have started working on updating my NetBSD src branch for LLVM 9. However, in middle of that I've been informed that Joerg has already finished doing that independently, so I've stopped.
Furthermore, I was informed that LLVM 9.0.0 will not make it to src, since it still lacks some fixes (most notably, adding a pass to lower is.constant and objectsize intrinsics). Joerg plans to import some revision of the trunk instead.
Buildbot regressions
Initial regressions
The first problem that needed solving was LLDB build failure caused by
replacing std::once_flag with llvm::once_flag.
I've came to the conclusion that the build fails because the call site
in LLDB combined std::call_once with llvm::once_flag. The solution
was to replace the former with llvm::call_once.
After fixing the build failure, we had a bunch of test failures on buildbot to address. Kamil helped me and tracked one of them down to a new test for stack exhaustion handling. The test author decided that it ‘is only a best-effort mitigation for the case where things have already gone wrong’, and marked it unsupported on NetBSD.
On the plus side, two of the tests previously failing on NetBSD have been fixed upstream. I've un-XFAIL-ed them appropriately. Five new test failures in LLDB were related to those tests being unconditionally skipped before — I've marked them XFAIL pending further investigation in the future.
Another set of issues was caused by enabling -fvisibility=hidden for libc++ which caused problems when building with GCC. After being pinged, the author decided to enable it only for builds done using clang.
New issues through September
During September, two new issues arose. The first one was my fault,
so I'm going to cover it in appropriate section below. The second one
was new thread_local test failing. Since it was a newly added test
that failed on most of the supported platforms, I've just added NetBSD
to the list of failing platforms.
Current buildbot status
After fixing the immediate issues, the buildbot returned to previous status. The majority of tests pass, with one flaky test repeatedly timing out. Normally, I would skip this specific test in order to have buildbot report only fresh failures. However, since it is threading-related I'm waiting to finish my threading update and reassert afterwards.
Furthermore, I have added --shuffle to lit arguments in order to randomize
the order in which the tests are run. According to upstream, this reduces
the chance of load-intensive tests being run simultaneously and therefore
causing timeouts.
The buildbot host seems to have started crashing recently. OpenMP tests were causing similar issues in the past, and I'm currently trying to figure out whether they are the culprit again.
__has_feature(leak_sanitizer)
Kamil asked me to implement a feature check for leak sanitizer being
used. The __has_feature(leak_sanitizer) preprocessor macro
is complementary to __SANITIZE_LEAK__ used in NetBSD gcc and is used to avoid
reports when leaks are known but the cost of fixing them exceeds the gain.
Progress in threading support
Fixing LLDB bugs
In the course of previous work, I had a patch for threading support in LLDB partially ready. However, the improvements have also resulted in some of the tests starting to hang. The main focus of my late work as investigating those problems.
The first issue that I've discovered was inconsistency in expressing no signal
sent. In some places, LLDB used LLDB_INVALID_SIGNAL (-1) to express that,
in others it used 0. So far this went unnoticed since the end result
in ptrace calls was the same. However, the reworked NetBSD threading support
used explicit PT_SET_SIGINFO which — combined with wrong signal parameter —
wiped previously queued signal.
I've fixed C packet handler,
then fixed c, vCont and s handlers
to use LLDB_INVALID_SIGNAL correctly. However, I've only tested the fixes
with my updated thread support, causing regression in the old code. Therefore,
I've also had to fix LLDB_INVALID_SIGNAL handling in NetBSD plugin for the time being.
Thread suspend/resume kernel problem
Sadly, further investigation of hanging tests led me to the conclusion
that they are caused by kernel bugs. The first bug I've noticed is that
PT_SUSPEND/PT_RESUME do not cause the thread to be resumed correctly.
I have written the following reproducer for it:
#include <assert.h>
#include <lwp.h>
#include <pthread.h>
#include <signal.h>
#include <stdio.h>
#include <unistd.h>
#include <sys/ptrace.h>
#include <sys/wait.h>
void* thread_func(void* foo) {
int i;
printf("in thread_func, lwp = %d\n", _lwp_self());
for (i = 0; i < 100; ++i) {
printf("t2 %d\n", i);
sleep(2);
}
printf("out thread_func\n");
return NULL;
}
int main() {
int ret;
int pid = fork();
assert(pid != -1);
if (pid == 0) {
int i;
pthread_t t2;
ret = ptrace(PT_TRACE_ME, 0, NULL, 0);
assert(ret != -1);
printf("in main, lwp = %d\n", _lwp_self());
ret = pthread_create(&t2, NULL, thread_func, NULL);
assert(ret == 0);
printf("thread started\n");
for (i = 0; i < 100; ++i) {
printf("t1 %d\n", i);
sleep(2);
}
ret = pthread_join(t2, NULL);
assert(ret == 0);
printf("thread joined\n");
}
sleep(1);
ret = kill(pid, SIGSTOP);
assert(ret == 0);
printf("stopped\n");
pid_t waited = waitpid(pid, &ret, 0);
assert(waited == pid);
printf("wait: %d\n", ret);
printf("t2 suspend\n");
ret = ptrace(PT_SUSPEND, pid, NULL, 2);
assert(ret == 0);
ret = ptrace(PT_CONTINUE, pid, (void*)1, 0);
assert(ret == 0);
sleep(3);
ret = kill(pid, SIGSTOP);
assert(ret == 0);
printf("stopped\n");
waited = waitpid(pid, &ret, 0);
assert(waited == pid);
printf("wait: %d\n", ret);
printf("t2 resume\n");
ret = ptrace(PT_RESUME, pid, NULL, 2);
assert(ret == 0);
ret = ptrace(PT_CONTINUE, pid, (void*)1, 0);
assert(ret == 0);
sleep(5);
ret = kill(pid, SIGTERM);
assert(ret == 0);
waited = waitpid(pid, &ret, 0);
assert(waited == pid);
printf("wait: %d\n", ret);
return 0;
}
The program should run a two-threaded subprocess, with both threads outputting successive numbers. The second thread should be suspended shortly, then resumed. However, currently it does not resume.
I believe that this caused by ptrace_startstop()
altering process flags without reimplementing the complete logic as used
by lwp_suspend()
and lwp_continue().
I've been able to move forward by calling the two latter functions
from ptrace_startstop(). However, Kamil has indicated that he'd like
to make those routines use separate bits (to distinguish LWPs stopped
by process from LWPs stopped by debugger), so I haven't pushed my patch
forward.
Multiple thread reporting kernel problem
The second and more important problem is related to how new LWPs are reported to the debugger. Or rather, that they are not reported reliably. When many threads are started by the process in a short time (e.g. in a loop), the debugger receives reports only for some of them.
This can be reproduced using the following program:
#include <assert.h>
#include <lwp.h>
#include <pthread.h>
#include <signal.h>
#include <stdio.h>
#include <unistd.h>
#include <sys/ptrace.h>
#include <sys/wait.h>
void* thread_func(void* foo) {
printf("in thread, lwp = %d\n", _lwp_self());
sleep(10);
return NULL;
}
int main() {
int ret;
int pid = fork();
assert(pid != -1);
if (pid == 0) {
int i;
pthread_t t[10];
ret = ptrace(PT_TRACE_ME, 0, NULL, 0);
assert(ret != -1);
printf("in main, lwp = %d\n", _lwp_self());
raise(SIGSTOP);
printf("main resumed\n");
for (i = 0; i < 10; i++) {
ret = pthread_create(&t[i], NULL, thread_func, NULL);
assert(ret == 0);
printf("thread %d started\n", i);
}
for (i = 0; i < 10; i++) {
ret = pthread_join(t[i], NULL);
assert(ret == 0);
printf("thread %d joined\n", i);
}
return 0;
}
pid_t waited = waitpid(pid, &ret, 0);
assert(waited == pid);
printf("wait: %d\n", ret);
assert(WSTOPSIG(ret) == SIGSTOP);
struct ptrace_event ev;
ev.pe_set_event = PTRACE_LWP_CREATE | PTRACE_LWP_EXIT;
ret = ptrace(PT_SET_EVENT_MASK, pid, &ev, sizeof(ev));
assert(ret == 0);
ret = ptrace(PT_CONTINUE, pid, (void*)1, 0);
assert(ret == 0);
while (1) {
waited = waitpid(pid, &ret, 0);
assert(waited == pid);
printf("wait: %d\n", ret);
if (WIFSTOPPED(ret)) {
assert(WSTOPSIG(ret) == SIGTRAP);
ptrace_siginfo_t info;
ret = ptrace(PT_GET_SIGINFO, pid, &info, sizeof(info));
assert(ret == 0);
struct ptrace_state pst;
ret = ptrace(PT_GET_PROCESS_STATE, pid, &pst, sizeof(pst));
assert(ret == 0);
printf("SIGTRAP: si_code = %d, ev = %d, lwp = %d\n",
info.psi_siginfo.si_code, pst.pe_report_event, pst.pe_lwp);
ret = ptrace(PT_CONTINUE, pid, (void*)1, 0);
assert(ret == 0);
} else
break;
}
return 0;
}
The program starts 10 threads, and the debugger should report 10 SIGTRAP
events for LWPs being started (ev = 8) and the same number for LWPs
exiting (ev = 16). However, initially I've been getting as many
as 4 SIGTRAPs, and the remaining 6 threads went unnoticed.
The issue is that do_lwp_create()
does not raise SIGTRAP directly but defers that to mi_startlwp()
that is called asynchronously as the LWP starts. This means that the former
function can return before SIGTRAP is emitted, and the program can start
another LWP. Since signals are not properly queued, multiple SIGTRAPs
can end up being issued simultaneously and lost.
Kamil has already worked on making simultaneous signal deliver more reliable. However, he reverted his commit as it caused regressions. Nevertheless, applying it made it possible for the test program to get all SIGTRAPs at least most of the time.
The ‘repeated’ SIGTRAPs did not include correct LWP information, though. Kamil has recently fixed that by moving the relevant data from process information to signal information struct. Combined with his earlier patch, this makes my test program pass most of the time (sadly, there seem to be some more race conditions involved).
Summary of threading work
My current work-in-progress patch can be found on Differential as D64647. However, it is currently unsuitable for merging as some tests start failing or hanging as a side effect of the changes. I'd like to try to get as many of them fixed as possible before pushing the changes to trunk, in order to avoid causing harm to the build bot.
The status with the current set of Kamil's work-in-progress patches applied to the kernel includes approximately 4 failing tests and 10 hanging tests.
Other LLVM news
Manikishan Ghantasala has been working on NetBSD-specific clang-format improvements in this year's Google Summer of Code. He is continuing to work on clang-format, and has recently been given commit access to the LLVM project!
Besides NetBSD-specific work, I've been trying to improve a few other areas
of LLVM. I've been working on fixing regressions in stand-alone build support
and regressions in support for BUILD_SHARED_LIBS=ON builds. I have to admit
that while a year ago I was the only person fixing those issues, nowadays I see
more contributions submitting patches for breakages specific to those builds.
I have recently worked on fixing bad assumptions in LLDB's Python support. However, it seems that Haibo Huang has taken it from me and is doing a great job.
My most recent endeavor was fixing LLVM_DISTRIBUTION_COMPONENTS support
in LLVM projects. This is going to make it possible to precisely fine-tune
which components are installed, both in combined tree and stand-alone builds.
Future plans
My first goal right now is to assert what is causing the test host to crash, and restore buildbot stability. Afterwards, I'd like to continue investigating threading problems and provide more reproducers for any kernel issues we may be having. Once this is done, I'd like to finally push my LLDB patch.
Since threading is not the only goal left in the TODO, I may switch between working on it and on the remaining TODO items. Those are:
-
Add support to backtrace through signal trampoline and extend the support to libexecinfo, unwind implementations (LLVM, nongnu). Examine adding CFI support to interfaces that need it to provide more stable backtraces (both kernel and userland).
-
Add support for i386 and aarch64 targets.
-
Stabilize LLDB and address breaking tests from the test suite.
-
Merge LLDB with the base system (under LLVM-style distribution).
This work is sponsored by The NetBSD Foundation
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL to chip in what you can:
Threading support
Threads and synchronization in the kernel, in general, is an evergreen task of the kernel developers. The process of enhancing support for tracing multiple threads has been documented by Michal Gorny in his LLDB entry Threading support in LLDB continued.
Overall I have introduced these changes:
- Separate suspend from userland (_lwp_suspend(2)) flag from suspend by a debugger (PT_SUSPEND). This removes one of the underlying problems of threading stability as a debuggee was able to accidentally unstop suspended thread. This property is needed whenever we want to trace a selection (typically single entity) of threads.
- Store SIGTRAP event information inside siginfo_t, rather than in struct proc. A single signal can only be reported at the time to the debugger, and its context is no longer prone to be overwritten by concurrent threads.
- Change that introduces restarts in functions notifying events for debuggers. There was a time window between registering an event by a thread, stopping the process and unlocking mutexes of the process; as another process could take the mutexes before being stopped and overwrite the event with its own data. Now each event routine for debugger checks whether a process is already stopping (or demising or no longer being tracked) and preserves the signal to be emitted locally in the context of the lwp local variable on the stack and continues stopping self as requested by the other LWP. Once the thread is awaken, it retries to emit the signal and deliver the event signal to the debugger.
- Introduce PT_STOP, that combines kill(SIGSTOP) and ptrace(PT_CONTINUE,SIGSTOP) semantics in a single call.
It works like:
- kill(SIGSTOP) for unstopped tracee
- ptrace(PT_CONTINUE,SIGSTOP) for stopped tracee
For stopped tracee kill(SIGSTOP) has no effect. PT_CONTINUE+SIGSTOP cannot be used on an unstopped process (EBUSY).
This operation is modeled after PT_KILL that is similar for the SIGKILL call. While there, allow PT_KILL on unstopped traced child.
This operation is useful in an abnormal exit of a debugger from a signal handler, usually followed by waitpid(2) and ptrace(PT_DETACH).
For the sake of tracking the missed in action signals emitted by tracee, I have introduced the feature in NetBSD truss (as part of the picotrace repository) to register syscall entry (SCE) and syscall exit (SCX) calls and track missing SCE/SCX events that were never delivered. Unfortunately, the number of missing events was huge, even for simple 2-threaded applications.
truss[2585] running for 22.205305922 seconds
truss[2585] attached to child=759 ('firefox') for 22.204289369 seconds
syscall seconds calls errors missed-sce missed-scx
read 0.048522952 609 0 54 76
write 0.044693735 487 0 35 66
open 0.002516815 18 0 5 5
close 0.001015263 17 0 9 6
unlink 0.001375463 13 0 3 0
getpid 0.093458089 1993 0 16 56
geteuid 0.000049301 1 0 0 1
recvmsg 0.343353019 4828 3685 90 112
access 0.001450653 12 3 5 4
dup 0.000570904 10 0 0 1
munmap 0.010375949 88 0 6 3
mprotect 0.196781932 2251 0 11 62
madvise 0.049820002 430 0 11 18
writev 0.237488362 1507 0 76 67
rename 0.000379918 2 0 1 0
mkdir 0.000283846 2 2 1 2
mmap 0.033342935 481 0 15 40
lseek 0.003341775 62 0 25 24
ftruncate 0.000507707 9 0 1 0
__sysctl 0.000144506 2 0 0 0
poll 18.694195617 4531 0 106 191
__sigprocmask14 0.001585329 20 0 0 2
getcontext 0.000083238 1 0 0 0
_lwp_create 0.000104646 1 0 0 0
_lwp_self 0.001456718 22 0 24 79
_lwp_unpark 0.035319633 607 0 14 39
_lwp_unpark_all 0.020660377 250 0 38 50
_lwp_setname 0.000118418 2 0 0 0
__select50 15.125525493 637 0 82 125
__gettimeofday50 3.279021049 2930 0 40 135
__clock_gettime50 10.673311747 33132 0 1418 3003
__stat50 0.006375356 52 3 12 5
__fstat50 0.001490944 17 0 3 2
__lstat50 0.000110906 1 0 1 0
__getrusage50 0.008863815 109 0 7 1
___lwp_park60 62.720893458 964 251 454 453
------------- ------- ------- ------- -------
111.638589870 56098 3944 2563 4628
With my kernel changes landed, the number of missed sce/scx events is down to zero (with exceptions to signals that e.g. never return such as the exit(2) call).
Once these changes settle in HEAD, I plan to backport them to NetBSD-9. I have already received feedback that GDB works much better now.
The kernel also has now more runtime asserts that validate correctness of the code paths.
Sanitizers
I've introduced a special preprocessor macro to detect LSan (__SANITIZE_LEAK__) and UBSan (__SANITIZE_UNDEFINED__) in GCC. The patches were submitted upstream to the GCC mailing list, in two patches (LSan + UBSan). Unfortunately, GCC does not see value in feature parity with LLVM and for the time being it will be a local NetBSD specific GCC extension. These macros are now integrated into the NetBSD public system headers, for use by the basesystem software.
The LSan macro is now used inside the LLVM codebase and the ps(1) program is the first user of it. The UBSan macro is now used to disable relaxed alignment on x86. While such code is still functional, it is not clean from undefined behavior as specified by C. This is especially needed in the kernel fuzzing process, as we can reduce noise from less interesting reports.
During the previous month a number of reports from kernel fuzzing were fixed. There is still more to go.
Almost all local patches needed for LSan were merged upstream. The last remaining local patch is scheduled for later as it is very invasive for all platforms and sanitizers. In the worst case we just have more false negatives in detection of leaks in specific scenarios.
Miscellaneous changes
I have fixed a regression in upstream GDB with SIGTTOU handling. This was an upstream bug fixed by Alan Hayward and cherry-picked by me. As a side effect, a certain environment setup would cause the tracer to sleep.
I have reverted the regression in changed in6_addr change. It appeased UBSan, but broke at least qemu networking. The regression was tracked down by Andreas Gustafsson and reported in the NetBSD's bug tracking system.
I have landed a patch that returns ELF loader dl_phdr_info information for dl_iterate_phdr(3). This synchronized the behavior with Linux, FreeBSD and OpenBSD and is used by sanitizers.
I have passed through core@ the patch to change the kevent::udata type from intptr_t to void*. The former is slightly more pedantic, but the latter is what is in all other kevent users and this mismatch of types affected specifically C++ users that needed special NetBSD-only workarounds.
I have marked git and hg meta files as ones to be ignored by cvs import. This was causing problems among people repackaging the NetBSD source code with other VCS software than CVS.
I keep working on getting GDB test-suite to run on NetBSD, I spent some time on getting fluent in the TCL programming language (as GDB uses dejagnu and TCL scripting). I have already fixed two bugs that affected NetBSD users in the TCL runtime: getaddrbyname_r and gethostbyaddr_r were falsely reported as available and picked on NetBSD, causing damage in operation. Fluency in TCL will allow me to be more efficient in addressing and debugging failing tests in GDB and likely reuse this knowledge in other fields useful for the project.
I made __CTASSERT a static assert again. Previously, this homegrown check for compile-time checks silently stopped working for C99 compilers supporting VLA (variable length array). It was caught by kUBSan that detected VLA of dynamic size of -1, that is still compatible but has unspecified runtime semantics. The new form is inspired by the Perl ctassert code and uses bit-field constant that enforces the assert to be effective again. Few misuses __CTASSERT, mostly in the Linux DRMKMS code, were fixed.
I have submitted a proposal to the C Working Group a proposal to add new methods for setting and getting the thread name.
Plan for the next milestone
Keep stabilizing the reliability debugging interfaces and get ATF and LLDB threading code reliably pass tests. Cover more scenarios with ptrace(2) in the ATF regression test-suite.
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL to chip in what you can:
Threading support
Threads and synchronization in the kernel, in general, is an evergreen task of the kernel developers. The process of enhancing support for tracing multiple threads has been documented by Michal Gorny in his LLDB entry Threading support in LLDB continued.
Overall I have introduced these changes:
- Separate suspend from userland (_lwp_suspend(2)) flag from suspend by a debugger (PT_SUSPEND). This removes one of the underlying problems of threading stability as a debuggee was able to accidentally unstop suspended thread. This property is needed whenever we want to trace a selection (typically single entity) of threads.
- Store SIGTRAP event information inside siginfo_t, rather than in struct proc. A single signal can only be reported at the time to the debugger, and its context is no longer prone to be overwritten by concurrent threads.
- Change that introduces restarts in functions notifying events for debuggers. There was a time window between registering an event by a thread, stopping the process and unlocking mutexes of the process; as another process could take the mutexes before being stopped and overwrite the event with its own data. Now each event routine for debugger checks whether a process is already stopping (or demising or no longer being tracked) and preserves the signal to be emitted locally in the context of the lwp local variable on the stack and continues stopping self as requested by the other LWP. Once the thread is awaken, it retries to emit the signal and deliver the event signal to the debugger.
- Introduce PT_STOP, that combines kill(SIGSTOP) and ptrace(PT_CONTINUE,SIGSTOP) semantics in a single call.
It works like:
- kill(SIGSTOP) for unstopped tracee
- ptrace(PT_CONTINUE,SIGSTOP) for stopped tracee
For stopped tracee kill(SIGSTOP) has no effect. PT_CONTINUE+SIGSTOP cannot be used on an unstopped process (EBUSY).
This operation is modeled after PT_KILL that is similar for the SIGKILL call. While there, allow PT_KILL on unstopped traced child.
This operation is useful in an abnormal exit of a debugger from a signal handler, usually followed by waitpid(2) and ptrace(PT_DETACH).
For the sake of tracking the missed in action signals emitted by tracee, I have introduced the feature in NetBSD truss (as part of the picotrace repository) to register syscall entry (SCE) and syscall exit (SCX) calls and track missing SCE/SCX events that were never delivered. Unfortunately, the number of missing events was huge, even for simple 2-threaded applications.
truss[2585] running for 22.205305922 seconds
truss[2585] attached to child=759 ('firefox') for 22.204289369 seconds
syscall seconds calls errors missed-sce missed-scx
read 0.048522952 609 0 54 76
write 0.044693735 487 0 35 66
open 0.002516815 18 0 5 5
close 0.001015263 17 0 9 6
unlink 0.001375463 13 0 3 0
getpid 0.093458089 1993 0 16 56
geteuid 0.000049301 1 0 0 1
recvmsg 0.343353019 4828 3685 90 112
access 0.001450653 12 3 5 4
dup 0.000570904 10 0 0 1
munmap 0.010375949 88 0 6 3
mprotect 0.196781932 2251 0 11 62
madvise 0.049820002 430 0 11 18
writev 0.237488362 1507 0 76 67
rename 0.000379918 2 0 1 0
mkdir 0.000283846 2 2 1 2
mmap 0.033342935 481 0 15 40
lseek 0.003341775 62 0 25 24
ftruncate 0.000507707 9 0 1 0
__sysctl 0.000144506 2 0 0 0
poll 18.694195617 4531 0 106 191
__sigprocmask14 0.001585329 20 0 0 2
getcontext 0.000083238 1 0 0 0
_lwp_create 0.000104646 1 0 0 0
_lwp_self 0.001456718 22 0 24 79
_lwp_unpark 0.035319633 607 0 14 39
_lwp_unpark_all 0.020660377 250 0 38 50
_lwp_setname 0.000118418 2 0 0 0
__select50 15.125525493 637 0 82 125
__gettimeofday50 3.279021049 2930 0 40 135
__clock_gettime50 10.673311747 33132 0 1418 3003
__stat50 0.006375356 52 3 12 5
__fstat50 0.001490944 17 0 3 2
__lstat50 0.000110906 1 0 1 0
__getrusage50 0.008863815 109 0 7 1
___lwp_park60 62.720893458 964 251 454 453
------------- ------- ------- ------- -------
111.638589870 56098 3944 2563 4628
With my kernel changes landed, the number of missed sce/scx events is down to zero (with exceptions to signals that e.g. never return such as the exit(2) call).
Once these changes settle in HEAD, I plan to backport them to NetBSD-9. I have already received feedback that GDB works much better now.
The kernel also has now more runtime asserts that validate correctness of the code paths.
Sanitizers
I've introduced a special preprocessor macro to detect LSan (__SANITIZE_LEAK__) and UBSan (__SANITIZE_UNDEFINED__) in GCC. The patches were submitted upstream to the GCC mailing list, in two patches (LSan + UBSan). Unfortunately, GCC does not see value in feature parity with LLVM and for the time being it will be a local NetBSD specific GCC extension. These macros are now integrated into the NetBSD public system headers, for use by the basesystem software.
The LSan macro is now used inside the LLVM codebase and the ps(1) program is the first user of it. The UBSan macro is now used to disable relaxed alignment on x86. While such code is still functional, it is not clean from undefined behavior as specified by C. This is especially needed in the kernel fuzzing process, as we can reduce noise from less interesting reports.
During the previous month a number of reports from kernel fuzzing were fixed. There is still more to go.
Almost all local patches needed for LSan were merged upstream. The last remaining local patch is scheduled for later as it is very invasive for all platforms and sanitizers. In the worst case we just have more false negatives in detection of leaks in specific scenarios.
Miscellaneous changes
I have fixed a regression in upstream GDB with SIGTTOU handling. This was an upstream bug fixed by Alan Hayward and cherry-picked by me. As a side effect, a certain environment setup would cause the tracer to sleep.
I have reverted the regression in changed in6_addr change. It appeased UBSan, but broke at least qemu networking. The regression was tracked down by Andreas Gustafsson and reported in the NetBSD's bug tracking system.
I have landed a patch that returns ELF loader dl_phdr_info information for dl_iterate_phdr(3). This synchronized the behavior with Linux, FreeBSD and OpenBSD and is used by sanitizers.
I have passed through core@ the patch to change the kevent::udata type from intptr_t to void*. The former is slightly more pedantic, but the latter is what is in all other kevent users and this mismatch of types affected specifically C++ users that needed special NetBSD-only workarounds.
I have marked git and hg meta files as ones to be ignored by cvs import. This was causing problems among people repackaging the NetBSD source code with other VCS software than CVS.
I keep working on getting GDB test-suite to run on NetBSD, I spent some time on getting fluent in the TCL programming language (as GDB uses dejagnu and TCL scripting). I have already fixed two bugs that affected NetBSD users in the TCL runtime: getaddrbyname_r and gethostbyaddr_r were falsely reported as available and picked on NetBSD, causing damage in operation. Fluency in TCL will allow me to be more efficient in addressing and debugging failing tests in GDB and likely reuse this knowledge in other fields useful for the project.
I made __CTASSERT a static assert again. Previously, this homegrown check for compile-time checks silently stopped working for C99 compilers supporting VLA (variable length array). It was caught by kUBSan that detected VLA of dynamic size of -1, that is still compatible but has unspecified runtime semantics. The new form is inspired by the Perl ctassert code and uses bit-field constant that enforces the assert to be effective again. Few misuses __CTASSERT, mostly in the Linux DRMKMS code, were fixed.
I have submitted a proposal to the C Working Group a proposal to add new methods for setting and getting the thread name.
Plan for the next milestone
Keep stabilizing the reliability debugging interfaces and get ATF and LLDB threading code reliably pass tests. Cover more scenarios with ptrace(2) in the ATF regression test-suite.
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL to chip in what you can:
- One in the base-system that includes a significant set of local patches.
- Another one in pkgsrc whose patching is limited to mostly build fixes.
The base-system version of GDB (GPLv3) still relies on local patching to work. I have set a goal to reduce the number of custom patches to bare minimum, ideally achieving the state of GDB working without any local modifications at all.
GDB changes
Last month, the NetBSD/amd64 support was merged into gdbserver. This month, the gdbserver target support was extended to NetBSD/i386 and NetBSD/aarch64. The gdbserver and gdb code was cleaned up, refactored and made capable of introducing even more NetBSD targets.
Meanwhile, the NetBSD/i386 build of GDB was fixed. The missing include of x86-bsd-nat.h as a common header was added to i386-bsd-nat.h. The i386 GDB code for BSD contained a runtime assert that verified whether the locally hardcoded struct sigcontext is compatible with the system headers. In reality, the system headers are no longer using this structure since 2003, after the switch to ucontext_t, and the validating code was no longer effective. After the switch to newer GCC, this was reported as a unused local variable by the compiler. I have decided to remove the check on NetBSD entirely. This was followed up by a small build fix.
The NetBSD team has noticed that the GDB's agent.cc code contains a portability bug and prepared a local fix. The traditional behavior of the BSD kernel is that passing random values of sun_len (part of sockaddr_un) can cause failures. In order to prevent the problems, the sockaddr_un structure is now zeroed before use. I've reimplemented the fix and successfully upstreamed it.
In order to easily resolve the issue with environment hardening enforced by PaX MPROTECT, I've introduced a runtime warning whenever byte transfers betweeen the debugee and debugger occur with the EACCES errno code.
binutils changes
I've added support for NetBSD/aarch64 upstream, in GNU BFD and GNU GAS. NetBSD still carries local patches for the GNU binutils components, and GNU ld does not build out of the box on NetBSD/aarch64.
Summary
The NetBSD support in GNU binutils and GDB is improving promptly, and the most popular platforms of amd64, i386 and aarch64 are getting proper support out of the box, without downstream patches. The remaining patches for these CPUs include: streamlining kgdb support, adding native GDB support for aarch64, upstreaming local modifications from the GNU binutils components (especially BFD and ld) and introducing portability enhancements in the dependent projects like libiberty and gnulib. Then, the remaining work is to streamline support for the remaining CPUs (Alpha, VAX, MIPS, HPPA, IA64, SH3, PPC, etc.), to develop the missing generic features (such as listing open file descriptors for the specified process) and to fix failures in the regression test-suite.
- One in the base-system that includes a significant set of local patches.
- Another one in pkgsrc whose patching is limited to mostly build fixes.
The base-system version of GDB (GPLv3) still relies on local patching to work. I have set a goal to reduce the number of custom patches to bare minimum, ideally achieving the state of GDB working without any local modifications at all.
GDB changes
Last month, the NetBSD/amd64 support was merged into gdbserver. This month, the gdbserver target support was extended to NetBSD/i386 and NetBSD/aarch64. The gdbserver and gdb code was cleaned up, refactored and made capable of introducing even more NetBSD targets.
Meanwhile, the NetBSD/i386 build of GDB was fixed. The missing include of x86-bsd-nat.h as a common header was added to i386-bsd-nat.h. The i386 GDB code for BSD contained a runtime assert that verified whether the locally hardcoded struct sigcontext is compatible with the system headers. In reality, the system headers are no longer using this structure since 2003, after the switch to ucontext_t, and the validating code was no longer effective. After the switch to newer GCC, this was reported as a unused local variable by the compiler. I have decided to remove the check on NetBSD entirely. This was followed up by a small build fix.
The NetBSD team has noticed that the GDB's agent.cc code contains a portability bug and prepared a local fix. The traditional behavior of the BSD kernel is that passing random values of sun_len (part of sockaddr_un) can cause failures. In order to prevent the problems, the sockaddr_un structure is now zeroed before use. I've reimplemented the fix and successfully upstreamed it.
In order to easily resolve the issue with environment hardening enforced by PaX MPROTECT, I've introduced a runtime warning whenever byte transfers betweeen the debugee and debugger occur with the EACCES errno code.
binutils changes
I've added support for NetBSD/aarch64 upstream, in GNU BFD and GNU GAS. NetBSD still carries local patches for the GNU binutils components, and GNU ld does not build out of the box on NetBSD/aarch64.
Summary
The NetBSD support in GNU binutils and GDB is improving promptly, and the most popular platforms of amd64, i386 and aarch64 are getting proper support out of the box, without downstream patches. The remaining patches for these CPUs include: streamlining kgdb support, adding native GDB support for aarch64, upstreaming local modifications from the GNU binutils components (especially BFD and ld) and introducing portability enhancements in the dependent projects like libiberty and gnulib. Then, the remaining work is to streamline support for the remaining CPUs (Alpha, VAX, MIPS, HPPA, IA64, SH3, PPC, etc.), to develop the missing generic features (such as listing open file descriptors for the specified process) and to fix failures in the regression test-suite.
- One in the base-system that includes a significant set of local patches.
- Another one in pkgsrc whose patching is limited to mostly build fixes.
The base-system version of GDB (GPLv3) still relies on local patching to work. I have set a goal to reduce the number of custom patches to bare minimum, ideally achieving the state of GDB working without any local modifications at all.
GDB changes
Last month, the NetBSD/amd64 support was merged into gdbserver. This month, the gdbserver target support was extended to NetBSD/i386 and NetBSD/aarch64. The gdbserver and gdb code was cleaned up, refactored and made capable of introducing even more NetBSD targets.
Meanwhile, the NetBSD/i386 build of GDB was fixed. The missing include of x86-bsd-nat.h as a common header was added to i386-bsd-nat.h. The i386 GDB code for BSD contained a runtime assert that verified whether the locally hardcoded struct sigcontext is compatible with the system headers. In reality, the system headers are no longer using this structure since 2003, after the switch to ucontext_t, and the validating code was no longer effective. After the switch to newer GCC, this was reported as a unused local variable by the compiler. I have decided to remove the check on NetBSD entirely. This was followed up by a small build fix.
The NetBSD team has noticed that the GDB's agent.cc code contains a portability bug and prepared a local fix. The traditional behavior of the BSD kernel is that passing random values of sun_len (part of sockaddr_un) can cause failures. In order to prevent the problems, the sockaddr_un structure is now zeroed before use. I've reimplemented the fix and successfully upstreamed it.
In order to easily resolve the issue with environment hardening enforced by PaX MPROTECT, I've introduced a runtime warning whenever byte transfers betweeen the debugee and debugger occur with the EACCES errno code.
binutils changes
I've added support for NetBSD/aarch64 upstream, in GNU BFD and GNU GAS. NetBSD still carries local patches for the GNU binutils components, and GNU ld does not build out of the box on NetBSD/aarch64.
Summary
The NetBSD support in GNU binutils and GDB is improving promptly, and the most popular platforms of amd64, i386 and aarch64 are getting proper support out of the box, without downstream patches. The remaining patches for these CPUs include: streamlining kgdb support, adding native GDB support for aarch64, upstreaming local modifications from the GNU binutils components (especially BFD and ld) and introducing portability enhancements in the dependent projects like libiberty and gnulib. Then, the remaining work is to streamline support for the remaining CPUs (Alpha, VAX, MIPS, HPPA, IA64, SH3, PPC, etc.), to develop the missing generic features (such as listing open file descriptors for the specified process) and to fix failures in the regression test-suite.
This post is a follow up of the first report and second report. Post summarizes the work done during the third and final coding period for the Google Summer of Code (GSoc’20) project - Enhance Syzkaller support for NetBSD
Sys2syz
Sys2syz would give an extra edge to Syzkaller for NetBSD. It has a potential of efficiently automating the conversion of syscall definitions to syzkaller’s grammar. This can aid in increasing the number of syscalls covered by Syzkaller significantly with the minimum possibility of manual errors. Let’s delve into its internals.
A peek into Syz2syz Internals
This tool parses the source code of device drivers present in C to a format which is compatible with grammar customized for syzkaller. Here, we try to cull the details of the target device by compiling, and then collocate the details with our python code. For further details about proposed design for the tool, refer to previous post.
Python code follows 4 major steps:
- Extractor.py - Extraction of all ioctl commands of a given device driver along with their arguments from the header files.
- Bear.py - Preprocessing of the device driver's files using compile_commands.json generated during the setup of tool using Bear.
- C2xml.py - XML files are generated by running c2xml on preprocessed device files. This eases the process of fetching the information related to arguments of commands
- Description.py - Generates descriptions for the ioctl commands and their arguments (builtin-types, arrays, pointers, structures and unions) using the XML files.
Extraction:
This step involves fetching the possible ioctl commands for the target device driver and getting the files which have to be included in our dev_target.txt file. We have already seen all the commands for device drivers are defined in a specific way. These commands defined in the header files need to be grepped along with the major details, regex comes in as a rescue for this
io = re.compile("#define\s+(.*)\s+_IO\((.*)\).*")
iow = re.compile("#define\s+(.*)\s+_IOW\((.*),\s+(.*),\s+(.*)\).*")
ior = re.compile("#define\s+(.*)\s+_IOR\((.*),\s+(.*),\s+(.*)\).*")
iowr = re.compile("#define\s+(.*)\s+_IOWR\((.*),\s+(.*),\s+(.*)\).*")
Code scans through all the header files present in the target device folder and extracts all the commands along with their details using compiled regex expressions. Details include the direction of buffer(null, in, out, inout) based on the types of Ioctl calls(_IO, _IOR, _IOW, _IOWR) and the argument of the call. These are stored in a file named ioctl_commands.txt at location out/<target_name>. Example output:
out, I2C_IOCTL_EXEC, i2c_ioctl_exec_t
Preprocessing:
Preprocessing is required for getting XML files, about which we would look in the next step. Bear plays a major role when it comes to preprocessing C files. It records the commands executed for building the target device driver. This step is performed when setup.sh script is executed.
Extracted commands are modified with the help of parse_commands() function to include ‘-E’ and ‘-fdirectives’ flags and give it a new output location. Commands extracted by this function are then used by the compile_target function which filters out the unnecessary flags and generates preprocessed files in our output directory.
Generating XML files
Run C2xml on the preprocessed files to fetch XML files which stores source code in a tree-like structure, making it easier to collect all the information related to each and every element of structures, unions etc. For eg:
<symbol type="struct" id="_5970" file="am2315.i" start-line="13240" start-col="16" end-line="13244" end-col="11" bit-size="96" alignment="4" offset="0">
<symbol type="node" id="_5971" ident="ipending" file="am2315.i" start-line="13241" start-col="33" end-line="13241" end-col="41" bit-size="32" alignment="4" offset="0" base-type-builtin="unsigned int"/<
<symbol type="node" id="_5972" ident="ilevel" file="am2315.i" start-line="13242" start-col="33" end-line="13242" end-col="39" bit-size="32" alignment="4" offset="4" base-type-builtin="int"/>
<symbol type="node" id="_5973" ident="imasked" file="am2315.i" start-line="13243" start-col="33" end-line="13243" end-col="40" bit-size="32" alignment="4" offset="8" base-type-builtin="unsigned int"/>
</symbol>
<symbol type="pointer" id="_5976" file="am2315.i" start-line="13249" start-col="14" end-line="13249" end-col="25" bit-size="64" alignment="8" offset="0" base-type-builtin="void"/>
<symbol type="array" id="_5978" file="am2315.i" start-line="13250" start-col="33" end-line="13250" end-col="39" bit-size="288" alignment="4" offset="0" base-type-builtin="unsigned int" array-size="9"/>
We would further see how attributes like - idents, id, type, base-type-builtin etc conveniently helps us to analyze code and generate descriptions in a trouble-free manner .
Descriptions.py
Final part, which offers a txt file storing all the required descriptions as its output. Here, information from the xml files and ioctl_commands.txt are combined together to generate descriptions of ioctl commands and their arguments.
Xml files for the given target device are parsed to form trees,
for file in (os.listdir(self.target)):
tree = ET.parse(self.target+file)
self.trees.append(tree)
We then traverse through these trees to search for the arguments of a particular ioctl command (particularly _IOR, _IOW, _IOWR commands) by the name of the argument. Once an element with the same value for ident attribute is found, attributes of the element are further examined to get its type. Possible types for these arguments are - struct, union, enum, function, array, pointer, macro and node. Using the type information we determine the way to define the element in accordance with syzkaller’s grammar syntax.
Building structs and unions involves defining their elements too, XML makes it easier. Program analyses each and every element which is a child of the root (struct/union) and generates its definitions. A dictionary helps in tracking the structs/unions which have been already built. Later, the dictionary is used to pretty print all the structs and union in the output file. Here is a code snippet which depicts the approach
name = child.get("ident")
if name not in self.structs_and_unions.keys():
elements = {}
for element in child:
elem_type = self.get_type(element)
elem_ident = element.get("ident")
if elem_type == None:
elem_type = element.get("type")
elements[element.get("ident")] = elem_type
element_str = ""
for element in elements:
element_str += element + "\t" + elements[element] + "\n"
self.structs_and_unions[name] = " {\n" + element_str + "}\n"
return str(name)
Task of creating descriptions for arrays is made simpler due to the attribute - `array-size`. When it comes to dealing with pointers, syzkaller needs the user to fill in the direction of the pointer. This has already been taken care of while analyzing the ioctl commands in Extractor.py. The second argument with in/out/inout as its possible value depends on ‘fun’ macros - _IOR, _IOW, _IOWR respectively.
There is another category named as nodes which can be distinguished using the base-type-builtin and base-type attributes.
Result
Once the setup script for sys2syz is executed, sys2syz can be used for a certain target_device file by executing the python wrapper script (sys2syz.py) with :
#bin/sh
python sys2syz.py -t <absolute_path_to_device_driver_source> -c compile_commands.json -v
This would generate a dev_<device_driver>.txt file in the out directory. An example description file autogenerated by sys2syz for i2c device driver.
#Autogenerated by sys2syz
include
resource fd_i2c[fd]
syz_open_dev$I2C(dev ptr[in, string["/dev/i2c"]], id intptr, flags flags[open_flags]) fd_i2c
ioctl$I2C_IOCTL_EXEC(fd fd_i2c, cmd const[I2C_IOCTL_EXEC], arg ptr[out, i2c_ioctl_exec])
i2c_ioctl_exec {
iie_op flags[i2c_op_t_flags]
iie_addr int16
iie_buflen len[iie_buf, intptr]
iie_buf buffer[out]
iie_cmdlen len[iie_cmd, intptr]
iie_cmd buffer[out]
}
Future Work
Though we have a basic working structure of this tool, yet a lot has to be worked upon for leveling it up to make the best of it. Perfect goals would be met when there would be least of manual labor needed. Sys2syz still looks forward to automating the detection of macros used by the flag types in syzkaller. List of to-dos also includes extending syzkaller’s support for generation of description of syscalls.
Some other yet-to-be-done tasks include-
- Generating descriptions for function type
- Calculating attributes for structs and unions
Summary
We have surely reached closer to our goals but the project needs active involvement and incremental updates to scale it up to its full potential. Looking forward to much more learning and making more contribution to NetBSD community.
Atlast, a word of thanks to my mentors William Coldwell, Siddharth Muralee, Santhosh Raju and Kamil Rytarowski as well as the NetBSD organization for being extremely supportive. Also, I owe a big thanks to Google for giving me such a glaring opportunity to work on this project.
This post is a follow up of the first report and second report. Post summarizes the work done during the third and final coding period for the Google Summer of Code (GSoc’20) project - Enhance Syzkaller support for NetBSD
Sys2syz
Sys2syz would give an extra edge to Syzkaller for NetBSD. It has a potential of efficiently automating the conversion of syscall definitions to syzkaller’s grammar. This can aid in increasing the number of syscalls covered by Syzkaller significantly with the minimum possibility of manual errors. Let’s delve into its internals.
A peek into Syz2syz Internals
This tool parses the source code of device drivers present in C to a format which is compatible with grammar customized for syzkaller. Here, we try to cull the details of the target device by compiling, and then collocate the details with our python code. For further details about proposed design for the tool, refer to previous post.
Python code follows 4 major steps:
- Extractor.py - Extraction of all ioctl commands of a given device driver along with their arguments from the header files.
- Bear.py - Preprocessing of the device driver's files using compile_commands.json generated during the setup of tool using Bear.
- C2xml.py - XML files are generated by running c2xml on preprocessed device files. This eases the process of fetching the information related to arguments of commands
- Description.py - Generates descriptions for the ioctl commands and their arguments (builtin-types, arrays, pointers, structures and unions) using the XML files.
Extraction:
This step involves fetching the possible ioctl commands for the target device driver and getting the files which have to be included in our dev_target.txt file. We have already seen all the commands for device drivers are defined in a specific way. These commands defined in the header files need to be grepped along with the major details, regex comes in as a rescue for this
io = re.compile("#define\s+(.*)\s+_IO\((.*)\).*")
iow = re.compile("#define\s+(.*)\s+_IOW\((.*),\s+(.*),\s+(.*)\).*")
ior = re.compile("#define\s+(.*)\s+_IOR\((.*),\s+(.*),\s+(.*)\).*")
iowr = re.compile("#define\s+(.*)\s+_IOWR\((.*),\s+(.*),\s+(.*)\).*")
Code scans through all the header files present in the target device folder and extracts all the commands along with their details using compiled regex expressions. Details include the direction of buffer(null, in, out, inout) based on the types of Ioctl calls(_IO, _IOR, _IOW, _IOWR) and the argument of the call. These are stored in a file named ioctl_commands.txt at location out/<target_name>. Example output:
out, I2C_IOCTL_EXEC, i2c_ioctl_exec_t
Preprocessing:
Preprocessing is required for getting XML files, about which we would look in the next step. Bear plays a major role when it comes to preprocessing C files. It records the commands executed for building the target device driver. This step is performed when setup.sh script is executed.
Extracted commands are modified with the help of parse_commands() function to include ‘-E’ and ‘-fdirectives’ flags and give it a new output location. Commands extracted by this function are then used by the compile_target function which filters out the unnecessary flags and generates preprocessed files in our output directory.
Generating XML files
Run C2xml on the preprocessed files to fetch XML files which stores source code in a tree-like structure, making it easier to collect all the information related to each and every element of structures, unions etc. For eg:
<symbol type="struct" id="_5970" file="am2315.i" start-line="13240" start-col="16" end-line="13244" end-col="11" bit-size="96" alignment="4" offset="0">
<symbol type="node" id="_5971" ident="ipending" file="am2315.i" start-line="13241" start-col="33" end-line="13241" end-col="41" bit-size="32" alignment="4" offset="0" base-type-builtin="unsigned int"/<
<symbol type="node" id="_5972" ident="ilevel" file="am2315.i" start-line="13242" start-col="33" end-line="13242" end-col="39" bit-size="32" alignment="4" offset="4" base-type-builtin="int"/>
<symbol type="node" id="_5973" ident="imasked" file="am2315.i" start-line="13243" start-col="33" end-line="13243" end-col="40" bit-size="32" alignment="4" offset="8" base-type-builtin="unsigned int"/>
</symbol>
<symbol type="pointer" id="_5976" file="am2315.i" start-line="13249" start-col="14" end-line="13249" end-col="25" bit-size="64" alignment="8" offset="0" base-type-builtin="void"/>
<symbol type="array" id="_5978" file="am2315.i" start-line="13250" start-col="33" end-line="13250" end-col="39" bit-size="288" alignment="4" offset="0" base-type-builtin="unsigned int" array-size="9"/>
We would further see how attributes like - idents, id, type, base-type-builtin etc conveniently helps us to analyze code and generate descriptions in a trouble-free manner .
Descriptions.py
Final part, which offers a txt file storing all the required descriptions as its output. Here, information from the xml files and ioctl_commands.txt are combined together to generate descriptions of ioctl commands and their arguments.
Xml files for the given target device are parsed to form trees,
for file in (os.listdir(self.target)):
tree = ET.parse(self.target+file)
self.trees.append(tree)
We then traverse through these trees to search for the arguments of a particular ioctl command (particularly _IOR, _IOW, _IOWR commands) by the name of the argument. Once an element with the same value for ident attribute is found, attributes of the element are further examined to get its type. Possible types for these arguments are - struct, union, enum, function, array, pointer, macro and node. Using the type information we determine the way to define the element in accordance with syzkaller’s grammar syntax.
Building structs and unions involves defining their elements too, XML makes it easier. Program analyses each and every element which is a child of the root (struct/union) and generates its definitions. A dictionary helps in tracking the structs/unions which have been already built. Later, the dictionary is used to pretty print all the structs and union in the output file. Here is a code snippet which depicts the approach
name = child.get("ident")
if name not in self.structs_and_unions.keys():
elements = {}
for element in child:
elem_type = self.get_type(element)
elem_ident = element.get("ident")
if elem_type == None:
elem_type = element.get("type")
elements[element.get("ident")] = elem_type
element_str = ""
for element in elements:
element_str += element + "\t" + elements[element] + "\n"
self.structs_and_unions[name] = " {\n" + element_str + "}\n"
return str(name)
Task of creating descriptions for arrays is made simpler due to the attribute - `array-size`. When it comes to dealing with pointers, syzkaller needs the user to fill in the direction of the pointer. This has already been taken care of while analyzing the ioctl commands in Extractor.py. The second argument with in/out/inout as its possible value depends on ‘fun’ macros - _IOR, _IOW, _IOWR respectively.
There is another category named as nodes which can be distinguished using the base-type-builtin and base-type attributes.
Result
Once the setup script for sys2syz is executed, sys2syz can be used for a certain target_device file by executing the python wrapper script (sys2syz.py) with :
#bin/sh
python sys2syz.py -t <absolute_path_to_device_driver_source> -c compile_commands.json -v
This would generate a dev_<device_driver>.txt file in the out directory. An example description file autogenerated by sys2syz for i2c device driver.
#Autogenerated by sys2syz
include
resource fd_i2c[fd]
syz_open_dev$I2C(dev ptr[in, string["/dev/i2c"]], id intptr, flags flags[open_flags]) fd_i2c
ioctl$I2C_IOCTL_EXEC(fd fd_i2c, cmd const[I2C_IOCTL_EXEC], arg ptr[out, i2c_ioctl_exec])
i2c_ioctl_exec {
iie_op flags[i2c_op_t_flags]
iie_addr int16
iie_buflen len[iie_buf, intptr]
iie_buf buffer[out]
iie_cmdlen len[iie_cmd, intptr]
iie_cmd buffer[out]
}
Future Work
Though we have a basic working structure of this tool, yet a lot has to be worked upon for leveling it up to make the best of it. Perfect goals would be met when there would be least of manual labor needed. Sys2syz still looks forward to automating the detection of macros used by the flag types in syzkaller. List of to-dos also includes extending syzkaller’s support for generation of description of syscalls.
Some other yet-to-be-done tasks include-
- Generating descriptions for function type
- Calculating attributes for structs and unions
Summary
We have surely reached closer to our goals but the project needs active involvement and incremental updates to scale it up to its full potential. Looking forward to much more learning and making more contribution to NetBSD community.
Atlast, a word of thanks to my mentors William Coldwell, Siddharth Muralee, Santhosh Raju and Kamil Rytarowski as well as the NetBSD organization for being extremely supportive. Also, I owe a big thanks to Google for giving me such a glaring opportunity to work on this project.
After a small delay*, the NetBSD Project is pleased to announce NetBSD 9.1, the first feature and stability maintenance release of the netbsd-9 stable branch.
The new release features (among various other changes) many bug fixes, a few performance enhancements, stability improvements for ZFS and LFS and support for USB security keys in a mode easily usable in Firefox and other applications.
For more details and instructions see the 9.1 announcement.
Get NetBSD 9.1 from our CDN (provided by fastly) or one of the ftp mirrors.
Complete source and binaries for NetBSD are available for download at many sites around the world. A list of download sites providing FTP, AnonCVS, and other services may be found at https://www.NetBSD.org/mirrors/.
* for the delay: let us say there was a minor hickup and we took the opportunity to provide up to date timezone files for NetBSD users in Fiji.
After a small delay*, the NetBSD Project is pleased to announce NetBSD 9.1, the first feature and stability maintenance release of the netbsd-9 stable branch.
The new release features (among various other changes) many bug fixes, a few performance enhancements, stability improvements for ZFS and LFS and support for USB security keys in a mode easily usable in Firefox and other applications.
For more details and instructions see the 9.1 announcement.
Get NetBSD 9.1 from our CDN (provided by fastly) or one of the ftp mirrors.
Complete source and binaries for NetBSD are available for download at many sites around the world. A list of download sites providing FTP, AnonCVS, and other services may be found at https://www.NetBSD.org/mirrors/.
* for the delay: let us say there was a minor hickup and we took the opportunity to provide up to date timezone files for NetBSD users in Fiji.
This was my first big BSD conference. We also planned - planned might be a big word - thought about doing a devsummit on Friday. Since the people who were in charge of that had a change of plans, I was sure it'd go horribly wrong.
The day before the devsummit and still in the wrong country, I mentioned the hours and venue on the wiki, and booked a reservation for a restaurant.
It turns out that everything was totally fine, and since the devsummit was at the conference venue (that was having tutorials that day), they even had signs pointing at the room we were given. Thanks EuroBSDCon conference organizers!
At the devsummit, we spent some time hacking. A few people came with "travel laptops" without access to anything, like Riastradh, so I gave him access to my own laptop. This didn't hold very long and I kinda forgot about it, but for a few moments he had access to a NetBSD source tree and an 8 thread, 16GB RAM machine with which to build things.
We had a short introduction and I suggested we take some pictures, so here's the
ones we got. A few people were concerned about privacy, so they're not pictured.
We had small team to hold the camera

At the actual conference days, I stayed at the speaker hotel with the other speakers.
I've attempted to make conversation with some visibly FreeBSD/OpenBSD people, but
didn't have plans to talk about anything, so there was a lot of just following
people silently.
Perhaps for the next conference I'll prepare a list of questions to random BSD people
and then very obviously grab a piece of paper and ask, "what was...", read a bit from
it, and say, "your latest kernel panic?", I'm sure it'll be a great conversation
starter.
At the conference itself, was pretty cool to have folks like Kirk McKusick give first person accounts of some past events (Kirk gave a talk about governance at FreeBSD), or the second keynote by Ron Broersma.
My own talk was hastily prepared, it was difficult to bring the topic together into a coherent talk. Nevertheless, I managed to talk about stuff for a while 40 minutes, though usually I skip over so many details that I have trouble putting together a sufficiently long talk.
I mentioned some of my coolest bugs to solve (I should probably make a separate article about some!). A few people asked for the slides after the talk, so I guess it wasn't totally incoherent.
It was really fun to meet some of my favourite NetBSD people. I got to show off my now fairly well working laptop (it took a lot of work by all of us!).
After the conference I came back with a conference cold, and it took a few days to recover from it. Hopefully I didn't infect too many people on the way back.
I gave two talks, one covered userland sanitizers and the other one kernel sanitizers. Unfortunately video recordings from the conference are not available, but I've uploaded my slides online:
- LLVM Sanitizers in the NetBSD userland
- Taking NetBSD kernel bug roast to the next level: Kernel Sanitizers
Besides participating in the conference and preparing for the travel and talks I've been researching the libunwind port to NetBSD and further integration of Lua. The libunwind port from the nongnu project has been approached to passing 22 out of 33 tests and the current blocker is the lack of signal trampoline handling or annotation. A signal trampoline is a special libc function, registered into the kernel, that is used as a helper routine to install and use signal handlers. Backtracing the function call stack is not trivial. We need to either annotate the assembly code in the trampoline with DWARF notes or handle it differently inside an unwinder.
I wrote a toy application using the newly created Lua binding for the curses(3) library. The process of writing the Lua bindings resulted in detecting various bugs in the native curses library. A majority of these bugs have been already fixed with aid of Roy Marples and Rin Okuyama, though they are still waiting for merge. I intend to keep working on the bindings in my spare time, but a shortcoming is that there are a lot of API functions (over 300!), and covering them all is time consuming process.
Meanwhile, I've made progress in the upstreaming of local LLVM patches. I've finally upstreamed to switch of indirect syscall (syscall(2)/__syscall(2)) to direct libc calls.
Plan for the next milestone
I will visit the GSoC Mentor Summit & MeetBSDCa in October (California, the U.S.). In the time besides the conference I will keep upstreaming local LLVM patches (almost 3000LOC to go!).
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL, and chip in what you can:
I have also transplanted basesystem GDB patched to my GDB repository and managed to run the GDB regression test-suite.
NetBSD distribution changes
I have enhanced and imported my local MKSANITIZER code that makes whole distribution sanitization possible. Few real bugs were fixed and a number of patches were newly written to reflect the current NetBSD sources state. I have also merged another chunk of the fruits of the GSoC-2018 project with fuzzing the userland (by plusun@).
The following changes were committed to the sources:
- ab7de18d0283 Cherry-pick upstream compiler-rt patches for LLVM sanitizers
- 966c62a34e30 Add LLVM sanitizers in the MKLLVM=yes build
- 8367b667adb9 telnetd: Stop defining the same variables concurrently in bss and data
- fe72740f64bf fsck: Stop defining the same variable concurrently in bss and data
- 40e89e890d66 Fix build of t_ubsan/t_ubsanxx under MKSANITIZER
- b71326fd7b67 Avoid symbol clashes in tests/usr.bin/id under MKSANITIZER
- c581f2e39fa5 Avoid symbol clashes in fs/nfs/nfsservice under MKSANITIZER
- 030a4686a3c6 Avoid symbol clashes in bin/df under MKSANITIZER
- fd9679f6e8b1 Avoid symbol clashes in usr.sbin/ypserv/ypserv under MKSANITIZER
- 5df2d7939ce3 Stop defining _rpcsvcdirty in bss and data
- 5fafbe8b8f64 Add missing extern declaration of ib_mach_emips in installboot
- d134584be69a Add SANITIZER_RENAME_CLASSES in bsd.prog.mk
- 2d00d9b08eae Adapt tests/kernel/t_subr_prf for MKSANITIZER
- ce54363fe452 Ship with sanitizer/lsan_interface.h for GCC 7
- 7bd5ee95e9a0 Ship with sanitizer/lsan_interface.h for LLVM 7
- d8671fba7a78 Set NODEBUG for LLVM sanitizers
- 242cd44890a2 Add PAXCTL_FLAG rules for MKSANITIZER
- 5e80ab99d9ce Avoid symbol clashes in test/rump/modautoload/t_modautoload with sanitizers
- e7ce7ecd9c2a sysctl: Add indirection of symbols to remove clash with sanitizers
- 231aea846aba traceroute: Add indirection of symbol to remove clash with sanitizers
- 8d85053f487c sockstat: Add indirection of symbols to remove clash with sanitizers
- 81b333ab151a netstat: Add indirection of symbols to remove clash with sanitizers
- a472baefefe8 Correct the memset(3)'s third argument in i386 biosdisk.c
- 7e4e92115bc3 Add ATF c and c++ tests for TSan, MSan, libFuzzer
- 921ddc9bc97c Set NOSANITIZER in i386 ramdisk image
- 64361771c78d Enhance MKSANITIZER support
- 3b5608f80a2b Define target_not_supported_body() in TSan, MSan and libFuzzer tests
- c27f4619d513 Avoids signedness bit shift in db_get_value()
- 680c5b3cc24f Fix LLVM sanitizer build by GCC (HAVE_LLVM=no)
- 4ecfbbba2f2a Rework the LLVM compiler_rt build rules
- 748813da5547 Correct the build rules of LLVM sanitizers
- 20e223156dee Enhance the support of LLVM sanitizers
- 0bb38eb2f20d Register syms.extra in LLVM sanitizer .syms files
Almost all of the mentioned commits were backported to NetBSD-9 and will land 9.0.
As a demo, I have crafted a writing on combining RUMPKERNEL, MKSANITIZER with the honggfuzz fuzzer: Rumpkernel assisted fuzzing of the NetBSD file system kernel code in userland.
GDB
I've merged NetBSD distribution downstream GDB patches into my local GDB tree and executed the regression tests (check-gdb):
[...]
Test run by kamil on Mon Sep 2 12:36:03 2019
Native configuration is x86_64-unknown-netbsd9.99
=== gdb tests ===
Schedule of variations:
unix
[...]
=== gdb Summary ===
# of expected passes 54591
# of unexpected failures 3267
# of expected failures 35
# of unknown successes 3
# of known failures 59
# of unresolved testcases 29
# of untested testcases 141
# of unsupported tests 399
Full log is here.
This means that there are a lot of more tests and known failures than in 2017-09-05:
$ uname -a
NetBSD chieftec 8.99.2 NetBSD 8.99.2 (GENERIC) #0: Sat Sep 2 22:55:29 CEST 2017 root@chieftec:/public/netbsd-root/sys/arch/amd64/compile/GENERIC amd64
Test run by kamil on Tue Sep 5 17:06:28 2017
Native configuration is x86_64--netbsd
=== gdb tests ===
Schedule of variations:
unix
[...]
=== gdb Summary ===
# of expected passes 16453
# of unexpected failures 483
# of expected failures 9
# of known failures 28
# of unresolved testcases 17
# of untested testcases 41
# of unsupported tests 25
There are actually some regressions and a set of tests that fails probably due to environment differences like lack of gfortran at hand.
Full log is here
GSoC Mentoring
The Google Summer of Code programme reached the end. My mentees wrote successfully their final reports:
I'm also mentoring the AFL+KCOV work by Maciej Grochowski. Maciej will visit EuroBSDCon-2019 and speak about his work.
Add methods for setting and getting the thread name
I've reached out to the people from standards bodies and I'm working on defining the standard approach for setting and getting the thread name. I have received a proper ID of my proposal and I'm now supposted to submit the text in either PDF or HTML format.
This change will allow to manage the thread name with an uniform interface on all comforming platforms.
Plan for the next milestone
Keep enhancing GDB support. Keep detecting ptrace(2) bugs and addressing them.
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL to chip in what you can:
I have also transplanted basesystem GDB patched to my GDB repository and managed to run the GDB regression test-suite.
NetBSD distribution changes
I have enhanced and imported my local MKSANITIZER code that makes whole distribution sanitization possible. Few real bugs were fixed and a number of patches were newly written to reflect the current NetBSD sources state. I have also merged another chunk of the fruits of the GSoC-2018 project with fuzzing the userland (by plusun@).
The following changes were committed to the sources:
- ab7de18d0283 Cherry-pick upstream compiler-rt patches for LLVM sanitizers
- 966c62a34e30 Add LLVM sanitizers in the MKLLVM=yes build
- 8367b667adb9 telnetd: Stop defining the same variables concurrently in bss and data
- fe72740f64bf fsck: Stop defining the same variable concurrently in bss and data
- 40e89e890d66 Fix build of t_ubsan/t_ubsanxx under MKSANITIZER
- b71326fd7b67 Avoid symbol clashes in tests/usr.bin/id under MKSANITIZER
- c581f2e39fa5 Avoid symbol clashes in fs/nfs/nfsservice under MKSANITIZER
- 030a4686a3c6 Avoid symbol clashes in bin/df under MKSANITIZER
- fd9679f6e8b1 Avoid symbol clashes in usr.sbin/ypserv/ypserv under MKSANITIZER
- 5df2d7939ce3 Stop defining _rpcsvcdirty in bss and data
- 5fafbe8b8f64 Add missing extern declaration of ib_mach_emips in installboot
- d134584be69a Add SANITIZER_RENAME_CLASSES in bsd.prog.mk
- 2d00d9b08eae Adapt tests/kernel/t_subr_prf for MKSANITIZER
- ce54363fe452 Ship with sanitizer/lsan_interface.h for GCC 7
- 7bd5ee95e9a0 Ship with sanitizer/lsan_interface.h for LLVM 7
- d8671fba7a78 Set NODEBUG for LLVM sanitizers
- 242cd44890a2 Add PAXCTL_FLAG rules for MKSANITIZER
- 5e80ab99d9ce Avoid symbol clashes in test/rump/modautoload/t_modautoload with sanitizers
- e7ce7ecd9c2a sysctl: Add indirection of symbols to remove clash with sanitizers
- 231aea846aba traceroute: Add indirection of symbol to remove clash with sanitizers
- 8d85053f487c sockstat: Add indirection of symbols to remove clash with sanitizers
- 81b333ab151a netstat: Add indirection of symbols to remove clash with sanitizers
- a472baefefe8 Correct the memset(3)'s third argument in i386 biosdisk.c
- 7e4e92115bc3 Add ATF c and c++ tests for TSan, MSan, libFuzzer
- 921ddc9bc97c Set NOSANITIZER in i386 ramdisk image
- 64361771c78d Enhance MKSANITIZER support
- 3b5608f80a2b Define target_not_supported_body() in TSan, MSan and libFuzzer tests
- c27f4619d513 Avoids signedness bit shift in db_get_value()
- 680c5b3cc24f Fix LLVM sanitizer build by GCC (HAVE_LLVM=no)
- 4ecfbbba2f2a Rework the LLVM compiler_rt build rules
- 748813da5547 Correct the build rules of LLVM sanitizers
- 20e223156dee Enhance the support of LLVM sanitizers
- 0bb38eb2f20d Register syms.extra in LLVM sanitizer .syms files
Almost all of the mentioned commits were backported to NetBSD-9 and will land 9.0.
As a demo, I have crafted a writing on combining RUMPKERNEL, MKSANITIZER with the honggfuzz fuzzer: Rumpkernel assisted fuzzing of the NetBSD file system kernel code in userland.
GDB
I've merged NetBSD distribution downstream GDB patches into my local GDB tree and executed the regression tests (check-gdb):
[...]
Test run by kamil on Mon Sep 2 12:36:03 2019
Native configuration is x86_64-unknown-netbsd9.99
=== gdb tests ===
Schedule of variations:
unix
[...]
=== gdb Summary ===
# of expected passes 54591
# of unexpected failures 3267
# of expected failures 35
# of unknown successes 3
# of known failures 59
# of unresolved testcases 29
# of untested testcases 141
# of unsupported tests 399
Full log is here.
This means that there are a lot of more tests and known failures than in 2017-09-05:
$ uname -a
NetBSD chieftec 8.99.2 NetBSD 8.99.2 (GENERIC) #0: Sat Sep 2 22:55:29 CEST 2017 root@chieftec:/public/netbsd-root/sys/arch/amd64/compile/GENERIC amd64
Test run by kamil on Tue Sep 5 17:06:28 2017
Native configuration is x86_64--netbsd
=== gdb tests ===
Schedule of variations:
unix
[...]
=== gdb Summary ===
# of expected passes 16453
# of unexpected failures 483
# of expected failures 9
# of known failures 28
# of unresolved testcases 17
# of untested testcases 41
# of unsupported tests 25
There are actually some regressions and a set of tests that fails probably due to environment differences like lack of gfortran at hand.
Full log is here
GSoC Mentoring
The Google Summer of Code programme reached the end. My mentees wrote successfully their final reports:
I'm also mentoring the AFL+KCOV work by Maciej Grochowski. Maciej will visit EuroBSDCon-2019 and speak about his work.
Add methods for setting and getting the thread name
I've reached out to the people from standards bodies and I'm working on defining the standard approach for setting and getting the thread name. I have received a proper ID of my proposal and I'm now supposted to submit the text in either PDF or HTML format.
This change will allow to manage the thread name with an uniform interface on all comforming platforms.
Plan for the next milestone
Keep enhancing GDB support. Keep detecting ptrace(2) bugs and addressing them.
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL to chip in what you can:
This year EuroBSDCon took place in Lillehammer Norway. I had the pleasure to attend as a speaker with my talk about fuzzing the NetBSD filesystems.
Venue
Lillehammer is a ski resort, nestled amid very beautiful scenery between mountains and lakes, just two hours from Oslo. The conference took place in the Scandic Lillehammer Hotel, a little bit away from the downtown of Lillehammer, close to the Olympic Ski Jumps.

Talks
Every year, EuroBSDCon has a lot of interesting talks. Unfortunately, it is hard to attend all the interesting seminars, as many of them take place at the same time, so I won't be able to highlight all of them; accordingly, I gratefully acknowledge several organizations for handling the live streaming from every session.
Keynote: Embedded Ethics
The conference started with an excellent Keynote from Patricia Aas (ex. Opera/Cisco/Vivaldi, cur Turtlesec), about the Ethics in the IT industry. As a person who is familiar with the issues with the privacy and many different threads of abusing user data by the company, I have to say that this talk started the avalanche of different thoughts and reflections in my mind. To my surprise, I was not the only one to have such thoughts. This topic arose quite often during the rest of the conference through many conversations between different people. For those of you who didn't see it yet, I highly recommend that you do. The key takeaway is that we, the people who are building today's digital world, need to think about the implications of our work and decisions upon the users of our services. This topic is getting more complicated even as we think about it. However, Patricia come here with the strategy "Annoying as a Service" that can be simply used in every situation to at least not makes things worse...
Conference Talks
During the first day, there were a couple of interesting talks about NetBSD: "Improving modularity of NetBSD compat code", and mine, on "Fuzzing NetBSD Filesystems" [+ Taking NetBSD kernel bug roast to the next level: Kernel Fuzzers (quick A.D. 2019 overview) by Kamil Rytarowski]. As it turns out, there was another interesting talk about foundations of kernel fuzzing by Andrew Turner, in which he presented the connection between sanitizers, tracing modes and fuzzers. After the break, I attended the excellent talk "7th Edition Unix at 40" by Warner Losh -- if you love the history of Unix, this is a must-see. The first day finished with the social mixer. The second day started with one of my favourites of the entire conference: "Kernel TLS and TLS hardware offload" via Drew Gallatin and Hans Petter Selasky. In another room was also a very interesting seminar on Rust for System Programmers. The next session via Netflix folks was about NUMA optimizations in the FreeBSD Network stack, another interesting talk about the usage of BSD as a high-speed CDN serving about 200Gbps Video content(!). After that, I attended the session on The Future of OpenZFS via Allan Jude, where he showed the progress done in the collaboration of different OSes on ZFS Filesystem. The last sessions I attended were the "23 years of software side-channel attacks" by Colin, and the last one before the closing notes: "Unbound & FreeBSD: A true love story", by Pablo Carboni.
Highlights
- Security: We can see clearly that the BSD community continues efforts for making BSDs more secure on various levels. This year we talked mostly about fuzzing, and in this area, it is impossible not to recognise NetBSD for great progress.
- CDN use-case: Netflix contributions to FreeBSD make it a great system for CDN, year after year innovating and increasing the performance. I hope we will see more companies using BSDs as core for their CDN infrastructure.
- ZFS: The filesystem has come a long way, despite being a project divided between different communities. Now thanks to the efforts of the developers, OpenZFS as a united community will be able to progress even faster and take advantage of projects that are using it. I believe the OpenZFS initiative is one of the most important steps taken by the community in many years.
Social Event
This year's social event took place in the Open Air Museum in Maihaugen, where we were able to see, preserved in excellent condition, parts of the Norwegian houses from the 19th century through the late 20th century. The fun part was that every house was open and you were able to go inside, some of them with people dressed up in the fashion of the same years, talking about the age. I very much enjoyed it, as it was a great opportunity to learn more about Norwegian culture and history.


Next Year!
The most important key point during closing notes is always: "where will the next EuroBSDCon take place?!" This year the guessing game was:
- Beer will be cheaper than in Norway
- [picture of Schnitzel]
- Photo of...
Vienna!

Hope to see you all next year in Vienna!
This year EuroBSDCon took place in Lillehammer Norway. I had the pleasure to attend as a speaker with my talk about fuzzing the NetBSD filesystems.
Venue
Lillehammer is a ski resort, nestled amid very beautiful scenery between mountains and lakes, just two hours from Oslo. The conference took place in the Scandic Lillehammer Hotel, a little bit away from the downtown of Lillehammer, close to the Olympic Ski Jumps.
Talks
Every year, EuroBSDCon has a lot of interesting talks. Unfortunately, it is hard to attend all the interesting seminars, as many of them take place at the same time, so I won't be able to highlight all of them; accordingly, I gratefully acknowledge several organizations for handling the live streaming from every session.
Keynote: Embedded Ethics
The conference started with an excellent Keynote from Patricia Aas (ex. Opera/Cisco/Vivaldi, cur Turtlesec), about the Ethics in the IT industry. As a person who is familiar with the issues with the privacy and many different threads of abusing user data by the company, I have to say that this talk started the avalanche of different thoughts and reflections in my mind. To my surprise, I was not the only one to have such thoughts. This topic arose quite often during the rest of the conference through many conversations between different people. For those of you who didn't see it yet, I highly recommend that you do. The key takeaway is that we, the people who are building today's digital world, need to think about the implications of our work and decisions upon the users of our services. This topic is getting more complicated even as we think about it. However, Patricia come here with the strategy "Annoying as a Service" that can be simply used in every situation to at least not makes things worse...
Conference Talks
During the first day, there were a couple of interesting talks about NetBSD: "Improving modularity of NetBSD compat code", and mine, on "Fuzzing NetBSD Filesystems" [+ Taking NetBSD kernel bug roast to the next level: Kernel Fuzzers (quick A.D. 2019 overview) by Kamil Rytarowski]. As it turns out, there was another interesting talk about foundations of kernel fuzzing by Andrew Turner, in which he presented the connection between sanitizers, tracing modes and fuzzers. After the break, I attended the excellent talk "7th Edition Unix at 40" by Warner Losh -- if you love the history of Unix, this is a must-see. The first day finished with the social mixer. The second day started with one of my favourites of the entire conference: "Kernel TLS and TLS hardware offload" via Drew Gallatin and Hans Petter Selasky. In another room was also a very interesting seminar on Rust for System Programmers. The next session via Netflix folks was about NUMA optimizations in the FreeBSD Network stack, another interesting talk about the usage of BSD as a high-speed CDN serving about 200Gbps Video content(!). After that, I attended the session on The Future of OpenZFS via Allan Jude, where he showed the progress done in the collaboration of different OSes on ZFS Filesystem. The last sessions I attended were the "23 years of software side-channel attacks" by Colin, and the last one before the closing notes: "Unbound & FreeBSD: A true love story", by Pablo Carboni.
Highlights
- Security: We can see clearly that the BSD community continues efforts for making BSDs more secure on various levels. This year we talked mostly about fuzzing, and in this area, it is impossible not to recognise NetBSD for great progress.
- CDN use-case: Netflix contributions to FreeBSD make it a great system for CDN, year after year innovating and increasing the performance. I hope we will see more companies using BSDs as core for their CDN infrastructure.
- ZFS: The filesystem has come a long way, despite being a project divided between different communities. Now thanks to the efforts of the developers, OpenZFS as a united community will be able to progress even faster and take advantage of projects that are using it. I believe the OpenZFS initiative is one of the most important steps taken by the community in many years.
Social Event
This year's social event took place in the Open Air Museum in Maihaugen, where we were able to see, preserved in excellent condition, parts of the Norwegian houses from the 19th century through the late 20th century. The fun part was that every house was open and you were able to go inside, some of them with people dressed up in the fashion of the same years, talking about the age. I very much enjoyed it, as it was a great opportunity to learn more about Norwegian culture and history.
Next Year!
The most important key point during closing notes is always: "where will the next EuroBSDCon take place?!" This year the guessing game was:
- Beer will be cheaper than in Norway
- [picture of Schnitzel]
- Photo of...
Vienna!
Hope to see you all next year in Vienna!
- One in the base-system with a stack of local patches.
- One in pkgsrc with mostly build fix patches.
The base-system version of GDB (GPLv3) still relies on a set of local patches. I set a goal to reduce the local patches to bare minimum, ideally reaching no local modifications at all.
GDB changes
Over the past month I worked on gdbserver for NetBSD/amd64 and finally upstreamed it to the GDB mainline, just in time for GDB 10.
What is gdbserver? Let's quote the official GDB documentation:
gdbserver is a control program for Unix-like systems, which allows you to connect your program with a remote GDB via target remote or target extended-but without linking in the usual debugging stub.
gdbserver is not a complete replacement for the debugging stubs, because it requires essentially the same operating-system facilities that GDB itself does. In fact, a system that can run gdbserver to connect to a remote GDB could also run GDB locally! gdbserver is sometimes useful nevertheless, because it is a much smaller program than GDB itself. It is also easier to port than all of GDB, so you may be able to get started more quickly on a new system by using gdbserver. Finally, if you develop code for real-time systems, you may find that the tradeoffs involved in real-time operation make it more convenient to do as much development work as possible on another system, for example by cross-compiling. You can use gdbserver to make a similar choice for debugging.
GDB and gdbserver communicate via either a serial line or a TCP connection, using the standard GDB remote serial protocol. remote
This illustrated that gdbserver is especially useful for debugging applications on embedded and thin devices, connected to a controlling computer equipped with full distribution sources, toolchain, debugging information etc. Eventually, this approach of gdb and gdbserver can replace the native gdb plugin entirely and spawn all connections debugging sessions using this protocol. This design decision was already introduced into LLDB, where remote process plugin is the only supported program on Linux, NetBSD and highly recommended for other kernels.
I've picked amd64 as the first target as it's the easiest to develop and test.
An example debugging session looks like this:
$ uname -rms NetBSD 9.99.72 amd64 $ LC_ALL=C date Thu Sep 10 22:43:10 CEST 2020 $ ./gdbserver/gdbserver --version GNU gdbserver (GDB) 10.0.50.20200910-git Copyright (C) 2020 Free Software Foundation, Inc. gdbserver is free software, covered by the GNU General Public License. This gdbserver was configured as "x86_64-unknown-netbsd9.99" $ ./gdbserver/gdbserver localhost:1234 /usr/bin/nslookup Process /usr/bin/nslookup created; pid = 26383 Listening on port 1234
Then on the other terminal:
$ ./gdb/gdb
GNU gdb (GDB) 10.0.50.20200910-git
Copyright (C) 2020 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law.
Type "show copying" and "show warranty" for details.
This GDB was configured as "x86_64-unknown-netbsd9.99".
Type "show configuration" for configuration details.
For bug reporting instructions, please see:
.
Find the GDB manual and other documentation resources online at:
--Type for more, q to quit, c to continue without paging--
.
For help, type "help".
Type "apropos word" to search for commands related to "word".
(gdb) target remote localhost:1234
Remote debugging using localhost:1234
Reading /usr/bin/nslookup from remote target...
warning: File transfers from remote targets can be slow. Use "set sysroot" to access files locally instead.
Reading /usr/bin/nslookup from remote target...
Reading symbols from target:/usr/bin/nslookup...
Reading /usr/bin/nslookup.debug from remote target...
Reading /usr/bin/.debug/nslookup.debug from remote target...
Reading /usr/libdata/debug//usr/bin/nslookup.debug from remote target...
Reading /usr/libdata/debug//usr/bin/nslookup.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/bin/nslookup.debug...
process 28353 is executing new program: /usr/bin/nslookup
Reading /usr/bin/nslookup from remote target...
Reading /usr/bin/nslookup from remote target...
Reading /usr/bin/nslookup.debug from remote target...
Reading /usr/bin/.debug/nslookup.debug from remote target...
Reading /usr/libdata/debug//usr/bin/nslookup.debug from remote target...
Reading /usr/libdata/debug//usr/bin/nslookup.debug from remote target...
Reading /usr/libexec/ld.elf_so from remote target...
Reading /usr/libexec/ld.elf_so from remote target...
Reading /usr/libexec/ld.elf_so.debug from remote target...
Reading /usr/libexec/.debug/ld.elf_so.debug from remote target...
Reading /usr/libdata/debug//usr/libexec/ld.elf_so.debug from remote target...
Reading /usr/libdata/debug//usr/libexec/ld.elf_so.debug from remote target...
warning: Invalid remote reply: timeout [kamil: repeated multiple times...]
Reading /usr/lib/libbind9.so.15 from remote target...
Reading /usr/lib/libisccfg.so.15 from remote target...
Reading /usr/lib/libdns.so.15 from remote target...
Reading /usr/lib/libns.so.15 from remote target...
Reading /usr/lib/libirs.so.15 from remote target...
Reading /usr/lib/libisccc.so.15 from remote target...
Reading /usr/lib/libisc.so.15 from remote target...
Reading /usr/lib/libkvm.so.6 from remote target...
Reading /usr/lib/libz.so.1 from remote target...
Reading /usr/lib/libblocklist.so.0 from remote target...
Reading /usr/lib/libpthread.so.1 from remote target...
Reading /usr/lib/libpthread.so.1.4.debug from remote target...
Reading /usr/lib/.debug/libpthread.so.1.4.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libpthread.so.1.4.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libpthread.so.1.4.debug from remote target...
Reading /usr/lib/libgssapi.so.11 from remote target...
Reading /usr/lib/libheimntlm.so.5 from remote target...
Reading /usr/lib/libkrb5.so.27 from remote target...
Reading /usr/lib/libcom_err.so.8 from remote target...
Reading /usr/lib/libhx509.so.6 from remote target...
Reading /usr/lib/libcrypto.so.14 from remote target...
Reading /usr/lib/libasn1.so.10 from remote target...
Reading /usr/lib/libwind.so.1 from remote target...
Reading /usr/lib/libheimbase.so.2 from remote target...
Reading /usr/lib/libroken.so.20 from remote target...
Reading /usr/lib/libsqlite3.so.1 from remote target...
Reading /usr/lib/libcrypt.so.1 from remote target...
Reading /usr/lib/libutil.so.7 from remote target...
Reading /usr/lib/libedit.so.3 from remote target...
Reading /usr/lib/libterminfo.so.2 from remote target...
Reading /usr/lib/libc.so.12 from remote target...
Reading /usr/lib/libgcc_s.so.1 from remote target...
Reading symbols from target:/usr/lib/libbind9.so.15...
Reading /usr/lib/libbind9.so.15.0.debug from remote target...
Reading /usr/lib/.debug/libbind9.so.15.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libbind9.so.15.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libbind9.so.15.0.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libbind9.so.15.0.debug...
Reading symbols from target:/usr/lib/libisccfg.so.15...
Reading /usr/lib/libisccfg.so.15.0.debug from remote target...
Reading /usr/lib/.debug/libisccfg.so.15.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libisccfg.so.15.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libisccfg.so.15.0.debug from remote target...
--Type for more, q to quit, c to continue without paging--
Reading symbols from target:/usr/libdata/debug//usr/lib/libisccfg.so.15.0.debug...
Reading symbols from target:/usr/lib/libdns.so.15...
Reading /usr/lib/libdns.so.15.0.debug from remote target...
Reading /usr/lib/.debug/libdns.so.15.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libdns.so.15.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libdns.so.15.0.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libdns.so.15.0.debug...
Reading symbols from target:/usr/lib/libns.so.15...
Reading /usr/lib/libns.so.15.0.debug from remote target...
Reading /usr/lib/.debug/libns.so.15.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libns.so.15.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libns.so.15.0.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libns.so.15.0.debug...
Reading symbols from target:/usr/lib/libirs.so.15...
Reading /usr/lib/libirs.so.15.0.debug from remote target...
Reading /usr/lib/.debug/libirs.so.15.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libirs.so.15.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libirs.so.15.0.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libirs.so.15.0.debug...
Reading symbols from target:/usr/lib/libisccc.so.15...
Reading /usr/lib/libisccc.so.15.0.debug from remote target...
Reading /usr/lib/.debug/libisccc.so.15.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libisccc.so.15.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libisccc.so.15.0.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libisccc.so.15.0.debug...
Reading symbols from target:/usr/lib/libisc.so.15...
Reading /usr/lib/libisc.so.15.0.debug from remote target...
Reading /usr/lib/.debug/libisc.so.15.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libisc.so.15.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libisc.so.15.0.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libisc.so.15.0.debug...
Reading symbols from target:/usr/lib/libkvm.so.6...
Reading /usr/lib/libkvm.so.6.0.debug from remote target...
Reading /usr/lib/.debug/libkvm.so.6.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libkvm.so.6.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libkvm.so.6.0.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libkvm.so.6.0.debug...
Reading symbols from target:/usr/lib/libz.so.1...
Reading /usr/lib/libz.so.1.0.debug from remote target...
Reading /usr/lib/.debug/libz.so.1.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libz.so.1.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libz.so.1.0.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libz.so.1.0.debug...
Reading symbols from target:/usr/lib/libblocklist.so.0...
Reading /usr/lib/libblocklist.so.0.0.debug from remote target...
Reading /usr/lib/.debug/libblocklist.so.0.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libblocklist.so.0.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libblocklist.so.0.0.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libblocklist.so.0.0.debug...
Reading symbols from target:/usr/lib/libgssapi.so.11...
Reading /usr/lib/libgssapi.so.11.0.debug from remote target...
Reading /usr/lib/.debug/libgssapi.so.11.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libgssapi.so.11.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libgssapi.so.11.0.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libgssapi.so.11.0.debug...
Reading symbols from target:/usr/lib/libheimntlm.so.5...
Reading /usr/lib/libheimntlm.so.5.0.debug from remote target...
Reading /usr/lib/.debug/libheimntlm.so.5.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libheimntlm.so.5.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libheimntlm.so.5.0.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libheimntlm.so.5.0.debug...
Reading symbols from target:/usr/lib/libkrb5.so.27...
Reading /usr/lib/libkrb5.so.27.0.debug from remote target...
Reading /usr/lib/.debug/libkrb5.so.27.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libkrb5.so.27.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libkrb5.so.27.0.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libkrb5.so.27.0.debug...
Reading symbols from target:/usr/lib/libcom_err.so.8...
Reading /usr/lib/libcom_err.so.8.0.debug from remote target...
Reading /usr/lib/.debug/libcom_err.so.8.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libcom_err.so.8.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libcom_err.so.8.0.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libcom_err.so.8.0.debug...
Reading symbols from target:/usr/lib/libhx509.so.6...
Reading /usr/lib/libhx509.so.6.0.debug from remote target...
Reading /usr/lib/.debug/libhx509.so.6.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libhx509.so.6.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libhx509.so.6.0.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libhx509.so.6.0.debug...
Reading symbols from target:/usr/lib/libcrypto.so.14...
Reading /usr/lib/libcrypto.so.14.0.debug from remote target...
Reading /usr/lib/.debug/libcrypto.so.14.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libcrypto.so.14.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libcrypto.so.14.0.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libcrypto.so.14.0.debug...
Reading symbols from target:/usr/lib/libasn1.so.10...
Reading /usr/lib/libasn1.so.10.0.debug from remote target...
Reading /usr/lib/.debug/libasn1.so.10.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libasn1.so.10.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libasn1.so.10.0.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libasn1.so.10.0.debug...
Reading symbols from target:/usr/lib/libwind.so.1...
Reading /usr/lib/libwind.so.1.0.debug from remote target...
Reading /usr/lib/.debug/libwind.so.1.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libwind.so.1.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libwind.so.1.0.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libwind.so.1.0.debug...
Reading symbols from target:/usr/lib/libheimbase.so.2...
Reading /usr/lib/libheimbase.so.2.0.debug from remote target...
Reading /usr/lib/.debug/libheimbase.so.2.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libheimbase.so.2.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libheimbase.so.2.0.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libheimbase.so.2.0.debug...
Reading symbols from target:/usr/lib/libroken.so.20...
Reading /usr/lib/libroken.so.20.0.debug from remote target...
Reading /usr/lib/.debug/libroken.so.20.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libroken.so.20.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libroken.so.20.0.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libroken.so.20.0.debug...
Reading symbols from target:/usr/lib/libsqlite3.so.1...
Reading /usr/lib/libsqlite3.so.1.4.debug from remote target...
Reading /usr/lib/.debug/libsqlite3.so.1.4.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libsqlite3.so.1.4.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libsqlite3.so.1.4.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libsqlite3.so.1.4.debug...
Reading symbols from target:/usr/lib/libcrypt.so.1...
Reading /usr/lib/libcrypt.so.1.0.debug from remote target...
Reading /usr/lib/.debug/libcrypt.so.1.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libcrypt.so.1.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libcrypt.so.1.0.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libcrypt.so.1.0.debug...
Reading symbols from target:/usr/lib/libutil.so.7...
Reading /usr/lib/libutil.so.7.24.debug from remote target...
Reading /usr/lib/.debug/libutil.so.7.24.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libutil.so.7.24.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libutil.so.7.24.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libutil.so.7.24.debug...
Reading symbols from target:/usr/lib/libedit.so.3...
Reading /usr/lib/libedit.so.3.1.debug from remote target...
Reading /usr/lib/.debug/libedit.so.3.1.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libedit.so.3.1.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libedit.so.3.1.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libedit.so.3.1.debug...
Reading symbols from target:/usr/lib/libterminfo.so.2...
Reading /usr/lib/libterminfo.so.2.0.debug from remote target...
Reading /usr/lib/.debug/libterminfo.so.2.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libterminfo.so.2.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libterminfo.so.2.0.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libterminfo.so.2.0.debug...
Reading symbols from target:/usr/lib/libc.so.12...
Reading /usr/lib/libc.so.12.217.debug from remote target...
Reading /usr/lib/.debug/libc.so.12.217.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libc.so.12.217.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libc.so.12.217.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libc.so.12.217.debug...
Reading symbols from target:/usr/lib/libgcc_s.so.1...
Reading /usr/lib/libgcc_s.so.1.0.debug from remote target...
Reading /usr/lib/.debug/libgcc_s.so.1.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libgcc_s.so.1.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libgcc_s.so.1.0.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libgcc_s.so.1.0.debug...
Reading /usr/libexec/ld.elf_so from remote target...
_rtld_debug_state () at /usr/src/libexec/ld.elf_so/rtld.c:1577
1577 __insn_barrier();
(gdb) b main
Breakpoint 1 at 0x211c00: file /usr/src/external/mpl/bind/bin/nslookup/../../dist/bin/dig/nslookup.c, line 990.
(gdb) c
Continuing.
Breakpoint 1, main (argc=1, argv=0x7f7fffffe768)
at /usr/src/external/mpl/bind/bin/nslookup/../../dist/bin/dig/nslookup.c:990
990 main(int argc, char **argv) {
(gdb) bt
#0 main (argc=1, argv=0x7f7fffffe768)
at /usr/src/external/mpl/bind/bin/nslookup/../../dist/bin/dig/nslookup.c:990
(gdb) info threads
Id Target Id Frame
* 1 Thread 28353.28353 main (argc=1, argv=0x7f7fffffe768)
at /usr/src/external/mpl/bind/bin/nslookup/../../dist/bin/dig/nslookup.c:990
(gdb) b pthread_setname_np
Breakpoint 2 at 0x7f7ff4e0c9e4: file /usr/src/lib/libpthread/pthread.c, line 792.
(gdb) c
Continuing.
[New Thread 28353.27773]
Thread 1 hit Breakpoint 2, pthread_setname_np (thread=0x7f7ff7e41000,
name=name@entry=0x7f7fffffe610 "work-0", arg=arg@entry=0x0)
at /usr/src/lib/libpthread/pthread.c:792
792 {
(gdb) info threads
Id Target Id Frame
* 1 Thread 28353.28353 pthread_setname_np (thread=0x7f7ff7e41000,
name=name@entry=0x7f7fffffe610 "work-0", arg=arg@entry=0x0)
at /usr/src/lib/libpthread/pthread.c:792
2 Thread 28353.27773 0x00007f7ff0aa623a in ___lwp_park60 () from target:/usr/lib/libc.so.12
(gdb) n
796 pthread__error(EINVAL, "Invalid thread",
(gdb) n
799 if (pthread__find(thread) != 0)
(gdb)
802 namelen = snprintf(newname, sizeof(newname), name, arg);
(gdb)
803 if (namelen >= PTHREAD_MAX_NAMELEN_NP)
(gdb)
806 cp = strdup(newname);
(gdb)
807 if (cp == NULL)
(gdb)
810 pthread_mutex_lock(&thread->pt_lock);
(gdb)
811 oldname = thread->pt_name;
(gdb)
812 thread->pt_name = cp;
(gdb)
813 (void)_lwp_setname(thread->pt_lid, cp);
(gdb)
814 pthread_mutex_unlock(&thread->pt_lock);
(gdb) n
816 if (oldname != NULL)
(gdb) n
isc_taskmgr_create (mctx=, workers=workers@entry=1, default_quantum=,
default_quantum@entry=0, nm=nm@entry=0x0, managerp=managerp@entry=0x418638 )
at /usr/src/external/mpl/bind/lib/libisc/../../dist/lib/isc/task.c:1431
1431 for (i = 0; i < workers; i++) {
(gdb) info threads
Id Target Id Frame
* 1 Thread 28353.28353 isc_taskmgr_create (mctx=, workers=workers@entry=1,
default_quantum=, default_quantum@entry=0, nm=nm@entry=0x0,
managerp=managerp@entry=0x418638 )
at /usr/src/external/mpl/bind/lib/libisc/../../dist/lib/isc/task.c:1431
2 Thread 28353.27773 "work-0" 0x00007f7ff0aa623a in ___lwp_park60 ()
from target:/usr/lib/libc.so.12
(gdb) dis 1
(gdb) b exit
Breakpoint 3 at 0x7f7ff0b530e0: exit. (2 locations)
(gdb) c
Continuing.
Thread 1 hit Breakpoint 2, pthread_setname_np (thread=0x7f7ff7e42c00,
name=name@entry=0x7f7ff5e6324e "isc-timer", arg=arg@entry=0x0)
at /usr/src/lib/libpthread/pthread.c:792
792 {
(gdb) dis 2
(gdb) c
Continuing.
Reading /usr/lib/i18n/libUTF8.so.5.0 from remote target...
Reading /usr/lib/i18n/libUTF8.so.5.0.debug from remote target...
Reading /usr/lib/i18n/.debug/libUTF8.so.5.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/i18n/libUTF8.so.5.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/i18n/libUTF8.so.5.0.debug from remote target...
Then, back to the first terminal:
> netbsd.org Server: 62.179.1.62 Address: 62.179.1.62#53 Non-authoritative answer: Name: netbsd.org Address: 199.233.217.205 Name: netbsd.org Address: 2001:470:a085:999::80 > exit
Thread 1 hit Breakpoint 3, exit (status=1) at /usr/src/lib/libc/stdlib/exit.c:55
55 {
(gdb) info threads
Id Target Id Frame
* 1 Thread 28353.28353 exit (status=1) at /usr/src/lib/libc/stdlib/exit.c:55
(gdb) bt
#0 exit (status=1) at /usr/src/lib/libc/stdlib/exit.c:55
#1 0x0000000000206122 in ___start ()
#2 0x00007f7ff7c0c840 in ?? () from target:/usr/libexec/ld.elf_so
#3 0x0000000000000001 in ?? ()
#4 0x00007f7fffffed20 in ?? ()
#5 0x0000000000000000 in ?? ()
(gdb) kill
Kill the program being debugged? (y or n) y
[Inferior 1 (process 28353) killed]
It worked!
In order to get this functionality operational I had to implement multiple GDB functions, in particular: create_inferior, post_create_inferior, attach, kill, detach, mourn, join, thread_alive, resume, wait, fetch_registers, store_registers, read_memory, write_memory, request_interrupt, supports_read_auxv, read_auxv, supports_hardware_single_step, sw_breakpoint_from_kind, supports_z_point_type, insert_point, remove_point, stopped_by_sw_breakpoint, supports_qxfer_siginfo, qxfer_siginfo, supports_stopped_by_sw_breakpoint, supports_non_stop, supports_multi_process, supports_fork_events, supports_vfork_events, supports_exec_events, supports_disable_randomization, supports_qxfer_libraries_svr4, qxfer_libraries_svr4, supports_pid_to_exec_file, pid_to_exec_file, thread_name, supports_catch_syscall.
NetBSD is the first BSD and actually the first Open Source UNIX-like OS besides Linux to grow support for gdbserver.
Plan for the next milestone
Introduce AArch64 support for GDB/NetBSD.
- One in the base-system with a stack of local patches.
- One in pkgsrc with mostly build fix patches.
The base-system version of GDB (GPLv3) still relies on a set of local patches. I set a goal to reduce the local patches to bare minimum, ideally reaching no local modifications at all.
GDB changes
Over the past month I worked on gdbserver for NetBSD/amd64 and finally upstreamed it to the GDB mainline, just in time for GDB 10.
What is gdbserver? Let's quote the official GDB documentation:
gdbserver is a control program for Unix-like systems, which allows you to connect your program with a remote GDB via target remote or target extended-but without linking in the usual debugging stub.
gdbserver is not a complete replacement for the debugging stubs, because it requires essentially the same operating-system facilities that GDB itself does. In fact, a system that can run gdbserver to connect to a remote GDB could also run GDB locally! gdbserver is sometimes useful nevertheless, because it is a much smaller program than GDB itself. It is also easier to port than all of GDB, so you may be able to get started more quickly on a new system by using gdbserver. Finally, if you develop code for real-time systems, you may find that the tradeoffs involved in real-time operation make it more convenient to do as much development work as possible on another system, for example by cross-compiling. You can use gdbserver to make a similar choice for debugging.
GDB and gdbserver communicate via either a serial line or a TCP connection, using the standard GDB remote serial protocol. remote
This illustrated that gdbserver is especially useful for debugging applications on embedded and thin devices, connected to a controlling computer equipped with full distribution sources, toolchain, debugging information etc. Eventually, this approach of gdb and gdbserver can replace the native gdb plugin entirely and spawn all connections debugging sessions using this protocol. This design decision was already introduced into LLDB, where remote process plugin is the only supported program on Linux, NetBSD and highly recommended for other kernels.
I've picked amd64 as the first target as it's the easiest to develop and test.
An example debugging session looks like this:
$ uname -rms NetBSD 9.99.72 amd64 $ LC_ALL=C date Thu Sep 10 22:43:10 CEST 2020 $ ./gdbserver/gdbserver --version GNU gdbserver (GDB) 10.0.50.20200910-git Copyright (C) 2020 Free Software Foundation, Inc. gdbserver is free software, covered by the GNU General Public License. This gdbserver was configured as "x86_64-unknown-netbsd9.99" $ ./gdbserver/gdbserver localhost:1234 /usr/bin/nslookup Process /usr/bin/nslookup created; pid = 26383 Listening on port 1234
Then on the other terminal:
$ ./gdb/gdb
GNU gdb (GDB) 10.0.50.20200910-git
Copyright (C) 2020 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law.
Type "show copying" and "show warranty" for details.
This GDB was configured as "x86_64-unknown-netbsd9.99".
Type "show configuration" for configuration details.
For bug reporting instructions, please see:
.
Find the GDB manual and other documentation resources online at:
--Type for more, q to quit, c to continue without paging--
.
For help, type "help".
Type "apropos word" to search for commands related to "word".
(gdb) target remote localhost:1234
Remote debugging using localhost:1234
Reading /usr/bin/nslookup from remote target...
warning: File transfers from remote targets can be slow. Use "set sysroot" to access files locally instead.
Reading /usr/bin/nslookup from remote target...
Reading symbols from target:/usr/bin/nslookup...
Reading /usr/bin/nslookup.debug from remote target...
Reading /usr/bin/.debug/nslookup.debug from remote target...
Reading /usr/libdata/debug//usr/bin/nslookup.debug from remote target...
Reading /usr/libdata/debug//usr/bin/nslookup.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/bin/nslookup.debug...
process 28353 is executing new program: /usr/bin/nslookup
Reading /usr/bin/nslookup from remote target...
Reading /usr/bin/nslookup from remote target...
Reading /usr/bin/nslookup.debug from remote target...
Reading /usr/bin/.debug/nslookup.debug from remote target...
Reading /usr/libdata/debug//usr/bin/nslookup.debug from remote target...
Reading /usr/libdata/debug//usr/bin/nslookup.debug from remote target...
Reading /usr/libexec/ld.elf_so from remote target...
Reading /usr/libexec/ld.elf_so from remote target...
Reading /usr/libexec/ld.elf_so.debug from remote target...
Reading /usr/libexec/.debug/ld.elf_so.debug from remote target...
Reading /usr/libdata/debug//usr/libexec/ld.elf_so.debug from remote target...
Reading /usr/libdata/debug//usr/libexec/ld.elf_so.debug from remote target...
warning: Invalid remote reply: timeout [kamil: repeated multiple times...]
Reading /usr/lib/libbind9.so.15 from remote target...
Reading /usr/lib/libisccfg.so.15 from remote target...
Reading /usr/lib/libdns.so.15 from remote target...
Reading /usr/lib/libns.so.15 from remote target...
Reading /usr/lib/libirs.so.15 from remote target...
Reading /usr/lib/libisccc.so.15 from remote target...
Reading /usr/lib/libisc.so.15 from remote target...
Reading /usr/lib/libkvm.so.6 from remote target...
Reading /usr/lib/libz.so.1 from remote target...
Reading /usr/lib/libblocklist.so.0 from remote target...
Reading /usr/lib/libpthread.so.1 from remote target...
Reading /usr/lib/libpthread.so.1.4.debug from remote target...
Reading /usr/lib/.debug/libpthread.so.1.4.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libpthread.so.1.4.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libpthread.so.1.4.debug from remote target...
Reading /usr/lib/libgssapi.so.11 from remote target...
Reading /usr/lib/libheimntlm.so.5 from remote target...
Reading /usr/lib/libkrb5.so.27 from remote target...
Reading /usr/lib/libcom_err.so.8 from remote target...
Reading /usr/lib/libhx509.so.6 from remote target...
Reading /usr/lib/libcrypto.so.14 from remote target...
Reading /usr/lib/libasn1.so.10 from remote target...
Reading /usr/lib/libwind.so.1 from remote target...
Reading /usr/lib/libheimbase.so.2 from remote target...
Reading /usr/lib/libroken.so.20 from remote target...
Reading /usr/lib/libsqlite3.so.1 from remote target...
Reading /usr/lib/libcrypt.so.1 from remote target...
Reading /usr/lib/libutil.so.7 from remote target...
Reading /usr/lib/libedit.so.3 from remote target...
Reading /usr/lib/libterminfo.so.2 from remote target...
Reading /usr/lib/libc.so.12 from remote target...
Reading /usr/lib/libgcc_s.so.1 from remote target...
Reading symbols from target:/usr/lib/libbind9.so.15...
Reading /usr/lib/libbind9.so.15.0.debug from remote target...
Reading /usr/lib/.debug/libbind9.so.15.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libbind9.so.15.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libbind9.so.15.0.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libbind9.so.15.0.debug...
Reading symbols from target:/usr/lib/libisccfg.so.15...
Reading /usr/lib/libisccfg.so.15.0.debug from remote target...
Reading /usr/lib/.debug/libisccfg.so.15.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libisccfg.so.15.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libisccfg.so.15.0.debug from remote target...
--Type for more, q to quit, c to continue without paging--
Reading symbols from target:/usr/libdata/debug//usr/lib/libisccfg.so.15.0.debug...
Reading symbols from target:/usr/lib/libdns.so.15...
Reading /usr/lib/libdns.so.15.0.debug from remote target...
Reading /usr/lib/.debug/libdns.so.15.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libdns.so.15.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libdns.so.15.0.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libdns.so.15.0.debug...
Reading symbols from target:/usr/lib/libns.so.15...
Reading /usr/lib/libns.so.15.0.debug from remote target...
Reading /usr/lib/.debug/libns.so.15.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libns.so.15.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libns.so.15.0.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libns.so.15.0.debug...
Reading symbols from target:/usr/lib/libirs.so.15...
Reading /usr/lib/libirs.so.15.0.debug from remote target...
Reading /usr/lib/.debug/libirs.so.15.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libirs.so.15.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libirs.so.15.0.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libirs.so.15.0.debug...
Reading symbols from target:/usr/lib/libisccc.so.15...
Reading /usr/lib/libisccc.so.15.0.debug from remote target...
Reading /usr/lib/.debug/libisccc.so.15.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libisccc.so.15.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libisccc.so.15.0.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libisccc.so.15.0.debug...
Reading symbols from target:/usr/lib/libisc.so.15...
Reading /usr/lib/libisc.so.15.0.debug from remote target...
Reading /usr/lib/.debug/libisc.so.15.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libisc.so.15.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libisc.so.15.0.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libisc.so.15.0.debug...
Reading symbols from target:/usr/lib/libkvm.so.6...
Reading /usr/lib/libkvm.so.6.0.debug from remote target...
Reading /usr/lib/.debug/libkvm.so.6.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libkvm.so.6.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libkvm.so.6.0.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libkvm.so.6.0.debug...
Reading symbols from target:/usr/lib/libz.so.1...
Reading /usr/lib/libz.so.1.0.debug from remote target...
Reading /usr/lib/.debug/libz.so.1.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libz.so.1.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libz.so.1.0.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libz.so.1.0.debug...
Reading symbols from target:/usr/lib/libblocklist.so.0...
Reading /usr/lib/libblocklist.so.0.0.debug from remote target...
Reading /usr/lib/.debug/libblocklist.so.0.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libblocklist.so.0.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libblocklist.so.0.0.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libblocklist.so.0.0.debug...
Reading symbols from target:/usr/lib/libgssapi.so.11...
Reading /usr/lib/libgssapi.so.11.0.debug from remote target...
Reading /usr/lib/.debug/libgssapi.so.11.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libgssapi.so.11.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libgssapi.so.11.0.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libgssapi.so.11.0.debug...
Reading symbols from target:/usr/lib/libheimntlm.so.5...
Reading /usr/lib/libheimntlm.so.5.0.debug from remote target...
Reading /usr/lib/.debug/libheimntlm.so.5.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libheimntlm.so.5.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libheimntlm.so.5.0.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libheimntlm.so.5.0.debug...
Reading symbols from target:/usr/lib/libkrb5.so.27...
Reading /usr/lib/libkrb5.so.27.0.debug from remote target...
Reading /usr/lib/.debug/libkrb5.so.27.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libkrb5.so.27.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libkrb5.so.27.0.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libkrb5.so.27.0.debug...
Reading symbols from target:/usr/lib/libcom_err.so.8...
Reading /usr/lib/libcom_err.so.8.0.debug from remote target...
Reading /usr/lib/.debug/libcom_err.so.8.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libcom_err.so.8.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libcom_err.so.8.0.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libcom_err.so.8.0.debug...
Reading symbols from target:/usr/lib/libhx509.so.6...
Reading /usr/lib/libhx509.so.6.0.debug from remote target...
Reading /usr/lib/.debug/libhx509.so.6.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libhx509.so.6.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libhx509.so.6.0.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libhx509.so.6.0.debug...
Reading symbols from target:/usr/lib/libcrypto.so.14...
Reading /usr/lib/libcrypto.so.14.0.debug from remote target...
Reading /usr/lib/.debug/libcrypto.so.14.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libcrypto.so.14.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libcrypto.so.14.0.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libcrypto.so.14.0.debug...
Reading symbols from target:/usr/lib/libasn1.so.10...
Reading /usr/lib/libasn1.so.10.0.debug from remote target...
Reading /usr/lib/.debug/libasn1.so.10.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libasn1.so.10.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libasn1.so.10.0.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libasn1.so.10.0.debug...
Reading symbols from target:/usr/lib/libwind.so.1...
Reading /usr/lib/libwind.so.1.0.debug from remote target...
Reading /usr/lib/.debug/libwind.so.1.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libwind.so.1.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libwind.so.1.0.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libwind.so.1.0.debug...
Reading symbols from target:/usr/lib/libheimbase.so.2...
Reading /usr/lib/libheimbase.so.2.0.debug from remote target...
Reading /usr/lib/.debug/libheimbase.so.2.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libheimbase.so.2.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libheimbase.so.2.0.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libheimbase.so.2.0.debug...
Reading symbols from target:/usr/lib/libroken.so.20...
Reading /usr/lib/libroken.so.20.0.debug from remote target...
Reading /usr/lib/.debug/libroken.so.20.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libroken.so.20.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libroken.so.20.0.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libroken.so.20.0.debug...
Reading symbols from target:/usr/lib/libsqlite3.so.1...
Reading /usr/lib/libsqlite3.so.1.4.debug from remote target...
Reading /usr/lib/.debug/libsqlite3.so.1.4.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libsqlite3.so.1.4.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libsqlite3.so.1.4.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libsqlite3.so.1.4.debug...
Reading symbols from target:/usr/lib/libcrypt.so.1...
Reading /usr/lib/libcrypt.so.1.0.debug from remote target...
Reading /usr/lib/.debug/libcrypt.so.1.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libcrypt.so.1.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libcrypt.so.1.0.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libcrypt.so.1.0.debug...
Reading symbols from target:/usr/lib/libutil.so.7...
Reading /usr/lib/libutil.so.7.24.debug from remote target...
Reading /usr/lib/.debug/libutil.so.7.24.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libutil.so.7.24.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libutil.so.7.24.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libutil.so.7.24.debug...
Reading symbols from target:/usr/lib/libedit.so.3...
Reading /usr/lib/libedit.so.3.1.debug from remote target...
Reading /usr/lib/.debug/libedit.so.3.1.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libedit.so.3.1.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libedit.so.3.1.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libedit.so.3.1.debug...
Reading symbols from target:/usr/lib/libterminfo.so.2...
Reading /usr/lib/libterminfo.so.2.0.debug from remote target...
Reading /usr/lib/.debug/libterminfo.so.2.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libterminfo.so.2.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libterminfo.so.2.0.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libterminfo.so.2.0.debug...
Reading symbols from target:/usr/lib/libc.so.12...
Reading /usr/lib/libc.so.12.217.debug from remote target...
Reading /usr/lib/.debug/libc.so.12.217.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libc.so.12.217.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libc.so.12.217.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libc.so.12.217.debug...
Reading symbols from target:/usr/lib/libgcc_s.so.1...
Reading /usr/lib/libgcc_s.so.1.0.debug from remote target...
Reading /usr/lib/.debug/libgcc_s.so.1.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libgcc_s.so.1.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/libgcc_s.so.1.0.debug from remote target...
Reading symbols from target:/usr/libdata/debug//usr/lib/libgcc_s.so.1.0.debug...
Reading /usr/libexec/ld.elf_so from remote target...
_rtld_debug_state () at /usr/src/libexec/ld.elf_so/rtld.c:1577
1577 __insn_barrier();
(gdb) b main
Breakpoint 1 at 0x211c00: file /usr/src/external/mpl/bind/bin/nslookup/../../dist/bin/dig/nslookup.c, line 990.
(gdb) c
Continuing.
Breakpoint 1, main (argc=1, argv=0x7f7fffffe768)
at /usr/src/external/mpl/bind/bin/nslookup/../../dist/bin/dig/nslookup.c:990
990 main(int argc, char **argv) {
(gdb) bt
#0 main (argc=1, argv=0x7f7fffffe768)
at /usr/src/external/mpl/bind/bin/nslookup/../../dist/bin/dig/nslookup.c:990
(gdb) info threads
Id Target Id Frame
* 1 Thread 28353.28353 main (argc=1, argv=0x7f7fffffe768)
at /usr/src/external/mpl/bind/bin/nslookup/../../dist/bin/dig/nslookup.c:990
(gdb) b pthread_setname_np
Breakpoint 2 at 0x7f7ff4e0c9e4: file /usr/src/lib/libpthread/pthread.c, line 792.
(gdb) c
Continuing.
[New Thread 28353.27773]
Thread 1 hit Breakpoint 2, pthread_setname_np (thread=0x7f7ff7e41000,
name=name@entry=0x7f7fffffe610 "work-0", arg=arg@entry=0x0)
at /usr/src/lib/libpthread/pthread.c:792
792 {
(gdb) info threads
Id Target Id Frame
* 1 Thread 28353.28353 pthread_setname_np (thread=0x7f7ff7e41000,
name=name@entry=0x7f7fffffe610 "work-0", arg=arg@entry=0x0)
at /usr/src/lib/libpthread/pthread.c:792
2 Thread 28353.27773 0x00007f7ff0aa623a in ___lwp_park60 () from target:/usr/lib/libc.so.12
(gdb) n
796 pthread__error(EINVAL, "Invalid thread",
(gdb) n
799 if (pthread__find(thread) != 0)
(gdb)
802 namelen = snprintf(newname, sizeof(newname), name, arg);
(gdb)
803 if (namelen >= PTHREAD_MAX_NAMELEN_NP)
(gdb)
806 cp = strdup(newname);
(gdb)
807 if (cp == NULL)
(gdb)
810 pthread_mutex_lock(&thread->pt_lock);
(gdb)
811 oldname = thread->pt_name;
(gdb)
812 thread->pt_name = cp;
(gdb)
813 (void)_lwp_setname(thread->pt_lid, cp);
(gdb)
814 pthread_mutex_unlock(&thread->pt_lock);
(gdb) n
816 if (oldname != NULL)
(gdb) n
isc_taskmgr_create (mctx=, workers=workers@entry=1, default_quantum=,
default_quantum@entry=0, nm=nm@entry=0x0, managerp=managerp@entry=0x418638 )
at /usr/src/external/mpl/bind/lib/libisc/../../dist/lib/isc/task.c:1431
1431 for (i = 0; i < workers; i++) {
(gdb) info threads
Id Target Id Frame
* 1 Thread 28353.28353 isc_taskmgr_create (mctx=, workers=workers@entry=1,
default_quantum=, default_quantum@entry=0, nm=nm@entry=0x0,
managerp=managerp@entry=0x418638 )
at /usr/src/external/mpl/bind/lib/libisc/../../dist/lib/isc/task.c:1431
2 Thread 28353.27773 "work-0" 0x00007f7ff0aa623a in ___lwp_park60 ()
from target:/usr/lib/libc.so.12
(gdb) dis 1
(gdb) b exit
Breakpoint 3 at 0x7f7ff0b530e0: exit. (2 locations)
(gdb) c
Continuing.
Thread 1 hit Breakpoint 2, pthread_setname_np (thread=0x7f7ff7e42c00,
name=name@entry=0x7f7ff5e6324e "isc-timer", arg=arg@entry=0x0)
at /usr/src/lib/libpthread/pthread.c:792
792 {
(gdb) dis 2
(gdb) c
Continuing.
Reading /usr/lib/i18n/libUTF8.so.5.0 from remote target...
Reading /usr/lib/i18n/libUTF8.so.5.0.debug from remote target...
Reading /usr/lib/i18n/.debug/libUTF8.so.5.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/i18n/libUTF8.so.5.0.debug from remote target...
Reading /usr/libdata/debug//usr/lib/i18n/libUTF8.so.5.0.debug from remote target...
Then, back to the first terminal:
> netbsd.org Server: 62.179.1.62 Address: 62.179.1.62#53 Non-authoritative answer: Name: netbsd.org Address: 199.233.217.205 Name: netbsd.org Address: 2001:470:a085:999::80 > exit
Thread 1 hit Breakpoint 3, exit (status=1) at /usr/src/lib/libc/stdlib/exit.c:55
55 {
(gdb) info threads
Id Target Id Frame
* 1 Thread 28353.28353 exit (status=1) at /usr/src/lib/libc/stdlib/exit.c:55
(gdb) bt
#0 exit (status=1) at /usr/src/lib/libc/stdlib/exit.c:55
#1 0x0000000000206122 in ___start ()
#2 0x00007f7ff7c0c840 in ?? () from target:/usr/libexec/ld.elf_so
#3 0x0000000000000001 in ?? ()
#4 0x00007f7fffffed20 in ?? ()
#5 0x0000000000000000 in ?? ()
(gdb) kill
Kill the program being debugged? (y or n) y
[Inferior 1 (process 28353) killed]
It worked!
In order to get this functionality operational I had to implement multiple GDB functions, in particular: create_inferior, post_create_inferior, attach, kill, detach, mourn, join, thread_alive, resume, wait, fetch_registers, store_registers, read_memory, write_memory, request_interrupt, supports_read_auxv, read_auxv, supports_hardware_single_step, sw_breakpoint_from_kind, supports_z_point_type, insert_point, remove_point, stopped_by_sw_breakpoint, supports_qxfer_siginfo, qxfer_siginfo, supports_stopped_by_sw_breakpoint, supports_non_stop, supports_multi_process, supports_fork_events, supports_vfork_events, supports_exec_events, supports_disable_randomization, supports_qxfer_libraries_svr4, qxfer_libraries_svr4, supports_pid_to_exec_file, pid_to_exec_file, thread_name, supports_catch_syscall.
NetBSD is the first BSD and actually the first Open Source UNIX-like OS besides Linux to grow support for gdbserver.
Plan for the next milestone
Introduce AArch64 support for GDB/NetBSD.
This report was written by Apurva Nandan as part of Google Summer of Code 2020.
Introduction
This blog post is in continuation of GSoC Reports: Benchmarking NetBSD, first evaluation report and GSoC Reports: Benchmarking NetBSD, second evaluation report blogs, and describes my progress in the final phase of GSoC 2020 under The NetBSD Foundation.
In the third phase, I upgraded to the latest stable version Phoronix Test Suite (PTS) 9.8.0 in pkgsrc-wip, resolved the TODOs and created patches for more test-profiles to fix their installation and runtime errors on NetBSD-current.
Progress in the third phase of GSoC
wip/phoronix-test-suite TODO and update
As a newer stable version of the Phoronix Test Suite was available in upstream, I upgraded the Phoronix Test Suite from version 9.6.1 to 9.8.0 in pkgsrc-wip and is available as wip/phoronix-test-suite. You can have a look at the PTS Changelog to know about the improvements between these two versions.
To get the package ready for merge in pkgsrc upstream, I also resolved the pkgsrc-wip TODOs.
pkgsrc-wip commits:
If any new problems are encountered, please document them in
wip/phoronix-test-suite/TODO file and/or contact me.
Testing of automated benchmarking framework
I had been assigned a remote testing machine having Intel 6138 dual processor, 40 cores, 80 threads, 192GB of RAM. I spent time reproducing my automated framework i.e., Phoromatic-Anita Integration on the machine. I was able to reproduce the integration framework working without networking configuration, but the network bridge needs to be setup on the remote machine and the integration script to be tested with it. I shall continue this task in the post-GSoC period.
Benchmarking Results
I also performed benchmarking of NetBSD-9 amd64 native installation by running 50 test-profiles on a remote machine assigned to me by mentors and uploaded the benchmark results to OpenBenchmarking.org at:
Test-profile debugging
I then continued the task of maintaining/porting test-profiles and fixed the following test-profiles:
Timed FFmpeg Compilation
This test times how long it takes to build FFmpeg.
This test is part of Processor Test category.
Original Test-profile:
https://openbenchmarking.org/test/pts/build-ffmpeg
Patched Test-profile:
https://github.com/apurvanandan1997/pts-test-profiles-dev/tree/master/build-ffmpeg-1.0.1
Commit:
Compile Bench
Compilebench tries to age a filesystem by simulating some of the disk
IO common in creating, compiling, patching, stating and reading kernel
trees. It indirectly measures how well filesystems can maintain
directory locality as the disk fills up and directories age.
This test is part of Disk Test category.
Original Test-profile:
https://openbenchmarking.org/test/pts/compilebench
Patched Test-profile:
https://github.com/apurvanandan1997/pts-test-profiles-dev/tree/master/compilebench-1.0.2
Commit:
Timed MAFFT Alignment
This test performs an alignment of 100 pyruvate decarboxylase sequences.
This test is part of Processor Test category.
Original Test-profile:
https://openbenchmarking.org/test/pts/mafft
Patched Test-profile:
https://github.com/apurvanandan1997/pts-test-profiles-dev/tree/master/mafft-1.5.0
Commits:
- Replaced the make -> gmake for compatibility with NetBSD
- Patch for replacing /bin/bash interpreter with /usr/pkg/bin/bash
Future Plans
This officially summarizes my GSoC project: Benchmark NetBSD, and my end goal of the project that is to integrate Phoronix Test Suite with NetBSD and Anita for automated benchmarking is complete and its deployment on benchmark.NetBSD.org will be continued to be worked on with the coordination of moderators and merging the wip of Phoronix Test Suite 9.8.0 will be done by the pkgsrc maintainers in next days.
I want to thank my mentors and the NetBSD community without whose constant support I wouldn't have achieved the goals.
This report was written by Apurva Nandan as part of Google Summer of Code 2020.
Introduction
This blog post is in continuation of GSoC Reports: Benchmarking NetBSD, first evaluation report and GSoC Reports: Benchmarking NetBSD, second evaluation report blogs, and describes my progress in the final phase of GSoC 2020 under The NetBSD Foundation.
In the third phase, I upgraded to the latest stable version Phoronix Test Suite (PTS) 9.8.0 in pkgsrc-wip, resolved the TODOs and created patches for more test-profiles to fix their installation and runtime errors on NetBSD-current.
Progress in the third phase of GSoC
wip/phoronix-test-suite TODO and update
As a newer stable version of the Phoronix Test Suite was available in upstream, I upgraded the Phoronix Test Suite from version 9.6.1 to 9.8.0 in pkgsrc-wip and is available as wip/phoronix-test-suite. You can have a look at the PTS Changelog to know about the improvements between these two versions.
To get the package ready for merge in pkgsrc upstream, I also resolved the pkgsrc-wip TODOs.
pkgsrc-wip commits:
If any new problems are encountered, please document them in
wip/phoronix-test-suite/TODO file and/or contact me.
Testing of automated benchmarking framework
I had been assigned a remote testing machine having Intel 6138 dual processor, 40 cores, 80 threads, 192GB of RAM. I spent time reproducing my automated framework i.e., Phoromatic-Anita Integration on the machine. I was able to reproduce the integration framework working without networking configuration, but the network bridge needs to be setup on the remote machine and the integration script to be tested with it. I shall continue this task in the post-GSoC period.
Benchmarking Results
I also performed benchmarking of NetBSD-9 amd64 native installation by running 50 test-profiles on a remote machine assigned to me by mentors and uploaded the benchmark results to OpenBenchmarking.org at:
Test-profile debugging
I then continued the task of maintaining/porting test-profiles and fixed the following test-profiles:
Timed FFmpeg Compilation
This test times how long it takes to build FFmpeg.
This test is part of Processor Test category.
Original Test-profile:
https://openbenchmarking.org/test/pts/build-ffmpeg
Patched Test-profile:
https://github.com/apurvanandan1997/pts-test-profiles-dev/tree/master/build-ffmpeg-1.0.1
Commit:
Compile Bench
Compilebench tries to age a filesystem by simulating some of the disk
IO common in creating, compiling, patching, stating and reading kernel
trees. It indirectly measures how well filesystems can maintain
directory locality as the disk fills up and directories age.
This test is part of Disk Test category.
Original Test-profile:
https://openbenchmarking.org/test/pts/compilebench
Patched Test-profile:
https://github.com/apurvanandan1997/pts-test-profiles-dev/tree/master/compilebench-1.0.2
Commit:
Timed MAFFT Alignment
This test performs an alignment of 100 pyruvate decarboxylase sequences.
This test is part of Processor Test category.
Original Test-profile:
https://openbenchmarking.org/test/pts/mafft
Patched Test-profile:
https://github.com/apurvanandan1997/pts-test-profiles-dev/tree/master/mafft-1.5.0
Commits:
- Replaced the make -> gmake for compatibility with NetBSD
- Patch for replacing /bin/bash interpreter with /usr/pkg/bin/bash
Future Plans
This officially summarizes my GSoC project: Benchmark NetBSD, and my end goal of the project that is to integrate Phoronix Test Suite with NetBSD and Anita for automated benchmarking is complete and its deployment on benchmark.NetBSD.org will be continued to be worked on with the coordination of moderators and merging the wip of Phoronix Test Suite 9.8.0 will be done by the pkgsrc maintainers in next days.
I want to thank my mentors and the NetBSD community without whose constant support I wouldn't have achieved the goals.
My GSoC project under NetBSD involves the development of the test framework of curses. This is the final blog report in a series of blog reports; you can look at the first report and second report of the series.
The first report gives a brief introduction of the project and some insights into the curses testframe through its architecture and language. To someone who wants to contribute to the test suite, this blog can act as the quick guide of how things work internally. Meanwhile, the second report discusses some of the concepts that were quite challenging for me to understand. I wanted to share them with those who may face such a challenge. Both of these reports also cover the progress made in various phases of the Summer of Code.
This being the final report in the series, I would love to share my experience throughout the project. I would be sharing some of the learning as well as caveats that I faced in the project.
Challenges and Caveats
By the time my application for GSoC was submitted, I had gained some knowledge about the curses library and the testing framework. Combined with compiler design and library testing experience, that knowledge proved useful but not sufficient as I progressed through the project. There were times when, while writing a test case, you have to look into documentation from various sources, be it NetBSD, FreeBSD, Linux, Solaris, etc. One may find questioning his understanding of the framework, documentation, or even curses itself. This leads to the conclusion that for being a tester, one has to become a user first. That made me write minimal programs to understand the behavior. The experience was excellent, and I felt amazed by the capability and complexity of curses.
Learnings
The foremost learning is from the experience of interacting with the open-source community and feeling confident in my abilities to contribute. Understanding the workflows; following the best practices like considering the maintainability, readability, and simplicity of the code were significant learning.
The project-specific learning was not limited to test-framework but a deeper understanding of curses as I have to browse through codes for the functions tested. As this blog says, getting the TTY demystified was a long-time desire, which got fulfilled to some extent.
Some tests from test suite
In this section, I would discuss a couple of tests of the test suite written during the third phase of GSoC. Curses input model provides a variety of ways to obtain input from keyboard. We will consider 2 tests keypad and halfdelay that belong to input processing category but are somewhat unrelated.
Keypad Processing
An application can enable or disable the tarnslation of keypad using keypad() function. When translation is enabled, curses attempts to translate input sequence into a single key code. If disabled, curses passes the input as it is and any interpretation has to be made by application.
include window
call $FALSE is_keypad $win1
input "\eOA"
call 0x1b wgetch $win1
call OK keypad $win1 $TRUE
input "\eOA"
call $KEY_UP wgetch $win1
# disable assembly of KEY_UP
call OK keyok $KEY_UP $FALSE
input "\eOA"
call 0x1b wgetch $win1
As keypad translation is disabled by default, on input of '\eOA', the input sequence is passed as it is and only '\e' (0x1b is hex code) is received on wgetch(). If we enable the translation, then the same input is translated as KEY_UP. In curses, one can disable assembly of specific key symbols using keyok(). See related man page.
Input Mode
Curses lets the application control the effect of input using four input modes; cooked, cbreak, half-delay, raw. They specify the effect of input in terms of echo-ing and delay. We will discuss about the halfdelay mode. The half-delay mode specifies how quickly certain curses function return to application when there is no terminal input waiting since the function is called.
include start
delay 1000
# input delay 1000 equals to 10 tenths of seconds
# getch must fail for halfdelay(5) and pass for halfdelay(15)
input "a"
call OK halfdelay 15
call 0x61 getch
call OK halfdelay 5
input "a"
call -1 getch
We have set the delay for feeding input to terminal with delay of 1s(10 tenths of second). If the application sets the halfdelay to 15, and makes a call to getch() it receives the input. But it fails to get the input with haldelay set to 5. See related man page.
Project Work
The work can be merged into organisation repository https://github.com/NetBSD/src under tests/lib/libcurses.
This project involved:
- Improvement in testframework:
- Automation of the checkfile generation.
- Enhnacement of support for complex character
- Addition of small features and code refactoring
- Testing and bug reports:
- Tests for a family of routines like wide character, complex character, line drawing, box drawing, pad, window operations, cursor manipulations, soft label keys, input-output stream, and the ones involving their interactions.
- Raising a bunch of Problem Report (PR) under
libcategory some of which have been fixed. The list of PRs raised can be found here
Future Work
- The current testframe supports complex character, but the support needs to be extended for its string. This will enable testing of
[mv][w]add_wch[n]str,[mv][w]in_wchstrfamily of routines. - Some of the tests for teminal manipulation routines like
intrflush,def_prog_mode,typeahead,raw, etc. are not there in test suite. - Not specifically related to the framework, but the documentation for wide character as well as complex character routines need to be added.
Acknowledgements
I want to extend my heartfelt gratitude to my mentor Mr. Brett Lymn, who helped me through all the technical difficulties and challenges I faced. I also thank my mentor Martin Huseman for valuable suggestions and guidance at various junctures of the project. A special thanks to Kamil Rytarowski for making my blogs published on the NetBSD site.
My GSoC project under NetBSD involves the development of the test framework of curses. This is the final blog report in a series of blog reports; you can look at the first report and second report of the series.
The first report gives a brief introduction of the project and some insights into the curses testframe through its architecture and language. To someone who wants to contribute to the test suite, this blog can act as the quick guide of how things work internally. Meanwhile, the second report discusses some of the concepts that were quite challenging for me to understand. I wanted to share them with those who may face such a challenge. Both of these reports also cover the progress made in various phases of the Summer of Code.
This being the final report in the series, I would love to share my experience throughout the project. I would be sharing some of the learning as well as caveats that I faced in the project.
Challenges and Caveats
By the time my application for GSoC was submitted, I had gained some knowledge about the curses library and the testing framework. Combined with compiler design and library testing experience, that knowledge proved useful but not sufficient as I progressed through the project. There were times when, while writing a test case, you have to look into documentation from various sources, be it NetBSD, FreeBSD, Linux, Solaris, etc. One may find questioning his understanding of the framework, documentation, or even curses itself. This leads to the conclusion that for being a tester, one has to become a user first. That made me write minimal programs to understand the behavior. The experience was excellent, and I felt amazed by the capability and complexity of curses.
Learnings
The foremost learning is from the experience of interacting with the open-source community and feeling confident in my abilities to contribute. Understanding the workflows; following the best practices like considering the maintainability, readability, and simplicity of the code were significant learning.
The project-specific learning was not limited to test-framework but a deeper understanding of curses as I have to browse through codes for the functions tested. As this blog says, getting the TTY demystified was a long-time desire, which got fulfilled to some extent.
Some tests from test suite
In this section, I would discuss a couple of tests of the test suite written during the third phase of GSoC. Curses input model provides a variety of ways to obtain input from keyboard. We will consider 2 tests keypad and halfdelay that belong to input processing category but are somewhat unrelated.
Keypad Processing
An application can enable or disable the tarnslation of keypad using keypad() function. When translation is enabled, curses attempts to translate input sequence into a single key code. If disabled, curses passes the input as it is and any interpretation has to be made by application.
include window
call $FALSE is_keypad $win1
input "\eOA"
call 0x1b wgetch $win1
call OK keypad $win1 $TRUE
input "\eOA"
call $KEY_UP wgetch $win1
# disable assembly of KEY_UP
call OK keyok $KEY_UP $FALSE
input "\eOA"
call 0x1b wgetch $win1
As keypad translation is disabled by default, on input of '\eOA', the input sequence is passed as it is and only '\e' (0x1b is hex code) is received on wgetch(). If we enable the translation, then the same input is translated as KEY_UP. In curses, one can disable assembly of specific key symbols using keyok(). See related man page.
Input Mode
Curses lets the application control the effect of input using four input modes; cooked, cbreak, half-delay, raw. They specify the effect of input in terms of echo-ing and delay. We will discuss about the halfdelay mode. The half-delay mode specifies how quickly certain curses function return to application when there is no terminal input waiting since the function is called.
include start
delay 1000
# input delay 1000 equals to 10 tenths of seconds
# getch must fail for halfdelay(5) and pass for halfdelay(15)
input "a"
call OK halfdelay 15
call 0x61 getch
call OK halfdelay 5
input "a"
call -1 getch
We have set the delay for feeding input to terminal with delay of 1s(10 tenths of second). If the application sets the halfdelay to 15, and makes a call to getch() it receives the input. But it fails to get the input with haldelay set to 5. See related man page.
Project Work
The work can be merged into organisation repository https://github.com/NetBSD/src under tests/lib/libcurses.
This project involved:
- Improvement in testframework:
- Automation of the checkfile generation.
- Enhnacement of support for complex character
- Addition of small features and code refactoring
- Testing and bug reports:
- Tests for a family of routines like wide character, complex character, line drawing, box drawing, pad, window operations, cursor manipulations, soft label keys, input-output stream, and the ones involving their interactions.
- Raising a bunch of Problem Report (PR) under
libcategory some of which have been fixed. The list of PRs raised can be found here
Future Work
- The current testframe supports complex character, but the support needs to be extended for its string. This will enable testing of
[mv][w]add_wch[n]str,[mv][w]in_wchstrfamily of routines. - Some of the tests for teminal manipulation routines like
intrflush,def_prog_mode,typeahead,raw, etc. are not there in test suite. - Not specifically related to the framework, but the documentation for wide character as well as complex character routines need to be added.
Acknowledgements
I want to extend my heartfelt gratitude to my mentor Mr. Brett Lymn, who helped me through all the technical difficulties and challenges I faced. I also thank my mentor Martin Huseman for valuable suggestions and guidance at various junctures of the project. A special thanks to Kamil Rytarowski for making my blogs published on the NetBSD site.
This post is the third update to the project RumpKernel Syscall Fuzzing.
Part1 - https://blog.netbsd.org/tnf/entry/gsoc_reports_fuzzing_rumpkernel_syscalls1
Part2 - https://blog.netbsd.org/tnf/entry/gsoc_reports_fuzzing_rumpkernel_syscalls
The first and second coding period was entirely dedicated to fuzzing rumpkernel syscalls using hongfuzz. Initially a dumb fuzzer was developed to start fuzzing but it soon reached its limits.
For the duration of second coding peroid we concentrated on crash reproduction and adding grammar to the fuzzer which yielded in better results as we tested on a bug in ioctl with grammar. Although this works for now crash reproduction needs to be improved to generate a working c reproducer.
For the last coding period I have looked into the internals of syzkaller to understand how it pregenerates input and how it mutates data. I have continued to work on integrating buildrump.sh with build.sh. buildrump eases the task fo building the rumpkernel on any host for any target.
buildrump.sh is like a wrapper around build.sh to build the tools and rumpkernel from the source relevant to rumpkernel. So I worked to get buildrump.sh working with netbsd-src. Building the toolchain was successfull from netbsd-src. So binaries like rumpmake work just fine to continue building the rumpkernel.
But the rumpkernel failed to build due to some warnings and errors similar to the following. It can be due to the fact that buildrump.sh has been dormant recently I faced a lot of build issues.
nbmake[2]: nbmake[2]: don't know how to make /root/buildrump.sh/obj/dest.stage/usr/lib/crti.o. Stop
nbmake[2]: stopped in /root/buildrump.sh/src/lib/librumpuser
>> ERROR:
>> make /root/buildrump.sh/obj/Makefile.first dependall
Few of the similar errors were easily fixed but I couldn't integrate it during the time span of the coding period.
To Do
- Research more on grammar definition and look into the existing grammar fuzzers for a better understanding of generating grammar.
- Integrate syz2sys with the existing fuzzer to include grammar generation for better results.
GSoC with NetBSD has been an amazing journey throughout, in which I had a chance to learn from awesome people and work on amazing projects. I will continue to work on the project to achieve the goal of integrating my fuzzer with OSS Fuzz. I thank my mentors Siddharth Muralee, Maciej Grochowski, Christos Zoulas for their support and Kamil for his continuous guidance.
This post is the third update to the project RumpKernel Syscall Fuzzing.
Part1 - https://blog.netbsd.org/tnf/entry/gsoc_reports_fuzzing_rumpkernel_syscalls1
Part2 - https://blog.netbsd.org/tnf/entry/gsoc_reports_fuzzing_rumpkernel_syscalls
The first and second coding period was entirely dedicated to fuzzing rumpkernel syscalls using hongfuzz. Initially a dumb fuzzer was developed to start fuzzing but it soon reached its limits.
For the duration of second coding peroid we concentrated on crash reproduction and adding grammar to the fuzzer which yielded in better results as we tested on a bug in ioctl with grammar. Although this works for now crash reproduction needs to be improved to generate a working c reproducer.
For the last coding period I have looked into the internals of syzkaller to understand how it pregenerates input and how it mutates data. I have continued to work on integrating buildrump.sh with build.sh. buildrump eases the task fo building the rumpkernel on any host for any target.
buildrump.sh is like a wrapper around build.sh to build the tools and rumpkernel from the source relevant to rumpkernel. So I worked to get buildrump.sh working with netbsd-src. Building the toolchain was successfull from netbsd-src. So binaries like rumpmake work just fine to continue building the rumpkernel.
But the rumpkernel failed to build due to some warnings and errors similar to the following. It can be due to the fact that buildrump.sh has been dormant recently I faced a lot of build issues.
nbmake[2]: nbmake[2]: don't know how to make /root/buildrump.sh/obj/dest.stage/usr/lib/crti.o. Stop
nbmake[2]: stopped in /root/buildrump.sh/src/lib/librumpuser
>> ERROR:
>> make /root/buildrump.sh/obj/Makefile.first dependall
Few of the similar errors were easily fixed but I couldn't integrate it during the time span of the coding period.
To Do
- Research more on grammar definition and look into the existing grammar fuzzers for a better understanding of generating grammar.
- Integrate syz2sys with the existing fuzzer to include grammar generation for better results.
GSoC with NetBSD has been an amazing journey throughout, in which I had a chance to learn from awesome people and work on amazing projects. I will continue to work on the project to achieve the goal of integrating my fuzzer with OSS Fuzz. I thank my mentors Siddharth Muralee, Maciej Grochowski, Christos Zoulas for their support and Kamil for his continuous guidance.
For more than 20 years, NetBSD has shipped X11 with the "classic" default window manager of twm. However, it's been showing its age for a long time now.
In 2015, ctwm was imported, but after that no progress was made. ctwm is a fork of twm with some extra features - the primary advantages are that it's still incredibly lightweight, but highly configurable, and has support for virtual desktops, as well as a NetBSD-compatible license and ongoing development. Thanks to its configuration options, we can provide a default experience that's much more usable to people experienced with other operating systems.
Recently, I've been installing NetBSD with some people in real life and was inspired by their reactions to the default twm to improve the situation, so I played with ctwm, wrote a config, and used it myself for a week. It's now the default in NetBSD-current.

We gain some nice features like an auto-generated application menu (that will fill up as packages are installed to /usr/pkg), and a range of useful keyboard shortcuts including volume controls - the default config should be fully usable without a mouse. It should also work at a range of screen resolutions. We can add HiDPI support after some larger bitmap fonts are imported - another advantage of ctwm is that we can support very slow and very fast hardware with one config.
If you're curious about ctwm, check out the ctwm website. It's also included in previous NetBSD releases, though not as the default window manager and not with this config.
For more than 20 years, NetBSD has shipped X11 with the "classic" default window manager of twm. However, it's been showing its age for a long time now.
In 2015, ctwm was imported, but after that no progress was made. ctwm is a fork of twm with some extra features - the primary advantages are that it's still incredibly lightweight, but highly configurable, and has support for virtual desktops, as well as a NetBSD-compatible license and ongoing development. Thanks to its configuration options, we can provide a default experience that's much more usable to people experienced with other operating systems.
Recently, I've been installing NetBSD with some people in real life and was inspired by their reactions to the default twm to improve the situation, so I played with ctwm, wrote a config, and used it myself for a week. It's now the default in NetBSD-current.
We gain some nice features like an auto-generated application menu (that will fill up as packages are installed to /usr/pkg), and a range of useful keyboard shortcuts including volume controls - the default config should be fully usable without a mouse. It should also work at a range of screen resolutions. We can add HiDPI support after some larger bitmap fonts are imported - another advantage of ctwm is that we can support very slow and very fast hardware with one config.
If you're curious about ctwm, check out the ctwm website. It's also included in previous NetBSD releases, though not as the default window manager and not with this config.
After I posted about the new default window manager in NetBSD I got a few questions, including "when is NetBSD switching from X11 to Wayland?", Wayland being X11's "new" rival. In this blog post, hopefully I can explain why we aren't yet!
Last year (and early this year) I was responsible for porting the first working Wayland compositor to NetBSD - swc. I chose it because it looked small and hackable. You can try it out by installing the velox window manager from pkgsrc.

Difficulties
In a Wayland system, the "compositor" (display server) is responsible for managing displays, input, and window management. Generally, this means a lot of OS-specific code is contained there.
Wayland does not define protocols for features X11 users expect, like screenshots, screen locking, or window management. Either you implement these inside the compositor (lots of work that has to be redone), or you define your own protocol extension.
The Wayland "reference implementation" is a small set of libraries that can be used to build a compositor or a client application. These libraries currently have hard dependencies on Linux kernel APIs like epoll. In pkgsrc we've patched the libraries to add kqueue(2) support, but the patches haven't been accepted upstream. Wayland is written with the assumption of Linux to the extent that every client application tends to #include <linux/input.h> because Wayland's designers didn't see the need to define a OS-neutral way to get mouse button IDs.
So far, all Wayland compositors but swc have a hard dependency on libinput, which only supports Linux's input API (also cloned in FreeBSD). In NetBSD we have an entirely different input API - wscons(4). wscons is actually fairly simple to write code for, someone just needs to go out there and do it. You can use my code in swc as a reference.
In general, Wayland is moving away from the modularity, portability, and standardization of the X server.
Is it ready for production?
No, but you can play with it.
- swc has some remaining bugs and instability.
- swc is incompatible with key applications like Firefox, but others like Luakit work, as do most things that use Qt5, GTK3, or SDL2. Not being able to run X11 applications currently is quite limiting.
- Other popular compositors are not yet available. Alternatively, someone could write some new ones.
- You need a supported GPU or SoC with kernel modesetting, since safe software fallbacks don't work here. So far, I've only tested this with Intel GPUs.
Task list
- Adding support for wscons to more Wayland compositors and persuading developers to accept the patches.
- Persuading developers not to add hard dependencies on
epolland instead use an abstraction layer like libevent. - Updating the NetBSD kernel DRM/KMS stack. This is a difficult undertaking that involves porting code from the Linux kernel (a very fast moving target).
- Getting support for newer DRM versions
- Getting support for atomic modesetting
- Getting support for Glamor X servers (for running X11 applications inside wayland, etc)
- Newer AMDGPU drivers, etc
- Adding support for basic (non-DRMKMS) framebuffers to a Wayland compositor. X11 can run from a basic unaccelerated NetBSD framebuffer, but this isn't yet possible in any Wayland compositor.
- Extending swc to add more features and fix bugs.
I've decided to take a break from this, since it's a fairly huge undertaking and uphill battle. Right now, X11 combined with a compositor like picom or xcompmgr is the more mature option.
After I posted about the new default window manager in NetBSD I got a few questions, including "when is NetBSD switching from X11 to Wayland?", Wayland being X11's "new" rival. In this blog post, hopefully I can explain why we aren't yet!
Last year (and early this year) I was responsible for porting the first working Wayland compositor to NetBSD - swc. I chose it because it looked small and hackable. You can try it out by installing the velox window manager from pkgsrc.
Difficulties
In a Wayland system, the "compositor" (display server) is responsible for managing displays, input, and window management. Generally, this means a lot of OS-specific code is contained there.
Wayland does not define protocols for features X11 users expect, like screenshots, screen locking, or window management. Either you implement these inside the compositor (lots of work that has to be redone), or you define your own protocol extension.
The Wayland "reference implementation" is a small set of libraries that can be used to build a compositor or a client application. These libraries currently have hard dependencies on Linux kernel APIs like epoll. In pkgsrc we've patched the libraries to add kqueue(2) support, but the patches haven't been accepted upstream. Wayland is written with the assumption of Linux to the extent that every client application tends to #include <linux/input.h> because Wayland's designers didn't see the need to define a OS-neutral way to get mouse button IDs.
So far, all Wayland compositors but swc have a hard dependency on libinput, which only supports Linux's input API (also cloned in FreeBSD). In NetBSD we have an entirely different input API - wscons(4). wscons is actually fairly simple to write code for, someone just needs to go out there and do it. You can use my code in swc as a reference.
In general, Wayland is moving away from the modularity, portability, and standardization of the X server.
Is it ready for production?
No, but you can play with it.
- swc has some remaining bugs and instability.
- swc is incompatible with key applications like Firefox, but others like Luakit work, as do most things that use Qt5, GTK3, or SDL2. Not being able to run X11 applications currently is quite limiting.
- Other popular compositors are not yet available. Alternatively, someone could write some new ones.
- You need a supported GPU or SoC with kernel modesetting, since safe software fallbacks don't work here. So far, I've only tested this with Intel GPUs.
Task list
- Adding support for wscons to more Wayland compositors and persuading developers to accept the patches.
- Persuading developers not to add hard dependencies on
epolland instead use an abstraction layer like libevent. - Updating the NetBSD kernel DRM/KMS stack. This is a difficult undertaking that involves porting code from the Linux kernel (a very fast moving target).
- Getting support for newer DRM versions
- Getting support for atomic modesetting
- Getting support for Glamor X servers (for running X11 applications inside wayland, etc)
- Newer AMDGPU drivers, etc
- Adding support for basic (non-DRMKMS) framebuffers to a Wayland compositor. X11 can run from a basic unaccelerated NetBSD framebuffer, but this isn't yet possible in any Wayland compositor.
- Extending swc to add more features and fix bugs.
I've decided to take a break from this, since it's a fairly huge undertaking and uphill battle. Right now, X11 combined with a compositor like picom or xcompmgr is the more mature option.
No videos are available yet to provide much-needed context to presentations, but we'll keep you posted.
Day -2 - Arrival in Vienna
After being thoroughly delayed by Deutsche Bahn, I hopped off an InterCity Express train to check out the hotel room for people speaking at EuroBSDCon, which was An Experience in itself. There was a mural of a shirtless man with a sword covered in snakes next to my bed, what else do you need in life? Lots of coffee, obviously.
Begin the march to the conference to listen to Marshall Kirk McKusick lecture on schedulers.
Day -1 - NetBSD Developer Summit
Around 16 NetBSD developers gathered in a room for the first time in two years. I was a little bit distracted and late due to Marshall Kirk McKusick's very detailed lecture on filesystems melting my brain somewhat, but we had the opportunity to present various informal presentations, after we'd finished showing off suspend/resume support on our ThinkPad laptops.
Benny Siegert opened with a presentation on the state of the Go programming language on NetBSD (and whether it is "in trouble"), covering various problems with instability being detected inside the Go test suite. Go is particularly interesting (and maybe error-prone) because it mostly bypasses NetBSD libc, which is unusual for software running on NetBSD, instead preferring to implement its own wrappers around the kernel's system calls.
A few problems had been narrowed down to being (likely) AMD CPU bugs, others weren't reproducible in production (outside of the test suite) at all, and others may have been fixed in NetBSD 9.1 - the NetBSD machines running tests for Go do need to be updated. If you're from AMD, please get in touch.
We've got a very impressive test suite for NetBSD itself, but outside tests are always useful for identifying problems that we can't catch... that said, they do require a lot of work to maintain, and a lack of patience is understandable. We'd love any help we can get with this.
I pointed out that we get occasional failures bootstrapping Go in pkgsrc, and better debug output would be nice -- Benny was able to arrange this within the day, and we should get nice detailed bootstrapping logs for Go now.
Pierre Pronchery (khorben@) discussed cross-BSD collaboration on synchronizing our device driver code bases, including his recent NetBSD Foundation-supported work on the emuxki(4) sound card driver, where other BSDs have taken the same code base but improvements had not yet been universal. We all agreed that collaboration and keeping drivers in sync is important. We talked about the on-going project to synchronize NetBSD Wi-Fi drivers with FreeBSD.
Martin Kjellstrand then gave us a very nice demonstration of his NetBSD docker images, and how easy it is to spin up NetBSD on-demand to run a command (this also has wide potential for being useful for testing). In turn, I rambled a bit about my own experiments of dynamically creating NetBSD images. This would lead to a later discussion about whether we need to prioritize improving the resize_ffs(8) command's support for new filesystems.
The theme of creating NetBSD images "for the cloud" continued, with Benny Siegert presenting again about NetBSD on Google Compute Engine.
Stephen Borrill then stepped up to give us an incredibly detailed history of the British computer company Acorn Computers, complete with his personal experiences servicing Acorn machines in the early 90s. We discussed the history of the ARM CPU, and NetBSD/acorn32.
Nia Alarie (surprise) finished up with a very short unplanned demonstration of some of the projects she's been working on lately - using NetBSD as a professional digital audio workstation, improving the default graphical experience of NetBSD with dynamically generated menus, and (again) creating customized micro-images of NetBSD. We discussed support for MIDI devices (I'd later chat with some of the FreeBSD people about collaborating on JACK MIDI).
We then retired to Thomas Klausner (wiz@)'s favorite ramen restaurant and discussed, among other things, Studio Ghibli films, and trains. Trains would be a recurring theme.
Day 0 - start of talks
We began the day with two NetBSD presentations scheduled back-to-back. This mostly meant that I got to talk about some of NetBSD 10's upcoming features, and why it's taking so long to a small crowd of interested people who didn't have much prior experience with NetBSD, while in another room Taylor R. Campbell (riastradh@) discussed his very dedicated efforts to make suddenly disappearing devices more reliable and not crash the kernel (we're still waiting for a live demonstration).
Next, Pierre Pronchery (khorben@) discussed the power of pkgsrc for creating consistent environments across platforms for software developers, serving as a nice portable, classic Unix alternative to technologies like Docker and Nix.
The final presentation of the day was riastradh@ again, this time providing a live lecture (from Emacs!) about memory barriers in the kernel. We all learned to appreciate the nice abstractions technologies like mutexes provide to stop CPUs from re-ordering code on multi-processor machines in inexplicable ways.
Day 1 - final talks
The second day of EuroBSDCon presentations was mostly devoid of anything NetBSD-focused, so we had a nice opportunity for cross-pollination and to learn and collaborate with other BSD projects. I chatted a bit with an OpenBSD Ports developer about the challenge technologies like Rust pose to developing a cross-architecture packaging system, and with a FreeBSD person about the state of professional audio on our respective platforms. Michael Dexter finished the day of presentations with a very passionate speech about why we all need BSD in our lives, regardless of our preferred flavour.
More topics were discussed in the various break periods, including whether our newest update to the GPU drivers is stable enough to include in a release (verdict: works for me).
We then watched as various BSD t-shirts and boxes of chocolates were auctioned away to support a local refugee center. The organizing committee forgot to include the NetBSD Foundation on the list of sponsors, but we forgive them.
Other news from the Project
I've recently made sure the NetBSD 10 changelog is up to date with all the new goodness, so you should check that out.
Prologue
When I bought my house in 2004 I went shopping for a outside thermometer - and ended up with a full weather-station instead (a WS2300). When I unpacked it I found a serial cable inside...
Long story short - I was still in the process of recabling the house (running ethernet to every room) and added a serial cable from the machine room to the WS2300, and then did some pkgsrc work and got misc/open2300 and misc/open2300-mysql. I used those to log the data from the weather-station to a mysql database, and later moved that (via misc/open2300-pgsql) to a postgres database.
Now sometime this year the machine running that database had to be replaced (should have done that earlier, it was power hungry and wasteful). The replacement was an aarch64 SoC (a Pine64 Quartz64 model A) - and it had no real com ports (of course) any more. I had experimented with USB serial adapters and the WS2300 before, but for unclear reasons this time I had no luck and couldn't get it to work. Since some of the outdoor sensors of the old weather-station had started failing, I decided to replace it.
New Weather-Station, new Sensors
I picked a WS3500 because it comes with a nice remote sensor arrangement:

I attached it to a satellite dish mount about 1.2m above my garage and ran a two wire cable through the mount to supply it with 3V and get rid of any batteries. It does not have a connector for that, but the battery compartment had enough space for a 330µF elco and soldering that and the cable directly to the battery contacts was easy.
The sensors report to the weather-station via a proprietary protocol in the 868 MHz band.
New Weather-Station, new Reporting
The weather-station can connect to a wifi network but does not offer any services itself. The app used to configure the station offers several predefined weather collection services.
I found the idea a bit strange to have my local weather data logged to some server somewhere else in the cloud and then get it back via my browser, but for others this is a good thing. I found this article that describes exactly the remote-only, no machines required on-site setup. I used that article as inspiration for the data collection (but that part turned out to be quite trivial, see below) and copied a lot of the presentation site from it (also more details below).
So in my setup I created web servers on two dedicated ports of my tiny machine running the postgres server. One is used by the weather-station for reporting the data, the other is used to query the database.
The configuration of the weather-station for a custom server was easy:


I tested the ecowitt protocol first. It uses a post to a fixed URL and the form data has nearly identical data as we get with the solution I ended up with - only a few names (of form fields) are slightly different.
The blacked items "StationID" and "StationKey" appear verbatim in the reported data, you can set them to whatever you want - the scripts below do not check them.
The weather underground protocol does a simple http GET and provides all data as query parameters (I had to add the trailing question mark in the configuration). This makes it very easy to extract the data in a script on the server side.
But lets get there step by step. NetBSD comes with a http/https server in base, originally called "bozohttpd". It is very lightweight, but it can run various types of scripts - I picked the plain old simple CGI and /bin/sh as language, using a bit of awk to convert units.
First I added two users, so I could separate file access rights. This is how they look like in vipw:
weatherupdate:*************:1004:1004::0:0:Weather Update Service:/weather/home:/sbin/nologin weatherquery:*************:1005:1004::0:0:Weather Query Service:/weather/query:/sbin/nologinand two httpd instances for them
/etc/inetd entry to collect the incoming data:
88 stream tcp nowait:600 weatherupdate /usr/libexec/httpd httpd -q -c /weather/cgi /weather/files 89 stream tcp nowait:600 weatherquery /usr/libexec/httpd httpd -q -c /weather/cgi -M .js "text/javascript" - - /weather/files
The document root (/weather/files) would not be used for the instance on port 88, but httpd needs one.
Note that these lines use the quiet flag ("-q") which is only available in netbsd-current. You can replace it with "-s" for older versions.
The home directories of both users are mostly empty, besides a .pgpass file that contains the password for this
user connection to the postgres server. They look like this:
127.0.0.1:5432:weatherhistory:open2300:xxxxxxxxxxxxxx
where "weatherhistory" is the datebase and "open2300" is the name of the postgres user for the update script and the password is x-ed out. The other file looks very similar:
127.0.0.1:5432:weatherhistory:weatherquery:xxxxxxxxxxx
At the postgres level the user "weatherquery" needs to have SELECT privilege on the table "weather", and "open2300" needs to have INSERT privilege. The table schema (output of "pg_dump -s") looks like this:
--
-- Name: weather; Type: TABLE; Schema: public; Owner: weathermaster
--
CREATE TABLE public.weather (
"timestamp" timestamp without time zone DEFAULT '1970-01-01 00:00:00'::timestamp without time zone NOT NULL,
temp_in double precision DEFAULT '0'::double precision NOT NULL,
temp_out double precision DEFAULT '0'::double precision NOT NULL,
dewpoint double precision DEFAULT '0'::double precision NOT NULL,
rel_hum_in integer DEFAULT 0 NOT NULL,
rel_hum_out integer DEFAULT 0 NOT NULL,
windspeed double precision DEFAULT '0'::double precision NOT NULL,
wind_angle double precision DEFAULT '0'::double precision NOT NULL,
wind_chill double precision DEFAULT '0'::double precision NOT NULL,
rain_1h double precision DEFAULT '0'::double precision NOT NULL,
rain_24h double precision DEFAULT '0'::double precision NOT NULL,
rain_total double precision DEFAULT '0'::double precision NOT NULL,
rel_pressure double precision DEFAULT '0'::double precision NOT NULL,
wind_gust double precision DEFAULT 0 NOT NULL,
light double precision DEFAULT 0 NOT NULL,
uvi double precision DEFAULT 0 NOT NULL
);
ALTER TABLE public.weather OWNER TO weathermaster;
--
-- Name: weather weather_pkey; Type: CONSTRAINT; Schema: public; Owner: weathermaster
--
ALTER TABLE ONLY public.weather
ADD CONSTRAINT weather_pkey PRIMARY KEY ("timestamp");
--
-- Name: TABLE weather; Type: ACL; Schema: public; Owner: weathermaster
--
GRANT INSERT ON TABLE public.weather TO open2300;
GRANT SELECT ON TABLE public.weather TO weatherquery;
As noted above, I carried this database over (with minor modifications) from previous instances of the whole setup - so it may not be optimal or elegant. One thing that needs special attention is the "timestamp" column - it carries date/time in UTC and has no timezone associated. This looked like a natural choice, but has some unexpected consequences. When querying data in JSON format, "timestamp" will not get the JavaScript marker for "UTC", a "Z" suffix. So in the JavaScript code in the web pages you will find quite a few places that cover up for this.
Now when the weather station sends data to the configured server, inetd(8) runs httpd(8) and that invokes a shell script /weather/cgi/update.cgi
as the "weatherupdate" user.
This script uses awk(1) to do a few unit conversions and output a SQL command to insert the data into the "weather" table.
This SQL command is then piped to psql(1) with the connection string passed on the command line.
The corresponding password is found in ~/.pgpass of the "weatherupdate" user.
The script looks like this:
#! /bin/sh
TZ=UTC; export TZ
awk -v $( echo "$QUERY_STRING" | sed 's/\&/ -v /g' ) 'BEGIN {
temp=(tempf-32)/1.8;
indoortemp=(indoortempf-32)/1.8;
dewpt=(dewptf-32)/1.8;
windchill=(windchillf-32)/1.8;
windspeed=windspeedmph*1.609344;
windgust=windgustmph*1.609344;
rain=rainin*25.4;
dailyrain=dailyrainin*25.4;
totalrain=totalrainin*25.4;
rel_preasure=baromin/0.029529980164712;
printf("INSERT INTO weather VALUES ('"'"'%s'"'"', %f, %f, %f, %d, %d, %f, %d, %f, %f, %f, %f, %f, %f, %f, %f);\n",
strftime("%F %T"),
indoortemp,
temp,
dewpt,
indoorhumidity,
humidity,
windspeed,
winddir,
windchill,
rain, dailyrain, totalrain,
rel_preasure,
windgust,
solarradiation, UV);
}' | psql "hostaddr='127.0.0.1'dbname='weatherhistory'user='open2300'" > /dev/null 2>&1
Note that it explicitly sets the timezone to UTC. The input data comes (as defined by CGI) via the QUERY_STRING environment variable, as a set of "field=value" items, separated by &. They are converted to sets of "-v" args for the awk invocation via a simple sed script.
With this in place, the weather-station adds a record every five minutes to the database, and it was fun to check it via SQL, but for reasons not quite clear to me most of the rest of the family did not like that kind of access very much.
psql (14.5) SSL connection (protocol: TLSv1.3, cipher: TLS_AES_256_GCM_SHA384, bits: 256, compression: off) Type "help" for help. weatherhistory=> select min(temp_out), max(temp_out) from weather; min | max -------+------ -18.1 | 80.9 (1 row)
I initially thought the 80.9°C were measured while I was soldering the power cable, but apparently they were fallout from the sometimes failing sensors of the old station. The database has 2840 rows with temp_out > 40°C and all of them are 80.something. I should replace them with an average of the neighbor records.
Presenting the data
So I needed an internal web site. Which needs access to the data.
The above setup already paved the way for that, via the second port I set up.
I wanted to show all the current data in one page, and variable history data on another - which meant two CGI scripts to query the data.
The /weather/cgi/latest.cgi script just fetches the last record logged and creates a JSON from it, and also uses pom(6) and the sunwait(1) program
from pkgsrc to supply some site and date specific data:
#! /bin/sh
PATH=/usr/games:/usr/pkg/bin:$PATH
GEOPOS="51.505554N 0.075278W" # geographic position of this weather station
UPDATE=300 # seconds between updates
# This script uses psql(1) from pkgsrc/databases/postgresql14-client,
# pom(6) from the NetBSD games set and pkgsrc/misc/sunwait.
# collect global site data: sunrise and friends
eval $( sunwait report ${GEOPOS} | awk -F": " '
/Sun directly north/ {
printf("zenith=\"%s\"\n", $2);
}
/Daylight:/ {
split($2,v," to ");
printf("sunrise=\"%s\"\nsunset=\"%s\"\n", v[1], v[2]);
}
/with Civil twilight:/ {
split($2,v," to ");
printf("dawn=\"%s\"\ndusk=\"%s\"\n", v[1], v[2]);
}
/It is: Day/ {
printf("day=true\n");
}
/It is: Night/ {
printf("day=false\n");
}
' )
# moon phase
eval $( pom | awk '-F(' '
/The Moon is Full/ { printf("moontrend=\"-\"\nmoon=100\n"); }
/The Moon is New/ { printf("moontrend=\"+\"\nmoon=0\n"); }
/First Quarter/ { printf("moontrend=\"+\"\nmoon=50\n"); }
/Last Quarter/ { printf("moontrend=\"-\"\nmoon=50\n"); }
/Waxing/ {
a=$0;
sub(/^.*\(/, "", a);
sub(/%.*$/, "", a);
printf("moontrend=\"+\"\nmoon=%d\n", a+0);
}
/Waning/ {
a=$0;
sub(/^.*\(/, "", a);
sub(/%.*$/, "", a);
printf("moontrend=\"-\"\nmoon=%d\n", a+0);
}
' )
# start the json output
printf "\n\n{ \"site\": { \"updates\": ${UPDATE},
\"dawn\": \"${dawn}\", \"sunrise\": \"${sunrise}\",
\"zenith\": \"${zenith}\", \"day\": ${day},
\"sunset\": \"${sunset}\", \"dusk\": \"${dusk}\",
\"moon\": { \"trend\": \"${moontrend}\", \"percent\": ${moon} }\n}, \"weather\":\n"
# fill database results
printf "WITH t AS ( SELECT * FROM weather ORDER BY timestamp DESC LIMIT 1 ) SELECT row_to_json(t) FROM t;\n" |
psql --tuples-only --no-align "hostaddr='127.0.0.1'dbname='weatherhistory'user='weatherquery'"
# terminate json
printf "\n}\n"
As you can see, if you would restrict output to plain data from the database, the script would be only four or five lines long. But I like the additional spicing.
The /weather/cgi/history.cgi script fetches rows between two timestamps passed to it (in JSON timestamp format)
and answers with a JSON containing an array of all the data in the requested time window:
#! /bin/sh
COND=$( echo "${QUERY_STRING}" | tr '&' '\n'| sed -e 's/%22/\"/g' -e 's/%3A/:/g' | awk '
/from=/ { v=$0; sub(/^[^"]*\"/, "", v); sub(/\".*$/, "", v); arg_from=v; }
/to=/ { v=$0; sub(/^[^"]*\"/, "", v); sub(/\".*$/, "", v); arg_to=v; }
END {
if (arg_from && arg_to) {
printf("timestamp >= '"'"'%s'"'"' AND timestamp <= '"'"'%s'"'"'\n",
arg_from, arg_to);
}
}
' )
if [ -z "${COND}" ]; then
# printf "could not parse: ${QUERY_STRING}\n" >> /tmp/sql.log
exit 0;
fi
# start output
printf "\n\n"
# printf "${COND}\n" >> /tmp/sql.log
# fill database results
printf "WITH t AS ( SELECT * FROM weather WHERE ${COND} ORDER by timestamp ASC ) SELECT json_agg(t) FROM t;\n" |
psql --tuples-only --no-align "hostaddr='127.0.0.1'dbname='weatherhistory'user='weatherquery'" # 2&>> /tmp/sql.err
Fetching this data now is easy in JavaScript.
We have a request URL defined as a const, like this:
const queryURL = 'http://weatherhost.duskware.de:89/cgi-bin/history.cgi?';
and then add (if needed) the paramaters for the query, like in this example function that gets passed a from-date and a to-date:
function showData(fromD, toD)
{
var url = new URL(queryURL);
url.searchParams.append("from", '"'+fromD.toJSON()+'"');
url.searchParams.append("to", '"'+toD.toJSON()+'"');
fetch(url).then(function(response) {
return response.json();
}).then(function(data) {
makeGraphs(data);
updateButtons();
}).catch(function(error) {
console.error(error)
});
}
When the answer from the server arrives, it is decoded as JSON and returned as input data to the next function that makes some graphs from the data array. Finally a few buttons are updated (in this example the time window is put into a start and a end date control.
Inspired by the post mentioned above I used canvas gauges for the display of the latest data and dygraphs for the display of historic data.
Here is an example of how the latest display looks:

And here is how the history display looks:

I have put an archive of the cgi scripts and web pages here, and also for the curious who just want to peek at the full glory of my web design skills the start page (showing the latest weather data) and the history page.
Besides those files, you will need
- a
/weather/files/favicon.icoif you like. - download
gauge.min.jsfrom canvas gauges and put it into/weather/files/. - download
dygraph.css,dygraph.min.jsfrom dygraph, plussynchronizer.jsfrom the dygraphextras/directory and put it also into/weather/files/.
Then you should be ready to go - easy, isn't it? And no heavy weight dependencies or pkgs needed.
What about other weather stations?
There are quite a few similar weather stations out there now that seem to run "related" firmware and have similar capabilities. Most likely the update script (and details in the presentation pages) will need adjustements for other types.
If you start with a different device, just log all the data it sends and adjust the cgi scripts/database/JavaScript accordingly. For protocol analyzis there are several easy means:
- Remove the "-q" flag in the httpd command (in
/etc/inetd.conf) and check/var/log/xferlogfor the quey paramaters sent by the weather station (when using the weather underground protocol). - Make the station log to a
debug.cgifirst to capture everything (including form data posted). This works for the ecowitt protocoll. - All this stations seem to use http only (not https), so you can sniff the traffic. Use
tcpdump -won the server to capture the data and analyze it with net/wireshark from pkgsrc.
Here is what a debug.cgi script could look like:
#! /bin/sh env > /tmp/debug.env printf "\n\nOK\n" cat > /tmp/debug.input &
This allows you to see the form input in /tmp/debug.input and the CGI environment in /tmp/debug.env.
The NetBSD Project is pleased to announce NetBSD 7.2, the second feature update of the NetBSD 7 release branch. It represents a selected subset of fixes deemed important for security or stability reasons, as well as new features and enhancements.
If you are running an earlier release of NetBSD and are (for whatever reasons) not able to update to the latest major release, NetBSD 8.0, we suggest updating to 7.2.
For more details, please see the release notes.
Complete source and binaries for NetBSD are available for download at many sites around the world and our CDN. A list of download sites providing FTP, AnonCVS, and other services may be found at the list of mirrors.
honggfuzz ptrace(2) features
I've introduced new ptrace(2) tests verifying attaching to a stopped process. This is an important scenario in debuggers, the ability to call a ptrace(2) operation with the PT_ATTACH argument with a process id (PID) of a process entity that is stopped. In typical circumstances PT_ATTACH causes an executing process to stop and emit SIGSTOP for the tracer. An already stopped process is a special case as we cannot stop it again. Not every UNIX-like kernel can handle this scenario in a sensible way, and the modern solution is to keep the process stopped (rather than e.g... resumed) and emit a new signal SIGSTOP to the debugger (rather than e.g. not emitting anything). There used to be complex workarounds for mainstream kernels in debuggers such as GDB to workaround kernel bugs of attaching to a stopped process.
honggfuzz is a security oriented, feedback-driven, evolutionary, easy-to-use fuzzer with interesting analysis options. This piece of software is developed by a Google employee, however the product is not an official Google software. honggfuzz uses on featured platforms ptrace(2) to monitor crash signals in traced processes. I've implemented a new backed in the fuzzer for NetBSD using its ptrace(2) API. The backend is designed to follow the existing scenarios and features in Linux & Android:
- Attaching to a manually stopped process, optionally spawned by the fuzzer.
- Option to attach to a selected process over its PID.
- Crash instruction decoding with aid of a disassembler (capstone for NetBSD).
- Ability to monitor multiple processes with an arbitrary number of threads.
- Monitor forks(2) and vforks(2) events, however unused in the current fuzzing model.
- Concurrent execution of multiple processes.
- Timeout of long-lasting (hanging?) processes in persistent mode (limit: 0.25[sec]).
There are few missing features:
- Intel BTS - hardware assisted tracing
- Intel PT - hardware assisted tracing
- hp libunwind - unwinding stack of a traced process for better detection of unique crashes
Sanitizers
I've started researching Kernel Address Sanitizer, checking the runtime internals and differences between its version ABIs. My intention was to join efforts with Siddharth (GSoC student) and head with a sanitzier for EuroBSDCon 2018 in Romania. However, Maxime Villard decided to join the efforts a little bit earlier and he managed to get quickly a functional bare version for NetBSD/amd64. In the end we have decided to leave the kASan work to Maxime for now and let Siddharth to work on a kCov (SanitizerCoverage) device. SanCov is a feature of compilers, designed as an aid for fuzzers to ship interesting information from a fuzzing point of view of a number of function calls, comparisons, divisions etc. Successful userland fuzzers (such as AFL, honggfuzz) use this feature as an aid in determining of new code-paths. It's the same with a renowned kernel fuzzer - syzkaller.
While, I'm helping Siddharth to port a kcov(4) device to NetBSD, I've switched to the remaining pending tasks in userland sanitizers. I've managed to switch the sanitizers from syscall(2) and __syscall(2) - indirect system call API - calls to libc routines. The approach of using an indirect generic interface didn't work well in the NetBSD case, as there is the need to handle multiple ABIs, Endians, CPU architectures, and the C language ABI is not a good choice to serialize and deserialize arbitrary function arguments with various types through a generic interface. The discussion on the rationale is perhaps not the proper place, and every low-level C developer is well aware of the problems. It's better to restrict the discussion to the statement that it's not possible (not trivial) to call in a portable way all the needed syscalls, without the aid of per-case auxiliary switches and macros. There are also some cases (such as pipe(2)) when is is not possible to express the system call semantics with syscall(2)/__syscall(2).
I've switched these routines to use internal libc symbols when possible. In the remaining cases I've used a fallback to libc's versions of the routines, with aid of indirect function pointers. I'm trying to detect the addresses of real functions with dlsym(3) calls. In the result, I've switched all the uses of syscall(2) and __syscall(2) and observed no regressions in tests.
I'm also in the process of deduplication of local patches to sanitizers. My current main focus is to finish switching syscall(2) and __syscall(2) to libc routines (patch pending upstream), introduce a new internal version of sysctl(3) that bypasses interceptors (partially merged upstream) and introduces new interceptors for sysctl(3) calls. This is a convoluted process in the internals with the goal to make the sanitizers more reliable across NetBSD targets and manage to sanitize less trivial examples such as rumpkernels. The RUMP code uses internally a modified and private versions of sysctl*() operations and we still must keep the internals in order and properly handle the RUMP code.
Merged commits
The NetBSD sources:
- Merge FreeBSD improvements to the man-page of timespec_get(3)
- Remove unused symbols from sys/sysctl.h
- Add a new ATF ptrace(2) test: child_attach_to_its_stopped_parent
- Add await_stopped() in t_ptrace_wait.h
- Add a new ATF test parent_attach_to_its_stopped_child
- Add a new ATF ptrace(2) test: tracer_attach_to_unrelated_stopped_process
- Drop a duplicate instruction line [libpthread]
- Mark kernel-asan as done (by maxv)
- TODO.sanitizers: Mark switch of syscall(2)/__syscall(2) to libc done
The LLVM sources:
- Introduce new type for inteceptors UINTMAX_T
- Add internal_sysctl() used by FreeBSD, NetBSD, OpenBSD and MacOSX
- Improve portability of internal_sysctl()
- Try to fix internal_sysctl() for MacOSX
- Try to unbreak internal_sysctl() for MacOSX
Summary
I'm personally proud of the success of the reliability of the ptrace(2) backend in the renowned honggfuzz fuzzer. NetBSD was capable to handling all the needed features and support all of them with an issue-free manner. Once, I will address the remaining ptrace(2) issues on my TODO list - the NetBSD kernel will be capable to host more software in a similar fashion, and most importantly a fully featured debugger such as GDB and LLDB, however without the remaining hiccups.
We are also approaching another milestone with the sanitizers' runtime available in the compiler toolchain: sanitizing rumpkernels. It is already possible to execute the rump code against a homegrown uUBSan runtime, but we are heading now to execute the code under the default runtime for the remaining sanitizers (ASan, MSan, TSan).
For the record, it has been reported that kUBSan has been ported from NetBSD to at least two kernels: FreeBSD and XNU.
Plan for the next milestone
I'm in preparation for my visit to EuroBSDCon (Bucharest, Romania) in September and GSoC Mentor Summit & MeetBSDCa in October (California, the U.S.). I intend to rest during this month and still provide added value to the project, porting and researching missing software dedicated for developers. Among others, I'm planning to research the HP libunwind library and if possible, port it to NetBSD.
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL, and chip in what you can:
- using DNS alias mode with sub-domains dedicated to ACME verification
- delegating the sub-domains to the servers where the certificate will be needed
- using bind on the servers where the certificate will be needed (where it was running as resolver already anyway)
- using dns_nsupdate (i.e. dynamic DNS) to add the challenge to the ACME subzone.
options {
....
allow-update { localhost; };
....
};
zone "acme-www.pkgsrc.org" {
type master;
file "acme/acme-www.pkgsrc.org";
update-policy {
grant acme-ddns name _acme-challenge.acme-www.pkgsrc.org. TXT;
};
};
And last but not least, deployment of certificates via make, i.e. completely independent of acme.sh.
Due to all of the above, acme.sh does not need to tentacle about in the filesystem and can run as a plain user in a chroot. It's not a tiny chroot, though (20M), since acme.sh needs a bunch of common shell tools:
- awk basename cat chmod cp curl cut date egrep/grep head mkdir mktemp mv nsupdate od openssl printf readlink rm sed sh sleep stat tail touch tr uname, and their shared libs, /libexec/ld.elf_so and /usr/libexec/ld.elf_so;
- under the chroot /etc a resolv.conf, the CA cert for Let's Encrypt (mozilla-rootcert-60.pem) and to make openssl complain less an empty openssl.cnf
- and in the chroot /dev: null, random and urandom.
I call both the acme.sh --cron job and the certificate deployment make from daily.local, which adds the output to the daily mail and makes it easy to keep an eye on things.
After initial work on the wifi renewal branch went quite fast and smooth, things have slowed down a bit in the last few months.
Most of the slow down was due to me not being available for this type of work for unexpectedly long times - a problem that should be fixed now.
However, there were other obstacles and unexpected issues on the way:
- bpf taps are handled differently in the new stack and some slightly obscure site conditions of this had been overlooked in the initial conversion. To make everything work, changes to our bpf framework were needed (and have landed in -current some time ago now).
- Many wifi drivers seem to be in a, let's say, slightly fragile state. When testing the random collection of wifi hardware that I acquired during this project in -current, many drivers did not work at first try and often I was able to provoke kernel panics quickly. This is not a happy base to start converting drivers from.
- After the great success of usbnet(9) for USB ethernet drivers, core and I agreed to do the same for wifi - the result is called usbwifi(9) and makes conversion of usb drivers a lot easier than other wifi drivers. See the conversion instructions for more details. usbwifi(9) is both quite similar but also quite different to usbnet(9), mostly for two reasons: it interfaces to a totally different stack, and many usb wlan chipsets are more complex than ethernet chipsets (e.g. have support for multiple send queues with different priorities). Developing usbwifi did cost quit some time (initially unplanned), but is expected to amortize over the next few drivers and quickly end up as a net win.
- I have been hitting a bug in the urtwn(4) driver used for inial usbwifi(9) development and still not found it (as of today). It seems to hit randomly and not be caused by the usbwifi(9) conversion - a fact that I found out only recently. So for now I will put this driver aside (after spending *way* too much time on it) and instead work on other usb drivers, returning to the bug every now and then and see if I can spot it. Maybe I can borrow a USB analyzer and get more insight that way.
The current state of driver conversion and what drivers are still open are listed in the wifi driver conversion matrix.
Next steps ahead are:
make another pass over documentation and improve things / fixup for recent changes(done before this blog post got published)- sync the branch with HEAD and keep tracking it more closely
- convert run(4) to usbwifi
- revisit rtwn(4) and decide if/how it should be merged with urtwn(4)
- revisit iwm(4) and make it work fully
- convert all other drivers, starting with the ones I have hardware for
Currently it is not clear if this branch can be merged to HEAD before branching for netbsd-10. We will not delay the netbsd-10 branch for this.
After initial work on the wifi renewal branch went quite fast and smooth, things have slowed down a bit in the last few months.
Most of the slow down was due to me not being available for this type of work for unexpectedly long times - a problem that should be fixed now.
However, there were other obstacles and unexpected issues on the way:
- bpf taps are handled differently in the new stack and some slightly obscure site conditions of this had been overlooked in the initial conversion. To make everything work, changes to our bpf framework were needed (and have landed in -current some time ago now).
- Many wifi drivers seem to be in a, let's say, slightly fragile state. When testing the random collection of wifi hardware that I acquired during this project in -current, many drivers did not work at first try and often I was able to provoke kernel panics quickly. This is not a happy base to start converting drivers from.
- After the great success of usbnet(9) for USB ethernet drivers, core and I agreed to do the same for wifi - the result is called usbwifi(9) and makes conversion of usb drivers a lot easier than other wifi drivers. See the conversion instructions for more details. usbwifi(9) is both quite similar but also quite different to usbnet(9), mostly for two reasons: it interfaces to a totally different stack, and many usb wlan chipsets are more complex than ethernet chipsets (e.g. have support for multiple send queues with different priorities). Developing usbwifi did cost quit some time (initially unplanned), but is expected to amortize over the next few drivers and quickly end up as a net win.
- I have been hitting a bug in the urtwn(4) driver used for inial usbwifi(9) development and still not found it (as of today). It seems to hit randomly and not be caused by the usbwifi(9) conversion - a fact that I found out only recently. So for now I will put this driver aside (after spending *way* too much time on it) and instead work on other usb drivers, returning to the bug every now and then and see if I can spot it. Maybe I can borrow a USB analyzer and get more insight that way.
The current state of driver conversion and what drivers are still open are listed in the wifi driver conversion matrix.
Next steps ahead are:
make another pass over documentation and improve things / fixup for recent changes(done before this blog post got published)- sync the branch with HEAD and keep tracking it more closely
- convert run(4) to usbwifi
- revisit rtwn(4) and decide if/how it should be merged with urtwn(4)
- revisit iwm(4) and make it work fully
- convert all other drivers, starting with the ones I have hardware for
Currently it is not clear if this branch can be merged to HEAD before branching for netbsd-10. We will not delay the netbsd-10 branch for this.
Over the past month, I've implemented from scratch a clean-room version of the UBSan runtime. The initial motivation was the need of developing one for the purposes of catching undefined behavior reports (unspecified code semantics in a compiled executable) in the NetBSD kernel. However, since we need to write a new runtime, I've decided to go two steps further and design code that will be usable inside libc and as a standalone library (linked .c source code) for the use of ATF regression tests.
The µUBSan (micro-UBSan) design and implementation
The original Clang/LLVM runtime is written in C++ with features that are not available in libc and in the NetBSD kernel. The Linux kernel version of an UBSan runtime is written natively in C, and mostly without additional unportable dependencies, however, it's GPL, and the number of features is beyond the code generation support in the newest version of Clang/LLVM from trunk (7svn).
The implementation of µUBSan is located in
common/lib/libc/misc/ubsan.c.
The implementation is mostly Machine Independent, however, it assumes a typical 32bit or 64bit CPU with support for typical floating point types.
Unlike the other implementations that I know, µUBSan is implemented without triggering Undefined Behavior.
The whole implementation inside a single C file
I've decided to write the whole µUBSan runtime as a single self-contained .c soure-code file,
as it makes it easier for it to be reused by every interested party.
This runtime can be either inserted inline or linked into the program.
The runtime is written in C, because C is more portable, it's the native language of libc and the kernel, and additionally
it's easier to match the symbols generated by the compilers (Clang and GCC).
According to C++ ABI, C++ symbols are mangled,
and in order to match the requested naming from the compiler instrumentation
I would need to partially tag the code as C file anyway (extern "C").
Additionally, going the C++ way without C++ runtime features is not a typical way to use C++,
and unless someone is a C++ enthusiast it does not buy much.
Additionally, the programming language used for the runtime is almost orthogonal to the instrumentated programming language
(although it must have at minimum the C-level properties to work on pointers and elementary types).
A set of supported reporting features
µUBSan supports all report types except -fsanitize=vtpr.
For vptr there is a need for low-level C++ routines to introspect and validate the low-level parts of the C++ code
(like vtable, compatiblity of dynamic types etc).
While all other UBSan checks are done directly in the instrumented and inlined code, the vptr one is performed in runtime.
This means that most of the work done by a minimal UBSan runtime is about deserializing reports into verbose messages and printing them out.
Furthermore there is an option to configure a compiler to inject crashes once an UB issue will be detected and the runtine might not be needed at all,
however this mode would be difficult to deal with and the sanitized code had to be executed with aid of a debugger to extract any useful information.
Lack of a runtime would make UBSan almost unusable in the internals of base libraries such as libc or inside the kernel.
These Clang/LLVM arguments for UBSan are documented as follows in the official documentation:
-fsanitize=alignment: Use of a misaligned pointer or creation of a misaligned reference.-fsanitize=bool: Load of a bool value which is neither true nor false.-fsanitize=builtin: Passing invalid values to compiler builtins.-fsanitize=bounds: Out of bounds array indexing, in cases where the array bound can be statically determined.-fsanitize=enum: Load of a value of an enumerated type which is not in the range of representable values for that enumerated type.-fsanitize=float-cast-overflow: Conversion to, from, or between floating-point types which would overflow the destination.-fsanitize=float-divide-by-zero: Floating point division by zero.-fsanitize=function: Indirect call of a function through a function pointer of the wrong type (Darwin/Linux[/NetBSD], C++ and x86/x86_64 only).-fsanitize=implicit-integer-truncation: Implicit conversion from integer of larger bit width to smaller bit width, if that results in data loss. That is, if the demoted value, after casting back to the original width, is not equal to the original value before the downcast. Issues caught by this sanitizer are not undefined behavior, but are often unintentional.-fsanitize=integer-divide-by-zero: Integer division by zero.-fsanitize=nonnull-attribute: Passing null pointer as a function parameter which is declared to never be null.-fsanitize=null: Use of a null pointer or creation of a null reference.-fsanitize=nullability-arg: Passing null as a function parameter which is annotated with _Nonnull.-fsanitize=nullability-assign: Assigning null to an lvalue which is annotated with _Nonnull.-fsanitize=nullability-return: Returning null from a function with a return type annotated with _Nonnull.-fsanitize=object-size: An attempt to potentially use bytes which the optimizer can determine are not part of the object being accessed. This will also detect some types of undefined behavior that may not directly access memory, but are provably incorrect given the size of the objects involved, such as invalid downcasts and calling methods on invalid pointers. These checks are made in terms of __builtin_object_size, and consequently may be able to detect more problems at higher optimization levels.-fsanitize=pointer-overflow: Performing pointer arithmetic which overflows.-fsanitize=return: In C++, reaching the end of a value-returning function without returning a value.-fsanitize=returns-nonnull-attribute: Returning null pointer from a function which is declared to never return null.-fsanitize=shift: Shift operators where the amount shifted is greater or equal to the promoted bit-width of the left hand side or less than zero, or where the left hand side is negative. For a signed left shift, also checks for signed overflow in C, and for unsigned overflow in C++. You can use-fsanitize=shift-baseor-fsanitize=shift-exponentto check only the left-hand side or right-hand side of shift operation, respectively.-fsanitize=signed-integer-overflow: Signed integer overflow, where the result of a signed integer computation cannot be represented in its type. This includes all the checks covered by -ftrapv, as well as checks for signed division overflow (INT_MIN/-1), but not checks for lossy implicit conversions performed before the computation (see-fsanitize=implicit-conversion). Both of these two issues are handled by-fsanitize=implicit-conversiongroup of checks.-fsanitize=unreachable: If control flow reaches an unreachable program point.-fsanitize=unsigned-integer-overflow: Unsigned integer overflow, where the result of an unsigned integer computation cannot be represented in its type. Unlike signed integer overflow, this is not undefined behavior, but it is often unintentional. This sanitizer does not check for lossy implicit conversions performed before such a computation (see-fsanitize=implicit-conversion).-fsanitize=vla-bound: A variable-length array whose bound does not evaluate to a positive value.-fsanitize=vptr: Use of an object whose vptr indicates that it is of the wrong dynamic type, or that its lifetime has not begun or has ended. Incompatible with-fno-rtti. Link must be performed by clang++, not clang, to make sure C++-specific parts of the runtime library and C++ standard libraries are present.
Additionally the following flags can be used:
-fsanitize=undefined: All of the checks listed above other thanunsigned-integer-overflow,implicit-conversionand thenullability-*group of checks.-fsanitize=undefined-trap: Deprecated alias of-fsanitize=undefined.-fsanitize=integer: Checks for undefined or suspicious integer behavior (e.g. unsigned integer overflow). Enablessigned-integer-overflow,unsigned-integer-overflow,shift,integer-divide-by-zero, andimplicit-integer-truncation.-fsanitize=implicit-conversion: Checks for suspicious behaviours of implicit conversions. Currently, only-fsanitize=implicit-integer-truncationis implemented.-fsanitize=nullability: Enablesnullability-arg,nullability-assign, andnullability-return. While violating nullability does not have undefined behavior, it is often unintentional, so UBSan offers to catch it.
The GCC runtime is a downstream copy of the Clang/LLVM runtime, and it has a reduced number of checks, since it's behind upstream. GCC developers sync the Clang/LLVM code from time to time. The first portion of merged NetBSD support for UBSan and ASan landed in GCC 8.x (NetBSD-8.0 uses GCC 5.x, NetBSD-current as of today uses GCC 6.x). This version of GCC also contains useful compiler attributes to mark certain parts of the code and disable sanitization of certain functions or files.
Format of the reports
I've decided to design the policy for reporting issues differently to the Linux kernel one. UBSan in the Linux kernel prints out messages in a multiline format with stacktrace:
================================================================================ UBSAN: Undefined behaviour in ../include/linux/bitops.h:110:33 shift exponent 32 is to large for 32-bit type 'unsigned int' CPU: 0 PID: 0 Comm: swapper Not tainted 4.4.0-rc1+ #26 0000000000000000 ffffffff82403cc8 ffffffff815e6cd6 0000000000000001 ffffffff82403cf8 ffffffff82403ce0 ffffffff8163a5ed 0000000000000020 ffffffff82403d78 ffffffff8163ac2b ffffffff815f0001 0000000000000002 Call Trace: [] dump_stack+0x45/0x5f [] ubsan_epilogue+0xd/0x40 [] __ubsan_handle_shift_out_of_bounds+0xeb/0x130 [] ? radix_tree_gang_lookup_slot+0x51/0x150 [] _mix_pool_bytes+0x1e6/0x480 [] ? dmi_walk_early+0x48/0x5c [] add_device_randomness+0x61/0x130 [] ? dmi_save_one_device+0xaa/0xaa [] dmi_walk_early+0x48/0x5c [] dmi_scan_machine+0x278/0x4b4 [] ? vprintk_default+0x1a/0x20 [] ? early_idt_handler_array+0x120/0x120 [] setup_arch+0x405/0xc2c [] ? early_idt_handler_array+0x120/0x120 [] start_kernel+0x83/0x49a [] ? early_idt_handler_array+0x120/0x120 [] x86_64_start_reservations+0x2a/0x2c [] x86_64_start_kernel+0x16b/0x17a ================================================================================
Multiline print has an issue of requiring locking that prevents interwinding multiple reports, as there might be a process of printing them out by multiple threads in the same time. There is no way to perform locking in a portable way that is functional inside libc and the kernel, across all supported CPUs and what is more important within all contexts. Certain parts of the kernel must not block or delay execution and in certain parts of the booting process (either kernel or libc) locking or atomic primitives might be unavailable.
I've decided that it is enough to print a single-line message where occurred a problem and what was it, assuming that printing routines are available and functional. A typical UBSan report looks this way:
Undefined Behavior in /public/netbsd-root/destdir.amd64/usr/include/ufs/lfs/lfs_accessors.h:747:1, member access within misaligned address 0x7f7ff7934444 for type 'union FINFO' which requires 8 byte alignment
These reports are pretty much selfcontained and similar to the ones from the Clang/LLVM runtime:
test.c:4:14: runtime error: left shift of 1 by 31 places cannot be represented in type 'int'
Not implementing __ubsan_on_report()
The Clang/LLVM runtime ships with a callback API for the purpose of debuggers that can be notified by sanitizers reports.
A debugger has to define __ubsan_on_report() function and call __ubsan_get_current_report_data() to collect report's information.
As an illustration of usage, there is a testing code shipped with compiler-rt for this feature
(test/ubsan/TestCases/Misc/monitor.cpp):
// Override the definition of __ubsan_on_report from the runtime, just for
// testing purposes.
void __ubsan_on_report(void) {
const char *IssueKind, *Message, *Filename;
unsigned Line, Col;
char *Addr;
__ubsan_get_current_report_data(&IssueKind, &Message, &Filename, &Line, &Col,
&Addr);
std::cout << "Issue: " << IssueKind << "\n"
<< "Location: " << Filename << ":" << Line << ":" << Col << "\n"
<< "Message: " << Message << std::endl;
(void)Addr;
}
Unfortunately this API is not thread aware and guaranteeing so in the implementation
would require excessively complicated code shared between the kernel and libc.
The usability is still restricted to debugger (like a LLDB plugin for UBSan),
there is already an alternative plugin for such use-cases when it would matter.
I've documented the __ubsan_get_current_report_data() routine with the following comment:
/* * Unimplemented. * * The __ubsan_on_report() feature is non trivial to implement in a * shared code between the kernel and userland. It's also opening * new sets of potential problems as we are not expected to slow down * execution of certain kernel subsystems (synchronization issues, * interrupt handling etc). * * A proper solution would need probably a lock-free bounded queue built * with atomic operations with the property of multiple consumers and * multiple producers. Maintaining and validating such code is not * worth the effort. * * A legitimate user - besides testing framework - is a debugger plugin * intercepting reports from the UBSan instrumentation. For such * scenarios it is better to run the Clang/GCC version. */
Reporting channels
The basic reporting channel for kernel messages is the dmesg(8) buffer.
As an implementation detail I'm using variadic output routines (va_list) such as vprintf() ones.
Depending on the type of a report there are two types of calls used in the kernel:
- printf(9) - for non-fatal reports, when a kernel can continue execution.
- panic(9) - for fatal reports stopping the kernel execution with a panic string.
The userland version has three reporting channels:
- standard output (
stdout), - standard error (
stderr), - syslog (
LOG_DEBUG | LOG_USER)
Additionally, a user can tune into the runtime whether non-fatal reports are turned into fatal messages or not.
The fatal messages stop the execution of a process and raise the abort signal (SIGABRT).
The dynamic options in uUBSan can be changed with LIBC_UBSAN environment variable. The variable accepts options specified with single characters that either enable or disable a specified option. There are the following options supported:
- a - abort on any report,
- A - do not abort on any report,
- e - output report to stderr,
- E - do not output report to stderr,
- l - output report to syslog,
- L - do not output report to syslog,
- o - output report to stdout,
- O - do not output report to stdout.
The default configuration is "AeLO". The flags are parsed from left to right and supersede previous options for the same property.
Differences between µUBsan in the kernel, libc and as a standalone library
There are three contexts of operation of µUBsan and there is need to use conditional compilation in few parts. I've been trying to keep to keep the differences to an absolute minimum, they are as follows:
- kUBSan uses kernel-specific headers only.
- uUBSan uses userland-specific headers, with a slight difference between libc ("namespace.h" internal header usage) and standalone userspace usage (in ATF tests).
- uUBSan defines a fallback definition of kernel-specific macros for the ISSET(9) API.
- kUBSan does not build and does not handle floating point routines.
- kUBSan outputs reports with either printf(9) or panic(9).
- uUBSan outputs reports to either stdout, stderr or syslog (or to a combination of them).
- kUBSan does not contain any runtime switches and is configured with build options (like whether certain reports are fatal or not) using the CFLAGS argument and upstream compiler flags.
- uUBSan does contain runtime dynamic configuration of the reporting channel and whether a report is turned into a fatal error.
MKLIBCSANITIZER
I've implemented a global build option of the distribution MKLIBCSANITIZER. A user can build the whole userland including libc, libm, librt, libpthread with a dedicated sanitizer implemented inside libc. Right now, there is only support for the Undefined Behavior sanitizer with the µUBSan runtime.
I've documented this feature in share/mk/bsd.README with the following text:
MKLIBCSANITIZER If "yes", use the selected sanitizer inside libc to compile
userland programs and libraries as defined in
USE_LIBCSANITIZER, which defaults to "undefined".
The undefined behavior detector is currently the only supported
sanitizer in this mode. Its runtime differs from the UBSan
available in MKSANITIZER, and it is reimplemented from scratch
as micro-UBSan in the user mode (uUBSan). Its code is shared
with the kernel mode variation (kUBSan). The runtime is
stripped down from C++ features, in particular -fsanitize=vptr
is not supported and explicitly disabled. The only runtime
configuration is restricted to the LIBC_UBSAN environment
variable, that is designed to be safe for hardening.
The USE_LIBCSANITIZER value is passed to the -fsanitize=
argument to the compiler in CFLAGS and CXXFLAGS, but not in
LDFLAGS, as the runtime part is located inside libc.
Additional sanitizer arguments can be passed through
LIBCSANITIZERFLAGS.
Default: no
This means that a user can build the distribution with the following command:
./build.sh -V MKLIBCSANITIZER=yes distribution
The number of issues detected is overwhelming. The Clang/LLVM toolchain - as mentioned above - reports much more potential bugs than GCC, but with both compilers during the execution of ATF tests there are thousands or reports. Most of them are reported multiple times and the number of potential code flaws is around 100.
An example log of execution of the ATF tests with MKLIBCSANITIZER (GCC): atf-mklibcsanitizer-2018-07-25.txt. I've also prepared a version that is preprocessed with identical lines removed, and reduced to UBSan reports only: atf-mklibcsanitizer-2018-07-25-processed.txt. I've fixed a selection of reported issues, mostly the low-hanging fruit ones. Part of the reports, especially the misaligned pointer usage ones (for variables it means that their address has to be a multiplication of their size) usage ones might be controversial. Popular CPU architectures such as X86 are tolerant to misaligned pointer usage and most programmers are not aware of potential issues in other environments. I defer further discussion on this topic to other resources, such as the kernel misaligned data pointer policy in other kernels.
Kernel Undefined Behavior Sanitizer
As already noted, kUBSan uses the same runtime as uBSan with a minimal conditional switches.
µUBSan can be enabled in a kernel config with the KUBSAN option.
Althought, the feature is Machine Independent, I've been testing it with the NetBSD/amd64 kernel.
The Sanitizer can be enabled in the kernel configuration with the following diff:
Index: sys/arch/amd64/conf/GENERIC =================================================================== RCS file: /cvsroot/src/sys/arch/amd64/conf/GENERIC,v retrieving revision 1.499 diff -u -r1.499 GENERIC --- sys/arch/amd64/conf/GENERIC 3 Aug 2018 04:35:20 -0000 1.499 +++ sys/arch/amd64/conf/GENERIC 7 Aug 2018 00:10:44 -0000 @@ -111,7 +111,7 @@ #options KGDB # remote debugger #options KGDB_DEVNAME="\"com\"",KGDB_DEVADDR=0x3f8,KGDB_DEVRATE=9600 makeoptions DEBUG="-g" # compile full symbol table for CTF -#options KUBSAN # Kernel Undefined Behavior Sanitizer (kUBSan) +options KUBSAN # Kernel Undefined Behavior Sanitizer (kUBSan) #options SYSCALL_STATS # per syscall counts #options SYSCALL_TIMES # per syscall times #options SYSCALL_TIMES_HASCOUNTER # use 'broken' rdtsc (soekris)
As a reminder, the command to build a kernel is as follows:
./build.sh kernel=GENERIC
A number of issues have been detected and a selection of them already fixed. Some of the fixes change undefined behavior into inplementation specific behavior, which might be treated as appeasing the sanitizer, e.g. casting a variable to an unsigned type, shifting bits and casting back to signed.
ATF tests
I've implemented 38 test scenarios verifying various types of Undefined Behavior that can be caught by the sanitizer. The are two sets of tests: C and C++ ones and they are located in tests/lib/libc/misc/t_ubsan.c and tests/lib/libc/misc/t_ubsanxx.cpp. Some of the issues are C and C++ specific only, others just C or C++ ones.
I've decided to achieve the following purposes of the tests:
- Validation of µUBSan.
- Validation of compiler instrumentation part (independent from the default compiler runtime correctness).
The following tests have been implemented:
- add_overflow_signed
- add_overflow_unsigned
- builtin_unreachable
- cfi_bad_type
- cfi_check_fail
- divrem_overflow_signed_div
- divrem_overflow_signed_mod
- dynamic_type_cache_miss
- float_cast_overflow
- function_type_mismatch
- invalid_builtin_ctz
- invalid_builtin_ctzl
- invalid_builtin_ctzll
- invalid_builtin_clz
- invalid_builtin_clzl
- invalid_builtin_clzll
- load_invalid_value_bool
- load_invalid_value_enum
- missing_return
- mul_overflow_signed
- mul_overflow_unsigned
- negate_overflow_signed
- negate_overflow_unsigned
- nonnull_arg
- nonnull_assign
- nonnull_return
- out_of_bounds
- pointer_overflow
- shift_out_of_bounds_signednessbit
- shift_out_of_bounds_signedoverflow
- shift_out_of_bounds_negativeexponent
- shift_out_of_bounds_toolargeexponent
- sub_overflow_signed
- sub_overflow_unsigned
- type_mismatch_misaligned
- vla_bound_not_positive
- integer_divide_by_zero
- float_divide_by_zero
The tests have all been verified to work with the following configurations:
- amd64 and i386,
- Clang/LLVM (started with 3.8, later switched to 7svn) and GCC 6.x,
- C and C++.
Changes merged with the NetBSD sources
- Avoid unportable signed integer left shift in intr_calculatemasks()
- Avoid unportable signed integer left shift in fd_used()
- Try to appease KUBSan in sys/sys/wait.h in W_EXITCODE()
- Avoid unportable signed integer left shift in fd_isused()
- Avoid unportable signed integer left shift in fd_copy()
- Avoid unportable signed integer left shift in fd_unused()
- Paper over Undefined Behavior in in6_control1()
- Avoid undefined operation in signed integer shift in MAP_ALIGNED()
- Avoid Undefined Behavior in pr_item_notouch_get()
- Avoid Undefined Behavior in ffs_clusteracct()
- Avoid undefined behavior in pr_item_notouch_put()
- Avoid undefined behavior in pciiide macros
- Avoid undefined behavior in scsipiconf.h in _4ltol() and _4btol()
- Avoid undefined behavior in mq_recv1()
- Avoid undefined behavior in mq_send1()
- Avoid undefined behavior in lwp_ctl_alloc()
- Avoid undefined behavior in lwp_ctl_free()
- Remove UB from definition of symbols in i915_reg.h
- Correct unportable signed integer left shift in i386/amd64 tss code
- Remove unaligned access to mpbios_page[] (reverted)
- Try to avoid signed integer overflow in callout_softclock()
- Avoid undefined behavior of signedness bit shift in ahcisata_core.c
- Disable profile and compat 32-bit tests cc sanitizer tests
- Disable profile and compat 32-bit c++ sanitizer tests
- Use __uint128_t conditionally in aarch64 reg.h
- TODO.sanitizers: Remove a finished item
- Avoid potential undefined behavior in bta2dpd(8)
- Appease GCC in hci_filter_test()
- Document the default value of MKSANITIZER in bsd.README
- Avoid undefined behavior in ecma167-udf.h
- Avoid undefined behavior in left bit shift in jemalloc(3)
- Avoid undefined behavior in an ATF test: t_types
- Avoid undefined behavior in an ATF test: t_bitops
- Avoid undefined behavior semantics in msdosfs_fat.c
- Document MKLIBCSANITIZER in bsd.README
- Introduce MKLIBCSANITIZER in the share/mk rules
- Introduce a new option -S in crunchgen(1)
- Specify NOLIBCSANITIZER in x86 bootloader-like code under sys/arch/
- Specify NOLIBCSANITIZER for rescue
- Avoid undefined behavior in the definition of LAST_FRAG in xdr_rec.c
- Avoid undefined behavior in ftok(3)
- Avoid undefined behavior in an cpuset.c
- Avoid undefined behavior in an inet_addr.c
- Avoid undefined behavior in netpgpverify
- Avoid undefined behavior in netpgpverify/sha2.c
- Avoid undefined behavior in snprintb.c
- Specify NOLIBCSANITIZER in lib/csu
- Import micro-UBSan (ubsan.c)
- Fix build failure in dhcpcd under uUBSan
- Fix dri7 build with Clang/LLVM
- Fix libGLU build with Clang/LLVM
- Fix libXfont2 build with Clang/LLVM on i386
- Fix xf86-video-wsfb build with Clang/LLVM
- Disable sanitization of -fsanitize=function in libc
- Allow to overwrite sanitizer flags for userland
- Tidy up the comment in ubsan.c
- Register a new directory in common/lib/libc/misc
- Import micro-UBSan ATF tests
- Register micro-UBSan ATF tests in the distribution
- Add a support to build ubsan.c in libc
- Appease GCC in the openssh code when built with UBSan
- Register kUBSan in the GENERIC amd64 kernel config
- Fix distribution lists with MKCATPAGES=yes
- Restrict -fno-sanitize=function to Clang/LLVM only
- Try to fix the evbppc-powerpc64 build
Summary
The NetBSD community has aquired a new clean-room Undefined Behavior sanitizer runtime µUBSan, that is already ready to use by the community of developers.
There are three modes of µUBSan:
- kUBSan - kernelmode UBSan,
- uUBSan - usermode UBSan - as MKLIBCSANITIZER inside libc,
- uUBSan - usermode UBSan - as a standalone .c library for use with ATF tests.
A new set of bugs can be detected with a new development tool, ensuring better quality of the NetBSD Operating System.
It's worth to note the selection of fixes have been ported and/or pushed to other projects. Among them FreeBSD developers merged some of the patches into their soures.
The new runtime is designed to be portable and resaonably licensed (BSD-2-clause) and can be reused by other operating systems, improving the overall quality in them.
Plan for the next milestone
The Google Summer of Code programming period is over and I intend to finish two leftover tasks::
- Port the ptrace(2) attach functionality in honggfuzz to NetBSD. It will allow catching crash signals more effectively during the fuzzing process.
- Resume the porting process (together with the student) of Address Sanitizer to the NetBSD kernel.
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL, and chip in what you can:
Prepared by Yang Zheng (tomsun.0.7 AT Gmail DOT com) as part of GSoC 2018
This is the final report of the project
of integrating
libFuzzer for the userland applications, here are
the former two parts of this project:
- GSoC 2018 Reports: Integrate libFuzzer with the Basesystem, Part 1
- GSoC 2018 Reports: Integrate libFuzzer with the Basesystem, Part 2
For the last month of GSoC 2018, there two kinds of contributions:
- Fuzzed some functions (instead of the whole program) from libraries and applications
- Honggfuzz related work
Fuzzing Functions with libFuzzer
In previous work, we mainly focus on the fuzzing of whole programs,
such
as expr(1), sed(1), ping(8) and
so on. However, fuzzing these applications as a whole usually needs
significant modifications for various kinds of reasons:
- Collocation of
mainfunctions and other target functions - Getting inputs from command line or network
- Complex options provided to the users
For the first problem, we cannot solve it without splitting them
into separate files or using some macro tricks such as
"ifdef". Under the second situation, the original program
may write some lines of code to handle the input sources. So we must
either wrap the input buffers provided by the libFuzzer
into the format the programs expect or we need to transform the
buffers into internal data structures. As for the third case, it may
be better to avoid it by manually trying different options because
fuzzing options blindly can easily result in meaningless test
cases.
For the first two cases, honggfuzz can probably handle
them elegantly and we will discuss it in the next section. But in this
section, we will focus on fuzzing single function
with libFuzzer.
Fuzzing regex(3)
Functions
The regex(3) functions we have fuzzed includes
the regcomp(3) and regexec interfaces. The
regcomp(3) is used to compile the pattern we used to
match strings; while the regexec(3) matches the strings
with the compiled pattern. We have fuzzed 6 versions
of regex(3) interfaces, they come from different
libraries or applications:
For all of these versions, we have found some potential bugs. In
the following part of this section, I will introduce what are these
bugs. For the links given in the following cases, the
"crash-XXXX" files are the input files to reproduce the
bug, the "output-XXXX" files are corresponding expected
outputs and the Makefile will generate the program to
reproduce the bugs.
Bug in agrep Version regcomp(3)
The potential bug for this version appears around these lines:
for (i = 0; i < TRE_PARAM_LAST; i++) params[i] = lit->u.params[i];The "
params" field of the lit->u is set to
NULL, so it will trigger a SIGSEGV. The
further reason for why it is NULL is still unknown yet.
You can reproduce this with files in
this link.
Bug in cvs Version regcomp(3)
This is a potential bug to result in unterminated recursion. With
the files from
this link,
this version of regcomp(3) will repeatedly call
the calc_eclosure_iter
function until it runs out of the stack memory.
Bug in diffutils and grep Version regcomp(3)
For these two versions of regcomp(3), they both use a
macro named EXTRACT_NUMBER_AND_INCR, and finally, this
macro will use this line to do left shift:
(destination) += SIGN_EXTEND_CHAR (*((source) + 1)) << 8;
So, it is possible that the result of SIGN_EXTEND_CHAR
(*((source) + 1)) will be a negative number and the left
shift operation might be an undefined behavior. To reproduce these
two bugs, you can refer to the links
for diffutils
and grep.
Bug in libc Version regexec(3)
There would be a buffer-overflow bug with the heap memory in
the libc regexec(3). This potential bug
appears here:
1. for (;;) {
2. /* next character */
3. lastc = c;
4. c = (p == m->endp) ? OUT : *p;
5. if (EQ(st, fresh))
6. coldp = p;
The pointer p starts from the matched string and it
will be increased in every round of this loop. However, it seems that
this loop fails to break even when the p points to the next character
after the end of the matched string. So at the line 4, the dereference
of pointer p will trigger an overflow error. This
potential bug can be reproduced with the files from
this link.
Fuzzing Checksum Functions
The checksum algorithms we have fuzzed are:
All these algorithms except the crc are implemented in
the libc. For these algorithms implemented in
the libc, the interfaces are quite similar. These
interfaces can be divided into two categories, the first one is
"update-style", which includes "XXXInit",
"XXXUpdate" and "XXXFinal". The
"XXX" is the name of checksum algorithm. The
"Init" function is used for initializing the context, the
"Update" function is used for executing the checksum
process incrementally and the "Final" function is used
for extracting the results. The second one is "data-style", which only
uses "XXXData" interface. This interface is used to directly calculate
the checksum from a complete buffer. For the crc
algorithms, we have fuzzed the implementations from kernel and
the cksum(1)
For the checksum algorithms, there has been no bug found during the fuzzing process.
Fuzzing libutil(3)
The libutil(3) contains various system-dependant used
in some system daemons. During this project, we have chosen these
functions from this library:
Bug in the strspct
Among all these functions, I have only found one potential bug in
the strspct function. The potential bug
of strspct appears
around these
lines:
if (numerator < 0) {
numerator = -numerator;
sign++;
}
From these lines, we can find that the numerator
variable is negated. So when we assign this variable with the minimum
integer, it is possible that this integer will overflow. You can
reproduce this bug with the files under
this directory,
where crash-XXXXX is the input
file, output-XXXXX is the expected output, and the
Makefile is used to compile the binary which can accept
the input file to reproduce the bug.
Fuzzing bozohttpd(8)
The main target function we have fuzzed for bozohttpd
is the "bozo_process_request". However, we cannot fuzz it
barely, because there are several dependencies to fuzz
it. Specifically, this function needs a "bozo_httpreq_t"
type to be processed. So we need to introduce the
"bozo_read_request" to get a request and the
"bozo_clean_request" to clean the request. To feed the
data through the "bozo_read_request", we also need to
mock some interfaces from the
"ssl-bozo.c"
The source for fuzzing bozohttpd(8) can be
found here.
Bug in bozohttpd(8)
The potential bug found in the bozohttpd(8) is
around these
lines:
1. val = bozostrnsep(&str, ":", &len);
2. debug((httpd, DEBUG_EXPLODING,
3. "read_req2: after bozostrnsep: str ``%s'' val ``%s''",
4. str, val));
5. if (val == NULL || len == -1) {
6. (void)bozo_http_error(httpd, 404, request,
7. "no header");
8. goto cleanup;
9. }
10. while (*str == ' ' || *str == '\t')
11. len--, str++;
The bug appears at the line 10, where the "str"
is NULL and it tirggers a SIGSEGV with the
input of this input
file: here. Please
notice that this file contains some non-printable characters.
The reason for this bug is that str is changed by
the bozostrnsep function in the first line, however, the
following lines only check whether val
is NULL bug ignore the str variable. The
possible workaround might be adding the check for this variable after
calling bozostrnsep.
Honggfuzz Related Work
Fuzzing ping(8) with LD_PRELOAD and HF_ITER
In this last post, we have fuzzed the ping(8)
with honggfuzz with plenty of modifications. This is
because we need to modify the behaviors of the socket interfaces to
get inputs from the honggfuzz. With the suggestions
from Robert Swiecki in
this pull
request, we have finished a fuzzing implementation without any
modification to the original source of ping(8).
The LD_PRELOAD environment variable can be used to
load a list of libraries in advance. This means that we can use it to
shadow the implementations of some functions in these
libraries. The HF_ITER interface is used to get the
inputs actively from the honggfuzz. So, if we combine
these two together, we can re-implement the socket interfaces in some
library and this implementation will retrieve the inputs with
the HF_ITER interface. After that, we can load this
library with LD_PRELOAD and then we can shadow the socket
interfaces for ping(8). You can find the detailed
implementation of this library in
this link.
Similar to this idea, Kamil Rytarowski also suggests me to
implement a fuzzing mode for honggfuzz to fuzz programs
with inputs from the command line. The basic idea is that we can
implement a library to replace the command line with inputs
from HF_ITER interface. Currently, we have
finished a
simple implementation but it seems that we have encountered some
problems
with exec(3)
interface because it might drop the information or states for
fuzzing.
Adding "Only-Printable" Mode for honggfuzz
The libFuzzer provides -only-ascii option
to provide only-printable inputs for fuzzed programs. This option is
useful for some programs such as
the expr(1), sed(1) and so on. So we have
added the only-printable mode for the honggfuzz to finish
similar tasks. This implementation has been merged by the official
repository in a
pull request.
Summary
The GSoC 2018 project of "Integrating libFuzzer for the Userland Applications" has finally ended. During this period, I have been more and more proficient with different fuzzing tools and the NetBSD system. At the same time, I also feel so good to contribute something to the community especially when some commits or suggestions have been accepted. With the help of Kamil Rytarowski, I fortunately also get a chance to give a talk about this project in the EuroBSDcon 2018.
Thanks to my mentors, Kamil Rytarowski and Christos Zoulas for
their patient guidance during this summer. Besides, I also want to
thank Robert Swiecki for his great suggestions on fuzzing
with honggfuzz, thank Kamil Frankowicz for his help on
fuzzing programs with both AFL
and honggfuzz, thank Matthew Green and Joerg Sonnenberger
for their help for working with LLVM on NetBSD. Finally, thanks to
Google Summer of Code and the NetBSD Community for this chance to work
with you in this unforgettable summer!
This is the third and final report of the Kernel Address Sanitizer(KASan) project that I have been doing as a part of Google Summer of Code (GSoC) ‘18 with the NetBSD.
You can refer the first and second reports here :
Sanitizers are tools which are used to detect various errors in programs. They are pretty commonly used as aides to fuzzers. The aim of the project was to build the NetBSD kernel with Kernel Address Sanitizer. This would allow us to find memory bugs in the NetBSD kernel that otherwise would be pretty hard to detect.
Design and principle of KASan
KASan maintains a shadow buffer which is 1/8th the size of the total accessible kernel memory. Each byte of kernel memory is mapped to a bit of shadow memory. Every byte of memory that is allocated and freed is noted in the shadow buffers with the help of the kernel memory allocators.
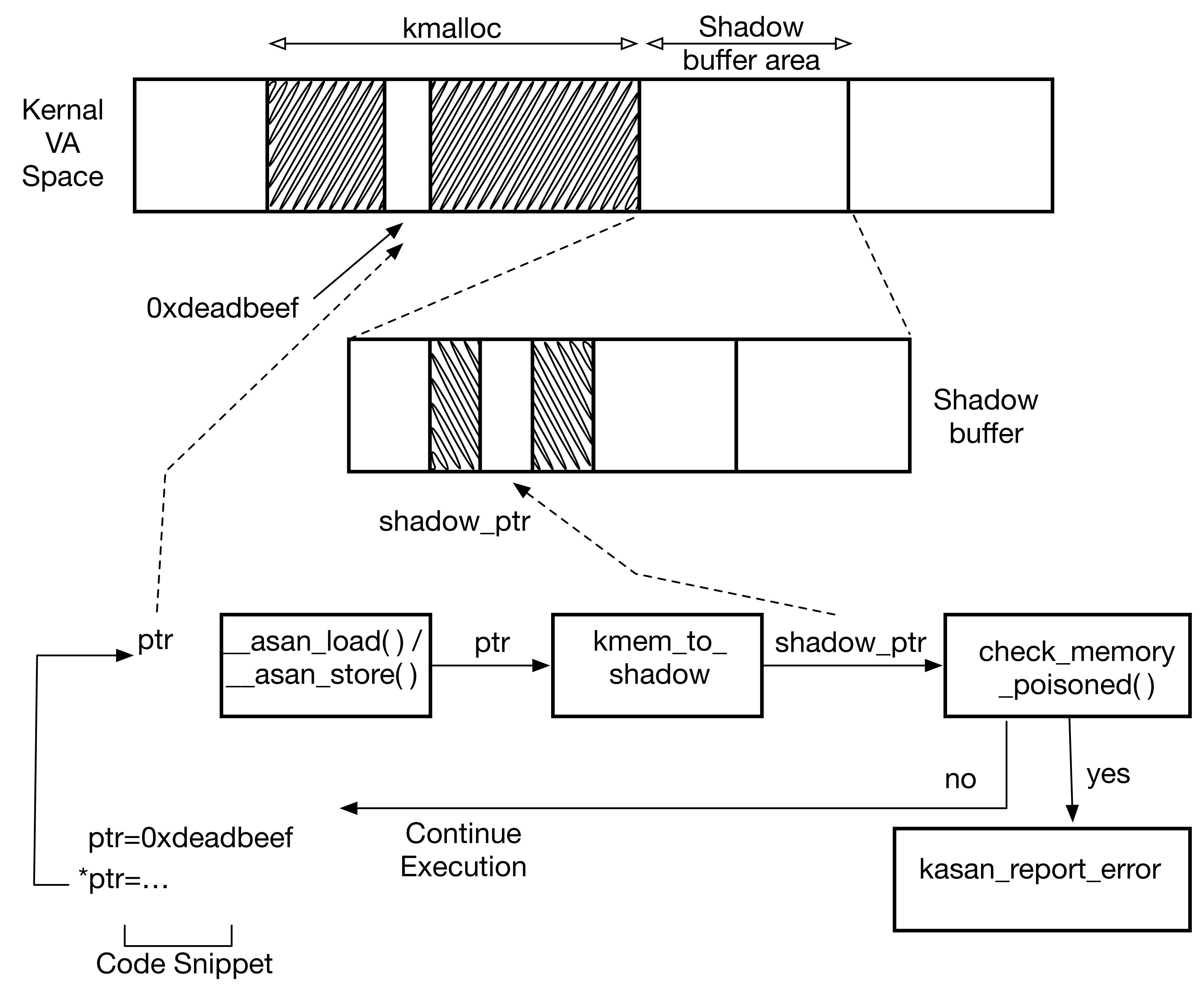
The above diagram shows how a piece of kernel code gets instrumented by the compiler and the checks that it undergoes.
Kasan Initialisation
During kernel boot the shadow memory needs to be initialised. This is done after the pmap(9) and the uvm(9) systems have been bootstrapped.Linux Initialisation model
Linux initialises the shadow buffer in two step method.
Kasan_early_init - Function called in main function of the kernel before the MMU is set up.- Initialises a physical zero page.
- maps the entire top level of the shadow region to a physical zero page.
- The earlier mapping of the shadow region is cleared.
- Allocation of the shadow buffer takes place
- Shadow offsets of regions of kernel memory that are not backed up by actual physical memory are mapped to a single zero page.
- This is done by traversing into the page table and modifying it to point to the zero page.
- Shadow offsets corresponding to the regions of kernel memory that are backed up by actual physical memory are populated with pages allocated from the same NUMA node
- This is done by traversing into the page table and allocating memory from the same NUMA node as the original memory by using early alloc.
- Shadow offsets of regions of kernel memory that are not backed up by actual physical memory are mapped to a single zero page.
- The modifications made to the page table are updated.
Our approach
We decided not to go for a approach which involves updating/modifying the page tables directly. The major reasons for this were
- Modifying the page tables increased the code size by a lot and created a lot of unnecessary complications.
- A lot of the linux code was architecture dependent - implementing the kernel sanitizer for an another architecture would mean reimplementing a lot of the code.
- A lot of this page table modification part was already handled by the low level memory allocators for the kernel. This meant we are rewriting a part of the code.
Hence we decided to move to use a higher level allocator for the allocation purpose and after some analysis decided to use uvm_km_alloc.
- This helped in reducing the code size from around 600 - 700 lines to around 50.
- We didn’t have to go through the pain of writing code to traverse through page tables and allocate pages.
- We feel this code can be reused for multiple architectures mostly by only changing a couple of offsets.
We identified the following memory regions to be backed by actual physical memory immediately after uvm bootstrap.
- Cpu Entry Area - Area containing early entry/exit code, entry stacks and per cpu information.
- Kernel Text Section - Memory with prebuilt kernel executable code
Since NetBSD support for NUMA (Non Uniform Memory Access) isn't available yet. We just allocate them normally.
The following regions were mapped to a single zero-page since they are not backed by actual physical memory at that point.
- Userland - user land doesn't exist at this point of kernel boot and hence isn't backed by physical memory.
- Kernel Heap - The entire kernel memory is basically unmapped at this point (pmap_bootstrap does have an small memory region - which we are avoiding for now)
- Module Map - The kernel module map doesn't have any modules loaded at this point.
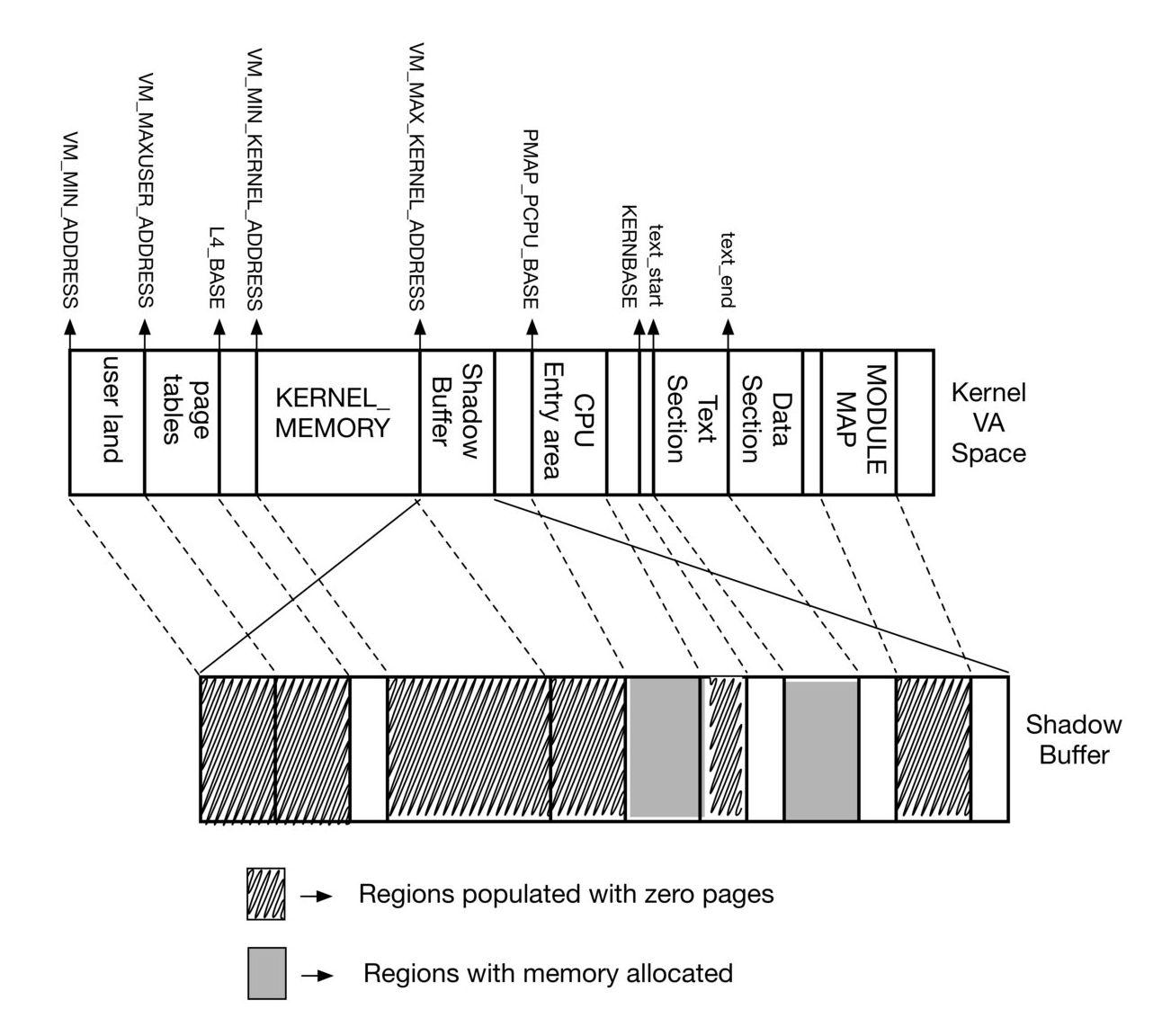
The above diagram shows the mapping of different memory ranges of the NetBSD kernel Virtual Address space and how they are mapped in the Shadow Memory.
You can find the implementation in the file kern_asan_init.c in my Github fork of NetBSD.
This part was time consuming since I had to read through a lot of Linux code, documentation, get a better idea of the Linux memory structure and finally search and figure about similar
Integrating KASan functions with the Allocators
All the memoryallocators(9) would have to be modified so that every allocation and freeing of memory is updated in the shadow memory, so that the checks that the compiler inserts in the code during compile time works properly.
Linux method
Linux has 3 main allocators - slab, slub and slob. Linux had a option to compile the kernel with only a single allocator and hence kasan was meant to work with a kernel that was compiled for using only the slub allocator.
The slub allocator is a object cache based allocator which exported only a short but powerful api of functions namely:
- kmem_cache_create - create an cache
- kmem_cache_reap - clears all slabs in a cache (When memory is tight)
- kmem_cache_shrink - deletes freed objects
- kmem_cache_alloc - allocates an object from a cache
- kmem_cache_free - frees an object from a cache
- kmem_cache_destroy - destroys all objects
- kmalloc - allocates a block of memory of given size from the cache
- kfree - frees memory allocated with kmalloc
All of the functions have a corresponding kasan function inside them to update the shadow buffer. This functions are dummy functions unless the kernel is compiled with KASAN.
Our Approach
NetBSD has four memory allocators and there is no way to build the kernel with just one allocator. Hence, the obvious solution is to instrument all the allocators.
So we had four targets to approach :
- Kmem allocator - General purpose kernel allocator
- Pool allocator - Fixed size allocator
- Pool cache allocator - Cache based fixed size allocator
- Uvm allocator - Low level memory allocator
Pool Cache Allocator
We decided to work on the pool cache allocator first since it was the only allocator which was pretty similar to the slab allocator in linux. We identified potential functions in the pool cache allocator which was similar to the API of the slab allocator.
The functions in pool_cache API which we instrumented with KASan functions.
- pool_cache _init - Allocates and initialises a new cache and returns it (Similar to kmem_cache_create)
- pool_cache_get_paddr - Get an object from the cache that was supplied as the argument. (Similar to kmem_cache_alloc)
- pool_cache_get - Wrapper function around pool_cache_get_paddr and hence skipped.
- pool_cache_put_paddr - Free an object and put it back in the cache. (Similar to kmem_cache_free)
- pool_cache_put - Wrapper function around pool_cache_put_paddr and hence skipped.
- pool_cache_destroy - Destroy and free all objects in the cache (Similar to kmem_cache_destroy)
We noticed that the functions which were responsible for clearing all the unused objects from a cache during shortage of memory were a part of the pagedeamon.
Kmem Allocator
The second target was the kmem allocator since during our initial analysis we found that most of the kmem functions relied on the pool_cache allocator functions initially. This was useful since we could use the same functions in the pool_cache allocator.
Pool Allocator and UVM Allocator
Unfortunately, we didn't get enough time to research and integrate the Kernel Address Sanitizer with the Pool and UVM allocators. I will resume work on it shortly.
Future Work
We are getting the Kernel Address Sanitizer closer and closer to work in the context of NetBSD kernel. After finishing the work on allocators there will be a process of bringing it up.
For future work we leave support of quarantine lists to reduce the number of detected false negatives, this means that we will keep a list of recently unmapped memory regions as poisoned without an option to allocate it again. This means that the probability of use-after-free will go down. Quarantine lists might be probably expanded to some kernel specific structs such as LWP (Light-Weight Process -- Thread entity) or Process ones, as these ones are allocated once and reused between the process of freeing one and allocating a new one.
From other items on the road map we keep handling of memory hotplugging, ATF regression tests, researching dynamic configuration options through sysctl(3) and last but not least getting the final implementation as clean room, unclobbered from potential licensing issues.
Conclusion
Even though officially the GSoC' 18 coding period is over, I definitely look forward keep contributing to this project and NetBSD foundation. I have had an amazing summer working with the NetBSD Foundation and Google. I will be presenting a talk about this at EuroBSDCon '18 at Romania with Kamil Rytarowski.
This summer has had me digging a lot into code from both Linux and NetBSD covering various fields such as the Memory Management System, Booting process and Compilation process. I can definitely say that I have a much better understanding of how Operating Systems work.
I would like to thank my mentor, Kamil Rytarowski for his constant support and patient guidance. A huge thanks to the NetBSD community who have been supportive and have pitched in to help whenever I have had trouble. Finally, A huge thanks for Google for their amazing initiative which provided me this opportunity.
In keeping with NetBSD's policy of supporting only the latest (8.x) and next most recent (7.x) major branches, the recent release of NetBSD 8.0 marks the end of life for NetBSD 6.x. As in the past, a month of overlapping support has been provided in order to ease the migration to newer releases.
As of now, the following branches are no longer maintained:
- netbsd-6-1
- netbsd-6-0
- netbsd-6
This means:
- There will be no more pullups to those branches (even for security issues)
- There will be no security advisories made for any those branches
- The existing 6.x releases on ftp.NetBSD.org will be moved into /pub/NetBSD-archive/
May NetBSD 8.0 serve you well! (And if it doesn't, please submit a PR!)
Prepared by Keivan Motavalli as part of GSoC 2018.
In Configuration files versioning in pkgsrc, Part 1 basic pkgsrc support for tracking package configuration changes was introduced, as were the features that attempt to automatically merge installed configuration files with new defaults, all shown using RCS as the backing Version Control System and passing options by setting environment variables.
Some of them have changed (conf tracking now needs to be explicitly enabled), support is now also in pkg_install.conf and aside from RCS, pkgsrc now supports CVS, Git, mercurial and SVN, both locally and connecting to remote resources.
Furthermore, pkgsrc is now able to deploy configuration from packages being installed from a remote, site-specific vcs repository.
User modified files are always tracked even if automerge functionality is not enabled, and a new tool, pkgconftrack(1), exists to manually store user changes made outside of package upgrade time.
Version Control software is executed as the same user running pkg_add or make install, unless the user is "root". In this case, a separate, unprivileged user, pkgvcsconf, gets created with its own home directory and a working login shell (but no password). The home directory is not strictly necessary, it exists to facilitate migrations betweens repositories and vcs changes; it also serves to store keys used to access remote repositories.
Files, objects and other data in the working directory are only accessible by UID 0 and pkgvcsconf, but be aware, if you want to login to remote repositories via ssh, keys will now need to be placed at pkgvcsconf own $HOME/.ssh/ directory, and ssh-agent, if you need to use it, also should have its socket, as defined by SSH_AUTH_SOCK, accessible by pkgvcsconf:pkgvcsconf.
New pkgsrc options
NOVCS, which was used to disable configuration tracking via Version Control Systems, doesn't exist anymore as an option or environment variable.
In its place, VCSTRACK_CONF now needs to be set truthfully in order to enable configuration files version tracking.
This can be done temporarily via environment variables before using pkgsrc or installing binary packages, such as by exporting
export VCSTRACK_CONF=yes
on the tty, or permanently in pkg_install.conf located under the PREFIX in use.
After bootstrapping a pkgsrc branch that supports the new features, check new options by calling, if you are using /usr/pkg as the PREFIX:
man -M /usr/pkg/man/ pkg_install.conf
Remember to edit /usr/pkg/etc/pkg_install.conf in order to set VCSTRACK_CONF=yes.
Also try out VCSAUTOMERGE=yes to attempt merging installed configuration files with new defaults, as described in the first blog post. Installed configuration files are always backed up before an attempt is made to merge changes, and if conflicts are reported no changes get automatically installed in place of the existing configuration files, so that the user can manually review them.
Both VCSTRACK_CONF and VCSAUTOMERGE variables, if set on the environment, take precedence over values defined in pkg_install.conf in order to allow for an easy override at runtime. All other vcs-related options defined in pkg_install.conf replace those defined as environment variables.
These are:
VCS, sets the backend used to track configuration files.
If unset, rcs gets called. pkgsrc now also supports Git, SVN, HG and CVS. More on that will get introduced later in the post.
VCSDIR, the path used as a working directory by pkginstall scripts run at package installation by pkg_add and looked up by pkgconftrack(1). Files are copied there before being tracked in a VCS or merged, this directory also stores a local configuration repository or objects and metadata associated with remote repositories, according to the solution in use.
By default, /var/confrepo is assumed as the default working directory and initialized.
REMOTEVCS, an URI describing how to access a remote repository, according to the format required by the chosen VCS. Remote repositories are disabled if this variable is unset, or if it is set to "no".
VCSCONFPULL, set it to "yes" to have pkgscr attempt to deploy configuration files from a remote repository upon package installation, instead of using package provided defaults. It now works with git, svn and mercurial.
ROLE, the role defined for the system, used when deploying configuration from a remote, site repository for packages being installed.
More details on system roles and configuration deployment are down in this post.
rcs vs network-capable systems
RCS, as stated, is the default backend because of its simplicity and widespread presence.
When packages are being compiled from source, system rcs is used if present, otherwise it gets installed automatically by pkgsrc as a TOOL when the first package gets built, being an mk/pkginstall/bsd.pkginstall.mk tool dependency.
Please note that binaries defined as pkgsrc TOOLs will get their path, as on the build system, hardcoded in binary packages install scripts.
This shouldn't be a problem for NetBSD binary package users since RCS is part of the base system installation and paths will match. Users who choose binary packages on other platforms and got pkgtools/pkg_install (e.g., pkg_add) by running pkgsrc bootstrap/bootstrap script should also be ok, since packages get built as part of the bootstrap procedure, making bsd.pkginstall.mk tool dependency on RCS tick.
Also note that even when using other systems, automerge functionality depends on merge, part of Revision Control System.
Other software, such as git, svn, cvs and hg is not installed or called in pkginstall scripts as TOOL dependencies: they get searched in the PATH defined on the environment, and must be manually installed by the user via pkgsrc itself or other means before setting VCS= to the desired system.
Each will get briefly introduced, with an example setting up and using remote repositories.
pkgsrc will try to import existing and new files into the chosen VCS when it gets switched, and a previously undefined REMOTEVCS URI may be added to an existing repository, already existing files may get imported and pushed to the repository.
It all depends on the workflow of the chosen system, but users SHOULD NOT expect pkgsrc to handle changes and the addition of remote repositories for them. At best there will be inconsistencies and the loss of revisions tracked in the old solution: the handling of repository switches is out of scope for this project.
Users who decide to switch to a different Version Control System should manually convert their local repository and start clean. Users who want to switch from local to using a remote repository should also, when setting it up, take care in populating it with local data and then start over, preferably by removing the path specified by VCSDIR or by setting it to a new path.
pkgsrc will try its best to ensure new package installations don't fail because of changes made without taking the aforementioned steps, but no consistency with information stored in the old system should then be expected.
Some words on REMOTEVCS
REMOTEVCS, if defined and different from "no", points to the URI of a remote repository in a way understandable by the chosen version control system.
It may include the access method, the user name, the remote FQDN or IP address, and the path to the repository.
if a password gets set via userName:password@hostname, care should be taken to only set REMOTEVCS as an environment variable, leaving out login information from pkg_install.conf.
The preferred way to access remote repositories is to use ssh with asymmetrical keys. These should be placed under $HOME/.ssh/ for the user pkgsrc runs under, or under pkgvcsconf home directory if you are installing packages as root. If keys are password protected or present in non-standard search paths, ssh-agent should be started and the appropriate key unlocked via ssh-add before package installations or upgrades are run.
If running ssh-agent, SSH_AUTH_SOCK and SSH_AGENT_PID variables must be appropriately exported on the environment the package installations will take place in; CVS_RSH should be set to the path of the ssh executable and exported on the environment when using CVS to access a remote repository over ssh.
Git and remotes
git, pretty straightforwardly, will store objects, metadata and configuration at VCSDIR/.git, while VCSDIR is defined as the working-tree files get checked out to.
The configuration under VCSDIR/.git includes the definition of the remote repository, which the +VERSIONING script will set once in the PREPARE phase; the script can also switch the remote to a new one, when using git. Data consistency should be ensured by actions taken beforehand by the user.
Using git instead of rcs is simply done by setting VCS=git in pkg_install.conf
pkgsrc will inizialize the repository.
Please do this before installing packages that come with configuration files, then remove the old VCSDIR (e.g., by running rm -fr /var/confrepo) and let pkgsrc take care of the rest, or set VCSDIR to a new path.
If you wish to migrate an existing repository to git, seek documentation for scripts such as rcs-fast-export and git fast-import, but initialize it under a new working directory. Running git on top of an older, different repository without migrating data first will allow you to store new files, but automerge may break in strange ways when it tries to extract the first revision of a configuration file from the repository, if it is only tracked in the previous version control system.
Now, some steps needed to setup a remote git repository are also common to cvs, svn and mercurial:
I will run a server at 192.168.100.112 with ssh access enabled for the user vcs.
An ssh key has been generated under /root/.ssh and added to vcs@192.168.100.112 authorized_keys list for the pkgsrc host to automatically login as vcs on the remote instance.
In order to create a remote repository, login as vcs on the server and run
$ pwd /usr/home/vcs $ mkdir gitconftrack.git $ cd gitconftrack.git/ $ git --bare init Initialized empty Git repository in /usr/home/vcs/gitconftrack.git/ $ cat /usr/home/vcs/.ssh/authorized_keys ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABA[...] $ /etc/rc.d/sshd status sshd is running as pid 1343.
now, on the client, set the URI as ssh://vcs@192.168.100.112/usr/home/vcs/gitconftrack.git (full path here! hg and svn use paths relative to the user's home directory
pkghost# echo "VCSTRACK_CONF=yes" >> /usr/pkg/etc/pkg_install.conf pkghost# echo "VCS=git" >> /usr/pkg/etc/pkg_install.conf pkghost# echo "VCSDIR=/var/gitandremote" >> /usr/pkg/etc/pkg_install.conf pkghost# echo "VCSAUTOMERGE=yes" >> /usr/pkg/etc/pkg_install.conf pkghost# echo "REMOTEVCS=ssh://vcs@192.168.100.112/usr/home/vcs/gitconftrack.git pkghost# cat /usr/pkg/etc/pkg_install.conf VCSTRACK_CONF=yes VCS=git VCSDIR=/var/gitandremote VCSAUTOMERGE=yes REMOTEVCS=ssh://vcs@192.168.100.112/usr/home/vcs/gitconftrack.git pkghost#
and try to install spamd as with the examples in the first post (it comes with a configuration file and is written in shell scripts that don't need to be compiled or many dependencies installed when testing things out)
pkghost# cd pkgsrc/mail/spamd
pkghost# make
=> Bootstrap dependency digest>=20010302: found digest-20160304
===> Skipping vulnerability checks.
WARNING: No /var/db/pkg/pkg-vulnerabilities file found.
WARNING: To fix run: `/usr/pkg/sbin/pkg_admin -K /var/db/pkg fetch-pkg-vulnerabilities'.
=> Fetching spamd-20060330.tar.gz
[...]
pkghost# make install
pkghost# make install
=> Bootstrap dependency digest>=20010302: found digest-20160304
===> Skipping vulnerability checks.
WARNING: No /var/db/pkg/pkg-vulnerabilities file found.
WARNING: To fix run: `/usr/pkg/sbin/pkg_admin -K /var/db/pkg fetch-pkg-vulnerabilities'.
===> Installing binary package of spamd-20060330nb2
fatal: Not a git repository: '/var/gitandremote/.git'
Initialized empty Git repository in /var/gitandremote/.git/
fatal: Couldn't find remote ref master
fatal: The remote end hung up unexpectedly
REGISTER /var/gitandremote/defaults//usr/pkg/etc/spamd.conf
spamd-20060330nb2: copying /usr/pkg/share/examples/spamd/spamd.conf to /usr/pkg/etc/spamd.conf
[master (root-commit) f84f8ee] pkgsrc: add spamd-20060330nb2
1 file changed, 86 insertions(+)
create mode 100644 defaults/usr/pkg/etc/spamd.conf
Conf commit: pkgsrc: add spamd-20060330nb2
Counting objects: 7, done.
Compressing objects: 100% (2/2), done.
Writing objects: 100% (7/7), 1.34 KiB | 688.00 KiB/s, done.
Total 7 (delta 0), reused 0 (delta 0)
To ssh://192.168.100.112/usr/home/vcs/gitconftrack.git
* [new branch] master -> master
===========================================================================
The following files should be created for spamd-20060330nb2:
/etc/rc.d/pfspamd (m=0755)
[/usr/pkg/share/examples/rc.d/pfspamd]
===========================================================================
===========================================================================
$NetBSD: MESSAGE,v 1.1.1.1 2005/06/28 12:43:57 peter Exp $
Don't forget to add the spamd ports to /etc/services:
spamd 8025/tcp # spamd(8)
spamd-cfg 8026/tcp # spamd(8) configuration
===========================================================================
pkghost#
Let's see what's at the VCSDIR now...
pkghost# cd /var/gitandremote/
pkghost# ls
.git automerged defaults user
pkghost# find defaults/ -type f -print
defaults/usr/pkg/etc/spamd.conf
pkghost# git log
commit f84f8ee278ec53f55d652e5c6bf52554216cfd49 (HEAD -> master, origin/master)
Author: kmotavalli
Date: Fri Aug 3 15:00:26 2018 +0000
pkgsrc: add spamd-20060330nb2
pkghost# git remote -v
origin ssh://vcs@192.168.100.112/usr/home/vcs/gitconftrack.git (fetch)
origin ssh://vcs@192.168.100.112/usr/home/vcs/gitconftrack.git (push)
on the server:
$ hostname
vers
$ pwd
/usr/home/vcs/gitconftrack.git
$ git log
commit f84f8ee278ec53f55d652e5c6bf52554216cfd49 (HEAD -> master)
Author: kmotavalli
Date: Fri Aug 3 15:00:26 2018 +0000
pkgsrc: add spamd-20060330nb2
$
All fine, let's simulate automerge:
pkghost# vi /usr/pkg/etc/spamd.conf
[...]
# Whitelists are done like this, and must be added to "all" after each
# blacklist from which you want the addresses in the whitelist removed.
#
#whitelist:\
# :white:\
# :method=file:\
# :file=/var/mail/whitelist.txt:
whitelist:\
:white:\
:method=file:\
:file=/var/mail/whitelist.txt:
:x
/usr/pkg/etc/spamd.conf: 86 lines, 2767 characters
pkghost# cd $HOME/pkgsrc/mail/spamd; make replace
=> Bootstrap dependency digest>=20010302: found digest-20160304
===> Skipping vulnerability checks.
WARNING: No /var/db/pkg/pkg-vulnerabilities file found.
WARNING: To fix run: `/usr/pkg/sbin/pkg_admin -K /var/db/pkg fetch-pkg-vulnerabilities'.
===> Replacing for spamd-20060330nb2
===> Updating using binary package of spamd-20060330nb2
/usr/bin/env /usr/pkg/sbin/pkg_add -K /var/db/pkg -U -D /root/pkgsrc/mail/spamd/work/.packages/spamd-20060330nb2.tgz
===========================================================================
The following users are no longer being used by spamd-20060330nb2,
and they can be removed if no other software is using them:
_spamd
===========================================================================
===========================================================================
The following groups are no longer being used by spamd-20060330nb2,
and they can be removed if no other software is using them:
_spamd
===========================================================================
===========================================================================
The following files are no longer being used by spamd-20060330nb2,
and they can be removed if no other packages are using them:
/usr/pkg/etc/spamd.conf
===========================================================================
Everything up-to-date
From ssh://192.168.100.112/usr/home/vcs/gitconftrack
* branch master -> FETCH_HEAD
Already up to date.
REGISTER /var/gitandremote/defaults//usr/pkg/etc/spamd.conf
spamd-20060330nb2: /usr/pkg/etc/spamd.conf already exists
spamd-20060330nb2: attempting to merge /usr/pkg/etc/spamd.conf with new defaults!
Saving the currently user-installed revision to /var/gitandremote/user//usr/pkg/etc/spamd.conf
[master eacdef9] pkgsrc: backup user conf before attempting merge for spamd-20060330nb2
1 file changed, 86 insertions(+)
create mode 100644 user/usr/pkg/etc/spamd.conf
Conf commit: pkgsrc: backup user conf before attempting merge for spamd-20060330nb2
Counting objects: 7, done.
Compressing objects: 100% (3/3), done.
Writing objects: 100% (7/7), 1.44 KiB | 1.44 MiB/s, done.
Total 7 (delta 0), reused 0 (delta 0)
To ssh://192.168.100.112/usr/home/vcs/gitconftrack.git
f84f8ee..eacdef9 master -> master
Merged with no conflicts. installing it to /usr/pkg/etc/spamd.conf!
Revert from the last revision of /var/gitandremote/user//usr/pkg/etc/spamd.conf if needed
[master 4f1d514] pkgsrc: add spamd-20060330nb2
1 file changed, 86 insertions(+)
create mode 100644 automerged/usr/pkg/etc/spamd.conf
Conf commit: pkgsrc: add spamd-20060330nb2
Counting objects: 2, done.
Compressing objects: 100% (2/2), done.
Writing objects: 100% (2/2), 280 bytes | 280.00 KiB/s, done.
Total 2 (delta 0), reused 0 (delta 0)
To ssh://192.168.100.112/usr/home/vcs/gitconftrack.git
eacdef9..4f1d514 master -> master
===========================================================================
The following files should be created for spamd-20060330nb2:
/etc/rc.d/pfspamd (m=0755)
[/usr/pkg/share/examples/rc.d/pfspamd]
===========================================================================
===========================================================================
$NetBSD: MESSAGE,v 1.1.1.1 2005/06/28 12:43:57 peter Exp $
Don't forget to add the spamd ports to /etc/services:
spamd 8025/tcp # spamd(8)
spamd-cfg 8026/tcp # spamd(8) configuration
===========================================================================
A new file backing up the installed configuration, as edited by the user, has been created in the working directory at /var/gitandremote/user/usr/pkg/etc/spamd.conf and pushed to the remote repository.
You can check it out and rever from it in case something breaks:
pkghost# cd /var/gitandremote/user/
pkghost# ls
usr
pkghost# git checkout usr/pkg/etc/spamd.conf
pkghost# tail /var/gitandremote/user/usr/pkg/etc/spamd.conf
# :method=exec:\
# :file=/usr/local/bin/relaydb -4lw:
# Whitelists are done like this, and must be added to "all" after each
# blacklist from which you want the addresses in the whitelist removed.
#
whitelist:\
:white:\
:method=file:\
:file=/var/mail/whitelist.txt:
pkghost#
running git log on the server, we can see two new commits: one pushed when backing up the installed configuration file, one after the automerge succeded and the package got installed.
$ hostname
vers
$ pwd
/usr/home/vcs/gitconftrack.git
$ git log
commit 4f1d514159860906154eeaaa24a10ec572a4d062 (HEAD -> master)
Author: kmotavalli
Date: Fri Aug 3 15:12:45 2018 +0000
pkgsrc: add spamd-20060330nb2
commit eacdef9f52b49e3ce6f544008dc7c75dc89cbd67
Author: kmotavalli
Date: Fri Aug 3 15:12:43 2018 +0000
pkgsrc: backup user conf before attempting merge for spamd-20060330nb2
commit f84f8ee278ec53f55d652e5c6bf52554216cfd49
Author: kmotavalli
Date: Fri Aug 3 15:00:26 2018 +0000
pkgsrc: add spamd-20060330nb2
$
Furthermore, I'll simulate the addition of a new comment to the package provided configuration file, then the change of a variable, which should generate an automerge conflict that needs manual user review. (Note: you don't need to change configuration files in pkgsrc package working directory! This is only done to simulate a change coming with a package upgrade!
pkghost# cd $HOME/pkgsrc/mail/spamd; make clean
===> Cleaning for spamd-20060330nb2
pkghost# make fetch
pkghost# sed -i 's/PKGREVISION=.*2/PKGREVISION=3/g' Makefile
pkghost# make extract
=> Bootstrap dependency digest>=20010302: found digest-20160304
===> Skipping vulnerability checks.
WARNING: No /var/db/pkg/pkg-vulnerabilities file found.
WARNING: To fix run: `/usr/pkg/sbin/pkg_admin -K /var/db/pkg fetch-pkg-vulnerabilities'.
=> Checksum SHA1 OK for spamd-20060330.tar.gz
=> Checksum RMD160 OK for spamd-20060330.tar.gz
=> Checksum SHA512 OK for spamd-20060330.tar.gz
===> Installing dependencies for spamd-20060330nb3
=> Build dependency cwrappers>=20150314: found cwrappers-20180325
===> Overriding tools for spamd-20060330nb3
===> Extracting for spamd-20060330nb3
pkghost# head work/spamd-20060330/etc/spamd.conf
# spamd config file, read by spamd-setup(8) for spamd(8)
#
# See spamd.conf(5)
#
# Configures whitelists and blacklists for spamd
#
# Strings follow getcap(3) convention escapes, other than you
# can have a bare colon (:) inside a quoted string and it
# will deal with it. See spamd-setup(8) for more details.
pkghost# sed -i 's/method=http/method=https/g' work/spamd-20060330/etc/spamd.conf
.
pkghost# make update
===> Skipping vulnerability checks.
WARNING: No /var/db/pkg/pkg-vulnerabilities file found.
WARNING: To fix run: `/usr/pkg/sbin/pkg_admin -K /var/db/pkg fetch-pkg-vulnerabilities'.
===> Deinstalling for spamd-20060330nb4
Running /usr/pkg/sbin/pkg_delete -K /var/db/pkg -r spamd-20060330nb3
===========================================================================
The following users are no longer being used by spamd-20060330nb3,
and they can be removed if no other software is using them:
_spamd
===========================================================================
===========================================================================
The following groups are no longer being used by spamd-20060330nb3,
and they can be removed if no other software is using them:
_spamd
===========================================================================
===========================================================================
The following files are no longer being used by spamd-20060330nb3,
and they can be removed if no other packages are using them:
/usr/pkg/etc/spamd.conf
===========================================================================
=> Bootstrap dependency digest>=20010302: found digest-20160304
===> Skipping vulnerability checks.
WARNING: No /var/db/pkg/pkg-vulnerabilities file found.
WARNING: To fix run: `/usr/pkg/sbin/pkg_admin -K /var/db/pkg fetch-pkg-vulnerabilities'.
===> Patching for spamd-20060330nb4
=> Applying pkgsrc patches for spamd-20060330nb4
=> Fixing configuration paths.
===> Creating toolchain wrappers for spamd-20060330nb4
===> Building for spamd-20060330nb4
[...]
=> Creating /root/pkgsrc/mail/spamd/work/.rc.d/pfspamd
===> Installing for spamd-20060330nb4
=> Generating pre-install file lists
=> Creating installation directories
/usr/bin/install -c -o root -g wheel -m 644 /root/pkgsrc/mail/spamd/work/spamd-20060330/man/spamd.conf.5 /ro5
/usr/bin/install -c -o root -g wheel -m 644 /root/pkgsrc/mail/spamd/work/spamd-20060330/spamd/spamd.8 /root/8
/usr/bin/install -c -o root -g wheel -m 644 /root/pkgsrc/mail/spamd/work/spamd-20060330/spamd-setup/spamd-set8
/usr/bin/install -c -o root -g wheel -m 644 /root/pkgsrc/mail/spamd/work/spamd-20060330/spamdb/spamdb.8 /roo8
/usr/bin/install -c -o root -g wheel -m 644 /root/pkgsrc/mail/spamd/work/spamd-20060330/spamlogd/spamlogd.8 8
/usr/bin/install -c -s -o root -g wheel -m 755 /root/pkgsrc/mail/spamd/work/spamd-20060330/spamd-setup/spamd-c
/usr/bin/install -c -s -o root -g wheel -m 755 /root/pkgsrc/mail/spamd/work/spamd-20060330/spamd/spamd /rootc
/usr/bin/install -c -s -o root -g wheel -m 755 /root/pkgsrc/mail/spamd/work/spamd-20060330/spamdb/spamdb /ron
/usr/bin/install -c -s -o root -g wheel -m 755 /root/pkgsrc/mail/spamd/work/spamd-20060330/spamlogd/spamlogd c
/usr/bin/install -c -o root -g wheel -m 644 /root/pkgsrc/mail/spamd/work/spamd-20060330/etc/spamd.conf /root/d
=> Automatic manual page handling
=> Generating post-install file lists
=> Checking file-check results for spamd-20060330nb4
=> Creating binary package /root/pkgsrc/mail/spamd/work/.packages/spamd-20060330nb4.tgz
===> Building binary package for spamd-20060330nb4
=> Creating binary package /root/pkgsrc/packages/All/spamd-20060330nb4.tgz
===> Installing binary package of spamd-20060330nb4
Everything up-to-date
From ssh://192.168.100.112/usr/home/vcs/gitconftrack
* branch master -> FETCH_HEAD
Already up to date.
REGISTER /var/gitretest/defaults//usr/pkg/etc/spamd.conf
spamd-20060330nb4: /usr/pkg/etc/spamd.conf already exists
spamd-20060330nb4: attempting to merge /usr/pkg/etc/spamd.conf with new defaults!
Saving the currently installed revision to /var/gitretest/automerged//usr/pkg/etc/spamd.conf
[master 8970767] pkgsrc: backup preexisting conf before attempting merge for spamd-20060330nb4
1 file changed, 17 insertions(+), 17 deletions(-)
Conf commit: pkgsrc: backup preexisting conf before attempting merge for spamd-20060330nb4
Counting objects: 7, done.
Compressing objects: 100% (3/3), done.
Writing objects: 100% (7/7), 599 bytes | 599.00 KiB/s, done.
Total 7 (delta 1), reused 0 (delta 0)
To ssh://192.168.100.112/usr/home/vcs/gitconftrack.git
8dd7368..8970767 master -> master
Merged with no conflict. installing it to /usr/pkg/etc/spamd.conf!
--- /usr/pkg/etc/spamd.conf 2018-08-04 06:13:39.017744154 +0000
+++ /var/gitretest/defaults//usr/pkg/etc/spamd.conf.automerge 2018-08-04 06:15:09.799758773 +0000
@@ -15,7 +15,7 @@
# may be applied to each blacklist.
#
# As of November 2004, a place to search for black lists is
-# http://spamlinks.net/filter-bl.htm
+# https://spamlinks.net/filter-bl.htm
#
# Some of the URLs below point to www.openbsd.org locations. Those
# files are likely to be mirrored to other OpenBSD www mirrors located
@@ -25,45 +25,45 @@
all:\
:spews1:china:korea:
-# Mirrored from http://spfilter.openrbl.org/data/sbl/SBL.cidr.bz2
+# Mirrored from https://spfilter.openrbl.org/data/sbl/SBL.cidr.bz2
spamhaus:\
:black:\
:msg="SPAM. Your address %A is in the Spamhaus Block List\n\
- See http://www.spamhaus.org/sbl and\
- http://www.abuse.net/sbl.phtml?IP=%A for more details":\
- :method=http:\
+ See https://www.spamhaus.org/sbl and\
+ https://www.abuse.net/sbl.phtml?IP=%A for more details":\
+ :method=https:\
:file=www.openbsd.org/spamd/SBL.cidr.gz:
-# Mirrored from http://www.spews.org/spews_list_level1.txt
+# Mirrored from https://www.spews.org/spews_list_level1.txt
spews1:\
:black:\
:msg="SPAM. Your address %A is in the spews level 1 database\n\
- See http://www.spews.org/ask.cgi?x=%A for more details":\
- :method=http:\
+ See https://www.spews.org/ask.cgi?x=%A for more details":\
+ :method=https:\
:file=www.openbsd.org/spamd/spews_list_level1.txt.gz:
-# Mirrored from http://www.spews.org/spews_list_level2.txt
+# Mirrored from https://www.spews.org/spews_list_level2.txt
spews2:\
:black:\
:msg="SPAM. Your address %A is in the spews level 2 database\n\
- See http://www.spews.org/ask.cgi?x=%A for more details":\
- :method=http:\
+ See https://www.spews.org/ask.cgi?x=%A for more details":\
+ :method=https:\
:file=www.openbsd.org/spamd/spews_list_level2.txt.gz:
-# Mirrored from http://www.okean.com/chinacidr.txt
+# Mirrored from https://www.okean.com/chinacidr.txt
china:\
:black:\
:msg="SPAM. Your address %A appears to be from China\n\
- See http://www.okean.com/asianspamblocks.html for more details":\
- :method=http:\
+ See https://www.okean.com/asianspamblocks.html for more details":\
+ :method=https:\
:file=www.openbsd.org/spamd/chinacidr.txt.gz:
-# Mirrored from http://www.okean.com/koreacidr.txt
+# Mirrored from https://www.okean.com/koreacidr.txt
korea:\
:black:\
:msg="SPAM. Your address %A appears to be from Korea\n\
- See http://www.okean.com/asianspamblocks.html for more details":\
- :method=http:\
+ See https://www.okean.com/asianspamblocks.html for more details":\
+ :method=https:\
:file=www.openbsd.org/spamd/koreacidr.txt.gz:
#relaydb-black:\
Revert from the penultimate revision of /var/gitretest/automerged//usr/pkg/etc/spamd.conf if needed
[master 1eef6d8] pkgsrc: add spamd-20060330nb4
1 file changed, 17 insertions(+), 17 deletions(-)
Conf commit: pkgsrc: add spamd-20060330nb4
Counting objects: 7, done.
Compressing objects: 100% (3/3), done.
Writing objects: 100% (7/7), 563 bytes | 563.00 KiB/s, done.
Total 7 (delta 1), reused 0 (delta 0)
To ssh://192.168.100.112/usr/home/vcs/gitconftrack.git
8970767..1eef6d8 master -> master
===========================================================================
The following files should be created for spamd-20060330nb4:
/etc/rc.d/pfspamd (m=0755)
[/usr/pkg/share/examples/rc.d/pfspamd]
===========================================================================
===========================================================================
$NetBSD: MESSAGE,v 1.1.1.1 2005/06/28 12:43:57 peter Exp $
Don't forget to add the spamd ports to /etc/services:
spamd 8025/tcp # spamd(8)
spamd-cfg 8026/tcp # spamd(8) configuration
===========================================================================
===> Cleaning for spamd-20060330nb4
[...]
pkghost# cat /var/gitandremote/automergedfiles
/usr/pkg/etc/spamd.conf
pkghost#
Should conflicts arise, these will be highlited as per rcs 3-way merge syntax in the file /var/gitandremote/defaults/usr/pkg/etc/spamd.conf.automerge and no action taken.
In that case, manually review the conflict opening spamd.conf.automerge in your favorite text editor, then manually copy it in place of the existing installed configuration file for spamd at /usr/pkg/etc/spamd.conf
CVS and remotes
CVS is used by having a CVSROOT directory at VCSDIR/CVSROOT, with VCSDIR as the working directory.
The same precautions treated illustrating Git usage also apply when chosing to use CVS (and svn, mercurial).
To use CVS, simply set VCS=cvs in PREFIX/etc/pkg_install.conf and change the VCSDIR to a new path.
pkgsrc will try to import existing files in CVS if the VCSDIR is not empty, but past files revision will not get migrated from whatever version control system was in use, nor will files present in the old repository but not checked out in the working directory. This will likely make automerge malfunction, so it's up to the user to migrate preeexisting repositories to CVS or to chose a new, empty path as the VCS working directory, if automerge has never been used up to this change (VCSAUTOMERGE not set to yes or VCSDIR/automergedfiles not existing/empty).
See CVS documentation for a description of how to form remote URIs (that will get passed to cvs with the -d flag)
In this example, I will use :ext:vcs@192.168.100.112:/usr/home/vcs/cvsconftrack as the REMOTEVCS uri
pkghost# cat /usr/pkg/etc/pkg_install.conf VCSTRACK_CONF=yes VCS=cvs VCSDIR=/var/cvsandremote VCSAUTOMERGE=yes REMOTEVCS=:ext:vcs@192.168.100.112:/usr/home/vcs/cvsconftrack pkghost# echo "export CVS_RSH=ssh" >> $HOME/.profile pkghost# export CVS_RSH=ssh pkghost#
and initialize a remote cvs repository on the server at 192.168.100.112:
$ hostname vers $ pwd /usr/home/vcs $ cvs -d/usr/home/vcs/cvsconftrack init
manually migrate existing data from other systems to the new repository if needed, then try installing some package:
pkghost# pwd
/root/pkgsrc/mail/spamd
pkghost# make install
=> Bootstrap dependency digest>=20010302: found digest-20160304
===> Skipping vulnerability checks.
WARNING: No /var/db/pkg/pkg-vulnerabilities file found.
WARNING: To fix run: `/usr/pkg/sbin/pkg_admin -K /var/db/pkg fetch-pkg-vulnerabilities'.
===> Installing binary package of spamd-20060330nb5
cvs rlog: cannot find module `defaults' - ignored
cvs checkout: Updating automerged
cvs checkout: Updating defaults
cvs checkout: Updating user
cvs update: Updating automerged
cvs update: Updating defaults
cvs update: Updating user
? usr/pkg
Directory /usr/home/vcs/cvsconftrack/defaults/usr added to the repository
? pkg/etc
Directory /usr/home/vcs/cvsconftrack/defaults/usr/pkg added to the repository
? etc/spamd.conf
Directory /usr/home/vcs/cvsconftrack/defaults/usr/pkg/etc added to the repository
cvs add: scheduling file `spamd.conf' for addition
cvs add: use 'cvs commit' to add this file permanently
REGISTER /var/cvsandremote/defaults//usr/pkg/etc/spamd.conf
spamd-20060330nb5: copying /usr/pkg/share/examples/spamd/spamd.conf to /usr/pkg/etc/spamd.conf
RCS file: /usr/home/vcs/cvsconftrack/defaults/usr/pkg/etc/spamd.conf,v
done
Checking in defaults/usr/pkg/etc/spamd.conf;
/usr/home/vcs/cvsconftrack/defaults/usr/pkg/etc/spamd.conf,v <-- spamd.conf
initial revision: 1.1
done
Conf commit: pkgsrc: add spamd-20060330nb5
===========================================================================
The following files should be created for spamd-20060330nb5:
/etc/rc.d/pfspamd (m=0755)
[/usr/pkg/share/examples/rc.d/pfspamd]
===========================================================================
===========================================================================
$NetBSD: MESSAGE,v 1.1.1.1 2005/06/28 12:43:57 peter Exp $
Don't forget to add the spamd ports to /etc/services:
spamd 8025/tcp # spamd(8)
spamd-cfg 8026/tcp # spamd(8) configuration
===========================================================================
pkghost#
On a successive run, the remote repository will get used without files being imported and checked out:
pkghost# cd /root/pkgsrc/pkgtools/pkgin/
pkghost# make install
=> Bootstrap dependency digest>=20010302: found digest-20160304
===> Skipping vulnerability checks.
WARNING: No /var/db/pkg/pkg-vulnerabilities file found.
WARNING: To fix run: `/usr/pkg/sbin/pkg_admin -K /var/db/pkg fetch-pkg-vulnerabilities'.
===> Installing for pkgin-0.9.4nb8
=> Generating pre-install file lists
=> Creating installation directories
[...]
=> Automatic manual page handling
=> Generating post-install file lists
=> Checking file-check results for pkgin-0.9.4nb8
=> Creating binary package /root/pkgsrc/pkgtools/pkgin/work/.packages/pkgin-0.9.4nb8.tgz
===> Building binary package for pkgin-0.9.4nb8
=> Creating binary package /root/pkgsrc/packages/All/pkgin-0.9.4nb8.tgz
===> Installing binary package of pkgin-0.9.4nb8
cvs rlog: Logging defaults
cvs rlog: Logging defaults/usr
cvs rlog: Logging defaults/usr/pkg
cvs rlog: Logging defaults/usr/pkg/etc
cvs update: Updating automerged
cvs update: Updating defaults
cvs update: Updating defaults/usr
cvs update: Updating defaults/usr/pkg
cvs update: Updating defaults/usr/pkg/etc
cvs update: Updating user
cvs [add aborted]: there is a version in usr already
cvs [add aborted]: there is a version in pkg already
cvs [add aborted]: there is a version in etc already
? pkgin/repositories.conf
Directory /usr/home/vcs/cvsconftrack/defaults/usr/pkg/etc/pkgin added to the repository
cvs add: scheduling file `repositories.conf' for addition
cvs add: use 'cvs commit' to add this file permanently
REGISTER /var/cvsandremote/defaults//usr/pkg/etc/pkgin/repositories.conf
pkgin-0.9.4nb8: copying /usr/pkg/share/examples/pkgin/repositories.conf.example to /usr/pkg/etc/pkgin/repositories.conf
RCS file: /usr/home/vcs/cvsconftrack/defaults/usr/pkg/etc/pkgin/repositories.conf,v
done
Checking in defaults/usr/pkg/etc/pkgin/repositories.conf;
/usr/home/vcs/cvsconftrack/defaults/usr/pkg/etc/pkgin/repositories.conf,v <-- repositories.conf
initial revision: 1.1
done
Conf commit: pkgsrc: add pkgin-0.9.4nb8
===========================================================================
$NetBSD: MESSAGE,v 1.3 2010/06/10 08:05:00 is Exp $
First steps before using pkgin.
. Modify /usr/pkg/etc/pkgin/repositories.conf to suit your platform
. Initialize the database :
# pkgin update
===========================================================================
pkghost#
Yes, I know, it's a bit too chatty. Once the script gets used (and tested) some more cvs should be invoked in a more quiet way.
See the next post for a walkthrough in using SVN and Mercurial!
In GSoC 2018 Reports: Configuration files versioning in pkgsrc, part 2: remote repositories (git and CVS) structural changes to the configuration tracking feature of pkgsrc got introduced, along with a short walkthrough in using remote Git and CVS repositories.
This third post will introduce SVN and Mercurial support, leaving configuration deployment for the final entry. Stay tuned!
SVN and remotes
Subversion, when used locally, needs to be set this way, as you can expect:
pkghost# cat /usr/pkg/etc/pkg_install.conf VCSTRACK_CONF=yes VCS=svn VCSDIR=/var/svnconfdir VCSAUTOMERGE=yes
A local repository will be created at VCSDIR/localsvn, files will get extracted and checkedin at VCSDIR/defaults, VCSDIR/automerged, VCSDIR/user
pkghost# make
[...]
WARNING: To fix run: `/usr/pkg/sbin/pkg_admin -K /var/db/pkg fetch-pkg-vulnerabilities'.
===> Installing for spamd-20060330nb5
=> Generating pre-install file lists
=> Creating installation directories
/usr/bin/install -c -o root -g wheel -m 644 /root/pkgsrc/mail/spamd/work/spamd-20060330/man/spamd.conf.5 /ro5
/usr/bin/install -c -o root -g wheel -m 644 /root/pkgsrc/mail/spamd/work/spamd-20060330/spamd/spamd.8 /root/8
/usr/bin/install -c -o root -g wheel -m 644 /root/pkgsrc/mail/spamd/work/spamd-20060330/spamd-setup/spamd-set8
/usr/bin/install -c -o root -g wheel -m 644 /root/pkgsrc/mail/spamd/work/spamd-20060330/spamdb/spamdb.8 /roo8
/usr/bin/install -c -o root -g wheel -m 644 /root/pkgsrc/mail/spamd/work/spamd-20060330/spamlogd/spamlogd.8 8
/usr/bin/install -c -s -o root -g wheel -m 755 /root/pkgsrc/mail/spamd/work/spamd-20060330/spamd-setup/spamd-c
/usr/bin/install -c -s -o root -g wheel -m 755 /root/pkgsrc/mail/spamd/work/spamd-20060330/spamd/spamd /rootc
/usr/bin/install -c -s -o root -g wheel -m 755 /root/pkgsrc/mail/spamd/work/spamd-20060330/spamdb/spamdb /ron
/usr/bin/install -c -s -o root -g wheel -m 755 /root/pkgsrc/mail/spamd/work/spamd-20060330/spamlogd/spamlogd c
/usr/bin/install -c -o root -g wheel -m 644 /root/pkgsrc/mail/spamd/work/spamd-20060330/etc/spamd.conf /root/d
=> Automatic manual page handling
=> Generating post-install file lists
=> Checking file-check results for spamd-20060330nb5
=> Creating binary package /root/pkgsrc/mail/spamd/work/.packages/spamd-20060330nb5.tgz
===> Building binary package for spamd-20060330nb5
=> Creating binary package /root/pkgsrc/packages/All/spamd-20060330nb5.tgz
===> Installing binary package of spamd-20060330nb5
REGISTER /var/svnconfdir/defaults//usr/pkg/etc/spamd.conf
spamd-20060330nb5: copying /usr/pkg/share/examples/spamd/spamd.conf to /usr/pkg/etc/spamd.conf
Conf commit: pkgsrc: add spamd-20060330nb5
===========================================================================
The following files should be created for spamd-20060330nb5:
/etc/rc.d/pfspamd (m=0755)
[/usr/pkg/share/examples/rc.d/pfspamd]
===========================================================================
===========================================================================
$NetBSD: MESSAGE,v 1.1.1.1 2005/06/28 12:43:57 peter Exp $
Don't forget to add the spamd ports to /etc/services:
spamd 8025/tcp # spamd(8)
spamd-cfg 8026/tcp # spamd(8) configuration
===========================================================================
pkghost# ls -lah /var/svnconfdir/localsvn/
total 3.2K
drwxr-xr-x 6 pkgvcsconf pkgvcsconf 512B Aug 4 07:22 .
drwx------ 6 pkgvcsconf pkgvcsconf 512B Aug 4 07:22 ..
-rw-r--r-- 1 pkgvcsconf pkgvcsconf 246B Aug 4 07:22 README.txt
drwxr-xr-x 2 pkgvcsconf pkgvcsconf 512B Aug 4 07:22 conf
drwxr-sr-x 6 pkgvcsconf pkgvcsconf 512B Aug 4 07:22 db
-r--r--r-- 1 pkgvcsconf pkgvcsconf 2B Aug 4 07:22 format
drwxr-xr-x 2 pkgvcsconf pkgvcsconf 512B Aug 4 07:22 hooks
drwxr-xr-x 2 pkgvcsconf pkgvcsconf 512B Aug 4 07:22 locks
pkghost# vi /usr/local/etc/spamd.conf
whitelist:\
:white:\
:method=file:\
:file=/var/mail/whitelist.txt:
/usr/pkg/etc/spamd.conf: 86 lines, 2767 characters
.
pkghost# make replace
[...]
and so on, you can come up with what follows. Let's test a remote repository, starting with preparations on the server:
$ hostname vers $ cd /usr/home/vcs $ svnadmin create svnremote
That's it, no branches or releases are used, so you don't need to create any further structure on the repository, the +VERSIONING script will take care of the remaining bits (you should migrate data from a local repository to the remote one, if you desire so, before running package installations).
Use a similarly structured REMOTEVCS URI: svn+ssh://vcs@192.168.100.112/usr/home/vcs/svnremote
(as with CVS, you can also run it as a standalone network server without ssh transport and authentication)
pkghost# cat /usr/pkg/etc/pkg_install.conf
VCSTRACK_CONF=yes
VCS=svn
VCSDIR=/var/svnwrkremote
VCSAUTOMERGE=yes
REMOTEVCS=svn+ssh://vcs@192.168.100.112/usr/home/vcs/svnremote
pkghost# make
[...]
pkghost# make install
=> Bootstrap dependency digest>=20010302: found digest-20160304
===> Skipping vulnerability checks.
WARNING: No /var/db/pkg/pkg-vulnerabilities file found.
WARNING: To fix run: `/usr/pkg/sbin/pkg_admin -K /var/db/pkg fetch-pkg-vulnerabilities'.
===> Installing for spamd-20060330nb6
=> Generating pre-install file lists
=> Creating installation directories
/usr/bin/install -c -o root -g wheel -m 644 /root/pkgsrc/mail/spamd/work/spamd-20060330/man/spamd.conf.5 /ro5
/usr/bin/install -c -o root -g wheel -m 644 /root/pkgsrc/mail/spamd/work/spamd-20060330/spamd/spamd.8 /root/8
/usr/bin/install -c -o root -g wheel -m 644 /root/pkgsrc/mail/spamd/work/spamd-20060330/spamd-setup/spamd-set8
/usr/bin/install -c -o root -g wheel -m 644 /root/pkgsrc/mail/spamd/work/spamd-20060330/spamdb/spamdb.8 /roo8
/usr/bin/install -c -o root -g wheel -m 644 /root/pkgsrc/mail/spamd/work/spamd-20060330/spamlogd/spamlogd.8 8
/usr/bin/install -c -s -o root -g wheel -m 755 /root/pkgsrc/mail/spamd/work/spamd-20060330/spamd-setup/spamd-c
/usr/bin/install -c -s -o root -g wheel -m 755 /root/pkgsrc/mail/spamd/work/spamd-20060330/spamd/spamd /rootc
/usr/bin/install -c -s -o root -g wheel -m 755 /root/pkgsrc/mail/spamd/work/spamd-20060330/spamdb/spamdb /ron
/usr/bin/install -c -s -o root -g wheel -m 755 /root/pkgsrc/mail/spamd/work/spamd-20060330/spamlogd/spamlogd c
/usr/bin/install -c -o root -g wheel -m 644 /root/pkgsrc/mail/spamd/work/spamd-20060330/etc/spamd.conf /root/d
=> Automatic manual page handling
=> Generating post-install file lists
=> Checking file-check results for spamd-20060330nb6
=> Creating binary package /root/pkgsrc/mail/spamd/work/.packages/spamd-20060330nb6.tgz
===> Building binary package for spamd-20060330nb6
=> Creating binary package /root/pkgsrc/packages/All/spamd-20060330nb6.tgz
===> Installing binary package of spamd-20060330nb6
svn: E155007: '/var/svnwrkremote/defaults' is not a working copy
Committing transaction...
Committed revision 1.
Checked out revision 1.
Committing transaction...
Committed revision 2.
Checked out revision 2.
Committing transaction...
Committed revision 3.
Checked out revision 3.
A usr
A pkg
A etc
A spamd.conf
REGISTER /var/svnwrkremote/defaults//usr/pkg/etc/spamd.conf
spamd-20060330nb6: copying /usr/pkg/share/examples/spamd/spamd.conf to /usr/pkg/etc/spamd.conf
Adding usr
Adding usr/pkg
Adding usr/pkg/etc
Adding usr/pkg/etc/spamd.conf
Transmitting file data .done
Committing transaction...
Committed revision 4.
Conf commit: pkgsrc: add spamd-20060330nb6
===========================================================================
The following files should be created for spamd-20060330nb6:
/etc/rc.d/pfspamd (m=0755)
[/usr/pkg/share/examples/rc.d/pfspamd]
===========================================================================
===========================================================================
$NetBSD: MESSAGE,v 1.1.1.1 2005/06/28 12:43:57 peter Exp $
Don't forget to add the spamd ports to /etc/services:
spamd 8025/tcp # spamd(8)
spamd-cfg 8026/tcp # spamd(8) configuration
===========================================================================
pkghost#
since I didn't show it with CVS, let's try again some simulated file edits:
pkghost# tail -n 5 /usr/pkg/etc/spamd.conf
#
#whitelist:\
# :white:\
# :method=file:\
# :file=/var/mail/whitelist.txt:
pkghost# vi /usr/pkg/etc/spamd.conf; tail -n 5 /usr/pkg/etc/spamd.conf
/usr/pkg/etc/spamd.conf: 86 lines, 2767 characters
.
#
whitelist:\
:white:\
:method=file:\
:file=/var/mail/whitelist.txt:
=> Bootstrap dependency digest>=20010302: found digest-20160304
===> Skipping vulnerability checks.
WARNING: No /var/db/pkg/pkg-vulnerabilities file found.
WARNING: To fix run: `/usr/pkg/sbin/pkg_admin -K /var/db/pkg fetch-pkg-vulnerabilities'.
===> Replacing for spamd-20060330nb6
===> Updating using binary package of spamd-20060330nb6
/usr/bin/env /usr/pkg/sbin/pkg_add -K /var/db/pkg -U -D /root/pkgsrc/mail/spamd/work/.packages/spamd-2006033z
===========================================================================
The following users are no longer being used by spamd-20060330nb6,
and they can be removed if no other software is using them:
_spamd
===========================================================================
===========================================================================
The following groups are no longer being used by spamd-20060330nb6,
and they can be removed if no other software is using them:
_spamd
===========================================================================
===========================================================================
The following files are no longer being used by spamd-20060330nb6,
and they can be removed if no other packages are using them:
/usr/pkg/etc/spamd.conf
===========================================================================
REGISTER /var/svcwrkremote/defaults//usr/pkg/etc/spamd.conf
spamd-20060330nb6: /usr/pkg/etc/spamd.conf already exists
spamd-20060330nb6: attempting to merge /usr/pkg/etc/spamd.conf with new defaults!
Saving the currently user-installed revision to /var/svnwrkremote/user//usr/pkg/etc/spamd.conf
A usr
A pkg
A etc
A spamd.conf
Adding usr
Adding usr/pkg
Adding usr/pkg/etc
Adding usr/pkg/etc/spamd.conf
Transmitting file data .done
Committing transaction...
Committed revision 5.
Conf commit: pkgsrc: backup user conf before attempting merge for spamd-20060330nb6
A defaults/usr/pkg/etc/spamd.conf
Export complete.
Merged with no conflicts. installing it to /usr/pkg/etc/spamd.conf!
A usr
A pkg
A etc
A spamd.conf
A defaults/usr/pkg/etc/spamd.conf
Export complete.
Revert from the last revision of /var/svcwrkremote/user//usr/pkg/etc/spamd.conf if needed
Adding usr
Adding usr/pkg
Adding usr/pkg/etc
Adding usr/pkg/etc/spamd.conf
Transmitting file data .done
Committing transaction...
Committed revision 6.
Conf commit: pkgsrc: add spamd-20060330nb6
===========================================================================
The following files should be created for spamd-20060330nb6:
/etc/rc.d/pfspamd (m=0755)
[/usr/pkg/share/examples/rc.d/pfspamd]
===========================================================================
===========================================================================
$NetBSD: MESSAGE,v 1.1.1.1 2005/06/28 12:43:57 peter Exp $
Don't forget to add the spamd ports to /etc/services:
spamd 8025/tcp # spamd(8)
spamd-cfg 8026/tcp # spamd(8) configuration
===========================================================================
pkghost# cd /var/svnwrkremote/
pkghost# ls
automerged automergedfiles defaults user
pkghost# cd automerged
pkghost# svn update
Updating '.':
At revision 6.
pkghost# svn log
------------------------------------------------------------------------
r6 | vcs | 2018-08-04 13:22:29 +0000 (Sat, 04 Aug 2018) | 1 line
pkgsrc: add spamd-20060330nb6
------------------------------------------------------------------------
r1 | vcs | 2018-08-04 13:19:29 +0000 (Sat, 04 Aug 2018) | 1 line
initial import
------------------------------------------------------------------------
pkghost# cd $HOME/pkgsrc/mail/spamd
pkghost# grep REVISION Makefile
PKGREVISION= 6
pkghost# sed -i "s/PKGREVISION=.*6/PKGREVISION=7/g" Makefile
pkghost# grep REVISION Makefile
PKGREVISION=7
pkghost# make clean; make extract; sed -i "s/http/https/g" work/spamd-20060330/etc/spamd.conf
pkghost# make update
===> Skipping vulnerability checks.
WARNING: No /var/db/pkg/pkg-vulnerabilities file found.
WARNING: To fix run: `/usr/pkg/sbin/pkg_admin -K /var/db/pkg fetch-pkg-vulnerabilities'.
===> Deinstalling for spamd-20060330nb7
Running /usr/pkg/sbin/pkg_delete -K /var/db/pkg -r spamd-20060330nb6
===========================================================================
[...]
===> Installing for spamd-20060330nb7
=> Generating pre-install file lists
=> Creating installation directories
/usr/bin/install -c -o root -g wheel -m 644 /root/pkgsrc/mail/spamd/work/spamd-20060330/man/spamd.conf.5 /ro5
/usr/bin/install -c -o root -g wheel -m 644 /root/pkgsrc/mail/spamd/work/spamd-20060330/spamd/spamd.8 /root/8
/usr/bin/install -c -o root -g wheel -m 644 /root/pkgsrc/mail/spamd/work/spamd-20060330/spamd-setup/spamd-set8
/usr/bin/install -c -o root -g wheel -m 644 /root/pkgsrc/mail/spamd/work/spamd-20060330/spamdb/spamdb.8 /roo8
/usr/bin/install -c -o root -g wheel -m 644 /root/pkgsrc/mail/spamd/work/spamd-20060330/spamlogd/spamlogd.8 8
/usr/bin/install -c -s -o root -g wheel -m 755 /root/pkgsrc/mail/spamd/work/spamd-20060330/spamd-setup/spamd-c
/usr/bin/install -c -s -o root -g wheel -m 755 /root/pkgsrc/mail/spamd/work/spamd-20060330/spamd/spamd /rootc
/usr/bin/install -c -s -o root -g wheel -m 755 /root/pkgsrc/mail/spamd/work/spamd-20060330/spamdb/spamdb /ron
/usr/bin/install -c -s -o root -g wheel -m 755 /root/pkgsrc/mail/spamd/work/spamd-20060330/spamlogd/spamlogd c
/usr/bin/install -c -o root -g wheel -m 644 /root/pkgsrc/mail/spamd/work/spamd-20060330/etc/spamd.conf /root/d
=> Automatic manual page handling
=> Generating post-install file lists
=> Checking file-check results for spamd-20060330nb7
=> Creating binary package /root/pkgsrc/mail/spamd/work/.packages/spamd-20060330nb7.tgz
===> Building binary package for spamd-20060330nb7
=> Creating binary package /root/pkgsrc/packages/All/spamd-20060330nb7.tgz
===> Installing binary package of spamd-20060330nb7
REGISTER /var/svcwrkremote/defaults//usr/pkg/etc/spamd.conf
spamd-20060330nb7: /usr/pkg/etc/spamd.conf already exists
spamd-20060330nb7: attempting to merge /usr/pkg/etc/spamd.conf with new defaults!
A automerged/usr/pkg/etc/spamd.conf
Export complete.
Saving the currently installed revision to /var/svcwrkremote/automerged//usr/pkg/etc/spamd.conf
Sending usr/pkg/etc/spamd.conf
Transmitting file data .done
Committing transaction...
Committed revision 7.
Conf commit: pkgsrc: backup preexisting conf before attempting merge for spamd-20060330nb7
A defaults/usr/pkg/etc/spamd.conf
Export complete.
Merged with no conflict. installing it to /usr/pkg/etc/spamd.conf!
--- /usr/pkg/etc/spamd.conf 2018-08-04 09:01:09.536149671 +0000
+++ /var/svcwrkremote/defaults//usr/pkg/etc/spamd.conf.automerge 2018-08-04 09:10:52.131955252 +0000
@@ -15,7 +15,7 @@
# may be applied to each blacklist.
#
# As of November 2004, a place to search for black lists is
-# http://spamlinks.net/filter-bl.htm
+# https://spamlinks.net/filter-bl.htm
#
# Some of the URLs below point to www.openbsd.org locations. Those
# files are likely to be mirrored to other OpenBSD www mirrors located
@@ -25,45 +25,45 @@
all:\
:spews1:china:korea:
-# Mirrored from http://spfilter.openrbl.org/data/sbl/SBL.cidr.bz2
+# Mirrored from https://spfilter.openrbl.org/data/sbl/SBL.cidr.bz2
spamhaus:\
:black:\
:msg="SPAM. Your address %A is in the Spamhaus Block List\n\
- See http://www.spamhaus.org/sbl and\
- http://www.abuse.net/sbl.phtml?IP=%A for more details":\
- :method=http:\
+ See https://www.spamhaus.org/sbl and\
+ https://www.abuse.net/sbl.phtml?IP=%A for more details":\
+ :method=https:\
:file=www.openbsd.org/spamd/SBL.cidr.gz:
-# Mirrored from http://www.spews.org/spews_list_level1.txt
+# Mirrored from https://www.spews.org/spews_list_level1.txt
spews1:\
:black:\
:msg="SPAM. Your address %A is in the spews level 1 database\n\
- See http://www.spews.org/ask.cgi?x=%A for more details":\
- :method=http:\
+ See https://www.spews.org/ask.cgi?x=%A for more details":\
+ :method=https:\
:file=www.openbsd.org/spamd/spews_list_level1.txt.gz:
-# Mirrored from http://www.spews.org/spews_list_level2.txt
+# Mirrored from https://www.spews.org/spews_list_level2.txt
spews2:\
:black:\
:msg="SPAM. Your address %A is in the spews level 2 database\n\
- See http://www.spews.org/ask.cgi?x=%A for more details":\
- :method=http:\
+ See https://www.spews.org/ask.cgi?x=%A for more details":\
+ :method=https:\
:file=www.openbsd.org/spamd/spews_list_level2.txt.gz:
-# Mirrored from http://www.okean.com/chinacidr.txt
+# Mirrored from https://www.okean.com/chinacidr.txt
china:\
:black:\
:msg="SPAM. Your address %A appears to be from China\n\
- See http://www.okean.com/asianspamblocks.html for more details":\
- :method=http:\
+ See https://www.okean.com/asianspamblocks.html for more details":\
+ :method=https:\
:file=www.openbsd.org/spamd/chinacidr.txt.gz:
-# Mirrored from http://www.okean.com/koreacidr.txt
+# Mirrored from https://www.okean.com/koreacidr.txt
korea:\
:black:\
:msg="SPAM. Your address %A appears to be from Korea\n\
- See http://www.okean.com/asianspamblocks.html for more details":\
- :method=http:\
+ See https://www.okean.com/asianspamblocks.html for more details":\
+ :method=https:\
:file=www.openbsd.org/spamd/koreacidr.txt.gz:
#relaydb-black:\
Revert from the penultimate revision of /var/svcwrkremote/automerged//usr/pkg/etc/spamd.conf if needed
Sending usr/pkg/etc/spamd.conf
Transmitting file data .done
Committing transaction...
Committed revision 8.
Sending usr/pkg/etc/spamd.conf
Transmitting file data .done
Committing transaction...
Committed revision 9.
Conf commit: pkgsrc: add spamd-20060330nb7
===========================================================================
The following files should be created for spamd-20060330nb7:
/etc/rc.d/pfspamd (m=0755)
[/usr/pkg/share/examples/rc.d/pfspamd]
===========================================================================
[...]
===> Cleaning for spamd-20060330nb7
HG and remotes
Yes, mercurial.
Mercurial, like git, uses a local directory (namely .hg) located under the working directory VCSDIR, it is also used to store configuration and URIs to remote repositories.
to initialize and test it (as said, no repository and vcs migrations are supported by pkgsrc itself, you should take care of migrations yourself if you want to), just set pkg_install.conf to use a local mercurial repo and install a package:
pkghost# rm /usr/pkg/etc/spamd.conf
pkghost# /usr/pkg/sbin/pkg_delete spamd
pkghost# vi /usr/pkg/etc/pkg_install.conf; cat /usr/pkg/etc/pkg_install.conf
/usr/pkg/etc/pkg_install.conf: 4 lines, 66 characters
.
VCSTRACK_CONF=yes
VCS=hg
VCSDIR=/var/hglocaldir
VCSAUTOMERGE=yes
pkghost# make
=> Bootstrap dependency digest>=20010302: found digest-20160304
===> Skipping vulnerability checks.
WARNING: No /var/db/pkg/pkg-vulnerabilities file found.
WARNING: To fix run: `/usr/pkg/sbin/pkg_admin -K /var/db/pkg fetch-pkg-vulnerabilities'.
=> Checksum SHA1 OK for spamd-20060330.tar.gz
[...]
To save some space and time, let's just say that it works as expected:
[...] Conf commit: pkgsrc: backup preexisting conf before attempting merge for spamd-20060330nb10 Merged with no conflict. installing it to /usr/pkg/etc/spamd.conf! --- /usr/pkg/etc/spamd.conf 2018-08-04 09:50:00.738099463 +0000 +++ /var/hglocaldir/defaults//usr/pkg/etc/spamd.conf.automerge 2018-08-04 09:52:18.467604445 +0000 @@ -15,7 +15,7 @@ # may be applied to each blacklist. # # As of November 2004, a place to search for black lists is -# http://spamlinks.net/filter-bl.htm +# https://spamlinks.net/filter-bl.htm # [...]
One nice thing about mercurial is the simplicity enabling one to clone a local repository to a remote server. The script, when using mercurial, tries exacly that, this should succeed if the remote repository is empty.
if ${TEST} "$_REMOTE" != "no" -a "$_REMOTE" != "NO"; then
execute "hg clone . \"$_REMOTE\""
execute "hg --repository \"$_VCSDIR\" push \"$_REMOTE\""
execute "hg --repository \"$_VCSDIR\" pull \"$_REMOTE\""
fi
let's init an empty repository on the server and let pkgsrc clone the existing files over there!
$ cd $ hostname vers $ pwd /home/vcs $ hg init pkgconftest $ ls pkgconftest/ $ ls pkgconftest/.hg/ 00changelog.i requires store $
URIs for REMOTEVCS take the following format, should you choose to use ssh instead of hg server, http or other access methods that you'll find documented on official Mercurial resources, as with svn, git and cvs:
ssh://vcs@192.168.100.112/usr/home/vcs/pkgconftest
pkghost# vi /usr/pkg/etc/pkg_install.conf; cat /usr/pkg/etc/pkg_install.conf
/usr/pkg/etc/pkg_install.conf: 5 lines, 127 characters
.
VCSTRACK_CONF=yes
VCS=hg
VCSDIR=/var/hglocaldir
VCSAUTOMERGE=yes
REMOTEVCS=ssh://vcs@192.168.100.112/usr/home/vcs/pkgconftest
pkghost# make replace
[...]
===> Updating using binary package of spamd-20060330nb10
/usr/bin/env /usr/pkg/sbin/pkg_add -K /var/db/pkg -U -D /root/pkgsrc/mail/spamd/work/.packages/spamd-2006033z
===========================================================================
The following users are no longer being used by spamd-20060330nb10,
and they can be removed if no other software is using them:
_spamd
===========================================================================
===========================================================================
The following groups are no longer being used by spamd-20060330nb10,
and they can be removed if no other software is using them:
_spamd
===========================================================================
===========================================================================
The following files are no longer being used by spamd-20060330nb10,
and they can be removed if no other packages are using them:
/usr/pkg/etc/spamd.conf
===========================================================================
searching for changes
remote: adding changesets
remote: adding manifests
remote: adding file changes
remote: added 5 changesets with 6 changes to 3 files
pushing to ssh://vcs@192.168.100.112/usr/home/vcs/pkgconftest
searching for changes
no changes found
pulling from ssh://vcs@192.168.100.112/usr/home/vcs/pkgconftest
searching for changes
no changes found
defaults/usr/pkg/etc/spamd.conf already tracked!
REGISTER /var/hglocaldir/defaults//usr/pkg/etc/spamd.conf
spamd-20060330nb10: /usr/pkg/etc/spamd.conf already exists
spamd-20060330nb10: attempting to merge /usr/pkg/etc/spamd.conf with new defaults!
Saving the currently installed revision to /var/hglocaldir/automerged//usr/pkg/etc/spamd.conf
automerged/usr/pkg/etc/spamd.conf already tracked!
Failed to commit conf: backup preexisting conf before attempting merge for spamd-20060330nb10
pushing to ssh://vcs@192.168.100.112/usr/home/vcs/pkgconftest
searching for changes
no changes found
hg: failed to push changes to the remote repository ssh://vcs@192.168.100.112/usr/home/vcs/pkgconftest
Merged with no conflict. installing it to /usr/pkg/etc/spamd.conf!
Revert from the penultimate revision of /var/hglocaldir/automerged//usr/pkg/etc/spamd.conf if needed
Failed to commit conf: add spamd-20060330nb10
pushing to ssh://vcs@192.168.100.112/usr/home/vcs/pkgconftest
searching for changes
no changes found
hg: failed to push changes to the remote repository ssh://vcs@192.168.100.112/usr/home/vcs/pkgconftest
===========================================================================
The following files should be created for spamd-20060330nb10:
/etc/rc.d/pfspamd (m=0755)
[/usr/pkg/share/examples/rc.d/pfspamd]
[...]
Yes, hg exits in error when there are no changes to be pushed. Everything is working fine.
Let's simulate some more package-provided changes in defaults
pkghost# make clean; sed -i "s/PKGREVISION=10/PKGREVISION=11/g" Makefile; make extract
pkghost# sed -i "s/http/https/g" work/spamd-20060330/etc/spamd.conf
pkghost# vi work/spamd-20060330/etc/spamd.conf; head work/spamd-20060330/etc/spamd.conf
work/spamd-20060330/etc/spamd.conf: 87 lines, 2812 characters
.
# $OpenBSD: spamd.conf,v 1.17 2006/02/01 20:22:43 dhartmei Exp $
#
# spamd config file, read by spamd-setup(8) for spamd(8)
#
# See spamd.conf(5)
#THIS IS A NEW COMMENT!
#
# Configures whitelists and blacklists for spamd
#
# Strings follow getcap(3) convention escapes, other than you
pkghost# make update
===> Skipping vulnerability checks.
WARNING: No /var/db/pkg/pkg-vulnerabilities file found.
WARNING: To fix run: `/usr/pkg/sbin/pkg_admin -K /var/db/pkg fetch-pkg-vulnerabilities'.
===> Deinstalling for spamd-20060330nb11
Running /usr/pkg/sbin/pkg_delete -K /var/db/pkg -r spamd-20060330nb10
===========================================================================
The following users are no longer being used by spamd-20060330nb10,
and they can be removed if no other software is using them:
[...]
===> Installing for spamd-20060330nb11
[...]
=> Automatic manual page handling
=> Generating post-install file lists
=> Checking file-check results for spamd-20060330nb11
=> Creating binary package /root/pkgsrc/mail/spamd/work/.packages/spamd-20060330nb11.tgz
===> Building binary package for spamd-20060330nb11
=> Creating binary package /root/pkgsrc/packages/All/spamd-20060330nb11.tgz
===> Installing binary package of spamd-20060330nb11
abort: repository usr/home/vcs/pkgconftest already exists!
abort: could not create remote repo!
pushing to ssh://vcs@192.168.100.112/usr/home/vcs/pkgconftest
searching for changes
no changes found
pulling from ssh://vcs@192.168.100.112/usr/home/vcs/pkgconftest
searching for changes
no changes found
defaults/usr/pkg/etc/spamd.conf already tracked!
REGISTER /var/hglocaldir/defaults//usr/pkg/etc/spamd.conf
spamd-20060330nb11: /usr/pkg/etc/spamd.conf already exists
spamd-20060330nb11: attempting to merge /usr/pkg/etc/spamd.conf with new defaults!
Saving the currently installed revision to /var/hglocaldir/automerged//usr/pkg/etc/spamd.conf
automerged/usr/pkg/etc/spamd.conf already tracked!
Conf commit: pkgsrc: backup preexisting conf before attempting merge for spamd-20060330nb11
pushing to ssh://vcs@192.168.100.112/usr/home/vcs/pkgconftest
searching for changes
remote: adding changesets
remote: adding manifests
remote: adding file changes
remote: added 1 changesets with 1 changes to 1 files
Merged with no conflict. installing it to /usr/pkg/etc/spamd.conf!
--- /usr/pkg/etc/spamd.conf 2018-08-04 10:43:37.554182167 +0000
+++ /var/hglocaldir/defaults//usr/pkg/etc/spamd.conf.automerge 2018-08-04 10:50:23.582806647 +0000
@@ -3,6 +3,7 @@
# spamd config file, read by spamd-setup(8) for spamd(8)
#
# See spamd.conf(5)
+#THIS IS A NEW COMMENT!
#
# Configures whitelists and blacklists for spamd
#
Revert from the penultimate revision of /var/hglocaldir/automerged//usr/pkg/etc/spamd.conf if needed
Conf commit: pkgsrc: add spamd-20060330nb11
pushing to ssh://vcs@192.168.100.112/usr/home/vcs/pkgconftest
searching for changes
remote: adding changesets
remote: adding manifests
remote: adding file changes
remote: added 1 changesets with 2 changes to 2 files
===========================================================================
The following files should be created for spamd-20060330nb11:
[...]
As introduced in GSoC 2018 Reports: Configuration files versioning in pkgsrc, part 2: remote repositories (git and CVS) pkgsrc supports using some version control system repositories to search for site-specific configuration for packages being installed, and deploys it on the system.
Configuration deployment: intro to VCSCONFPULL
Support for configuration tracking is in scripts, pkginstall scripts, that get built into binary packages and are run by pkg_add upon installation. The idea behind the proposal suggested that users of the new feature should be able to store revisions of their installed configuration files, and of package-provided default, both in local or remote repositories. With this capability in place, it doesn't take much to make the scripts "pull" configuration from a VCS repository at installation time.
That's what setting VCSCONFPULL=yes in pkg_install.conf after having enabled VCSTRACK_CONF does:
You are free to use official, third party prebuilt packages that have no customization in them, enable these options, and point pkgsrc to a private conf repository. If it contains custom configuration for the software you are installing, an attempt will be made to use it and install it on your system. If it fails, pkginstall will fall back to using the defaults that come inside the package. RC scripts are always deployed from the binary package, if existing and PKG_RCD_SCRIPTS=yes in pkg_install.conf or the environment.
This will be part of packages, not a separate solution like configuration management tools. It doesn't support running scripts on the target system to customize the installation, it doesn't come with its domain-specific language, it won't run as a daemon or require remote logins to work. It's quite limited in scope, but you can define a ROLE for your system in pkg_install.conf or in the environment, and pkgsrc will look for configuration you or your organization crafted for such a role (e.g., public, standalone webserver vs reverse proxy or node in a database cluster)
Configuration files should be put in branches named according to a specific convention, their paths relative to the repository is implied to be their absolute path, prepending a "/", on the target system.
Branch names define the package name they contain configuration for, the role, the version of the package the configuration is made for and a range of compatible software releases that should work with such configuration options, a best match is attemped inside of compatible ranges to the nearest software release, and roles can be undefined (both on the branch, to make it apt for any system, or on the target to ignore roles specified in branch names where they don't matter). More on that later, now some practical examples using git:
Set up a remote repository on some machine, if you are not using a public facing service or private repositories in third party services:
$ id uid=1001(vcs) gid=1001(vcs) groups=1001(vcs) $ mkdir confpullexample.git $ cd confpullexample.git/ $ git --bare init Initialized empty Git repository in /usr/home/vcs/confpullexample.git/
Check for correct settings on the target machine: (a REMOTEVCS URI is required, the VCSDIR is NOT used)
pkghost# cat /usr/pkg/etc/pkg_install.conf VCSTRACK_CONF=yes VCSCONFPULL=yes REMOTEVCS=ssh://vcs@192.168.100.112/usr/home/vcs/confpullexample.git VCS=git
Do no reuse repositories that track existing configuration files from packages, set a new one here. It will be structured differently, with branches that can specialize between them and yet contain configuration files common to each one (from master/trunk/...). Some technicalities are needed before making practical examples. I will now cheat and cite direcly the comment in mk/pkginstall/versioning:
The remote configuration repository should contain branches named
according to the following convention:
category_pkgName_pkgVersion_compatRangeStart_compatRangeEnd_systemRole
an optional field may exist that explicitates part of the system hostname
category_pkgName_pkgVersion_compatRangeStart_compatRangeEnd_systemRole_hostname
.
the branch should contain needed configuration files. Their path relative to the repository is then prepended with a "/" and files force copied to the system and chmod 0600 executed on them. Permission handling and removal upon package uninstallation are not supported.
The branch to be used, among the available ones, is chosen this way:
branches named according to the convention that provide configuration
for category/packageName are filtered from the VCS output;
then, all branches whose ranges are compatible with the version of the
package being installed are selected. The upper bound of the range is
excluded as a compatible release if using sequence based identifiers.
If system role is set through the ROLE environment variable,
and it's different from "any",
and branches exists whose role is different from "any", then their
role gets compared with the one defined on the system or in pkg_add config.
The last part of the branch name is optional and, if present, is compared
character by character with the system hostname,
finally selecting the branches that best match it.
As an example, a branch named mail_postfix_3.3.0_3.0.0_3.3.20_mailrelay_ams
will match with system hostname amsterdam09.
A system with its ROLE unspecified or set to ANY will select branches
independently of the role they are created for, scoring and using the one
with the best matching optional hostname and/or nearest to the target release
as explained below:
Let's suppose that an hypothetical team uses a common ssh configuration, on all systems, to disable root and passwordless logins, and enable logins from users in a specific group.
the main/master branch of the repository will then contain one custom object,
etc/ssh/sshd_config
that will get included when branching from there (specific removals are always possible).
$ whoami devuser $ file $HOME/.ssh/id_rsa /home/devuser/.ssh/id_rsa: PEM RSA private key $ pwd /home/devuser/sim $ git clone ssh://vcs@192.168.100.112/usr/home/vcs/confpullexample.git . Cloning into '.'... The authenticity of host '192.168.100.112 (192.168.100.112)' can't be established. ECDSA key fingerprint is SHA256:RMkiZlYqNIKlgDQUvhFBXLUpW2qcLd1nuEi4NaROkLg. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added '192.168.100.112' (ECDSA) to the list of known hosts. warning: You appear to have cloned an empty repository. $ mkdir -p etc/ssh $ cat /etc/ssh/sshd_config > etc/ssh/sshd_config
customize it as needed, then
$ echo "PermitEmptyPasswords no" >> $HOME/sim/etc/ssh/sshd_config $ echo "PermitRootLogin no" >> $HOME/sim/etc/ssh/sshd_config $ echo "AllowGroup ops" >> $HOME/sim/etc/ssh/sshd_config
and load it in the repo:
$ git add etc/ssh/sshd_config $ git commit -m "add common sshd_config to master" [master (root-commit) ec91ffc] add common sshd_config to master 1 file changed, 134 insertions(+) create mode 100644 etc/ssh/sshd_config $ git push Counting objects: 5, done. Compressing objects: 100% (2/2), done. Writing objects: 100% (5/5), 1.89 KiB | 966.00 KiB/s, done. Total 5 (delta 0), reused 0 (delta 0) To ssh://192.168.100.112/usr/home/vcs/confpullexample.git * [new branch] master -> master
With respect to this example, two different nginx configuration sets will exist, one for reverse proxies (role reverseproxy) and one for standalone webservers (role webserver). A standalone webserver will also install a default database configuration file, which will be customized for clustered postgresql instances (roles dbcluster-master and dbcluster-replicas).
Furthermore, nodes part of the same cluster will have hostnames the likes of toontowndc-node03 so that branches ending with _toontowndc-node will match and have configuration files with the addresses of nodes in the same cluster deployed.
The branch net_net-snmp_5.7.3_5.2_6_any will work on all systems you want to monitor via snmpd independently of their defined role, provided the version of net-snmp being installed is >= 5.2 and < 6
In order to keep the tutorial short, I will only show how to deploy configuration for postgresql.
I'll start with a generic configuration file, for the role webserver;
the branch databases_postgresql10_10.4nb1_10.0_11_default may be created to contain default configuration from the package (the role isn't any, so it will not be accidentally selected on systems that define a role), then branch it into the specialized roles webserver, dbcluster-master, dbcluster-deplicas.
A master-node address specific to each cluster site will be included in recovery.conf by specializing the branch ...dbcluster-replicas to branches specific for earch location, e.g., dbcluster-replicas_toontowndc that will be deployed on db nodes in the "Toontown" site.
NOTE that files from the branch will get copied unconditionally on the system, replacing existing files or files coming with the binary package, even if they are not installed to location/handled by the +FILES script
This means that it's possible to write configuration files to ${pgsql_home}/data, by default /usr/pkg/pgsql/data/, where the rc.d script usually sets postgresql to look into.
$ pwd
/home/devuser
$ mkdir -p sim/usr/pkg/pgsql/data
$ cd sim
$ ls -a
. .. .git etc usr
$ git checkout -b databases_postgresql10_10.4nb1_10.0_11_default
Switched to a new branch 'databases_postgresql10_10.4nb1_10.0_11_default'
$ ls
etc usr
$ cp /home/devuser/postgresql.conf.sample usr/pkg/pgsql/data/postgresql.conf
$ cp /home/devuser/pg_hba.conf.sample usr/pkg/pgsql/data/pg_hba.conf
$ vi usr/pkg/pgsql/data/pg_hba.conf
$ tail -n 23 usr/pkg/pgsql/data/pg_hba.conf
# Put your actual configuration here
# ----------------------------------
#
# If you want to allow non-local connections, you need to add more
# "host" records. In that case you will also need to make PostgreSQL
# listen on a non-local interface via the listen_addresses
# configuration parameter, or via the -i or -h command line switches.
@authcomment@
# TYPE DATABASE USER ADDRESS METHOD
@remove-line-for-nolocal@# "local" is for Unix domain socket connections only
@remove-line-for-nolocal@local all all ident
# IPv4 local connections:
host all all 127.0.0.1/32 md5
# IPv6 local connections:
host all all ::1/128 md5
# Allow replication connections from localhost, by a user with the
# replication privilege.
@remove-line-for-nolocal@local replication all ident
#host replication all 127.0.0.1/32 md5
#host replication all ::1/128 md5
$ echo "log_destination = 'syslog'" >> usr/pkg/pgsql/data/postgresql.conf
$ echo "syslog_ident = 'postgres'" >> usr/pkg/pgsql/data/postgresql.conf
$ git add usr/pkg/pgsql/*
$ git commit -m "import common config for not to be deployed default role"
[databases_postgresql10_10.4nb1_10.0_11_default 1ce080d] import common config for not to be deployed default e
2 files changed, 749 insertions(+)
create mode 100644 usr/pkg/pgsql/data/pg_hba.conf
create mode 100644 usr/pkg/pgsql/data/postgresql.conf
$ git push --set-upstream origin databases_postgresql10_10.4nb1_10.0_11_default
Counting objects: 8, done.
Compressing objects: 100% (5/5), done.
Writing objects: 100% (8/8), 9.10 KiB | 4.55 MiB/s, done.
Total 8 (delta 0), reused 0 (delta 0)
To ssh://192.168.100.112/usr/home/vcs/confpullexample.git
* [new branch] databases_postgresql10_10.4nb1_10.0_11_default -> databases_postgresql10_10.4nb1_10.0_11_default
Branch 'databases_postgresql10_10.4nb1_10.0_11_default' set up to track remote branch 'databases_postgresql10_10.4nb1_10.0_11_default'
the branch with role webserver will get deployed, and doesn't differ in configuration from the default branch:
$ git checkout -b databases_postgresql10-server_10.4nb1_10.0_11_webserver Switched to a new branch 'databases_postgresql10-server_10.4nb1_10.0_11_webserver' $ git push --set-upstream origin databases_postgresql10_10.4nb1_10.0_11_webserver Total 0 (delta 0), reused 0 (delta 0) To ssh://192.168.100.112/usr/home/vcs/confpullexample.git * [new branch] databases_postgresql10_10.4nb1_10.0_11_webserver -> databases_postgresql10_10.4nb1_10.0_11_webserver Branch 'databases_postgresql10_10.4nb1_10.0_11_webserver' set up to track remote branch 'databases_postgresql10_10.4nb1_10.0_11_webserver'
now change it for the role dbcluster-master:
$ git checkout -b databases_postgresql10_10.4nb1_10.0_11_dbcluster-master
M usr/pkg/pgsql/data/pg_hba.conf
M usr/pkg/pgsql/data/postgresql.conf
Switched to a new branch 'databases_postgresql10_10.4nb1_10.0_11_dbcluster-master'
$ vi usr/pkg/pgsql/data/pg_hba.conf
$ tail -n 23 usr/pkg/pgsql/data/pg_hba.conf
# Put your actual configuration here
# ----------------------------------
#
# If you want to allow non-local connections, you need to add more
# "host" records. In that case you will also need to make PostgreSQL
# listen on a non-local interface via the listen_addresses
# configuration parameter, or via the -i or -h command line switches.
@authcomment@
# TYPE DATABASE USER ADDRESS METHOD
@remove-line-for-nolocal@# "local" is for Unix domain socket connections only
@remove-line-for-nolocal@local all all ident
# IPv4 local connections:
host all all 127.0.0.1/32 md5
# IPv6 local connections:
host all all ::1/128 md5
# Allow replication connections from localhost, by a user with the
# replication privilege.
@remove-line-for-nolocal@local replication all ident
host replication all 127.0.0.1/32 trust
host replication all ::1/128 trust
$ cat << EOF >> usr/pkg/pgsql/data/postgresql.conf
> listen_addresses = '*'
> wal_level = hot_standby
> max_wal_senders = 10
> hot_standby = on
> archive_mode = on
> archive_command = 'cp %p /usr/pkg/pgsql/archive/%f'
> EOF
No automation exists to run mkdir other than creating a placeholder file. you will have to chown the archive dir! File permissions are not yet handled. This may change in the future, by reusing the +DIRS script with new input for example, if deemed necessary by the community.
$ mkdir -p usr/pkg/pgsql/archive/ $ echo "remember to chown this dir to the user pgsql runs as" > usr/pkg/pgsql/archive/placeholder $ git add usr/pkg/pgsql/archive/placeholder $ git commit -m "create dbcluster-master role for postgresql10" [databases_postgresql10_10.4nb1_10.0_11_dbcluster-master 98fe514] create dbcluster-master role for postgresql0 3 files changed, 9 insertions(+), 2 deletions(-) create mode 100644 usr/pkg/pgsql/archive/placeholder $ git push -u origin databases_postgresql10_10.4nb1_10.0_11_dbcluster-master Counting objects: 10, done. Compressing objects: 100% (7/7), done. Writing objects: 100% (10/10), 827 bytes | 827.00 KiB/s, done. Total 10 (delta 2), reused 0 (delta 0) To ssh://192.168.100.112/usr/home/vcs/confpullexample.git * [new branch] databases_postgresql10_10.4nb1_10.0_11_dbcluster-master -> databases_postgresql10_10.4nb1_10.0_11_dbcluster-master Branch 'databases_postgresql10_10.4nb1_10.0_11_dbcluster-master' set up to track remote branch 'databases_postgresql10_10.4nb1_10.0_11_dbcluster-master'
create a generic node/replica configuration from the default config files and add the recovery.conf file...
$ git checkout databases_postgresql10_10.4nb1_10.0_11_default Switched to branch 'databases_postgresql10_10.4nb1_10.0_11_default' Your branch is up to date with 'origin/databases_postgresql10_10.4nb1_10.0_11_default'. $ mkdir -p usr/pkg/pgsql/archive/ $ echo "remember to chown this dir to the user pgsql runs as" > usr/pkg/pgsql/archive/placeholder $ cp /home/devuser/recovery.conf.sample usr/pkg/pgsql/data/recovery.conf $ echo "standby_mode = 'on'" >> usr/pkg/pgsql/data/recovery.conf $ echo "restore_command = 'cp /usr/pkg/pgsql/archive/%f \"%p%\"'" >> usr/ $ git checkout -b databases_postgresql10_10.4nb1_10.0_11_dbcluster-replicas A usr/pkg/pgsql/archive/placeholder A usr/pkg/pgsql/data/recovery.conf Switched to a new branch 'databases_postgresql10_10.4nb1_10.0_11_dbcluster-replicas' $ git add usr/pkg/pgsql/archive/placeholder $ git add usr/pkg/pgsql/data/recovery.conf $ git add usr/pkg/pgsql/data/postgresql.conf $ git add usr/pkg/pgsql/data/pg_hba.conf $ git commit -m "create generalized dbcluster-replica role schema" [databases_postgresql10_10.4nb1_10.0_11_dbcluster-replicas 9260a88] create generalized dbcluster-replica role schema 2 files changed, 161 insertions(+) create mode 100644 usr/pkg/pgsql/archive/placeholder create mode 100644 usr/pkg/pgsql/data/recovery.conf $ git push -u origin databases_postgresql10_10.4nb1_10.0_11_dbcluster-replicas Counting objects: 9, done. Compressing objects: 100% (6/6), done. Writing objects: 100% (9/9), 2.71 KiB | 2.71 MiB/s, done. Total 9 (delta 0), reused 0 (delta 0) To ssh://192.168.100.112/usr/home/vcs/confpullexample.git * [new branch] databases_postgresql10_10.4nb1_10.0_11_dbcluster-replicas -> databases_postgresql10_10.4nb1_10.0_11_dbcluster-replicas Branch 'databases_postgresql10_10.4nb1_10.0_11_dbcluster-replicas' set up to track remote branch 'databases_postgresql10_10.4nb1_10.0_11_dbcluster-replicas'.
Now specialize the schema for the cluster at @ToonTown by specifying part of the hostname the machines will have in that cluster:
$ git checkout -b databases_postgresql10_10.4nb1_10.0_11_dbcluster-replicas_toontowndc-node Switched to a new branch 'databases_postgresql10_10.4nb1_10.0_11_dbcluster-replicas_toontowndc-node' $ echo "primary_conninfo = 'host=10.0.10.200 port=5432 user=replicauser application_name=toons'" >> usr/pkg/pgsql/data/recovery.conf $ git add usr/pkg/pgsql/data/recovery.conf $ git commit -m "create specialized branch for dbcluster at ToonTown dc" [databases_postgresql10_10.4nb1_10.0_11_dbcluster-replicas_toontowndc-node 90d9731] create specialized branch for dbcluster at ToonDown dc 1 file changed, 1 insertion(+) $ git push -u origin databases_postgresql10_10.4nb1_10.0_11_dbcluster-replicas_toontowndc-node Counting objects: 7, done. Compressing objects: 100% (5/5), done. Writing objects: 100% (7/7), 604 bytes | 604.00 KiB/s, done. Total 7 (delta 2), reused 0 (delta 0) To ssh://192.168.100.112/usr/home/vcs/confpullexample.git * [new branch] databases_postgresql10_10.4nb1_10.0_11_dbcluster-replicas_toontowndc-node -> databases_postgresql10_10.4nb1_10.0_11_dbcluster-replicas_toontowndc-node Branch 'databases_postgresql10_10.4nb1_10.0_11_dbcluster-replicas_toontowndc-node' set up to track remote branch 'databases_postgresql10_10.4nb1_10.0_11_dbcluster-replicas_toontowndc-node'.
Let's try to deploy it on a node!
pkghost# whoami root pkghost# hostname pkghost pkghost# cat /usr/pkg/etc/pkg_install.conf VCSTRACK_CONF=yes VCSCONFPULL=yes REMOTEVCS=ssh://vcs@192.168.100.112/usr/home/vcs/confpullexample.git VCS=git pkghost# echo "ROLE=dbcluster-replicas" >> /usr/pkg/etc/pkg_install.conf pkghost# hostname toontowndc-node05 toontowndc-node05# #show use with pkg_add and a local package, for once toontowndc-node05# /usr/pkg/sbin/pkg_add ./postgresql10-10.3.tgz Trying to deploy configuration from ssh://vcs@192.168.100.112/usr/home/vcs/confpullexample.git via git About to use remote branch databases_postgresql10_10.4nb1_10.0_11_dbcluster-replicas_toontowndc-node Cloning into 'confpullexample'... remote: Enumerating objects: 45, done. remote: Counting objects: 100% (45/45), done. remote: Compressing objects: 100% (28/28), done. remote: Total 45 (delta 5), reused 0 (delta 0) Receiving objects: 100% (45/45), 15.23 KiB | 12.00 KiB/s, done. Resolving deltas: 100% (5/5), done. /tmp/pkgsrcdeploy-17103/work/etc/ssh/sshd_config -> /etc/ssh/sshd_config /tmp/pkgsrcdeploy-17103/work/usr/pkg/pgsql/archive/placeholder -> /usr/pkg/pgsql/archive/placeholder /tmp/pkgsrcdeploy-17103/work/usr/pkg/pgsql/data/pg_hba.conf -> /usr/pkg/pgsql/data/pg_hba.conf /tmp/pkgsrcdeploy-17103/work/usr/pkg/pgsql/data/postgresql.conf -> /usr/pkg/pgsql/data/postgresql.conf /tmp/pkgsrcdeploy-17103/work/usr/pkg/pgsql/data/recovery.conf -> /usr/pkg/pgsql/data/recovery.conf toontowndc-node05# tail /etc/ssh/sshd_config # Example of overriding settings on a per-user basis #Match User anoncvs # X11Forwarding no # AllowTcpForwarding no # PermitTTY no # ForceCommand cvs server PermitEmptyPasswords no PermitRootLogin no AllowGroup ops toontowndc-node05# tail /usr/pkg/pgsql/data/recovery.conf #--------------------------------------------------------------------------- # HOT STANDBY PARAMETERS #--------------------------------------------------------------------------- # # Hot Standby related parameters are listed in postgresql.conf # #--------------------------------------------------------------------------- standby_mode = 'on' restore_command = 'cp /usr/pkg/pgsql/archive/%f "%p%"' primary_conninfo = 'host=10.0.10.200 port=5432 user=replicauser application_name=toons' toontowndc-node05# ls /tmp/pkgsrcdeploy-17103 ls: /tmp/pkgsrcdeploy-17103: No such file or directory
The same way goes if you should choose to set VCS=hg or VCS=svn in pkg_install.conf. All are supported when pulling configuration, you should adapt to managing branches the way these other VCSs expect you to work with them. It might be in scope for this tutorial, but it's getting a bit long!
Also remember to set an appropriate URI in REMOTEVCS for these other Version Control Systems.
CVS is not supported: tags (branch names) cannot contain dots with CVS, and this breaks the chosen naming scheme for many software applications. It could be replaced with another special meaning character when using this vcs, but this workaround would make for possible confusion in branch naming. Furthermore, as with svn, there is no way to list remote branches before getting a local copy of the repository, with the added headcache of having to parse its log to extract branch names. I considered it not to be worth the hassle, but I'm open to adding PULL mode support for cvs if required by any user.
One word about subversion: I expect you to follow conventions and keep branches at /branches/ in your repository!
pkgconftrack store: storing changes when not upgrading packages
Even when merging changes in configuration files is not attempted because of VCSAUTOMERGE=no or unset, pkgsrc will keep track of installed configuration files by committing them to the configuration repository, as a user-modified file under user/$filePath (see mk/pkginstall/files).
No VCS will commit files that haven't changed since the last revision (I hope!).
But what if you made changes to a configuration file and you want to store it in the configuration repository as a manually edited file, neither waiting for its package to be updated nor forcing a reinstallation? You could interact with your vcs of choice direcly, or just use the new script in pkgsrc at pkgtools/pkgconftrack
pkgconf# cd pkgtools/pkgconftrack/ pkgconf# make install ===> Skipping vulnerability checks. [...] ===> Installing binary package of pkgconftrack-1.0 pkgconf# pkgconftrack prefix: /usr/pkg, VCSDIR: /var/confrepo, VCS: svn, REMOTEVCS: no : unknown action Usage: pkgconftrack [-p PREFIX] [-m commit message] store packagename [... packagenames]
pkgconftrack will search for pkgsrc VCS configuration on your shell environment or in pkg_install.conf, reading it via pkg_admin config-var $VARNAME.
pkg_admin, in order to work with the correct configuration file, and look in the right package database to check if a package exists and its list of configuration files, is called relative to the prefix.
By default, if unspecified, /usr/pkg is assumed and /usr/pkg/sbin/pkg_admin is executed.
You can work in packages of a different prefix by calling pkgconftrack -p /path/to/other/prefix followed by other options (you are free to chose a custom commit message with -m "my commit message") and the action to be performed.
As of now, pkgconftrack only support one action: store followed by one or more packages you wish to store configuration files from, into the configuration repository.
When storing configuration for more than one package, a unique commit is made (if using a VCS other than the old RCS, which doesn't support multi file commits and atomic transactions). This opens the way to storing config files for a service made working by a combination of software packages when these are in a known-good status, to be accessed and restored checking out one commit id.
So, let's say one last change was needed to have mail working:
pkgconf# diff /usr/pkg/etc/spamd.conf /usr/pkg/share/examples/spamd/spamd.conf 7a8 > # 33c34 < :method=https:\ --- > :method=http:\ pkgconf# pkgconftrack -m "5 august 2018: mail service: blacklist only accessible via https" store spamd postfix dovecot opendkim prefix: /usr/pkg, VCSDIR: /var/confrepo, VCS: svn, REMOTEVCS: no Storing configuration files for opendkim A opendkim.conf Package not found: dovecot in the pkgdb for /usr/pkg Package not found: postfix in the pkgdb for /usr/pkg Storing configuration files for spamd Adding usr/pkg/etc/opendkim.conf Transmitting file data .done Committing transaction... Committed revision 7. pkgconf#
Yeah, I haven't really installed a mail server just to test pkgconftrack, so neither dovecot nor postfix are installed on the system!
future improvements
Well, it all begins with the new features being tested by end users, more bugs being found, changes made as requested. Then, once things get more stable, the versioning script could be reimplemented as part of pkgtasks, and files.subr changed there to interact with the new functions.
More VCSs could be handled, there could be more automation in switching repositories and adding remote sources, but all this is maybe best kept in a separate tool such as pkgconftrack. Speaking of which, well, it stores installed config files for one or more packages at once, but it does not restore them yet! RCS needs to be supported, being the default Version Control System, but it has no concept of an atomic transaction involving more than one file, so there would be nothing the user could reference to when asking the script to restore configuration. The script could track, by checking the log for all files, for identical commit message and restore each revision of each file having the same commit message, but what if some user mistakingly reused the same commit message as part of different transactions? Should each custom commit message be prepended with a timestamp?
All this would still lead to differences in referencing to a transaction, or the simulation thereof, and in listing available changes the user can select for restore.
pkgconftrack could also help in interactively reviewing conflicting automerge results, some scripts already do it, and in restoring the last user-installed file from the repository in case of breakage. This should really consist in a cp from vcsdir/user/path/to/file /path/to/installed/file, maybe preceded by a checkout, but there is good marging for making the tool more useful.
And yes, configuraction deployment/VCSCONFPULL does not handle permissions or the creation of empty directories, executable files: I think this would require making the way users interact with the configuration repository more complex, more akin to a configuration management and monitoring software, and widen the chances for mistakes when working across branches. Any good idea of how to implement these missing bits while still keeping things simple for users?
I'd really like to see the code tried out! it's now at Github
.This report was written by Naveen Narayanan as part of Google Summer of Code 2019.
This report encompasses the progress of the project during the second coding period.
WINE on amd64
As getting Wine to work with WoW64 support was of foremost
importance, my focus was on compat32 dependency packages without
which Wine's functionality would be limited and more importantly
untestable. Initially, being unaware of what to expect, I just
wanted Wine to run, at the earliest. So, with outmost support from
mentors, the consensus was to install libs from 32-bit packages to
${PREFIX}/lib/32 and ignore everything else that came with the
respective packages.
I had most of the compat32 packages ready after a couple of
days. And it was time we gave Wine a whirl. Well, the build was
successful. However, I had problems with 32-bit Xorg. The
applications which came packaged with Wine worked fine, but, other
Microsoft Windows applications like notepad++, Mario etc had a
hard time running. Additionally, I noticed that fontconfig went
wild and crashed spewing errors symptomatic of Wine (32-bit) not
playing nice with the fontconfig lib that came with 32-bit Xorg
package. On top of this, I found that build failed on certain
machines due to unavailability of headers. This made us reconsider
our decision to install 32-bit libs to ${PREFIX}/lib/32 and ignore
everything else which included headers and binaries.
Ultimately, we realized that it was time we found a proper
solution to the problem of where 32-bit packages should be
installed on NetBSD amd64 and then, we eventually settled on
${PREFIX}/emul/netbsd32/. It seemed logical, and I
got on with the task of adapting the respective Makefiles of
dependency packages to install
to ${PREFIX}/emul/netbsd32/. Additionally, I packaged
fontconfig (32-bit) in high hopes that Wine would behave
appropriately with the former. Wine build was successful. However,
I noticed that Wine wasn't linking against the fontconfig libs
from my package but against the ones which came with 32-bit Xorg
package. Later, I realized, after consulting with mentors, that
pkgsrc doesn't search for pkgconfig files (*.pc)
in ${PREFIX}/emul/netbsd32/lib by default. pkgsrc
sets
_PKG_CONFIG_LIBDIR appropriately based
on ${LIBABISUFFIX}. As you can see, it doesn't search
for .pc files in ${PREFIX}/emul/netbsd32/lib and
hence, pkgconfig couldn't get the right flags for fontconfig
package. On the other hand, Wine configure script found fontconfig
libs provided by 32-bit Xorg package against which it linked
wine. A kludgy workaround was to use configure args for the
respective libs thereby, obviating configure from finding the
wrong libs. Finally, with the help of aforementioned kludgy
workarounds, we were able to build Wine and successfully run Mario
and Lua (32-bit binaries).
How to run Wine on NetBSD -current
- Build -current distribution.
- Compile -current kernel with USER_LDT enabled and SVS disabled.
- Install kernel and distribution.
- Clone wip repo.
-
cd /usr/pkgsrc/wip/wine64; make install -
export LD_LIBRARY_PATH=/usr/pkg/emul/netbsd32/lib; wine mario.exe
Future Plans
Wine requires the kernel option USER_LDT to be able to run 32-bit applications on amd64 - facilitated by WoW64. Presently, this feature isn't enabled by default on NetBSD and hence, the kernel has to be compiled with USER_LDT enabled. This also warrants the kernel option SVS to be disabled currently owing to compatability issues. Work is being done to resolve the conflict which would apparently allow USER_LDT to be enabled by default in the GENERIC kernel.
pkgsrc
can be made to search for pkgconf config files in
${PREFIX}/emul/netbsd32/lib by setting
_PKG_CONFIG_LIBDIR to
${BUILDLINK_DIR}${LIBABIPREFIX}/lib${LIBABISUFFIX} as
per @maya's suggestion. It might take some more thought and time
before we finalize it.
Summary
Presently, Wine on amd64 is in test phase. It seems to work fine
with caveats like LD_LIBRARY_PATH which has to be set as 32-bit
Xorg libs don't have ${PREFIX}/emul/netbsd32/lib in its rpath
section. The latter is due to us extracting 32-bit libs from
tarballs in lieu of building 32-bit Xorg on amd64. As previously
stated, pkgsrc doesn't search for pkgconfig files in
${PREFIX}/emul/netbsd32/lib which might have inadvertent effects
that I am unaware of as of now. I shall be working on these issues
during the final coding period. I would like to thank @leot, @maya
and @christos for saving me from shooting myself in the foot
many a time. I, admittedly, have had times when multiple
approaches, which all seemed right at that time, perplexed me. I
believe those are times when having a mentor counts, and I have
been lucky enough to have really good ones. Once again, thanks to
Google for this wonderful opportunity.
This report was written by Naveen Narayanan as part of Google Summer of Code 2019.
This report encompasses the progress of the project during the second coding period.
WINE on amd64
As getting Wine to work with WoW64 support was of foremost
importance, my focus was on compat32 dependency packages without
which Wine's functionality would be limited and more importantly
untestable. Initially, being unaware of what to expect, I just
wanted Wine to run, at the earliest. So, with outmost support from
mentors, the consensus was to install libs from 32-bit packages to
${PREFIX}/lib/32 and ignore everything else that came with the
respective packages.
I had most of the compat32 packages ready after a couple of
days. And it was time we gave Wine a whirl. Well, the build was
successful. However, I had problems with 32-bit Xorg. The
applications which came packaged with Wine worked fine, but, other
Microsoft Windows applications like notepad++, Mario etc had a
hard time running. Additionally, I noticed that fontconfig went
wild and crashed spewing errors symptomatic of Wine (32-bit) not
playing nice with the fontconfig lib that came with 32-bit Xorg
package. On top of this, I found that build failed on certain
machines due to unavailability of headers. This made us reconsider
our decision to install 32-bit libs to ${PREFIX}/lib/32 and ignore
everything else which included headers and binaries.
Ultimately, we realized that it was time we found a proper
solution to the problem of where 32-bit packages should be
installed on NetBSD amd64 and then, we eventually settled on
${PREFIX}/emul/netbsd32/. It seemed logical, and I
got on with the task of adapting the respective Makefiles of
dependency packages to install
to ${PREFIX}/emul/netbsd32/. Additionally, I packaged
fontconfig (32-bit) in high hopes that Wine would behave
appropriately with the former. Wine build was successful. However,
I noticed that Wine wasn't linking against the fontconfig libs
from my package but against the ones which came with 32-bit Xorg
package. Later, I realized, after consulting with mentors, that
pkgsrc doesn't search for pkgconfig files (*.pc)
in ${PREFIX}/emul/netbsd32/lib by default. pkgsrc
sets
_PKG_CONFIG_LIBDIR appropriately based
on ${LIBABISUFFIX}. As you can see, it doesn't search
for .pc files in ${PREFIX}/emul/netbsd32/lib and
hence, pkgconfig couldn't get the right flags for fontconfig
package. On the other hand, Wine configure script found fontconfig
libs provided by 32-bit Xorg package against which it linked
wine. A kludgy workaround was to use configure args for the
respective libs thereby, obviating configure from finding the
wrong libs. Finally, with the help of aforementioned kludgy
workarounds, we were able to build Wine and successfully run Mario
and Lua (32-bit binaries).
How to run Wine on NetBSD -current
- Build -current distribution.
- Compile -current kernel with USER_LDT enabled and SVS disabled.
- Install kernel and distribution.
- Clone wip repo.
-
cd /usr/pkgsrc/wip/wine64; make install -
export LD_LIBRARY_PATH=/usr/pkg/emul/netbsd32/lib; wine mario.exe
Future Plans
Wine requires the kernel option USER_LDT to be able to run 32-bit applications on amd64 - facilitated by WoW64. Presently, this feature isn't enabled by default on NetBSD and hence, the kernel has to be compiled with USER_LDT enabled. This also warrants the kernel option SVS to be disabled currently owing to compatability issues. Work is being done to resolve the conflict which would apparently allow USER_LDT to be enabled by default in the GENERIC kernel.
pkgsrc
can be made to search for pkgconf config files in
${PREFIX}/emul/netbsd32/lib by setting
_PKG_CONFIG_LIBDIR to
${BUILDLINK_DIR}${LIBABIPREFIX}/lib${LIBABISUFFIX} as
per @maya's suggestion. It might take some more thought and time
before we finalize it.
Summary
Presently, Wine on amd64 is in test phase. It seems to work fine
with caveats like LD_LIBRARY_PATH which has to be set as 32-bit
Xorg libs don't have ${PREFIX}/emul/netbsd32/lib in its rpath
section. The latter is due to us extracting 32-bit libs from
tarballs in lieu of building 32-bit Xorg on amd64. As previously
stated, pkgsrc doesn't search for pkgconfig files in
${PREFIX}/emul/netbsd32/lib which might have inadvertent effects
that I am unaware of as of now. I shall be working on these issues
during the final coding period. I would like to thank @leot, @maya
and @christos for saving me from shooting myself in the foot
many a time. I, admittedly, have had times when multiple
approaches, which all seemed right at that time, perplexed me. I
believe those are times when having a mentor counts, and I have
been lucky enough to have really good ones. Once again, thanks to
Google for this wonderful opportunity.
I have been working on adapting TriforceAFL for NetBSD kernel syscall fuzzing. This blog post summarizes the work done until the second evaluation.
For work done during the first coding period, check out this post.
Input Generation
For a feedback driven mutation based fuzzer that is TriforceAFL, fuzzing can be greatly improved by providing it with proper input test cases. The fuzzer can then alter parts of the valid input leading to more coverage and hopefully more bugs.
The TriforceNetBSDSyscallFuzzer itself was a working fuzzer at the end of the first evaluation, but it was missing some proper input generation for most of the syscalls.
A greater part of the time during this coding period was spent adding and testing basic templates for a majority of NetBSD syscalls, scripts have also been added for cases where more complex input generation was required.
This should now allow the fuzzer to find bugs it previously could not have.
Templates for 160 of the 483 syscalls in NetBSD have been added, below is the complete list:
1 exit, 2 fork, 3 read, 4 write, 5 open, 6 close, 7 compat_50_wait4, 8 compat_43_ocreat, 9 link, 10 unlink, 12 chdir, 13 fchdir, 14 compat_50_mknod, 15 chmod, 16 chown, 17 break, 19 compat_43_olseek, 20 getpid, 22 unmount, 23 setuid, 24 getuid, 25 geteuid, 26 ptrace, 33 access, 34 chflags, 35 fchflags, 36 sync, 37 kill, 39 getppid, 41 dup, 42 pipe, 43 getegid, 44 profil, 45 ktrace, 47 getgid, 49 __getlogin, 50 __setlogin, 51 acct, 55 compat_12_oreboot, 56 revoke, 57 symlink, 58 readlink, 59 execve, 60 umask, 61 chroot, 62 compat_43_fstat43, 63 compat_43_ogetkerninfo, 64 compat_43_ogetpagesize, 66 vfork, 73 munmap, 78 mincore, 79 getgroups, 80 setgroups, 81 getpgrp, 82 setpgid, 83 compat_50_setitimer, 86 compat_50_getitimer, 89 compat_43_ogetdtablesize, 90 dup2, 95 fsync, 96 setpriority, 97 compat_30_socket, 100 getpriority, 106 listen, 116 compat_50_gettimeofday, 117 compat_50_getrusage, 120 readv, 121 writev, 122 compat_50_settimeofday, 123 fchown, 124 fchmod, 126 setreuid, 127 setregid, 128 rename, 131 flock, 132 mkfifo, 134 shutdown, 135 socketpair, 136 mkdir, 137 rmdir, 140 compat_50_adjtime, 147 setsid, 161 compat_30_getfh, 165 sysarch, 181 setgid, 182 setegid, 183 seteuid, 191 pathconf, 192 fpathconf, 194 getrlimit, 195 setrlimit, 199 lseek, 200 truncate, 201 ftruncate, 206 compat_50_futimes, 207 getpgid, 209 poll, 231 shmget, 232 compat_50_clock_gettime, 233 compat_50_clock_settime, 234 compat_50_clock_getres, 240 compat_50_nanosleep, 241 fdatasync, 242 mlockall, 243 munlockall, 247 _ksem_init, 250 _ksem_close, 270 __posix_rename, 272 compat_30_getdents, 274 lchmod, 275 lchown, 276 compat_50_lutimes, 289 preadv, 290 pwritev, 286 getsid, 296 __getcwd, 306 utrace, 344 kqueue, 157 compat_20_statfs, 158 compat_20_fstatfs, 416 __posix_fadvise50, 173 pread, 174 pwrite, 197 mmap, 462 faccessat, 463 fchmodat, 464 fchownat, 461 mkdirat, 459 mkfifoat, 460 mknodat, 468 openat, 469 readlinkat, 458 renameat, 470 symlinkat, 471 unlinkat, 453 pipe2, 467 utimensat
A separate script (targ/gen2.py) generating tricker input cases was added for the following:
104 bind, 105 setsockopt, 118 getsockopt, 98 connect, 30 accept, 31 getpeername, 32 getsockname, 133 sendto, 29 recvfrom, 21 compat_40_mount, 298 compat_30_fhopen
299 compat_30_fhstat, 300 compat_20_fhstatfs, 93 compat_50_select, 373 compat_50_pselect, 345 compat_50_kevent, 92 fcntl, 74 mprotect, 203 mlock, 273 minherit, 221 semget, 222 semop, 202 __sysctl

Reproducibility
The fuzzer uses the simplest way to reproduce a crash which is by storing the exact input for the test case that resulted in a crash. This input can then be passed to the driver program, which will be able to parse the input and execute the syscalls that were executed in the order that they were executed.
A better prototype reproducer generator has now been added to the fuzzer that provides us with human readable and executable C code. This C code can be compiled and executed to reproduce the crash.
To generate the reproducers simply run the genRepro script from the targ directory. If everything goes right, the C reproducers will now be available in targ/reproducers, in separate files as follows:
// id:000009,sig:00,src:005858+002155,op:splice,rep:8
#include <sys/syscall.h>
#include <unistd.h>
int main() {
__syscall( SYS_mincore, 0x/* removed from the report due to security concerns */, 0x/* ... */, 0x/* ... */);
return 0;
}
// id:000010,sig:00,src:005859+004032,op:splice,rep:2
#include <sys/syscall.h>
#include <unistd.h>
int main() {
__syscall( SYS_mprotect, 0x/* ... */, 0x/* ... */, 0x/* ... */);
__syscall( SYS_mincore, 0x/* ... */, 0x/* ... */, 0x/* ... */);
return 0;
}
// id:000011,sig:00,src:005859+004032,op:splice,rep:4
#include <sys/syscall.h>
#include <unistd.h>
int main() {
__syscall( SYS_mprotect, 0x/* ... */, 0x/* ... */, 0x/* ... */);
__syscall( SYS_mincore, 0x/* ... */, 0x/* ... */, 0x/* ... */);
return 0;
}
Fuzzing
The fuzzer was run for ~4 days. We were getting ~50 execs/sec on a single core. Please note that this is using qemu with softemu (TCG) as hardware acceleration cannot be used here. During this period the fuzzer detected 23 crashes that it marked as unique. Not all of these were truly unique, there is the scope of adding a secondary filter here to detect truly unique crashes. Most of them were duplicates of the crashes highlighted below:
compat_43_osendmsg - tcp_output: no template
call 114 - compat_43_osendmsg
arg 0: argStdFile 4 - type 12
arg 1: argVec64 77d0549cc000 - size 4
arg 2: argNum 8003
read 83 bytes, parse result 0 nrecs 1
syscall 114 (4, 77d0549cc000, 8003)
[ 191.8169124] panic: tcp_output: no template
[ 191.8169124] cpu0: Begin traceback...
[ 191.8269174] vpanic() at netbsd:vpanic+0x160
[ 191.8269174] snprintf() at netbsd:snprintf
[ 191.8269174] tcp_output() at netbsd:tcp_output+0x2869
[ 191.8385864] tcp_sendoob_wrapper() at netbsd:tcp_sendoob_wrapper+0xfe
[ 191.8469824] sosend() at netbsd:sosend+0x6e3
[ 191.8469824] do_sys_sendmsg_so() at netbsd:do_sys_sendmsg_so+0x231
[ 191.8469824] do_sys_sendmsg() at netbsd:do_sys_sendmsg+0xac
[ 191.8569944] compat_43_sys_sendmsg() at netbsd:compat_43_sys_sendmsg+0xea
[ 191.8569944] sys___syscall() at netbsd:sys___syscall+0x74
[ 191.8655484] syscall() at netbsd:syscall+0x181
[ 191.8655484] --- syscall (number 198) ---
[ 191.8655484] 40261a:
[ 191.8655484] cpu0: End traceback...
[ 191.8655484] fatal breakpoint trap in supervisor mode
[ 191.8655484] trap type 1 code 0 rip 0xffffffff8021ddf5 cs 0x8 rflags 0x202 cr2
0x7f7795402000 ilevel 0x4 rsp 0xffffc58032d589f0
[ 191.8655484] curlwp 0xfffff7e8b1c63220 pid 700.1 lowest kstack 0xffffc58032d55
2c0
Stopped in pid 700.1 (driver) at netbsd:breakpoint+0x5: leave
mincore - uvm_fault_unwire_locked: address not in map
call 78 - mincore
arg 0: argNum d000000
arg 1: argNum 7600000000000000
arg 2: argNum 1b0000000000
read 65 bytes, parse result 0 nrecs 1
syscall 78 (d000000, 7600000000000000, 1b0000000000)
[ 141.0578675] panic: uvm_fault_unwire_locked: address not in map
[ 141.0578675] cpu0: Begin traceback...
[ 141.0691345] vpanic() at netbsd:vpanic+0x160
[ 141.0691345] snprintf() at netbsd:snprintf
[ 141.0774205] uvm_fault_unwire() at netbsd:uvm_fault_unwire
[ 141.0774205] uvm_fault_unwire() at netbsd:uvm_fault_unwire+0x29
[ 141.0774205] sys_mincore() at netbsd:sys_mincore+0x23c
[ 141.0884435] sys___syscall() at netbsd:sys___syscall+0x74
[ 141.0884435] syscall() at netbsd:syscall+0x181
[ 141.0884435] --- syscall (number 198) ---
[ 141.0996065] 40261a:
[ 141.0996065] cpu0: End traceback...
[ 141.0996065] fatal breakpoint trap in supervisor mode
[ 141.0996065] trap type 1 code 0 rip 0xffffffff8021ddf5 cs 0x8 rflags 0x202 cr2
0x761548094000 ilevel 0 rsp 0xffff870032e48d90
[ 141.0996065] curlwp 0xffff829094e51b00 pid 646.1 lowest kstack 0xffff870032e45
2c0
Stopped in pid 646.1 (driver) at netbsd:breakpoint+0x5: leave
extattrctl - KASSERT fail
call 360 - extattrctl
arg 0: argBuf 7b762b514044 from 2 bytes
arg 1: argNum ff8001
arg 2: argFilename 7b762b515020 - 2 bytes from /tmp/file0
arg 3: argNum 0
arg 4: argNum 0
arg 5: argNum 2100000000
read 59 bytes, parse result 0 nrecs 1
syscall 360 (7b762b514044, ff8001, 7b762b515020, 0, 0, 2100000000)
[ 386.4528838] panic: kernel diagnostic assertion "fli->fli_trans_cnt == 0" fail
ed: file "src/sys/kern/vfs_trans.c", line 201
[ 386.4528838] cpu0: Begin traceback...
[ 386.4528838] vpanic() at netbsd:vpanic+0x160
[ 386.4648968] stge_eeprom_wait.isra.4() at netbsd:stge_eeprom_wait.isra.4
[ 386.4724138] fstrans_lwp_dtor() at netbsd:fstrans_lwp_dtor+0xbd
[ 386.4724138] exit1() at netbsd:exit1+0x1fa
[ 386.4724138] sys_exit() at netbsd:sys_exit+0x3d
[ 386.4832968] syscall() at netbsd:syscall+0x181
[ 386.4832968] --- syscall (number 1) ---
[ 386.4832968] 421b6a:
[ 386.4832968] cpu0: End traceback...
[ 386.4832968] fatal breakpoint trap in supervisor mode
[ 386.4944688] trap type 1 code 0 rip 0xffffffff8021ddf5 cs 0x8 rflags 0x202 cr2
0xffffc100324bd000 ilevel 0 rsp 0xffffc10032ce9dc0
[ 386.4944688] curlwp 0xfffff6278e2fc240 pid 105.1 lowest kstack 0xffffc10032ce6
2c0
Stopped in pid 105.1 (driver) at netbsd:breakpoint+0x5: leave
pkgsrc Package
Lastly, the TriforceNetBSDSyscallFuzzer has now been made available in the form of a pkgsrc package in pkgsrc/wip as triforcenetbsdsyscallfuzzer. The package will require wip/triforceafl which was ported earlier.
All other changes mentioned can be found in the github repo.
script(1) recording
A typescript recording of a functional TriforceAFL fuzzer setup and execution is available here.
Download it and replay it with script -p.
Future Work
Work that remains to be done include:
- Restructuring of files
The file structure needs to be modified to suit the specific case of the Host and Target being the same OS. Right now, files are separated into Host and Target directories, this is not required. - Testing with Sanitizers enabled
Until now the fuzzing done was without using KASAN or kUBSAN. Testing with them enabled and fuzzing with them will be of major focus in the third coding period. - Improving the 'reproducer generator'
There is some scope of improvement for the prototype that was added. Incremental updates to it are to be expected. - Analysis of crash reports and fixing bugs
- Documentation
Summary
So far, the TriforceNetBSDSyscallFuzzer has been made available in the form of a pkgsrc package with the ability to fuzz most of NetBSD syscalls. In the final coding period of GSoC. I plan to analyse the crashes that were found until now. Integrate sanitizers, try and find more bugs and finally wrap up neatly with detailed documentation.
Last but not least, I would like to thank my mentor, Kamil Rytarowski for helping me through the process and guiding me. It has been a wonderful learning experience so far!
I have been working on adapting TriforceAFL for NetBSD kernel syscall fuzzing. This blog post summarizes the work done until the second evaluation.
For work done during the first coding period, check out this post.
Input Generation
For a feedback driven mutation based fuzzer that is TriforceAFL, fuzzing can be greatly improved by providing it with proper input test cases. The fuzzer can then alter parts of the valid input leading to more coverage and hopefully more bugs.
The TriforceNetBSDSyscallFuzzer itself was a working fuzzer at the end of the first evaluation, but it was missing some proper input generation for most of the syscalls.
A greater part of the time during this coding period was spent adding and testing basic templates for a majority of NetBSD syscalls, scripts have also been added for cases where more complex input generation was required.
This should now allow the fuzzer to find bugs it previously could not have.
Templates for 160 of the 483 syscalls in NetBSD have been added, below is the complete list:
1 exit, 2 fork, 3 read, 4 write, 5 open, 6 close, 7 compat_50_wait4, 8 compat_43_ocreat, 9 link, 10 unlink, 12 chdir, 13 fchdir, 14 compat_50_mknod, 15 chmod, 16 chown, 17 break, 19 compat_43_olseek, 20 getpid, 22 unmount, 23 setuid, 24 getuid, 25 geteuid, 26 ptrace, 33 access, 34 chflags, 35 fchflags, 36 sync, 37 kill, 39 getppid, 41 dup, 42 pipe, 43 getegid, 44 profil, 45 ktrace, 47 getgid, 49 __getlogin, 50 __setlogin, 51 acct, 55 compat_12_oreboot, 56 revoke, 57 symlink, 58 readlink, 59 execve, 60 umask, 61 chroot, 62 compat_43_fstat43, 63 compat_43_ogetkerninfo, 64 compat_43_ogetpagesize, 66 vfork, 73 munmap, 78 mincore, 79 getgroups, 80 setgroups, 81 getpgrp, 82 setpgid, 83 compat_50_setitimer, 86 compat_50_getitimer, 89 compat_43_ogetdtablesize, 90 dup2, 95 fsync, 96 setpriority, 97 compat_30_socket, 100 getpriority, 106 listen, 116 compat_50_gettimeofday, 117 compat_50_getrusage, 120 readv, 121 writev, 122 compat_50_settimeofday, 123 fchown, 124 fchmod, 126 setreuid, 127 setregid, 128 rename, 131 flock, 132 mkfifo, 134 shutdown, 135 socketpair, 136 mkdir, 137 rmdir, 140 compat_50_adjtime, 147 setsid, 161 compat_30_getfh, 165 sysarch, 181 setgid, 182 setegid, 183 seteuid, 191 pathconf, 192 fpathconf, 194 getrlimit, 195 setrlimit, 199 lseek, 200 truncate, 201 ftruncate, 206 compat_50_futimes, 207 getpgid, 209 poll, 231 shmget, 232 compat_50_clock_gettime, 233 compat_50_clock_settime, 234 compat_50_clock_getres, 240 compat_50_nanosleep, 241 fdatasync, 242 mlockall, 243 munlockall, 247 _ksem_init, 250 _ksem_close, 270 __posix_rename, 272 compat_30_getdents, 274 lchmod, 275 lchown, 276 compat_50_lutimes, 289 preadv, 290 pwritev, 286 getsid, 296 __getcwd, 306 utrace, 344 kqueue, 157 compat_20_statfs, 158 compat_20_fstatfs, 416 __posix_fadvise50, 173 pread, 174 pwrite, 197 mmap, 462 faccessat, 463 fchmodat, 464 fchownat, 461 mkdirat, 459 mkfifoat, 460 mknodat, 468 openat, 469 readlinkat, 458 renameat, 470 symlinkat, 471 unlinkat, 453 pipe2, 467 utimensat
A separate script (targ/gen2.py) generating tricker input cases was added for the following:
104 bind, 105 setsockopt, 118 getsockopt, 98 connect, 30 accept, 31 getpeername, 32 getsockname, 133 sendto, 29 recvfrom, 21 compat_40_mount, 298 compat_30_fhopen
299 compat_30_fhstat, 300 compat_20_fhstatfs, 93 compat_50_select, 373 compat_50_pselect, 345 compat_50_kevent, 92 fcntl, 74 mprotect, 203 mlock, 273 minherit, 221 semget, 222 semop, 202 __sysctl
Reproducibility
The fuzzer uses the simplest way to reproduce a crash which is by storing the exact input for the test case that resulted in a crash. This input can then be passed to the driver program, which will be able to parse the input and execute the syscalls that were executed in the order that they were executed.
A better prototype reproducer generator has now been added to the fuzzer that provides us with human readable and executable C code. This C code can be compiled and executed to reproduce the crash.
To generate the reproducers simply run the genRepro script from the targ directory. If everything goes right, the C reproducers will now be available in targ/reproducers, in separate files as follows:
// id:000009,sig:00,src:005858+002155,op:splice,rep:8
#include <sys/syscall.h>
#include <unistd.h>
int main() {
__syscall( SYS_mincore, 0x/* removed from the report due to security concerns */, 0x/* ... */, 0x/* ... */);
return 0;
}
// id:000010,sig:00,src:005859+004032,op:splice,rep:2
#include <sys/syscall.h>
#include <unistd.h>
int main() {
__syscall( SYS_mprotect, 0x/* ... */, 0x/* ... */, 0x/* ... */);
__syscall( SYS_mincore, 0x/* ... */, 0x/* ... */, 0x/* ... */);
return 0;
}
// id:000011,sig:00,src:005859+004032,op:splice,rep:4
#include <sys/syscall.h>
#include <unistd.h>
int main() {
__syscall( SYS_mprotect, 0x/* ... */, 0x/* ... */, 0x/* ... */);
__syscall( SYS_mincore, 0x/* ... */, 0x/* ... */, 0x/* ... */);
return 0;
}
Fuzzing
The fuzzer was run for ~4 days. We were getting ~50 execs/sec on a single core. Please note that this is using qemu with softemu (TCG) as hardware acceleration cannot be used here. During this period the fuzzer detected 23 crashes that it marked as unique. Not all of these were truly unique, there is the scope of adding a secondary filter here to detect truly unique crashes. Most of them were duplicates of the crashes highlighted below:
compat_43_osendmsg - tcp_output: no template
call 114 - compat_43_osendmsg
arg 0: argStdFile 4 - type 12
arg 1: argVec64 77d0549cc000 - size 4
arg 2: argNum 8003
read 83 bytes, parse result 0 nrecs 1
syscall 114 (4, 77d0549cc000, 8003)
[ 191.8169124] panic: tcp_output: no template
[ 191.8169124] cpu0: Begin traceback...
[ 191.8269174] vpanic() at netbsd:vpanic+0x160
[ 191.8269174] snprintf() at netbsd:snprintf
[ 191.8269174] tcp_output() at netbsd:tcp_output+0x2869
[ 191.8385864] tcp_sendoob_wrapper() at netbsd:tcp_sendoob_wrapper+0xfe
[ 191.8469824] sosend() at netbsd:sosend+0x6e3
[ 191.8469824] do_sys_sendmsg_so() at netbsd:do_sys_sendmsg_so+0x231
[ 191.8469824] do_sys_sendmsg() at netbsd:do_sys_sendmsg+0xac
[ 191.8569944] compat_43_sys_sendmsg() at netbsd:compat_43_sys_sendmsg+0xea
[ 191.8569944] sys___syscall() at netbsd:sys___syscall+0x74
[ 191.8655484] syscall() at netbsd:syscall+0x181
[ 191.8655484] --- syscall (number 198) ---
[ 191.8655484] 40261a:
[ 191.8655484] cpu0: End traceback...
[ 191.8655484] fatal breakpoint trap in supervisor mode
[ 191.8655484] trap type 1 code 0 rip 0xffffffff8021ddf5 cs 0x8 rflags 0x202 cr2
0x7f7795402000 ilevel 0x4 rsp 0xffffc58032d589f0
[ 191.8655484] curlwp 0xfffff7e8b1c63220 pid 700.1 lowest kstack 0xffffc58032d55
2c0
Stopped in pid 700.1 (driver) at netbsd:breakpoint+0x5: leave
mincore - uvm_fault_unwire_locked: address not in map
call 78 - mincore
arg 0: argNum d000000
arg 1: argNum 7600000000000000
arg 2: argNum 1b0000000000
read 65 bytes, parse result 0 nrecs 1
syscall 78 (d000000, 7600000000000000, 1b0000000000)
[ 141.0578675] panic: uvm_fault_unwire_locked: address not in map
[ 141.0578675] cpu0: Begin traceback...
[ 141.0691345] vpanic() at netbsd:vpanic+0x160
[ 141.0691345] snprintf() at netbsd:snprintf
[ 141.0774205] uvm_fault_unwire() at netbsd:uvm_fault_unwire
[ 141.0774205] uvm_fault_unwire() at netbsd:uvm_fault_unwire+0x29
[ 141.0774205] sys_mincore() at netbsd:sys_mincore+0x23c
[ 141.0884435] sys___syscall() at netbsd:sys___syscall+0x74
[ 141.0884435] syscall() at netbsd:syscall+0x181
[ 141.0884435] --- syscall (number 198) ---
[ 141.0996065] 40261a:
[ 141.0996065] cpu0: End traceback...
[ 141.0996065] fatal breakpoint trap in supervisor mode
[ 141.0996065] trap type 1 code 0 rip 0xffffffff8021ddf5 cs 0x8 rflags 0x202 cr2
0x761548094000 ilevel 0 rsp 0xffff870032e48d90
[ 141.0996065] curlwp 0xffff829094e51b00 pid 646.1 lowest kstack 0xffff870032e45
2c0
Stopped in pid 646.1 (driver) at netbsd:breakpoint+0x5: leave
extattrctl - KASSERT fail
call 360 - extattrctl
arg 0: argBuf 7b762b514044 from 2 bytes
arg 1: argNum ff8001
arg 2: argFilename 7b762b515020 - 2 bytes from /tmp/file0
arg 3: argNum 0
arg 4: argNum 0
arg 5: argNum 2100000000
read 59 bytes, parse result 0 nrecs 1
syscall 360 (7b762b514044, ff8001, 7b762b515020, 0, 0, 2100000000)
[ 386.4528838] panic: kernel diagnostic assertion "fli->fli_trans_cnt == 0" fail
ed: file "src/sys/kern/vfs_trans.c", line 201
[ 386.4528838] cpu0: Begin traceback...
[ 386.4528838] vpanic() at netbsd:vpanic+0x160
[ 386.4648968] stge_eeprom_wait.isra.4() at netbsd:stge_eeprom_wait.isra.4
[ 386.4724138] fstrans_lwp_dtor() at netbsd:fstrans_lwp_dtor+0xbd
[ 386.4724138] exit1() at netbsd:exit1+0x1fa
[ 386.4724138] sys_exit() at netbsd:sys_exit+0x3d
[ 386.4832968] syscall() at netbsd:syscall+0x181
[ 386.4832968] --- syscall (number 1) ---
[ 386.4832968] 421b6a:
[ 386.4832968] cpu0: End traceback...
[ 386.4832968] fatal breakpoint trap in supervisor mode
[ 386.4944688] trap type 1 code 0 rip 0xffffffff8021ddf5 cs 0x8 rflags 0x202 cr2
0xffffc100324bd000 ilevel 0 rsp 0xffffc10032ce9dc0
[ 386.4944688] curlwp 0xfffff6278e2fc240 pid 105.1 lowest kstack 0xffffc10032ce6
2c0
Stopped in pid 105.1 (driver) at netbsd:breakpoint+0x5: leave
pkgsrc Package
Lastly, the TriforceNetBSDSyscallFuzzer has now been made available in the form of a pkgsrc package in pkgsrc/wip as triforcenetbsdsyscallfuzzer. The package will require wip/triforceafl which was ported earlier.
All other changes mentioned can be found in the github repo.
script(1) recording
A typescript recording of a functional TriforceAFL fuzzer setup and execution is available here.
Download it and replay it with script -p.
Future Work
Work that remains to be done include:
- Restructuring of files
The file structure needs to be modified to suit the specific case of the Host and Target being the same OS. Right now, files are separated into Host and Target directories, this is not required. - Testing with Sanitizers enabled
Until now the fuzzing done was without using KASAN or kUBSAN. Testing with them enabled and fuzzing with them will be of major focus in the third coding period. - Improving the 'reproducer generator'
There is some scope of improvement for the prototype that was added. Incremental updates to it are to be expected. - Analysis of crash reports and fixing bugs
- Documentation
Summary
So far, the TriforceNetBSDSyscallFuzzer has been made available in the form of a pkgsrc package with the ability to fuzz most of NetBSD syscalls. In the final coding period of GSoC. I plan to analyse the crashes that were found until now. Integrate sanitizers, try and find more bugs and finally wrap up neatly with detailed documentation.
Last but not least, I would like to thank my mentor, Kamil Rytarowski for helping me through the process and guiding me. It has been a wonderful learning experience so far!
Prepared by Siddharth Muralee(@R3x) as a part of Google Summer of Code’19
As a part of Google Summer of Code’19, I am working on improving the support for Syzkaller kernel fuzzer. Syzkaller is an unsupervised coverage-guided kernel fuzzer, that supports a variety of operating systems including NetBSD. This report details the work done during the second coding period.
You can also take a look at the first report to learn more about the initial support that we added.
Network Packet Injection
As a part of improving the fuzzing support for the NetBSD kernel. We decided to add support for fuzzing the Network stack. This feature already exists for operating systems such as Linux and OpenBSD.
Motivation
The aim is to fuzz the Network stack by sending packets with malformed/random data and see if it causes any kernel anomalies. We aim to send packets in such a way that the code paths in the kernel which would usually get triggered normally (during ordinary usage of the networking system) would also get triggered here. This is achieved using the TAP/TUN interface.
TAP/TUN Interface
TAP/TUN interface is a software-only interface - which means there are no hardware links involved. This makes it an ideal option to be used for interacting with the kernel networking code.
Userspace programs can create TAP/TUN interfaces and then write properly formatted data into it which will then be sent to the kernel. Also reading from the TAP/TUN interface would give us the data that the interface is sending out.
Basic Design
We create a virtual interface using TAP/TUN and send packets through it. We add two syscalls - syz_emit_ethernet and syz_extract_tcp_res. The former does the job of sending a packet into the kernel and the latter receives the response.
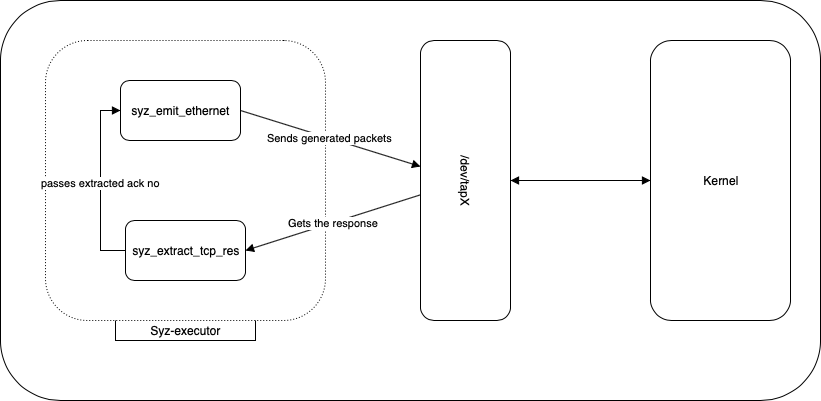
We need the response from the kernel to be read because we need the TCP acknowledgement number to be used for the next packet that we send. So syz_extract_tcp_res also extracts the acknowledgement number from the reply the kernel sent. This article explains the concept of TCP acknowledgement and sequence numbers very well.
Parallelizing Network fuzzing
In the syzkaller config you can define the number of processes that syzkaller can run in a single VM instance. And since we can have multiple instances of the fuzzer(executor) running at the same time we need to make sure that there is no collision between the interfaces. For solving this we create a seperate interface per fuzzer and assign it with a different IP address (both IPv4 and IPv6) to create an isolated network.
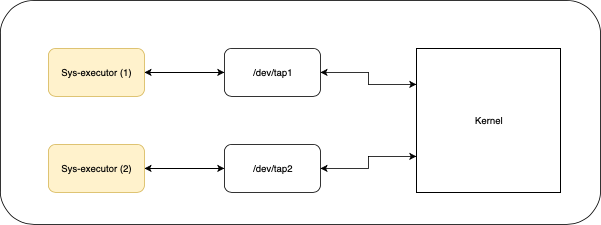
Filesystem Image fuzzing
A very less explored area in fuzzing is Filesystem image fuzzing. Syzkaller supports filesystem fuzzing only for the Linux kernel. We are currently working on porting the existing support that Linux has and then improve it.
Motivation
The aim is to fuzz filesystem specific code by mounting custom images and then perform operations on these images. This would lead to execution of the kernel components of filesystem code and allow us to find out potential bugs.
Existing Design
As I mentioned in the previous report - syzkaller generats inputs based on a pseudo formal grammar. This allows us to also write grammar to generate filesystem images on the fly. This is what the current implementation does - generate random images, write the segments into memory and then mount the resulting image.
Miscellaneous work
I have also been fine tuning the syzkaller fuzzer whenever necessary. This involves adding new features and fixing issues.
Coverage Display
Syzkaller has a utility which uses the coverage from KCoV and marks the corresponding lines on the source code and displays the same. This feature wasn’t working for some of the operating systems.
The issue was that syzkaller was trying to strip off the common prefix on all the file paths retrieved from Kcov and then appending the directory where the source code is present to access the files.
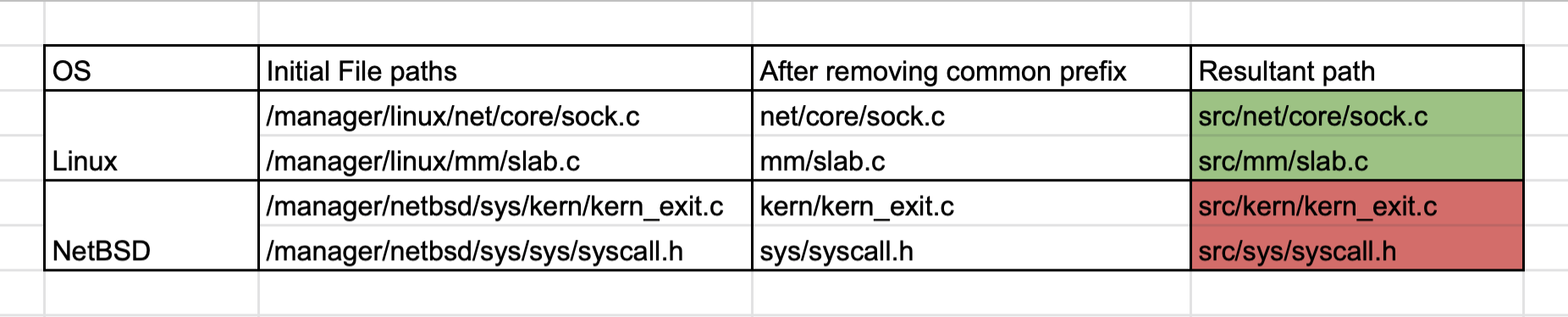
Stripping the common prefix made sense for Linux since its files were distributed across multiple folders in the src/ directory. This created issues for NetBSD since almost all of the kernel files are present in src/sys/ which lead to `sys` also being removed from the resultant path leading to an invalid file name.
I worked on revamping the syz-manager such that it removes prefix computation altogether and take the prefix we need to strip as a part of the config for syz-manager. Then we add the filepath of the kernel sources to get the path to the file.
The coverage for NetBSD can be viewed on the NetBSD dashboard.
TODO
The Filesystem fuzzing code isn’t upstream as of now and will be done shortly.
I have added a basic support for fuzzing both the Filesystem and the Network stack. Now there are a lot of improvements to be done for the same. This mainly involves adding more detailed and improved descriptions.
Relevant Links
Summary
So far, we have found around 70 unique crashes with syzkaller. During the final coding period - I would be working on improving the support for the Filesystem fuzzing.
Last but not least, I want to thank my mentors, @kamil and @cryo for their useful suggestions and guidance. I would also like to thank Dmitry Vyukov, Google for helping with any issues faced with regard to Syzkaller. Finally, thanks to Google to give me a good chance to work with NetBSD community.
Prepared by Siddharth Muralee(@R3x) as a part of Google Summer of Code’19
As a part of Google Summer of Code’19, I am working on improving the support for Syzkaller kernel fuzzer. Syzkaller is an unsupervised coverage-guided kernel fuzzer, that supports a variety of operating systems including NetBSD. This report details the work done during the second coding period.
You can also take a look at the first report to learn more about the initial support that we added.
Network Packet Injection
As a part of improving the fuzzing support for the NetBSD kernel. We decided to add support for fuzzing the Network stack. This feature already exists for operating systems such as Linux and OpenBSD.
Motivation
The aim is to fuzz the Network stack by sending packets with malformed/random data and see if it causes any kernel anomalies. We aim to send packets in such a way that the code paths in the kernel which would usually get triggered normally (during ordinary usage of the networking system) would also get triggered here. This is achieved using the TAP/TUN interface.
TAP/TUN Interface
TAP/TUN interface is a software-only interface - which means there are no hardware links involved. This makes it an ideal option to be used for interacting with the kernel networking code.
Userspace programs can create TAP/TUN interfaces and then write properly formatted data into it which will then be sent to the kernel. Also reading from the TAP/TUN interface would give us the data that the interface is sending out.
Basic Design
We create a virtual interface using TAP/TUN and send packets through it. We add two syscalls - syz_emit_ethernet and syz_extract_tcp_res. The former does the job of sending a packet into the kernel and the latter receives the response.
We need the response from the kernel to be read because we need the TCP acknowledgement number to be used for the next packet that we send. So syz_extract_tcp_res also extracts the acknowledgement number from the reply the kernel sent. This article explains the concept of TCP acknowledgement and sequence numbers very well.
Parallelizing Network fuzzing
In the syzkaller config you can define the number of processes that syzkaller can run in a single VM instance. And since we can have multiple instances of the fuzzer(executor) running at the same time we need to make sure that there is no collision between the interfaces. For solving this we create a seperate interface per fuzzer and assign it with a different IP address (both IPv4 and IPv6) to create an isolated network.
Filesystem Image fuzzing
A very less explored area in fuzzing is Filesystem image fuzzing. Syzkaller supports filesystem fuzzing only for the Linux kernel. We are currently working on porting the existing support that Linux has and then improve it.
Motivation
The aim is to fuzz filesystem specific code by mounting custom images and then perform operations on these images. This would lead to execution of the kernel components of filesystem code and allow us to find out potential bugs.
Existing Design
As I mentioned in the previous report - syzkaller generats inputs based on a pseudo formal grammar. This allows us to also write grammar to generate filesystem images on the fly. This is what the current implementation does - generate random images, write the segments into memory and then mount the resulting image.
Miscellaneous work
I have also been fine tuning the syzkaller fuzzer whenever necessary. This involves adding new features and fixing issues.
Coverage Display
Syzkaller has a utility which uses the coverage from KCoV and marks the corresponding lines on the source code and displays the same. This feature wasn’t working for some of the operating systems.
The issue was that syzkaller was trying to strip off the common prefix on all the file paths retrieved from Kcov and then appending the directory where the source code is present to access the files.
Stripping the common prefix made sense for Linux since its files were distributed across multiple folders in the src/ directory. This created issues for NetBSD since almost all of the kernel files are present in src/sys/ which lead to `sys` also being removed from the resultant path leading to an invalid file name.
I worked on revamping the syz-manager such that it removes prefix computation altogether and take the prefix we need to strip as a part of the config for syz-manager. Then we add the filepath of the kernel sources to get the path to the file.
The coverage for NetBSD can be viewed on the NetBSD dashboard.
TODO
The Filesystem fuzzing code isn’t upstream as of now and will be done shortly.
I have added a basic support for fuzzing both the Filesystem and the Network stack. Now there are a lot of improvements to be done for the same. This mainly involves adding more detailed and improved descriptions.
Relevant Links
Summary
So far, we have found around 70 unique crashes with syzkaller. During the final coding period - I would be working on improving the support for the Filesystem fuzzing.
Last but not least, I want to thank my mentors, @kamil and @cryo for their useful suggestions and guidance. I would also like to thank Dmitry Vyukov, Google for helping with any issues faced with regard to Syzkaller. Finally, thanks to Google to give me a good chance to work with NetBSD community.
Upstream describes LLDB as a next generation, high-performance debugger. It is built on top of LLVM/Clang toolchain, and features great integration with it. At the moment, it primarily supports debugging C, C++ and ObjC code, and there is interest in extending it to more languages.
In February, I have started working on LLDB, as contracted by the NetBSD Foundation. So far I've been working on reenabling continuous integration, squashing bugs, improving NetBSD core file support, extending NetBSD's ptrace interface to cover more register types and fix compat32 issues, and lately fixing watchpoint support. You can read more about that in my June 2019 report.
My July's work has been focused on improving support for NetBSD threads in LLDB. This involved a lot of debugging and fighting hanging tests, and I have decided to delay committing the results until I manage to provide fixes for all the immediate issues.
Buildbot updates
During July, upstream has made two breaking changes to the build system:
-
Automatic switching to libc++abi when present in ebuild tree was initially removed in D63883. I needed to force it explicitly because of this. However, upstream has eventually reverted the change.
-
LLDB has enabled Python 3 support, and started requiring SWIG 2+ in the process (D64782). We had to upgrade SWIG on the build host, and eventually switched to Python 3 as well.
As a result of earlier watchpoint fixes, a number of new tests started running. Due to lacking multithreading support, I had to XFAIL a number of LLDB tests in r365338.
A few days later, upstream has fixed the issue causing TestFormattersSBAPI to fail. I un-XFAILED it in r365991.
The breaking xfer:libraries-svr4:read change has been reapplied and broke NetBSD process plugin again. And I've reapplied my earlier fix as r366889.
Lit maintainers have broken NetBSD support in tests by starting to use
env -u VAR syntax in
r366980.
The -u switch is not specified by POSIX, and not supported by NetBSD
env(1). In order to fix the problem, I've changed FileCheck's behavior
to consider empty envvar as equivalent to disabled
(r367122),
and then switched lit to set both envvars to empty instead
(r367123).
Finally, I've investigated a number of new test failures by the end of the month:
-
New
functionalities/signal/handle-abrttest was added in r366580. Since trampolines are not properly supported at the moment, I've marked it XFAIL in r367228. -
Two
functionalities/exectests started failing since upstream fixed@skipIfSanitizedthat previously caused the test to be skipped unconditionally (r366903). Since it's not a regression, I've marked it XFAIL in r367228. -
Same happened for one of the
python_api/hello_worldtests. It was clearly related to another failing test, so I've marked it XFAIL in r367285. -
Two
tools/lldb-vscodetests were failing since upstream compared realpath'd path with normal path, and our build path happens to include symlinks as one of the parent directories. I've fixed the test to compare realpath in r367291. While at it, I've replaced weirdos.path.split(...)[0]with cleareros.path.dirname(...)as suggested by Pavel Labath, in r367290.
NetBSD ptrace() interfaces for thread control
NetBSD currently provides two different methods for thread-related operations.
The legacy method consists of the following requests:
-
PT_CONTINUEwith negativedataargument. It is used to resume execution of a single thread while suspending all other threads. -
PT_STEPwith positivedataargument. It is used to single-step the specified thread, while all other threads continue execution. -
PT_STEPwith negativedataargument. It is used to single-step the specified thread, while all other threads remain suspended.
This means that using those methods, you can effectively either:
-
run all threads, and optionally send signal to the process,
-
run one thread, while keeping other threads suspended,
-
single-step one thread, with all other threads either running or being suspended as a whole.
Furthermore, it is impossible to combine single-stepping with syscall
tracing via PT_SYSCALL.
The new method introduced by Kamil Rytarowski during his ptrace(2) work is more flexible, and includes the following requests:
-
PT_RESUMEthat sets the specified thread to continue running afterPT_CONTINUE. -
PT_SUSPENDthat sets the specified thread to remain suspended afterPT_CONTINUE. -
PT_SETSTEPthat enables single-stepping for the specified thread afterPT_CONTINUE. -
PT_CLEARSTEPthat disables single-stepping for the specified thread.
Using the new API, it is possible to control both execution and single- stepping per thread, and to combine syscall tracing with that. It is also possible to deliver a single signal either to the whole process or to one of the threads.
Implementing threading in LLDB NetBSD process plugin
When I started my work, the support for threads in the NetBSD plugin was minimal. Technically, the code had structures needed to keep the threads and filled it in at start. However, it did not register new or terminated threads, and it did not support per-thread execution control.
The first change necessary was therefore to implement support for
reporting new and terminated threads. I've prepared an initial patch
in D65555. With this patch enabled,
the thread list command now correctly reports the list of threads
at any moment.
The second change necessary is to fix process resuming routine to support multiple threads properly. The routine is passed a data structure containing requested action for each thread. The old code simply took the action for the first thread, and applied it to the whole process. D64647 is my work-in-progress attempt at using the new ptrace calls to apply correct action for each thread.
However, the patch is currently buggy as it assumed that LLDB should
provide explicit eStateSuspended action for each thread that is
supposed to be supposed. The current LLDB implementation, on the other
hand, assumes that thread should be suspended if no action is specified
for it. I am currently discussing with upstream whether the current
approach is correct, or should be changed to the explicit
eStateSuspended usage.
The third change necessary is that we need to explicitly copy debug registers to newly created threads, in order to enable watchpoints on them. However, I haven't gotten to writing a patch for this yet.
Fixing nasty process interrupt bug
While debugging my threading code, I've hit a nasty bug in LLDB. After
issuing process interrupt command from remote LLDB session, the server
terminated. After putting a lot of effort into debugging why the server
terminates with no obvious error, I've discovered that it's terminating
because… the client has disconnected.
Further investigation with help of Pavel Labath uncovered that
the client is silently disconnecting because it expects a packet
indicating that the process has stopped and times out waiting for it.
In order to make the server send this packet, NetBSD process plugin
needed to explicitly mark process as stopped in the SIGSTOP handler.
I've fixed it in r367047.
Future plans
The initial 6 months of my LLDB contract have passed. I am currently taking a month's break from the work, then I will resume it for 3 more months. During that time, I will continue working on threading support and my remaining goals.
The remaining TODO items are:
-
Add support to backtrace through signal trampoline and extend the support to libexecinfo, unwind implementations (LLVM, nongnu). Examine adding CFI support to interfaces that need it to provide more stable backtraces (both kernel and userland).
-
Add support for i386 and aarch64 targets.
-
Stabilize LLDB and address breaking tests from the test suite.
-
Merge LLDB with the base system (under LLVM-style distribution).
This work is sponsored by The NetBSD Foundation
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL to chip in what you can:
Upstream describes LLDB as a next generation, high-performance debugger. It is built on top of LLVM/Clang toolchain, and features great integration with it. At the moment, it primarily supports debugging C, C++ and ObjC code, and there is interest in extending it to more languages.
In February, I have started working on LLDB, as contracted by the NetBSD Foundation. So far I've been working on reenabling continuous integration, squashing bugs, improving NetBSD core file support, extending NetBSD's ptrace interface to cover more register types and fix compat32 issues, and lately fixing watchpoint support. You can read more about that in my June 2019 report.
My July's work has been focused on improving support for NetBSD threads in LLDB. This involved a lot of debugging and fighting hanging tests, and I have decided to delay committing the results until I manage to provide fixes for all the immediate issues.
Buildbot updates
During July, upstream has made two breaking changes to the build system:
-
Automatic switching to libc++abi when present in ebuild tree was initially removed in D63883. I needed to force it explicitly because of this. However, upstream has eventually reverted the change.
-
LLDB has enabled Python 3 support, and started requiring SWIG 2+ in the process (D64782). We had to upgrade SWIG on the build host, and eventually switched to Python 3 as well.
As a result of earlier watchpoint fixes, a number of new tests started running. Due to lacking multithreading support, I had to XFAIL a number of LLDB tests in r365338.
A few days later, upstream has fixed the issue causing TestFormattersSBAPI to fail. I un-XFAILED it in r365991.
The breaking xfer:libraries-svr4:read change has been reapplied and broke NetBSD process plugin again. And I've reapplied my earlier fix as r366889.
Lit maintainers have broken NetBSD support in tests by starting to use
env -u VAR syntax in
r366980.
The -u switch is not specified by POSIX, and not supported by NetBSD
env(1). In order to fix the problem, I've changed FileCheck's behavior
to consider empty envvar as equivalent to disabled
(r367122),
and then switched lit to set both envvars to empty instead
(r367123).
Finally, I've investigated a number of new test failures by the end of the month:
-
New
functionalities/signal/handle-abrttest was added in r366580. Since trampolines are not properly supported at the moment, I've marked it XFAIL in r367228. -
Two
functionalities/exectests started failing since upstream fixed@skipIfSanitizedthat previously caused the test to be skipped unconditionally (r366903). Since it's not a regression, I've marked it XFAIL in r367228. -
Same happened for one of the
python_api/hello_worldtests. It was clearly related to another failing test, so I've marked it XFAIL in r367285. -
Two
tools/lldb-vscodetests were failing since upstream compared realpath'd path with normal path, and our build path happens to include symlinks as one of the parent directories. I've fixed the test to compare realpath in r367291. While at it, I've replaced weirdos.path.split(...)[0]with cleareros.path.dirname(...)as suggested by Pavel Labath, in r367290.
NetBSD ptrace() interfaces for thread control
NetBSD currently provides two different methods for thread-related operations.
The legacy method consists of the following requests:
-
PT_CONTINUEwith negativedataargument. It is used to resume execution of a single thread while suspending all other threads. -
PT_STEPwith positivedataargument. It is used to single-step the specified thread, while all other threads continue execution. -
PT_STEPwith negativedataargument. It is used to single-step the specified thread, while all other threads remain suspended.
This means that using those methods, you can effectively either:
-
run all threads, and optionally send signal to the process,
-
run one thread, while keeping other threads suspended,
-
single-step one thread, with all other threads either running or being suspended as a whole.
Furthermore, it is impossible to combine single-stepping with syscall
tracing via PT_SYSCALL.
The new method introduced by Kamil Rytarowski during his ptrace(2) work is more flexible, and includes the following requests:
-
PT_RESUMEthat sets the specified thread to continue running afterPT_CONTINUE. -
PT_SUSPENDthat sets the specified thread to remain suspended afterPT_CONTINUE. -
PT_SETSTEPthat enables single-stepping for the specified thread afterPT_CONTINUE. -
PT_CLEARSTEPthat disables single-stepping for the specified thread.
Using the new API, it is possible to control both execution and single- stepping per thread, and to combine syscall tracing with that. It is also possible to deliver a single signal either to the whole process or to one of the threads.
Implementing threading in LLDB NetBSD process plugin
When I started my work, the support for threads in the NetBSD plugin was minimal. Technically, the code had structures needed to keep the threads and filled it in at start. However, it did not register new or terminated threads, and it did not support per-thread execution control.
The first change necessary was therefore to implement support for
reporting new and terminated threads. I've prepared an initial patch
in D65555. With this patch enabled,
the thread list command now correctly reports the list of threads
at any moment.
The second change necessary is to fix process resuming routine to support multiple threads properly. The routine is passed a data structure containing requested action for each thread. The old code simply took the action for the first thread, and applied it to the whole process. D64647 is my work-in-progress attempt at using the new ptrace calls to apply correct action for each thread.
However, the patch is currently buggy as it assumed that LLDB should
provide explicit eStateSuspended action for each thread that is
supposed to be supposed. The current LLDB implementation, on the other
hand, assumes that thread should be suspended if no action is specified
for it. I am currently discussing with upstream whether the current
approach is correct, or should be changed to the explicit
eStateSuspended usage.
The third change necessary is that we need to explicitly copy debug registers to newly created threads, in order to enable watchpoints on them. However, I haven't gotten to writing a patch for this yet.
Fixing nasty process interrupt bug
While debugging my threading code, I've hit a nasty bug in LLDB. After
issuing process interrupt command from remote LLDB session, the server
terminated. After putting a lot of effort into debugging why the server
terminates with no obvious error, I've discovered that it's terminating
because… the client has disconnected.
Further investigation with help of Pavel Labath uncovered that
the client is silently disconnecting because it expects a packet
indicating that the process has stopped and times out waiting for it.
In order to make the server send this packet, NetBSD process plugin
needed to explicitly mark process as stopped in the SIGSTOP handler.
I've fixed it in r367047.
Future plans
The initial 6 months of my LLDB contract have passed. I am currently taking a month's break from the work, then I will resume it for 3 more months. During that time, I will continue working on threading support and my remaining goals.
The remaining TODO items are:
-
Add support to backtrace through signal trampoline and extend the support to libexecinfo, unwind implementations (LLVM, nongnu). Examine adding CFI support to interfaces that need it to provide more stable backtraces (both kernel and userland).
-
Add support for i386 and aarch64 targets.
-
Stabilize LLDB and address breaking tests from the test suite.
-
Merge LLDB with the base system (under LLVM-style distribution).
This work is sponsored by The NetBSD Foundation
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL to chip in what you can:
Introduction
As a memory hard hashing scheme, Argon2 attempts to maximize utilization over multiple compute units, providing a defense against both Time Memory Trade-off (TMTO) and side-channel attacks. In our first post, we introduced our GSOC project's phase 1 to integrate the Argon2 reference implementation into NetBSD. Having successfully completed phase 1, here we briefly discuss parameter tuning as it relates to password management and performance.
Parameter Tuning
Both the reference paper [1] and the forthcoming RFC [2] provide recommendations on how to determine appropriate parameter values. While there are no hard-and-fast rules, the general idea is to maximize resource utilization while keeping performance, measured in execution run-time, within a tolerable bound. We summarize this process as follows
- Determine the Argon2 variant to use
- Determine the appropriate salt length
- Determine the appropriate tag length
- Determine the acceptable time cost
- Determine the maximum amount of memory to utilize
- Determine the appropriate degree of parallelism
Step 1
All three Argon2 variants are available in NetBSD. First, argon2i is a slower variant using data-independent memory access suitable for password hashing and password-based key derivation. Second, argon2d is a faster variant using data-dependent memory access, but is only suitable for application with no threats from side-channel attacks. Lastly, argon2id runs argon2i on the first half of memory passes and argon2d for the remaining passes. If you are unsure of which variant to use, it is recommended that you use argon2id.[1][2]Step 2-3
Our current implementation uses a constant 32-byte hash length (defined in crypt-argon2.c) and a 16-byte salt length (defined in pw_gensalt.c). Both of these values are on the high-end of the recommendations.
Steps 4-6
We paramaterize Argon2 on the remaining three variables: time (t), memory (m), and parallelism (p). Time t is defined as the amount of required computation and is specified as the number of iterations. Memory m is defined as the amount of memory utilized, specified in Kilobytes (KB). Parallelism p defines the number of independent threads. Taken together, these three parameters form the knobs with which Argon2 may be tuned.Recommended Default Parameters
For default values, [2] recommends both argon2id and argon2d be used with a time t cost of 1 and memory m set to the maximum available memory. For argon2i, it is recommended to use a time t cost of 3 for all reasonable memory sizes (reasonable is not well-defined). Parallelism p is a factor of workload partitioning and is typically recommended to use twice the number of cores dedicated to hashing.
Evaluation and Results
Given the above recommendations, we evaluate Argon2 based on execution run-time. Targeting password hashing, we use an execution time cost of 500ms to 1sec. This is slightly higher than common recommendations, but is largely a factor of user tolerance. Our test machine has a 4-core i5-2500 CPU @ 3.30GHz running NetBSD 8. To evaluate the run-time performance of Argon2 on your system, you may use either the argon2(1) or libargon2. Header argon2.h provides sufficient documentation, as well as the PHC git repo at [4]. For those wanting to use argon2(1), an example of using argon2(1) is below
m2# echo -n 'password'|argon2 somesalt -id -p 2 -t 1 -m 19 Type: Argon2id Iterations: 1 Memory: 524288 KiB Parallelism: 2 Hash: 7b9618bf35b02c00cfef32cb4455206dc400b140116710a6c02732e068021609 Encoded: $argon2id$v=19$m=524288,t=1,p=2$c29tZXNhbHQ$e5YYvzWwLADP7zLLRFUgbcQAsUARZxCmwCcy4GgCFgk 0.950 seconds Verification ok
In order to establish a performance baseline, we first evaluate the run-time of all three variants using the recommended default parameters without parallelism. Our objective is to maximize memory m while constraining the execution cost between 500ms to 1sec. While we graph all three variants for comparison, our target is variant argon2id. We loop over Argon2 with monotonically increasing values of m for all three variants. Graphing our results below, we determine the maximum memory m value within our bound is 219. However, to follow common suggestions [3], we chose 220 (1048576 Bytes) with the assumption that increased parallelism will bring the execution time cost down within acceptable limits.
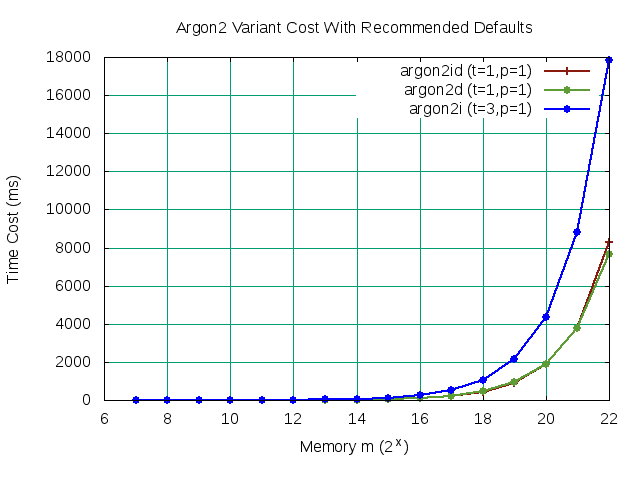
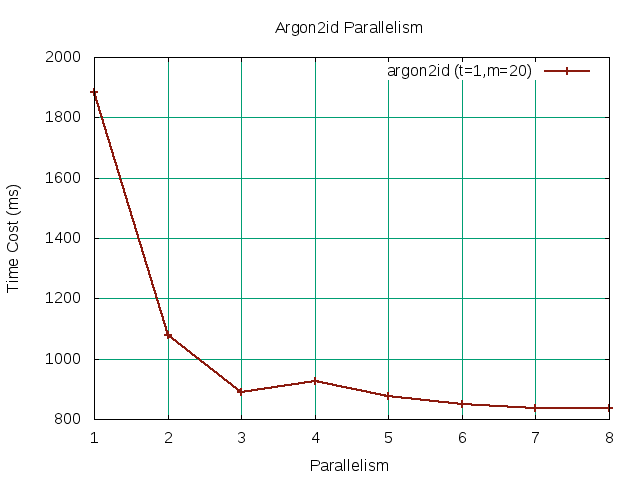
Our baseline memory m value initially exceed our desired upper bound of 1sec without parallelism. Fortunately, we found that increasing the thread count sufficiently parallelizes the work until it starts to settle around p=8. To see if we can further increase our baseline memory m value, we can look at following the graph for argon2id with t=1, p=8. We note that our initial baseline value of m=20 is the maximum m value falling within our bound.
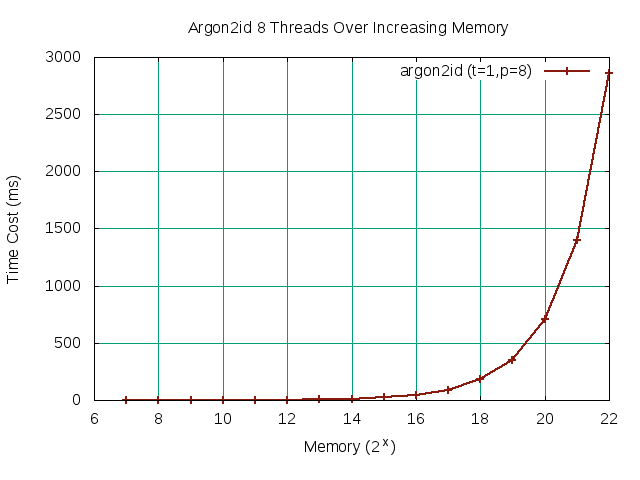
m2# echo -n 'password'|argon2 somesalt -id -m 20 -p 8 -t 1 Type: Argon2id Iterations: 1 Memory: 524288 KiB Parallelism: 8 Hash: c62dbebec4a2da3a37dcfa2d82bd2f55541fce80992cd2c1cb887910e859589f Encoded: $argon2id$v=19$m=524288,t=1,p=8$c29tZXNhbHQ$xi2+vsSi2jo33Potgr0vVVQfzoCZLNLBy4h5EOhZWJ8 0.858 seconds Verification ok
Summary
Argon2 is well-known for its high resource requirements. Fortunately, we are able to tune Argon2 so that we can achieve reasonable performance on NetBSD. In this post, we consider an approach to selecting appropriate parameter values for tuning Argon2 for password hashing. There are no hard-and-fast rules. We have found that it is easiest to start with a baseline value of memory m, then tweaking the values of parallelism p in order to achieve the desired performance.Remaining Tasks
For the third and final portion of Google Summer of Code, we will focus on clean-up, documentation, and finalizing all imported code and build scripts. If you have any questions and/or comments, please let us know.References
[2] https://tools.ietf.org/html/draft-irtf-cfrg-argon2-04#section-4
[3] https://argon2-cffi.readthedocs.io/en/stable/parameters.html
[4] https://github.com/P-H-C/phc-winner-argon2
Introduction
As a memory hard hashing scheme, Argon2 attempts to maximize utilization over multiple compute units, providing a defense against both Time Memory Trade-off (TMTO) and side-channel attacks. In our first post, we introduced our GSOC project's phase 1 to integrate the Argon2 reference implementation into NetBSD. Having successfully completed phase 1, here we briefly discuss parameter tuning as it relates to password management and performance.
Parameter Tuning
Both the reference paper [1] and the forthcoming RFC [2] provide recommendations on how to determine appropriate parameter values. While there are no hard-and-fast rules, the general idea is to maximize resource utilization while keeping performance, measured in execution run-time, within a tolerable bound. We summarize this process as follows
- Determine the Argon2 variant to use
- Determine the appropriate salt length
- Determine the appropriate tag length
- Determine the acceptable time cost
- Determine the maximum amount of memory to utilize
- Determine the appropriate degree of parallelism
Step 1
All three Argon2 variants are available in NetBSD. First, argon2i is a slower variant using data-independent memory access suitable for password hashing and password-based key derivation. Second, argon2d is a faster variant using data-dependent memory access, but is only suitable for application with no threats from side-channel attacks. Lastly, argon2id runs argon2i on the first half of memory passes and argon2d for the remaining passes. If you are unsure of which variant to use, it is recommended that you use argon2id.[1][2]Step 2-3
Our current implementation uses a constant 32-byte hash length (defined in crypt-argon2.c) and a 16-byte salt length (defined in pw_gensalt.c). Both of these values are on the high-end of the recommendations.
Steps 4-6
We paramaterize Argon2 on the remaining three variables: time (t), memory (m), and parallelism (p). Time t is defined as the amount of required computation and is specified as the number of iterations. Memory m is defined as the amount of memory utilized, specified in Kilobytes (KB). Parallelism p defines the number of independent threads. Taken together, these three parameters form the knobs with which Argon2 may be tuned.Recommended Default Parameters
For default values, [2] recommends both argon2id and argon2d be used with a time t cost of 1 and memory m set to the maximum available memory. For argon2i, it is recommended to use a time t cost of 3 for all reasonable memory sizes (reasonable is not well-defined). Parallelism p is a factor of workload partitioning and is typically recommended to use twice the number of cores dedicated to hashing.
Evaluation and Results
Given the above recommendations, we evaluate Argon2 based on execution run-time. Targeting password hashing, we use an execution time cost of 500ms to 1sec. This is slightly higher than common recommendations, but is largely a factor of user tolerance. Our test machine has a 4-core i5-2500 CPU @ 3.30GHz running NetBSD 8. To evaluate the run-time performance of Argon2 on your system, you may use either the argon2(1) or libargon2. Header argon2.h provides sufficient documentation, as well as the PHC git repo at [4]. For those wanting to use argon2(1), an example of using argon2(1) is below
m2# echo -n 'password'|argon2 somesalt -id -p 2 -t 1 -m 19 Type: Argon2id Iterations: 1 Memory: 524288 KiB Parallelism: 2 Hash: 7b9618bf35b02c00cfef32cb4455206dc400b140116710a6c02732e068021609 Encoded: $argon2id$v=19$m=524288,t=1,p=2$c29tZXNhbHQ$e5YYvzWwLADP7zLLRFUgbcQAsUARZxCmwCcy4GgCFgk 0.950 seconds Verification ok
In order to establish a performance baseline, we first evaluate the run-time of all three variants using the recommended default parameters without parallelism. Our objective is to maximize memory m while constraining the execution cost between 500ms to 1sec. While we graph all three variants for comparison, our target is variant argon2id. We loop over Argon2 with monotonically increasing values of m for all three variants. Graphing our results below, we determine the maximum memory m value within our bound is 219. However, to follow common suggestions [3], we chose 220 (1048576 Bytes) with the assumption that increased parallelism will bring the execution time cost down within acceptable limits.
Our baseline memory m value initially exceed our desired upper bound of 1sec without parallelism. Fortunately, we found that increasing the thread count sufficiently parallelizes the work until it starts to settle around p=8. To see if we can further increase our baseline memory m value, we can look at following the graph for argon2id with t=1, p=8. We note that our initial baseline value of m=20 is the maximum m value falling within our bound.
m2# echo -n 'password'|argon2 somesalt -id -m 20 -p 8 -t 1 Type: Argon2id Iterations: 1 Memory: 524288 KiB Parallelism: 8 Hash: c62dbebec4a2da3a37dcfa2d82bd2f55541fce80992cd2c1cb887910e859589f Encoded: $argon2id$v=19$m=524288,t=1,p=8$c29tZXNhbHQ$xi2+vsSi2jo33Potgr0vVVQfzoCZLNLBy4h5EOhZWJ8 0.858 seconds Verification ok
Summary
Argon2 is well-known for its high resource requirements. Fortunately, we are able to tune Argon2 so that we can achieve reasonable performance on NetBSD. In this post, we consider an approach to selecting appropriate parameter values for tuning Argon2 for password hashing. There are no hard-and-fast rules. We have found that it is easiest to start with a baseline value of memory m, then tweaking the values of parallelism p in order to achieve the desired performance.Remaining Tasks
For the third and final portion of Google Summer of Code, we will focus on clean-up, documentation, and finalizing all imported code and build scripts. If you have any questions and/or comments, please let us know.References
[2] https://tools.ietf.org/html/draft-irtf-cfrg-argon2-04#section-4
[3] https://argon2-cffi.readthedocs.io/en/stable/parameters.html
[4] https://github.com/P-H-C/phc-winner-argon2
This report was prepared by Manikishan Ghantasala as a part of Google Summer of Code 2019
This report encloses the progress of the project Add KNF (NetBSD style) clang-format configuration during the second coding period of GSoC 2019.
Clang-format
Clang-format is a powerful code formatter which is a part of clang. Clang-format formats the code either by a configuration file .clang-format or can be chosen from some predefined coding styles namely LLVM, Google, Chromium, Mozilla, WebKit.
The final goal of the project is to add a new style NetBSD
along with them by patching the libFormat to support the missing styles and add the configuration according to NetBSD KNF.
clang-format -style=NetBSD
Style options introduced in the first coding period:
- BitFieldDeclarationsOnePerLine
- SortNetBSDIncludes
You can also take a look at the first report to learn more about these style options.
Work done in the second coding period
I have worked on the following styles during this second coding period.
- Withdrawn SortNetBSDIncludes and modified existing sortIncludes.
- Modified spacesBeforeTralingComments to support block comments.
- New style option alignConsecutiveListElements introduced.
Sortincludes:
The native SortIncludes sorts the includes/headers in alphabetical order. And we also have IncludeCategories which allows setting custom priorities to group the includes matching via a regex after sorting.
Example:
Configuration:
IncludeCategories:
-Regex: ^<(a|b|c)/
Priority: 1
-Regex: ^<(foo)/
Priority: 2
-Regex: .*
Priority: 3
Input
#include exe.h
#include gaz.h
#include <a/dee.h>
#include <foo/b.h>
#include <a/bee.h>
#include <exc.h>
#include <b/dee.h>
#include <c/abc.h>
#include <foo/a.h>
Output
#include <a/bee.h>
#include <a/dee.h>
#include <b/dee.h>
#include <c/abc.h>
#include <foo/a.h>
#include <foo/b.h>
#include <exc.h>
#include gaz.h
>
Modified SortIncludes
The new sortIncludes supports to give custom priority for sorting in addition to grouping priority. Now the IncludeCategories have a new field named SortPriority along with Priority to set the priority while sorting the includes, and the default priority will be alphabetical. The usage and working of the new IncludeCategories style shown in the following example.
Example
IncludeCategories:
-Regex: <^c/
Priority: 1
SortPriority: 0
-Regex: ^<(a|b)/
Priority: 1
SortPriority: 1
-Regex: ^<(foo)/
Priority: 2
-Regex: .*
Priority: 3
Input
#include exe.h
#include <a/dee.h>
#include <foo/b.h>
#include <a/bee.h>
#include <exc.h>
#include <b/dee.h>
#include <c/abc.h>
#include <foo/a.h>
Output
#include <c/abc.h>
#include <a/bee.h>
#include <a/dee.h>
#include <b/dee.h>
#include <foo/a.h>
#include <foo/b.h>
#include <exc.h>
#include gaz.h
As we observe in the above example, the includes having the same Priority are grouped, and SortPriority defines the sort priority.
The patch was accepted and ready to merge, and you can find the patch here -> SortIncludesPatch. This patch also introduces the NetBSD style to clang-format with configurations to supported styles.
Spaces Before Trailing Comments
This option is also a native style option in clang-format which enables a user to decide the number of spaces to be given before trailing comments (// - comments) but not block comments (/* - comments). The reason for this is that block comments have different usage patterns and different exceptional cases. The following is an example of the native style option.
SpacesBeforeTrailingComments: 3
void f() {
if (true) { //foo
f(); //bar
} //foo1
}
Modifications to spaceBeforeTrailingComments:
I am working on modifying this style option to support block comments by covering cases where block comments are used. There are some cases yet to be covered. Once the patch is ready, this is the deliverable
The initial revision can be found here -> patch
SpacesBeforeTrailingComments: 3
void f() {
if (true) { /*foo */
f(); /*bar */
} /*foo1*/
}
AlignConsecutiveListElements
AlignConsecutiveListElements is a new style option that I am going to introduce to clang-format. This style option aligns elements in consecutive definitions, declarations of lists. The style is not yet ready to patch, and I have to modify a lot of functionalities in alignTokens() which aligns tokens to support this style.
Example:
Input
keys[] = {
{"all", f_all, 0 },
{ "cbreak", f_cbreak, F_OFFOK },
{"cols", f_columns, F_NEEDARG },
{ "columns", f_columns, F_NEEDARG },
};
Output
keys[] = {
{ "all", f_all, 0 },
{ "cbreak", _cbreak, F_OFFOK },
{ "cols", f_columns, F_NEEDARG },
{ "columns", f_columns, F_NEEDARG },
};
The blocker to this style is the nested structure for list declarations, alignTokens() should be equipped to parse the nested list declarations to support this style option. I will make sure this style option is available by the next report.
Further plans
For the next phase, I will make all the style options that were modified or introduced till now during the first two phases mergeable to upstream along with required unit tests. With these style options ready, I will test the new clang-format with NetBSD style patched across NetBSD source and check for bugs. After the testing will try to fix the bugs and get the NetBSDStyle ready for the final evaluation.
Summary
In the final coding period, the main focus will be on testing the new/modified style options and fix them. Add any missing styles for NetBSD and get the NetBSDStyle by the final evaluation.
I want to thank my mentors Michal, Christos and developers of both LLVM and NetBSD for supporting to complete this project.
This report was prepared by Manikishan Ghantasala as a part of Google Summer of Code 2019
This report encloses the progress of the project Add KNF (NetBSD style) clang-format configuration during the second coding period of GSoC 2019.
Clang-format
Clang-format is a powerful code formatter which is a part of clang. Clang-format formats the code either by a configuration file .clang-format or can be chosen from some predefined coding styles namely LLVM, Google, Chromium, Mozilla, WebKit.
The final goal of the project is to add a new style NetBSD
along with them by patching the libFormat to support the missing styles and add the configuration according to NetBSD KNF.
clang-format -style=NetBSD
Style options introduced in the first coding period:
- BitFieldDeclarationsOnePerLine
- SortNetBSDIncludes
You can also take a look at the first report to learn more about these style options.
Work done in the second coding period
I have worked on the following styles during this second coding period.
- Withdrawn SortNetBSDIncludes and modified existing sortIncludes.
- Modified spacesBeforeTralingComments to support block comments.
- New style option alignConsecutiveListElements introduced.
Sortincludes:
The native SortIncludes sorts the includes/headers in alphabetical order. And we also have IncludeCategories which allows setting custom priorities to group the includes matching via a regex after sorting.
Example:
Configuration:
IncludeCategories:
-Regex: ^<(a|b|c)/
Priority: 1
-Regex: ^<(foo)/
Priority: 2
-Regex: .*
Priority: 3
Input
#include exe.h
#include gaz.h
#include <a/dee.h>
#include <foo/b.h>
#include <a/bee.h>
#include <exc.h>
#include <b/dee.h>
#include <c/abc.h>
#include <foo/a.h>
Output
#include <a/bee.h>
#include <a/dee.h>
#include <b/dee.h>
#include <c/abc.h>
#include <foo/a.h>
#include <foo/b.h>
#include <exc.h>
#include gaz.h
>
Modified SortIncludes
The new sortIncludes supports to give custom priority for sorting in addition to grouping priority. Now the IncludeCategories have a new field named SortPriority along with Priority to set the priority while sorting the includes, and the default priority will be alphabetical. The usage and working of the new IncludeCategories style shown in the following example.
Example
IncludeCategories:
-Regex: <^c/
Priority: 1
SortPriority: 0
-Regex: ^<(a|b)/
Priority: 1
SortPriority: 1
-Regex: ^<(foo)/
Priority: 2
-Regex: .*
Priority: 3
Input
#include exe.h
#include <a/dee.h>
#include <foo/b.h>
#include <a/bee.h>
#include <exc.h>
#include <b/dee.h>
#include <c/abc.h>
#include <foo/a.h>
Output
#include <c/abc.h>
#include <a/bee.h>
#include <a/dee.h>
#include <b/dee.h>
#include <foo/a.h>
#include <foo/b.h>
#include <exc.h>
#include gaz.h
As we observe in the above example, the includes having the same Priority are grouped, and SortPriority defines the sort priority.
The patch was accepted and ready to merge, and you can find the patch here -> SortIncludesPatch. This patch also introduces the NetBSD style to clang-format with configurations to supported styles.
Spaces Before Trailing Comments
This option is also a native style option in clang-format which enables a user to decide the number of spaces to be given before trailing comments (// - comments) but not block comments (/* - comments). The reason for this is that block comments have different usage patterns and different exceptional cases. The following is an example of the native style option.
SpacesBeforeTrailingComments: 3
void f() {
if (true) { //foo
f(); //bar
} //foo1
}
Modifications to spaceBeforeTrailingComments:
I am working on modifying this style option to support block comments by covering cases where block comments are used. There are some cases yet to be covered. Once the patch is ready, this is the deliverable
The initial revision can be found here -> patch
SpacesBeforeTrailingComments: 3
void f() {
if (true) { /*foo */
f(); /*bar */
} /*foo1*/
}
AlignConsecutiveListElements
AlignConsecutiveListElements is a new style option that I am going to introduce to clang-format. This style option aligns elements in consecutive definitions, declarations of lists. The style is not yet ready to patch, and I have to modify a lot of functionalities in alignTokens() which aligns tokens to support this style.
Example:
Input
keys[] = {
{"all", f_all, 0 },
{ "cbreak", f_cbreak, F_OFFOK },
{"cols", f_columns, F_NEEDARG },
{ "columns", f_columns, F_NEEDARG },
};
Output
keys[] = {
{ "all", f_all, 0 },
{ "cbreak", _cbreak, F_OFFOK },
{ "cols", f_columns, F_NEEDARG },
{ "columns", f_columns, F_NEEDARG },
};
The blocker to this style is the nested structure for list declarations, alignTokens() should be equipped to parse the nested list declarations to support this style option. I will make sure this style option is available by the next report.
Further plans
For the next phase, I will make all the style options that were modified or introduced till now during the first two phases mergeable to upstream along with required unit tests. With these style options ready, I will test the new clang-format with NetBSD style patched across NetBSD source and check for bugs. After the testing will try to fix the bugs and get the NetBSDStyle ready for the final evaluation.
Summary
In the final coding period, the main focus will be on testing the new/modified style options and fix them. Add any missing styles for NetBSD and get the NetBSDStyle by the final evaluation.
I want to thank my mentors Michal, Christos and developers of both LLVM and NetBSD for supporting to complete this project.
Recently I started working on Fuzzing Filesystems on NetBSD using AFL.
You can take a look at the previous post to learn more details about background of this project.
This post summarizes the work that has been done in this area, and is divided into 3 sections:
- Porting AFL kernel mode to work with NetBSD
- Running kernel fuzzing benchmark
- Example howto fuzzing particular Filesystem
AFL Port for NetBSD
AFL is a well known fuzzer for user space programs and libraries, but with some changes it can be used for fuzzing the kernel binary itself.
For the first step to fuzz the NetBSD kernel via AFL, I needed to modify it to use coverage data provided by the kernel instead of compiled instrumentations.
My initial plan was to replace the coverage data gathered via afl-as with that provided by kcov(4). In this scenario, AFL would just run a wrapper and see the real coverage from the kernel.
I also saw previous work done by Oracle in this area, where instead of running the wrapper as a binary, the wrapper code was included in a custom library (.so object).
Both approaches have some pros and cons. One thing that convinced me to use a solution based on the shared library with initialization code was the potentially easier integration with remote fork server. AFL has some constraints in the way of managing fuzzed binary, and keeping it on a remote VM is less portable than fuzzing using a shared library and avoiding introducing changes to the original binary fuzzing.
Porting AFL kernel fuzzing mode to be compatible with NetBSD kernel mainly relied on how the operating system manages the coverage data. The port can be found currently on github.
Writing a kernel fuzzing benchmark
Performance is one of the key factors of fuzzing. If performance of the fuzzing process is not good enough, it's likely that the entire solution won't be useful in practice. In this section we will evaluate our fuzzer with a practice benchmark.
One exercise that I want to perform to check the AFL kernel fuzzing in practice is similar to a password cracking benchmark. The high level idea is that a fuzzer based on coverage should be much smarter than bruteforce or random generation.
To do this, we can write a simple program that will take a text input and compare it with a hardcoded value. If the values match, then the fuzzer cracked the password. Otherwise, it will perform another iteration with a modified input.
Instead of "password cracker", I called my kernel program "lottery dev". It's a character device that takes an input and compares it with a string.
The chance to find one 6 byte combination (or the "lucky byte" combination, because of the name) are similar to winning big in the lottery: every byte contains 8 bits, thus we have 2**(8*6) => 281,474,976,710,656 combinations. The coverage based fuzzer should be able to do this much quicker and in fewer iterations, as feedback from code instrumentations will show, compared to blindly guessing.
I performed a similar test using a simple C program: the program read stdio and compared it with the hardcoded pattern. If the pattern matches, the program panics, and otherwise returns zero. Such a test took an AFL about a few hours on my local laptop to break the challenge (some important details can make it faster). The curious reader who wants to learn some basics of AFL should try to do run a similar test on their machine.
I ran the fuzzer on my lottery dev for several days, and after almost a week it was still not able to find the combination. So something was fundamentally not right. The kernel module with the wrapper code can be found here.
Measuring Coverage for a particular function
In the previous article, I mentioned that the NetBSD kernel seems to be 'more verbose' in terms of coverage reporting.
I ran my lottery dev wrapper code (the code that writes a given input to the char device) to check the coverage data using standard kcov(4) without the AFL module. My idea was to check the ratio between entries of my code that I wanted to track and other kernel functions that can be considered noise from other subsystems. These operations are caused by the context services, such as Memory Management, File Systems or Power Management, that are executed in the same process.
To my surprise, there was a lot of data, but I could not find any of functions from lottery dev. I quickly noticed that the amount of addresses is equal to the size of kcov(4) buffer, so maybe my data didn't fit in the buffer inside kernel space?
I changed the size of the coverage buffer to make it significantly larger and recompiled the kernel. With this change I reran the test. Now, with the buffer being large enough, I collected the data and printed top 20 entries with a number of occurrences. There were 30578 entries in total.
1544 /usr/netbsd/src/sys/uvm/uvm_page.c:847
1536 /usr/netbsd/src/sys/uvm/uvm_page.c:869
1536 /usr/netbsd/src/sys/uvm/uvm_page.c:890
1536 /usr/netbsd/src/sys/uvm/uvm_page.c:880
1536 /usr/netbsd/src/sys/uvm/uvm_page.c:858
1281 /usr/netbsd/src/sys/arch/amd64/compile/obj/GENERIC/./machine/cpu.h:70
1281 /usr/netbsd/src/sys/arch/amd64/compile/obj/GENERIC/./machine/cpu.h:71
478 /usr/netbsd/src/sys/kern/kern_mutex.c:840
456 /usr/netbsd/src/sys/arch/x86/x86/pmap.c:3046
438 /usr/netbsd/src/sys/kern/kern_mutex.c:837
438 /usr/netbsd/src/sys/kern/kern_mutex.c:835
398 /usr/netbsd/src/sys/kern/kern_mutex.c:838
383 /usr/netbsd/src/sys/uvm/uvm_page.c:186
308 /usr/netbsd/src/sys/lib/libkern/../../../common/lib/libc/gen/rb.c:129
307 /usr/netbsd/src/sys/lib/libkern/../../../common/lib/libc/gen/rb.c:130
307 /usr/netbsd/src/sys/uvm/uvm_page.c:178
307 /usr/netbsd/src/sys/uvm/uvm_page.c:1568
231 /usr/netbsd/src/sys/lib/libkern/../../../common/lib/libc/gen/rb.c:135
230 /usr/netbsd/src/sys/uvm/uvm_page.c:1567
228 /usr/netbsd/src/sys/kern/kern_synch.c:416
It should not be a surprise that the coverage data does not much help our fuzzing with AFL. Most of the information that the fuzzer sees is related to UVM page management and machine-dependent code.
I decided to remove instrumentation from these most common functions to check the difference. Using the attribute no_instrument_function tells the compiler to not put instrumentation for coverage tracing inside these functions.
Unfortunately, after recompiling the kernel, the most common functions did not disappear from the list. As I figured out, the support in GCC 7 may not be fully in place.
GCC 8 for help
To solve this issue, I decided to work on reusing GCC 8 for building the NetBSD kernel. After fixing basic build warnings, I got my basic kernel working. This still needs more work to get kcov(4) fully functional. Hopefully, in the next report, I will be able to share these results.
Fuzzing Filesystem
Given what we already know, we can run Filesystem fuzzing. As a target I chose FFS as it is a default FS that is delivered with NetBSD.
The reader may ask the question: why would you run coverage based fuzzer if the data is not 100% accurate?
So here is the trick: For coverage based fuzzers, it is usually recommended to leave the input format as is, as genetic algorithms can do a pretty good job here. There is great post on Michal Zalewski's Blog about this process applied for the JPEG format: "Pulling JPEGs out of thin air".
But what will AFL do if we provide an input format that is already correct? We already know what a valid FS image should look like (or we can simply just generate one). As it turns out, AFL will start performing operations on the input in a similar way as mutation fuzzers do - another great source that explains this process can be found here: "Binary fuzzing strategies: what works, what doesn't"
Writing mount wrapper
As we discussed in the previous paragraph, to fuzz the kernel itself, we need some code to run operations inside the kernel. We will call it a wrapper, as it wraps the operations of every cycle of fuzzing.
The first step to write a wrapper for AFL is to describe it as a sequence of operations. Bash style scripting is usually good enough to do that.
We need to have an input that will be modified by the fuzzer, and be able to mount it. NetBSD comes with vnd(4) that allows exposing regular files as block devices.
The simplest sequence can be described as:
# Expose file from tmpfs as block device
vndconfig vnd0 /tmp/rand.tmp
# Create a new FS image on the blk dev that we created
newfs /dev/vnd0
# Mount our fresh FS
mount /dev/vnd0 /mnt
# Check if FS works fine
echo "FFS mounted!" > /mnt/test
# Undo mount
umount /mnt
# Last undo step
vndconfig -u vnd0From bash to C and system calls
At this point, the reader has probably figured out that a shell script won't be the best approach for fuzzer usage. We need to change it to C code and use proper syscall/libc interfaces.
vndconfig uses the opendisk(3) combined with vnd_ioctl.
mount(2) is a simple system call which can operate directly after file is added to vnd(4)
Below is an example conceptual code for mounting an FS:
// Structure required by mount()
struct ufs_args ufs_args;
// VNConfigure step
rv = run_config(VND_CONFIG, dev, fpath);
if (rv)
printf("VND_CONFIG failed: rv: %d\n", rv);
// Mount FS
if (mount(FS_TYPE, fs_name, mntflags, &ufs_args, 8) == -1) {
printf("Mount failed: %s", strerror(errno));
} else {
// Here FS is mounted
// We can perform any other operations on it
// Umount FS
if (unmount(fs_name, 0) == -1) printf("#: Umount failed!\n");
}
// VNC-unconfigure
rv = run_config(VND_UNCONFIG, dev, fpath);
if (rv) {
printf("VND_UNCONFIG failed: rv: %d\n", rv);
}The complete code can be found here
Ready to fuzz FFS! aka Running FS Fuzzing with a predifined corpus
The first thing that we need to do is to have a wrapper that provides mount/umount functionality. In the previous section, we have already shown how that can be done. For now, we will be fuzzing the same kernel that we are running on. Isn't that dangerous? Taking a saw to the branch we are sitting on? Of course it is! In this exercise I want to illustrate an idea from a technical perspective so the curious reader is able to understand it better and do any modifications by their own. The take away from this exercise is that the fuzzing target is the kernel itself, the same binary that is running the fuzzing process.

Let's come back to the wrapper code. We've already discussed how it works. Now we need to compile it as a shared library. This is not obvious, but should be easy to understand after we already brought this sawing-off metaphor.
To compile the so object:
gcc -fPIC -lutil -g -shared ./wrapper_mount.c -o wrapper_mount.so Now we need to create the input corpus, for the first attempt we will use a large enough empty file.
dd if=/dev/zero of=./in/test1 bs=10k count=8And finally run. The @@ tells AFL to put here the name of input file that will be used for fuzzing.
./afl-fuzz -k -i ./in -o ./out -- /mypath/wrapper_mount.so @@Now, as we described earlier, we need a proper FS image to allow AFL perform mutations on it. The only difference is the additional newfs(8) command.
# We need a file, big enough to fit FS image but not too big
dd if=/dev/zero of=./in/test1 bs=10k count=8
# A block is already inside fuzzer ./in
vndconfig vnd0 ./in/test1
# Create new FFS filesystem
newfs /dev/vnd0
vndconfig -u vnd0Now we are ready for another run!
./afl-fuzz -k -i ./in -o ./out -- /mypath/wrapper_mount.so @@
american fuzzy lop 2.35b (wrapper_mount.so)
┌─ process timing ─────────────────────────────────────┬─ overall results ─────┐
│ run time : 0 days, 0 hrs, 0 min, 17 sec │ cycles done : 0 │
│ last new path : none seen yet │ total paths : 1 │
│ last uniq crash : none seen yet │ uniq crashes : 0 │
│ last uniq hang : none seen yet │ uniq hangs : 0 │
├─ cycle progress ────────────────────┬─ map coverage ─┴───────────────────────┤
│ now processing : 0 (0.00%) │ map density : 17.28% / 17.31% │
│ paths timed out : 0 (0.00%) │ count coverage : 3.53 bits/tuple │
├─ stage progress ────────────────────┼─ findings in depth ────────────────────┤
│ now trying : trim 512/512 │ favored paths : 1 (100.00%) │
│ stage execs : 15/160 (9.38%) │ new edges on : 1 (100.00%) │
│ total execs : 202 │ total crashes : 0 (0 unique) │
│ exec speed : 47.74/sec (slow!) │ total hangs : 0 (0 unique) │
├─ fuzzing strategy yields ───────────┴───────────────┬─ path geometry ────────┤
│ bit flips : 0/0, 0/0, 0/0 │ levels : 1 │
│ byte flips : 0/0, 0/0, 0/0 │ pending : 1 │
│ arithmetics : 0/0, 0/0, 0/0 │ pend fav : 1 │
│ known ints : 0/0, 0/0, 0/0 │ own finds : 0 │
│ dictionary : 0/0, 0/0, 0/0 │ imported : n/a │
│ havoc : 0/0, 0/0 │ stability : 23.66% │
│ trim : n/a, n/a ├────────────────────────┘
┴─────────────────────────────────────────────────────┘ [cpu: 0%]
Future work
Support for the NetBSD kernel fuzzing was developed as a part of the AFL FileSystems Fuzzing project, which aims to improve quality of filesystems and catch various issues.
The very next thing that I have on my todo list is to provide support for kernel tracing on GCC 8 to turn off coverage data from other functions that generate a lot of noise.
During the FFS fuzzing, I found a few issues that I need to analyze in detail.
Last but not least, for the next report I plan to show a remote setup of AFL running on a VM, reporting crashes, and being remotely rebooted by the master controller.
Recently I started working on Fuzzing Filesystems on NetBSD using AFL.
You can take a look at the previous post to learn more details about background of this project.
This post summarizes the work that has been done in this area, and is divided into 3 sections:
- Porting AFL kernel mode to work with NetBSD
- Running kernel fuzzing benchmark
- Example howto fuzzing particular Filesystem
AFL Port for NetBSD
AFL is a well known fuzzer for user space programs and libraries, but with some changes it can be used for fuzzing the kernel binary itself.
For the first step to fuzz the NetBSD kernel via AFL, I needed to modify it to use coverage data provided by the kernel instead of compiled instrumentations.
My initial plan was to replace the coverage data gathered via afl-as with that provided by kcov(4). In this scenario, AFL would just run a wrapper and see the real coverage from the kernel.
I also saw previous work done by Oracle in this area, where instead of running the wrapper as a binary, the wrapper code was included in a custom library (.so object).
Both approaches have some pros and cons. One thing that convinced me to use a solution based on the shared library with initialization code was the potentially easier integration with remote fork server. AFL has some constraints in the way of managing fuzzed binary, and keeping it on a remote VM is less portable than fuzzing using a shared library and avoiding introducing changes to the original binary fuzzing.
Porting AFL kernel fuzzing mode to be compatible with NetBSD kernel mainly relied on how the operating system manages the coverage data. The port can be found currently on github.
Writing a kernel fuzzing benchmark
Performance is one of the key factors of fuzzing. If performance of the fuzzing process is not good enough, it's likely that the entire solution won't be useful in practice. In this section we will evaluate our fuzzer with a practice benchmark.
One exercise that I want to perform to check the AFL kernel fuzzing in practice is similar to a password cracking benchmark. The high level idea is that a fuzzer based on coverage should be much smarter than bruteforce or random generation.
To do this, we can write a simple program that will take a text input and compare it with a hardcoded value. If the values match, then the fuzzer cracked the password. Otherwise, it will perform another iteration with a modified input.
Instead of "password cracker", I called my kernel program "lottery dev". It's a character device that takes an input and compares it with a string.
The chance to find one 6 byte combination (or the "lucky byte" combination, because of the name) are similar to winning big in the lottery: every byte contains 8 bits, thus we have 2**(8*6) => 281,474,976,710,656 combinations. The coverage based fuzzer should be able to do this much quicker and in fewer iterations, as feedback from code instrumentations will show, compared to blindly guessing.
I performed a similar test using a simple C program: the program read stdio and compared it with the hardcoded pattern. If the pattern matches, the program panics, and otherwise returns zero. Such a test took an AFL about a few hours on my local laptop to break the challenge (some important details can make it faster). The curious reader who wants to learn some basics of AFL should try to do run a similar test on their machine.
I ran the fuzzer on my lottery dev for several days, and after almost a week it was still not able to find the combination. So something was fundamentally not right. The kernel module with the wrapper code can be found here.
Measuring Coverage for a particular function
In the previous article, I mentioned that the NetBSD kernel seems to be 'more verbose' in terms of coverage reporting.
I ran my lottery dev wrapper code (the code that writes a given input to the char device) to check the coverage data using standard kcov(4) without the AFL module. My idea was to check the ratio between entries of my code that I wanted to track and other kernel functions that can be considered noise from other subsystems. These operations are caused by the context services, such as Memory Management, File Systems or Power Management, that are executed in the same process.
To my surprise, there was a lot of data, but I could not find any of functions from lottery dev. I quickly noticed that the amount of addresses is equal to the size of kcov(4) buffer, so maybe my data didn't fit in the buffer inside kernel space?
I changed the size of the coverage buffer to make it significantly larger and recompiled the kernel. With this change I reran the test. Now, with the buffer being large enough, I collected the data and printed top 20 entries with a number of occurrences. There were 30578 entries in total.
1544 /usr/netbsd/src/sys/uvm/uvm_page.c:847
1536 /usr/netbsd/src/sys/uvm/uvm_page.c:869
1536 /usr/netbsd/src/sys/uvm/uvm_page.c:890
1536 /usr/netbsd/src/sys/uvm/uvm_page.c:880
1536 /usr/netbsd/src/sys/uvm/uvm_page.c:858
1281 /usr/netbsd/src/sys/arch/amd64/compile/obj/GENERIC/./machine/cpu.h:70
1281 /usr/netbsd/src/sys/arch/amd64/compile/obj/GENERIC/./machine/cpu.h:71
478 /usr/netbsd/src/sys/kern/kern_mutex.c:840
456 /usr/netbsd/src/sys/arch/x86/x86/pmap.c:3046
438 /usr/netbsd/src/sys/kern/kern_mutex.c:837
438 /usr/netbsd/src/sys/kern/kern_mutex.c:835
398 /usr/netbsd/src/sys/kern/kern_mutex.c:838
383 /usr/netbsd/src/sys/uvm/uvm_page.c:186
308 /usr/netbsd/src/sys/lib/libkern/../../../common/lib/libc/gen/rb.c:129
307 /usr/netbsd/src/sys/lib/libkern/../../../common/lib/libc/gen/rb.c:130
307 /usr/netbsd/src/sys/uvm/uvm_page.c:178
307 /usr/netbsd/src/sys/uvm/uvm_page.c:1568
231 /usr/netbsd/src/sys/lib/libkern/../../../common/lib/libc/gen/rb.c:135
230 /usr/netbsd/src/sys/uvm/uvm_page.c:1567
228 /usr/netbsd/src/sys/kern/kern_synch.c:416
It should not be a surprise that the coverage data does not much help our fuzzing with AFL. Most of the information that the fuzzer sees is related to UVM page management and machine-dependent code.
I decided to remove instrumentation from these most common functions to check the difference. Using the attribute no_instrument_function tells the compiler to not put instrumentation for coverage tracing inside these functions.
Unfortunately, after recompiling the kernel, the most common functions did not disappear from the list. As I figured out, the support in GCC 7 may not be fully in place.
GCC 8 for help
To solve this issue, I decided to work on reusing GCC 8 for building the NetBSD kernel. After fixing basic build warnings, I got my basic kernel working. This still needs more work to get kcov(4) fully functional. Hopefully, in the next report, I will be able to share these results.
Fuzzing Filesystem
Given what we already know, we can run Filesystem fuzzing. As a target I chose FFS as it is a default FS that is delivered with NetBSD.
The reader may ask the question: why would you run coverage based fuzzer if the data is not 100% accurate?
So here is the trick: For coverage based fuzzers, it is usually recommended to leave the input format as is, as genetic algorithms can do a pretty good job here. There is great post on Michal Zalewski's Blog about this process applied for the JPEG format: "Pulling JPEGs out of thin air".
But what will AFL do if we provide an input format that is already correct? We already know what a valid FS image should look like (or we can simply just generate one). As it turns out, AFL will start performing operations on the input in a similar way as mutation fuzzers do - another great source that explains this process can be found here: "Binary fuzzing strategies: what works, what doesn't"
Writing mount wrapper
As we discussed in the previous paragraph, to fuzz the kernel itself, we need some code to run operations inside the kernel. We will call it a wrapper, as it wraps the operations of every cycle of fuzzing.
The first step to write a wrapper for AFL is to describe it as a sequence of operations. Bash style scripting is usually good enough to do that.
We need to have an input that will be modified by the fuzzer, and be able to mount it. NetBSD comes with vnd(4) that allows exposing regular files as block devices.
The simplest sequence can be described as:
# Expose file from tmpfs as block device
vndconfig vnd0 /tmp/rand.tmp
# Create a new FS image on the blk dev that we created
newfs /dev/vnd0
# Mount our fresh FS
mount /dev/vnd0 /mnt
# Check if FS works fine
echo "FFS mounted!" > /mnt/test
# Undo mount
umount /mnt
# Last undo step
vndconfig -u vnd0From bash to C and system calls
At this point, the reader has probably figured out that a shell script won't be the best approach for fuzzer usage. We need to change it to C code and use proper syscall/libc interfaces.
vndconfig uses the opendisk(3) combined with vnd_ioctl.
mount(2) is a simple system call which can operate directly after file is added to vnd(4)
Below is an example conceptual code for mounting an FS:
// Structure required by mount()
struct ufs_args ufs_args;
// VNConfigure step
rv = run_config(VND_CONFIG, dev, fpath);
if (rv)
printf("VND_CONFIG failed: rv: %d\n", rv);
// Mount FS
if (mount(FS_TYPE, fs_name, mntflags, &ufs_args, 8) == -1) {
printf("Mount failed: %s", strerror(errno));
} else {
// Here FS is mounted
// We can perform any other operations on it
// Umount FS
if (unmount(fs_name, 0) == -1) printf("#: Umount failed!\n");
}
// VNC-unconfigure
rv = run_config(VND_UNCONFIG, dev, fpath);
if (rv) {
printf("VND_UNCONFIG failed: rv: %d\n", rv);
}The complete code can be found here
Ready to fuzz FFS! aka Running FS Fuzzing with a predifined corpus
The first thing that we need to do is to have a wrapper that provides mount/umount functionality. In the previous section, we have already shown how that can be done. For now, we will be fuzzing the same kernel that we are running on. Isn't that dangerous? Taking a saw to the branch we are sitting on? Of course it is! In this exercise I want to illustrate an idea from a technical perspective so the curious reader is able to understand it better and do any modifications by their own. The take away from this exercise is that the fuzzing target is the kernel itself, the same binary that is running the fuzzing process.
Let's come back to the wrapper code. We've already discussed how it works. Now we need to compile it as a shared library. This is not obvious, but should be easy to understand after we already brought this sawing-off metaphor.
To compile the so object:
gcc -fPIC -lutil -g -shared ./wrapper_mount.c -o wrapper_mount.so Now we need to create the input corpus, for the first attempt we will use a large enough empty file.
dd if=/dev/zero of=./in/test1 bs=10k count=8And finally run. The @@ tells AFL to put here the name of input file that will be used for fuzzing.
./afl-fuzz -k -i ./in -o ./out -- /mypath/wrapper_mount.so @@Now, as we described earlier, we need a proper FS image to allow AFL perform mutations on it. The only difference is the additional newfs(8) command.
# We need a file, big enough to fit FS image but not too big
dd if=/dev/zero of=./in/test1 bs=10k count=8
# A block is already inside fuzzer ./in
vndconfig vnd0 ./in/test1
# Create new FFS filesystem
newfs /dev/vnd0
vndconfig -u vnd0Now we are ready for another run!
./afl-fuzz -k -i ./in -o ./out -- /mypath/wrapper_mount.so @@
american fuzzy lop 2.35b (wrapper_mount.so)
┌─ process timing ─────────────────────────────────────┬─ overall results ─────┐
│ run time : 0 days, 0 hrs, 0 min, 17 sec │ cycles done : 0 │
│ last new path : none seen yet │ total paths : 1 │
│ last uniq crash : none seen yet │ uniq crashes : 0 │
│ last uniq hang : none seen yet │ uniq hangs : 0 │
├─ cycle progress ────────────────────┬─ map coverage ─┴───────────────────────┤
│ now processing : 0 (0.00%) │ map density : 17.28% / 17.31% │
│ paths timed out : 0 (0.00%) │ count coverage : 3.53 bits/tuple │
├─ stage progress ────────────────────┼─ findings in depth ────────────────────┤
│ now trying : trim 512/512 │ favored paths : 1 (100.00%) │
│ stage execs : 15/160 (9.38%) │ new edges on : 1 (100.00%) │
│ total execs : 202 │ total crashes : 0 (0 unique) │
│ exec speed : 47.74/sec (slow!) │ total hangs : 0 (0 unique) │
├─ fuzzing strategy yields ───────────┴───────────────┬─ path geometry ────────┤
│ bit flips : 0/0, 0/0, 0/0 │ levels : 1 │
│ byte flips : 0/0, 0/0, 0/0 │ pending : 1 │
│ arithmetics : 0/0, 0/0, 0/0 │ pend fav : 1 │
│ known ints : 0/0, 0/0, 0/0 │ own finds : 0 │
│ dictionary : 0/0, 0/0, 0/0 │ imported : n/a │
│ havoc : 0/0, 0/0 │ stability : 23.66% │
│ trim : n/a, n/a ├────────────────────────┘
┴─────────────────────────────────────────────────────┘ [cpu: 0%]
Future work
Support for the NetBSD kernel fuzzing was developed as a part of the AFL FileSystems Fuzzing project, which aims to improve quality of filesystems and catch various issues.
The very next thing that I have on my todo list is to provide support for kernel tracing on GCC 8 to turn off coverage data from other functions that generate a lot of noise.
During the FFS fuzzing, I found a few issues that I need to analyze in detail.
Last but not least, for the next report I plan to show a remote setup of AFL running on a VM, reporting crashes, and being remotely rebooted by the master controller.
As NetBSD-9 has finally branched and I keep receiving requests to finish the integration of LLVM sanitizers, I have pushed this task forward too. I have also completed a few leftover tasks from my previous months that still needed fixes.
GNU GDB
Originally the GDB debugger was meant for local debugging. However with the request of tracing remote setups, it has been extended to remote debugging capabilities and this move standardized the protocol for many debuggers.
In fact the native / local / non-remote debugging is redundant with the remote capabilities, however this blog entry is not the right place to discuss the technical merits in comparision between them trying to convince someone. What matters: the developers of LLDB (LLVM debugger) already removed their local debugging variation (for Linux) and implements only the remote process plugin. The NetBSD support for LLDB started with this mode of copying the Linux approach. Bypassing no longer exists for Linux local-debugging-only support plugin.
Inside the GNU world, the transition from local process debugging to remote process debugging is progressing slowly. In the current state of affairs there is a need to support two separate (however whenever possible, with code sharing) plugins for each OS. Also, there is intention from some GNU debugger developers to completely drop the native-only process plugin to debugging code. The state in NetBSD one month ago handled only local-debugging and no code for remote process debugging. The state is the same with other BSD derived systems (FreeBSD, DragonFlyBSD...) and this state was in general kept alive with a reduced set of features compared to Linux.
I have decided to refresh the GDB support for NetBSD as this is still the primary debugger on NetBSD (LLDB support is still work-in-progress) for two primary reasons:
- Slight ptrace(2) changes in the kernel code can alter support in GDB/NetBSD. With proper NetBSD handling in GDB and ability to run its regression tests the fallout will be minimized.
- Certain ptrace(2) reported bugs are in fact specific GDB bugs. In order to close them as resolved I need to revamp and validate the GDB support.
I have managed to get a basic GDB client/server session to work for tracing a simple application. The following features have been implemented targetting as of now NetBSD/amd64:
- creating inferior (debuggee in GDB terminology)
- attaching
- killing
- detaching
- resuming (with optional: single step, signal, resuming single thread)
- waiting
- checking whether a thread is alive
- fetching registers
- storing registers
- reading memory
- writing memory
- requesting interruption
- auxv reading
- software breakpoint support
- hardware single step support
- svr4 ELF loader tracing
- retrieving exec file name from pid
- reading thread name
- i386 support
- multilib support amd64/i386
- reading TLS BASE (x86) register (there is still missing a ptrace(2) interface)
- EXEC events handling improvement in the generic code (that maps Linux restricted semantics only)
- hardware watchpoint/breakpoint support
- FPU support
- FORK, VFORK, POSIX_SPAWN events
- reading loadmap
- research for other features: multiprocess, mulifs, async, btrace, tracepoints, new gdb connections..
The main difficulty was with overly elaborated version of Linux proccess tracing in GDB that contains various workaround for various kernel bugs, handles differences between behavior of the Linux kernel (like different set of ptrace(2) calls or.. swapped arguments) between CPUs.. Finally, I have decided to base my work on unfortunately dated (and probably broken today) gdbserver for lynxos/i386 and then keep adding missing features that are implemented for Linux. I have passed most of the past month on debugging spurious crashes and anomalies in my GDB remote port to NetBSD. After much work, I have finally managed to get gdbserver to work and perform successful operations of spawning a process, inserting a breakpoint, single-stepping, detaching and running a process until its natural completion.
I plan to validate the native tracing support for NetBSD, checking whether it needs upgrading and planning to run the GDB regression tests as soon as possible.
LLVM changes
I have updated the list of ioctl(2) operations to the state as of 9.99.3 (+36 ioctls). The support for NVMM ioctl(2)s has been enabled and restricted as of now to amd64 only.
I have also finally managed to resolve the crash of dynamic (as DSO library) Address Sanitizer that blocked the integration with base in Januray 2019. My original suspect on the root cause was finally verified to be false (mismatch in the source code files composing .so libraries). The real reason to ship with broken dynamic ASan was inability to reuse the same implementation of TSD (Thread-Specific Data) in asan-dynamic. The static (default in LLVM) version of ASan can use in early initialization TLS (Thread-Local Storage), while TSD (Thread-Specific Data) is broken. It happened that the state with dynamic ASan is inversed and TLS breaks and TSD works.
I have also landed build rules for LLVM sanitizers into src/, for:
- asan
- ubsan
- tsan
- msan
- xray
- safestack
- libfuzzer
MAXRSS changes
During the work on libfuzzer last year for GSoC-2018 one of the changes that landed the kernel was the restoration of the MAXRSS option. MAXRSS presents the maxiumum resident set size of the process during its lifetime. In order to finalize this work, there was still need to enable printing it in ps(1). I have pushed a kernel fix to update the RSS related values for sysctl(3) query of a process statistics and with help of Krzysztof Lasocki reenabled printing MAXRSS, IDRSS (integral unshared data), ISRSS (integral unshared stack) and IXRSS (integral shared memory size) in ps(1). These values were commented out in the ps(1) program since the inception of NetBSD, the first registered commit.
$ ps -O maxrss,idrss,isrss,ixrss|head -3 PID MAXRSS IDRSS ISRSS IXRSS TTY STAT TIME COMMAND 910 5844 20 12 216 pts/0 Is 0:00.01 -ksh 1141 5844 20 12 152 pts/0 I+ 0:00.01 mg event.h
These change have been backported to the NetBSD-9 branch and will land 9.0. Welcome back!
Plan for the next milestone
Start executing GDB regression tests. Keep enhancing GDB support. Keep detecting ptrace(2) bugs and addressing them.
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL to chip in what you can:
As NetBSD-9 has finally branched and I keep receiving requests to finish the integration of LLVM sanitizers, I have pushed this task forward too. I have also completed a few leftover tasks from my previous months that still needed fixes.
GNU GDB
Originally the GDB debugger was meant for local debugging. However with the request of tracing remote setups, it has been extended to remote debugging capabilities and this move standardized the protocol for many debuggers.
In fact the native / local / non-remote debugging is redundant with the remote capabilities, however this blog entry is not the right place to discuss the technical merits in comparision between them trying to convince someone. What matters: the developers of LLDB (LLVM debugger) already removed their local debugging variation (for Linux) and implements only the remote process plugin. The NetBSD support for LLDB started with this mode of copying the Linux approach. Bypassing no longer exists for Linux local-debugging-only support plugin.
Inside the GNU world, the transition from local process debugging to remote process debugging is progressing slowly. In the current state of affairs there is a need to support two separate (however whenever possible, with code sharing) plugins for each OS. Also, there is intention from some GNU debugger developers to completely drop the native-only process plugin to debugging code. The state in NetBSD one month ago handled only local-debugging and no code for remote process debugging. The state is the same with other BSD derived systems (FreeBSD, DragonFlyBSD...) and this state was in general kept alive with a reduced set of features compared to Linux.
I have decided to refresh the GDB support for NetBSD as this is still the primary debugger on NetBSD (LLDB support is still work-in-progress) for two primary reasons:
- Slight ptrace(2) changes in the kernel code can alter support in GDB/NetBSD. With proper NetBSD handling in GDB and ability to run its regression tests the fallout will be minimized.
- Certain ptrace(2) reported bugs are in fact specific GDB bugs. In order to close them as resolved I need to revamp and validate the GDB support.
I have managed to get a basic GDB client/server session to work for tracing a simple application. The following features have been implemented targetting as of now NetBSD/amd64:
- creating inferior (debuggee in GDB terminology)
- attaching
- killing
- detaching
- resuming (with optional: single step, signal, resuming single thread)
- waiting
- checking whether a thread is alive
- fetching registers
- storing registers
- reading memory
- writing memory
- requesting interruption
- auxv reading
- software breakpoint support
- hardware single step support
- svr4 ELF loader tracing
- retrieving exec file name from pid
- reading thread name
- i386 support
- multilib support amd64/i386
- reading TLS BASE (x86) register (there is still missing a ptrace(2) interface)
- EXEC events handling improvement in the generic code (that maps Linux restricted semantics only)
- hardware watchpoint/breakpoint support
- FPU support
- FORK, VFORK, POSIX_SPAWN events
- reading loadmap
- research for other features: multiprocess, mulifs, async, btrace, tracepoints, new gdb connections..
The main difficulty was with overly elaborated version of Linux proccess tracing in GDB that contains various workaround for various kernel bugs, handles differences between behavior of the Linux kernel (like different set of ptrace(2) calls or.. swapped arguments) between CPUs.. Finally, I have decided to base my work on unfortunately dated (and probably broken today) gdbserver for lynxos/i386 and then keep adding missing features that are implemented for Linux. I have passed most of the past month on debugging spurious crashes and anomalies in my GDB remote port to NetBSD. After much work, I have finally managed to get gdbserver to work and perform successful operations of spawning a process, inserting a breakpoint, single-stepping, detaching and running a process until its natural completion.
I plan to validate the native tracing support for NetBSD, checking whether it needs upgrading and planning to run the GDB regression tests as soon as possible.
LLVM changes
I have updated the list of ioctl(2) operations to the state as of 9.99.3 (+36 ioctls). The support for NVMM ioctl(2)s has been enabled and restricted as of now to amd64 only.
I have also finally managed to resolve the crash of dynamic (as DSO library) Address Sanitizer that blocked the integration with base in Januray 2019. My original suspect on the root cause was finally verified to be false (mismatch in the source code files composing .so libraries). The real reason to ship with broken dynamic ASan was inability to reuse the same implementation of TSD (Thread-Specific Data) in asan-dynamic. The static (default in LLVM) version of ASan can use in early initialization TLS (Thread-Local Storage), while TSD (Thread-Specific Data) is broken. It happened that the state with dynamic ASan is inversed and TLS breaks and TSD works.
I have also landed build rules for LLVM sanitizers into src/, for:
- asan
- ubsan
- tsan
- msan
- xray
- safestack
- libfuzzer
MAXRSS changes
During the work on libfuzzer last year for GSoC-2018 one of the changes that landed the kernel was the restoration of the MAXRSS option. MAXRSS presents the maxiumum resident set size of the process during its lifetime. In order to finalize this work, there was still need to enable printing it in ps(1). I have pushed a kernel fix to update the RSS related values for sysctl(3) query of a process statistics and with help of Krzysztof Lasocki reenabled printing MAXRSS, IDRSS (integral unshared data), ISRSS (integral unshared stack) and IXRSS (integral shared memory size) in ps(1). These values were commented out in the ps(1) program since the inception of NetBSD, the first registered commit.
$ ps -O maxrss,idrss,isrss,ixrss|head -3 PID MAXRSS IDRSS ISRSS IXRSS TTY STAT TIME COMMAND 910 5844 20 12 216 pts/0 Is 0:00.01 -ksh 1141 5844 20 12 152 pts/0 I+ 0:00.01 mg event.h
These change have been backported to the NetBSD-9 branch and will land 9.0. Welcome back!
Plan for the next milestone
Start executing GDB regression tests. Keep enhancing GDB support. Keep detecting ptrace(2) bugs and addressing them.
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL to chip in what you can:
Once upon a time a developer wrote a temperature sensor driver for one system and decided to port it to another, similar, system. For days and then weeks, the developer waited and waited for the other, similar, system to arrive.
One day, joy of joys, the other, similar, system arrived. A National Day of Celebration commenced, and the porting effort began. Over hours, perhaps even as many as five hours of time, the sensors were finally able to tell you whether they were hot or not.
This other, similar, system suddenly was purposeless and was pondering what else life could provide when the Remote Server task popped up and said "Hey, first media file is free", and sadly, this other, similar, system tried its first media file, and then purchased many, many more media files, and suddenly this other, similar, system was suddenly hooked.
Unfortunately, this other, similar, system had a problem talking on the network without falling asleep on the job, so the developer says "let's try a USB network instead!", and initially this seemed like a good idea. Many bits were transferred over USB, but soon whispers of a lurking monster, known to developers, experience or otherwise, as KASSERT, were heard and soon found common.
The developer attempted other USB network as the other, similar, system was destined to be flown many thousands of miles away soon, but the only other option was similarly plagued by the KASSERT monster. The developer reached into his Bag Of Holding and pulled out a magical weapon known capable of slaying the KASSERT monster. The mighty blade of MPSAFE was free again!
After much planning and many failed attacks, the developer was able to slay the KASSERT monster and all the bits wanting to be transferred were able to be.
For a day and for a night there were celebrations. Much food and ale was consumed until finally everyone was asleep, and the music and lights were finally turned off. In the morning a great clean up was needed and while the developer was cleaning off the shiny, happy and working USB network the original USB network was accidentally reconnected. Oh no, the KASSERT monster has returned! Lock your doors and hide your children.
The developer quickly pulled out MPSAFE again, and once again the KASSERT monster was slain, though the face of this monster was different to the previous monster. The developer then searched and searched for surely they were more KASSERT monsters to be found. Indeed, many many others were found, though they retreated to safety after two more of their number were slain by the mighty MPSAFE.
The developer called upon his friends Shared and Code and with them forged a new weapon against the KASSERT monster, using the mighty MPSAFE in ways unheard of before. After much research and planning, and with the help of some friends, the USBNET was born. All the angels and all the birds of the world were said to sing all at once at this moment, for the USBNET would bring happiness to both the Code Deletionist and the Code Sharers, bound to war against each other from time immemorial.
With this new USBNET the developer was able to blaze a trail across the landscape, searching out each KASSERT monster lurking in every USB network corner. All told, fourteen faces of KASSERT monster were found and the developer and his friends have slain seven of these faces, with the remaining seven under attack, life looks grim for them.
The other, similar, system is safe now. Turns out that MPSAFE also has cleared up the sleeping problem using the cousins, NET and FDT in a tight, dual-blade combination.
Let the world rejoice, for soon the KASSERT monster will be no more!
--mrg @ 2019-08-11
tl;dr:
i fixed many bugs across several USB ethernet adapters and got sick of fixing the same bug across multiple drivers so made common code for them to use instead. the original 4 drivers fixed were axen(4), axe(4), cdce(4), and ure(4). the current list of fixed drivers, at time of writing, includes smsc(4), udav(4) and urndis(4). all drivers except umb(4) are ported but either not tested or not yet working with the usbnet(9) framework.
update 2019-09-02:
all 13 known working drivers converted and will be present in netbsd 9.
Once upon a time a developer wrote a temperature sensor driver for one system and decided to port it to another, similar, system. For days and then weeks, the developer waited and waited for the other, similar, system to arrive.
One day, joy of joys, the other, similar, system arrived. A National Day of Celebration commenced, and the porting effort began. Over hours, perhaps even as many as five hours of time, the sensors were finally able to tell you whether they were hot or not.
This other, similar, system suddenly was purposeless and was pondering what else life could provide when the Remote Server task popped up and said "Hey, first media file is free", and sadly, this other, similar, system tried its first media file, and then purchased many, many more media files, and suddenly this other, similar, system was suddenly hooked.
Unfortunately, this other, similar, system had a problem talking on the network without falling asleep on the job, so the developer says "let's try a USB network instead!", and initially this seemed like a good idea. Many bits were transferred over USB, but soon whispers of a lurking monster, known to developers, experience or otherwise, as KASSERT, were heard and soon found common.
The developer attempted other USB network as the other, similar, system was destined to be flown many thousands of miles away soon, but the only other option was similarly plagued by the KASSERT monster. The developer reached into his Bag Of Holding and pulled out a magical weapon known capable of slaying the KASSERT monster. The mighty blade of MPSAFE was free again!
After much planning and many failed attacks, the developer was able to slay the KASSERT monster and all the bits wanting to be transferred were able to be.
For a day and for a night there were celebrations. Much food and ale was consumed until finally everyone was asleep, and the music and lights were finally turned off. In the morning a great clean up was needed and while the developer was cleaning off the shiny, happy and working USB network the original USB network was accidentally reconnected. Oh no, the KASSERT monster has returned! Lock your doors and hide your children.
The developer quickly pulled out MPSAFE again, and once again the KASSERT monster was slain, though the face of this monster was different to the previous monster. The developer then searched and searched for surely they were more KASSERT monsters to be found. Indeed, many many others were found, though they retreated to safety after two more of their number were slain by the mighty MPSAFE.
The developer called upon his friends Shared and Code and with them forged a new weapon against the KASSERT monster, using the mighty MPSAFE in ways unheard of before. After much research and planning, and with the help of some friends, the USBNET was born. All the angels and all the birds of the world were said to sing all at once at this moment, for the USBNET would bring happiness to both the Code Deletionist and the Code Sharers, bound to war against each other from time immemorial.
With this new USBNET the developer was able to blaze a trail across the landscape, searching out each KASSERT monster lurking in every USB network corner. All told, fourteen faces of KASSERT monster were found and the developer and his friends have slain seven of these faces, with the remaining seven under attack, life looks grim for them.
The other, similar, system is safe now. Turns out that MPSAFE also has cleared up the sleeping problem using the cousins, NET and FDT in a tight, dual-blade combination.
Let the world rejoice, for soon the KASSERT monster will be no more!
--mrg @ 2019-08-11
tl;dr:
i fixed many bugs across several USB ethernet adapters and got sick of fixing the same bug across multiple drivers so made common code for them to use instead. the original 4 drivers fixed were axen(4), axe(4), cdce(4), and ure(4). the current list of fixed drivers, at time of writing, includes smsc(4), udav(4) and urndis(4). all drivers except umb(4) are ported but either not tested or not yet working with the usbnet(9) framework.
update 2019-09-02:
all 13 known working drivers converted and will be present in netbsd 9.
This report was written by Naveen Narayanan as part of Google Summer of Code 2019.
This report encompasses the progress of the project during the third coding period. You can make sense of the overall progress of the project by going through the first evaluation report and second evaluation report.
WINE on amd64
Wine-4.4 (released on Mar 2019) is working fine on amd64
and i386. I have been able to use a script as a workaround for
the problem of setting LD_LIBRARY_PATH. My patch for
setting guard size to 0 and hence, precluding Wine from
segfaulting, that got upstreamed, can be
found here.
I have updated the package to the latest development version of
Wine which is Wine-4.13 (released on Aug 2019). I have
added support to Wine pkgsrc packages to run tests using make
test, and at the time of writing, they are failing. I have also
noticed them fail on Linux non-pkgsrc environment and hence, will
require further investigation. Initially, they were disabled
owing to pkgsrc setting FORTIFY_SOURCE which is a macro that
provides support for detecting buffer overflows. In pkgsrc, the
wip/wine* packages honor PKGSRC_USE_FORTIFY variable passing
_FORTIFY_SOURCE macro accordingly. Programs compiled with
FORTIFY_SOURCE substitute wrappers for commonly used libc
functions that don't do bounds checking regularly, but could in some
cases. Wine unconditionally disables that via their configure
script because for some platforms that triggered false positives
in the past. However, in my experience, no false positive were
found.
Running tests on Wine-4.13 throws errors as you can see below:
mode64# make test /usr/pkgsrc/wip/wine64-dev/work/wine-4.13/tools/runtest -q -P wine -T ../../.. -M adsldp.dll -p adsldp_test.exe.so sysinfo && touch sysinfo.ok /usr/pkg/emul/netbsd32/lib/wine/libwine.so.1: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/ntdll.dll.so: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/kernel32.dll.so: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/kernelbase.dll.so: text relocations 002a:err:winediag:SECUR32_initNTLMSP ntlm_auth was not found or is outdated. Make sure that ntlm_auth >= 3.0.25 is in your path. Usually, you can find it in the winbind package of your distribution. 002a:fixme:advapi:LsaOpenPolicy ((null),0x22f150,0x00000001,0x22f120) stub 002a:fixme:security:GetWindowsAccountDomainSid (000000000022EEA0 000000000002B028 000000000022EE9C): semi-stub 002a:fixme:advapi:LsaClose (0xcafe) stub 002a:fixme:advapi:LsaOpenPolicy ((null),0x22f0e0,0x00000001,0x22f0b0) stub 002a:fixme:security:GetWindowsAccountDomainSid (000000000022EE30 000000000002B318 000000000022EE2C): semi-stub 002a:fixme:advapi:LsaClose (0xcafe) stub 002a:fixme:advapi:LsaOpenPolicy ((null),0x22f0e0,0x00000001,0x22f0b0) stub 002a:fixme:security:GetWindowsAccountDomainSid (000000000022EE30 000000000002B318 000000000022EE2C): semi-stub 002a:fixme:advapi:LsaClose (0xcafe) stub 002a:fixme:adsldp:sysinfo_get_UserName 0000000000021670,000000000022F0C8: stub 002a:fixme:advapi:LsaOpenPolicy ((null),0x22f980,0x00000001,0x22f950) stub 002a:fixme:security:GetWindowsAccountDomainSid (000000000022F6D0 000000000002B318 000000000022F6CC): semi-stub 002a:fixme:advapi:LsaClose (0xcafe) stub 002a:fixme:advapi:LsaOpenPolicy ((null),0x22f980,0x00000001,0x22f950) stub 002a:fixme:security:GetWindowsAccountDomainSid (000000000022F6D0 000000000002B318 000000000022F6CC): semi-stub 002a:fixme:advapi:LsaClose (0xcafe) stub 002a:fixme:adsldp:sysinfo_get_UserName 0000000000021670,000000000022FB48: stub /usr/pkgsrc/wip/wine64-dev/work/wine-4.13/tools/runtest -q -P wine -T ../../.. -M advapi32.dll -p advapi32_test.exe.so cred && touch cred.ok /usr/pkg/emul/netbsd32/lib/wine/libwine.so.1: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/ntdll.dll.so: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/kernel32.dll.so: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/kernelbase.dll.so: text relocations 002e:fixme:cred:CredReadW unhandled type -1 002e:fixme:cred:CredReadW unhandled flags 0xdeadbeef 002e:err:cred:CredWriteW bad username L"winetest" 002e:err:cred:CredWriteW bad username (null) 002e:err:cred:CredWriteW bad username (null) 002e:fixme:cred:CredDeleteW unhandled type -1 002e:fixme:cred:CredDeleteW unhandled flags 0xdeadbeef 002e:fixme:cred:CredReadDomainCredentialsW (0x1b1d0, 0x0, 0x22fa50, 0x22f908) stub 002e:fixme:cred:CredReadDomainCredentialsW (0x1b1d0, 0x0, 0x22fa50, 0x22f908) stub 002e:fixme:cred:CredReadDomainCredentialsW (0x1b3c0, 0x0, 0x22fa50, 0x22f908) stub cred.c:820: Tests skipped: CRED_TYPE_DOMAIN_VISIBLE_PASSWORD credentials are not supported or are disabled. Skipping 002e:fixme:cred:CredIsMarshaledCredentialW BinaryBlobCredential not checked 002e:fixme:cred:CredIsMarshaledCredentialW BinaryBlobCredential not checked /usr/pkgsrc/wip/wine64-dev/work/wine-4.13/tools/runtest -q -P wine -T ../../.. -M advapi32.dll -p advapi32_test.exe.so crypt && touch crypt.ok /usr/pkg/emul/netbsd32/lib/wine/libwine.so.1: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/ntdll.dll.so: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/kernel32.dll.so: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/kernelbase.dll.so: text relocations /usr/pkgsrc/wip/wine64-dev/work/wine-4.13/tools/runtest -q -P wine -T ../../.. -M advapi32.dll -p advapi32_test.exe.so crypt_lmhash && touch crypt_lmhash.ok /usr/pkg/emul/netbsd32/lib/wine/libwine.so.1: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/ntdll.dll.so: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/kernel32.dll.so: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/kernelbase.dll.so: text relocations /usr/pkgsrc/wip/wine64-dev/work/wine-4.13/tools/runtest -q -P wine -T ../../.. -M advapi32.dll -p advapi32_test.exe.so crypt_md4 && touch crypt_md4.ok /usr/pkg/emul/netbsd32/lib/wine/libwine.so.1: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/ntdll.dll.so: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/kernel32.dll.so: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/kernelbase.dll.so: text relocations /usr/pkgsrc/wip/wine64-dev/work/wine-4.13/tools/runtest -q -P wine -T ../../.. -M advapi32.dll -p advapi32_test.exe.so crypt_md5 && touch crypt_md5.ok /usr/pkg/emul/netbsd32/lib/wine/libwine.so.1: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/ntdll.dll.so: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/kernel32.dll.so: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/kernelbase.dll.so: text relocations /usr/pkgsrc/wip/wine64-dev/work/wine-4.13/tools/runtest -q -P wine -T ../../.. -M advapi32.dll -p advapi32_test.exe.so crypt_sha && touch crypt_sha.ok /usr/pkg/emul/netbsd32/lib/wine/libwine.so.1: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/ntdll.dll.so: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/kernel32.dll.so: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/kernelbase.dll.so: text relocations /usr/pkgsrc/wip/wine64-dev/work/wine-4.13/tools/runtest -q -P wine -T ../../.. -M advapi32.dll -p advapi32_test.exe.so eventlog && touch eventlog.ok /usr/pkg/emul/netbsd32/lib/wine/libwine.so.1: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/ntdll.dll.so: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/kernel32.dll.so: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/kernelbase.dll.so: text relocations 0046:fixme:advapi:CloseEventLog (0x0) stub 0046:fixme:advapi:CloseEventLog (0x0) stub 0046:fixme:advapi:OpenEventLogW ((null),(null)) stub 0046:fixme:advapi:OpenEventLogW (L"IDontExist",(null)) stub 0046:fixme:advapi:OpenEventLogW (L"IDontExist",L"deadbeef") stub 0046:fixme:advapi:OpenEventLogW Remote server not supported 0046:fixme:advapi:OpenEventLogW ((null),L"deadbeef") stub 0046:fixme:advapi:CloseEventLog (0xcafe4242) stub 0046:fixme:advapi:CloseEventLog (0xcafe4242) stub 0046:fixme:advapi:OpenEventLogW (L"",L"Application") stub 0046:fixme:advapi:CloseEventLog (0xcafe4242) stub 0046:fixme:advapi:OpenEventLogW ((null),L"Application") stub 0046:fixme:advapi:CloseEventLog (0xcafe4242) stub 0046:fixme:advapi:GetEventLogInformation (0x0, 1, 0x0, 0, 0x0) stub 0046:fixme:advapi:GetEventLogInformation (0x0, 0, 0x0, 0, 0x0) stub 0046:fixme:advapi:OpenEventLogW ((null),L"Application") stub 0046:fixme:advapi:GetEventLogInformation (0xcafe4242, 0, 0x0, 0, 0x0) stub 0046:fixme:advapi:GetEventLogInformation (0xcafe4242, 0, 0x0, 0, 0x22fb40) stub 0046:fixme:advapi:GetEventLogInformation (0xcafe4242, 0, 0x22fb59, 0, 0x0) stub 0046:fixme:advapi:GetEventLogInformation (0xcafe4242, 0, 0x22fb59, 0, 0x22fb40) stub 0046:fixme:advapi:GetEventLogInformation (0xcafe4242, 0, 0x22fb59, 8, 0x22fb40) stub 0046:fixme:advapi:CloseEventLog (0xcafe4242) stub 0046:fixme:advapi:GetNumberOfEventLogRecords (0x0,0x0) stub 0046:fixme:advapi:GetNumberOfEventLogRecords (0x0,0x22fb40) stub 0046:fixme:advapi:OpenEventLogW ((null),L"Application") stub 0046:fixme:advapi:GetNumberOfEventLogRecords (0xcafe4242,0x0) stub 0046:fixme:advapi:GetNumberOfEventLogRecords (0xcafe4242,0x22fb40) stub 0046:fixme:advapi:CloseEventLog (0xcafe4242) stub 0046:fixme:advapi:OpenEventLogW ((null),L"Application") stub 0046:fixme:advapi:BackupEventLogW (0xcafe4242,L"backup.evt") stub 0046:fixme:advapi:CloseEventLog (0xcafe4242) stub 0046:fixme:advapi:OpenBackupEventLogW ((null),L"backup.evt") stub 0046:fixme:advapi:GetNumberOfEventLogRecords (0x0,0x22fb40) stub 0046:fixme:advapi:CloseEventLog (0x0) stub 0046:fixme:advapi:GetOldestEventLogRecord (0x0,0x0) stub 0046:fixme:advapi:GetOldestEventLogRecord (0x0,0x22fb40) stub 0046:fixme:advapi:OpenEventLogW ((null),L"Application") stub 0046:fixme:advapi:GetOldestEventLogRecord (0xcafe4242,0x0) stub 0046:fixme:advapi:GetOldestEventLogRecord (0xcafe4242,0x22fb40) stub 0046:fixme:advapi:CloseEventLog (0xcafe4242) stub 0046:fixme:advapi:OpenEventLogW ((null),L"Application") stub 0046:fixme:advapi:BackupEventLogW (0xcafe4242,L"backup.evt") stub 0046:fixme:advapi:CloseEventLog (0xcafe4242) stub 0046:fixme:advapi:OpenBackupEventLogW ((null),L"backup.evt") stub 0046:fixme:advapi:GetOldestEventLogRecord (0x0,0x22fb40) stub 0046:fixme:advapi:CloseEventLog (0x0) stub 0046:fixme:advapi:BackupEventLogW (0x0,(null)) stub 0046:fixme:advapi:BackupEventLogW (0x0,L"backup.evt") stub 0046:fixme:advapi:OpenEventLogW ((null),L"Application") stub 0046:fixme:advapi:BackupEventLogW (0xcafe4242,(null)) stub 0046:fixme:advapi:BackupEventLogW (0xcafe4242,L"backup.evt") stub 0046:fixme:advapi:BackupEventLogW (0xcafe4242,L"backup.evt") stub 0046:fixme:advapi:CloseEventLog (0xcafe4242) stub 0046:fixme:advapi:OpenBackupEventLogW ((null),L"backup.evt") stub 0046:fixme:advapi:BackupEventLogW (0x0,L"backup2.evt") stub 0046:fixme:advapi:CloseEventLog (0x0) stub 0046:fixme:advapi:OpenBackupEventLogW ((null),(null)) stub 0046:fixme:advapi:OpenBackupEventLogW ((null),L"idontexist.evt") stub 0046:fixme:advapi:OpenBackupEventLogW (L"IDontExist",(null)) stub 0046:fixme:advapi:OpenBackupEventLogW (L"IDontExist",L"idontexist.evt") stub 0046:fixme:advapi:OpenBackupEventLogW Remote server not supported 0046:fixme:advapi:OpenEventLogW ((null),L"Application") stub 0046:fixme:advapi:BackupEventLogW (0xcafe4242,L"backup.evt") stub 0046:fixme:advapi:CloseEventLog (0xcafe4242) stub eventlog.c:546: Tests skipped: We don't have a backup eventlog to work with 0046:fixme:advapi:ReadEventLogA (0x0,0x00000000,0x00000000,0x0,0x00000000,0x0,0x0) stub 0046:fixme:advapi:ReadEventLogA (0x0,0x00000000,0x00000000,0x0,0x00000000,0x22fa88,0x0) stub 0046:fixme:advapi:ReadEventLogA (0x0,0x00000000,0x00000000,0x0,0x00000000,0x0,0x22fa8c) stub 0046:fixme:advapi:ReadEventLogA (0x0,0x00000000,0x00000000,0x0,0x00000000,0x22fa88,0x22fa8c) stub 0046:fixme:advapi:ReadEventLogA (0x0,0x00000005,0x00000000,0x0,0x00000000,0x0,0x0) stub 0046:fixme:advapi:ReadEventLogA (0x0,0x00000005,0x00000000,0x0,0x00000000,0x22fa88,0x22fa8c) stub 0046:fixme:advapi:ReadEventLogA (0x0,0x00000005,0x00000000,0x0,0x00000038,0x22fa88,0x22fa8c) stub 0046:fixme:advapi:ReadEventLogA (0x0,0x00000005,0x00000000,0x1b3d0,0x00000038,0x22fa88,0x22fa8c) stub 0046:fixme:advapi:OpenEventLogW ((null),L"Application") stub 0046:fixme:advapi:ReadEventLogA (0xcafe4242,0x00000000,0x00000000,0x1b3d0,0x00000038,0x22fa88,0x22fa8c) stub 0046:fixme:advapi:ReadEventLogA (0xcafe4242,0x00000001,0x00000000,0x1b3d0,0x00000038,0x22fa88,0x22fa8c) stub 0046:fixme:advapi:ReadEventLogA (0xcafe4242,0x00000002,0x00000000,0x1b3d0,0x00000038,0x22fa88,0x22fa8c) stub 0046:fixme:advapi:ReadEventLogA (0xcafe4242,0x0000000d,0x00000000,0x1b3d0,0x00000038,0x22fa88,0x22fa8c) stub 0046:fixme:advapi:ReadEventLogA (0xcafe4242,0x0000000e,0x00000000,0x1b3d0,0x00000038,0x22fa88,0x22fa8c) stub 0046:fixme:advapi:ReadEventLogA (0xcafe4242,0x00000007,0x00000000,0x1b3d0,0x00000038,0x22fa88,0x22fa8c) stub 0046:fixme:advapi:GetNumberOfEventLogRecords (0xcafe4242,0x22fa84) stub eventlog.c:479: Tests skipped: No records in the 'Application' log 0046:fixme:advapi:CloseEventLog (0xcafe4242) stub 0046:fixme:advapi:ClearEventLogW (0x0,(null)) stub 0046:fixme:advapi:OpenEventLogW ((null),L"Application") stub 0046:fixme:advapi:BackupEventLogW (0xcafe4242,L"backup.evt") stub 0046:fixme:advapi:CloseEventLog (0xcafe4242) stub 0046:fixme:advapi:ClearEventLogW (0x0,L"backup.evt") stub 0046:fixme:advapi:OpenBackupEventLogW ((null),L"backup.evt") stub 0046:fixme:advapi:ClearEventLogW (0x0,L"backup.evt") stub 0046:fixme:advapi:ClearEventLogW (0x0,L"backup2.evt") stub 0046:fixme:advapi:ClearEventLogW (0x0,(null)) stub 0046:fixme:advapi:CloseEventLog (0x0) stub 0046:fixme:advapi:OpenEventLogW ((null),L"Wine") stub 0046:fixme:advapi:GetNumberOfEventLogRecords (0xcafe4242,0x22fa80) stub 0046:fixme:advapi:ReportEventA (0xcafe4242,0x0020,0x0000,0x00000000,0x0,0x0000,0x00000000,0x0,0x0): stub 0046:fixme:advapi:ReadEventLogA (0xcafe4242,0x00000005,0x00000000,0x1b1e0,0x00000038,0x22fa88,0x22fa8c) stub 0046:fixme:advapi:ClearEventLogW (0xcafe4242,(null)) stub 0046:fixme:advapi:CloseEventLog (0xcafe4242) stub 0046:fixme:advapi:RegisterEventSourceA ((null),"Wine"): stub 0046:fixme:advapi:RegisterEventSourceW (L"",L"Wine"): stub 0046:fixme:advapi:ReportEventA (0xcafe4242,0x0004,0x0001,0x00000001,0x0,0x0001,0x00000000,0x7f7ff72beb00,0x0): stub 0046:fixme:advapi:ReportEventW (0xcafe4242,0x0004,0x0001,0x00000001,0x0,0x0001,0x00000000,0x1b1e0,0x0): stub 0046:fixme:advapi:GetNumberOfEventLogRecords (0xcafe4242,0x22fa80) stub 0046:fixme:advapi:GetOldestEventLogRecord (0xcafe4242,0x22fa8c) stub 0046:fixme:advapi:DeregisterEventSource (0xcafe4242) stub 0046:fixme:advapi:OpenEventLogW ((null),L"WineSrc") stub 0046:fixme:advapi:ReportEventA (0xcafe4242,0x0002,0x0001,0x00000002,0x0,0x0000,0x00000000,0x0,0x0): stub 0046:fixme:advapi:GetNumberOfEventLogRecords (0xcafe4242,0x22fa80) stub 0046:fixme:advapi:GetOldestEventLogRecord (0xcafe4242,0x22fa8c) stub 0046:fixme:advapi:CloseEventLog (0xcafe4242) stub 0046:fixme:advapi:RegisterEventSourceA ((null),"WineSrc1"): stub 0046:fixme:advapi:RegisterEventSourceW (L"",L"WineSrc1"): stub 0046:fixme:advapi:ReportEventA (0xcafe4242,0x0010,0x0001,0x00000003,0x0,0x0002,0x00000000,0x7f7ff72beaf0,0x0): stub 0046:fixme:advapi:ReportEventW (0xcafe4242,0x0010,0x0001,0x00000003,0x0,0x0002,0x00000000,0x1b1e0,0x0): stub 0046:fixme:advapi:GetNumberOfEventLogRecords (0xcafe4242,0x22fa80) stub 0046:fixme:advapi:GetOldestEventLogRecord (0xcafe4242,0x22fa8c) stub 0046:fixme:advapi:DeregisterEventSource (0xcafe4242) stub 0046:fixme:advapi:OpenEventLogW ((null),L"WineSrc20") stub 0046:fixme:advapi:ReportEventA (0xcafe4242,0x0001,0x0001,0x00000004,0x0,0x0000,0x00000000,0x0,0x0): stub 0046:fixme:advapi:GetNumberOfEventLogRecords (0xcafe4242,0x22fa80) stub 0046:fixme:advapi:GetOldestEventLogRecord (0xcafe4242,0x22fa8c) stub 0046:fixme:advapi:CloseEventLog (0xcafe4242) stub 0046:fixme:advapi:RegisterEventSourceA ((null),"WineSrc300"): stub 0046:fixme:advapi:RegisterEventSourceW (L"",L"WineSrc300"): stub 0046:fixme:advapi:ReportEventA (0xcafe4242,0x0002,0x0001,0x00000005,0x0,0x0001,0x00000000,0x7f7ff72beb00,0x0): stub 0046:fixme:advapi:ReportEventW (0xcafe4242,0x0002,0x0001,0x00000005,0x0,0x0001,0x00000000,0x1b1e0,0x0): stub 0046:fixme:advapi:GetNumberOfEventLogRecords (0xcafe4242,0x22fa80) stub 0046:fixme:advapi:GetOldestEventLogRecord (0xcafe4242,0x22fa8c) stub 0046:fixme:advapi:DeregisterEventSource (0xcafe4242) stub 0046:fixme:advapi:OpenEventLogW ((null),L"Wine") stub 0046:fixme:advapi:ReportEventA (0xcafe4242,0x0000,0x0002,0x00000006,0x1b3d0,0x0002,0x00000000,0x7f7ff72beaf0,0x0): stub 0046:fixme:advapi:ReportEventW (0xcafe4242,0x0000,0x0002,0x00000006,0x1b3d0,0x0002,0x00000000,0x1b1e0,0x0): stub 0046:fixme:advapi:GetNumberOfEventLogRecords (0xcafe4242,0x22fa80) stub 0046:fixme:advapi:GetOldestEventLogRecord (0xcafe4242,0x22fa8c) stub 0046:fixme:advapi:CloseEventLog (0xcafe4242) stub 0046:fixme:advapi:RegisterEventSourceA ((null),"WineSrc"): stub 0046:fixme:advapi:RegisterEventSourceW (L"",L"WineSrc"): stub 0046:fixme:advapi:ReportEventA (0xcafe4242,0x0010,0x0002,0x00000007,0x1b3d0,0x0000,0x00000000,0x0,0x0): stub 0046:fixme:advapi:GetNumberOfEventLogRecords (0xcafe4242,0x22fa80) stub 0046:fixme:advapi:GetOldestEventLogRecord (0xcafe4242,0x22fa8c) stub 0046:fixme:advapi:DeregisterEventSource (0xcafe4242) stub 0046:fixme:advapi:OpenEventLogW ((null),L"WineSrc1") stub 0046:fixme:advapi:ReportEventA (0xcafe4242,0x0008,0x0002,0x00000008,0x1b3d0,0x0002,0x00000000,0x7f7ff72beaf0,0x0): stub 0046:fixme:advapi:ReportEventW (0xcafe4242,0x0008,0x0002,0x00000008,0x1b3d0,0x0002,0x00000000,0x1b1e0,0x0): stub 0046:fixme:advapi:GetNumberOfEventLogRecords (0xcafe4242,0x22fa80) stub 0046:fixme:advapi:GetOldestEventLogRecord (0xcafe4242,0x22fa8c) stub 0046:fixme:advapi:CloseEventLog (0xcafe4242) stub 0046:fixme:advapi:RegisterEventSourceA ((null),"WineSrc20"): stub 0046:fixme:advapi:RegisterEventSourceW (L"",L"WineSrc20"): stub 0046:fixme:advapi:ReportEventA (0xcafe4242,0x0002,0x0002,0x00000009,0x1b3d0,0x0000,0x00000000,0x0,0x0): stub 0046:fixme:advapi:GetNumberOfEventLogRecords (0xcafe4242,0x22fa80) stub 0046:fixme:advapi:GetOldestEventLogRecord (0xcafe4242,0x22fa8c) stub 0046:fixme:advapi:DeregisterEventSource (0xcafe4242) stub 0046:fixme:advapi:OpenEventLogW ((null),L"WineSrc300") stub 0046:fixme:advapi:ReportEventA (0xcafe4242,0x0001,0x0002,0x0000000a,0x1b3d0,0x0001,0x00000000,0x7f7ff72beb00,0x0): stub 0046:fixme:advapi:ReportEventW (0xcafe4242,0x0001,0x0002,0x0000000a,0x1b3d0,0x0001,0x00000000,0x1b1e0,0x0): stub 0046:err:eventlog:ReportEventW L"First string" 0046:fixme:advapi:GetNumberOfEventLogRecords (0xcafe4242,0x22fa80) stub 0046:fixme:advapi:GetOldestEventLogRecord (0xcafe4242,0x22fa8c) stub 0046:fixme:advapi:CloseEventLog (0xcafe4242) stub 0046:fixme:advapi:OpenEventLogW ((null),L"Wine") stub 0046:fixme:advapi:GetNumberOfEventLogRecords (0xcafe4242,0x22fa80) stub 0046:fixme:advapi:CloseEventLog (0xcafe4242) stub eventlog.c:889: Tests skipped: No events were written to the eventlog 0046:fixme:advapi:StartTraceA (0x22fb40, "wine", 0x1b1e0) stub 0046:fixme:advapi:StartTraceA (0x22fb40, "this name is too long", 0x1b1e0) stub 0046:fixme:advapi:StartTraceA (0x22fb40, "wine", 0x0) stub 0046:fixme:advapi:StartTraceA (0x0, "wine", 0x1b1e0) stub 0046:fixme:advapi:StartTraceA (0x22fb40, "wine", 0x1b1e0) stub 0046:fixme:advapi:StartTraceA (0x22fb40, "wine", 0x1b1e0) stub 0046:fixme:advapi:StartTraceA (0x22fb40, "wine", 0x1b1e0) stub 0046:fixme:advapi:StartTraceA (0x22fb40, "wine", 0x1b1e0) stub 0046:fixme:advapi:StartTraceA (0x22fb40, "wine", 0x1b1e0) stub 0046:fixme:advapi:StartTraceA (0x22fb40, "wine", 0x1b1e0) stub 0046:fixme:advapi:StartTraceA (0x22fb40, "wine", 0x1b1e0) stub 0046:fixme:advapi:ControlTraceA (cafe4242, "wine", 0x1b1e0, 1) stub /usr/pkgsrc/wip/wine64-dev/work/wine-4.13/tools/runtest -q -P wine -T ../../.. -M advapi32.dll -p advapi32_test.exe.so lsa && touch lsa.ok /usr/pkg/emul/netbsd32/lib/wine/libwine.so.1: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/ntdll.dll.so: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/kernel32.dll.so: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/kernelbase.dll.so: text relocations 004a:fixme:advapi:LsaOpenPolicy ((null),0x22f960,0x000f0fff,0x22f930) stub 004a:fixme:security:GetWindowsAccountDomainSid (000000000022F690 0000000000019078 000000000022F68C): semi-stub 004a:fixme:advapi:LsaEnumerateAccountRights (0xcafe,0x22fa20,0x22f990,0x22f92c) stub 004a:fixme:advapi:LsaClose (0xcafe) stub 004a:fixme:advapi:LsaOpenPolicy ((null),0x22fb10,0x000f0fff,0x22fae8) stub 004a:fixme:advapi:LsaClose (0xcafe) stub 004a:fixme:advapi:LsaOpenPolicy ((null),0x22fb40,0x00000800,0x22fb00) stub 004a:fixme:advapi:LsaClose (0xcafe) stub 004a:fixme:advapi:LsaOpenPolicy ((null),0x22fb40,0x00000800,0x22fb08) stub /usr/pkgsrc/wip/wine64-dev/work/wine-4.13/tools/runtest -q -P wine -T ../../.. -M advapi32.dll -p advapi32_test.exe.so registry && touch registry.ok /usr/pkg/emul/netbsd32/lib/wine/libwine.so.1: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/ntdll.dll.so: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/kernel32.dll.so: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/kernelbase.dll.so: text relocations 004e:fixme:reg:RegQueryInfoKeyA security argument not supported. 004e:fixme:reg:RegQueryInfoKeyW security argument not supported. 004e:fixme:reg:RegQueryInfoKeyA security argument not supported. 004e:fixme:reg:RegQueryInfoKeyW security argument not supported. 004e:fixme:reg:RegQueryInfoKeyA security argument not supported. 004e:fixme:reg:RegQueryInfoKeyW security argument not supported. registry.c:2850: Tests skipped: HKCR key merging not supported registry.c:3146: Tests skipped: HKCR key merging not supported 004e:fixme:winspool:PerfOpen (null): stub 004e:fixme:winspool:PerfCollect L"Global", 0x22ead8, 0x22eabc, 0x22eac0: stub 004e:fixme:winspool:PerfClose stub 004e:fixme:winspool:PerfOpen (null): stub 004e:fixme:winspool:PerfCollect L"invalid counter name", 0x22ead8, 0x22eabc, 0x22eac0: stub 004e:fixme:winspool:PerfClose stub registry.c:4032: Test failed: [ 9] expected 1168, got 2 registry.c:4032: Test failed: [10] expected 1814, got 2 *** Error code 2 Stop. make[1]: stopped in /usr/pkgsrc/wip/wine64-dev/work/wine-4.13/wine64/dlls/advapi32/tests *** Error code 1 Stop. make: stopped in /usr/pkgsrc/wip/wine64-dev/work/wine-4.13/wine64
Running programs on Wine
You can find obligatory screenshots of Wine-4.4/4.13 on amd64/i386 below:
 010 Editor (Professional Text/Hex Editor) on Wine-4.13 (amd64)
010 Editor (Professional Text/Hex Editor) on Wine-4.13 (amd64) Notepad++ on Wine-4.4 (i386)
Notepad++ on Wine-4.4 (i386) Pinball on Wine-4.13 (amd64)
Pinball on Wine-4.13 (amd64)How to run Wine on NetBSD/amd64
- Compile kernel with USER_LDT enabled.
- Install kernel.
- Clone wip repo.
cd /usr/pkgsrc/wip/wine64; make install(for 4.4) or
cd /usr/pkgsrc/wip/wine64-dev; make install(for 4.13)wine notepad
Future Plans
Wine requires the kernel option
USER_LDT
to be able to run 32-bit applications on amd64 - facilitated by
WoW64. Presently, this feature isn't enabled by
default on NetBSD and hence, the kernel has to be compiled with
USER_LDT enabled. I will work on getting the tests to pass and
finding a better approach to deal with LD_LIBRARY_PATH issue.
In addition to that, I shall work on incorporating a NetBSD VM to Wine
Test Bot infrastructure so we can preclude Wine from getting out of
shape on NetBSD in the future (work in progress).
Summary
Presently, Wine-4.4 and Wine-4.13 are working fine on amd64/i386. I
have been able to meet all the goals as per my original plan. I
would like to attribute the success to the support provided by my
mentors @leot, @maya and @christos. I would also like to thank my
mentor @maxv for solving the conflict between SVS and USER_LDT
kernel options. I intend to maintain the packages
wine64/wine64-dev/wine32 for the foreseeable future. As stated
above, I shall try to set up a NetBSD VM as Wine Test Bot for
purpose of CI. Once again, thanks to Google for enabling me to do
what I love.
Source Code
This report was written by Naveen Narayanan as part of Google Summer of Code 2019.
This report encompasses the progress of the project during the third coding period. You can make sense of the overall progress of the project by going through the first evaluation report and second evaluation report.
WINE on amd64
Wine-4.4 (released on Mar 2019) is working fine on amd64
and i386. I have been able to use a script as a workaround for
the problem of setting LD_LIBRARY_PATH. My patch for
setting guard size to 0 and hence, precluding Wine from
segfaulting, that got upstreamed, can be
found here.
I have updated the package to the latest development version of
Wine which is Wine-4.13 (released on Aug 2019). I have
added support to Wine pkgsrc packages to run tests using make
test, and at the time of writing, they are failing. I have also
noticed them fail on Linux non-pkgsrc environment and hence, will
require further investigation. Initially, they were disabled
owing to pkgsrc setting FORTIFY_SOURCE which is a macro that
provides support for detecting buffer overflows. In pkgsrc, the
wip/wine* packages honor PKGSRC_USE_FORTIFY variable passing
_FORTIFY_SOURCE macro accordingly. Programs compiled with
FORTIFY_SOURCE substitute wrappers for commonly used libc
functions that don't do bounds checking regularly, but could in some
cases. Wine unconditionally disables that via their configure
script because for some platforms that triggered false positives
in the past. However, in my experience, no false positive were
found.
Running tests on Wine-4.13 throws errors as you can see below:
mode64# make test /usr/pkgsrc/wip/wine64-dev/work/wine-4.13/tools/runtest -q -P wine -T ../../.. -M adsldp.dll -p adsldp_test.exe.so sysinfo && touch sysinfo.ok /usr/pkg/emul/netbsd32/lib/wine/libwine.so.1: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/ntdll.dll.so: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/kernel32.dll.so: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/kernelbase.dll.so: text relocations 002a:err:winediag:SECUR32_initNTLMSP ntlm_auth was not found or is outdated. Make sure that ntlm_auth >= 3.0.25 is in your path. Usually, you can find it in the winbind package of your distribution. 002a:fixme:advapi:LsaOpenPolicy ((null),0x22f150,0x00000001,0x22f120) stub 002a:fixme:security:GetWindowsAccountDomainSid (000000000022EEA0 000000000002B028 000000000022EE9C): semi-stub 002a:fixme:advapi:LsaClose (0xcafe) stub 002a:fixme:advapi:LsaOpenPolicy ((null),0x22f0e0,0x00000001,0x22f0b0) stub 002a:fixme:security:GetWindowsAccountDomainSid (000000000022EE30 000000000002B318 000000000022EE2C): semi-stub 002a:fixme:advapi:LsaClose (0xcafe) stub 002a:fixme:advapi:LsaOpenPolicy ((null),0x22f0e0,0x00000001,0x22f0b0) stub 002a:fixme:security:GetWindowsAccountDomainSid (000000000022EE30 000000000002B318 000000000022EE2C): semi-stub 002a:fixme:advapi:LsaClose (0xcafe) stub 002a:fixme:adsldp:sysinfo_get_UserName 0000000000021670,000000000022F0C8: stub 002a:fixme:advapi:LsaOpenPolicy ((null),0x22f980,0x00000001,0x22f950) stub 002a:fixme:security:GetWindowsAccountDomainSid (000000000022F6D0 000000000002B318 000000000022F6CC): semi-stub 002a:fixme:advapi:LsaClose (0xcafe) stub 002a:fixme:advapi:LsaOpenPolicy ((null),0x22f980,0x00000001,0x22f950) stub 002a:fixme:security:GetWindowsAccountDomainSid (000000000022F6D0 000000000002B318 000000000022F6CC): semi-stub 002a:fixme:advapi:LsaClose (0xcafe) stub 002a:fixme:adsldp:sysinfo_get_UserName 0000000000021670,000000000022FB48: stub /usr/pkgsrc/wip/wine64-dev/work/wine-4.13/tools/runtest -q -P wine -T ../../.. -M advapi32.dll -p advapi32_test.exe.so cred && touch cred.ok /usr/pkg/emul/netbsd32/lib/wine/libwine.so.1: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/ntdll.dll.so: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/kernel32.dll.so: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/kernelbase.dll.so: text relocations 002e:fixme:cred:CredReadW unhandled type -1 002e:fixme:cred:CredReadW unhandled flags 0xdeadbeef 002e:err:cred:CredWriteW bad username L"winetest" 002e:err:cred:CredWriteW bad username (null) 002e:err:cred:CredWriteW bad username (null) 002e:fixme:cred:CredDeleteW unhandled type -1 002e:fixme:cred:CredDeleteW unhandled flags 0xdeadbeef 002e:fixme:cred:CredReadDomainCredentialsW (0x1b1d0, 0x0, 0x22fa50, 0x22f908) stub 002e:fixme:cred:CredReadDomainCredentialsW (0x1b1d0, 0x0, 0x22fa50, 0x22f908) stub 002e:fixme:cred:CredReadDomainCredentialsW (0x1b3c0, 0x0, 0x22fa50, 0x22f908) stub cred.c:820: Tests skipped: CRED_TYPE_DOMAIN_VISIBLE_PASSWORD credentials are not supported or are disabled. Skipping 002e:fixme:cred:CredIsMarshaledCredentialW BinaryBlobCredential not checked 002e:fixme:cred:CredIsMarshaledCredentialW BinaryBlobCredential not checked /usr/pkgsrc/wip/wine64-dev/work/wine-4.13/tools/runtest -q -P wine -T ../../.. -M advapi32.dll -p advapi32_test.exe.so crypt && touch crypt.ok /usr/pkg/emul/netbsd32/lib/wine/libwine.so.1: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/ntdll.dll.so: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/kernel32.dll.so: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/kernelbase.dll.so: text relocations /usr/pkgsrc/wip/wine64-dev/work/wine-4.13/tools/runtest -q -P wine -T ../../.. -M advapi32.dll -p advapi32_test.exe.so crypt_lmhash && touch crypt_lmhash.ok /usr/pkg/emul/netbsd32/lib/wine/libwine.so.1: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/ntdll.dll.so: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/kernel32.dll.so: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/kernelbase.dll.so: text relocations /usr/pkgsrc/wip/wine64-dev/work/wine-4.13/tools/runtest -q -P wine -T ../../.. -M advapi32.dll -p advapi32_test.exe.so crypt_md4 && touch crypt_md4.ok /usr/pkg/emul/netbsd32/lib/wine/libwine.so.1: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/ntdll.dll.so: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/kernel32.dll.so: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/kernelbase.dll.so: text relocations /usr/pkgsrc/wip/wine64-dev/work/wine-4.13/tools/runtest -q -P wine -T ../../.. -M advapi32.dll -p advapi32_test.exe.so crypt_md5 && touch crypt_md5.ok /usr/pkg/emul/netbsd32/lib/wine/libwine.so.1: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/ntdll.dll.so: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/kernel32.dll.so: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/kernelbase.dll.so: text relocations /usr/pkgsrc/wip/wine64-dev/work/wine-4.13/tools/runtest -q -P wine -T ../../.. -M advapi32.dll -p advapi32_test.exe.so crypt_sha && touch crypt_sha.ok /usr/pkg/emul/netbsd32/lib/wine/libwine.so.1: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/ntdll.dll.so: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/kernel32.dll.so: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/kernelbase.dll.so: text relocations /usr/pkgsrc/wip/wine64-dev/work/wine-4.13/tools/runtest -q -P wine -T ../../.. -M advapi32.dll -p advapi32_test.exe.so eventlog && touch eventlog.ok /usr/pkg/emul/netbsd32/lib/wine/libwine.so.1: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/ntdll.dll.so: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/kernel32.dll.so: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/kernelbase.dll.so: text relocations 0046:fixme:advapi:CloseEventLog (0x0) stub 0046:fixme:advapi:CloseEventLog (0x0) stub 0046:fixme:advapi:OpenEventLogW ((null),(null)) stub 0046:fixme:advapi:OpenEventLogW (L"IDontExist",(null)) stub 0046:fixme:advapi:OpenEventLogW (L"IDontExist",L"deadbeef") stub 0046:fixme:advapi:OpenEventLogW Remote server not supported 0046:fixme:advapi:OpenEventLogW ((null),L"deadbeef") stub 0046:fixme:advapi:CloseEventLog (0xcafe4242) stub 0046:fixme:advapi:CloseEventLog (0xcafe4242) stub 0046:fixme:advapi:OpenEventLogW (L"",L"Application") stub 0046:fixme:advapi:CloseEventLog (0xcafe4242) stub 0046:fixme:advapi:OpenEventLogW ((null),L"Application") stub 0046:fixme:advapi:CloseEventLog (0xcafe4242) stub 0046:fixme:advapi:GetEventLogInformation (0x0, 1, 0x0, 0, 0x0) stub 0046:fixme:advapi:GetEventLogInformation (0x0, 0, 0x0, 0, 0x0) stub 0046:fixme:advapi:OpenEventLogW ((null),L"Application") stub 0046:fixme:advapi:GetEventLogInformation (0xcafe4242, 0, 0x0, 0, 0x0) stub 0046:fixme:advapi:GetEventLogInformation (0xcafe4242, 0, 0x0, 0, 0x22fb40) stub 0046:fixme:advapi:GetEventLogInformation (0xcafe4242, 0, 0x22fb59, 0, 0x0) stub 0046:fixme:advapi:GetEventLogInformation (0xcafe4242, 0, 0x22fb59, 0, 0x22fb40) stub 0046:fixme:advapi:GetEventLogInformation (0xcafe4242, 0, 0x22fb59, 8, 0x22fb40) stub 0046:fixme:advapi:CloseEventLog (0xcafe4242) stub 0046:fixme:advapi:GetNumberOfEventLogRecords (0x0,0x0) stub 0046:fixme:advapi:GetNumberOfEventLogRecords (0x0,0x22fb40) stub 0046:fixme:advapi:OpenEventLogW ((null),L"Application") stub 0046:fixme:advapi:GetNumberOfEventLogRecords (0xcafe4242,0x0) stub 0046:fixme:advapi:GetNumberOfEventLogRecords (0xcafe4242,0x22fb40) stub 0046:fixme:advapi:CloseEventLog (0xcafe4242) stub 0046:fixme:advapi:OpenEventLogW ((null),L"Application") stub 0046:fixme:advapi:BackupEventLogW (0xcafe4242,L"backup.evt") stub 0046:fixme:advapi:CloseEventLog (0xcafe4242) stub 0046:fixme:advapi:OpenBackupEventLogW ((null),L"backup.evt") stub 0046:fixme:advapi:GetNumberOfEventLogRecords (0x0,0x22fb40) stub 0046:fixme:advapi:CloseEventLog (0x0) stub 0046:fixme:advapi:GetOldestEventLogRecord (0x0,0x0) stub 0046:fixme:advapi:GetOldestEventLogRecord (0x0,0x22fb40) stub 0046:fixme:advapi:OpenEventLogW ((null),L"Application") stub 0046:fixme:advapi:GetOldestEventLogRecord (0xcafe4242,0x0) stub 0046:fixme:advapi:GetOldestEventLogRecord (0xcafe4242,0x22fb40) stub 0046:fixme:advapi:CloseEventLog (0xcafe4242) stub 0046:fixme:advapi:OpenEventLogW ((null),L"Application") stub 0046:fixme:advapi:BackupEventLogW (0xcafe4242,L"backup.evt") stub 0046:fixme:advapi:CloseEventLog (0xcafe4242) stub 0046:fixme:advapi:OpenBackupEventLogW ((null),L"backup.evt") stub 0046:fixme:advapi:GetOldestEventLogRecord (0x0,0x22fb40) stub 0046:fixme:advapi:CloseEventLog (0x0) stub 0046:fixme:advapi:BackupEventLogW (0x0,(null)) stub 0046:fixme:advapi:BackupEventLogW (0x0,L"backup.evt") stub 0046:fixme:advapi:OpenEventLogW ((null),L"Application") stub 0046:fixme:advapi:BackupEventLogW (0xcafe4242,(null)) stub 0046:fixme:advapi:BackupEventLogW (0xcafe4242,L"backup.evt") stub 0046:fixme:advapi:BackupEventLogW (0xcafe4242,L"backup.evt") stub 0046:fixme:advapi:CloseEventLog (0xcafe4242) stub 0046:fixme:advapi:OpenBackupEventLogW ((null),L"backup.evt") stub 0046:fixme:advapi:BackupEventLogW (0x0,L"backup2.evt") stub 0046:fixme:advapi:CloseEventLog (0x0) stub 0046:fixme:advapi:OpenBackupEventLogW ((null),(null)) stub 0046:fixme:advapi:OpenBackupEventLogW ((null),L"idontexist.evt") stub 0046:fixme:advapi:OpenBackupEventLogW (L"IDontExist",(null)) stub 0046:fixme:advapi:OpenBackupEventLogW (L"IDontExist",L"idontexist.evt") stub 0046:fixme:advapi:OpenBackupEventLogW Remote server not supported 0046:fixme:advapi:OpenEventLogW ((null),L"Application") stub 0046:fixme:advapi:BackupEventLogW (0xcafe4242,L"backup.evt") stub 0046:fixme:advapi:CloseEventLog (0xcafe4242) stub eventlog.c:546: Tests skipped: We don't have a backup eventlog to work with 0046:fixme:advapi:ReadEventLogA (0x0,0x00000000,0x00000000,0x0,0x00000000,0x0,0x0) stub 0046:fixme:advapi:ReadEventLogA (0x0,0x00000000,0x00000000,0x0,0x00000000,0x22fa88,0x0) stub 0046:fixme:advapi:ReadEventLogA (0x0,0x00000000,0x00000000,0x0,0x00000000,0x0,0x22fa8c) stub 0046:fixme:advapi:ReadEventLogA (0x0,0x00000000,0x00000000,0x0,0x00000000,0x22fa88,0x22fa8c) stub 0046:fixme:advapi:ReadEventLogA (0x0,0x00000005,0x00000000,0x0,0x00000000,0x0,0x0) stub 0046:fixme:advapi:ReadEventLogA (0x0,0x00000005,0x00000000,0x0,0x00000000,0x22fa88,0x22fa8c) stub 0046:fixme:advapi:ReadEventLogA (0x0,0x00000005,0x00000000,0x0,0x00000038,0x22fa88,0x22fa8c) stub 0046:fixme:advapi:ReadEventLogA (0x0,0x00000005,0x00000000,0x1b3d0,0x00000038,0x22fa88,0x22fa8c) stub 0046:fixme:advapi:OpenEventLogW ((null),L"Application") stub 0046:fixme:advapi:ReadEventLogA (0xcafe4242,0x00000000,0x00000000,0x1b3d0,0x00000038,0x22fa88,0x22fa8c) stub 0046:fixme:advapi:ReadEventLogA (0xcafe4242,0x00000001,0x00000000,0x1b3d0,0x00000038,0x22fa88,0x22fa8c) stub 0046:fixme:advapi:ReadEventLogA (0xcafe4242,0x00000002,0x00000000,0x1b3d0,0x00000038,0x22fa88,0x22fa8c) stub 0046:fixme:advapi:ReadEventLogA (0xcafe4242,0x0000000d,0x00000000,0x1b3d0,0x00000038,0x22fa88,0x22fa8c) stub 0046:fixme:advapi:ReadEventLogA (0xcafe4242,0x0000000e,0x00000000,0x1b3d0,0x00000038,0x22fa88,0x22fa8c) stub 0046:fixme:advapi:ReadEventLogA (0xcafe4242,0x00000007,0x00000000,0x1b3d0,0x00000038,0x22fa88,0x22fa8c) stub 0046:fixme:advapi:GetNumberOfEventLogRecords (0xcafe4242,0x22fa84) stub eventlog.c:479: Tests skipped: No records in the 'Application' log 0046:fixme:advapi:CloseEventLog (0xcafe4242) stub 0046:fixme:advapi:ClearEventLogW (0x0,(null)) stub 0046:fixme:advapi:OpenEventLogW ((null),L"Application") stub 0046:fixme:advapi:BackupEventLogW (0xcafe4242,L"backup.evt") stub 0046:fixme:advapi:CloseEventLog (0xcafe4242) stub 0046:fixme:advapi:ClearEventLogW (0x0,L"backup.evt") stub 0046:fixme:advapi:OpenBackupEventLogW ((null),L"backup.evt") stub 0046:fixme:advapi:ClearEventLogW (0x0,L"backup.evt") stub 0046:fixme:advapi:ClearEventLogW (0x0,L"backup2.evt") stub 0046:fixme:advapi:ClearEventLogW (0x0,(null)) stub 0046:fixme:advapi:CloseEventLog (0x0) stub 0046:fixme:advapi:OpenEventLogW ((null),L"Wine") stub 0046:fixme:advapi:GetNumberOfEventLogRecords (0xcafe4242,0x22fa80) stub 0046:fixme:advapi:ReportEventA (0xcafe4242,0x0020,0x0000,0x00000000,0x0,0x0000,0x00000000,0x0,0x0): stub 0046:fixme:advapi:ReadEventLogA (0xcafe4242,0x00000005,0x00000000,0x1b1e0,0x00000038,0x22fa88,0x22fa8c) stub 0046:fixme:advapi:ClearEventLogW (0xcafe4242,(null)) stub 0046:fixme:advapi:CloseEventLog (0xcafe4242) stub 0046:fixme:advapi:RegisterEventSourceA ((null),"Wine"): stub 0046:fixme:advapi:RegisterEventSourceW (L"",L"Wine"): stub 0046:fixme:advapi:ReportEventA (0xcafe4242,0x0004,0x0001,0x00000001,0x0,0x0001,0x00000000,0x7f7ff72beb00,0x0): stub 0046:fixme:advapi:ReportEventW (0xcafe4242,0x0004,0x0001,0x00000001,0x0,0x0001,0x00000000,0x1b1e0,0x0): stub 0046:fixme:advapi:GetNumberOfEventLogRecords (0xcafe4242,0x22fa80) stub 0046:fixme:advapi:GetOldestEventLogRecord (0xcafe4242,0x22fa8c) stub 0046:fixme:advapi:DeregisterEventSource (0xcafe4242) stub 0046:fixme:advapi:OpenEventLogW ((null),L"WineSrc") stub 0046:fixme:advapi:ReportEventA (0xcafe4242,0x0002,0x0001,0x00000002,0x0,0x0000,0x00000000,0x0,0x0): stub 0046:fixme:advapi:GetNumberOfEventLogRecords (0xcafe4242,0x22fa80) stub 0046:fixme:advapi:GetOldestEventLogRecord (0xcafe4242,0x22fa8c) stub 0046:fixme:advapi:CloseEventLog (0xcafe4242) stub 0046:fixme:advapi:RegisterEventSourceA ((null),"WineSrc1"): stub 0046:fixme:advapi:RegisterEventSourceW (L"",L"WineSrc1"): stub 0046:fixme:advapi:ReportEventA (0xcafe4242,0x0010,0x0001,0x00000003,0x0,0x0002,0x00000000,0x7f7ff72beaf0,0x0): stub 0046:fixme:advapi:ReportEventW (0xcafe4242,0x0010,0x0001,0x00000003,0x0,0x0002,0x00000000,0x1b1e0,0x0): stub 0046:fixme:advapi:GetNumberOfEventLogRecords (0xcafe4242,0x22fa80) stub 0046:fixme:advapi:GetOldestEventLogRecord (0xcafe4242,0x22fa8c) stub 0046:fixme:advapi:DeregisterEventSource (0xcafe4242) stub 0046:fixme:advapi:OpenEventLogW ((null),L"WineSrc20") stub 0046:fixme:advapi:ReportEventA (0xcafe4242,0x0001,0x0001,0x00000004,0x0,0x0000,0x00000000,0x0,0x0): stub 0046:fixme:advapi:GetNumberOfEventLogRecords (0xcafe4242,0x22fa80) stub 0046:fixme:advapi:GetOldestEventLogRecord (0xcafe4242,0x22fa8c) stub 0046:fixme:advapi:CloseEventLog (0xcafe4242) stub 0046:fixme:advapi:RegisterEventSourceA ((null),"WineSrc300"): stub 0046:fixme:advapi:RegisterEventSourceW (L"",L"WineSrc300"): stub 0046:fixme:advapi:ReportEventA (0xcafe4242,0x0002,0x0001,0x00000005,0x0,0x0001,0x00000000,0x7f7ff72beb00,0x0): stub 0046:fixme:advapi:ReportEventW (0xcafe4242,0x0002,0x0001,0x00000005,0x0,0x0001,0x00000000,0x1b1e0,0x0): stub 0046:fixme:advapi:GetNumberOfEventLogRecords (0xcafe4242,0x22fa80) stub 0046:fixme:advapi:GetOldestEventLogRecord (0xcafe4242,0x22fa8c) stub 0046:fixme:advapi:DeregisterEventSource (0xcafe4242) stub 0046:fixme:advapi:OpenEventLogW ((null),L"Wine") stub 0046:fixme:advapi:ReportEventA (0xcafe4242,0x0000,0x0002,0x00000006,0x1b3d0,0x0002,0x00000000,0x7f7ff72beaf0,0x0): stub 0046:fixme:advapi:ReportEventW (0xcafe4242,0x0000,0x0002,0x00000006,0x1b3d0,0x0002,0x00000000,0x1b1e0,0x0): stub 0046:fixme:advapi:GetNumberOfEventLogRecords (0xcafe4242,0x22fa80) stub 0046:fixme:advapi:GetOldestEventLogRecord (0xcafe4242,0x22fa8c) stub 0046:fixme:advapi:CloseEventLog (0xcafe4242) stub 0046:fixme:advapi:RegisterEventSourceA ((null),"WineSrc"): stub 0046:fixme:advapi:RegisterEventSourceW (L"",L"WineSrc"): stub 0046:fixme:advapi:ReportEventA (0xcafe4242,0x0010,0x0002,0x00000007,0x1b3d0,0x0000,0x00000000,0x0,0x0): stub 0046:fixme:advapi:GetNumberOfEventLogRecords (0xcafe4242,0x22fa80) stub 0046:fixme:advapi:GetOldestEventLogRecord (0xcafe4242,0x22fa8c) stub 0046:fixme:advapi:DeregisterEventSource (0xcafe4242) stub 0046:fixme:advapi:OpenEventLogW ((null),L"WineSrc1") stub 0046:fixme:advapi:ReportEventA (0xcafe4242,0x0008,0x0002,0x00000008,0x1b3d0,0x0002,0x00000000,0x7f7ff72beaf0,0x0): stub 0046:fixme:advapi:ReportEventW (0xcafe4242,0x0008,0x0002,0x00000008,0x1b3d0,0x0002,0x00000000,0x1b1e0,0x0): stub 0046:fixme:advapi:GetNumberOfEventLogRecords (0xcafe4242,0x22fa80) stub 0046:fixme:advapi:GetOldestEventLogRecord (0xcafe4242,0x22fa8c) stub 0046:fixme:advapi:CloseEventLog (0xcafe4242) stub 0046:fixme:advapi:RegisterEventSourceA ((null),"WineSrc20"): stub 0046:fixme:advapi:RegisterEventSourceW (L"",L"WineSrc20"): stub 0046:fixme:advapi:ReportEventA (0xcafe4242,0x0002,0x0002,0x00000009,0x1b3d0,0x0000,0x00000000,0x0,0x0): stub 0046:fixme:advapi:GetNumberOfEventLogRecords (0xcafe4242,0x22fa80) stub 0046:fixme:advapi:GetOldestEventLogRecord (0xcafe4242,0x22fa8c) stub 0046:fixme:advapi:DeregisterEventSource (0xcafe4242) stub 0046:fixme:advapi:OpenEventLogW ((null),L"WineSrc300") stub 0046:fixme:advapi:ReportEventA (0xcafe4242,0x0001,0x0002,0x0000000a,0x1b3d0,0x0001,0x00000000,0x7f7ff72beb00,0x0): stub 0046:fixme:advapi:ReportEventW (0xcafe4242,0x0001,0x0002,0x0000000a,0x1b3d0,0x0001,0x00000000,0x1b1e0,0x0): stub 0046:err:eventlog:ReportEventW L"First string" 0046:fixme:advapi:GetNumberOfEventLogRecords (0xcafe4242,0x22fa80) stub 0046:fixme:advapi:GetOldestEventLogRecord (0xcafe4242,0x22fa8c) stub 0046:fixme:advapi:CloseEventLog (0xcafe4242) stub 0046:fixme:advapi:OpenEventLogW ((null),L"Wine") stub 0046:fixme:advapi:GetNumberOfEventLogRecords (0xcafe4242,0x22fa80) stub 0046:fixme:advapi:CloseEventLog (0xcafe4242) stub eventlog.c:889: Tests skipped: No events were written to the eventlog 0046:fixme:advapi:StartTraceA (0x22fb40, "wine", 0x1b1e0) stub 0046:fixme:advapi:StartTraceA (0x22fb40, "this name is too long", 0x1b1e0) stub 0046:fixme:advapi:StartTraceA (0x22fb40, "wine", 0x0) stub 0046:fixme:advapi:StartTraceA (0x0, "wine", 0x1b1e0) stub 0046:fixme:advapi:StartTraceA (0x22fb40, "wine", 0x1b1e0) stub 0046:fixme:advapi:StartTraceA (0x22fb40, "wine", 0x1b1e0) stub 0046:fixme:advapi:StartTraceA (0x22fb40, "wine", 0x1b1e0) stub 0046:fixme:advapi:StartTraceA (0x22fb40, "wine", 0x1b1e0) stub 0046:fixme:advapi:StartTraceA (0x22fb40, "wine", 0x1b1e0) stub 0046:fixme:advapi:StartTraceA (0x22fb40, "wine", 0x1b1e0) stub 0046:fixme:advapi:StartTraceA (0x22fb40, "wine", 0x1b1e0) stub 0046:fixme:advapi:ControlTraceA (cafe4242, "wine", 0x1b1e0, 1) stub /usr/pkgsrc/wip/wine64-dev/work/wine-4.13/tools/runtest -q -P wine -T ../../.. -M advapi32.dll -p advapi32_test.exe.so lsa && touch lsa.ok /usr/pkg/emul/netbsd32/lib/wine/libwine.so.1: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/ntdll.dll.so: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/kernel32.dll.so: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/kernelbase.dll.so: text relocations 004a:fixme:advapi:LsaOpenPolicy ((null),0x22f960,0x000f0fff,0x22f930) stub 004a:fixme:security:GetWindowsAccountDomainSid (000000000022F690 0000000000019078 000000000022F68C): semi-stub 004a:fixme:advapi:LsaEnumerateAccountRights (0xcafe,0x22fa20,0x22f990,0x22f92c) stub 004a:fixme:advapi:LsaClose (0xcafe) stub 004a:fixme:advapi:LsaOpenPolicy ((null),0x22fb10,0x000f0fff,0x22fae8) stub 004a:fixme:advapi:LsaClose (0xcafe) stub 004a:fixme:advapi:LsaOpenPolicy ((null),0x22fb40,0x00000800,0x22fb00) stub 004a:fixme:advapi:LsaClose (0xcafe) stub 004a:fixme:advapi:LsaOpenPolicy ((null),0x22fb40,0x00000800,0x22fb08) stub /usr/pkgsrc/wip/wine64-dev/work/wine-4.13/tools/runtest -q -P wine -T ../../.. -M advapi32.dll -p advapi32_test.exe.so registry && touch registry.ok /usr/pkg/emul/netbsd32/lib/wine/libwine.so.1: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/ntdll.dll.so: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/kernel32.dll.so: text relocations /usr/pkg/emul/netbsd32/lib/wine/wine/kernelbase.dll.so: text relocations 004e:fixme:reg:RegQueryInfoKeyA security argument not supported. 004e:fixme:reg:RegQueryInfoKeyW security argument not supported. 004e:fixme:reg:RegQueryInfoKeyA security argument not supported. 004e:fixme:reg:RegQueryInfoKeyW security argument not supported. 004e:fixme:reg:RegQueryInfoKeyA security argument not supported. 004e:fixme:reg:RegQueryInfoKeyW security argument not supported. registry.c:2850: Tests skipped: HKCR key merging not supported registry.c:3146: Tests skipped: HKCR key merging not supported 004e:fixme:winspool:PerfOpen (null): stub 004e:fixme:winspool:PerfCollect L"Global", 0x22ead8, 0x22eabc, 0x22eac0: stub 004e:fixme:winspool:PerfClose stub 004e:fixme:winspool:PerfOpen (null): stub 004e:fixme:winspool:PerfCollect L"invalid counter name", 0x22ead8, 0x22eabc, 0x22eac0: stub 004e:fixme:winspool:PerfClose stub registry.c:4032: Test failed: [ 9] expected 1168, got 2 registry.c:4032: Test failed: [10] expected 1814, got 2 *** Error code 2 Stop. make[1]: stopped in /usr/pkgsrc/wip/wine64-dev/work/wine-4.13/wine64/dlls/advapi32/tests *** Error code 1 Stop. make: stopped in /usr/pkgsrc/wip/wine64-dev/work/wine-4.13/wine64
Running programs on Wine
You can find obligatory screenshots of Wine-4.4/4.13 on amd64/i386 below:
010 Editor (Professional Text/Hex Editor) on Wine-4.13 (amd64)
Notepad++ on Wine-4.4 (i386)
Pinball on Wine-4.13 (amd64)How to run Wine on NetBSD/amd64
- Compile kernel with USER_LDT enabled.
- Install kernel.
- Clone wip repo.
cd /usr/pkgsrc/wip/wine64; make install(for 4.4) or
cd /usr/pkgsrc/wip/wine64-dev; make install(for 4.13)wine notepad
Future Plans
Wine requires the kernel option
USER_LDT
to be able to run 32-bit applications on amd64 - facilitated by
WoW64. Presently, this feature isn't enabled by
default on NetBSD and hence, the kernel has to be compiled with
USER_LDT enabled. I will work on getting the tests to pass and
finding a better approach to deal with LD_LIBRARY_PATH issue.
In addition to that, I shall work on incorporating a NetBSD VM to Wine
Test Bot infrastructure so we can preclude Wine from getting out of
shape on NetBSD in the future (work in progress).
Summary
Presently, Wine-4.4 and Wine-4.13 are working fine on amd64/i386. I
have been able to meet all the goals as per my original plan. I
would like to attribute the success to the support provided by my
mentors @leot, @maya and @christos. I would also like to thank my
mentor @maxv for solving the conflict between SVS and USER_LDT
kernel options. I intend to maintain the packages
wine64/wine64-dev/wine32 for the foreseeable future. As stated
above, I shall try to set up a NetBSD VM as Wine Test Bot for
purpose of CI. Once again, thanks to Google for enabling me to do
what I love.
Source Code
This report was prepared by Manikishan Ghantasala as a part of Google Summer of Code 2019
This is the third and final report of the project Add KNF (NetBSD style) clang-format configuration that I have been doing as a part of Google Summer of Code (GSoC) ‘19 with the NetBSD.
You can refer to the first and second reports here:
About the project
ClangFormat is a set of tools to format C/C++/Java/JavaScript/Objective-C/Protobuf code. It is built on top of LibFormat to support workflow in various ways including a standalone tool called clang-format, and editor integrations. It supports a few built-in CodingStyles that include: LLVM, Google, Chromium, Mozilla, Webkit. When the desired code formatting style is different from the available options, the style can be customized using a configuration file. The aim of this project is to add NetBSD KNF support to clang-format and new styles to libFormat that support NetBSD’s style of coding. This would allow us to format NetBSD code by passing `-style=NetBSD` as an argument.
How to use clang-format
While using clang-format one can choose a style from the predefined styles or create a custom style by configuring specific style options.
Use the following command if you are using one of the predefined styles
clang-format filename -style=<Name of the style>
Configuring style with clang-format
clang-format supports two ways to provide custom style options: directly specify style name in the -style= command line option or use -style=file and put style configuration in a .clang-format or _clang-format file in the project’s top directory.
Check Clang-Format Style Options to know how different Style Options works and how to use them.
When specifying configuration in the -style= option, the same configuration is applied for all input files. The format of the configuration is:
-style=’{key1: value1, key2: value2, ...}'
The .clang-format file uses YAML format. An easy way to get a valid .clang-format file containing all configuration options of a certain predefined style is:
clang-format -style=llvm -dump-config > .clang-format
After making required changes to the .clang-format file it can be used as a custom Style by:
clang-format <filename> -style=file
Changes made to clang-format
The following changes were made to the clang-format as a part of adding NetBSD KNF:
New Style options added:
Modifications made to existing styles:
- Modified SortIncludes and IncludeCategories to support NetBSD like includes.
- Modified SpacesBeforeTrailingComments to support block comments.
The new NetBSD Style Configurations:
This is the final configurations for clang-format with modified changes to support NetBSD KNF.
AlignTrailingComments: true
AlwaysBreakAfterReturnType: All
AlignConsecutiveMacros: true
AlignConsecutiveLists: true
BitFieldDeclarationsOnePerLine: true
BreakBeforeBraces: Mozilla
ColumnLimit: 80
ContinuationIndentWidth: 4
Cpp11BracedListStyle: false
FixNamespaceComments: true
IndentCaseLabels: false
IndentWidth: 8
IncludeBlocks: Regroup
IncludeCategories:
- Regex: '^<sys/param\.h>'
Priority: 1
SortPriority: 0
- Regex: '^<sys/types\.h>'
Priority: 1
SortPriority: 1
- Regex: '^<sys.*/'
Priority: 1
SortPriority: 2
- Regex: '^<uvm/'
Priority: 2
SortPriority: 3
- Regex: '^<machine/'
Priority: 3
SortPriority: 4
- Regex: '^<dev/'
Priority: 4
SortPriority: 5
- Regex: '^<net.*/'
Priority: 5
SortPriority: 6
- Regex: '^<protocols/'
Priority: 5
SortPriority: 7
- Regex: '^<(fs|miscfs|msdosfs|nfs|ufs)/'
Priority: 6
SortPriority: 8
- Regex: '^<(x86|amd64|i386|xen)/'
Priority: 7
SortPriority: 8
- Regex: '^<path'
Priority: 9
SortPriority: 11
- Regex: '^<[^/].*\.h'
Priority: 8
SortPriority: 10
- Regex: '^\".*\.h\"'
Priority: 10
SortPriority: 12
SortIncludes: true
SpacesBeforeCpp11BracedList: true
SpacesBeforeTrailingComments: 4
TabWidth: 8
UseTab: Always
Status of each Style Option
Styles Ready to Merge:
1.Modified SortIncludes and IncludeCategories:
Patch: https://reviews.llvm.org/D64695
Styles needing revision
1.BitFieldDeclarationsOnePerLine:
Patch: https://reviews.llvm.org/D63062
Bugs: 1
2.SpacesBeforeTrailingComments supports Block Comments:
Patch: https://reviews.llvm.org/D65648
Remark: I have to discuss more on the cases that Block comments are used but where the Spaces are not to be added before them.
WIP Style
1.AlignConsecutiveListElements:
Commit: https://github.com/sh4nnu/clang/commit/4b4cd45a5f3d211008763f1c0235a22352faa81e
Bugs: 1
About Styles
BitfieldDeclarationsOnePerLine:
Patch: https://reviews.llvm.org/D63062
This style lines up BitField declarations on consecutive lines with correct indentation.
Input:
unsigned int bas :3, hh : 4, jjj : 8;
unsigned int baz:1,
fuz:5,
zap:2;
Output:
unsigned int bas : 3,
hh : 4,
jjj : 8;
unsigned int baz:1,
fuz:5,
zap:2;
Bug: Indentation breaks in the presence of block comments in between.
Input:
unsigned int bas : 3, /* foo */
hh : 4, /* bar */
jjj : 8;
Output:
unsigned int bas : 3, /* foo */
hh : 4, /* bar */
jjj : 8;
Modification for SortIncludes and IncludeCategories:
Patch: https://reviews.llvm.org/D64695
Status: Accepted, and ready to land.
Clang-format has a style option named SortIncludes which sorts the includes in alphabetical order.The IncludeCategories Style allows us to define a custom order for sorting the includes.
It supports POSIX extended regular expressions to assign Categories for includes.
The SortIncludes then sorts the #includes first according to increasing category number and then lexically within each category. When IncludeBlocks is set to Regroup merge multiple #includes blocks together and sort as one. Then split into groups based on category priority.
The problem arises when you want to define the order within each category, which is not supported. In this modification a new field named SortPriority is added, which is optional.
The #includes matching the regexs are sorted according to the values of SortPriority, and Regrouping after sorting is done according to the values of Priority. If SortPriority is not defined it is set to the value of Priority as a default value.
IncludeCategories:
- Regex: ‘<^c/’
Priority: 1
SortPriority: 0
- Regex: ‘^<(a|b)/’
Priority: 1
SortPriority: 1
- Regex: ‘^<(foo)/’
Priority: 2
- Regex: ‘.*’
Priority: 3
Input
#include "exe.h"
#include <a/dee.h>
#include <foo/b.h>
#include <a/bee.h>
#include <exc.h>
#include <b/dee.h>
#include <c/abc.h>
#include <foo/a.h>
Output
#include <c/abc.h>
#include <a/bee.h>
#include <a/dee.h>
#include <b/dee.h>
#include <foo/a.h>
#include <foo/b.h>
#include <exc.h>
#include "exe.h"
As you can observe in the above example the #includes are grouped by different priority and were sorted by different priority. Introduction of this new patch doesn’t affect the old configurations as it will work as the same old SortIncludes if sortPriority is not defined.
Refer to Report 2 for detailed examples on this.
Modification for SpacesBeforeTrailingComments
Patch: https://reviews.llvm.org/D64695
The SpacesBeforeTrailingComments is modified to support Block Comments which was used to support only line comments. The reason for this is block comments have different usage patterns and different exceptional cases. I have tried to exclude cases where some tests doesn’t support spaces before block comments. I have been discussing in the community for getting to know which cases should be included, and which to exclude.
Cases that were excluded due to failing tests:
- If it is a Preprocessor directive,
- If it is followed by a LeftParenthesis
- And if it is after a Template closer
AlignConsecutiveListElements
Status: Work In Progress
This is a new style that aligns elements of consecutive lists in a nested list. The Style is still in work in progress. There are few cases that needed to be covered and fix few bugs.
Input:
keys[] = {
{"all", f_all, 0 },
{ "cbreak", f_cbreak, F_OFFOK },
{"cols", f_columns, F_NEEDARG },
{ "columns", f_columns, F_NEEDARG },
};
Output:
keys[] = { { "all", f_all, 0 },
{ "cbreak", _cbreak, F_OFFOK },
{ "cols", f_columns, F_NEEDARG },
{ "columns", f_columns, F_NEEDARG },
};
Work to be done:
This style option aligns list declarations that are nested inside a list, I would also like to extend this style to align individual single line list declarations that are consecutive.
The problem with this style is the case in which there can be different number of elements for each individual.
Example:
keys[] = { "all", f_all, 0 };
keys2[] = { "cbreak", _cbreak, F_OFFOK };
keys3[] = { "cols", f_columns, F_NEEDARG, 7 };
keys4[] = { "columns", f_columns };
Future Work
Some Style Options that were introduced during this GSoC were made in order to meet all the cases in NetBSD KNF. So they may need some revisions with respect to other languages and coding styles that clang-format supports. I will continue working on this project even after the GSoC period on the style options that are yet to be merged and add new style options if necessary and will get the NetBSD Style merged with upstream which is the final deliverable for the project. I would like to take up the responsibility of maintaining the “NetBSD KNF” support to clang-format.
Summary
Even though officially the GSoC’19 coding period is over, I definitely look forward to keep contributing to this project. This summer has had me digging a lot into the code from CLANG and NetBSD for references for creating or modifying the Style Options. I am pretty much interested to work with NetBSD again, I like being in the community and I would like to improve my skills and learn more about Operating Systems by contributing to this organisation.
I would like to thank my mentors Michal and Christos for their constant support and patient guidance. A huge thanks to both the NetBSD and LLVM community who have been supportive and have helped me whenever I have had trouble. Finally a huge thanks to Google for providing me this opportunity.
This report was prepared by Manikishan Ghantasala as a part of Google Summer of Code 2019
This is the third and final report of the project Add KNF (NetBSD style) clang-format configuration that I have been doing as a part of Google Summer of Code (GSoC) ‘19 with the NetBSD.
You can refer to the first and second reports here:
About the project
ClangFormat is a set of tools to format C/C++/Java/JavaScript/Objective-C/Protobuf code. It is built on top of LibFormat to support workflow in various ways including a standalone tool called clang-format, and editor integrations. It supports a few built-in CodingStyles that include: LLVM, Google, Chromium, Mozilla, Webkit. When the desired code formatting style is different from the available options, the style can be customized using a configuration file. The aim of this project is to add NetBSD KNF support to clang-format and new styles to libFormat that support NetBSD’s style of coding. This would allow us to format NetBSD code by passing `-style=NetBSD` as an argument.
How to use clang-format
While using clang-format one can choose a style from the predefined styles or create a custom style by configuring specific style options.
Use the following command if you are using one of the predefined styles
clang-format filename -style=<Name of the style>
Configuring style with clang-format
clang-format supports two ways to provide custom style options: directly specify style name in the -style= command line option or use -style=file and put style configuration in a .clang-format or _clang-format file in the project’s top directory.
Check Clang-Format Style Options to know how different Style Options works and how to use them.
When specifying configuration in the -style= option, the same configuration is applied for all input files. The format of the configuration is:
-style=’{key1: value1, key2: value2, ...}'
The .clang-format file uses YAML format. An easy way to get a valid .clang-format file containing all configuration options of a certain predefined style is:
clang-format -style=llvm -dump-config > .clang-format
After making required changes to the .clang-format file it can be used as a custom Style by:
clang-format <filename> -style=file
Changes made to clang-format
The following changes were made to the clang-format as a part of adding NetBSD KNF:
New Style options added:
Modifications made to existing styles:
- Modified SortIncludes and IncludeCategories to support NetBSD like includes.
- Modified SpacesBeforeTrailingComments to support block comments.
The new NetBSD Style Configurations:
This is the final configurations for clang-format with modified changes to support NetBSD KNF.
AlignTrailingComments: true
AlwaysBreakAfterReturnType: All
AlignConsecutiveMacros: true
AlignConsecutiveLists: true
BitFieldDeclarationsOnePerLine: true
BreakBeforeBraces: Mozilla
ColumnLimit: 80
ContinuationIndentWidth: 4
Cpp11BracedListStyle: false
FixNamespaceComments: true
IndentCaseLabels: false
IndentWidth: 8
IncludeBlocks: Regroup
IncludeCategories:
- Regex: '^<sys/param\.h>'
Priority: 1
SortPriority: 0
- Regex: '^<sys/types\.h>'
Priority: 1
SortPriority: 1
- Regex: '^<sys.*/'
Priority: 1
SortPriority: 2
- Regex: '^<uvm/'
Priority: 2
SortPriority: 3
- Regex: '^<machine/'
Priority: 3
SortPriority: 4
- Regex: '^<dev/'
Priority: 4
SortPriority: 5
- Regex: '^<net.*/'
Priority: 5
SortPriority: 6
- Regex: '^<protocols/'
Priority: 5
SortPriority: 7
- Regex: '^<(fs|miscfs|msdosfs|nfs|ufs)/'
Priority: 6
SortPriority: 8
- Regex: '^<(x86|amd64|i386|xen)/'
Priority: 7
SortPriority: 8
- Regex: '^<path'
Priority: 9
SortPriority: 11
- Regex: '^<[^/].*\.h'
Priority: 8
SortPriority: 10
- Regex: '^\".*\.h\"'
Priority: 10
SortPriority: 12
SortIncludes: true
SpacesBeforeCpp11BracedList: true
SpacesBeforeTrailingComments: 4
TabWidth: 8
UseTab: Always
Status of each Style Option
Styles Ready to Merge:
1.Modified SortIncludes and IncludeCategories:
Patch: https://reviews.llvm.org/D64695
Styles needing revision
1.BitFieldDeclarationsOnePerLine:
Patch: https://reviews.llvm.org/D63062
Bugs: 1
2.SpacesBeforeTrailingComments supports Block Comments:
Patch: https://reviews.llvm.org/D65648
Remark: I have to discuss more on the cases that Block comments are used but where the Spaces are not to be added before them.
WIP Style
1.AlignConsecutiveListElements:
Commit: https://github.com/sh4nnu/clang/commit/4b4cd45a5f3d211008763f1c0235a22352faa81e
Bugs: 1
About Styles
BitfieldDeclarationsOnePerLine:
Patch: https://reviews.llvm.org/D63062
This style lines up BitField declarations on consecutive lines with correct indentation.
Input:
unsigned int bas :3, hh : 4, jjj : 8;
unsigned int baz:1,
fuz:5,
zap:2;
Output:
unsigned int bas : 3,
hh : 4,
jjj : 8;
unsigned int baz:1,
fuz:5,
zap:2;
Bug: Indentation breaks in the presence of block comments in between.
Input:
unsigned int bas : 3, /* foo */
hh : 4, /* bar */
jjj : 8;
Output:
unsigned int bas : 3, /* foo */
hh : 4, /* bar */
jjj : 8;
Modification for SortIncludes and IncludeCategories:
Patch: https://reviews.llvm.org/D64695
Status: Accepted, and ready to land.
Clang-format has a style option named SortIncludes which sorts the includes in alphabetical order.The IncludeCategories Style allows us to define a custom order for sorting the includes.
It supports POSIX extended regular expressions to assign Categories for includes.
The SortIncludes then sorts the #includes first according to increasing category number and then lexically within each category. When IncludeBlocks is set to Regroup merge multiple #includes blocks together and sort as one. Then split into groups based on category priority.
The problem arises when you want to define the order within each category, which is not supported. In this modification a new field named SortPriority is added, which is optional.
The #includes matching the regexs are sorted according to the values of SortPriority, and Regrouping after sorting is done according to the values of Priority. If SortPriority is not defined it is set to the value of Priority as a default value.
IncludeCategories:
- Regex: ‘<^c/’
Priority: 1
SortPriority: 0
- Regex: ‘^<(a|b)/’
Priority: 1
SortPriority: 1
- Regex: ‘^<(foo)/’
Priority: 2
- Regex: ‘.*’
Priority: 3
Input
#include "exe.h"
#include <a/dee.h>
#include <foo/b.h>
#include <a/bee.h>
#include <exc.h>
#include <b/dee.h>
#include <c/abc.h>
#include <foo/a.h>
Output
#include <c/abc.h>
#include <a/bee.h>
#include <a/dee.h>
#include <b/dee.h>
#include <foo/a.h>
#include <foo/b.h>
#include <exc.h>
#include "exe.h"
As you can observe in the above example the #includes are grouped by different priority and were sorted by different priority. Introduction of this new patch doesn’t affect the old configurations as it will work as the same old SortIncludes if sortPriority is not defined.
Refer to Report 2 for detailed examples on this.
Modification for SpacesBeforeTrailingComments
Patch: https://reviews.llvm.org/D64695
The SpacesBeforeTrailingComments is modified to support Block Comments which was used to support only line comments. The reason for this is block comments have different usage patterns and different exceptional cases. I have tried to exclude cases where some tests doesn’t support spaces before block comments. I have been discussing in the community for getting to know which cases should be included, and which to exclude.
Cases that were excluded due to failing tests:
- If it is a Preprocessor directive,
- If it is followed by a LeftParenthesis
- And if it is after a Template closer
AlignConsecutiveListElements
Status: Work In Progress
This is a new style that aligns elements of consecutive lists in a nested list. The Style is still in work in progress. There are few cases that needed to be covered and fix few bugs.
Input:
keys[] = {
{"all", f_all, 0 },
{ "cbreak", f_cbreak, F_OFFOK },
{"cols", f_columns, F_NEEDARG },
{ "columns", f_columns, F_NEEDARG },
};
Output:
keys[] = { { "all", f_all, 0 },
{ "cbreak", _cbreak, F_OFFOK },
{ "cols", f_columns, F_NEEDARG },
{ "columns", f_columns, F_NEEDARG },
};
Work to be done:
This style option aligns list declarations that are nested inside a list, I would also like to extend this style to align individual single line list declarations that are consecutive.
The problem with this style is the case in which there can be different number of elements for each individual.
Example:
keys[] = { "all", f_all, 0 };
keys2[] = { "cbreak", _cbreak, F_OFFOK };
keys3[] = { "cols", f_columns, F_NEEDARG, 7 };
keys4[] = { "columns", f_columns };
Future Work
Some Style Options that were introduced during this GSoC were made in order to meet all the cases in NetBSD KNF. So they may need some revisions with respect to other languages and coding styles that clang-format supports. I will continue working on this project even after the GSoC period on the style options that are yet to be merged and add new style options if necessary and will get the NetBSD Style merged with upstream which is the final deliverable for the project. I would like to take up the responsibility of maintaining the “NetBSD KNF” support to clang-format.
Summary
Even though officially the GSoC’19 coding period is over, I definitely look forward to keep contributing to this project. This summer has had me digging a lot into the code from CLANG and NetBSD for references for creating or modifying the Style Options. I am pretty much interested to work with NetBSD again, I like being in the community and I would like to improve my skills and learn more about Operating Systems by contributing to this organisation.
I would like to thank my mentors Michal and Christos for their constant support and patient guidance. A huge thanks to both the NetBSD and LLVM community who have been supportive and have helped me whenever I have had trouble. Finally a huge thanks to Google for providing me this opportunity.
This article was prepared by Surya P as a part of Google Summer of Code 2019
To begin with where we left off last time, we were able to fix the suse131 package with this commit.This commit adds the GPU-specific bits to the package. And with that we had direct rendering enabled and working.I tested it out with glxinfo and glxgears applications.

Testing
In order to make sure that applications did not break with this commit,I tried Libreoffice and to no surprise everything ran as expected without any hiccups.
Then I had to make a choice between porting steam and implementing compat_netbsd32 but since steam had lot of dependencies which needed to be resolved and since implementation of compat_netbsd32 had much more priority I started with the implementation of compat_netbsd32.
Implementing compat_netbsd32 DRM ioctls - The Setup
For the Setup I downloaded i386 sets from the official NetBSD site and extracted it in the /emul directory. I ran some arbitrary programs like cat and ls from the emulated netbsd32 directory to make sure everything ran perfectly without any problems. I then tried running the 32bit glxinfo and glxgears application and to no surprise it kept segfaulting. I ktraced the application and identified the DRM ioctl that needed to be implemented.
Implementing compat_netbsd32 DRM ioctls - The Code
There were several functions which were required for the complete working of the compat_netbsd32 DRM ioctl. We implemented each and every function and had the code compiled. We then made sure that the code compiled both as a module and as well as a non module option with which the kernel can be built.I initially tested the code with 32bit glxinfo and glxgears , and the program didn't segfault and ran as expected.
Implementing compat_netbsd32 DRM ioctls - Testing
In order to test the code I built a test application leveraging the api’s provided in libdrm. It is a very simple application which initializes the DRM connection, setup and draws a gradient on screen and exits. I initially ran it against the native amd64 architecture, but to my surprise the application didn't work as expected. After some hours of debugging I realized that there can be only one DRM master and X was already a master. After exiting the X session and running the application, everything ran perfectly for both amd64 as well as i386 architectures.


What is done
- The Drm Ioctls implementation of Netbsd has been tested and verified
- The suse131 package has patched and updated (committed)
- Compat_netbsd32 DRM ioctls has been implemented (Merged)
- Subsequently DRM ioctls for emulated 32bit linux as well
- Created a Test GUI Application for the code (yet to PR)
TODO
- Create an ATF for the code and merge it into the tree
- Read the code, look for bugs and clean it up
- Port Steam and make it available in NetBSD
Conclusion
Completing the tasks listed in the TODO is of highest priority and would be carried over even if it exceeds the GSOC time period.
Last but not the least I would like to thank my mentors @christos and @maya for helping me out and guiding me throughout the process and Google for providing me with such a wonderful opportunity to work with NetBSD community.
This article was prepared by Surya P as a part of Google Summer of Code 2019
To begin with where we left off last time, we were able to fix the suse131 package with this commit.This commit adds the GPU-specific bits to the package. And with that we had direct rendering enabled and working.I tested it out with glxinfo and glxgears applications.
Testing
In order to make sure that applications did not break with this commit,I tried Libreoffice and to no surprise everything ran as expected without any hiccups.
Then I had to make a choice between porting steam and implementing compat_netbsd32 but since steam had lot of dependencies which needed to be resolved and since implementation of compat_netbsd32 had much more priority I started with the implementation of compat_netbsd32.
Implementing compat_netbsd32 DRM ioctls - The Setup
For the Setup I downloaded i386 sets from the official NetBSD site and extracted it in the /emul directory. I ran some arbitrary programs like cat and ls from the emulated netbsd32 directory to make sure everything ran perfectly without any problems. I then tried running the 32bit glxinfo and glxgears application and to no surprise it kept segfaulting. I ktraced the application and identified the DRM ioctl that needed to be implemented.
Implementing compat_netbsd32 DRM ioctls - The Code
There were several functions which were required for the complete working of the compat_netbsd32 DRM ioctl. We implemented each and every function and had the code compiled. We then made sure that the code compiled both as a module and as well as a non module option with which the kernel can be built.I initially tested the code with 32bit glxinfo and glxgears , and the program didn't segfault and ran as expected.
Implementing compat_netbsd32 DRM ioctls - Testing
In order to test the code I built a test application leveraging the api’s provided in libdrm. It is a very simple application which initializes the DRM connection, setup and draws a gradient on screen and exits. I initially ran it against the native amd64 architecture, but to my surprise the application didn't work as expected. After some hours of debugging I realized that there can be only one DRM master and X was already a master. After exiting the X session and running the application, everything ran perfectly for both amd64 as well as i386 architectures.
What is done
- The Drm Ioctls implementation of Netbsd has been tested and verified
- The suse131 package has patched and updated (committed)
- Compat_netbsd32 DRM ioctls has been implemented (Merged)
- Subsequently DRM ioctls for emulated 32bit linux as well
- Created a Test GUI Application for the code (yet to PR)
TODO
- Create an ATF for the code and merge it into the tree
- Read the code, look for bugs and clean it up
- Port Steam and make it available in NetBSD
Conclusion
Completing the tasks listed in the TODO is of highest priority and would be carried over even if it exceeds the GSOC time period.
Last but not the least I would like to thank my mentors @christos and @maya for helping me out and guiding me throughout the process and Google for providing me with such a wonderful opportunity to work with NetBSD community.
This is the third report summarising the work done in the third coding period for the GSoC project of Adapting TriforceAFL for NetBSD kernel syscall fuzzing.
Please also go through the first and second report.
This post also outlines the work done throughout the duration of GSoC, describes the implications of the same and future improvements to come.
Current State
As of now TriforceAFL has been made available in the form of a pkgsrc package (wip/triforceafl). This package allows you to essentially fuzz anything in QEMU’s full system emulation mode using AFL. TriforceNetBSDSyscallFuzzer is built on top of TriforceAFL, specifically to fuzz the NetBSD kernel syscalls. It has also now been made available as wip/triforcenetbsdsyscallfuzzer.
Several minor issues found in the above two packages have now been resolved, and the project restructured.
Issues found include:
- The input generators would also test the the generated inputs, causing several syscalls to be executed which messed up permissions of several other directories and lead to other unwanted consequences. Testing of syscalls has now been disabled as the working ones are specified.
- Directory specified for the BIOS, VGA BIOS and keymaps for QEMU in the runFuzz script was incorrect. This was because wip/triforceafl did not install the specified directory. The package has now been patched to install the
pc-biosdirectory. - The project was structured in a manner where the host was Linux and the target was NetBSD. Since that is no longer the case and the fuzzer is meant to be run on a NetBSD machine, the project was restructured so that everything is now in one directory and there is no longer a need to move files around.
The packages should now work as intended by following the instructions outlined in the README.
The fuzzer was able to detect a few bugs in the last coding period, details can be found in the last report. During this coding period, the Fuzzer was able to detect 79 unique crashes in a period of 2 weeks running on a single machine. The kernel was built with DEBUG + LOCKDEBUG + DIAGNOSTIC. Work is underway to analyse, report and fix the new bugs and to make the process faster.
With an initial analysis on the outputs on the basis of the syscall that lead to the crash, 6 of the above crashes were unique bugs, the rest were duplicates or slight variants, of which 3 have been previously reported.
Here are the backtraces of the new bugs found (The reproducers were run with kUBSan Enabled):
BUG1:
[ 110.4035826] panic: cv_enter,172: uninitialized lock (lock=0xffffe3c1b9
fc0c50, from=ffffffff81a436e9)
[ 110.4035826] cpu0: Begin traceback...
[ 110.4035826] vpanic() at netbsd:vpanic+0x1fd
[ 110.4035826] snprintf() at netbsd:snprintf
[ 110.4035826] lockdebug_locked() at netbsd:lockdebug_locked+0x45e
[ 110.4035826] cv_timedwait_sig() at netbsd:cv_timedwait_sig+0xe7
[ 110.4035826] lfs_segwait() at netbsd:lfs_segwait+0x6e
[ 110.4035826] sys___lfs_segwait50() at netbsd:sys___lfs_segwait50+0xe2
[ 110.4035826] sys___syscall() at netbsd:sys___syscall+0x121
[ 110.4035826] syscall() at netbsd:syscall+0x1a5
[ 110.4035826] --- syscall (number 198) ---
[ 110.4035826] 40261a:
[ 110.4035826] cpu0: End traceback...
[ 110.4035826] fatal breakpoint trap in supervisor mode
[ 110.4035826] trap type 1 code 0 rip 0xffffffff8021ddf5 cs 0x8 rflags 0x282 cr2
0x73f454b70000 ilevel 0x8 rsp 0xffff8a0068390d70
[ 110.4035826] curlwp 0xffffe3c1efc556a0 pid 709.1 lowest kstack 0xffff8a006838d
2c0
Stopped in pid 709.1 (driver) at netbsd:breakpoint+0x5: leave
db{0}> bt
breakpoint() at netbsd:breakpoint+0x5
vpanic() at netbsd:vpanic+0x1fd
snprintf() at netbsd:snprintf
lockdebug_locked() at netbsd:lockdebug_locked+0x45e
cv_timedwait_sig() at netbsd:cv_timedwait_sig+0xe7
lfs_segwait() at netbsd:lfs_segwait+0x6e
sys___lfs_segwait50() at netbsd:sys___lfs_segwait50+0xe2
sys___syscall() at netbsd:sys___syscall+0x121
syscall() at netbsd:syscall+0x1a5
--- syscall (number 198) ---
40261a:
BUG2:
[ 161.4877660] panic: LOCKDEBUG: Mutex error: rw_vector_enter,296: spin lock hel
d
[ 161.4877660] cpu0: Begin traceback...
[ 161.4877660] vpanic() at netbsd:vpanic+0x1fd
[ 161.4877660] snprintf() at netbsd:snprintf
[ 161.4877660] lockdebug_abort1() at netbsd:lockdebug_abort1+0x115
[ 161.4877660] rw_enter() at netbsd:rw_enter+0x645
[ 161.4877660] uvm_fault_internal() at netbsd:uvm_fault_internal+0x1c5
[ 161.4877660] trap() at netbsd:trap+0xa71
[ 161.4877660] --- trap (number 6) ---
[ 161.4877660] config_devalloc() at netbsd:config_devalloc+0x644
[ 161.4877660] config_attach_pseudo() at netbsd:config_attach_pseudo+0x1c
[ 161.4877660] vndopen() at netbsd:vndopen+0x1f3
[ 161.4877660] cdev_open() at netbsd:cdev_open+0x12d
[ 161.4877660] spec_open() at netbsd:spec_open+0x2d0
[ 161.4877660] VOP_OPEN() at netbsd:VOP_OPEN+0xba
[ 161.4877660] vn_open() at netbsd:vn_open+0x434
[ 161.4877660] sys_ktrace() at netbsd:sys_ktrace+0x1ec
[ 161.4877660] sys___syscall() at netbsd:sys___syscall+0x121
[ 161.4877660] syscall() at netbsd:syscall+0x1a5
[ 161.4877660] --- syscall (number 198) ---
[ 161.4877660] 40261a:
[ 161.4877660] cpu0: End traceback...
[ 161.4877660] fatal breakpoint trap in supervisor mode
[ 161.4877660] trap type 1 code 0 rip 0xffffffff8021ddf5 cs 0x8 rflags 0x286 cr2
0xfffffffffffff800 ilevel 0x8 rsp 0xffff9c80683cd4f0
[ 161.4877660] curlwp 0xfffffcbcda7d36a0 pid 41.1 lowest kstack 0xffff9c80683ca2
c0
db{0}> bt
breakpoint() at netbsd:breakpoint+0x5
vpanic() at netbsd:vpanic+0x1fd
snprintf() at netbsd:snprintf
lockdebug_abort1() at netbsd:lockdebug_abort1+0x115
rw_enter() at netbsd:rw_enter+0x645
uvm_fault_internal() at netbsd:uvm_fault_internal+0x1c5
trap() at netbsd:trap+0xa71
--- trap (number 6) ---
config_devalloc() at netbsd:config_devalloc+0x644
config_attach_pseudo() at netbsd:config_attach_pseudo+0x1c
vndopen() at netbsd:vndopen+0x1f3
cdev_open() at netbsd:cdev_open+0x12d
spec_open() at netbsd:spec_open+0x2d0
VOP_OPEN() at netbsd:VOP_OPEN+0xba
vn_open() at netbsd:vn_open+0x434
sys_ktrace() at netbsd:sys_ktrace+0x1ec
sys___syscall() at netbsd:sys___syscall+0x121
syscall() at netbsd:syscall+0x1a5
--- syscall (number 198) ---
40261a:
BUG3:
[ 350.9942146] UBSan: Undefined Behavior in /home/ubuntu/triforce/kernel/
src/sys/kern/kern_ktrace.c:1398:2, member access within misaligned address 0x2b0
000002a for type 'struct ktr_desc' which requires 8 byte alignment
[ 351.0025346] uvm_fault(0xffffffff85b73100, 0x2b00000000, 1) -> e
[ 351.0025346] fatal page fault in supervisor mode
[ 351.0025346] trap type 6 code 0 rip 0xffffffff81b9dbf9 cs 0x8 rflags 0x286 cr2
0x2b00000032 ilevel 0 rsp 0xffff8780684d7fb0
[ 351.0025346] curlwp 0xffffa992128116e0 pid 0.54 lowest kstack 0xffff8780684d42
c0
kernel: page fault trap, code=0
Stopped in pid 0.54 (system) at netbsd:ktrace_thread+0x1fd: cmpq %rbx,8(%
r12)
db{0}> bt
ktrace_thread() at netbsd:ktrace_thread+0x1fd
Reproducing Crashes
Right now the best way to reproduce a bug detected is to use the Fuzzer’s driver program itself:
./driver -tv < crash_file
The crash_file can be found in the outputs directory and is a custom file format made for the driver.
Memory allocation and Socket Creation remain to be added to the reproducer generator(genRepro) highlighted in the previous post and will be prioritised in the future.
Implications
Considering that we have a working fuzzer now, it is a good time to analyse how effective TriforceAFL is compared to other fuzzers.
Recently Syzkaller has been really effective in finding bugs in NetBSD. As shown in the below diagrams, both TriforceAFL and Syzkaller create multiple instances of the system to be fuzzed, gather coverage data, mutate input accordingly and continue fuzzing, but there are several differences in the way they work.
TriforceAFL
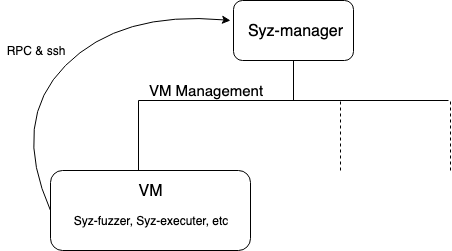
Syzkaller
Key differences between the two include:
- KCOV
Syzkaller relies on the KCOV module for coverage data in NetBSD whereas TriforceAFL gets coverage information from its modified version of QEMU. - VMs
Syzkaller creates multiple VM’s and manages them with syz-manager. Whereas TriforceAFL simply forks the VM for each testcase. - Communication
Syzkaller uses RPC and ssh to communicate with the VMs whereas TriforceAFL uses a custom hypercall. - Hardware Acceleration
Syzkaller can use hardware acceleration to run the VMs at native speeds, whereas TriforceAFL can only utilize QEMU’s full system emulation mode, as it relies on it for coverage data.
These differences lead to very different results. To get a perspective, here are some stats from syzkaller, which can be found on the syzbot dashboard.
| Bugs Found | Upstream | Fixed |
|---|---|---|
| 57 | 37 | 20 |
Comparatively in 1st Weekend of Fuzzing:
| Bugs Found | |
|---|---|
| Syzkaller | 18 |
| TriforceAFL | 3 |
- Compared to syzkaller, the number of bugs found by TriforceAFL in the first few days were significantly less, but nevertheless TriforceAFL was able to find variants of bugs found by syzkaller and 1 which was different with simpler reproducers.
- Going by the stats provided by Syzbot and AFL, Syzkaller does ~80 execs / min whereas TriforceAFL can do ~1500 execs / min on average, Although this statistic is without any of the sanitizers enabled for TriforceAFL and kASan enabled for Syzkaller.
- TriforceAFL has an advantage when it comes to the fact that it does not rely on KCOV for coverage data. This means it can get coverage data for fuzzing other interfaces easily too. This will be beneficial when we move onto Network and USB Fuzzing. Issues have been found with KCOV where in certain cases the fuzzer lost track of the kernel trace, especially in networking where after enqueuing a networking packet the fuzzer lost track as the packet was then handled by some other thread. Coverage data gathered using TriforceAFL will not be sensitive to this, considering that noise from the kernel is handled in some way to an extent.
- Efforts were made in the original design of TriforceAFL to make the traces as deterministic as possible at a basic block level. To quote from this article: Sometimes QEMU starts executing a basic block and then gets interrupted. It may then re-execute the block from the start or translate a portion of the block that wasn't yet executed and execute that. This introduced non-determinism. To reduce the non-determinism, cpu-exec.c was altered to disable QEMU's "chaining" feature, and moved AFL's tracing feature to cpu_tb_exec to trace a basic block only after it has been executed to completion. Although nothing has been specifically done to reduce noise from the kernel, such as disabling coverage during interrupts.
- TriforceAFL runs 1 fuzzing process per instance, whereas Syzkaller can run upto 32 fuzzing processes. But multiple fuzzing instance can be created with TriforceAFL as detailed in this document to take advantage of parallelization.
- Maxime Villard was also able to rework TriforceNetBSDSyscallFuzzer to now also support compat_netbsd32 kernel. This work will be integrated as soon as possible.
- On the other hand, Syzkaller has syzbot which can be thought of as a 24/7 fuzzing service. TriforceAFL does not have a such a service or a dedicated server for fuzzing.
A service like this will surely be advantageous in the future, but it is still a bit too early to set up one. To truly efficiently utilize such a service, it would be better to improve TriforceAFL in all ways possible first.
Targets to be met before a 24/7 fuzzing service is setup, include but are not limited to:
- Automatic initial Analysis & Report Generation
Right now, There is nothing that can automatically perform an initial analysis to detect truly unique crashes and prepare reports with backtraces, this will be required and very helpful. - Better Reproducers
As mentioned before, the generated reproducers do not take care of Memory Allocation and Socket Creation, etc. These need to be included, if a good C reproducer is expected. - Parallel Fuzzing and Management
There is no central interface that summarises the statistics from all fuzzing instances, and manages such instances in case of anomalies/errors. Something like this would be needed for a service that will be run for longer periods of time without supervision. - Updated AFL and QEMU versions
Updated AFL and QEMU might significantly increase executions per second and lead to better mutation of inputs and also decrease the memory requirements. - Fuzzing more Interfaces
Right now we are only fuzzing syscalls, Network and USB Layers are great future prospects, at least prototype versions can be added in the near future.
Future Work
Although GSoC will be officially ending, I am looking forward to continuing the development of TriforceAFL, adding features and making it more effective.
Some improvements that can be expected include:
- Fuzzing different interfaces - Network Fuzzing, USB Fuzzing
- Updating AFL and QEMU versions
- Better Reproducers
- Syzbot like service
A new repo has been created at https://github.com/NetBSD/triforce4netbsd. Collaborative work in the future will be updated here.
Conclusion
TriforceAFL has been successfully adapted for NetBSD and all of the original goals of the GSoC proposal have been met, but the work is far from complete. Work done so far shows great potential, and incremental updates will surely make TriforceAFL a great fuzzer. I am looking forward to continuing the work and making sure that this is the case.
GSoC has been an amazing learning experience! I would like to thank Maxime Villard for taking an active interest in TriforceAFL and for assisting in testing and development. I would like to thank my mentor Kamil Rytarowski for being the guiding force throughout the project and for assisting me whenever I needed help. And finally I would like to thank Google for giving me this wonderful opportunity.
This is the third report summarising the work done in the third coding period for the GSoC project of Adapting TriforceAFL for NetBSD kernel syscall fuzzing.
Please also go through the first and second report.
This post also outlines the work done throughout the duration of GSoC, describes the implications of the same and future improvements to come.
Current State
As of now TriforceAFL has been made available in the form of a pkgsrc package (wip/triforceafl). This package allows you to essentially fuzz anything in QEMU’s full system emulation mode using AFL. TriforceNetBSDSyscallFuzzer is built on top of TriforceAFL, specifically to fuzz the NetBSD kernel syscalls. It has also now been made available as wip/triforcenetbsdsyscallfuzzer.
Several minor issues found in the above two packages have now been resolved, and the project restructured.
Issues found include:
- The input generators would also test the the generated inputs, causing several syscalls to be executed which messed up permissions of several other directories and lead to other unwanted consequences. Testing of syscalls has now been disabled as the working ones are specified.
- Directory specified for the BIOS, VGA BIOS and keymaps for QEMU in the runFuzz script was incorrect. This was because wip/triforceafl did not install the specified directory. The package has now been patched to install the
pc-biosdirectory. - The project was structured in a manner where the host was Linux and the target was NetBSD. Since that is no longer the case and the fuzzer is meant to be run on a NetBSD machine, the project was restructured so that everything is now in one directory and there is no longer a need to move files around.
The packages should now work as intended by following the instructions outlined in the README.
The fuzzer was able to detect a few bugs in the last coding period, details can be found in the last report. During this coding period, the Fuzzer was able to detect 79 unique crashes in a period of 2 weeks running on a single machine. The kernel was built with DEBUG + LOCKDEBUG + DIAGNOSTIC. Work is underway to analyse, report and fix the new bugs and to make the process faster.
With an initial analysis on the outputs on the basis of the syscall that lead to the crash, 6 of the above crashes were unique bugs, the rest were duplicates or slight variants, of which 3 have been previously reported.
Here are the backtraces of the new bugs found (The reproducers were run with kUBSan Enabled):
BUG1:
[ 110.4035826] panic: cv_enter,172: uninitialized lock (lock=0xffffe3c1b9
fc0c50, from=ffffffff81a436e9)
[ 110.4035826] cpu0: Begin traceback...
[ 110.4035826] vpanic() at netbsd:vpanic+0x1fd
[ 110.4035826] snprintf() at netbsd:snprintf
[ 110.4035826] lockdebug_locked() at netbsd:lockdebug_locked+0x45e
[ 110.4035826] cv_timedwait_sig() at netbsd:cv_timedwait_sig+0xe7
[ 110.4035826] lfs_segwait() at netbsd:lfs_segwait+0x6e
[ 110.4035826] sys___lfs_segwait50() at netbsd:sys___lfs_segwait50+0xe2
[ 110.4035826] sys___syscall() at netbsd:sys___syscall+0x121
[ 110.4035826] syscall() at netbsd:syscall+0x1a5
[ 110.4035826] --- syscall (number 198) ---
[ 110.4035826] 40261a:
[ 110.4035826] cpu0: End traceback...
[ 110.4035826] fatal breakpoint trap in supervisor mode
[ 110.4035826] trap type 1 code 0 rip 0xffffffff8021ddf5 cs 0x8 rflags 0x282 cr2
0x73f454b70000 ilevel 0x8 rsp 0xffff8a0068390d70
[ 110.4035826] curlwp 0xffffe3c1efc556a0 pid 709.1 lowest kstack 0xffff8a006838d
2c0
Stopped in pid 709.1 (driver) at netbsd:breakpoint+0x5: leave
db{0}> bt
breakpoint() at netbsd:breakpoint+0x5
vpanic() at netbsd:vpanic+0x1fd
snprintf() at netbsd:snprintf
lockdebug_locked() at netbsd:lockdebug_locked+0x45e
cv_timedwait_sig() at netbsd:cv_timedwait_sig+0xe7
lfs_segwait() at netbsd:lfs_segwait+0x6e
sys___lfs_segwait50() at netbsd:sys___lfs_segwait50+0xe2
sys___syscall() at netbsd:sys___syscall+0x121
syscall() at netbsd:syscall+0x1a5
--- syscall (number 198) ---
40261a:
BUG2:
[ 161.4877660] panic: LOCKDEBUG: Mutex error: rw_vector_enter,296: spin lock hel
d
[ 161.4877660] cpu0: Begin traceback...
[ 161.4877660] vpanic() at netbsd:vpanic+0x1fd
[ 161.4877660] snprintf() at netbsd:snprintf
[ 161.4877660] lockdebug_abort1() at netbsd:lockdebug_abort1+0x115
[ 161.4877660] rw_enter() at netbsd:rw_enter+0x645
[ 161.4877660] uvm_fault_internal() at netbsd:uvm_fault_internal+0x1c5
[ 161.4877660] trap() at netbsd:trap+0xa71
[ 161.4877660] --- trap (number 6) ---
[ 161.4877660] config_devalloc() at netbsd:config_devalloc+0x644
[ 161.4877660] config_attach_pseudo() at netbsd:config_attach_pseudo+0x1c
[ 161.4877660] vndopen() at netbsd:vndopen+0x1f3
[ 161.4877660] cdev_open() at netbsd:cdev_open+0x12d
[ 161.4877660] spec_open() at netbsd:spec_open+0x2d0
[ 161.4877660] VOP_OPEN() at netbsd:VOP_OPEN+0xba
[ 161.4877660] vn_open() at netbsd:vn_open+0x434
[ 161.4877660] sys_ktrace() at netbsd:sys_ktrace+0x1ec
[ 161.4877660] sys___syscall() at netbsd:sys___syscall+0x121
[ 161.4877660] syscall() at netbsd:syscall+0x1a5
[ 161.4877660] --- syscall (number 198) ---
[ 161.4877660] 40261a:
[ 161.4877660] cpu0: End traceback...
[ 161.4877660] fatal breakpoint trap in supervisor mode
[ 161.4877660] trap type 1 code 0 rip 0xffffffff8021ddf5 cs 0x8 rflags 0x286 cr2
0xfffffffffffff800 ilevel 0x8 rsp 0xffff9c80683cd4f0
[ 161.4877660] curlwp 0xfffffcbcda7d36a0 pid 41.1 lowest kstack 0xffff9c80683ca2
c0
db{0}> bt
breakpoint() at netbsd:breakpoint+0x5
vpanic() at netbsd:vpanic+0x1fd
snprintf() at netbsd:snprintf
lockdebug_abort1() at netbsd:lockdebug_abort1+0x115
rw_enter() at netbsd:rw_enter+0x645
uvm_fault_internal() at netbsd:uvm_fault_internal+0x1c5
trap() at netbsd:trap+0xa71
--- trap (number 6) ---
config_devalloc() at netbsd:config_devalloc+0x644
config_attach_pseudo() at netbsd:config_attach_pseudo+0x1c
vndopen() at netbsd:vndopen+0x1f3
cdev_open() at netbsd:cdev_open+0x12d
spec_open() at netbsd:spec_open+0x2d0
VOP_OPEN() at netbsd:VOP_OPEN+0xba
vn_open() at netbsd:vn_open+0x434
sys_ktrace() at netbsd:sys_ktrace+0x1ec
sys___syscall() at netbsd:sys___syscall+0x121
syscall() at netbsd:syscall+0x1a5
--- syscall (number 198) ---
40261a:
BUG3:
[ 350.9942146] UBSan: Undefined Behavior in /home/ubuntu/triforce/kernel/
src/sys/kern/kern_ktrace.c:1398:2, member access within misaligned address 0x2b0
000002a for type 'struct ktr_desc' which requires 8 byte alignment
[ 351.0025346] uvm_fault(0xffffffff85b73100, 0x2b00000000, 1) -> e
[ 351.0025346] fatal page fault in supervisor mode
[ 351.0025346] trap type 6 code 0 rip 0xffffffff81b9dbf9 cs 0x8 rflags 0x286 cr2
0x2b00000032 ilevel 0 rsp 0xffff8780684d7fb0
[ 351.0025346] curlwp 0xffffa992128116e0 pid 0.54 lowest kstack 0xffff8780684d42
c0
kernel: page fault trap, code=0
Stopped in pid 0.54 (system) at netbsd:ktrace_thread+0x1fd: cmpq %rbx,8(%
r12)
db{0}> bt
ktrace_thread() at netbsd:ktrace_thread+0x1fd
Reproducing Crashes
Right now the best way to reproduce a bug detected is to use the Fuzzer’s driver program itself:
./driver -tv < crash_file
The crash_file can be found in the outputs directory and is a custom file format made for the driver.
Memory allocation and Socket Creation remain to be added to the reproducer generator(genRepro) highlighted in the previous post and will be prioritised in the future.
Implications
Considering that we have a working fuzzer now, it is a good time to analyse how effective TriforceAFL is compared to other fuzzers.
Recently Syzkaller has been really effective in finding bugs in NetBSD. As shown in the below diagrams, both TriforceAFL and Syzkaller create multiple instances of the system to be fuzzed, gather coverage data, mutate input accordingly and continue fuzzing, but there are several differences in the way they work.
TriforceAFL
Syzkaller
Key differences between the two include:
- KCOV
Syzkaller relies on the KCOV module for coverage data in NetBSD whereas TriforceAFL gets coverage information from its modified version of QEMU. - VMs
Syzkaller creates multiple VM’s and manages them with syz-manager. Whereas TriforceAFL simply forks the VM for each testcase. - Communication
Syzkaller uses RPC and ssh to communicate with the VMs whereas TriforceAFL uses a custom hypercall. - Hardware Acceleration
Syzkaller can use hardware acceleration to run the VMs at native speeds, whereas TriforceAFL can only utilize QEMU’s full system emulation mode, as it relies on it for coverage data.
These differences lead to very different results. To get a perspective, here are some stats from syzkaller, which can be found on the syzbot dashboard.
| Bugs Found | Upstream | Fixed |
|---|---|---|
| 57 | 37 | 20 |
Comparatively in 1st Weekend of Fuzzing:
| Bugs Found | |
|---|---|
| Syzkaller | 18 |
| TriforceAFL | 3 |
- Compared to syzkaller, the number of bugs found by TriforceAFL in the first few days were significantly less, but nevertheless TriforceAFL was able to find variants of bugs found by syzkaller and 1 which was different with simpler reproducers.
- Going by the stats provided by Syzbot and AFL, Syzkaller does ~80 execs / min whereas TriforceAFL can do ~1500 execs / min on average, Although this statistic is without any of the sanitizers enabled for TriforceAFL and kASan enabled for Syzkaller.
- TriforceAFL has an advantage when it comes to the fact that it does not rely on KCOV for coverage data. This means it can get coverage data for fuzzing other interfaces easily too. This will be beneficial when we move onto Network and USB Fuzzing. Issues have been found with KCOV where in certain cases the fuzzer lost track of the kernel trace, especially in networking where after enqueuing a networking packet the fuzzer lost track as the packet was then handled by some other thread. Coverage data gathered using TriforceAFL will not be sensitive to this, considering that noise from the kernel is handled in some way to an extent.
- Efforts were made in the original design of TriforceAFL to make the traces as deterministic as possible at a basic block level. To quote from this article: Sometimes QEMU starts executing a basic block and then gets interrupted. It may then re-execute the block from the start or translate a portion of the block that wasn't yet executed and execute that. This introduced non-determinism. To reduce the non-determinism, cpu-exec.c was altered to disable QEMU's "chaining" feature, and moved AFL's tracing feature to cpu_tb_exec to trace a basic block only after it has been executed to completion. Although nothing has been specifically done to reduce noise from the kernel, such as disabling coverage during interrupts.
- TriforceAFL runs 1 fuzzing process per instance, whereas Syzkaller can run upto 32 fuzzing processes. But multiple fuzzing instance can be created with TriforceAFL as detailed in this document to take advantage of parallelization.
- Maxime Villard was also able to rework TriforceNetBSDSyscallFuzzer to now also support compat_netbsd32 kernel. This work will be integrated as soon as possible.
- On the other hand, Syzkaller has syzbot which can be thought of as a 24/7 fuzzing service. TriforceAFL does not have a such a service or a dedicated server for fuzzing.
A service like this will surely be advantageous in the future, but it is still a bit too early to set up one. To truly efficiently utilize such a service, it would be better to improve TriforceAFL in all ways possible first.
Targets to be met before a 24/7 fuzzing service is setup, include but are not limited to:
- Automatic initial Analysis & Report Generation
Right now, There is nothing that can automatically perform an initial analysis to detect truly unique crashes and prepare reports with backtraces, this will be required and very helpful. - Better Reproducers
As mentioned before, the generated reproducers do not take care of Memory Allocation and Socket Creation, etc. These need to be included, if a good C reproducer is expected. - Parallel Fuzzing and Management
There is no central interface that summarises the statistics from all fuzzing instances, and manages such instances in case of anomalies/errors. Something like this would be needed for a service that will be run for longer periods of time without supervision. - Updated AFL and QEMU versions
Updated AFL and QEMU might significantly increase executions per second and lead to better mutation of inputs and also decrease the memory requirements. - Fuzzing more Interfaces
Right now we are only fuzzing syscalls, Network and USB Layers are great future prospects, at least prototype versions can be added in the near future.
Future Work
Although GSoC will be officially ending, I am looking forward to continuing the development of TriforceAFL, adding features and making it more effective.
Some improvements that can be expected include:
- Fuzzing different interfaces - Network Fuzzing, USB Fuzzing
- Updating AFL and QEMU versions
- Better Reproducers
- Syzbot like service
A new repo has been created at https://github.com/NetBSD/triforce4netbsd. Collaborative work in the future will be updated here.
Conclusion
TriforceAFL has been successfully adapted for NetBSD and all of the original goals of the GSoC proposal have been met, but the work is far from complete. Work done so far shows great potential, and incremental updates will surely make TriforceAFL a great fuzzer. I am looking forward to continuing the work and making sure that this is the case.
GSoC has been an amazing learning experience! I would like to thank Maxime Villard for taking an active interest in TriforceAFL and for assisting in testing and development. I would like to thank my mentor Kamil Rytarowski for being the guiding force throughout the project and for assisting me whenever I needed help. And finally I would like to thank Google for giving me this wonderful opportunity.
Prepared by Siddharth Muralee(@R3x) as a part of Google Summer of Code’19
As a part of Google Summer of Code’19, I am working on improving the support for Syzkaller kernel fuzzer. Syzkaller is an unsupervised coverage-guided kernel fuzzer, that supports a variety of operating systems including NetBSD.
You can take a look through the first report to see the initial changes that we made and you can look at the second report to read about the initial support we added for fuzzing the network stack.
This report details the work done during the final coding period where the target was to improve the support for fuzzing the filesystem stack.
Filesystem fuzzing is a relatively less explored area. Syzkaller itself only has filesystem fuzzing support for Linux.
Analysis of the existing Linux setup
Filesystems are more complex fuzzing target than standalone system calls. To fuzz Filesystems we do have a standard operation like mount which comes with system call vector and an additional binary image of the filesystem itself. While normal syscalls generally have a size of a few bytes, sizes of real world Filesystem images is in order of Gigabytes or larger, however for fuzzing minimal size can be used which is in order of KB-MB. Since syzkaller uses a technique called as mutational fuzzing - where it mutates random parts of the input (according to specified guidelines), having a large input size causes delay due to higher I/O time.
Syzkaller deals with large images by disassembling them to non-zero chunks of the filesystem image. Syzkaller extracts the non-zero chunks and their offsets and stores it as separate segments and just before execution it writes all the chunks into the corresponding offsets - generating back the new/modified image.
Porting it to NetBSD
As an initial step towards filesystem fuzzing we decided to port the existing Linux approach of creating random segments to NetBSD. There are a few differences between the mounting process in both the operating systems - the most significant of them being the difference in the arguments to mount(2).
Linux:
int mount(const char *source, const char *target, const char *filesystemtype, unsigned long mountflags, const void *data);
The data argument is interpreted by the different filesystems. Typically it is a string of comma-separated options understood by this filesystem. mount(8) - shows possible arguments for each of the filesystem.
possible options for xfs filesystem in linux :
wsync, noalign, swalloc, nouuid, mtpt, grpid, nogrpid, bsdgroups,
sysvgroups,norecovery, inode64, inode32, ikeep, noikeep,
largeio, nolargeio, attr2, noattr2, filestreams, quota,
noquota, lazytime, nolazytime, usrquota, grpquota, prjquota,
uquota, gquota, pquota, uqnoenforce, gqnoenforce, pqnoenforce,
qnoenforce, discard, nodiscard, dax, barrier, nobarrier, logbufs,
biosize, sunit, swidth, logbsize, allocsize, logdev, rtdev
NetBSD:
Int mount(const char *type, const char *dir, int flags, void *data, size_t data_len);
The argument data describes the file system object to be mounted, and is data_len bytes long. data is a pointer to a structure that contains the type specific arguments to mount.
For FFS (one of the most common filesystems for NetBSD) - the arguments look like :
struct ufs_args {
char *fspec; /* block special file to mount */
};
Currently, we have a pseudo syscall syz_mount_image which does the job of writing the mutated chunks of the filesystem into a file based on their offsets and later configuring the loop device using vndconfig(8) and mounting the filesystem image using mount(8).
Analysis of the current approach
One way to create mountable filesystems is to convert an existing filesystem image into a syzkaller pseudo grammar representation and then add it to the corpus so that syzkaller uses it for mutation and we have a proper image.
Some of the noted issues with syzkaller approach (as noted in "Fuzzing File Systems via Two-Dimensional Input Space Exploration) :
Steps Forward
We also spent some time researching possible options to solve the existing issues and developing an approach that would give us better results.
Image mutator approach
One possible way forward is to actually use a seed image (a working filesystem image) and write a mutator which would be aware of all the metadata in the image. The mutator should be also be able to recreate metadata components such as the checksum so that the image is mountable.
An existing implementation of such a mutator is JANUS which is a filesystem mutator written for Linux with inspiration from fsck.
Grammar based approach
Syzkaller uses a pseudo-formal grammar for representing arguments to syscalls. This grammar can also be modified to actually be able to properly generate filesystem images.
Writing grammar to represent a filesystem image is quite a daunting task and we are not yet sure if it is possible but it is the approach that we have planned to take up as of now.
Proper documentation detailing the structure of a filesystem image is rather scarce which has led me to actually go through filesystem code to figure out the type, uses and limits of a certain filesystem image. This data then has to be converted to syzkaller representation to be used for fuzzing.
One advantage of writing a grammar that would be able to generate mountable images is that we would be able to get more coverage than fuzzing with a seed image, since we are also creating new images instead of just mutating the same image.
I am currently working on learning the internals of FFS and trying to write a grammar definition which can properly generate filesystem images.
Miscellaneous Work
Meanwhile, I have also been working in parallel on improving the existing state of Syzkaller.
Add kernel compiled with KUBSAN for fuzzing
So far we only used a kernel compiled with KCOV and KASAN for fuzzing with syzkaller. We also decided to add support for syzkaller building a kernel with KUBSAN and KCOV. This would help us have an another dimension in the fuzzing process.
This required some changes in the build config. We had to remove the hardcoded kernel config and add support for building a kernel with a config passed to the fuzzer. This move would also help us to easily add support for upcoming sanitizers such as KMSAN.
Improve syscall descriptions
Improving system call descriptions is a constant ongoing work - I recently added support for fuzzing syscalls such as mount, fork and posix_spawn.
We are also planning to add support for fuzzing device drivers soon.
Relevant Links
Summary
We have managed to meet most of the goals that we had planned for the GSoC project. Overall, I have had a wonderful summer with the NetBSD foundation and I look forward to working with them to complete the project.
Last but not least, I want to thank my mentors, @kamil and @cryo for their useful suggestions and guidance. I also thank Maciej for his insight and guidance which was very fundamental during the course of the project. I would also like to thank Dmitry Vyukov, Google for helping with any issues faced with regard to Syzkaller. Finally, thanks to Google to give me a good chance to work with NetBSD community.
Prepared by Siddharth Muralee(@R3x) as a part of Google Summer of Code’19
As a part of Google Summer of Code’19, I am working on improving the support for Syzkaller kernel fuzzer. Syzkaller is an unsupervised coverage-guided kernel fuzzer, that supports a variety of operating systems including NetBSD.
You can take a look through the first report to see the initial changes that we made and you can look at the second report to read about the initial support we added for fuzzing the network stack.
This report details the work done during the final coding period where the target was to improve the support for fuzzing the filesystem stack.
Filesystem fuzzing is a relatively less explored area. Syzkaller itself only has filesystem fuzzing support for Linux.
Analysis of the existing Linux setup
Filesystems are more complex fuzzing target than standalone system calls. To fuzz Filesystems we do have a standard operation like mount which comes with system call vector and an additional binary image of the filesystem itself. While normal syscalls generally have a size of a few bytes, sizes of real world Filesystem images is in order of Gigabytes or larger, however for fuzzing minimal size can be used which is in order of KB-MB. Since syzkaller uses a technique called as mutational fuzzing - where it mutates random parts of the input (according to specified guidelines), having a large input size causes delay due to higher I/O time.
Syzkaller deals with large images by disassembling them to non-zero chunks of the filesystem image. Syzkaller extracts the non-zero chunks and their offsets and stores it as separate segments and just before execution it writes all the chunks into the corresponding offsets - generating back the new/modified image.
Porting it to NetBSD
As an initial step towards filesystem fuzzing we decided to port the existing Linux approach of creating random segments to NetBSD. There are a few differences between the mounting process in both the operating systems - the most significant of them being the difference in the arguments to mount(2).
Linux:
int mount(const char *source, const char *target, const char *filesystemtype, unsigned long mountflags, const void *data);
The data argument is interpreted by the different filesystems. Typically it is a string of comma-separated options understood by this filesystem. mount(8) - shows possible arguments for each of the filesystem.
possible options for xfs filesystem in linux :
wsync, noalign, swalloc, nouuid, mtpt, grpid, nogrpid, bsdgroups,
sysvgroups,norecovery, inode64, inode32, ikeep, noikeep,
largeio, nolargeio, attr2, noattr2, filestreams, quota,
noquota, lazytime, nolazytime, usrquota, grpquota, prjquota,
uquota, gquota, pquota, uqnoenforce, gqnoenforce, pqnoenforce,
qnoenforce, discard, nodiscard, dax, barrier, nobarrier, logbufs,
biosize, sunit, swidth, logbsize, allocsize, logdev, rtdev
NetBSD:
Int mount(const char *type, const char *dir, int flags, void *data, size_t data_len);
The argument data describes the file system object to be mounted, and is data_len bytes long. data is a pointer to a structure that contains the type specific arguments to mount.
For FFS (one of the most common filesystems for NetBSD) - the arguments look like :
struct ufs_args {
char *fspec; /* block special file to mount */
};
Currently, we have a pseudo syscall syz_mount_image which does the job of writing the mutated chunks of the filesystem into a file based on their offsets and later configuring the loop device using vndconfig(8) and mounting the filesystem image using mount(8).
Analysis of the current approach
One way to create mountable filesystems is to convert an existing filesystem image into a syzkaller pseudo grammar representation and then add it to the corpus so that syzkaller uses it for mutation and we have a proper image.
Some of the noted issues with syzkaller approach (as noted in "Fuzzing File Systems via Two-Dimensional Input Space Exploration) :
Steps Forward
We also spent some time researching possible options to solve the existing issues and developing an approach that would give us better results.
Image mutator approach
One possible way forward is to actually use a seed image (a working filesystem image) and write a mutator which would be aware of all the metadata in the image. The mutator should be also be able to recreate metadata components such as the checksum so that the image is mountable.
An existing implementation of such a mutator is JANUS which is a filesystem mutator written for Linux with inspiration from fsck.
Grammar based approach
Syzkaller uses a pseudo-formal grammar for representing arguments to syscalls. This grammar can also be modified to actually be able to properly generate filesystem images.
Writing grammar to represent a filesystem image is quite a daunting task and we are not yet sure if it is possible but it is the approach that we have planned to take up as of now.
Proper documentation detailing the structure of a filesystem image is rather scarce which has led me to actually go through filesystem code to figure out the type, uses and limits of a certain filesystem image. This data then has to be converted to syzkaller representation to be used for fuzzing.
One advantage of writing a grammar that would be able to generate mountable images is that we would be able to get more coverage than fuzzing with a seed image, since we are also creating new images instead of just mutating the same image.
I am currently working on learning the internals of FFS and trying to write a grammar definition which can properly generate filesystem images.
Miscellaneous Work
Meanwhile, I have also been working in parallel on improving the existing state of Syzkaller.
Add kernel compiled with KUBSAN for fuzzing
So far we only used a kernel compiled with KCOV and KASAN for fuzzing with syzkaller. We also decided to add support for syzkaller building a kernel with KUBSAN and KCOV. This would help us have an another dimension in the fuzzing process.
This required some changes in the build config. We had to remove the hardcoded kernel config and add support for building a kernel with a config passed to the fuzzer. This move would also help us to easily add support for upcoming sanitizers such as KMSAN.
Improve syscall descriptions
Improving system call descriptions is a constant ongoing work - I recently added support for fuzzing syscalls such as mount, fork and posix_spawn.
We are also planning to add support for fuzzing device drivers soon.
Relevant Links
Summary
We have managed to meet most of the goals that we had planned for the GSoC project. Overall, I have had a wonderful summer with the NetBSD foundation and I look forward to working with them to complete the project.
Last but not least, I want to thank my mentors, @kamil and @cryo for their useful suggestions and guidance. I also thank Maciej for his insight and guidance which was very fundamental during the course of the project. I would also like to thank Dmitry Vyukov, Google for helping with any issues faced with regard to Syzkaller. Finally, thanks to Google to give me a good chance to work with NetBSD community.
- One in the base-system with a stack of local patches.
- One in pkgsrc with mostly build fix patches.
The base-system version of GDB (GPLv3) still relies on a set of local patches. I set a goal to reduce the local patches to bare minimum, ideally reaching no local modifications at all.
GDB changes
I've written an integration of GDB with fork(2) and vfork(2) events. Unfortunately, this support (present in a local copy of GDB in the base-system) had not been merged so far, because there is a generic kernel regression with the pg_jobc variable. This variable can be called a reference counter of the number of processes within a process group that has a parent with control over a terminal. The semantics of this variable are not very well defined and in the result the number can become negative. This unexpected state of pg_jobc resulted in spurious crashes during kernel fuzzing. As a result new kernel assertions checking for non-negative pg_jobc values were introduced in order to catch the anomalies quickly. GDB as a ptrace(2)-based application happened to reproduce negative pg_jobc values quickly and reliably and this stopped the further adoption of the fork(2) and vfork(2) patch in GDB, until the pg_jobc behavior is enhanced. I was planning to include support for posix_spawn(3) events as well, as they are implemented as a first-class operation through a syscall, however this is also blocked by the pg_jobc blocker.
A local patch for GDB is stored here for the time being.
I've enable multi-process mode in the NetBSD native target. This enabled proper support for multiple inferiors and ptrace(2) assisted management of the inferior processes and their threads.
(gdb) info inferior
Num Description Connection Executable
* 1 process 14952 1 (native) /usr/bin/dig
2 <null> 1 (native)
3 process 25684 1 (native) /bin/ls
4 <null> 1 (native) /bin/ls
Without this change, additional inferiors could be already added, but not properly controlled.
I've implemented the xfer_partial TARGET_OBJECT_SIGNAL_INFO support for NetBSD. NetBSD implements reading and overwriting siginfo_t received by the tracee. With TARGET_OBJECT_SIGNAL_INFO signal information can be examined and modified through the special variable $_siginfo. Currently NetBSD uses an identical siginfo type on all architectures, so there is no support for architecture-specific fields.
(gdb) b main
Breakpoint 1 at 0x71a0
(gdb) r
Starting program: /bin/ps
Breakpoint 1, 0x00000000002071a0 in main ()
(gdb) p $_siginfo
$1 = {si_pad = {5, 0, 0, 0, 1, 0 , 1, 0 }, _info = {_signo = 5,
_code = 1, _errno = 0, _pad = 0, _reason = {_rt = {_pid = 0, _uid = 0, _value = {sival_int = 1,
sival_ptr = 0x1}}, _child = {_pid = 0, _uid = 0, _status = 1, _utime = 0, _stime = 0},
_fault = {_addr = 0x0, _trap = 1, _trap2 = 0, _trap3 = 0}, _poll = {_band = 0, _fd = 1},
_syscall = {_sysnum = 0, _retval = {0, 1}, _error = 0, _args = {0, 0, 0, 0, 0, 0, 0, 0}},
_ptrace_state = {_pe_report_event = 0, _option = {_pe_other_pid = 0, _pe_lwp = 0}}}}}
NetBSD, contrary to Linux and other BSDs, supports a ptrace(2) operation to generate a core(5) file from a running process. This operation is used in the base-system gcore(1) program. The gcore functionality is also delivered by GDB, and I have prepared new code for GDB to wire PT_DUMPCORE into the GDB code for NetBSD, and thus support GDB's gcore functionality. This patch is still waiting in upstream review. A local copy of the patch is here.
(gdb) r Starting program: /bin/ps Breakpoint 1, 0x00000000002071a0 in main () (gdb) gcore Saved corefile core.4378 (gdb) !file core.4378 core.4378: ELF 64-bit LSB core file, x86-64, version 1 (SYSV), NetBSD-style, from 'ps', pid=4378, uid=1000, gid=100, nlwps=1, lwp=4378 (signal 5/code 1)
Plan for the next milestone
Rewrite the gdbserver support and submit upstream.
- One in the base-system with a stack of local patches.
- One in pkgsrc with mostly build fix patches.
The base-system version of GDB (GPLv3) still relies on a set of local patches. I set a goal to reduce the local patches to bare minimum, ideally reaching no local modifications at all.
GDB changes
I've written an integration of GDB with fork(2) and vfork(2) events. Unfortunately, this support (present in a local copy of GDB in the base-system) had not been merged so far, because there is a generic kernel regression with the pg_jobc variable. This variable can be called a reference counter of the number of processes within a process group that has a parent with control over a terminal. The semantics of this variable are not very well defined and in the result the number can become negative. This unexpected state of pg_jobc resulted in spurious crashes during kernel fuzzing. As a result new kernel assertions checking for non-negative pg_jobc values were introduced in order to catch the anomalies quickly. GDB as a ptrace(2)-based application happened to reproduce negative pg_jobc values quickly and reliably and this stopped the further adoption of the fork(2) and vfork(2) patch in GDB, until the pg_jobc behavior is enhanced. I was planning to include support for posix_spawn(3) events as well, as they are implemented as a first-class operation through a syscall, however this is also blocked by the pg_jobc blocker.
A local patch for GDB is stored here for the time being.
I've enable multi-process mode in the NetBSD native target. This enabled proper support for multiple inferiors and ptrace(2) assisted management of the inferior processes and their threads.
(gdb) info inferior
Num Description Connection Executable
* 1 process 14952 1 (native) /usr/bin/dig
2 <null> 1 (native)
3 process 25684 1 (native) /bin/ls
4 <null> 1 (native) /bin/ls
Without this change, additional inferiors could be already added, but not properly controlled.
I've implemented the xfer_partial TARGET_OBJECT_SIGNAL_INFO support for NetBSD. NetBSD implements reading and overwriting siginfo_t received by the tracee. With TARGET_OBJECT_SIGNAL_INFO signal information can be examined and modified through the special variable $_siginfo. Currently NetBSD uses an identical siginfo type on all architectures, so there is no support for architecture-specific fields.
(gdb) b main
Breakpoint 1 at 0x71a0
(gdb) r
Starting program: /bin/ps
Breakpoint 1, 0x00000000002071a0 in main ()
(gdb) p $_siginfo
$1 = {si_pad = {5, 0, 0, 0, 1, 0 , 1, 0 }, _info = {_signo = 5,
_code = 1, _errno = 0, _pad = 0, _reason = {_rt = {_pid = 0, _uid = 0, _value = {sival_int = 1,
sival_ptr = 0x1}}, _child = {_pid = 0, _uid = 0, _status = 1, _utime = 0, _stime = 0},
_fault = {_addr = 0x0, _trap = 1, _trap2 = 0, _trap3 = 0}, _poll = {_band = 0, _fd = 1},
_syscall = {_sysnum = 0, _retval = {0, 1}, _error = 0, _args = {0, 0, 0, 0, 0, 0, 0, 0}},
_ptrace_state = {_pe_report_event = 0, _option = {_pe_other_pid = 0, _pe_lwp = 0}}}}}
NetBSD, contrary to Linux and other BSDs, supports a ptrace(2) operation to generate a core(5) file from a running process. This operation is used in the base-system gcore(1) program. The gcore functionality is also delivered by GDB, and I have prepared new code for GDB to wire PT_DUMPCORE into the GDB code for NetBSD, and thus support GDB's gcore functionality. This patch is still waiting in upstream review. A local copy of the patch is here.
(gdb) r Starting program: /bin/ps Breakpoint 1, 0x00000000002071a0 in main () (gdb) gcore Saved corefile core.4378 (gdb) !file core.4378 core.4378: ELF 64-bit LSB core file, x86-64, version 1 (SYSV), NetBSD-style, from 'ps', pid=4378, uid=1000, gid=100, nlwps=1, lwp=4378 (signal 5/code 1)
Plan for the next milestone
Rewrite the gdbserver support and submit upstream.
- One in the base-system with a stack of local patches.
- One in pkgsrc with mostly build fix patches.
The base-system version of GDB (GPLv3) still relies on a set of local patches. I set a goal to reduce the local patches to bare minimum, ideally reaching no local modifications at all.
GDB changes
I've written an integration of GDB with fork(2) and vfork(2) events. Unfortunately, this support (present in a local copy of GDB in the base-system) had not been merged so far, because there is a generic kernel regression with the pg_jobc variable. This variable can be called a reference counter of the number of processes within a process group that has a parent with control over a terminal. The semantics of this variable are not very well defined and in the result the number can become negative. This unexpected state of pg_jobc resulted in spurious crashes during kernel fuzzing. As a result new kernel assertions checking for non-negative pg_jobc values were introduced in order to catch the anomalies quickly. GDB as a ptrace(2)-based application happened to reproduce negative pg_jobc values quickly and reliably and this stopped the further adoption of the fork(2) and vfork(2) patch in GDB, until the pg_jobc behavior is enhanced. I was planning to include support for posix_spawn(3) events as well, as they are implemented as a first-class operation through a syscall, however this is also blocked by the pg_jobc blocker.
A local patch for GDB is stored here for the time being.
I've enable multi-process mode in the NetBSD native target. This enabled proper support for multiple inferiors and ptrace(2) assisted management of the inferior processes and their threads.
(gdb) info inferior
Num Description Connection Executable
* 1 process 14952 1 (native) /usr/bin/dig
2 <null> 1 (native)
3 process 25684 1 (native) /bin/ls
4 <null> 1 (native) /bin/ls
Without this change, additional inferiors could be already added, but not properly controlled.
I've implemented the xfer_partial TARGET_OBJECT_SIGNAL_INFO support for NetBSD. NetBSD implements reading and overwriting siginfo_t received by the tracee. With TARGET_OBJECT_SIGNAL_INFO signal information can be examined and modified through the special variable $_siginfo. Currently NetBSD uses an identical siginfo type on all architectures, so there is no support for architecture-specific fields.
(gdb) b main
Breakpoint 1 at 0x71a0
(gdb) r
Starting program: /bin/ps
Breakpoint 1, 0x00000000002071a0 in main ()
(gdb) p $_siginfo
$1 = {si_pad = {5, 0, 0, 0, 1, 0 , 1, 0 }, _info = {_signo = 5,
_code = 1, _errno = 0, _pad = 0, _reason = {_rt = {_pid = 0, _uid = 0, _value = {sival_int = 1,
sival_ptr = 0x1}}, _child = {_pid = 0, _uid = 0, _status = 1, _utime = 0, _stime = 0},
_fault = {_addr = 0x0, _trap = 1, _trap2 = 0, _trap3 = 0}, _poll = {_band = 0, _fd = 1},
_syscall = {_sysnum = 0, _retval = {0, 1}, _error = 0, _args = {0, 0, 0, 0, 0, 0, 0, 0}},
_ptrace_state = {_pe_report_event = 0, _option = {_pe_other_pid = 0, _pe_lwp = 0}}}}}
NetBSD, contrary to Linux and other BSDs, supports a ptrace(2) operation to generate a core(5) file from a running process. This operation is used in the base-system gcore(1) program. The gcore functionality is also delivered by GDB, and I have prepared new code for GDB to wire PT_DUMPCORE into the GDB code for NetBSD, and thus support GDB's gcore functionality. This patch is still waiting in upstream review. A local copy of the patch is here.
(gdb) r Starting program: /bin/ps Breakpoint 1, 0x00000000002071a0 in main () (gdb) gcore Saved corefile core.4378 (gdb) !file core.4378 core.4378: ELF 64-bit LSB core file, x86-64, version 1 (SYSV), NetBSD-style, from 'ps', pid=4378, uid=1000, gid=100, nlwps=1, lwp=4378 (signal 5/code 1)
Plan for the next milestone
Rewrite the gdbserver support and submit upstream.
As a part of Google summer code 2020, I have been working on Enhance the Syzkaller support for NetBSD. This post summarises the work done in the past month.
For work done in the first coding period, you can take a look at the previous post.
Automation for enhancement
With an aim of increasing the number of syscalls fuzzed, we have decided to automate the addition of descriptions for syscalls as well as ioctl device drivers in a customised way for NetBSD.
Design
All the ioctl commands for a device driver in NetBSD are stored inside the /src/sys/dev/<driver_name>/
folder. The idea is to get information related to a particular ioctl command by extracting required information from the source code of drivers. To achieve the same, we have broken down our project into majorly three phases.
- Generating preprocessed files
- Extracting information required for generating descriptions
- Conversion to syzkaller’s grammar
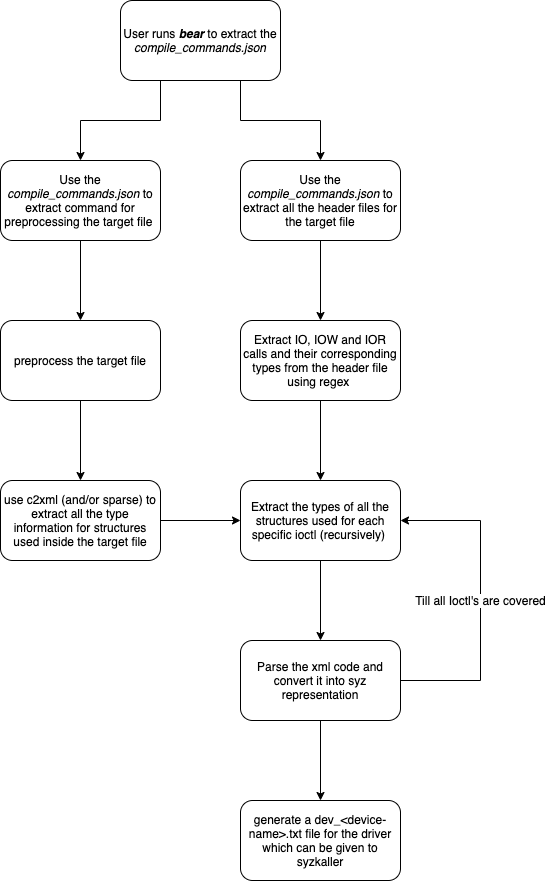
Generating Preprocessed files
For a given preprocessed file, c2xml tool outputs the preprocessed C code in xml format. Further, the intermediate xml format descriptions would help us to smoothly transform the c code to syzkaller specific descriptions, in the last stage of this tool. We have used Bear as an aid for fetching commands to preprocess files for a particular driver. Bear generates a file called compile_commands.json which stores the commands used for compiling a file in json format. We then run these commands with ‘-E’ gcc flag to fetch the preprocessed files.These preprocessed files then serve as an input to the c2xml program.
Extractor
Definition of ioctl calls defined in header files of device driver in NetBSD can be broken down to:

When we see it from syzkaller’s perspective, there are basically three significant parts we need to extract for adding description to syzkaller.
Description of a particular ioctl command acc to syzkaller’s grammar:
ioctl$FOOIOCTL(fd <fd_driver>, cmd const[FOOIOCTL], pt ptr[DIR, <ptr_type>])
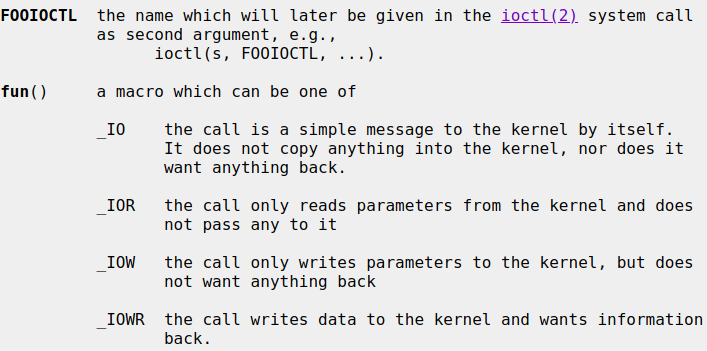

These definitions can be grepped from a device’s header files. The type information or description for pointer can then be extracted from the output files generated by c2xml. If the third argument is a struct, the direction of the pointer is determined with the help of fun() macros.
To-Do
The extracted descriptions have to be converted into syzkaller-friendly grammer. We plan to add support for syscalls too , which would ease the addition of complex compat syscalls. This would help us to increase the syzkaller’s coverage significantly.
Stats
Along with this, We have continued to add support for few more syscalls these include:- ksem(2) family
- mount(2) family
Atlast, I would like to thank my mentors - Cryo, Siddharth Muralee and Santhosh along with Kamil for their guidance and support. I am thankful to NetBSD community too along with Google for providing me such an amazing opportunity.
As a part of Google summer code 2020, I have been working on Enhance the Syzkaller support for NetBSD. This post summarises the work done in the past month.
For work done in the first coding period, you can take a look at the previous post.
Automation for enhancement
With an aim of increasing the number of syscalls fuzzed, we have decided to automate the addition of descriptions for syscalls as well as ioctl device drivers in a customised way for NetBSD.
Design
All the ioctl commands for a device driver in NetBSD are stored inside the /src/sys/dev/<driver_name>/
folder. The idea is to get information related to a particular ioctl command by extracting required information from the source code of drivers. To achieve the same, we have broken down our project into majorly three phases.
- Generating preprocessed files
- Extracting information required for generating descriptions
- Conversion to syzkaller’s grammar
Generating Preprocessed files
For a given preprocessed file, c2xml tool outputs the preprocessed C code in xml format. Further, the intermediate xml format descriptions would help us to smoothly transform the c code to syzkaller specific descriptions, in the last stage of this tool. We have used Bear as an aid for fetching commands to preprocess files for a particular driver. Bear generates a file called compile_commands.json which stores the commands used for compiling a file in json format. We then run these commands with ‘-E’ gcc flag to fetch the preprocessed files.These preprocessed files then serve as an input to the c2xml program.
Extractor
Definition of ioctl calls defined in header files of device driver in NetBSD can be broken down to:
When we see it from syzkaller’s perspective, there are basically three significant parts we need to extract for adding description to syzkaller.
Description of a particular ioctl command acc to syzkaller’s grammar:
ioctl$FOOIOCTL(fd <fd_driver>, cmd const[FOOIOCTL], pt ptr[DIR, <ptr_type>])
These definitions can be grepped from a device’s header files. The type information or description for pointer can then be extracted from the output files generated by c2xml. If the third argument is a struct, the direction of the pointer is determined with the help of fun() macros.
To-Do
The extracted descriptions have to be converted into syzkaller-friendly grammer. We plan to add support for syscalls too , which would ease the addition of complex compat syscalls. This would help us to increase the syzkaller’s coverage significantly.
Stats
Along with this, We have continued to add support for few more syscalls these include:- ksem(2) family
- mount(2) family
Atlast, I would like to thank my mentors - Cryo, Siddharth Muralee and Santhosh along with Kamil for their guidance and support. I am thankful to NetBSD community too along with Google for providing me such an amazing opportunity.
I have been working on Fuzzing Rumpkernel Syscalls. This blogpost details the work I have done during my second coding period.
Reproducing crash found in ioctl()
Kamil has worked on reproducing the following crash
Thread 1 "" received signal SIGSEGV, Segmentation fault.
pipe_ioctl (fp=<optimized out>, cmd=<optimized out>, data=0x7f7fffccd700)
at /usr/src/lib/librump/../../sys/rump/../kern/sys_pipe.c:1108
warning: Source file is more recent than executable.
1108 *(int *)data = pipe->pipe_buffer.cnt;
(gdb) bt
#0 pipe_ioctl (fp=<optimized out>, cmd=<optimized out>, data=0x7f7fffccd700)
at /usr/src/lib/librump/../../sys/rump/../kern/sys_pipe.c:1108
#1 0x000075b0de65083f in sys_ioctl (l=<optimized out>, uap=0x7f7fffccd820, retval=<optimized out>)
at /usr/src/lib/librump/../../sys/rump/../kern/sys_generic.c:671
#2 0x000075b0de6b8957 in sy_call (rval=0x7f7fffccd810, uap=0x7f7fffccd820, l=0x75b0de126500,
sy=<optimized out>) at /usr/src/lib/librump/../../sys/rump/../sys/syscallvar.h:65
#3 sy_invoke (code=54, rval=0x7f7fffccd810, uap=0x7f7fffccd820, l=0x75b0de126500, sy=<optimized out>)
at /usr/src/lib/librump/../../sys/rump/../sys/syscallvar.h:94
#4 rump_syscall (num=num@entry=54, data=data@entry=0x7f7fffccd820, dlen=dlen@entry=24,
retval=retval@entry=0x7f7fffccd810)
at /usr/src/lib/librump/../../sys/rump/librump/rumpkern/rump.c:769
#5 0x000075b0de6ad2ca in rump___sysimpl_ioctl (fd=<optimized out>, com=<optimized out>,
data=<optimized out>) at /usr/src/lib/librump/../../sys/rump/librump/rumpkern/rump_syscalls.c:979
#6 0x0000000000400bf7 in main (argc=1, argv=0x7f7fffccd8c8) at test.c:15
in the rump using a fuzzer that uses pip2, dup2 and ioctl syscalls and specific arguments that are known to cause a crash upon which my work develops.
https://github.com/adityavardhanpadala/rumpsyscallfuzz/blob/master/honggfuzz/ioctl/ioctl_fuzz2.c
Since rump is a multithreaded process. Crash occurs in any of those threads. By using a core dump we can quickly investigate the crash and fetch the backtrace from gdb for verification however this is not viable in the long run as you would be loading your working directory with lots of core dumps which consume a lot of space. So we need a better way to reproduce crashes.
Crash Reproducers
Getting crash reproducers working took quite a while. If we look at HF_ITER() function in honggfuzz, it is a simple wrapper for HonggfuzzFetchData() to fetch buffer of fixed size from the fuzzer.
void HonggfuzzFetchData(const uint8_t** buf_ptr, size_t* len_ptr) {
.
.
.
.
*buf_ptr = inputFile;
*len_ptr = (size_t)rcvLen;
.
.
}
And if we observe the attribute we notice that inputFile is mmaped.
//libhfuzz/fetch.c:26
if ((inputFile = mmap(NULL, _HF_INPUT_MAX_SIZE, PROT_READ, MAP_SHARED, _HF_INPUT_FD, 0)) ==
MAP_FAILED) {
PLOG_F("mmap(fd=%d, size=%zu) of the input file failed", _HF_INPUT_FD,
(size_t)_HF_INPUT_MAX_SIZE);
}
So in a similar approach HF_ITER() can be modified to read input from a file and be mmapped so that we can reuse the reproducers generated by honggfuzz.
Attempts have been made to use getchar(3) for fetching the buffer via STDIN but for some unknown reason it failed so we switched to mmap(2)
So we overload HF_ITER() function whenever we require to reproduce a crash. I chose the following approach to use the reproducers. So whenever we need to reproduce a crash we just define CRASH_REPR.
static
void Initialize(void)
{
#ifdef CRASH_REPR
FILE *fp = fopen(argv[1], "r+");
data = malloc(max_size);
fread(data, max_size, 1, fp);
fclose(fp);
#endif
// Initialise the rumpkernel only once.
if(rump_init() != 0)
__builtin_trap();
}
#ifdef CRASH_REPR
void HF_ITER(uint8_t **buf, size_t *len) {
*buf = (uint8_t *)data;
*len = max_size;
return;
}
#else
EXTERN void HF_ITER(uint8_t **buf, size_t *len);
#endif
This way we can easily reproduce crashes that we get and get the backtraces.
Generating C reproducers
Now the main goal is to create a c file which can reproduce the same crash occuring due to the reproducer. This is done by writing all the syscall executions to a file with arguments so they can directly be compiled and used.
#ifdef CRASH_REPR
FILE *fp = fopen("/tmp/repro.c","a+");
fprintf(fp, "rump_sys_ioctl(%" PRIu8 ", %" PRIu64 ");\n",get_u8(),get_ioctl_request());
fclose(fp);
#else
rump_sys_ioctl(get_u8(), get_ioctl_request());
#endif
I followed the same above method for all the syscalls that are executed. So I get a proper order of syscalls executed in native c code that I can simply reuse.
Obstacles
The number of times each syscall is executed before getting to a crash is quite high. So trying to perform a write to a file or STDOUT will create a lot of overhead when the number of syscalls executed are quite high. This method is good enough but a bit of optimization will make it even better.
To-Do
- ./build.sh building rump on linux+netbsd
- pregenerating fuzzer input using the implementation similar to that used in syzkaller.
Finally I thank my mentors Siddharth Muralee, Maciej Grochowski, Christos Zoulas for their guidance and Kamil Rytarowski for his constant support whenever I needed it.
I have been working on Fuzzing Rumpkernel Syscalls. This blogpost details the work I have done during my second coding period.
Reproducing crash found in ioctl()
Kamil has worked on reproducing the following crash
Thread 1 "" received signal SIGSEGV, Segmentation fault.
pipe_ioctl (fp=<optimized out>, cmd=<optimized out>, data=0x7f7fffccd700)
at /usr/src/lib/librump/../../sys/rump/../kern/sys_pipe.c:1108
warning: Source file is more recent than executable.
1108 *(int *)data = pipe->pipe_buffer.cnt;
(gdb) bt
#0 pipe_ioctl (fp=<optimized out>, cmd=<optimized out>, data=0x7f7fffccd700)
at /usr/src/lib/librump/../../sys/rump/../kern/sys_pipe.c:1108
#1 0x000075b0de65083f in sys_ioctl (l=<optimized out>, uap=0x7f7fffccd820, retval=<optimized out>)
at /usr/src/lib/librump/../../sys/rump/../kern/sys_generic.c:671
#2 0x000075b0de6b8957 in sy_call (rval=0x7f7fffccd810, uap=0x7f7fffccd820, l=0x75b0de126500,
sy=<optimized out>) at /usr/src/lib/librump/../../sys/rump/../sys/syscallvar.h:65
#3 sy_invoke (code=54, rval=0x7f7fffccd810, uap=0x7f7fffccd820, l=0x75b0de126500, sy=<optimized out>)
at /usr/src/lib/librump/../../sys/rump/../sys/syscallvar.h:94
#4 rump_syscall (num=num@entry=54, data=data@entry=0x7f7fffccd820, dlen=dlen@entry=24,
retval=retval@entry=0x7f7fffccd810)
at /usr/src/lib/librump/../../sys/rump/librump/rumpkern/rump.c:769
#5 0x000075b0de6ad2ca in rump___sysimpl_ioctl (fd=<optimized out>, com=<optimized out>,
data=<optimized out>) at /usr/src/lib/librump/../../sys/rump/librump/rumpkern/rump_syscalls.c:979
#6 0x0000000000400bf7 in main (argc=1, argv=0x7f7fffccd8c8) at test.c:15
in the rump using a fuzzer that uses pip2, dup2 and ioctl syscalls and specific arguments that are known to cause a crash upon which my work develops.
https://github.com/adityavardhanpadala/rumpsyscallfuzz/blob/master/honggfuzz/ioctl/ioctl_fuzz2.c
Since rump is a multithreaded process. Crash occurs in any of those threads. By using a core dump we can quickly investigate the crash and fetch the backtrace from gdb for verification however this is not viable in the long run as you would be loading your working directory with lots of core dumps which consume a lot of space. So we need a better way to reproduce crashes.
Crash Reproducers
Getting crash reproducers working took quite a while. If we look at HF_ITER() function in honggfuzz, it is a simple wrapper for HonggfuzzFetchData() to fetch buffer of fixed size from the fuzzer.
void HonggfuzzFetchData(const uint8_t** buf_ptr, size_t* len_ptr) {
.
.
.
.
*buf_ptr = inputFile;
*len_ptr = (size_t)rcvLen;
.
.
}
And if we observe the attribute we notice that inputFile is mmaped.
//libhfuzz/fetch.c:26
if ((inputFile = mmap(NULL, _HF_INPUT_MAX_SIZE, PROT_READ, MAP_SHARED, _HF_INPUT_FD, 0)) ==
MAP_FAILED) {
PLOG_F("mmap(fd=%d, size=%zu) of the input file failed", _HF_INPUT_FD,
(size_t)_HF_INPUT_MAX_SIZE);
}
So in a similar approach HF_ITER() can be modified to read input from a file and be mmapped so that we can reuse the reproducers generated by honggfuzz.
Attempts have been made to use getchar(3) for fetching the buffer via STDIN but for some unknown reason it failed so we switched to mmap(2)
So we overload HF_ITER() function whenever we require to reproduce a crash. I chose the following approach to use the reproducers. So whenever we need to reproduce a crash we just define CRASH_REPR.
static
void Initialize(void)
{
#ifdef CRASH_REPR
FILE *fp = fopen(argv[1], "r+");
data = malloc(max_size);
fread(data, max_size, 1, fp);
fclose(fp);
#endif
// Initialise the rumpkernel only once.
if(rump_init() != 0)
__builtin_trap();
}
#ifdef CRASH_REPR
void HF_ITER(uint8_t **buf, size_t *len) {
*buf = (uint8_t *)data;
*len = max_size;
return;
}
#else
EXTERN void HF_ITER(uint8_t **buf, size_t *len);
#endif
This way we can easily reproduce crashes that we get and get the backtraces.
Generating C reproducers
Now the main goal is to create a c file which can reproduce the same crash occuring due to the reproducer. This is done by writing all the syscall executions to a file with arguments so they can directly be compiled and used.
#ifdef CRASH_REPR
FILE *fp = fopen("/tmp/repro.c","a+");
fprintf(fp, "rump_sys_ioctl(%" PRIu8 ", %" PRIu64 ");\n",get_u8(),get_ioctl_request());
fclose(fp);
#else
rump_sys_ioctl(get_u8(), get_ioctl_request());
#endif
I followed the same above method for all the syscalls that are executed. So I get a proper order of syscalls executed in native c code that I can simply reuse.
Obstacles
The number of times each syscall is executed before getting to a crash is quite high. So trying to perform a write to a file or STDOUT will create a lot of overhead when the number of syscalls executed are quite high. This method is good enough but a bit of optimization will make it even better.
To-Do
- ./build.sh building rump on linux+netbsd
- pregenerating fuzzer input using the implementation similar to that used in syzkaller.
Finally I thank my mentors Siddharth Muralee, Maciej Grochowski, Christos Zoulas for their guidance and Kamil Rytarowski for his constant support whenever I needed it.
My GSoC project under NetBSD involves the development of test framework of curses library. This blog report is second in series of blog reports; you can have a look at the first report. This report would cover the progress made in second coding phase along with providing some insights into the libcurses.
Complex characters
A complex character is a set of associated character, which may include a spacing character and non-spacing characters associated with it. Typical effects of non-spacing character on associated complex character c include: modifying the appearance of c (like adding diacritical marks) or bridge c with the following character. The cchar_t data type represents a complex character and its rendition. In NetBSD, this data type has following structure:
struct cchar_t {
attr_t attributes; /* character attributes */
unsigned elements; /* number of wide char in vals*/
wchar_t vals[CURSES_CCHAR_MAX]; /* wide chars including non-spacing */
};vals array contains the spacing character and associated non-spacing characters. Note that NetBSD supports wchar_t (wide character) due to which multi-byte characters are supported. To use the complex characters one has to correctly set the locale settings. In this coding period, I wrote tests for routines involving complex characters.
Alternate character set
When you print "BSD", you would send the hex-codes 42, 53, 44 to the terminal. Capability of graphic capable printers was limited by 8-bit ASCII code. To solve this, additional character sets were introduced. We can switch between the modes using escape sequence. One such character set for Special Graphics is used by curses for line drawing. In a shell you can type
echo -e "\e(0j\e(b"to get a lower-right corner glyph. This enables alternate character mode (\e(), prints a character(j) and disables alternate character mode (\e(b). One might wonder where this 'j' to 'Lower Right Corner glyph' comes from. You may see that mapping ("acsc=``aaffggiijjkkllmmnnooppqqrrssttuuvvwwxxyyzz{{||}}~~,) via
infocmp -1 $TERM | grep acscThese characters are used in box_set(), border_set(), etc. functions which I tested in the second coding period.
Progress in the second coding phase
Improvements in the framework:
- Added support for testing of functions to be called before
initscr() - Updated the unsupported function definitions with some minor bug fixes.
Testing and bug reports
- Added tests for following families of functions:
- Complex character routines.
- Line/box drawing routines.
- Pad routines.
- Window and sub-window operations.
- Curson manipulation routines
- Reported bugs (and possible fixes if I know):
- lib/55454
wredrawln()in libcurses does not follow the sensible behaviour [fixed] - lib/55460 copy error in libcurses [fixed]
- lib/55474
wattroff()unsets all attributes if passed STANDOUT as argument [standard is not clear, so decided to have as it is] - lib/55482
slk_restore()does not restore the slk screen - lib/55484
newwin()results into seg fault [fixed] - lib/55496
bkgrnd()doesn't work as expected - lib/55517
wresize()function incorrectly resizes the subwindows
- lib/55454
I would like to thank my mentors Brett and Martin, as well as the NetBSD community for their support whenever I faced some issues.
My GSoC project under NetBSD involves the development of test framework of curses library. This blog report is second in series of blog reports; you can have a look at the first report. This report would cover the progress made in second coding phase along with providing some insights into the libcurses.
Complex characters
A complex character is a set of associated character, which may include a spacing character and non-spacing characters associated with it. Typical effects of non-spacing character on associated complex character c include: modifying the appearance of c (like adding diacritical marks) or bridge c with the following character. The cchar_t data type represents a complex character and its rendition. In NetBSD, this data type has following structure:
struct cchar_t {
attr_t attributes; /* character attributes */
unsigned elements; /* number of wide char in vals*/
wchar_t vals[CURSES_CCHAR_MAX]; /* wide chars including non-spacing */
};vals array contains the spacing character and associated non-spacing characters. Note that NetBSD supports wchar_t (wide character) due to which multi-byte characters are supported. To use the complex characters one has to correctly set the locale settings. In this coding period, I wrote tests for routines involving complex characters.
Alternate character set
When you print "BSD", you would send the hex-codes 42, 53, 44 to the terminal. Capability of graphic capable printers was limited by 8-bit ASCII code. To solve this, additional character sets were introduced. We can switch between the modes using escape sequence. One such character set for Special Graphics is used by curses for line drawing. In a shell you can type
echo -e "\e(0j\e(b"to get a lower-right corner glyph. This enables alternate character mode (\e(), prints a character(j) and disables alternate character mode (\e(b). One might wonder where this 'j' to 'Lower Right Corner glyph' comes from. You may see that mapping ("acsc=``aaffggiijjkkllmmnnooppqqrrssttuuvvwwxxyyzz{{||}}~~,) via
infocmp -1 $TERM | grep acscThese characters are used in box_set(), border_set(), etc. functions which I tested in the second coding period.
Progress in the second coding phase
Improvements in the framework:
- Added support for testing of functions to be called before
initscr() - Updated the unsupported function definitions with some minor bug fixes.
Testing and bug reports
- Added tests for following families of functions:
- Complex character routines.
- Line/box drawing routines.
- Pad routines.
- Window and sub-window operations.
- Curson manipulation routines
- Reported bugs (and possible fixes if I know):
- lib/55454
wredrawln()in libcurses does not follow the sensible behaviour [fixed] - lib/55460 copy error in libcurses [fixed]
- lib/55474
wattroff()unsets all attributes if passed STANDOUT as argument [standard is not clear, so decided to have as it is] - lib/55482
slk_restore()does not restore the slk screen - lib/55484
newwin()results into seg fault [fixed] - lib/55496
bkgrnd()doesn't work as expected - lib/55517
wresize()function incorrectly resizes the subwindows
- lib/55454
I would like to thank my mentors Brett and Martin, as well as the NetBSD community for their support whenever I faced some issues.
This report was written by Apurva Nandan as part of Google Summer of Code 2020.
This blog post is in continuation of GSoC Reports: Benchmarking NetBSD, first evaluation report blog and describes my progress in the second phase of GSoC 2020 under The NetBSD Foundation.
In this phase, I worked on the automation of the regression suite made using Phoronix Test Suite (PTS) and its integration with Anita.
The automation framework consists of two components Phoromatic server, provided by Phoronix Test Suite in pkgsrc, and Anita, a Python tool for automating NetBSD installation.
About Phoromatic
Phoromatic is a remote management system for the Phoronix Test Suite, which allows the automatic scheduling of tests, remote installation of new tests, and the management of multiple test systems through a web interface. Tests can be scheduled to run on a routine basis across multiple test systems automatically. Phoromatic can also interface with revision control systems to offer support for issuing new tests on a context-basis, such as whenever a Git commit has been pushed. The test results are then available from the web interface.
Phoromatic client-server architecture
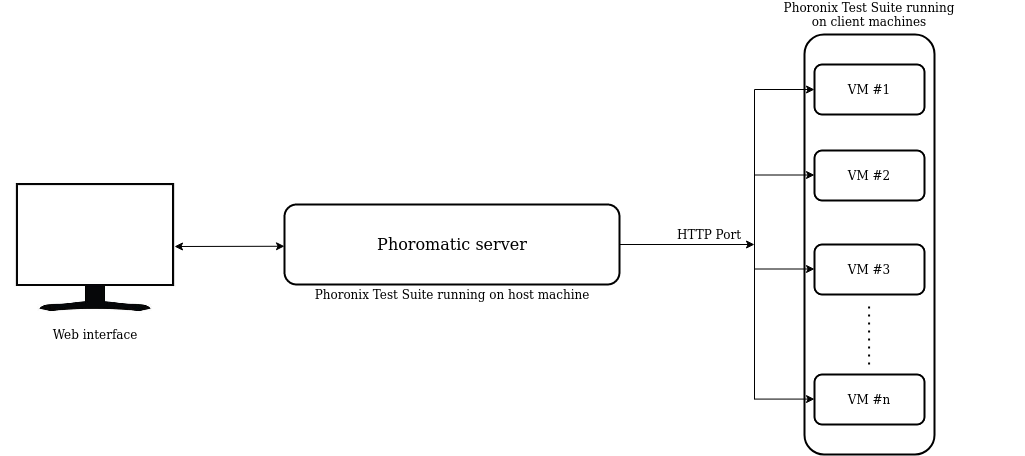
The Phoromatic server relies upon a PHP/HHVM built-in web server process and a PTS-hosted WebSocket server. The web server process handles the web UI and the responsibilities of the Phoromatic server.
Phoromatic clients are testing machines installed with PTS that connect to the Phoromatic web server through the HTTP port of the server.
Phoromatic Setup
To start the Phoromatic server, Phoromatic server HTTP port and web
server socket port needs to be set in
~/.phoronix-test-suite/user-config.xml as shown:
...
<Server>
<RemoteAccessPort>8640</RemoteAccessPort>
<Password></Password>
<WebSocketPort>8642</WebSocketPort>
<AdvertiseServiceZeroConf>TRUE</AdvertiseServiceZeroConf>
<AdvertiseServiceOpenBenchmarkRelay>TRUE</AdvertiseServiceOpenBenchmarkRelay>
<PhoromaticStorage>~/.phoronix-test-suite/phoromatic/</PhoromaticStorage>
</Server>
Phoromatic Usage
To start the Phoromatic web server for controlling local Phoronix Test Suite client systems:
$ phoronix-test-suite start-phoromatic-server
The Phoromatic web server will be hosted at localhost:8640 and will require a local account creation on the server.
Phoromatic Clients
The Phoromatic client is used for connecting to a Phoromatic server to facilitate the automatic running of tests on that client.
Phoromatic clients can be created and connected to the server using the following command:
$ phoronix-test-suite phoromatic.connect SERVER_IP:SERVER_HTTP_PORT/ACCOUNT_ID
Phoromatic server interacts with the Phoromatic clients through the HTTP port specified in the ~/.phoronix-test-suite/user-config.xml.
Phoromatic Test-schedules
A test schedule is used to facilitate automatically running a set of test(s)/suite(s) on either a routine timed basis or whenever triggered by an external script or process, e.g. Git/VCS commit, manually triggered, etc. Phoromatic provides an option for pre-install, pre-run, post-install and post-run shell scripts that are executed on the Phoromatic clients. Test-schedules can be configured to run any tests on any specific systems.
About Anita
Anita is a tool for automated testing of the NetBSD operating system. Using Anita, we can download a NetBSD distribution and install it in a virtual machine in a fully automated fashion. Anita is written in Python and uses the pexpect module to “screen scrape” the sysinst output over an emulated serial console and script the installation procedure.
Installation
Anita can be installed on NetBSD, Linux and macOS systems using the following:
$ pip install pexpect $ git clone https://github.com/gson1703/anita/ $ python setup.py install
Phoromatic-Anita Integration
I would like to describe the workflow here briefly:
- A test-schedule was created on the Phoromatic server meant to run
pts/idle-1.2.0test on the host machine that contains the phoromatic-anita-integration.sh as a pre-run script. - The script performs the following:
- Creates a mountable disk image with an executable script for setting up Phoronix Test Suite and Phoromatic client creation on the benchmarking VM systems.
- Invokes Anita with the appropriate command-line options for configurations and network setup and mounts the image to run the configuration script on the VM.
- Configuration script performs hostname change, DHCP setup, NFS
setup,
PKG_PATHsetup, PTS installation, its configuration and connecting it to the Phoromatic server through a network bridge.
- Once the benchmarking VM systems get connected to the Phoromatic server, Phoromatic server identifies the benchmarking VM systems with their IP address, hostname and MAC address.
- After the identification, Phoromatic initiates the pending tests on VM (test-profiles are downloaded on the go in the VM and executed) and maintains a history of the test result data.
Few points to be noted:
- I have used a local PKG_PATH with a NFS server setup as PTS 9.6.1 is available in wip and recompiling it would be a wastage of time. Later I have planned to use the binary shard by Joyent: https://pkgsrc.joyent.com/packages/NetBSD/9.99.69/amd64/All/ once the updated PTS gets upstreamed.
- The host machine needs some one-time manual setup like installation of QEMU, Anita, pexpect, term, cvs, etc., initial user registration on Phoromatic server, Phoromatic port setup, network bridge setup. Apart from this, the rest of the framework does not require user supervision.
VM configuration script
The following script is used as a pre-run script in the test-schedules for invoking Anita and setting up the VMs:
https://gist.github.com/apurvanandan1997/48b54402db1df3723920735f85fc7934
Networking Setup
A bridged networking mode configuration of QEMU has been used in Anita as multiple VMs will be able to accommodate with a single bridge (created on the host machine, one-time setup) using dhcpcd(8), without complicated host forwarding setup (Phoromatic server requires HTTP port forwarding).
In order to enable bridged networking for your QEMU guests, you must first create and configure a bridge interface on your host.
# ifconfig virbr0 create
Next, you must specify the newly-created bridge interface in
/etc/qemu/bridge.conf:
$ sudo mkdir /etc/qemu $ sudo touch /etc/qemu/bridge.conf && sudo chmod 644 /etc/qemu/bridge.conf $ sudo sh -c "echo 'allow virbr0' >> /etc/qemu/bridge.conf"
Finally, in order for non-privileged processes to be able to invoke qemu-bridge-helper, you must set the setuid bit on the utility:
$ sudo chmod u+s /usr/local/libexec/qemu-bridge-helper
For more details on the bridged mode networking setup in QEMU, please refer to the following guides:
- https://t.pagef.lt/basic-networking-with-qemu/
- https://www.NetBSD.org/docs/guide/en/chap-net-practice.html#chap-net-practice-bridge
Reproducing the framework
To reproduce the framework, you need to have Phoronix Test Suite, QEMU, Anita, pexpect, cvs, xterm, makefs installed on your host machine.
For example on NetBSD:
# pkg_add qemu # pkg_add py37-anita $ cd pkgsrc/wip/phoronix-test-suite $ make install
The step-by-step process to get the framework after installing PTS, including the one-time manual setup, can be summarized as follows: All control and configuration of the Phoromatic Server is done via the web-based interface when the Phoromatic Server is active.
- Configure the port of Phoromatic server as 8640 and web socket as 8642 as described above.
- Start the Phoromatic server using the command stated above.
- Create your user account on the Phoromatic server using the web interface GUI.
- Disable client system approval for new system addition from the settings menu in the web interface.
- Connect the host machine as a Phoromatic client to the Phoromatic server using the command stated above.
- Create a test-schedule for the host machine with the
pre-run script
as specified above and
pts/idle-1.2.0as the test-profile.
- Execute the test-schedule or assign it on a timed-schedule and watch it running!
- New VM systems with the latest NetBSD-current binaries and packages will be created and identified by Phoromatic server automatically.
- Once for all, we need to specify what benchmarking test-profiles need
to be run on the VM systems in the test-schedules section and it will
be taken care of by Phoromatic.
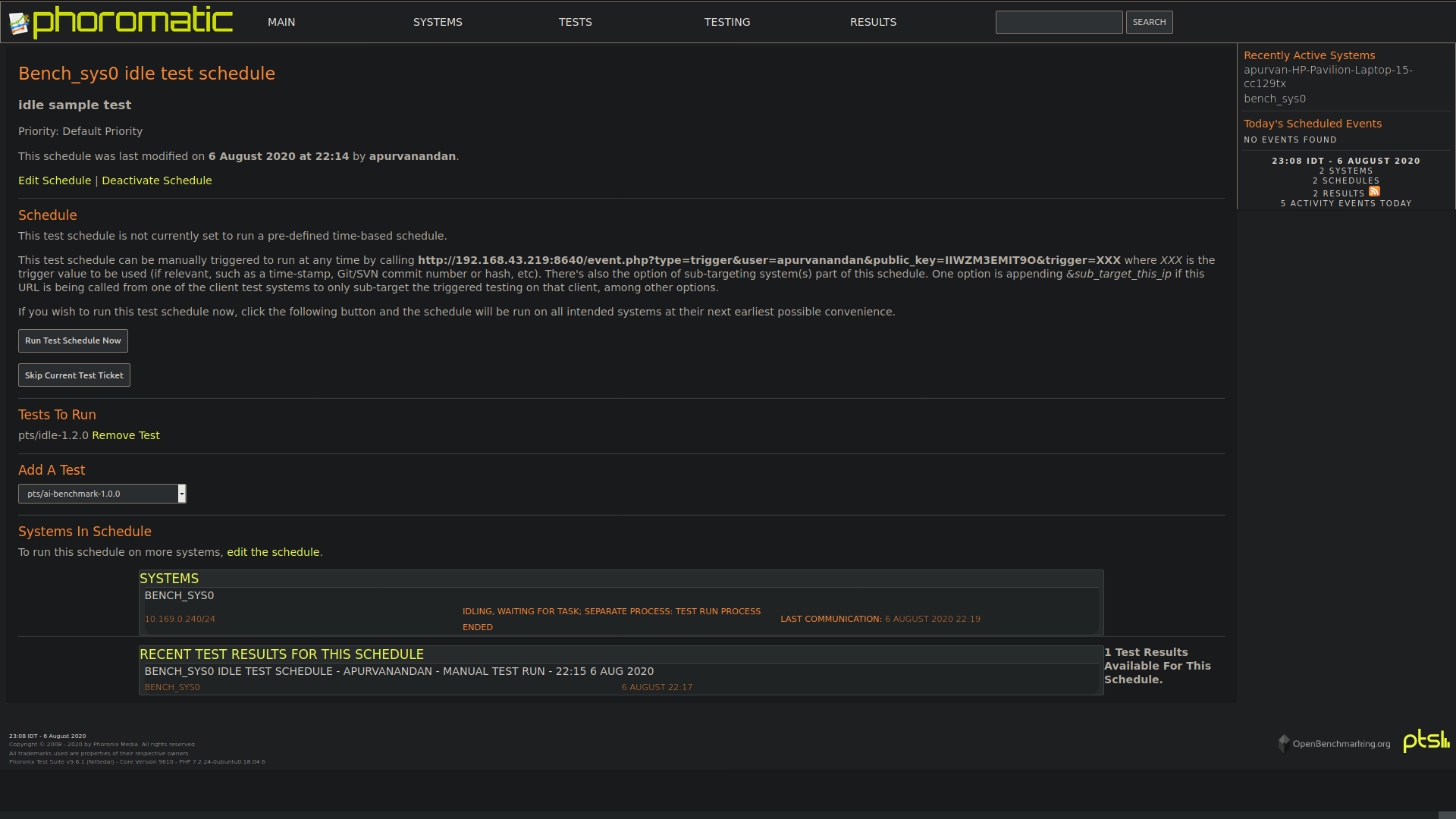
- The result history can also be viewed from Phoromatic web interface.
You can have a look at the video to get a clearer picture of how to setup the framework:
Future Plans
The regression suite is complete and final tasks of deploying it on benchmark.NetBSD.org and upstreaming the wip of Phoronix Test Suite will be done in the final phase of my GSoC project. I want to thank my mentors for their constant support.
This report was written by Apurva Nandan as part of Google Summer of Code 2020.
This blog post is in continuation of GSoC Reports: Benchmarking NetBSD, first evaluation report blog and describes my progress in the second phase of GSoC 2020 under The NetBSD Foundation.
In this phase, I worked on the automation of the regression suite made using Phoronix Test Suite (PTS) and its integration with Anita.
The automation framework consists of two components Phoromatic server, provided by Phoronix Test Suite in pkgsrc, and Anita, a Python tool for automating NetBSD installation.
About Phoromatic
Phoromatic is a remote management system for the Phoronix Test Suite, which allows the automatic scheduling of tests, remote installation of new tests, and the management of multiple test systems through a web interface. Tests can be scheduled to run on a routine basis across multiple test systems automatically. Phoromatic can also interface with revision control systems to offer support for issuing new tests on a context-basis, such as whenever a Git commit has been pushed. The test results are then available from the web interface.
Phoromatic client-server architecture
The Phoromatic server relies upon a PHP/HHVM built-in web server process and a PTS-hosted WebSocket server. The web server process handles the web UI and the responsibilities of the Phoromatic server.
Phoromatic clients are testing machines installed with PTS that connect to the Phoromatic web server through the HTTP port of the server.
Phoromatic Setup
To start the Phoromatic server, Phoromatic server HTTP port and web
server socket port needs to be set in
~/.phoronix-test-suite/user-config.xml as shown:
...
<Server>
<RemoteAccessPort>8640</RemoteAccessPort>
<Password></Password>
<WebSocketPort>8642</WebSocketPort>
<AdvertiseServiceZeroConf>TRUE</AdvertiseServiceZeroConf>
<AdvertiseServiceOpenBenchmarkRelay>TRUE</AdvertiseServiceOpenBenchmarkRelay>
<PhoromaticStorage>~/.phoronix-test-suite/phoromatic/</PhoromaticStorage>
</Server>
Phoromatic Usage
To start the Phoromatic web server for controlling local Phoronix Test Suite client systems:
$ phoronix-test-suite start-phoromatic-server
The Phoromatic web server will be hosted at localhost:8640 and will require a local account creation on the server.
Phoromatic Clients
The Phoromatic client is used for connecting to a Phoromatic server to facilitate the automatic running of tests on that client.
Phoromatic clients can be created and connected to the server using the following command:
$ phoronix-test-suite phoromatic.connect SERVER_IP:SERVER_HTTP_PORT/ACCOUNT_ID
Phoromatic server interacts with the Phoromatic clients through the HTTP port specified in the ~/.phoronix-test-suite/user-config.xml.
Phoromatic Test-schedules
A test schedule is used to facilitate automatically running a set of test(s)/suite(s) on either a routine timed basis or whenever triggered by an external script or process, e.g. Git/VCS commit, manually triggered, etc. Phoromatic provides an option for pre-install, pre-run, post-install and post-run shell scripts that are executed on the Phoromatic clients. Test-schedules can be configured to run any tests on any specific systems.
About Anita
Anita is a tool for automated testing of the NetBSD operating system. Using Anita, we can download a NetBSD distribution and install it in a virtual machine in a fully automated fashion. Anita is written in Python and uses the pexpect module to “screen scrape” the sysinst output over an emulated serial console and script the installation procedure.
Installation
Anita can be installed on NetBSD, Linux and macOS systems using the following:
$ pip install pexpect $ git clone https://github.com/gson1703/anita/ $ python setup.py install
Phoromatic-Anita Integration
I would like to describe the workflow here briefly:
- A test-schedule was created on the Phoromatic server meant to run
pts/idle-1.2.0test on the host machine that contains the phoromatic-anita-integration.sh as a pre-run script. - The script performs the following:
- Creates a mountable disk image with an executable script for setting up Phoronix Test Suite and Phoromatic client creation on the benchmarking VM systems.
- Invokes Anita with the appropriate command-line options for configurations and network setup and mounts the image to run the configuration script on the VM.
- Configuration script performs hostname change, DHCP setup, NFS
setup,
PKG_PATHsetup, PTS installation, its configuration and connecting it to the Phoromatic server through a network bridge.
- Once the benchmarking VM systems get connected to the Phoromatic server, Phoromatic server identifies the benchmarking VM systems with their IP address, hostname and MAC address.
- After the identification, Phoromatic initiates the pending tests on VM (test-profiles are downloaded on the go in the VM and executed) and maintains a history of the test result data.
Few points to be noted:
- I have used a local PKG_PATH with a NFS server setup as PTS 9.6.1 is available in wip and recompiling it would be a wastage of time. Later I have planned to use the binary shard by Joyent: https://pkgsrc.joyent.com/packages/NetBSD/9.99.69/amd64/All/ once the updated PTS gets upstreamed.
- The host machine needs some one-time manual setup like installation of QEMU, Anita, pexpect, term, cvs, etc., initial user registration on Phoromatic server, Phoromatic port setup, network bridge setup. Apart from this, the rest of the framework does not require user supervision.
VM configuration script
The following script is used as a pre-run script in the test-schedules for invoking Anita and setting up the VMs:
https://gist.github.com/apurvanandan1997/48b54402db1df3723920735f85fc7934
Networking Setup
A bridged networking mode configuration of QEMU has been used in Anita as multiple VMs will be able to accommodate with a single bridge (created on the host machine, one-time setup) using dhcpcd(8), without complicated host forwarding setup (Phoromatic server requires HTTP port forwarding).
In order to enable bridged networking for your QEMU guests, you must first create and configure a bridge interface on your host.
# ifconfig virbr0 create
Next, you must specify the newly-created bridge interface in
/etc/qemu/bridge.conf:
$ sudo mkdir /etc/qemu $ sudo touch /etc/qemu/bridge.conf && sudo chmod 644 /etc/qemu/bridge.conf $ sudo sh -c "echo 'allow virbr0' >> /etc/qemu/bridge.conf"
Finally, in order for non-privileged processes to be able to invoke qemu-bridge-helper, you must set the setuid bit on the utility:
$ sudo chmod u+s /usr/local/libexec/qemu-bridge-helper
For more details on the bridged mode networking setup in QEMU, please refer to the following guides:
- https://t.pagef.lt/basic-networking-with-qemu/
- https://www.NetBSD.org/docs/guide/en/chap-net-practice.html#chap-net-practice-bridge
Reproducing the framework
To reproduce the framework, you need to have Phoronix Test Suite, QEMU, Anita, pexpect, cvs, xterm, makefs installed on your host machine.
For example on NetBSD:
# pkg_add qemu # pkg_add py37-anita $ cd pkgsrc/wip/phoronix-test-suite $ make install
The step-by-step process to get the framework after installing PTS, including the one-time manual setup, can be summarized as follows: All control and configuration of the Phoromatic Server is done via the web-based interface when the Phoromatic Server is active.
- Configure the port of Phoromatic server as 8640 and web socket as 8642 as described above.
- Start the Phoromatic server using the command stated above.
- Create your user account on the Phoromatic server using the web interface GUI.
- Disable client system approval for new system addition from the settings menu in the web interface.
- Connect the host machine as a Phoromatic client to the Phoromatic server using the command stated above.
- Create a test-schedule for the host machine with the
pre-run script
as specified above and
pts/idle-1.2.0as the test-profile. - Execute the test-schedule or assign it on a timed-schedule and watch it running!
- New VM systems with the latest NetBSD-current binaries and packages will be created and identified by Phoromatic server automatically.
- Once for all, we need to specify what benchmarking test-profiles need
to be run on the VM systems in the test-schedules section and it will
be taken care of by Phoromatic.
- The result history can also be viewed from Phoromatic web interface.
You can have a look at the video to get a clearer picture of how to setup the framework:
Future Plans
The regression suite is complete and final tasks of deploying it on benchmark.NetBSD.org and upstreaming the wip of Phoronix Test Suite will be done in the final phase of my GSoC project. I want to thank my mentors for their constant support.
The objective of this project is to fuzz the various protocols and layers of the network stack of NetBSD using rumpkernel. This project is being carried out as a part of GSoC 2020. This blog post is regarding the project, the concepts and tools involved, the objectives and the current progress and next steps.
You can read the previous post/report here.
Overview of the work done:
The major time of the phase 1 and 2 were spent in analyzing the input and output paths of the particular protocols being fuzzed. During that time, 5 major protocols of the internet stack were taken up:
- IPv4 (Phase 1)
- UDP (Phase 1)
- IPv6 (Phase 2)
- ICMP (Phase 2)
- Ethernet (Phase 2)
Quite a good amount of time was spent in understanding the input and output processing functions of the particular protocols, the information gathered was to be applied in packet creation code for that protocol. This is important so that we know which parts of the packet can be kept random by the fuzzer based input and which part of the packet need to be set to proper fixed values. Fixing some values in the data packet to be correct is important so that the packet does not get rejected for trivial cases like IP Protocol Version or Internet Checksum. (The procedure to come up with the decisions and the code design and flow is explained in IPv4 Protocol section as an example)
For each protocol, mainly 2 things needed to be implemented:
- The Network Config: the topology for sending and receiving packets example using a TUN device or a TAP device, the socket used and so on. Configuring these devices was the first step in being able to send or receive packets
- Packet Creation: Using the information gathered in the code walkthrough of the protocol functions, packet creation is decided where certain parts of the packet are kept fixed and others random from the fuzzer input itself. Doing so we try to gain maximum code coverage. Also one thing to be noted here, we should not randomly change the fuzzer input, rather do it deterministically following the same rules for each packet, otherwise the evolutionary fuzzer cannot easily grow the corpus.
In the next section, a few of the protocols will be explained in detail.
Protocols
In this section we will talk about the various protocols implemented for fuzzing and talk about the approach taken to create a packet.
IPv4:
IPv4 stands for the Internet protocol version 4. It is one of the most widely used protocols in the internet family of protocols. It is used as a network layer protocol for routing and host to host packet delivery using an addressing scheme called IP Address(A 32 bit address scheme). IP Protocol also handles a lot of other functions like fragmentation and reassembly of packets to accommodate for transmission of packets over varying sizes of physical channel capacities. It also supports the concept of multicasting and broadcasting (Via IP Options).
In order to come up with a strategy for fuzzing, the first step was to carry out a code walkthrough of relevant functions/APIs and data structures involved in the IPv4 protocol. For that the major files and components studied were:
- ip_input() => Which carries out the processing of a incoming packet at the network layer for IPv4 (src here)
- ip_output() => Which carries out the processing of an outgoing packet at the network layer for IPv4 (src here)
- struct ip => Represents the IP header (src here)
These sections of code represent the working of the input and output processing paths of IPv4 protocol and the struct ip is the main IPv4 header. On top of that other APIs related to mbuf (The NetBSD packet), ip_forward(), IP assembly and fragmentation etc. were also studied in order to determine information about packet structure that could be followed.
In order to be able to reach these various aspects of the protocol and be able to fuzz it, we went forward with packet creation that took care of basic fields of the IP Header so that it would not get rejected in trivial cases as mentioned before. Hence we went ahead and fixed these fields:
- IP Version: Set it to 0x4 which is a 4 bit value.
- IP Header Len: Which is set to a value greater than or equal to sizeof(struct ip). Setting this to greater than that allows for IP Options processing.
- IP Len: Set it to the size of the random buffer passed by fuzzer.
- IP Checksum: We calculate the correct checksum for the packet using the internet checksum algorithm.
Other fields were allowed to be populated randomly by fuzzer input. Here is an illustration of the IPv4 header with the fields marked in red as fixed.
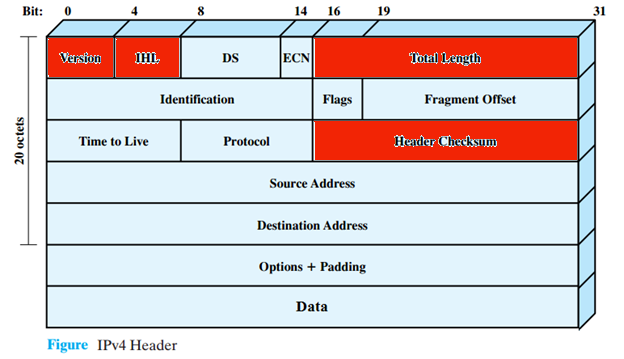
The packet creation code lies in the following section inside [pkt_create.c]. Another important component is the network configuration [located here net_config] where the code related to configuring a TUN/TAP device is present. All the code uses the rumpkernel exposed APIs and syscalls (prepended with rump_sys_) so as to utilize the rumpkernel while executing the application binary. After packet creation and network config is handled the main fuzzing function is written where a series of steps are followed:
- We call rump_init() to initialize the rumpkernel linked via libraries
- We setup the Client and server IP addresses
- We setup the TUN device by calling the network config functions described above
- We create the packet using the packet creation function utilizing the random buffer passed by the fuzzer and transforming that into a semi-random buffer.
- Pass this forged packet into the network stack of the rumpkernel linked with the application binary by calling rump_sys_write on the TUN device setup.
IPv6:
IPv6 stands for the Internet protocol version 4. It is the successor of the IPv4 protocol. It came into existence in order to overcome the addressing requirements that could not fit in a 32 bit IPv4 address. It is used as a network layer protocol for routing and host to host packet delivery using an addressing scheme called IPv6 Address(A 128 bit address scheme). It also supports almost similar other functions as IPv4 except some things like fragmentation, broadcast(instead uses multicast).
In order to be able to reach these various aspects of the protocol and be able to fuzz it, we went forward with packet creation that took care of basic fields of the IP Header so that it would not get rejected in trivial cases as mentioned before. Hence we went ahead and fixed these fields:
- IP Version: Set it to 0x6 which is a 4 bit value.
- IP Hop Limit: This is an alias for TTL. Set it to a maximum possible value of 255(8 bits).
Other fields were allowed to be populated randomly by fuzzer input. Allowing the payload len value to be randomly populated allowed processing of various “next headers” or ”Extension headers”. Extension headers carry optional Internet Layer information, and are placed between the fixed header and the upper-layer protocol header. The headers form a chain, using the Next Header fields. The Next Header field in the fixed header indicates the type of the first extension header; the Next Header field of the last extension header indicates the type of the upper-layer protocol header in the payload of the packet. A further work can be done to set the value of the next header chain and form packets for multiple scenarios with a combination of various next headers.
UDP:
UDP stands for User Datagram Protocol. It is one of the simplest protocols and is designed to be simple so that it simply carries payload with minimal overhead. It does not have many options except for checksum information and ports in order to demultiplex the packet to the processes.
Since UDP runs at the transport layer and hence is wrapped up in an IP header. Since we do not want to fuzz the IP code section, we form a well formed IP header so that the packet does not get rejected in the IP processing section. We only randomize the UDP header using the fuzzer input. We used previously built out IP packet creation utilities to form the IP header and then use the fuzzer input for UDP header.
In UDP, we fix the following fields:
- UDP Checksum: Set it to zero in order to avoid checksums.
ICMP:
ICMP stands for Internet control message protocol. This protocol is sometimes called a sister protocol of IP protocol and is used as a troubleshooting protocol at the network layer. It is used for major 2 purposes:
- Error messages
- Request-Reply Queries.
ICMP has a lot of options and is quite generic in the sense that it handles a lot of error messages and queries. Although ICMP is generally considered at the network layer, it is actually wrapped inside an IP header, hence it has its own protocol number(= 1). Again similar to UDP, we wrap the ICMP headers inside IP headers, hence we do not randomize the IP header and only the ICMP headers using fuzzer input.
In order to test various ICMP messages and queries, we could not fix values for the type and code fields in the ICMP header since they decide the ICMP message type. Also if we allowed random input, most of the packets would get rejected since the number of options of type and code fields are limited and most other values would discard the packet while processing. Hence we came up with a solution where we deterministically modified the input bits from the fuzzer corresponding to the code and type fields. For the type field we simply took a modulo of the number of types(ICMP_NTYPES macro used here). For the value of code , we had to fix values in a certain range based on the type value set already. This technique allowed us to cover all different ICMP message types via the fuzzer input. We also ensured that the input buffer was not modified completely randomly, since that is a bad practice for a feedback-driven fuzzer like ours. Apart from this we fixed the ICMP Checksum field as well by calculating the checksum using the internet checksum algorithm.
Ethernet:
Ethernet protocol defined by the IEEE 802.3 standard is a widely used data link layer protocol. The ethernet packet called a frame carries an IP(or the network layer protocol) datagram. The header is simple with Link Layer Addresses called MAC address (used for switching at data link layer which is a part of addressing), for source and destination each of 6 octets(=48 bytes) present, followed by a 4 octet Ethertype and QTag field. This is followed by payload and finally the FCS(frame check sequence) which is a four-octet cyclic redundancy check (CRC) that allows detection of corrupted data within the entire frame as received on the receiver side.
In case of Ethernet protocol fuzzing, we had to use a TAP device instead of a TUN device, since the TUN device supports passing an IP packet to the network stack, whereas a TAP device accepts an ethernet frame.
For packet creation, we set the source and destination MAC address and let the payload and ethertype be randomly populated by the fuzzer.
Current Progress and Next steps
The project currently has reached a stage where many major internet family protocols have been covered for fuzzing. As described above a structured approach to fuzzing them have been taken by forming packets based on the internal workings of the protocols. Also as mentioned in the previous post, Rumpkernel environment is being used for fuzzing all these protocols. In order to get better results as compared to raw fuzzing, we have taken these steps. In the next report we shall talk about and compare the coverage of raw fuzzing with our approach.
For the next phase of GSoC, the major focus would be to validate this process of fuzzing by various methods to check the penetration of packets into the network stack as well as the code coverage. Also the code would be made more streamlined and standardized so that it can be extended for adding more protocols even beyond the scope of the GSoC project.
The objective of this project is to fuzz the various protocols and layers of the network stack of NetBSD using rumpkernel. This project is being carried out as a part of GSoC 2020. This blog post is regarding the project, the concepts and tools involved, the objectives and the current progress and next steps.
You can read the previous post/report here.
Overview of the work done:
The major time of the phase 1 and 2 were spent in analyzing the input and output paths of the particular protocols being fuzzed. During that time, 5 major protocols of the internet stack were taken up:
- IPv4 (Phase 1)
- UDP (Phase 1)
- IPv6 (Phase 2)
- ICMP (Phase 2)
- Ethernet (Phase 2)
Quite a good amount of time was spent in understanding the input and output processing functions of the particular protocols, the information gathered was to be applied in packet creation code for that protocol. This is important so that we know which parts of the packet can be kept random by the fuzzer based input and which part of the packet need to be set to proper fixed values. Fixing some values in the data packet to be correct is important so that the packet does not get rejected for trivial cases like IP Protocol Version or Internet Checksum. (The procedure to come up with the decisions and the code design and flow is explained in IPv4 Protocol section as an example)
For each protocol, mainly 2 things needed to be implemented:
- The Network Config: the topology for sending and receiving packets example using a TUN device or a TAP device, the socket used and so on. Configuring these devices was the first step in being able to send or receive packets
- Packet Creation: Using the information gathered in the code walkthrough of the protocol functions, packet creation is decided where certain parts of the packet are kept fixed and others random from the fuzzer input itself. Doing so we try to gain maximum code coverage. Also one thing to be noted here, we should not randomly change the fuzzer input, rather do it deterministically following the same rules for each packet, otherwise the evolutionary fuzzer cannot easily grow the corpus.
In the next section, a few of the protocols will be explained in detail.
Protocols
In this section we will talk about the various protocols implemented for fuzzing and talk about the approach taken to create a packet.
IPv4:
IPv4 stands for the Internet protocol version 4. It is one of the most widely used protocols in the internet family of protocols. It is used as a network layer protocol for routing and host to host packet delivery using an addressing scheme called IP Address(A 32 bit address scheme). IP Protocol also handles a lot of other functions like fragmentation and reassembly of packets to accommodate for transmission of packets over varying sizes of physical channel capacities. It also supports the concept of multicasting and broadcasting (Via IP Options).
In order to come up with a strategy for fuzzing, the first step was to carry out a code walkthrough of relevant functions/APIs and data structures involved in the IPv4 protocol. For that the major files and components studied were:
- ip_input() => Which carries out the processing of a incoming packet at the network layer for IPv4 (src here)
- ip_output() => Which carries out the processing of an outgoing packet at the network layer for IPv4 (src here)
- struct ip => Represents the IP header (src here)
These sections of code represent the working of the input and output processing paths of IPv4 protocol and the struct ip is the main IPv4 header. On top of that other APIs related to mbuf (The NetBSD packet), ip_forward(), IP assembly and fragmentation etc. were also studied in order to determine information about packet structure that could be followed.
In order to be able to reach these various aspects of the protocol and be able to fuzz it, we went forward with packet creation that took care of basic fields of the IP Header so that it would not get rejected in trivial cases as mentioned before. Hence we went ahead and fixed these fields:
- IP Version: Set it to 0x4 which is a 4 bit value.
- IP Header Len: Which is set to a value greater than or equal to sizeof(struct ip). Setting this to greater than that allows for IP Options processing.
- IP Len: Set it to the size of the random buffer passed by fuzzer.
- IP Checksum: We calculate the correct checksum for the packet using the internet checksum algorithm.
Other fields were allowed to be populated randomly by fuzzer input. Here is an illustration of the IPv4 header with the fields marked in red as fixed.
The packet creation code lies in the following section inside [pkt_create.c]. Another important component is the network configuration [located here net_config] where the code related to configuring a TUN/TAP device is present. All the code uses the rumpkernel exposed APIs and syscalls (prepended with rump_sys_) so as to utilize the rumpkernel while executing the application binary. After packet creation and network config is handled the main fuzzing function is written where a series of steps are followed:
- We call rump_init() to initialize the rumpkernel linked via libraries
- We setup the Client and server IP addresses
- We setup the TUN device by calling the network config functions described above
- We create the packet using the packet creation function utilizing the random buffer passed by the fuzzer and transforming that into a semi-random buffer.
- Pass this forged packet into the network stack of the rumpkernel linked with the application binary by calling rump_sys_write on the TUN device setup.
IPv6:
IPv6 stands for the Internet protocol version 4. It is the successor of the IPv4 protocol. It came into existence in order to overcome the addressing requirements that could not fit in a 32 bit IPv4 address. It is used as a network layer protocol for routing and host to host packet delivery using an addressing scheme called IPv6 Address(A 128 bit address scheme). It also supports almost similar other functions as IPv4 except some things like fragmentation, broadcast(instead uses multicast).
In order to be able to reach these various aspects of the protocol and be able to fuzz it, we went forward with packet creation that took care of basic fields of the IP Header so that it would not get rejected in trivial cases as mentioned before. Hence we went ahead and fixed these fields:
- IP Version: Set it to 0x6 which is a 4 bit value.
- IP Hop Limit: This is an alias for TTL. Set it to a maximum possible value of 255(8 bits).
Other fields were allowed to be populated randomly by fuzzer input. Allowing the payload len value to be randomly populated allowed processing of various “next headers” or ”Extension headers”. Extension headers carry optional Internet Layer information, and are placed between the fixed header and the upper-layer protocol header. The headers form a chain, using the Next Header fields. The Next Header field in the fixed header indicates the type of the first extension header; the Next Header field of the last extension header indicates the type of the upper-layer protocol header in the payload of the packet. A further work can be done to set the value of the next header chain and form packets for multiple scenarios with a combination of various next headers.
UDP:
UDP stands for User Datagram Protocol. It is one of the simplest protocols and is designed to be simple so that it simply carries payload with minimal overhead. It does not have many options except for checksum information and ports in order to demultiplex the packet to the processes.
Since UDP runs at the transport layer and hence is wrapped up in an IP header. Since we do not want to fuzz the IP code section, we form a well formed IP header so that the packet does not get rejected in the IP processing section. We only randomize the UDP header using the fuzzer input. We used previously built out IP packet creation utilities to form the IP header and then use the fuzzer input for UDP header.
In UDP, we fix the following fields:
- UDP Checksum: Set it to zero in order to avoid checksums.
ICMP:
ICMP stands for Internet control message protocol. This protocol is sometimes called a sister protocol of IP protocol and is used as a troubleshooting protocol at the network layer. It is used for major 2 purposes:
- Error messages
- Request-Reply Queries.
ICMP has a lot of options and is quite generic in the sense that it handles a lot of error messages and queries. Although ICMP is generally considered at the network layer, it is actually wrapped inside an IP header, hence it has its own protocol number(= 1). Again similar to UDP, we wrap the ICMP headers inside IP headers, hence we do not randomize the IP header and only the ICMP headers using fuzzer input.
In order to test various ICMP messages and queries, we could not fix values for the type and code fields in the ICMP header since they decide the ICMP message type. Also if we allowed random input, most of the packets would get rejected since the number of options of type and code fields are limited and most other values would discard the packet while processing. Hence we came up with a solution where we deterministically modified the input bits from the fuzzer corresponding to the code and type fields. For the type field we simply took a modulo of the number of types(ICMP_NTYPES macro used here). For the value of code , we had to fix values in a certain range based on the type value set already. This technique allowed us to cover all different ICMP message types via the fuzzer input. We also ensured that the input buffer was not modified completely randomly, since that is a bad practice for a feedback-driven fuzzer like ours. Apart from this we fixed the ICMP Checksum field as well by calculating the checksum using the internet checksum algorithm.
Ethernet:
Ethernet protocol defined by the IEEE 802.3 standard is a widely used data link layer protocol. The ethernet packet called a frame carries an IP(or the network layer protocol) datagram. The header is simple with Link Layer Addresses called MAC address (used for switching at data link layer which is a part of addressing), for source and destination each of 6 octets(=48 bytes) present, followed by a 4 octet Ethertype and QTag field. This is followed by payload and finally the FCS(frame check sequence) which is a four-octet cyclic redundancy check (CRC) that allows detection of corrupted data within the entire frame as received on the receiver side.
In case of Ethernet protocol fuzzing, we had to use a TAP device instead of a TUN device, since the TUN device supports passing an IP packet to the network stack, whereas a TAP device accepts an ethernet frame.
For packet creation, we set the source and destination MAC address and let the payload and ethertype be randomly populated by the fuzzer.
Current Progress and Next steps
The project currently has reached a stage where many major internet family protocols have been covered for fuzzing. As described above a structured approach to fuzzing them have been taken by forming packets based on the internal workings of the protocols. Also as mentioned in the previous post, Rumpkernel environment is being used for fuzzing all these protocols. In order to get better results as compared to raw fuzzing, we have taken these steps. In the next report we shall talk about and compare the coverage of raw fuzzing with our approach.
For the next phase of GSoC, the major focus would be to validate this process of fuzzing by various methods to check the penetration of packets into the network stack as well as the code coverage. Also the code would be made more streamlined and standardized so that it can be extended for adding more protocols even beyond the scope of the GSoC project.
The NetBSD Project is pleased to announce NetBSD 9.3, the third release from the NetBSD 9 stable branch.
It represents a selected subset of fixes deemed important for security or stability reasons since the release of NetBSD 9.2 in May 2021, as well some enhancements backported from the development branch. It is fully compatible with NetBSD 9.0. Users running 9.2 or an earlier release are strongly recommended to upgrade.
Aside from many bug fixes, 9.3 includes backported improvements to suspend and resume support, various minor additions of new hardware to existing device drivers, compatibility with UDF file systems created on Windows 10, enhanced support for newer Intel Gigabit Ethernet chipsets, better support for new Intel and AMD Zen 3 chipsets, support for configuring connections to Wi-Fi networks using sysinst(8), support for wsfb-based X11 servers on the Commodore Amiga, and minor performance improvements for the Xen hypervisor.
The general NetBSD community is very excited about NetBSD 10.0, but it was deemed necessary to make this bug fix release available while we wait for the resolution of some compatibility problems in NetBSD-current concerning FFS Access Control Lists preventing the netbsd-10 release.
It has been a great opportunity to contribute to NetBSD as a part of Google Summer Of Code '20. The aim of the project I am working on is to setup a proper environment to fuzz the rumpkernel syscalls. This is the first report on the progress made so far.
Rumpkernels provide all the necessary components to run applications on baremetal without the necessity of an operating system. Simply put it is way to run kernel code in user space.
The main goal of rumpkernels in netbsd is to run,debug,examine and develop kernel drivers as easy as possible in the user space without having to run the entire kernel but run the exact same kernel code in userspace. This makes most of the components(drivers) easily portable to different environments.
Rump Kernels are constructed out of components, So the drivers are built as libraries and these libraries are linked to an interface(some application) that makes use of the libraries(drivers). So we need not build the entire monolithic kernel just the required parts of the kernel.
Why Honggfuzz?
I considered Honggfuzz the best place to start with for fuzzing the syscall layer as suggested by my mentors. LibFuzzer style library fuzzing method helped me in exploring how syscalls are implemented in the rumpkernel. With LibFuzzer we have the flexibility of modifying a few in-kernel functions as per the requirements to best suit the fuzzing target.
Fuzzing target
Taking a close look at src/sys/rump/librump/rumpkern/rump_syscalls.c
we observe that this is where the rump syscalls are defined. These functions are responsible for creating the arguments structure (like wrappers) and passing it to syscalls which is define
rsys_syscall(num, data, dlen, retval)
which is defined from
rump_syscall(num, data, dlen, retval)
This function is the one that invokes the execution of the syscalls. So this should be the target for fuzzing syscalls.
Fuzzing Using Honggfuzz
Initially we used the classic LibFuzzer style.
int
LLVMFuzzerTestOneInput(const uint8_t *Data, size_t Size)
{
if(Size != 2 + 8+sizeof(uint8_t))
return 0;
ExecuteSyscallusingtheData();
return 0;
}
However this approach into issues when we had to overload copyin(), copyout(), copyinstr(), copyoutstr() functions as the pointers that is used in these functions are from the Data buffer that the fuzzer provides for each fuzz iteration.
int
copyin(const void *uaddr, void *kaddr, size_t len)
{
..
..
..
..
if (RUMP_LOCALPROC_P(curproc)) {
memcpy(kaddr, uaddr, len); <- slow
} else if (len) {
error = rump_sysproxy_copyin(RUMP_SPVM2CTL(curproc->p_vmspace),
uaddr, kaddr, len);
}
return error;
}
Honggfuzz provides us HF_ITER interface which will be useful to actively fetch inputs from the fuzzer for example.
extern void HF_ITER(uint8_t **buf, size_t *len);
int
main()
{
for (;;) {
uint8_t *buf;
size_t len;
HF_ITER(&buf, &len);
DoSomethingWithInput(buf, len);
}
return 0;
}
So we switched to a faster method of using HF_ITER() in honggfuzz to fetch the data from the fuzzer as it is relatively flexible to use.
EXTERN int
rumpns_copyin(const void *uaddr, void *kaddr, size_t len)
{
int error = 0;
if (len == 0)
return 0;
//HF_MEMGET() is a wrapper around HF_ITER()
HF_MEMGET(kaddr, len);
return error;
}
Similar overloading is done for copyout(), copyinstr(), copyoutstr().
The current efforts to fuzz the rump syscalls using honggfuzz can be found here.
This gave quite a speed bump to the "dumb" fuzzer from few tens iterations to couple of hundreds as we replaced the memcpys with a wrapper around HF_ITER().
Further work by Kamil Rytarowski
Kamil has detected that overloading copyin()/copyout() functions have a shortcoming that we are mangling internal functionality of the rump that uses this copying mechanism, especially in rump_init(), but also in other rump wrappers, e.g. opening a file with rump_sys_open().
The decision has been made to alter the fuzzing mechanism from pumping random honggfuzz assisted data into the rump-kernel APIs and intercept copyin()/copyount() family of functions to add prior knowledge of the arguments that are valid. The initial target set by Kamil was to reproduce the following rump kernel crash (first detected with syzkaller in the real kernel):
#include <sys/types.h>
#include <sys/ioctl.h>
#include <rump/rump.h>
#include <rump/rump_syscalls.h>
int
main(int argc, char **argv)
{
int filedes[2];
rump_init();
rump_sys_pipe2(filedes, 0);
rump_sys_dup2(filedes[1], filedes[0]);
rump_sys_ioctl(filedes[1], FIONWRITE);
}
https://www.netbsd.org/~kamil/panic/rump_panic.c
We can compare that panicking the real kernel was analogous to the rump calls:
#include <sys/types.h>
#include <sys/ioctl.h>
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include <err.h>
#include <fcntl.h>
int
main(int argc, char **argv)
{
int filedes[2];
pipe2(filedes, 0);
dup2(filedes[1], filedes[0]);
ioctl(filedes[1], FIONWRITE);
return 0;
}
https://www.netbsd.org/~kamil/panic/panic.c
Thus, Kamil wrote a new fuzzing program that uses pip2, dup2 and ioctl APIs exclusively and has prior knowledge about valid arguments to these functions (as the reproducer is using perfectly valid NetBSD syscalls and arguments):
https://github.com/adityavardhanpadala/rumpsyscallfuzz/blob/master/honggfuzz/ioctl/ioctl_fuzz2.c
The code instead of checking out impossible (non-existent) kernel code paths, it ensures that e.g. ioctl(2) operations are always existing ioctl(2) operations.
static unsigned long
get_ioctl_request(void)
{
unsigned long u;
// ioctlprint -l -f '\t\t%x /* %n */,\n'
static const unsigned long vals[] = {
0x8014447e /* DRVRESUMEDEV */,
0xc0784802 /* HPCFBIO_GDSPCONF */,
/* A lot of skipped lines here... */
0xc0186b01 /* KFILTER_BYNAME */,
0x80047476 /* TIOCSPGRP */,
};
u = get_ulong() % __arraycount(vals);
return vals[u];
}
Kamil also rewrote the HF_MEMGET() function, so instead of recharging the buffer from the fuzzer, whenever the buffer expired the fuzzed program terminates resetting its state and checks another honggfuzz input. This intends to make the fuzzing process more predictable in terms of getting good reproducers. So far we were unable to generate good reproducers and we are still working on it.
Unfortunately (or fortunately) the code in ioctl_fuzz2.c triggers another (rump)kernel bug, unrelated to the reproducer in rump_panic.c. Furthermore, the crash looks like a race condition that breaks randomly, sometimes and honggfuzz doesn't generate good reproducers for it.
The obvious solution to this is to run the fuzzing process with TSan involved and catch such bugs quickly, unfortunately reaching MKSANITIZER for TSan + rumpkernel is still unfinished and beyond the opportunities during this GSoC.
Obstacles
- The fuzzer is still dumb meaning that we are still using just random data as arguments to the fuzzer so the coverage did not show that much improvement b/w 13 mins and 13 hours of fuzzing.
- Crash reproducers get sliced due to the way we are fetching input from fuzzer using HF_ITER() and as functions like
copyin()andcopyout()requesting quite large buffers from the fuzzers for some non-trivial functions like rump_init().
To-Do
- Improving the crash reproduction mechanism.
- Making the fuzzer smart by using grammar so that the arguments to syscalls are syntactically valid.
- Finding an optimal way to fetch data from fuzzer so that the reproducers are not sliced.
If the above improvements are done we get more coverage and if we are lucky enough lot more crashes.
Finally I'd like to thank my mentors Siddharth Muralee, Maciej Grochowski, Christos Zoulas for their guidance and Kamil Rytarowski for his constant support throughout the coding period.
This is my first report for the Google Summer of Code project I am working on for NetBSD.
Prior work: In GSoC 2012 Charles Zhang added the posix_spawn syscall which according to its SF repository at the time (maybe even now, I have not looked very much into comparing all other systems and libcs + kernels) is an in-kernel implementation of posix_spawn which provides performance benefits compared to FreeBSD and other systems which had a userspace implementation (in 2012).
After 1 week of reading POSIX and writing code, 2 weeks of coding and another 1.5 weeks of bugfixes I have successfully implemented posix_spawn in usage in system(3) and popen(3) internally.
The biggest challenge for me was to understand POSIX, to read the standard. I am used to reading more formal books, but I can't remember working with the posix standard directly before.
The next part of my Google Summer of Code project will focus on similar rewrites of NetBSD's sh(1).
system(3)
The prototype
int system(const char *command);
remains the same. Below I'm just commenting on the differences, not the whole function, and therefore only include code block where the versions differ the most. The full work can be found at gsoc2020 as well as src and will be submitted for inclusion later in the project.
Previously we'd use vfork, sigaction, and execve in this stdlib function.
The biggest difference to the 2015 version of our system version is the usage of posix_spawnattr_ where we'd use sigaction before, and posix_spawn where execve executes the command in a vfork'd child:
posix_spawnattr_init(&attr); posix_spawnattr_setsigmask(&attr, &omask); posix_spawnattr_setflags(&attr, POSIX_SPAWN_SETSIGDEF|POSIX_SPAWN_SETSIGMASK); (void)__readlockenv(); status = posix_spawn(&pid, _PATH_BSHELL, NULL, &attr, __UNCONST(argp), environ); (void)__unlockenv(); posix_spawnattr_destroy(&attr);
The full version can be found here.
The prototype of posix_spawn is:
int posix_spawn(pid_t *restrict pid, const char *restrict path, const posix_spawn_file_actions_t *file_actions, const posix_spawnattr_t *restrict attrp, char *const argv[restrict], char *const envp[restrict]);
We first initialize a spawn attributes object with the default value for all of its attributes set. A spawn attributes object is used to modify the behavior of posix_spawn().
The previous fork-exec switch included calls to sigaction to set the behavior associated with SIGINT and SIGQUIT as defined by POSIX:
The system() function shall ignore the SIGINT and SIGQUIT signals, and shall block the SIGCHLD signal, while waiting for the command to terminate. If this might cause the application to miss a signal that would have killed it, then the application should examine the return value from system() and take whatever action is appropriate to the application if the command terminated due to receipt of a signal. source: https://pubs.opengroup.org/onlinepubs/9699919799/functions/system.html
This has been achieved with a combination of posix_spawnattr_setsigmask() and posix_spawnattr_setflags() in the initialized attributes object referenced by attr.
As before we call __readlockenv() and then call posix_spawn() which returns the process ID of the child process in the variable pointed to by 'pid', and returns zero as the function return value.
The old code:
(void)__readlockenv(); switch(pid = vfork()) { case -1: /* error */ (void)__unlockenv(); sigaction(SIGINT, &intsa, NULL); sigaction(SIGQUIT, &quitsa, NULL); (void)sigprocmask(SIG_SETMASK, &omask, NULL); return -1; case 0: /* child */ sigaction(SIGINT, &intsa, NULL); sigaction(SIGQUIT, &quitsa, NULL); (void)sigprocmask(SIG_SETMASK, &omask, NULL); execve(_PATH_BSHELL, __UNCONST(argp), environ); _exit(127); } (void)__unlockenv();
popen(3), popenve(3)
As with system, the prototype of both functions remains the same:
FILE * popenve(const char *cmd, char *const *argv, char *const *envp, const char *type); FILE * popen(const char *cmd, const char *type);
Since the popen and popenve implementation in NetBSD's libc use a couple of shared helper functions, I was able to change both functions while keeping the majority of the changes focused on (some of ) the helper functions (pdes_child).
pdes_child, an internal function in popen.c, now takes one more argument (const char *cmd) for the command to pass to posix_spawn which is called in pdes_child.
pdes_child previously looked like this:
static void
pdes_child(int *pdes, const char *type)
{
struct pid *old;
/* POSIX.2 B.3.2.2 "popen() shall ensure that any streams
from previous popen() calls that remain open in the
parent process are closed in the new child process. */
for (old = pidlist; old; old = old->next)
#ifdef _REENTRANT
(void)close(old->fd); /* don't allow a flush */
#else
(void)close(fileno(old->fp)); /* don't allow a flush */
#endif
if (type[0] == 'r') {
(void)close(pdes[0]);
if (pdes[1] != STDOUT_FILENO) {
(void)dup2(pdes[1], STDOUT_FILENO);
(void)close(pdes[1]);
}
if (type[1] == '+')
(void)dup2(STDOUT_FILENO, STDIN_FILENO);
} else {
(void)close(pdes[1]);
if (pdes[0] != STDIN_FILENO) {
(void)dup2(pdes[0], STDIN_FILENO);
(void)close(pdes[0]);
}
}
}This is the new version (the whole file is here):
static int
pdes_child(int *pdes, const char *type, const char *cmd)
{
struct pid *old;
posix_spawn_file_actions_t file_action_obj;
pid_t pid;
const char *argp[] = {"sh", "-c", NULL, NULL};
argp[2] = cmd;
int error;
error = posix_spawn_file_actions_init(&file_action_obj);
if (error) {
goto fail;
}
/* POSIX.2 B.3.2.2 "popen() shall ensure that any streams
from previous popen() calls that remain open in the
parent process are closed in the new child process. */
for (old = pidlist; old; old = old->next)
#ifdef _REENTRANT
error = posix_spawn_file_actions_addclose(&file_action_obj, old->fd); /* don't allow a flush */
if (error) {
goto fail;
}
#else
error = posix_spawn_file_actions_addclose(&file_action_obj, fileno(old->fp)); /* don't allow a flush */
if (error) {
goto fail;
}
#endif
if (type[0] == 'r') {
error = posix_spawn_file_actions_addclose(&file_action_obj, pdes[0]);
if (error) {
goto fail;
}
if (pdes[1] != STDOUT_FILENO) {
error = posix_spawn_file_actions_adddup2(&file_action_obj, pdes[1], STDOUT_FILENO);
if (error) {
goto fail;
}
error = posix_spawn_file_actions_addclose(&file_action_obj, pdes[1]);
if (error) {
goto fail;
}
}
if (type[1] == '+') {
error = posix_spawn_file_actions_adddup2(&file_action_obj, STDOUT_FILENO, STDIN_FILENO);
if (error) {
goto fail;
}
}
} else {
error = posix_spawn_file_actions_addclose(&file_action_obj, pdes[1]);
if (error) {
goto fail;
}
if (pdes[0] != STDIN_FILENO) {
error = posix_spawn_file_actions_adddup2(&file_action_obj, pdes[0], STDIN_FILENO);
if (error) {
goto fail;
}
error = posix_spawn_file_actions_addclose(&file_action_obj, pdes[0]);
if (error) {
goto fail;
}
}
}
(void)__readlockenv();
error = posix_spawn(&pid, _PATH_BSHELL, &file_action_obj, 0, __UNCONST(argp), environ);
if (error) {
(void)__unlockenv();
goto fail;
}
(void)__unlockenv();
error = posix_spawn_file_actions_destroy(&file_action_obj);
/*
* TODO: if _destroy() fails we have to go on, otherwise we
* leak the pid.
*/
if (error) {
errno = error;
return -1;
}
return pid;
fail:
errno = error;
posix_spawn_file_actions_destroy(&file_action_obj);
return -1;
}On a high level what happens in pdes_child() and popen is that we first lock the pidlist_mutex. Then we create a file file action list for all concurrent popen() / popenve() instances and the side of the pipe not necessary, and the move to stdin/stdout. We unlock the pidlist_mutex. Finally we return the list and destroy.
In the new version of this helper function which now handles the majority of what popen/popenve did, we have to initialize a file_actions object which by default contains no file actions for posix_spawn() to perform. Since we have to have error handling and a common return value for the functions calling pdes_child() and deconstruction, we make use of goto in some parts of this function.
The close() and dup2() actions now get replaced by corresponding file_actions syscalls, they are used to specify a series of actions to be performed by a posix_spawn operation.
After this series of actions, we call _readlockenv(), and call posix_spawn with the file_action object and the other arguments to be executed. If it succeeds, we return the pid of the child to popen, otherwise we return -1, in both cases we destroy the file_action object before we proceed.
In popen and popenve our code has been reduced to just the 'pid == -1' branch, everything else happens in pdes_child() now.
After readlockenv we call pdes_child and pass it the command to execute in the posix_spawn'd child process; if pdes_child returns -1 we run the old error handling code. Likewise for popenve.
popen, old:
FILE *
popen(const char *cmd, const char *type)
{
struct pid *cur;
int pdes[2], serrno;
pid_t pid;
_DIAGASSERT(cmd != NULL);
_DIAGASSERT(type != NULL);
if ((cur = pdes_get(pdes, &type)) == NULL)
return NULL;
MUTEX_LOCK();
(void)__readlockenv();
switch (pid = vfork()) {
case -1: /* Error. */
serrno = errno;
(void)__unlockenv();
MUTEX_UNLOCK();
pdes_error(pdes, cur);
errno = serrno;
return NULL;
/* NOTREACHED */
case 0: /* Child. */
pdes_child(pdes, type);
execl(_PATH_BSHELL, "sh", "-c", cmd, NULL);
_exit(127);
/* NOTREACHED */
}
(void)__unlockenv();
pdes_parent(pdes, cur, pid, type);
MUTEX_UNLOCK();
return cur->fp;
}popen, new:
FILE *
popen(const char *cmd, const char *type)
{
struct pid *cur;
int pdes[2], serrno;
pid_t pid;
_DIAGASSERT(cmd != NULL);
_DIAGASSERT(type != NULL);
if ((cur = pdes_get(pdes, &type)) == NULL)
return NULL;
MUTEX_LOCK();
(void)__readlockenv();
pid = pdes_child(pdes, type, cmd);
if (pid == -1) {
/* Error. */
serrno = errno;
(void)__unlockenv();
MUTEX_UNLOCK();
pdes_error(pdes, cur);
errno = serrno;
return NULL;
/* NOTREACHED */
}
(void)__unlockenv();
pdes_parent(pdes, cur, pid, type);
MUTEX_UNLOCK();
return cur->fp;
}popenve, old:
FILE *
popenve(const char *cmd, char *const *argv, char *const *envp, const char *type)
{
struct pid *cur;
int pdes[2], serrno;
pid_t pid;
_DIAGASSERT(cmd != NULL);
_DIAGASSERT(type != NULL);
if ((cur = pdes_get(pdes, &type)) == NULL)
return NULL;
MUTEX_LOCK();
switch (pid = vfork()) {
case -1: /* Error. */
serrno = errno;
MUTEX_UNLOCK();
pdes_error(pdes, cur);
errno = serrno;
return NULL;
/* NOTREACHED */
case 0: /* Child. */
pdes_child(pdes, type);
execve(cmd, argv, envp);
_exit(127);
/* NOTREACHED */
}
pdes_parent(pdes, cur, pid, type);
MUTEX_UNLOCK();
return cur->fp;
}popenve, new:
FILE *
popenve(const char *cmd, char *const *argv, char *const *envp, const char *type)
{
struct pid *cur;
int pdes[2], serrno;
pid_t pid;
_DIAGASSERT(cmd != NULL);
_DIAGASSERT(type != NULL);
if ((cur = pdes_get(pdes, &type)) == NULL)
return NULL;
MUTEX_LOCK();
pid = pdes_child(pdes, type, cmd);
if (pid == -1) {
/* Error. */
serrno = errno;
MUTEX_UNLOCK();
pdes_error(pdes, cur);
errno = serrno;
return NULL;
/* NOTREACHED */
}
pdes_parent(pdes, cur, pid, type);
MUTEX_UNLOCK();
return cur->fp;
}This is my first report for the Google Summer of Code project I am working on for NetBSD.
Prior work: In GSoC 2012 Charles Zhang added the posix_spawn syscall which according to its SF repository at the time (maybe even now, I have not looked very much into comparing all other systems and libcs + kernels) is an in-kernel implementation of posix_spawn which provides performance benefits compared to FreeBSD and other systems which had a userspace implementation (in 2012).
After 1 week of reading POSIX and writing code, 2 weeks of coding and another 1.5 weeks of bugfixes I have successfully implemented posix_spawn in usage in system(3) and popen(3) internally.
The biggest challenge for me was to understand POSIX, to read the standard. I am used to reading more formal books, but I can't remember working with the posix standard directly before.
The next part of my Google Summer of Code project will focus on similar rewrites of NetBSD's sh(1).
system(3)
The prototype
int system(const char *command);
remains the same. Below I'm just commenting on the differences, not the whole function, and therefore only include code block where the versions differ the most. The full work can be found at gsoc2020 as well as src and will be submitted for inclusion later in the project.
Previously we'd use vfork, sigaction, and execve in this stdlib function.
The biggest difference to the 2015 version of our system version is the usage of posix_spawnattr_ where we'd use sigaction before, and posix_spawn where execve executes the command in a vfork'd child:
posix_spawnattr_init(&attr); posix_spawnattr_setsigmask(&attr, &omask); posix_spawnattr_setflags(&attr, POSIX_SPAWN_SETSIGDEF|POSIX_SPAWN_SETSIGMASK); (void)__readlockenv(); status = posix_spawn(&pid, _PATH_BSHELL, NULL, &attr, __UNCONST(argp), environ); (void)__unlockenv(); posix_spawnattr_destroy(&attr);
The full version can be found here.
The prototype of posix_spawn is:
int posix_spawn(pid_t *restrict pid, const char *restrict path, const posix_spawn_file_actions_t *file_actions, const posix_spawnattr_t *restrict attrp, char *const argv[restrict], char *const envp[restrict]);
We first initialize a spawn attributes object with the default value for all of its attributes set. A spawn attributes object is used to modify the behavior of posix_spawn().
The previous fork-exec switch included calls to sigaction to set the behavior associated with SIGINT and SIGQUIT as defined by POSIX:
The system() function shall ignore the SIGINT and SIGQUIT signals, and shall block the SIGCHLD signal, while waiting for the command to terminate. If this might cause the application to miss a signal that would have killed it, then the application should examine the return value from system() and take whatever action is appropriate to the application if the command terminated due to receipt of a signal. source: https://pubs.opengroup.org/onlinepubs/9699919799/functions/system.html
This has been achieved with a combination of posix_spawnattr_setsigmask() and posix_spawnattr_setflags() in the initialized attributes object referenced by attr.
As before we call __readlockenv() and then call posix_spawn() which returns the process ID of the child process in the variable pointed to by 'pid', and returns zero as the function return value.
The old code:
(void)__readlockenv(); switch(pid = vfork()) { case -1: /* error */ (void)__unlockenv(); sigaction(SIGINT, &intsa, NULL); sigaction(SIGQUIT, &quitsa, NULL); (void)sigprocmask(SIG_SETMASK, &omask, NULL); return -1; case 0: /* child */ sigaction(SIGINT, &intsa, NULL); sigaction(SIGQUIT, &quitsa, NULL); (void)sigprocmask(SIG_SETMASK, &omask, NULL); execve(_PATH_BSHELL, __UNCONST(argp), environ); _exit(127); } (void)__unlockenv();
popen(3), popenve(3)
As with system, the prototype of both functions remains the same:
FILE * popenve(const char *cmd, char *const *argv, char *const *envp, const char *type); FILE * popen(const char *cmd, const char *type);
Since the popen and popenve implementation in NetBSD's libc use a couple of shared helper functions, I was able to change both functions while keeping the majority of the changes focused on (some of ) the helper functions (pdes_child).
pdes_child, an internal function in popen.c, now takes one more argument (const char *cmd) for the command to pass to posix_spawn which is called in pdes_child.
pdes_child previously looked like this:
static void
pdes_child(int *pdes, const char *type)
{
struct pid *old;
/* POSIX.2 B.3.2.2 "popen() shall ensure that any streams
from previous popen() calls that remain open in the
parent process are closed in the new child process. */
for (old = pidlist; old; old = old->next)
#ifdef _REENTRANT
(void)close(old->fd); /* don't allow a flush */
#else
(void)close(fileno(old->fp)); /* don't allow a flush */
#endif
if (type[0] == 'r') {
(void)close(pdes[0]);
if (pdes[1] != STDOUT_FILENO) {
(void)dup2(pdes[1], STDOUT_FILENO);
(void)close(pdes[1]);
}
if (type[1] == '+')
(void)dup2(STDOUT_FILENO, STDIN_FILENO);
} else {
(void)close(pdes[1]);
if (pdes[0] != STDIN_FILENO) {
(void)dup2(pdes[0], STDIN_FILENO);
(void)close(pdes[0]);
}
}
}This is the new version (the whole file is here):
static int
pdes_child(int *pdes, const char *type, const char *cmd)
{
struct pid *old;
posix_spawn_file_actions_t file_action_obj;
pid_t pid;
const char *argp[] = {"sh", "-c", NULL, NULL};
argp[2] = cmd;
int error;
error = posix_spawn_file_actions_init(&file_action_obj);
if (error) {
goto fail;
}
/* POSIX.2 B.3.2.2 "popen() shall ensure that any streams
from previous popen() calls that remain open in the
parent process are closed in the new child process. */
for (old = pidlist; old; old = old->next)
#ifdef _REENTRANT
error = posix_spawn_file_actions_addclose(&file_action_obj, old->fd); /* don't allow a flush */
if (error) {
goto fail;
}
#else
error = posix_spawn_file_actions_addclose(&file_action_obj, fileno(old->fp)); /* don't allow a flush */
if (error) {
goto fail;
}
#endif
if (type[0] == 'r') {
error = posix_spawn_file_actions_addclose(&file_action_obj, pdes[0]);
if (error) {
goto fail;
}
if (pdes[1] != STDOUT_FILENO) {
error = posix_spawn_file_actions_adddup2(&file_action_obj, pdes[1], STDOUT_FILENO);
if (error) {
goto fail;
}
error = posix_spawn_file_actions_addclose(&file_action_obj, pdes[1]);
if (error) {
goto fail;
}
}
if (type[1] == '+') {
error = posix_spawn_file_actions_adddup2(&file_action_obj, STDOUT_FILENO, STDIN_FILENO);
if (error) {
goto fail;
}
}
} else {
error = posix_spawn_file_actions_addclose(&file_action_obj, pdes[1]);
if (error) {
goto fail;
}
if (pdes[0] != STDIN_FILENO) {
error = posix_spawn_file_actions_adddup2(&file_action_obj, pdes[0], STDIN_FILENO);
if (error) {
goto fail;
}
error = posix_spawn_file_actions_addclose(&file_action_obj, pdes[0]);
if (error) {
goto fail;
}
}
}
(void)__readlockenv();
error = posix_spawn(&pid, _PATH_BSHELL, &file_action_obj, 0, __UNCONST(argp), environ);
if (error) {
(void)__unlockenv();
goto fail;
}
(void)__unlockenv();
error = posix_spawn_file_actions_destroy(&file_action_obj);
/*
* TODO: if _destroy() fails we have to go on, otherwise we
* leak the pid.
*/
if (error) {
errno = error;
return -1;
}
return pid;
fail:
errno = error;
posix_spawn_file_actions_destroy(&file_action_obj);
return -1;
}On a high level what happens in pdes_child() and popen is that we first lock the pidlist_mutex. Then we create a file file action list for all concurrent popen() / popenve() instances and the side of the pipe not necessary, and the move to stdin/stdout. We unlock the pidlist_mutex. Finally we return the list and destroy.
In the new version of this helper function which now handles the majority of what popen/popenve did, we have to initialize a file_actions object which by default contains no file actions for posix_spawn() to perform. Since we have to have error handling and a common return value for the functions calling pdes_child() and deconstruction, we make use of goto in some parts of this function.
The close() and dup2() actions now get replaced by corresponding file_actions syscalls, they are used to specify a series of actions to be performed by a posix_spawn operation.
After this series of actions, we call _readlockenv(), and call posix_spawn with the file_action object and the other arguments to be executed. If it succeeds, we return the pid of the child to popen, otherwise we return -1, in both cases we destroy the file_action object before we proceed.
In popen and popenve our code has been reduced to just the 'pid == -1' branch, everything else happens in pdes_child() now.
After readlockenv we call pdes_child and pass it the command to execute in the posix_spawn'd child process; if pdes_child returns -1 we run the old error handling code. Likewise for popenve.
popen, old:
FILE *
popen(const char *cmd, const char *type)
{
struct pid *cur;
int pdes[2], serrno;
pid_t pid;
_DIAGASSERT(cmd != NULL);
_DIAGASSERT(type != NULL);
if ((cur = pdes_get(pdes, &type)) == NULL)
return NULL;
MUTEX_LOCK();
(void)__readlockenv();
switch (pid = vfork()) {
case -1: /* Error. */
serrno = errno;
(void)__unlockenv();
MUTEX_UNLOCK();
pdes_error(pdes, cur);
errno = serrno;
return NULL;
/* NOTREACHED */
case 0: /* Child. */
pdes_child(pdes, type);
execl(_PATH_BSHELL, "sh", "-c", cmd, NULL);
_exit(127);
/* NOTREACHED */
}
(void)__unlockenv();
pdes_parent(pdes, cur, pid, type);
MUTEX_UNLOCK();
return cur->fp;
}popen, new:
FILE *
popen(const char *cmd, const char *type)
{
struct pid *cur;
int pdes[2], serrno;
pid_t pid;
_DIAGASSERT(cmd != NULL);
_DIAGASSERT(type != NULL);
if ((cur = pdes_get(pdes, &type)) == NULL)
return NULL;
MUTEX_LOCK();
(void)__readlockenv();
pid = pdes_child(pdes, type, cmd);
if (pid == -1) {
/* Error. */
serrno = errno;
(void)__unlockenv();
MUTEX_UNLOCK();
pdes_error(pdes, cur);
errno = serrno;
return NULL;
/* NOTREACHED */
}
(void)__unlockenv();
pdes_parent(pdes, cur, pid, type);
MUTEX_UNLOCK();
return cur->fp;
}popenve, old:
FILE *
popenve(const char *cmd, char *const *argv, char *const *envp, const char *type)
{
struct pid *cur;
int pdes[2], serrno;
pid_t pid;
_DIAGASSERT(cmd != NULL);
_DIAGASSERT(type != NULL);
if ((cur = pdes_get(pdes, &type)) == NULL)
return NULL;
MUTEX_LOCK();
switch (pid = vfork()) {
case -1: /* Error. */
serrno = errno;
MUTEX_UNLOCK();
pdes_error(pdes, cur);
errno = serrno;
return NULL;
/* NOTREACHED */
case 0: /* Child. */
pdes_child(pdes, type);
execve(cmd, argv, envp);
_exit(127);
/* NOTREACHED */
}
pdes_parent(pdes, cur, pid, type);
MUTEX_UNLOCK();
return cur->fp;
}popenve, new:
FILE *
popenve(const char *cmd, char *const *argv, char *const *envp, const char *type)
{
struct pid *cur;
int pdes[2], serrno;
pid_t pid;
_DIAGASSERT(cmd != NULL);
_DIAGASSERT(type != NULL);
if ((cur = pdes_get(pdes, &type)) == NULL)
return NULL;
MUTEX_LOCK();
pid = pdes_child(pdes, type, cmd);
if (pid == -1) {
/* Error. */
serrno = errno;
MUTEX_UNLOCK();
pdes_error(pdes, cur);
errno = serrno;
return NULL;
/* NOTREACHED */
}
pdes_parent(pdes, cur, pid, type);
MUTEX_UNLOCK();
return cur->fp;
}This is my first report for the Google Summer of Code project I am working on for NetBSD.
Prior work: In GSoC 2012 Charles Zhang added the posix_spawn syscall which according to its SF repository at the time (maybe even now, I have not looked very much into comparing all other systems and libcs + kernels) is an in-kernel implementation of posix_spawn which provides performance benefits compared to FreeBSD and other systems which had a userspace implementation (in 2012).
After 1 week of reading POSIX and writing code, 2 weeks of coding and another 1.5 weeks of bugfixes I have successfully implemented posix_spawn in usage in system(3) and popen(3) internally.
The biggest challenge for me was to understand POSIX, to read the standard. I am used to reading more formal books, but I can't remember working with the posix standard directly before.
The next part of my Google Summer of Code project will focus on similar rewrites of NetBSD's sh(1).
system(3)
The prototype
int system(const char *command);
remains the same. Below I'm just commenting on the differences, not the whole function, and therefore only include code block where the versions differ the most. The full work can be found at gsoc2020 as well as src and will be submitted for inclusion later in the project.
Previously we'd use vfork, sigaction, and execve in this stdlib function.
The biggest difference to the 2015 version of our system version is the usage of posix_spawnattr_ where we'd use sigaction before, and posix_spawn where execve executes the command in a vfork'd child:
posix_spawnattr_init(&attr); posix_spawnattr_setsigmask(&attr, &omask); posix_spawnattr_setflags(&attr, POSIX_SPAWN_SETSIGDEF|POSIX_SPAWN_SETSIGMASK); (void)__readlockenv(); status = posix_spawn(&pid, _PATH_BSHELL, NULL, &attr, __UNCONST(argp), environ); (void)__unlockenv(); posix_spawnattr_destroy(&attr);
The full version can be found here.
The prototype of posix_spawn is:
int posix_spawn(pid_t *restrict pid, const char *restrict path, const posix_spawn_file_actions_t *file_actions, const posix_spawnattr_t *restrict attrp, char *const argv[restrict], char *const envp[restrict]);
We first initialize a spawn attributes object with the default value for all of its attributes set. A spawn attributes object is used to modify the behavior of posix_spawn().
The previous fork-exec switch included calls to sigaction to set the behavior associated with SIGINT and SIGQUIT as defined by POSIX:
The system() function shall ignore the SIGINT and SIGQUIT signals, and shall block the SIGCHLD signal, while waiting for the command to terminate. If this might cause the application to miss a signal that would have killed it, then the application should examine the return value from system() and take whatever action is appropriate to the application if the command terminated due to receipt of a signal. source: https://pubs.opengroup.org/onlinepubs/9699919799/functions/system.html
This has been achieved with a combination of posix_spawnattr_setsigmask() and posix_spawnattr_setflags() in the initialized attributes object referenced by attr.
As before we call __readlockenv() and then call posix_spawn() which returns the process ID of the child process in the variable pointed to by 'pid', and returns zero as the function return value.
The old code:
(void)__readlockenv(); switch(pid = vfork()) { case -1: /* error */ (void)__unlockenv(); sigaction(SIGINT, &intsa, NULL); sigaction(SIGQUIT, &quitsa, NULL); (void)sigprocmask(SIG_SETMASK, &omask, NULL); return -1; case 0: /* child */ sigaction(SIGINT, &intsa, NULL); sigaction(SIGQUIT, &quitsa, NULL); (void)sigprocmask(SIG_SETMASK, &omask, NULL); execve(_PATH_BSHELL, __UNCONST(argp), environ); _exit(127); } (void)__unlockenv();
popen(3), popenve(3)
As with system, the prototype of both functions remains the same:
FILE * popenve(const char *cmd, char *const *argv, char *const *envp, const char *type); FILE * popen(const char *cmd, const char *type);
Since the popen and popenve implementation in NetBSD's libc use a couple of shared helper functions, I was able to change both functions while keeping the majority of the changes focused on (some of ) the helper functions (pdes_child).
pdes_child, an internal function in popen.c, now takes one more argument (const char *cmd) for the command to pass to posix_spawn which is called in pdes_child.
pdes_child previously looked like this:
static void
pdes_child(int *pdes, const char *type)
{
struct pid *old;
/* POSIX.2 B.3.2.2 "popen() shall ensure that any streams
from previous popen() calls that remain open in the
parent process are closed in the new child process. */
for (old = pidlist; old; old = old->next)
#ifdef _REENTRANT
(void)close(old->fd); /* don't allow a flush */
#else
(void)close(fileno(old->fp)); /* don't allow a flush */
#endif
if (type[0] == 'r') {
(void)close(pdes[0]);
if (pdes[1] != STDOUT_FILENO) {
(void)dup2(pdes[1], STDOUT_FILENO);
(void)close(pdes[1]);
}
if (type[1] == '+')
(void)dup2(STDOUT_FILENO, STDIN_FILENO);
} else {
(void)close(pdes[1]);
if (pdes[0] != STDIN_FILENO) {
(void)dup2(pdes[0], STDIN_FILENO);
(void)close(pdes[0]);
}
}
}This is the new version (the whole file is here):
static int
pdes_child(int *pdes, const char *type, const char *cmd)
{
struct pid *old;
posix_spawn_file_actions_t file_action_obj;
pid_t pid;
const char *argp[] = {"sh", "-c", NULL, NULL};
argp[2] = cmd;
int error;
error = posix_spawn_file_actions_init(&file_action_obj);
if (error) {
goto fail;
}
/* POSIX.2 B.3.2.2 "popen() shall ensure that any streams
from previous popen() calls that remain open in the
parent process are closed in the new child process. */
for (old = pidlist; old; old = old->next)
#ifdef _REENTRANT
error = posix_spawn_file_actions_addclose(&file_action_obj, old->fd); /* don't allow a flush */
if (error) {
goto fail;
}
#else
error = posix_spawn_file_actions_addclose(&file_action_obj, fileno(old->fp)); /* don't allow a flush */
if (error) {
goto fail;
}
#endif
if (type[0] == 'r') {
error = posix_spawn_file_actions_addclose(&file_action_obj, pdes[0]);
if (error) {
goto fail;
}
if (pdes[1] != STDOUT_FILENO) {
error = posix_spawn_file_actions_adddup2(&file_action_obj, pdes[1], STDOUT_FILENO);
if (error) {
goto fail;
}
error = posix_spawn_file_actions_addclose(&file_action_obj, pdes[1]);
if (error) {
goto fail;
}
}
if (type[1] == '+') {
error = posix_spawn_file_actions_adddup2(&file_action_obj, STDOUT_FILENO, STDIN_FILENO);
if (error) {
goto fail;
}
}
} else {
error = posix_spawn_file_actions_addclose(&file_action_obj, pdes[1]);
if (error) {
goto fail;
}
if (pdes[0] != STDIN_FILENO) {
error = posix_spawn_file_actions_adddup2(&file_action_obj, pdes[0], STDIN_FILENO);
if (error) {
goto fail;
}
error = posix_spawn_file_actions_addclose(&file_action_obj, pdes[0]);
if (error) {
goto fail;
}
}
}
(void)__readlockenv();
error = posix_spawn(&pid, _PATH_BSHELL, &file_action_obj, 0, __UNCONST(argp), environ);
if (error) {
(void)__unlockenv();
goto fail;
}
(void)__unlockenv();
error = posix_spawn_file_actions_destroy(&file_action_obj);
/*
* TODO: if _destroy() fails we have to go on, otherwise we
* leak the pid.
*/
if (error) {
errno = error;
return -1;
}
return pid;
fail:
errno = error;
posix_spawn_file_actions_destroy(&file_action_obj);
return -1;
}On a high level what happens in pdes_child() and popen is that we first lock the pidlist_mutex. Then we create a file file action list for all concurrent popen() / popenve() instances and the side of the pipe not necessary, and the move to stdin/stdout. We unlock the pidlist_mutex. Finally we return the list and destroy.
In the new version of this helper function which now handles the majority of what popen/popenve did, we have to initialize a file_actions object which by default contains no file actions for posix_spawn() to perform. Since we have to have error handling and a common return value for the functions calling pdes_child() and deconstruction, we make use of goto in some parts of this function.
The close() and dup2() actions now get replaced by corresponding file_actions syscalls, they are used to specify a series of actions to be performed by a posix_spawn operation.
After this series of actions, we call _readlockenv(), and call posix_spawn with the file_action object and the other arguments to be executed. If it succeeds, we return the pid of the child to popen, otherwise we return -1, in both cases we destroy the file_action object before we proceed.
In popen and popenve our code has been reduced to just the 'pid == -1' branch, everything else happens in pdes_child() now.
After readlockenv we call pdes_child and pass it the command to execute in the posix_spawn'd child process; if pdes_child returns -1 we run the old error handling code. Likewise for popenve.
popen, old:
FILE *
popen(const char *cmd, const char *type)
{
struct pid *cur;
int pdes[2], serrno;
pid_t pid;
_DIAGASSERT(cmd != NULL);
_DIAGASSERT(type != NULL);
if ((cur = pdes_get(pdes, &type)) == NULL)
return NULL;
MUTEX_LOCK();
(void)__readlockenv();
switch (pid = vfork()) {
case -1: /* Error. */
serrno = errno;
(void)__unlockenv();
MUTEX_UNLOCK();
pdes_error(pdes, cur);
errno = serrno;
return NULL;
/* NOTREACHED */
case 0: /* Child. */
pdes_child(pdes, type);
execl(_PATH_BSHELL, "sh", "-c", cmd, NULL);
_exit(127);
/* NOTREACHED */
}
(void)__unlockenv();
pdes_parent(pdes, cur, pid, type);
MUTEX_UNLOCK();
return cur->fp;
}popen, new:
FILE *
popen(const char *cmd, const char *type)
{
struct pid *cur;
int pdes[2], serrno;
pid_t pid;
_DIAGASSERT(cmd != NULL);
_DIAGASSERT(type != NULL);
if ((cur = pdes_get(pdes, &type)) == NULL)
return NULL;
MUTEX_LOCK();
(void)__readlockenv();
pid = pdes_child(pdes, type, cmd);
if (pid == -1) {
/* Error. */
serrno = errno;
(void)__unlockenv();
MUTEX_UNLOCK();
pdes_error(pdes, cur);
errno = serrno;
return NULL;
/* NOTREACHED */
}
(void)__unlockenv();
pdes_parent(pdes, cur, pid, type);
MUTEX_UNLOCK();
return cur->fp;
}popenve, old:
FILE *
popenve(const char *cmd, char *const *argv, char *const *envp, const char *type)
{
struct pid *cur;
int pdes[2], serrno;
pid_t pid;
_DIAGASSERT(cmd != NULL);
_DIAGASSERT(type != NULL);
if ((cur = pdes_get(pdes, &type)) == NULL)
return NULL;
MUTEX_LOCK();
switch (pid = vfork()) {
case -1: /* Error. */
serrno = errno;
MUTEX_UNLOCK();
pdes_error(pdes, cur);
errno = serrno;
return NULL;
/* NOTREACHED */
case 0: /* Child. */
pdes_child(pdes, type);
execve(cmd, argv, envp);
_exit(127);
/* NOTREACHED */
}
pdes_parent(pdes, cur, pid, type);
MUTEX_UNLOCK();
return cur->fp;
}popenve, new:
FILE *
popenve(const char *cmd, char *const *argv, char *const *envp, const char *type)
{
struct pid *cur;
int pdes[2], serrno;
pid_t pid;
_DIAGASSERT(cmd != NULL);
_DIAGASSERT(type != NULL);
if ((cur = pdes_get(pdes, &type)) == NULL)
return NULL;
MUTEX_LOCK();
pid = pdes_child(pdes, type, cmd);
if (pid == -1) {
/* Error. */
serrno = errno;
MUTEX_UNLOCK();
pdes_error(pdes, cur);
errno = serrno;
return NULL;
/* NOTREACHED */
}
pdes_parent(pdes, cur, pid, type);
MUTEX_UNLOCK();
return cur->fp;
}Introduction:
The objective of this project is to fuzz the various protocols and layers of the network stack of NetBSD using rumpkernel. This project is being carried out as a part of GSoC 2020. This blog post is regarding the project, the concepts and tools involved, the objectives and the current progress and next steps.
Fuzzing:
Fuzzing or fuzz testing is an automated software testing technique in which a program is tested by passing unusual, unexpected or semi-random input generated data to the input of the program and repeatedly doing so, trying to crash the program and detect potential bugs or undealt corner cases.
There are several tools available today that enable this which are known as fuzzers. An effective fuzzer generates semi-valid inputs that are "valid enough" in that they are not directly rejected by the parser, but do create unexpected behaviors deeper in the program and are "invalid enough" to expose corner cases that have not been properly dealt with.
Fuzzers can be of various types like dumb vs smart, generation-based vs mutation-based and so on. A dumb fuzzer generates random input without looking at the input format or model but it can follow some sophisticated algorithms like in AFL, though considered a dumb fuzzer as it just flips bits and replaces bytes, still uses a genetic algorithm to create new test cases, where as a smart fuzzer will follow an input model to generate semi-random data that can penetrate well in the code and trigger more edge cases. Mutation and generation fuzzers handle test case generation differently. Mutation fuzzers mutate a supplied seed input object, while generation fuzzers generate new test cases from a supplied model.
Some examples of popular fuzzers are: AFL(American Fuzzy Lop), Syzkaller, Honggfuzz.
RumpKernel
Kernels can have several different architectures like monolithic, microkernel, exokernel etc. An interesting architecture is the “anykernel” architecture, according to wikipedia, “The "anykernel" concept refers to an architecture-agnostic approach to drivers where drivers can either be compiled into the monolithic kernel or be run as a userspace process, microkernel-style, without code changes.” Rumpkernel is an implementation of this anykernel architecture. In case of the NetBSD rumpkernel, all the NetBSD subsystems like file system, network stack, drivers etc are compiled into standalone libraries that can be linked into any application process to utilize the functionalities of the kernel, like the file system or the drivers. This allows us to run and test various components of NetBSD kernel as a library linked to programs running in the user space.
This idea of rumpkernel is really helpful in fuzzing the components of the kernel. We can fuzz separate subsystems and allow it to crash without having to manage the crash of a running Operating System. Also the fact that context switching has an overhead in case syscalls are made to the kernel, Rumpkernel running in the userspace can eliminate this and save time.(Also since the spectre-meltdown vulnerabilities, system calls have become more costly due to the security reasons)
HonggFuzz + Rumpkernel Network Stack:
In this project we will use the outlined Rumpkernel’s network stack and a fuzzer called the honggfuzz. Honggfuzz is a security oriented, feedback-driven, evolutionary, easy-to-use fuzzer. It is maintained by google.(https://github.com/google/honggfuzz)
The project is hosted on github at: https://github.com/NJnisarg/fuzznetrump/ .The Readme can help in setting it up. We first require NetBSD installed either on a physical machine or on a virtual machine like qemu. Then we will build the NetBSD distribution by grabbing the latest sources(https://github.com/NetBSD/src). We will enable fuzzer coverage by using MKSANITIZER and MKLIBCSANITIZER flags and using the ASan(Address) and UBSan(Undefined Behavior) sanitizers. These sanitizers will help the fuzzer in catching bugs related to undefined behavior and address and memory leaks. After that we will grab one of the fuzzer programs(example: src/hfuzz_ip_output_fuzz.c) and chroot into the newly built distribution from the host NetBSD OS. Then we will compile it using hfuzz-clang by linking the required rumpkernel libraries (for example in our case: rump, rumpnet, rumpnet_netinet and so on). This is where we use the rumpkernel as libraries linked to our program. The program will access the network stack of the linked rumpkernel and the fuzzer will fuzz those components of the kernel. The compiled binary will be run with honggfuzz. Detailed steps are outlined in the Readme of the linked repository.
Our Approach for network stack fuzzing:
We have planned to fuzz various protocols at different layers of the TCP/IP stack. We have started with mostly widely used yet simple protocols like IP(v4), UDP etc. Along the progress of the project, we will be adding support for more L3(and above) protocols like ICMP, IP(v6), TCP as well as L2 protocols like Ethernet as a bit later phase.
The network stack has 2 paths:
- Input/ingress path
- Output/egress path
A packet is sent down the network stack via a socket from an application from the output path, whereas a packet is said to be received on a network interface into the network stack via the input path. Each network protocol has major input and output APIs for the packet processing. Example IP protocol has an ip_input() function to process an incoming packet and an ip_output() function to process an outgoing packet. We are planning to fuzz each protocol’s output and input APIs by sending the packet via the output path and receiving the packet via input path respectively.
In order to fuzz the output and input path, the network stack setup and configuration we have is as follows:
- We have a TUN device to which we can read and write a packet.
- We have a socket that is bound to the TUN device, which can send and receive packets
- In order to fuzz the input path, we “write” a packet to the TUN interface, which emulates a received packet on the network stack.
- In order to fuzz the output path, we send a packet via the socket to the TUN interface to fuzz the output path.
For carrying out all the above setup, we have separated out the common function for creating and configuring the TUN device and socket into a file called “net_config.c”
Also in order to reduce the rejection of packets carrying random data for trivial cases like checksum or header len, we have created functions that create/forge semi-random packets using the input data from honggfuzz. We manipulate certain fields in the packet to ensure that it does not get rejected trivially by the network stack and hence can reach and trigger deeper parts of the code. These functions for packet creations are located in the “pkt_create.c” file. For each protocol we fuzz, we add these functions to forge the headers and the packet. Currently we have support from UDP and IP(v4).
With these building blocks we have written programs like hfuzz_ip_output_fuzz.c, hfuzz_ip_input_fuzz.c etc, which setup the TUN device and socket using net_config.c and after taking the random data from honggfuzz, use it to forge a packet and send it down or up the stack. We compile these programs using hfuzz-clang as mentioned above and run it under honggfuzz to fuzz the network stack’s particular APIs.
Current Progress:
Following things were worked upon in the first phase:
- Getting honggfuzz functional for NetBSD(thanks to Kamil for those patches)
- Coming up with the strategy for network configuration and packet creation. Writing utilities for the same.
- Adding fuzzing code for protocols like IP(v4) and UDP.
- Carrying out fuzzing for those protocols.
Next Steps:
As next steps following things are planned for upcoming phase:
- Making changes and improvements by taking suggestions from the mentors.
- Adding support for ICMP, IP(v6), TCP and later on for Ethernet.
- Analyze and come up with effective ways to improve the fuzzing by focusing on the packet creation part.
- Standardize the code to be extensible for adding future protocols.
Introduction:
The objective of this project is to fuzz the various protocols and layers of the network stack of NetBSD using rumpkernel. This project is being carried out as a part of GSoC 2020. This blog post is regarding the project, the concepts and tools involved, the objectives and the current progress and next steps.
Fuzzing:
Fuzzing or fuzz testing is an automated software testing technique in which a program is tested by passing unusual, unexpected or semi-random input generated data to the input of the program and repeatedly doing so, trying to crash the program and detect potential bugs or undealt corner cases.
There are several tools available today that enable this which are known as fuzzers. An effective fuzzer generates semi-valid inputs that are "valid enough" in that they are not directly rejected by the parser, but do create unexpected behaviors deeper in the program and are "invalid enough" to expose corner cases that have not been properly dealt with.
Fuzzers can be of various types like dumb vs smart, generation-based vs mutation-based and so on. A dumb fuzzer generates random input without looking at the input format or model but it can follow some sophisticated algorithms like in AFL, though considered a dumb fuzzer as it just flips bits and replaces bytes, still uses a genetic algorithm to create new test cases, where as a smart fuzzer will follow an input model to generate semi-random data that can penetrate well in the code and trigger more edge cases. Mutation and generation fuzzers handle test case generation differently. Mutation fuzzers mutate a supplied seed input object, while generation fuzzers generate new test cases from a supplied model.
Some examples of popular fuzzers are: AFL(American Fuzzy Lop), Syzkaller, Honggfuzz.
RumpKernel
Kernels can have several different architectures like monolithic, microkernel, exokernel etc. An interesting architecture is the “anykernel” architecture, according to wikipedia, “The "anykernel" concept refers to an architecture-agnostic approach to drivers where drivers can either be compiled into the monolithic kernel or be run as a userspace process, microkernel-style, without code changes.” Rumpkernel is an implementation of this anykernel architecture. In case of the NetBSD rumpkernel, all the NetBSD subsystems like file system, network stack, drivers etc are compiled into standalone libraries that can be linked into any application process to utilize the functionalities of the kernel, like the file system or the drivers. This allows us to run and test various components of NetBSD kernel as a library linked to programs running in the user space.
This idea of rumpkernel is really helpful in fuzzing the components of the kernel. We can fuzz separate subsystems and allow it to crash without having to manage the crash of a running Operating System. Also the fact that context switching has an overhead in case syscalls are made to the kernel, Rumpkernel running in the userspace can eliminate this and save time.(Also since the spectre-meltdown vulnerabilities, system calls have become more costly due to the security reasons)
HonggFuzz + Rumpkernel Network Stack:
In this project we will use the outlined Rumpkernel’s network stack and a fuzzer called the honggfuzz. Honggfuzz is a security oriented, feedback-driven, evolutionary, easy-to-use fuzzer. It is maintained by google.(https://github.com/google/honggfuzz)
The project is hosted on github at: https://github.com/NJnisarg/fuzznetrump/ .The Readme can help in setting it up. We first require NetBSD installed either on a physical machine or on a virtual machine like qemu. Then we will build the NetBSD distribution by grabbing the latest sources(https://github.com/NetBSD/src). We will enable fuzzer coverage by using MKSANITIZER and MKLIBCSANITIZER flags and using the ASan(Address) and UBSan(Undefined Behavior) sanitizers. These sanitizers will help the fuzzer in catching bugs related to undefined behavior and address and memory leaks. After that we will grab one of the fuzzer programs(example: src/hfuzz_ip_output_fuzz.c) and chroot into the newly built distribution from the host NetBSD OS. Then we will compile it using hfuzz-clang by linking the required rumpkernel libraries (for example in our case: rump, rumpnet, rumpnet_netinet and so on). This is where we use the rumpkernel as libraries linked to our program. The program will access the network stack of the linked rumpkernel and the fuzzer will fuzz those components of the kernel. The compiled binary will be run with honggfuzz. Detailed steps are outlined in the Readme of the linked repository.
Our Approach for network stack fuzzing:
We have planned to fuzz various protocols at different layers of the TCP/IP stack. We have started with mostly widely used yet simple protocols like IP(v4), UDP etc. Along the progress of the project, we will be adding support for more L3(and above) protocols like ICMP, IP(v6), TCP as well as L2 protocols like Ethernet as a bit later phase.
The network stack has 2 paths:
- Input/ingress path
- Output/egress path
A packet is sent down the network stack via a socket from an application from the output path, whereas a packet is said to be received on a network interface into the network stack via the input path. Each network protocol has major input and output APIs for the packet processing. Example IP protocol has an ip_input() function to process an incoming packet and an ip_output() function to process an outgoing packet. We are planning to fuzz each protocol’s output and input APIs by sending the packet via the output path and receiving the packet via input path respectively.
In order to fuzz the output and input path, the network stack setup and configuration we have is as follows:
- We have a TUN device to which we can read and write a packet.
- We have a socket that is bound to the TUN device, which can send and receive packets
- In order to fuzz the input path, we “write” a packet to the TUN interface, which emulates a received packet on the network stack.
- In order to fuzz the output path, we send a packet via the socket to the TUN interface to fuzz the output path.
For carrying out all the above setup, we have separated out the common function for creating and configuring the TUN device and socket into a file called “net_config.c”
Also in order to reduce the rejection of packets carrying random data for trivial cases like checksum or header len, we have created functions that create/forge semi-random packets using the input data from honggfuzz. We manipulate certain fields in the packet to ensure that it does not get rejected trivially by the network stack and hence can reach and trigger deeper parts of the code. These functions for packet creations are located in the “pkt_create.c” file. For each protocol we fuzz, we add these functions to forge the headers and the packet. Currently we have support from UDP and IP(v4).
With these building blocks we have written programs like hfuzz_ip_output_fuzz.c, hfuzz_ip_input_fuzz.c etc, which setup the TUN device and socket using net_config.c and after taking the random data from honggfuzz, use it to forge a packet and send it down or up the stack. We compile these programs using hfuzz-clang as mentioned above and run it under honggfuzz to fuzz the network stack’s particular APIs.
Current Progress:
Following things were worked upon in the first phase:
- Getting honggfuzz functional for NetBSD(thanks to Kamil for those patches)
- Coming up with the strategy for network configuration and packet creation. Writing utilities for the same.
- Adding fuzzing code for protocols like IP(v4) and UDP.
- Carrying out fuzzing for those protocols.
Next Steps:
As next steps following things are planned for upcoming phase:
- Making changes and improvements by taking suggestions from the mentors.
- Adding support for ICMP, IP(v6), TCP and later on for Ethernet.
- Analyze and come up with effective ways to improve the fuzzing by focusing on the packet creation part.
- Standardize the code to be extensible for adding future protocols.
Introduction
My GSoC project under NetBSD involves the development of test framework of curses library. Automated Test Framework (ATF) was introduced in 2007 but ATF cannot be used directly for curses testing for several reasons most important of them being curses has functions which do timed reads/writes which is hard to do with just piping characters to test applications. Also, stdin is not a tty device and behaves differently and may affect the results. A lot of work regarding this has been done and we have a separate test framework in place for testing curses.
The aim of project is to build a robust test suite for the library and complete the SUSv2 specification. This includes writing tests for the remaining functions and enhancing the existing ones. Meanwhile, the support for complex character function has to be completed along with fixing some bugs, adding features and improving the test framework.
Why did I chose this project?
I am a final year undergraduate at Indian Institute of Technology, Kanpur. I have my majors in Computer Science and Engineering, and I am specifically interested in algorithms and computer systems. I had worked on building and testing a library on Distributed Tracing at an internship and understand the usefulness of having a test suite in place. Libcurses being very special in itself for the testing purpose interested me. Knowing some of the concepts of compiler design made my interest a bit more profound.
Test Framwork
The testframework consists of 2 programs, director and slave. The framework provides its own simple language for writing tests. The slave is a curses application capable of running any curses function, while the director acts as a coordinator and interprets the test file and drives the slave program. The director can also capture slave's output which can be used for comparison with desired output.

The director forks a process operating in pty and executes a slave program on that fork. The master side of pty is used for getting the data stream that the curses function call produces which can be futher used to check the correctness of behaviour. Director and slave communicate via pipes; command pipe and slave pipe. The command pipe carries the function name and arguments, while slave pipe carries return codes and values from function calls.
Let's walk through a sample test to understand how this works. Consider a sample program:
include start
call win newwin 2 5 2 5
check win NON_NULL
call OK waddstr $win "Hello World!"
call OK wrefresh $win
compare waddstr_refresh.chk
This is a basic program which initialises the screen, creates new window, checks if the window creation was successful, adds as string "Hello World!" on the window, refreshes the window, and compares it with desired output stored in check file. The details of the language can be accessed at libcurses testframe.
The test file is interpreted by the language parser and the correponding actions are taken. Let's look how line #2 is processed. This command creates a window using newwin(). The line is ultimately parsed as call: CALL result fn_name args eol grammar rule and executes the function do_funtion_call()). Now, this function sends function name and arguments using command pipe to the slave. The slave, who is waiting to get command from the director, reads from the pipe and executes the command. This executes the correponding curses function from the command table and the pointer to new window is returned via the slave pipe (here) after passing wrappers of functions. The director recieves them, and returned value is assigned to a variable(win in line#2) or compared (OK in line#4). This is the typical life cycle of a certain function call made in tests.
Along with these, the test framework provides capability to include other test (line#1), check the variable content (line#3), compare the data stream due to function call in pty with desired stream (line#6). Tester can also provide inputs to functions via input directive, perform delay via delay directive, assign values to variables via assign directive, and create a wide or complex charater via wchar and cchar directives respectively. The framework supports 3 kind of strings; null terminated string, byte string, and string of type chtype, based on the quotes enclosing it.
Progress till the first evaluation
Improvements in the framework:
- Automated the checkfile generation that has to be done manually earlier.
- Completed the support for complex chacter tests in director and slave.
- Added features like variable-variable comparison.
- Fixed non-critical bugs in the framework.
- Refactored the code.
Testing and bug reports
- Wrote tests for wide character routines.
- Reported bugs (and possible fixes if I know):
Project Proposal and References:
- Proposal: https://github.com/NamanJain8/curses/blob/master/reports/proposal.pdf
- Project Repo: https://github.com/NamanJain8/curses
- Test Language Details: https://github.com/NetBSD/src/blob/trunk/tests/lib/libcurses/testframe.txt
- Wonderful report by Brett Lymn: https://github.com/NamanJain8/curses/blob/master/reports/curses-testframe.pdf
Introduction
My GSoC project under NetBSD involves the development of test framework of curses library. Automated Test Framework (ATF) was introduced in 2007 but ATF cannot be used directly for curses testing for several reasons most important of them being curses has functions which do timed reads/writes which is hard to do with just piping characters to test applications. Also, stdin is not a tty device and behaves differently and may affect the results. A lot of work regarding this has been done and we have a separate test framework in place for testing curses.
The aim of project is to build a robust test suite for the library and complete the SUSv2 specification. This includes writing tests for the remaining functions and enhancing the existing ones. Meanwhile, the support for complex character function has to be completed along with fixing some bugs, adding features and improving the test framework.
Why did I chose this project?
I am a final year undergraduate at Indian Institute of Technology, Kanpur. I have my majors in Computer Science and Engineering, and I am specifically interested in algorithms and computer systems. I had worked on building and testing a library on Distributed Tracing at an internship and understand the usefulness of having a test suite in place. Libcurses being very special in itself for the testing purpose interested me. Knowing some of the concepts of compiler design made my interest a bit more profound.
Test Framwork
The testframework consists of 2 programs, director and slave. The framework provides its own simple language for writing tests. The slave is a curses application capable of running any curses function, while the director acts as a coordinator and interprets the test file and drives the slave program. The director can also capture slave's output which can be used for comparison with desired output.
The director forks a process operating in pty and executes a slave program on that fork. The master side of pty is used for getting the data stream that the curses function call produces which can be futher used to check the correctness of behaviour. Director and slave communicate via pipes; command pipe and slave pipe. The command pipe carries the function name and arguments, while slave pipe carries return codes and values from function calls.
Let's walk through a sample test to understand how this works. Consider a sample program:
include start
call win newwin 2 5 2 5
check win NON_NULL
call OK waddstr $win "Hello World!"
call OK wrefresh $win
compare waddstr_refresh.chk
This is a basic program which initialises the screen, creates new window, checks if the window creation was successful, adds as string "Hello World!" on the window, refreshes the window, and compares it with desired output stored in check file. The details of the language can be accessed at libcurses testframe.
The test file is interpreted by the language parser and the correponding actions are taken. Let's look how line #2 is processed. This command creates a window using newwin(). The line is ultimately parsed as call: CALL result fn_name args eol grammar rule and executes the function do_funtion_call()). Now, this function sends function name and arguments using command pipe to the slave. The slave, who is waiting to get command from the director, reads from the pipe and executes the command. This executes the correponding curses function from the command table and the pointer to new window is returned via the slave pipe (here) after passing wrappers of functions. The director recieves them, and returned value is assigned to a variable(win in line#2) or compared (OK in line#4). This is the typical life cycle of a certain function call made in tests.
Along with these, the test framework provides capability to include other test (line#1), check the variable content (line#3), compare the data stream due to function call in pty with desired stream (line#6). Tester can also provide inputs to functions via input directive, perform delay via delay directive, assign values to variables via assign directive, and create a wide or complex charater via wchar and cchar directives respectively. The framework supports 3 kind of strings; null terminated string, byte string, and string of type chtype, based on the quotes enclosing it.
Progress till the first evaluation
Improvements in the framework:
- Automated the checkfile generation that has to be done manually earlier.
- Completed the support for complex chacter tests in director and slave.
- Added features like variable-variable comparison.
- Fixed non-critical bugs in the framework.
- Refactored the code.
Testing and bug reports
- Wrote tests for wide character routines.
- Reported bugs (and possible fixes if I know):
Project Proposal and References:
- Proposal: https://github.com/NamanJain8/curses/blob/master/reports/proposal.pdf
- Project Repo: https://github.com/NamanJain8/curses
- Test Language Details: https://github.com/NetBSD/src/blob/trunk/tests/lib/libcurses/testframe.txt
- Wonderful report by Brett Lymn: https://github.com/NamanJain8/curses/blob/master/reports/curses-testframe.pdf
NetPGP is a library and suite of tools implementing OpenPGP under a BSD license. As part of Google Summer of Code 2020, we are working to extend its functionality and work towards greater parity with similar tools. During the first phase, we have made the following contributions
- Added the Blowfish block cipher
- ECDSA key creation
- ECDSA signature and verification
- Symmetric file encryption/decryption
- S2K Iterated+Salt for symmetric encryption
ECDSA key generation is done using the '--ecdsa' flag with netpgpkeys or the 'ecdsa' property if using libnetpgp
[jhigh@gsoc2020nb gsoc]$ netpgpkeys --generate-key --ecdsa --homedir=/tmp
signature secp521r1/ECDSA a0cdb04e3e8c5e34 2020-06-25
fingerprint d9e0 2ae5 1d2f a9ae eb96 ebd4 a0cd b04e 3e8c 5e34
uid jhigh@localhost
Enter passphrase for a0cdb04e3e8c5e34:
Repeat passphrase for a0cdb04e3e8c5e34:
generated keys in directory /tmp/a0cdb04e3e8c5e34
[jhigh@gsoc2020nb gsoc]$
[jhigh@gsoc2020nb gsoc]$ ls -l /tmp/a0cdb04e3e8c5e34
total 16
-rw------- 1 jhigh wheel 331 Jun 25 16:03 pubring.gpg
-rw------- 1 jhigh wheel 440 Jun 25 16:03 secring.gpg
[jhigh@gsoc2020nb gsoc]$
Signing with ECDSA does not require any changes
[jhigh@gsoc2020nb gsoc]$ netpgp --sign --homedir=/tmp/a0cdb04e3e8c5e34 --detach --armor testfile.txt
signature secp521r1/ECDSA a0cdb04e3e8c5e34 2020-06-25
fingerprint d9e0 2ae5 1d2f a9ae eb96 ebd4 a0cd b04e 3e8c 5e34
uid jhigh@localhost
netpgp passphrase:
[jhigh@gsoc2020nb gsoc]$
[jhigh@gsoc2020nb gsoc]$ cat testfile.txt.asc
-----BEGIN PGP MESSAGE-----
wqcEABMCABYFAl71EYwFAwAAAAAJEKDNsE4+jF40AAAVPgIJASyzuZgyS13FHHF/9qk6E3pYra2H
tDdkqxYzNIqKnWHaB+a4J+/R7FkZItbC/EyXH5YA68AC1dJ7tRN/tJNIWfYjAgUb75SvM2mLHk13
qmBo48S0Ai8C82G4nT7/16VF2OOUn7F/3XICghoQOyS1nxJilj8u2uphLOoy9VayL1ErORIZVw==
=p30e
-----END PGP MESSAGE-----
[jhigh@gsoc2020nb gsoc]$
Verification remains the same, as well.
[jhigh@gsoc2020nb gsoc]$ netpgp --homedir=/tmp/a0cdb04e3e8c5e34 --verify testfile.txt.asc
netpgp: assuming signed data in "testfile.txt"
Good signature for testfile.txt.asc made Thu Jun 25 16:05:16 2020
using ECDSA key a0cdb04e3e8c5e34
signature secp521r1/ECDSA a0cdb04e3e8c5e34 2020-06-25
fingerprint d9e0 2ae5 1d2f a9ae eb96 ebd4 a0cd b04e 3e8c 5e34
uid jhigh@localhost
[jhigh@gsoc2020nb gsoc]$
Symmetric encryption is now possible using the '--symmetric' flag with netpgp or the 'symmetric' property in libnetpgp
[jhigh@gsoc2020nb gsoc]$ netpgp --encrypt --symmetric --armor testfile.txt
Enter passphrase:
Repeat passphrase:
[jhigh@gsoc2020nb gsoc]$
[jhigh@gsoc2020nb gsoc]$ cat testfile.txt.asc
-----BEGIN PGP MESSAGE-----
wwwEAwEIc39k1V6xVi3SPwEl2ww75Ufjhw7UA0gO/niahHWK50DFHSD1lB10nUyCTgRLe6iS9QZl
av5Nji9BuQFcrqo03I1jG/L9s/4hww==
=x41O
-----END PGP MESSAGE-----
[jhigh@gsoc2020nb gsoc]$
Decryption of symmetric packets requires no changes
[jhigh@gsoc2020nb gsoc]$ netpgp --decrypt testfile.txt.asc
netpgp passphrase:
[jhigh@gsoc2020nb gsoc]$
We added two new flags to support s2k mode 3: '--s2k-mode' and '--s2k-count'. See RFC4880 for details.
[jhigh@gsoc2020nb gsoc]$ netpgp --encrypt --symmetric --s2k-mode=3 --s2k-count=96 testfile.txt
Enter passphrase:
Repeat passphrase:
[jhigh@gsoc2020nb gsoc]$
[jhigh@gsoc2020nb gsoc]$ gpg -d testfile.txt.gpg
gpg: CAST5 encrypted data
gpg: encrypted with 1 passphrase
this
is
a
test
[jhigh@gsoc2020nb gsoc]$
NetPGP is a library and suite of tools implementing OpenPGP under a BSD license. As part of Google Summer of Code 2020, we are working to extend its functionality and work towards greater parity with similar tools. During the first phase, we have made the following contributions
- Added the Blowfish block cipher
- ECDSA key creation
- ECDSA signature and verification
- Symmetric file encryption/decryption
- S2K Iterated+Salt for symmetric encryption
ECDSA key generation is done using the '--ecdsa' flag with netpgpkeys or the 'ecdsa' property if using libnetpgp
[jhigh@gsoc2020nb gsoc]$ netpgpkeys --generate-key --ecdsa --homedir=/tmp
signature secp521r1/ECDSA a0cdb04e3e8c5e34 2020-06-25
fingerprint d9e0 2ae5 1d2f a9ae eb96 ebd4 a0cd b04e 3e8c 5e34
uid jhigh@localhost
Enter passphrase for a0cdb04e3e8c5e34:
Repeat passphrase for a0cdb04e3e8c5e34:
generated keys in directory /tmp/a0cdb04e3e8c5e34
[jhigh@gsoc2020nb gsoc]$
[jhigh@gsoc2020nb gsoc]$ ls -l /tmp/a0cdb04e3e8c5e34
total 16
-rw------- 1 jhigh wheel 331 Jun 25 16:03 pubring.gpg
-rw------- 1 jhigh wheel 440 Jun 25 16:03 secring.gpg
[jhigh@gsoc2020nb gsoc]$
Signing with ECDSA does not require any changes
[jhigh@gsoc2020nb gsoc]$ netpgp --sign --homedir=/tmp/a0cdb04e3e8c5e34 --detach --armor testfile.txt
signature secp521r1/ECDSA a0cdb04e3e8c5e34 2020-06-25
fingerprint d9e0 2ae5 1d2f a9ae eb96 ebd4 a0cd b04e 3e8c 5e34
uid jhigh@localhost
netpgp passphrase:
[jhigh@gsoc2020nb gsoc]$
[jhigh@gsoc2020nb gsoc]$ cat testfile.txt.asc
-----BEGIN PGP MESSAGE-----
wqcEABMCABYFAl71EYwFAwAAAAAJEKDNsE4+jF40AAAVPgIJASyzuZgyS13FHHF/9qk6E3pYra2H
tDdkqxYzNIqKnWHaB+a4J+/R7FkZItbC/EyXH5YA68AC1dJ7tRN/tJNIWfYjAgUb75SvM2mLHk13
qmBo48S0Ai8C82G4nT7/16VF2OOUn7F/3XICghoQOyS1nxJilj8u2uphLOoy9VayL1ErORIZVw==
=p30e
-----END PGP MESSAGE-----
[jhigh@gsoc2020nb gsoc]$
Verification remains the same, as well.
[jhigh@gsoc2020nb gsoc]$ netpgp --homedir=/tmp/a0cdb04e3e8c5e34 --verify testfile.txt.asc
netpgp: assuming signed data in "testfile.txt"
Good signature for testfile.txt.asc made Thu Jun 25 16:05:16 2020
using ECDSA key a0cdb04e3e8c5e34
signature secp521r1/ECDSA a0cdb04e3e8c5e34 2020-06-25
fingerprint d9e0 2ae5 1d2f a9ae eb96 ebd4 a0cd b04e 3e8c 5e34
uid jhigh@localhost
[jhigh@gsoc2020nb gsoc]$
Symmetric encryption is now possible using the '--symmetric' flag with netpgp or the 'symmetric' property in libnetpgp
[jhigh@gsoc2020nb gsoc]$ netpgp --encrypt --symmetric --armor testfile.txt
Enter passphrase:
Repeat passphrase:
[jhigh@gsoc2020nb gsoc]$
[jhigh@gsoc2020nb gsoc]$ cat testfile.txt.asc
-----BEGIN PGP MESSAGE-----
wwwEAwEIc39k1V6xVi3SPwEl2ww75Ufjhw7UA0gO/niahHWK50DFHSD1lB10nUyCTgRLe6iS9QZl
av5Nji9BuQFcrqo03I1jG/L9s/4hww==
=x41O
-----END PGP MESSAGE-----
[jhigh@gsoc2020nb gsoc]$
Decryption of symmetric packets requires no changes
[jhigh@gsoc2020nb gsoc]$ netpgp --decrypt testfile.txt.asc
netpgp passphrase:
[jhigh@gsoc2020nb gsoc]$
We added two new flags to support s2k mode 3: '--s2k-mode' and '--s2k-count'. See RFC4880 for details.
[jhigh@gsoc2020nb gsoc]$ netpgp --encrypt --symmetric --s2k-mode=3 --s2k-count=96 testfile.txt
Enter passphrase:
Repeat passphrase:
[jhigh@gsoc2020nb gsoc]$
[jhigh@gsoc2020nb gsoc]$ gpg -d testfile.txt.gpg
gpg: CAST5 encrypted data
gpg: encrypted with 1 passphrase
this
is
a
test
[jhigh@gsoc2020nb gsoc]$
I have been working on the project - Enhance the Syzkaller support for NetBSD, as a part of GSoc’20. Past two months have given me quite an enriching experience, pushing me to comprehend more knowledge on fuzzers. This post would give a peek into the work which has been done so far.
Syzkaller
Syzkaller is a coverage guided fuzzer developed by Google, to fuzz the system calls mainly keeping linux in mind. However, the support has been extended to fuzz the system calls of other Operating Systems as well for eg. Akaros, FreeBSD, NetBSD, OpenBSD, Windows etc.
An automated system Syzbot continuously runs the syzkaller fuzzer on NetBSD kernel and reports the crashes
Increasing syscall support
Initially, the syscall support for Linux as well as FreeBSD was analysed by an automated script. Also coverage of NetBSD syscalls was looked over. This helped us to easily port a few syscalls descriptions for NetBSD. The necessary tweaks were made according to the documentation which describes rules for writing syscall descriptions.
Major groups of syscalls which have been added:
- statfs
- __getlogin
- getsid
- mknod
- utimes
- wait4
- seek
- setitimer
- setpriority
- getrusage
- clock_settime
- nanosleep
- getdents
- acct
- dup
Bugs Found
There were a few bugs reported as a result of adding the descriptions for syscalls of the mentioned syscall families. Few of them are yet to be fixed.Stats
Syscall coverage percent for NetBSD has now increased from nearly 30 to 44.96. Addition of compat syscalls resulted in getting a few new bugs.
Percentage of syscalls covered in few of the other Operating Systems:
- Linux: 82
- FreeBSD: 37
- OpenBSD: 61
Conclusion
In the next phase I would be working on generating the syscall descriptions using automation and adding ioctl device drivers with it’s help.
Atlast, I would like to thank my mentors Cryo, Siddharth and Santhosh for their constant support and guidance.I am also thankful to NetBSD community for being kind to give me this opportunity of having an amazing summer this year.
I have been working on the project - Enhance the Syzkaller support for NetBSD, as a part of GSoc’20. Past two months have given me quite an enriching experience, pushing me to comprehend more knowledge on fuzzers. This post would give a peek into the work which has been done so far.
Syzkaller
Syzkaller is a coverage guided fuzzer developed by Google, to fuzz the system calls mainly keeping linux in mind. However, the support has been extended to fuzz the system calls of other Operating Systems as well for eg. Akaros, FreeBSD, NetBSD, OpenBSD, Windows etc.
An automated system Syzbot continuously runs the syzkaller fuzzer on NetBSD kernel and reports the crashes
Increasing syscall support
Initially, the syscall support for Linux as well as FreeBSD was analysed by an automated script. Also coverage of NetBSD syscalls was looked over. This helped us to easily port a few syscalls descriptions for NetBSD. The necessary tweaks were made according to the documentation which describes rules for writing syscall descriptions.
Major groups of syscalls which have been added:
- statfs
- __getlogin
- getsid
- mknod
- utimes
- wait4
- seek
- setitimer
- setpriority
- getrusage
- clock_settime
- nanosleep
- getdents
- acct
- dup
Bugs Found
There were a few bugs reported as a result of adding the descriptions for syscalls of the mentioned syscall families. Few of them are yet to be fixed.Stats
Syscall coverage percent for NetBSD has now increased from nearly 30 to 44.96. Addition of compat syscalls resulted in getting a few new bugs.
Percentage of syscalls covered in few of the other Operating Systems:
- Linux: 82
- FreeBSD: 37
- OpenBSD: 61
Conclusion
In the next phase I would be working on generating the syscall descriptions using automation and adding ioctl device drivers with it’s help.
Atlast, I would like to thank my mentors Cryo, Siddharth and Santhosh for their constant support and guidance.I am also thankful to NetBSD community for being kind to give me this opportunity of having an amazing summer this year.
I have been working on the project - Enhance the Syzkaller support for NetBSD, as a part of GSoc’20. Past two months have given me quite an enriching experience, pushing me to comprehend more knowledge on fuzzers. This post would give a peek into the work which has been done so far.
Syzkaller
Syzkaller is a coverage guided fuzzer developed by Google, to fuzz the system calls mainly keeping linux in mind. However, the support has been extended to fuzz the system calls of other Operating Systems as well for eg. Akaros, FreeBSD, NetBSD, OpenBSD, Windows etc.
An automated system Syzbot continuously runs the syzkaller fuzzer on NetBSD kernel and reports the crashes
Increasing syscall support
Initially, the syscall support for Linux as well as FreeBSD was analysed by an automated script. Also coverage of NetBSD syscalls was looked over. This helped us to easily port a few syscalls descriptions for NetBSD. The necessary tweaks were made according to the documentation which describes rules for writing syscall descriptions.
Major groups of syscalls which have been added:
- statfs
- __getlogin
- getsid
- mknod
- utimes
- wait4
- seek
- setitimer
- setpriority
- getrusage
- clock_settime
- nanosleep
- getdents
- acct
- dup
Bugs Found
There were a few bugs reported as a result of adding the descriptions for syscalls of the mentioned syscall families. Few of them are yet to be fixed.Stats
Syscall coverage percent for NetBSD has now increased from nearly 30 to 44.96. Addition of compat syscalls resulted in getting a few new bugs.
Percentage of syscalls covered in few of the other Operating Systems:
- Linux: 82
- FreeBSD: 37
- OpenBSD: 61
Conclusion
In the next phase I would be working on generating the syscall descriptions using automation and adding ioctl device drivers with it’s help.
Atlast, I would like to thank my mentors Cryo, Siddharth and Santhosh for their constant support and guidance.I am also thankful to NetBSD community for being kind to give me this opportunity of having an amazing summer this year.
This report was written by Apurva Nandan as part of Google Summer of Code 2020.
My GSoC project under NetBSD involves developing an automated regression and performance test framework for NetBSD that offers reproducible benchmarking results with detailed history and logs across various hardware & architectures.
To achieve this performance testing framework, I am using the Phoronix Test Suite (PTS) which is an open-source, cross-platform automated testing/benchmarking software for Linux, Windows and BSD environments. It allows the creation of new tests using simple XML files and shell scripts and integrates with revision control systems for per-commit regression testing.
About PTS
PTS core
PTS core is the engine of the Phoronix Test Suite and handles the following jobs:
- Regularly updating the test profiles, test suites, and repository index.
- Downloading, compilation, installation and evaluation of test packages.
- Test result management and uploading results and user-defined test-profiles/suites to OpenBenchmarking.org
Test-profiles/Suites & OpenBenchmarking
Test-profiles are light-weight XMLs and shell scripts that allow easy installation of the benchmarking packages and their evaluation. Test-profiles generally contains the following files:
downloads.xml: Stores the links of the benchmarking packages, required additional packages, patches to be applied, etc. with their hash sums.install.sh: Actual compilation, installation, and test evaluation shell script. Also handles the task of applying patches.results-definition.xml: Meta-data to define the information for test result data (e.g. result data units, LIB or HIB, etc.)test-definition.xml: Meta-data to specify test-profile details, such as compatible OS, external dependencies, test arguments, etc.
A simple test-profile C-Ray-1.2.0 can be seen to get an idea of the XMLs and shell scripts.
Test-suites are bundles of related test-profiles or more suites, focusing on a subsystem or certain category of tests e.g. Disk Test Suite, Kernel, CPU suite, etc.
OpenBenchmarking.org serves as a repository for storing test profiles, test suites, hence allowing new/updated tests to be seamlessly obtained via PTS. OpenBenchmarking.org also provides a platform to store the test result data openly and do a comparison between any test results stored in the OpenBenchmarking.org cloud.
Usage
Test installation
The command:
$ phoronix-test-suite install test-profile-name
Fetches the sources of the tests related to the the test-profile in
~/.phoronix-test-suite/installed-tests, applies patches and
carries out compilation of test sources for generating the executables
to run the tests.
Test execution
The command:
$ phoronix-test-suite run test-profile-name
Performs installation of the test (similar to $ phoronix-test-suite
install test-profile-name) followed by exectution the binary from
the compiled sources of the test in
~/.phoronix-test-suite/installed-tests and finally reports the
tests results/outcome to the user and provides an option to upload
results to OpenBenchmarking.org.
Progress in the first phase of GSoC
pkgsrc-wip
The first task performed by me was upgrading the Phoronix Test Suite
from version 8.8 to the latest stable version 9.6.1 in pkgsrc-wip
and is available as
wip/phoronix-test-suite.
You can have a look at the
PTS Changelog
to know about the improvements between these two versions.
Major Commits:
- wip/phoronix-test-suite: update phoronix-test-suite to 9.6.1
- Added required PHP dependencies & removed TODO file
Currently, the PTS upgrade to 9.6.1 is subject to more modifications
and fixes before it gets finally merged to the pkgsrc upstream.
To test the Phoronix Test Suite 9.6.1 on NetBSD till then, you can
setup pkgsrc-wip on your system via:
$ cd /usr/pkgsrc $ git clone git://wip.pkgsrc.org/pkgsrc-wip.git wip
To learn more about pkgsrc-wip please see The pkgsrc-wip project homepage.
After setting up pkgsrc-wip, use the following command for
installation of PTS 9.6.1:
$ cd /usr/pkgsrc/wip/phoronix-test-suite $ make install
If any new build/installation errors are encountered, please document them in wip/phoronix-test-suite/TODO file and/or contact me.
Testing & Debugging
As we now know, having a look over OpenBenchmarking.org’s available
test-profiles section or using
$ phoronix-test-suite list-available-tests,
there are 309 test-profiles available on PTS for Linux, and only 166 of
309 tests have been ported to NetBSD (can be differentiated by a
thunder symbol on the test profile on the website). These 166
test-profiles can be fetch, build and executed on NetBSD using just a
single command $ phoronix-test-suite run test-profile-name. I am
ignoring the graphics ones in both Linux & NetBSD as GPU benchmarking
wasn’t required in the project.
Many of the test profiles available on NetBSD have installation, build,
or runtime errors i.e. they don’t work out of the box using the command
$ phoronix-test-suite run test-profile-name. I ran 90 of these
test profiles on a NetBSD-current x86_64 QEMU VM (took a lot of time
due to the heavy tests) and have reported the status in the sheet:
NetBSD GSoC: Test Porting Progress Report
You can have a look at how a PTS test-profile under action looks like!
Aircrack-NG test-profile demonstration
Aircrack-ng is a tool for assessing WiFi/WLAN network security.
The PTS test-profile is available at: https://openbenchmarking.org/test/pts/aircrack-ng
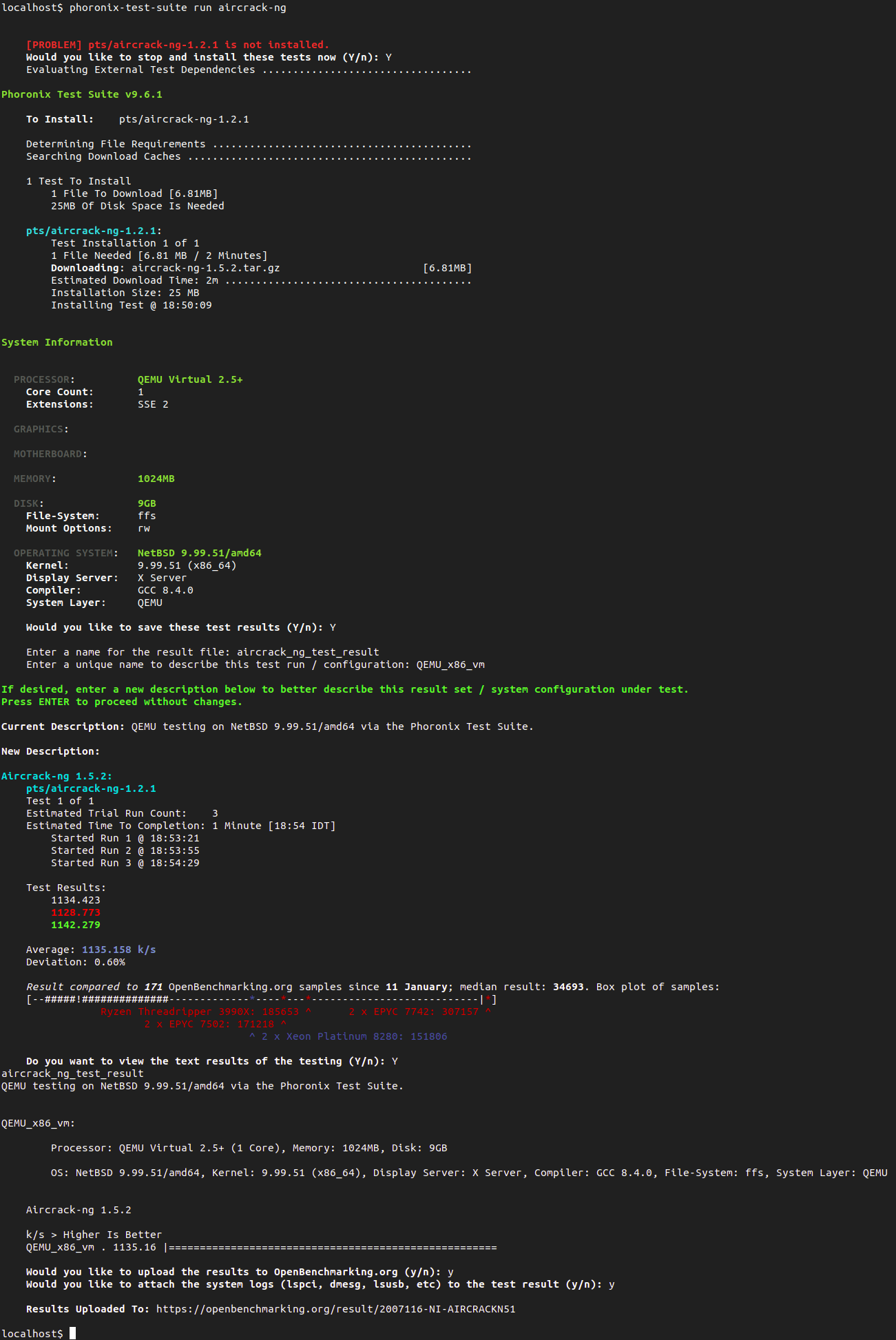
For further information, complete results can be seen at https://openbenchmarking.org/result/2007116-NI-AIRCRACKN51
AOBench test-profile demonstration
AOBench is a lightweight ambient occlusion renderer, written in C.
The PTS test-profile is available at: https://openbenchmarking.org/test/pts/aircrack-ng
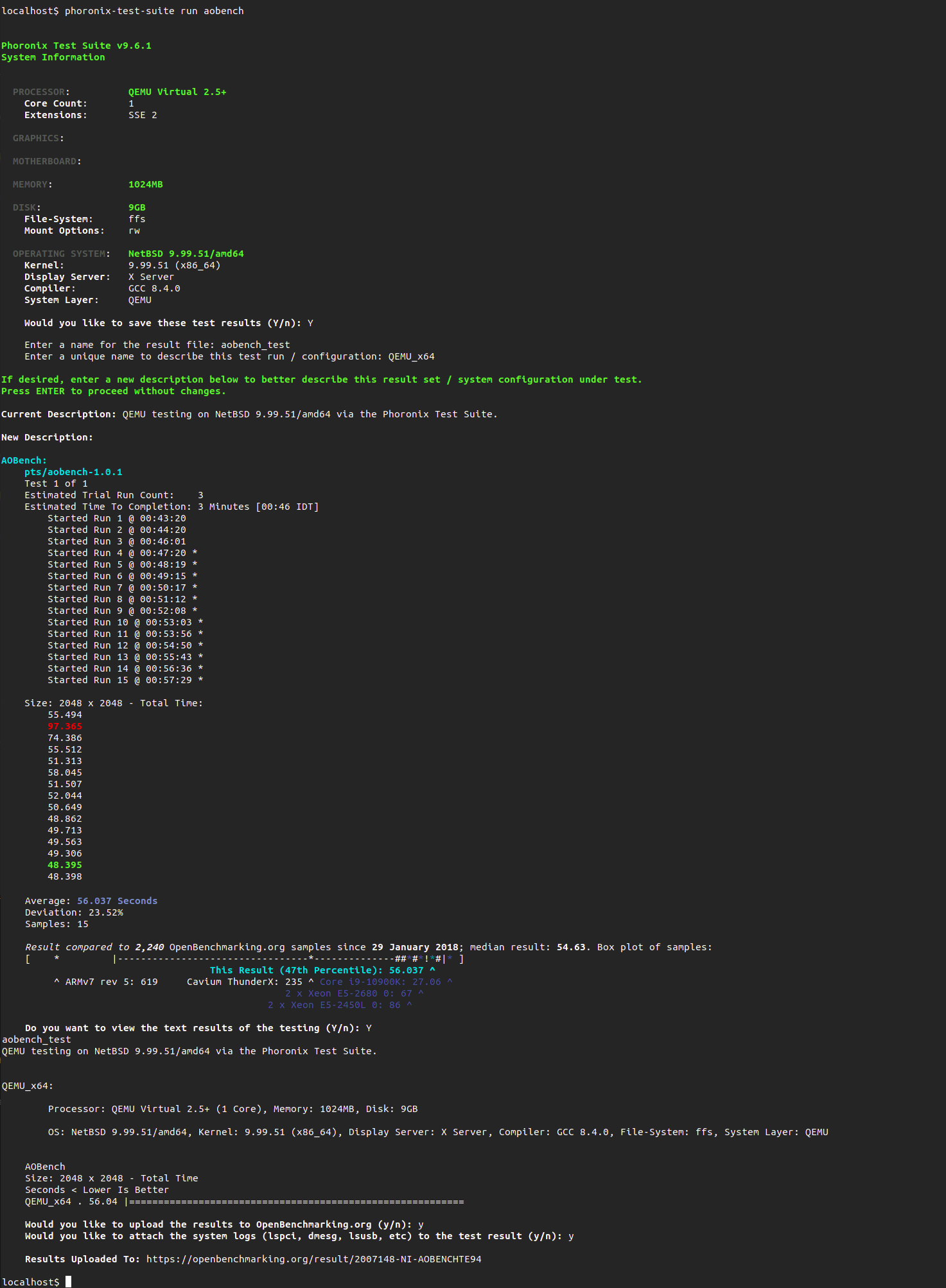
For further information, complete results can be seen at: https://openbenchmarking.org/result/2007148-NI-AOBENCHTE94
Debugging and fixing non-working test-profiles
After testing these test-profiles, I debugged the following build errors in the following test-profiles:
- pts/t-test1-1.0.1:
memalign()not available on NetBSD - pts/coremark-1.0.0: calling bmake instead of gmake
- pts/apache-siege-1.0.4: Missing
signal.hheader - pts/mbw-1.0.0:
mempcpy()not available on NetBSD
Fixes to the above bugs can be found in the sheet or in the GitHub repositories shared in the next paragraph.
The modified test-profiles have been pushed to
pts-test-profiles-dev
and the fix patches to
pts-test-profiles-patches.
These patches are automatically downloaded by the debugged
test-profiles and automatically applied before building of tests. The
steps to install the debugged test-profiles have been added in the
README.md of
pts-test-profiles-dev.
These patches have been added in the downloads.xml of the
modified test-profiles, and hence they get fetched during the test
installation. The install.sh script in these modified
test-profiles applies them on the benchmarking packages if the
operating system is detected as NetBSD, thereby removing the build
errors.
coremark test-profile demonstration
You can have a look at the patched coremark-1.0.0 test-profile under execution:
The patched PTS test-profile is available at: https://github.com/apurvanandan1997/pts-test-profiles-dev/tree/master/coremark-1.0.0
This is a test of EEMBC CoreMark processor benchmark.
For further information, complete results can be seen at: https://openbenchmarking.org/result/2007148-NI-LOCALCORE64
Porting more test-profiles to NetBSD
Attempts were made to port new test-profiles from Linux to NetBSD, but the major incompatibility issue was missing external dependencies in NetBSD. Hence, this may reduce the number of test-profiles we can actually port, but more sincere efforts will be made in this direction in the next phase.
Future Plans
My next steps would involve porting the non-available tests to NetBSD i.e. the non-graphics ones available on Linux but unavailable on NetBSD, and fix the remaining test-profiles for NetBSD.
After gaining an availability of a decent number of test-profiles on NetBSD, I will use Phoromatic, a remote tests management system for the PTS (allows the automatic scheduling of tests, remote installation of new tests, and the management of multiple test systems) to host the live results of the automated benchmarking framework on benchmark.NetBSD.org, thereby delivering a functional performance and regression testing framework.
This report was written by Apurva Nandan as part of Google Summer of Code 2020.
My GSoC project under NetBSD involves developing an automated regression and performance test framework for NetBSD that offers reproducible benchmarking results with detailed history and logs across various hardware & architectures.
To achieve this performance testing framework, I am using the Phoronix Test Suite (PTS) which is an open-source, cross-platform automated testing/benchmarking software for Linux, Windows and BSD environments. It allows the creation of new tests using simple XML files and shell scripts and integrates with revision control systems for per-commit regression testing.
About PTS
PTS core
PTS core is the engine of the Phoronix Test Suite and handles the following jobs:
- Regularly updating the test profiles, test suites, and repository index.
- Downloading, compilation, installation and evaluation of test packages.
- Test result management and uploading results and user-defined test-profiles/suites to OpenBenchmarking.org
Test-profiles/Suites & OpenBenchmarking
Test-profiles are light-weight XMLs and shell scripts that allow easy installation of the benchmarking packages and their evaluation. Test-profiles generally contains the following files:
downloads.xml: Stores the links of the benchmarking packages, required additional packages, patches to be applied, etc. with their hash sums.install.sh: Actual compilation, installation, and test evaluation shell script. Also handles the task of applying patches.results-definition.xml: Meta-data to define the information for test result data (e.g. result data units, LIB or HIB, etc.)test-definition.xml: Meta-data to specify test-profile details, such as compatible OS, external dependencies, test arguments, etc.
A simple test-profile C-Ray-1.2.0 can be seen to get an idea of the XMLs and shell scripts.
Test-suites are bundles of related test-profiles or more suites, focusing on a subsystem or certain category of tests e.g. Disk Test Suite, Kernel, CPU suite, etc.
OpenBenchmarking.org serves as a repository for storing test profiles, test suites, hence allowing new/updated tests to be seamlessly obtained via PTS. OpenBenchmarking.org also provides a platform to store the test result data openly and do a comparison between any test results stored in the OpenBenchmarking.org cloud.
Usage
Test installation
The command:
$ phoronix-test-suite install test-profile-name
Fetches the sources of the tests related to the the test-profile in
~/.phoronix-test-suite/installed-tests, applies patches and
carries out compilation of test sources for generating the executables
to run the tests.
Test execution
The command:
$ phoronix-test-suite run test-profile-name
Performs installation of the test (similar to $ phoronix-test-suite
install test-profile-name) followed by exectution the binary from
the compiled sources of the test in
~/.phoronix-test-suite/installed-tests and finally reports the
tests results/outcome to the user and provides an option to upload
results to OpenBenchmarking.org.
Progress in the first phase of GSoC
pkgsrc-wip
The first task performed by me was upgrading the Phoronix Test Suite
from version 8.8 to the latest stable version 9.6.1 in pkgsrc-wip
and is available as
wip/phoronix-test-suite.
You can have a look at the
PTS Changelog
to know about the improvements between these two versions.
Major Commits:
- wip/phoronix-test-suite: update phoronix-test-suite to 9.6.1
- Added required PHP dependencies & removed TODO file
Currently, the PTS upgrade to 9.6.1 is subject to more modifications
and fixes before it gets finally merged to the pkgsrc upstream.
To test the Phoronix Test Suite 9.6.1 on NetBSD till then, you can
setup pkgsrc-wip on your system via:
$ cd /usr/pkgsrc $ git clone git://wip.pkgsrc.org/pkgsrc-wip.git wip
To learn more about pkgsrc-wip please see The pkgsrc-wip project homepage.
After setting up pkgsrc-wip, use the following command for
installation of PTS 9.6.1:
$ cd /usr/pkgsrc/wip/phoronix-test-suite $ make install
If any new build/installation errors are encountered, please document them in wip/phoronix-test-suite/TODO file and/or contact me.
Testing & Debugging
As we now know, having a look over OpenBenchmarking.org’s available
test-profiles section or using
$ phoronix-test-suite list-available-tests,
there are 309 test-profiles available on PTS for Linux, and only 166 of
309 tests have been ported to NetBSD (can be differentiated by a
thunder symbol on the test profile on the website). These 166
test-profiles can be fetch, build and executed on NetBSD using just a
single command $ phoronix-test-suite run test-profile-name. I am
ignoring the graphics ones in both Linux & NetBSD as GPU benchmarking
wasn’t required in the project.
Many of the test profiles available on NetBSD have installation, build,
or runtime errors i.e. they don’t work out of the box using the command
$ phoronix-test-suite run test-profile-name. I ran 90 of these
test profiles on a NetBSD-current x86_64 QEMU VM (took a lot of time
due to the heavy tests) and have reported the status in the sheet:
NetBSD GSoC: Test Porting Progress Report
You can have a look at how a PTS test-profile under action looks like!
Aircrack-NG test-profile demonstration
Aircrack-ng is a tool for assessing WiFi/WLAN network security.
The PTS test-profile is available at: https://openbenchmarking.org/test/pts/aircrack-ng
For further information, complete results can be seen at https://openbenchmarking.org/result/2007116-NI-AIRCRACKN51
AOBench test-profile demonstration
AOBench is a lightweight ambient occlusion renderer, written in C.
The PTS test-profile is available at: https://openbenchmarking.org/test/pts/aircrack-ng
For further information, complete results can be seen at: https://openbenchmarking.org/result/2007148-NI-AOBENCHTE94
Debugging and fixing non-working test-profiles
After testing these test-profiles, I debugged the following build errors in the following test-profiles:
- pts/t-test1-1.0.1:
memalign()not available on NetBSD - pts/coremark-1.0.0: calling bmake instead of gmake
- pts/apache-siege-1.0.4: Missing
signal.hheader - pts/mbw-1.0.0:
mempcpy()not available on NetBSD
Fixes to the above bugs can be found in the sheet or in the GitHub repositories shared in the next paragraph.
The modified test-profiles have been pushed to
pts-test-profiles-dev
and the fix patches to
pts-test-profiles-patches.
These patches are automatically downloaded by the debugged
test-profiles and automatically applied before building of tests. The
steps to install the debugged test-profiles have been added in the
README.md of
pts-test-profiles-dev.
These patches have been added in the downloads.xml of the
modified test-profiles, and hence they get fetched during the test
installation. The install.sh script in these modified
test-profiles applies them on the benchmarking packages if the
operating system is detected as NetBSD, thereby removing the build
errors.
coremark test-profile demonstration
You can have a look at the patched coremark-1.0.0 test-profile under execution:
The patched PTS test-profile is available at: https://github.com/apurvanandan1997/pts-test-profiles-dev/tree/master/coremark-1.0.0
This is a test of EEMBC CoreMark processor benchmark.
For further information, complete results can be seen at: https://openbenchmarking.org/result/2007148-NI-LOCALCORE64
Porting more test-profiles to NetBSD
Attempts were made to port new test-profiles from Linux to NetBSD, but the major incompatibility issue was missing external dependencies in NetBSD. Hence, this may reduce the number of test-profiles we can actually port, but more sincere efforts will be made in this direction in the next phase.
Future Plans
My next steps would involve porting the non-available tests to NetBSD i.e. the non-graphics ones available on Linux but unavailable on NetBSD, and fix the remaining test-profiles for NetBSD.
After gaining an availability of a decent number of test-profiles on NetBSD, I will use Phoromatic, a remote tests management system for the PTS (allows the automatic scheduling of tests, remote installation of new tests, and the management of multiple test systems) to host the live results of the automated benchmarking framework on benchmark.NetBSD.org, thereby delivering a functional performance and regression testing framework.
How Fuzzing works? The dummy Fuzzer.
The easy way to describe fuzzing is to compare it to the process of unit testing a program, but with different input. This input can be random, or it can be generated in some way that makes it unexpected form standard execution perspective.
The simplest 'fuzzer' can be written in few lines of bash, by getting N bytes from /dev/rand, and putting them to the program as a parameter.

Coverage and Fuzzing
What can be done to make fuzzing more effective? If we think about fuzzing as a process, where we place data into the input of the program (which is a black box), and we can only interact via input, not much more can be done.
However, programs usually process different inputs at different speeds, which can give us some insight into the program's behavior. During fuzzing, we are trying to crash the program, thus we need additional probes to observe the program's behaviour.
Additional knowledge about program state can be exploited as a feedback loop for generating new input vectors. Knowledge about the program itself and the structure of input data can also be considered. As an example, if the input data is in the form of HTML, changing characters inside the body will probably cause less problems for the parser than experimenting with headers and HTML tags.
For open source programs, we can read the source code to know what input takes which execution path. Nonetheless, this might be very time consuming, and it would be much more helpful if this can be automated. As it turns out, this process can be improved by tracing coverage of the execution.

AFL (American Fuzzy Lop) is one of the first successful fuzzers. It uses a technique where the program is compiled with injected traces for every execution branch instruction. During the program execution, every branch is counted, and the analyzer builds a graph out of execution paths and then explores different "interesting" paths.
Now, fuzzing has become a mainstream technique, and compilers provide an option to embed fuzzing hooks at compilation time via switches.
The same process can be applied to the kernel world. However, it would be quite hard to run another program on the same machine outside of the kernel to read these counters. Because of that, they usually are made available inside the kernel.
To illustrate how that is done, we can compile a hello world program written in C for tracing the Program Counter (PC).
gcc main.c -fsanitize-coverage=trace-pc /usr/local/bin/ld: /tmp/ccIKK7Eo.o: in function `handler': main.c:(.text+0xd): undefined reference to `__sanitizer_cov_trace_pc' /usr/local/bin/ld: main.c:(.text+0x1b): undefined reference to `__sanitizer_cov_trace_pc'
The compiler added additional references to the __sanitizer_cov_trace_pc, but we didn't implement them, or link with something else to provide the implementation. If we grep the head of the NetBSD kernel sources for the same function, we will find within sys/kern/subr_kcov.c an implementation: kcov(4).
Which Fuzzer should I choose?
In recent years, AFL has grown into an industry standard. Many projects have integrated it into their development process. This has caused many different bugs and issues to be found and fixed in a broad spectrum of projects (see AFL website for examples). As this technique has become mainstream, many people have started developing custom fuzzers. Some of them were just modified clones of AFL, but there were also many different and innovative approaches. Connecting a custom fuzzer or testing some unusual execution path is no longer considered as just a hackathon project, but part of security research.
I personally believe that we are still in the early state of fuzzing. A lot of interesting work and research is already available, but we cannot explain or prove why one way is better than another one, or how the reference fuzzer should work, and what are its technical specifications.
Many approaches have been developed to do efficient fuzzing, and many bugs have been reported, but most of the knowledge comes still from empirical experiments and comparison between different techniques.
Modular kcov inside the kernel
Coverage metrics inside kernel became a standard even before the fuzzing era. A primary use-case of coverage is not fuzzing, but testing, and measuring test coverage. While code coverage is well understood, kernel fuzzing is still kind of a Wild West, where most of the projects have their own techniques. There are some great projects with a large community around them, like Honggfuzz and Syzkaller. Various companies and projects manitain several fuzzers for kernel code. This shows us that as a kernel community, we need to be open and flexible for different approaches, that allow people interested in fuzzing to do their job efficiently. In return, various fuzzers can find different sets of bugs and improve the overall quality of our kernel.
In the past, Oracle made some effort to upstream an interface for AFL inside Linux kernel (see the patch here. However, the patches were rejected via the kernel community for various reasons.
We did our own research on the needs of fuzzers in context of kcov(4) internals, and quickly figured out that per-fuzzer changes in the main code do not scale up, and can leave unused code inside the kernel driver.
In NetBSD, we want to be compatible with AFL, Hongfuzz, Syzkaller and few other fuzzers, so keeping all fuzzer specific data inside one module would be hard to maintain.
One idea that we had was to keep raw coverage data inside the kernel, and process it inside the user space fuzzer module. Unfortunately, we found that current coverage verbosity in the NetBSD kernel is higher than in Linux, and more advanced traces can have thousand of entries. One of the main requirements for fuzzers is performance. If the fuzzer is slow, even if it is smarter than others, it will most likely will find fewer bugs. If it is significantly slower, then it is not useful at all. We found that storing raw kernel traces in kcov(4), copying the data into user-space, and transfoming it into the AFL format, is not an option. The performance suffers, and the fuzzing process becomes very slow, making it not useful in practice.
We decided to keep AFL conversion of the data inside the kernel, and not introduce too much complexity to the coverage part. As a current proof of concept API, we made kcov more modular, allowing different modules to implement functionality outside of the core requirements. The current code can be viewed here or on the GitHub.
KCOV Modules
As we mentioned earlier, coverage data available in the kernel is generated during tracing by one of the hooks enabled by the compiler. Currently, NetBSD supports PC and CMP tracing. The Kcov module can gather this data during the trace, convert it and expose to the user space via mmap. To write our own coverage module for new PoC API, we need to provide such operations as: open, free, enable, disable, mmap and handling traces.
This can be done via using kcov_ops structure:
static struct kcov_ops kcov_mod_ops = {
.open = kcov_afl_open,
.free = kcov_afl_free,
.setbufsize = kcov_afl_setbufsize,
.enable = kcov_afl_enable,
.disable = kcov_afl_disable,
.mmap = kcov_afl_mmap,
.cov_trace_pc = kcov_afl_cov_trace_pc,
.cov_trace_cmp = kcov_afl_cov_trace_cmp
};
During load or unload, the module must to run kcov_ops_set or kcov_ops_unset. After set, default kcov_ops are overwritten via the module. After unset, they are returned to the default.
Porting AFL as a module
The next step would be to develop a sub-module compatible with the AFL fuzzer.
To do that, the module would need to expose a buffer to user space, and from kernelspace would need to keep information about the 64kB SHM region, previous PC, and thread id. The thread id is crucial, as usually fuzzing runs few tasks. This data is gathered inside the AFL context structure:
typedef struct afl_ctx {
uint8_t *afl_area;
struct uvm_object *afl_uobj;
size_t afl_bsize;
uint64_t afl_prev_loc;
lwpid_t lid;
} kcov_afl_t;
The most important part of the integration is to translate the execution shadow, a list of previous PCs along the execution path, to the AFL compatible hash-map, which is a pair of (prev PC, PC). That can be done according to the documentation of AFL by this method:
++afl->afl_area[(afl->afl_prev_loc ^ pc) & (bsize-1)]; afl->afl_prev_loc = pc;

In our implementation, we use a trick by Quentin Casasnovas of Oracle to improve the distribution of the counters, by storing the hashed PC pairs instead of raw.
The rest of operations, like open, mmap, and enable, can be reviewed in the GitHub repository together with the testing code that dumps 64kB of SHM data.
Debug your fuzzer
Everyone knows that kernel debugging is more complicated than programs running in the user space. Many tools can be used for doing that, and there is always a discussion about usability vs complexity of the setup. People tend to be divided into two groups: those that prefer to use a complicated setup like kernel debugger (with remote debugging), and those for which tools like printf and other simple debug interfaces are sufficient enough.

Enabling coverage brings even more complexity to kernel debugging. Everyone's favourite printf also becomes traced, so putting it inside the trace function will result in a stack overflow. Also, touching any kcov internal structures becomes very tricky and, should be avoided if possible.
A debugger is still a sufficient tool. However, as we mentioned earlier, trace functions are called for every branch, which can be translated to thousand or even tens of thousand break points before any specific condition will occur.
I am personally more of a printf than gdb guy, and in most cases, the ability to print variables' contents is enough to find the issues. For validating my AFL kcov plugin, I found out that debugcon_printf written by Kamil Rytarowski is a great tool.
Example of debugcon_printf
To illustrate that idea, lets say that we want to print every PC trace that comes to our AFL submodule.
The most intuitive way would be put printf("#:%p\n", pc) at very beginning of the kcov_afl_cov_trace_pc, but as mentioned earlier, such a trick would end up with a kernel crash whenever we enable tracing with our module. However, if we switch printf to the debugcon_printf, and add a simple option to our QEMU:
-debugcon file:/tmp/qemu.debug.log -global isa-debugcon.iobase=0xe9
we can see on our host machine that all traces are written to the file qemu.debug.log.
kcov_afl_cov_trace_pc(void *priv, intptr_t pc) {
kcov_afl_t *afl = priv;
debugcon_printf("#:%x\n", pc);
++afl->afl_area[(afl->afl_prev_loc ^ pc) & (afl->afl_bsize-1)];
afl->afl_prev_loc = _long_hash64(pc, BITS_PER_LONG);
return;
}
Future work
The AFL submodule was developed as part of the AFL FileSystems Fuzzing project to simplify the fuzzing of different parts of the NetBSD kernel.
I am using it currently for fuzzing different filesystems. In a future article I plan to show more practical examples.
Another great thing to do will be to refactor KLEAK, which is using PC trace data and is disconnected from kcov. A good idea would be to rewrite it as a kcov module, to have one unified way to access coverage data inside NetBSD kernel.
Summary
In this article, we familiarized the reader with the technique of fuzzing, starting from theoretical background up to the level of kernel fuzzing.
Based on these pieces of information, we demonstrated the purpose of the a modular coverage framework inside the kernel and an example implementation of submodule that can be consumed by AFL.
More details can be learned via downloading and trying the sample code shown in the example.
At the end of this article, I want to thank Kamil, for such a great idea for a project, and for allowing me to work on NetBSD development.
How Fuzzing works? The dummy Fuzzer.
The easy way to describe fuzzing is to compare it to the process of unit testing a program, but with different input. This input can be random, or it can be generated in some way that makes it unexpected form standard execution perspective.
The simplest 'fuzzer' can be written in few lines of bash, by getting N bytes from /dev/rand, and putting them to the program as a parameter.
Coverage and Fuzzing
What can be done to make fuzzing more effective? If we think about fuzzing as a process, where we place data into the input of the program (which is a black box), and we can only interact via input, not much more can be done.
However, programs usually process different inputs at different speeds, which can give us some insight into the program's behavior. During fuzzing, we are trying to crash the program, thus we need additional probes to observe the program's behaviour.
Additional knowledge about program state can be exploited as a feedback loop for generating new input vectors. Knowledge about the program itself and the structure of input data can also be considered. As an example, if the input data is in the form of HTML, changing characters inside the body will probably cause less problems for the parser than experimenting with headers and HTML tags.
For open source programs, we can read the source code to know what input takes which execution path. Nonetheless, this might be very time consuming, and it would be much more helpful if this can be automated. As it turns out, this process can be improved by tracing coverage of the execution.
AFL (American Fuzzy Lop) is one of the first successful fuzzers. It uses a technique where the program is compiled with injected traces for every execution branch instruction. During the program execution, every branch is counted, and the analyzer builds a graph out of execution paths and then explores different "interesting" paths.
Now, fuzzing has become a mainstream technique, and compilers provide an option to embed fuzzing hooks at compilation time via switches.
The same process can be applied to the kernel world. However, it would be quite hard to run another program on the same machine outside of the kernel to read these counters. Because of that, they usually are made available inside the kernel.
To illustrate how that is done, we can compile a hello world program written in C for tracing the Program Counter (PC).
gcc main.c -fsanitize-coverage=trace-pc /usr/local/bin/ld: /tmp/ccIKK7Eo.o: in function `handler': main.c:(.text+0xd): undefined reference to `__sanitizer_cov_trace_pc' /usr/local/bin/ld: main.c:(.text+0x1b): undefined reference to `__sanitizer_cov_trace_pc'
The compiler added additional references to the __sanitizer_cov_trace_pc, but we didn't implement them, or link with something else to provide the implementation. If we grep the head of the NetBSD kernel sources for the same function, we will find within sys/kern/subr_kcov.c an implementation: kcov(4).
Which Fuzzer should I choose?
In recent years, AFL has grown into an industry standard. Many projects have integrated it into their development process. This has caused many different bugs and issues to be found and fixed in a broad spectrum of projects (see AFL website for examples). As this technique has become mainstream, many people have started developing custom fuzzers. Some of them were just modified clones of AFL, but there were also many different and innovative approaches. Connecting a custom fuzzer or testing some unusual execution path is no longer considered as just a hackathon project, but part of security research.
I personally believe that we are still in the early state of fuzzing. A lot of interesting work and research is already available, but we cannot explain or prove why one way is better than another one, or how the reference fuzzer should work, and what are its technical specifications.
Many approaches have been developed to do efficient fuzzing, and many bugs have been reported, but most of the knowledge comes still from empirical experiments and comparison between different techniques.
Modular kcov inside the kernel
Coverage metrics inside kernel became a standard even before the fuzzing era. A primary use-case of coverage is not fuzzing, but testing, and measuring test coverage. While code coverage is well understood, kernel fuzzing is still kind of a Wild West, where most of the projects have their own techniques. There are some great projects with a large community around them, like Honggfuzz and Syzkaller. Various companies and projects manitain several fuzzers for kernel code. This shows us that as a kernel community, we need to be open and flexible for different approaches, that allow people interested in fuzzing to do their job efficiently. In return, various fuzzers can find different sets of bugs and improve the overall quality of our kernel.
In the past, Oracle made some effort to upstream an interface for AFL inside Linux kernel (see the patch here. However, the patches were rejected via the kernel community for various reasons.
We did our own research on the needs of fuzzers in context of kcov(4) internals, and quickly figured out that per-fuzzer changes in the main code do not scale up, and can leave unused code inside the kernel driver.
In NetBSD, we want to be compatible with AFL, Hongfuzz, Syzkaller and few other fuzzers, so keeping all fuzzer specific data inside one module would be hard to maintain.
One idea that we had was to keep raw coverage data inside the kernel, and process it inside the user space fuzzer module. Unfortunately, we found that current coverage verbosity in the NetBSD kernel is higher than in Linux, and more advanced traces can have thousand of entries. One of the main requirements for fuzzers is performance. If the fuzzer is slow, even if it is smarter than others, it will most likely will find fewer bugs. If it is significantly slower, then it is not useful at all. We found that storing raw kernel traces in kcov(4), copying the data into user-space, and transfoming it into the AFL format, is not an option. The performance suffers, and the fuzzing process becomes very slow, making it not useful in practice.
We decided to keep AFL conversion of the data inside the kernel, and not introduce too much complexity to the coverage part. As a current proof of concept API, we made kcov more modular, allowing different modules to implement functionality outside of the core requirements. The current code can be viewed here or on the GitHub.
KCOV Modules
As we mentioned earlier, coverage data available in the kernel is generated during tracing by one of the hooks enabled by the compiler. Currently, NetBSD supports PC and CMP tracing. The Kcov module can gather this data during the trace, convert it and expose to the user space via mmap. To write our own coverage module for new PoC API, we need to provide such operations as: open, free, enable, disable, mmap and handling traces.
This can be done via using kcov_ops structure:
static struct kcov_ops kcov_mod_ops = {
.open = kcov_afl_open,
.free = kcov_afl_free,
.setbufsize = kcov_afl_setbufsize,
.enable = kcov_afl_enable,
.disable = kcov_afl_disable,
.mmap = kcov_afl_mmap,
.cov_trace_pc = kcov_afl_cov_trace_pc,
.cov_trace_cmp = kcov_afl_cov_trace_cmp
};
During load or unload, the module must to run kcov_ops_set or kcov_ops_unset. After set, default kcov_ops are overwritten via the module. After unset, they are returned to the default.
Porting AFL as a module
The next step would be to develop a sub-module compatible with the AFL fuzzer.
To do that, the module would need to expose a buffer to user space, and from kernelspace would need to keep information about the 64kB SHM region, previous PC, and thread id. The thread id is crucial, as usually fuzzing runs few tasks. This data is gathered inside the AFL context structure:
typedef struct afl_ctx {
uint8_t *afl_area;
struct uvm_object *afl_uobj;
size_t afl_bsize;
uint64_t afl_prev_loc;
lwpid_t lid;
} kcov_afl_t;
The most important part of the integration is to translate the execution shadow, a list of previous PCs along the execution path, to the AFL compatible hash-map, which is a pair of (prev PC, PC). That can be done according to the documentation of AFL by this method:
++afl->afl_area[(afl->afl_prev_loc ^ pc) & (bsize-1)]; afl->afl_prev_loc = pc;
In our implementation, we use a trick by Quentin Casasnovas of Oracle to improve the distribution of the counters, by storing the hashed PC pairs instead of raw.
The rest of operations, like open, mmap, and enable, can be reviewed in the GitHub repository together with the testing code that dumps 64kB of SHM data.
Debug your fuzzer
Everyone knows that kernel debugging is more complicated than programs running in the user space. Many tools can be used for doing that, and there is always a discussion about usability vs complexity of the setup. People tend to be divided into two groups: those that prefer to use a complicated setup like kernel debugger (with remote debugging), and those for which tools like printf and other simple debug interfaces are sufficient enough.
Enabling coverage brings even more complexity to kernel debugging. Everyone's favourite printf also becomes traced, so putting it inside the trace function will result in a stack overflow. Also, touching any kcov internal structures becomes very tricky and, should be avoided if possible.
A debugger is still a sufficient tool. However, as we mentioned earlier, trace functions are called for every branch, which can be translated to thousand or even tens of thousand break points before any specific condition will occur.
I am personally more of a printf than gdb guy, and in most cases, the ability to print variables' contents is enough to find the issues. For validating my AFL kcov plugin, I found out that debugcon_printf written by Kamil Rytarowski is a great tool.
Example of debugcon_printf
To illustrate that idea, lets say that we want to print every PC trace that comes to our AFL submodule.
The most intuitive way would be put printf("#:%p\n", pc) at very beginning of the kcov_afl_cov_trace_pc, but as mentioned earlier, such a trick would end up with a kernel crash whenever we enable tracing with our module. However, if we switch printf to the debugcon_printf, and add a simple option to our QEMU:
-debugcon file:/tmp/qemu.debug.log -global isa-debugcon.iobase=0xe9
we can see on our host machine that all traces are written to the file qemu.debug.log.
kcov_afl_cov_trace_pc(void *priv, intptr_t pc) {
kcov_afl_t *afl = priv;
debugcon_printf("#:%x\n", pc);
++afl->afl_area[(afl->afl_prev_loc ^ pc) & (afl->afl_bsize-1)];
afl->afl_prev_loc = _long_hash64(pc, BITS_PER_LONG);
return;
}
Future work
The AFL submodule was developed as part of the AFL FileSystems Fuzzing project to simplify the fuzzing of different parts of the NetBSD kernel.
I am using it currently for fuzzing different filesystems. In a future article I plan to show more practical examples.
Another great thing to do will be to refactor KLEAK, which is using PC trace data and is disconnected from kcov. A good idea would be to rewrite it as a kcov module, to have one unified way to access coverage data inside NetBSD kernel.
Summary
In this article, we familiarized the reader with the technique of fuzzing, starting from theoretical background up to the level of kernel fuzzing.
Based on these pieces of information, we demonstrated the purpose of the a modular coverage framework inside the kernel and an example implementation of submodule that can be consumed by AFL.
More details can be learned via downloading and trying the sample code shown in the example.
At the end of this article, I want to thank Kamil, for such a great idea for a project, and for allowing me to work on NetBSD development.
Debugger related changes
NetBSD might be the only mainstream OS that implements posix_spawn(3) with a dedicated syscall. All the other recognized kernels have an implementation as a libc wrapper around either fork(2), vfork(2) or clone(2). I've introduced a new ptrace(2) event, PTRACE_POSIX_SPAWN, improved the posix_spawn(3) documentation, and introduced new ATF regression tests for posix_spawn(3).
The new ptrace(2) code has been exercised under load with LLDB test-suite, picotrace, and NetBSD truss.
I intend to resume porting of edb-debugger from work I began two years ago. I hope to use it for verifying FPU registers. I've spent some time porting this debugger to NetBSD/amd64 and managed to get a functional process attached. Unfortunately the code is highly specific to a single Operating System. That OS is the only one that is really functional at the moment and the code needs rework to be more agnostic with respect to the different semantics of kernels.
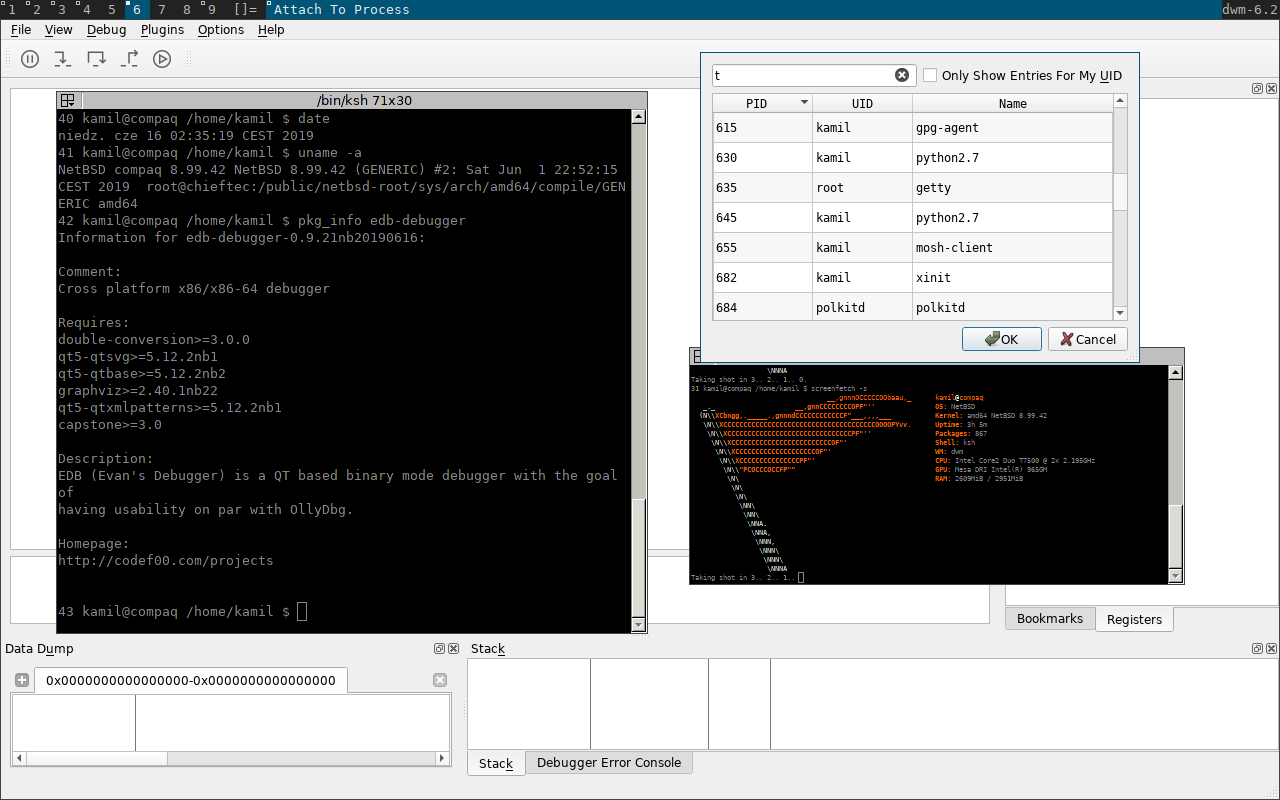
Issues with threaded debugging
I've analyzed the problems with multiple thread programs under debuggers. They could be classified into the following groups:
- There is suboptimal support in GDB/NetBSD. However, events such as software breakpoint, watchpoint, and single step trap are reported correctly by the kernel. A debugger can detect the exact reason of interruption of execution. Unfortunately, the current NetBSD code tries to be compatible with Linux which prevents the NetBSD kernel from being able to precisely point to the stop reason. This causes GDB to randomly misbehave, e.g. single step over forking code.
- Events reported from two or more events compete in the kernel for being reported to a debugger. A selection of events that lost this race will not be delivered as the winner event will overwrite signal information for a debugger from losing threads/events.
- PT_RESUME/PT_SUSPEND shares the same suspended bit as pthread_suspend_np(3) and pthread_resume_np(3) (_lwp_suspend(2), _lwp_continue(2)).
- In some circumstances event from an exiting thread never hits the tracer (WAIT() vs LWP_EXIT() race).
- Corner cases that can cause a kernel crash or kill trace can negatively effect the debugging process.
I've found that focusing on kernel correctness now and fixing thread handling bugs can have paradoxically random impact on GDB/NetBSD. The solution for multiple events reported from multiple threads concurrently has a fix in progress, but the initial changes caused some fallout in GDB support so I have decided to revert it for now. This pushed me to the conclusion that before fixing LWP events, there is a priority to streamline the GDB support: modernize it, upstream it, run regression tests.
Meanwhile there is an ongoing work on covering more kernel code paths with fuzzers. We will catch and address problems out there only because they're able to be found. I'm supervising 3 ongoing projects in this domain: syzkaller support enhancements, TriforceAFL porting and AFL+KCOV integration. This work makes the big picture of what is still needed to be fixed clearer and lowers the cost of improving the quality.
LSan/NetBSD
The original implementation of Leak Sanitizer for NetBSD was developed for GCC by Christos Zoulas. The whole magic of a functional LSan software is the Stop-The-World operation. This means that a process suspends all other threads while having the capability to investigate the register frame and the stacks of suspended threads.
Until recently there were two implementations of LSan: for Linux (ab)using ptrace(2) and for Darwin using low-level Mach interfaces. Furthermore the Linux version needs a special version of fork(2) and makes assumptions about the semantics of the signal kernel code.
The original Linux code must separately attach to each thread via a pid. This applies to all other operations, such as detaching or killing a process through ptrace(2). Additionally listing threads of a debugged process on Linux is troublesome as there is need to iterate through directories in /proc.
The implementation in GCC closely reused the semantics of Linux. There was room for enhancement. I've picked this code as an inspiration and wrote a clean implementation reflecting the NetBSD kernel behavior and interfaces. In the end the NetBSD code is simpler than the Linux code without needing any recovery fallbacks or port specific kludges (in Linux every CPU needs discrete treatment.)
Much to my chagrin, this approach abuses the ptrace(2) interface, making sanitizing for leaking programs incompatible with debuggers. The whole StopTheWorld() operation could be cleanly implemented on the kernel side as a new syscall. I have a semicompleted implementation of this syscall, however I really want to take care of all threading issues under ptrace(2) before moving on. The threading issues must be fully reliable in one domain of debugging before implementing other kernel code. Both LLVM 9.0 and NetBSD-9 are branching soon and it will be a good enough solution for the time being. My current goal before the LLVM branching is to address a semantic behavioral difference in atexit(3) that raises a false positive in LSan tests. Request for comments on this specific atexit(3) issue will be available pending feedback from upstream.
Plan for the next milestone
Modernize GDB/NetBSD support, upstream it, and run GDB regression tests for NetBSD/amd64. Switch back to addressing threading kernel issues under a debugger.
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL to chip in what you can:
Debugger related changes
NetBSD might be the only mainstream OS that implements posix_spawn(3) with a dedicated syscall. All the other recognized kernels have an implementation as a libc wrapper around either fork(2), vfork(2) or clone(2). I've introduced a new ptrace(2) event, PTRACE_POSIX_SPAWN, improved the posix_spawn(3) documentation, and introduced new ATF regression tests for posix_spawn(3).
The new ptrace(2) code has been exercised under load with LLDB test-suite, picotrace, and NetBSD truss.
I intend to resume porting of edb-debugger from work I began two years ago. I hope to use it for verifying FPU registers. I've spent some time porting this debugger to NetBSD/amd64 and managed to get a functional process attached. Unfortunately the code is highly specific to a single Operating System. That OS is the only one that is really functional at the moment and the code needs rework to be more agnostic with respect to the different semantics of kernels.
Issues with threaded debugging
I've analyzed the problems with multiple thread programs under debuggers. They could be classified into the following groups:
- There is suboptimal support in GDB/NetBSD. However, events such as software breakpoint, watchpoint, and single step trap are reported correctly by the kernel. A debugger can detect the exact reason of interruption of execution. Unfortunately, the current NetBSD code tries to be compatible with Linux which prevents the NetBSD kernel from being able to precisely point to the stop reason. This causes GDB to randomly misbehave, e.g. single step over forking code.
- Events reported from two or more events compete in the kernel for being reported to a debugger. A selection of events that lost this race will not be delivered as the winner event will overwrite signal information for a debugger from losing threads/events.
- PT_RESUME/PT_SUSPEND shares the same suspended bit as pthread_suspend_np(3) and pthread_resume_np(3) (_lwp_suspend(2), _lwp_continue(2)).
- In some circumstances event from an exiting thread never hits the tracer (WAIT() vs LWP_EXIT() race).
- Corner cases that can cause a kernel crash or kill trace can negatively effect the debugging process.
I've found that focusing on kernel correctness now and fixing thread handling bugs can have paradoxically random impact on GDB/NetBSD. The solution for multiple events reported from multiple threads concurrently has a fix in progress, but the initial changes caused some fallout in GDB support so I have decided to revert it for now. This pushed me to the conclusion that before fixing LWP events, there is a priority to streamline the GDB support: modernize it, upstream it, run regression tests.
Meanwhile there is an ongoing work on covering more kernel code paths with fuzzers. We will catch and address problems out there only because they're able to be found. I'm supervising 3 ongoing projects in this domain: syzkaller support enhancements, TriforceAFL porting and AFL+KCOV integration. This work makes the big picture of what is still needed to be fixed clearer and lowers the cost of improving the quality.
LSan/NetBSD
The original implementation of Leak Sanitizer for NetBSD was developed for GCC by Christos Zoulas. The whole magic of a functional LSan software is the Stop-The-World operation. This means that a process suspends all other threads while having the capability to investigate the register frame and the stacks of suspended threads.
Until recently there were two implementations of LSan: for Linux (ab)using ptrace(2) and for Darwin using low-level Mach interfaces. Furthermore the Linux version needs a special version of fork(2) and makes assumptions about the semantics of the signal kernel code.
The original Linux code must separately attach to each thread via a pid. This applies to all other operations, such as detaching or killing a process through ptrace(2). Additionally listing threads of a debugged process on Linux is troublesome as there is need to iterate through directories in /proc.
The implementation in GCC closely reused the semantics of Linux. There was room for enhancement. I've picked this code as an inspiration and wrote a clean implementation reflecting the NetBSD kernel behavior and interfaces. In the end the NetBSD code is simpler than the Linux code without needing any recovery fallbacks or port specific kludges (in Linux every CPU needs discrete treatment.)
Much to my chagrin, this approach abuses the ptrace(2) interface, making sanitizing for leaking programs incompatible with debuggers. The whole StopTheWorld() operation could be cleanly implemented on the kernel side as a new syscall. I have a semicompleted implementation of this syscall, however I really want to take care of all threading issues under ptrace(2) before moving on. The threading issues must be fully reliable in one domain of debugging before implementing other kernel code. Both LLVM 9.0 and NetBSD-9 are branching soon and it will be a good enough solution for the time being. My current goal before the LLVM branching is to address a semantic behavioral difference in atexit(3) that raises a false positive in LSan tests. Request for comments on this specific atexit(3) issue will be available pending feedback from upstream.
Plan for the next milestone
Modernize GDB/NetBSD support, upstream it, and run GDB regression tests for NetBSD/amd64. Switch back to addressing threading kernel issues under a debugger.
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL to chip in what you can:
Upstream describes LLDB as a next generation, high-performance debugger. It is built on top of LLVM/Clang toolchain, and features great integration with it. At the moment, it primarily supports debugging C, C++ and ObjC code, and there is interest in extending it to more languages.
In February, I have started working on LLDB, as contracted by the NetBSD Foundation. So far I've been working on reenabling continuous integration, squashing bugs, improving NetBSD core file support and lately extending NetBSD's ptrace interface to cover more register types and fix compat32 issues. You can read more about that in my May 2019 report.
In June, I have finally finished the remaining ptrace() work
for xstate and got it merged both on NetBSD and LLDB end (meaning it's
going to make it into NetBSD 9). I have also worked on debug register
support in LLDB, effectively fixing watchpoint support. Once again
I had to fight some upstream regressions.
ptrace() XSTATE interface
In the previous report, I was comparing two approaches to resolving
unpredictable XSAVE data offsets.
Both solutions had their merits but I eventually went with having
a pair of requests with a single predictable, extensible structure.
As a result, I have implemented two new ptrace() requests:
-
PT_GETXSTATEthat obtains full FPU state and stores it instruct xstate, -
PT_SETXSTATEthat updates FPU state as requested fromstruct xstate.
The main features of this API are:
-
It provides single call to obtain all supported XSAVE components. This is especially useful for YMM or ZMM registers whose contents are split between disjoint XSAVE components.
-
It provides a
xs_rfbmbitfield that clearly indicates which XSAVE components were available, and which can be used to issue partial updates viaPT_SETXSTATE. -
It requires the caller to explicitly specify structure size. As a result, new fields (= component types) can be added to it without breaking compatibility with already built programs.
-
It provides identical API to i386 and amd64 programs, removing the need for code duplication.
-
It provides backwards compatibility with FSAVE- and FXSAVE-only systems, with
xs_rfbmclearly indicating which fields were filled. -
It can replace disjoint
PT_GETFPREGSandPT_GETXMMREGSAPIs on i386/amd64 with a single convenient method.
From user's perspective, the main gain is ability to read YMM (AVX) registers. The code supports ZMM (AVX-512) registers as well but I have not been able to test it due to lack of hardware. That said, if one of the readers is running NetBSD on AVX-512 capable CPU and is willing to help, please contact me and I'll give you some tests to run.
The two relevant commits are:
-
Fetch XSAVE area component offsets and sizes when initializing x86 CPU that obtains the necessary offsets and stores them in kernel,
-
Implement PT_GETXSTATE and PT_SETXSTATE that adds the new calls along with tests.
The two new calls are covered by tests for reading and writing MM (MMX), XMM (SSE) and YMM (AVX) registers. I have also done some work on ZMM (AVX-512) test but I did not complete it due to aforementioned lack of hardware.
On the LLDB end, the change was preceded with some bugfixes and cleanup suggested by Pavel Labath. The relevant commits are:
-
[lldb] [Process/NetBSD] Fix error handling in register operations,
-
[lldb] [Process/NetBSD] Remove unnecessary FPU presence checks for x86_64,
-
[lldb] [Process/NetBSD] Remove unnecessary register buffer abstraction,
-
[lldb] [Process] Introduce common helpers to split/recombine YMM data,
-
[lldb] [Process/NetBSD] Support reading YMM registers via PT_*XSTATE.
XSTATE in core dumps
The ptrace() XSTATE supports provides the ability to introspect registers
in running programs. However, in order to improve the support for debugging
crashed programs the respective support needs to be also added to core dumps.
NetBSD core dumps are built on ELF file format, with additional process
information stored in ELF notes. Notes can be conveniently read
via readelf -n. Each note is uniquely identified by a pair of name and numeric
type identifier. NetBSD-specific notes are split into two groups:
-
process-specific notes (shared by all LWPs) use
NetBSD-COREname and successive type numbers defined insys/exec_elf.h, -
LWP-specific notes use
NetBSD-CORE@nnwhere nn is LWP number, and type numbers corresponding toptrace()requests.
Two process-specific notes are used at the moment:
-
ELF_NOTE_NETBSD_CORE_PROCINFOcontaining process information — including killing signal information, PIDs, UIDs, GIDs… -
ELF_NOTE_NETBSD_CORE_AUXVcontaining auxiliary information provided by the dynamic linker.
The LWP-specific notes currently contain register dumps. They are stored
in the same format as returned by ptrace() calls, and use the same numeric
identifiers as PT_GET* requests.
Previously, only PT_GETREGS and PT_GETFPREGS dumps were supported. This
implies that i386 coredumps do not include MMX register values. Both requests were
handled via common code, with a TODO for providing machdep (arch-specific) hooks.
My work on core dumps involved three aspects:
-
Writing ATF tests for their correctness.
-
Providing machdep API for injecting additional arch-specific notes.
-
Injecting
PT_GETXSTATEdata into x86 core dumps.
To implement the ATF tests, I've used PT_DUMPCORE to dump core into
a temporary file with predictable filename. Afterwards, I've used libelf
to process the ELF file and locate notes in it. The note format I had to
process myself — I have included a reusable function to find and read specific
note in the tests.
Firstly, I wrote a test for process information. Then, I refactored register
tests to reduce code duplication and make writing additional variants much
easier, and created matching core dump tests for all existing PT_GET* register
tests. Finally, I implemented the support for dumping PT_GETXSTATE
information.
Of this work, only the first test was merged. The relevant commits and patches are:
LLDB debug register / watchpoint support
The next item on my TODO was fixing debug register support in LLDB. There are six debug registers on x86, and they are used to support up to four hardware breakpoints or watchpoints (each can serve as either). Those are:
-
DR0 through DR3 registers used to specify the breakpoint or watchpoint address,
-
DR6 acting as status register, indicating which debug conditions have occurred,
-
DR7 acting as control register, used to enable and configure breakpoints or watchpoints.
DR4 and DR5 are obsolete synonyms for DR6 and DR7.
For each breakpoint, the control register provides the following options:
-
Enabling it as global or local breakpoint. Global breakpoints remain active through hardware task switches, while local breakpoints are disabled on task switches.
-
Setting it to trigger on code execution (breakpoint), memory write or memory write or read (watchpoints). Read-only hardware watchpoints are not supported on x86, and are normally emulated via read/write watchpoints.
-
Specifying the size of watched memory to 1, 2, 4 or 8 bytes. 8-byte watchpoints are not supported on i386.
According to my initial examination, watchpoint support was already present in LLDB (most likely copied from relevant Linux code) but it was not working correctly. More specifically, the accesses were reported as opaque tracepoints rather than as watchpoints. While the program was correctly stopped, LLDB was not aware which watchpoint was triggered.
Upon investigating this further, I've noticed that this happens specifically because LLDB is using local watchpoints. After switching it to use global watchpoints, NetBSD started reporting triggered watchpoints correctly.
As a result, new branch of LLDB code started being used… and turned out to segfault. Therefore, my next goal was to locate the invalid memory use and correct it. In this case, the problem lied in the way thread data was stored in a list. Specifically, the program wrongly assumed that the list index will match LWP number exactly. This had two implications.
Firstly, it suffered from off-by-one error. Since LWPs start with 1, and list indexes start with 0, a single-threaded program crashed trying to access past the list. Secondly, the assumption that thread list will be always in order seemed fragile. After all, it relied on LWPs being reported with successive numbers. Therefore, I've decided to rewrite the code to iterate through thread list and locate the correct LWP explicitly.
With those two fixes, some of the watchpoint tests started passing. However, some are still failing because we are not handling threads correctly yet. According to earlier research done by Kamil Rytarowski, we need to copy debug register values into new LWPs as they are created. I am planning to work on this shortly.
Additionally, NetBSD normally disallows unprivileged processes from modifying
debug registers. This can be changed via enabling
security.models.extensions.user_set_dbregs. Since LLDB tests are normally run
via unprivileged users, I had to detect this condition from within LLDB test
suite and skip watchpoint tests appropriately.
The LLDB commits relevant to this topic are:
- [lldb] [test] Skip watchpoint tests on NetBSD if userdbregs is disabled,
- [lldb] [test] Watchpoint tests can be always run as root on NetBSD,
- [lldb] [Process/NetBSD] Fix segfault when handling watchpoint,
- [lldb] [Process/NetBSD] Use global enable bits for watchpoints.
Regressions caught by buildbot
Finally, let's go over the regressions that were caught by our buildbot instance throughout the passing month:
-
[COFF, ARM64] Add CodeView register mapping broke LLDB builds due to API incompatibility; fixed by the author: [COFF, ARM64] Fix CodeView API change for getRegisterNames;
-
Implement deduction guides for map/multimap broke libc++ builds with trunk clang; recommitted with a fix as [libc++] Take 2: Implement CTAD for map and multimap;
-
Fix a crash in option parsing broke LLDB tests on NetBSD due to relying on specific
getopt_long()output (bug?); fixed by Options: Correctly check for missing arguments; -
[ABI] Implement Windows ABI for x86_64 broke NetBSD at runtime by omitting NetBSD from list of platforms using SysV ABI; I've fixed it via [lldb] [Plugins/SysV-x86_64] NetBSD is also using SysV ABI;
-
Implement xfer:libraries-svr4:read packet changed internal LLDB API, breaking NetBSD plugin builds; I've fixed it via [lldb] [Process/NetBSD] Fix constructor after r363707;
-
Revert "Implement xfer:libraries-svr4:read packet" changed the API back and broke NetBSD again; I've reverted my change to fix it: Revert "[lldb] [Process/NetBSD] Fix constructor after r363707";
-
Change LaunchThread interface to return an expected broke builds, most likely due to GCC incompatibility; not fixed yet.
Future plans
Since Kamil has managed to move the kernel part of threading support forward, I'm going to focus on improving threading support in LLDB right now. Most notably, this includes ensuring that LLDB can properly handle multithreaded applications, and that all thread-level actions (stepping, resuming, signalling) are correctly handled. As mentoned above, this also includes handling watchpoints in threads.
Of course, I am also going to finish the work on XSTATE in coredumps, and handle any possible bugs I might have introduced in my earlier work.
Afterwards I will work on the remaining TODO items, that are:
-
Add support to backtrace through signal trampoline and extend the support to libexecinfo, unwind implementations (LLVM, nongnu). Examine adding CFI support to interfaces that need it to provide more stable backtraces (both kernel and userland).
-
Add support for i386 and aarch64 targets.
-
Stabilize LLDB and address breaking tests from the test suite.
-
Merge LLDB with the base system (under LLVM-style distribution).
This work is sponsored by The NetBSD Foundation
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL to chip in what you can:
Upstream describes LLDB as a next generation, high-performance debugger. It is built on top of LLVM/Clang toolchain, and features great integration with it. At the moment, it primarily supports debugging C, C++ and ObjC code, and there is interest in extending it to more languages.
In February, I have started working on LLDB, as contracted by the NetBSD Foundation. So far I've been working on reenabling continuous integration, squashing bugs, improving NetBSD core file support and lately extending NetBSD's ptrace interface to cover more register types and fix compat32 issues. You can read more about that in my May 2019 report.
In June, I have finally finished the remaining ptrace() work
for xstate and got it merged both on NetBSD and LLDB end (meaning it's
going to make it into NetBSD 9). I have also worked on debug register
support in LLDB, effectively fixing watchpoint support. Once again
I had to fight some upstream regressions.
ptrace() XSTATE interface
In the previous report, I was comparing two approaches to resolving
unpredictable XSAVE data offsets.
Both solutions had their merits but I eventually went with having
a pair of requests with a single predictable, extensible structure.
As a result, I have implemented two new ptrace() requests:
-
PT_GETXSTATEthat obtains full FPU state and stores it instruct xstate, -
PT_SETXSTATEthat updates FPU state as requested fromstruct xstate.
The main features of this API are:
-
It provides single call to obtain all supported XSAVE components. This is especially useful for YMM or ZMM registers whose contents are split between disjoint XSAVE components.
-
It provides a
xs_rfbmbitfield that clearly indicates which XSAVE components were available, and which can be used to issue partial updates viaPT_SETXSTATE. -
It requires the caller to explicitly specify structure size. As a result, new fields (= component types) can be added to it without breaking compatibility with already built programs.
-
It provides identical API to i386 and amd64 programs, removing the need for code duplication.
-
It provides backwards compatibility with FSAVE- and FXSAVE-only systems, with
xs_rfbmclearly indicating which fields were filled. -
It can replace disjoint
PT_GETFPREGSandPT_GETXMMREGSAPIs on i386/amd64 with a single convenient method.
From user's perspective, the main gain is ability to read YMM (AVX) registers. The code supports ZMM (AVX-512) registers as well but I have not been able to test it due to lack of hardware. That said, if one of the readers is running NetBSD on AVX-512 capable CPU and is willing to help, please contact me and I'll give you some tests to run.
The two relevant commits are:
-
Fetch XSAVE area component offsets and sizes when initializing x86 CPU that obtains the necessary offsets and stores them in kernel,
-
Implement PT_GETXSTATE and PT_SETXSTATE that adds the new calls along with tests.
The two new calls are covered by tests for reading and writing MM (MMX), XMM (SSE) and YMM (AVX) registers. I have also done some work on ZMM (AVX-512) test but I did not complete it due to aforementioned lack of hardware.
On the LLDB end, the change was preceded with some bugfixes and cleanup suggested by Pavel Labath. The relevant commits are:
-
[lldb] [Process/NetBSD] Fix error handling in register operations,
-
[lldb] [Process/NetBSD] Remove unnecessary FPU presence checks for x86_64,
-
[lldb] [Process/NetBSD] Remove unnecessary register buffer abstraction,
-
[lldb] [Process] Introduce common helpers to split/recombine YMM data,
-
[lldb] [Process/NetBSD] Support reading YMM registers via PT_*XSTATE.
XSTATE in core dumps
The ptrace() XSTATE supports provides the ability to introspect registers
in running programs. However, in order to improve the support for debugging
crashed programs the respective support needs to be also added to core dumps.
NetBSD core dumps are built on ELF file format, with additional process
information stored in ELF notes. Notes can be conveniently read
via readelf -n. Each note is uniquely identified by a pair of name and numeric
type identifier. NetBSD-specific notes are split into two groups:
-
process-specific notes (shared by all LWPs) use
NetBSD-COREname and successive type numbers defined insys/exec_elf.h, -
LWP-specific notes use
NetBSD-CORE@nnwhere nn is LWP number, and type numbers corresponding toptrace()requests.
Two process-specific notes are used at the moment:
-
ELF_NOTE_NETBSD_CORE_PROCINFOcontaining process information — including killing signal information, PIDs, UIDs, GIDs… -
ELF_NOTE_NETBSD_CORE_AUXVcontaining auxiliary information provided by the dynamic linker.
The LWP-specific notes currently contain register dumps. They are stored
in the same format as returned by ptrace() calls, and use the same numeric
identifiers as PT_GET* requests.
Previously, only PT_GETREGS and PT_GETFPREGS dumps were supported. This
implies that i386 coredumps do not include MMX register values. Both requests were
handled via common code, with a TODO for providing machdep (arch-specific) hooks.
My work on core dumps involved three aspects:
-
Writing ATF tests for their correctness.
-
Providing machdep API for injecting additional arch-specific notes.
-
Injecting
PT_GETXSTATEdata into x86 core dumps.
To implement the ATF tests, I've used PT_DUMPCORE to dump core into
a temporary file with predictable filename. Afterwards, I've used libelf
to process the ELF file and locate notes in it. The note format I had to
process myself — I have included a reusable function to find and read specific
note in the tests.
Firstly, I wrote a test for process information. Then, I refactored register
tests to reduce code duplication and make writing additional variants much
easier, and created matching core dump tests for all existing PT_GET* register
tests. Finally, I implemented the support for dumping PT_GETXSTATE
information.
Of this work, only the first test was merged. The relevant commits and patches are:
LLDB debug register / watchpoint support
The next item on my TODO was fixing debug register support in LLDB. There are six debug registers on x86, and they are used to support up to four hardware breakpoints or watchpoints (each can serve as either). Those are:
-
DR0 through DR3 registers used to specify the breakpoint or watchpoint address,
-
DR6 acting as status register, indicating which debug conditions have occurred,
-
DR7 acting as control register, used to enable and configure breakpoints or watchpoints.
DR4 and DR5 are obsolete synonyms for DR6 and DR7.
For each breakpoint, the control register provides the following options:
-
Enabling it as global or local breakpoint. Global breakpoints remain active through hardware task switches, while local breakpoints are disabled on task switches.
-
Setting it to trigger on code execution (breakpoint), memory write or memory write or read (watchpoints). Read-only hardware watchpoints are not supported on x86, and are normally emulated via read/write watchpoints.
-
Specifying the size of watched memory to 1, 2, 4 or 8 bytes. 8-byte watchpoints are not supported on i386.
According to my initial examination, watchpoint support was already present in LLDB (most likely copied from relevant Linux code) but it was not working correctly. More specifically, the accesses were reported as opaque tracepoints rather than as watchpoints. While the program was correctly stopped, LLDB was not aware which watchpoint was triggered.
Upon investigating this further, I've noticed that this happens specifically because LLDB is using local watchpoints. After switching it to use global watchpoints, NetBSD started reporting triggered watchpoints correctly.
As a result, new branch of LLDB code started being used… and turned out to segfault. Therefore, my next goal was to locate the invalid memory use and correct it. In this case, the problem lied in the way thread data was stored in a list. Specifically, the program wrongly assumed that the list index will match LWP number exactly. This had two implications.
Firstly, it suffered from off-by-one error. Since LWPs start with 1, and list indexes start with 0, a single-threaded program crashed trying to access past the list. Secondly, the assumption that thread list will be always in order seemed fragile. After all, it relied on LWPs being reported with successive numbers. Therefore, I've decided to rewrite the code to iterate through thread list and locate the correct LWP explicitly.
With those two fixes, some of the watchpoint tests started passing. However, some are still failing because we are not handling threads correctly yet. According to earlier research done by Kamil Rytarowski, we need to copy debug register values into new LWPs as they are created. I am planning to work on this shortly.
Additionally, NetBSD normally disallows unprivileged processes from modifying
debug registers. This can be changed via enabling
security.models.extensions.user_set_dbregs. Since LLDB tests are normally run
via unprivileged users, I had to detect this condition from within LLDB test
suite and skip watchpoint tests appropriately.
The LLDB commits relevant to this topic are:
- [lldb] [test] Skip watchpoint tests on NetBSD if userdbregs is disabled,
- [lldb] [test] Watchpoint tests can be always run as root on NetBSD,
- [lldb] [Process/NetBSD] Fix segfault when handling watchpoint,
- [lldb] [Process/NetBSD] Use global enable bits for watchpoints.
Regressions caught by buildbot
Finally, let's go over the regressions that were caught by our buildbot instance throughout the passing month:
-
[COFF, ARM64] Add CodeView register mapping broke LLDB builds due to API incompatibility; fixed by the author: [COFF, ARM64] Fix CodeView API change for getRegisterNames;
-
Implement deduction guides for map/multimap broke libc++ builds with trunk clang; recommitted with a fix as [libc++] Take 2: Implement CTAD for map and multimap;
-
Fix a crash in option parsing broke LLDB tests on NetBSD due to relying on specific
getopt_long()output (bug?); fixed by Options: Correctly check for missing arguments; -
[ABI] Implement Windows ABI for x86_64 broke NetBSD at runtime by omitting NetBSD from list of platforms using SysV ABI; I've fixed it via [lldb] [Plugins/SysV-x86_64] NetBSD is also using SysV ABI;
-
Implement xfer:libraries-svr4:read packet changed internal LLDB API, breaking NetBSD plugin builds; I've fixed it via [lldb] [Process/NetBSD] Fix constructor after r363707;
-
Revert "Implement xfer:libraries-svr4:read packet" changed the API back and broke NetBSD again; I've reverted my change to fix it: Revert "[lldb] [Process/NetBSD] Fix constructor after r363707";
-
Change LaunchThread interface to return an expected broke builds, most likely due to GCC incompatibility; not fixed yet.
Future plans
Since Kamil has managed to move the kernel part of threading support forward, I'm going to focus on improving threading support in LLDB right now. Most notably, this includes ensuring that LLDB can properly handle multithreaded applications, and that all thread-level actions (stepping, resuming, signalling) are correctly handled. As mentoned above, this also includes handling watchpoints in threads.
Of course, I am also going to finish the work on XSTATE in coredumps, and handle any possible bugs I might have introduced in my earlier work.
Afterwards I will work on the remaining TODO items, that are:
-
Add support to backtrace through signal trampoline and extend the support to libexecinfo, unwind implementations (LLVM, nongnu). Examine adding CFI support to interfaces that need it to provide more stable backtraces (both kernel and userland).
-
Add support for i386 and aarch64 targets.
-
Stabilize LLDB and address breaking tests from the test suite.
-
Merge LLDB with the base system (under LLVM-style distribution).
This work is sponsored by The NetBSD Foundation
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL to chip in what you can:
This report was prepared by Surya P as a part of Google Summer of Code 2019
What is DRM ioctl ?
Ioctls are input/output control system calls and DRM stands for direct rendering manager The DRM layer provides several services to graphics drivers, many of them driven by the application interfaces it provides through libdrm, the library that wraps most of the DRM ioctls. These include vblank event handling, memory management, output management, framebuffer management, command submission & fencing, suspend/resume support, and DMA services.
Native DRM ioctl calls
NetBSD was able to make native DRM ioctl calls with hardware rendering once xorg and proper mesa packages where installed. We used the glxinfo and glxgears applications to test this out.
DRM ioctl calls from emulation
In order to make sure DRM ioctl calls where also made from the linux emulation layer of NetBSD . We used rpm and suse131 packages In specific base,compat,X11,libdrm,libglx,libexpat packages where used. To my surprise the applications kept segfaulting . I used glxgears and glxinfo rpm packages for this test .when I analyzed the segfault and traced the process , I was able to identify the cause of the segfault which was caused due to broken suse131 libdrm package which did not support nouveau based cards. To further make user that the problem was with the suse packages , I downgraded to suse121 and as expected the glxinfo and glxgears rpm packages ran, but it was using software rendering instead of hardware rendering but nevertheless we were still able to see the DRM ioctl calls made by the emulation layer hence we added some print statements in the kernel source to identify the calls made.
Summary
Fixing the Suse131 package and enabling hardware rendering from emulation is of highest priority , I have also planned to port steam and its dependencies to NetBSD to incorporate some gaming on NetBSD! And finally conversion between 32bit DRM ioctl calls 64bit DRM ioctl calls will be implemented.
Last but not the least I would like to thank my mentor @christos , @maya , @leot for helping me out and guiding me throughout the process and Google for providing me with such a wonderful opportunity to work with NetBSD community.
This report was prepared by Surya P as a part of Google Summer of Code 2019
What is DRM ioctl ?
Ioctls are input/output control system calls and DRM stands for direct rendering manager The DRM layer provides several services to graphics drivers, many of them driven by the application interfaces it provides through libdrm, the library that wraps most of the DRM ioctls. These include vblank event handling, memory management, output management, framebuffer management, command submission & fencing, suspend/resume support, and DMA services.
Native DRM ioctl calls
NetBSD was able to make native DRM ioctl calls with hardware rendering once xorg and proper mesa packages where installed. We used the glxinfo and glxgears applications to test this out.
DRM ioctl calls from emulation
In order to make sure DRM ioctl calls where also made from the linux emulation layer of NetBSD . We used rpm and suse131 packages In specific base,compat,X11,libdrm,libglx,libexpat packages where used. To my surprise the applications kept segfaulting . I used glxgears and glxinfo rpm packages for this test .when I analyzed the segfault and traced the process , I was able to identify the cause of the segfault which was caused due to broken suse131 libdrm package which did not support nouveau based cards. To further make user that the problem was with the suse packages , I downgraded to suse121 and as expected the glxinfo and glxgears rpm packages ran, but it was using software rendering instead of hardware rendering but nevertheless we were still able to see the DRM ioctl calls made by the emulation layer hence we added some print statements in the kernel source to identify the calls made.
Summary
Fixing the Suse131 package and enabling hardware rendering from emulation is of highest priority , I have also planned to port steam and its dependencies to NetBSD to incorporate some gaming on NetBSD! And finally conversion between 32bit DRM ioctl calls 64bit DRM ioctl calls will be implemented.
Last but not the least I would like to thank my mentor @christos , @maya , @leot for helping me out and guiding me throughout the process and Google for providing me with such a wonderful opportunity to work with NetBSD community.
Argon2 is a modern memory-hard hashing scheme designed by Biryukov et al.[1] Compared to currently supported hashing algorithms in NetBSD, memory-hard Argon2 provides improved resistance against Time Memory Trade-off (TMTO) and side-channel attacks. In our project, we are working to incorporate Argon2 into the local password management framework of NetBSD.
Phase 1 goals and work completed
Phase 1 of the project focused on incorporating the Argon2 reference implementation into NetBSD. As such, we focused on building the associated libraries and integrating the functionality into the existing password management framework. Our initial phase 1 goals were as follows
- Integrate Argon2 reference code into the existing build framework
- Support automated building and installation of argon2 binary and libraries
- Extend the existing password management framework to support Argon2 encoding
Towards these goals, we have added the Argon2 reference code into the external source tree and created the necessary build scripts. This work allows us to successfully add Argon2 into our system by adding MKARGON2=yes to /usr/share/mk/bsd.own.mk. After successfully building and installation, we have the following
/usr/bin/argon2 /lib/libargon2.so /lib/libargon2.so.1 /lib/libargon2.so.1.0
We then extended the functionality of pwhash(1) and libcrypt(3) to support Argon2 encoding. Currently we support all three Argon2 variants, although not all variants are recommended (see [1][2]). We support the following standard parameters: execution time (t), memory utiltized (m), and degree of parallelism (p). Salt length is currently fixed at the recommended 16 bytes.[1]
With our phase 1 goals successfully completed, we have the following functionality available. The argon2(1) binary allows us to easily validate parameters and encodings
m2# echo -n password|argon2 somesalt -id -p 3 -m 8 Type: Argon2id Iterations: 3 Memory: 256 KiB Parallelism: 3 Hash: 97f773f68715d27272490d3d2e74a2a9b06a5bca759b71eab7c02be8a453bfb9 Encoded: $argon2id$v=19$m=256,t=3,p=3$c29tZXNhbHQ$l/dz9ocV0nJySQ09LnSiqbBqW8p1m3Hqt8Ar6KRTv7k 0.000 seconds Verification ok
m2# pwhash -A argon2id password $argon2id$v=19$m=4096,t=3,p=1$.SJJCiU575MDnA8s$+pjT4JsF2eLNQuLPEyhRA5LCFGQWAKsksIPl5ewTWNY
m2# pwhash -Aargon2id,p=3,m=8192 password $argon2id$v=19$m=8192,t=3,p=3$gGs/lLnXIESuSl4H$fGuqUn2PeNeoCFqV3ASvNdkXLZ2A1wZTb2s7LTe4SE0
m1# grep -A1 testuser /etc/passwd.conf
testuser:
localcipher = argon2i,t=6,m=4096,p=1
m1# id testuser uid=1001(testuser) gid=100(users) groups=100(users) m1# grep testuser /etc/master.passwd testuser:$argon2i$v=19$m=4096,t=6,p=1$MpbO25MF2m4Y/aQT$9STuNmQLMSgYBVoQiXyDLGcb+DSHysJOQh1spI6qEuE:1001:100::0:0::/home/testuser:/sbin/nologin m1# passwd testuser Changing password for testuser. New Password: Retype New Password: m1# grep testuser /etc/master.passwd testuser:$argon2i$v=19$m=4096,t=6,p=1$PDd65qr6JU0Pfnpr$8YOMYcwINuKHoxIV8Q0FJHG+RP82xtmAuGep26brilU:1001:100::0:0::/home/testuser:/sbin/nologin
Plans for next phase
Phase 2 will focus on code cleanup and incorporation of any improvements suggested during review. We are also extending our ATF test-set and will begin our performance evaluation. Primary deliverables for phase 2 will be a performance evaluation.Summary
We have successfully integrated Argon2 into NetBSD using the native build framework. We have extended existing functionality to support local password management using Argon2 encoding. Moving forward in phase 2, we will work on cleanup, validation, and performance evaluation.References
[1] Biryukov, Alex, Daniel Dinu, and Dmitry Khovratovich. "Argon2: new generation of memory-hard functions for password hashing and other applications." 2016 IEEE European Symposium on Security and Privacy (EuroS&P). IEEE, 2016.[2] Alwen, Joël, and Jeremiah Blocki. "Towards practical attacks on argon2i and balloon hashing." 2017 IEEE European Symposium on Security and Privacy (EuroS&P). IEEE, 2017.
Argon2 is a modern memory-hard hashing scheme designed by Biryukov et al.[1] Compared to currently supported hashing algorithms in NetBSD, memory-hard Argon2 provides improved resistance against Time Memory Trade-off (TMTO) and side-channel attacks. In our project, we are working to incorporate Argon2 into the local password management framework of NetBSD.
Phase 1 goals and work completed
Phase 1 of the project focused on incorporating the Argon2 reference implementation into NetBSD. As such, we focused on building the associated libraries and integrating the functionality into the existing password management framework. Our initial phase 1 goals were as follows
- Integrate Argon2 reference code into the existing build framework
- Support automated building and installation of argon2 binary and libraries
- Extend the existing password management framework to support Argon2 encoding
Towards these goals, we have added the Argon2 reference code into the external source tree and created the necessary build scripts. This work allows us to successfully add Argon2 into our system by adding MKARGON2=yes to /usr/share/mk/bsd.own.mk. After successfully building and installation, we have the following
/usr/bin/argon2 /lib/libargon2.so /lib/libargon2.so.1 /lib/libargon2.so.1.0
We then extended the functionality of pwhash(1) and libcrypt(3) to support Argon2 encoding. Currently we support all three Argon2 variants, although not all variants are recommended (see [1][2]). We support the following standard parameters: execution time (t), memory utiltized (m), and degree of parallelism (p). Salt length is currently fixed at the recommended 16 bytes.[1]
With our phase 1 goals successfully completed, we have the following functionality available. The argon2(1) binary allows us to easily validate parameters and encodings
m2# echo -n password|argon2 somesalt -id -p 3 -m 8 Type: Argon2id Iterations: 3 Memory: 256 KiB Parallelism: 3 Hash: 97f773f68715d27272490d3d2e74a2a9b06a5bca759b71eab7c02be8a453bfb9 Encoded: $argon2id$v=19$m=256,t=3,p=3$c29tZXNhbHQ$l/dz9ocV0nJySQ09LnSiqbBqW8p1m3Hqt8Ar6KRTv7k 0.000 seconds Verification ok
m2# pwhash -A argon2id password $argon2id$v=19$m=4096,t=3,p=1$.SJJCiU575MDnA8s$+pjT4JsF2eLNQuLPEyhRA5LCFGQWAKsksIPl5ewTWNY
m2# pwhash -Aargon2id,p=3,m=8192 password $argon2id$v=19$m=8192,t=3,p=3$gGs/lLnXIESuSl4H$fGuqUn2PeNeoCFqV3ASvNdkXLZ2A1wZTb2s7LTe4SE0
m1# grep -A1 testuser /etc/passwd.conf
testuser:
localcipher = argon2i,t=6,m=4096,p=1
m1# id testuser uid=1001(testuser) gid=100(users) groups=100(users) m1# grep testuser /etc/master.passwd testuser:$argon2i$v=19$m=4096,t=6,p=1$MpbO25MF2m4Y/aQT$9STuNmQLMSgYBVoQiXyDLGcb+DSHysJOQh1spI6qEuE:1001:100::0:0::/home/testuser:/sbin/nologin m1# passwd testuser Changing password for testuser. New Password: Retype New Password: m1# grep testuser /etc/master.passwd testuser:$argon2i$v=19$m=4096,t=6,p=1$PDd65qr6JU0Pfnpr$8YOMYcwINuKHoxIV8Q0FJHG+RP82xtmAuGep26brilU:1001:100::0:0::/home/testuser:/sbin/nologin
Plans for next phase
Phase 2 will focus on code cleanup and incorporation of any improvements suggested during review. We are also extending our ATF test-set and will begin our performance evaluation. Primary deliverables for phase 2 will be a performance evaluation.Summary
We have successfully integrated Argon2 into NetBSD using the native build framework. We have extended existing functionality to support local password management using Argon2 encoding. Moving forward in phase 2, we will work on cleanup, validation, and performance evaluation.References
[1] Biryukov, Alex, Daniel Dinu, and Dmitry Khovratovich. "Argon2: new generation of memory-hard functions for password hashing and other applications." 2016 IEEE European Symposium on Security and Privacy (EuroS&P). IEEE, 2016.[2] Alwen, Joël, and Jeremiah Blocki. "Towards practical attacks on argon2i and balloon hashing." 2017 IEEE European Symposium on Security and Privacy (EuroS&P). IEEE, 2017.
- New AArch64 architecture support:
- Symmetric and asymmetrical multiprocessing support (aka big.LITTLE)
- Support for running 32-bit binaries
- UEFI and ACPI support
- Support for SBSA/SBBR (server-class) hardware.
- The FDT-ization of many ARM boards:
- the 32-bit GENERIC kernel lists 129 different DTS configurations
- the 64-bit GENERIC64 kernel lists 74 different DTS configurations
All supported by a single kernel, without requiring per-board configurations. - Graphics driver update, matching Linux 4.4, adding support for up to Kaby Lake based Intel graphics devices.
- ZFS has been updated to a modern version and seen many bugfixes.
- New hardware-accelerated virtualization via NVMM.
- NPF performance improvements and bug fixes. A new lookup algorithm, thmap, is now the default.
- NVMe performance improvements
- Optional kernel ASLR support, and partial kernel ASLR for the default configuration.
- Kernel sanitizers:
- KLEAK, detecting memory leaks
- KASAN, detecting memory overruns
- KUBSAN, detecting undefined behaviour
These have been used together with continuous fuzzing via the syzkaller project to find many bugs that were fixed. - The removal of outdated networking components such as ISDN and all of its drivers
- The installer is now capable of performing GPT UEFI installations.
- Dramatically improved support for userland sanitizers, as well as the option to build all of NetBSD's userland using them for bug-finding.
- Update to graphics userland: Mesa was updated to 18.3.4, and llvmpipe is now available for several architectures, providing 3D graphics even in the absence of a supported GPU.
We try to test NetBSD as best as we can, but your testing can help NetBSD 9.0 a great release. Please test it and let us know of any bugs you find.
You can find binaries here.
- New AArch64 architecture support:
- Symmetric and asymmetrical multiprocessing support (aka big.LITTLE)
- Support for running 32-bit binaries
- UEFI and ACPI support
- Support for SBSA/SBBR (server-class) hardware.
- The FDT-ization of many ARM boards:
- the 32-bit GENERIC kernel lists 129 different DTS configurations
- the 64-bit GENERIC64 kernel lists 74 different DTS configurations
All supported by a single kernel, without requiring per-board configurations. - Graphics driver update, matching Linux 4.4, adding support for up to Kaby Lake based Intel graphics devices.
- ZFS has been updated to a modern version and seen many bugfixes.
- New hardware-accelerated virtualization via NVMM.
- NPF performance improvements and bug fixes. A new lookup algorithm, thmap, is now the default.
- NVMe performance improvements
- Optional kernel ASLR support, and partial kernel ASLR for the default configuration.
- Kernel sanitizers:
- KLEAK, detecting memory leaks
- KASAN, detecting memory overruns
- KUBSAN, detecting undefined behaviour
These have been used together with continuous fuzzing via the syzkaller project to find many bugs that were fixed. - The removal of outdated networking components such as ISDN and all of its drivers
- The installer is now capable of performing GPT UEFI installations.
- Dramatically improved support for userland sanitizers, as well as the option to build all of NetBSD's userland using them for bug-finding.
- Update to graphics userland: Mesa was updated to 18.3.4, and llvmpipe is now available for several architectures, providing 3D graphics even in the absence of a supported GPU.
We try to test NetBSD as best as we can, but your testing can help NetBSD 9.0 a great release. Please test it and let us know of any bugs you find.
You can find binaries here.
LLVM sanitizers are compiler features that help find common software bugs. The following sanitizers are available:
- TSan: Finds threading bugs,
- MSan: Finds uninitialized memory read,
- ASan: Finds invalid address usage bugs,
- UBSan: Finds unspecified code semantics in runtime.
The new MKSANITIZER option supports full coverage of the NetBSD code base with these sanitizers, which helps reduce bugs and serve high security demands.
A brief overview of MKSANITIZER
A sanitizer is a special type of addition to a compiled program, and is included from a toolchain (LLVM or GCC). There are a few types of sanitizers. Their usual purposes are: bug detecting, profiling, and security hardening.
NetBSD already supports the most useful ones with a decent completeness:
- Address Sanitizer (ASan, memory usage bug detector),
- Undefined Behavior Sanitizer (UBSan, unspecified semantics in runtime detector),
- Thread Sanitizer (TSan, data race detector), and
- Memory Sanitizer (MSan, uninitialized memory read detector).
It's possible to combine compatible sanitizers in a single application; NetBSD and MKSANITIZER support doing so.
There are various advantages and limitations. Properties and requirements vary, mainly reflecting the type of sanitization. Comparisons against other software with similar properties (such as Valgrind) may provide a fuller picture.
Sanitizers usually introduce a relatively small overhead (~2x) compared to Valgrind (~20x). The portability is decent as the sanitizers don't depend heavily on the underlying CPU architecture, and in the UBSan case they basically work on everything including VAX. In the Valgrind case the portability is extremely dependent on the kernel and CPU, thus making this diagnostic tool very difficult to port across platforms. ASan, MSan and TSan require large addressable memory due to their design. This restricts MSan and TSan to 64-bit architectures with a lot of RAM, with ASan for ones that cover completely all of the 4GB (32-bit) address space (it's still possible to use small resources with ASan but it's a tradeoff between usability, time investment, and gain). Although the memory usage is higher with sanitized programs, the modern design and implementation of the memory management subystem in the NetBSD kernel allows to manage it lazily and regardless of reserving TBs of buffers for metadata, the physically used memory is significantly lower usually doubling the regular memory usage by a process. Memory demands are higher for processes that are in the process of fuzzing and thus there is an option to restrict the maximum number of used physical pages that will cause the program to halt (by default 2GB for libFuzzer). A selection of LLVM Sanitizers may conflict with some tools (like Valgrind) and mechanisms (like PaX ASLR in the ASan, TSan and MSan case). Other ones like PaX MPROTECT (sometimes called W^X) are fully compatible with all the currently supported sanitizers.
The main purposes of sanitizations from a user point of view are:
- bug detecting and assuring correctness,
- high security demands, and
- auxiliary feature for fuzzing.
It's worth adding a few notes on the security part as there are numerous good security approaches. One of them is proactive secure coding that is a regime of using safe constructs in the source code and replacement of functions that are prone to errors with versions that are harder to misuse.
However the disadvantage of this approach is that it's just a regime in the coding period. The probability of introducing a bug is minimized, however it does still exist. A problem that is in a program of either style (proactive secure style and careless coding) are almost indistinguishable in the final product and an attacker can use the same methods to violate the program like integer overflow or use after free.
The usual way to prevent bugs is to assume that a code is buggy and add mitigation that will aim to reduce the chance to exploit it. An example of this is the sandboxing of an application.
A code that is aided with sanitizers can be configured, either at build-time or run-time, to report the bug in the execution time of e.g. integer overflow and cause an application to halt immediately. No coding regime can have the same effect and perhaps the number of programming languages with this property is also limited.
In order to use sanitizers effectively within a distribution there is need to rebuild a program and all of its dependencies (with few exceptions) with the same sanitizing configuration. Furthermore, in order to use some versions of fuzzing engines with some types of sanitizers we need to build the fuzzing libraries with the same sanitization as well (this is true for e.g. Memory Sanitizer used together with libFuzzer).
This was my primary motivation towards introduction of a new NetBSD distribution build option: MKSANITIZER.
NetBSD is probably the only distribution that ships with a fully sanitized distribution option. Today there is "just" need for a locally patched external LLVM toolchain and the work on this is still ongoing.
The whole userland sanitization skips not applicable exceptions:
- low-level libc libraries crt0, crtbegin, crtend, crti, crtn etc,
- libc,
- libm,
- librt,
- libpthread,
- bootloader,
- crunchgen programs like rescue,
- dynamic ELF loader (implemented as a library),
- as of today static libraries and executables,
- as of today as an exception ldd(1) that borrows parts from the dynamic ELF loader.
The sanitization of static programs as of today is a low priority and falls outside the scope of my work.
The situation with ldd(1) will be cleared in future and it will be most probably sanitized.
Kernel and kernel modules use a different version of sanitizers and the porting process of Kernel-AddressSanitizer and Kernel-UndefinedBehaviorSanitizer is ongoing out of the MKSANITIZER context.
There used to be an analogous attempt in the Gentoo land (asantoo), however these efforts stalled two years ago. The Google Chromium team uses a set of scripts to bootstrap sanitized dependencies for their programs on top of a Linux distribution (as of today Ubuntu Trusty x86_64).
I've started to document bugs detected with MKSANITIZER in a dedicated directory on my NetBSD homepage with my code and notes. So far there are 35 documented findings. Most of them are real problems in programs, some of them might be considered overcautious (mostly ones detected with UBSan) and probably all of them are without serious security risk or privilege escalation or system crash. Some of the findings (0029-0035 - MemorySanitizer userland one) contain problems located probably in sanitizers (the proper NetBSD support in them).
- 0001-ifconfig-in_prefixlen.txt
- 0002-libc-rowcol_parse_variable_compat.txt
- 0003-grep-_obstack_begin.txt
- 0004-gzip-print_list.txt
- 0005-nawk-word.txt
- 0006-ksh-expand.txt
- 0007-grep-dfa.txt
- 0008-expr-perform_arith_op.txt
- 0009-nvi-log_line.txt
- 0010-man-main.txt
- 0011-sshd-ssh_packet_connection_is_on_socket.txt
- 0012-login-screen.txt
- 0013-sh-evaltree.txt
- 0014-sh-evaltree.txt
- 0015-sh-evaltree.txt
- 0016-sh-fstatvfs1.txt
- 0017-t_kauth_pr_47598.txt
- 0018-sysinst-partition.txt
- 0019-ksh-exit.txt
- 0020-installboot-ffsv2.txt
- 0021-sysinst-sets.txt
- 0022-sysinst-scripting_fprintf.txt (ASan, still not fixed)
- 0023-sysinst-libcurses.txt (ASan, still not fixed)
- 0024-passwd-pwpam_process.txt
- 0025-tmux-forkpty.txt
- 0026-sysinst-run.txt
- 0027-tmux-window-copy.txt
- 0028-disklabel-find_label.txt
- 0029-init-getty.txt (MSan, still not fixed)
- 0030-ksh-exchild.txt (MSan, still not fixed)
- 0031-sh-setjobctl.txt (MSan, still not fixed)
- 0032-top-summary_format_memory.txt (MSan, still not fixed)
- 0033-hangman-cbreak.txt (MSan, still not fixed)
- 0034-nvi-log1.txt (MSan, still not fixed)
- 0035-csh-execute.txt (MSan, still not fixed)
This list presents that some of the problems are located in formally externally-maintained software like tmux, heimdal, grep, nvi or nawk.
I think that the following patch is a good example of a good finding for a privileged (setuid) program passwd(1) that reads a vector out of bounds and write a null character into a random byte on the stack (documented as report 0024).
From 28dd358940af30f434a930fd1977e3bf2b69dcb1 Mon Sep 17 00:00:00 2001
From: kamil
Date: Sun, 24 Jun 2018 01:53:14 +0000
Subject: [PATCH] Prevent underflow buffer read in trim_whitespace() in
libutil/passwd.c
If a string is empty or contains only white characters, the algorithm of
removal of white characters at the end of the passed string will read
buffer at index -1 and keep iterating backward.
Detected with MKSANITIZER/ASan when executing passwd(1).
---
lib/libutil/passwd.c | 14 +++++++++++---
1 file changed, 11 insertions(+), 3 deletions(-)
diff --git a/lib/libutil/passwd.c b/lib/libutil/passwd.c
index 9cc1d481a349..cee168e7d678 100644
--- a/lib/libutil/passwd.c
+++ b/lib/libutil/passwd.c
@@ -1,4 +1,4 @@
-/* $NetBSD: passwd.c,v 1.52 2012/06/25 22:32:47 abs Exp $ */
+/* $NetBSD: passwd.c,v 1.53 2018/06/24 01:53:14 kamil Exp $ */
/*
* Copyright (c) 1987, 1993, 1994, 1995
@@ -31,7 +31,7 @@
#include
#if defined(LIBC_SCCS) && !defined(lint)
-__RCSID("$NetBSD: passwd.c,v 1.52 2012/06/25 22:32:47 abs Exp $");
+__RCSID("$NetBSD: passwd.c,v 1.53 2018/06/24 01:53:14 kamil Exp $");
#endif /* LIBC_SCCS and not lint */
#include
@@ -503,13 +503,21 @@ trim_whitespace(char *line)
_DIAGASSERT(line != NULL);
+ /* Handle empty string */
+ if (*line == '\0')
+ return;
+
/* Remove leading spaces */
p = line;
while (isspace((unsigned char) *p))
p++;
memmove(line, p, strlen(p) + 1);
- /* Remove trailing spaces */
+ /* Handle empty string after removal of whitespace characters */
+ if (*line == '\0')
+ return;
+
+ /* Remove trailing spaces, line must not be empty string here */
p = line + strlen(line) - 1;
while (isspace((unsigned char) *p))
p--;
The first boot of a MKSANITIZER distribution with Address Sanitizer
The process of getting a bootable and installable (and ignoring the aspect of buildable and generatable) installation ISO image was a loop of fixing bugs and retrying the process. At the end of the process there is an option to install a fully sanitized userland with ASan, UBSan or both. The MSan version is scheduled after finishing the kernel ptrace(2) work. Other options like a target prebuilt with ThreadSanitizer, safestack or The Scudo Hardened Allocator are untested.
I have also documented an example of the Heimdal bug that appeared during the login attempt (and actually preventing it) to a fully ASanitized userland:



This particular issue has been fixed with the following patch:
From ddc98829a64357ad73af0d0fa60c8d9c8499cce3 Mon Sep 17 00:00:00 2001
From: kamil
Date: Sat, 16 Jun 2018 18:51:36 +0000
Subject: [PATCH] Do not reference buffer after the code scope {}
rk_getpwuid_r() returns a pointer pwd->pw_dir to a buffer pwbuf[].
It's not safe to store another a copy of pwd->pw_dir in outter scope and
use it out of the scope where there exists pwbuf[].
This fixes a problem reported by ASan under MKSANITIZER.
---
crypto/external/bsd/heimdal/dist/lib/krb5/config_file.c | 7 +++----
1 file changed, 3 insertions(+), 4 deletions(-)
diff --git a/crypto/external/bsd/heimdal/dist/lib/krb5/config_file.c b/crypto/external/bsd/heimdal/dist/lib/krb5/config_file.c
index 47cb4481962e..6af30502ed5e 100644
--- a/crypto/external/bsd/heimdal/dist/lib/krb5/config_file.c
+++ b/crypto/external/bsd/heimdal/dist/lib/krb5/config_file.c
@@ -1,4 +1,4 @@
-/* $NetBSD: config_file.c,v 1.3 2017/09/08 15:29:43 christos Exp $ */
+/* $NetBSD: config_file.c,v 1.4 2018/06/16 18:51:36 kamil Exp $ */
/*
* Copyright (c) 1997 - 2004 Kungliga Tekniska Hogskolan
@@ -430,6 +430,8 @@ krb5_config_parse_file_multi (krb5_context context,
if (ISTILDE(fname[0]) && ISPATHSEP(fname[1])) {
#ifndef KRB5_USE_PATH_TOKENS
const char *home = NULL;
+ struct passwd pw, *pwd = NULL;
+ char pwbuf[2048];
if (!_krb5_homedir_access(context)) {
krb5_set_error_message(context, EPERM,
@@ -441,9 +443,6 @@ krb5_config_parse_file_multi (krb5_context context,
home = getenv("HOME");
if (home == NULL) {
- struct passwd pw, *pwd = NULL;
- char pwbuf[2048];
-
if (rk_getpwuid_r(getuid(), &pw, pwbuf, sizeof(pwbuf), &pwd) == 0)
home = pwd->pw_dir;
}
Sending this patch upstream is on my TODO list, this means that other projects can benefit from this work. A single patch preventing NULL pointer arithmetic for tmux has been already submitted upstream and merged.
After the process of long run of booting newer versions of locally patched distribution I've finally entered the functional shell.

And a stored "copy-pasted" terminal screenshot after login into a shell:
also known as NetBSD-current. It is very possible that it has serious bugs, regressions, broken features or other problems. Please bear this in mind and use the system with care. You are encouraged to test this version as thoroughly as possible. Should you encounter any problem, please report it back to the development team using the send-pr(1) utility (requires a working MTA). If yours is not properly set up, use the web interface at: http://www.NetBSD.org/support/send-pr.html Thank you for helping us test and improve NetBSD. We recommend that you create a non-root account and use su(1) for root access. qemu# uname -a NetBSD qemu 8.99.19 NetBSD 8.99.19 (GENERIC) #12: Sat Jun 16 02:39:37 CEST 2018 root@chieftec:/public/netbsd-root/sys/arch/amd64/compile/GENERIC amd64 qemu# nm /bin/ksh |grep asan|grep init 0000000000439bf8 B _ZN6__asan11asan_initedE 0000000000439bfc B _ZN6__asan20asan_init_is_runningE 00000000004387a1 b _ZN6__asanL14tsd_key_initedE 0000000000430f18 b _ZN6__asanL20dynamic_init_globalsE 000000000043a190 b _ZZN6__asan18asanThreadRegistryEvE11initialized 00000000000cfaf0 T __asan_after_dynamic_init 00000000000cf8a0 T __asan_before_dynamic_init 0000000000199b50 T __asan_init qemu# |
The sshd(8) crash has been fixed by Christos Zoulas. There are still at least 2 ASan unfixed bugs left in the installer and few ones that prevent booting and using the distribution without noting that the sanitizers are enabled. The most notorious ones are ssh(1) & sshd(8) startup breakage and egrep(1) misbehavior in corner cases, both might be false positives and bugs in the sanitizers.
Validation of the MKSANITIZER=yes distribution
I've managed to execute the ATF regression tests against a sanitized distribution prebuilt with Address Sanitizer and in another attempt against Undefined Behavior Sanitizer.
In my setup of the external toolchain I had broken C++ runtime library caused with a complicated bootstrap chain. The process of building various LLVM projects from a GCC distribution requires generic work with the LLVM projects and there is need to build and reuse intermediate steps. For example, the compiler-rt project that contains various low-level libraries (including sanitizers) requires Clang as the compiler, as otherwise it's not buildable. This is the reason why I've deferred testing all the features in the current stage and I'm trying to coordinate with the maintainer Joerg Sonnenberger the process of upgrading the LLVM projects in the NetBSD distribution. I will reuse it to rebase the patches of mine and ship a readme text to users and other developers expecting to run a release with the MKSANITIZER option.
The lack of C++ runtime pushed me towards reusing non-sanitized ATF tests (as the ATF framework is written in C++) against the sanitized userland. Two bugs have been detected:
- expr(1) triggering Undefined Behavior in the routines detecting overflow in arithmetic operations,
- sh(1) use after free in corner case of redefining an active function.
I've addressed the expr(1) issues and added new ATF tests in order to catch regressions in future potential changes. The Almquist Shell bug has been reported to the maintainer K. Robert Elz and fixed accordingly.
libFuzzer integration with the userland programs
During the Google Summer of Code project: libFuzzer integration with the basesystem by Yang Zheng it has been detected that the original expr(1) fix introduced by myself is not fully correct.
Yang Zheng has detected that the new version of expr(1) is still crashing in narrow cases. I've checked his integration patch of expr(1) with libFuzzer, reproduced the problem myself and documented:
$ ./expr -only_ascii=1 -max_len=32 -dict=expr-dict expr_corpus/ 1>/dev/null Dictionary: 12 entries INFO: Seed: 2332047193 INFO: Loaded 1 modules (725 inline 8-bit counters): 725 [0x7a11f0, 0x7a14c5), INFO: Loaded 1 PC tables (725 PCs): 725 [0x579d18,0x57ca68), INFO: 269 files found in expr_corpus/ INFO: seed corpus: files: 269 min: 1b max: 31b total: 3629b rss: 29Mb expr.y:377:12: runtime error: signed integer overflow: 9223172036854775807 * -3 cannot be represented in type 'long' SUMMARY: UndefinedBehaviorSanitizer: undefined-behavior expr.y:377:12 in MS: 0 ; base unit: 0000000000000000000000000000000000000000 0x39,0x32,0x32,0x33,0x31,0x37,0x32,0x30,0x33,0x36,0x38,0x35,0x34,0x37,0x37,0x35,0x38,0x30,0x37,0x20,0x2a,0x20,0x2d,0x33, 9223172036854775807 * -3 artifact_prefix='./'; Test unit written to ./crash-9c3dd31298882557484a14ce0261e7bfd38e882d Base64: OTIyMzE3MjAzNjg1NDc3NTgwNyAqIC0z
And the offending operation is INT * -INT:
$ eval ./expr-ubsan '9223372036854775807 \* -3' expr.y:377:12: runtime error: signed integer overflow: 9223372036854775807 * -3 cannot be represented in type 'long' -9223372036854775805
This has been fixed as well and the set of ATF tests for expr(1) extended for missing scenarios.
MKSANITIZER implementation
The initial implementation of MKSANITIZER has been designed and implemented by Christos Zoulas. I took this code and continued working on it with an external LLVM toolchain (version 7svn with local patches). The final result has been documented in share/mk/bsd.README:
MKSANITIZER if "yes", use the selected sanitizer to compile userland
programs as defined in USE_SANITIZER, which defaults to
"address". A selection of available sanitizers:
address: A memory error detector (default)
thread: A data race detector
memory: An uninitialized memory read detector
undefined: An undefined behavior detector
leak: A memory leak detector
dataflow: A general data flow analysis
cfi: A control flow detector
safe-stack: Protect against stack-based corruption
scudo: The Scudo Hardened allocator
It's possible to specify multiple sanitizers within the
USE_SANITIZER option (comma separated). The USE_SANITIZER value
is passed to the -fsanitize= argument to the compiler.
Additional arguments can be passed through SANITIZERFLAGS.
The list of supported features and their valid combinations
depends on the compiler version and target CPU architecture.
As an illustration, in order to build a distribution with ASan and UBSan, using the LLVM toolchain one needs to enter a command line like:
./build.sh -V MKLLVM=yes -V MKGCC=no -V HAVE_LLVM=yes -V MKSANITIZER=yes -V USE_SANITIZER="address,undefined" distribution
There is an ongoing effort on upstreaming the remaining toolchain patches and right now we need to use a specially preprocessed external LLVM toolchain with a pile of local patches.
The GCC toolchain is a downstream for LLVM sanitizers and is out of the current focus, although there are local NetBSD patches for ASan, UBSan and LSan in GCC's libsanitizer. Starting with GCC 8.x, there is the first upstreamed block of NetBSD code pulled in from LLVM sanitizers.
Golang and TSan (-race)
There has been finally merged the compiler-rt update patch in Golang.
runtime/race: update most syso files to compiler-rt fe2c72 These were generated using the racebuild configuration from https://golang.org/cl/115375, with the LLVM compiler-rt repository at commit fe2c72c59aa7f4afa45e3f65a5d16a374b6cce26 for most platforms. The Windows build is from an older compiler-rt revision, because the compiler-rt build script for the Go race detector has been broken since January 2017 (https://reviews.llvm.org/D28596). Updates #24354. Change-Id: Ica05a5d0545de61172f52ab97e7f8f57fb73dbfd Reviewed-on: https://go-review.googlesource.com/112896 Reviewed-by: Brad Fitzpatrick Run-TryBot: Brad Fitzpatrick TryBot-Result: Gobot Gobot
This means that the TSan/amd64 support syzo file has been included for NetBSD next to Darwin, FreeBSD and Linux (Windows is broken and no longer maintained). There is still need to merge the remaining patches for shell scripts and go files, and the code is still in review waiting for feedback.
Changes merged with the NetBSD sources
- ksh: Remove symbol clash with libc -- rename twalk() to ksh_twalk()
- ktruss: Remove symbol clash with libc -- rename wprintf() to xwprintf()
- ksh: Remove symbol clash with libc -- rename glob() to ksh_glob()
- Don't pass -z defs to libc++ with MKSANITIZER=yes
- Mark sigbus ATF tests in t_ptrace_wait as expected failure
- Make new DTrace and ZFS code buildable with Clang/LLVM
- Fix the MKGROFF=no MKCXX=yes build
- Correct Undefined Behavior in ifconfig(8)
- Correct Undefined Behavior in libc/citrus
- Correct Undefined Behavior in gzip(1)
- Do not use index out of bounds in nawk
- Change type of tilde_ok from int to unsigned int in ksh(1)
- Rework perform_arith_op() in expr(1) to omit Undefined Behavior
- Add 2 new expr(1) ATF tests
- Prevent Undefined Behavior in shift of signed integer in grep(1)
- Set NOSANITIZER in i386 mbr files
- Disable sanitizers for libm and librt
- Avoid Undefind Behavior in DEFAULT_ALIGNMENT in GNU grep(1)
- Detect properly overflow in expr(1) for 0 + INT
- Make the alignof() usage more portable in grep(1)
- heimdal: Do not reference buffer after the code scope {}
- Do not cause Undefined Behavior in vi(1)
- Disable MKSANITIZER in lib/csu
- Disable SANITIZER for ldd(1)
- Set NOSANITIZER in rescue/Makefile
- Add new option -s to crunchgen(1) -- enable sanitization
- Make building of dhcp compatible with MKSANITIZER
- Refactor MKSANITIZER flags in mk rules
- Specify NOSANITIZER in distrib/amd64/ramdisks/common
- Fix invalid free(3) in sysinst(8)
- Fix integer overflow in installboot(8)
- Specify -Wno-format-extra-args for Clang/LLVM in gpl2/gettext
- sysinst: Enlarge the set_status[] array by a single element
- Prevent underflow buffer read in trim_whitespace() in libutil/passwd.c
- Fix stack use after scope in libutil/pty
- Prevent signed integer left shift UB in FD_SET(), FD_CLR(), FD_ISSET()
- Reset SANITIZERFLAGS when specified NOSANITIZER / MKSANITIZER=no
- Enhance the documentation of MKSANITIZER in bsd.README
- Avoid unportable offsetof(3) calculation in nvi in log1.c
- Add a framework for renaming symbols in libc&co for MKSANITIZER
- Specify SANITIZER_RENAME_SYMBOL in nvi
- Specify SANITIZER_RENAME_SYMBOL in diffutils
- Specify SANITIZER_RENAME_SYMBOL in grep
- Specify SANITIZER_RENAME_SYMBOL in cvs
- Specify SANITIZER_RENAME_SYMBOL in chpass
- Include for offsetof(3)
- Avoid UB in tmux/window_copy_add_formats()
- Document sanitizers in acronyms.comp
- Add TODO.sanitizer
- Avoid misaligned access in disklabel(8) in find_label() (patch by Christos Zoulas)
- Improve the * operator handling in expr(1)
- Add a couple of new ATF expr(1) tests
- Add a missing check to handle correctly 0 * 0 in expr(1)
- Add 3 more expr(1) ATF tests detecting overflow
Changes merged with the LLVM projects
- LLVM: Handle NetBSD specific path in findDebugBinary()
- compiler-rt: Disable recursive interceptors in signal(3)/MSan
- Introduce CheckASLR() in sanitizers
Plan for the next milestone
The ptrace(2) tasks have been preempted by the suspended work on sanitizers, in order to actively collaborate with the Google Summer of Code students (libFuzzer integration with userland, KUBSan, KASan).
I have planned the following tasks before returning back to the ptrace(2) fixes:
- upgrade base Clang/LLVM, libcxx, libcxxabi to at least 7svn (HEAD) (needs cooperation with Joerg Sonnenberger)
- compiler-rt import and integration with base (needs cooperation with Joerg Sonnenberger)
- merge TSan, MSan and libFuzzer ATF tests
- prepare MKSANITIZER readme
- kernel-asan port
- kernel-ubsan port
- switch syscall(2)/__syscall(2) to libc calls
- upstream local patches, mostly to compiler-rt
- develop fts(3) interceptors (MSan, for ls(1), find(1), mtree(8)
- investigate and address the libcxx failing tests on NetBSD
- no-ASLR boot.cfg option, required for MKSANITIZER
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL, and chip in what you can:
The NetBSD Project is pleased to announce NetBSD 8.0 RC 2, the second (and hopefully final) release candidate for the upcoming NetBSD 8.0 release.
Unfortunately the first release candidate did not hold up in our extensive testing (also know as eating our own dog food): many NetBSD.org servers/machines were updated to it and worked fine, but the auto build cluster, where we produce our binaries, did not work well. The issue was tracked down to a driver bug (Intel 10 GBit ethernet), only showing up in certain configurations, and it has been fixed now.
Other security events, like the new FPU related exploit on some Intel CPUs, caused further kernel changes, so we are not going to release NetBSD 8.0 directly, but instead provide this new release candidate for additional testing.
The official RC2 announcement list these major changes compared to older releases:
- USB stack rework, USB3 support added
- In-kernel audio mixer
- Reproducible builds
- Full userland debug information (MKDEBUG) available. While most install media do not come with them (for size reasons), the debug and xdebug sets can be downloaded and extracted as needed later. They provide full symbol information for all base system and X binaries and libraries and allow better error reporting and (userland) crash analyzis.
- PaX MPROTECT (W^X) memory protection enforced by default on some architectures with fine-grained memory protection and suitable ELF formats: i386, amd64, evbarm, landisk, pmax
- PaX ASLR enabled by default on:
i386, amd64, evbarm, landisk, pmax, sparc64 - MKPIE (position independent executables) by default for userland on: i386, amd64, arm, m68k, mips, sh3, sparc64
- added can(4), a socket layer for CAN busses
- added ipsecif(4) for route-based VPNs
- made part of the network stack MP-safe NET_MPSAFE kernel option is required to try
- WAPBL stability and performance improvements
Specific to i386 and amd64 CPUs:
- Meltdown mitigation: SVS (separate virtual address spaces)
- Spectre mitigation (support in gcc, used by default for kernels)
- Lazy cpu saving disabled on some Intel CPUs ("eagerfpu")
- SMAP support
- (U)EFI bootloader
Various new drivers:
- nvme(4) for modern solid state disks
- iwm(4), a driver for Intel Wireless devices (AC7260, AC7265, AC3160...)
- ixg(4): X540, X550 and newer device support.
- ixv(4): Intel 10G Ethernet virtual function driver.
- bta2dpd - new Bluetooth Advanced Audio Distribution Profile daemon
Many evbarm kernels now use FDT (flat device tree) information (loadable at boot time from an external file) for device configuration, the number of kernels has decreased but the numer of boards has vastly increased.
Lots of updates to 3rd party software included:
- GCC 5.5 with support for Address Sanitizer and Undefined Behavior Sanitizer
- GDB 7.12
- GNU binutils 2.27
- Clang/LLVM 3.8.1
- OpenSSH 7.6
- OpenSSL 1.0.2k
- mdocml 1.14.1
- acpica 20170303
- ntp 4.2.8p11-o
- dhcpcd 7.0.6
- Lua 5.3.4
The NetBSD developers and the release engineering team have spent a lot of effort to make sure NetBSD 8.0 will be a superb release, but we have not yet fixed most of the accompanying documentation. So the included release notes and install documents will be updated before the final release, and also the above list of major items may lack important things.
Get NetBSD 8.0 RC2 from our CDN (provided by fastly) or one of the ftp mirrors.
Complete source and binaries for NetBSD are available for download at many sites around the world. A list of download sites providing FTP, AnonCVS, and other services may be found at http://www.NetBSD.org/mirrors/.
Please test RC2, so we can make the final release the best one ever so far. We are looking forward to your feedback. Please send-pr any bugs or mail us at releng at NetBSD.org for more general comments.
[0 comments]Prepared by Siddharth Muralee (@Tr3x__) as a part of GSoC'18
I have been working on porting the Kernel Address Sanitizer(KASAN) for the NetBSD kernel. This summarizes the work done until the second evaluation.
Refer here for the link to the first report.
What is a Kernel Address Sanitizer?
The Kernel Address Sanitizer or KASAN is a fast and efficient memory error detector designed by developers at Google. It is heavily based on compiler optimization and has been very effective in reporting bugs in the Linux Kernel.
The aim of my project is to build the NetBSD kernel with the KASAN and use it to find bugs and improve code quality in the kernel. This Sanitizer will help detect a lot of memory errors that otherwise would be hard to detect.
Porting code from Linux to NetBSD
The design of KASAN in the NetBSD kernel is based on its Linux counterpart. Linux code is GPL licensed hence we intend to rewrite it completely or/and relicense certain code parts. We will be handling this once we have a working prototype ready.
This is in no way an easy task especially when the code we try to port is from multiple areas in the kernel like the Memory management system, Process Management etc.
The total port requires a transfer of around 3000 lines in around 6 files with references in around 20 other locations or more.
Design of KASAN and how it works
Kernel Address Sanitizer works by instrumenting all the memory accesses and having a separate "shadow buffer" to keep track of all the addresses that are legitimate and accessible and complains (Very Descriptively!!) when the kernel reads/writes elsewhere.
The basic idea behind Kernel ASan is to set aside a map/buffer where each byte in the kernel is represented by using a bit. This means the size of the buffer would be 1/8th of the total memory accessible by the kernel. In amd64(also x86_64) this would mean setting aside 16TB of memory to handle a total of 128TB of kernel memory.
Implementation Outline
A bulk of the work is done by the compiler inserted code itself(GCC as of now), but still there are a lot of features we have to implement.
- Checking and reporting Infrastructure
- Allocation and population of the Shadow buffer during boot
- Modification of Allocators to update the Shadow buffer upon allocations and deallocations
Kernel Address Sanitizer is useful in finding bugs/coding errors in the kernel such as :
- Use - after - free
- Stack, heap and global buffer overflows
- Double free
- Use - after - scope
The design makes it faster than other tools such as kmemcheck etc. The average slowdown is expected to be around ~2x times or less.
KASAN Initialisation
KASAN initialization happens in two stages -
- early in the boot stage, we set each page entry of the entire shadow region to zero_page (early_kasan_init)
- after the physical memory has been mapped and the pmap(9) has been bootstrapped during kernel startup, the zero_pages are unmapped and the real pages are allocated and mapped (kasan_init).
Below is a short description of what kasan_init() does in Linux code :
- It loads the kernel boot time page table and clears all the page table entries for the shadow buffer region which had been populated with zero_pages during early_kasan_init.
- It marks shadow buffer offsets of parts of kernel memory; which we don't want to track or are prohibited, by populating them using kasan_populate_zero_shadow which iterates through all the page tables.
- Write-protects the mappings and flushes the TLB.
Allocating the shadow buffer
Instead of iterating through the page table entries as Linux preferred to do, we decided to use our low-level kernel memory allocators to do the job for us. This helped in reducing the code complexity and allowed us to reduce the size of the code by a significant amount.
One may ask then does that allocator need to be sanitized? We propose to add a kasan_inited variable which would help the sanitization to occur after the initialization.
We are still in the process of testing this part.
Shadow translation (Address Sanitizer Algorithm)
The translation from a memory address to the corresponding shadow offset must be done pretty fast since it happens during every memory read/write. This is implemented similar to the below code
shadow_address = KmemToShadow(address);
void * KmemToShadow(void * addr) {
return (addr >> Shadow_scale) + Shadow_buffer_start;
}
The reverse shadow offsets to kernel memory addresses function is also similar to this.
The shadow translation functions have already been implemented and can be found in kasan.h in my Github repository.
Error Detection
Every read/write is instrumented to have a check which would decide if the memory access was legitimate or not. This would be done in the manner shown below.
shadow_address = KmemToShadow(address);
if (IsPoisoned(shadow_address)) {
ReportError(address, Size, IsWrite);
}
The actual implementation of the Error detection is a bit more complex since we have to include the mapping aspect as well.
Each byte of shadow buffer memory maps to a qword(8 bytes) of kernel memory. Because of which poisoned memory(*shadow_address) values have only 3 possibilities :
- The value can be 0 ( Meaning that all 8 bytes are unpoisoned )
- The value can be -ve ( Meaning that all 8 bytes are poisoned )
- The value can have first k bits unpoisoned and the rest (8 - k) poisoned
Therefore we can use the value also to help assist us while doing Error detection.
Basic Bug Report
The information about each bug is stored in struct kasan_access_info which is then used to determine the following information
- The kind of bug
- Whether read/write caused it
- Process ID of the task being executed
- The address which caused the error
We also print the stack backtrace which helps in identifying the function with the bug and also helps in finding the execution flow which caused the bug.
One of the best features is that we will be able to use the address where the error occurred to show the poisoning in the shadow buffer. This diagram will be pretty useful for developers trying to fix the bugs found by KASAN.
Unfortunately, since we haven't finished modifying the allocators to update the shadow buffer on read/write we will not be able to test this as of now.
Summary
I have managed to get a good initial grasp of the internals of NetBSD kernel over the last two months.
I would like to thank my mentor Kamil for his constant support and valuable suggestions. A huge thanks to the NetBSD community who have been supportive throughout.
Most of my work is done on my fork of NetBSD.
Work left to be done
There is a lot of important features that still remains to be implemented. Below is the list of features that I will be working on.
- Solve licensing issues
- sysctl switches to tune options of kern_asan.c (quarantine size, halt_on_error etc)
- Move the KASAN code to src/sys/kernel and the MI part call kern_asan.c (similar to kern_ubsan.c)
- Ability to run concurrently KUBSAN & KASAN
- Refactor kasan_depth and in_ubsan to be shared between sanitizers: probably as a bit in private LWP bitfield
- ATF tests verifying KASAN's detection of bugs
- The first boot to a functional shell of a kernel executing with KASAN
- Finish execution of ATF tests with a kernel running with KASAN
- Quarantine List
- Report generation
- Continue execution
- Allocator hooks and functions
- Memory hotplug
- Kernel module shadowing
- Quarantine for reusable structs like LWP
Prepared by Yang Zheng (tomsun.0.7 AT Gmail DOT com) as part of GSoC 2018
This is the second part of the project
of integrating
libFuzzer for the userland applications, you can
learn about the first part of this project
in this
post.
After the preparation of the first part, I started to fuzz the
userland programs with the libFuzzer. The programs we
chose are five:
After we fuzzed them with libFuzzer, we also tried
other fuzzers,
i.e.: American Fuzzy
Lop
(AFL), honggfuzz
and Radamsa.
Fuzz Userland Programs with libFuzzer

In this section, I'll introduce how to fuzz the five programs
with libFuzzer. The libFuzzer is an
in-process, coverage-guided fuzzing engine. It can provide some
interfaces to be implemented by the users:
LLVMFuzzerTestOneInput: fuzzing targetLLVMFuzzerInitialize: initialization function to accessargcandargvLLVMFuzzerCustomMutator: user-provided custom mutatorLLVMFuzzerCustomCrossOver: user-provided custom cross-over function
LLVMFuzzerTestOneInput
is necessary to be implemented for any fuzzing programs. This function
takes a buffer and the buffer length as input, it is the target to be
fuzzed again and again. When the users want to finish some
initialization job with argc and argv
parameters, they also need to
implement LLVMFuzzerInitialize. With LLVMFuzzerCustomMutator
and LLVMFuzzerCustomCrossOver, the users can also change
the behaviors of producing input buffer with one or two old input
buffers. For more details, you can refer
to this document.
Fuzz Userland Programs with Sanitizers
libFuzzer can be used with different sanitizers. It is
quite simple to use sanitizers together with libFuzzer,
you just need to add sanitizer names to the option
like -fsanitize=fuzzer,address,undefined. However,
memory sanitizer seems to be an exception. When we tried
to use it together with libFuzzer, we got some runtime
errors. The official
document has mentioned that "using MemorySanitizer (MSAN) with
libFuzzer is possible too, but tricky", but it doesn't mention how to
use it properly.
In the following part of this article, you can assume that we have
used the address and undefined sanitizers
together with fuzzers if there is no explicit description.
Fuzz expr(1) with libFuzzer
The expr(1) takes some parameters from the command line as
input and then treat the command line as a whole expression to be
calculated. A example usage of the expr(1) would be
like this:
$ expr 1 + 1
2
This program is relatively easy to fuzz, what we only to do is
transform the original main function to the form
of LLVMFuzzerTestOneInput. Since the implementation of
the parser in expr(1) takes the argc
and argv parameters as input, we need to transform the
buffer provided by the LLVMFuzzerTestOneInput to the
format needed by the parser. In the implementation, I assume the
buffer is composed of several strings separated by the space
characters (i.e.: ' ', '\t'
and '\n'). Then, we can split the buffer into different
strings and organize them into the form of argc
and argv parameters.
However, there comes the first problem when I start to
fuzz expr(1) with this modification. Since
the libFuzzer will treat
every exit
as an error while fuzzing, there will be a lot of false
positives. Fortunately, the implementation of expr(1)
is simple, so we only need to replace the exit(3)
with the return statement. In the fuzzing process of other
programs, I'll introduce how to handle the exit(3)
and other error handling interfaces elegantly.
You can also pass the fuzzing dictionary file (to provide keywords)
and initial input cases to the libFuzzer, so that it
can produce test cases more smartly. For expr(1), the
dictionary file will be like this:
min="-9223372036854775808"
max="9223372036854775807"
zero="0"
one="1"
negone="-1"
div="/"
mod="%"
add="+"
sub="-"
or="|"
add="&"
And there is only one initial test case:
1 / 2
With this setting, we can quickly reproduce an existing bug which
has been fixed by Kamil
Rytarowski in
this patch, that is, when you try to feed one of
-9223372036854775808 / -1 or -9223372036854775808
% -1 expressions to expr(1), you will get
a SIGFPE. After adopting the fix of this bug, it also
detected a bug of integer overflow by feeding expr(1)
with 9223372036854775807 * -3. This bug is detected
with the help of undefined sanitizer
(UBSan). This has been fixed
in this
commit. The fuzzing of expr(1) can be reproduced
with this
script.
Fuzz sed(1) with libFuzzer
The sed(1) reads from files or standard input
(stdin) and modifying the input as specified by a list
of commands. It is more complicated than the expr(1) to
be fuzzed as it can receive input from several sources including
command line parameters (commands), standard input (text to be
operated on) and files (both commands and text). After reading the
source code of
sed(1), I have two findings:
- The commands are added by the
add_compunitfunction - The input files (including standard input) are organized by
the
s_fliststructure and themf_fgetsfunction
libFuzzer buffer with the interfaces above. So I
organized the buffer as below:
command #1
command #2
...
command #N
// an empty line
text strings
The first several lines are the commands, one line for one
command. Then there will be an empty line to identify the end of
command lists. At last, the remaining part of this buffer is the
text to be operated on. After parsing the buffer like this, we can
add the commands one by one with the add_compunit
interface. For the text, since we can directly get the whole text
buffer as the format of a buffer, I re-implement
the mf_fgets interface to get the input directly from
the buffer provided by the libFuzzer.
As mentioned before in the fuzzing
of expr(1), exit(3) will result in false
positives with libFuzzer. Replacing
the exit(3) with return statement can
solve this problem in expr(1), but it will not work
in sed(1) due to the deeper function call
stack. The exit(3) interface is usually used to handle
the unexpected cases in the programs. So, it will be a good idea to
replace it with exceptions. Unfortunately, the programs we fuzzed
are all implemented in C language instead
of C++. Finally, I choose to
use setjmp/longjmp
interfaces to handle it: use the setjmp interface to
define an exit point in the LLVMFuzzerTestOneInput
function, and use longjmp to jmp to this point whenever
the original implementation wants to call exit(3).
The dictionary file for it is like this:
newline="\x0A"
"a\\\"
"b"
"c\\\"
"d"
"D"
"g"
"G"
"h"
"H"
"i\\\"
"l"
"n"
"N"
"p"
"P"
"q"
"t"
"x"
"y"
"!"
":"
"="
"#"
"/"
And here is an initial test case:
s/hello/hi/g
hello, world!
which means replacing the "hello"
into "hi" in the text of "hello,
world!". The fuzzing script of sed(1) can be
found here.
Fuzz sh(1) with libFuzzer
sh(1) is the standard command interpreter for the
system. I choose the evalstring function as the fuzzing
entry for sh(1). This function takes a string as the
commands to be executed, so we can directly pass
the libFuzzer input buffer to this function to start
fuzzing. The dictionary file we used is like this:
"echo"
"ls"
"cat"
"hostname"
"test"
"["
"]"
We can also add some other commands and shell script syntax to this
file to reproduce other conditions. And also an initial test case is
provided:
echo "hello, world!"
You can also reproduce the fuzzing of sh(1)
by this
script.
Fuzz file(1) with libFuzzer
The fuzzing of file has been done by Christos Zoulas
in this
project. The difference between this program and other programs
from the list is that the main functionality is provided by
the libmagic library. As a result, we can directly fuzz
the important functions (e.g.: magic_buffer) from this
library.
Fuzz ping(8) with libFuzzer
The ping(8) is quite different from all of the programs
mentioned above, the main input source is from the network instead of
the command line, standard input or files. This challenges us a lot
because we usually use the socket interface to receive
network data and thus more complex to transform a single buffer into
the socket model.
Fortunately, the ping(8) organizes all the network
interfaces as the form of hooks to be registered in a structure. So
I re-implement all these necessary interfaces
(including socket(2), recvfrom(2), sendto(2), poll(2)
and etc.) for ping(8).These re-implemented interfaces
will take the data from the libFuzzer buffer and
transform it into the data to be accessed by the network
interfaces. After that, then we can use libFuzzer to
fuzz the network data for ping(8). The script to
reproduce can be
found here.
Fuzz Userland Programs with Other Fuzzers
To compare libFuzzer with other fuzzers from different
aspects, including the effort to modify, performance and
functionalities, we also fuzzed these five programs
with AFL, honggfuzz
and radamsa.
Fuzz Programs with AFL and honggfuzz
The AFL and honggfuzz can fuzz the input
from standard input and file. They both provide specific compilers
(such
as afl-cc, afl-clang, hfuzz-cc, hfuzz-clang
and etc.) to fuzz programs with coverage information. So, the basic
process to fuzz programs with them is to:
- Use the specific compilers to compile programs with necessary sanitizers
- Run the fuzzed programs with proper command line parameters

There is no need to do any modification to
fuzz sed(1), sh(1)
and file(1) with AFL
and honggfuzz, because these programs mainly get input
from standard input or files. But this doesn't mean that they can
achieve the same functionalities as libFuzzer. For
example, to fuzz the sed(1), you may also need to pass
the commands in the command line parameters. This means that you
need to manually specify the commands in the command line and you
cannot fuzz them with AFL and honggfuzz,
because they can only fuzz input from standard input and
files. There is an option of reusing the modifications from the
fuzzing process with libFuzzer, but we need to further
add a main function for the fuzzed program.

For expr(1) and ping(8), we even need
more modifications than the libFuzzer solution, because
expr(1) mainly gets input from command line parameters
and ping(8) mainly gets input from the network.
During this period, I have also prepared a package to install
honggfuzz for the pkgsrc-wip
repository. To make it compatible with NetBSD, we have also
contributed to improving the code in the official repository, for more
details, you can refer to
this pull
request.
Fuzz Programs with Radamsa
Radamsa is a test case generator, it works by reading
sample files and generating different interesting
outputs. Radamsa is not dependant on the fuzzed programs,
it is only dependant on the input sample, which means it will not
record the coverage information.

With Radamsa, we can use scripts to fuzz different
programs with different input sources. For
the expr(1),
we can generate the mutated string and store it to a variable in the
shell script and then feed it to the expr(1) in
command line parameters. For
the sed(1),
we can generate both command strings and text
by Radamsa and then feed them by command line
parameters and file separately. For
both sh(1)
and file(1),
we can generate the needed input file by Radamsa in the
shell scripts.
It seems that the shell script and Radamsa combination
can fuzz any kinds of programs, but it encounters some problems
with ping(8). Although Radamsa supports
generating input cases as a network server or client, it doesn't
support the ICMP protocol. This means that we can not
fuzz ping(8) with modifications or help from other
applications.
Comparison Among Different Fuzzers
In this project, we have tried four different
fuzzers: libFuzzer, AFL, honggfuzz
and Radamsa. In this section, I will introduce a
comparison from different aspects.
Modification of Fuzzing
For the programs we mentioned above, here I list the lines of code we need to modify as a factor of porting difficulties:
expr(1) |
sed(1) |
sh(1) |
file(1) |
ping(8) |
|
|---|---|---|---|---|---|
libFuzzer |
128 | 96 | 60 | 48 | 582 |
AFL/honggfuzz |
142 | 0 | 0 | 0 | 590 |
Radamsa |
0 | 0 | 0 | 0 | N/A |
libFuzzer needs to modify more
lines for programs who mainly get input from standard input and
files. However, for other programs (i.e.: expr(1)
and ping(8)), the AFL
and honggfuzz need to add more lines of code to get
input from these sources. As for Radamsa, since it only
needs the sample input data to generate outputs, it can fuzz all
programs without modifications except ping(8).
Binary Sizes
The binary sizes for these fuzzers should also be considered if we
want to ship them with NetBSD. The following binary sizes are based
on the NetBSD-current with the nearly newest LLVM
(compiled from source) as an external toolchain:
| Dependency | Compilers | Fuzzer | Tools | Total | |
|---|---|---|---|---|---|
libFuzzer |
0 | 56MB | N/A | 0 | 56MB |
AFL |
0 | 24KB | 292KB | 152KB | 468KB |
honggfuzz |
36KB | 840KB | 124KB | 0 | 1000KB |
Radamsa |
588KB | 0 | 608KB | 0 | 1196KB |
For the libFuzzer, if the system has already included
the LLVM together with compiler-rt as the
toolchain, we don't need extra space to import it. The fuzzer
of libFuzzer is compiled together with the user's
program, so the size is not counted. The compiler size shown above
in this table is the size of statically compiled
compiler clang. If we compile it dynamically, then
there will be a plenty of dependant libraries should be considered.
For the AFL, there is no dependant library
except libc, so the size is zero. It will also
introduce some tools
like afl-analyze, afl-cmin and
etc. The honggfuzz is dependant on
the libBlocksRuntime library whose size
is 36KB. This library is also included in
the compiler-rt of LLVM. So, if you have
already installed it, this size can be ignored. As for
the Radamsa, it needs
the Owl Lisp
during the building process. So the size of the dependency is the
size of Owl Lisp interpreter.
Compiler Compatibility
All these fuzzers except libFuzzer are compatible with
both GCC and clang. The AFL
and honggfuzz provide a wrapper for the native compiler,
and the Radamsa does not care about the compilers. As
for the libFuzzer, it is implemented in
the compiler-rt of LLVM, so it cannot
support the GCC compiler.
Support for Sanitizers
All these fuzzers can work together with sanitizers, but only
the libFuzzer can provide a relatively strong guarantee
that it can provide them. The AFL
and honggfuzz, as I mentioned above, provide some
wrappers for the underlying compiler. This means that it is
dependant on the native compiler to decide whether they can fuzz the
programs with the support of sanitizers. The Radamsa
can only fuzz the binary directly, so the programs should be
compiled with the sanitizers first. However, since the sanitizers
are in the compiler-rt together
with libFuzzer, you can directly add some flags of
sanitizers while compiling the fuzzed programs.
Performance
At last, you may wonder how fast are those fuzzers to find an
existing bug. For the above programs we have fuzzed in NetBSD,
only libFuzzer can find two bugs for
the expr(1). However, we cannot assert that
the libFuzzer performs well than others. To further
evaluate the performance of different fuzzers we have used, I choose
some simple functions with bugs to measure how fast they can find
them out. Here is a table to show the time for them to find the
first bug:
libFuzzer |
AFL |
honggfuzz |
Radamsa |
|
|---|---|---|---|---|
DivTest+S |
<1s | 7s | 1s | 7s |
DivTest |
>10min | >10min | 2s | >10min |
SimpleTest+S |
<1s | >10min | 1s | >10min |
SimpleTest |
<1s | >10min | 1s | >10min |
CxxStringEqTest+S |
<1s | >10min | 2s | >10min |
CxxStringEqTest |
>10min | >10min | 2s | >10min |
CounterTest+S |
1s | 5min | 1s | 7min |
CounterTest |
1s | 4min | 1s | 7min |
SimpleHashTest+S |
<1s | 3s | 1s | 2s |
The "+S" symbol means the version with sanitizers (in this
evaluation, I used address and undefined
sanitizers). In this table, we can observe
that libFuzzer and honggfuzz perform
better than others in most cases. And another point is that
fuzzers can work better with sanitizers. For example, in the case
of DivTest, the primary goal of this test is to
trigger a "divide-by-zero" error, however, when working with
the undefined sanitizer, all these fuzzers will
trigger the "integer overflow" error more quickly. I only present
a part of the interesting results of this evaluation here. You can
refer to
this
script to reproduce some results or do more evaluation by
yourself.
Summary
In the past one month, I mainly contributed to:
- Porting the
libFuzzertoNetBSD - Preparing a
pkgsrc-wippackage forhonggfuzz - Fuzzing some userland programs with libFuzzer and other three different fuzzers
- Evaluating different fuzzers from different aspects
expr(1).
I'd like to thank my mentor Kamil Rytarowski and Christos Zoulas for
their suggestions and proposals. I also want to thank Kamil
Frankowicz for his advice on fuzzing and playing
with AFL. At last, thanks to Google and the NetBSD
community for giving me a good opportunity to work on this project.
On July 7th and 8th there was pkgsrcCon 2018 in Berlin, Germany. It was my first pkgsrcCon and it was really really nice... So, let's share a report about it, what we have done, the talk presented and everything else!
Friday (06/07): Social Event
I arrived by plane at Berlin Tegel Airport in the middle of the afternoon. TXL buses were pretty full but after waiting for 3 of them, I was finally in the direction for Berlin Hauptbahnhof (nice thing about the buses is that after many are getting too full they start to arrive minute after minute!) and then took the S7 for Berlin Jannowitzbrücke station, just a couple of minutes on foot to republik-berlin (for the Friday social event).
On 18:00 we met in
republik-berlin for the social event.
We had good burgers there and one^Wtwo^Wsome beers
together!
The place were a bit noisy for the Belgium vs Brazil World Cup match, but we
still had nice discussions together (and also without losing a lot of
people cheering on!
There was also a table tennis table and spz, maya,
youri and myself played (I'm a terrible table tennis player
but it was very funny to play the wild west without any rules! :)).
Saturday (07/07): Talks session
Meet & Greet -- Pierre Pronchery (khorben), Thomas Merkel (tm)
Pierre and Thomas welcomed us (aliens! in
c-base. c-base is a space station under
Berlin (or probably one of the oldest hackerspace, at least old enough that the
word "hackerspace" even didn't existed!).
Slides (PDF) are available!
Keynote: Beautiful Open Source -- Hugo Teso
Hugo talked about his experience as an open source developer and focused in particular how important is the user interface.
He discussed that examinating some projects he worked on: Inguma, Bokken, Iaitö and Cutter extracting patterns about his experience.
Slides (PDF) are available!
The state of desktops in pkgsrc -- Youri Mouton (youri)
Youri discussed about the state of desktop environments (DE) in pkgsrc starting with xfce, MATE, LXDE, KDE and Defora.
He then discussed about the WIP desktop environments: Cinnamon, LXQT, Gnome 3 and CDE, hardware support and login managers.
Especially for the WIP desktop environments help is more than welcomed so if
you're interested in any of that, would like to help (that's also a great way to
start involved in pkgsrc!) please get in touch with youri and/or
give a look at the wip/*/TODO files in pkgsrc-wip!
NetBSD & Mercurial: One year later -- Jörg Sonnenberger (joerg)
Jörg started discussing about Git (citing High-level Problems with Git and How to Fix Them - Gregory Szorc) and then discussed on why using Mercurial.
Then he announced the latest changes: hgmaster.NetBSD.org and
anonhg.NetBSD.org that permits to experiment with Mercurial and
source-changes-hg@ and pkgsrc-changes-hg@ mailing
lists.
The talk ended describing missing/TODO steps.
Slides (HTML) are available!
Maintaining qmail in 2018 -- Amitai Schleier (schmonz)
Amitai shared his long experience in maintaining qmail.
A lot of lesson learned in doing that were shared and it was also funny to see that at a certain point from MAINTAINER he was more and more involved doing that and ending up writing patches and tools for qmail.
Slides (HTML) are available!
A beginner's introduction to GCC -- Maya Rashish (maya)
Maya discussed about GCC. First she talked about an overview of the toolchain (in general) and the corresponding GCC projects, how to pass flags to each of them and how to stop the compilation process for each of them.
Then she talked about the black magic that happens in preprocessor, for example, what
a program does an #include <math.h> and why
__NetBSD__ is defined.
We then saw that with -save-temps is possible to save all
intermediary results and how this is very helpful to debug possible problems.
Compiler, assembler and linker were then discussed. We have also seen
specfiles, readelf and other GCC internals.
Slides (HTML) are available!
Handling the workflow of pkgsrc-security -- Leonardo Taccari (leot)
I discussed about the workflow of the pkgsrc Security Team (pkgsrc-security).
I gave a brief introduction to nmh (new MH) message handling system.
Then talked about the mission, tasks and workflow of the pkgsrc-security.
For the last part of the talk, I tried to put everything together
and showed how to try to automate some part of the pkgsrc-security
with nmh and some shell scripting.
Slides (PDF) are available!
Preaching for releng-pkgsrc -- Benny Siegert (bsiegert)
Benny discussed about pkgsrc Releng team (releng-pkgsrc).
The talk started discussing about the pkgsrc Quarterly Releases. Since 2003Q4, every quarter a new pkgsrc release is released. Stable releases are the basis for binary packages. Security, build and bug fixes get applied over the liftime of the release via pullups, until the next quarterly release. The release procedure and freeze period were also discussed.
Then we examined the life of a pullup. Benny first introduced what a
pullup is, the rules for requesting them and a practical example of how to file
a good pullup request.
Under the hood parts of releng were also discussed, for example how tickets are
handled with req, help script to ease the pullup, etc..
The talk concluded with the importance of releng-pkgsrc and also a call for volunteers to join releng-pkgsrc! (despite they're really doing a great work, at the moment there is a shortage of members in releng-pkgsrc, so, if you are interested and would like to join them please get in touch with them!)
Something old, something new, something borrowed -- Sevan Janiyan (sevan)
Sevan discussed about the state of NetBSD/macppc port.
Lot of improvements and news happened (a particular kudos to
macallan for doing an amazing work on the macppc port!)!
HEAD-llvm builds for macppc were added;
awacs(4)
Bluetooth support, IPsec support, Veriexec support are all enabled
by default now.
radeonfb(4) and XCOFF boot loader had several improvements and now DVI is supported on the G4 Mac Mini.
The other big news in the macppc land is the G5 support that will
probably be interesting also for possible pkgsrc bulk builds.
Sevan also discussed about some current problems (and workarounds!), bulk builds takes time, no modern browser with JavaScript support is easily available right now but also how using macppc port helped to spot several bugs.
Then he discussed about Upspin (please also
give a look to the corresponding package in
wip/go-upspin!)
Slides (PDF) are available!
Magit -- Christoph Badura (bad)
Christoph talk was a live introduction to Magit, a Git interface for Emacs.
The talk started quoting James Mickens It Was Never Going to Work, So Let's Have Some Tea talk presented at USENIX LISA15 when James Mickens talked about an high level picture of how Git works.
We then saw how to clone a repository inside Magit, how to navigate the commits, how to create a new branch, edit a file and look at unstaged changes, stage just some hunks of a change and commit them and how to rebase them (everything is just one or two keystrokes far!).
Post conf dinner
After the talks we had some burgers and beers together at Spud Bencer.
We formed several groups to go there from c-base and I was actually in the
group that went there on foot so it was also a nice chance to sightsee Berlin
(thanks to khorben for being a very nice guide! :)).
Sunday (08/07): Hacking session
An introduction to Forth -- Valery Ushakov (uwe)
On Sunday morning Valery talked about Forth from the ground up.
We saw how to implement a Forth interpreter step by step and discussed threaded code.
Unfortunately the talk was not recorded... However, if
you are curious I suggest taking a look to
nbuwe/forth BitBucket repository.
internals.txt file also contains a lot of interesting resources
about Forth.

Hacking session
After Valery talk there was the hacking session where we hacked on pkgsrc, discussed together, etc..
Late in the afternoon some of us visited Computerspielemuseum.
More than 50 years of computer games were covered there and it was fun to also play to several historical and also more recent video games.
We then met again for a dinner together in Potsdamer Platz.

Conclusion
pkgsrcCon 2018 was really really great!
First of all I would like to thank all the pkgsrcCon organizers:
khorben and tm. It was very well organized and
everything went well, thank you Pierre and Thomas!
A big thank you also to
wiedi, just after few hours all the recordings of the talk were
shared and that's really impressive!
Thanks also to youri and
Gilberto for photographs.
Last, but not least, thanks to The NetBSD Foundation for supporting three developers to attend the conference. c-base for kindly providing a very nice location for the pkgsrcCon. Our sponsors: Defora Networks for sponsoring the t-shirts and badges for the conference and SkyLime for sponsoring the catering on Saturday.
Thank you!
Prepared by Keivan Motavalli as part of GSoC 2018.
Packages may install code (both machine executable code and interpreted programs), documentation and manual pages, source headers, shared libraries and other resources such as graphic elements, sounds, fonts, document templates, translations and configuration files, or a combination of them.
Configuration files are usually the mean through which the behaviour of software without a user interface is specified. This covers parts of the operating systems, network daemons and programs in general that don't come with an interactive graphical or textual interface as the principal mean for setting options.
System wide configuration for operating system software tends to
be kept under /etc, while configuration for software installed via
pkgsrc ends up under LOCALBASE/etc
(e.g., /usr/pkg/etc).
Software packaged as part of pkgsrc provides example configuration
files, if any, which usually get extracted to
LOCALBASE/share/examples/PKGBASE/.
After a package has been extracted pre-pending the
PREFIX(/LOCALBASE?)
to relative file paths as listed in the PLIST file, metadata entries
(such as +BUILD_INFO, +DESC, etc) get extracted to
PKG_DBDIR/PKGNAME-PKGVERSION (creating files under
/usr/pkg/pkgdb/tor-0.3.2.10, as an example).
Some shell script also get extracted there, such as +INSTALL and
+DEINSTALL. These incorporate further snippets that get copied
out to distinct files after pkg_add executes the +INSTALL script
with UNPACK as argument.
Two main frameworks exist taking care of installation and deinstallation
operations: pkgtasks, still experimental, is structured as a library
of POSIX-compliant shell scripts implementing functions that get
included from LOCALBASE/share/pkgtasks-1 and called by the
+INSTALL and +DEINSTALL scripts upon execution.
Currently pkgsrc defaults to using the pkginstall
framework, which as mentioned copies out from the main file separate,
monolithic scripts handling the creation and removal of directories
on the system outside the PKGBASE, user accounts, shells, the setup
of fonts... Among these and other duties, +FILES ADD, as
called by +INSTALL, copies with correct permissions files from the
PKGBASE to the system, if required by parts of the package such as init
scripts and configuration files.
Files to be copied are added as comments to the script at package build time, here's an example:
# FILE: /etc/rc.d/tor cr share/examples/rc.d/tor 0755 # FILE: etc/tor/torrc c share/examples/tor/torrc.sample 0644
"c" indicates that LOCALBASE/share/examples/rc.d/tor
is to be copied in place to /etc/rc.d/tor with permissions 755,
"r" that it is to be handled as an rc.d script.
LOCALBASE/share/examples/tor/torrc.sample, the example file coming
with default configuration options for the tor network daemon, is
to be copied to LOCALBASE/etc/tor/torrc.
As of today, this only happens if the package has never been installed before and said configuration file doesn't already exist on the system, this to avoid overwriting explicit option changes made by the user (or site administrator) when upgrading or reinstalling packages.
Let's see where how it's done... actions are defined under case switches:
case $ACTION in
ADD)
${SED} -n "/^\# FILE: /{s/^\# FILE: //;p;}" ${SELF} | ${SORT} -u |
while read file f_flags f_eg f_mode f_user f_group; do
…
case "$f_flags:$_PKG_CONFIG:$_PKG_RCD_SCRIPTS" in
*f*:*:*|[!r]:yes:*|[!r][!r]:yes:*|[!r][!r][!r]:yes:*|*r*:yes:yes)
if ${TEST} -f "$file"; then
${ECHO} "${PKGNAME}: $file already exists"
elif ${TEST} -f "$f_eg" -o -c "$f_eg"; then
${ECHO} "${PKGNAME}: copying $f_eg to $file"
${CP} $f_eg $file
[...]
[...]
Programs and commands are called using variables set in the script
and replaced with platform specific paths at build time, using the
FILES_SUBST facility (see mk/pkginstall/bsd.pkginstall.mk) and
platform tools definitions under mk/tools.
In order to also store revisions of example configuration files in
a version control system, +FILES needs to be modified to always
store revisions in a VCS, and to attempt merging changes non
interactively when a configuration file is already installed on
the system.
In order to avoid breakage, installed configuration is backed up first in the VCS, separating user-modified files from files that have been already automatically merged in the past, in order to allow the administrator to easily restore the last manually edited file in case of breakage.
Branches are deliberately not used, since not everyone may wish to get familiar with version control systems technicalities when attempting to make a broken system work again.
Here's what the modified pkginstall +FILES script does when installing spamd:
case "$f_flags:$_PKG_CONFIG:$_PKG_RCD_SCRIPTS" in
*f*:*:*|[!r]:yes:*|[!r][!r]:yes:*|[!r][!r][!r]:yes:*|*r*:yes:yes)
if ${TEST} "$_PKG_RCD_SCRIPTS" = "no" -a ! -n "$NOVCS"; then
VCS functionality only applies to configuration files, not to rc.d
scripts, and only if the environment variable $NOVCS
is unset. Set it to any value - yes will work - to disable the
handling of configuration file revisions.
A small note: these options could, in the future, be parsed by
pkg_add from some configuration file and passed calling
setenv before executing +INSTALL, without the need to
pass them as arguments and thus minimizing code path changes.
$VCSDIR is used to set a working directory for VCS
functionality different from the default one, VARBASE/confrepo.
VCSDIR/automergedfiles
is a textual list made by the absolute paths of installed configuration
files already automatically merged in the past during package
upgrades.
Manually remove entries from the list when you make manual configuration changes after a package has been automatically merged!
And don't worry: automatic merging is disabled by default, set
$VCSAUTOMERGE to enable it.
When a configuration file already exists on the system, if it is
absent from VCSDIR/automergedfiles, it is assumed to be user
edited and copied to
VCSDIR/user/path/to/installed/file is a working file
REGISTERed (added and committed) to the version control system.
Check it out and restore it from there in case of breakage!
If the file is about to get automatically merged, and the operation
already succeeded in the past, then you can find automatically
merged revisions of installed configuration files under
VCSDIR/automerged/path/to/installed/file
checkout the required revision!
A new script, +VERSIONING, handles operations such as
PREPARE (checks that a vcs repository is initialized),
REGISTER (adds a configuration file from the working directory to the repo),
COMMIT (commit multiple REGISTER actions after all configuration
has been handled by the +FILES script, for VCSs that support atomic
transactions), CHECKOUT (checks out the last revision of a file to
the working directory) and CHECKOUT-FIRST (checks out the first
revision of a file).
The version control system to be used as a backend can be set
through $VCS. It default to RCS, the Revision Control System, which
works only locally and doesn't support atomic transactions.
It will get setup as a tool when bootstrapping pkgsrc on platforms that don't already come with it.
Other backends such as CVS are supported and more will come; these,
being used at the explicit request of the administrator, need to
be already installed and placed in a directory part of $PATH.
Let's see what happens with rcs when NOVCS is unset, installing
spamd (for the first time).
cd pkgsrc/mail/spamd
# bmake
=> Bootstrap dependency digest>=20010302: found digest-20160304
===> Skipping vulnerability checks.
> Fetching spamd-20060330.tar.gz
[...]
bmake install
===> Installing binary package of spamd-20060330nb2
spamd-20060330nb2: Creating group ``_spamd''
spamd-20060330nb2: Creating user ``_spamd''
useradd: Warning: home directory `/var/chroot/spamd' doesn't exist, and -m was not specified
rcs: /var/confrepo/defaults//usr/pkg/etc/RCS/spamd.conf,v: No such file or directory
/var/confrepo/defaults//usr/pkg/etc/spamd.conf,v <-- /var/confrepo/defaults//usr/pkg/etc/spamd.conf
initial revision: 1.1
done
REGISTER /var/confrepo/defaults//usr/pkg/etc/spamd.conf
spamd-20060330nb2: copying /usr/pkg/share/examples/spamd/spamd.conf to /usr/pkg/etc/spamd.conf
===========================================================================
The following files should be created for spamd-20060330nb2:
/etc/rc.d/pfspamd (m=0755)
[/usr/pkg/share/examples/rc.d/pfspamd]
===========================================================================
===========================================================================
$NetBSD: MESSAGE,v 1.1.1.1 2005/06/28 12:43:57 peter Exp $
Don't forget to add the spamd ports to /etc/services:
spamd 8025/tcp # spamd(8)
spamd-cfg 8026/tcp # spamd(8) configuration
===========================================================================
/usr/pkg/etc/spamd.conf didn't already exists, so in the end,
as usual, the example/default configuration
/usr/pkg/share/examples/spamd/spamd.conf gets copied to
PKG_SYSCONFDIR/spamd.conf.
The modified +FILES script also copied the example
file under the VCS working directory at
/var/confrepo/default/share/examples/spamd/spamd.conf
it then REGISTEREd this (initial) revision of the default configuration with RCS.
When installing an updated (ouch!) spamd package, the installed
configuration at /usr/pkg/etc/spamd.conf won't get touched, but a
new revision of share/examples/spamd/spamd.conf will get stored
using the revision control system.
For VCSs that support them, remote repositories can also be used via $REMOTEVCS.
From the +VERSIONING comment:
REMOTEVCS, if set, must contain a string that the chosen VCS understands as an URI to a remote repository, including login credentials if not specified through other means. This is non standard across different backends, and additional environment variables and cryptographic material may need to be provided.
So, if using CVS accessing a remote repository over ssh, one should setup keys on the systems, then set and export
VCS=cvs CVS_RSH=/usr/bin/ssh REMOTEVCS=user@hostname:/path/to/existing/repo
Remember to initialize (e.g., mkdir -p /path/to/repo; cd /path/to/repo;
cvs init) the repository on the remote system before attempting to
install new packages.
Let's try to make a configuration change to spamd.conf and reinstall it:
I will enable whitelists uncommenting
#whitelist:\ # :white:\ # :method=file:\ # :file=/var/mail/whitelist.txt:
...and enable automerge:
export VCSAUTOMERGE=yes bmake install [...] merged with no conflict. installing it to /usr/pkg/etc/spamd.conf!
No conflicts get reported, diff shows no output since the installed file is already identical to the automerged one, which is installed again and contains the whitelisting options uncommented:
more /usr/pkg/etc/spamd.conf
# Whitelists are done like this, and must be added to "all" after each
# blacklist from which you want the addresses in the whitelist removed.
#
whitelist:\
:white:\
:method=file:\
:file=/var/mail/whitelist.txt:
Let's simulate instead the addition of a new configuration option in a new package revision: this shouldn't generate conflicts!
bmake extract ===> Extracting for spamd-20060330nb2 vi work/spamd-20060330/etc/spamd.conf # spamd config file, read by spamd-setup(8) for spamd(8) # # See spamd.conf(5) # this is a new comment! #
save, run bmake; bmake install:
===> Installing binary package of spamd-20060330nb2
RCS file: /var/confrepo/defaults//usr/pkg/etc/spamd.conf,v
done
/var/confrepo/defaults//usr/pkg/etc/spamd.conf,v <-- /var/confrepo/defaults//usr/pkg/etc/spamd.conf
new revision: 1.9; previous revision: 1.8
done
REGISTER /var/confrepo/defaults//usr/pkg/etc/spamd.conf
spamd-20060330nb2: /usr/pkg/etc/spamd.conf already exists
spamd-20060330nb2: attempting to merge /usr/pkg/etc/spamd.conf with new defaults!
saving the currently installed revision to /var/confrepo/automerged//usr/pkg/etc/spamd.conf
RCS file: /var/confrepo/automerged//usr/pkg/etc/spamd.conf,v
done
/var/confrepo/automerged//usr/pkg/etc/spamd.conf,v <-- /var/confrepo/automerged//usr/pkg/etc/spamd.conf
file is unchanged; reverting to previous revision 1.1
done
/var/confrepo/defaults//usr/pkg/etc/spamd.conf,v --> /var/confrepo/defaults//usr/pkg/etc/spamd.conf
revision 1.1
done
merged with no conflict. installing it to /usr/pkg/etc/spamd.conf!
--- /usr/pkg/etc/spamd.conf 2018-07-09 22:21:47.310545283 +0200
+++ /var/confrepo/defaults//usr/pkg/etc/spamd.conf.automerge 2018-07-09 22:29:16.597901636 +0200
@@ -5,6 +5,7 @@
# See spamd.conf(5)
#
# Configures whitelists and blacklists for spamd
+# this is a new comment!
#
# Strings follow getcap(3) convention escapes, other than you
# can have a bare colon (:) inside a quoted string and it
revert from the last revision of /var/confrepo/automerged//usr/pkg/etc/spamd.conf if needed
===========================================================================
The following files should be created for spamd-20060330nb2:
/etc/rc.d/pfspamd (m=0755)
[/usr/pkg/share/examples/rc.d/pfspamd]
===========================================================================
===========================================================================
$NetBSD: MESSAGE,v 1.1.1.1 2005/06/28 12:43:57 peter Exp $
Don't forget to add the spamd ports to /etc/services:
spamd 8025/tcp # spamd(8)
spamd-cfg 8026/tcp # spamd(8) configuration
===========================================================================
more /usr/pkg/etc/spamd.conf
[...]
# See spamd.conf(5)
#
# Configures whitelists and blacklists for spamd
# this is a new comment!
#
# Strings follow getcap(3) convention escapes, other than you
[...]
# Whitelists are done like this, and must be added to "all" after each
# blacklist from which you want the addresses in the whitelist removed.
#
whitelist:\
:white:\
:method=file:\
:file=/var/mail/whitelist.txt:
We're set for now. In case of conflicts merging, the user is
notified, the installed configuration file is not replaced and the
conflict can be manually resolved by opening the file (as an example,
/var/confrepo/defaults/usr/pkg/etc/spamd.conf.automerge)
in a text editor.
The NetBSD Project is pleased to announce NetBSD 8.0, the sixteenth major release of the NetBSD operating system. It represents many bug fixes, additional hardware support and new security features. If you are running an earlier release of NetBSD, we strongly suggest updating to 8.0.
For more details, please see the release notes.
Complete source and binaries for NetBSD are available for download at many sites around the world and our CDN. A list of download sites providing FTP, AnonCVS, and other services may be found at the list of mirrors.
The NetBSD release engineering team is announcing a new support policy for our release branches. This affects NetBSD 8.0 and subsequent major releases (9.0, 10.0, etc.). All currently supported releases (6.x and 7.x) will keep their existing support policies.
Beginning with NetBSD 8.0, there will be no more teeny branches (e.g., netbsd-8-0).
This means that netbsd-8 will be the only branch for 8.x and there will be only one category of releases derived from 8.0: update releases. The first update release after 8.0 will be 8.1, the next will be 8.2, and so on. Update releases will contain security and bug fixes, and may contain new features and enhancements that are deemed safe for the release branch.
With this simplification of our support policy, users can expect:
- More frequent releases
- Better long-term support (example: quicker fixes for security issues, since there is only one branch to fix per major release)
- New features and enhancements to make their way to binary releases faster (under our current scheme, no major release has received more than two feature updates in its life)
We understand that users of teeny branches may be concerned about the increased number of changes that update releases will bring. Historically, NetBSD stable branches (e.g., netbsd-7) have been managed very conservatively. Under this new scheme, the release engineering team will be even more strict in what changes we allow on the stable branch. Changes that would create issues with backwards compatibility are not allowed, and any changes made that prove to be problematic will be promptly reverted.
The support policy we've had until now was nice in theory, but it has not worked out in practice. We believe that this change will benefit the situation for vast majority of NetBSD users.
I took part in BSDCan 2019 and during the event wrote a NetBSD version of truss, a ptrace(2)-powered syscall tracing utility from FreeBSD. I've finished the port after getting back home and published it to the NetBSD community. This work allowed me to validate the ptrace(2) interfaces in another application and catch new problems that affect every ptrace(2)-based debugger.
Changes in the basesystem
A number of modifications were introduced to the main NetBSD repository which include ptrace(2), kernel sanitizer, and kernel coverage.
Improvements in the ptrace(2) code:
- Reporting exec(3) events in the PT_SYSCALL mode. This simplifies debuggers adding MI interface to detect exec(3) of a tracee.
- Relax prohibition of Program Counter set to 0x0 in ptrace(2). In theory certain applications can map Virtual Address 0x0 and run code there. In practice this will probably never happen in modern computing.
- New ATF tests for user_va0_disable sysctl(3) node checking if PT_CONTINUE/PT_SYSCALL/PT_DETACH can set Program Counter to 0x0.
- Fixing kernel races with threading code when reports for events compare with process termination. This unbroke tracing Go programs, which call exit(2) before collecting all the running threads.
- Refreshed ptrace(2) and siginfo(2) documentation with recent changes and discoveries.
I mentor two GSoC projects and support community members working on kernel fuzzers. As a result of this work, fixes are landing in the distribution source code from time to time. We have achieved an important milestone with being able to run NetBSD/amd64 on real hardware with Kernel Undefined Behavior Sanitizer without any reports from boot and execution of ATF tests. This achievement will allow us to enable kUBSan reports as fatal ones and use in the fuzzing process, capturing bugs such as integer overflow, out of bounds array use, invalid shifts, etc.
I have also introduced a support of a new sysctl(3) operation: KERN_PROC_CWD.
This call retrieves the current working directory of a specified process.
This operation is used typically in terminal-related applications
(tmux, terminator, ...) and generic process status prompters (Python psutils).
I have found out that my terminal emulator after system upgrade doesn't work correctly
and it uses a fallback of resolving the symbolic link of /proc/*/cwd.
ptrace(2) utilities
In order to more easily validate the kernel interfaces I wrote a number of utility programs that use the ptrace(2) functionality. New programs reuse the previously announced picotrace (https://github.com/krytarowski/picotrace) code as a framework.
Some programs have been already published, other are still in progress and kept locally on my disk only. New programs that have been published so far:
- NetBSD truss - reimplementation from scratch of FreeBSD truss for the NetBSD kernel.
- sigtracer - stripped down picotrace reporting signal events.
- coredumper - crash detector and core(5) dumper regardless of signal handing or masking options in programs.
More elaborated introduction with examples is documented on the GitHub repository. I use these programs for profit as they save my precious time on debugging issues in programs and as validators for kernel interfaces as they are working closely over the kernel APIs (contrary to large code base of GDB or LLDB). I've already detected and verified various kernel ptrace(2) issues with these programs. With a debugger it's always unclear whether a problem is in the debugger, its libraries or the kernel.
Among the detected issues, the notable list of them is as follows:
- Reporting events to a debugger in the same time from two or more sources is racy and one report can be registered and other dropped.
- Either questionable or broken handling of process stopped by other process with a stop signal.
- Attaching to sleeping process terminates it as interrupted nanosleep does not return EINTR.
- Exiting of a process with running multiple threads broken (fixed).
- Attaching to applications due to unknown reasons can sometimes kill them.
- Callbacks from pthread_atfork(3) (can?) generate crash signals unhandled by a tracer.
Update in Problem Report entries
I've reiterated over reported bugs in the gnats tracking system. These problems were still valid in the beginning of this year and are now reported to be gone:
- kern/52548 (GDB breakpoint does not work properly in the binary created with golang on NetBSD (both pkgsrc/lang/go and pkgsrc/lang/go14).)
- kern/53120 (gdb issues with threaded programs)
- bin/49662 (gdb has trouble with threaded programs)
- port-arm/51677 (gdb can not debug threaded programs)
- kern/16284 (running function in stoped gdb causes signal 93)
- bin/49979 (gdb does not work properly on NetBSD-6.1.1/i386)
- kern/52628 (tracing 32-bit application on 64-bit kernel panic)
Summary
There are still sometimes new bugs reported in ptrace(2) or GDB, but they are usually against racy ATF test and complex programs. I can also observe a difference that simple and moderately complex programs usually work now and the reports are for heavy ones like firefox (multiple threads and multiple processes).
I estimate that there are still at least 3 critical threading issues to be resolved, races and use-after-free scenaris in vfork(2) and a dozen of other more generic problems typically in signal routing semantics.
Plan for the next milestone
Cover with regression tests the posix_spawn(2) interface, if needed correct the kernel code. This will be followed by resolving the use-after-free scenarios in vfork(2). This is expected to accomplish the tasks related to forking code.
My next goal on the roadmap is to return to LWP (threading) code and fix all currently known problems.
Independently I will keep supporting the work on kernel fuzzing projects within the GSoC context.
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL to chip in what you can:
The NetBSD Project is pleased to announce NetBSD 8.1, the first feature and stability maintenance release of the netbsd-8 stable branch.
Besides the workarounds for the latest CPU specific vulnerabilities, this also includes many bug fixes and a few selected new drivers. For more details and instructions see the 8.1 announcement.
Get NetBSD 8.1 from our CDN (provided by fastly) or one of the ftp mirrors.
Complete source and binaries for NetBSD are available for download at many sites around the world. A list of download sites providing FTP, AnonCVS, and other services may be found at https://www.NetBSD.org/mirrors/.
Upstream describes LLDB as a next generation, high-performance debugger. It is built on top of LLVM/Clang toolchain, and features great integration with it. At the moment, it primarily supports debugging C, C++ and ObjC code, and there is interest in extending it to more languages.
In February, I have started working on LLDB, as contracted by the NetBSD Foundation. So far I've been working on reenabling continuous integration, squashing bugs, improving NetBSD core file support and lately extending NetBSD's ptrace interface to cover more register types. You can read more about that in my Apr 2019 report.
In May, I was primarily continuing the work on new ptrace interface. Besides that, I've found and fixed a bug in ptrace() compat32 code, pushed LLVM buildbot to ‘green’ status and found some upstream LLVM regressions. More below.
Buildbot status update
Traditionally, let's start with buildbot updates. The buildbot is providing continuous integration for a number of LLVM projects on NetBSD, including LLDB, clang and clang's runtime libraries. Its available at: http://lab.llvm.org:8011/builders/netbsd-amd64.
Previously, the most significant problem in using buildbot was flakiness of LLDB tests which resulted in frequent false positives. I was able to finally reduce this effect through reducing the number of parallel test runs for LLDB tests. To avoid slowing down other test suites, I have used a sed hack that overrides job count directly in the specific lit invocation.
Additionally, I have fixed a few regressions during the period, notably:
worked around missing nexttowardl() in NetBSD 8 causing libc++ test failure, by using std::nextafter() in the problematic test: r360673,
fixed compiler path test to work correctly without specific linker being available: r360761,
fixed inferring source paths in libunwind that prevented the tests from finding libc++: r361931,
removed test case that relied on read() attempt from a directory producing very specific error message: r362404 (NB: this failed because NetBSD permits reading from directory descriptors).
Those fixes permitted the buildbot to become green for a short period of time. Sadly, shortly afterwards one of AMDGPU tests started failing and we are still trying to find the cause.
Adding register read/write tests to ATF tests
Last month, I have implemented a number of register reading/writing tests for LLDB. This month I've introduced matching tests inside NetBSD's ATF test suite. This provides the ability to test NetBSD's ptrace implementation directly on the large variety of platforms and kernels supported by NetBSD. With the dynamic development of NetBSD, running LLDB tests everywhere would not be feasible.
While porting the tests, I've made a number of improvements, some of them requested specifically by LLDB upstream. Those include:
starting to use better input/output operands for assembly, effectively reducing the number of direct register references and redundant code: r359978,
using more readable/predictable constants for register data, read part: r360041, write part: r360154,
using %0 and %1 operands to reference memory portably between i386 and amd64: r360148.
The relevant NetBSD commits for added tests are (using the git mirror):
general-purpose register reading tests: 7a58d92435a9,
fix to the above: split tests for reading i386 gp registers as not to require MMX: 06be77bbafa6,
r8..r15 amd64 register reading tests: 86f6b1d4dab6,
mm & xmm register reading tests: 3ef02e1666ae,
general-purpose register writing tests: 95bfedcb6a89,
mm & xmm register writing tests: 2c8335920f61.
While working on this, I've also noticed that struct fpreg and struct xmmregs are not fully specified on i386. In bbc3f184d470, I've added the fields needed to make use of those structures convenient.
Fixing compat32: request mapping and debug registers
Kamil has asked me to look into PR#54233 indicating problems with 32-bit application debugging on amd64. While the problem in question most likely combines multiple issues, one specifically related to my work was missing PT_*DBREGS support in compat32.
While working on this, I've found out that the functions responsible for implementing those requests were not called at all. After investigating, I've came to the following conclusion. The i386 userland code has passed PT_* request codes corresponding to i386 headers to the compat32 layer. The compat32 layer has passed those codes unmodified to the common kernel code and compared them to PT_* constants available in kernel code which happened to be amd64 constants.
This worked fine for low requests numbers that happened to match on both architectures. However, i386 adds two additional requests (PT_*XMMREGS) after PT_SETFPREGS, and therefore all remaining requests are offset.
To solve this, I've created a request code mapping function that converts i386 codes coming from userland to the matching amd64 values used in the kernel. For the time being, this supports only requests common to both architectures, and therefore PT_*XMMREGS can't be implemented without further hacking it.
Once I've managed to fix compat32, I went ahead to implement PT_*DBREGS in compat32. Kamil has made an initial implementation in the past but it was commented out and lacked input verification. However, I've chosen to change the implementation a bit and reuse x86_dbregs_read() and x86_dbregs_write() functions rather than altering pcb directly. I've also added the needed value checks for PT_SETDBREGS.
Both changes were committed to /usr/src:
Initial XSAVE work
In the previous report, I have been considering which approach to take in order to provide access to the additional FPU registers via ptrace. Eventually, the approach to expose the raw contents of XSAVE area got the blessing, and I've started implementing it.
However, this approach proved impractical. The XSAVE area in standard format (which we are using) consists of three parts: FXSAVE-compatible legacy area, XSAVE header and zero or more extended components. The offsets of those extended components turned out to be unpredictable and potentially differing between various CPUs. The architecture developer's manual indicates that the relevant offsets can be obtained using CPUID calls.
Apparently both Linux and FreeBSD did not take this into consideration when implementing their API, and they effectively require the caller to issue CPUID calls directly. While such an approach could be doable in NetBSD, it would prevent core dumps from working correctly on a different CPU. Therefore, it would be necessary to perform the calls in kernel instead, and include the results along with XSAVE data.
However, I believe that doing so would introduce unnecessary complexity for no clear gain. Therefore, I proposed two alternative solutions. They were to either:
copy XSAVE data into custom structure with predictable indices, or
implement separate PT_* requests for each component group, with separate data structure each.
Comparison of the two proposed solutions
Both solutions are roughly equivalent. The main difference between them is that the first solution covers all extended registers (and is future-extensible) in one request call, while the second one requires new pair of requests for each new register set.
I personally prefer the former solution because it reduces the number of ptrace calls needed to perform typical operations. This is especially relevant when reading registers whose contents are split between multiple components: YMM registers (whose lower bits are in SSE area), and lower ZMM registers (whose lower bits are YMM registers).
Example code reading the ZMM register using a single request solution would look like:
struct xstate xst; struct iovec iov; char zmm_reg[64]; iov.iov_base = &xst; iov.iov_len = sizeof(xst); ptrace(PT_GETXSTATE, child_pid, &iov, 0); // verify that all necessary components are available assert(xst.xs_xstate_bv & XCR0_SSE); assert(xst.xs_xstate_bv & XCR0_YMM_Hi128); assert(xst.xs_xstate_bv & XCR0_ZMM_Hi256); // combine the values memcpy(&zmm_reg[0], &xst.xs_fxsave.fx_xmm[0], 16); memcpy(&zmm_reg[16], &xst.xs_ymm_hi128.xs_ymm[0], 16); memcpy(&zmm_reg[32], &xst.xs_zmm_hi256.xs_zmm[0], 32);
For comparison, the equivalent code for the other variant would roughly be:
#if defined(__x86_64__) struct fpreg fpr; #else struct xmmregs fpr; #endif struct ymmregs ymmr; struct zmmregs zmmr; char zmm_reg[64]; #if defined(__x86_64__) ptrace(PT_GETFPREGS, child_pid, &fpr, 0); #else ptrace(PT_GETXMMREGS, child_pid, &fpr, 0); #endif ptrace(PT_GETYMMREGS, child_pid, &ymmr, 0); ptrace(PT_GETZMMREGS, child_pid, &zmmr, 0); memcpy(&zmm_reg[0], &fpr.fxstate.fx_xmm[0], 16); memcpy(&zmm_reg[16], &ymmr.xs_ymm_hi128.xs_ymm[0], 16); memcpy(&zmm_reg[32], &zmmr.xs_zmm_hi256.xs_zmm[0], 32);
I've submitted a patch set implementing the first solution, as it was easier to convert to from the initial approach. If the feedback indicates the preference of the other solution, a conversion to it should also be easier to the other way around. It is available on tech-kern mailing list: [PATCH 0/2] PT_{GET,SET}XSTATE implementation, WIP v1.
The initial implementation should support getting and setting x87, SSE, AVX and AVX-512 registers (i.e. all types currently enabled in the kernel). The tests cover all but AVX-512. I have tested it on native amd64 and i386, and via compat32.
Future plans
The most immediate goal is to finish the work on XSAVE. This includes responding to any feedback received, finding AVX-512 hardware to test it on, writing tests for AVX-512 registers and eventually committing the patches to the NetBSD kernel. Once this is done, I need to extend XSAVE support into core dumps, and implement userland-side of both into LLDB.
Besides that, the next items on TODO are:
Adding support for debug registers (moved from last month's TODO).
Adding support to backtrace through signal trampoline.
Working on i386 and aarch64 LLDB port.
In the meantime, Kamil's going to continue working on improving fork and thread support kernel-side, preparing it for my work LLDB-side.
This work is sponsored by The NetBSD Foundation
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL to chip in what you can:
The first coding period of The Google Summer of Code has come to an end. It has been a great experience so far and I got the opportunity to learn a lot of new stuff. This is a report on the work I have during this coding period.
About TriforceAFL
TriforceAFL is a modified version of AFL that supports fuzzing using QEMU's full system emulation. This offers several advantages such as the fact that pieces of the kernel need not be recompiled with AFL or that the kernel does not need to be built with coverage support. More details on other advantages, design and implementation of TriforceAFL can be found here.
The TriforceLinuxSyscallFuzzer and the TriforceOpenBSDSyscallFuzzer are syscall fuzzers built on top of TriforceAFL. The end goal of this project is to adapt TriforceAFL for NetBSD syscall fuzzing.
Adapted TriforceAFL for pkgsrc-wip
One of the end goals of the project is to make the fuzzer available as a pkgsrc package. To do so, TriforceAFL had to be first ported to pkgsrc. TriforceAFL uses qemu, so the appropriate patches to qemu for NetBSD were applied and few other minor issues resolved. The working package is now available in pkgsrc-wip.
The NetBSD Syscall Fuzzer
TriforceNetBSDSyscallFuzzer can be now used to perform system call fuzzing of NetBSD kernels using AFL and QEMU. The setup scripts and the driver program are functioning. The syscalls list has been updated for NetBSD and basic input generation works. Documentation detailing the process of setup(of the NetBSD installation/kernel image), building and fuzzing along with the code is available on github.
The fuzzer functions properly and detects crashes which can be reproduced using the driver. Although it can severely benefit from better input generation and optimisation. This will be the focus in the next coding period.
Summary
In the coming weeks, the work of optimizing the fuzzer is to be done, so that it is more efficient at catching bugs, I am looking forward to doing so and making TriforceNetBSDSyscallFuzzer available on NetBSD through pkgsrc.
Lastly I would like to thank my mentor, Kamil Rytarowski for always helping me through the process and guiding me whenever I needed any help.
Prepared by Siddharth Muralee(@R3x) as a part of Google Summer of Code 2019
As a part of Google Summer of Code 19, I am working on improving the support for Syzkaller kernel fuzzer. Syzkaller is an unsupervised coverage-guided kernel fuzzer, that supports a variety of operating systems including NetBSD. This report details the work done during the first coding period.
Syzkaller
Initially, Syzkaller was developed with Linux kernel fuzzing in mind, but now it's being extended to support other OS kernels as well. The main target of the Syzkaller fuzzer is the system call layer.
Thanks to Google, we now have a 24/7 continuous fuzzing instance on a Google Cloud engine for NetBSD managed by Syzbot, a sub-system of the Syzkaller fuzzer. Syzbot maintains a dashboard where it reports all the bugs that were found. Syzbot also maintains a mailing list to report bugs found.
Syzbot is currently fuzzing NetBSD-HEAD which it updates from the Github mirror.
You can go through the Syzkaller documentation or take a look at my slides from Troopers 19 for learning more about Syzkaller.
Automated Image creation
Syzkaller required NetBSD images with ssh-keys for continous fuzzing. Due to frequent updates to HEAD sometimes images become unusable. So I decided to automate the process of creating NetBSD images with ssh-keys and appropriate settings.
Initial attempts with packer by Hashicorp failed because the boot sequence was controlled by waits and not output matching. So I wrote a shell script which basically adds a wrapper around anita to do the job.
Kcov(4) support
Kernel Code Coverage(KCov) is a compiler instrumented feature which helps us in finding the code paths executed inside the kernel for a certain set of system calls. An initial port was done by me with modifications by @kamil and @maxv.
Syzkaller uses coverage for modifying and mutating the arguments of syscalls. Coverage information for NetBSD is publicly available.
Sanitizers Support
Sanitizers are compiler instrumented tools to improve code correctness. Currently, NetBSD supports Kernel Address Sanitizer(KASAN) and Kernel Undefined behaviour Sanitizer(KUBSAN).
We use the Sanitizers to increase the chances of finding bugs. Syzkaller now compiles kernels with the Sanitizers.
Report Generation and Symbolization
Syzkaller logs the console and in the event of a crash it records the log to find out details about the crash, these details are then used to classify the crash and create a report.
For better crash reports, we decided to enable a ddb(4) shell on event of a kernel panic. This allowed us to print backtraces, details of locks and processes.
Also I added support for better Symbolization of the reports. Symbolization is adding more details in the crash report to make them easier for developers to go through. Currently we have added file names and line numbers for functions in the crash based on the kernel object (netbsd.gdb).
Initial backtrace :
do_ptrace() at netbsd:do_ptrace+0x33d sys_ptrace() at netbsd:sys_ptrace+0x71 sys_syscall() at netbsd:sys_syscall+0xf5
After Symbolization :
do_ptrace() at netbsd:do_ptrace+0x33d sys/kern/sys_ptrace_common.c:1430 sys_ptrace() at netbsd:sys_ptrace+0x71 sys/kern/sys_ptrace.c:218 sys_syscall() at netbsd:sys_syscall+0xf5 sy_call sys/sys/syscallvar.h:65 [inline]
Syscall Coverage Improvements
Syzkaller uses a pseudo-formal grammar for system calls. It uses the same to build programs to fuzz the kernel. The files related to the same are stored at sys/netbsd in the syzkaller repo. These files were a rough copy from the linux files with whatever was unable to compile removed.
We had to review all the existing syscall descriptions, find the missing ones and add them.
I wrote a python script which would help in finding out existing syscall descriptions and match them with the NetBSD description. The script also finds missing syscalls and logs them.
I have listed the system calls that are currently fuzzed with Syzkaller.
We are currently working on adding and improving descriptions for the more important syscalls. If you would like to see a NetBSD system call fuzzed you can reach out to us.
Summary
During the last month, I was focusing on improving support for NetBSD. I have managed to complete the tasks that we had planned for the first evaluation.
For the next coding period (28th June - 22nd July) I will be working on adding support for fuzzing the Network layer.
Last but not least, I want to thank my mentors, @kamil and @cryo for their useful suggestions and guidance. I would also like to thank Dmitry Vyukov, Google for helping with any issues faced with regard to Syzkaller. Finally, thanks to Google to give me a good chance to work with NetBSD community.
Prepared by Manikishan Ghantasala (shannu) as a part of Google Summer of Code 2019.
Greetings everyone, I am Manikishan an Undergraduate pursuing my Bachelors Degree in Computer Science from Amrita Vishwa Vidyapeetham, Amritapuri, Kerala, India. I have been very interested in working on the lower level development such as Operating Systems, Kernels, and Compilers. I have also worked on building a computer from scratch. The project is named From Nand To Tetris
. It had helped me elevate my interest in the field of Operating Systems and to apply for this organization. I am very grateful to be a part of this program and also would like to thank the community and my mentors for granting me the opportunity and being supportive at all times.
Regarding the first evaluation, it has been quite interesting working on Add KNF (NetBSD style) in clang-format project. I love the NetBSD community and look forward to continue. It has helped me to learn a lot during this period. It has been challenging and amazing so far.
This is a blog post about the work I have done prior to the first evaluation period.
What is clang-format?
Clang-format is a set of tools that format code built upon LibFormat. It supports some of the coding styles such as LLVM, Google, Chromium, Mozilla, Webkit which can be chosen by -style=<StyleName>. There is another option of writing a config file named .clang-format with custom style rules. My project is to add NetBSD KNF support to clang-format.
With the added support to clang-format, it will be able to format the code according to the NetBSD Style when run with -style=NetBSD.
Getting familiar to LLVM Source
For the first week, I went on exploring LLVM source to find out implementations for the similar style rules I have listed in my proposal. I have managed to figure out a way for the same with the help of my supportive mentors. I have implemented two styles:
- BitFieldDeclarationsOnePerLine
- SortNetBSDIncludes
About BitFieldDeclarationsOnePerLine
This rule lines up BitField declarations on consecutive lines with correct indentation.
Example:
Input:
unsigned int bas :3, hh : 4, jjj : 8;
unsigned int baz:1,
fuz:5,
zap:2;
Output:
unsigned int bas:3,
hh:4,
jjj:8;
unsigned int baz:1,
fuz:5,
zap:2;
Submitted a patch regarding this in the differential for review.
-> Patch: https://reviews.llvm.org/D63062
There is a bug in the implementation where the indentation breaks when there is a comment in between the bitfields, which I kept aside for getting on to go with the next style and will fix it in the coming weeks.
About SortNetBSDIncludes
Clang-format has a native SortIncludes style, which sorts all the headers in alphabetical order where NetBSD headers follow a special order due to dependencies between each header. After discussing with my mentors and in the tech-toolchain we have come up with more precise order in which we should follow for headers:
- <sys/param.h>
- <sys/types.h>
- <sys/*> -- kernel headers
- <uvm/*> -- vm headers
- <net*/*> -- network protocol headers
- <*fs/*> -- filesystem headers
- <dev/*> -- device driver headers
- <protocols/.h>
- <machine/*>
- <[arch]/*>
- < /usr includes next>
- <paths.h>
- User include files
I have made more smarter version with Regex with necessary changes from the approach I had before which was a harcoded one, the patch for this will be up by this weekend.
Plan for the next phase
I was a bit behind the proposed schedule because understanding the LLVM source took more time than expected. I am confident that I will be speeding up my progress in the upcoming phase and complete as many styles possible. The final plan is to add support for NetBSD in clang-format which can be used by --style=NetBSD.
Summary
In the coming weeks, I will fix and add all the missing features to existing styles and new ones, and concentrate on optimizing and testing following all guidelines of NetBSD and make sure a formatted code doesn't cause a build fail.
Lastly, I would like to thank my wonderful mentors Michal and Christos for helping me to the process and guiding me whenever needed.
Prepared by Manikishan Ghantasala (shannu) as a part of Google Summer of Code 2019.
Greetings everyone, I am Manikishan an Undergraduate pursuing my Bachelors Degree in Computer Science from Amrita Vishwa Vidyapeetham, Amritapuri, Kerala, India. I have been very interested in working on the lower level development such as Operating Systems, Kernels, and Compilers. I have also worked on building a computer from scratch. The project is named From Nand To Tetris
. It had helped me elevate my interest in the field of Operating Systems and to apply for this organization. I am very grateful to be a part of this program and also would like to thank the community and my mentors for granting me the opportunity and being supportive at all times.
Regarding the first evaluation, it has been quite interesting working on Add KNF (NetBSD style) in clang-format project. I love the NetBSD community and look forward to continue. It has helped me to learn a lot during this period. It has been challenging and amazing so far.
This is a blog post about the work I have done prior to the first evaluation period.
What is clang-format?
Clang-format is a set of tools that format code built upon LibFormat. It supports some of the coding styles such as LLVM, Google, Chromium, Mozilla, Webkit which can be chosen by -style=<StyleName>. There is another option of writing a config file named .clang-format with custom style rules. My project is to add NetBSD KNF support to clang-format.
With the added support to clang-format, it will be able to format the code according to the NetBSD Style when run with -style=NetBSD.
Getting familiar to LLVM Source
For the first week, I went on exploring LLVM source to find out implementations for the similar style rules I have listed in my proposal. I have managed to figure out a way for the same with the help of my supportive mentors. I have implemented two styles:
- BitFieldDeclarationsOnePerLine
- SortNetBSDIncludes
About BitFieldDeclarationsOnePerLine
This rule lines up BitField declarations on consecutive lines with correct indentation.
Example:
Input:
unsigned int bas :3, hh : 4, jjj : 8;
unsigned int baz:1,
fuz:5,
zap:2;
Output:
unsigned int bas:3,
hh:4,
jjj:8;
unsigned int baz:1,
fuz:5,
zap:2;
Submitted a patch regarding this in the differential for review.
-> Patch: https://reviews.llvm.org/D63062
There is a bug in the implementation where the indentation breaks when there is a comment in between the bitfields, which I kept aside for getting on to go with the next style and will fix it in the coming weeks.
About SortNetBSDIncludes
Clang-format has a native SortIncludes style, which sorts all the headers in alphabetical order where NetBSD headers follow a special order due to dependencies between each header. After discussing with my mentors and in the tech-toolchain we have come up with more precise order in which we should follow for headers:
- <sys/param.h>
- <sys/types.h>
- <sys/*> -- kernel headers
- <uvm/*> -- vm headers
- <net*/*> -- network protocol headers
- <*fs/*> -- filesystem headers
- <dev/*> -- device driver headers
- <protocols/.h>
- <machine/*>
- <[arch]/*>
- < /usr includes next>
- <paths.h>
- User include files
I have made more smarter version with Regex with necessary changes from the approach I had before which was a harcoded one, the patch for this will be up by this weekend.
Plan for the next phase
I was a bit behind the proposed schedule because understanding the LLVM source took more time than expected. I am confident that I will be speeding up my progress in the upcoming phase and complete as many styles possible. The final plan is to add support for NetBSD in clang-format which can be used by --style=NetBSD.
Summary
In the coming weeks, I will fix and add all the missing features to existing styles and new ones, and concentrate on optimizing and testing following all guidelines of NetBSD and make sure a formatted code doesn't cause a build fail.
Lastly, I would like to thank my wonderful mentors Michal and Christos for helping me to the process and guiding me whenever needed.
This report was written by Naveen Narayanan as part of Google Summer of Code 2019.
I have been working on porting Wine to amd64 on NetBSD as a GSoC 2019 project. Wine is a compatibility layer which allows running Microsoft Windows applications on POSIX-complaint operating systems. This report provides an overview of the progress of the project during the first coding period.
WINE on i386
Initially, when I started working on getting Wine-4.4 to build and run on NetBSD i386 the primary issue that I faced was Wine displaying black windows instead of UI, and this applied to any graphical program I tried running with Wine.
I suspected it , as it is related to graphics, to be an issue with the graphics driver or Xorg. Subsequently, I tried building modular Xorg, and I tried running Wine on it only to realize that Xorg being modular didn't affect it in the least. After having tried a couple of configurations, I realized that trying to hazard out every other probability is going to take an awful lot of time that I didn't have. This motivated me to bisect the repo using git, and find the first version of Wine which failed on NetBSD.
I started with the last version of Wine that worked on NetBSD which is 1.9.18. After two days of git bisect, I had the culprit. It was a commit that introduced a single clipboard manager thread per window station in Wine. Later, I found that pthread_create(3) calls were borked and didn't return anything. I tried to walk through the code to know where in pthreads lib was the program getting stuck at. Finally, I got a segfault.
I realized the address at which it segfaulted was identical to the address at which Wine has been throwing an unhandled page fault. I had a hunch that these two issues were some how correlated. After learning more about memory mapping and /proc, I was sure black windows was an effect of this unhandled page fault.
Eventually, I found that pthread_attr_setstack(3) was setting the guard size to 65536 bytes even though the man page said otherwise. And Wine relied on it not being set. This resulted in out-of-bound access which caused the unhandled page fault. After setting the guard size to 0 using pthread_attr_setguardsize(3), Wine started behaving fine.
I discussed about the patch with Wine devs, and they were happy to upstream it as long as it didn't cause any inadvertent issues on other platforms. Of course, who wouldn't want to play mario now?
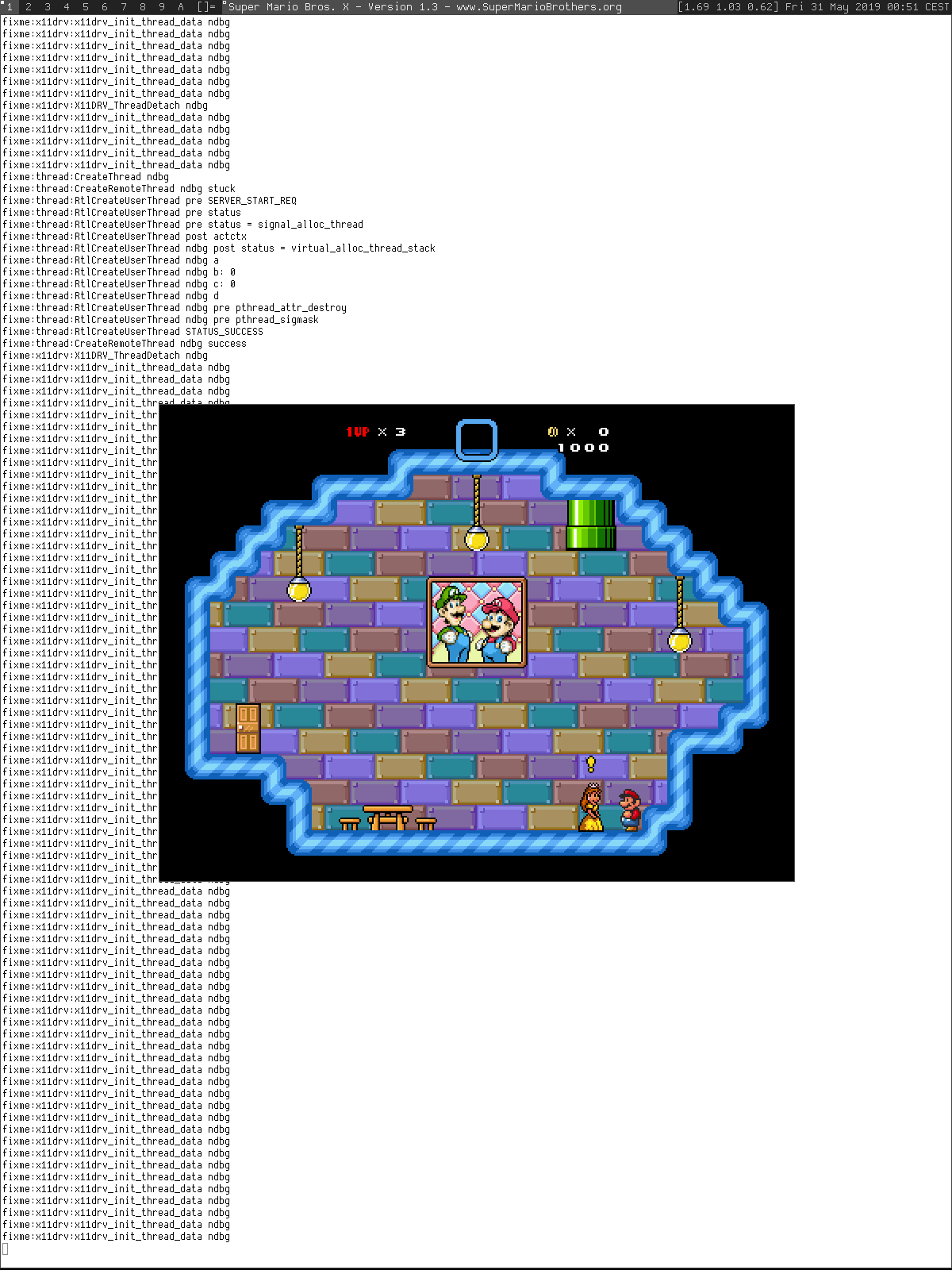
WINE on amd64
Compiling Wine with 32 bit support is a bit tricky on amd64. I proceeded with the chroot approach as I wanted to know if Wine worked as promised on NetBSD, and if it didn't, to what degree, it required patching. So, as the first step, I compiled Wine on amd64 and it ran fine. The subsequent step was to build a chroot environment for i386. I corresponded with my mentors to learn more about compat32_netbsd and successfully built an i386 chroot. I had to compile Wine twice under i386 to have it inject the 32 bit components to 64 bit Wine for WoW64 support. And to my amazement, it worked!

Summary
I think Wine-4.4 is in pretty good shape as of right now, but packaging it is tricky especially since chroot isn't an option, as it is privileged. I have been writing compat32 packages for dependencies of Wine to have them crosscompiled on amd64. I shall be working on getting Wine crosscompiled for 32 bit support on amd64 during the next coding period. On a different note and a very important one, I would like to thank my mentors @christos, @leot, @maya, and @maxv for their valuable suggestions. From where I see it, I wouldn't have reached this phase if it weren't for them. I would also like to thank @kamil for his feedback and input.
This report was written by Naveen Narayanan as part of Google Summer of Code 2019.
I have been working on porting Wine to amd64 on NetBSD as a GSoC 2019 project. Wine is a compatibility layer which allows running Microsoft Windows applications on POSIX-complaint operating systems. This report provides an overview of the progress of the project during the first coding period.
WINE on i386
Initially, when I started working on getting Wine-4.4 to build and run on NetBSD i386 the primary issue that I faced was Wine displaying black windows instead of UI, and this applied to any graphical program I tried running with Wine.
I suspected it , as it is related to graphics, to be an issue with the graphics driver or Xorg. Subsequently, I tried building modular Xorg, and I tried running Wine on it only to realize that Xorg being modular didn't affect it in the least. After having tried a couple of configurations, I realized that trying to hazard out every other probability is going to take an awful lot of time that I didn't have. This motivated me to bisect the repo using git, and find the first version of Wine which failed on NetBSD.
I started with the last version of Wine that worked on NetBSD which is 1.9.18. After two days of git bisect, I had the culprit. It was a commit that introduced a single clipboard manager thread per window station in Wine. Later, I found that pthread_create(3) calls were borked and didn't return anything. I tried to walk through the code to know where in pthreads lib was the program getting stuck at. Finally, I got a segfault.
I realized the address at which it segfaulted was identical to the address at which Wine has been throwing an unhandled page fault. I had a hunch that these two issues were some how correlated. After learning more about memory mapping and /proc, I was sure black windows was an effect of this unhandled page fault.
Eventually, I found that pthread_attr_setstack(3) was setting the guard size to 65536 bytes even though the man page said otherwise. And Wine relied on it not being set. This resulted in out-of-bound access which caused the unhandled page fault. After setting the guard size to 0 using pthread_attr_setguardsize(3), Wine started behaving fine.
I discussed about the patch with Wine devs, and they were happy to upstream it as long as it didn't cause any inadvertent issues on other platforms. Of course, who wouldn't want to play mario now?
WINE on amd64
Compiling Wine with 32 bit support is a bit tricky on amd64. I proceeded with the chroot approach as I wanted to know if Wine worked as promised on NetBSD, and if it didn't, to what degree, it required patching. So, as the first step, I compiled Wine on amd64 and it ran fine. The subsequent step was to build a chroot environment for i386. I corresponded with my mentors to learn more about compat32_netbsd and successfully built an i386 chroot. I had to compile Wine twice under i386 to have it inject the 32 bit components to 64 bit Wine for WoW64 support. And to my amazement, it worked!
Summary
I think Wine-4.4 is in pretty good shape as of right now, but packaging it is tricky especially since chroot isn't an option, as it is privileged. I have been writing compat32 packages for dependencies of Wine to have them crosscompiled on amd64. I shall be working on getting Wine crosscompiled for 32 bit support on amd64 during the next coding period. On a different note and a very important one, I would like to thank my mentors @christos, @leot, @maya, and @maxv for their valuable suggestions. From where I see it, I wouldn't have reached this phase if it weren't for them. I would also like to thank @kamil for his feedback and input.
This report was written by Saurav Prakash as part of Google Summer of Code 2019.
My venture into the first phase of The Google Summer of Code is nearing an end. The experience was enriching in every dimension, and the learning exposure I was subjected to was genuinely worthwhile. Here is a brief report on the work I have performed during this coding period.
About HummingBoard Pulse
HummingBoard Pulse is an arm64 board developed by SolidRun, with iMX8 System-on-Chip, Dual/Quad core Cortex A53 processor. This project involves extending the GENERIC64 kernel to support iMX8 SoC.
Device Tree Files
We compare the compatible property of the root node in the device tree with the list of ARM platforms compiled into the kernel. We add the .dts file for imx8 which is compatible with the imx8mq.dtsi file adopted from the Linux mainline 5.1.4. At this early stage, nodes for uart, iomux and clock only were created.
Board Platform Code
The platform code provides SoC specific code needed early at boot. The arm_platform structure for imx8 is initialised here. It contains function pointers like .ap_attach_init_args, .ap_device_register, .ap_reset, .ap_delay, .ap_uart_freq, .ap_mpstart and a, platform_early_putchar_function so that we can send a character to UART.
Clock Driver
During the booting stage we only need to enable the uart clocks (IMX8MQ_CLK_UART*_ROOT) and its parents. This includes writing drivers for fixed clocks (OSC_25M, OSC_27M, OSC_32K, and more), fixed-factor clocks, divider clocks, mux clocks, composite clocks (IMX8MQ_CLK_UART*), gate clocks (IMX8MQ_CLK_UART*_ROOT), sccg-pll clocks, and frac-pll clocks.
UART Driver
The imx drivers are separated between "core driver" and "bus glue". <arch/arm/imx/imxuart.c> is a "core driver", and we need to write a fdt based "bus glue" for the custom bus, this non-fdt based imx code currently uses.
You can checkout the code from here.What's Next
The sccg-pll, frac-pll, composite clocks aren't complete yet. So the focus in the next weeks would be to complete the unfinished work as required for the board to be booting till root. Finalising the UART driver code. Modifying the drivers written now, to suit the needs later. And then moving on further to write iomux driver, and then a USB driver for a storage device to boot from.
Lastly I would like to thank my mentors, @jmcneill, @martin @Cryo for being a constant support and non-flickering guidance throughout the process.
This report was written by Saurav Prakash as part of Google Summer of Code 2019.
My venture into the first phase of The Google Summer of Code is nearing an end. The experience was enriching in every dimension, and the learning exposure I was subjected to was genuinely worthwhile. Here is a brief report on the work I have performed during this coding period.
About HummingBoard Pulse
HummingBoard Pulse is an arm64 board developed by SolidRun, with iMX8 System-on-Chip, Dual/Quad core Cortex A53 processor. This project involves extending the GENERIC64 kernel to support iMX8 SoC.
Device Tree Files
We compare the compatible property of the root node in the device tree with the list of ARM platforms compiled into the kernel. We add the .dts file for imx8 which is compatible with the imx8mq.dtsi file adopted from the Linux mainline 5.1.4. At this early stage, nodes for uart, iomux and clock only were created.
Board Platform Code
The platform code provides SoC specific code needed early at boot. The arm_platform structure for imx8 is initialised here. It contains function pointers like .ap_attach_init_args, .ap_device_register, .ap_reset, .ap_delay, .ap_uart_freq, .ap_mpstart and a, platform_early_putchar_function so that we can send a character to UART.
Clock Driver
During the booting stage we only need to enable the uart clocks (IMX8MQ_CLK_UART*_ROOT) and its parents. This includes writing drivers for fixed clocks (OSC_25M, OSC_27M, OSC_32K, and more), fixed-factor clocks, divider clocks, mux clocks, composite clocks (IMX8MQ_CLK_UART*), gate clocks (IMX8MQ_CLK_UART*_ROOT), sccg-pll clocks, and frac-pll clocks.
UART Driver
The imx drivers are separated between "core driver" and "bus glue". <arch/arm/imx/imxuart.c> is a "core driver", and we need to write a fdt based "bus glue" for the custom bus, this non-fdt based imx code currently uses.
You can checkout the code from here.What's Next
The sccg-pll, frac-pll, composite clocks aren't complete yet. So the focus in the next weeks would be to complete the unfinished work as required for the board to be booting till root. Finalising the UART driver code. Modifying the drivers written now, to suit the needs later. And then moving on further to write iomux driver, and then a USB driver for a storage device to boot from.
Lastly I would like to thank my mentors, @jmcneill, @martin @Cryo for being a constant support and non-flickering guidance throughout the process.
The VAX is the oldest machine architecture still supported by NetBSD.
The support for it sometimes causes heated discussions, but it also has benefits:
- It uses a pre-IEEE 754 version of floating point numbers, while all other (later) architectures use some variant of IEEE 754 floating point in hardware or emulate it.
- By today's standards all machines are slow and have little memory.
This are severe challenges for a general purpose operating system like NetBSD, but also provides reality checks for our claim to be a very portable operating system.
Unfortunately there is another challenge, totally outside of NetBSD, but affecting the VAX port big time: the compiler support for VAX is ... let's say sub-optimal. It is also risking to be dropped completely by gcc upstream.
Now here is where people can help: there is a bounty campaign to finance a gcc hacker to fix the hardest and most immediate issue with gcc for VAX. Without this being resolved, gcc will drop support for VAX in a near future version.
This post was written by Piyush Sachdeva:
What really happens when you double click an icon on your desktop?
Support for chdir(2) in posix_spawn(3)
Processes are the bread and butter of your operating system. The moment you double click an icon, that particular program gets loaded in your Random Access Memory (RAM) and your operating system starts to run it. At this moment the program becomes a process. Though you can only see the execution of your process, the operating system (the Kernel) is always running a lot of processes in the background to facilitate you.
From the moment you hit that power button, everything that happens on the screen is the result of some or the other process. In this post we are going to talk about one such interface which helps in creation of your programs.
The fork() & exec() shenanigans
The moment a computer system comes alive, it launches a bunch of processes. For the purpose of this blog let’s call them, ‘the master processes’. These processes run in perpetuity, provided the computer is switched on. One such process is init/systemd/launchd (depending on your OS). This ‘init’ master process owns all the other processes in the computer, either directly or indirectly.
Operating systems are elegant, majestic software that work seamlessly under the hood. They do so much without even breaking a sweat (unless it’s Windows). Let's consider a scenario where you have decided to take a trip down memory lane and burst open those old photos. The ‘init master process’ just can’t terminate itself and let you look at your photos. What if you unknowingly open a malicious file, which corrupts all your data? So init doesn’t just exit, rather it employs fork() and exec() to start a new process. The fork() function is used to create child processes which are an exact copy of their parents. Whichever process calls fork, gets duplicated. The newly created process becomes the child of the original running process and the original running process is called the parent. Just how parents look after their kids, the parent process makes sure that the child process doesn't do any mischief. So now you have two exactly similar processes running in your computer.
One might think that the newly created child process doesn’t really help us. But actually, it does. Now exec() comes into the picture. What exec() does is, it replaces any process which calls it. So what if we replace the child process, the one we just thought to be useless, with our photos? That's exactly what we are going to do indeed. This will result in replacement of the fork() created child process with your photos. Therefore, the master init process is still running and you can also enjoy your photos with no threat to your data.
“Neither abstraction nor simplicity is a substitute for getting it right. Sometimes, you just have to do the right thing, and when you do, it is way better than the alternatives. There are lots of ways to design APIs for process creation; however, the combination of fork() and exec() is simple and immensely powerful. Here, the UNIX designers simply got it right.” Lampson’s Law - Getting it RightNow you could ask me, `But what about the title, some ‘posix_spawn()’ thing?´ Don’t worry, that’s next.
posix_spawn()
posix_spawn() is an alternative to the fork() + exec() routine. It implements fork() and exec(), but not directly (as that would make it slow, and we all need everything to be lightning fast). What actually happens is that posix_spawn() only implements the functionality of the fork() + exec() routines, but in one single call. However, because fork() + exec() is a combination of two different calls, there is a lot of room for customization. Whatever software you are running on your computer, calls these routines on its own and does the necessary. Meanwhile a lot is cooking in the background. Between the call to fork() and exec() there is plenty of leeway for tweaking different aspects of the exec-ing process. But posix_spawn doesn’t bear this flexibility and therefore has a lot of limitations. It does take a lot of parameters to give the caller some flexibility, but it is not enough.
Now the question before us is,
“If fork() + exec() is so much more powerful, then why have,
or use the posix_spawn() routine?” The answer to that is, that
fork() and exec() are UNIX system routines.
They are not present in operating systems that are not a derivative of UNIX.
Eg- Windows implements a family of spawn functions.
There is another issue with fork() (not exec() ), which in reality is one
of the biggest reasons behind the growth of posix_spawn(). The outline of
the issue is that, creating child processes in multi-threaded programs is a
whole another ball game altogether.
Concurrency is one of those disciplines in operating systems where the order in which the cards are going to unravel is not always how you expect them to. Multi-threading in a program is a way to do different and independent tasks of a program simultaneously, to save time. No matter how jazzy or intelligent the above statement looks, multi-threaded programs require an eagle’s eye as they can often have a lot of holes. Though the “tasks” are different and independent, they often share a few common attributes. When these different tasks due to concurrency start running in parallel, a data race begins to access those shared attributes. To not wreak havoc, there are mechanisms through which, when modifying/accessing these common attributes (Critical Section) we can provide a sort of mutual exclusion (locks/conditional variables) - only letting one of the processes modify the shared attribute at a time. Here when things are already so intricate due to multithreading, and to top it off, we start creating child processes. Complications are bound to arise. When one of the threads from the multi-threaded program calls fork() to create a child process, fork() does clone everything (variables, their states, functions, etc) but it fails to clone other threads (though this is not required at all times).
The child process now knows only about that one thread which called fork(). But all the other attributes of the child that were inherited from the parent (locks, mutexes) are set from the parent’s address space (considering multiple threads). So there is no way for the child process to know which attributes conform to which parts of the parent. Also, those mechanisms that we used to provide mutual exclusion, like locks and conditional variables, need to be reset. This reset step is essential in letting the parent access it’s attributes. Failing this reset can cause deadlocks. To put it simply, you can see how difficult things have become all of a sudden. The posix_spawn() call is free from these limitations of fork() encountered in multi-threaded programs. However, as mentioned by me earlier, there needs to be enough rope to meet all the requirements before posix_spawn() does the implicit exec().
About my Project
Hi, I am Piyush Sachdeva and I am going to start a project which will focus on relaxing one limitation of posix_spawn - changing the current directory of the child process, before the said call to exec() is made. This is not going to restrict it to the parent’s current working directory. Just passing the new directory as one of the parameters will do the trick. Resolving all the impediments would definitely be marvelous. Alas! That is not possible. Every attempt to resolve even a single hindrance can create plenty of new challenges.
As already mentioned by me, posix_spawn() is a POSIX standard. Hence the effect of my project will probably be reflected in the next POSIX release. I came across this project through Google Summer of Code 2021. It was being offered by The NetBSD Foundation Inc. However, as the slots for Google Summer of Code were numbered, my project didn’t make the selection. Nevertheless, the Core Team at The NetBSD Foundation offered me to work on the project and even extended a handsome stipend. I will forever be grateful to The NetBSD Foundation for this opportunity.
Notes
- init, systemd & launchd are system daemon processes. init is the historical process present since System III UNIX. systemd was the replacement for the authentic init which was written for the Linux kernel. launchd is the MacOS alternative of init/systemd.
- This is taken from Operating Systems: The Three Easy Pieces book by Andrea C. Arpaci-Dusseau and Remzi H. Arpaci-Dusseau.
- UNIX is the original AT&T UNIX operating system developed at the Bell Labs research center, headed by Ken Thompson and Dennis Ritchie.
References
This post was written by Piyush Sachdeva:
What really happens when you double click an icon on your desktop?
Support for chdir(2) in posix_spawn(3)
Processes are the bread and butter of your operating system. The moment you double click an icon, that particular program gets loaded in your Random Access Memory (RAM) and your operating system starts to run it. At this moment the program becomes a process. Though you can only see the execution of your process, the operating system (the Kernel) is always running a lot of processes in the background to facilitate you.
From the moment you hit that power button, everything that happens on the screen is the result of some or the other process. In this post we are going to talk about one such interface which helps in creation of your programs.
The fork() & exec() shenanigans
The moment a computer system comes alive, it launches a bunch of processes. For the purpose of this blog let’s call them, ‘the master processes’. These processes run in perpetuity, provided the computer is switched on. One such process is init/systemd/launchd (depending on your OS). This ‘init’ master process owns all the other processes in the computer, either directly or indirectly.
Operating systems are elegant, majestic software that work seamlessly under the hood. They do so much without even breaking a sweat (unless it’s Windows). Let's consider a scenario where you have decided to take a trip down memory lane and burst open those old photos. The ‘init master process’ just can’t terminate itself and let you look at your photos. What if you unknowingly open a malicious file, which corrupts all your data? So init doesn’t just exit, rather it employs fork() and exec() to start a new process. The fork() function is used to create child processes which are an exact copy of their parents. Whichever process calls fork, gets duplicated. The newly created process becomes the child of the original running process and the original running process is called the parent. Just how parents look after their kids, the parent process makes sure that the child process doesn't do any mischief. So now you have two exactly similar processes running in your computer.
One might think that the newly created child process doesn’t really help us. But actually, it does. Now exec() comes into the picture. What exec() does is, it replaces any process which calls it. So what if we replace the child process, the one we just thought to be useless, with our photos? That's exactly what we are going to do indeed. This will result in replacement of the fork() created child process with your photos. Therefore, the master init process is still running and you can also enjoy your photos with no threat to your data.
“Neither abstraction nor simplicity is a substitute for getting it right. Sometimes, you just have to do the right thing, and when you do, it is way better than the alternatives. There are lots of ways to design APIs for process creation; however, the combination of fork() and exec() is simple and immensely powerful. Here, the UNIX designers simply got it right.” Lampson’s Law - Getting it RightNow you could ask me, `But what about the title, some ‘posix_spawn()’ thing?´ Don’t worry, that’s next.
posix_spawn()
posix_spawn() is an alternative to the fork() + exec() routine. It implements fork() and exec(), but not directly (as that would make it slow, and we all need everything to be lightning fast). What actually happens is that posix_spawn() only implements the functionality of the fork() + exec() routines, but in one single call. However, because fork() + exec() is a combination of two different calls, there is a lot of room for customization. Whatever software you are running on your computer, calls these routines on its own and does the necessary. Meanwhile a lot is cooking in the background. Between the call to fork() and exec() there is plenty of leeway for tweaking different aspects of the exec-ing process. But posix_spawn doesn’t bear this flexibility and therefore has a lot of limitations. It does take a lot of parameters to give the caller some flexibility, but it is not enough.
Now the question before us is,
“If fork() + exec() is so much more powerful, then why have,
or use the posix_spawn() routine?” The answer to that is, that
fork() and exec() are UNIX system routines.
They are not present in operating systems that are not a derivative of UNIX.
Eg- Windows implements a family of spawn functions.
There is another issue with fork() (not exec() ), which in reality is one
of the biggest reasons behind the growth of posix_spawn(). The outline of
the issue is that, creating child processes in multi-threaded programs is a
whole another ball game altogether.
Concurrency is one of those disciplines in operating systems where the order in which the cards are going to unravel is not always how you expect them to. Multi-threading in a program is a way to do different and independent tasks of a program simultaneously, to save time. No matter how jazzy or intelligent the above statement looks, multi-threaded programs require an eagle’s eye as they can often have a lot of holes. Though the “tasks” are different and independent, they often share a few common attributes. When these different tasks due to concurrency start running in parallel, a data race begins to access those shared attributes. To not wreak havoc, there are mechanisms through which, when modifying/accessing these common attributes (Critical Section) we can provide a sort of mutual exclusion (locks/conditional variables) - only letting one of the processes modify the shared attribute at a time. Here when things are already so intricate due to multithreading, and to top it off, we start creating child processes. Complications are bound to arise. When one of the threads from the multi-threaded program calls fork() to create a child process, fork() does clone everything (variables, their states, functions, etc) but it fails to clone other threads (though this is not required at all times).
The child process now knows only about that one thread which called fork(). But all the other attributes of the child that were inherited from the parent (locks, mutexes) are set from the parent’s address space (considering multiple threads). So there is no way for the child process to know which attributes conform to which parts of the parent. Also, those mechanisms that we used to provide mutual exclusion, like locks and conditional variables, need to be reset. This reset step is essential in letting the parent access it’s attributes. Failing this reset can cause deadlocks. To put it simply, you can see how difficult things have become all of a sudden. The posix_spawn() call is free from these limitations of fork() encountered in multi-threaded programs. However, as mentioned by me earlier, there needs to be enough rope to meet all the requirements before posix_spawn() does the implicit exec().
About my Project
Hi, I am Piyush Sachdeva and I am going to start a project which will focus on relaxing one limitation of posix_spawn - changing the current directory of the child process, before the said call to exec() is made. This is not going to restrict it to the parent’s current working directory. Just passing the new directory as one of the parameters will do the trick. Resolving all the impediments would definitely be marvelous. Alas! That is not possible. Every attempt to resolve even a single hindrance can create plenty of new challenges.
As already mentioned by me, posix_spawn() is a POSIX standard. Hence the effect of my project will probably be reflected in the next POSIX release. I came across this project through Google Summer of Code 2021. It was being offered by The NetBSD Foundation Inc. However, as the slots for Google Summer of Code were numbered, my project didn’t make the selection. Nevertheless, the Core Team at The NetBSD Foundation offered me to work on the project and even extended a handsome stipend. I will forever be grateful to The NetBSD Foundation for this opportunity.
Notes
- init, systemd & launchd are system daemon processes. init is the historical process present since System III UNIX. systemd was the replacement for the authentic init which was written for the Linux kernel. launchd is the MacOS alternative of init/systemd.
- This is taken from Operating Systems: The Three Easy Pieces book by Andrea C. Arpaci-Dusseau and Remzi H. Arpaci-Dusseau.
- UNIX is the original AT&T UNIX operating system developed at the Bell Labs research center, headed by Ken Thompson and Dennis Ritchie.
References
This post was written by Piyush Sachdeva:
What really happens when you double click an icon on your desktop?
Support for chdir(2) in posix_spawn(3)
Processes are the bread and butter of your operating system. The moment you double click an icon, that particular program gets loaded in your Random Access Memory (RAM) and your operating system starts to run it. At this moment the program becomes a process. Though you can only see the execution of your process, the operating system (the Kernel) is always running a lot of processes in the background to facilitate you.
From the moment you hit that power button, everything that happens on the screen is the result of some or the other process. In this post we are going to talk about one such interface which helps in creation of your programs.
The fork() & exec() shenanigans
The moment a computer system comes alive, it launches a bunch of processes. For the purpose of this blog let’s call them, ‘the master processes’. These processes run in perpetuity, provided the computer is switched on. One such process is init/systemd/launchd (depending on your OS). This ‘init’ master process owns all the other processes in the computer, either directly or indirectly.
Operating systems are elegant, majestic software that work seamlessly under the hood. They do so much without even breaking a sweat (unless it’s Windows). Let's consider a scenario where you have decided to take a trip down memory lane and burst open those old photos. The ‘init master process’ just can’t terminate itself and let you look at your photos. What if you unknowingly open a malicious file, which corrupts all your data? So init doesn’t just exit, rather it employs fork() and exec() to start a new process. The fork() function is used to create child processes which are an exact copy of their parents. Whichever process calls fork, gets duplicated. The newly created process becomes the child of the original running process and the original running process is called the parent. Just how parents look after their kids, the parent process makes sure that the child process doesn't do any mischief. So now you have two exactly similar processes running in your computer.
One might think that the newly created child process doesn’t really help us. But actually, it does. Now exec() comes into the picture. What exec() does is, it replaces any process which calls it. So what if we replace the child process, the one we just thought to be useless, with our photos? That's exactly what we are going to do indeed. This will result in replacement of the fork() created child process with your photos. Therefore, the master init process is still running and you can also enjoy your photos with no threat to your data.
“Neither abstraction nor simplicity is a substitute for getting it right. Sometimes, you just have to do the right thing, and when you do, it is way better than the alternatives. There are lots of ways to design APIs for process creation; however, the combination of fork() and exec() is simple and immensely powerful. Here, the UNIX designers simply got it right.” Lampson’s Law - Getting it RightNow you could ask me, `But what about the title, some ‘posix_spawn()’ thing?´ Don’t worry, that’s next.
posix_spawn()
posix_spawn() is an alternative to the fork() + exec() routine. It implements fork() and exec(), but not directly (as that would make it slow, and we all need everything to be lightning fast). What actually happens is that posix_spawn() only implements the functionality of the fork() + exec() routines, but in one single call. However, because fork() + exec() is a combination of two different calls, there is a lot of room for customization. Whatever software you are running on your computer, calls these routines on its own and does the necessary. Meanwhile a lot is cooking in the background. Between the call to fork() and exec() there is plenty of leeway for tweaking different aspects of the exec-ing process. But posix_spawn doesn’t bear this flexibility and therefore has a lot of limitations. It does take a lot of parameters to give the caller some flexibility, but it is not enough.
Now the question before us is,
“If fork() + exec() is so much more powerful, then why have,
or use the posix_spawn() routine?” The answer to that is, that
fork() and exec() are UNIX system routines.
They are not present in operating systems that are not a derivative of UNIX.
Eg- Windows implements a family of spawn functions.
There is another issue with fork() (not exec() ), which in reality is one
of the biggest reasons behind the growth of posix_spawn(). The outline of
the issue is that, creating child processes in multi-threaded programs is a
whole another ball game altogether.
Concurrency is one of those disciplines in operating systems where the order in which the cards are going to unravel is not always how you expect them to. Multi-threading in a program is a way to do different and independent tasks of a program simultaneously, to save time. No matter how jazzy or intelligent the above statement looks, multi-threaded programs require an eagle’s eye as they can often have a lot of holes. Though the “tasks” are different and independent, they often share a few common attributes. When these different tasks due to concurrency start running in parallel, a data race begins to access those shared attributes. To not wreak havoc, there are mechanisms through which, when modifying/accessing these common attributes (Critical Section) we can provide a sort of mutual exclusion (locks/conditional variables) - only letting one of the processes modify the shared attribute at a time. Here when things are already so intricate due to multithreading, and to top it off, we start creating child processes. Complications are bound to arise. When one of the threads from the multi-threaded program calls fork() to create a child process, fork() does clone everything (variables, their states, functions, etc) but it fails to clone other threads (though this is not required at all times).
The child process now knows only about that one thread which called fork(). But all the other attributes of the child that were inherited from the parent (locks, mutexes) are set from the parent’s address space (considering multiple threads). So there is no way for the child process to know which attributes conform to which parts of the parent. Also, those mechanisms that we used to provide mutual exclusion, like locks and conditional variables, need to be reset. This reset step is essential in letting the parent access it’s attributes. Failing this reset can cause deadlocks. To put it simply, you can see how difficult things have become all of a sudden. The posix_spawn() call is free from these limitations of fork() encountered in multi-threaded programs. However, as mentioned by me earlier, there needs to be enough rope to meet all the requirements before posix_spawn() does the implicit exec().
About my Project
Hi, I am Piyush Sachdeva and I am going to start a project which will focus on relaxing one limitation of posix_spawn - changing the current directory of the child process, before the said call to exec() is made. This is not going to restrict it to the parent’s current working directory. Just passing the new directory as one of the parameters will do the trick. Resolving all the impediments would definitely be marvelous. Alas! That is not possible. Every attempt to resolve even a single hindrance can create plenty of new challenges.
As already mentioned by me, posix_spawn() is a POSIX standard. Hence the effect of my project will probably be reflected in the next POSIX release. I came across this project through Google Summer of Code 2021. It was being offered by The NetBSD Foundation Inc. However, as the slots for Google Summer of Code were numbered, my project didn’t make the selection. Nevertheless, the Core Team at The NetBSD Foundation offered me to work on the project and even extended a handsome stipend. I will forever be grateful to The NetBSD Foundation for this opportunity.
Notes
- init, systemd & launchd are system daemon processes. init is the historical process present since System III UNIX. systemd was the replacement for the authentic init which was written for the Linux kernel. launchd is the MacOS alternative of init/systemd.
- This is taken from Operating Systems: The Three Easy Pieces book by Andrea C. Arpaci-Dusseau and Remzi H. Arpaci-Dusseau.
- UNIX is the original AT&T UNIX operating system developed at the Bell Labs research center, headed by Ken Thompson and Dennis Ritchie.
References
ptrace(2) and related distribution changes
I am actively working on handling of processes, forks/vforks, signals and threads that is reliable and fully functional under a debugger. This is a process and the situation is actively improving. For the end-user this means that we are achieving the state when a developer will be able to trace an application like Firefox using modern tools and save time detecting the issues quickly.
I am using the Test-Driven Development approach in my work. I keep extending the Automatic Test Framework with new tests, covering sets of scenarios handled by debuggers and related code. This is followed by kernel fixes. Thanks to the tests, I can more confidently introduce changes to critical routines inside the Operating System, test new changes quickly for regressions and keep covering new verifiable scenarios.
Titles of the merged commits with the main tree of NetBSD:
- Remove an element from struct emul: e_tracesig.
e_tracesig used to be implemented for Darwin compat. Nowadays the Darwin compatib[i]lity layer is gone and there are no other users.
- Refactoring of can_we_set_dbregs() in ATF ptrace(2) tests. Push this auxiliary function to all ports.
- Add a new ptrace(2) ATF exploit for: CVE-2018-8897 (POP SS debug exception).
- Correct handling of: vfork(2) + PT_TRACE_ME + raise(2).
- Add a new ATF ptrace(2) test: traceme_vfork_breakpoint.
- Improve the description of traceme_vfork_raise in ATF ptrace(2) tests.
- Add a new ATF ptrace(2) test: traceme_vfork_exec.
- Improve the description of traceme_vfork_breakpoint (ATF ptrace(2) test).
- Add extra asserts in three ATF ptrace(2) tests.
In traceme* tests after validate_status_stopped() include additional check the verify the received signal with PT_GET_SIGINFO.
- Correct assert in ATF t_zombie test.
- Add new ATF tests: t_fork and t_vfork.
- Stop masking SIGSTOP in a vfork(2)ed child.
- Stop masking raise(SIGSTOP) in a vfork(2)ed child that called PT_TRACE_ME.
- Add new auxiliary functions in t_ptrace_wait.h
New functions:
- FORKEE_ASSERT_NEQ()
- await_stopped_child()
- Enable traceme_vfork_raise2 in ATF ptrace(2) tests.
raise(SIGSTOP) is now handled correctly by the kernel, in a child that vfork(2)ed and called PT_TRACE_ME.
- Cover SIGTSTP, SIGTTIN and SIGTTOU in traceme_vfork_raise ATF tests.
- Note in vfork(2) that SIGTSTP is masked.
- Fix and enable traceme_signal_nohandler2 in ATF ptrace(2) tests.
- Make stopsigmask a non-static symbol now as it's used in ptrace(2) code.
- Refactor and enable the signal3 ATF ptrace(2) test
Adapt the test to be independent from the software breakpoint trap behavior, whether the Program Counter is moved or not. Just kill the process after catching the expected signal, instead of pretending to resume it.
- Add new ATF test: t_trapsignal:trap_ignore.
- Minor update to signal(7)
Note that SIGCHLD is not just a child exit signal. Note that SIGIOT is PDP-11 specific signal.
- Minor improvement in sigaction(2)
Note that SIGCHLD covers process continued event.
- Extend ATF tests in t_trapsignal.sh to verify software breakpoint traps.
- Add new ATF ptrace(2) tests: traceme_sendsignal_{masked,ignored}[1-3].
- Define PTRACE_BREAKPOINT_ASM for i386 in the MD part of .
- Refactor the attach[1-8] and race1 ATF t_ptrace_wait* tests.
- Cherry-pick upstream patch for internal_mmap() in GCC sanitizers.
- Cherry-pick upstream patch for internal_mmap() in GCC(.old) sanitizers
- Add new auxiliary functions in ATF ptrace(2) tests
Introduce:
- trigger_trap()
- trigger_segv()
- trigger_ill()
- trigger_fpe()
- trigger_bus()
- Extend traceme_vfork_breakpoint in ATF ptrace(2) tests for more scenarios
Added tests:
- traceme_vfork_crash_trap
- traceme_vfork_crash_segv (renamed from traceme_vfork_breakpoint)
- traceme_vfork_crash_ill (disabled)
- traceme_vfork_crash_fpe
- traceme_vfork_crash_bus
- Merge the eventmask[1-6] ATF ptrace(2) tests into a shared function body.
- Introduce can_we_write_to_text() to ATF ptrace(2) tests
The purpose of this function is to detect whether a tracer can write to the .text section of its tracee.
- Refactor the PT_WRITE*/PT_READ* and PIOD_* ATF ptrace(2) tests.
- Handle vm.maxaddress in compat_netbsd32(8).
- Port the CVE 2018-8897 mitigation to i386 ATF ptrace(2) tests.
- Fix sysctl(3):vm.minaddress in compat_netbsd32(8).
- Fix ATF ptrace(2) bytes_transfer_piod_read_auxv test.
- Handle FPE and BUS scenarios in the ATF t_trapsignal tests.
- Try to fool $CC harder in ATF ptrace(2) tests in trigger_fpe().
- Correct reporting SIGTRAP TRAP_EXEC when SIGTRAP is masked.
- Correct the t_ptrace_wait*:signal5 ATF test case.
- Add new ATF ptrace(2) tests verifying crash signal handling.
- Harden PT_ATTACH in ptrace(2).
Don't allow to PT_ATTACH from a vfork(2)ed child (before exec(3)/_exit(3)) to its parent. Return error with EPERM errno.
This scenario does not have a purpose and there is no clear picture how to route signals.
- Simplify comparison of two processes
No need to check p_pid to compare whether two processes are the same.
This functionality now works.
LLVM compiler-rt features
I have helped the GSoC student to prepare for LLVM libfuzzer integration with the NetBSD base system. We have managed to get down to the following results for the test target in the upstream repository:
$ check-fuzzer-default Expected Passes : 105 Unsupported Tests : 8 Unexpected Failures: 2 $ check-fuzzer Expected Passes : 105 Unsupported Tests : 8 Unexpected Failures: 2 $ check-fuzzer-unit Expected Passes : 35
The remaining two failures appear to be false positives and specific to the differences between the NetBSD setup difference and other supported Operating Systems (including Linux). I have decided not to investigate them and instead to move on to more urgent tasks.
While there, I have been working on restoring a good state to userland LLVM sanitizers in the upstream repository, in order ship them in the NetBSD distribution along with the libfuzzer utility.
A number of patches were merged upstream:
- LLVM: Register NetBSD/i386 in AddressSanitizer.cpp
- Clang: Permit -fxray-instrument for NetBSD/amd64
- Clang: Support XRay in the NetBSD driver
- compiler-rt: Remove dead sanitizer_procmaps_freebsd.cc
- compiler-rt: wrong usages of sem_open in the libFuzzer (patch by Yang Zheng, the GSoC student)
- compiler-rt: Register NetBSD/i386 in asan_mapping.h
- compiler-rt: Setup ORIGIN/NetBSD option in sanitizer tests
- compiler-rt: Enable SANITIZER_INTERCEPTOR_HOOKS for NetBSD
There is also at least a single pending upstream patch that is worth to note: Introduce CheckASLR() in sanitizers
At least the ASan, MSan, TSan sanitizers require disabled ASLR on a NetBSD. Introduce a generic CheckASLR() routine, that implements a check for the current process. This flag depends on the global or per-process settings. There is no simple way to disable ASLR in the build process from the level of a sanitizer or during the runtime execution. With ASLR enabled sanitizers that operate over the process virtual address space can misbehave usually breaking with cryptic messages. This check is dummy for !NetBSD.
The current results for test targets in the compiler-rt features are as follows:
$ make check-builtins Expected Passes : 343 Expected Failures : 4 Unsupported Tests : 36 Unexpected Failures: 5 $ check-interception -- Testing: 0 tests, 0 threads -- $ check-lsan Expected Passes : 6 Unsupported Tests : 60 Unexpected Failures: 106 $ check-ubsan Expected Passes : 229 Expected Failures : 1 Unsupported Tests : 32 Unexpected Failures: 2 $ check-cfi Unsupported Tests : 232 $ check-cfi-and-supported BaseException: Tests unsupported $ make check-sanitizer Expected Passes : 576 Expected Failures : 13 Unsupported Tests : 206 Unexpected Failures: 31 $ check-asan Expected Passes : 852 Expected Failures : 4 Unsupported Tests : 440 Unexpected Failures: 16 $ check-asan-dynamic Expected Passes : 394 Expected Failures : 3 Unsupported Tests : 440 Unexpected Passes : 1 Unexpected Failures: 222 $ check-msan Expected Passes : 102 Expected Failures : 1 Unsupported Tests : 30 Unexpected Failures: 4 $ check-tsan Expected Passes : 288 Expected Failures : 1 Unsupported Tests : 84 Unexpected Failures: 8 $ check-safestack Expected Passes : 7 Unsupported Tests : 1 $ check-scudo Expected Passes : 14 Unexpected Failures: 28 $ check-ubsan-minimal Expected Passes : 6 Unsupported Tests : 2 $ check-profile Unsupported Tests : 116 $ check-xray Expected Passes : 21 Unsupported Tests : 1 Unexpected Failures: 21 $ check-shadowcallstack Unsupported Tests : 4
Sanitization of userland and the kernel
I am helping to setup the process for shipping a NetBSD userland that is prebuilt with a desired sanitizer. This involves consulting the Google Summer of Code student, fixing known issues, reviewing patches etc.
There were two new uninitialized memory read bugs detected in the top(1) program:
Fix unitialized signal mask passed to sigaction(2) in top(1) Detected with Memory Sanitizer during the integration of sanitizers with the NetBSD basesystem. Reported by <Yang Zheng>
Fix read of uni[ni]tialized array elements in top(1) The cp_old array is allocated with malloc(3) and its pointer is passed to percentages64(). In this function there happens a calculation of total_change, which value depends on the value inside the unitialized cp_old[] array. ==26662==WARNING: MemorySanitizer: use-of-uninitialized-value #0 0x268a2c in percentages64 /usr/src/external/bsd/top/bin/../dist/machine/m_netbsd.c:1341:6 #1 0x26748b in get_system_info /usr/src/external/bsd/top/bin/../dist/machine/m_netbsd.c:478:6 #2 0x25518e in do_display /usr/src/external/bsd/top/bin/../dist/top.c:507:5 #3 0x253038 in main /usr/src/external/bsd/top/bin/../dist/top.c:975:2 #4 0x21cad1 in ___start (/usr/bin/top+0x1cad1) SUMMARY: MemorySanitizer: use-of-uninitialized-value /usr/src/external/bsd/top/bin/../dist/machine/m_netbsd.c:1341:6 in percentages64 Exiting Fix this issue by chang[]ing malloc(3) with calloc(3). Detected with Memory Sanitizer during the integration of sanitizers with the NetBSD basesystem. Reported by <Yang Zheng>
As similar process happens with two kernel sanitizer GSoC tasks: kernel-ubsan and kernel-asan.
Thanks to the involvement to The NetBSD Foundation tasks, I can be reachable for students (although not always in all cases) for active feedback and collaboration.
Summary
The number of ATF ptrace(2) tests cases has been significantly incremented, however there is still a substantial amount of work to be done and a number of serious bugs to be resolved.
With fixes and addition of new test cases, as of today we are passing 1,206 (last month: 961) ptrace(2) tests and skipping 1 (out of 1,256 total; last month: 1,018 total). No counted here tests that appeared outside the ptrace(2) context.
Plan for the next milestone
Cover with regression tests remaining elementary scenarios of handling crash signals. Fix known bugs in the NetBSD kernel.
Follow up the process with the remaining fork(2) and vfork(2) scenarios.
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL, and chip in what you can:
I like to use CLI email clients (mutt). This by itself is not unusual, but I happen
to do this while speaking a language written right-to-left, Hebrew.
Decent bidi support in CLI tools is rare, so my impression is that very few people do this.
In the dark ages before Unicode, Hebrew used its own encodings which allowed typing
both Latin and Hebrew letters: Windows-1255, ISO-8859-8.
I speculate that people initially expected input to be written in reverse order
(aka "visual order"), assuming that everything will display text left to right.
When people wanted to use e-mail, they decided they'll write a line stating the charset encoding as others do, and use quoted-printable or base64 to avoid the content being mangled by clueless servers (8BITMIME wasn't around then).
But then they thought about bidi, and realized that writing in reverse isn't that great when you can have some bidi support. I've yet to write a bidi algorithm, but I suspect it makes line-wrapping illogical.
To avoid conflicts with existing emails, they decided on a separate encoding
for the purpose of conveying that the information isn't in reverse:
iso-8859-8-i: the content is in logical order, and Hebrew is assumed to be rtl.
iso-8859-8-e: the text direction is explicit using control codes.
The latter is a neat idea, but hasn't caught on. Now it's common to assume
logical order, and even iso-8859-8 might be in that format.
While defining this, they've also done the same for Arabic (iso-8859-6).
This is a discussion that should've been part of the past - Unicode is
now a thing, and I can send messages that contain Hebrew, Arabic, Chinese,
English - without flipping back and forth in encoding (if that was ever
even possible?), and out of the box! Never a need to enable support
for specifying charset. Unicode has a detailed algorithm for handling bidi.
Unicode is love. Unicode is life. Use Unicode.
But I recently was looking for work, and HR's presumed Microsoft Outlook MUA
did not use Unicode.
One of the emails I got was encoded as iso-8859-8-i.
It turns out, my MUA setup cannot handle this charset. It ended up looking
like \344 things, and the subject as boxes.
mail is a plaintext format with extensions hacked into it, so you can
view the raw content as a file. I used 'e' on mutt to open it:
Subject: =?iso-8859-8-i?B?base64stuff(The magical 'encode this in a different way' for email subjects)
Content-Type: text/plain; charset="iso-8859-8-i" Content-Transfer-Encoding: quoted-printableSo this is an iso-8859-8-i file.
OK, let's just read this file. I've got python.
I saved the file, which looked like this in its raw format:
=EE=E0=E9=E4Or quoted-printable. Gotta turn that into raw data, then convert ISO-8859-8 to UTF-8.
import quopri
import sys
rawmsg = sys.stdin.read()
notutf8msg = quopri.decodestring(rawmsg)
utf8msg = notutf8msg.decode('iso-8859-8')
print(utf8msg)
Cool. I can read the message. I even discover 'fribidi' isn't just a library, but also provides a command I can pipe this into and see nicely-formatted Hebrew even without using weirdo terminal emulators.
But let's not leave bugs like that lurking around. It is my duty as an RTL warrior to fix it.
One of the perks to using pkgsrc/netbsd and open source is that I can immediately look at mutt's source code. I knew it could handle iso-8859-8, so that's what I looked for.
The amount of results (combined with experience) quickly suggested that
the encoding is handled by the OS, netbsd in this case.
NetBSD didn't know about iso-8859-8-i.
Experience meant I knew to look in either src/lib/ (wasn't there) or src/share/ for 'data used by things'. I've looked for 'iso-8859-8' to see if it appears anywhere, and found it. It was good to see that NetBSD does appear to have a way to alias charsets as being equivalent, and I added iso-8859-8-i here, and did a full build because I didn't know how the files are used.
Testing locally, I could now read the email with mutt! But what about replying?
I have a weird email setup again. I had a hard time setting up a remote
POP/IMAP thing, so I ssh to sdf.org and email from there. And I can't
change their libc or install.
Hoping to just elide all the corrupted characters and reply with UTF-8
was too optimistic - mutt wanted to reply in the original encoding, and
again could not handle it properly.
Well, I'll just put in my updated libc, and LD_PRELOAD it, then!
Except, after ktracing it (via 'ktruss -i mutt |grep esdb'), it turns
out that it opens a file in /usr/share/i18n/ to figure out charset
aliases.
I'll need to tell it to look elsewhere I can modify.
I've edited out paths.h, which is where the lookup path is stored,
changed it to my home on sdf.org, and then built myself a fresh libc.
(It was during this I realized I could've just edited the email to say
it's iso-8859-8, rather than iso-8859-8-i)
A few minor setbacks, and I could finally reply to the email, saying that yes, I will show up to the job interview.
I leave you with this tidbit from the RFC announcing these encodings and
that finally, emails in Hebrew are possible:
"Within Israel there are in excess of 40 Listserv lists which will now
start using Hebrew for part of their conversations."
Hurray!
Prepared by Yang Zheng (tomsun.0.7 AT Gmail DOT com) as part of GSoC 2018
During the Google
Summer of Code 2018, I'm working on the project
of integrating
libFuzzer for the userland
applications. The libFuzzer is a fuzzing engine
based on the coverage information provided by
the SanitizerCoverage
in LLVM. It can repeatedly generate mutations of input data and test
them until it finds the potential bugs. In this post, I'm going to
share what I have done in the first month of this summer.
For the first month, I mainly tried to apply the sanitizers to the
userland applications. Sanitizers (such as
MemorySanitizer,
AddressSanitizer,
and etc.) are helpful to the fuzzing process because they can
detect various types of run-time errors like uninitialized reads,
out-of-bounds accesses, use-after-free and so on. I tried to
apply MemorySanitizer as a start and there were three
steps to finish this:
- Import new version LLVM as an external toolchain
- Add new interceptors for userland applications
- Enable
MemorySanitizerfor userland applications and test them
Compile New Version LLVM Statically
with EXTERNAL_TOOLCHAIN
Using a new version of LLVM toolchain is necessary because the LLVM
in NetBSD trunk is old and there are some changes in the new
version. However, updating the toolchain in the src
will introduce extra work for this project, so we decided to use
the EXTERNAL_TOOLCHAIN parameter provided by NetBSD to
work with the new version.
During this period, I chose to use a pure-LLVM userland to avoid
potential problems. This means that we should replace
the libc++ instead of libstdc++ library
for the userland programs. As a result, I
used -DSANITIZER_CXX_ABI=libc++
and -DCLANG_DEFAULT_CXX_STDLIB=libc++ flags to
eliminate some compilation errors while compiling the LLVM
toolchain.
Another compiling issue is related to the sanitizers. Whenever there is failed check with sanitizers, the program will abort with backtrace information like this:
==15299==WARNING: MemorySanitizer: use-of-uninitialized-value
#0 0x41c837 in main /home/zhengy/free.c:6:3
#1 0x41c580 in ___start (//./a.out+0x41c580)
SUMMARY: MemorySanitizer: use-of-uninitialized-value /home/zhengy/free.c:6:3 in main
Exiting
The backtrace is generated with the support
of llvm-symbolizer. However, if we compile some dynamic
libraries, which are needed by llvm-symbolizer, with
sanitizers (because some userland programs with sanitizers also need
them), then it will not available for generating a readable
backtrace anymore:
==1623==WARNING: MemorySanitizer: use-of-uninitialized-value
#0 0x41c837 (//./a.out+0x41c837)
#1 0x41c580 (//./a.out+0x41c580)
SUMMARY: MemorySanitizer: use-of-uninitialized-value (//./a.out+0x41c837)
Exiting
So, to remove the dependencies of the sanitized dynamic libraries
for llvm-symbolizer and other LLVM tools, we chose to
compile the whole LLVM toolchain statically. For this purpose, we
found that the static building behavior of LLVM on NetBSD is not
workable, so we need to do
some subtle
modification to the cmake file. But this modification still
needs some correctness confirmation from the LLVM community.
After all of these preparations, I
wrote a
shell script to automatically do the jobs of preparing external
LLVM toolchains, compiling the NetBSD from source and finally
generate a chroot(8)-able environment to work with
sanitizers and libFuzzer.
With this environment, I first tried to run the test cases from both
the LLVM and the NetBSD. For the LLVM part, I found that some
libFuzzer cases were not working. But finally, we found
that this resulted from the improper usages
of sem_open(3) interface in the libFuzzer and so I
submitted a patch to
fix this.
For the NetBSD part, it worked well with the
existing ATF(7) test cases for
the AddressSanitizer
and UndefinedBehaviorSanitizer.
To test
the MemorySanitizer, ThreadSanitizer,
and libFuzzer, I added some test cases for them.
Add New Interceptors
Some libraries (such as libc, libm,
and libpthread) and syscalls cannot be applied properly
with sanitizers. This will introduce some troubles because we will
lack information with these unsanitized interfaces. Fortunately,
sanitizers can provide wrappers, namely interceptors, for these
interfaces to manually provide some information. However, the set of
interceptors is quite incomplete and thus need some effort to add
some unsanitized functions needed by userland applications. As a
summary, I added interceptors for the following interfaces:
- strtonum(3) family: strtonum(3), strtoi(3), strtou(3)
- vis(3) family: vis(3), nvis(3), strvis(3) and etc.
- getmntinfo(3)
- puts(3), fputs(3)
- Hash interfaces: sha1(3), md2(3), md4(3), md5(3), rmd160(3) and sha2(3)
- getvfsstat(2)
- nl_langinfo(3)
- fparseln(3)
- unvis(3) family: unvis(3), strunvis(3) and etc.
- statvfs(2) family: statvfs(2), fstatvfs(2) and etc.
- mount(2) and unmount(2)
- fseek(3) family: fseek(3), ftell(3), rewind(3) and etc.
- cdbr(3) family: cdbr_open(3), cdbr_get(3), cdbr_find(3) and etc.
- setvbuf(3) family: setbuf(3), setbuffer(3), setlinebuf(3), setvbuf(3)
- mi_vector_hash(3)
Most of these interceptors are easy to add, we only need to leverage
the interceptor interfaces provided by the compiler-rt and do the
pre- and post- function call check. As an example, I choose the
interceptor
of strvis(3)
to illustrate the implementation:
INTERCEPTOR(int, strvis, char *dst, const char *src, int flag) {
void *ctx;
COMMON_INTERCEPTOR_ENTER(ctx, strvis, dst, src, flag);
if (src)
COMMON_INTERCEPTOR_READ_RANGE(ctx, src, REAL(strlen)(src) + 1);
int len = REAL(strvis)(dst, src, flag);
if (dst)
COMMON_INTERCEPTOR_WRITE_RANGE(ctx, dst, len + 1);
return len;
}
The strvis(3) interface will transform the
representation of string stored in src and then return
it with dst. So, its interceptor wants to tell the
sanitizers two messages:
strvis(3)will read the string insrc(COMMON_INTERCEPTOR_READ_RANGEinterface)strvis(3)will write a string todst(COMMON_INTERCEPTOR_WRITE_RANGEinterface)
So, with interceptors, the sanitizers can obtain information of unsanitized interfaces. There are three unsolved issues with interceptors:
- Interceptors with
FILEtype: theFILEtype is implemented as a structure and contains some pointers inside. This means that we should check these pointers one by one in the interceptors. However, theFILEtype is common among different OSs and their implementations vary a lot. So, for different OSs, we should write different conditions. What's worse, there are some interceptors (such asfopen) implemented by others skipping the checks forFILE. This will introduce some incompatible problems if we enforce the check with other interfaces (likefputs). For example, thefopenis the interface to initialize theFILEtype, if we skip marking the returnedFILEpointer as initialized (withCOMMON_INTERCEPTOR_WRITE_RANGE), we will get an error in the interceptor offputsafter we enforce the check of this pointer (withCOMMON_INTERCEPTOR_READ_RANGE). -
mount(2)interface: The mount(2) interface requiresdataparameter for different file systems. This parameter can be different types, such asstruct ufs_args,struct nfs_argsand so on. These types usually contain pointers, so we need to check them one by one. However, there are around 34 differentstruct xxx_argstypes in NetBSD, so it will be quite hard to add and maintain them in compiler-rt repository. -
getchar(3)andputchar(3)family interfaces: these interfaces will be defined by macros with some compiler conditions, so their implementation will be complicated.
Enable the Sanitizers for the Userland
with MKSANITIZER
After adding interceptors, we can then enable the sanitizers for
userland applications. To ship the sanitizers to the user, Christos
Zoulas prepared the MKSANITIZER framework, dedicated
for building the whole sanitizer userland with a dedicated sanitizer
(including UndefinedBehaviorSanitizer, Control
Flow
Integrity, MemorySanitizer, ThreadSanitizer,
SafeStack, LeakSanitizer
and etc).
Based on this framework, Kamil Rytarowski used the NetBSD building
parameters like MKSANITIZER=yes USE_SANITIZER=undefined
HAVE_LLVM=yes and managed to enable
the UndefinedBehaviorSanitizer option for the whole
userland. There is the ongoing effort on upstreaming local patches,
fixing
detected bugs. It is planned to follow up this with the
remaining sanitizer options.
I also tried to enable the MemorySanitizer for the
userland programs
and here
is the result. If you have any insights or suggestions, please feel
free to comment on it. Applying the MemorySanitizer
option also helped to improve the interceptors and
integrate MKSANITIZER. The MemorySanitizer
is sensitive to the interceptor issues and so actually this job was
twisted with the process of adding and improving the
interceptors. With the MemorySanitizer, I also find out
two bugs with top(1) program. You can refer
to this
post to learn about it.
There are also some unsolved issues with some applications. As shown in the sheet, I divide them into five categories:
DEADLYSIGNAL: mainly happening when sendingCTRL-Cto programsIOCTL:ioctl(2)-related errorsGETC, PUTC, FFLUSH: stdio(3)-related errorsREALLOC:realloc(3)-related errors- Compilation errors: conflict symbols between programs and base libraries
GETC, PUTC, FFLUSH category has been
mentioned above, it mainly results from lacking the interceptors of
these interfaces. The other categories are still remained to be
investigated.
Summary
In the last month, I have a good start of working with LLVM and
NetBSD and successfully build some userland programs
with MemorySanitizer. All of these jobs mentioned above
are based on the forked repositories instead of the official
ones. If you have interests in them, please refer to these
repositories: NetBSD
source, pkgsrc-wip,
LLVM, clang,
and compiler-rt. Next,
I will switch to the integration work of libFuzzer and
try to run some programs as a trial.
Last but not least, I want to thank my mentors, Christos Zoulas and Kamil Rytarowski, they help me a lot with so many good suggestions and assistance. I also want to thank Matthew Green and Joerg Sonnenberger for their help with LLVM-related suggestions. Finally, thanks to Google to give me a good chance to work with NetBSD community.
It's been a fun couple of weeks since I started working on the Kernel Address Sanitizer (KASan) project with NetBSD. I have learned a lot during this period. It's been pretty amazing. This is a report on the work I have done prior to the first evaluation period.
What is an Address Sanitizer?
The Address Sanitizer (ASan) is an open source tool that was developed by Google to detect memory corruption bugs such as buffer overflows or access to dangling pointers (use after free). Its a part of the toolset that Google has which includes an Undefined Behaviour Sanitizer (UBSan), a Thread Sanitizer (TSan) and a Leak Sanitizer (LSan).On adding the feature to NetBSD it would be possible to add build the kernel with ASan and then use it to find memory corruption bugs.
Testing ASan in the User Space
My first step was to testing whether ASan had been implemented in the NetBSD userspace. I wrote a couple of ATF regression tests for checking whether ASan worked in the userspace for C and C++ compilers and also whether manual poisoning would work.This allowed me to get familiar with the ATF testing framework that NetBSD.
Added a couple of Kernel Modules
I was asked to add a set of example kernel modules to the kernel. I added an example module to show how to make a /dev module multiprocessor safe and to add a node in the sysctl tree.Reading about UVM
My next task was to get familiar with the UVM (virtual memory system of NetBSD). I read through a 1998 dissertation by Dr. Chuck Cranor. I published a blog article containing my scratch notes on reading the article.Adding an option to compile the kernel with KASan
Finally, I had to build the kernel with the KASan stubs (Dummy functions so that the build would be working). I added a configuration file which can be used to build the kernel with KASAN. I also published a blog post regarding how to do the same.Summary
In short, I am pretty excited to move forward with the project. The community has been supportive and helpful all the way.I would like to thank my mentor, Kamil Rytarowski who was always ready to dive deep into code and help whenever required. I also want to thank Cherry Mathews for helping clear up doubts related to UVM.
For GSoC '18, I'm working on the Kernel Undefined Behavior Sanitizer (KUBSAN) project for the integration of Undefined Behavior regression testing on the amd64 kernel. This article summarizes what has been done up to this point (Phase 1 Evaluation), future goals and a brief introduction to Undefined Behavior.
So, first things first, let's get started. The mailing list project presentation
What is Undefined Behavior?
For Turing-complete languages we cannot reliably decide offline whether a program has the potential to execute an error; we just have to run it and see. DUH!
Undefined Behavior in C is basically what the ANSI standard leaves unexplained. Code containing Undefined Behavior is ANSI C compatible. It follows all the rules explained in the standard and causes real trouble. In programming terms, it involves all the possible functionalities C code can run. It's whatever the compiler doesn't moan about, but when run it causes run-time bugs, hard to locate.
The C FAQ defines "Undefined Behavior" like this:
Anything at all can happen; the Standard imposes no requirements. The program may fail to compile, or it may execute incorrectly (either crashing or silently generating incorrect results), or it may fortuitously do exactly what the programmer intended.
A brief explanation of what is classifed as UB and some real case scenarios
A great blog post explaining more than mere mortals might need
The important and scary thing to realize is that just about *any* optimization based on undefined behavior can start being triggered on buggy code at any time in the future. Inlining, loop unrolling, memory promotion and other optimizations will and a significant part of their reason for existing is to expose secondary optimizations like the ones above.
Solution: Make a UB Sanitizer
What we can do to find undefined behavior errors in our code, is creating a Sanitizer. Hopefully both CLang and GCC have taken care of such "dream" tools, covering the majority of undefined behavior cases in a very nice manner. They allow us to simply parse the -fsanitize=undefined option when we build our code and the compiler "spits out" simple warnings for us to see. The CLang supported flags (same as GCC's but they don't have such extensive explanation docs).
Adding ATF Tests for Userland UBSan
This was my first deliverable for the integration of KUBSan. The concept was to include tests causing simple C programs to portray Undefined Behavior, such as overflows, erroneous shifting and out of bounds accessing of arrays (VLAs actually). The ATF framework is not a real "sweetheart" to learn, so it took me more than expected to complete this preliminary step to the project. The good news was that I had enough time to understand Undefined Behavior to a suave depth and make my extensive research for ideas (and not only).
The initial commit of the tests cleaned up and submitted by my mentor Kamil Rytarowski.
Addition of Example Kernel Module Panic_String
Next on our roadmap was the understanding of NetBSD's loadable kernel modules. For this, I created a kernel module parsing a string from a device named /dev/panic and calling the kernel panic(9) with it as argument, after syncing the system. This took a long time, but in the process I had the priviledge of reading FreeBSD Device Drivers: A Guide for the Intrepid, which unfortunatelyfor our foundation is the only book in close resemblance to our kernel module infrastructure.
The panic_string module commit revised, corrected and uploaded by Kamil.
Compiling the kernel with -fsanitize=undefined
Compiled the kernel with the aforementioned option to catch UB bugs. We got one. Only one! Which was reported to the tech-kern mailing list in this Thread.
Adding the option to compile the Kernel with KUBSan
At last what was our last deliverable for GSoC's first evaluation, was getting the amd64 kernel to boot with the KUBSan option enabled. This was a trick. We only needed the appropriate dummy functions, so we could use them as symbols in the linking process of a kernel build. At first I created KUBSan as a loadable kernel module, but the chaotic structure of our codebase was to much for me. This means that I searched for 4 whole days a way to link the exported symbols to the kernel build and was unsuccessful :(. But everything happens for a reason, because that one failure ignited me to search for all the available UBSan implementations and I was able to locate the initial support of the KUBSan functionality for: Linux, Chromium and FreeBSD. Which in turn, made me realise that the module was not necessary, since I could include the KUBSan functiuonality to our /sys infrastructure. Which I did and which was successful and which allowed me to boot and run a fully KUBSan-ed kernel.
It hasn't been uploaded to upstream yet, but you can have a look at my local (and totally messy) fork.
Summary and Future Goals
This first month of GSoC has been a great experience. Last year I participated again with project trying to "revamp" support for Scheme R7RS in the Eclipse IDE (we later tried to create a Kawa-Scheme Language Server-LSP, but that's a sad story) and my overall experience was really bad (I had to quit mid-July). This year we are doing things in much friendlier, cooperative and result-producing manner. I'm really happy about that.
A brief summary is that: the Kernel booted with KUBSan and I'm in knowledge of all the tools needed to extent that functionality. That's of ye need to know up to this point.
- Future goals include:
- Making a full implementation of KUBSan, with an edge on surpassing other existing implementations,
- Clear up any license issues,
- Finish the amd64 implementation and switch focus to the i386,
- Spead the NetBSD hype
At last I would like to deliver a huge thanks to my mentors Kamil and Christos for their advices and help with the project, but mostly for their
incredible behavior towards the problems I went through this past month. Much love
![]() The NetBSD Foundation has finalized the list of projects for this year’s Google Summer of Code. The contributors and projects are the following:
The NetBSD Foundation has finalized the list of projects for this year’s Google Summer of Code. The contributors and projects are the following:
- Brian Schnepp - Raspberry Pi GPU Driver
- Arjun Bemarkar - inetd enhancements
- Piyush Sachdeva - Emulating missing linux syscalls
- Vihas Makwana - Introduce a new Wi-Fi driver
- Vivek Kumar Sah - Automating donor acknowledgement and information storage
The community bonding period has already started (from May 20) and it will last until June 12. During this time, the contributors are expected to coordinate with their mentors and community.
This will be immediately followed by the coding period from June 13 to September 4. After which, the contributors are expected to submit their final work, evaluate their mentors, and get evaluated by their mentors as well. Results will be announced on September 20.
For more information about the Google Summer of Code 2022 kindly refer to the official GSoC website.
We would like to express our gratitude to Google for organizing the yearly GSoC, and to The NetBSD Foundation mentors and administrators for their efforts and hardwork!
Let us welcome all the contributors to our growing NetBSD community!
![]() The NetBSD Foundation has finalized the list of projects for this year’s Google Summer of Code. The contributors and projects are the following:
The NetBSD Foundation has finalized the list of projects for this year’s Google Summer of Code. The contributors and projects are the following:
- Brian Schnepp - Raspberry Pi GPU Driver
- Arjun Bemarkar - inetd enhancements
- Piyush Sachdeva - Emulating missing linux syscalls
- Vihas Makwana - Introduce a new Wi-Fi driver
- Vivek Kumar Sah - Automating donor acknowledgement and information storage
The community bonding period has already started (from May 20) and it will last until June 12. During this time, the contributors are expected to coordinate with their mentors and community.
This will be immediately followed by the coding period from June 13 to September 4. After which, the contributors are expected to submit their final work, evaluate their mentors, and get evaluated by their mentors as well. Results will be announced on September 20.
For more information about the Google Summer of Code 2022 kindly refer to the official GSoC website.
We would like to express our gratitude to Google for organizing the yearly GSoC, and to The NetBSD Foundation mentors and administrators for their efforts and hardwork!
Let us welcome all the contributors to our growing NetBSD community!
- One in the base-system with a stack of local patches.
- One in pkgsrc with mostly build fix patches.
The base-system version of GDB (GPLv3) still relies on a set of local patches. I set a goal to reduce the local patches to bare minimum, ideally reaching no local modifications at all.
Over the past month I've reimplemented debugging support for multi-threaded programs and upstreamed the support. It's interesting to note that the old support relied on GDB tracking only a single inferior process. This caused the need to reimplement the support and be agnostic to the number of traced processes. Meanwhile the upstream developers introduced new features for multi-target tracing and a lot of preexisting code broke and needed resurrection. This affected also the code kept in the GDB basesystem version. Additionally over the past 30 days, I've also developed new CPU-independent GDB features that were for a long time on a TODO list for NetBSD.
After the past month NetBSD has now a decent and functional GDB support in the mainline. It's still not as featured as it could and CPU-specific handling will need a dedicated treatment.
Signal conversions
GDB maintains an internal representation of signals and translates e.g. SIGTRAP to GDB_SIGNAL_TRAP. The kernel independent management of signal names is used by the GDB core and requires translation on the border of kernel-specific implementation. So far, the NetBSD support relied on an accidental overlap of signal names between the GDB core and the NetBSD definitions, while this worked for some signals it wasn't matching for others. I've added a patch with appropriate NetBSD->GDB and GDB->NetBSD signal number conversions and enabled it in all NetBSD CPU-specific files.
Later, newly added code respects now these signal conversions in the management of processes.
Threading support
I've implemented the NetBSD specific methods for dealing with threads. Previously the pristine version of GDB was unaware about threading on NetBSD and the basesystem GDB relied on local patches that needed reimplementation to meet the expectations (especially rewrite to C++) of the upstream maintainers.
I have upstreamed this with the following commit:
Implement basic threading support in the NetBSD target Use sysctl(3) as the portable interface to prompt NetBSD threads on all supported NetBSD versions. In future newer versions could switch to PT_LWPSTATUS ptrace(2) API that will be supported on NetBSD 10.0 and newer. Implement as part of nbsd_nat_target: - thread_name() - read descriptive thread name - thread_alive() - check whether a thread is alive - post_attach() - updates the list of threads after attach - update_thread_list() - updates the list of threads - pid_to_str() - translates ptid to a descriptive string There are two local static functions: - nbsd_thread_lister() - generic LWP lister for a specified pid - nbsd_add_threads() - utility to update the list of threads Now, GDB on NetBSD can attach to a multithreaded process, spawn a multithreaded process, list threads, print their LWP+PID numbers and descriptive thread names.
ELF symbol resolver
The NetBSD operating system relies on the ELF file format for native applications.
One of the features in GDB is to skip single-stepping over the internal ELF loader code.
When a user of GDB instructs ther debugger to step a line in a source code,
and whenever we land into an unresolved symbol in the GOT table, we could step internal code of the ELF loader,
for the first usage of a public symbol, which is not necessarily wrong, but could be confusing.
This is typically worked around with a generic code that tries to detect such scenario examining
among others the code sections of the stepped code, but the default fallback is not functional on every
NetBSD port, especially Alpha and ARM.
The new code merged into GDB uses the same logic for all NetBSD ports, trying to detect the
_rtld_bind_start symbol and act acordingly in case of detecting it.
SVR4 psABI parsers of AUXV entries
The ELF format ships with a mechanism to transfer certain kernel level information to the user process. AUXV is a key-value array located on the stack and available to an ELF loader. While Linux uses a different format than the one specified in SVR4 psABI, NetBSD follows the standard and stores the key value in a 32-bit integer always. This caused breakage on 64-bit CPUs and the NetBSD developers used to patch the Linux AUXV code to be compatible with the NetBSD behavior. I've added a dedicated function for the NetBSD AUXV handling and switched to it all NetBSD CPUs.
Process information (info proc)
As documented by the
GDB project:
Some operating systems provide interfaces to fetch additional
information about running processes beyond memory and per-thread
register state. If GDB is configured for an operating system with
a supported interface, the command info proc is available to report
information about the process running your program, or about any
process running on your system.
Previously the info proc functionality was implemented only for Linux and FreeBSD.
I've implemented support for the following commands:
info proc|info proc process-id- Summarize available information about a process.info proc cmdline- Show the original command line of the process.info proc cwd- Show the current working directory of the process.info proc exe- Show the name of executable of the process.info proc mappings- Report the memory address space ranges accessible in a process.info proc stat|info proc status- Show additional process-related information.info proc all- Show all the information about the process described under all of the above info proc subcommands.
All of these pieces of information are retrieved with the sysctl(3) interface. Example of an execution of the command is below:
(gdb) info proc all
process 26015
cmdline = '/usr/bin/cal'
cwd = '/public/binutils-gdb-netbsd'
exe = '/usr/bin/cal'
Mapped address spaces:
Start Addr End Addr Size Offset Flags File
0x200000 0x204000 0x4000 0x0 r-x C-PD /usr/bin/cal
0x404000 0x405000 0x1000 0x4000 r-- C-PD /usr/bin/cal
0x405000 0x406000 0x1000 0x0 rw- C-PD
0x7f7ff6c00000 0x7f7ff6c10000 0x10000 0x0 rw- C-PD
0x7f7ff6c10000 0x7f7ff6db0000 0x1a0000 0x0 rw- CNPD
0x7f7ff6db0000 0x7f7ff6dc0000 0x10000 0x0 rw- C-PD
0x7f7ff6dc0000 0x7f7ff7000000 0x240000 0x0 rw- CNPD
0x7f7ff7000000 0x7f7ff7010000 0x10000 0x0 rw- C-PD
0x7f7ff7010000 0x7f7ff7200000 0x1f0000 0x0 rw- CNPD
0x7f7ff7200000 0x7f7ff7260000 0x60000 0x0 r-x CNPD /lib/libc.so.12.215
0x7f7ff7260000 0x7f7ff7270000 0x10000 0x60000 r-x C-PD /lib/libc.so.12.215
0x7f7ff7270000 0x7f7ff73c6000 0x156000 0x70000 r-x CNPD /lib/libc.so.12.215
0x7f7ff73c6000 0x7f7ff75c6000 0x200000 0x1c6000 --- CNPD /lib/libc.so.12.215
0x7f7ff75c6000 0x7f7ff75d1000 0xb000 0x1c6000 r-- C-PD /lib/libc.so.12.215
0x7f7ff75d1000 0x7f7ff75d7000 0x6000 0x1d1000 rw- C-PD /lib/libc.so.12.215
0x7f7ff75d7000 0x7f7ff75f0000 0x19000 0x0 rw- C-PD
0x7f7ff75f0000 0x7f7ff76e0000 0xf0000 0x0 rw- CNPD
0x7f7ff76e0000 0x7f7ff76f0000 0x10000 0x0 rw- C-PD
0x7f7ff76f0000 0x7f7ff77e0000 0xf0000 0x0 rw- CNPD
0x7f7ff77e0000 0x7f7ff77f8000 0x18000 0x0 rw- C-PD
0x7f7ff7800000 0x7f7ff780e000 0xe000 0x0 r-x CNPD /lib/libterminfo.so.2.0
0x7f7ff780e000 0x7f7ff7a0d000 0x1ff000 0xe000 --- CNPD /lib/libterminfo.so.2.0
0x7f7ff7a0d000 0x7f7ff7a0e000 0x1000 0xd000 r-- C-PD /lib/libterminfo.so.2.0
0x7f7ff7a0e000 0x7f7ff7a0f000 0x1000 0xe000 rw- C-PD /lib/libterminfo.so.2.0
0x7f7ff7c00000 0x7f7ff7c0f000 0xf000 0x0 r-x C-PD /libexec/ld.elf_so
0x7f7ff7c0f000 0x7f7ff7e0f000 0x200000 0x0 --- CNPD
0x7f7ff7e0f000 0x7f7ff7e10000 0x1000 0xf000 rw- C-PD /libexec/ld.elf_so
0x7f7ff7e10000 0x7f7ff7e11000 0x1000 0x0 rw- C-PD
0x7f7ff7eed000 0x7f7ff7eff000 0x12000 0x0 rw- C-PD
0x7f7ff7eff000 0x7f7fffbff000 0x7d00000 0x0 --- CNPD
0x7f7fffbff000 0x7f7fffff0000 0x3f1000 0x0 rw- CNPD
0x7f7fffff0000 0x7f7ffffff000 0xf000 0x0 rw- C-PD
Name: cal
State: STOP
Parent process: 11837
Process group: 26015
Session id: 15656
TTY: 1288
TTY owner process group: 11837
User IDs (real, effective, saved): 1000 1000 1000
Group IDs (real, effective, saved): 100 100 100
Groups: 100 0 5
Minor faults (no memory page): 292
Major faults (memory page faults): 0
utime: 0.000000
stime: 0.003510
utime+stime, children: 0.000000
'nice' value: 20
Start time: 1588600926.724211
Data size: 8 kB
Stack size: 8 kB
Text size: 16 kB
Resident set size: 1264 kB
Maximum RSS: 2000 kB
Pending Signals: 00000000 00000000 00000000 00000000
Ignored Signals: 98488000 00000000 00000000 00000000
Caught Signals: 00000000 00000000 00000000 00000000
Event handling
I've implemented event handling for the following trap types:
- single step (
TRAP_TRACE) - software breakpoint (
TRAP_DBREG) - exec() (
TRAP_EXEC) - syscall entry/exit (
TRAP_SCE/TRAP_SCX)
While there, I have added proper support for ::wait () and ::resume () methods.
Syscall entry/exit tracing
I've added a support for syscall entry/exit breakpoint traps.
There used to be some support for this mode in the basesystem GDB, however we missed a list of mapping
of syscall number to syscall name.
I've borrowed the script from FreeBSD to generate netbsd.xml with the mapping,
based on definitions in /usr/include/sys/syscall.h.
This approach of mapping syscalls for NetBSD is imperfect as the internal names are not stable and change whenever
a syscall is versioned. There is no ideal approach to handle this
(e.g. debugging programs on NetBSD 9.0 and NetBSD 10.0 can behave differently), and end-users will need to deal with it.
Threading events
As threading support is mandatory these days, I have implemented and upstreamed support for thread creation and thread exit events.
Other changes
As in general,
I oppose to treating all BSD Operating Systems under the same ifdef in existing software,
as it leads to conditionals like #if defined(AllBSDs) && !defined(ThisBSD) and/or
a spaghetti of #define symbol renames.
There was an attempt to define support for all BSDs in a shared file inf-ptrace.c, however in the
end developers pushing for that reimplemented support part of the code for their kernels in private per-OS
files.
This left a lot of shared, sometimes unneeded code in the common layer.
I was kind to fix the build of OpenBSD support in GDB (and only build-tested) and moved OpenBSD-specific code from inf-ptrace.c to obsd-nat.c. Code that was no longer needed for OpenBSD in inf-ptrace.c (as it was reimplemented in obsd-nat.c) and in theory shared with NetBSD was removed.
My intention is to restrict common shared code of GDB to really common parts and whenever kernels differ, implement their specific handling in dedicated files. There are still some hacks left in the GDB shared code (even in inf-ptrace.c) for long removed kernels that obfuscate the support... especially the Gould NP1 support from the 1980s and definitely removed in 2000.
Plan for the next milestone
Finish and upstream operational support of follow-fork, follow-vfork and follow-spawn events. Rewrite the gdbserver support and submit upstream.
![]() We are very happy to announce
The NetBSD Foundation Google Summer of Code 2020 projects:
We are very happy to announce
The NetBSD Foundation Google Summer of Code 2020 projects:
- Apurva Nandan - Benchmark NetBSD
- Jain Naman - Curses library automated testing
- Nikita Gillmann - Make system(3) and popen(3) use posix_spawn(3) internally
- Ayushi Sharma - Enhance the syzkaller support for NetBSD
- Aditya Vardhan Padala - Rumpkernel Syscall Fuzzing
- Nisarg Joshi - Fuzzing the network stack of NetBSD in a rumpkernel environment
- Jason High - Extending the functionality of the netpgp suite
The community bonding period - where students get in touch with mentors and community - started on May 4 and will go on until June 1. The coding period will be June 1 to August 24.
Please welcome all our students and a big good luck to students and mentors!
A big thank you to Google and The NetBSD Foundation organization mentors and administrators!
Looking forward to having another nice Google Summer of Code!
Upstream describes LLDB as a next generation, high-performance debugger. It is built on top of LLVM/Clang toolchain, and features great integration with it. At the moment, it primarily supports debugging C, C++ and ObjC code, and there is interest in extending it to more languages.
In February, I have started working on LLDB, as contracted by the NetBSD Foundation. So far I've been working on reenabling continuous integration, squashing bugs, improving NetBSD core file support and updating NetBSD distribution to LLVM 8 (which is still stalled by unresolved regressions in inline assembly syntax). You can read more about that in my Mar 2019 report.
In April, my main focus was on fixing and enhancing the support for reading and writing CPU registers. In this report, I'd like to shortly summarize what I have done, what I have learned in the process and what I still need to do.
Buildbot status update
Last month I reported a temporary outage of buildbot service. I am glad to follow up on that and inform you that the service has been restored and the results of CI testing are once again available at: http://lab.llvm.org:8011/builders/netbsd-amd64. While the tests are currently failing, they still serve as useful source of information on potential issues and regressions.
The new discoveries include update on flaky tests problem. It turned out that the flaky markings I've tried to use to workaround it does not currently work with the lit test runner. However, I am still looking for a good way of implementing this. I will probably work on it more when I finish my priority tasks. It is possible that I will just skip the most problematic instead for the time being instead.
Additionally, the libc++ test suite identified that NetBSD is missing
the nexttowardl() function. Kamil noticed that and asked me if
I could implement it. From quick manpage reading, I've came to
the conclusion that nexttowardl() is equivalent to nextafterl(),
and appropriately implemented it as an alias: 517c7caa3d9643 in src.
Fixing MM register support
The first task in my main TODO was to fix a bug in reading/writing MM
registers that was identified earlier. The MM registers were introduced
as part of MMX extensions to x86, and they were designed as overlapping
with the earlier ST registers used by x87 FPU. For this reason, they
are returned by the ptrace() call as a single fx_87_ac array
whose elements are afterwards to work on both kinds of registers.
The bug in question turned out to be mistaken use of fx_xmm instead
of fx_87_ac. As a result, the values of mm0..mm7 registers were
mapped to subsets of xmm0..xmm7 registers, rather than the correct
set of st(0)..st(7) registers. The fix for the problem in question
landed as r358178.
However, the fix itself was the easier part. The natural consequence of identifying a problem with the register was to add a regression test for it. This in turn triggered a whole set of events that deserve a section of their own.
Adding tests for register operations
Initially, the test for MM and XMM registers consisted of a simple
program written in pure amd64 assembler that wrote known patterns
to the registers in question, then triggered SIGTRAP via int3,
and a lit test that run LLDB in order to execute the program, read
registers and compare their values to expected patterns. However,
following upstream recommendations it quickly evolved.
Firstly, upstream suggested replacing the assembly file with inline assembly in C or C++ program, in order to improve portability between platforms. As a result, I ended up learning how to use GCC extended inline assembly syntax (whose documentation is not exactly the most straightfoward to use) and created a test case that works fine both for i386 and amd64, and in a wide range of platforms supported by LLDB.
Secondly, it was necessary to restrict the tests into native runs
on i386 and amd64 hardware. I discovered that lit partially provides
for this, by defining native feature whenever LLDB is being built
as native executable (vs cross-compiling). It also defined a few
platform-related features, so it seemed only natural to extend them
to provide explicit target-x86 and target-x86_64 features,
corresponding to i386 and amd64 targets. This was done in r358177.
Thirdly, upstream asked me to add tests also for other register types, as well as for writing registers. This overlapped with our need to test new register routines for NetBSD, so I've focused on them.
The main problem in adding more tests was that I needed to verify whether the processor supported specific instruction sets. For the time being, it seemed reasonable to assume that every possible user of LLDB would have at least SSE, and to filter tests specific to long mode on amd64 platform. However, adding tests for registers introduced by AVX extension required explicit check.
I have discussed the problem with Pavel Labath of LLDB upstream, and considered multiple options. His suggestion was to make the test program itself run cpuid instruction, and exit with a specific status if the needed registers are not supported. Then I could catch this status from dotest.py test and mark the test as unsupported. However, I really preferred using plain lit over dotest.py (mostly because it naturally resembled LLDB usage), and wanted to avoid duplicating cpuid code in multiple tests.
However, lit does not seem to support translating a specific exit status into 'unsupported'. The 'lit way' of solving this is to determine whether the necessary feature is available up front, and make the test depend on it. Of course, the problem was how to check supported CPU extensions from within lit.
Firstly, I've considered the possibility of determining cpuinfo from within Python. This would be the most trivial option, however Python stdlib does not seem to provide appropriate functions and I wanted to avoid relying on external modules.
Secondly, I've considered the possibility of running clang from within lit in order to build a simple test program running cpuid, and using it to fill the supported features.
Finally, I've arrived at the simpler idea of making lit-cpuid,
an additional utility program built as part of LLDB. This program
uses very nice cpuid API exposed by LLVM libraries in order to determine
the available extensions and print them for lit's use. This landed
as r359303
and opened the way for more register tests.
To this moment, I've implemented the following tests:
tests for mm0..mm7 64-bit MMX registers and xmm0..xmm7 128-bit SSE registers mentioned above, common to i386 and amd64; read: r358178, write: r359681.
tests for the 8 general purpose registers:
*AX..*DX,*SP,*BP,*SI,*DI, in separate versions for i386 (32-bit registers) and amd64 (64-bit registers); read: r359438, write: r359441.tests for the 8 additional 64-bit general purpose registers r8..r15, and 8 additional 128-bit xmm8..xmm15 registers introduced in amd64; read: r359210, write: r359682.
tests for the 256-bit ymm0..ymm15 registers introduced by AVX, in separate versions for i386 (where only ymm0..ymm7 are available) and amd64; read: r359304, write: r359783.
tests for the 512-bit zmm0..zmm31 registers introduced by AVX-512, in separate versions for i386 (where only zmm0..zmm7 are available) and amd64; read: r359439, write: r359797.
tests for the xmm16..xmm31 and ymm16..ymm31 registers that were implicitly added by AVX-512 (xmm, ymm and zmm registers overlap/extend their predecessors); read: r359780, write: r359797.
Fixing memory reading and writing routine
The general-purpose register tests were initially failing on NetBSD. More specifically, the test worked correctly to the point of reading registers but afterwards lldb indicated a timeout and terminated the program instead of resuming it.
While investigating this, I've discovered that it is caused
by overwriting RBP. Curious enough, it happened only when large values
were written to it. I've 'bisected' it to an approximate max value
that still worked fine, and Kamil has identified it to be close to
vm.maxaddress.
GDB did not suffer from this issue. I've discussed it with Pavel Labath
and he suggested it might be related to unwinding. Upon debugging it
further, I've noticed that lldb-server is apparently calling ptrace()
in an infinite loop, and this is causing communications with the CLI
process (LLDB is using client-server model internally) to timeout.
Ultimately, I've pinpointed it to memory reading routine not expecting
read to set piod_len to 0 bytes (EOF). Apparently, this is exactly
what happens when you try to read past max virtual memory address.
I've made a patch for this. While reviewing it, Kamil also noticed that the routines are not summing up results of multiple split read/write calls as well. I've addressed both issues in r359572
Necessary extension of ptrace interface
At the moment, NetBSD implements 4 requests related to i386/amd64 registers:
PT_[GS]ETREGSwhich covers general-purpose registers, IP, flags and segment registers,PT_[GS]ETFPREGSwhich covers FPU registers (and xmm0..xmm15 registers on amd64),PT_[GS]ETDBREGSwhich covers debug registers,PT_[GS]ETXMMREGSwhich covers xmm0..xmm15 registers on i386 (not present on amd64).
The interface is missing methods to get AVX and AVX-512 registers,
namely ymm0..ymm15 and zmm0..zmm31. Apparently there's struct xsave_ymm for the former in kernel headers but it is not used
anywhere. I am considering different options for extending this.
Important points worth noting are that:
YMM registers extend XMM registers, and therefore overlap with them. The existing
struct xsave_ymmseems to use that, and expect only the upper half of YMM register to be stored there, with the lower half being accessible via XMM. Similar fact holds for ZMM vs YMM.AVX-512 increased the register count from 16 to 32. This means that there are 16 new XMM registers that are not accessible via current API.
This also opens questions about future extensibility of the interface. After all, we are not only seeing new register types added but also an increase in number of registers of existing types. What I'd really like to avoid is having an increasingly cluttered interface.
How are other systems solving it?
Linux introduced PT_[GS]ETREGSET request that accepts a NT_*
constant identifying register set to operate on, and iovec structure
containing buffer location and size. For x86, the constants equivalent
to older PT_* requests are available, and a NT_X86_XSTATE that
uses full XSAVE area. The interface supports operating on complete
XSAVE area only, and requires the caller to identify the correct size
for the CPU used beforehand.
FreeBSD introduced PT_[GS]ETXSTATE request that operates on full or
partial XSAVE data. If the buffer provided is smaller than necessary,
it is partially filled. Additionally, PT_GETXSTATE_INFO is provided
to get the buffer size for the CPU used.
A similar solution would be convenient for future extensions, as the caller would be able to implement them without having the kernel updated. Its main disadvantage is that it requires all callers to implement XSAVE area format parsing. Pavel Labath also suggested that we could further optimize it by supplying an offset argument, in order to support partial XSAVE area transfer.
An alternative is to keep adding new requests for new register types,
i.e. PT_[GS]ETYMMREGS for YMM, and PT_[GS]ETZMMREGS for ZMM.
In this case, it is necessary to further discuss the data format used.
It could either be the 'native' XSAVE format (i.e. YMM would contain
only upper halves of the registers, ZMM would contain upper halves
of zmm0..zmm15 and complete data of zmm16..zmm31), or more conveniently
to clients (at the cost of data duplication) whole registers.
If the latter, another question is posed: should we provide a dedicated
interface for xmm16..xmm31 (and ymm16..ymm31) then, or infer them from
zmm16..zmm31 registers?
Future plans
My work continues with the two milestones from last month, plus a third that's closely related:
Add support for FPU registers support for NetBSD/i386 and NetBSD/amd64.
Support XSAVE, XSAVEOPT, ... registers in core(5) files on NetBSD/amd64.
Add support for Debug Registers support for NetBSD/i386 and NetBSD/amd64.
The most important point right now is deciding on the format for passing the remaining registers, and implementing the missing ptrace interface kernel-side. The support for core files should follow using the same format then.
Userland-side, I will work on adding matching ATF tests for ptrace features and implement LLDB side of support for the new ptrace interface and core file notes. Afterwards, I will start working on improving support for the same things on 32-bit (i386) executables.
This work is sponsored by The NetBSD Foundation
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL to chip in what you can:
![]() We are very happy to announce
The NetBSD Foundation Google Summer of Code 2019 projects:
We are very happy to announce
The NetBSD Foundation Google Summer of Code 2019 projects:
- Akul Abhilash Pillai - Adapting TriforceAFL for NetBSD kernel fuzzing
- Manikishan Ghantasala - Add KNF (NetBSD style) clang-format configuration
- Siddharth Muralee - Enhancing Syzkaller support for NetBSD
- Surya P - Implementation of COMPAT_LINUX and COMPAT_NETBSD32 DRM ioctls support for NetBSD kernel
- Jason High - Incorporation of Argon2 Password Hashing Algorithm into NetBSD
- Saurav Prakash - Porting NetBSD to HummingBoard Pulse
- Naveen Narayanan - Porting WINE to amd64 architecture on NetBSD
The communiting bonding period - where students get in touch with mentors and community - started yesterday. The coding period will start from May 27 until August 19.
Please welcome all our students and a big good luck to students and mentors!
A big thank to Google and The NetBSD Foundation organization mentors and administrators!
Looking forward to a great Google Summer of Code!
I am improving signaling code in the NetBSD kernel, covering corner cases with regression tests, and improving the documentation. I've been working at the level of sytems calls (syscalls): forking, threading, handling these with GDB, and tracing syscalls. Some work happens behind the scenes as I support the work of Michal Gorny on LLDB/ptrace features.
clone(2)/__clone(2) tracing fixes
clone(2) (and its alias __clone(2)) is a Linux-compatible system call that is equivalent to fork(2) and vfork(2). However it was more customization options. Some programs use clone(2) directly and in some cases it's just easier to precompile the same program also for the NetBSD distribution, without extra changes, using clone(2) directly in the program for NetBSD.
During my work on the fork1(9) kernel function -- which handles debugger-related events -- I implemented regression tests of this syscall. This was combined with certain supported modes of operation of clone(2), particularly checking supported flags. These combinations did not use more than a one in the same test.
Naturally, a judicious selection of edge cases in the regression tests should give meaningful results. I plan to stress the kernel with a random set of flags with a kernel fuzzer. In turn, this will help to catch immediate kernel problems quickly.
During my work I have discovered that support for clone(2) for a debugger has been defective since inception. This never worked due to a small 1-byte programming mistake. The fix landed in sys/kern/kern_fork.c r.1.207. As the fork1(9) code evolved since the introduction of PSL_TRACEFORK, the fix is no longer a single-liner, but still it removes only 3 bytes from the kernel code (in the past it would be 1 byte removal)!
@@ -477,11 +477,11 @@ fork1(struct lwp *l1, int flags, int exitsig, void *stack, size_t stacksize,
* Trace fork(2) and vfork(2)-like events on demand in a debugger.
*/
tracefork = (p1->p_slflag & (PSL_TRACEFORK|PSL_TRACED)) ==
- (PSL_TRACEFORK|PSL_TRACED) && (flags && FORK_PPWAIT) == 0;
+ (PSL_TRACEFORK|PSL_TRACED) && (flags & FORK_PPWAIT) == 0;
tracevfork = (p1->p_slflag & (PSL_TRACEVFORK|PSL_TRACED)) ==
- (PSL_TRACEVFORK|PSL_TRACED) && (flags && FORK_PPWAIT) != 0;
+ (PSL_TRACEVFORK|PSL_TRACED) && (flags & FORK_PPWAIT) != 0;
tracevforkdone = (p1->p_slflag & (PSL_TRACEVFORK_DONE|PSL_TRACED)) ==
- (PSL_TRACEVFORK_DONE|PSL_TRACED) && (flags && FORK_PPWAIT);
+ (PSL_TRACEVFORK_DONE|PSL_TRACED) && (flags & FORK_PPWAIT);
if (tracefork || tracevfork)
proc_changeparent(p2, p1->p_pptr);
if (tracefork) {
(flags & FORK_PPWAIT) &
implements bitwise AND. Logical AND (&&) was intended.
Despite many eyes reading and editing this code, this particular issue
was overlooked
until the introduction of the regression tests.
The effect of this change was that every clone(2) variation was incorrectly
mapped into corresponding fork(2)/vfork(2) event.
More information about the C semantics can be checked in web resources on web pages.
Now clone(2) should work comparably well, for example, when compared to fork(2) and vfork(2). Current work is to map all clone(2) calls that have the property of a stopped parent to vfork(2); otherwise, if they don't have this property, they should be mapped to fork(2). This approach allows me to directly map clone(2) variations into well defined interfaces in debuggers that distinguish 3 types of forking events:
- FORK
- VFORK
- VFORK_DONE
From a debugger's point of view it doesn't matter whether or not clone(2) shares the file descriptor table with its parent. It's an implementation detail, and either way it is expected to be handled by a tracer in the same way.
More options of clone(2) can be found in the NetBSD manual pages.
I still plan to check a similar interface, posix_spawn(3), which performs both operations in one call: clone(2) and exec(2). Most likely, according to my code reading, the syscall is not handled appropriately in the kernel space and I will need to map it into proper forking events. My motivation here is to support all system interfaces spawning new processes.
child_return(9) refactoring
child_return(9) is a kernel function that prepares a newly spawned child to return value 0 from fork(2), while its parent process returns child's process id. Originally the child_return(9) function was purely implemented in the MD part of each NetBSD port. I've since changed this and converted child_return(9) into MI code that is shared between all architectures. md_child_return() is now used for port specific code only.
The updated child_return(9) contains ptrace(2)- and ktruss(1)-related code that is shared now between all ports.
Incidentally, I noted a bug in a set of functions in NetBSD's aarch64 (ARM64) port. A set of functions called in thir original child_return() failed to call userret(9). In turn, the return path to user-mode procedures was incorrect. The bug has since been corrected and this resulted in passing several ATF tests.
This code has been also hardened for races that are theoretically possible, but unlikely to happen in practice.. on the other hand such statement usually means that a bug can be triggered easily in a loop within a short period of time. In order to stop risking and assuming that all the code now and in future changes is safe enough, I've added additional checks that assume that we won't generate a debugger related event in abnormal conditions like just receiving a SIGKILL, ignoring it and overwriting it with another signal SIGTRAP. The code has been modified to use racy-check, check for condition and if it evaluates to true, I am performing locking operations and recheck in new conditions the state, rechecking the integrity state before generating an event for a debugger.
/*
* MI code executed in each newly spawned process before returning to userland.
*/
void
child_return(void *arg)
{
struct lwp *l = arg;
struct proc *p = l->l_proc;
if (p->p_slflag & PSL_TRACED) {
/* Paranoid check */
mutex_enter(proc_lock);
if (!(p->p_slflag & PSL_TRACED)) {
mutex_exit(proc_lock);
goto my_tracer_is_gone;
}
mutex_enter(p->p_lock);
eventswitch(TRAP_CHLD);
}
my_tracer_is_gone:
md_child_return(l);
/*
* Return SYS_fork for all fork types, including vfork(2) and clone(2).
*
* This approach simplifies the code and avoids extra locking.
*/
ktrsysret(SYS_fork, 0, 0);
}
Forking improvements under ptrace(2)
I've refactored the test cases and verified some of the forking semantics in the kernel. This included narrow cases such as nested vfork(2). Thankfully this worked correctly "as is" (except typical vforking(2) races that still exist).
I've added support to fork1(9) scenarios for detaching or killing a process in the middle of the process of spawning of a new child. This is needed in debuggers such as GDB that can either follow forkers or forkees, immediately detaching the other one. Bugs in these scenarios have been corrected and I have verified that GDB behaves correctly in these situations.
Threading improvements under ptrace(2)
I've reworked the current code for reporting threading (LWP) events to debuggers (LWP_CREATE and LWP_EXITED). The updated revision is also no longer prone to masking SIGTRAP in a child. Since these improvements, LWP events are now significantly more stable than they used to be. Reporting LWP_EXITED is still incorrect as there is a race condition between WAIT() and EXIT(). The effect of this is that the signal from EXIT() is never delivered to a debugger that is polling for it, and therefore it is missed.
Other changes
ATF ptrace(2) test corrections for handling of SIGILL crashes on SPARC, and detection of FPU availability on ARM, have been added.
The PT_IO operation in ptrace(2) can result in a false positive success value, however no byte transfer operation has been performed. Michal Gorny detected this problem in LLDB for invalid frame pointer reads. The NetBSD driver overlooked this scenario and was looping infinitely. This surprising property was also detected in PT_WRITE/PT_READ operations and found to be triggered in GDB. As a workaround I have disabled 0-length transfer requests in PT_IO by returning EINVAL. Zero-byte transfer operations bring the PT_WRITE/PT_READ calls into question, as we have no way to distinguish successful operation from an empty-byte transfer returning success.
In turn, this means PT_WRITE/PT_READ should be deprecated. I plan to document this clearly.
I've decided to finally forbid setting Program Counter to 0x0 in PT_CONTINUE/PT_DETACH/etc as it's hardly ever a valid executable address. There are two main factors here:
I've added previously missing support for KTR (ktrace(1)) events. In particular, this is for debugger-related signals except vfork(2) because this creates unkillable processes. I am considering fixing this by synchronizing the parent of the vfork(2)ed process and its child. This change will enable the debugger to process event signals in ktruss(1) logs.
GDB support improvements
During the last month I introduced a regression bug in passing crash signals to the debugger. I reduced some specific information passed to a tracer, indirectly improving NetBSD stability support while debugging in GDB. The trade-off was a slight reduction in readability of LLDB backtraces and crash reports.
Independently I've been asked by Christos Zoulas to fix GDB support for threads. I addressed the kernel shortage quickly and reworked the NetBSD platform code in GDB. Dead code (which was leftover from the original FreeBSD original code) was removed, missing code added, and monitoring debugger-related events was reworked. The latter supports the improved kernel APIs produced during my overall work. GDB still exhibits issues with threads, for example, for convoluted Golang binaries, but has been improved to the extent that ATF regression tests for GDB pass again.
Syscall tracing API
The episode of GDB fixes stimulated me to add support for passing the syscall number along with the SIGTRAP signal. I've described the interface in the commit message:
commit 7dd3c39f7d951a10642fce0f99d9e86d28156836
Author: kamil
Date: Mon May 6 08:05:03 2019 +0000
Ship with syscall information with SIGTRAP TRAP_SCE/TRAP_SCX for tracers
Expand siginfo_t (struct size not changed) to new values for
SIGTRAP TRAP_SCE/TRAP_SCX events.
- si_sysnum -- syscall number (int)
- si_retval -- return value (2 x int)
- si_error -- error code (int)
- si_args -- syscall arguments (8 x uint64_t)
TRAP_SCE delivers si_sysnum and si_args.
TRAP_SCX delivers si_sysnum, si_retval, si_error and si_args.
Users: debuggers (like GDB) and syscall tracers (like strace, truss).
This MI interface is similar to the Linux kernel proposal of
PTRACE_GET_SYSCALL_INFO by the strace developer team.
In order to verify the updated API before merging it into the kernel, I wrote a truss-like or strace-like tool for the kernel interfaces. I authored three versions of picotrace: the first in C; the second in Lua+C; and the third one with C. The final 3rd version has been published and imported as pkgsrc/devel/picotrace.
The upstream source code is available online at https://github.com/krytarowski/picotrace.
It is documented in pkgsrc as follows:
picotrace enables syscall trace logging for the specified processes. The tracer uses the ptrace(2) system call to perform the tracing. The picotrace program implements bare functionality by design. It has no pretty printing of data structures or interpretation of numberical arguments to their corresponding syscalls. picotrace is designed to be a framework for other more advanced tracers, and to illustrate canonical usage of the ptrace(2). New features are not expected unless they reflect a new feature in the kernel.
Summary
I was able run literally all existing ATF ptrace(2) from the testsuite and pass all of them. Unfortunately, VFORK and LWP operations still present race conditions in the kernel and can cause failures. In order to reduce concerns from other developers, I have disabled the racy tests by default. There is also a new observation that one test that used to be rock stable is now sometimes flaky. It has not been investigated, but I suspect that something with the pipe(2) kernel code has a regression or surfaced an old problem. I plan to investigate this once I will finish other ptrace(2) tasks.
Plan for the next milestone
I will visit BSDCan this month to speak about NVMM and HAXM. I will resume my work on forking and threading bugs after the conference. The lwp_exit() and wait() race will be prioritized as it affects most current users. After resolving this problem, I will be back to posix_spawn(2), followed by addressing vfork(2) races.
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL to chip in what you can:
The NetBSD Project is pleased to announce NetBSD 8.1 RC1, the first (and hopefully final) release candidate for the upcoming NetBSD 8.1 release.
Over the last year, many changes have been made to the NetBSD 8 stable branch. As a stable branch the release engineering team and the NetBSD developers are conservative with changes to this branch and many users rely on the binaries from our regular auto-builds for production use. Now it is high time to cut a formal release, right before we go into the next release cycle with the upcoming branch for NetBSD 9.
Besides the workarounds for the latest CPU specific vulnerabilities, this also includes many bug fixes and a few selected new drivers. For more details and instructions see the 8.1 RC1 announcement.
Get NetBSD 8.1 RC1 from our CDN (provided by fastly) or one of the ftp mirrors.
Complete source and binaries for NetBSD are available for download at many sites around the world. A list of download sites providing FTP, AnonCVS, and other services may be found at https://www.NetBSD.org/mirrors/.
Please test RC1, we are looking forward to your feedback. Please send-pr any bugs or mail us at releng at NetBSD.org for more general comments.
![]() We are very happy to announce
The NetBSD Foundation Google Summer of Code 2018 projects:
We are very happy to announce
The NetBSD Foundation Google Summer of Code 2018 projects:
- Harsh Khatore - Modern cryptographic algorithms to netpgp, netpgpverify
- Nizar Benshaqi - SQL Database for ATF tests results with online query and statistics page
- Marwa Desouky - Tickless Kernel with high-resolution timers
- Harry Pantazis - Kernel Undefined Behavior SANitizer
- Does025 - Porting FreeBSD Atheros driver to NetBSD
- Saad Mahmood - Machine-independent EFI bootloader
- Yang Zheng - Integrate libFuzzer With the Basesystem
- Keivan Motavalli - configuration files versioning in pkgsrc
- R3x - Implementing Kernel Address Sanitizer (KASan) in the NetBSD kernel
We have started the community bonding period where students get in touch with mentors and community and get more confident with documentation and the code base. The coding period will start from May 14 until August 6.
Please welcome all our students and a big good luck to students and mentors!
A big thank you also to Google and The NetBSD Foundation Organization Administrators!
Looking forward to a nice Google Summer of Code!
LLDB
I've rebased my old patches for handling NetBSD core(5) files to recent LLDB from HEAD (7.0svn). I had to implement the support for aarch64, as requested by Joerg Sonnenberger for debugging NetBSD/arm64 bugs. The NetBSD case is special here, as we set general purpose registers in 128bit containers, while other OSes prefer 64-bit ones. I had to add a local kludge to cast the interesting 64-bit part of the value.
I've generated a local prebuilt toolchain with lldb prepared for a NetbBSD/amd64 host and shared with developers.
Debug Registers
I've improved the security of Debug Registers, with the following changes:
- x86_dbregs_setup_initdbstate() stores the initial status of Debug Registers, I've explicitly disabled some of their bits for further operation. This register context is used when initializing Debug Registers for a userland thread. This is a paranoid measure used just in case a bootloader uses them and leaves the bits lit up.
- I've added a new sysctl(3) switch security.models.extensions.user_set_dbregs: "Whether unprivileged users may set CPU Debug Registers". The Debug Registers use privileged operations and we decided to add another check, disabling them by default. There is no regress in the elementary functionality and a user can still read the Debug Register context.
- This new sysctl(3) functionality has been covered by ATF checks in existing tests (i386 and amd64 for now).
fork(2) and vfork(2)
I've pushed various changes in the kernel subsystems and ATF userland tests for the ptrace(2) functionality:
- I've integrated all fork(2) and vfork(2) tests into the shared function body. They tests PTRACE_FORK, PTRACE_VFORK and PTRACE_VFORK_DONE. There are now eight fork1..fork8 and eight vfork1..vfork8 tests (total 16). I'm planning to cover several remaining corner case scenarios in the forking code.
- I've removed an unused variable from linux_sys_clone(), which calls fork1(9). This provides an opportunity to refactor the generic code.
- I've refactored start_init() setting inside it the initproc pointer. This eliminates the remaining user of rnewprocp in the fork1(9) API.
- I've removed the rnewprocp argument from fork1(9). This argument in the current implementation could cause use-after-free in corner cases.
- PTRACE_VFORK has been implemented and made functional.
Security hardening
I've prohibited calling PT_TRACE_ME for a process that is either initproc (PID1) or a direct child of PID1.
I've prohibited calling PT_ATTACH from initproc. This shouldn't happen in normal circumstances, but just in case this would lead to invalid branches in the kernel.
With the above alternations, I've removed a bug causing a creation of a process that is not debuggable. It's worth to note that this bug still exists in other popular kernels. A simple reproducer for pre-8.0 and other OSes using ptrace(2) (Linux, most BSDs ...):
$ cat antidebug.c
#include <sys/types.h>
#include <sys/ptrace.h>
#include <stdlib.h>
#include <unistd.h>
#include <stdio.h>
#include <errno.h>
int
main(int argc, char **argv)
{
pid_t child;
int rv;
int n = 0;
child = fork();
if (child == 0) {
while (getppid() != 1)
continue;
rv = ptrace(PT_TRACE_ME, 0, 0, 0);
if (rv != 0)
abort();
printf("Try to detach to me with a debugger!! ");
printf("haha My PID is %d\n", getpid());
while (1) {
printf("%d\n", n++);
sleep(1);
}
}
exit(0);
}
Additionally it's no longer valid calling and returning success PT_TRACE_ME when a process is already traced.
These security changes are covered by new ATF ptrace(2) tests:
- traceme_pid1_parent - Assert that a process cannot mark its parent a debugger twice.
- traceme_twice - Verify that PT_TRACE_ME is not allowed when our parent is PID1.
Other ptrace(2) enhancements
A list of other changes:
- I've refactored part of the existing ATF ptrace(2) tests, focusing on code deduplication and covering more corner cases. I'm now especially testing PT_TRACE_ME existing scenarios with signals from various categories: SIGSTOP, SIGCONT, SIGKILL, SIGABRT, SIGHUP. Some signals are non-maskable ones, some generate core(5) files etc. They might use different kernel paths and I'm now covering them in a more uniform and hopefully more maintainable form.
-
In the kernel, I've removed unused branch in the proc_stop_done() and sigswitch() functions.
This functionality was used in deprecated filesystem tracing feature (/proc).
It prevented emitting child signals to a debugging program, namely with the SIGCHLD signal.
The modern solution to perform tracing without signals in a debugger is to spawn a debugging server and outsource the tracing functionality to it. This is done in software like gdb-server, lldb-server etc.
-
I've removed a stray XXX comment from I and D read/write operations, and added a proper explanation:
+ /* + * The I and D separate address space has been inherited from PDP-11. + * The 16-bit UNIX started with a single address space per program, + * but was extended to two 16-bit (2 x 64kb) address spaces. + * + * We no longer maintain this feature in maintained architectures, but + * we keep the API for backward compatiblity. Currently the I and D + * operations are exactly the same and not distinguished in debuggers. + */
- I've improved the WCOREDUMP() checker in the ATF tests, casting it to either 1 or 0. This helps to handler correctly the tests generating core(5) files.
- Improve of the proc_stoptrace() function.
proc_stoptrace() is dedicated for emitting a syscall trap for a debugger,
either on entry or exit of the system function routine.
Changes:
- Change an if() branch of an invalid condition of being traced by initproc (PID1) to KASSERT(9).
- Assert that the current process has set appropriate flags (PSL_TRACED and PSL_SYSCALL).
- Use ktrpoint(KTR_PSIG) and ktrpsig()/e_ktrpsig() in order to register the emitted signal for the ktrace(1) event debugging.
Summary
A critical Problem Report kern/51630 regarding lack of PTRACE_VFORK implementation has been fixed. This means that there are no other unimplemented API calls, but there are still bugs in the existing ones.
With fixes and addition of new test cases, as of today we are passing 961 ptrace(2) tests and skipping 1 (out of 1018 total).
Plan for the next milestone
Cover the remaining forking corner-cases in the context of debuggers with new ATF tests and fix the remaining bugs.
The first step is to implement proper support for handling PT_TRACE_ME-traced scenarios from a vfork(2)ed child. Next I plan to keep covering the corner cases of the forking code and finish this by removal of subtle bugs that are still left in the code since the SMP'ification.
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL, and chip in what you can:
I've recently been gifted a fancy laptop - a Dell XPS 15 9550.
I want to run NetBSD on it and have it run well, and I've set aside time to achieve this.
Things work surprisingly well out of the box - touchscreen and touchpad work, but need to be calibrated better. 4K video is displayed, but without graphical acceleration, which is somewhat slow. I could adjust the resolution to be lower, but haven't tried yet.
These are some of the lessons I learned from doing this, being new to drivers and networking.
rtsx - SD card reader
This one was simple and straightforward.
The PCI ID of my SD is 10ec:525a, a realtek PCI device with ID 0x525a.
Normal SD card readers are supported by a generic driver, but mine wasn't.
I've been told that when SD cards don't present themselves as the generic device, it is for good reason.
Adding the PCI device ID to sys/dev/pci/pcidevs would have revealed the adjacent entries:
product REALTEK RTS5229 0x5229 RTS5229 PCI-E Card Reader product REALTEK RTS5249 0x5249 RTS5249 PCI-E Card Reader product REALTEK RTS525A 0x525A RTS525A PCI-E Card Reader <- my addition product REALTEK RTL8402 0x5286 RTL8402 PCI-E Card Reader
These are all supported by rtsx(4), which is a driver originally from OpenBSD.
Looking at the driver in OpenBSD, it has diverged since, and indeed someone had added RTS525A support.
I've initially tried to synchronize the driver, but it seemed beyond my capabilities, and just went to steal the support.
Found the individual commit and it was kinda ugly, there are conditionals for variants in some functions.
I've added the RTS525A in the matching conditionals.
It would have been nice to make it less ugly, but I'm only adding a bit of fuel to the fire.
I've received hints that drivers for hardware from some manufacturers is going to be ugly either way.
I saw that "read-only detect" is not supported. Curious if I could added, I wondered what happens if you try to write when the SD card's read-only switch is held. Apparently this is a suggestion for software, I could read back the contents I wrote after detach. perhaps not having the support isn't too bad.
bwfm - wireless networking
Previously, Broadcom wifi in a laptop would have resulted in sadness, followed by disassembly and hopeful replacement, unless the manufacturer has chosen to whitelist wireless cards, in which case I am doomed to a USB wifi card.
Thanks to bluerise@openbsd, jmcneill and Broadcom for open sourcing their drivers, we now have a port of the linux brcmfmac driver, for Broadcom FullMAC wireless devices. Mine is one.
These devices do a lot of 802.11 weight lifting on their own. Unfortunately that means that if they hadn't had their firmware updated, vulnerabilities are likely, such as KRACK. Previously jmcneill had made it work for the USB variant, and even made it use some of the kernel's 802.11 code, allowing to avoid some vulnerabilities.
He did not port the PCI variant, added later in OpenBSD. I've set out to steal this code.
First and foremost, I need the ability to express 'please build the pci variant code', or to add it to the pci config.
The files I have for the driver are:
sys/dev/ic/{bwfm.c, bwfmvar.h, bwfmreg.h}
sys/dev/pci/if_bwfm_pci.{c,h}
The USB variant already exists, it uses:
sys/dev/ic/{bwfm.c, bwfmvar.h, bwfmreg.h}
sys/dev/usb/if_bwfm_usb.{c,h}
ic is something shared among pci, usb, sdio code. the code for it is already built due to being added to sys/conf/files.I only need to add the PCI code.
The file for this is sys/dev/pci/files.pci. Fortunately it has plenty of examples, and here is what I added:
# Broadcom FullMAC USB wireless adapter attach bwfm at pci with bwfm_pci: firmload file dev/pci/if_bwfm_pci.c bwfm_pci
I've had to adapt APIs - some OpenBSD ones not existing in NetBSD. Fortunately there are lots of drivers to look around. I've made a very simple if_rxr_* and made it static. MCLGETI I copied from another driver, again static.
My first attempt at if_rxr_* (however simple) didn't seem to work. I rewrote it and made sure to KASSERT assumptions I assume are correct.
I was hoping to find an existing "NetBSD-ish" API for this, but I'm not sure there is something quite like it, and it is pretty simple. But it was a good opportunity to learn more about NetBSD APIs.
Once I got it to compile and not panic on attach, I had a problem. sending a message to the device failed to get the appropriate response, and attach failed.
I've spent a long time reading the initialization sequence, in OpenBSD and in linux brcmfmac, but couldn't find anything. I was ready to give up, but then I decided to diff my file to OpenBSD, and saw that in an attempt to calm type warnings (fatal by default, as NetBSD builds with -Werror), I made some unnecessary and incorrect changes.
I've switched to building without -Werror (that means passing -V NOGCCERROR=1 to build.sh, or adding to mk.conf) and reverted this changes, and then it attached cleanly.
In retrospect, I shouldn't have made unnecessary changes as a beginner. -V NOGCCERROR=1 is there. Device work first, cosmetic warning fixes second.
After it had attached, I tried to connect. I hoped wpa_supplicant -d would tell why it failed, but it only said that the connection times out.
Like many drivers in the *BSD world, bwfm has a BWFM_DEBUG and a debug printf that is controllable. I turned it on to get these messages from bwfm_rx_event:
bwfm0: newstate 0 -> 1 bwfm0: newstate 1 -> 1 bwfm_rx_event: buf 0xffffe404b97f9010 len 354 datalen 280 code 69 status 8 reason 0 bwfm_rx_event: buf 0xffffe404b97f9010 len 354 datalen 280 code 69 status 8 reason 0 bwfm_rx_event: buf 0xffffe404b97f9010 len 362 datalen 288 code 69 status 8 reason 0 bwfm_rx_event: buf 0xffffe404b97f9010 len 354 datalen 280 code 69 status 8 reason 0 bwfm_rx_event: buf 0xffffe404b97f9010 len 354 datalen 280 code 69 status 8 reason 0 bwfm_rx_event: buf 0xffffe404b97f9010 len 354 datalen 280 code 69 status 8 reason 0 bwfm_rx_event: buf 0xffffe404b97f9010 len 362 datalen 288 code 69 status 8 reason 0 bwfm_rx_event: buf 0xffffe404b97f9010 len 354 datalen 280 code 69 status 8 reason 0 bwfm_rx_event: buf 0xffffe404b97f9010 len 86 datalen 12 code 69 status 0 reason 0 bwfm_rx_event: buf 0xffffe404b9837010 len 74 datalen 0 code 26 status 0 reason 0 bwfm0: newstate 1 -> 2 bwfm_rx_event: buf 0xffffe404b9837010 len 82 datalen 8 code 0 status 3 reason 0 bwfm0: newstate 2 -> 1
To decipher the messages, I picked up what the various numbers means. Deciphered, it says:
802.11 state INIT -> SCAN 802.11 state SCAN -> SCAN received messages from the driver: code 69 (scan result) ... code 26 (scan end) 802.11 state SCAN -> AUTH code 0 (SET_SSID) status 3 (NO NETWORKS) 802.11 state AUTH -> SCAN
Authenticating is failing to find a matching network. But why?
Now experienced with the previous experience ("I've found my problem! it was me!"), I went back to some more attempts to sync the driver, which changed the SSID-setting code.
With this corrected, the driver worked as expected.
In total, it would have been easier to start with a working driver and adapting it to make some changes, like having the USB variant or testing on OpenBSD, but I managed anyway, it just took longer.
In two weeks I will receive the USB variant, but the driver is already working for me. I had trouble installing OpenBSD on the same machine.
I'll clean up my changes and post it for review soon.
Thanks to jak, pgoyette, rkujawa, phone for various fixes.
Thanks to maxv for fixing a bug affecting my use of a network stack API.
Thanks to bluerise@openbsd and jmcneill for the prior driver work.
Thanks to Broadcom for providing open source drivers under a friendly license.
remaining work - graphical acceleration.
NetBSD's x86 graphical acceleration is mostly from Linux, from linux 3.15.
This predates support for my Skylake GPU and nVidia graphics on my machine, and also the ability to dual-GPU effectively.
I'll try to sync the drivers and made previous attempts to learn about graphics, but I can't promise anything.
Pinebook is an affordable 64-bit ARM notebook. Today we're going to take a look at the kernel output at startup and talk about what hardware support is available on NetBSD.
MATE 1.20 on NetBSD arm64 (Pinebook), thanks @YouriMouton ! pic.twitter.com/VYHDzQY1gb
— Jared McNeill (@jmcwhatever) May 20, 2018
Loaded initial symtab at 0xffffffc0007342c0, strtab at 0xffffffc0007e3208, # entries 29859
Copyright (c) 1996, 1997, 1998, 1999, 2000, 2001, 2002, 2003, 2004, 2005,
2006, 2007, 2008, 2009, 2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017,
2018 The NetBSD Foundation, Inc. All rights reserved.
Copyright (c) 1982, 1986, 1989, 1991, 1993
The Regents of the University of California. All rights reserved.
NetBSD 8.99.17 (GENERIC64) #272: Mon May 21 07:25:46 ADT 2018
jmcneill@persona.local:/Users/jmcneill/netbsd/cvs-src/sys/arch/evbarm/compile/obj/GENERIC64
total memory = 2007 MB
avail memory = 1942 MB
Pinebook comes with 2GB RAM standard. A small amount of this is reserved by the kernel and framebuffer.
timecounter: Timecounters tick every 10.000 msec armfdt0 (root) fdt0 at armfdt0: Pine64 Pinebook fdt1 at fdt0 fdt2 at fdt0
NetBSD uses flattened device-tree (FDT) to enumerate devices on all Allwinner based SoCs. On a running system, you can inspect the device tree using the ofctl(8) utility:
$ ofctl -p /sound
[Caching 111 nodes and 697 properties]
compatible 73696d70 6c652d61 7564696f 2d636172 "simple-audio-car
0010: 6400.... ........ ........ ........ d"
name 736f756e 6400.... ........ ........ "sound"
simple-audio-card,format
69327300 ........ ........ ........ i2s.
simple-audio-card,frame-master
0000001c ........ ........ ........ ....
simple-audio-card,name 53554e35 30492041 7564696f 20436172 SUN50I Audio Car
0010: 6400.... ........ ........ ........ d.
cpus0 at fdt0 cpu0 at cpus0: Cortex-A53 r0p4 (Cortex V8-A core) cpu0: CPU Affinity 0-0-0-0 cpu0: IC enabled, DC enabled, EL0/EL1 stack Alignment check enabled cpu0: Cache Writeback Granule 16B, Exclusives Reservation Granule 16B cpu0: Dcache line 64, Icache line 64 cpu0: L1 32KB/64B 2-way read-allocate VIPT Instruction cache cpu0: L1 32KB/64B 4-way write-back read-allocate write-allocate PIPT Data cache cpu0: L2 512KB/64B 16-way write-back read-allocate write-allocate PIPT Unified cache cpu0: revID=0x80, PMCv3, 4k table, 64k table, 16bit ASID cpu0: auxID=0x11120, FP, CRC32, SHA1, SHA256, AES+PMULL, NEON, rounding, NaN propagation, denormals, 32x64bitRegs, Fused Multiply-Add
Pinebook's Allwinner A64 processor is based on the ARM Cortex-A53. It is designed to run at frequencies up to 1.2GHz.
cpufreqdt0 at cpu0
Dynamic voltage and frequency scaling (DVFS) is supported for the CPU. More on this in a bit...
cpu1 at cpus0: disabled (uniprocessor kernel) cpu2 at cpus0: disabled (uniprocessor kernel) cpu3 at cpus0: disabled (uniprocessor kernel)
The A64 is a quad core design. NetBSD's aarch64 pmap does not yet support SMP, so three cores are disabled for now.
gic0 at fdt1: GIC armgic0 at gic0: Generic Interrupt Controller, 224 sources (215 valid) armgic0: 16 Priorities, 192 SPIs, 7 PPIs, 16 SGIs
The interrupt controller is a standard ARM GIC-400 design.
fclock0 at fdt0: 24000000 Hz fixed clock fclock1 at fdt0: 32768 Hz fixed clock fclock2 at fdt0: 16000000 Hz fixed clock
Fixed clock input signals.
gtmr0 at fdt0: Generic Timer gtmr0: interrupting on GIC irq 27 armgtmr0 at gtmr0: ARMv7 Generic 64-bit Timer (24000 kHz) timecounter: Timecounter "armgtmr0" frequency 24000000 Hz quality 500
Standard ARMv7/ARMv8 architected timer.
sun50ia64ccu0 at fdt1: A64 CCU sun50ia64rccu0 at fdt1: A64 PRCM CCU
Clock drivers for managing PLLs, module clock dividers, clock gating, software resets, etc. Information about the clock tree is exported in the hw.clk sysctl namespace (root access required to read these values).
# sysctl hw.clk.sun50ia64ccu0.mmc2 hw.clk.sun50ia64ccu0.mmc2.rate = 200000000 hw.clk.sun50ia64ccu0.mmc2.parent = pll_periph0_2x hw.clk.sun50ia64ccu0.mmc2.parent_domain = sun50ia64ccu0
sunxinmi0 at fdt1: R_INTC
NMI interrupt controller. This is wired to the POK (power on key) pin on the power management IC. In NetBSD, a long (>1.5s) press of the power button on Pinebook triggers a power down event.
sunxigpio0 at fdt1: PIO gpio0 at sunxigpio0: 103 pins sunxigpio0: interrupting on GIC irq 43 sunxigpio1 at fdt1: PIO gpio1 at sunxigpio1: 13 pins sunxigpio1: interrupting on GIC irq 77
GPIO and multi-function I/O pin support.
sunxipwm0 at fdt1: PWM
Pulse-width modulation driver. This is used on Pinebook to control the brightness of the display backlight.
sunxiusbphy0 at fdt1: USB PHY
USB 2.0 PHY, responsible for powering up and initialization of USB ports.
sunxirsb0 at fdt1: RSB sunxirsb0: interrupting on GIC irq 71 iic0 at sunxirsb0: I2C bus
Allwinner "Reduced Serial Bus" is an I2C-like interface used to communicate with power management ICs.
axppmic0 at iic0 addr 0x3a3: AXP803 axpreg0 at axppmic0: dldo1 axpreg1 at axppmic0: dldo2 axpreg2 at axppmic0: dldo3 axpreg3 at axppmic0: dldo4 axpreg4 at axppmic0: eldo1 axpreg5 at axppmic0: eldo2 axpreg6 at axppmic0: eldo3 axpreg7 at axppmic0: fldo1 axpreg8 at axppmic0: fldo2 axpreg9 at axppmic0: dcdc1 axpreg10 at axppmic0: dcdc2 axpreg11 at axppmic0: dcdc3 axpreg12 at axppmic0: dcdc4 axpreg13 at axppmic0: dcdc5 axpreg14 at axppmic0: dcdc6 axpreg15 at axppmic0: aldo1 axpreg16 at axppmic0: aldo2 axpreg17 at axppmic0: aldo3
The X-Powers AXP803 power management IC (PMIC) controls power outputs and battery charging. Power, charging, and battery status is exported to userland with the envsys(4) API:
$ envstat -d axppmic0
Current CritMax WarnMax WarnMin CritMin Unit
ACIN present: TRUE
VBUS present: FALSE
battery present: TRUE
charging: FALSE
charge state: NORMAL
battery percent: 100 none
sun6idma0 at fdt1: DMA controller (8 channels) sun6idma0: interrupting on GIC irq 82
8-channel programmable DMA controller. Used by the audio driver.
/soc/syscon@1c00000 at fdt1 not configured
A miscellaneous register set of registers. The Allwinner A64 ethernet driver uses these resources to configure the PHY interface. Not used on Pinebook.
ausoc0 at fdt0: SUN50I Audio Card a64acodec0 at fdt1: A64 Audio Codec (analog part) sunxii2s0 at fdt1: Audio Codec (digital part) sun8icodec0 at fdt1: Audio Codec sun8icodec0: interrupting on GIC irq 60
Analog audio codec. On Allwinner A64 this functionality is spread across multiple modules. The ausoc driver is responsible for talking to these drivers and exposing a single audio device. Initialization is deferred until all drivers are ready, so the audio device is attached below.
psci0 at fdt0: PSCI 0.2
ARM "Power State Coordination Interface". NetBSD uses this to implement reset, power off, and (for multiprocessor kernels) starting secondary CPUs.
gpiokeys0 at fdt0: Lid Switch
Pinebook has a Hall effect sensor wired to a GPIO to signal whether the lid is open or closed. On NetBSD state change events are sent to powerd, as well as broadcast to other drivers in the kernel. For example, the backlight driver will automatically turn off the display when the lid is closed.
pwmbacklight0 at fdt0: PWM Backlight <0 30 40 50 60 70 80 90 100>
The backlight brightness on Pinebook is controlled by the PWM controller. These controls are exported via sysctl:
$ sysctl hw.pwmbacklight0 hw.pwmbacklight0.levels = 0 30 40 50 60 70 80 90 100 hw.pwmbacklight0.level = 80
In addition, the framebuffer driver will pass WSDISPLAYIO_SVIDEO ioctl requests through to the backlight driver, so screen blanking in Xorg will work.
sunximmc0 at fdt1: SD/MMC controller sunximmc0: interrupting on GIC irq 92 sunximmc1 at fdt1: SD/MMC controller sunximmc1: interrupting on GIC irq 93 sunximmc2 at fdt1: SD/MMC controller sunximmc2: interrupting on GIC irq 94
SD/MMC controllers. On Pinebook, they are used for the following functions:
- #0: SD card slot
- #1: SDIO Wi-Fi
- #2: Onboard eMMC
motg0 at fdt1: USB OTG motg0: interrupting on GIC irq 103 usb0 at motg0: USB revision 2.0
USB OTG controller. NetBSD supports this in host mode only.
ehci0 at fdt1: EHCI ehci0: interrupting on GIC irq 104 ehci0: EHCI version 1.0 ehci0: 1 companion controller, 1 port usb1 at ehci0: USB revision 2.0 ohci0 at fdt1: OHCI ohci0: interrupting on GIC irq 105 ohci0: OHCI version 1.0 usb2 at ohci0: USB revision 1.0 ehci1 at fdt1: EHCI ehci1: interrupting on GIC irq 106 ehci1: EHCI version 1.0 ehci1: 1 companion controller, 1 port usb3 at ehci1: USB revision 2.0 ohci1 at fdt1: OHCI ohci1: interrupting on GIC irq 107 ohci1: OHCI version 1.0 usb4 at ohci1: USB revision 1.0
USB 2.0 host controllers.
com0 at fdt1: ns16550a, working fifo com0: interrupting on GIC irq 32
Serial console.
sunxirtc0 at fdt1: RTC
Real-time clock. Note that the Pinebook does not include a battery backed RTC.
sunxiwdt0 at fdt1: Watchdog sunxiwdt0: default watchdog period is 16 seconds
The watchdog timer can be enabled with the wdogctl(8) utility:
# wdogctl
Available watchdog timers:
sunxiwdt0, 16 second period
sunxithermal0 at fdt1: Thermal sensor controller sunxithermal0: interrupting on GIC irq 63 sunxithermal0: cpu: alarm 85C hyst 58C shut 106C sunxithermal0: gpu1: alarm 85C hyst 58C shut 106C sunxithermal0: gpu2: alarm 85C hyst 58C shut 106C
CPU and GPU temperatures are exported to userland with the envsys(4) API:
$ envstat -d sunxithermal0
Current CritMax WarnMax WarnMin CritMin Unit
CPU temperature: 54.000 degC
GPU temperature 1: 52.000 degC
GPU temperature 2: 52.000 degC
In addition, the thermal sensor driver coordinates with the DVFS driver to automatically throttle CPU frequency and voltage when temperatures exceed alarm thresholds.
genfb0 at fdt2: Simple Framebuffer (1366x768 32-bpp @ 0xbe000000) genfb0: switching to framebuffer console genfb0: framebuffer at 0xbe000000, size 1366x768, depth 32, stride 5464 wsdisplay0 at genfb0 kbdmux 1: console (default, vt100 emulation) wsmux1: connecting to wsdisplay0 wsdisplay0: screen 1-3 added (default, vt100 emulation)
NetBSD will automatically use a framebuffer configured by U-Boot using the simplefb protocol. Since the simple frame buffer driver uses genfb(4), it is supported by Xorg out of the box.
ausoc0: codec: sun8icodec0, cpu: sunxii2s0, aux: a64acodec0 audio0 at ausoc0: full duplex, playback, capture, mmap, independent ausoc0: Virtual format configured - Format SLINEAR, precision 16, channels 2, frequency 48000 ausoc0: Latency: 256 milliseconds
Analog playback and capture are supported on Pinebook. In addition, headphone jack sensing is supported to automatically mute the internal speakers when headphones are plugged in. The following mixer controls are available:
$ mixerctl -a outputs.master=192,192 outputs.mute=off outputs.source=line inputs.line=192,192 inputs.headphones=128,128 record.line=0,0 record.mic=96,96 record.mic.preamp=off record.mic2=96,96 record.mic2.preamp=off record.agc=96,96 record.source=
spkr0 at audio0: PC Speaker (synthesized) wsbell at spkr0 not configured
Pseudo PC speaker driver (not currently enabled in GENERIC64 kernel).
timecounter: Timecounter "clockinterrupt" frequency 100 Hz quality 0 Lid Switch: lid opened. cpufreqdt0: 1152.000 MHz, 1300000 uV cpufreqdt0: 1104.000 MHz, 1260000 uV cpufreqdt0: 1008.000 MHz, 1200000 uV cpufreqdt0: 816.000 MHz, 1080000 uV cpufreqdt0: 648.000 MHz, 1040000 uV cpufreqdt0: 408.000 MHz, 1000000 uV
Dynamic voltage and frequency scaling is supported. The desired frequency can be set manually with sysctl, or automatically by installing sysutils/estd from pkgsrc.
# sysctl machdep.cpu machdep.cpu.frequency.target = 1152 machdep.cpu.frequency.current = 1152 machdep.cpu.frequency.available = 1152 1104 1008 816 648 408
sdmmc0 at sunximmc0 sdmmc1 at sunximmc1 sdmmc2 at sunximmc2 uhub0 at usb0: NetBSD (0000) MOTG root hub (0000), class 9/0, rev 2.00/1.00, addr 1 uhub0: 1 port with 1 removable, self powered uhub1 at usb1: NetBSD (0000) EHCI root hub (0000), class 9/0, rev 2.00/1.00, addr 1 uhub1: 1 port with 1 removable, self powered uhub2 at usb2: NetBSD (0000) OHCI root hub (0000), class 9/0, rev 1.00/1.00, addr 1 uhub2: 1 port with 1 removable, self powered uhub3 at usb3: NetBSD (0000) EHCI root hub (0000), class 9/0, rev 2.00/1.00, addr 1 uhub3: 1 port with 1 removable, self powered uhub4 at usb4: NetBSD (0000) OHCI root hub (0000), class 9/0, rev 1.00/1.00, addr 1 uhub4: 1 port with 1 removable, self powered IPsec: Initialized Security Association Processing. (manufacturer 0x24c, product 0xb703, standard function interface code 0x7) at sdmmc1 function 1 not configured
SDIO Wi-Fi is not yet supported.
ld2 at sdmmc2: <0x88:0x0103:NCard :0x00:0x30601836:0x000> ld2: 14800 MB, 7517 cyl, 64 head, 63 sec, 512 bytes/sect x 30310400 sectors ld2: 8-bit width, HS200, 64 MB cache, 200.000 MHz
Pinebook comes with 16GB of built-in eMMC storage. NetBSD drives this in High Speed HS200 mode, which can support up to 200MB/s at 200MHz.
uhub5 at uhub3 port 1: vendor 05e3 (0x5e3) USB2.0 Hub (0x608), class 9/0, rev 2.00/88.32, addr 2 uhub5: single transaction translator uhub5: 4 ports with 1 removable, self powered uhidev0 at uhub5 port 1 configuration 1 interface 0 uhidev0: HAILUCK CO.,LTD (0x258a) USB KEYBOARD (0x0c), rev 1.10/1.00, addr 3, iclass 3/1 ukbd0 at uhidev0: 8 Variable keys, 6 Array codes wskbd0 at ukbd0: console keyboard, using wsdisplay0 uhidev1 at uhub5 port 1 configuration 1 interface 1 uhidev1: HAILUCK CO.,LTD (0x258a) USB KEYBOARD (0x0c), rev 1.10/1.00, addr 3, iclass 3/0 uhidev1: 9 report ids ums0 at uhidev1 reportid 1: 5 buttons, W and Z dirs wsmouse0 at ums0 mux 0 uhid0 at uhidev1 reportid 2: input=1, output=0, feature=0 uhid1 at uhidev1 reportid 3: input=3, output=0, feature=0 uhid2 at uhidev1 reportid 5: input=0, output=0, feature=5 uhid3 at uhidev1 reportid 6: input=0, output=0, feature=1039 uhid4 at uhidev1 reportid 9: input=1, output=0, feature=0
The Pinebook's keyboard and touchpad are connected internally to a USB controller.
The sleep (Fn+Esc), home (Fn+F1), volume down (Fn+F3), volume up (Fn+F4), and mute (Fn+F5) keys on the keyboard are mapped to uhid(4) devices. These can be used with usbhidaction(1):
# cat /etc/usbhidaction.conf
Consumer:Consumer_Control.Consumer:Volume_Up 1
mixerctl -n -w outputs.master++
Consumer:Consumer_Control.Consumer:Volume_Down 1
mixerctl -n -w outputs.master--
Consumer:Consumer_Control.Consumer:Mute 1
mixerctl -n -w outputs.mute++
Consumer:Consumer_Control.Consumer:AC_Home 1
/etc/powerd/scripts/hotkey_button AC_Home pressed
Generic_Desktop:System_Control.Generic_Desktop:System_Sleep 1
/etc/powerd/scripts/sleep_button System_Sleep pressed
# /usr/bin/usbhidaction -c /etc/usbhidaction.conf -f /dev/uhid0 -i -p /var/run/usbhidaction-uhid0.pid
# /usr/bin/usbhidaction -c /etc/usbhidaction.conf -f /dev/uhid1 -i -p /var/run/usbhidaction-uhid1.pid
urtwn0 at uhub5 port 2 urtwn0: Realtek (0x7392) 802.11n WLAN Adapter (0x7811), rev 2.00/2.00, addr 4 urtwn0: MAC/BB RTL8188CUS, RF 6052 1T1R, address 80:1f:02:94:40:12 urtwn0: 1 rx pipe, 2 tx pipes urtwn0: 11b rates: 1Mbps 2Mbps 5.5Mbps 11Mbps urtwn0: 11g rates: 1Mbps 2Mbps 5.5Mbps 11Mbps 6Mbps 9Mbps 12Mbps 18Mbps 24Mbps 36Mbps 48Mbps 54Mbps
Externally connected USB Wi-Fi adapter (not included).
uvideo0 at uhub5 port 3 configuration 1 interface 0: Image Processor (0x90c) USB 2.0 PC Cam (0x37c), rev 2.00/0.05, addr 5 video0 at uvideo0: Image Processor (0x90c) USB 2.0 PC Cam (0x37c), rev 2.00/0.05, addr 5
The built-in video camera is supported using standard V4L2 APIs.
$ videoctl -a info.cap.card=Image Processor (0x90c) USB 2.0 info.cap.driver=uvideo info.cap.bus_info=usb:00000009 info.cap.version=8.99.17 info.cap.capabilities=0x5000001 info.format.0=YUYV info.input.0=Camera info.input.0.type=baseband info.standard.0=webcam
boot device: ld2 root on ld2a dumps on ld2b
NetBSD supports a wide variety of Allwinner boards. The wiki contains more information about supported Allwinner SoCs and peripherals.
Fixing, Strengthening, Simplifying
Over the last five months, hundreds of patches were committed to the source tree as a result of this work. Dozens of bugs were fixed, among which a good number of actual, remotely-triggerable vulnerabilities.
Changes were made to strengthen the networking subsystems and improve code quality: reinforce the mbuf API, add many KASSERTs to enforce assumptions, simplify packet handling, and verify compliance with RFCs. This was done in several layers of the NetBSD kernel, from device drivers to L4 handlers.
A lot of cleanup took place, too. For example I managed to remove more than one thousand lines of code in IPsec, while at the same time improving robustness and performance. This kind of cleanup results in a networking code that is much easier to understand and maintain.
The fixes for critical bugs were quickly propagated to the stable branches (NetBSD-6, NetBSD-7) and the NetBSD-8_BETA branch. Along the way, several changes too were discreetly propagated, when they were considered as good mitigations against possible attack vectors.
Fixes in Other Operating Systems
In the course of investigating several bugs discovered in NetBSD, I happened to look at the network stacks of other operating systems, to see whether they had already fixed the issues, and if so how. Needless to say, I found bugs there too.
So far the trophies are:
| NetBSD | OpenBSD | FreeBSD |
|---|---|---|
| SA2018-003 (1) | 6.2-Errata-#005 (2) | SA-18:01.ipsec (2) |
| SA2018-004 (1) | 6.2-Errata-#006 (1) | SA-18:05.ipsec (2) |
| SA2018-006 (5+) | 6.2-Errata-#007 (1) | |
| SA2018-007 (10) | 6.2-Errata-#010 (1) | |
| SA2018-008 (2) | 6.3-Errata-#006 (2) | |
| 6.3-Errata-#008 (1) |
Fig. A: advisory_name (number_of_bugs).
Of course, I am focusing on NetBSD, so it is no surprise the number of bugs found there is higher than in the other OSes.
Also, it is to be noted that FreeBSD hasn’t yet published advisories for several bugs that I reported to them (which they nonetheless fixed pretty quickly).
Some Examples
The IPv6 Buffer Overflow
In January I discovered, in NetBSD’s IPv6 stack, a subtle buffer overflow, which turned out to affect the other BSDs as well.
The overflow allowed an attacker to write one byte of packet-controlled data into ‘packet_storage+off’, where ‘off’ could be approximately controlled too.
This allowed at least a pretty bad remote DoS: by sending specially-crafted packets in a loop, an attacker could overwrite several areas of memory with wrong values, which would eventually lead to undefined behavior and crash.
One way of exploiting this bug was to use a special combination of nested fragments.
Fig. B: A simplified view.
In short, when receiving the last fragment of a packet, the kernel would iterate over the previous IPv6 options of the packet, assuming that everything was located in the first mbuf. It was possible to break this assumption, by sending a fragment nested into another.
Given the nature of the bug there were probably other (and perhaps more direct) ways to trigger it.
This overflow was of course fixed pretty quickly, but in addition the NetBSD kernel was changed to automatically drop nested fragments. This is an example of the many miscellaneous changes made in order to strengthen the network stack.
The IPsec Infinite Loop
When receiving an IPv6-AH packet, the IPsec entry point was not correctly computing the length of the IPv6 suboptions, and this, before authentication. As a result, a specially-crafted IPv6 packet could trigger an infinite loop in the kernel (making it unresponsive). In addition this flaw allowed a limited buffer overflow - where the data being written was however not controllable by the attacker.
The other BSDs too were affected by this vulnerability. In addition they were subject to another buffer overflow, in IPv4-AH this time, which happened to have been already fixed in NetBSD several years earlier.
The IPPROTO Typo
While looking at the IPv6 Multicast code, I stumbled across a pretty simple yet pretty bad mistake: at one point the Pim6 entry point would return IPPROTO_NONE instead of IPPROTO_DONE. Returning IPPROTO_NONE was entirely wrong: it caused the kernel to keep iterating on the IPv6 packet chain, while the packet storage was already freed.
Therefore it was possible to remotely cause a use-after-free if the packet was forged in such a way that the kernel would take the IPPROTO_NONE branch. Generally the kernel would panic shortly afterwards, because it figured out it was double-freeing the same packet storage. (A use-after-free detector is also one of the things that were added in NetBSD to prevent the exploitation of such bugs.)
This typo was found in the Multicast entry code, which is enabled only with a particular, non-default configuration. Therefore it didn’t affect a default install of NetBSD.
While looking for other occurrences of this typo, I found the exact same bug in the exact same place in FreeBSD. Curiously enough, OpenBSD had the same bug too, but in a totally different place: the typo existed in their EtherIP entry point, but there, it was more dangerous, because it was in a branch taken by default, and therefore a default install of OpenBSD was vulnerable.
The PF Signedness Bug
A bug was found in NetBSD’s implementation of the PF firewall, that did not affect the other BSDs. In the initial PF code a particular macro was used as an alias to a number. This macro formed a signed integer.
In NetBSD, however, the macro was defined differently: it contained the sizeof statement. This was a terrible mistake, because it resulted in an unsigned integer.
This was not the intended signedness. Given that the macro in question was used to perform length validation checks in PF’s TCP-SYN entry point when a modulate rule was active, it was easy to cause a remote DoS by sending a malformed packet.
But PF was not a component I was supposed to look at as part of my work. So how did I still manage to find this bug? Well, while closing dozens of reports in NetBSD’s Problem Report database, I stumbled across a PR from 2010, which was briefly saying that PF’s TCP-SYN entry point could crash the kernel if a special packet was received. Looking at the PF code, it was clear, after two minutes, where the problem was.
The NPF Integer Overflow
An integer overflow could be triggered in NPF, when parsing an IPv6 packet with large options. This could cause NPF to look for the L4 payload at the wrong offset within the packet, and it allowed an attacker to bypass any L4 filtering rule on IPv6.

Fig. C: Simplified example of an exploit.
In the example above, NPF allows the packet to enter, based on validation performed on the wrong TCP header (orange, dashed lines). The kernel reads the correct TCP header (red), and delivers it to a socket. NPF was supposed to reject it.
More generally, several problems existed in NPF’s handling of IPv6 packets.
The IPsec Fragment Attack
(A more detailed example)I noticed some time ago that when reassembling fragments (in either IPv4 or IPv6), the kernel was not removing the M_PKTHDR flag on the secondary mbufs in mbuf chains. This flag is supposed to indicate that a given mbuf is the head of the chain it forms; having the flag on secondary mbufs was suspicious.
Later, deep in the IPsec-ESP handler, I found a function that was assuming that M_PKTHDR was set only in the first mbuf of the chain – assumption that evidently didn’t hold, since reassembled fragments had several M_PKTHDRs. Later in the handler, it resulted in a wrong length being stored in the mbuf header (the packet had become shorter than the actual length registered). The wrong length would in turn trigger a kernel panic shortly afterwards.
This remote DoS was triggerable if the ESP payload was located in a secondary mbuf of the chain, which never is the case in practice. The function in question was called after ESP decryption. Therefore, in order for an attacker to reach this place, it was necessary to send a correct ESP payload – which meant having the ESP key. So at a first glance, this looked like a non-critical bug.
But there was still a theoretical way to exploit the bug. In the case of IPv6 at least, the IP options can be huge, and more importantly, can be located in the unencrypted part of the packet. Let’s say you are MITMing a NetBSD host that is having an ESP conversation with another host. You intercept a packet directed to the NetBSD host. You take the ESP payload as-is (which you can’t decrypt since you don’t have the key), you craft a new two-fragment packet: you put the other IPsec host’s IPv6 address as source, insert a dummy IP option in the first fragment, insert the ESP payload as-is in the second fragment, and send the two fragments to the NetBSD host.
The NetBSD host reassembles the fragments, decrypts the ESP payload correctly, reaches the aforementioned handler, miscomputes the packet length, and crashes.
The other BSDs were affected.
And the rest...
Many security fixes and improvements in different places that I didn’t list here.
What Now
Not all protocols and layers of the network stack were verified, because of time constraints, and also because of unexpected events: the recent x86 CPU bugs, which I was the only one able to fix promptly. A todo list will be left when the project end date is reached, for someone else to pick up. Me perhaps, later this year? We’ll see.This security audit of NetBSD’s network stack is sponsored by The NetBSD Foundation, and serves all users of BSD-derived operating systems. The NetBSD Foundation is a non-profit organization, and welcomes any donations that help continue funding projects of this kind.
aiomixer is an application that I've been maintaining outside of NetBSD for a few years. It was available as a package, and was a "graphical" (curses, terminal-based) mixer for NetBSD's audio API, inspired by programs like alsamixer. For some time I've thought that it should be integrated into the NetBSD base system - it's small and simple, very useful, and many developers and users had it installed (some told me that they would install it on all of their machines that needed audio output). For my particular use case, as well as my NetBSD laptop, I have some small NetBSD machines around the house plugged into speakers that I play music from. Sometimes I like to SSH into them to adjust the playback volume, and it's often easier to do visually than with mixerctl(1).
However, there was one problem: when I first wrote aiomixer 2 years ago, I was intimidated by the curses API, so opted to use the Curses Development Kit instead. This turned out to be a mistake, as not only was CDK inflexible for an application like aiomixer, it introduced a hard dependency on ncurses.
X/Open Curses and ncurses
Many people think ncurses is the canonical way to develop terminal-based applications for Unix, but it's actually an implementation of the X/Open Curses specification. There's a few other Curses implementations:
- NetBSD libcurses
- Solaris libcurses
- PDCurses, used on Windows
NetBSD curses is descended from the original BSD curses, but contains many useful extensions from ncurses as well. We use it all over the base system, and for most packages in pkgsrc. It's also been ported to other operating systems, including Linux. As far as I'm aware, NetBSD is one of the last operating systems left that doesn't primarily depend on ncurses.
There's one crucial incompatibility, however: ncurses exposes its internal data structures, NetBSD libcurses keeps them opaque. Since CDK development is very tied to ncurses development (they have the same maintainer), CDK peeks into those structures, and can't be used with NetBSD libcurses. There are also a few places where ncurses breaks with X/Open Curses, like this case I recently fixed in irssi.
Rewriting aiomixer
I was able to rewrite aiomixer in a few days using only my free time and NetBSD libcurses. It's now been imported to the base system. It was a good lesson in why Curses isn't actually that intimidating - while there are many functions, they're mostly variations on the same thing. Using Curses directly resulted in a much lighter and more usable application, and provided a much better fit for the types of widgets I needed.
Many people also provided testing, and I learned a lot about how different terminal attributes should be used in the process. NetBSD is probably one of the few communities where you'll get easy and direct feedback on how to not only make your software work well in a variety of terminal emulators, but also old school hardware terminals. During development, I was also able to find a strange bug in the curses library's window resizing function.
The API support was also improved, and the new version of aiomixer should work better with a wider variety of sound hardware drivers.
Other happenings
Since I'm done plugging my own work, I thought I might talk a bit about some other recent changes to CURRENT.
- Most ports of NetBSD now build with GCC 10, thanks to work by mrg.
The new version of GCC introduced many new compiler warnings. By
default, since NetBSD is compiled with a fixed toolchain version,
we use
-Werror. Many minor warnings and actual-bugs were uncovered and fixed with the new compiler. - On the ARM front, support for the Allwiner V3S system-on-a-chip was introduced thanks to work by Rui-Xiang Guo. This is an older model Allwinner core, primarily used on small embedded devices. It's of likely interest to hardware hackers because it comes in an easily soldered package. A development board is available, the Lichee Pi Zero. Also in the Allwinner world, support for the H3 SoC (including the NanoPi R1) was added to the sun8icrypto(4) driver by bad.
- Support for RISC-V is progressing, including an UEFI bootloader for 64-bit systems, and an in-kernel disassembler. Some NetBSD developers have recently obtained Beagle-V development boards.
- On the SPARC64 front, support for sun4v is progressing thanks to work by palle. The sun4v architecture includes most newer SPARC servers that are based on the Logical Domains architecture - virtualization is implemented at the hardware/firmware level, and operating systems get an abstracted view of the underlying hardware. With other operating systems are discussing removing support for SPARC64, there's an interest among NetBSD developers in adding and maintaining support for this very interesting hardware from Oracle, Fujitsu, and Sun in an open source operating system, not just Oracle Solaris.
- A kernel-wide audit and rework of the auto-configuration APIs was completed by thorpej.
- Various new additions and fixes have been made to the networking stack's PPP over Ethernet support by yamaguchi.
- A new API was introduced by macallan that allows adding
a
-loption to the wsfontload(8) command, allowing easy viewing of the tty fonts currently loaded into the kernel. - ... OK, I'm not done plugging my own work: I recently wrote new documentation on using NetBSD for virtualization, Power Management, and rewrote the NetBSD Guide's sections on Networking in Practice and Audio. I also recently added support for the Neo 2 keyboard layout to NetBSD's console system - Neo 2 is a Dvorak-like optimized layout for German and other languages based on multiple layers for alphabetical characters, navigation, and symbols.
aiomixer is an application that I've been maintaining outside of NetBSD for a few years. It was available as a package, and was a "graphical" (curses, terminal-based) mixer for NetBSD's audio API, inspired by programs like alsamixer. For some time I've thought that it should be integrated into the NetBSD base system - it's small and simple, very useful, and many developers and users had it installed (some told me that they would install it on all of their machines that needed audio output). For my particular use case, as well as my NetBSD laptop, I have some small NetBSD machines around the house plugged into speakers that I play music from. Sometimes I like to SSH into them to adjust the playback volume, and it's often easier to do visually than with mixerctl(1).
However, there was one problem: when I first wrote aiomixer 2 years ago, I was intimidated by the curses API, so opted to use the Curses Development Kit instead. This turned out to be a mistake, as not only was CDK inflexible for an application like aiomixer, it introduced a hard dependency on ncurses.
X/Open Curses and ncurses
Many people think ncurses is the canonical way to develop terminal-based applications for Unix, but it's actually an implementation of the X/Open Curses specification. There's a few other Curses implementations:
- NetBSD libcurses
- Solaris libcurses
- PDCurses, used on Windows
NetBSD curses is descended from the original BSD curses, but contains many useful extensions from ncurses as well. We use it all over the base system, and for most packages in pkgsrc. It's also been ported to other operating systems, including Linux. As far as I'm aware, NetBSD is one of the last operating systems left that doesn't primarily depend on ncurses.
There's one crucial incompatibility, however: ncurses exposes its internal data structures, NetBSD libcurses keeps them opaque. Since CDK development is very tied to ncurses development (they have the same maintainer), CDK peeks into those structures, and can't be used with NetBSD libcurses. There are also a few places where ncurses breaks with X/Open Curses, like this case I recently fixed in irssi.
Rewriting aiomixer
I was able to rewrite aiomixer in a few days using only my free time and NetBSD libcurses. It's now been imported to the base system. It was a good lesson in why Curses isn't actually that intimidating - while there are many functions, they're mostly variations on the same thing. Using Curses directly resulted in a much lighter and more usable application, and provided a much better fit for the types of widgets I needed.
Many people also provided testing, and I learned a lot about how different terminal attributes should be used in the process. NetBSD is probably one of the few communities where you'll get easy and direct feedback on how to not only make your software work well in a variety of terminal emulators, but also old school hardware terminals. During development, I was also able to find a strange bug in the curses library's window resizing function.
The API support was also improved, and the new version of aiomixer should work better with a wider variety of sound hardware drivers.
Other happenings
Since I'm done plugging my own work, I thought I might talk a bit about some other recent changes to CURRENT.
- Most ports of NetBSD now build with GCC 10, thanks to work by mrg.
The new version of GCC introduced many new compiler warnings. By
default, since NetBSD is compiled with a fixed toolchain version,
we use
-Werror. Many minor warnings and actual-bugs were uncovered and fixed with the new compiler. - On the ARM front, support for the Allwiner V3S system-on-a-chip was introduced thanks to work by Rui-Xiang Guo. This is an older model Allwinner core, primarily used on small embedded devices. It's of likely interest to hardware hackers because it comes in an easily soldered package. A development board is available, the Lichee Pi Zero. Also in the Allwinner world, support for the H3 SoC (including the NanoPi R1) was added to the sun8icrypto(4) driver by bad.
- Support for RISC-V is progressing, including an UEFI bootloader for 64-bit systems, and an in-kernel disassembler. Some NetBSD developers have recently obtained Beagle-V development boards.
- On the SPARC64 front, support for sun4v is progressing thanks to work by palle. The sun4v architecture includes most newer SPARC servers that are based on the Logical Domains architecture - virtualization is implemented at the hardware/firmware level, and operating systems get an abstracted view of the underlying hardware. With other operating systems are discussing removing support for SPARC64, there's an interest among NetBSD developers in adding and maintaining support for this very interesting hardware from Oracle, Fujitsu, and Sun in an open source operating system, not just Oracle Solaris.
- A kernel-wide audit and rework of the auto-configuration APIs was completed by thorpej.
- Various new additions and fixes have been made to the networking stack's PPP over Ethernet support by yamaguchi.
- A new API was introduced by macallan that allows adding
a
-loption to the wsfontload(8) command, allowing easy viewing of the tty fonts currently loaded into the kernel. - ... OK, I'm not done plugging my own work: I recently wrote new documentation on using NetBSD for virtualization, Power Management, and rewrote the NetBSD Guide's sections on Networking in Practice and Audio. I also recently added support for the Neo 2 keyboard layout to NetBSD's console system - Neo 2 is a Dvorak-like optimized layout for German and other languages based on multiple layers for alphabetical characters, navigation, and symbols.
aiomixer is an application that I've been maintaining outside of NetBSD for a few years. It was available as a package, and was a "graphical" (curses, terminal-based) mixer for NetBSD's audio API, inspired by programs like alsamixer. For some time I've thought that it should be integrated into the NetBSD base system - it's small and simple, very useful, and many developers and users had it installed (some told me that they would install it on all of their machines that needed audio output). For my particular use case, as well as my NetBSD laptop, I have some small NetBSD machines around the house plugged into speakers that I play music from. Sometimes I like to SSH into them to adjust the playback volume, and it's often easier to do visually than with mixerctl(1).
However, there was one problem: when I first wrote aiomixer 2 years ago, I was intimidated by the curses API, so opted to use the Curses Development Kit instead. This turned out to be a mistake, as not only was CDK inflexible for an application like aiomixer, it introduced a hard dependency on ncurses.
X/Open Curses and ncurses
Many people think ncurses is the canonical way to develop terminal-based applications for Unix, but it's actually an implementation of the X/Open Curses specification. There's a few other Curses implementations:
- NetBSD libcurses
- Solaris libcurses
- PDCurses, used on Windows
NetBSD curses is descended from the original BSD curses, but contains many useful extensions from ncurses as well. We use it all over the base system, and for most packages in pkgsrc. It's also been ported to other operating systems, including Linux. As far as I'm aware, NetBSD is one of the last operating systems left that doesn't primarily depend on ncurses.
There's one crucial incompatibility, however: ncurses exposes its internal data structures, NetBSD libcurses keeps them opaque. Since CDK development is very tied to ncurses development (they have the same maintainer), CDK peeks into those structures, and can't be used with NetBSD libcurses. There are also a few places where ncurses breaks with X/Open Curses, like this case I recently fixed in irssi.
Rewriting aiomixer
I was able to rewrite aiomixer in a few days using only my free time and NetBSD libcurses. It's now been imported to the base system. It was a good lesson in why Curses isn't actually that intimidating - while there are many functions, they're mostly variations on the same thing. Using Curses directly resulted in a much lighter and more usable application, and provided a much better fit for the types of widgets I needed.
Many people also provided testing, and I learned a lot about how different terminal attributes should be used in the process. NetBSD is probably one of the few communities where you'll get easy and direct feedback on how to not only make your software work well in a variety of terminal emulators, but also old school hardware terminals. During development, I was also able to find a strange bug in the curses library's window resizing function.
The API support was also improved, and the new version of aiomixer should work better with a wider variety of sound hardware drivers.
Other happenings
Since I'm done plugging my own work, I thought I might talk a bit about some other recent changes to CURRENT.
- Most ports of NetBSD now build with GCC 10, thanks to work by mrg.
The new version of GCC introduced many new compiler warnings. By
default, since NetBSD is compiled with a fixed toolchain version,
we use
-Werror. Many minor warnings and actual-bugs were uncovered and fixed with the new compiler. - On the ARM front, support for the Allwiner V3S system-on-a-chip was introduced thanks to work by Rui-Xiang Guo. This is an older model Allwinner core, primarily used on small embedded devices. It's of likely interest to hardware hackers because it comes in an easily soldered package. A development board is available, the Lichee Pi Zero. Also in the Allwinner world, support for the H3 SoC (including the NanoPi R1) was added to the sun8icrypto(4) driver by bad.
- Support for RISC-V is progressing, including an UEFI bootloader for 64-bit systems, and an in-kernel disassembler. Some NetBSD developers have recently obtained Beagle-V development boards.
- On the SPARC64 front, support for sun4v is progressing thanks to work by palle. The sun4v architecture includes most newer SPARC servers that are based on the Logical Domains architecture - virtualization is implemented at the hardware/firmware level, and operating systems get an abstracted view of the underlying hardware. With other operating systems are discussing removing support for SPARC64, there's an interest among NetBSD developers in adding and maintaining support for this very interesting hardware from Oracle, Fujitsu, and Sun in an open source operating system, not just Oracle Solaris.
- A kernel-wide audit and rework of the auto-configuration APIs was completed by thorpej.
- Various new additions and fixes have been made to the networking stack's PPP over Ethernet support by yamaguchi.
- A new API was introduced by macallan that allows adding
a
-loption to the wsfontload(8) command, allowing easy viewing of the tty fonts currently loaded into the kernel. - ... OK, I'm not done plugging my own work: I recently wrote new documentation on using NetBSD for virtualization, Power Management, and rewrote the NetBSD Guide's sections on Networking in Practice and Audio. I also recently added support for the Neo 2 keyboard layout to NetBSD's console system - Neo 2 is a Dvorak-like optimized layout for German and other languages based on multiple layers for alphabetical characters, navigation, and symbols.
The NetBSD Project is pleased to announce NetBSD 9.2 "Nakatomi Socrates", the second update of the NetBSD 9 release branch.
As well as the usual bug, stability, and security fixes, this release includes: support for exporting ZFS filesystems over NFS, various updates to the bozotic HTTP daemon, improvements to ARM 32-bit and Linux compatibility, fread() performance improvements, support for the TP-Link TL-WN821N V6 wireless adapter, support for the Allwinner H5 cryptographic accelerator, Pinebook Pro display brightness fixes, new defaults for kern.maxfiles, and accessibility improvements for the default window manager configuration.
The NetBSD Project is pleased to announce NetBSD 9.2 "Nakatomi Socrates", the second update of the NetBSD 9 release branch.
As well as the usual bug, stability, and security fixes, this release includes: support for exporting ZFS filesystems over NFS, various updates to the bozotic HTTP daemon, improvements to ARM 32-bit and Linux compatibility, fread() performance improvements, support for the TP-Link TL-WN821N V6 wireless adapter, support for the Allwinner H5 cryptographic accelerator, Pinebook Pro display brightness fixes, new defaults for kern.maxfiles, and accessibility improvements for the default window manager configuration.
Hi everyone,
Due to the unfortunate situation regarding changes in administration on freenode.net, and the resulting chaos, we have decided to move the public NetBSD IRC chat channels from freenode to irc.libera.chat.
This includes:
- #NetBSD - general discussion
- #netbsd-code - development discussion
- #pkgsrc - pkgsrc (primarily development) discussion
You can find information on connecting to Libera at https://libera.chat/
Hi everyone,
Due to the unfortunate situation regarding changes in administration on freenode.net, and the resulting chaos, we have decided to move the public NetBSD IRC chat channels from freenode to irc.libera.chat.
This includes:
- #NetBSD - general discussion
- #netbsd-code - development discussion
- #pkgsrc - pkgsrc (primarily development) discussion
You can find information on connecting to Libera at https://libera.chat/
Hi everyone,
Due to the unfortunate situation regarding changes in administration on freenode.net, and the resulting chaos, we have decided to move the public NetBSD IRC chat channels from freenode to irc.libera.chat.
This includes:
- #NetBSD - general discussion
- #netbsd-code - development discussion
- #pkgsrc - pkgsrc (primarily development) discussion
You can find information on connecting to Libera at https://libera.chat/
Distribution cleanup
As planned in the previous month, I've performed cleanup in the distribution:
- Removal of unneeded PT_SET_SIGMASK and PT_GET_SIGMASK, followed by pullup to NetBSD-8.
- regnsub(3) and regasub(3) API change has been abandoned as it causes backward compatibility bootstrap breakage from older distributions. Altering it could require additional changes in libtre, but it has been abandoned too. At the end I've finally removed just the USE_LIBTRE build option, replacing the libc's regex(3) implementation with an alternative library from libtre/agrep, because it no longer builds as a regex-replacement and the upstream development stalled few years ago.
- Backport of _UC_MACHINE_FP() to NetBSD-8 has been finished, this means that we can use the same code in NetBSD-8 and NetBSD-current in the sources of sanitizers.
Improvements in the ATF ptrace(2) tests
I've performed the following operations in the ATF ptrace(2) and related tests, in the following commit order:
- Correct all ATF failures in t_ptrace_x86_wait.h (debug registers)
- ATF: Correct a race bug in attach2 (t_ptrace_wait*)
- ATF: Reenable attach2 in t_ptrace_wait*
- Add a new function in ATF t_ptrace_wait*: await_zombie_raw()
- ATF t_ptrace_wait*: Disable debug messages in msg.h
- ATF: Add new test race1 in t_ptrace_wait*
- Add new ATF tests: kernel/t_zombie
Zombie detection race
I've detected that the operation polling for a single process status - using sysctl(3) - can report the same process twice, for the first time as an alive process and for the second time as a zombie. This used to break the ATF ptrace(2) tests where we have a polling function, detecting the state change of a dying process.
I've prepared an applied a fix for this case and the bug detected in ATF ptrace(2) tests is now gone. I've included additional regression tests as noted below, to catch the race in a dedicated t_zombie test-suite.
There is also a controversy here, as it's not specified by POSIX what happens when we are polling an unrelated process, that is not a child of its parent. This operation can fail and we the previous approach we could report the same process twice, while with the newer one reporting twice is much more unlikely on the cost of missing the process at times.
My preference is that a process between the state transition of alive->dying->dead and dead->zombie, can disappear for a while. I find this metaphor more natural rather than observing two entities that one is dying and the other is a zombie. There is no perfect solution to this process watch and just following the narrow cases requested with POSIX seems to be the proper solution and it de facto assumes such races.
Bohrbug in X86 Debug Registers
The release engineering machines were observing occasional failures with the X86 Debug Registers in the ptrace(2) ATF test-suite. This was appearing once a while, approximately quarterly, on both amd64 and i386 machines.
I've missed them previously in my original work a year ago, as this happened to be caused by the fact that this bug is not reproducible on newer (quicker? more cores?) Intel CPUs. This failure was reproduced only in software-emulation (slow!) qemu and on Intel Core 2 Duo.
An attempt to execute the same X86 Debug Register test on Intel i7 for 100M times does not make this crash to pop up even a single time.
I've spent the majority of the past month on researching this bug and it happened to be a bohrbug, this means that adding almost any debug code anywhere makes it disappear completely or make reproducible siginificantly less often.
It's not worth the space to describe the process of understanding this bug more closely, step by step - it's worth to mention the current state of the understanding of mine. We can observe a repeated syscall for the _lwp_kill(2) operation (executed with raise(SIGSTOP)), with the same trap frame (or very similar). I still don't know how is it possible.
I've finally added support to the NetBSD kernel - in my local copy of the sources - for Bochs-style debug console/protocol (ISA port 0xe9). This allows me to log internal qemu debug and NetBSD kernel messages into a single buffer and output to a single file. I need this property as matching two logging buffers isn't trivial, especially since just the logging of interrupt frames in qemu can quickly generate hundreds of megabytes of text. Assuming that I've reproduced the bohrbug after 20k executions of the same test and there is a lot of noise from unrelated kernel/hardware traps, it's a useful property. I'm planning to cleanup this code and submit to the NetBSD sources.
For completeness I had to patch the qemu isa-debugcon (Bochs-style debug console) source code to log into the same buffer as the internal qemu debug messages... sometimes bugs require non-conventional approaches to research them. Ideally I would like to have a rewind/record feature in qemu together with the gdb-server emulation, but we are still not there.
ptrace(2) status and plans
Now there is the X86 Debug Register race. Also, the following tests still marked as expected failures:
- eventmask3
- resume1
- signal3, signal5, signal6, signal7, signal8, signal9
- suspend1, suspend2
- vfork1
This shows that the remaining major problems are in:
- vfork(2)
- signals
- threads
Once I will squash the X86 Debug Register race, I plan to work on these bugs in this oder: vfork handling bugs, signals and threads.
I have in mind addition of a lot of a lot of tests verifying correct signal processing in traced programs.
In this iteration of ptrace(2) hardening, I plan to skip Machine-Dependent extensions (like AVXv2 registers) and extending core(5) files with additional features (for example we might want to know exact ABI or FPU hardware layout).
Plan for the next milestone
Keep working on the bug reproducible with X86 Debug Registers and switch to the remaining ptrace(2) failures.
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL, and chip in what you can:
The NetBSD Project is pleased to announce NetBSD 8.0 RC 1, the first release candidate for the upcoming NetBSD 8.0 release.
25 years and a few days after the first official NetBSD release (NetBSD 0.8 on April 19, 1993) we are now quickly approaching the first final release from the netbsd-8 branch that has been in the work for more most of a year now.
The official RC1 announcement list these major changes compared to older releases:
- USB stack rework, USB3 support added
- In-kernel audio mixer
- Reproducible builds
- PaX MPROTECT (W^X) memory protection enforced by default on some architectures with fine-grained memory protection and suitable ELF formats: i386, amd64, evbarm, landisk, pmax
- PaX ASLR enabled by default on:
i386, amd64, evbarm, landisk, pmax, sparc64 - MKPIE (position independent executables) by default for userland on: i386, amd64, arm, m68k, mips, sh3, sparc64
- added can(4), a socket layer for CAN busses
- added ipsecif(4) for route-based VPNs
- made part of the network stack MP-safe NET_MPSAFE kernel option is required to try
- WAPBL stability and performance improvements
Specific to i386 and amd64 CPUs:
- Meltdown mitigation: SVS (separate virtual address spaces)
- Spectre mitigation (support in gcc, used by default for kernels)
- SMAP support
- (U)EFI bootloader
Various new drivers:
- nvme(4) for modern solid state disks
- iwm(4), a driver for Intel Wireless devices (AC7260, AC7265, AC3160...)
- ixg(4): X540, X550 and newer device support.
- ixv(4): Intel 10G Ethernet virtual function driver.
- bta2dpd - new Bluetooth Advanced Audio Distribution Profile daemon
Many evbarm kernels now use FDT (flat device tree) information (loadable at boot time from an external file) for device configuration, the number of kernels has decreased but the numer of boards has vastly increased.
Lots of updates to 3rd party software included:
- GCC 5.5 with support for Address Sanitizer and Undefined Behavior Sanitizer
- GDB 7.12
- GNU binutils 2.27
- Clang/LLVM 3.8.1
- OpenSSH 7.6
- OpenSSL 1.0.2k
- mdocml 1.14.1
- acpica 20170303
- ntp 4.2.8p11-o
- dhcpcd 7.0.3
- Lua 5.3.4
The NetBSD developers and the release engineering team have spent a lot of effort to make sure NetBSD 8.0 will be a superb release, but we have not yet fixed most of the accompanying documentation. So the included release notes and install documents will be updated before the final release, and also the above list of major items may lack important things.
Get NetBSD 8.0 RC1 from our CDN (provided by fastly) or one of the ftp mirrors.
Complete source and binaries for NetBSD are available for download at many sites around the world. A list of download sites providing FTP, AnonCVS, and other services may be found at http://www.NetBSD.org/mirrors/.
Please test RC1, so we can make the final release the best one ever so far. We are looking forward to your feedback. Please send-pr any bugs or mail us at releng at NetBSD.org for more general comments.
Upstream describes LLDB as a next generation, high-performance debugger. It is built on top of LLVM/Clang toolchain, and features great integration with it. At the moment, it primarily supports debugging C, C++ and ObjC code, and there is interest in extending it to more languages.
Originally, LLDB was ported to NetBSD by Kamil Rytarowski. However, multiple upstream changes and lack of continuous testing have resulted in decline of support. So far we haven't been able to restore the previous state.
In February, I have started working on LLDB, as contracted by the NetBSD Foundation. My initial effort was focused on restoring continuous integration via buildbot and restoring core file support. You can read more about that in my Feb 2019 report.
In March, I have been continuing this work and this report aims to summarize what I have done and what challenges still lie ahead of me.
Followup from last month and buildbot updates
By the end of February, I was working on fixing the most urgent test failures in order to resume continuous testing on buildbot. In early March, I was able to get all the necessary fixes committed. The list includes:
fixing tests to always use libc++ to avoid libstdc++-related breakage: r355273,
enabling passing -pthread flag: r355274,
enabling support for finding libc++ headers relatively to the executable location: r355282,
fixing additional case of bind/connect address mismatch: r355285,
passing appropriate -L and -Wl,-rpath flags for tests: r355502 with followup test fix in r355510.
The commit series also included an update for the code finding main executable location to use sysctl(): r355283. However, I've reverted it afterwards as it did not work reliably: r355302. Since this was neither really necessary nor unanimously considered correct, I've abandoned the idea.
Once those initial issues were fixed, I was able to enable the full LLDB test suite on the buildbot. Based on the initial results, I updated the list of tests known to fail on NetBSD: r355320, and later r355774, and start looking into ‘flaky’ tests.
Tests are called flaky if they can either pass or fail unpredictably — usually as a result of race conditions, timeouts and other events that may depend on execution order, system load, etc. The LLDB test suite provides a workaround for flaky tests — through executing them multiple times, and requiring only one of the runs to pass.
I have initially attempted to take advantage of this, committing r355830, then r355838. However, this approach turned out to be suboptimal. Sadly, marking more tests flaky only yielded more failures than previously — presumably because of the load increased through rerunning failing tests. Therefore, I've decided it more prudent to instead focus on finding the root issue.
Currently we are facing a temporary interruption in our buildbot service. We will restore it as soon as possible.
Threaded and AArch64 core file support
The next task on the list was to finish work on improving NetBSD core file support that was started by Kamil Rytarowski from almost two years ago. This involved rebasing his old patches after major upstream refactoring, adding tests and addressing remarks from upstream.
Firstly, I've addressed support for core files created from threaded programs. The new code itself landed as r355736. However, one of the tests was initially broken as it relied on symbol names provided by libc, and therefore failed on non-NetBSD systems. After initially disabling the test, I've finally fixed it by refactoring the code to fail in regular program function rather than libc call: r355786.
Secondly, I've added support for core files from AArch64 systems. To achieve this, I have set up a QEMU VM with a lot of help from Jared McNeill. For completeness, I include his very helpful instructions here:
Fetch and uncompress latest arm64.img.gz from http://nycdn.netbsd.org/pub/NetBSD-daily/HEAD/latest/evbarm-aarch64/binary/gzimg/
Use qemu-img resize arm64.img <newsize> to expand the image for your needs
Start qemu:
SMP=4 MEM=2g qemu-system-aarch64 -M virt -machine gic-version=3 -cpu cortex-a53 -smp $SMP -m $MEM \ -drive if=none,file=arm64.img,id=hd0 -device virtio-blk-device,drive=hd0 \ -netdev type=user,id=net0 -device virtio-net-device,netdev=net0,mac=00:11:22:33:44:55 \ -bios QEMU_EFI.fd \ -nographic
With this approach, I've finally been able to run NetBSD/arm64 via QEMU. I used it to create matching core dumps for the tests, and afterwards implemented AArch64 support: r357399.
Other improvements
During the month, upstream has introduced a new SBReproducer module that wrapped most of the LLDB API. The original implementation involved generating the wrappers for all modules in a single file. Combined with heavy use of templates, building this file caused huge memory consumption, making it impossible to build on systems with 4 GiB of RAM. I've discussed possible solutions with upstream and finally implemented one splitting and moving wrappers to individual modules: r356481.
Furthermore, as an effort to reduce flakiness of tests, I've worked on catching and fixing more functions potentially interrupted via signals (EINTR): r356703, with fixup in r356960. Once the LLVM bot will be back, we will check whether that solved our flakiness problem.
LLVM 8 release
Additionally, during the month LLVM 8.0.0 was finally released. Following Kamil's request, by the end of the month I've started working on updating NetBSD src for this release. This is still a work in progress, and I've only managed to get LLVM and Clang to build (with other system components failing afterwards). Nevertheless, if you're interested the current set of changes can be seen on my GitHub fork of netbsd/src, llvm8 branch. The URL for comparison is: https://github.com/NetBSD/src/compare/6e11444..mgorny:llvm8
Please note that for practical reasons this omits the commit updating distributed LLVM and Clang sources.
Future plans
The plans for the nearest future include finishing the efforts mentioned here and working with others on resuming the buildbot. I have also discussed with Pavel Labath and he suggested working on improving error reporting to help us resolve current and future test failures.
The next milestones in the LLDB development plan are:
Add support for FPU registers support for NetBSD/i386 and NetBSD/amd64.
Support XSAVE, XSAVEOPT, ... registers in core(5) files on NetBSD/amd64.
This work is sponsored by The NetBSD Foundation
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL to chip in what you can:
Crash signal masking
Certain applications and frameworks mask signals that occur during crashes. This can happen deliberately or by an accident when masking all signals in a process.
There are two basic types of signals in this regard:
- emitted by a debugger-related event (such as software or hardware breakpoint),
- emitted by other source such as other process (kill(2)) or raised in a thread (raise(2)).
Not only debuggers were affected, but software reusing the debugging APIs internally, including the DTrace tools in userland.
Right now the semantics of crash signals has been fixed for traps issued by crashes (such as software breakpoint of segmentation fault) and fork(2)/vfork(2) events.
New ATF tests for ptrace(2)
Browsing the available Linux resources with tests against ptrace(2), I got an inspiration to validate whether unaligned memory access through the PT_READ/PT_WRITE and PIOD READ/WRITE/READ_AUXV operations. These calls are needed to transfer data between the memory of a debugger and a debuggee. They are documented and expected to be safe for a potentially misaligned access. Newly added tests validate whether it is true.
It's much better to detect a potential problem with ATF rather than a kernel crash on a more sensitive CPU (most RISC-ones) during operation.
Plan for the next milestone
Keep preparing kernel fixes and after thorough verification applying them to the mainline distribution.
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL to chip in what you can:

Design Aspects
General Considerations
In order to achieve hardware-accelerated virtualization, two components need to interact together:- A kernel driver that will switch machine's CPU to a mode where it will be able to safely execute guest instructions.
- A userland emulator, which talks to the kernel driver to run virtual machines.
The NVMM Design
NVMM provides the infrastructure needed for both the kernel driver and the userland emulators.
The kernel NVMM driver comes as a kernel module that can be dynamically loaded into the kernel. It is made of a generic machine-independent frontend, and of several machine-dependent backends. In practice, it means that NVMM is not specific to x86, and could support ARM 64bit for example. During initialization, NVMM selects the appropriate backend for the system. The frontend handles everything that is not CPU-specific: the virtual machines, the virtual CPUs, the guest physical address spaces, and so forth. The frontend also has an IOCTL interface, that a userland emulator can use to communicate with the driver.
When it comes to the userland emulators, NVMM does not provide one. In other words, it does not re-implement a Qemu, a VirtualBox, a Bhyve (FreeBSD) or a VMD (OpenBSD). Rather, it provides a virtualization API via the libnvmm library, which allows to effortlessly add NVMM support in already existing emulators. This API is meant to be simple and straightforward, and is fully documented. It has some similarities with WHPX on Windows and HVF on MacOS.
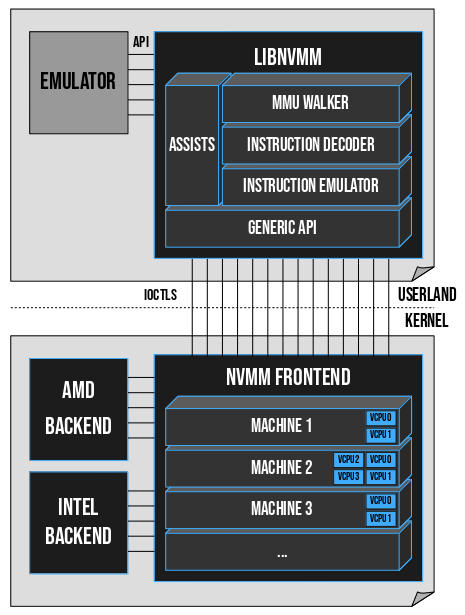
Fig. A: General overview of the NVMM design.
The Virtualization API: An Example
The virtualization API is installed by default on NetBSD. The idea is to provide an easy way for applications to use NVMM to implement services, which can go from small sandboxing systems to advanced system emulators.
Let's put ourselves in the context of a simple C application we want to write, to briefly showcase the virtualization API. Note that this API may change a little in the future.
Creating Machines and VCPUs
In libnvmm, each machine is described by an opaque nvmm_machine structure. We start with:
#include <nvmm.h>
...
struct nvmm_machine mach;
nvmm_machine_create(&mach);
nvmm_vcpu_create(&mach, 0);
This creates a machine in 'mach', and then creates VCPU number zero (VCPU0) in this machine. This VM is associated with our process, so if our application gets killed or exits bluntly, NVMM will automatically destroy the VM.
Fetching and Setting the VCPU State
In order to operate our VM, we need to be able to fetch and set the state of its VCPU0, that is, the content of VCPU0's registers. Let's say we want to set the value '123' in VCPU0's RAX register. We can do this by adding four more lines:
struct nvmm_x64_state state;
nvmm_vcpu_getstate(&mach, 0, &state, NVMM_X64_STATE_GPRS);
state.gprs[NVMM_X64_GPR_RAX] = 123;
nvmm_vcpu_setstate(&mach, 0, &state, NVMM_X64_STATE_GPRS);
Here, we fetch the GPR component of the VCPU0 state (GPR stands for General Purpose Registers), we set RAX to '123', and we put the state back into VCPU0. We're done.
Allocating Guest Memory
Now is time to give our VM some memory, let's say one single page. (What follows is a bit technical.)
The VM has its own MMU, which translates guest virtual addresses (GVA) to guest physical addresses (GPA). A secondary MMU (which we won't discuss) is set up by the host to translate the GPAs to host physical addresses. To give our single page of memory to our VM, we need to tell the host to create this secondary MMU.
Then, we will want to read/write data in the guest memory, that is to say, read/write data into our guest's single GPA. To do that, in NVMM, we also need to tell the host to associate the GPA we want to read/write with a host virtual address (HVA) in our application. The big picture:
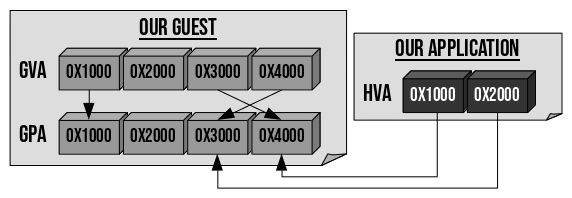
Fig. B: Memory relations between our application and our VM.
In Fig. B above, if the VM wants to read data at virtual address 0x4000, the CPU will perform a GVA→GPA translation towards the GPA 0x3000. Our application is able to see the content of this GPA, via its virtual address 0x2000. For example, if our application wants to zero out the page, it can simply invoke:
memset((void *)0x2000, 0, PAGE_SIZE);
With this system, our application can modify guest memory, by reading/writing to it as if it was its own memory. All of this sounds complex, but comes down to only the following four lines of code:
uintptr_t hva = (uintptr_t)mmap(NULL, PAGE_SIZE, PROT_READ|PROT_WRITE, MAP_ANON|MAP_PRIVATE, -1, 0);
gpaddr_t gpa = 0x3000;
nvmm_hva_map(&mach, hva, PAGE_SIZE);
nvmm_gpa_map(&mach, hva, gpa, PAGE_SIZE, PROT_READ|PROT_WRITE);
Here we allocate a simple HVA in our application via mmap. Then, we turn this HVA into a special buffer that NVMM will be able to use. Finally, we tell the host to link the GPA (0x3000) towards the HVA. From then on, the guest is allowed to touch what it perceives as being a simple physical page located at address 0x3000, and our application can directly modify the content of this page by reading and writing into the address pointed to by 'hva'.
Running the VM
The final step is running the VM for real. This is achieved with a VCPU Loop, which runs our VCPU0 and processes the different exit reasons, typically in the following form:
struct nvmm_exit exit;
while (1) {
nvmm_vcpu_run(&mach, 0, &exit);
switch (exit.reason) {
case NVMM_EXIT_NONE:
break; /* nothing to do */
case ... /* completed as needed */
}
}
The nvmm_vcpu_run function blocks, and runs the VM until an exit or a rescheduling occurs.
Full Code
We're done now: we know how to create a VM and give it VCPUs, we know how to modify the registers of the VCPUs, we know how to allocate and modify guest memory, and we know how to run a guest.
Let's sum it all up in one concrete example: a calculator that runs inside a VM. This simple application receives two 16bit ints as parameters, launches a VM that performs the addition of these two ints, fetches the result, and displays it.
That's about it, we have our first NVMM-based application in less than 100 lines of C code, and it is an example of how NetBSD's new virtualization API can be used to easily implement VM-related services.
Advanced Use of the Virtualization API
Libnvmm can go farther than just providing wrapper functions around IOCTLs. Simply said, certain exit reasons are very complex to handle, and libnvmm provides assists that can emulate certain guest operations on behalf of the userland emulator.
Libnvmm embeds a comprehensive machinery, made of three main components:
- The MMU Walker: the component in charge of performing a manual GVA→GPA translation. It basically walks the MMU page tree of the guest; if the guest is running in x86 64bit mode for example, it will walk the four layers of pages in the guest to obtain a GPA.
- The Instruction decoder: fetches and disassembles the guest instructions that cause MMIO exits. The disassembler uses a Finite State Machine. The result of the disassembly is summed up in a structure that is passed to the instruction emulator, possibly several times consecutively.
- The instruction emulator: as its name indicates, it emulates the execution of an instruction. Contrary to many other disassemblers and hypervisors, NVMM makes a clear distinction between the decoder and the emulator.
An NVMM-based application can therefore avoid the burden of implementing these components, by just leveraging the assists provided in libnvmm.
Security Aspects
NVMM can be used in security products, such as sandboxing systems, to provide contained environments. Without elaborating more on my warplans, this is a project I've been thinking about for some time on NetBSD.
One thing you may have noticed from Fig. A, is that the complex emulation machinery is not in the kernel, but in userland. This is an excellent security property of NVMM, because it reduces the risk for the host in case of bug or vulnerability – the host kernel remains unaffected –, and also has the advantage of making the machinery easily fuzzable. Currently, this property is not found in other hypervisors such as KVM, HAXM or Bhyve, and I hope we'll be able to preserve it as we move forward with more backends.
Another security property of NVMM is that the assists provided by libnvmm are invoked only if the emulator explicitly called them. In other words, the complex machinery is not launched automatically, and an emulator is free not to use it if it doesn't want to. This can limit the attack surface of applications that create limited VMs, and want to keep things simple and under control as much as possible.
Finally, NVMM naturally benefits from the modern bug detection features available in NetBSD (KASAN, KUBSAN, and more), and from NetBSD's automated test framework.
Performance Aspects
Contrary to other pseudo-cross-platform kernel drivers such as VirtualBox or HAXM, NVMM is well integrated into the NetBSD kernel, and this allows us to optimize the context switches between the guests and the host, in order to avoid expensive operations in certain cases.
Another performance aspect of NVMM is the fact that in order to implement the secondary MMU, NVMM uses NetBSD's pmap subsystem. This allows us to have pageable guest pages, that the host can allocate on-demand to limit memory consumption, and can then swap out when it comes under memory pressure.
It also goes without saying that NVMM is fully MP-safe, and uses fine-grained locking to be able to run many VMs and many VCPUs simultaneously.
On the userland side, libnvmm tries to minimize the processing cost, by for example doing only a partial emulation of certain instructions, or by batching together certain guest IO operations. A lot of work has been done to try to reduce the number of syscalls an emulator would have to make, in order to increase the overall performance on the userland side; but there are several cases where it is not easy to keep a clean design.
Hardware Support
As of this writing, NVMM supports two backends, x86-SVM for AMD CPUs and x86-VMX for Intel CPUs. In each case, NVMM can support up to 128 virtual machines, each having a maximum of 256 VCPUs and 128GB of RAM.
Emulator Support
Armed with our full virtualization stack, our flexible backends, our user-friendly virtualization API, our comprehensive assists, and our swag NVMM logo, we can now add NVMM support in whatever existing emulator we want.
That's what was done in Qemu, with this patch, which shall soon be upstreamed. It uses libnvmm to provide hardware-accelerated virtualization on NetBSD.
It is now fully functional, and can run a wide variety of operating systems, such as NetBSD (of course), FreeBSD, OpenBSD, Linux, Windows XP/7/8.1/10, among others. All of that works equally across the currently supported NVMM backends, which means that Qemu+NVMM can be used on both AMD and Intel CPUs.
Fig. C: Example, Windows 10 running on Qemu+NVMM, with 3 VCPUs, on a host that has a quad-core AMD CPU.
Fig. D: Example, Fedora 29 running on Qemu+NVMM, with 8 VCPUs, on a host that has a quad-core Intel CPU.
The instructions on how to use Qemu+NVMM are available on this page.
What Now
All of NVMM is available in NetBSD-current, and will be part of the NetBSD 9 release.
Even if perfectly functional, the Intel backend of NVMM is younger than its AMD counterpart, and it will probably receive some more performance and stability improvements.
There still are, also, several design aspects that I haven't yet settled, because I haven't yet decided the best way to fix them.
Overall, I expect new backends to be added for other architectures than x86, and I also expect to add NVMM support in more emulators.
That's all, ladies and gentlemen. In six months of spare time, we went from Zero to NVMM, and now have a full virtualization stack that can run advanced operating systems in a flexible, fast and secure fashion.
Not bad
The third release in the NetBSD-8 is now available.
This release includes all the security fixes in NetBSD-8 up until this point, and other fixes deemed important for stability.
Some highlights include:
- x86: fixed regression in booting old CPUs
- x86: Hyper-V Gen.2 VM framebuffer support
- httpd(8): fixed various security issues
- ixg(4): various fixes / improvements
- x86 efiboot: add tftp support, fix issues on machines with many memory segments, improve graphics mode logic to work on more machines.
- Various kernel memory info leaks fixes
- Update expat to 2.2.8
- Fix ryzen USB issues and support xHCI version 3.10.
- Accept root device specification as NAME=label.
- Add multiboot 2 support to x86 bootloaders.
- Fix for CVE-2019-9506: 'Key Negotiation of Bluetooth' attack.
- nouveau: limit the supported devices and fix firmware loading.
- radeon: fix loading of the TAHITI VCE firmware.
- named(8): stop using obsolete dnssec-lookaside.
You can download binaries of NetBSD 8.2 from our Fastly-provided CDN.
For more details refer to the CHANGES-8.2 file.
Please note that we are looking for donations again, see Fundraising 2020.
Enjoy!
Maya
Typically, some time after releasing a new NetBSD major version (such as NetBSD 9.0), we will announce the end-of-life of the N-2 branch, in this case NetBSD-7.
We've decided to hold off on doing that to ensure our users don't feel rushed to perform a major version update on any remote machines, possibly needing to reach the machine if anything goes wrong.
Security fixes will still be made to the NetBSD-7 branch.
We hope you're all safe. Stay home.
- One in the base-system with a stack of local patches.
- One in pkgsrc with mostly build fix patches.
The process of maintaining a modern version (GPLv3) of GDB in basesystem is tainted with a constant extra cost. The NetBSD developers need to rebase the stack of local patches for the newer releases of the debugger and resurrect the support. The GDB project is under an active development and in active refactoring of the code, that was originally written in C, to C++.
Unfortunately we cannot abandon the local basesystem patches and rely on a pristine version as there is lack of feature parity in the pkgsrc version of GDB: no threading support, not operational support for most targets, no fork/vfork/etc events support, no auxv reading support on 64-bit kernels, no proper support of signals, single step etc.
Additionally there are extra GDB patches stored in pkgsrc-wip (created by me last year), that implement the gdbserver support for NetBSD/amd64. gdbserver is a GDB version that makes it possible to remotely debug other programs even across different Operating Systems and CPUs. This code has still not been merged into the mainline base-system version. This month, I have discovered that support needs to be reworked, as the preexisting source code directory hierarchy was rearranged.
Unless otherwise specified all the following changes were upstreamed to the mainstream GDB repository. According to the GDB schedule, the GDB10 branch point is planned on 2020-05-15 with release on 2020-06-05. It's a challenge to see how much the GDB support can be improved by then for NetBSD!
PSIM
The GDB debugger contains PSIM (Model of the PowerPC Architecture) originally developed by Andrew Cagney between 1994 and 1996. This is a simulator that contains, among other things, NetBSD support in the UEA mode. This means that GDB can run static programs prebuilt for NetBSD without execution on a real PowerPC hardware. In order to make it work, there is need to wrap the kernel interfaces such as syscalls, errno values and signals and handle them in the simulator.
I have updated the list of errno names and signal names with NetBSD 9.99.49.
It would be nice to still update the list of syscalls to reflect the current kernels, but I have deferred this into future.
bfd changes
The AArch64 (NetBSD/evbarm) target uses PT_GETREGS and PT_GETFPREGS operation names with the same Machine Dependent values as NetBSD/alpha and NetBSD/sparc. This knowledge is required as these values are used in core(5) files, as emitted by a crashing program. I've added a patch that recognizes these ELF notes in arm64 coredumps appropriately.
I've also added a new define constant NT_NETBSDCORE_AUXV. This allows properly identifying AUXV ELF notes in core files. Meanwhile I have implemented and added detection of LWPSTATUS notes. This note ships with meta information (name, signal context, TLS base, etc) about threads in a process in a core.
The number of ARM and MIPS boards supported by NetBSD is huge and there are multiple variations of them. I have fixed the detection macro in bfd to recognize more arm and mips NetBSD installations.
GDB/NetBSD fixes in CPU specific files
I have reached the state of GDB being more operational for more NetBSD ports out of the box. There were missing features and build issues that has been addressed. I have committed the following changes:
- Define _KERNTYPES in vax-bsd-nat.c
- Define _KERNTYPES in ppc-nbsd-nat.c
- Define _KERNTYPES in mips-nbsd-nat.c
- Inherit vax_bsd_nat_target from nbsd_nat_target
- Add explicit cast to fix build of vax-bsd-nat.c
- Add support for threads in vax_bsd_nat_target
- Add support for NetBSD threads in x86-bsd-nat.c
- Inherit arm_netbsd_nat_target from nbsd_nat_target
- Add support for NetBSD threads in arm-nbsd-nat.c
- Define _KERNTYPES in alpha-bsd-nat.c
- Inherit alpha_netbsd_nat_target from nbsd_nat_target
- Remove unused code from alpha-bsd-nat.c
- Add support for NetBSD threads in alpha-bsd-nat.c
- Define _KERNTYPES in m68k-bsd-nat.c
- Inherit m68k_bsd_nat_target from nbsd_nat_target
- m68k: bsd: Change type from char * to gdb_byte *
- Add support for NetBSD threads in m68k-bsd-nat.c
- Include missing header to get missing declarations
- Inherit sh_nbsd_nat_target from nbsd_nat_target
- Add support for NetBSD threads in sh-nbsd-nat.c
- Add support for NetBSD threads in sparc-nat.c
- Add support for NetBSD threads in amd64-bsd-nat.c
- Add support for NetBSD threads in i386-bsd-nat.c
- Add support for NetBSD threads in ppc-nbsd-nat.c
- Add support for NetBSD threads in hppa-nbsd-nat.c
- Inherit ppc_nbsd_nat_target from nbsd_nat_target
- Update the return type of gdb_ptrace to be more flexible
- Avoid get_ptrace_pid() usage on NetBSD in x86-bsd-nat.c
Now support for NetBSD in various CPU-specific files improved significantly, however there are still missing features, especially KGDB debugging and unwinding the stack over the signal trampoline. There are still smaller or larger changes that might be needed on per-port basis and I will keep working on them. There is need to develop at least proper aarch64 support as it is missing upstream. We might evaluate what to do with at least Itanium and RISCV.
CPU Generic improvements in the GDB codebase
I've switched
the nbsd_nat_target::pid_to_exec_file() function from a logic of reading the /proc
entries to a sysctl(3) based solution.
As the gdbserver support is around the corner, I have improved small parts of the code base to be compatibile with NetBSD.
I've fixed
the unconditional inclusion of alloca.h in gdbsupport.
Another
fix
namespaced a local class reg, because it conflicted with the struct reg
from the NetBSD headers.
The current logic of get_ptrace_pid function matches the semantics of other kernels suchs as Linux and FreeBSD.
With the guidance of upstream developers,
I have disabled
this function completely for NetBSD instead of patching it for
the NetBSD specific behavior of maintaining pairs PID+LWP for each internal ptid_t entry (that reflects the relation of PID, LWP and TID).
Plan for the next milestone
Finish reimplementing operational support of debugging of multi-threaded programs and upstream more patches, especially CPU-independent ones.
Upstream describes LLDB as a next generation, high-performance debugger. It is built on top of LLVM/Clang toolchain, and features great integration with it. At the moment, it primarily supports debugging C, C++ and ObjC code, and there is interest in extending it to more languages.
In February 2019, I have started working on LLDB, as contracted by the NetBSD Foundation. So far I've been working on reenabling continuous integration, squashing bugs, improving NetBSD core file support, extending NetBSD's ptrace interface to cover more register types and fix compat32 issues, fixing watchpoint and threading support, porting to i386.
March 2020 was the last month of my contract. During it my primary focus was to prepare integration of LLDB into NetBSD's src tree.
LLDB integration
The last important goal for the contract was to include LLDB in the NetBSD src tree. This mainly involved porting LLDB build into NetBSD src tree Makefiles. The resulting patches were sent to the tech-toolchain mailing list: [PATCH 0/7] LLDB import to src.
My proposed integration is based on LLDB tree from 2019-10-29. This matches the LLVM/Clang version currently imported in NetBSD. Newer version can not be used directly due to API incompatibility between the projects, and it is easier to backport LLDB fixes than to fix LLVM API missync.
The backports applied on top of this commit include all my contracted
work, plus Kamil Rytarowski's work on LLDB. This also includes necessary fixes
to make LLDB build against current NetBSD ptrace() API. Two source
files in liblldbHost are renamed to ensure unique filenames within that
library, as necessary to build from NetBSD Makefiles without resorting
to ugly hacks.
Upstream uses to build individual LLDB components and plugins into
split static libraries, then combine them all into a shared liblldb.so
library. Both lldb and lldb-server executables link to it. We
currently can not follow this model as LLVM and Clang sources are built
without -fPIC and therefore are not suitable for shared libraries.
Therefore, we build everything as static libraries instead. This causes the logic that upstream uses to find lldb-server to fail, as it relies on obtaining the library path from the dynamic loader and finding executables relative to it. I have replaced it with hardcoded path to make LLDB work.
The patches are currently waiting for Joerg Sonnenberger to finish LLVM/Clang update that's in progress already.
Pending tasks
The exact list of pending tasks from my contract follows:
-
Add support to backtrace through signal trampoline and extend the support to libexecinfo, unwind implementations (LLVM, nongnu). Examine adding CFI support to interfaces that need it to provide more stable backtraces (both kernel and userland).
-
Add support for aarch64 target.
-
Stabilize LLDB and address breaking tests from the test suite.
Notes on backtracing through signal trampoline
I have described the problem of backtracing through signal trampoline in February's report. I haven't managed to finish the work on the topic within the contract but I will try to work on it in my free time.
Most likely, the solution would involve modifying the assembly in
lib/libc/arch/*/sys/__sigtramp2.S. As suggested by Andrew Cagney,
the CFI directives for amd64 would look like:
NENTRY(__sigtramp_siginfo_2)
.cfi_startproc
.cfi_signal_frame
.cfi_def_cfa r15, 0
/* offsets from mcontext_t */
.cfi_offset rax, 0x70
.cfi_offset rbx, 0x68
.cfi_offset rcx, 0x18
.cfi_offset rdx, 0x10
/* ... */
.cfi_def_cfa rsp, 8
movq %r15,%rdi
movq $SYS_setcontext, %rax
syscall
movq $-1,%rdi /* if we return here, something is wrong */
movq $SYS_exit, %rax
syscall
.cfi_endproc
END(__sigtramp_siginfo_2)
Addressing breaking tests
While the most important functions of LLDB work on NetBSD, there are
still many test failures. At this moment, there are 80 instances
of @expectedFailureNetBSD decorator and 18 cases of @skipIfNetBSD.
The former generally indicates that the test reliably fails on NetBSD
and needs a fix, the latter is sometimes used to decorate tests specific
to other systems but also to indicate that the test crashes, hangs
or otherwise can not be reliably run.
Some tests are failing due to the concurrent signal kernel bug explained in the previous post and covered by XFAIL-ing ATF tests.
New regressions both in LLDB and in LLVM in general appear every month. Most of them are fixed by their authors once we report them. I will continue fighting new bugs in my free time and trying to keep the build bot green.
This work is sponsored by The NetBSD Foundation
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL to chip in what you can:
Back in 2018, Phil Nelson started a long needed WiFi-refresh, basically syncing our src/sys/net80211/ with the version from FreeBSD. He got a few things working, but then ran out of time and was unable to spend enough time on this to complete the task. I am now taking over this work, Phil hopes to join in again later this summer.
The main idea is to get better SMP (locking) support, support for newer (faster) WiFi standards, and support for virtual access points, while also making future updates (and import of drivers) from FreeBSD easier.
I have collected quite a few WiFi cards and USB dongles, but will ask for help with other hardware I don't have handy later.
I hope to have a working setup and a few working drivers by the end of this months.
Thanks to the NetBSD Foundation for funding this work! Please note that we are looking for donations again, see Fundraising 2020.
P.S.: for the curious: the first drivers I hope to have working are the ones we have already drivers for and I have hardware:
followed by things other developers can convert and have hardware (with me assisting where needed), optionally followed by some of the ones where I have hardware but we have no driver yet:- Realtek (0x2357) 802.11ac WLAN Adapter (0x011e)
- (old) pinebook sdio wifi
- cubietruck a20 wifi (broadcom 40181?)
- GuruPlug wifi: Marvell, 802.11 SDIO (manufacturer 0x2df, product 0x9103)
There's two ways user applications can communicate with the kernel audio layer in NetBSD:
- audio(4) – the native API, based on the Sun API with a number of very useful NetBSD extensions
- ossaudio(3) – a translation layer providing approximate compatibility with OSSv4's ioctls, as also supported in FreeBSD, Solaris, and popular in the past on Linux.
Linux drifted away from OSS and towards ALSA due to licensing disagreements.
Because of this drift, we're seeing increasing problems with OSS adoption today, even if the licensing concerns are no longer relevant, and other implementations of OSS have surpassed the original Linux OSSv3 implementation as far as their feature set and usability are concerned.
So, in NetBSD, it's recommended to use the native API for new code and only rely on the OSS layer for compatibility with existing code.
I spent a while working on third-party software to improve support for native NetBSD audio. These included Firefox, SDL, PortAudio, ffmpeg (working with yhardy@), and more.
However, I've turned my attention to the OSS translation layer. Since a lot of older and less popular software still relies on it, I wanted to go over the OSSv4 specification and iron out surprising differences.
Audacity/PortAudio's OSS usage is strange
I should note that most of these fixes were to enable Audacity to work without patching. Audacity is interesting because it hits a lot of edge cases as far as OSS API usage is concerned. Once I fixed the most notable issues, I made sure Audacity also supported the native API. Writing the necessary PortAudio glue for Sun/NetBSD audio and implementing these fixes took approximately two days.
Incompatibility 1 – SNDCTL_DSP_SPEED
[Out of range sample rates are now handled properly by the OSS layer in NetBSD-current.]
The NetBSD 9 kernel supports sample rates up to 192kHz. Specify anything higher, and NetBSD's audio API returns an error code and keeps the sample rate at its original value, or the legacy default of 8000 Hz (not particularly useful with modern devices).
However, OSS applications expected setting the sample rate to always succeed. The specification states that the actual set sample value may be an approximation and will not always use the exact requested value. So, if the requested value is out of range, NetBSD will now return as if the call succeeded, and set the sample rate to the current configured hardware rate (usually some multiple of 48kHz).
During its startup process, Audacity requested an overly high sample rate of 384kHz. This is well above the maximum supported. I'm still not sure why it does this, because it later configures the audio device to standard CD rate, but it meant that Audacity couldn't properly start without our local patches.
Incompatibility 2 – SNDCTL_DSP_CHANNELS
[Out of range channel numbers are now handled properly by the OSS layer in NetBSD-current.]
This was a very simple fix, similar to that of SNDCTL_DSP_SPEED. The NetBSD
kernel supports between 1 and 12 channels for audio playback. Most commonly
1 is mono, 2 is stereo, and higher numbers are used with surround sound
systems. The limit of 12 comes from the USB audio device specification.
If an out of range number is specified, libossaudio will now set the channel count to the currently configured number in use at the hardware level.
However, we encounter a more difficult difference between OSS and NetBSD audio
when using the audio device in full duplex (recording from and playing back to
the same device simultaneously). If your mic is mono and your speakers aren't,
how do you set the channel counts to different numbers in OSS? You can't.
There is one ioctl for setting both the recording and playback channels.
In the native API, this is possible by setting info.record.channels and
info.play.channels separately. We should ensure that the recording channels
are always duplicated to be same as the number of playback channels.
Incompatibility 3 – SNDCTL_DSP_SETTRIGGER
[NetBSD-current now implements SNDCTL_DSP_SETTRIGGER.]
SNDCTL_DSP_SETTRIGGER is a somewhat more obscure part of the OSS API,
in that it's only really useful if you are using poll() or another
event notification mechanism on an audio device before performing
any I/O, or you're performing I/O via mmap(), neither being particularly
common in practice. It has the ability to force initialisation of
playback/recording for the device if this isn't already the case.
In terms of the native API, this means that playback/recording becomes unpaused.
Previously in NetBSD, this part of the OSS API wasn't implemented and simply did nothing. However, it became obviously needed due to an incompatible change in NetBSD 9, as discussed on tech-kern.
Basically, we needed recording to be properly triggered without
a read() so a few applications using poll() without prior I/O wouldn't
block indefinitely.
Incompatibility 4 – SNDCTL_DSP_SETPLAYVOL
OSSv4 has special bits to manipulate the volume of an individual stream in an application while doing all the maths for this inside the kernel.
We don't support this properly yet (but reasonably could)... so code needs to be modified to do the volume manipulation in the application, or the OSSv4 support disabled.
I've only found a couple of applications that try to use this feature (audacious, qmmp). Currently, they're configured to avoid using OSSv4 and layer the audio through SDL or qt-multimedia instead.
I've at least fixed SNDCTL_DSP_GETPLAYVOL to return conforming values.
NetBSD audio uses 0-255 for the gain of all channels. OSSv4 uses
a range of 0-100 and encodes two channels into an integer, which
is very odd in my opinion, and also limits surround sound support.
The future of libossaudio in NetBSD?
Hopefully, after my changes, OSS compatibility is in a much better shape when dealing with unusual parameters and uncommon API usage. The quality of the code also improves – in the process of this work, maxv@ pointed me towards a related information leak in the Linux OSSv3 compatibility layer in the kernel, and I was able to deal with it properly after looking at the OSS specification and Linux headers. All the fixes should be pulled up to 9-stable.
However, I'd personally like to eventually reach a point where we no longer need libossaudio. I've been writing a lot of code towards this goal.
In many cases, the applications relying on it could be easily modified or told to use libao/SDL2/PortAudio/OpenAL/etc instead, which all have native NetBSD audio support.
OSS aside...
We probably need to start thinking about supporting 24-bit PCM in the kernel, since I've found a few audio players that can't handle making the samples 32-bit before writing them to the device. The Sun audio implementation in Solaris has supported this for a long time now.
We nearly hit our 2020 donation milestone set after the release of 9.0 of $50,000. These donations have enabled us to fund significant work on NetBSD in 2020 such as:
- an aarch64 package build server, victory.netbsd.org. Thanks to Western Washington University for hosting this machine.
- Modernizing wi-fi network stack and release engineering work by Martin Husemann
- LLDB support by Michał Górny
- ptrace and GDB improvements by Kamil Rytarowski
If you are interested in seeing more work like this, please consider donating via PayPal or GitHub sponsors.
The financial report for 2020 is also available.
Note: We realize that this data is inconsistent with the website indicator of donations. This is due to the fact the website is updated manually in an error-prone process as the donations are processed. The financial report (just completed) is prepared separately using ledger.
We nearly hit our 2020 donation milestone set after the release of 9.0 of $50,000. These donations have enabled us to fund significant work on NetBSD in 2020 such as:
- an aarch64 package build server, victory.netbsd.org. Thanks to Western Washington University for hosting this machine.
- Modernizing wi-fi network stack and release engineering work by Martin Husemann
- LLDB support by Michał Górny
- ptrace and GDB improvements by Kamil Rytarowski
If you are interested in seeing more work like this, please consider donating via PayPal or GitHub sponsors.
The financial report for 2020 is also available.
Note: We realize that this data is inconsistent with the website indicator of donations. This is due to the fact the website is updated manually in an error-prone process as the donations are processed. The financial report (just completed) is prepared separately using ledger.
This is my second and final report for the Google Summer of Code project I am working on for NetBSD.
My code can be found at github.com//src in the gsoc2020 branch, at the time of writing some of it is still missing. The test facilities and logs can be found in github.com/nikicoon/gsoc2020. A diff can be found at github which will later be split into several patches before it is sent to QA for merging.
The initial and defined goal of this project was to make system(3) and popen(3) use posix_spawn(3) internally, which had been completed in June. For the second part I was given the task to replace fork+exec calls in our standard shell (sh) in one scenario. Similar to the previous goal we determined through implementation if the initial motivation, to get performance improvements, is correct otherwise we collect metrics for why posix_spawn() in this case should be avoided. This second part meant in practice that I had to add and change code in the kernel, add a new public libc function, and understand shell internals.
Summary of part 1
Prior work: In GSoC 2012 Charles Zhang added the posix_spawn syscall which according to its SF repository at the time (maybe even now, I have not looked very much into comparing all other systems and libcs + kernels) is an in-kernel implementation of posix_spawn which provides performance benefits compared to FreeBSD and other systems which had a userspace implementation (in 2012).
After 1 week of reading POSIX and writing code, 2 weeks of coding and another 1.5 weeks of bugfixes I have successfully implemented posix_spawn in usage in system(3) and popen(3) internally.
The biggest challenge for me was to understand POSIX, to read the standard. I am used to reading more formal books, but I can't remember working with POSIX Standard directly before.
system(3)
system(3) was changed to use posix_spawnattr_ (where we used sigaction before) and posix_spawn (which replaced execve + vfork calls).
popen(3) and popenve(3)
Since the popen and popenve implementation in NetBSD's libc use a couple of shared helper functions, I was able to change both functions while keeping the majority of the changes focused on (some of ) the helper functions (pdes_child).
pdes_child, an internal function in popen.c, now takes one more argument (const char *cmd) for the command to pass to posix_spawn which is called in pdes_child.
On a high level what happens in pdes_child() and popen is that we first lock the pidlist_mutex. Then we create a file file action list for all concurrent popen() / popenve() instances and the side of the pipe not necessary, and the move to stdin/stdout. We unlock the pidlist_mutex. Finally we return the list and destroy.
In the new version of this helper function which now handles the majority of what popen/popenve did, we have to initialize a file_actions object which by default contains no file actions for posix_spawn() to perform. Since we have to have error handling and a common return value for the functions calling pdes_child() and deconstruction, we make use of goto in some parts of this function.
The close() and dup2() actions now get replaced by corresponding file_actions syscalls, they are used to specify a series of actions to be performed by a posix_spawn operation.
After this series of actions, we call _readlockenv(), and call posix_spawn with the file_action object and the other arguments to be executed. If it succeeds, we return the pid of the child to popen, otherwise we return -1, in both cases we destroy the file_action object before we proceed.
In popen and popenve our code has been reduced to the pid == -1 branch, everything else happens in pdes_child() now.
After readlockenv we call pdes_child and pass it the command to execute in the posix_spawn'd child process; if pdes_child returns -1 we run the old error handling code. Likewise for popenve.
The outcome of the first part is, that thanks to how we implement posix_spawn in NetBSD we reduced the syscalls being made for popen and system. A full test with proper timing should indicate this, my reading was based on comparing old and new logs with ktrace and kdump.
sh, posix_spawn actions, libc and kernel - Part 2
Motivation
The main goal of part 2 of this project was to change sh(1) to determine which simple cases of (v)fork + exec I could replace, and to replace them with posix_spawn where it makes sense.
fork needs to create a new address space by cloning the address space, or in the case of vfork update at least some reference counts. posix_spawn can avoid most of this as it creates the new address space from scratch.
Issues
The current posix_spawn as defined in POSIX has no good way to do tcsetpgrp, and we found that fish just avoids posix_spawn for foreground processes.
Implementation
Since, roughly speaking, modern BSDs handle "#!" execution in the kernel (probably since before the 1990s, systems which didn't handle this started to disappear most likely in the mid to late 90s), our main concern so far was in the evalcmd function the default cmd switch case ('NORMALCMD').
After adjusting the function to use posix_spawn, I hit an issue in the execution of the curses application htop where htop would run but input would not be accepted properly (keysequences pressed are visible). In pre-posix_spawn sh, every subprocess that sh (v)forked runs forkchild() to set up the subprocess's environment. With posix_spawn, we need to arrange posix_spawn actions to do the same thing.
The intermediate resolution was to switch FORK_FG processes to fork+exec again. For foreground processes with job control we're in an interactive shell, so the performance benefit is small enough in this case to be negligible. It's really only for shell scripts that it matters.
Next I implemented a posix_spawn file_action, with the prototype
int posix_spawn_file_actions_addtcsetpgrp(posix_spawn_file_actions_t *fa, int fildes)
The kernel part of this was implemented inline in sys/kern/kern_exec.c, in the function handle_posix_spawn_file_actions() for the new case 'FAE_TCSETPGRP'.
The new version of the code is still in testing and debugging phase and at the time of writing not included in my repository (it will be published after Google Summer of Code when I'm done moving).
Future steps
posix_spawnp kernel implementation
According to a conversation with kre@, the posix_spawnp() implementation we have is just itterating over $PATH calling posix_spawn until it succeeds. For some changes we might want a kernel implementation of posix_spawnp(), as the path search is supposed to happen in the kernel so the file actions are only ever run once:
some of the file actions may be "execute once only",
they can't be repeated (eg: handling "set -C; cat foo >file" - file
can only be created once, that has to happen before the exec (as the fd
needs to be made stdout), and then the exec part of posix_spawn is
attempted - if that fails, when it can't find "cat" in $HOME/bin (or
whatever is first in $PATH) and we move along to the next entry (maybe /bin
doesn't really matter) then the repeated file action fails, as file now
exists, and "set -C" demands that we cannot open an already existing file
(noclobber mode). It would be nice for this if there were "clean up on
failure" actions, but that is likely to be very difficult to get right,
and each would need to be attached to a file action, so only those which
had been performed would result in cleanup attempts.
Replacing all of fork+exec in sh
Ideally we could replace all of (v)fork + exec with posix_spawn. According to my mentors there is pmap synchronisation as an impact of constructing the vm space from scratch with (v)fork. Less IPIs (inter-processor interrupts) matter for small processes too.
posix_spawn_file_action_ioctl
Future directions could involve a posix_spawn action for an arbitrary ioctl.
Thanks
My thanks go to fellow NetBSD developers for answering questions, most recently kre@ for sharing invaluable sh knowledge, Riastradh and Jörg as the mentors I've interacted with most of the time and for their often in-depth explanations as well as allowing me to ask questions I sometimes felt were too obvious. My friends, for sticking up with my "weird" working schedule. Lastly would like to thank the Google Summer of Code program for continuing through the ongoing pandemic and giving students the chance to work on projects full-time.
This is my second and final report for the Google Summer of Code project I am working on for NetBSD.
My code can be found at github.com//src in the gsoc2020 branch, at the time of writing some of it is still missing. The test facilities and logs can be found in github.com/nikicoon/gsoc2020. A diff can be found at github which will later be split into several patches before it is sent to QA for merging.
The initial and defined goal of this project was to make system(3) and popen(3) use posix_spawn(3) internally, which had been completed in June. For the second part I was given the task to replace fork+exec calls in our standard shell (sh) in one scenario. Similar to the previous goal we determined through implementation if the initial motivation, to get performance improvements, is correct otherwise we collect metrics for why posix_spawn() in this case should be avoided. This second part meant in practice that I had to add and change code in the kernel, add a new public libc function, and understand shell internals.
Summary of part 1
Prior work: In GSoC 2012 Charles Zhang added the posix_spawn syscall which according to its SF repository at the time (maybe even now, I have not looked very much into comparing all other systems and libcs + kernels) is an in-kernel implementation of posix_spawn which provides performance benefits compared to FreeBSD and other systems which had a userspace implementation (in 2012).
After 1 week of reading POSIX and writing code, 2 weeks of coding and another 1.5 weeks of bugfixes I have successfully implemented posix_spawn in usage in system(3) and popen(3) internally.
The biggest challenge for me was to understand POSIX, to read the standard. I am used to reading more formal books, but I can't remember working with POSIX Standard directly before.
system(3)
system(3) was changed to use posix_spawnattr_ (where we used sigaction before) and posix_spawn (which replaced execve + vfork calls).
popen(3) and popenve(3)
Since the popen and popenve implementation in NetBSD's libc use a couple of shared helper functions, I was able to change both functions while keeping the majority of the changes focused on (some of ) the helper functions (pdes_child).
pdes_child, an internal function in popen.c, now takes one more argument (const char *cmd) for the command to pass to posix_spawn which is called in pdes_child.
On a high level what happens in pdes_child() and popen is that we first lock the pidlist_mutex. Then we create a file file action list for all concurrent popen() / popenve() instances and the side of the pipe not necessary, and the move to stdin/stdout. We unlock the pidlist_mutex. Finally we return the list and destroy.
In the new version of this helper function which now handles the majority of what popen/popenve did, we have to initialize a file_actions object which by default contains no file actions for posix_spawn() to perform. Since we have to have error handling and a common return value for the functions calling pdes_child() and deconstruction, we make use of goto in some parts of this function.
The close() and dup2() actions now get replaced by corresponding file_actions syscalls, they are used to specify a series of actions to be performed by a posix_spawn operation.
After this series of actions, we call _readlockenv(), and call posix_spawn with the file_action object and the other arguments to be executed. If it succeeds, we return the pid of the child to popen, otherwise we return -1, in both cases we destroy the file_action object before we proceed.
In popen and popenve our code has been reduced to the pid == -1 branch, everything else happens in pdes_child() now.
After readlockenv we call pdes_child and pass it the command to execute in the posix_spawn'd child process; if pdes_child returns -1 we run the old error handling code. Likewise for popenve.
The outcome of the first part is, that thanks to how we implement posix_spawn in NetBSD we reduced the syscalls being made for popen and system. A full test with proper timing should indicate this, my reading was based on comparing old and new logs with ktrace and kdump.
sh, posix_spawn actions, libc and kernel - Part 2
Motivation
The main goal of part 2 of this project was to change sh(1) to determine which simple cases of (v)fork + exec I could replace, and to replace them with posix_spawn where it makes sense.
fork needs to create a new address space by cloning the address space, or in the case of vfork update at least some reference counts. posix_spawn can avoid most of this as it creates the new address space from scratch.
Issues
The current posix_spawn as defined in POSIX has no good way to do tcsetpgrp, and we found that fish just avoids posix_spawn for foreground processes.
Implementation
Since, roughly speaking, modern BSDs handle "#!" execution in the kernel (probably since before the 1990s, systems which didn't handle this started to disappear most likely in the mid to late 90s), our main concern so far was in the evalcmd function the default cmd switch case ('NORMALCMD').
After adjusting the function to use posix_spawn, I hit an issue in the execution of the curses application htop where htop would run but input would not be accepted properly (keysequences pressed are visible). In pre-posix_spawn sh, every subprocess that sh (v)forked runs forkchild() to set up the subprocess's environment. With posix_spawn, we need to arrange posix_spawn actions to do the same thing.
The intermediate resolution was to switch FORK_FG processes to fork+exec again. For foreground processes with job control we're in an interactive shell, so the performance benefit is small enough in this case to be negligible. It's really only for shell scripts that it matters.
Next I implemented a posix_spawn file_action, with the prototype
int posix_spawn_file_actions_addtcsetpgrp(posix_spawn_file_actions_t *fa, int fildes)
The kernel part of this was implemented inline in sys/kern/kern_exec.c, in the function handle_posix_spawn_file_actions() for the new case 'FAE_TCSETPGRP'.
The new version of the code is still in testing and debugging phase and at the time of writing not included in my repository (it will be published after Google Summer of Code when I'm done moving).
Future steps
posix_spawnp kernel implementation
According to a conversation with kre@, the posix_spawnp() implementation we have is just itterating over $PATH calling posix_spawn until it succeeds. For some changes we might want a kernel implementation of posix_spawnp(), as the path search is supposed to happen in the kernel so the file actions are only ever run once:
some of the file actions may be "execute once only",
they can't be repeated (eg: handling "set -C; cat foo >file" - file
can only be created once, that has to happen before the exec (as the fd
needs to be made stdout), and then the exec part of posix_spawn is
attempted - if that fails, when it can't find "cat" in $HOME/bin (or
whatever is first in $PATH) and we move along to the next entry (maybe /bin
doesn't really matter) then the repeated file action fails, as file now
exists, and "set -C" demands that we cannot open an already existing file
(noclobber mode). It would be nice for this if there were "clean up on
failure" actions, but that is likely to be very difficult to get right,
and each would need to be attached to a file action, so only those which
had been performed would result in cleanup attempts.
Replacing all of fork+exec in sh
Ideally we could replace all of (v)fork + exec with posix_spawn. According to my mentors there is pmap synchronisation as an impact of constructing the vm space from scratch with (v)fork. Less IPIs (inter-processor interrupts) matter for small processes too.
posix_spawn_file_action_ioctl
Future directions could involve a posix_spawn action for an arbitrary ioctl.
Thanks
My thanks go to fellow NetBSD developers for answering questions, most recently kre@ for sharing invaluable sh knowledge, Riastradh and Jörg as the mentors I've interacted with most of the time and for their often in-depth explanations as well as allowing me to ask questions I sometimes felt were too obvious. My friends, for sticking up with my "weird" working schedule. Lastly would like to thank the Google Summer of Code program for continuing through the ongoing pandemic and giving students the chance to work on projects full-time.
This is my second and final report for the Google Summer of Code project I am working on for NetBSD.
My code can be found at github.com//src in the gsoc2020 branch, at the time of writing some of it is still missing. The test facilities and logs can be found in github.com/nikicoon/gsoc2020. A diff can be found at github which will later be split into several patches before it is sent to QA for merging.
The initial and defined goal of this project was to make system(3) and popen(3) use posix_spawn(3) internally, which had been completed in June. For the second part I was given the task to replace fork+exec calls in our standard shell (sh) in one scenario. Similar to the previous goal we determined through implementation if the initial motivation, to get performance improvements, is correct otherwise we collect metrics for why posix_spawn() in this case should be avoided. This second part meant in practice that I had to add and change code in the kernel, add a new public libc function, and understand shell internals.
Summary of part 1
Prior work: In GSoC 2012 Charles Zhang added the posix_spawn syscall which according to its SF repository at the time (maybe even now, I have not looked very much into comparing all other systems and libcs + kernels) is an in-kernel implementation of posix_spawn which provides performance benefits compared to FreeBSD and other systems which had a userspace implementation (in 2012).
After 1 week of reading POSIX and writing code, 2 weeks of coding and another 1.5 weeks of bugfixes I have successfully implemented posix_spawn in usage in system(3) and popen(3) internally.
The biggest challenge for me was to understand POSIX, to read the standard. I am used to reading more formal books, but I can't remember working with POSIX Standard directly before.
system(3)
system(3) was changed to use posix_spawnattr_ (where we used sigaction before) and posix_spawn (which replaced execve + vfork calls).
popen(3) and popenve(3)
Since the popen and popenve implementation in NetBSD's libc use a couple of shared helper functions, I was able to change both functions while keeping the majority of the changes focused on (some of ) the helper functions (pdes_child).
pdes_child, an internal function in popen.c, now takes one more argument (const char *cmd) for the command to pass to posix_spawn which is called in pdes_child.
On a high level what happens in pdes_child() and popen is that we first lock the pidlist_mutex. Then we create a file file action list for all concurrent popen() / popenve() instances and the side of the pipe not necessary, and the move to stdin/stdout. We unlock the pidlist_mutex. Finally we return the list and destroy.
In the new version of this helper function which now handles the majority of what popen/popenve did, we have to initialize a file_actions object which by default contains no file actions for posix_spawn() to perform. Since we have to have error handling and a common return value for the functions calling pdes_child() and deconstruction, we make use of goto in some parts of this function.
The close() and dup2() actions now get replaced by corresponding file_actions syscalls, they are used to specify a series of actions to be performed by a posix_spawn operation.
After this series of actions, we call _readlockenv(), and call posix_spawn with the file_action object and the other arguments to be executed. If it succeeds, we return the pid of the child to popen, otherwise we return -1, in both cases we destroy the file_action object before we proceed.
In popen and popenve our code has been reduced to the pid == -1 branch, everything else happens in pdes_child() now.
After readlockenv we call pdes_child and pass it the command to execute in the posix_spawn'd child process; if pdes_child returns -1 we run the old error handling code. Likewise for popenve.
The outcome of the first part is, that thanks to how we implement posix_spawn in NetBSD we reduced the syscalls being made for popen and system. A full test with proper timing should indicate this, my reading was based on comparing old and new logs with ktrace and kdump.
sh, posix_spawn actions, libc and kernel - Part 2
Motivation
The main goal of part 2 of this project was to change sh(1) to determine which simple cases of (v)fork + exec I could replace, and to replace them with posix_spawn where it makes sense.
fork needs to create a new address space by cloning the address space, or in the case of vfork update at least some reference counts. posix_spawn can avoid most of this as it creates the new address space from scratch.
Issues
The current posix_spawn as defined in POSIX has no good way to do tcsetpgrp, and we found that fish just avoids posix_spawn for foreground processes.
Implementation
Since, roughly speaking, modern BSDs handle "#!" execution in the kernel (probably since before the 1990s, systems which didn't handle this started to disappear most likely in the mid to late 90s), our main concern so far was in the evalcmd function the default cmd switch case ('NORMALCMD').
After adjusting the function to use posix_spawn, I hit an issue in the execution of the curses application htop where htop would run but input would not be accepted properly (keysequences pressed are visible). In pre-posix_spawn sh, every subprocess that sh (v)forked runs forkchild() to set up the subprocess's environment. With posix_spawn, we need to arrange posix_spawn actions to do the same thing.
The intermediate resolution was to switch FORK_FG processes to fork+exec again. For foreground processes with job control we're in an interactive shell, so the performance benefit is small enough in this case to be negligible. It's really only for shell scripts that it matters.
Next I implemented a posix_spawn file_action, with the prototype
int posix_spawn_file_actions_addtcsetpgrp(posix_spawn_file_actions_t *fa, int fildes)
The kernel part of this was implemented inline in sys/kern/kern_exec.c, in the function handle_posix_spawn_file_actions() for the new case 'FAE_TCSETPGRP'.
The new version of the code is still in testing and debugging phase and at the time of writing not included in my repository (it will be published after Google Summer of Code when I'm done moving).
Future steps
posix_spawnp kernel implementation
According to a conversation with kre@, the posix_spawnp() implementation we have is just itterating over $PATH calling posix_spawn until it succeeds. For some changes we might want a kernel implementation of posix_spawnp(), as the path search is supposed to happen in the kernel so the file actions are only ever run once:
some of the file actions may be "execute once only",
they can't be repeated (eg: handling "set -C; cat foo >file" - file
can only be created once, that has to happen before the exec (as the fd
needs to be made stdout), and then the exec part of posix_spawn is
attempted - if that fails, when it can't find "cat" in $HOME/bin (or
whatever is first in $PATH) and we move along to the next entry (maybe /bin
doesn't really matter) then the repeated file action fails, as file now
exists, and "set -C" demands that we cannot open an already existing file
(noclobber mode). It would be nice for this if there were "clean up on
failure" actions, but that is likely to be very difficult to get right,
and each would need to be attached to a file action, so only those which
had been performed would result in cleanup attempts.
Replacing all of fork+exec in sh
Ideally we could replace all of (v)fork + exec with posix_spawn. According to my mentors there is pmap synchronisation as an impact of constructing the vm space from scratch with (v)fork. Less IPIs (inter-processor interrupts) matter for small processes too.
posix_spawn_file_action_ioctl
Future directions could involve a posix_spawn action for an arbitrary ioctl.
Thanks
My thanks go to fellow NetBSD developers for answering questions, most recently kre@ for sharing invaluable sh knowledge, Riastradh and Jörg as the mentors I've interacted with most of the time and for their often in-depth explanations as well as allowing me to ask questions I sometimes felt were too obvious. My friends, for sticking up with my "weird" working schedule. Lastly would like to thank the Google Summer of Code program for continuing through the ongoing pandemic and giving students the chance to work on projects full-time.
LLDB
Since the last time I worked on LLDB, we have introduced many changes to the kernel interfaces (most notably related to signals) that apparently fixed some bugs in Go and introduced regressions in ptrace(2). Part of the regressions were noted by the existing ATF tests. However, the breakage was only marked as a new problem to resolve. For completeness, the ptrace(2) code was also cleaned up by Christos Zoulas, and we fixed some bugs with compat32.
I've fixed a crash in *NetBSD::Factory::Launch(), triggered on startup of the lldb-server application.
Here is the commit message:
We cannot call process_up->SetState() inside the NativeProcessNetBSD::Factory::Launch function because it triggers a NULL pointer deference. The generic code for launching a process in: GDBRemoteCommunicationServerLLGS::LaunchProcess sets the m_debugged_process_up pointer after a successful call to m_process_factory.Launch(). If we attempt to call process_up->SetState() inside a platform specific Launch function we end up dereferencing a NULL pointer in NativeProcessProtocol::GetCurrentThreadID(). Use the proper call process_up->SetState(,false) that sets notify_delegates to false.
I've synchronized the logging interfaces in PlatformNetBSD.cpp with Linux, switching to a more generic and modern API and thus reducing the unneeded code difference with this OS.
I've submitted a patch to fix recognition of NetBSD images (programs and userland core(5) files). This code is still pending a review and now marked as "Changes Planned", because I was requested to ship tests and I feel more comfortable shipping tests with a more functional debugger.
The immediate kernel tracing bug is generating invalid signals, SIGSTOP instead of SIGTRAP and they are apparently occurring under abnormal conditions. This is the reason why I decided to return to ptrace(2) and correct all the problems.
The abnormal breakage looks like this:
Process 1369 stopped
* thread #1, stop reason = signal SIGSTOP
frame #0: 0x00007f7efc000770 ld.elf_so`.rtld_start
ld.elf_so`.rtld_start:
-> 0x7f7efc000770 <+0>: subq $0x10, %rsp
0x7f7efc000774 <+4>: movq %rsp, %r12
0x7f7efc000777 <+7>: pushq %rbx
0x7f7efc000778 <+8>: andq $-0x10, %rsp
I can step few instructions, but after stepping through a few indeterministic number of them the process is killed and lldb-server detaches abnormally.
Process 1369 stopped
* thread #1, stop reason = instruction step over
frame #0: 0x00007f7efc000774 ld.elf_so`.rtld_start + 4
ld.elf_so`.rtld_start:
-> 0x7f7efc000774 <+4>: movq %rsp, %r12
0x7f7efc000777 <+7>: pushq %rbx
0x7f7efc000778 <+8>: andq $-0x10, %rsp
0x7f7efc00077c <+12>: leaq 0x21087d(%rip), %rax ; _GLOBAL_OFFSET_TABLE_
(lldb)
< 16> send packet: $vCont;s:0001#b3
Process 1369 exited with status = -1 (0xffffffff) lost connection
My observation is that without fixing the kernel we won't make much more progress.
Sanitizers
I suspended development of new features in sanitizers last month, but I was still in the process of upstreaming of local patches. This process was time-consuming as it required rebasing patches, adding dedicated tests, and addressing all other requests and comments from the upstream developers.
A fairly complete list of changes that landed upstream:
- Add new interceptors: strlcpy(3) and strlcat(3)
- Add new NetBSD interceptors: devname(3), devname_r(3)
- Handle NetBSD symbol mangling devname -> __devname50
- Correct a bug in GetArgsAndEnv() for NetBSD
- Add new interceptor: lstat(2)
- Add NetBSD syscall hooks skeleton in sanitizers
- Prevent recursive MSan interceptors in fgets(3)
- Prevent recursive MSan interceptors in strftime(3) like functions
- Teach sanitizer about NetBSD specific ioctl(2) calls
- Enable syscall-specific functions in TSan/NetBSD
- Enable test/asan for NetBSD
- Implement a large part of NetBSD syscalls of netbsd_syscall_hooks.h
- Add initial XRay support for NetBSD
- Recognize all NetBSD architectures in UBSan
- Stop intercepting forkpty(3) and openpty(3) on NetBSD
- Add new interceptor: fgetln(3)
- Add new interceptor: strmode(3)
- Correct ctype(3) functions with NLS on NetBSD
- Skip two more ioctl interceptors for NetBSD
- Add new interceptors: getttyent(3) family
- Add new interceptors: getprotoent(3) family
- Add new interceptors: getnetent(3) family
- Disable ASan exceptions on NetBSD
- Stop linking sanitized applications with -lutil and -lkvm on NetBSD
- Handle the NetBSD case in ToolChain::getOSLibName()
- Skip two more ioctl interceptors for NetBSD
- Mark the textdomain.cc test as unsupported on BSDs
I'm not counting hot fixes, as some changes were triggering build or test issues on !NetBSD hosts. Thankfully all these issues were addressed quickly. The final result is a reduction of local delta size of almost 1MB to less than 100KB (1205 lines of diff). The remaining patches are rescheduled for later, mostly because they depend on extra work with cross-OS tests and prior integration of sanitizers with the basesystem distribution. I didn't want to put extra work here in the current state of affairs and, I've registered as a mentor for Google Summer of Code for the NetBSD Foundation and prepared Software Quality improvement tasks in order to outsource part of the labour.
Userland changes
Part of the work landed the basesystem tree. Here is a list:
- Install GCC (gcc.old/) headers for Sanitizers
- Install GCC (gcc) headers for Sanitizers
- Introduce _UC_MACHINE_FP() as a macro
- Stop installing dbregs.h
- Add new tests in lib/libc/sys/t_ucontext
I've also improved documentation for some of the features of NetBSD, described in man-pages. These pieces of information were sometimes wrong or incomplete, and this makes covering the NetBSD system with features such as sanitizers harder as there is a mismatch between the actual code and the documented code.
Some pieces of software also require better namespacing support, these days mostly for the POSIX standard. I've fixed few low-hanging fruits there and requested pullups to NetBSD-8(BETA).
I thank the developers for improving the landed code in order to ship the best solutions for users.
mdnsd - Multicast and Unicast DNS daemon
I've been debugging the connectivity issues between lldb client and lldb-server. I've observed a dying connection for one particular message (these programs communicate using the GDB remote protocol, with LLDB extensions): qHostInfo. This message emitted by a client asks the server about the Host Information.
The communication looks like this:
$ ./lldb
(lldb) log enable gdb-remote packets
(lldb) process connect connect://localhost:1234
< 1> send packet: +
history[1] tid=0x0001 < 1> send packet: +
< 19> send packet: $QStartNoAckMode#b0
< 1> read packet: +
< 6> read packet: $OK#9a
< 1> send packet: +
< 41> send packet: $qSupported:xmlRegisters=i386,arm,mips#12
< 124> read packet: $PacketSize=20000;QStartNoAckMode+;QThreadSuffixSupported+;QListThreadsInStopReply+;qEcho+;QPassSignals+;qXfer:auxv:read+#be
< 26> send packet: $QThreadSuffixSupported#e4
< 6> read packet: $OK#9a
< 27> send packet: $QListThreadsInStopReply#21
< 6> read packet: $OK#9a
< 13> send packet: $qHostInfo#9b
The communication is now hanging and data is no longer being received by the client.
I was debugging the server, the client side, and even tapping the wire to test if there was ongoing communication and to find the lost answer. The answer looks like this and is 400-500 octets long (originally sent as a single line, divided into 100-octet rows):
$triple:7838365f36342d756e6b6e6f776e2d6e6574627364382e39392e3132;ptrsize:8;watchpoint_exceptions_rec eived:after;endian:little;os_version:8.99.12;os_build:30383939303031323030;os_kernel:4e6574425344203 82e39392e3132202847454e45524943292023303a20576564204665622032382030383a30363a33332043455420323031382 020726f6f744063686965667465633a2f7075626c69632f6e65746273642d726f6f742f7379732f617263682f616d6436342 f636f6d70696c652f47454e45524943;hostname:6c6f63616c686f7374;#88
We can decode the string using e.g. radare2 tools:
$ rax2 -s 7838365f36342d756e6b6e6f776e2d6e6574627364382e39392e3132;echo x86_64-unknown-netbsd8.99.12
The debugging took a while, and after finding no bugs on the client and server side I've finally detected the root cause of the problem: mdnsd. An upgrade in the development branch broke mdnsd and it couldn't resolve the hostname anymore. LLDB was calling the following algorithm on the server side:
#include <stdio.h>
#include <unistd.h>
#include <netdb.h>
#include <limits.h>
int
main(int argc, char **argv)
{
char hostname[PATH_MAX];
hostname[sizeof(hostname) - 1] = '\0';
if (gethostname(hostname, sizeof(hostname) - 1) == 0) {
printf("gethostname done\n");
struct hostent *h = gethostbyname(hostname);
printf("gethostbyname done\n");
if (h)
printf("h: '%s'\n", h->h_name);
else
printf("!h: '%s'\n", hostname);
} else {
printf("gethostname error\n");
}
return 0;
}
The gethostbyname(3) operation was taking 10 seconds, instead of returning a proper result almost immediately. I've verified that LLDB expects a response in 1 second and GDB within 2 seconds. This was a good sign that something was broken on the NetBSD side. Thanks to the excellent ktruss(1) tool I tracked down the root cause quickly and with feedback provided by more experienced networking engineers we concluded that mdnsd was broken.
I've found a workaround, defining my host in /etc/hosts and assuring that /etc/nsswitch.conf lists files before dns & mdnsd for the hosts option.
The mdnsd problem has been reported to developers and was quickly fixed by Christos Zoulas.
The name resolution with mdnsd is quick and correct again:
$ time getent hosts rugged.local
192.168.0.241 rugged.local
0.03s real 0.00s user 0.00s system
BSD collaboration in LLVM
A One-man-show in human activity is usually less fun and productive than collaboration in a team. This is also true in software development. Last month I was helping as a reviewer to port LLVM features to FreeBSD and when possible to OpenBSD. This included MSan/FreeBSD, libFuzzer/FreeBSD, XRay/FreeBSD and UBSan/OpenBSD.
I've landed most of the submitted and reviewed code to the mainstream LLVM tree.
Part of the code also verified the correctness of NetBSD routes in the existing porting efforts and showed new options for improvement. This is the reason why I've landed preliminary XRay/NetBSD code and added missing NetBSD bits to ToolChain::getOSLibName(). The latter produced setup issues with the prebuilt LLVM toolchain, as the directory name with compiler-rt goodies were located in a path like ./lib/clang/7.0.0/lib/netbsd8.99.12 with a varying OS version. This could stop working after upgrades, so I've simplified it to "netbsd", similar to FreeBSD and Solaris.
Prebuilt toolchain for testers
I've prepared a build of Clang/LLVM with LLDB and compiler-rt features prebuilt on NetBSD/amd64 v. 8.99.12:
llvm-clang-compilerrt-lldb-7.0.0beta_2018-02-28.tar.bz2
Plan for the next milestone
With the approaching NetBSD 8.0 release I plan to finish backporting a few changes there from HEAD:
- Remove one unused feature from ptrace(2), PT_SET_SIGMASK & PT_GET_SIGMASK. I've originally introduced these operations with criu/rr-like software in mind, but they are misusing or even abusing ptrace(2) and are not regular process debuggers. I plan to remove this operation from HEAD and backport this to NetBSD-8(BETA), before the release, so no compat will be required for this call. Future ports of criu/rr should involve dedicated kernel support for such requirements.
- Finish the backport of _UC_MACHINE_FP() to NetBSD-8. This will allow use of the same code in sanitizers in HEAD and NetBSD-8.0.
- By popular demand, improve the regnsub(3) and regasub(3) API, adding support for more or less substitutions than 10.
Once done, I will return to ptrace(2) debugging and corrections.
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL, and chip in what you can:
The NetBSD Project is pleased to announce NetBSD 7.1.2, the second security/bugfix update of the NetBSD 7.1 release branch. It represents a selected subset of fixes deemed important for security or stability reasons. If you are running an earlier release of NetBSD, we strongly suggest updating to 7.1.2.
For more details, please see the release notes.
Complete source and binaries for NetBSD are available for download at many sites around the world. A list of download sites providing FTP, AnonCVS, and other services may be found at http://www.NetBSD.org/mirrors/.
In recent years, no one in the releng team has had adequate time to devote to release engineering work. To address this shortcoming, the foundation has agreed to pay me part time to carry out the following duties:
- process pullup tickets
- write and update release notes
- coordinate with the security team
- plan for future releases and release milestones
- identify and document critical bugs preventing a release
- create documents/web-/wikipages describing the current status of releases/release branches and keep them up to date
- identify missing pullups and push developers to submit pullup requests
While this does not automatically provide developer time (still subject to volunteer time and motivation), it is however still a major step forward towards handling the release cycle, which is (currently) taking too long, in a professional manner.
We hope to
- Speed up the release process for all pending releases on all active branches, as specified by the releng team and documented on the releng wiki page(s)
- Make the release process more transparent by providing up to date and easily accessible status documents
- Create better releases by making sure critical bugs get identified and fixed (if possible)
To help the other issue mentioned above, we plan to offer (small) bug bounties for bugs identified as release show-stoppers.
Upstream describes LLDB as a next generation, high-performance debugger. It is built on top of LLVM/Clang toolchain, and features great integration with it. At the moment, it primarily supports debugging C, C++ and ObjC code, and there is interest in extending it to more languages.
Originally, LLDB was ported to NetBSD by Kamil Rytarowski. However, multiple upstream changes and lack of continuous testing have resulted in decline of support. So far we haven't been able to restore the previous state.
In February, I have started working on LLDB, as contracted by the NetBSD Foundation. My four first goals as detailed in the previous report were:
Restore tracing in LLDB for NetBSD (i386/amd64/aarch64) for single-threaded applications.
Restore execution of LLDB regression tests, unless there is need for a significant LLDB or kernel work, mark detected bugs as failing or unsupported ones.
Enable execution of LLDB regression tests on the buildbot in order to catch regressions.
Upstream NetBSD (i386/amd64) core(5) support. Develop LLDB regression tests (and the testing framework enhancement) as requested by upstream.
Of those tasks, I consider running regression tests on the buildbot the highest priority. Bisecting regressions post-factum is hard due to long build times, and having continuous integration working is going to be very helpful to maintaining the code long-term.
In this report, I'd like to summarize what I achieved and what technical difficulties I met.
The kqueue interoperability issues
Given no specific clue as to why LLDB was no longer able to start processes on NetBSD, I've decided to start by establishing the status of the test suites. More specifically, I've started with a small subset of LLDB test suite — unittests. In this section, I'd like to focus on two important issues I had with them.
Firstly, one of the tests was hanging indefinitely. As I established, the purpose of the test was to check whether the main loop implementation correctly detects and reports when all the slaves of a pty are disconnected (and therefore the reads on master would fail). Through debugging, I've came to the conclusion that kevent() is not reporting this particular scenario.
I have built a simple test case (which is now part of kqueue ATF tests) and confirmed it. Afterwards, I have attempted to establish whether this behavior is correct. While kqueue(2) does not mention ptys specifically, it states the following for pipes:
- Fifos, Pipes
Returns when there is data to read; data contains the number of bytes available.
When the last writer disconnects, the filter will set EV_EOF in flags. This may be cleared by passing in EV_CLEAR, at which point the filter will resume waiting for data to become available before returning.
Furthermore, my test program indicated that FreeBSD exhibits the described EV_EOF behavior. Therefore, I have decided to write a kernel patch adding this functionality, submitted it to review and eventually committed it after applying helpful suggestions from Robert Elz ([PATCH v3] kern/tty_pty: Fix reporting EOF via kevent and add a test case). I have also disabled the test case temporarily since the functionality is non-critical to LLDB (r353545).
Secondly, a few gdbserver-based tests were flaky — i.e. unpredictably passed and failed every iteration. I've started debugging this with a test whose purpose was to check verbose error messages support in the protocol. To my surprise, it seemed as if gdbserver worked fine as far as error message exchange was concerned. This packet was followed by a termination request from client — and it seemed that the server sometimes replies to it correctly, and sometimes terminates just before receiving it.
While working on this particular issue, I've noticed a few deficiencies in LLDB's error handling. In this case, this involved two major issues:
gdbserver ignored errors from main loop. As a result, if kevent() failed, it silently exited with a successful status. I've fixed it to catch and report the error verbosely instead: r354030.
Main loop reported meaningless return value (-1) from kevent(). I've established that most likely all kevent() implementation use errno instead, and made the function return it: r354029.
After applying those two fixes, gdbserver clearly indicated the problem: kevent() returned due to EINTR (i.e. the process receiving a signal). Lacking correct handling for this value, the main loop implementation wrongly treated it as fatal error and terminated the program. I've fixed this via implementing EINTR support for kevent() in r354122.
This trivial fix not only resolved most of the flaky tests but also turned out to be the root cause for LLDB being unable to start processes. Therefore, at this point tracing for single-threaded processes was restored on amd64. Testing on other platforms is pending.
Now, for the moral: working error reporting can save a lot of time.
Socket issues
The next issue I hit while working on the unittests is rather curious, and I have to admit I haven't managed to neither find the root cause or build a good reproducer for it. Nevertheless, I seem to have caught the gist of it and found a good workaround.
The test in question focuses on the high-level socket API in LLDB. It is rather trivial — it binds a server in one thread, and tries to connect to it from a second thread. So far, so good. Most of the time the test works just fine. However, sometimes — especially early after booting — it hangs forever.
I've debugged this thoroughly and came to the following conclusion: the test binds to 127.0.0.1 (i.e. purely IPv4) but tries to connect to localhost. The latter results in the client trying IPv6 first, failing and then succeeding with IPv4. The connection is accepted, the test case moves forward and terminates successfully.
Now, in the failing case, the IPv6 connection attempt succeeds, even though there is no server bound to that port. As a result, the client part is happily connected to a non-existing service, and the server part hangs forever waiting for the connection to come.
I have attempted to reproduce this with an isolated test case, reproducing the use of threads, binding to port zero, the IPv4/IPv6 mixup and I simply haven't been able to reproduce this. However, curiously enough my test case actually fixes the problem. I mean, if I start my test case before LLDB unit tests, they work fine afterwards (until next reboot).
Being unable to make any further progress on this weird behavior, I've decided to fix the test design instead — and make it connect to the same address it binds to: r353868.
Getting the right toolchain for live testing
The largest problem so far was getting LLDB tests to interoperate with NetBSD's clang driver correctly. On other systems, clang either defaults to libstdc++, or has libc++ installed as part of the system (FreeBSD, Darwin). The NetBSD driver wants to use libc++ but we do not have it installed by default.
While this could be solved via installing libc++ on the buildbot host, I thought it would be better to establish a solution that would allow LLDB to use just-built clang — similarly to how other LLVM projects (such as OpenMP) do. This way, we would be testing the matching libc++ revision and users would be able to run the tests in a single checkout out of the box.
Sadly, this is non-trivial. While it could be all hacked into the driver itself, it does not really belong there. While it is reasonable to link tests into the build tree, we wouldn't want regular executables built by user to bind to it. This is why normally this is handled via the test system. However, the tests in LLDB are an accumulation of at least three different test systems, each one calling the compiler separately.
In order to establish a baseline for this, I have created wrappers for clang that added the necessary command-line options. The state-of-art wrapper for clang looked like the following:
#!/usr/bin/env bash topdir=/home/mgorny/llvm-project/build-rel-master cxxinc="-cxx-isystem $topdir/include/c++/v1" lpath="-L $topdir/lib" rpath="-Wl,-rpath,$topdir/lib" pthread="-pthread" libs="-lunwind" # needed to handle 'clang -v' correctly [ $# -eq 1 ] && [ "$1" = -v ] && exec $topdir/bin/clang-9-real "$@" exec $topdir/bin/clang-9-real $cxxinc $lpath $rpath "$@" $pthread $libs
The actual executable I renamed to clang-9-real, and this wrapper replaced clang and a similar one replaced clang++. clang-cl was linked to the real executable (as it wasn't called in wrapper-relevant contexts), while clang-9 was linked to the wrapper.
After establishing a baseline of working tests, I've looked into migrating the necessary bits one by one to the driver and/or LLDB test system, removing the migrated parts and verifying whether tests pass the same.
My proposal so far involves, appropriately:
Replacing -cxx-isystem with libc++ header search using path relative the compiler executable: D58592.
Integrating -L and -Wl,-rpath with the LLDB test system: D58630.
Adding NetBSD to list of platforms needing -pthread: r355274.
The need for -lunwind is solved via switching the test failing due to the lack of it to use libc++ instead of libstdc++: r355273.
The reason for adjusting libc++ header search in the driver rather than in LLDB tests is that the path is specific to building against libc++, and the driver makes it convenient to adjust the path conditionally to standard C++ library being used. In other words, it saves us from hard-relying on the assumption that tests will be run against libc++ only.
I've went for integrating -L in the test system since we do not want to link arbitrary programs to the libraries in LLVM's build directory. Appending this path unconditionally should be otherwise harmless to LLDB's tests, so that is the easier way to go.
Originally I wanted to avoid appending RPATHs. However, it seems that the LD_LIBRARY_PATH solution that works for Linux does not reliably work on NetBSD with LLDB. Therefore, passing -Wl,-rpath along with -L allowed me to solve the problem simpler.
Furthermore, those design solutions match other LLVM projects. I've mentioned OpenMP before — so far we had to pass -cxx-isystem to its tests explicitly but it passed -L for us. Those patches render passing -cxx-isystem unnecessary, and therefore make LLDB follow the suit of OpenMP.
Finishing touches
Having a reasonably working compiler and major regressions fixed, I have focused on establishing a baseline for running tests. The goal is to mark broken tests XFAIL or skip them. With all tests marked appropriately, we would be able to start running tests on the buildbot and catch regressions compared to this baseline. The current progress on this can be see in D58527.
Sadly, besides failing tests there is still a small number of flaky or hanging tests which are non-trivial to detect. The upstream maintainer, Pavel Labath is very helpful and I hope to be able to finally get all the flaky tests either fixed or covered with his help.
Other fixes not worth a separate section include:
fixing compiler warnings about empty format strings: r354922,
fixing two dlopen() based test cases not to link -ldl on NetBSD: r354617,
finishing Kamil's patch for core file support: r354466, followup fix in r354483,
removing dead code in main loop: r354050,
fixing stand-alone builds after they've been switched to LLVMConfig.cmake: r353925,
skipping lldb-mi tests when Python support (needed by lldb-mi) is disabled: r353700,
fixing incorrect initialization of sigset_t (not actually used right now): r353675.
Buildbot updates
The last part worth mentioning is that the NetBSD LLVM buildbot has seen some changes. Notably, zorg r354820 included:
fixing the bot commit filtering to include all projects built,
renaming the bot to shorter netbsd-amd64,
and moving it to toolchain category.
One of the most useful functions of buildbot is that it associated every successive build with new commits. If the build fails, it blames the authors of those commits and reports the failure to them. However, for this to work buildbot needs to be aware which projects are being tested.
Our buildbot configuration has been initially based on one used for LLDB, and it assumed LLVM, Clang and LLDB are the only projects built and tested. Over time, we've added additional projects but we failed to update the buildbot configs appropriately. Finally, with the help of Jonas Hahnfeld, Pavel Labath and Galina Kistanova we've managed to update the list and make the bot blame all projects correctly.
While at it, we were suggested to rename the bot. The previous name was lldb-amd64-ninja-netbsd8, and others suggested that the developers may ignore failures in other projects seeing lldb there. Kamil Rytarowski also pointed out that the version number confuses users to believe that we're running separate bots for different versions. The new name and category mean to clearly indicate that we're running a single bot instance for multiple projects.
Quick summary and future plans
At this point, the most important regressions in LLDB have been fixed and it is able to debug simple programs on amd64 once again. The test suite patches are still waiting for review, and once they're approved I still need to work on flaky tests before we can reliably enable that on the buildbot. This is the first priority.
The next item on the TODO list is to take over and finish Kamil's patch for core files with thread. Most notably, the patch requires writing tests, and verifying whether there are no new bugs affecting it.
On a semi-related note, LLVM 8.0.0 will be released in a few days and I will be probably working on updating src to the new version. I will also try to convince Joerg to switch from unmaintained libcxxrt to upstream libc++abi. Kamil also wanted to change libc++ include path to match upstream (NetBSD is dropping /v1 suffix at the moment).
Once this is done, the next big step is to fix threading support. Testing on non-amd64 arches is deferred until I gain access to some hardware.
This work is sponsored by The NetBSD Foundation
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL to chip in what you can:
The NetBSD distribution changes
I've also introduced non-ptrace(2) related changes namely from the domain of kernel sanitizers, kernel fixes and corresponding ATF tests. I won't discuss them further as they were beyond the ptrace(2) scope. These changes were largely stimulated by students preparing for summer work as a part of Google Summer of Code.
The ptrace(2) ATF commits landed into the repository:
- Define PTRACE_ILLEGAL_ASM for NetBSD/amd64 in ptrace.h
- Enable 3 new ptrace(2) tests for SIGILL
- Refactor GPR and FPR tests in t_ptrace_wait* tests
- Refactor definition of PT_STEP tests into single macro
- Correct a style in description of PT_STEP tests in t_ptrace_wait*
- Refactor kill* test in t_ptrace_wait*
- Add infinite_thread() for ptrace(2) ATF tests
- Add initial pthread(3) tests in ATF t_prace_wait* tests
- Link t_ptrace_wait* tests with -pthread
- Initial refactoring of siginfo* tests in t_ptrace_wait*
- Drop siginfo5 from ATF tests in t_ptrace_wait*
- Merge siginfo6 into other PT_STEP tests in t_ptrace_wait*
- Rename the siginfo4 test in ATF t_ptrace_wait*
- Refactor lwp_create1 and lwp_exit1 into trace_thread* in ptrace(2) tests
- Rename signal1 to signal_mask_unrelated in t_ptrace_wait*
- Add new regression scenarios for crash signals in t_ptrace_wait*
- Replace signal2 in t_ptrace_wait* with new tests
- Add new ATF tests traceme_raisesignal_ignored in t_ptrace_wait*
- Add new ATF tests traceme_signal{ignored,masked}_crash* in t_ptrace_wait*
- Add additional assert in traceme_signalmasked_crash t_ptrace_wait* tests
- Add additional assert in traceme_signalignored_crash t_ptrace_wait* tests
- Remove redundant test from ATF t_ptrace_wait*
- Add new ATF t_ptrace_wait* vfork(2) tests
- Add minor improvements in unrelated_tracer_sees_crash in t_ptrace_wait*
- Add more tests for variations of unrelated_tracer_sees_crash in ATF
- Replace signal4 (PT_STEP) test with refactored ones with extra asserts
- Add signal masked and ignored variations of traceme_vfork_exec in ATF tests
- Add signal masked and ignored variations of traceme_exec in ATF tests
- Drop signal5 test-case from ATF t_ptrace_wait*
- Refactor signal6-8 tests in t_ptrace_wait*
Trap signals processing without signal context reset
The current NetBSD kernel approach of processing crash signals (SEGV, FPE, BUS, ILL, TRAP) is to reset the context of signals. This behavior was introduced as an intermediate and partially legitimate fix for cases of masking a crash signal that was causing infinite loop in a dying process.
The expected behavior is to never reset signal context of a trap signal (or any other signal) when executed under a debugger. In order to achieve these semantics I've introduced a fix for this for the first time last year, but I had to revert quickly, as it caused side effect breakage, not covered by existing at that time ATF ptrace(2) regression tests. This time I made sure to cover upfront almost all interesting scenarios that are requested to function properly. Surprisingly after grabbing old faulty fix and improving it locally, the current signal maze code caused various side effects in corner cases, such as translating SIGKILL in certain tests to previous trap signal (like SIGSEGV).. In other cases side effect behavior seems to be probably even stranger, as one tests hangs only against a certain type of wait(2)-like function (waitid(2)), and executes without hangs against other wait(2)-like function types.
For the reference such surprises can be achieved with the following patch:
Index: sys/kern/kern_sig.c
===================================================================
RCS file: /cvsroot/src/sys/kern/kern_sig.c,v
retrieving revision 1.350
diff -u -r1.350 kern_sig.c
--- sys/kern/kern_sig.c 29 Nov 2018 10:27:36 -0000 1.350
+++ sys/kern/kern_sig.c 3 Mar 2019 19:26:54 -0000
@@ -911,13 +911,25 @@
KASSERT(!cpu_intr_p());
mutex_enter(proc_lock);
mutex_enter(p->p_lock);
+
+ if (ISSET(p->p_slflag, PSL_TRACED) &&
+ !(p->p_pptr == p->p_opptr && ISSET(p->p_lflag, PL_PPWAIT))) {
+ p->p_xsig = signo;
+ p->p_sigctx.ps_faked = true; // XXX
+ p->p_sigctx.ps_info._signo = signo;
+ p->p_sigctx.ps_info._code = ksi->ksi_code;
+ sigswitch(0, signo, false);
+ // XXX ktrpoint(KTR_PSIG)
+ mutex_exit(p->p_lock);
+ return;
+ }
+
mask = &l->l_sigmask;
ps = p->p_sigacts;
- const bool traced = (p->p_slflag & PSL_TRACED) != 0;
const bool caught = sigismember(&p->p_sigctx.ps_sigcatch, signo);
const bool masked = sigismember(mask, signo);
- if (!traced && caught && !masked) {
+ if (caught && !masked) {
mutex_exit(proc_lock);
l->l_ru.ru_nsignals++;
kpsendsig(l, ksi, mask);
Such changes need proper investigation and addressing bugs that are now detectable easier with the extended test-suite.
Plan for the next milestone
Keep preparing kernel fixes and after thorough verification applying them to the mainline.
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL to chip in what you can:
Upstream describes LLDB as a next generation, high-performance debugger. It is built on top of LLVM/Clang toolchain, and features great integration with it. At the moment, it primarily supports debugging C, C++ and ObjC code, and there is interest in extending it to more languages.
In February 2019, I have started working on LLDB, as contracted by the NetBSD Foundation. So far I've been working on reenabling continuous integration, squashing bugs, improving NetBSD core file support, extending NetBSD's ptrace interface to cover more register types and fix compat32 issues, fixing watchpoint and threading support, porting to i386.
During the last month, I've finally managed to create proper reproducers (and tests) for the remaining concurrent signal delivery problems. I have started working on backtracing through signal trampolines, and prepared a libc++ update.
NetBSD concurrent signal updates
While finishing the last report, I was trying to reproduce some
of the concurrent test failures in LLDB with plain ptrace(). I've
finally managed to do that and therefore discover the factor causing
all my earlier attempts to fail — concurrent signal delivery works fine
unless the signal is actually delivered to the process and handled
by it.
Let me explain this a bit. When a signal is delivered to a debugged
process (or one of its threads), it is stopped and the debugger receives
stopping signal via waitpid(). Now, if the debugger wishes the signal
to be delivered to the process (thread), it needs to pass the signal
number as an argument to PT_CONTINUE. If it neglects to do so (passes
0), the signal is discarded.
My tests so far were doing precisely that — discarding the signal. However, once I modified them to pass it back, they started failing similarly to how LLDB tests are failing.
Whenever the debugged program receives concurrent signals to different threads and the debugger requests their delivery, the process is stopped with some of the signals multiple times. Curiously enough, during my testing every signal to a thread was reported at least once which means no signals were lost. I suspect that in an attempt to deliver pending concurrent signals the kernel is passing them again to the debugger rather than to the process itself.
I've used this research to extend testing of concurrent behavior. More specifically, I have:
-
Extended the test to verify that signal is actually being delivered.
-
Finally, started testing combination of simultaneous signals, breakpoints and watchpoints.
Research into backtrace through signal trampoline
The most important of the remaining tasks was to enhance LLDB with NetBSD signal trampoline support.
Signal trampolines on NetBSD
Signal trampolines are shortly covered by Signal delivery chapter of NetBSD Internals.
When a signal is delivered to a running program, the system needs to interrupt its execution and run its defined signal handler. Once the signal handler finishes, the program execution resumes where it left off. How this is achieved differs from system to system.
On NetBSD, so-called signal trampoline is used. The kernel (this is
done by sendsig_siginfo() e.g. in amd64/machdep.c
function on newer ABIs) saves the program context and executes the
signal handler. When the signal handler returns, it returns to a
trampoline function defined by the libc that restores the saved context
and therefore resumes the program execution.
From debugger's perspective, the backtrace for a process interrupted in midst of a signal handler ends on this trampoline function. However, it is often considered useful to be able to know the status of the process just before the signal was received — and therefore, the point where program execution will continue. The goal in this point was to make LLDB aware of NetBSD's trampoline design and capable of locating and using the saved context to produce full backtrace.
The two possible solutions
There are two approaches to implementing signal trampoline handling:
-
Explicitly detecting and processing signal trampolines in debugger.
-
Adding CFI code to signal trampoline implementation in order to store the necessary information in libc itself.
GDB on NetBSD is currently using the first approach. The code (found in nbsd-tdep.c and e.g. amd64-nbsd-tdep.c) explicitly establishes whether the current frame corresponds to a signal trampoline, finds the saved context and processes it.
Long-term, the second approach is preferable. Instead of explicitly writing platform-specific code, we add CFI annotations to the trampoline code (e.g. in __sigtramp2.S). Those annotations are consumed by the toolchain and used to construct frame information inside the executable that can be afterwards consumed by the debugger.
Both approaches are therefore roughly equivalent. The main difference is that approach 1. stores platform-specific logic in the debugger, while approach 2. stores it in the executable for all debuggers to consume.
libc++ update
Another task to undergo during this period was to update libc++ in NetBSD src tree. It was last imported in 2015, to the version roughly corresponding to LLVM 3.7 release. This version is dated and has some bugs, particularly it is prone to miscompilation due to undefined behavior (e.g. segfault in std::map). I've decided to upgrade to the commit corresponding to the most recent LLVM/Clang update.
max_align_t visibility
The first problem I've hit after upgrading is that max_align_t is declared on NetBSD only for C11/C++11. However, on NetBSD libc++ is exposing it unconditionally.
Kamil Rytarowski proposed to expose max_align_t unconditionally in our headers as well. Joerg Sonnenberger on the other hand wants to change libc++ instead.
Missing errno constants
Another issue I've found is that NetBSD is missing the two errno
constants for robust mutexes: EOWNERDEAD and ENOTRECOVERABLE.
While libc++ has a hack to redefine them when missing,
it seemed a better idea to assign them on our end.
I've learned that adding errno constants involves a few changes besides adding new constants:
-
Adding mapping to Linux compat in sys/compat/linux/common/linux_errno.c.
-
Adding descriptions to manpage lib/libc/sys/intro.2.
-
Adding messages to libc catalogs.
-
Enabling appropriate features in libstdc++.
-
Adding new error codes to libdtrace.
-
Adding errno mapping to NFS support in sys/nfs/nfs_subs.c.
While at it, I've made sure to make it harder to accidentally miss doing some of that in the future. Notably:
-
I've added ATF tests to make sure that libc catalogs stay in sync with errno and signal descriptions in code.
-
I've added a script to autogenerate libdtrace errno lists.
-
I've added a compile-time assertion that NFS errno mapping covers all values.
The complete list of commits:
The update
I have sent libc++ update to 01f3a59fb3e2542fce74c768718f594d0debd0da to the mailing list for review. The proposed patch set includes:
-
Adjust the cleanup script for the new version.
-
Cleaning up extraneous files from the old import (to make the diff clearer).
-
Importing the new version and updating Makefiles.
-
Moving headers to standard
/usr/include/c++/v1location for better interoperability. -
Moving libc++ to apache2 license group.
Future plans
This is the final month of my contract and therefore I would like to primarily focus on importing LLDB into src tree. As time permits, I will continue attempting to improve support for backtracing through signal trampolines.
The exact list of remaining tasks in my contract follows:
-
Add support to backtrace through signal trampoline and extend the support to libexecinfo, unwind implementations (LLVM, nongnu). Examine adding CFI support to interfaces that need it to provide more stable backtraces (both kernel and userland).
-
Add support for aarch64 target.
-
Stabilize LLDB and address breaking tests from the test suite.
-
Merge LLDB with the base system (under LLVM-style distribution).
This work is sponsored by The NetBSD Foundation
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL to chip in what you can:
As my work is reaching the end, I was trying to clean up the state with other projects.
ptrace(2) ATF tests
I have determined which test scenarios were missing and integrated them. Certain tests like wrapping FreeBSD specific pdfork(2) call were omitted as not applicable.
There are few new tests that are marked as expected failure for corner cases that are scheduled for fixing in future.
I have also worked on SIGCHLD-based debugging and analysis of its behavior.
I have found out that SA_NOCLDWAIT behaves suspiciously.
This flag passed to sigaction(2) is an extension.
If set, the system will not create a zombie when the child
exits, but the child process will be automatically waited
for. The same effect can be achieved by setting the
signal handler for SIGCHLD to SIG_IGN.
Currently it behaves differently under a debugger as the child process is never collected and is waiting for parent to collect it.
According to my research this behavior is unexpected.
A potential fix might not be difficult in the kernel, but due to time constraints
I have decided to add an ATF tests for this scenario, mark it as failed and include a comment deferring this case into future.
I have also refactored the remaining threaded tests, switching them from low-level LWP API to pthread(3) one.
Other changes
I was working on finishing projects that were left behind.
GDB and qemu upstreaming
I'm working on upstreaming NVMM support to mainline QEMU. This process is still ongoing.
I am slowly reducing the patchset against the GDB repository.
jemalloc changes
The jemalloc allocator is a general purpose malloc(3) implementation that emphasizes fragmentation avoidance and scalable concurrency support. It's the default allocator in the NetBSD Operating System since 2007.
There are a few workarounds that make jemalloc compatible with NetBSD internals and I was trying to remove them. Unfortunately, the allocator tries to initialize itself too early using a C++-like constructor and intercepts the first malloc(3). The is done before initializing libpthread, and the pthread startup code uses malloc() when registering pthread_atfork(3) callbacks. In order to make it work, we allow premature usage of the libpthread functionality. I was trying to correct this, but I've introduced slight regressions in corner cases. They are hard to debug as the allocator is corrupted internally and randomly misbehaves (hangs, occasional crashes). I've discussed with the upstream developers about addressing this properly, but as reproducing the setup needs familiarity with the process of development NetBSD, we are still working on it.
Meanwhile, I have managed to correct known Undefined Behavior issues in jemalloc and address all known issues working together with upstream.
syzkaller
I received write access to the syzkaller GitHub repository. I also helped to get Kernel MSan (unauthorized memory access) operational on the syzbot node.
Miscellaneous changes
I helped with the libc++ upgrade that was done by Michal Gorny (but still not merged into mainline). As part of this work we gained a support for errno codes for POSIX robust mutexes.
I have implemented missing DT_GNU_HASH support as specified by GNU and LLVM linkers. This code was based on the implementation from three other major BSDs.
The micro-UBSan implementation gained support for alignment_assumptions. A number of UBSan reports were addressed.
Plan for the next and the last milestone
Upstream gdbserver support and address as many remaining bugs as the time will permit.
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL to chip in what you can:
The time has come to upgrade my SunBlade 2500s to something more power friendly and faster. I'd already removed one CPU and thus half the ram from two of these systems to reduce their power consumption, but it's still much higher than it could be.
After much searching, I've decided on Pine64's RockPro64 4GiB ram model (technically, only 3.875GiB ram.) Pine64 make SBCs, laptops, phones, and various other mostly ARM gadgets, and the RockPro64 has the fastest CPU they ship (Rockchip RK3399), and can use a small "NAS Case", that is sufficient to house 2 HDDs and, at a stretch, upto 6 SSDs (cooling would become quite an issue at this point.)
In my SATA setup, I have 3 SSDs with a JMicron 585 card in the PCIe slot, two SSDs in the NAS case SSD region, and the third is in the HDD region with an adapter. I have used two SATA power splitters to convert the NAS case's 2 SATA power ports into 4, with the 4th one also powering a Noctua case fan. The cabling is not great with this, with enough SATA power cabling for 6 devices to lay. Probably a bespoke power cable to connect to the RockPro64 would make this nicer and probably improve cooling slightly, but I'm just using off-the-shelf components for now.
In the last year or so I've been working on making NetBSD/arm64 big-endian more featureful. In particular, I've added support for:
- other-endian access disklabels, FFS file-systems in the NetBSD libsa
- the "look 64 sectors later" for RAIDFrame partitions in MI efiboot (the x86 specific efiboot has more extensive support for this that should be ported over)
- other-endian access to RAIDFrame labels in the kernel
- updated the U-Boot package and featureset to include AHCI/SATA support, workaround some bugs and fix the newer U-Boot SPI loader location, and figured out how to default loading from either SATA or NVMe
There are not too many special actions needed for this sort of setup compared to a normal NetBSD or Arm system. While I built my installations by hand, the standard NetBSD Arm images are suitable for this task. It's easiest to start from an SD card with the RockPro64 u-boot installed. There are two U-Boot images available, one for SD/eMMC, and one for SPI (there is an odd problem with the early SPI loader that requires a portion of the image to be different.) The pkgsrc package for sysutils/u-boot-rockpro64 version 2022.01 has these suggested methods for installing the U-Boot image (this package should be buildable on any supported pkgsrc platform).
To install U-Boot into the SD/eMMC card (can run on any system, the image must be written at 32KiB into the device):
# dd if=/usr/pkg/share/u-boot/rockpro64/rksd_loader.img seek=64 of=/dev/rld0c
To install U-Boot into the SPI flash (must be run on the host, and lives at the very start of the device:
# dd if=/usr/pkg/share/u-boot/rockpro64/rkspi_loader.img bs=64k of=/dev/spiflash0
When booting from NVMe or SATA, one must drop to the U-Boot prompt and adjust the "boot_targets" value to put scsi* (SATA) or nvme* ahead of the mmc* and usb* options.
The original value for me:
=> printenv boot_targets boot_targets=mmc1 usb0 mmc0 nvme0 scsi0 pxe dhcp sf0
Which is then adjusted and saved with eg:
=> setenv boot_targets nvme0 scsi0 mmc1 usb0 mmc0 pxe dhcp sf0 => saveenv Saving Environment to SPIFlash... Erasing SPI flash...Writing to SPI flash...done OK
(In this list, mmc1 is the SD slot, mmc0 is the eMMC card, pxe and dhcp are netbooting, and sf0 attempts to load further U-Boot scripts from SPI.)
There are some minor issues with the RockPro64. It has no ability to use ECC memory. It only comes with 1 PCIe 4x slot, and Rockchip errata limited this to PCIe 1.x (though no NetBSD users encounted any issues with PCIe 2.x enabled, and this can be forced back on via a DTS patch.) It is possible to use a PCIe bridge (I have never done this, though I would like to try in the future) to enable more devices for booting, or to enable both a network and storage device.
The time has come to upgrade my SunBlade 2500s to something more power friendly and faster. I'd already removed one CPU and thus half the ram from two of these systems to reduce their power consumption, but it's still much higher than it could be.
After much searching, I've decided on Pine64's RockPro64 4GiB ram model (technically, only 3.875GiB ram.) Pine64 make SBCs, laptops, phones, and various other mostly ARM gadgets, and the RockPro64 has the fastest CPU they ship (Rockchip RK3399), and can use a small "NAS Case", that is sufficient to house 2 HDDs and, at a stretch, upto 6 SSDs (cooling would become quite an issue at this point.)
In my SATA setup, I have 3 SSDs with a JMicron 585 card in the PCIe slot, two SSDs in the NAS case SSD region, and the third is in the HDD region with an adapter. I have used two SATA power splitters to convert the NAS case's 2 SATA power ports into 4, with the 4th one also powering a Noctua case fan. The cabling is not great with this, with enough SATA power cabling for 6 devices to lay. Probably a bespoke power cable to connect to the RockPro64 would make this nicer and probably improve cooling slightly, but I'm just using off-the-shelf components for now.
In the last year or so I've been working on making NetBSD/arm64 big-endian more featureful. In particular, I've added support for:
- other-endian access disklabels, FFS file-systems in the NetBSD libsa
- the "look 64 sectors later" for RAIDFrame partitions in MI efiboot (the x86 specific efiboot has more extensive support for this that should be ported over)
- other-endian access to RAIDFrame labels in the kernel
- updated the U-Boot package and featureset to include AHCI/SATA support, workaround some bugs and fix the newer U-Boot SPI loader location, and figured out how to default loading from either SATA or NVMe
There are not too many special actions needed for this sort of setup compared to a normal NetBSD or Arm system. While I built my installations by hand, the standard NetBSD Arm images are suitable for this task. It's easiest to start from an SD card with the RockPro64 u-boot installed. There are two U-Boot images available, one for SD/eMMC, and one for SPI (there is an odd problem with the early SPI loader that requires a portion of the image to be different.) The pkgsrc package for sysutils/u-boot-rockpro64 version 2022.01 has these suggested methods for installing the U-Boot image (this package should be buildable on any supported pkgsrc platform).
To install U-Boot into the SD/eMMC card (can run on any system, the image must be written at 32KiB into the device):
# dd if=/usr/pkg/share/u-boot/rockpro64/rksd_loader.img seek=64 of=/dev/rld0c
To install U-Boot into the SPI flash (must be run on the host, and lives at the very start of the device:
# dd if=/usr/pkg/share/u-boot/rockpro64/rkspi_loader.img bs=64k of=/dev/spiflash0
When booting from NVMe or SATA, one must drop to the U-Boot prompt and adjust the "boot_targets" value to put scsi* (SATA) or nvme* ahead of the mmc* and usb* options.
The original value for me:
=> printenv boot_targets boot_targets=mmc1 usb0 mmc0 nvme0 scsi0 pxe dhcp sf0
Which is then adjusted and saved with eg:
=> setenv boot_targets nvme0 scsi0 mmc1 usb0 mmc0 pxe dhcp sf0 => saveenv Saving Environment to SPIFlash... Erasing SPI flash...Writing to SPI flash...done OK
(In this list, mmc1 is the SD slot, mmc0 is the eMMC card, pxe and dhcp are netbooting, and sf0 attempts to load further U-Boot scripts from SPI.)
There are some minor issues with the RockPro64. It has no ability to use ECC memory. It only comes with 1 PCIe 4x slot, and Rockchip errata limited this to PCIe 1.x (though no NetBSD users encounted any issues with PCIe 2.x enabled, and this can be forced back on via a DTS patch.) It is possible to use a PCIe bridge (I have never done this, though I would like to try in the future) to enable more devices for booting, or to enable both a network and storage device.

We are happy to announce that The NetBSD Fundation is a mentoring organization at Google Summer of Code 2022!
Would you like to contribute to NetBSD or pkgsrc during the summer? Please give a look to NetBSD wiki Google Summer of Code page with possible ideas list and/or please join #NetBSD-code IRC channel on libera or get in touch with us via mailing lists to propose new projects!
Please note that unlike past years where Google Summer of Code was opened only to university students since this year if you are 18 or older you can be a GSoC contributor.
For more information about Google Summer of Code please give a look to the official GSoC website.
Looking forward to have a nice Google Summer of Code!
We are happy to announce that The NetBSD Fundation is a mentoring organization at Google Summer of Code 2022!
Would you like to contribute to NetBSD or pkgsrc during the summer? Please give a look to NetBSD wiki Google Summer of Code page with possible ideas list and/or please join #NetBSD-code IRC channel on libera or get in touch with us via mailing lists to propose new projects!
Please note that unlike past years where Google Summer of Code was opened only to university students since this year if you are 18 or older you can be a GSoC contributor.
For more information about Google Summer of Code please give a look to the official GSoC website.
Looking forward to have a nice Google Summer of Code!
- ASan
- UBSan
- TSan
- MSan
- libFuzzer
- SafeStack
- XRay
Integration of sanitizers with the base system
I've submitted a patch for internal review but I was asked to push it through tech-toolchain@ first. I'm still waiting for active feedback on moving it in the proper direction.
The final merge of build rules will be done once we get LLVM 8.0(rc2) in the base as there is a small ABI mismatch between Clang/LLVM (7.0svn) and compilr-rt (8.0svn). I've ported/adapted-with-a-hack all the upstream tests for supported sanitizers to be executed against the newly integrated ones with the base system and everything has been adjusted to pass with a few exceptions that still need to be fixed: ASan dynamic (.so) tests are still crashy and UBSan tests where around 1/3 of them are failing due to an ABI mismatch. This caused by a number of new features for UBSan that are not supported by older Clang/LLVM.
Changes intergrated with LLVM projects
There has been a branching of LLVM 8.0 in the middle of January, causing a lot of breakage that required collaboration with the LLVM people to get things back into proper shape. I've also taken part in the LLD porting effort with Michal Gorny.
Post branching point there was also a refactoring of existing features in compiler-rt, such as LSan, SafeStack and Scudo. I had to apply appropriate patches in these sanitizers and temporarily disable LSan until it can be fully ported.
Changes in the base system
Out of the context of sanitizer I've fixed two bugs that relate to my previous work on interfaces for debuggers:
- PR kern/53817 Random panics in vfs_mountroot()
- PR lib/53343 t_ptrace_wait*:traceme_vfork_crash_bus test cases fail
Plan for the next milestone
Collect feedback for the patch integrating LLVM sanitizers and merge the final version with the base system.
Return to ptrace(2) kernel fixes and start the work with a focus on improving correctness of signal handling.
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL to chip in what you can:
Starting this month, I will be focusing my effort on LLDB, the debugger of the LLVM toolchain, as work contracted by the NetBSD Foundation. In this entry, I would like to shortly summarize what I've been working on before and what I have been able to accomplish, and what I am going to do next.
Final status of LLD support
LLD is the link editor (linker) component of Clang toolchain. Its main advantage over GNU ld is much lower memory footprint, and linking speed. I started working on LLD this month, and encountered a few difficulties. I have explained them in detail in the first report on NetBSD LLD porting.
The aforementioned impasse between LLD and NetBSD toolchain maintainers still stands. A few comments have been exchanged but it doesn't seem that either of the sides have managed to convince the other. Right now, it seems that the most probable course of action for the future would be for NetBSD to maintain necessary changes as a local patchset.
To finish my work on LLD, I have committed devel/lld to pkgsrc. It is based on 7.0.1 release with NetBSD patches. I will update it to 8.0.0 once it is released.
Other work on LLVM
Besides the specific effort on LLD, I have been focusing on preparing and testing for the upcoming 8.0.0 release of LLVM. Upstream has set branching point to Jan 16th, and we wanted to get all the pending changes merged if possible.
Of the compiler-rt patches previously submitted for review, the following changes have been merged (and will be included in 8.0.0):
added interceptor tests for clearerr, feof, ferrno, fileno, fgetc, getc, ungetc (r350225)
fixed more interceptor tests to use assert in order to report potential errors verbosely (r350227)
fixed return type of devname_r() interceptor (r350228)
added interceptor tests for fputc, putc, putchar, getc_unlocked, putc_unlocked, putchar_unlocked (r350229)
added interceptor tests for popen, pclose (r350230)
added interceptor tests for funopen (r350231)
added interception support for popen, popenve, pclose (r350232)
added interception support for funopen* (r350233)
implemented FILE structure sanitization (r350882)
Additionally, the following changes have been made to other LLVM components and merged into 8.0.0:
enabled system-linker-elf LLD feature on NetBSD (NFC) (r350253)
made clang driver permit building instrumented code for all kinds of sanitizers (r351002)
added appropriate RPATH when building instrumented code with shared sanitizer runtime (e.g. via -shared-libasan option) (r352610)
Post-release commits were focused on fixing new or newly noticed bugs:
fixed Mac-specific compilation-db test to not fail on systems where getMainExecutable function results depends on argv[0] being correct (r351752) (see below)
fixed formatting error in polly that caused tests to fail (r351808)
fixed missing -lutil linkage in LLDB that caused build using LLD as linker to fail (r352116)
Finding executable path in LLVM
The LLVM support library defines getMainExecutable() function whose purpose is to find the path to the currently executed program. It is used e.g. by clang to determine the driver mode depending on whether you executed clang or clang++, etc. It is also used to determine resource directory when it is specified relatively to the program installation directory.
The function implements a few different execution paths depending on the platform used:
on Apple platforms, it uses _NSGetExecutablePath()
on BSD variants and AIX, it does path lookup on argv[0]
on Linux and Cygwin, it uses /proc/self/exe, or argv[0] lookup if it is not present
on other platforms supporting dladdr(), it attempts to find the program path via Dl_info structure corresponding to the main function
on Windows, it uses GetModuleFileNameW()
For consistency, all symlinks are eliminated via realpath().
The different function versions require different arguments. argv[0]-based methods require passing argv[0]; dladdr method requires passing pointer to the main function. Other variants ignore those parameters.
When clang-check-mac-libcxx-fixed-compilation-db test was added to clang, it failed on NetBSD because the variant of getMainExecutable() used on NetBSD requires passing argv[0], and the specific part of Clang did not pass it correctly. However, the test authors did not notice the problem since non-BSD platforms normally do not use argv[0] for executable path.
I have determined three possible solutions here (ideally, all of them would be implemented simultaneously):
Modifying getMainExecutable() to use KERN_PROC_PATHNAME sysctl on NetBSD (D56975).
Fixing the compilation database code to pass argv[0] through.
Adding -ccc-install-dir argument to the invocation in the test to force assuming specific install directory (D56976).
The sysctl change was already historically implemented (r303015). It was afterwards reverted (r303285) since it did not provide expected paths on FreeBSD when the executable was referenced via multiple links. However, NetBSD does not suffer from the same issue, so we may switch back to sysctl.
Fixing compilation database would be non-trivial as it would probably involve passing argv[0] to constructor, and effectively some API changes. Given that the code is apparently only used on Apple where argv[0] is not used, I have decided not to explore it for the time being.
Finally, passing -ccc-install-dir seems like the simplest workaround for the problem. Other tests based on paths in clang already pass this option to reliably override path detection. I've committed it as r351752.
Future plans: LLDB
The plan for the next 6 months is as follows:
Restore tracing in LLDB for NetBSD (i386/amd64/aarch64) for single-threaded applications.
Restore execution of LLDB regression tests, unless there is need for a significant LLDB or kernel work, mark detected bugs as failing or unsupported ones.
Enable execution of LLDB regression tests on the build bot in order to catch regressions.
Upstream NetBSD (i386/amd64) core(5) support. Develop LLDB regression tests (and the testing framework enhancement) as requested by upstream.
Upstream NetBSD aarch64 core(5) support. This might involve generic LLDB work on the interfaces and/or kernel fixes. Add regression tests as will be requested by upstream.
Rework threading plan in LLDB in Remote Process Plugin to be more agnostic to non-Linux world and support the NetBSD threading model.
Add support for FPU registers support for NetBSD/i386 and NetBSD/amd64.
Support XSAVE, XSAVEOPT, ... registers in core(5) files on NetBSD/amd64.
Add support for Debug Registers support for NetBSD/i386 and NetBSD/amd64.
Add support to backtrace through signal trampoline and extend the support to libexecinfo, unwind implementations (LLVM, nongnu). Examine adding CFI support to interfaces that need it to provide more stable backtraces (both kernel and userland).
Stabilize LLDB and address breaking tests from the test-suite.
Merge LLDB with the basesystem (under LLVM-style distribution).
I will be working closely with Kamil Rytarowski who will support me on the NetBSD kernel side. I'm officially starting today in order to resolve the presented problems one by one.
This work will be sponsored by The NetBSD Foundation
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL to chip in what you can:
![]() For the 4th year in a row and for the 13th time The NetBSD Foundation
will participate in
Google Summer of Code 2019!
For the 4th year in a row and for the 13th time The NetBSD Foundation
will participate in
Google Summer of Code 2019!
If you are a student and would like to learn more about Google Summer of Code please go to the Google Summer of Code homepage.
You can find a list of projects in Google Summer of Code project proposals in the wiki.
Do not hesitate to get in touch with us via #netbsd-code IRC channel on Freenode and via NetBSD mailing lists!
Looking forward to have a great summer!
Sixth months after the start of the release engineering process for 9.0, the second (and most likely final) release candidate is now available.
Shortly after the first release candidate had been published and feedback came it, it became clear that this was not going to be the final state of 9.0. In the end a lot of fixes were done, but we used the opportunity to also incorporate more hardware support (Pinebook Pro) and update a few components (dhcpcd, openssl).
We will be very restrictive with further changes and expect a quick and smooth release from this point on. Tentative release date is February 14, 2020.
Since the start of the release process a lot of improvements went into the branch - nearly 700 pullups were processed!
This includes usbnet (a common framework for usb ethernet drivers), aarch64 stability enhancements and lots of new hardware support, installer/sysinst fixes and changes to the NVMM (hardware virtualization) interface.
We hope this will lead to the best NetBSD release ever (only to be topped by NetBSD 10 - hopefully later this year).
Here are a few highlights of the new release:
- Support for Arm AArch64 (64-bit Armv8-A) machines, including "Arm ServerReady" compliant machines (SBBR+SBSA)
- Enhanced hardware support for Armv7-A
- Updated GPU drivers (e.g. support for Intel Kabylake)
- Enhanced virtualization support
- Support for hardware-accelerated virtualization (NVMM)
- Support for Performance Monitoring Counters
- Support for Kernel ASLR
- Support several kernel sanitizers (KLEAK, KASAN, KUBSAN)
- Support for userland sanitizers
- Audit of the network stack
- Many improvements in NPF
- Updated ZFS
- Reworked error handling and NCQ support in the SATA subsystem
- Support a common framework for USB Ethernet drivers (usbnet)
You can download binaries of NetBSD 9.0_RC2 from our Fastly-provided CDN.
For more details refer to the official release announcement.
Please help us out by testing 9.0_RC2. We love any and all feedback. Report problems through the usual channels (submit a PR or write to the appropriate list). More general feedback is welcome, please mail releng. Your input will help us put the finishing touches on what promises to be a great release!
Enjoy!
Martin
Upstream describes LLDB as a next generation, high-performance debugger. It is built on top of LLVM/Clang toolchain, and features great integration with it. At the moment, it primarily supports debugging C, C++ and ObjC code, and there is interest in extending it to more languages.
In February 2019, I have started working on LLDB, as contracted by the NetBSD Foundation. So far I've been working on reenabling continuous integration, squashing bugs, improving NetBSD core file support, extending NetBSD's ptrace interface to cover more register types and fix compat32 issues, fixing watchpoint and threading support.
The original NetBSD port of LLDB was focused on amd64 only. In January, I have extended it to support i386 executables. This includes both 32-bit builds of LLDB (running natively on i386 kernel or via compat32) and debugging 32-bit programs from 64-bit LLDB.
Build bot failure report
I have finished the previous report with indication that upstream broke libc++ builds with gcc. The change in question has been reverted afterwards and recommitted with the necessary fixes.
A test breakage has been caused by adding a clang driver test using
env -u. The problem has been
resolved by setting the variable to an empty value instead of unsetting
it. However, maybe it is time to implement env -u on NetBSD?
Yet another problem was basic_string copy constructor optimization that broke programs at runtime, in particular TableGen. The commit in question has been reverted.
Lastly, adding sigaltstack interception in compiler-rt broke our builds. Missing bits for NetBSD have been added afterwards.
I would like to thank all upstream contributors who are putting an effort to fix their patches to work with NetBSD.
LLDB i386 support
Onto the mysterious UserArea
LLDB uses quite an interesting approach to support reading and writing registers on Linux. It abstracts two register lists for i386 and amd64 respectively. Those lists contain offsets to appropriate fields in data returned by ptrace. When debugging a 32-bit program on amd64, it uses a hybrid. It takes the i386 register list and combines it with offsets specific to amd64 structures. The offsets themselves are not written explicitly but instead established from UserData structure defined in the plugin.
The NetBSD plugin uses a different approach. Rather than using binary offsets, it explicitly accesses appropriate fields in ptrace structures. However, the plugin needs to declare UserData nevertheless in order to fill the offsets in register lists. What are those offsets used for then? That's the first problem I had to answer.
According to LLDB upstream developer Pavel Labath those offsets are additionally used to serialize and deserialize register values in gdb protocol packets. This opened a consideration of improving the protocol-wise compatibility between LLDB and GDB. I'm going to elaborate on this problem separately below. However, the immediate implication was that the precise field order does not matter and can be changed arbitrarily.
My first attempts at reordering the fields to improve GDB compatibility have resulted in new test failures. The offsets must be used for something else as well! After further research, I've realized that our plugin has two register reading/writing interfaces: an interface for operating on a single register, and an interface for reading/writing all registers (in this case, just the general-purpose registers). While the former uses explicit field names/indices, the latter just passes the whole structure as an abstract blob — and apparently the offsets are used to access data in this blob.
This meant that the initial portion of UserData must match the GPR structure as returned by ptrace. However, the remaining registers can be ordered and structured arbitrarily.
Native i386 support
I've decided to follow the ideas used in the Linux plugin. Most importantly, this meant having a single plugin for both 32-bit and 64-bit x86 variants. This is useful because, on one hand, both ptrace interfaces are similar, and on the other, 64-bit debugger uses 64-bit ptrace interface on 32-bit programs. The resulting code uses preprocessor conditions to distinguish between 32-bit and 64-bit API whenever necessary, and debugged program ABI to switch between appropriate register data.
Initially, I've started by implementing a minimal proof-of-concept for 32-bit program on 64-bit debugger support. This way I've aimed to ensure that I won't have to change design in the future in order to support both variants. Once this version started working, I've stashed it and focused on getting native i386 working first.
The result was introducing i386 support in NetBSD Process plugin. The patch added i386 register definitions, and the code to handle them. To reduce code duplication, the functions operate almost exclusively on amd64 constants, and map i386 constants to them when debugging 32-bit programs.
The main differences are in GPR structure for i386/amd64, using
PT_GETXMMREGS on i386 (rather than PT_GETFPREGS) and abstracting
out debug register constants. The actual floating-point and debug
registers are handled via common code.
The second part is improving debugging 32-bit programs on amd64. It adds two features: explicitly recognizing 32-bit executables, and providing 32-bit-alike register context for them. The first part reuses existing LLDB routines in order to read the header of the underlying executable in order to distinguish whether it is 32-bit or 64-bit ELF file. The second part reuses the approach from Linux: takes 32-bit register context, and updates it with 64-bit offsets.
More on LLDB/GDB packet compatibility
I have mentioned the compatibility between LLDB and GDB protocols. In fact, LLDB is using a modified version of the GDB protocol that is only partially compatible with the original. This incompatibility particularly applies to handling registers.
The register packets transmit register values as packet binary data. On NetBSD, the layout used by LLDB is different than the one used by GDB, rendering them incompatible. This incompatibility also means that LLDB cannot be successfully used to connect to other implementations of GDB protocol server, e.g. in qemu.
Both GDB and LLDB support additional abstraction over register packet layout, making it possible to work with a different layout that the default. However, both implement different protocol for exposing those abstractions. LLDB has explicit register layout packet as JSON, while GDB transmits target definition as series of XML files. Ideally, LLDB should grow support for the latter in order to improve its compatibility with different servers.
i386 outside NetBSD
While working on i386 support in NetBSD plugin, I have noticed a number of failing tests that do not seem to be specific to NetBSD. Indeed, upstream indicates that i386 is not actively tested on any platform nowadays.
In order to improve its state a little, I have applied a few small fixes that could be done quickly:
- adding missing platform restriction for x86-64-write register test
- skipping tests requiring
__int128_t - fixing segment IDs when processing ELF files
Future plans
I am currently trying to build minimal reproducers for remaining race conditions in concurrent event handling (in particular signal delivery to debugged program).
The remaining tasks in my contract are:
-
Add support to backtrace through signal trampoline and extend the support to libexecinfo, unwind implementations (LLVM, nongnu). Examine adding CFI support to interfaces that need it to provide more stable backtraces (both kernel and userland).
-
Add support for aarch64 target.
-
Stabilize LLDB and address breaking tests from the test suite.
-
Merge LLDB with the base system (under LLVM-style distribution).
This work is sponsored by The NetBSD Foundation
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL to chip in what you can:
ptrace(2) and the surrounding code.
This month I complete a set of older pending tasks.
dlinfo(3) - information about a dynamically loaded object
I've documented dlinfo(3) and added missing cross-reference from the dlfcn(3) API.
dlinfo(3) is a Solaris-style and first appeared in NetBSD 5.1.
Today this API is also implemented in Linux and FreeBSD, making it the right portable tool for certain operations.
Today we support only the RTLD_DI_LINKMAP operation out of few functionalities.
RTLD_DI_LINKMAP translates the dlopen(3) opaque handler to struct link_map.
This is the exact functionality needed in the LLVM sanitizers. So far we have been using manual extraction of the struct's field with offset over an opaque pointer. Unfortunately the existing algorithm was prone to internal modifications of the ELF loader and it used to break few times a year.
#define _GET_LINK_MAP_BY_DLOPEN_HANDLE(handle, shift) \ ((link_map *)((handle) == nullptr ? nullptr : ((char *)(handle) + (shift)))) #if defined(__x86_64__) #define GET_LINK_MAP_BY_DLOPEN_HANDLE(handle) \ _GET_LINK_MAP_BY_DLOPEN_HANDLE(handle, 264) #elif defined(__i386__) #define GET_LINK_MAP_BY_DLOPEN_HANDLE(handle) \ _GET_LINK_MAP_BY_DLOPEN_HANDLE(handle, 136) #endif
I was pondering how to implement a dedicated interface until I found this interface in rumpkernels! Antti Kantee, a NetBSD developer and author of rumpkernels, implemented this feature but left it undocumented. I quickly scanned this interface, picked the man page from FreeBSD, adapted for NetBSD and pushed to LLVM. The FreeBSD Operating system support in sanitizers also suffered from the offset struct changes and with collaboration with me from the NetBSD side, we switched the appropriate code to a dynamic value. This also improves compatibility with all NetBSD ports that could potentially support the LLVM sanitizers, as previously the offsets were calculated only for x86 platforms (i386, amd64).
ktruss(1) enhancements
I've switched ktruss(1) to ptrace descriptive operation names.
Previously ptrace(2) requests were encoded with a magic value like 0x10 or 0x14.
This style of encoding fields is not human-friendly and required checking appropriate system headers.
Now the output looks like this (reduced to ptrace syscalls only):
3902 1 t_ptrace_waitpid ptrace(PT_ATTACH, 0xfd7, 0, 0) = 0 3902 1 t_ptrace_waitpid ptrace(PT_GET_SIGINFO, 0xfd7, 0x7f7fff51a4f0, 0x88) = 0 3902 1 t_ptrace_waitpid ptrace(PT_LWPINFO, 0xfd7, 0x7f7fff51a4c8, 0x8) = 0 3902 1 t_ptrace_waitpid ptrace(PT_LWPINFO, 0xfd7, 0x7f7fff51a4c8, 0x8) = 0 3902 1 t_ptrace_waitpid ptrace(PT_CONTINUE, 0xfd7, 0x1, 0) = 0 3902 1 t_ptrace_waitpid ptrace(PT_GET_SIGINFO, 0xfd7, 0x7f7fff51a4f0, 0x88) = 0 3902 1 t_ptrace_waitpid ptrace(PT_LWPINFO, 0xfd7, 0x7f7fff51a4c8, 0x8) = 0 3902 1 t_ptrace_waitpid ptrace(PT_LWPINFO, 0xfd7, 0x7f7fff51a4c8, 0x8) = 0 3902 1 t_ptrace_waitpid ptrace(PT_LWPINFO, 0xfd7, 0x7f7fff51a4c8, 0x8) = 0 3902 1 t_ptrace_waitpid ptrace(PT_LWPINFO, 0xfd7, 0x7f7fff51a4c8, 0x8) = 0 3902 1 t_ptrace_waitpid ptrace(PT_LWPINFO, 0xfd7, 0x7f7fff51a4c8, 0x8) = 0 3902 1 t_ptrace_waitpid ptrace(PT_CONTINUE, 0xfd7, 0x1, 0x9) = 0 5449 1 t_ptrace_waitpid ptrace(PT_TRACE_ME, 0, 0, 0) = 0 6086 1 t_ptrace_waitpid ptrace(PT_GET_SIGINFO, 0x1549, 0x7f7fffa7c230, 0x88) = 0 6086 1 t_ptrace_waitpid ptrace(PT_IO, 0x1549, 0x7f7fffa7c210, 0x20) = 0
libc threading stubs improvements
I have adjusted the error return value of pthread_sigmask(3) whenever libpthread is either not loaded or initialized.
Now instead of returning -1, return errno on error.
This caught up after the fix in libpthread by Andrew Doran in 2008 in lib/libpthread/pthread_misc.c r.1.9.
It remains an open question whether this function shall be used without linked
in the POSIX thread library.
This incompatibility was detected by Bruno Haible (GNU) and documented in gnulib in commit
pthread_sigmask: Avoid test failure on NetBSD 8.0. r. 4d16a83b0c1fcb6c.
Compatibility fixes in compat_netbsd32(8)
There was a longstanding issue with incompatibility between few syscalls in the native NetBSD ABI and 32-bit compat one. I've addressed this with the following change:
commit 2e2cec309dca0021e364d52597388665c500d66e
Author: kamil
Date: Sat Jan 18 07:33:24 2020 +0000
Catch up after getpid/getgid/getuid changes in native ABI in 2008
getpid(), getuid() and getgid() used to call respectively sys_getpid(),
sys_getuid() and sys_getgid(). In the BSD4.3 compat mode there was a
fallback to call sys_getpid_with_ppid() and related functions.
In 2008 the compat ifdef was removed in sys/kern/syscalls.master r. 1.216.
For purity reasons we probably shall restore the NetBSD original behavior
and implement BSD4.3 one as a compat module, however it is not worth the
complexity.
Align the netbsd32 compat ABI to native ABI and call functions that return
two integers as in BSD4.3.
New ptrace(2) ATF tests (OpenBSD)
I have finished importing the OpenBSD test (regress/sys/ptrace/ptrace.c) for unaligned program counter register.
For a long time it was cryptic what the original intention was to test,
whether it was some concept of what values should be rejected in the API for purity reasons,
whether we were testing SIGILL, whether there was a kernel problem or something else.
Finally, I reached the original committer (Miod Vallat) and he pointed out to me that there was a sparc/OpenBSD bug that could break the kernel.
https://marc.info/?l=openbsd-bugs&m=107558043319084&w=2
Instead of hardcoding magic program counter register on a per-cpu basis, I added tests using 3 types of them for all CPUs. At the end of the day these tests crashed the NetBSD kernel for at least a single port.
New ptrace(2) ATF tests (FreeBSD)
Scanning the ptrace(2) scenarios in FreeBSD, I decided to expand the ATF framework for
unrelated tracer variation (as opposed to real parent = debugger) for tests: fork1-16,
vfork1-16, posix_spawn1-16.
New tests were also introduced for:
posix_spawn_detach_spawner, fork_detach_forker, vfork_detach_vforkerdone,
posix_spawn_kill_spawner, fork_kill_forker, vfork_kill_vforker, vfork_kill_vforkerdone.
libpthread(3) enhancements
I have added missing sanity checks in the libpthread(3) API functions.
This means that now on entry to calls like pthread_mutex_lock(3) we will first check whether the passed object
is a valid and alive mutex.
I have retired conditional (preprocessor variable) checks in API families (rwlock, spin-lock) as they were always enabled.
This behavior matches the Linux implementation and is assumed in LLVM sanitizers.
I also found out that these semantics are expected by third-party code, especially WolfSSL.
Our current sanity checking version of pthread_equal(3) found at least one abuse of the interface in the NSPR package
and its downstream users: Firefox, Thunderbird and Seamonkey.
For the time being a workaround has been applied and the bug is scheduled for proper investigation and fix.
While working on this. I found that the jemalloc (system's malloc) initialization is misused and we initialize a jemalloc's mutex with uninitialized data. A workaround has been applied by Christos Zoulas but we are still looking for proper initialization model of our libc, libpthread and malloc code. There is a problem with mutual dependencies between the components and we are looking for a clean solution.
env(1) and putenv(3)
The NetBSD project maintains a LLVM buildbot in the LLVM buildfarm.
We build and execute tests for virtually every LLVM project which we find important
(llvm, clang, lldb, lld, compiler-rt,
polly, openmp, libc++, libc++abi etc.)
A frequent issue is that LLVM developers use constructs that are portable only to a selection of OSs that are worth supporting in the tests.
One such incompatibility introduced from time to time is env(1) with the -u option.
This option is an extension to POSIX, but supported by FreeBSD, Linux and Darwin. It unsets a variable in the environment.
It was a constant cost to see this regressing over and over again on the NetBSD buildbot and
I decided to just implement it natively.
While there, I have implemented another popular option: -0.
This switch ends each output line with NUL, not newline.
While investigating the env(1) differences between Operating Systems,
I have learnt that putenv(3) changed its behavior.
This function call originally allocated its content internally, however it was changed in future versions as requested by POSIX
to not allocate memory.
I have audited the base system to see whether we obey these semantics everywhere and detected a use-after-free bug in the PAM
(Pluggable Authentication Modules framework)!
I have fixed the problem with a potential security implication.
commit 5c19ff198d69f48222ab4907235addbfa60d4e2a
Author: kamil
Date: Sat Feb 8 13:44:35 2020 +0000
Avoid use-after-free bug in PAM environment
Traditional BSD putenv(3) was creating an internal copy of the passed
argument. Unfortunately this was causing memory leaks and was changed by
POSIX to not allocate.
Adapt the putenv(3) usage to modern POSIX (and NetBSD) semantics.
diff --git a/usr.bin/login/login_pam.c b/usr.bin/login/login_pam.c
index 66303006b514..7d877ebeb1c0 100644
--- a/usr.bin/login/login_pam.c
+++ b/usr.bin/login/login_pam.c
@@ -1,6 +1,6 @@
-/* $NetBSD: login_pam.c,v 1.25 2015/10/29 11:31:52 shm Exp $ */
+/* $NetBSD: login_pam.c,v 1.26 2020/02/08 13:44:35 kamil Exp $ */
/*-
* Copyright (c) 1980, 1987, 1988, 1991, 1993, 1994
* The Regents of the University of California. All rights reserved.
*
@@ -37,11 +37,11 @@ __COPYRIGHT("@(#) Copyright (c) 1980, 1987, 1988, 1991, 1993, 1994\
#ifndef lint
#if 0
static char sccsid[] = "@(#)login.c 8.4 (Berkeley) 4/2/94";
#endif
-__RCSID("$NetBSD: login_pam.c,v 1.25 2015/10/29 11:31:52 shm Exp $");
+__RCSID("$NetBSD: login_pam.c,v 1.26 2020/02/08 13:44:35 kamil Exp $");
#endif /* not lint */
/*
* login [ name ]
* login -h hostname (for telnetd, etc.)
@@ -600,12 +600,12 @@ skip_auth:
*/
if ((pamenv = pam_getenvlist(pamh)) != NULL) {
char **envitem;
for (envitem = pamenv; *envitem; envitem++) {
- putenv(*envitem);
- free(*envitem);
+ if (putenv(*envitem) == -1)
+ free(*envitem);
}
free(pamenv);
}
Other changes
I have fixed LLVM sanitizers after recent basesystem changes and they are again functional.
There was a need to adapt the code for urio(4) device driver removal
(USB driver for the Diamond Multimedia Rio500 MP3 player).
With the clang version 9 we were also required to adapt paths for installation of the sanitizers.
I have fixed a race in the ptrace(2) ATF test resume1.
There was a bug when two events were triggered concurrently from two competing threads.
This bug appeared after recent changes by Andrew Doran who refactored the internals and so the race was now more frequent
than before.
I am working with students and volunteers who are learning how to use sanitizers in the NetBSD context.
Over the past month we fixed MKLIBCSANITIZER
build with recent GCC 8.x and addressed a number of Undefined Behavior reports in the system.
I have helped to upstream chunks of the NetBSD code to GDB and GCC. I'm working on upstreaming NVMM support to qemu. The patchset is still in review waiting for more feedback before the final merge.
I have imported realpath(1) utility from FreeBSD as it is used sometimes by existing scripts (even if there are more portable alternatives).
Plan for the next milestone
Port remaining ptrace(2) test scenarios from Linux and FreeBSD to ATF and ensure that they are properly operational.
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL to chip in what you can:
Is it really more than 10 years since we last had an official fundraising drive?
Looking at old TNF financial reports I noticed that we have been doing quite well financially over the last years, with a steady stream of small and medium donations, and most of the time only moderate expenditures. The last fundraising drive back in 2009 was a giant success, and we have lived off it until now.
In the last two or three years the core team was able to find developers doing various tasks of funded development. Not all of them ended in a full success and were integrated into the main source tree — like the WiFi IEEE 802.11 rework, which still needs to be finished — but others pushed the project forward in big steps (like Support for "Arm ServerReady" compliant machines (SBBR+SBSA) debuting with the new aarch64 architecture in NetBSD 9.0).
There is more room for improvements, and not always volunteer time available, so funding some critical parts of development makes NetBSD better faster.
Besides the big development contracts we often buy hardware for developers working on special machines, and we also invest in our server infrastructure.
But now it is time: we would like to officially ask for donations this year. We are trying to raise $50,000 in 2020, to support ongoing development and new upcoming contracts - helping to make NetBSD 10 happen this year and be the best NetBSD ever!
The NetBSD Foundation is a non-profit organization as per section 501(c)(3) of the Internal Revenue Code. If you are a US company or citizen, your donations may be tax deductible. Your donations may also be eligible for matching offers from your employer.
Sixth months after the start of the release engineering process, NetBSD 9.0 is now available.
Since the start of the release process a lot of improvements went into the branch - over 700 pullups were processed!
This includes usbnet (a common framework for usb ethernet drivers), aarch64 stability enhancements and lots of new hardware support, installer/sysinst fixes and changes to the NVMM (hardware virtualization) interface.
We hope this will lead to the best NetBSD release ever (only to be topped by NetBSD 10 - hopefully later this year).
Here are a few highlights of the new release:
- Support for Arm AArch64 (64-bit Armv8-A) machines, including "Arm ServerReady" compliant machines (SBBR+SBSA)
- Enhanced hardware support for Armv7-A
- Updated GPU drivers (e.g. support for Intel Kabylake)
- Enhanced virtualization support
- Support for hardware-accelerated virtualization (NVMM)
- Support for Performance Monitoring Counters
- Support for Kernel ASLR
- Support several kernel sanitizers (KLEAK, KASAN, KUBSAN)
- Support for userland sanitizers
- Audit of the network stack
- Many improvements in NPF
- Updated ZFS
- Reworked error handling and NCQ support in the SATA subsystem
- Support a common framework for USB Ethernet drivers (usbnet)
You can download binaries of NetBSD 9.0 from our Fastly-provided CDN.
For more details refer to the official release announcement.
Please note that we are looking for donations again, see Fundraising 2020.
Enjoy!
Martin
FOSDEM took place last week-end, as an offline-first event again for the first time since 2020. It was located as usual at the university campus of the ULB in Brussels. It was packed with developers, users, passionate and professionals of Open Source software, and while NetBSD did not have a booth this year, its presence could be felt on Saturday morning at the BSD DevRoom thanks to the many developers who made it to the conference.
Together with Rodrigo Osorio of the FreeBSD project, I had the pleasure to help manage the DevRoom, have a front seat for the talks, and even start the session by introducing the BSD Driver Harmony initiative.
The staff and respective speakers are currently busy uploading slides and reviewing videos, so keep in mind to check again for new content in the coming few days and weeks if you missed anything or need to dig further into any event from this awesome conference!
Finally, I would like to thank the NetBSD Foundation for sponsoring me to manage the room and attend the GSoC meet-up.
A prebuilt LLVM toolchain
I've prepared a prebuilt toolchain with Clang, LLVM, LLDB and compiler-rt for NetBSD/amd64. I prepared the toolchain on 8.99.12, however I have received reports that it works on other older releases.
Link: llvm-clang-compilerrt-lldb-7.0.0beta_2018-01-24.tar.bz2
The archive has to be untarballed to /usr/local (however it might work to some extent in other paths).
This toolchain contains a prebuilt tree of the LLVM projects from a snapshot of 7.0.0(svn). It is a pristine snapshot of HEAD with patches from pkgsrc-wip for llvm, clang, compiler-rt and lldb.
Sanitizers
Notable changes in sanitizers, all of them are in the context of NetBSD support.
- Added fstat(2) MSan interceptor.
- Support for kvm(3) interceptors in the common sanitizer code.
- Added devname(3) and devname_r(3) interceptors to the common sanitizer code.
- Added sysctl(3) familty of functions interceptors in the common sanitizer code.
- Added strlcpy(3)/strlcat(3) interceptors in the common sanitizer code.
- Added getgrouplist(3)/getgroupmembership(3) interceptors in the common sanitizer code.
- Correct ctype(3) interceptors in a code using Native Language Support.
- Correct tzset(3) interceptor in MSan.
- Correct localtime(3) interceptor in the common sanitizer code.
- Added paccept(2) interceptor to the common sanitizer code.
- Added access(2) and faccessat(2) interceptors to the common sanitizer code.
- Added acct(2) interceptor to the common sanitizer code.
- Added accept4(2) interceptor to the common sanitizer code.
- Added fgetln(3) interceptor to the common sanitizer code.
- Added interceptors for the pwcache(3)-style functions in the common sanitizer code.
- Added interceptors for the getprotoent(3)-style functions in the common sanitizer code.
- Added interceptors for the getnetent(3)-style functions in the common sanitizer code.
- Added interceptors for the fts(3)-style functions in the common sanitizer code.
- Added lstat(3) interceptor in MSan.
- Added strftime(3) interceptor in the common sanitizer code.
- Added strmode(3) interceptor in the common sanitizer code.
- Added interceptors for the regex(3)-style functions in the common sanitizer code.
- Disabled unwanted interceptor __sigsetjmp in TSan.
Base system changes
I've tidied up inclusion of the internal namespace.h header in libc. This has hidden the usage of public global symbol names of:
- strlcat -> _strlcat
- sysconf -> __sysconf
- closedir -> _closedir
- fparseln -> _fparseln
- kill -> _kill
- mkstemp -> _mkstemp
- reallocarr -> _reallocarr
- strcasecmp -> _strcasecmp
- strncasecmp -> _strncasecmp
- strptime -> _strptime
- strtok_r -> _strtok_r
- sysctl -> _sysctl
- dlopen -> __dlopen
- dlclose -> __dlclose
- dlsym -> __dlsym
- strlcpy -> _strlcpy
- fdopen -> _fdopen
- mmap -> _mmap
- strdup -> _strdup
The purpose of these changes was to stop triggering interceptors recursively. Such interceptors lead to sanitization of internals of unprepared (not recompiled with sanitizers) prebuilt code. It's not trivial to sanitize libc's internals and the sanitizers are not designed to do so. This means that they are not a full replacement of Valgrind-like software, but a a supplement in the developer toolbox. Valgrind translates native code to a bytecode virtual machine, while sanitizers are designed to work with interceptors inside the pristine elementary libraries (libc, libm, librt, libpthread) and embed functionality into the executable's code.
I've also reverted the vadvise(2) syscall removal, from the previous month. This caused a regression in legacy code recompiled against still supported compat layers. Newly compiled code will use a libc's stub of vadvise(2).
I've also prepared a patch installing dedicated headers for sanitizers along with the base system GCC. It's still discussed and should land the sources soon.
Future directions and goals
Possible paths in random order:
- In the quartet of UBSan (Undefined Behavior Sanitizer), ASan (Address Sanitizer), TSan (Thread Sanitizer), MSan (Memory Sanitizer) we need to add the fifth basic sanitizer: LSan (Leak Sanitizer). The Leak Sanitizer (detector of memory leaks) demands a stable ptrace(2) interface for processes with multiple threads (unless we want to build a custom kernel interface).
- Integrate the sanitizers with the userland framework in order to ship with the native toolchain to users.
- Port sanitizers from LLVM to GCC.
- Allow to sanitize programs linked against userland libraries other than libc, librt, libm and libpthread; by a global option (like MKSANITIZER) producing a userland that is partially prebuilt with a desired sanitizer. This is required to run e.g. MSanitized programs against editline(3). So far, there is no Operating System distribution in existence with a native integration with sanitizers. There are 3rd party scripts for certain OSes to build a stack of software dependencies in order to validate a piece of software.
- Execute ATF tests with the userland rebuilt with supported flavors of sanitizers and catch regressions.
- Finish porting of modern linkers designed for large C++ software, such as GNU GOLD and LLVM LLD. Today the bottleneck with building the LLVM toolchain is a suboptimal linker GNU ld(1).
I've decided to not open new battlefields and return now to porting LLDB and fixing ptrace(2).
Plan for the next milestone
Keep upstreaming a pile of local compiler-rt patches.
Restore the LLDB support for traced programs with a single thread.
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL, and chip in what you can:
DEFCON 25 and 34c3
Ilja Van Sprundel presented at Defcon 25 (July 2017) and 34c3 (December 2017) the results of his audit of the BSD kernels.
The issues affecting NetBSD were fixed overnight in the NetBSD-current branch, and were propagated to the stable branches within a month. Kernels from NetBSD-6 and NetBSD-7 built after August 23rd 2017 had all the necessary fixes.
Some reports published recently suggest that the stable branches remained vulnerable for months, and that NetBSD was lagging behind; that is simply not true.
In Ilja Van Sprundel’s report, NetBSD was criticized for having too much legacy and buggy code. Several proactive measures were taken, within a month again, to clean up the system. These measures were:
- TCP_COMPAT_42 was removed.
- COMPAT_FREEBSD was disabled.
- COMPAT_SVR4 and COMPAT_SVR4_32 were disabled on all architectures.
- COMPAT_IBCS2 was disabled on all architectures but Vax.
- COMPAT_SVR4 support for i386 was removed.
- COMPAT_IBCS2 support for i386 was removed.
- VM86 was removed.
Several of these changes were propagated to the stable branches. Since, several additional improvements were made to further externalize some parts of the kernel, in such a way that features can be taken out of the system by default, but still be loaded as kernel modules dynamically when they are needed. This aims, of course, at reducing the attack surface in the base system.
Due to the limited human resources available in security-team@, Security Advisories generally take time to be issued. A Security Advisory for the reported problems had not been issued in time, and it was decided not to issue one. The Security Team will continue working on more recent security issues.
Meltdown and Spectre
The counter-measure for Meltdown, called SVS (Separate Virtual Space), is being developed. It was first committed on January 7th 2018, and has now reached a stable state. It is available only on x86 64bit (amd64) for now, this architecture being our primary target.
A significant effort is required to back-port SVS to the stable branches: many improvements were made in the amd64 port (better security and performance) since the last release, and they will have to be, at some point, back-ported too.
Regarding Spectre, Intel and AMD have issued microcode updates. In the case of Intel, the new microcode adds several MSRs, that the OS can tune to disable branch prediction. Given that NetBSD supports microcode updates, it is possible to install a new microcode; however, no option is available yet to tune the aforementioned MSRs.
It is not clear whether the fixes proposed by Intel and AMD are sufficiently reliable. Recent reports suggest that some CPUs have started misbehaving when running with the new microcodes. Therefore, the fix for Spectre is expected to take a little more time to produce than that of Meltdown.
The NetBSD support is no longer visibly lacking behind Linux in sanitizers, although there are still failing tests on NetBSD that are not observed on Linux. On the other hand there are features working on NetBSD that are not functional on Linux, like sanitizing programs during early initialization process of OS (this is caused by /proc dependency on Linux that is mounted by startup programs, while NetBSD relies on sysctl(3) interfaces that is always available).
Changes in compiler-rt
A number of patches have been merged upstream this month. Part of the upstreamed code has been originally written by Yang Zheng during GSoC-2018. My work was about cleaning the patches, applying comments from upstream review and writing new regression tests. Some of the changes were newly written over the past month, like background thread support in ASan/NetBSD or NetBSD compatible per-thread cleanup destructors in ASan and MSan.
Additionally, I've also ported the LLVM profile (--coverage) feature to NetBSD and investigated the remaining failing tests. Part of the failures were caused by already a copy of older runtime inside the NetBSD libc (ABIv2 libc vs ABIv4 current). The remaining two tests are affected by incompatible behavior of atexit(3) in Dynamic Shared Objects. Replacing the functionality with destructors didn't work and I've marked these tests as expected failures and moved on.
Changes in compiler-rt:
- 3d5a3668a Reenable hard_rss_limit_mb_test.cc for android-26
- decb231c3 Add support for background thread on NetBSD in ASan
- 3ebc523bb Fix a mistake in previous
- df1f46250 Update NetBSD ioctl(2) entries with 8.99.28
- 2de4ff725 Enable asan_and_llvm_coverage_test.cc for NetBSD
- 4d9ac421b Reimplement Thread Static Data MSan routines with TLS
- f4a536af4 Adjust NetBSD/sha2.cc to be portable to more environments
- 21bd4bd9f Adjust NetBSD/md2.cc to be portable to more environments
- 1f2d0324e Adjust NetBSD/md[45].cc to be portable to more environments
- 2835fe7cf Add support for LLVM profile for NetBSD
- 52af2fe7c Reimplement Thread Static Data ASan routines with TLS
- 79d385b5c Improve the comment in previous
- 384486fa4 Expand TSan sysroot workaround to NetBSD
- 81e370964 Enable test/msan/pthread_getname_np.cc for NetBSD
- 19e2af50e Enable SANITIZER_INTERCEPT_PTHREAD_GETNAME_NP for NetBSD
- 5088473c7 Fix internal_sleep() for NetBSD
- cd24f2f94 Mark interception_failure_test.cc as passing for NetBSD and asan-dynamic-runtime
- ececda6ca Set shared_libasan_path in lit tests for NetBSD
- 429bc2d51 Add a new interceptors for cdbr(3) and cdbw(3) API from NetBSD
- 71553eb50 Add new interceptors for vis(3) API in NetBSD
- a3e78a793 Add data types needed for md2(3)/NetBSD interceptors
- 0ddb9d099 Add interceptors for the sha2(3) from NetBSD
- 9e2ff43a6 Add interceptors for md2(3) from NetBSD
- 42ac31ee6 Add new interceptors for FILE repositioning stream
- 8627b4b30 Fix a typo in the strtoi test
- 660f7441b Revert a chunk of previous change in sanitizer_platform_limits_netbsd.h
- 9a087462c Add interceptors for md5(3) from NetBSD
- 086caf6a2 Add interceptors for the rmd160(3) from NetBSD
- 8f77a2e89 Add interceptors for the md4(3) from NetBSD
- 27af3db52 Add interceptors for the sha1(3) from NetBSD
- 6b9f7889b Add interceptors for the strtoi(3)/strtou(3) from NetBSD
- 195044df9 Add a new interceptors for statvfs1(2) and fstatvfs1(2) from NetBSD
- f0835eb01 Add a new interceptor for fparseln(3) from NetBSD
- 11ecbe602 Add new interceptor for strtonum(3)
- 19b47fcc0 Remove XFAIL in get_module_and_offset_for_pc.cc for NetBSD-MSan
- b3a7f1d78 Add a new interceptor for modctl(2) from NetBSD
- 39c2acc81 Add a new interceptor for nl_langinfo(3) from NetBSD
- 2eb9a4c53 Update GET_LINK_MAP_BY_DLOPEN_HANDLE() for NetBSD x86
- e8dd644be Improve the regerror(3) interceptor
- dd939986a Add interceptors for the sysctl(3) API family from NetBSD
- 67639f9cc Add interceptors for the fts(3) API family from NetBSD
- c8fae517a Add new interceptor for regex(3) in NetBSD
Part of the new code has been quickly ported from NetBSD to other Operating Systems, mostly FreeBSD, and when applicable to Darwin and Linux.
Changes in other LLVM projects
In order to eliminate local diffs in other LLVM projects, I've upstreamed two patches to LLVM and two to OpenMP. I've also helped other BSDs to get their support in OpenMP (DragonFlyBSD and OpenBSD).
LLVM changes:
- 50df229c26a Add NetBSD support in needsRuntimeRegistrationOfSectionRange.
- 267dfed3ade Register kASan shadow offset for NetBSD/amd64
OpenMP changes:
- 67d037d Implement __kmp_is_address_mapped() for NetBSD
- 9761977 Implement __kmp_gettid() for NetBSD
- a72c79b Add OpenBSD support to OpenMP
- b3d05ab Add DragonFlyBSD support to OpenMP
NetBSD changes
I've introduced 5 changes to the NetBSD source tree over the past month, not counting updates to TODO lists.
- Raise the fill_vmentries() E2BIG limit from 1MB to 10MB
- Correct libproc_p.a in distribution sets
- compiler_rt: Update prepare-import.sh according to future updates
- Correct handling of minval > maxval in strtonum(3)
- Stop mangling __func__ for C++11 and newer
The first change is needed to handle large address space with sysctl(3) operation to retrieve the map. This feature is required in sanitizers and part of the tests were failing because within 1MB it wasn't possible to pass all the information about the process virtual map (mostly due to a large number of small allocations).
The second change was introduced to unbreak MKPROFILE=no build, I needed this during my work of porting the modern LLVM profile feature.
The third change is a preparation for import of compiler-rt sanitizers into the NetBSD distribution.
The forth change was a bug fix for strtonum(3) implementation in libc.
The fifth change was intended to reuse native compiler support for the __func__ compiler symbol.
Integration of LLVM sanitizers with the NetBSD basesystem
We are ready to push support for LLVM sanitizers into the NetBSD basesystem as all the needed patches have been merged. I've divided the remaining tests of integration of LLVM sanitizers into three milestones:
- Import compiler-rt sources into src/. A complete diff is pending for final acceptance in internal review.
- Integrate building of compiler-rt stanitizer under the MKLLVM=yes option. This has been made functional, but it needs polishing and submitting to internal review.
- Make MKSANITIZER available out of the box with the toolchain available in "./build.sh tools". This will be continuation of the previous point. All the MKSANITIZER patches independent from compiler type are already committed into the NetBSD distribution, however there will be likely some extra minor adaptation work here too.
Plan for the next milestone
Finish the integration of LLVM sanitizers with the NetBSD distribution.
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL, and chip in what you can:
LLD is the link editor (linker) component of Clang toolchain. Its main advantage over GNU ld is much lower memory footprint, and linking speed. It is of specific interest to me since currently 8 GiB of memory are insufficient to link LLVM statically (which is the upstream default).
The first goal of LLD porting is to ensure that LLD can produce working NetBSD executables, and be used to build LLVM itself. Then, it is desirable to look into trying to build additional NetBSD components, and eventually into replacing /usr/bin/ld entirely with lld.
In this report, I would like to shortly summarize the issues I have found so far trying to use LLD on NetBSD.
DT_RPATH vs DT_RUNPATH
RPATH is used to embed a library search path in the executable. Since it takes precedence over default system library paths, it can be used both to specify the location of additional program libraries and to override system libraries.
Currently, RPATH can be embedded in executables using two tags: the “old” DT_RPATH tag and the “new” DT_RUNPATH tag. The existence of two tags comes from behavior exhibited by some operating systems (e.g. glibc systems): DT_RPATH used to take precedence over LD_LIBRARY_PATH, making it impossible to override the paths specified there. Therefore, a new DT_RUNPATH tag was added that comes after LD_LIBRARY_PATH in precedence. When both DT_RPATH and DT_RUNPATH are specified, the former is ignored.
On NetBSD, DT_RPATH does not take precedence over LD_LIBRARY_PATH. Therefore, there wasn't ever a need for DT_RUNPATH and the support for it (as alias to DT_RPATH) was added only very recently: on 2018-12-30.
Unlike GNU ld, LLD defaults to using “new” tag by default and therefore produces executables whose RPATHs do not work on older NetBSD versions. Given that using DT_RUNPATH on NetBSD has no real advantage, using the --disable-new-dtags option to suppress them is preferable.
More than two PT_LOAD segments
PT_LOAD segments are used to map executable image into the memory. Traditionally, GNU ld produces exactly two PT_LOAD segments: a RX text (code) segment, and a RW data segment. NetBSD dynamic loader (ld.elf_so) hardcodes the assumption of that design. However, lld sometimes produces an additional read-only data segment, causing the assertions to fail in the dynamic loader.
I have attempted to rewrite the memory mapping routine to allow for arbitrary number of segments. However, apparently my patch is just “a step in the wrong direction” and Joerg Sonnenberger is working on a proper fix.
Alternatively, LLD has a --no-rosegment option that can be used to suppress the additional segment and work around the problem.
Clang/LLD driver design issues
Both GCC and Clang use a design based on a front-end driver component. That is, the executable called directly by the user is a driver whose purpose is to perform initial command-line option and input processing, and run appropriate tools performing the actual work. Those tools may include the C preprocessor (cpp), C/C++ compiler (cc1), assembler, link editor (ld).
This follows the original UNIX principle of simple tools that perform a single task well, and a wrapper that combines those tools into complete workflows. Interesting enough, it makes it possible to keep all system-specific defaults and logic in a single place, without having to make every single tool aware of them. Instead, they are passed to those tools as command-line options.
This also accounts for simpler and more portable build system design. The gcc/clang driver provides a single high-level interface for performing a multitude of tasks, including compiling assembly files or linking executables. Therefore, the build system and the user do not need to be explicitly aware of low-level tooling and its usage. Not to mention it makes much easier to swap that tooling transparently.
For example, if you are linking an executable via the driver, it takes care of finding the appropriate link editor (and makes it easy to change it via -fuse-ld), preparing appropriate command-line options (e.g. if you do a -m32 multilib build, it sets the emulation for you) and passes necessary libraries to link (e.g. an appropriate standard C++ library when building a C++ program).
The clang toolchain considers LLD an explicit part of this workflow, and — unlike GNU ld — ld.lld is not really suitable for using stand-alone. For example, it does not include any standard search paths for libraries, expecting the driver to provide them in form of appropriate -L options. This way, all the logic responsible for figuring out the operating system used (including possible cross-compilation scenarios) and using appropriate paths is located in one component.
However, Joerg Sonnenberger disagrees with this and believes LLD should contain all the defaults necessary for it to be used stand-alone on NetBSD. Effectively, we have two conflicting designs: one where all logic is in clang driver, and the other where some of the logic is moved into LLD. At this moment, LLD is following the former assumption, and clang driver for NetBSD — the latter. As a result, neither using LLD directly nor via clang works out of the box on NetBSD; to use either, the user would have to pass all appropriate -L and -z options explicitly.
Fixing LLD to work with the current clang driver would require adding target awareness to LLD and changing a number of defaults for NetBSD based on the target used. However, LLD maintainer Rui Ueyama is opposed to introducing this extra logic specifically for NetBSD, and believes it should be added to the clang driver as for other platforms. On the other side, the NetBSD toolchain driver maintainer Joerg Sonnenberger blocks adding this to the driver. Therefore, we have reached a impasse that prevents LLD from working out of the box on NetBSD without local patches.
A work-in-progress implementation of the local target logic approach requested by Joerg can be seen in D56650. Afterwards, additional behavior can be enabled on NetBSD by using target triple properties such as in D56215 (which copies the libdir logic from clang).
For comparison, the same problem solved in a way consistent with other distributions (and rejected by Joerg) can be seen in D56932 (which updates D33726). However, in some cases it will require adding additional options to LLD (e.g. -z nognustack, D56554), and corresponding dummy switches in GNU ld.
Summary
At this point, it seems that using LLD for the majority of regular packages is a goal that can be achieved soon. The main blocker right now is the disagreement between developers on how to proceed. When we can resolve that and agree on a single way forward, most of the patches become trivial.
Sadly, at this point I really do not see any way to convince either of the sides. The problem was reported in May 2017, and in the same month a fix consistent with all other platforms was provided. However, it is being blocked and LLD can not work out of the box.
Hopefully, we will able to finally find a way forward that does not involve keeping upstream clang driver for NetBSD incompatible with upstream LLD, and carrying a number of patches to LLD locally to make it work.
The further goals include attempting to build the kernel and complete userland using LLD, as well as further verifying compatibility of executables produced with various combinations of linker options (e.g. static PIE executables).
Today, I am here to report: Mission Accomplished!
It's been a long road, but we now have hardware-accelerated virtualization in the kernel! And while I had only initially planned to get Oracle VirtualBox working, I have with the help of the Intel HAXM engine (the same backend used for virtualization in Android Studio) and a qemu frontend, successfully managed to boot a range of mainstream operating systems.
With the advent of Intel's open-sourcing of their HAXM engine, we now have access to an important set of features:
- A BSD-style license.
- Support for multiple platforms: Windows, Darwin, Linux, and now NetBSD .
- HAXM is an Intel hardware assisted virtualization for their CPUs (VTx and EPT needed).
- Support for an arbitrary number of concurrent VMs. For simplicity's sake, NetBSD only supports 8, whereas Windows/Darwin/Linux support 64.
- An arbitary number of supported VCPUS per VM. All OSes support up to 64 VCPUs.
- ioctl(2) based API (/dev/HAX, /dev/haxmvm/vmXX, /dev/haxmvm/haxmvmXXvcpuYY).
- Implement non-intrusively as part of the kernel, rather than as an out-of-tree, standalone executable kernel module.
- Default compatibility with qemu as a frontend.
- Active upstream support from Intel, which is driven by commercial needs.
- Optimized for desktop scenarios.
- Probably the only open-source cross-OS virtualization engine.
- An active and passionate community that's dedicated to keep improving it.
As well as a few of HAXM's downsides:
- No AMD (SVM) support (althought there are community plans to implement it).
- No support for non-x86 architectures.
- Need for a relatively recent Intel CPU (EPT required).
- Not as flexible as KVM-like solutions for embedded use-cases or servers.
- Not as quick as KVM (probably 80% as fast as KVM).
If you'd like more details on HAXM, check out the following sites:
- https://www.qemu.org/2017/11/22/haxm-usage-windows/
- https://software.intel.com/en-us/articles/intel-hardware-accelerated-execution-manager-intel-haxm
- https://github.com/intel/haxm
Showcase
I've managed to boot and run several operating systems as guests running on HAXM/NetBSD, all of which are multi-core (2-4 VCPUs):
- NetBSD.
And as our motto goes, of course it runs NetBSD.
And, of course, my main priority as a NetBSD developer is achieving excellent support for NetBSD guest operating systems.
With the massive performance gains of hardware-accelerated virtualization,
it'll finally be possible to run kernel fuzzers and many other practical, real-world workloads on virtualized NetBSD systems.
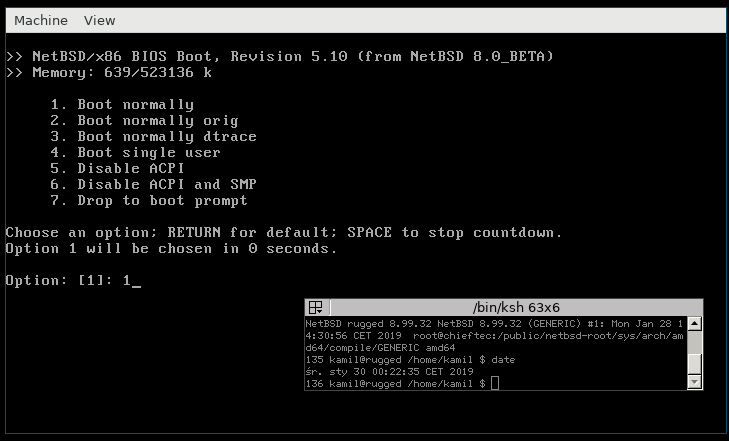
[NetBSD at the bootloader]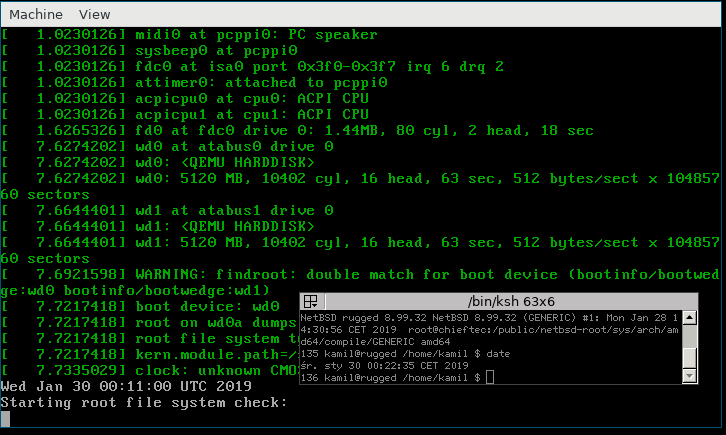
[NetBSD kernel booting]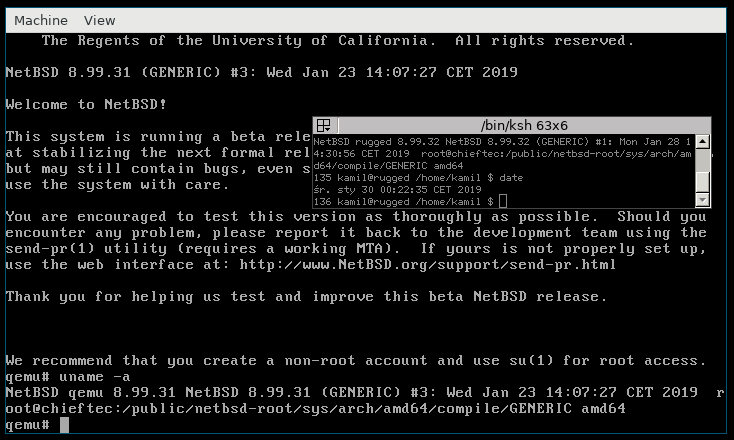
[NetBSD at a shell prompt]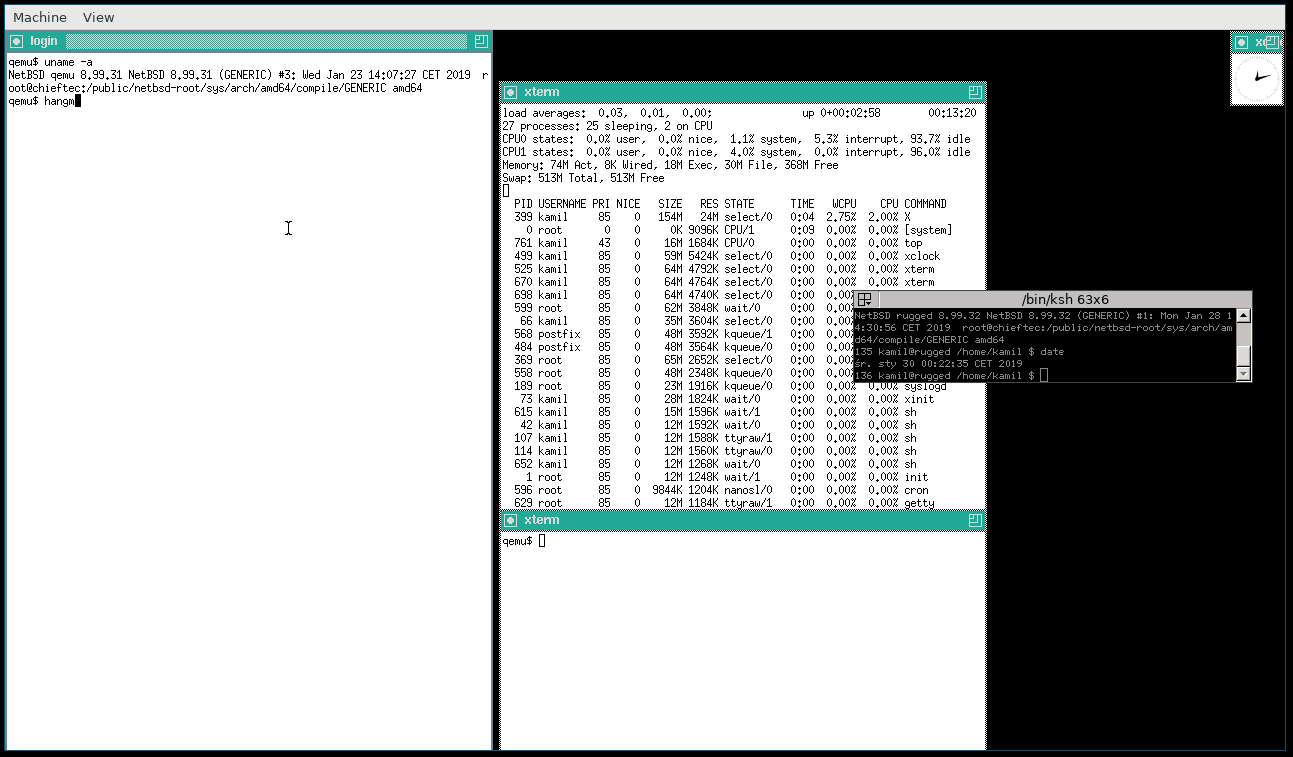
[NetBSD with X Window session]
[NetBSD with X Window session]
[NetBSD guest and qemu's ACPI integration - emitted poweroff button press]
[NetBSD in the qemu's curses mode display, which I find convenient to use, especially on a headless remote computer] - Linux. When I pledged myself to not boot any other OS before accomplishing my goal, I was mostly thinking about
resigning from benefits of the Linux ecosystem (driver and software base).
There is still a selection of programs that I miss such as valgrind.. but with each week we are getting closer to fill the missing gaps.
Linux guests seem to work, however there is need to tune or disable IOAPIC in order to get it running
(I had to pass "noapic" as a Linux kernel option).
[ArchLinux at a bootloader]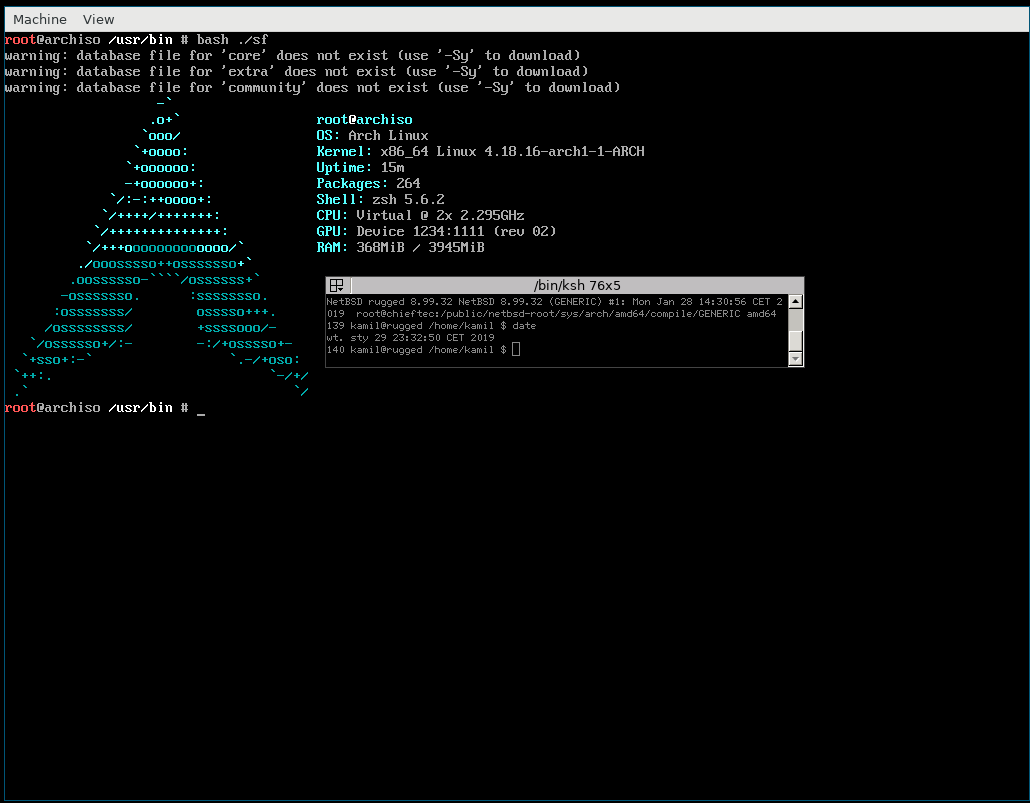
[ArchLinux at a shell (ZSH) prompt]
[Ubuntu's installer]
[Ubuntu at a bootloader] - Windows. While I have no personal need nor use-case to run Windows, it's a must-have prestigious target for virtualization.
I've obtained a Windows 7 86 trial image from the official Microsoft webpage for testing purposes.
Windows 8.1 or newer and 64-bit version is still in development in HAXM.
[Windows 7 booting]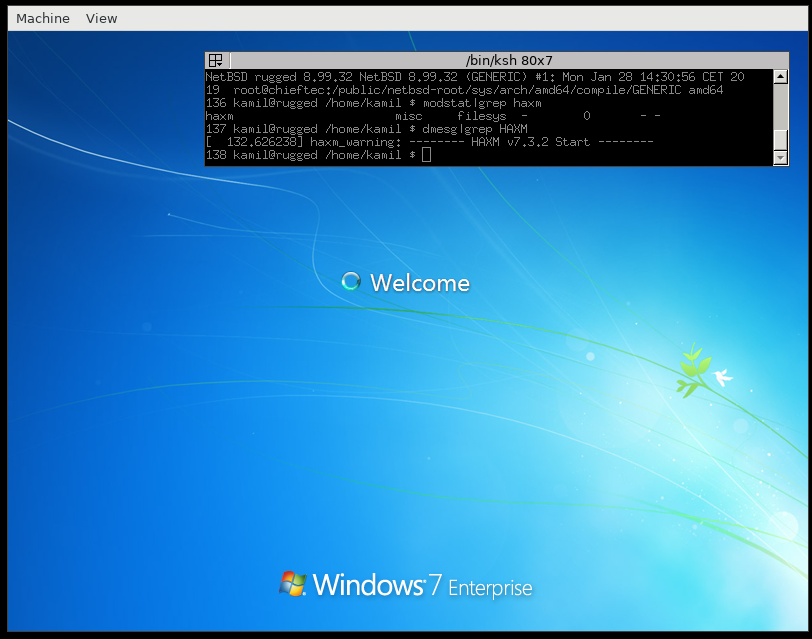
[Windows 7 welcome message]
[Windows 7 running]
[Windows 7 Control Panel]
[Windows 7 multitasking]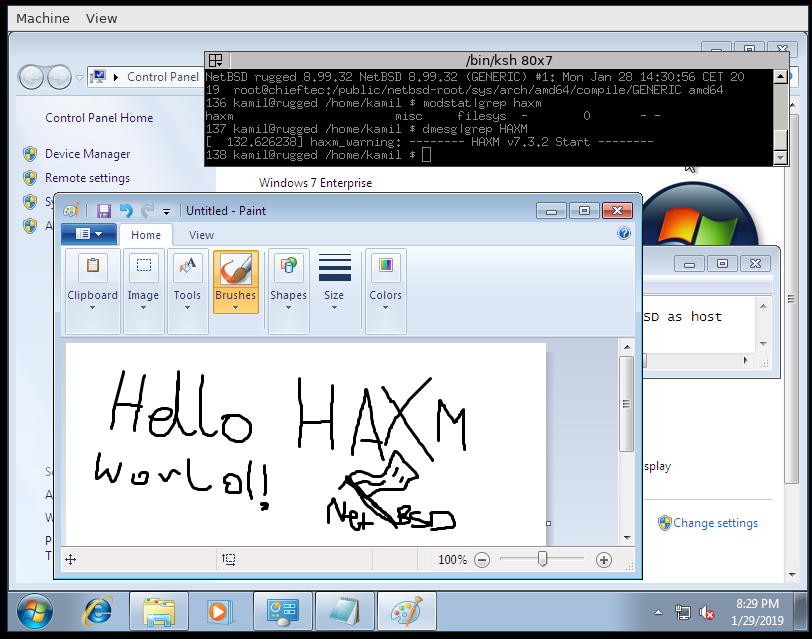
[Windows 7 MS Paint] - DragonflyBSD. I was prompted to test this FreeBSD derivation by a developer of this OS and it just worked flawlessly.
[DragonflyBSD at a bootloader]
[DragonflyBSD at a shell prompt] - FreeDOS. It seems to just work, but I have no idea what I can use it for.
[FREEDOS at an installer]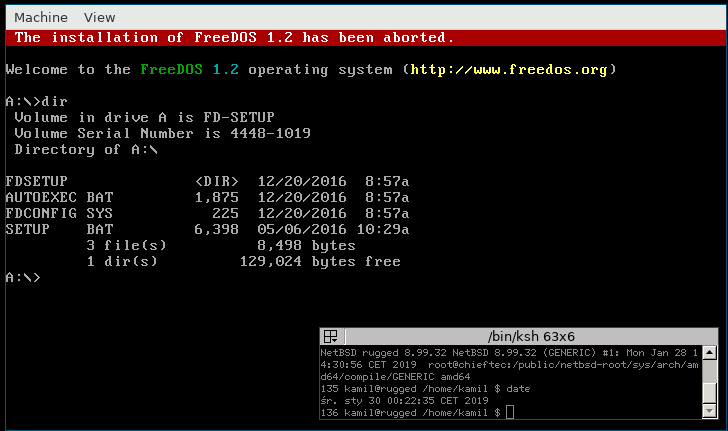
[FREEDOS at a command line]
- Android. The kernel booting seems fine (with "noapic"), but later during distribution load it freezes the host computer.
[Android bootloader]
[Android just before the host crash] - FreeBSD. Hangs during the booting process.
[FreeBSD hanging at boot]
Summary and future plans
One thing I must clarify, since I'm frequently asked about it, is that HAXM/NetBSD does not attempt to compete with the NVMM (NetBSD Virtual Machine Monitor) work being done by Maxime Villard. I'm primarily doing this for my own educational purposes, and because I find reaching feature-parity with other open-source projects is important work. Additionally, NVMM only has AMD CPU support, whereas I'm primarily a user of the Intel x86 platform, and thus, so is HAXM/NetBSD. The Intel port of NVMM and NVMM in general is still in development, and this means that HAXM is probably the first solution that has ever successfuly managed to run Windows on NetBSD (has anyone done it with Xen before?)
I will keep working on this project in my spare time and try to correct IOAPIC issues on Linux, hangs during FreeBSD's boot process, and Android crashes.
Most of the NetBSD-specific patches for qemu and Intel HAXM have already been merged upstream. And after this process has been completed, there are plans to make it available in pkgsrc. There's also at least one kernel-level workaround for HAXM behavior related to FPU state, which triggers an assert due to an abnormal condition. For this to be amended, fixes would have to land upstream into HAXM's code.
Subnote
Althought I confess that I've been playing with OpenVMS/VAX in SIMH as I have got a hobbyist license, but on the other hand it's hardly to be treated as a competition to NetBSD. Another exception was during a DTrace tutorial during EuroBSDCon 2017 in Paris, where I had to boot and use a FreeBSD image shared by the lecturer.
Introduction
We successfully incorporated the Argon2 reference implementation into NetBSD/amd64 for our 2019 Google Summer of Coding project. We introduced our project here and provided some hints on how to select parameters here. For our final report, we will provide an overview of what changes were made to complete the project.
Incorporating the Argon2 Reference Implementation
The Argon2 reference implementation, available here, is available under both the Creative Commons CC0 1.0 and the Apache Public License 2.0. To import the reference implementation into src/external, we chose to use the Apache 2.0 license for this project.During our initial phase 1, we focused on building the libargon2 library and integrating the functionality into the existing password management framework via libcrypt. Toward this end, we imported the reference implementation and created the "glue" to incorporate the changes into /usr/src/external/apache. The reference implementation is found in
m2$ ls /usr/src/external/apache2/argon2 Makefile dist lib usr.bin
_MKVARS.yes= \
...
MKARGON2 \
...
.if (defined(MKARGON2) && ${MKARGON2} != "no")
SUBDIR+= argon2
.endif
/usr/bin/argon2 /usr/lib/libargon2.a /usr/lib/libargon2.so /usr/lib/libargon2.so.1 /usr/lib/libargon2.so.1.0
.if (defined(MKARGON2) && ${MKARGON2} != "no")
HAVE_ARGON2=1
.endif
.if defined(HAVE_ARGON2) SRCS+= crypt-argon2.c CFLAGS+= -DHAVE_ARGON2 -I../../external/apache2/argon2/dist/phc-winner -argon2/include/ LDADD+= -largon2 .endif
Having completed the backend support, we pull Argon2 into userland tools, such as pwhash(1), in the same way as above
.if ( defined(MKARGON2) && ${MKARGON2} != "no" )
CPPFLAGS+= -DHAVE_ARGON2
.endif
m2# pwhash -A argon2id password $argon2id$v=19$m=4096,t=3,p=1$.SJJCiU575MDnA8s$+pjT4JsF2eLNQuLPEyhRA5LCFG QWAKsksIPl5ewTWNY
m1# grep -A1 testuser /etc/passwd.conf
testuser:
localcipher = argon2i,t=6,m=4096,p=1
m1# passwd testuser Changing password for testuser. New Password: Retype New Password: m1# grep testuser /etc/master.passwd testuser:$argon2i$v=19$m=4096,t=6,p=1$PDd65qr6JU0Pfnpr$8YOMYcwINuKHoxIV8Q0FJHG+ RP82xtmAuGep26brilU:1001:100::0:0::/home/testuser:/sbin/nologin
Testing
The argon2(1) binary allows us to easily validate parameters and encoding. This is most useful during performance testing, see here. With argon2(1), we can specify our parameterized values and evaluate both the resulting encoding and timing.m2# echo -n password|argon2 somesalt -id -p 3 -m 8 Type: Argon2id Iterations: 3 Memory: 256 KiB Parallelism: 3 Hash: 97f773f68715d27272490d3d2e74a2a9b06a5bca759b71eab7c02be8a453bfb9 Encoded: $argon2id$v=19$m=256,t=3,p=3$c29tZXNhbHQ$l/dz9ocV0nJySQ09LnSiqb BqW8p1m3Hqt8Ar6KRTv7k 0.000 seconds Verification ok
/usr/src/tests/usr.bin/argon2 tp: t_argon2_v10_hash tp: t_argon2_v10_verify tp: t_argon2_v13_hash tp: t_argon2_v13_verify cd /usr/src/tests/usr.bin/argon2 atf-run info: atf.version, Automated Testing Framework 0.20 (atf-0.20) info: tests.root, /usr/src/tests/usr.bin/argon2 .. tc-so:Executing command [ /bin/sh -c echo -n password | \ argon2 somesalt -v 13 -t 2 -m 8 -p 1 -r ] tc-end: 1567497383.571791, argon2_v13_t2_m8_p1, passed ...
Conclusion
We have successfully integrated Argon2 into NetBSD using the native build framework. We have extended existing functionality to support local password management using Argon2 encoding. We are able to tune Argon2 so that we can achieve reasonable performance on NetBSD. In this final post, we summarize the work done to incorporate the reference implementation into NetBSD and how to use it. We hope you can use the work completed during this project. Thank you for the opportunity to participate in the Google Summer of Code 2019 and the NetBSD project!Introduction
We successfully incorporated the Argon2 reference implementation into NetBSD/amd64 for our 2019 Google Summer of Coding project. We introduced our project here and provided some hints on how to select parameters here. For our final report, we will provide an overview of what changes were made to complete the project.
Incorporating the Argon2 Reference Implementation
The Argon2 reference implementation, available here, is available under both the Creative Commons CC0 1.0 and the Apache Public License 2.0. To import the reference implementation into src/external, we chose to use the Apache 2.0 license for this project.During our initial phase 1, we focused on building the libargon2 library and integrating the functionality into the existing password management framework via libcrypt. Toward this end, we imported the reference implementation and created the "glue" to incorporate the changes into /usr/src/external/apache. The reference implementation is found in
m2$ ls /usr/src/external/apache2/argon2 Makefile dist lib usr.bin
_MKVARS.yes= \
...
MKARGON2 \
...
.if (defined(MKARGON2) && ${MKARGON2} != "no")
SUBDIR+= argon2
.endif
/usr/bin/argon2 /usr/lib/libargon2.a /usr/lib/libargon2.so /usr/lib/libargon2.so.1 /usr/lib/libargon2.so.1.0
.if (defined(MKARGON2) && ${MKARGON2} != "no")
HAVE_ARGON2=1
.endif
.if defined(HAVE_ARGON2) SRCS+= crypt-argon2.c CFLAGS+= -DHAVE_ARGON2 -I../../external/apache2/argon2/dist/phc-winner -argon2/include/ LDADD+= -largon2 .endif
Having completed the backend support, we pull Argon2 into userland tools, such as pwhash(1), in the same way as above
.if ( defined(MKARGON2) && ${MKARGON2} != "no" )
CPPFLAGS+= -DHAVE_ARGON2
.endif
m2# pwhash -A argon2id password $argon2id$v=19$m=4096,t=3,p=1$.SJJCiU575MDnA8s$+pjT4JsF2eLNQuLPEyhRA5LCFG QWAKsksIPl5ewTWNY
m1# grep -A1 testuser /etc/passwd.conf
testuser:
localcipher = argon2i,t=6,m=4096,p=1
m1# passwd testuser Changing password for testuser. New Password: Retype New Password: m1# grep testuser /etc/master.passwd testuser:$argon2i$v=19$m=4096,t=6,p=1$PDd65qr6JU0Pfnpr$8YOMYcwINuKHoxIV8Q0FJHG+ RP82xtmAuGep26brilU:1001:100::0:0::/home/testuser:/sbin/nologin
Testing
The argon2(1) binary allows us to easily validate parameters and encoding. This is most useful during performance testing, see here. With argon2(1), we can specify our parameterized values and evaluate both the resulting encoding and timing.m2# echo -n password|argon2 somesalt -id -p 3 -m 8 Type: Argon2id Iterations: 3 Memory: 256 KiB Parallelism: 3 Hash: 97f773f68715d27272490d3d2e74a2a9b06a5bca759b71eab7c02be8a453bfb9 Encoded: $argon2id$v=19$m=256,t=3,p=3$c29tZXNhbHQ$l/dz9ocV0nJySQ09LnSiqb BqW8p1m3Hqt8Ar6KRTv7k 0.000 seconds Verification ok
/usr/src/tests/usr.bin/argon2 tp: t_argon2_v10_hash tp: t_argon2_v10_verify tp: t_argon2_v13_hash tp: t_argon2_v13_verify cd /usr/src/tests/usr.bin/argon2 atf-run info: atf.version, Automated Testing Framework 0.20 (atf-0.20) info: tests.root, /usr/src/tests/usr.bin/argon2 .. tc-so:Executing command [ /bin/sh -c echo -n password | \ argon2 somesalt -v 13 -t 2 -m 8 -p 1 -r ] tc-end: 1567497383.571791, argon2_v13_t2_m8_p1, passed ...
Conclusion
We have successfully integrated Argon2 into NetBSD using the native build framework. We have extended existing functionality to support local password management using Argon2 encoding. We are able to tune Argon2 so that we can achieve reasonable performance on NetBSD. In this final post, we summarize the work done to incorporate the reference implementation into NetBSD and how to use it. We hope you can use the work completed during this project. Thank you for the opportunity to participate in the Google Summer of Code 2019 and the NetBSD project!Upstream describes LLDB as a next generation, high-performance debugger. It is built on top of LLVM/Clang toolchain, and features great integration with it. At the moment, it primarily supports debugging C, C++ and ObjC code, and there is interest in extending it to more languages.
In February 2019, I have started working on LLDB, as contracted by the NetBSD Foundation. So far I've been working on reenabling continuous integration, squashing bugs, improving NetBSD core file support, extending NetBSD's ptrace interface to cover more register types and fix compat32 issues, fixing watchpoint and threading support.
Throughout December I've continued working on our build bot maintenance, in particular enabling compiler-rt tests. I've revived and finished my old patch for extended register state (XState) in core dumps. I've started working on bringing proper i386 support to LLDB.
Generic LLVM updates
Enabling and fixing more test suites
In my last report, I've indicated that I've started fixing test suite regressions and enabling additional test suites belonging to compiler-rt. So far I've been able to enable the following suites:
- builtins library (alternative to libgcc)
- profiling library
- ASAN (address sanitizer, static and dynamic)
- CFI (control flow integrity)
- LSAN (leak sanitizer)
- MSAN (memory sanitizer)
- SafeStack (stack buffer overflow protection)
- TSAN (thread sanitizer)
- UBSAN (undefined behavior sanitizer)
- UBSAN minimal
- XRay (function call tracing)
In case someone's wondering how different memory-related sanitizers differ, here's a short answer: ASAN covers major errors that can be detected with approximate 2x slowdown (out-of-bounds accesses, use-after-free, double-free...), LSAN focuses on memory leaks and has almost no overhead, while MSAN detects unitialized reads with 3x slowdown.
The following test suites were skipped because of major known breakage, pending investigation:
- generic interception tests (test runner can't find tests?)
- fuzzer tests (many test failures, most likely as a side effect of LSAN integration)
- clangd tests (many test failures)
The changes done to improve test suite status are:
- disable instantiation-depth-default.cpp as it requires more stack than the default ulimit
- disable ASLR for fuzzer tests
- disable ASLR for combined LSAN+ASAN tests
- disable ASLR for combined UBSAN+ASAN/MSAN/TSAN tests
- fix MSAN test not respecting the above
- disable MPROTECT for two builtin tests
- disable MPROTECT for XRay tests
Repeating the rationale for disabling ASLR/MPROTECT from my previous report: the sanitizers or tools in question do not work with the listed hardening features by design, and we explicitly make them fail. We are using paxctl to disable the relevant feature per-executable, and this makes it possible to run the relevant tests on systems where ASLR and MPROTECT are enabled globally.
This also included two builtin tests. In case of
clear_cache_test.c, this is a problem with test itself and I have
submitted a better MPROTECT support for
clear_cache_test already. In case of enable_execute_stack_test.c,
it's a problem with the API itself and I don't think it can be fixed
without replacing it with something more suitable for NetBSD. However,
it does not seem to be actually used by programs created by clang, so I
do not think it's worth looking into at the moment.
Demise and return of LLD
In my last report, I've mentioned that we've switched to using LLD as the linker for the second stage builds. Sadly, this was only to discover that some of the new test failures were caused exactly by that.
As I've reported back in January 2019, NetBSD's dynamic loader does not support executables with more than two segments. The problem has not been fixed yet, and we were so far relying on explicitly disabling the additional read-only segment in LLD. However, upstream started splitting the RW segment on GNU RELRO, effectively restoring three segments (or up to four, without our previous hack).
This forced me to initially disable LLD and return to GNU ld. However,
upstream has suggested using -znorelro recently, and we were enable
to go back down to two segments and reenable it.
libc++ system feature list update
Kamil has noticed that our feature list for libc++ is outdated. We have
missed indicating that NetBSD supports aligned_alloc(),
timespec_get() and C11 features. I have updated the feature
list.
Current build bot status
The stage 1 build currently fails as upstream has broken libc++ builds with GCC. Hopefully, this will be fixed after the weekend.
Before that, we had a bunch of failing tests: 7 related to profiling and 4 related to XRay. Plus, the flaky LLDB tests mentioned earlier.
Core dump XState support finally in
I was working on including full register set ('XState') in core dumps before my summer vacation. I've implemented the requested changes and finally pushed them. The patch set included four patches:
-
Include XSTATE note in x86 core dump, including preliminary support for machine-dependent core dump notes.
-
Fix alignment when reading core notes fixing a bug in my tests for core dumps that were added earlier,
-
Combine x86 register tests into unified test function simplifying the test suite a lot (by almost a half of the original lines).
-
Add tests for reading registers from x86 core dumps covering both old and new notes.
NetBSD/i386 support for LLDB
As the next step in my LLDB work, I've started working on providing i386 support. This covers both native i386 systems, and 32-bit executable support on amd64. In total, the combined amd64/i386 support covers four scenarios:
-
64-bit kernel, 64-bit debugger, 64-bit executable (native 64-bit).
-
64-bit kernel, 64-bit debugger, 32-bit executable.
-
64-bit kernel, 32-bit debugger, 32-bit executable.
-
32-bit kernel, 32-bit debugger, 32-bit executable (native 32-bit).
Those cases are really different only from kernel's point-of-view. For scenarios 1. and 2. the debugger is using 64-bit ptrace API, while in cases 3. and 4. it is using 32-bit ptrace API. In case 2., the application runs via compat32 and the kernel fits its data into 64-bit ptrace API. In case 3., the debugger runs via compat32.
Technically, cases 1. and 2. are already covered by the amd64 code in LLDB. However, for user's convenience LLDB needs to be extended to recognize 32-bit processes on NetBSD and adjust the data obtained from ptrace to 32-bit executables. Cases 3. and 4. need to be covered via making the code build on i386.
Other LLDB plugins implement this via creating separate i386 and amd64 modules, then including 32-bit branch in amd64 that reuses parts of i386 code. I am following suit with that. My plan is to implement 32-bit process support for case 2. first, then port everything to i386.
So far I have implemented the code to recognize 32-bit processes and I have started implementing i386 register interface that is meant to map data from 64-bit ptrace register dumps. However, it does not seem to map registers correctly at the moment and I am still debugging the problem.
Future plans
As mentioned above, I am currently working on providing support for debugging 32-bit executables on amd64. Afterwards, I am going to work on porting LLDB to run on i386.
I am also tentatively addressing compiler-rt test suite problems in order to reduce the number of build bot failures. I also need to look into remaining kernel problems regarding simultaneous delivery of signals and breakpoints or watchpoints.
Furthermore, I am planning to continue with the items from the original LLDB plan. Those are:
-
Add support to backtrace through signal trampoline and extend the support to libexecinfo, unwind implementations (LLVM, nongnu). Examine adding CFI support to interfaces that need it to provide more stable backtraces (both kernel and userland).
-
Add support for aarch64 target.
-
Stabilize LLDB and address breaking tests from the test suite.
-
Merge LLDB with the base system (under LLVM-style distribution).
This work is sponsored by The NetBSD Foundation
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL to chip in what you can:
Upstream describes LLDB as a next generation, high-performance debugger. It is built on top of LLVM/Clang toolchain, and features great integration with it. At the moment, it primarily supports debugging C, C++ and ObjC code, and there is interest in extending it to more languages.
In February 2019, I have started working on LLDB, as contracted by the NetBSD Foundation. So far I've been working on reenabling continuous integration, squashing bugs, improving NetBSD core file support, extending NetBSD's ptrace interface to cover more register types and fix compat32 issues, fixing watchpoint and threading support.
Throughout December I've continued working on our build bot maintenance, in particular enabling compiler-rt tests. I've revived and finished my old patch for extended register state (XState) in core dumps. I've started working on bringing proper i386 support to LLDB.
Generic LLVM updates
Enabling and fixing more test suites
In my last report, I've indicated that I've started fixing test suite regressions and enabling additional test suites belonging to compiler-rt. So far I've been able to enable the following suites:
- builtins library (alternative to libgcc)
- profiling library
- ASAN (address sanitizer, static and dynamic)
- CFI (control flow integrity)
- LSAN (leak sanitizer)
- MSAN (memory sanitizer)
- SafeStack (stack buffer overflow protection)
- TSAN (thread sanitizer)
- UBSAN (undefined behavior sanitizer)
- UBSAN minimal
- XRay (function call tracing)
In case someone's wondering how different memory-related sanitizers differ, here's a short answer: ASAN covers major errors that can be detected with approximate 2x slowdown (out-of-bounds accesses, use-after-free, double-free...), LSAN focuses on memory leaks and has almost no overhead, while MSAN detects unitialized reads with 3x slowdown.
The following test suites were skipped because of major known breakage, pending investigation:
- generic interception tests (test runner can't find tests?)
- fuzzer tests (many test failures, most likely as a side effect of LSAN integration)
- clangd tests (many test failures)
The changes done to improve test suite status are:
- disable instantiation-depth-default.cpp as it requires more stack than the default ulimit
- disable ASLR for fuzzer tests
- disable ASLR for combined LSAN+ASAN tests
- disable ASLR for combined UBSAN+ASAN/MSAN/TSAN tests
- fix MSAN test not respecting the above
- disable MPROTECT for two builtin tests
- disable MPROTECT for XRay tests
Repeating the rationale for disabling ASLR/MPROTECT from my previous report: the sanitizers or tools in question do not work with the listed hardening features by design, and we explicitly make them fail. We are using paxctl to disable the relevant feature per-executable, and this makes it possible to run the relevant tests on systems where ASLR and MPROTECT are enabled globally.
This also included two builtin tests. In case of
clear_cache_test.c, this is a problem with test itself and I have
submitted a better MPROTECT support for
clear_cache_test already. In case of enable_execute_stack_test.c,
it's a problem with the API itself and I don't think it can be fixed
without replacing it with something more suitable for NetBSD. However,
it does not seem to be actually used by programs created by clang, so I
do not think it's worth looking into at the moment.
Demise and return of LLD
In my last report, I've mentioned that we've switched to using LLD as the linker for the second stage builds. Sadly, this was only to discover that some of the new test failures were caused exactly by that.
As I've reported back in January 2019, NetBSD's dynamic loader does not support executables with more than two segments. The problem has not been fixed yet, and we were so far relying on explicitly disabling the additional read-only segment in LLD. However, upstream started splitting the RW segment on GNU RELRO, effectively restoring three segments (or up to four, without our previous hack).
This forced me to initially disable LLD and return to GNU ld. However,
upstream has suggested using -znorelro recently, and we were enable
to go back down to two segments and reenable it.
libc++ system feature list update
Kamil has noticed that our feature list for libc++ is outdated. We have
missed indicating that NetBSD supports aligned_alloc(),
timespec_get() and C11 features. I have updated the feature
list.
Current build bot status
The stage 1 build currently fails as upstream has broken libc++ builds with GCC. Hopefully, this will be fixed after the weekend.
Before that, we had a bunch of failing tests: 7 related to profiling and 4 related to XRay. Plus, the flaky LLDB tests mentioned earlier.
Core dump XState support finally in
I was working on including full register set ('XState') in core dumps before my summer vacation. I've implemented the requested changes and finally pushed them. The patch set included four patches:
-
Include XSTATE note in x86 core dump, including preliminary support for machine-dependent core dump notes.
-
Fix alignment when reading core notes fixing a bug in my tests for core dumps that were added earlier,
-
Combine x86 register tests into unified test function simplifying the test suite a lot (by almost a half of the original lines).
-
Add tests for reading registers from x86 core dumps covering both old and new notes.
NetBSD/i386 support for LLDB
As the next step in my LLDB work, I've started working on providing i386 support. This covers both native i386 systems, and 32-bit executable support on amd64. In total, the combined amd64/i386 support covers four scenarios:
-
64-bit kernel, 64-bit debugger, 64-bit executable (native 64-bit).
-
64-bit kernel, 64-bit debugger, 32-bit executable.
-
64-bit kernel, 32-bit debugger, 32-bit executable.
-
32-bit kernel, 32-bit debugger, 32-bit executable (native 32-bit).
Those cases are really different only from kernel's point-of-view. For scenarios 1. and 2. the debugger is using 64-bit ptrace API, while in cases 3. and 4. it is using 32-bit ptrace API. In case 2., the application runs via compat32 and the kernel fits its data into 64-bit ptrace API. In case 3., the debugger runs via compat32.
Technically, cases 1. and 2. are already covered by the amd64 code in LLDB. However, for user's convenience LLDB needs to be extended to recognize 32-bit processes on NetBSD and adjust the data obtained from ptrace to 32-bit executables. Cases 3. and 4. need to be covered via making the code build on i386.
Other LLDB plugins implement this via creating separate i386 and amd64 modules, then including 32-bit branch in amd64 that reuses parts of i386 code. I am following suit with that. My plan is to implement 32-bit process support for case 2. first, then port everything to i386.
So far I have implemented the code to recognize 32-bit processes and I have started implementing i386 register interface that is meant to map data from 64-bit ptrace register dumps. However, it does not seem to map registers correctly at the moment and I am still debugging the problem.
Future plans
As mentioned above, I am currently working on providing support for debugging 32-bit executables on amd64. Afterwards, I am going to work on porting LLDB to run on i386.
I am also tentatively addressing compiler-rt test suite problems in order to reduce the number of build bot failures. I also need to look into remaining kernel problems regarding simultaneous delivery of signals and breakpoints or watchpoints.
Furthermore, I am planning to continue with the items from the original LLDB plan. Those are:
-
Add support to backtrace through signal trampoline and extend the support to libexecinfo, unwind implementations (LLVM, nongnu). Examine adding CFI support to interfaces that need it to provide more stable backtraces (both kernel and userland).
-
Add support for aarch64 target.
-
Stabilize LLDB and address breaking tests from the test suite.
-
Merge LLDB with the base system (under LLVM-style distribution).
This work is sponsored by The NetBSD Foundation
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL to chip in what you can:
ptrace(2) API, removing one legacy
interface with a few flaws and replacing it with two new calls with new
features, and removing technical debt.
As LLVM 10.0 is branching now soon (Jan 15th 2020), I worked on proper support of the LLVM features for NetBSD 9.0 (today RC1) and NetBSD HEAD (future 10.0).
ptrace(2) API changes
There are around 20 Machine Independentptrace(2) calls.
The origin of some of these calls trace back to BSD4.3.
The PT_LWPINFO call was introduced in 2003 and was loosely inspired
by a similar interface in HP-UX ttrace(2).
As that was the early in the history of POSIX threads and SMP support,
not every bit of the interface remained ideal for the current computing needs.
The PT_LWPINFO call was originally intended
to retrieve the thread (LWP) information inside a traced process.
This call was designed to work as an
iterator over threads to retrieve the LWP id + event information. The
event information is received in a raw format (PL_EVENT_NONE,
PL_EVENT_SIGNAL, PL_EVENT_SUSPENDED).
Problems:
1. PT_LWPINFO shares the operation name with PT_LWPINFO from FreeBSD
that works differently and is used for different purposes:
- On FreeBSD
PT_LWPINFOreturns pieces of information for the suspended thread, not the next thread in the iteration. - FreeBSD uses a custom interface for iterating over threads (actually
retrieving the threads is done with
PT_GETNUMLWPS+PT_GETLWPLIST). - There is almost no overlapping correct usage of
PT_LWPINFOon NetBSD andPL_LWPINFOon FreeBSD, and this causes confusion and misuse of the interfaces (recently I fixed such misuse in the DTrace code).
2. pl_event can only return whether a signal was emitted to all threads or a single one. There is no information whether this is a per-LWP signal or per-PROC signal, no siginfo_t information is attached etc.
3. Syncing our behavior with FreeBSD would mean complete breakage of our
PT_LWPINFO users and it is actually unnecessary, as we receive full
siginfo_t through Linux-like PT_GET_SIGINFO, instead of reimplementing
siginfo_t inside ptrace_lwpinfo in FreeBSD-style. (FreeBSD
wanted to follow NetBSD and adopt some of our APIs in ptrace(2)
and signals.).
4. Our PT_LWPINFO is unable to list LWP ids in a traced
process.
5. The PT_LWPINFO semantics cannot be used in core files as-is (as our
PT_LPWINFO returns next LWP, not the indicated one) and pl_event is
redundant with netbsd_elfcore_procinfo.cpi_siglwp, and still
less powerful (as it cannot distinguish between a per-LWP and a per-PROC signal in a
single-threaded application).
6. PT_LWPINFO is already documented in the BUGS section of ptrace(2),
as it contains additional flaws.
Solution:
1. Remove PT_LWPINFO from the public ptrace(2) API, keeping it only as a
hidden namespaced symbol for legacy compatibility.
2. Introduce the PT_LWPSTATUS that prompts the kernel about exact thread
and retrieves useful information about LWP.
3. Introduce PT_LWPNEXT with the iteration semantics from PT_LWPINFO,
namely return the next LWP.
4. Include per-LWP information in core(5) files as "PT_LWPSTATUS@nnn".
5. Fix flattening the signal context in netbsd_elfcore_procinfo in
core(5) files, and move per-LWP signal information to the per-LWP structure
"PT_LWPSTATUS@nnn".
6. Do not bother with FreeBSD like PT_GETNUMLWPS + PT_GETLWPLIST calls,
as this is a micro-optimization. We intend to retrieve the list of
threads once on attach/exec and later trace them through the LWP events
(PTRACE_LWP_CREATE, PTRACE_LWP_EXIT). It's more important to keep
compatibility with current usage of PT_LWPINFO.
7. Keep the existing ATF tests for PT_LWPINFO to avoid rot.
PT_LWPSTATUS and PT_LWPNEXT operate over newly introduced "struct
ptrace_lwpstatus". This structure is inspired by:
- SmartOS lwpstatus_t,
- struct ptrace_lwpinfo from NetBSD,
- struct ptrace_lwpinfo from FreeBSD
and their usage in real existing open-source software.
#define PL_LNAMELEN 20 /* extra 4 for alignment */
struct ptrace_lwpstatus {
lwpid_t pl_lwpid; /* LWP described */
sigset_t pl_sigpend; /* LWP signals pending */
sigset_t pl_sigmask; /* LWP signal mask */
char pl_name[PL_LNAMELEN]; /* LWP name, may be empty */
void *pl_private; /* LWP private data */
/* Add fields at the end */
};
pt_lwpidis picked fromPT_LWPINFO.pl_eventis removed entirely as useless, misleading and harmful.pl_sigpendandpl_sigmaskare mainly intended to untangle thecpi_sig*fields from"struct ptrace_lwpstatus"(fix "XXX" in the kernel code).- pl_name is an easy to use API to retrieve the LWP name, replacing
sysctl()retrieval. (Previous algorithm: retrieve the number of LWPs, retrieve all LWPs; iterate over them; finding the matching ID; copy the LWP name.)pl_namewill also be included with the missing LWP name information incore(5)files. - pl_private implements currently missing interface to read the TLS base value.
I have decided to avoid a writable version of PT_LWPSTATUS
that rewrites signals, name, or private pointer. These options are
practically unused in existing open-source software. There are two
exceptions that I am familiar with, but both are specific to kludges
overusing ptrace(2). If these operations are needed, they
can be implemented without a writable version of PT_LWPSTATUS, patching
tracee's code.
I have switched GDB (in base), LLDB, picotrace and sanitizers to the new API.
As NetBSD 9.0 is nearing release, this API change will land NetBSD 10.0
and existing ptrace(2) software will use PT_LWPINFO for now.
New interfaces are ensured to be stable and continuously verified by the ATF infrastructure.
pthreadtracer
In the early in the history of libpthread, the NetBSD developers
designed and programmed a libpthread_dbg library.
It's use-case was initially intended to handle user-space scheduling of threads
in the M:N threading model inspired by Solaris.
After the switch of the internals to new SMP design (1:1 model) by Andrew Doran,
this library lost its purpose and was no longer used
(except being linked for some time in a local base system GDB version).
I removed the libpthread_dbg when I modernized the ptrace(2) API,
as it no longer had any use
(and it was broken in several ways for years without being noticed).
As I have introduced the PT_LWPSTATUS call, I have decided to verify this interface
in a fancy way. I have mapped ptrace_lwpstatus::pl_private into the tls_base structure as it
is defined in the sys/tls.h header:
struct tls_tcb {
#ifdef __HAVE_TLS_VARIANT_I
void **tcb_dtv;
void *tcb_pthread;
#else
void *tcb_self;
void **tcb_dtv;
void *tcb_pthread;
#endif
};
The pl_private pointer is in fact a pointer to a structure in debugger's address space, pointing to a tls_tcl structure.
This is not true universally in every environment, but it is true in regular programs using the ELF loader and the libpthread library.
Now, with the tcb_pthread field we can reference a regular C-style pthread_t object.
Now, wrapping it into a real tracer, I have implemented a program that can either start a debuggee or attach to a process and
on demand
(as a SIGINFO handler, usually triggered in the BSD environment with ctrl-t)
dump the full state of pthread_t objects within a process. A part of the example usage is below:
$ ./pthreadtracer -p `pgrep nslookup`
[ 21088.9252645] load: 2.83 cmd: pthreadtracer 6404 [wait parked] 0.00u 0.00s 0% 1600k
DTV=0x7f7ff7ee70c8 TCB_PTHREAD=0x7f7ff7e94000
LID=4 NAME='sock-0' TLS_TSD=0x7f7ff7eed890
pt_self = 0x7f7ff7e94000
pt_tls = 0x7f7ff7eed890
pt_magic = 0x11110001 (= PT_MAGIC=0x11110001)
pt_state = 1
pt_lock = 0x0
pt_flags = 0
pt_cancel = 0
pt_errno = 35
pt_stack = {.ss_sp = 0x7f7fef9e0000, ss_size = 4194304, ss_flags = 0}
pt_stack_allocated = YES
pt_guardsize = 65536
Full log is stored here. The source code of this program, on top of picotrace is here.
The problem with this utility is that it requires libpthread sources available and reachable by the build rules.
pthreadtracer reaches each field of pthread_t knowing its exact internal structure.
This is enough for validation of PT_LWPSTATUS,
but is it enough for shipping it to users and finding its real world use-case?
Debuggers (GDB, LLDB) using debug information can reach the same data with DWARF,
but supporting DWARF in pthreadtracer is currently harder than it ought to be for the interface tests.
There is also an option to revive at some point libpthread_dbg(3), revamping it for modern libpthread(3),
this would help avoid DWARF introspection and it could find some use in self-introspection programs, but are there any?
LLD
I keep searching for a solution to properly support lld (LLVM linker).
NetBSD's major issue with LLVM lld is the lack of standalone linker support, therefore being a real GNU ld replacement. I was forced to publish a standalone wrapper for lld, called lld-standalone and host it on GitHub for the time being, at least until we will sort out the talks with LLVM developers.
LLVM sanitizers
As the NetBSD code is evolving, there is a need to support multiple kernel versions starting from 9.0 with the LLVM sanitizers. I have introduced the following changes:
- [compiler-rt] [netbsd] Switch to syscall for ThreadSelfTlsTcb()
- [compiler-rt] [netbsd] Add support for versioned statvfs interceptors
- [compiler-rt] Sync NetBSD ioctl definitions with 9.99.26
- [compiler-rt] [fuzzer] Include stdarg.h for va_list
- [compiler-rt] [fuzzer] Enable LSan in libFuzzer tests on NetBSD
- [compiler-rt] Enable SANITIZER_CAN_USE_PREINIT_ARRAY on NetBSD
- [compiler-rt] Adapt stop-the-world for ptrace changes in NetBSD-9.99.30
- [compiler-rt] Adapt for ptrace(2) changes in NetBSD-9.99.30
The purpose of these changes is as follows:
- Stop using internal interface to retrieve the
tcl_tcbstruct (TLS base) and switch to public API with the syscall_lwp_getprivate(2). While there, I have harmonized the namespacing of__lwp_getprivate_fast()and__lwp_gettcb_fast()in the NetBSD distribution. Now, every port will need to use the same define (-D_RTLD_SOURCE,-D_LIBC_SOURCEor-D__LIBPTHREAD_SOURCE__). Previously these interfaces were conflicting with the public namespaces (affecting kernel builds) and wrongly suggesting that these interfaces might be available to public third party code. Initially I used it in LLVM sanitizers, but switched it to full-syscall_lwp_getspecific(). - Nowadays almost every mainstream OS implements support for preinit/initarray/finitarray in all ports, regardless of ABI requirements. NetBSD originally supported these features only when they were mandated by an ABI specification. Christos Zoulas in 2018 enabled these features for all CPUs, and this eventually allowed to enable this feature unconditionally for consumption in the sanitizer code. This allows use of the same interface as Linux or Solaris, rather than relying on C++-style constructors that have their own issues (need to abuse priorities of constructors and lack of guarantee that our code will be called before other constructors, which can be fatal).
- Support for kernels between 9.0 and 9.99.30 (and later, unless there are breaking changes).
There is still one portability issue in the sanitizers, as we hard-code the offset of the link_map field within the internal dlopen handle pointer.
The dlopen handler is internal to the ELF loader object of type Obj_Entry.
This type is not available to third party code and it is not stable.
It also has a different layout depending on the CPU architecture.
The same problem exists for at least FreeBSD, and to some extent to Linux.
I have prepared a patch that utilizes
the dlinfo(3) call with option RTLD_DI_LINKMAP.
Unfortunately there is a regression with MSan on NetBSD HEAD (it works on 9.0rc1) that makes it harder for me to finalize the patch.
I suspect that after the switch to GCC 8,
there is now incompatible behavior that causes a recursive call
sequence: _Unwind_Backtrace() calling
_Unwind_Find_FDE(), calling search_object, and triggering the
__interceptor_malloc interceptor again, which calls _Unwind_Backtrace(), resulting in deadlock.
The offending code is located in src/external/gpl3/gcc/dist/libgcc/unwind-dw2-fde.c and needs proper investigation.
A quick workaround to stop recursive stack unwinding unfortunately did not work, as
there is another (related?) problem:
==4629==MemorySanitizer CHECK failed: /public/llvm-project/llvm/projects/compiler-rt/lib/msan/msan_origin.h:104 "((stack_id)) != (0)" (0x0, 0x0)
This shows that this low-level code is very sensitive to slight changes, and needs maintenance power. We keep improving the coverage of tested scenarios on the LLVM buildbot, and we enabled sanitizer tests on 9.0 NetBSD/amd64; however we could make use of more manpower in order to reach full Linux parity in the toolchain.
Other changes
As my project in LLVM and ptrace(2) is slowly concluding, I'm trying to finalize the related tasks that were left behind.
I've finished researching why we couldn't use syscall restart on
kevent(2) call in LLDB and improved the
system documentation on it.
I have also fixed small nits in the NetBSD
wiki page on kevent(2).
I have updated the list of ELF defines
for CPUs and OS ABIs in sys/exec_elf.h.
Plan for the next milestone
Port remaining ptrace(2) test scenarios from Linux, FreeBSD and OpenBSD to ATF and ensure that they are properly operational.
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL to chip in what you can:
ptrace(2) API, removing one legacy
interface with a few flaws and replacing it with two new calls with new
features, and removing technical debt.
As LLVM 10.0 is branching now soon (Jan 15th 2020), I worked on proper support of the LLVM features for NetBSD 9.0 (today RC1) and NetBSD HEAD (future 10.0).
ptrace(2) API changes
There are around 20 Machine Independentptrace(2) calls.
The origin of some of these calls trace back to BSD4.3.
The PT_LWPINFO call was introduced in 2003 and was loosely inspired
by a similar interface in HP-UX ttrace(2).
As that was the early in the history of POSIX threads and SMP support,
not every bit of the interface remained ideal for the current computing needs.
The PT_LWPINFO call was originally intended
to retrieve the thread (LWP) information inside a traced process.
This call was designed to work as an
iterator over threads to retrieve the LWP id + event information. The
event information is received in a raw format (PL_EVENT_NONE,
PL_EVENT_SIGNAL, PL_EVENT_SUSPENDED).
Problems:
1. PT_LWPINFO shares the operation name with PT_LWPINFO from FreeBSD
that works differently and is used for different purposes:
- On FreeBSD
PT_LWPINFOreturns pieces of information for the suspended thread, not the next thread in the iteration. - FreeBSD uses a custom interface for iterating over threads (actually
retrieving the threads is done with
PT_GETNUMLWPS+PT_GETLWPLIST). - There is almost no overlapping correct usage of
PT_LWPINFOon NetBSD andPL_LWPINFOon FreeBSD, and this causes confusion and misuse of the interfaces (recently I fixed such misuse in the DTrace code).
2. pl_event can only return whether a signal was emitted to all threads or a single one. There is no information whether this is a per-LWP signal or per-PROC signal, no siginfo_t information is attached etc.
3. Syncing our behavior with FreeBSD would mean complete breakage of our
PT_LWPINFO users and it is actually unnecessary, as we receive full
siginfo_t through Linux-like PT_GET_SIGINFO, instead of reimplementing
siginfo_t inside ptrace_lwpinfo in FreeBSD-style. (FreeBSD
wanted to follow NetBSD and adopt some of our APIs in ptrace(2)
and signals.).
4. Our PT_LWPINFO is unable to list LWP ids in a traced
process.
5. The PT_LWPINFO semantics cannot be used in core files as-is (as our
PT_LPWINFO returns next LWP, not the indicated one) and pl_event is
redundant with netbsd_elfcore_procinfo.cpi_siglwp, and still
less powerful (as it cannot distinguish between a per-LWP and a per-PROC signal in a
single-threaded application).
6. PT_LWPINFO is already documented in the BUGS section of ptrace(2),
as it contains additional flaws.
Solution:
1. Remove PT_LWPINFO from the public ptrace(2) API, keeping it only as a
hidden namespaced symbol for legacy compatibility.
2. Introduce the PT_LWPSTATUS that prompts the kernel about exact thread
and retrieves useful information about LWP.
3. Introduce PT_LWPNEXT with the iteration semantics from PT_LWPINFO,
namely return the next LWP.
4. Include per-LWP information in core(5) files as "PT_LWPSTATUS@nnn".
5. Fix flattening the signal context in netbsd_elfcore_procinfo in
core(5) files, and move per-LWP signal information to the per-LWP structure
"PT_LWPSTATUS@nnn".
6. Do not bother with FreeBSD like PT_GETNUMLWPS + PT_GETLWPLIST calls,
as this is a micro-optimization. We intend to retrieve the list of
threads once on attach/exec and later trace them through the LWP events
(PTRACE_LWP_CREATE, PTRACE_LWP_EXIT). It's more important to keep
compatibility with current usage of PT_LWPINFO.
7. Keep the existing ATF tests for PT_LWPINFO to avoid rot.
PT_LWPSTATUS and PT_LWPNEXT operate over newly introduced "struct
ptrace_lwpstatus". This structure is inspired by:
- SmartOS lwpstatus_t,
- struct ptrace_lwpinfo from NetBSD,
- struct ptrace_lwpinfo from FreeBSD
and their usage in real existing open-source software.
#define PL_LNAMELEN 20 /* extra 4 for alignment */
struct ptrace_lwpstatus {
lwpid_t pl_lwpid; /* LWP described */
sigset_t pl_sigpend; /* LWP signals pending */
sigset_t pl_sigmask; /* LWP signal mask */
char pl_name[PL_LNAMELEN]; /* LWP name, may be empty */
void *pl_private; /* LWP private data */
/* Add fields at the end */
};
pt_lwpidis picked fromPT_LWPINFO.pl_eventis removed entirely as useless, misleading and harmful.pl_sigpendandpl_sigmaskare mainly intended to untangle thecpi_sig*fields from"struct ptrace_lwpstatus"(fix "XXX" in the kernel code).- pl_name is an easy to use API to retrieve the LWP name, replacing
sysctl()retrieval. (Previous algorithm: retrieve the number of LWPs, retrieve all LWPs; iterate over them; finding the matching ID; copy the LWP name.)pl_namewill also be included with the missing LWP name information incore(5)files. - pl_private implements currently missing interface to read the TLS base value.
I have decided to avoid a writable version of PT_LWPSTATUS
that rewrites signals, name, or private pointer. These options are
practically unused in existing open-source software. There are two
exceptions that I am familiar with, but both are specific to kludges
overusing ptrace(2). If these operations are needed, they
can be implemented without a writable version of PT_LWPSTATUS, patching
tracee's code.
I have switched GDB (in base), LLDB, picotrace and sanitizers to the new API.
As NetBSD 9.0 is nearing release, this API change will land NetBSD 10.0
and existing ptrace(2) software will use PT_LWPINFO for now.
New interfaces are ensured to be stable and continuously verified by the ATF infrastructure.
pthreadtracer
In the early in the history of libpthread, the NetBSD developers
designed and programmed a libpthread_dbg library.
It's use-case was initially intended to handle user-space scheduling of threads
in the M:N threading model inspired by Solaris.
After the switch of the internals to new SMP design (1:1 model) by Andrew Doran,
this library lost its purpose and was no longer used
(except being linked for some time in a local base system GDB version).
I removed the libpthread_dbg when I modernized the ptrace(2) API,
as it no longer had any use
(and it was broken in several ways for years without being noticed).
As I have introduced the PT_LWPSTATUS call, I have decided to verify this interface
in a fancy way. I have mapped ptrace_lwpstatus::pl_private into the tls_base structure as it
is defined in the sys/tls.h header:
struct tls_tcb {
#ifdef __HAVE_TLS_VARIANT_I
void **tcb_dtv;
void *tcb_pthread;
#else
void *tcb_self;
void **tcb_dtv;
void *tcb_pthread;
#endif
};
The pl_private pointer is in fact a pointer to a structure in debugger's address space, pointing to a tls_tcl structure.
This is not true universally in every environment, but it is true in regular programs using the ELF loader and the libpthread library.
Now, with the tcb_pthread field we can reference a regular C-style pthread_t object.
Now, wrapping it into a real tracer, I have implemented a program that can either start a debuggee or attach to a process and
on demand
(as a SIGINFO handler, usually triggered in the BSD environment with ctrl-t)
dump the full state of pthread_t objects within a process. A part of the example usage is below:
$ ./pthreadtracer -p `pgrep nslookup`
[ 21088.9252645] load: 2.83 cmd: pthreadtracer 6404 [wait parked] 0.00u 0.00s 0% 1600k
DTV=0x7f7ff7ee70c8 TCB_PTHREAD=0x7f7ff7e94000
LID=4 NAME='sock-0' TLS_TSD=0x7f7ff7eed890
pt_self = 0x7f7ff7e94000
pt_tls = 0x7f7ff7eed890
pt_magic = 0x11110001 (= PT_MAGIC=0x11110001)
pt_state = 1
pt_lock = 0x0
pt_flags = 0
pt_cancel = 0
pt_errno = 35
pt_stack = {.ss_sp = 0x7f7fef9e0000, ss_size = 4194304, ss_flags = 0}
pt_stack_allocated = YES
pt_guardsize = 65536
Full log is stored here. The source code of this program, on top of picotrace is here.
The problem with this utility is that it requires libpthread sources available and reachable by the build rules.
pthreadtracer reaches each field of pthread_t knowing its exact internal structure.
This is enough for validation of PT_LWPSTATUS,
but is it enough for shipping it to users and finding its real world use-case?
Debuggers (GDB, LLDB) using debug information can reach the same data with DWARF,
but supporting DWARF in pthreadtracer is currently harder than it ought to be for the interface tests.
There is also an option to revive at some point libpthread_dbg(3), revamping it for modern libpthread(3),
this would help avoid DWARF introspection and it could find some use in self-introspection programs, but are there any?
LLD
I keep searching for a solution to properly support lld (LLVM linker).
NetBSD's major issue with LLVM lld is the lack of standalone linker support, therefore being a real GNU ld replacement. I was forced to publish a standalone wrapper for lld, called lld-standalone and host it on GitHub for the time being, at least until we will sort out the talks with LLVM developers.
LLVM sanitizers
As the NetBSD code is evolving, there is a need to support multiple kernel versions starting from 9.0 with the LLVM sanitizers. I have introduced the following changes:
- [compiler-rt] [netbsd] Switch to syscall for ThreadSelfTlsTcb()
- [compiler-rt] [netbsd] Add support for versioned statvfs interceptors
- [compiler-rt] Sync NetBSD ioctl definitions with 9.99.26
- [compiler-rt] [fuzzer] Include stdarg.h for va_list
- [compiler-rt] [fuzzer] Enable LSan in libFuzzer tests on NetBSD
- [compiler-rt] Enable SANITIZER_CAN_USE_PREINIT_ARRAY on NetBSD
- [compiler-rt] Adapt stop-the-world for ptrace changes in NetBSD-9.99.30
- [compiler-rt] Adapt for ptrace(2) changes in NetBSD-9.99.30
The purpose of these changes is as follows:
- Stop using internal interface to retrieve the
tcl_tcbstruct (TLS base) and switch to public API with the syscall_lwp_getprivate(2). While there, I have harmonized the namespacing of__lwp_getprivate_fast()and__lwp_gettcb_fast()in the NetBSD distribution. Now, every port will need to use the same define (-D_RTLD_SOURCE,-D_LIBC_SOURCEor-D__LIBPTHREAD_SOURCE__). Previously these interfaces were conflicting with the public namespaces (affecting kernel builds) and wrongly suggesting that these interfaces might be available to public third party code. Initially I used it in LLVM sanitizers, but switched it to full-syscall_lwp_getspecific(). - Nowadays almost every mainstream OS implements support for preinit/initarray/finitarray in all ports, regardless of ABI requirements. NetBSD originally supported these features only when they were mandated by an ABI specification. Christos Zoulas in 2018 enabled these features for all CPUs, and this eventually allowed to enable this feature unconditionally for consumption in the sanitizer code. This allows use of the same interface as Linux or Solaris, rather than relying on C++-style constructors that have their own issues (need to abuse priorities of constructors and lack of guarantee that our code will be called before other constructors, which can be fatal).
- Support for kernels between 9.0 and 9.99.30 (and later, unless there are breaking changes).
There is still one portability issue in the sanitizers, as we hard-code the offset of the link_map field within the internal dlopen handle pointer.
The dlopen handler is internal to the ELF loader object of type Obj_Entry.
This type is not available to third party code and it is not stable.
It also has a different layout depending on the CPU architecture.
The same problem exists for at least FreeBSD, and to some extent to Linux.
I have prepared a patch that utilizes
the dlinfo(3) call with option RTLD_DI_LINKMAP.
Unfortunately there is a regression with MSan on NetBSD HEAD (it works on 9.0rc1) that makes it harder for me to finalize the patch.
I suspect that after the switch to GCC 8,
there is now incompatible behavior that causes a recursive call
sequence: _Unwind_Backtrace() calling
_Unwind_Find_FDE(), calling search_object, and triggering the
__interceptor_malloc interceptor again, which calls _Unwind_Backtrace(), resulting in deadlock.
The offending code is located in src/external/gpl3/gcc/dist/libgcc/unwind-dw2-fde.c and needs proper investigation.
A quick workaround to stop recursive stack unwinding unfortunately did not work, as
there is another (related?) problem:
==4629==MemorySanitizer CHECK failed: /public/llvm-project/llvm/projects/compiler-rt/lib/msan/msan_origin.h:104 "((stack_id)) != (0)" (0x0, 0x0)
This shows that this low-level code is very sensitive to slight changes, and needs maintenance power. We keep improving the coverage of tested scenarios on the LLVM buildbot, and we enabled sanitizer tests on 9.0 NetBSD/amd64; however we could make use of more manpower in order to reach full Linux parity in the toolchain.
Other changes
As my project in LLVM and ptrace(2) is slowly concluding, I'm trying to finalize the related tasks that were left behind.
I've finished researching why we couldn't use syscall restart on
kevent(2) call in LLDB and improved the
system documentation on it.
I have also fixed small nits in the NetBSD
wiki page on kevent(2).
I have updated the list of ELF defines
for CPUs and OS ABIs in sys/exec_elf.h.
Plan for the next milestone
Port remaining ptrace(2) test scenarios from Linux, FreeBSD and OpenBSD to ATF and ensure that they are properly operational.
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL to chip in what you can:
The sixth Reproducible Builds Summit took place exactly two months ago in Venice, Italy. These three days of workshops were filled with a succession of interactive sessions, where everyone attending had the opportunity to present or learn about anything related to Build Reproducibility. This included the status of specific Open Source projects, techniques to locate, analyse, and understand issues, or also how to explain and communicate better around this topic.
But what is this about?
Reproducible Builds are a set of software development practices that create an independently-verifiable path from source to binary code.
Why is this important?
Anyone may inspect the source code of Free and Open Source Software for correctness or vulnerabilities. However, most software is distributed pre-compiled, with no method to confirm whether it actually corresponds to the source code published. This allows attacks in a number of different situations, from a malicious developer to network attacks, or the compromise of build infrastructure.
What can be done about it?
The purpose of Reproducible Builds is therefore to allow the verification that no vulnerabilities or backdoors have been introduced during the compilation process. By promising identical results for a given source, Build Reproducibility allows multiple third-parties to compare “correct” results, and to flag any deviations as suspect and worthy of scrutiny.
How is NetBSD doing in this regard?
The base system of NetBSD can be built reproducibly since its 8.0 release! It can be enabled in mk.conf when building NetBSD for instance.
And in pkgsrc?
A first step has been implemented, when using GCC on NetBSD to build packages. Some important tools have been packaged, such as diffoscope. However, further aspects of build reproducibility are not covered in pkgsrc yet, and we welcome contributions to improve this situation! This would help bring this additional security mitigation to the NetBSD community as well as to other systems and users of pkgsrc.
Summary and conclusion
If not already, you should definitely consider Build Reproducibility for your environment or software projects. It also applies to firmware, when sources are available. Thankfully NetBSD offers this ability for the base system already, but more work is required for packages.
As for myself, it was an honour and a pleasure to attend the Summit, keep in touch with the community, participate to the event, learn from everyone attending, and obviously to represent the NetBSD Foundation there. I am looking forward to the next Summit, which should take place in Hamburg from October 30th to November 2nd of 2023.
In the meantime, do not hesitate to get in touch, including to the NetBSD Foundation or to the pkgsrc community specifically, if you want to get involved with any aspect of Build Reproducibility or represent the NetBSD or pkgsrc projects for the Reproducible Builds community.
Most of the work has been done directly for MSan. However, part of the work helped generic features in compiler-rt.
Sanitizers
Changes in the sanitizer are listed below in chronological order. Almost all of the changes mentioned here landed upstream. A few small patches were reverted due to breaking non-NetBSD hosts and are rescheduled for further investigation. I maintain these patches locally and have moved on for now to work on the remaining features.
- Move __tsan::Vector to the __sanitizer namespace. This move allows reuse of the homegrown Vector container in sanitizers other than TSan. I've implemented atexit(3) and __cxa_atexit() handling in MSan using this class.
- I've added function renaming of the NetBSD libc calls to the common code of sanitizer interceptors (sanitizer_common_interceptors.inc).
There have been 37 renames registered.
In general, I don't intend to support compat code and focus entirely on newly compiled features, taking NetBSD-8 as the basesystem release.
Therefore I support only the newest function version that is basically always used in new code.
- clock_gettime -> __clock_gettime50
- clock_getres -> __clock_getres50
- clock_settime -> __clock_settime50
- setitimer -> __setitimer50
- getitimer -> __getitimer50
- opendir -> __opendir30
- readdir -> __readdir30
- time -> __time50
- localtime_r -> __localtime_r50
- gmtime_r -> __gmtime_r50
- gmtime -> __gmtime50
- ctime -> __ctime50
- ctime_r -> __ctime_r50
- mktime -> __mktime50
- getpwnam -> __getpwnam50
- getpwuid -> __getpwuid50
- getpwnam_r -> __getpwnam_r50
- getpwuid_r -> __getpwuid_r50
- getpwent -> __getpwent50
- glob -> __glob30
- wait3 -> __wait350
- wait4 -> __wait450
- readdir_r -> __readdir_r30
- setlocale -> __setlocale50
- scandir -> __scandir30
- sigtimedwait -> __sigtimedwait50
- sigemptyset -> __sigemptyset14
- sigfillset -> __sigfillset14
- sigpending -> __sigpending14
- sigprocmask -> __sigprocmask14
- shmctl -> __shmctl50
- times -> __times13
- stat -> __stat50
- getutent -> __getutent50
- getutxent -> __getutxent50
- getutxid -> __getutxid50
- getutxline -> __getutxline50
- I've disabled intercepting absent functions on NetBSD, located in the MSan specific code: mempcpy, __libc_memalign, malloc_usable_size, stpcpy, gcvt, wmempcpy, fcvt.
- I've added handling of symbol aliases of certain POSIX threading library functions in MSan interceptors, namely __libc_thr_keycreate -> pthread_key_create.
- I've reused the Linux/x86_64 memory layout for NetBSD/amd64. There is a requirement to disable ASLR to get a functional mapping of memory regions on NetBSD. The NetBSD PaX ASLR implementation is too aggressive for the MSan needs, and this is similar to the TSan/NetBSD case.
- I've switched the strerror_r(3) interceptor for NetBSD from the GNU-specific to the POSIX one. They behave differently and are not interchangeable.
- I've disabled unsupported MSan tests on NetBSD: ftime and pvalloc and tsearch. They ship with unportable function calls that are absent on NetBSD.
- I've corrected execution of the ifaddrs, textdomain and iconv tests on NetBSD. They were adapted for the NetBSD specific behavior.
- I've finished handling in the interceptors the TLS block of the main program. This is a continuation of the past month's effort, the new solution is now corrected and has been made machine independent. It's worth noting that NetBSD is the only OS that is handling the main thread TLS block with generic interfaces.
- I've introduced dlopen(3) support fixes. I've corrected the retrieval of link_map pointer from the dlopen(3) opaque handler structure.
- I've fixed the list of intercepting functions for NetBSD: disabling getpshared-specific functions from POSIX pthreading library and switching from UTMP-like to UTMPX-like interceptors.
- I've disabled a MSan test verifying fgetgrent_r() on NetBSD, as this function call is absent.
- By mistake, I've disabled handling of fstatat()/MSan on NetBSD, and I've enabled it again.
- MSan is supporting all GLIBC strtol-like function symbols in the GNU C library. I've adopted this for the NetBSD case intercepting only the _l variations.
NetBSD syscall hooks
I wrote a large patch (815kb!) adding support for NetBSD syscall hooks for use with sanitizers. I wrote the following description on the still pending patch for review:
Implement the initial set of NetBSD syscall hooks for use with sanitizers.Add a script that generates the rules to handle syscalls
on NetBSD: generate_netbsd_syscalls.awk. It has been written
in NetBSD awk(1) (patched nawk) and is compatible with gawk.
Generate lib/sanitizer_common/sanitizer_platform_limits_netbsd.h
that is a public header for applications, and included as:
<sanitizer_common/sanitizer_platform_limits_netbsd.h>.Generate sanitizer_netbsd_syscalls.inc that defines all the
syscall rules for NetBSD. This file is modeled after the Linux
specific file: sanitizer_common_syscalls.inc.Start recognizing NetBSD syscalls with existing sanitizers:
ASan, ESan, HWASan, TSan, MSan, TSan.Update the list of platform (NetBSD OS) specific structs
in lib/sanitizer_common/sanitizer_platform_limits_netbsd.This patch does contain the most wanted structs
and handles the most wanted syscalls as of now, the rest
of them will be implemented in future when needed.This patch is 815KB, therefore I will restrict the detailed
description to a demo:
$ uname -a NetBSD chieftec 8.99.9 NetBSD 8.99.9 (GENERIC) #0: Mon Dec 25 12:58:16 CET 2017 root@chieftec:/public/netbsd-root/sys/arch/amd64/compile/GENERIC amd64 $ cat s.cc #include <assert.h> #include <errno.h> #include <glob.h> #include <stdio.h> #include <string.h> #include <sanitizer/netbsd_syscall_hooks.h> int main(int argc, char *argv[]) { char buf[1000]; __sanitizer_syscall_pre_recvmsg(0, buf - 1, 0); // CHECK: AddressSanitizer: stack-buffer-{{.*}}erflow // CHECK: READ of size {{.*}} at {{.*}} thread T0 // CHECK: #0 {{.*}} in __sanitizer_syscall{{.*}}recvmsg return 0; } $ ./a.out ================================================================= ==18015==ERROR: AddressSanitizer: stack-buffer-underflow on address 0x7f7fffe9c2ff at pc 0x000000467798 bp 0x7f7fffe9c2d0 sp 0x7f7fffe9ba90 WRITE of size 48 at 0x7f7fffe9c2ff thread T16777215 #0 0x467797 in __sanitizer_syscall_pre_impl_recvmsg /public/llvm/projects/compiler-rt/lib/asan/../sanitizer_common/sanitizer_netbsd_syscalls.inc:394:3 #1 0x4abeb2 in main (/public/llvm-build/./a.out+0x4abeb2) #2 0x419bba in ___start (/public/llvm-build/./a.out+0x419bba) Address 0x7f7fffe9c2ff is located in stack of thread T0 at offset 31 in frame #0 0x4abd7f in main (/public/llvm-build/./a.out+0x4abd7f) This frame has 1 object(s): [32, 1032) 'buf' <== Memory access at offset 31 partially underflows this variable HINT: this may be a false positive if your program uses some custom stack unwind mechanism or swapcontext (longjmp and C++ exceptions *are* supported) SUMMAR.Y: AddressSanitizer: stack-buffer-underflow /public/llvm/projects/compiler-rt/lib/asan/../sanitizer_common/sanitizer_netbsd_syscalls.inc:394:3 in __sanitizer_syscall_pre_impl_recvmsg Shadow bytes around the buggy address: 0x4feffffd3800: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 0x4feffffd3810: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 0x4feffffd3820: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 0x4feffffd3830: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 0x4feffffd3840: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 =>0x4feffffd3850: 00 00 00 00 00 00 00 00 00 00 00 00 f1 f1 f1[f1] 0x4feffffd3860: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 0x4feffffd3870: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 0x4feffffd3880: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 0x4feffffd3890: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 0x4feffffd38a0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 Shadow byte legend (one shadow byte represents 8 application bytes): Addressable: 00 Partially addressable: 01 02 03 04 05 06 07 Heap left redzone: fa Freed heap region: fd Stack left redzone: f1 Stack mid redzone: f2 Stack right redzone: f3 Stack after return: f5 Stack use after scope: f8 Global redzone: f9 Global init order: f6 Poisoned by user: f7 Container overflow: fc Array cookie: ac Intra object redzone: bb ASan internal: fe Left alloca redzone: ca Right alloca redzone: cb ==18015==ABORTING
NetBSD ioctl(2) hooks
Similar to the syscall hooks, there is need to handle every ioctl(2) call. I've created the needed patch, this time shorter - for less than 300kb. This code is still pending in upstream review:
Introduce handling of 1200 NetBSD specific ioctl(2) calls.
Over 100 operations are disabled as unavailable or conflicting
with the existing ones (the same operation number).Add a script that generates the rules to detect ioctls on NetBSD.
The generate_netbsd_ioctls.awk script has been written
in NetBSD awk(1) (patched nawk) and is compatible with gawk.Generate lib/sanitizer_common/sanitizer_netbsd_interceptors_ioctl.inc
with the awk(1) script.Update sanitizer_platform_limits_netbsd accordingly to add the needed
definitions.
New patches still pending for upstream review
There are two corrections that I've created, and they are still pending upstream for review:
I've got a few more local patches that require cleanup before submitting to review.
NetBSD basesystem corrections
I've introduced few corrections in the NetBSD codebase:
- Rename of a local function uname() in ps(1) to usrname(). This removes a name clash with libc. This situation is legal in the C language, but unwanted in the POSIX environment and it makes harder to reuse sanitizers with such code.
- Removal of three unused and unimplemented legacy syscalls: sstk (stack section size change), sbrk (change data segment size) and vadvise (specify system paging behaviour). The sbrk syscall could be removed as the functionality is implemented in libc brk(2) in assembly.
- I've detected and corrected a bug in the pipe2() syscall, as it was returning incorrectly two integers instead of the one with the status of operation. This was leftover from the pipe(2) system call behavior and implementation detail. I've introduced refactoring to address this and make the code cleaner.
- Committed and fixed the jobs variable usage in sh(1) - by Christos Zoulas and K. Robert Elz - the first real (but harmless) bug detected and squashed thanks to MSan.
Sanitizers in Go
I've prepared a scratch port of TSan and MSan to the Go language environment. This code mostly works. However, there are remaining bugs that must be fixed.
Results of ./race.bash:
Passed 340 of 347 tests (97.98%, 0+, 7-) 0 expected failures (0 has not fail)
The MSan state as of today
Although, I've managed to pass more than 90% of tests in the check-msan target within approximately one week, the gap between passing most of the test and sanitizing real world applications - even the small ones like cat(1) - is large. This pushed me towards supporting most of the important NetBSD syscalls and NetBSD ioctls, and demands from me to support most of the libc, libutil, librt, libm and libkvm entry calls.
********************
Testing: 0 .. 10.. 20.. 30.. 40.. 50.. 60.. 70.. 80.. 90..
Testing Time: 27.92s
********************
Failing Tests (7):
MemorySanitizer-X86_64 :: chained_origin_with_signals.cc
MemorySanitizer-X86_64 :: dtls_test.c
MemorySanitizer-X86_64 :: ioctl_custom.cc
MemorySanitizer-X86_64 :: sem_getvalue.cc
MemorySanitizer-X86_64 :: signal_stress_test.cc
MemorySanitizer-X86_64 :: textdomain.cc
MemorySanitizer-X86_64 :: tzset.cc
Expected Passes : 97
Expected Failures : 1
Unsupported Tests : 27
Unexpected Failures: 7
I can already execute cat(1) under sanitizers, and this milestone was achieved just at the end of the passed month.
Most other from the NetBSD base programs are not usable, few examples:
- test(1) - bug with handling isspace(3), still not understood.
- sh(1) - bug with signal-specific function calls.
- ksh(1) - clash with a libc symbol.
- ps(1) - lack of libkvm(3) handling.
There are also general stability problems with signals and forks. This all makes MSan not ready for larger applications like LLDB.
Solaris support in sanitizers
I've helped the Solaris team add basic support for Sanitizers (ASan, UBsan). This does not help NetBSD directly, however indirectly it improves the overall support for non-Linux hosts and helps to catch more Linuxisms in the code.
Plan for the next milestone
I plan to continue the work on MSan and correct sanitizing of the NetBSD basesystem utilities. This mandates me to iterate over the basesystem libraries implementing the missing interceptors and correcting the current support of the existing ones. My milestone is to build all src/*bin* programs against Memory Sanitizer and when possible execute them cleanly.
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL, and chip in what you can:
Most of the work has been done directly for MSan. However, part of the work helped generic features in compiler-rt.
Sanitizers
Changes in the sanitizer are listed below in chronological order. Almost all of the changes mentioned here landed upstream. A few small patches were reverted due to breaking non-NetBSD hosts and are rescheduled for further investigation. I maintain these patches locally and have moved on for now to work on the remaining features.
- Move __tsan::Vector to the __sanitizer namespace. This move allows reuse of the homegrown Vector container in sanitizers other than TSan. I've implemented atexit(3) and __cxa_atexit() handling in MSan using this class.
- I've added function renaming of the NetBSD libc calls to the common code of sanitizer interceptors (sanitizer_common_interceptors.inc).
There have been 37 renames registered.
In general, I don't intend to support compat code and focus entirely on newly compiled features, taking NetBSD-8 as the basesystem release.
Therefore I support only the newest function version that is basically always used in new code.
- clock_gettime -> __clock_gettime50
- clock_getres -> __clock_getres50
- clock_settime -> __clock_settime50
- setitimer -> __setitimer50
- getitimer -> __getitimer50
- opendir -> __opendir30
- readdir -> __readdir30
- time -> __time50
- localtime_r -> __localtime_r50
- gmtime_r -> __gmtime_r50
- gmtime -> __gmtime50
- ctime -> __ctime50
- ctime_r -> __ctime_r50
- mktime -> __mktime50
- getpwnam -> __getpwnam50
- getpwuid -> __getpwuid50
- getpwnam_r -> __getpwnam_r50
- getpwuid_r -> __getpwuid_r50
- getpwent -> __getpwent50
- glob -> __glob30
- wait3 -> __wait350
- wait4 -> __wait450
- readdir_r -> __readdir_r30
- setlocale -> __setlocale50
- scandir -> __scandir30
- sigtimedwait -> __sigtimedwait50
- sigemptyset -> __sigemptyset14
- sigfillset -> __sigfillset14
- sigpending -> __sigpending14
- sigprocmask -> __sigprocmask14
- shmctl -> __shmctl50
- times -> __times13
- stat -> __stat50
- getutent -> __getutent50
- getutxent -> __getutxent50
- getutxid -> __getutxid50
- getutxline -> __getutxline50
- I've disabled intercepting absent functions on NetBSD, located in the MSan specific code: mempcpy, __libc_memalign, malloc_usable_size, stpcpy, gcvt, wmempcpy, fcvt.
- I've added handling of symbol aliases of certain POSIX threading library functions in MSan interceptors, namely __libc_thr_keycreate -> pthread_key_create.
- I've reused the Linux/x86_64 memory layout for NetBSD/amd64. There is a requirement to disable ASLR to get a functional mapping of memory regions on NetBSD. The NetBSD PaX ASLR implementation is too aggressive for the MSan needs, and this is similar to the TSan/NetBSD case.
- I've switched the strerror_r(3) interceptor for NetBSD from the GNU-specific to the POSIX one. They behave differently and are not interchangeable.
- I've disabled unsupported MSan tests on NetBSD: ftime and pvalloc and tsearch. They ship with unportable function calls that are absent on NetBSD.
- I've corrected execution of the ifaddrs, textdomain and iconv tests on NetBSD. They were adapted for the NetBSD specific behavior.
- I've finished handling in the interceptors the TLS block of the main program. This is a continuation of the past month's effort, the new solution is now corrected and has been made machine independent. It's worth noting that NetBSD is the only OS that is handling the main thread TLS block with generic interfaces.
- I've introduced dlopen(3) support fixes. I've corrected the retrieval of link_map pointer from the dlopen(3) opaque handler structure.
- I've fixed the list of intercepting functions for NetBSD: disabling getpshared-specific functions from POSIX pthreading library and switching from UTMP-like to UTMPX-like interceptors.
- I've disabled a MSan test verifying fgetgrent_r() on NetBSD, as this function call is absent.
- By mistake, I've disabled handling of fstatat()/MSan on NetBSD, and I've enabled it again.
- MSan is supporting all GLIBC strtol-like function symbols in the GNU C library. I've adopted this for the NetBSD case intercepting only the _l variations.
NetBSD syscall hooks
I wrote a large patch (815kb!) adding support for NetBSD syscall hooks for use with sanitizers. I wrote the following description on the still pending patch for review:
Implement the initial set of NetBSD syscall hooks for use with sanitizers.Add a script that generates the rules to handle syscalls
on NetBSD: generate_netbsd_syscalls.awk. It has been written
in NetBSD awk(1) (patched nawk) and is compatible with gawk.
Generate lib/sanitizer_common/sanitizer_platform_limits_netbsd.h
that is a public header for applications, and included as:
<sanitizer_common/sanitizer_platform_limits_netbsd.h>.Generate sanitizer_netbsd_syscalls.inc that defines all the
syscall rules for NetBSD. This file is modeled after the Linux
specific file: sanitizer_common_syscalls.inc.Start recognizing NetBSD syscalls with existing sanitizers:
ASan, ESan, HWASan, TSan, MSan, TSan.Update the list of platform (NetBSD OS) specific structs
in lib/sanitizer_common/sanitizer_platform_limits_netbsd.This patch does contain the most wanted structs
and handles the most wanted syscalls as of now, the rest
of them will be implemented in future when needed.This patch is 815KB, therefore I will restrict the detailed
description to a demo:
$ uname -a NetBSD chieftec 8.99.9 NetBSD 8.99.9 (GENERIC) #0: Mon Dec 25 12:58:16 CET 2017 root@chieftec:/public/netbsd-root/sys/arch/amd64/compile/GENERIC amd64 $ cat s.cc #include <assert.h> #include <errno.h> #include <glob.h> #include <stdio.h> #include <string.h> #include <sanitizer/netbsd_syscall_hooks.h> int main(int argc, char *argv[]) { char buf[1000]; __sanitizer_syscall_pre_recvmsg(0, buf - 1, 0); // CHECK: AddressSanitizer: stack-buffer-{{.*}}erflow // CHECK: READ of size {{.*}} at {{.*}} thread T0 // CHECK: #0 {{.*}} in __sanitizer_syscall{{.*}}recvmsg return 0; } $ ./a.out ================================================================= ==18015==ERROR: AddressSanitizer: stack-buffer-underflow on address 0x7f7fffe9c2ff at pc 0x000000467798 bp 0x7f7fffe9c2d0 sp 0x7f7fffe9ba90 WRITE of size 48 at 0x7f7fffe9c2ff thread T16777215 #0 0x467797 in __sanitizer_syscall_pre_impl_recvmsg /public/llvm/projects/compiler-rt/lib/asan/../sanitizer_common/sanitizer_netbsd_syscalls.inc:394:3 #1 0x4abeb2 in main (/public/llvm-build/./a.out+0x4abeb2) #2 0x419bba in ___start (/public/llvm-build/./a.out+0x419bba) Address 0x7f7fffe9c2ff is located in stack of thread T0 at offset 31 in frame #0 0x4abd7f in main (/public/llvm-build/./a.out+0x4abd7f) This frame has 1 object(s): [32, 1032) 'buf' <== Memory access at offset 31 partially underflows this variable HINT: this may be a false positive if your program uses some custom stack unwind mechanism or swapcontext (longjmp and C++ exceptions *are* supported) SUMMAR.Y: AddressSanitizer: stack-buffer-underflow /public/llvm/projects/compiler-rt/lib/asan/../sanitizer_common/sanitizer_netbsd_syscalls.inc:394:3 in __sanitizer_syscall_pre_impl_recvmsg Shadow bytes around the buggy address: 0x4feffffd3800: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 0x4feffffd3810: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 0x4feffffd3820: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 0x4feffffd3830: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 0x4feffffd3840: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 =>0x4feffffd3850: 00 00 00 00 00 00 00 00 00 00 00 00 f1 f1 f1[f1] 0x4feffffd3860: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 0x4feffffd3870: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 0x4feffffd3880: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 0x4feffffd3890: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 0x4feffffd38a0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 Shadow byte legend (one shadow byte represents 8 application bytes): Addressable: 00 Partially addressable: 01 02 03 04 05 06 07 Heap left redzone: fa Freed heap region: fd Stack left redzone: f1 Stack mid redzone: f2 Stack right redzone: f3 Stack after return: f5 Stack use after scope: f8 Global redzone: f9 Global init order: f6 Poisoned by user: f7 Container overflow: fc Array cookie: ac Intra object redzone: bb ASan internal: fe Left alloca redzone: ca Right alloca redzone: cb ==18015==ABORTING
NetBSD ioctl(2) hooks
Similar to the syscall hooks, there is need to handle every ioctl(2) call. I've created the needed patch, this time shorter - for less than 300kb. This code is still pending in upstream review:
Introduce handling of 1200 NetBSD specific ioctl(2) calls.
Over 100 operations are disabled as unavailable or conflicting
with the existing ones (the same operation number).Add a script that generates the rules to detect ioctls on NetBSD.
The generate_netbsd_ioctls.awk script has been written
in NetBSD awk(1) (patched nawk) and is compatible with gawk.Generate lib/sanitizer_common/sanitizer_netbsd_interceptors_ioctl.inc
with the awk(1) script.Update sanitizer_platform_limits_netbsd accordingly to add the needed
definitions.
New patches still pending for upstream review
There are two corrections that I've created, and they are still pending upstream for review:
I've got a few more local patches that require cleanup before submitting to review.
NetBSD basesystem corrections
I've introduced few corrections in the NetBSD codebase:
- Rename of a local function uname() in ps(1) to usrname(). This removes a name clash with libc. This situation is legal in the C language, but unwanted in the POSIX environment and it makes harder to reuse sanitizers with such code.
- Removal of three unused and unimplemented legacy syscalls: sstk (stack section size change), sbrk (change data segment size) and vadvise (specify system paging behaviour). The sbrk syscall could be removed as the functionality is implemented in libc brk(2) in assembly.
- I've detected and corrected a bug in the pipe2() syscall, as it was returning incorrectly two integers instead of the one with the status of operation. This was leftover from the pipe(2) system call behavior and implementation detail. I've introduced refactoring to address this and make the code cleaner.
- Committed and fixed the jobs variable usage in sh(1) - by Christos Zoulas and K. Robert Elz - the first real (but harmless) bug detected and squashed thanks to MSan.
Sanitizers in Go
I've prepared a scratch port of TSan and MSan to the Go language environment. This code mostly works. However, there are remaining bugs that must be fixed.
Results of ./race.bash:
Passed 340 of 347 tests (97.98%, 0+, 7-) 0 expected failures (0 has not fail)
The MSan state as of today
Although, I've managed to pass more than 90% of tests in the check-msan target within approximately one week, the gap between passing most of the test and sanitizing real world applications - even the small ones like cat(1) - is large. This pushed me towards supporting most of the important NetBSD syscalls and NetBSD ioctls, and demands from me to support most of the libc, libutil, librt, libm and libkvm entry calls.
********************
Testing: 0 .. 10.. 20.. 30.. 40.. 50.. 60.. 70.. 80.. 90..
Testing Time: 27.92s
********************
Failing Tests (7):
MemorySanitizer-X86_64 :: chained_origin_with_signals.cc
MemorySanitizer-X86_64 :: dtls_test.c
MemorySanitizer-X86_64 :: ioctl_custom.cc
MemorySanitizer-X86_64 :: sem_getvalue.cc
MemorySanitizer-X86_64 :: signal_stress_test.cc
MemorySanitizer-X86_64 :: textdomain.cc
MemorySanitizer-X86_64 :: tzset.cc
Expected Passes : 97
Expected Failures : 1
Unsupported Tests : 27
Unexpected Failures: 7
I can already execute cat(1) under sanitizers, and this milestone was achieved just at the end of the passed month.
Most other from the NetBSD base programs are not usable, few examples:
- test(1) - bug with handling isspace(3), still not understood.
- sh(1) - bug with signal-specific function calls.
- ksh(1) - clash with a libc symbol.
- ps(1) - lack of libkvm(3) handling.
There are also general stability problems with signals and forks. This all makes MSan not ready for larger applications like LLDB.
Solaris support in sanitizers
I've helped the Solaris team add basic support for Sanitizers (ASan, UBsan). This does not help NetBSD directly, however indirectly it improves the overall support for non-Linux hosts and helps to catch more Linuxisms in the code.
Plan for the next milestone
I plan to continue the work on MSan and correct sanitizing of the NetBSD basesystem utilities. This mandates me to iterate over the basesystem libraries implementing the missing interceptors and correcting the current support of the existing ones. My milestone is to build all src/*bin* programs against Memory Sanitizer and when possible execute them cleanly.
This work was sponsored by The NetBSD Foundation.
The NetBSD Foundation is a non-profit organization and welcomes any donations to help us continue funding projects and services to the open-source community. Please consider visiting the following URL, and chip in what you can: